
COVID-19 Detection Systems Using Deep-Learning Algorithms Based on Speech and Image Data


Abstract
:1. Introduction and Literature Review
- We used a two-level classification system that is capable of automatically detecting the acoustic sounds of coughing, breathing, and speaking, along with the presence of COVID-19.
- The grid-search algorithm has been utilized to optimize the hypermeters of the different CNN models for the image-based model.
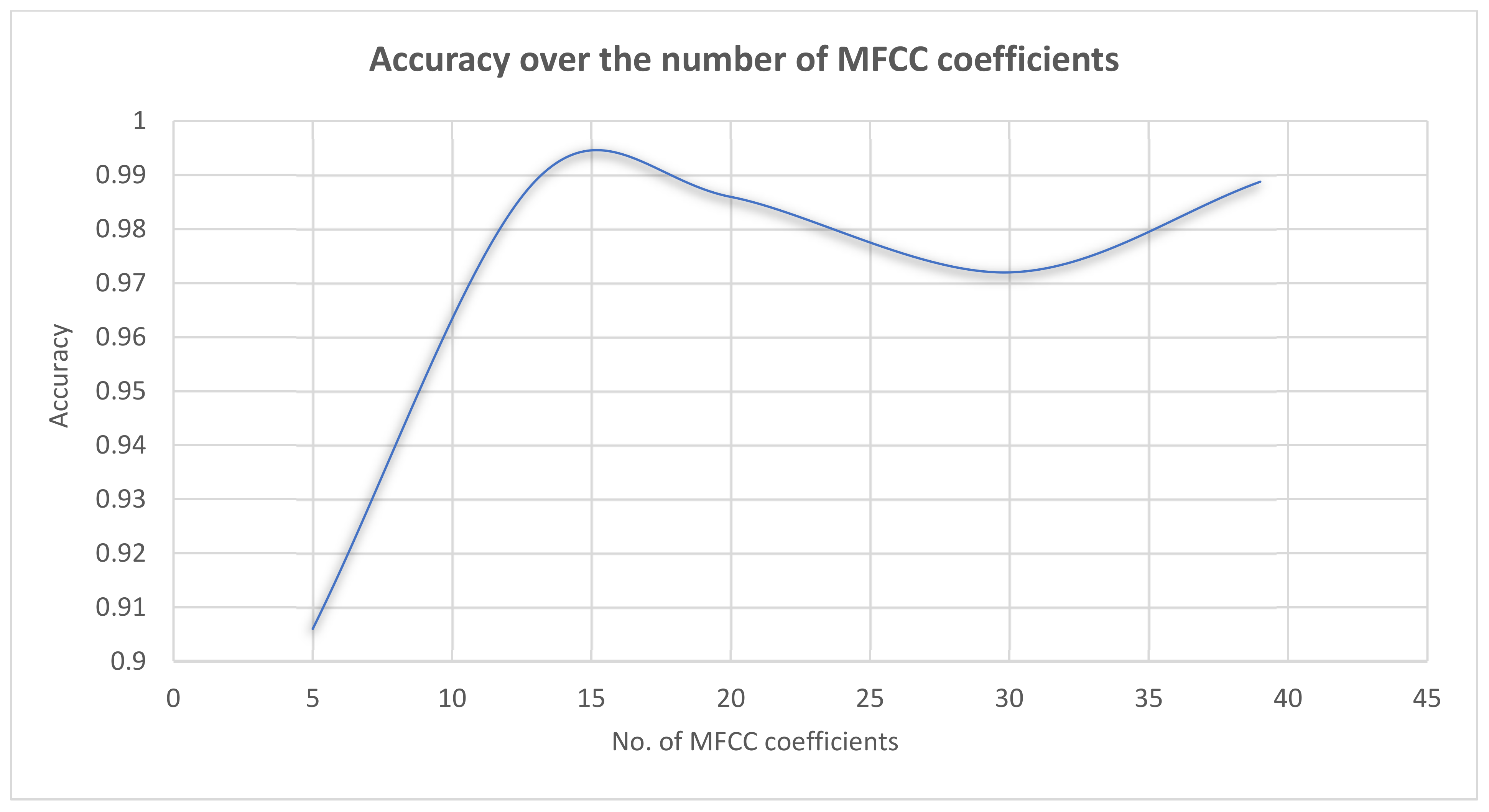
- We conducted a deep investigation on the effect of the number of MFCC coefficients on the system’s overall performance.
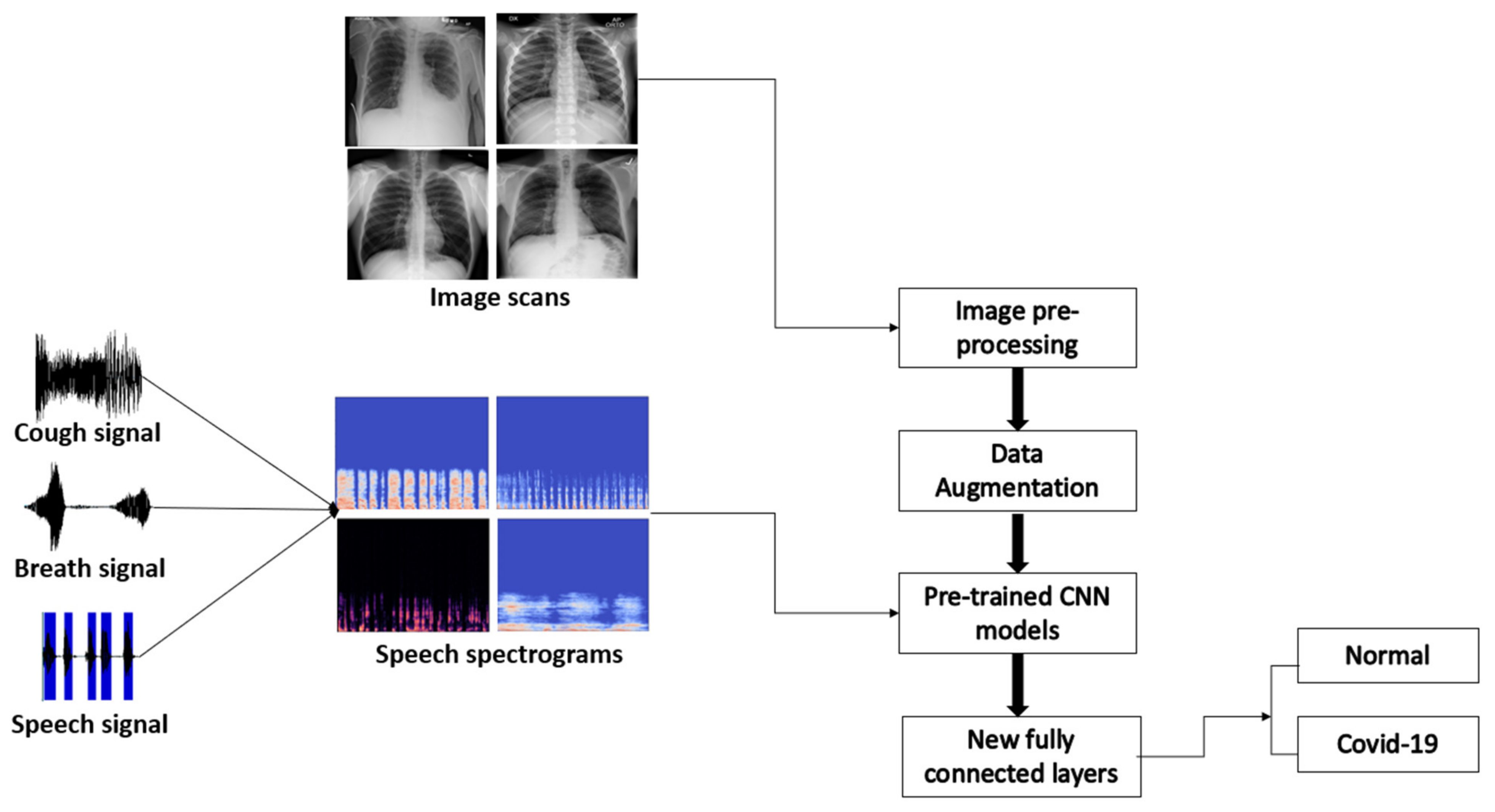
- We created a novel multimodal system utilizing audio and X-ray chest modalities.
- We assembled a new multimodal dataset encompassing both healthy and COVID-19 patients.
2. Speech-Based Model Methodology
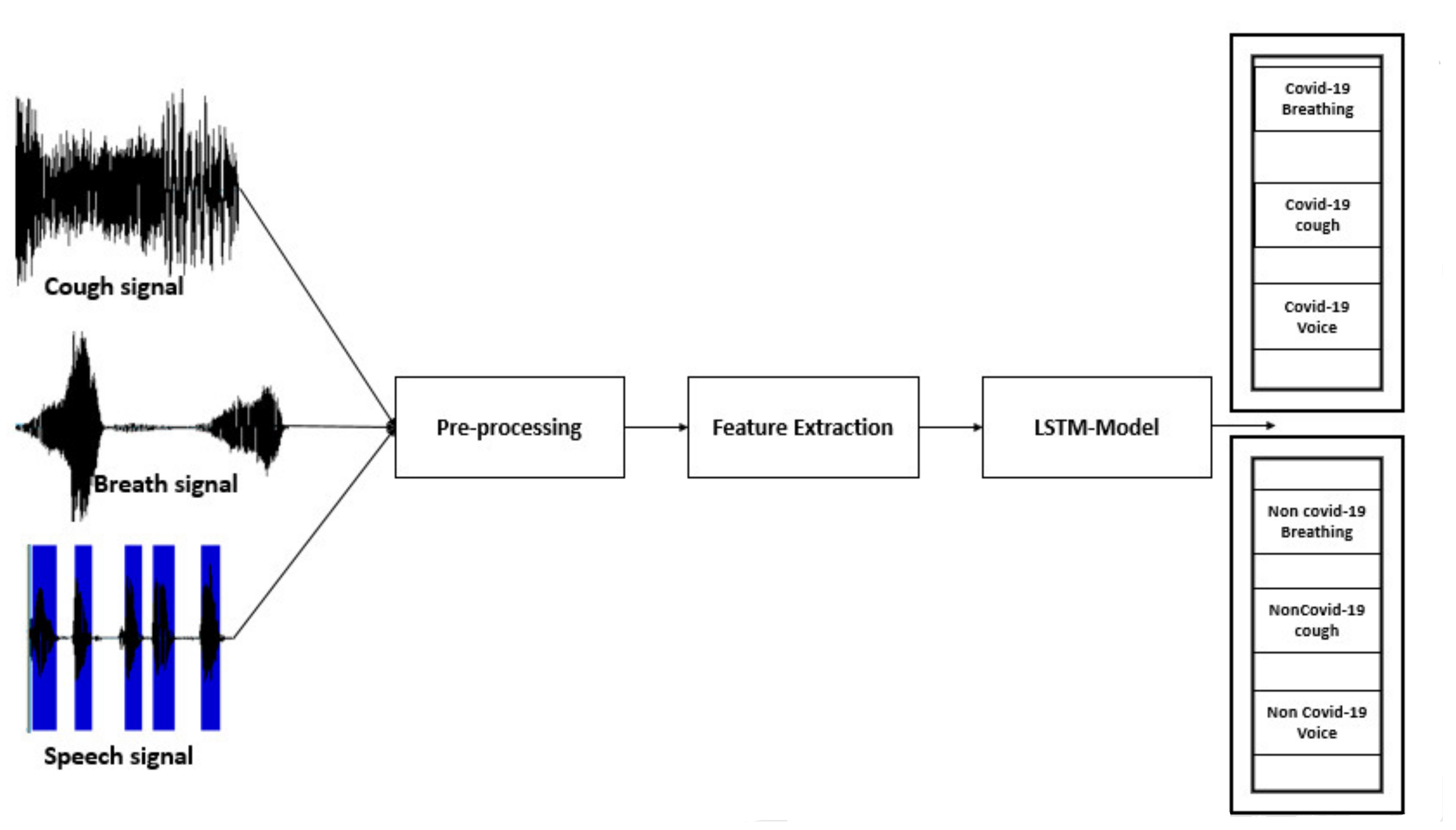
2.1. Data Acquisition
2.2. Speech Corpus
2.3. Speech Preprocessing
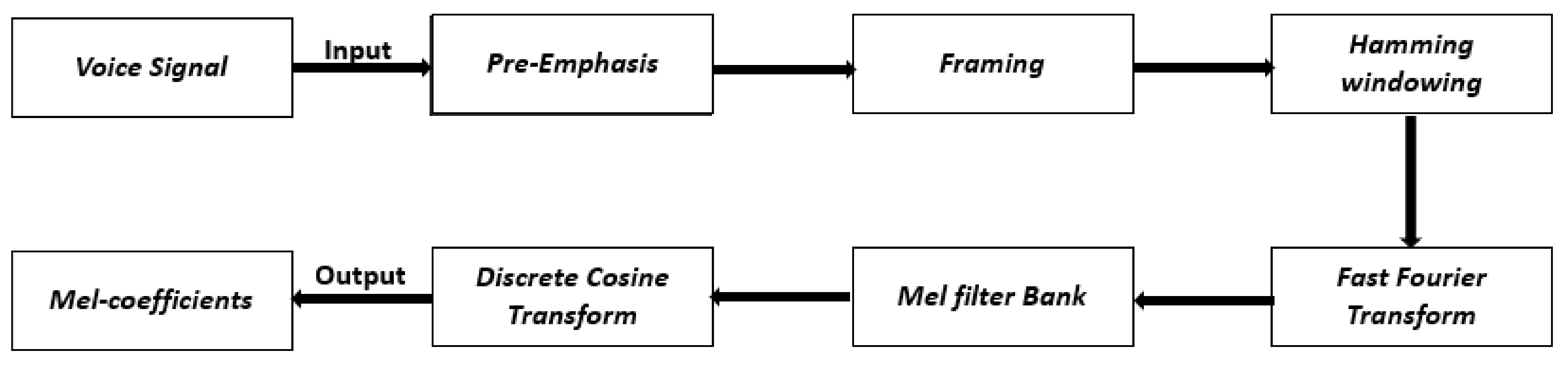
2.4. Feature Extraction
- Step 1: Pre-emphasis. In this step, the speech signal is passed to a high-pass filter. This process aims to increase the energy of the signal at higher frequencies and is represented by [36],where x(n) denotes the audio signal, y(n) refers to the output signal, and the value of a is roughly between 0.9 and 1.0.y(n) = x(n) − a × x (n − 1)
- Step 2: Framing. In this step, the speech signals that have N samples are divided into segments, where each segment is evaluated and described as a vector; the division of signals is made with a fixed N interval in a range between 20 and 40 ms. The framing is carried out with a 50% overlap of the frame size, and the overlapping is used for frames continuity [37]. The contiguous frames are separated by M, where M is less than N. The typical utilized values are N = 256 and M = 100.
- Step 3: Windowing. In windowing, each frame will be passed through a Hamming window; the main purpose of this phase is to provide an incrementation for both frame continuity and spectrum accuracy. In addition, the Hamming window can be denoted as w(n) where 0 ≤ n ≤ N − 1. Then, the output signal Y(n) after applying the Hamming windowing becomes,Y (n) = X (n) × W (n)where N refers to the number of samples in each frame and X(n) is the input signal.
- Step 4: Fast Fourier Transform (FFT). In this phase, all the frames obtained from the previous windowing phase are represented in the frequency domain by applying the Fast Fourier Transform (FFT). This process aims to achieve better representations of the speech signal characteristics. To perform FFT on a signal, the framed signal should be periodic and continuous. Nevertheless, FFT could still be applied on a discontinuous signal, but the result is undesirable. Consequently, Hamming windowing is applied to each frame to guarantee continuity between the first and the last frame. The FFT can be performed by using the following formula:where X(n) refers to the input signal, Y(n) refers to the output signal, h(n) is the vocal tract impulse response in the time domain, and X(w), H (w), and Y (w) are the FFT representations of X(n), h(n) and Y(n), respectively.Y(w) = FFT [h(n) × X(n)] = H(w) × X(w)
- Step 5: Mel Filter Bank. The obtained spectrum from the FFT will be exposed to a Mel Filter Bank, which contains a set of triangular bandpass filters. Moreover, the Mel frequency is computed using the following formula,
- Step 6: Discrete Cosine Transform (DCT). This phase represents the Mel spectrum in the time domain to obtain the MFCCs. The collection of coefficients is denoted as the acoustic vectors. Consequently, the input signals are represented as acoustic vector sequences. DCT can be expressed in the following formula,where n = 0, 1, … to N, and a number of triangular bandpass filters is referred to N, represents the obtained energy from the filter bank, and L is equal to that number of Mel-scale cepstral coefficients.
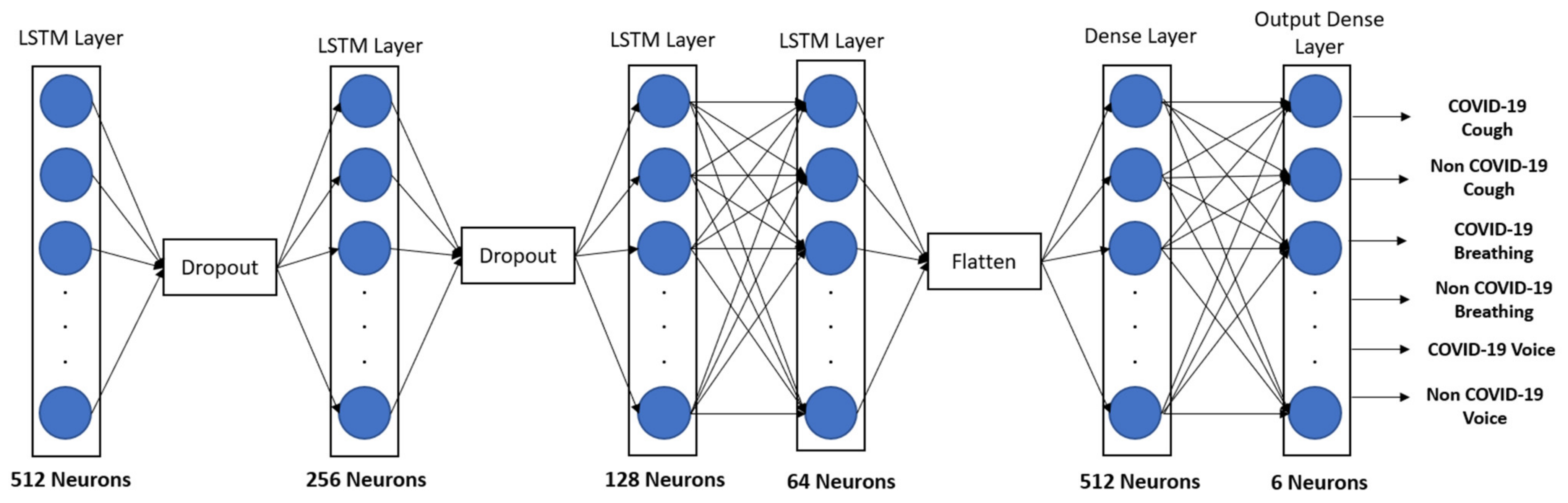
2.5. Long Short-Term Memory (LSTM)
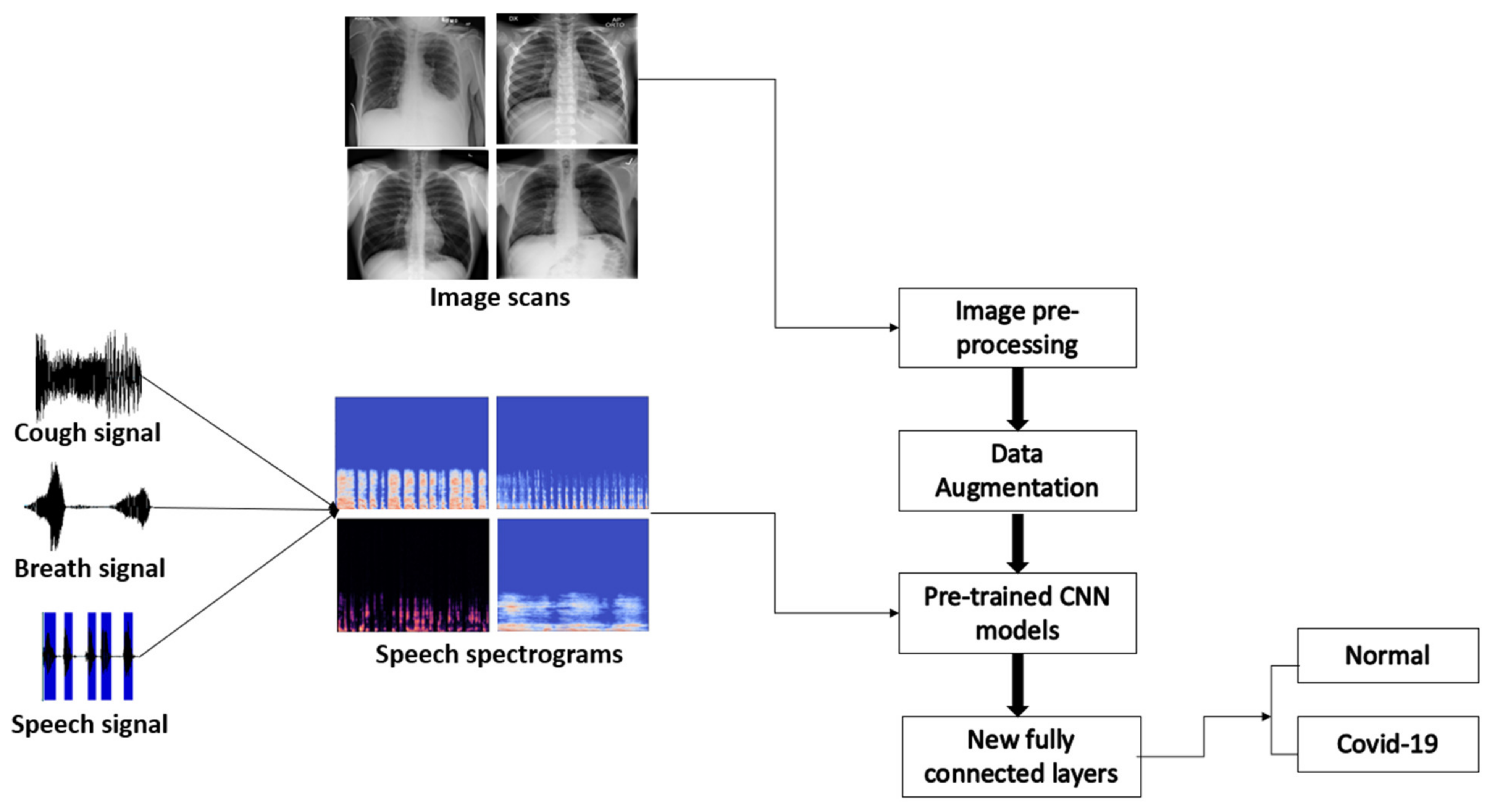
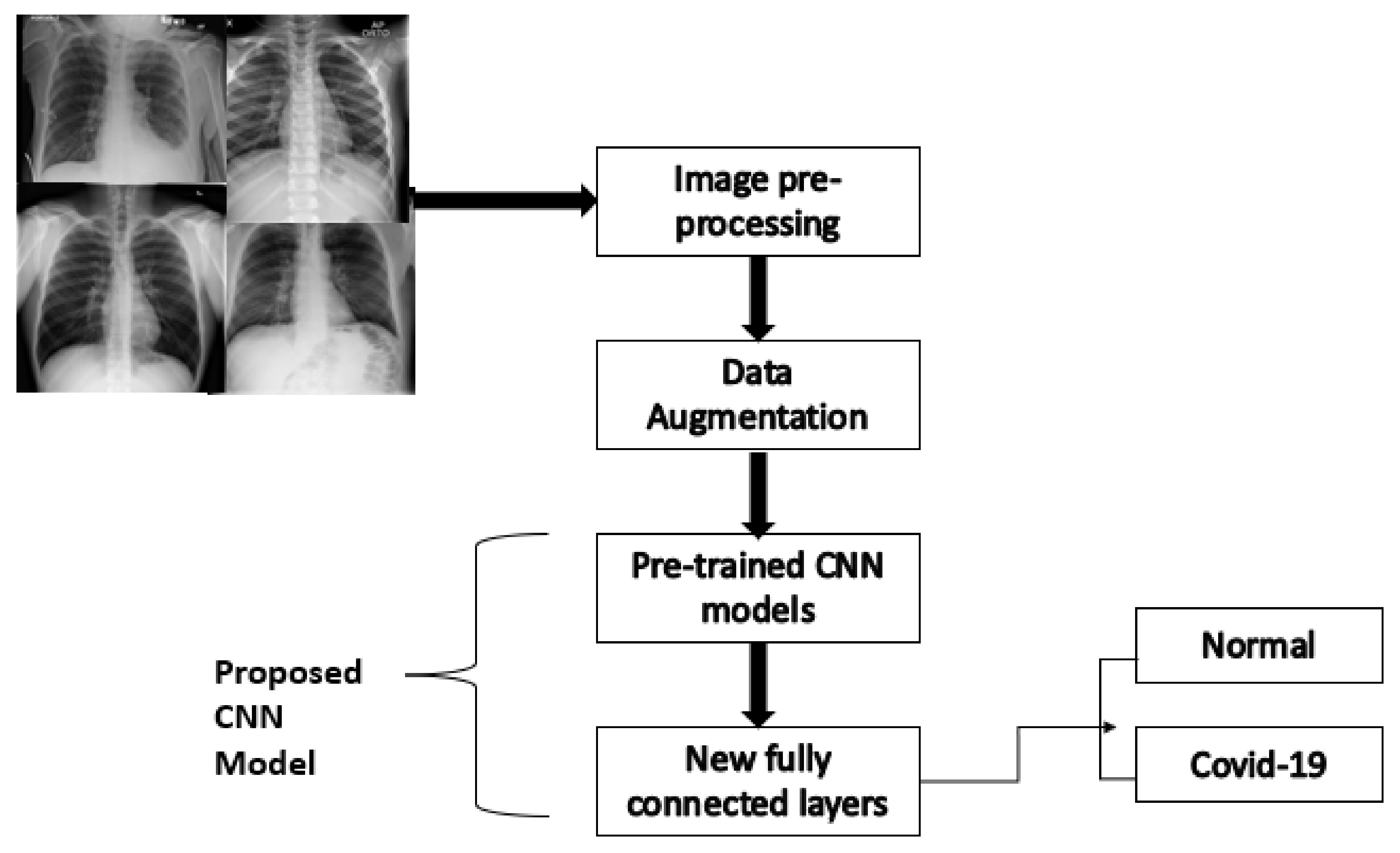
3. Image-Based Model Methodology
3.1. Image Dataset
3.2. Image Preprocessing
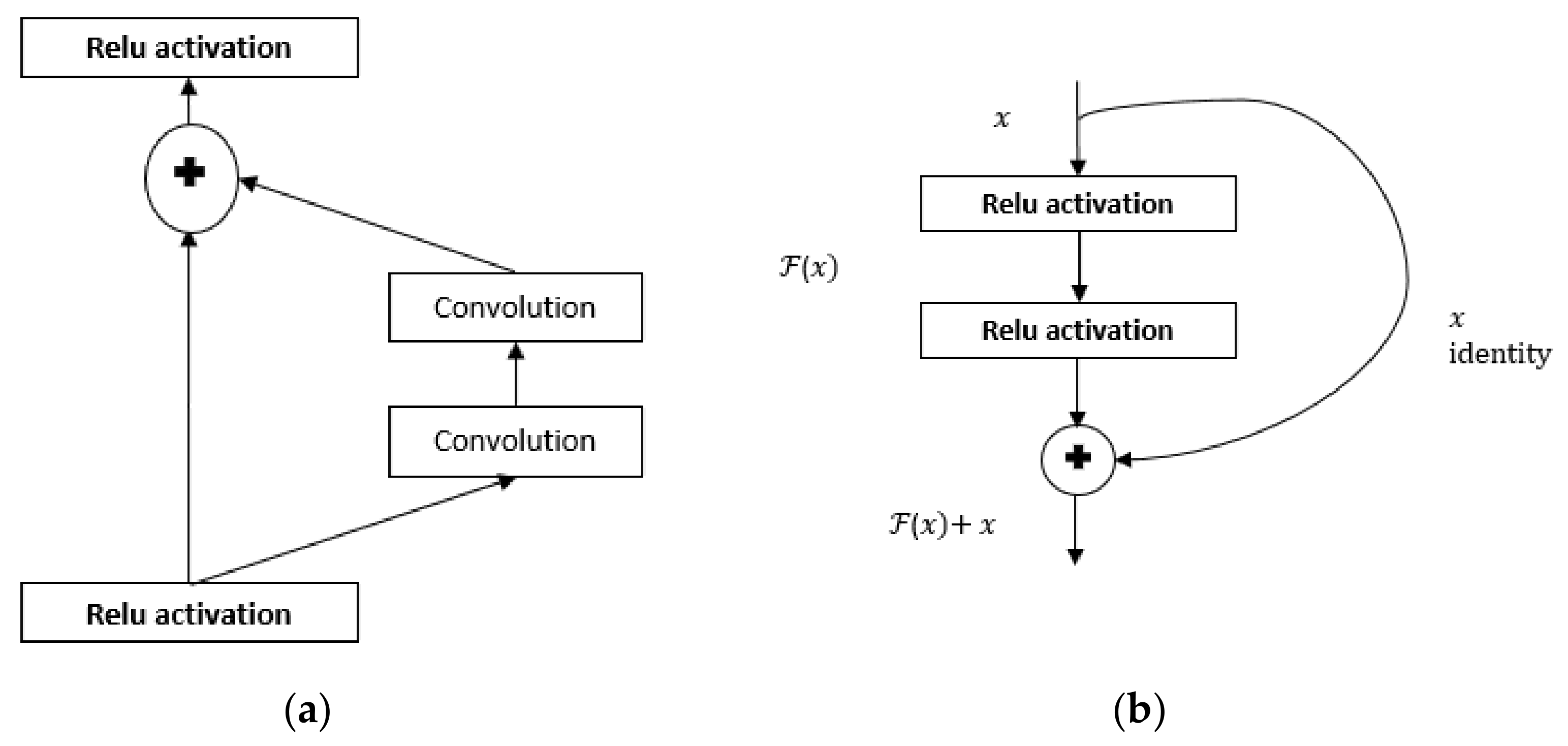
3.3. Convolution Neural Network (CNN)
- The input layer is responsible for holding the pixel value for the images.
- The convolutional layer is responsible for the determination and computation of the neurons output, which are connected to local regions of the input, by calculating the scalar product between their weights and the region which is connected to the input volume. Convolutional layers are able to reduce the model complexity by optimizing its output. They are optimized through the following hyperparameters: the depth, the zero-padding, and the stride.
- The non-linearity layer, which is the next layer after the convolutional layer. This layer can be utilized to adjust the generated output. The reason for using this layer is to saturate or limit the generated output. In this layer, the rectified linear unit (RELU) applies an activation function that converts all negative pixels to 0, which is similar to tanh and sigmoid for the same reasons.
- The pooling layers, which are responsible for performing the downsampling along with the given input’s spatial dimensionality, in addition to the reduction of the number of the parameters.
- The fully connected layers are responsible for computing the class scores.
3.4. CNN Hyperparameters
- Hidden layers: located between input and output layers.
- Padding: added layers composed of 0s to ensure the flow of the kernel over the image edge.
- Depth: used for visual recognition and refers to the third dimension of the image.
- Stride: represents the rate at which the kernel passes over the input image.
- Kernel type: the actual filter values such as sharpening, edge detection, etc.
- Kernel size: the size of the actual filter.
- Number of epochs: representing the number of iterations of the whole training dataset to the network during the training phase.
- Batch size: representing the number of patterns that are visible to the network before the weights are updated.
- Learning rate: regulating the update of the weight at the end of each patch.
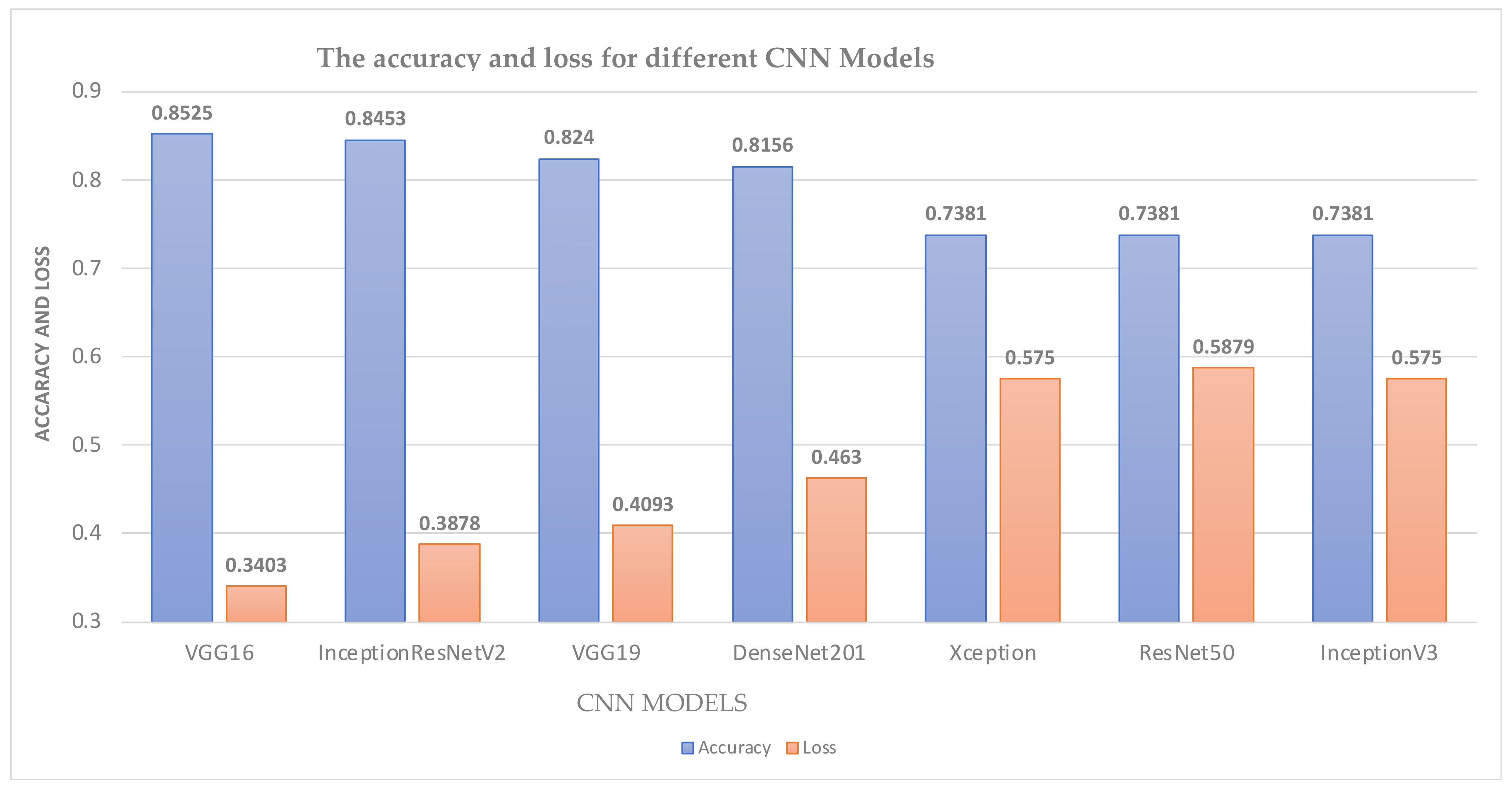
3.5. CNN Models
3.6. K-Fold Cross-Validation
3.7. Grid Search
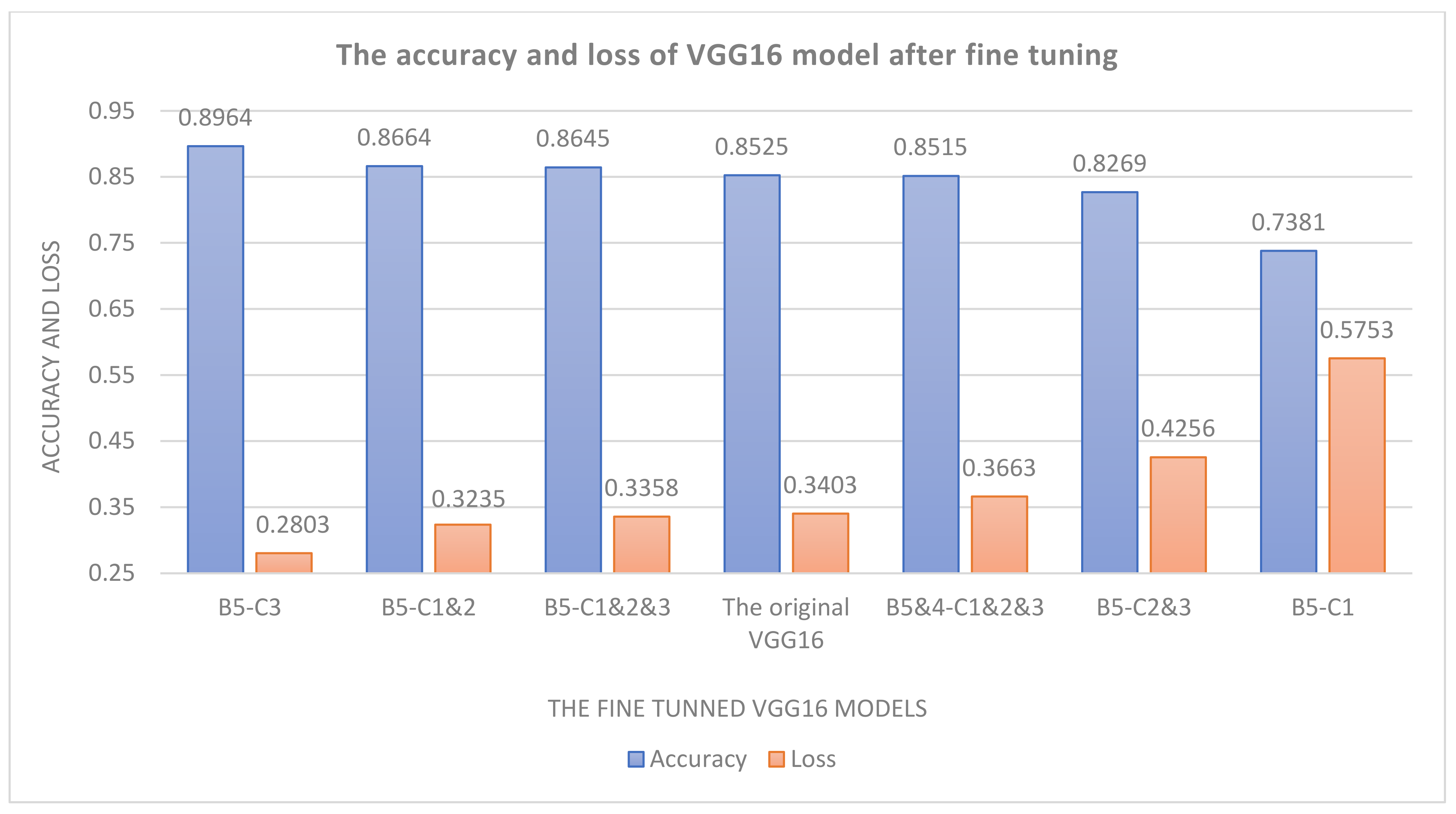
3.8. Fine-Tuning
4. Experiments and Results
4.1. Evaluation Criteria
- TP (true positive)
- FP (false positive)
- TN (true negative)
- FN (false negative)
4.2. Speech-Based Model Experimental Results
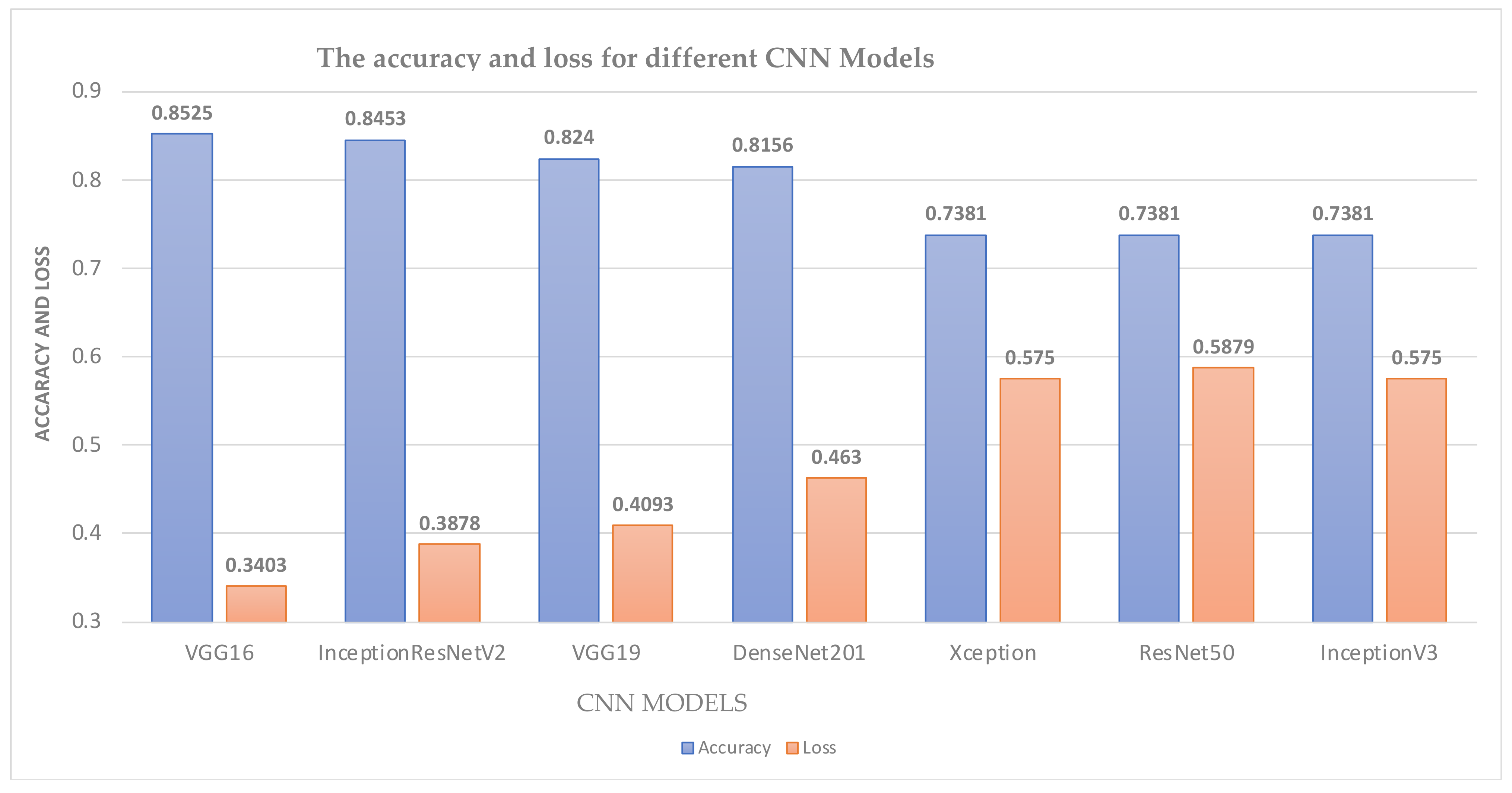
4.3. Image-Based Model Experimental Results
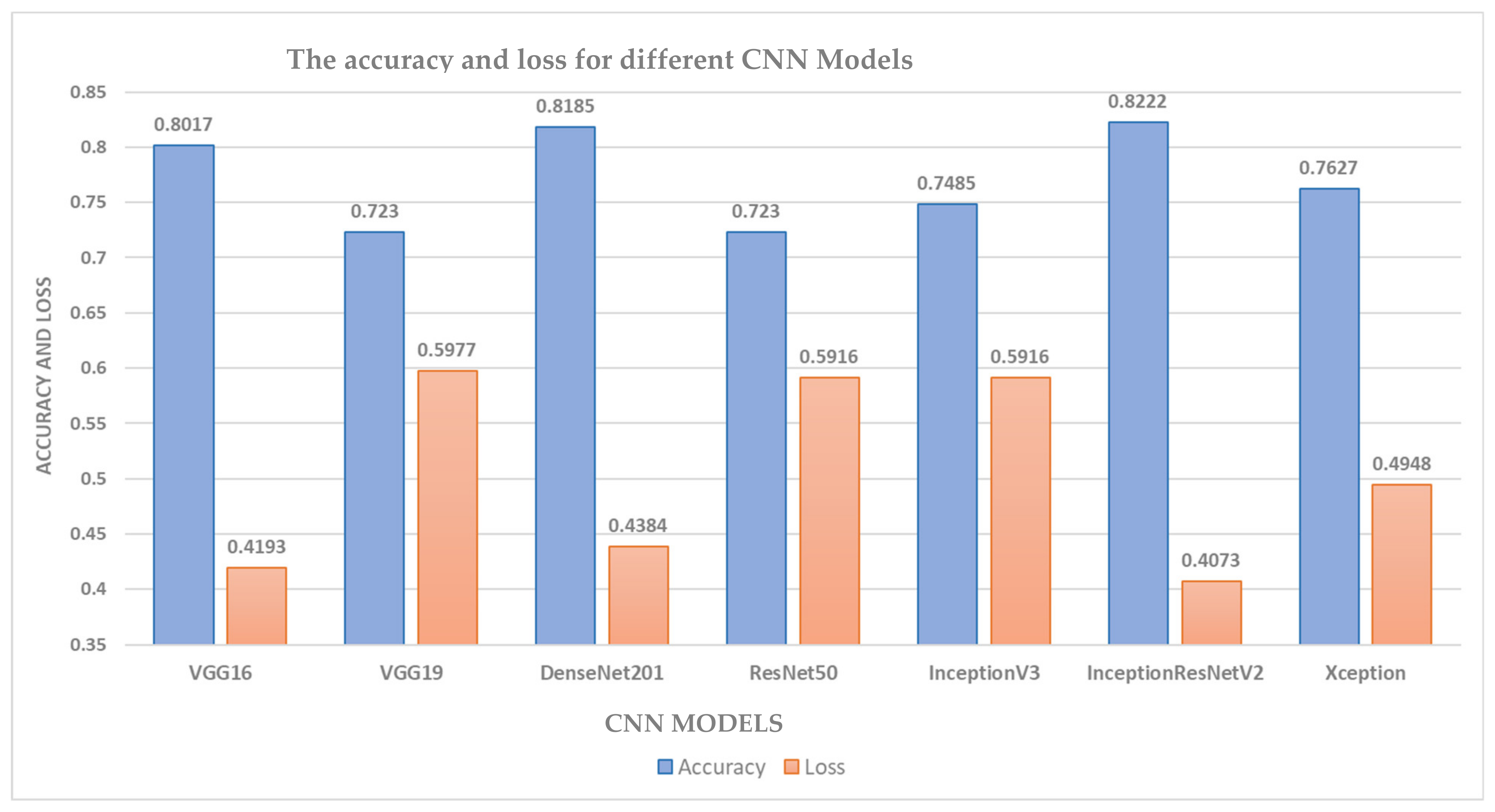
4.4. Speech-Image-Based Model Experimental Results
4.5. Statistical Significance Analysis
4.6. Comparison of the Proposed Designs with Previous Techniques
5. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Available online: https://covid19.who.int/ (accessed on 31 August 2021).
- Alsabek, M.B.; Shahin, I.; Hassan, A. Studying the Similarity of COVID-19 Sounds based on Correlation Analysis of MFCC. In Proceedings of the 2020 International Conference on Communications, Computing, Cybersecurity, and Informatics, Sharjah, United Arab Emirates, 3–5 November 2020. [Google Scholar] [CrossRef]
- Aggarwal, S.; Gupta, S.; Alhudhaif, A.; Koundal, D.; Gupta, R.; Polat, K. Automated COVID-19 detection in chest X-ray images using fine-tuned deep learning architectures. Expert Syst. 2021, e12749. [Google Scholar] [CrossRef]
- Chan, J.F.-W.; Yuan, S.; Kok, K.-H.; To, K.K.-W.; Chu, H.; Yang, J.; Xing, F.; Liu, J.; Yip, C.C.-Y.; Poon, R.W.-S.; et al. A familial cluster of pneumonia associated with the 2019 novel coronavirus indicating person-to-person transmission: A study of a family cluster. Lancet 2020, 395, 514–523. [Google Scholar] [CrossRef] [Green Version]
- Armstrong, S. Covid-19: Tests on students are highly inaccurate, early findings show. BMJ 2020, 371, m4941. [Google Scholar] [CrossRef]
- Roy, S. Physicians’ Dilemma of False-Positive RT-PCR for COVID-19: A Case Report. SN Compr. Clin. Med. 2021, 3, 255–258. [Google Scholar] [CrossRef]
- Hijazi, H.; Abu Talib, M.; Hasasneh, A.; Nassif, A.B.; Ahmed, N.; Nasir, Q. Wearable Devices, Smartphones, and Interpretable Artificial Intelligence in Combating COVID-19. Sensors 2021, 21, 8424. [Google Scholar] [CrossRef]
- Hassan, A.; Shahin, I.; Alsabek, M.B. COVID-19 Detection System using Recurrent Neural Networks. In Proceedings of the 2020 International Conference on Communications, Computing, Cybersecurity, and Informatics, Sharjah, United Arab Emirates, 3–5 November 2020. [Google Scholar] [CrossRef]
- Rajkarnikar, L.; Shrestha, S.; Shrestha, S. AI Applications to Combat COVID-19 Pandemic. Int. J. Adv. Eng. 2021, 4, 337–339. [Google Scholar]
- Alafif, T.; Tehame, A.; Bajaba, S.; Barnawi, A.; Zia, S. Machine and Deep Learning towards COVID-19 Diagnosis and Treatment: Survey, Challenges, and Future Directions. Int. J. Environ. Res. Public Health 2021, 18, 1117. [Google Scholar] [CrossRef]
- Saxena, A. Grey forecasting models based on internal optimization for Novel Corona virus (COVID-19). Appl. Soft Comput. 2021, 111, 107735. [Google Scholar] [CrossRef]
- Zhang, J.; Jiang, Z. A new grey quadratic polynomial model and its application in the COVID-19 in China. Sci. Rep. 2021, 11, 12588. [Google Scholar] [CrossRef]
- Pahar, M.; Klopper, M.; Warren, R.; Niesler, T. COVID-19 cough classification using machine learning and global smartphone recordings. Comput. Biol. Med. 2021, 135, 104572. [Google Scholar] [CrossRef]
- Deshpande, G.; Schuller, W. The DiCOVA 2021 Challenge–An Encoder-Decoder Approach for COVID-19 Recognition from Coughing Audio. In Proceedings of the Proceedings of Interspeech 2021, Brno, Czechia, 30 August–3 September 2021; pp. 931–935. [Google Scholar]
- Das, R.K.; Madhavi, M.; Li, H. Diagnosis of COVID-19 Using Auditory Acoustic Cues. Interspeech 2021, 2021, 921–925. [Google Scholar]
- Laguarta, J.; Hueto, F.; Subirana, B. COVID-19 Artificial Intelligence Diagnosis Using Only Cough Recordings. IEEE Open J. Eng. Med. Biol. 2020, 1, 275–281. [Google Scholar] [CrossRef]
- Chaudhari, G.; Jiang, X.; Fakhry, A.; Han, A.; Xiao, J.; Shen, S.; Khanzada, A. Virufy: Global applicability of crowdsourced and clinical datasets for AI detection of COVID-19 from cough audio samples. arXiv 2020, arXiv:2011.13320. [Google Scholar]
- Maghdid, H.S.; Asaad, A.T.; Ghafoor, K.Z.; Sadiq, A.S.; Mirjalili, S.; Khan, M.K. Diagnosing COVID-19 pneumonia from x-ray and CT images using deep learning and transfer learning algorithms. Int. Soc. Opt. Photonics 2021, 11734, 117340E. [Google Scholar] [CrossRef]
- Gunraj, H.; Wang, L.; Wong, A. COVIDNet-CT: A Tailored Deep Convolutional Neural Network Design for Detection of COVID-19 Cases From Chest CT Images. Front. Med. 2020, 7, 608525. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, Y.; He, X.; Xie, P. COVID-CT-Dataset: A CT Scan Dataset about COVID-19. arXiv 2020, arXiv:2003.13865. [Google Scholar]
- Ardakani, A.A.; Kanafi, A.R.; Acharya, U.R.; Khadem, N.; Mohammadi, A. Application of deep learning technique to manage COVID-19 in routine clinical practice using CT images: Results of 10 convolutional neural networks. Comput. Biol. Med. 2020, 121, 103795. [Google Scholar] [CrossRef]
- Jaiswal, A.; Gianchandani, N.; Singh, D.; Kumar, V.; Kaur, M. Classification of the COVID-19 infected patients using DenseNet201 based deep transfer learning. J. Biomol. Struct. Dyn. 2021, 39, 5682–5689. [Google Scholar] [CrossRef]
- Wang, S.; Kang, B.; Ma, J.; Zeng, X.; Xiao, M.; Guo, J.; Cai, M.; Yang, J.; Li, Y.; Meng, X.; et al. A deep learning algorithm using CT images to screen for Corona Virus Disease (COVID-19). medRxiv 2020, 31, 6096–6104. [Google Scholar] [CrossRef]
- Narin, A.; Kaya, C.; Pamuk, Z. Automatic detection of coronavirus disease (COVID-19) using X-ray images and deep convolutional neural networks. Pattern Anal. Appl. 2021, 24, 1207–1220. [Google Scholar] [CrossRef]
- Sharma, N.; Krishnan, P.; Kumar, R.; Ramoji, S.; Chetupalli, S.R.; Ghosh, P.K.; Ganapathy, S. Coswara–A Database of Breathing, Cough, and Voice Sounds for COVID-19 Diagnosis. arXiv 2020, arXiv:2005.10548. [Google Scholar]
- Akçay, M.B.; Oğuz, K. Speech emotion recognition: Emotional models, databases, features, preprocessing methods, supporting modalities, and classifiers. Speech Commun. 2020, 116, 56–76. [Google Scholar] [CrossRef]
- Keerio, A.; Mitra, B.K.; Birch, P.; Young, R.; Chatwin, C. On preprocessing of speech signals. World Acad. Sci. Eng. Technol. 2009, 35, 818–824. [Google Scholar] [CrossRef]
- Ibrahim, Y.A.; Odiketa, J.C.; Ibiyemi, T.S. Preprocessing technique in automatic speech recognition for human computer interaction: An overview. Ann. Comput. Sci. Ser. 2017, 15, 186–191. [Google Scholar]
- Available online: https://ai.googleblog.com/2019/04/?hl=es_CL (accessed on 14 July 2021).
- Kurzekar, P.K.; Deshmukh, R.R.; Waghmare, V.B.; Shrishrimal, P. A Comparative Study of Feature Extraction Techniques for Speech Recognition System. Int. J. Innov. Res. Sci. Eng. Technol. 2014, 3, 18006–18016. [Google Scholar] [CrossRef]
- Shahin, I.; Hindawi, N.; Nassif, A.B.; Alhudhaif, A.; Polat, K. Novel dual-channel long short-term memory compressed capsule networks for emotion recognition. Expert Syst. Appl. 2021, 188, 116080. [Google Scholar] [CrossRef]
- Nassif, A.B.; Shahin, I.; Hamsa, S.; Nemmour, N.; Hirose, K. CASA-based speaker identification using cascaded GMM-CNN classifier in noisy and emotional talking conditions. Appl. Soft Comput. 2021, 103, 107141. [Google Scholar] [CrossRef]
- Nassif, A.B.; Shahin, I.; Elnagar, A.; Velayudhan, D.; Alhudhaif, A.; Polat, K. Emotional speaker identification using a novel capsule nets model. Expert Syst. Appl. 2022, 193, 116469. [Google Scholar] [CrossRef]
- Muda, L.; Begam, M.; Elamvazuthi, I. Voice Recognition Algorithms using Mel Frequency Cepstral Coefficient (MFCC) and Dynamic Time Warping (DTW) Techniques. arXiv 2010, arXiv:1003.4083. [Google Scholar]
- Molau, S.; Pitz, M.; Schlüter, R.; Ney, H. Computing mel-frequency cepstral coefficients on the power spectrum. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Salt Lake City, UT, USA, 7–11 May 2001; Volume 1, pp. 73–76. [Google Scholar] [CrossRef] [Green Version]
- Shahin, I.; Nassif, A.B.; Hamsa, S. Emotion Recognition Using Hybrid Gaussian Mixture Model and Deep Neural Network. IEEE Access 2019, 7, 26777–26787. [Google Scholar] [CrossRef]
- Asmita, C.; Savitha, T.; Upadhya, K. Voice Recognition Using MFCC Algorithm. Int. J. Innov. Res. Adv. Eng. 2014, 1, 158–161. Available online: www.ijirae.com (accessed on 14 July 2021).
- Tawfik, K. Towards The Development of Computer Aided Speech Therapy Tool in Arabic Language Using Artificial Intelligence. Ph.D. Thesis, Cardiff Metropolitan University, Wales, UK, 2016. [Google Scholar]
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Speech Recognition Using Deep Neural Networks: A Systematic Review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Shewalkar, A.; Nyavanandi, D.; Ludwig, S.A. Performance Evaluation of Deep Neural Networks Applied to Speech Recognition: RNN, LSTM and GRU. J. Artif. Intell. Soft Comput. Res. 2019, 9, 235–245. [Google Scholar] [CrossRef] [Green Version]
- Geiger, J.T.; Zhang, Z.; Weninger, F.; Schuller, B.; Rigoll, G. Robust speech recognition using long short-term memory recurrent neural networks for hybrid acoustic modelling. In Proceedings of the Interspeech 2014: 15th Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014; pp. 631–635. [Google Scholar]
- Available online: https://www.kaggle.com/c/rsna-pneumonia-detection-challenge/data (accessed on 14 July 2021).
- Available online: https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia (accessed on 14 July 2021).
- Available online: https://bimcv.cipf.es/bimcv-projects/bimcv-covid19/#1590858128006-9e640421-6711 (accessed on 14 July 2021).
- Available online: https://github.com/ml-workgroup/covid-19-image-repository/tree/master/png (accessed on 14 July 2021).
- Available online: https://sirm.org/category/senza-categoria/covid-19/ (accessed on 14 July 2021).
- Available online: https://eurorad.org (accessed on 14 July 2021).
- Available online: https://github.com/ieee8023/covid-chestxray-dataset (accessed on 14 July 2021).
- Available online: https://figshare.com/articles/COVID-19_Chest_X-Ray_Image_Repository/12580328 (accessed on 14 July 2021).
- Taylor, L.; Nitschke, G. Improving Deep Learning with Generic Data Augmentation Luke. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence, SSCI 2018, Bengaluru, India, 18–21 November 2018; pp. 1542–1547. [Google Scholar] [CrossRef]
- Gómez-Ríos, A.; Tabik, S.; Luengo, J.; Shihavuddin, A.; Krawczyk, B.; Herrera, F. Towards highly accurate coral texture images classification using deep convolutional neural networks and data augmentation. Expert Syst. Appl. 2019, 118, 315–328. [Google Scholar] [CrossRef] [Green Version]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the ICET 2017: The International Conference on Engineering & Technology 2017, Antalya, Turkey, 21–24 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Aszemi, N.M.; Dominic, P.D.D. Hyperparameter optimization in convolutional neural network using genetic algorithms. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 269–278. [Google Scholar] [CrossRef]
- Theckedath, D.; Sedamkar, R.R. Detecting Affect States Using VGG16, ResNet50 and SE-ResNet50 Networks. SN Comput. Sci. 2020, 1, 79. [Google Scholar] [CrossRef] [Green Version]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Esesn, B.C.V.; Awwal, A.A.S.; Asari, V.K. The History Began from AlexNet: A Comprehensive Survey on Deep Learning Approaches. arXiv 2018, arXiv:1803.01164. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 2017, pp. 1800–1807. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 2017, pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; Volume 2016, pp. 2818–2826. [Google Scholar] [CrossRef] [Green Version]
- Berrar, D. Cross-validation. Encycl. Bioinform. Comput. Biol. 2018, 1, 542–545. [Google Scholar] [CrossRef]
- Peña Yañez, A. El anillo esofágico inferior. Rev. Esp. Enferm. Apar. Dig. 1967, 26, 505–516. [Google Scholar]
- Kääriäinen, M. Semi-supervised model selection based on cross-validation. In Proceedings of the 2006 IEEE International Joint Conference on Neural Network Proceedings, Montreal, QC, Canada, 16–21 July 2006; pp. 1894–1899. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Ridella, S.; Sterpi, D. K-Fold Cross Validation for Error Rate Estimate in Support Vector Machines. In Proceedings of the 2014 IEEE International Conference on Data Mining, Shenzhen, China, 14 December 2014; pp. 291–297. [Google Scholar]
- Liashchynskyi, P.; Liashchynskyi, P. Grid Search, Random Search, Genetic Algorithm: A Big Comparison for NAS. arXiv 2017, arXiv:1912.06059. [Google Scholar]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. AI 2006: Advances in Artificial Intelligence. In Proceedings of the 19th Australian Joint Conference on Artificial Intelligence, Hobart, Australia, 4–8 December 2006; pp. 1015–1021. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Epoch | Batch Size | Dropout | Learning Rate | Accuracy | F1 Score | Precision | Recall |
|---|---|---|---|---|---|---|---|
| 50 | 16 | 0.1 | 0.01 | 73.8% | 76.4% | 79.2% | 73.8% |
| 0.001 | 94.3% | 94.4% | 94.6% | 94.3% | |||
| 0.0001 | 86.6% | 87.5% | 88.4% | 86.6% | |||
| 0.3 | 0.01 | 72.1% | 75.2% | 78.6% | 72.1% | ||
| 0.001 | 93.2% | 93.6% | 94.0% | 93.2% | |||
| 0.0001 | 83.2% | 84.1% | 85.1% | 83.2% | |||
| 0.5 | 0.01 | 60.1% | 65.3% | 71.5% | 60.1% | ||
| 0.001 | 92.6% | 92.6% | 92.6% | 92.6% | |||
| 0.0001 | 75.2% | 77.0% | 78.8% | 75.2% | |||
| 32 | 0.1 | 0.01 | 86.9% | 87.4% | 87.9% | 86.9% | |
| 0.001 | 97.4% | 97.4% | 97.4% | 97.4% | |||
| 0.0001 | 84.3% | 85.4% | 86.5% | 84.3% | |||
| 0.3 | 0.01 | 71.5% | 74.2% | 77.0% | 71.5% | ||
| 0.001 | 97.2% | 97.2% | 97.2% | 97.2% | |||
| 0.0001 | 78.6% | 80.7% | 82.9% | 78.6% | |||
| 0.5 | 0.01 | 69.5% | 72.9% | 76.7% | 69.5% | ||
| 0.001 | 92.9% | 93.4% | 93.9% | 92.9% | |||
| 0.0001 | 67.0% | 69.4% | 72.1% | 67.0% | |||
| 64 | 0.1 | 0.01 | 91.7% | 92.4% | 93.1% | 91.7% | |
| 0.001 | 93.4% | 93.7% | 94.0% | 93.4% | |||
| 0.0001 | 73.2% | 75.8% | 78.6% | 73.2% | |||
| 0.3 | 0.01 | 79.2% | 80.6% | 82% | 79.2% | ||
| 0.001 | 96.3% | 96.6% | 96.8% | 96.3% | |||
| 0.0001 | 66.4% | 69.9% | 73.7% | 66.4% | |||
| 0.5 | 0.01 | 68.7% | 71.9% | 75.5% | 68.7% | ||
| 0.001 | 94.0% | 94.2% | 94.3% | 94.0% | |||
| 0.0001 | 61.8% | 66.6% | 72.1% | 61.8% | |||
| 100 | 16 | 0.1 | 0.01 | 84.3% | 86.4% | 88.6% | 84.3% |
| 0.001 | 98.6% | 98.6% | 98.6% | 98.6% | |||
| 0.0001 | 92.6% | 92.7% | 92.9% | 92.6% | |||
| 0.3 | 0.01 | 76.9% | 79.5% | 82.3% | 76.9% | ||
| 0.001 | 95.4% | 95.7% | 96.0% | 95.4% | |||
| 0.0001 | 93.2% | 93.3% | 93.4% | 93.2% | |||
| 0.5 | 0.01 | 77.2% | 80.1% | 83.1% | 77.2% | ||
| 0.001 | 94.3% | 94.3% | 94.3% | 94.3% | |||
| 0.0001 | 88.3% | 88.6% | 88.3% | 88.3% | |||
| 32 | 0.1 | 0.01 | 91.5% | 92.4% | 93.3% | 91.5% | |
| 0.001 | 98.9% | 98.9% | 98.9% | 98.9% | |||
| 0.0001 | 84.9% | 85.4% | 85.9% | 84.9% | |||
| 0.3 | 0.01 | 76.1% | 78.0% | 79.9% | 76.1% | ||
| 0.001 | 98.0% | 98.0% | 98.0% | 98.0% | |||
| 0.0001 | 94.3% | 94.4% | 94.6% | 94.3% | |||
| 0.5 | 0.01 | 87.5% | 88.2% | 89.0% | 87.5% | ||
| 0.001 | 93.4% | 93.7% | 94.0% | 93.4% | |||
| 0.0001 | 89.2% | 89.6% | 89.9% | 89.2% | |||
| 64 | 0.1 | 0.01 | 90.3% | 90.7% | 91.1% | 90.3% | |
| 0.001 | 96.0% | 96.0% | 96.0% | 96.0% | |||
| 0.0001 | 90.9% | 91.3% | 91.7% | 90.9% | |||
| 0.3 | 0.01 | 87.5% | 88.3% | 89.2% | 87.5% | ||
| 0.001 | 97.4% | 97.4% | 97.4% | 97.4% | |||
| 0.0001 | 90.3% | 90.7% | 91.1% | 90.3% | |||
| 0.5 | 0.01 | 59.8% | 65.1% | 71.4% | 59.8% | ||
| 0.001 | 96.9% | 97.1% | 97.1% | 96.9% | |||
| 0.0001 | 86.9% | 87.6% | 88.4% | 86.9% |
| Classifier | LSTM | VGG16 | InceptionResnetV2 |
|---|---|---|---|
| LSTM | NA | 0.00018 | 0.0008 |
| VGG16 | 0.0018 | NA | 0.03318 |
| InceptionResnetV2 | 0.0008 | 0.03318 | NA |
| Work | Techniques | Description | Performance Metrics |
|---|---|---|---|
| Mohamed Bader et al. [2] | MFCC features | Performs early diagnosis of COVID-19 by evaluating the MFCC acoustic features and providing analysis for the correlation coefficients | 0.42 average correlation coefficient (low positive correlation) |
| Hassan Abdelfatah et al. [8] | Long short-term memory (LSTM) | Performs early diagnosis of COVID-19 and evaluates different acoustic features | Accuracy: 98.2% Precision: 100% Recall: 97.7% F1-score: 98.8% AUC: 98.8% |
| Pahar Madhurananda et al. [13] | Multilayer perceptron (MLP), logistic regression (LR), long short-term memory (LSTM), support vector machine (SVM), convolutional neural network (CNN), and residual-based neural network (RSNET) | Discriminating COVID-19-positive coughs from COVID-19-negative coughs | Accuracy: 95.33% AUC: 97.6% Specificity: 98% Sensitivity: 93% |
| Deshpande et al. [14] | Bi-directional long short-term | Providing a COVID-19 recognition system based on cough analysis | AUC: 64.42% |
| Kumar et al. [15] | Logistic regression (LR), random forest (RF) multilayer perceptron (MLP). | Providing an early screening for COVID-19 based on cough analysis | AUC: 81.89 |
| Laguarta Jord et al. [16] | MFCC, CNN, Rsnet50 | Providing an early screening for COVID-19 based on cough analysis | Accuracy: 97.3% |
| Gunavant et al. [17] | MFCC | Providing an early screening for COVID-19 based on cough analysis | ROC: 77.1% AUC: 77.1% Accuracy: 78.3% |
| Maghdid et al. [18] | CNN and Alex-Net | COVID-19 detection based on the X-rays and CT scans of patients | Accuracy: 98% |
| Wang et al. [19] | Densenet Resnet-50 Nasnet-Amobile | Detecting the presence of COVID-19 from chest CT scans | Accuracy: 99.1% |
| Jaiswal et al. [22] | Densenet-201 pretrained CNN model | Detecting the presence of COVID -19 from chest CT scans | Accuracy: 97% F1-score: 96.29% Recall: 96.29% Precision: 96.29% |
| Weng et al. [23] | Inception pretrained CNN model | Detecting the presence of COVID-19 from chest CT-scans | Accuracy: 89.5% Specificity: 88% sensitivity: 87% |
| Narin, Ali et al. [24] | ResNet50, ResNet101, ResNet152, InceptionV3 and Inception-ResNetV2 | Detection of coronavirus or pneumonia-infected patients by the chest X-ray radiographs | Accuracy: 99.7% |
| Proposed System | Long short-term memory (LSTM) | COVID-19 detection system based on cough, voice, and breathing sounds | Accuracy: 98.9% Precision: 98.9% Recall: 98.9% F1-score: 98.9% |
| Proposed System | VGG16, VGG19, ResNet50, DenseNet201, Xception, InceptionV3 and Inception-ResNetV2 | COVID-19 detection system based on cough, voice, and breathing spectrograms, and chest X-ray images | Accuracy: 82.22% |
| Proposed System | VGG16, VGG19, ResNet50, DenseNet201, Xception, InceptionV3 and Inception-ResNetV2 | COVID-19 detection system based on chest X-ray images | Accuracy: 89.64% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nassif, A.B.; Shahin, I.; Bader, M.; Hassan, A.; Werghi, N. COVID-19 Detection Systems Using Deep-Learning Algorithms Based on Speech and Image Data. Mathematics 2022, 10, 564. https://doi.org/10.3390/math10040564
Nassif AB, Shahin I, Bader M, Hassan A, Werghi N. COVID-19 Detection Systems Using Deep-Learning Algorithms Based on Speech and Image Data. Mathematics. 2022; 10(4):564. https://doi.org/10.3390/math10040564
Chicago/Turabian StyleNassif, Ali Bou, Ismail Shahin, Mohamed Bader, Abdelfatah Hassan, and Naoufel Werghi. 2022. "COVID-19 Detection Systems Using Deep-Learning Algorithms Based on Speech and Image Data" Mathematics 10, no. 4: 564. https://doi.org/10.3390/math10040564
APA StyleNassif, A. B., Shahin, I., Bader, M., Hassan, A., & Werghi, N. (2022). COVID-19 Detection Systems Using Deep-Learning Algorithms Based on Speech and Image Data. Mathematics, 10(4), 564. https://doi.org/10.3390/math10040564