
TAID-LCA: Segmentation Algorithm Based on Ternary Trees

 ,
,  and
and {kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. TAID-LCA Algorithm General Steps
- Find a latent variable from the manifest ones employing the LCA and regard this one as the target variable.
- The root node is made up of the complete sample.
- Repeat while there is at least one non-terminal node (recursive partition loop):
- (a)
- Choose a non-terminal node and perform the following steps within it;
- (b)
- Choose the best explanatory variable concerning the target variable, according to the index;
- (c)
- (d)
- Segment according to the weak, left strong and right strong categories (see Section 4);
- (e)
- Test whether the new nodes are terminal or not, regarding the stop criteria (see Section 5).
3. Latent Multivariate Response
4. Two-Way Contingency Tables with Response Variable
- a column variable X that takes values in the set , and
- a row variable Y that takes values in the set ,
4.1. τ Index
- is the relative frequency of the event ;
- is the value for the entry of the contingency table, i.e., the absolute frequency of the event ;
- is the total sample size;
- is the relative frequency of the event ; and
- is the relative frequency of the event .
- if there is total independence, i.e., if the null hypothesis is satisfied.
- in the case of ideal explanation, i.e., if there is only one non-null value in each column, this suggests that the value of Y is univocally determined given the value of X.
4.2. Explanation Significance
4.3. Decomposition of τ
- , fulfills ,
- , fulfills , and
- .
- for the column categories, and
- for the row categories.
| Condition | Category Type |
| weak category | |
| right strong category | |
| left strong category |
5. Terminal Segments Criteria
5.1. Impurity Measures
- C is the number of categories of the response variable (i.e., the number of classes),
- is the number of subjects of the segment that belong to class c,
- the is the total number of subjects in the segment, and
- is the proportion of subjects belonging to class c.
5.1.1. Gini Index
5.1.2. Cross-Entropy Index
5.1.3. Graphical Behavior
- Gini: ,
- Entropy: .
5.2. Stop Criteria
- The sample size of the segment is less than a previously specified percentage of the total sample size.
- Both of the following are fulfilled simultaneously:
- the explanation significance is less than the required one, this is, the p-value of the CATANOVA index is greater than the specified significance level; and
- the impurity level, measured from the chosen index (Gini or Cross-Entropy) is less than the specified threshold.
6. Post-Pruning
- Approaches that stop the growing of the tree before it classifies perfectly the dataset.
- Approaches that allow over-fitting initially and later remove some subtrees of the tree, replacing them by the corresponding terminal nodes, this process is generally called post-pruning, inspired in the act of cutting branches from a tree.
- To use a subset of the dataset, called the training set, to fit the model, and use the remaining data to assess the pruning utility, these data are called the validation set.
- To use all the data for training and apply a statistical test to estimate the likelihood of improvement in the generalization model, given by the expansion or pruning of a node.
- To use an explicit measure of the complexity for the training set and the decision tree, stopping the growth of the tree when this measure is minimized.
6.1. Rule Based Post-Pruning
- Infer the decision tree from the training set, allowing over-fitting.
- Convert the generated tree in an equivalent set of rules, creating a rule for each path from the root to a terminal node. Where each test for the value of a variable becomes an antecedent (precondition) of the rule, and the classification in the terminal node becomes the conclusion of the rule (postcondition).
- Prune (generalize) each rule by removing some of the preconditions, provided that this leads to an improvement in the rule precision concerning the validation set (see below).
- Rank the pruned rules decreasingly according to their estimated precision and consider such a priority order when classifying new instances.
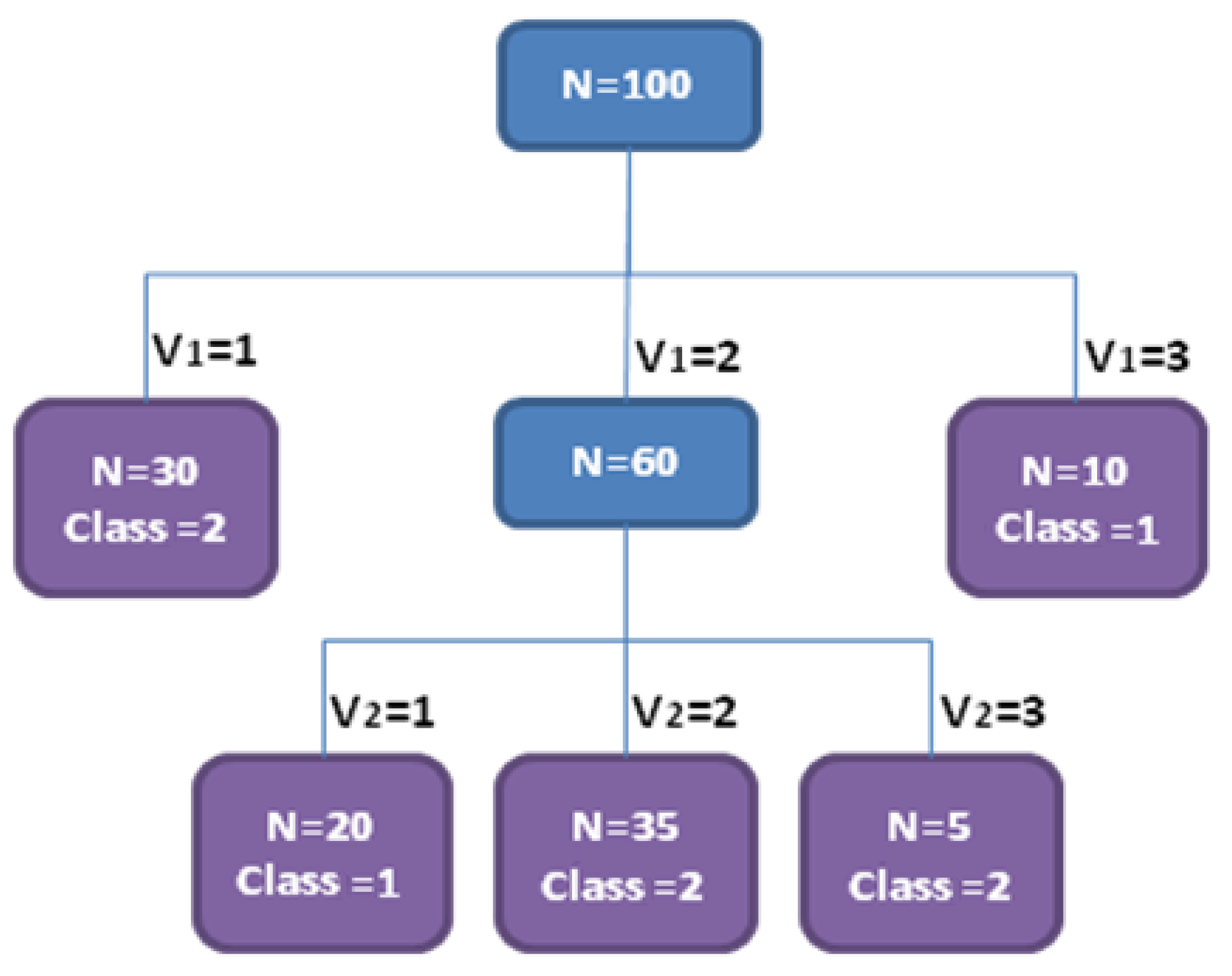
| Class 1|Class 2 | V2 | Total | |||
| 1 | 2 | 3 | |||
| V1 | 1 | 3|0 | 1|9 | 2|0 | 6|9 |
| 2 | 6|2 | 08|12 | 3|3 | 17|17 | |
| 3 | 0|1 | 0|6 | 0|1 | 0|8 | |
| Total | 9|3 | 09|27 | 5|4 | 23|34 | |
| No. | Premise | Conclusion | Precision |
| 1 | V1 = 1 | Class = 2 | 60% |
| 2 | V1 = 2, V2 = 1 | Class = 1 | 75% |
| 3 | V1 = 2, V2 = 2 | Class = 2 | 60% |
| 4 | V1 = 2, V2 = 3 | Class = 1 | 50% |
| 5 | V1 = 3 | Class = 1 | 00% |
- (3.1) If V1 = 2 then Class = 2, or
- (3.2) If V2 = 2 then Class = 2;
6.2. Strengths of Rule Based Post-Pruning Methods
- The post-pruning of rules ensures greater flexibility and widest exploration of the hypothesis space. Since each path in the tree (from the root to a leaf (terminal node)) becomes into a different rule, the antecedents (precondition) can be removed iteratively in any order, being possible to consider any combination of antecedents of the rule. On the other hand, whether the growing of the tree is truncated or the post-pruning is performed over the tree, the search space is more limited, since, in the corresponding set of classification rules, any pair of rules is constrained to have a common trunk of antecedents.
- The conversion to rules avoids the removal priority induced by the level of the nodes.
- Generally, the generated models are more readable. For many people rules are generally easier to understand than tree models. Furthermore, the set of rules is simplified iteratively due to the the removal of either antecedents or complete rules.
6.3. Measuring Goodness of Fit for a Sorted List of Rules
| Prediction | |||
| YES | NO | ||
| Real | YES | True Positives (TP) | False Negatives (FN) |
| NO | False Positives (FP) | True Negatives (TN) | |
6.4. Simulated Annealing as a Search Strategy
6.5. Simulated Annealing for TAID Rules
- A candidate solution consists of a sorted list of rules (that represent our model).
- The initial solution is obtained from the TAID tree (with rules sorted decreasingly according to their precision).
- The neighbors (candidate successors) of a solution are generated by considering the elimination of one antecedent in each rule and any permutation of the rules.
- The F-measure (see Section 6.3) is considered as a function to be maximized, i.e., the energy of the system is the opposite of the F-measure. The F-measure of the model is computed according to the validation set.
7. TAID-LCA Implementation
- Browse and load the dataset file (input) to be analyzed. Different column separator characters can be specified. New columns can be added, and the values for the variables can be set or modified.
- Specify the explanatory and manifest variables. Optionally, a frequencies column for the dataset records can be specified.
- Specify the LCA parameters.
- –
- The maximum number of iterations of the Expectation-Maximization (EM) algorithm launched by the LCA.
- –
- The number of repetitions (initializations) of the EM algorithm.
- –
- The range for the number of classes (different models) to be considered.
- Set the parameters for the stop conditions of the segmentation algorithm.
- –
- The minimum ratio of items that a node should contain with respect to the total sample size can be partitioned.
- –
- The minimum p-value associated to the CATANOVA index in the significance test (a p-value smaller than this threshold suggests to continue partitioning).
- –
- The impurity index to be used: Gini or Cross-Entropy.
- –
- The impurity tolerance (an impurity greater than this threshold suggests that partitioning should continue).
- Show the fit parameters for the LCA models (marginal and posterior probabilities), as well as some goodness of fit indicators.
- Show a graphical representation of the tree generated by the algorithm, it can be saved as image in different file formats: PNG, JPG, BMP, TIFF or PDF.
- Know details about the segmentation in each node:
- –
- The variable and collapsed categories used in the segmentation that generated the node.
- –
- The number of items contained in the node.
- –
- The proportions corresponding to each class.
- –
- The index value for the variable of greatest explanatory capability.
- –
- The CATANOVA index p-value.
- –
- The impurity measure value.
- Show a graphical representation in the plane of the NSCA between the response variable and the best explanatory one in non-terminal nodes.
- Generate a set of rules from the tree model.
- Perform the rule based post-pruning in a SA algorithm and compare the models before and after the pruning.
7.1. TAID-LCA Application
- Find a latent variable of the manifested variables employing the LCA and consider this one as the target variable.
- The root node is made up of the complete sample. Repeat while there is at least one non-terminal node (recursive partition loop).
- Choose a non-terminal node and perform the following steps within it
- Choose the best explanatory variable concerning the target variable, according to the index.
- Perform the Non-Symmetrical Correspondence Analysis (NSCA) for the best explanatory variable and the target one.
- Segment according to the weak, left strong, and right strong categories,
- Test whether the new nodes are terminal or not, regarding the stop criteria.
7.2. Variables Used
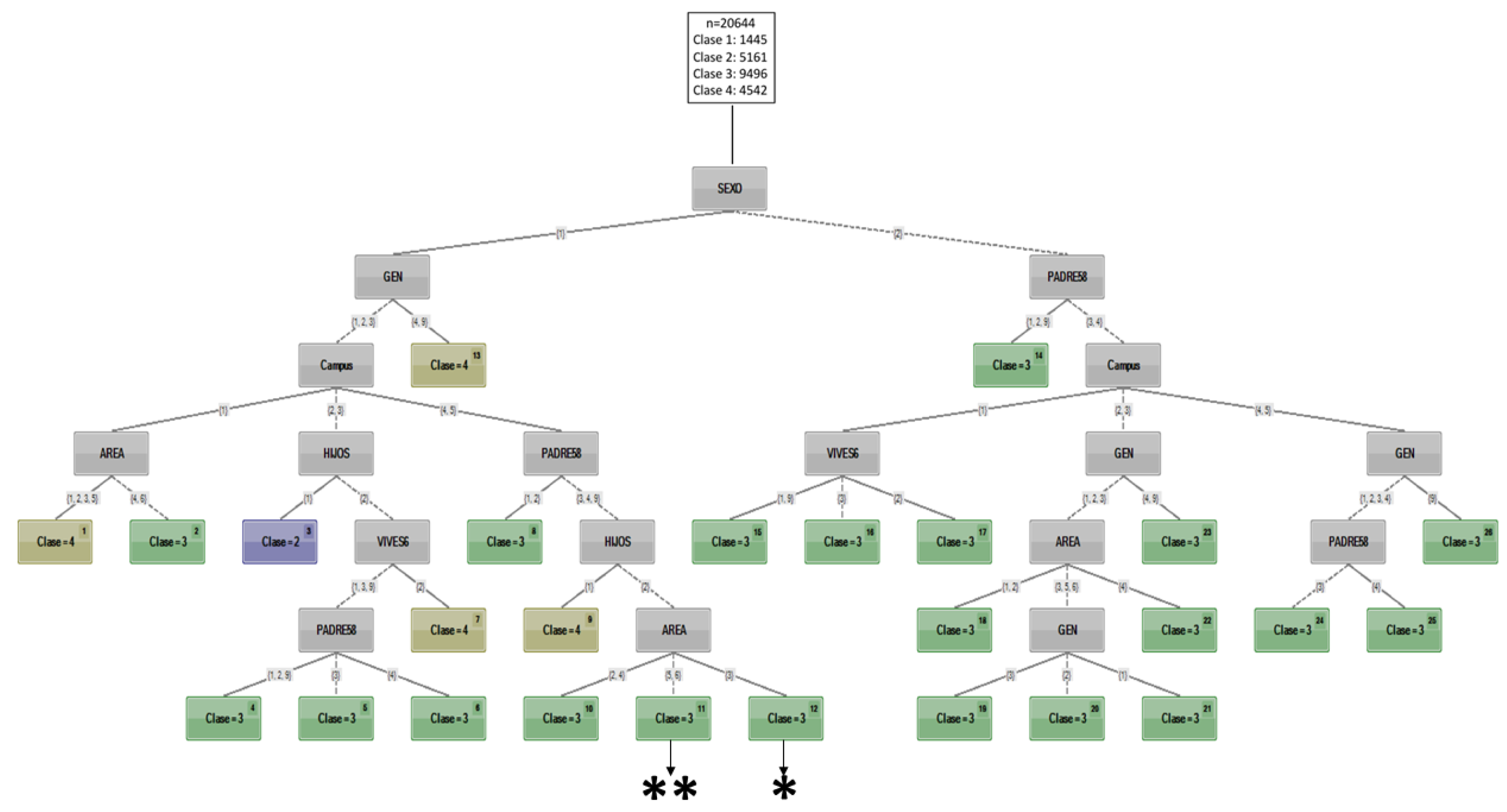
- Class 1: Smokers-alcohol abusers and have consumed Cannabis.
- Class 2: Moderate-alcohol drinkers and who get drunk.
- Class 3: Moderate-alcohol drinkers who get drunk.
- Class 4: Smokers and moderate-alcohol consumers
- ✱
- Male students in port and mountain regions, from the economy department, are mostly classified in latent class 3.
- ✱✱
- Male students in capital regions, from the arts department, are mostly classified in latent class 3.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kass, G. An Exploratory Technique for Investigating Large Quantities of Categorical Data. J. Appl. Stat. 1980, 29, 127–199. [Google Scholar] [CrossRef]
- Morgan, J.; Sonquist, J. Problems in the Analysis of Survey Data and A Proposal. J. Am. Satistical Assoc. 1963, 67, 768–772. [Google Scholar] [CrossRef]
- Antipov, E.; Pokryshevskaya, E. Applying CHAID for logistic regression diagnostics and classification accuracy improvement. J. Target. Meas. Anal. Mark. 2010, 18, 109–117. [Google Scholar] [CrossRef]
- Antipov, E.; Pokryshevskaya, E. Profiling satisfied and dissatisfied hotel visitors using publicly available data from a booking platform. Int. J. Hosp. Manag. 2017, 67, 1–10. [Google Scholar]
- StatSoft. STATISTICA 10.0; StatSoft, Inc.: Tulsa, OK, USA, 2010. [Google Scholar]
- IBM Corp. IBM SPSS Statistics for Windows, Version 27.0; IBM Corporation: Endicott, NY, USA, 2020. [Google Scholar]
- Hothorn, T.; Zeileis, A. partykit: A modular toolkit for recursive partytioning in R. J. Mach. Learn. Res. 2015, 16, 3905–3909. [Google Scholar]
- Breiman, L.; Friedman, J.; Olsen, R.; Stone, C. Classification and Regression Trees; Chapman and Hall: London, UK, 1984. [Google Scholar]
- Galindo-Villardón, P.; Vicente-Villardón, J.L.; Díaz, A.D.; Vicente-Galindo, P.; Patino-Alonso, M.C. An alternative to CHAID segmentation algorithm based on entropy. Rev. Mat. Teor. Y Apl. CIMPA—UCR 2010, 17, 185–204. [Google Scholar]
- Avila, C.A. Una Alternativa al Análisis de Segmentación Basada en el Análisis de Hipótesis de Independencia Condicionada. Ph.D. Thesis, Universidad de Salamanca, Salamanca, Spain, 1996. [Google Scholar]
- Dorado-Díaz, A. Métodos de Búsqueda de Variables Relevantes en Análisis de Segmentación: Aportaciones desde una Perspectiva Multivariante. Ph.D. Thesis, Universidad de Salamanca, Salamanca, Spain, 1998. [Google Scholar]
- Castro, C.; Galindo, P. Colapsabilidad de Tablas de Contingencia Multivariantes; Editorial Académica Española: Alemania, Germany, 2011. [Google Scholar]
- Siciliano, R.; Mola, F. Ternary Classification Trees: A Factorial Approach. In Visualization of Categorical Data; Academic Press: Cambridge, MA, USA, 1997; Chapter 22; pp. 311–323. [Google Scholar]
- Gunduz, M.; Lutfi, H. Go/No-Go Decision Model for Owners Using Exhaustive CHAID and QUEST Decision Tree Algorithms. Sustainability 2021, 13, 815. [Google Scholar] [CrossRef]
- Djordjevic, D.; Cockalo, D.; Bogetic, S.; Bakator, M. Predicting Entrepreneurial Intentions among the Youth in Serbia with a Classification Decision Tree Model with the QUEST Algorithm. Mathematics 2021, 9, 1487. [Google Scholar] [CrossRef]
- Lauro, N.; D’ambra, L. L’analyse non symétrique des correspondances. Data Anal. Inform. 1984, 3, 433–446. [Google Scholar]
- Lazarsfeld, P.F.; Henry, N.W. Latent Structure Analysis; Houghton Mifflin: Boston, MA, USA, 1968. [Google Scholar]
- Goodman, L.A. Exploratory latent structure analysis using both identifiable and unidentifiable models. Biometrika 1974, 61, 215–231. [Google Scholar] [CrossRef]
- Lindsay, B.; Clogg, C.C.; Greco, J. Semiparametric estimation in the Rash model and related exponential response models, including a simple latent class model for item analysis. J. Am. Satistical Assoc. 1991, 86, 96–107. [Google Scholar] [CrossRef]
- Uebersax, J.S. Statistical modeling of expert ratings on medical treatment appropriateness. J. Am. Satistical Assoc. 1993, 88, 421–427. [Google Scholar] [CrossRef]
- Magidson, J.; Vermunt, J. Latent class factor and cluster models, bi-plots and related graphical displays. Sociol. Methodol. 2001, 31, 223–264. [Google Scholar] [CrossRef]
- Reyna, C.; Brussino, S. Revisión de los fundamentos del análisis de clases latentes y ejemplo de aplicación en el área de las adicciones. Trastor. Adict. 2011, 13, 11–19. [Google Scholar] [CrossRef]
- Araya Alpízar, C. Modelos de clases latentes en tablas poco ocupadas: Una contribución basada en bootstrap. Ph.D. Thesis, Universidad de Salamanca, Salamanca, Spain, 2010. [Google Scholar]
- Lanza, S.T.; Rhoades, B.L. Latent class analysis: An alternative perspective on subgroup analysis in prevention and treatment. Prev. Sci. 2013, 14, 157–168. [Google Scholar] [CrossRef] [Green Version]
- Oberski, D.; van Kollenburg, G.; Vermunt, J. A Monte Carlo evaluation of three methods to detect local dependence in binary data latent class models. Adv. Data Anal. Classif. 2013, 7, 267–279. [Google Scholar] [CrossRef]
- McLanchlan, L.; Basford, M. Mixture Models: Inference and Appliccation to Clustering; Marcel Dekker: New York, NY, USA, 1988. [Google Scholar]
- Fop, S.K.M.; Murphy, T. Variable Selection for Latent Class Analysis with Application to Low Back Pain Diagnosis. Ann. Appl. Stat. 2017, 11, 2085–2115. [Google Scholar] [CrossRef] [Green Version]
- Gonçalves, T.; Lourenço-Gomes, L.; Pinto, L. Modelling consumer preferences heterogeneity in emerging wine markets: A latent class analysis. Appl. Econ. 2020, 52, 6136–6144. [Google Scholar] [CrossRef]
- Goodman, L.A. Simple Models for The Analysis of Association in Cross-Classification Having Order Categories. J. Am. Satistical Assoc. 1979, 74, 537–552. [Google Scholar] [CrossRef]
- Goodman, L.A. The Analysis of Cross-classified Data Having Ordered and/or Unordered Categories: Association Models, Correlation Models and Asymmetry Models for Contingency Tables with or without Missing Entries. Ann. Stat. 1985, 13, 10–69. [Google Scholar] [CrossRef]
- Wermuth, N.; Cox, D.R. On the Application of Conditional Independence to Ordinal Data. Int. Stat. Rev. 1998, 66, 181–199. [Google Scholar] [CrossRef]
- Gilula, Z.; Krierger, A.M. Collapsed Two-Way Contingency Tables and the Chi-square Reduction Principle. J. Am. Satistical Assoc. 1989, 51, 424–433. [Google Scholar] [CrossRef]
- Lauro, N.C.; D’Ambra, L. L’analyse non symétrique des correspondances. In Data Analysis and Informatics; Data Analysis and Informatics III; Elsevier: Amsterdam, The Netherlands, 1984; pp. 433–446. [Google Scholar]
- Goodman, L.; Kruskal, W. Measures of association for cross classifications. J. Am. Satistical Assoc. 1954, 49, 732–764. [Google Scholar]
- Light, R.; Margolin, B. An analysis of variance for categorical data. J. Am. Satistical Assoc. 1971, 66, 534–544. [Google Scholar] [CrossRef]
- Olmuş, H.; Erbaş, S. Catanova method for determining of zero partial association structures in multidimensional contigency tables. Gazi Univ. J. Sci. 2014, 27, 953–963. [Google Scholar]
- Tan, P.N.; Steinbach, M.; Kumar, V. Introduction to data mining; Pearson Education India: Delhi, India, 2016. [Google Scholar]
- Mitchell, T. Machine Learning; McGraw Hill: New York, NY, USA, 1997; pp. 66–72. [Google Scholar]
- Van Rijsbergen, C.J. Information Retrieval; Butterworth-Heinemann: Oxford, UK, 1979; p. 224. [Google Scholar]
- Kirkpatrick, S.; Gelatt, C.J.; Vecchi, M.P. Optimization by Simulated Annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Aarts, E.; van Laarhoven, P. Simulated annealing: An introduction. Stat. Neerl. 1989, 43, 31–52. [Google Scholar] [CrossRef]
- Zarandia, M.F.; Zarinbala, M.; Ghanbaria, N.; Turksen, I. A new fuzzy functions model tuned by hybridizing imperialist competitive algorithm and simulatedannealing. Application: Stock price prediction. Inf. Sci. 2012, 217, 213–228. [Google Scholar]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020; ISBN 3-900051-07-0. [Google Scholar]
- Linzer, D.A.; Lewis, J.B. poLCA: An R Package for Polytomous Variable Latent Class Analysis. J. Stat. Softw. 2011, 42, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Therneau, T.; Atkinson, B. rpart: Recursive Partitioning and Regression Trees; R Package Version 4.1-15. Available online: https://cran.r-project.org/web/packages/rpart/rpart.pdf (accessed on 1 December 2021).

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Castro-López, C.; Vicente-Galindo, P.; Galindo-Villardón, P.; Borrego-Hernández, O. TAID-LCA: Segmentation Algorithm Based on Ternary Trees. Mathematics 2022, 10, 560. https://doi.org/10.3390/math10040560
Castro-López C, Vicente-Galindo P, Galindo-Villardón P, Borrego-Hernández O. TAID-LCA: Segmentation Algorithm Based on Ternary Trees. Mathematics. 2022; 10(4):560. https://doi.org/10.3390/math10040560
Chicago/Turabian StyleCastro-López, Claudio, Purificación Vicente-Galindo, Purificación Galindo-Villardón, and Oscar Borrego-Hernández. 2022. "TAID-LCA: Segmentation Algorithm Based on Ternary Trees" Mathematics 10, no. 4: 560. https://doi.org/10.3390/math10040560
APA StyleCastro-López, C., Vicente-Galindo, P., Galindo-Villardón, P., & Borrego-Hernández, O. (2022). TAID-LCA: Segmentation Algorithm Based on Ternary Trees. Mathematics, 10(4), 560. https://doi.org/10.3390/math10040560