1. Introduction
The covariance matrix is a simple and popular method to describe the variation and correlation between random variables in multivariate statistics. A valid covariance matrix must be symmetric and semi-positive definite. In some areas, like social sciences, finance, economics and geology, people are more interested in studying the covariance matrices than mean models. Meanwhile, an appropriate working covariance matrix could increase the estimator’s efficiency. Moreover, Pourahmadi (2013) [
1] suggests a good estimate of the covariance matrix can lead to an accurate statistical inference and test results. Little and Rubin (2019) [
2] show that an accurate estimate of covariance is essential in dealing with missing data problems. A sample covariance is usually used to estimate the population covariance matrix for its convenience. In some special cases, for example, high-dimensional situations where the number of repeated measurements
n is less than that of unknown parameters in covariance matrix, using sample covariance matrix would end up with a biased estimator of mean model [
3].
Pourahmadi (1999) [
4] introduced the modified Cholesky decomposition method (MCD ) into the estimation of covariance matrix by applying regression-based ideas into matrix decomposition methods. However, the interpretation of the relationship between model coefficients and correlation/variance of population
Y is indirect. Pan and Pan (2017) [
5] proposed the alternative Cholesky decomposition method (ACD) in 2017 that improves the correlation-interpretation problem of MCD by applying Cholesky decomposition on the correlation matrix
R,
where matrix
D is a diagonal matrix with standard deviations
of population
Y, and
T is a lower-triangular matrix with unit row vectors,
, whose Euclidean norm is 1. The same model regression procedure as in MCD cannot be applied in ACD due to the extra unit-norm-restriction on row vectors in matrix
T. Rebonato and Jäckel (2011) [
6] projected
T in ACD into a unit Hyper-sphere coordinate system and proposed the Hyper-sphere decomposition method (HPC), in which elements
in
T are
where
are corresponding new angular coordinates of vector
in a unit hyper-sphere coordinate system. As a result we have
where
refer to
. Comparing to ACD there is an additional matrix
, which is also a lower triangular with diagonal elements 0 and with the lower off-diagonal being angles
,
This method can guarantee the unit-row vectors in
T for any given estimator matrix
; meanwhile, this decomposition has a geometry meaning for
[
7]. In that sense, the regular model regression procedure can be applied in HPC just as in Pourahmadi (2000) [
8]. To ensure
we can do a further triangular transpose on the liner model:
where
and
are design matrices and vectors for angles
and variances
, respectively. Meanwhile,
and
in Equation (
2) are unknown correlation and variance components.
The current popular methods like HPC work well in longitudinal data analysis in which there is a natural order of the sample data. While in analyses like geometric and causal data there is no natural permutation of data, these methods generate estimates that depend on the permutation of sample data. The purpose of this article is to illustrate the permutation variance of covariance estimator of HPC. After that, we redefine the translation between T and , then propose an alternative Hyper-sphere decomposition (AHPC) method that inherits most of the advantages of HPC while improving the permutation variance. Meanwhile, the AHPC has a more straightforward geometrical interpretation.
2. Interpretations of Hyper-Sphere Decomposition Method
Rapisarda, Brigo and Mercurio (2007) [
7] explained HPC from the aspect of Jacobi rotation. In a
p-dimensional right-hand system, axis
are selected as follows:
- 1.
Set the direction of as the first axis .
- 2.
In the plane containing vectors and , make the vertical to in a right-hand system.
- 3.
is perpendicular to the previous axis, and , and on the same side of their cross product .
- 4.
After the signed j axis, the next axis is defined as vertical to all previous axes and on the same direction of , while .
Cross product determines a direction perpendicular to the plane containing and given by the right-hand rule.
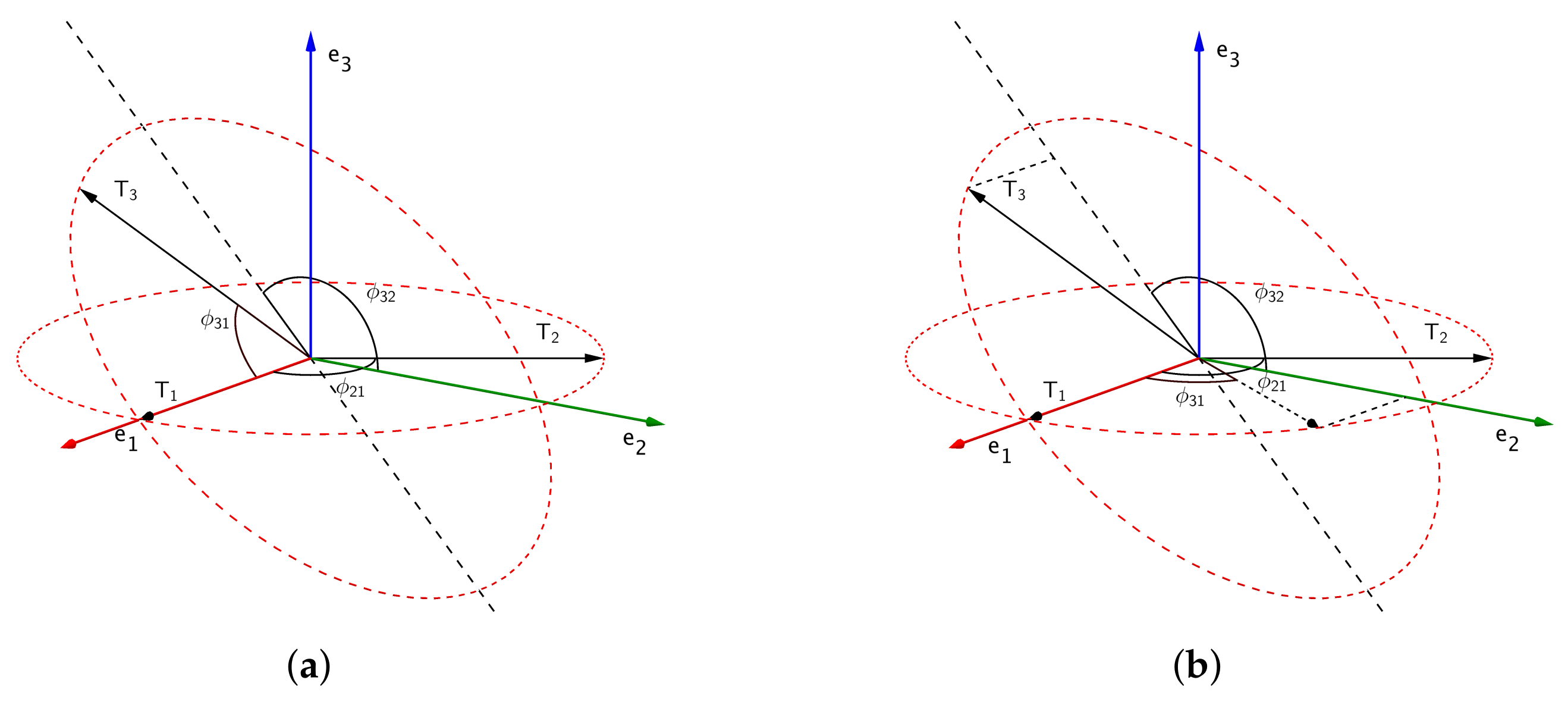
With all axes having been set up, the row vectors
shows us the coordinate of
in this Cartesian system. According to [
7], the relation between angles
and coordinates of
s is (
Figure 1a):
- 1.
We begin with . Next we turn counter-clockwise in hyper-plane with angle . Then we have . The hyper-plane is built with and .
- 2.
Turn in with angle ; then do another rotation in with angle . We then have .
- 3.
is built up with times turn as: .
In a p-dimensional space,
is a Jacobi rotation matrix in hyper-plane
with counter-clockwise angle
. Besides the geometric explanation from [
7], we also propose a new interpretation of the correlation between matrices
T and
in the HPC method, regarding angles between two hyper-planes in a row space of
T (
Figure 1b):
- 1.
Lower off-diagonal entries in the first column of , s, are angles between the first and ith row vectors in T.
- 2.
The lower off-diagonal entries in second column of contains angles, s, between plane , which is defined by the first and second row vectors in T, and , which is defined by the first and ith row vectors in T.
- 3.
After that, elements in kth column of matrix , , are angles between two hyper-planes and .
The
’s are built with the first, second and until the
kth row vectors. The angle between hyper-planes is well known in the mathematics literature, see, e.g., [Chep. 3] of Murty [
9]. The angle
’s between two hyper-planes,
and
can be calculated recursively via
According to [
7], when
’s and
’s are in
, the translation in Equation (
3) is unique,
.
3. Order-Dependence of Hyper-Sphere Decomposition Method
Based on both explanations of the HPC method above, we show that the HPC is order-dependent from two aspects in this section.
Setting
R as a correlation matrix between random sample
, and after a standard Cholesky decomposition
, where
, based on the definition of HPC decomposition, the correlation
in
R is actually the
value of an angle between two unit vectors
and
,
. So eventually we say that these unit vectors
in lower-triangular matrix
T represent the whole correlation information of corresponding random sample
. In that sense, the order of row vectors in
T has almost the same representation of the order of
in correlation matrix
R. For example, when
, under the order
, we have
R and the lower triangular
T matrix in (4) where, for example,
is the coordinate on axis
for vector
, which corresponds to
. Then we will have a
matrix as the left one in (5) where in the matrix
, from left to right,
is the
kth Jacobi rotation angle in hyper-plane
, which is built with
and
. For example,
is the second Jacobi rotation angle in
.
From the aspect of angles between two hyper-planes, we have the table for matrix as in the right one in (5) where j stands for row number. In this table, for example, is the angle between and . Hyper-plane is built with the first, second and fifth row vectors in T.
Eventually we have the same equation between
and
as in [
10]:
where
and
stand for
and
, respectively.
If we change the order of s in correlation matrix R, simultaneously we change the corresponding row vectors, s, in lower-triangular matrix T. While the elements in new matrix may change after changing order, the relationship between and remains the same. As illustrated before, elements in matrix T are coordinates. When the order of s is different, we set up a new set of axes. That leads us to have a new set of coordinates for s. If we change the order into , then the new correlation matrix can be obtained by swapping elements in R and doing the Cholesky decomposition on we get as in (7).
Since we changed the order from position
, simultaneously a new set of axes
,
,
and
are selected. As a result we will have new value for the coordinate on
,
and
, represented as *s. Meanwhile, the corresponding
matrix will be like in (8).
From the aspect of Jacobi rotation, element in is a rotating angle in plane built by axes and . Because the definition of axis s depend on the order of , which is again also the order of , still depends on the order of . We can observe that , and which shows that and only relay on , and . This explains the reason why and remain the same, respectively. Since the third vector becomes , angles on the column 3 all will have a new value, except , for obvious reasons, the angle between and equals that between and .
We summarize this dependency in
Table 1.
Table 1 indicates how the value of entries in
depend on the order of row vectors in matrix
T.
After proving the permutation variation of the values in the
matrix, we consider how this would affect our modeling process. If the HPC method were permutation invariant, the model assumption should always hold no matter how we change the order of data
Y. However, a different order gives different values of
, proven above. Then, under the model (
2), with the same covariates
and
in which the corresponding values have been rearranged according to the new order, HPC would have a different estimator of
and
. In some cases, even the whole model assumption would be wrong under the new permutation of sample data.
Due to the definition of translation between matrices T and , according to our study, the data order affects element-wise. Furthermore, there is no way of transforming a new angle matrix under the new data order back to its previous one only by rearranging elements. In other words, a change of the order will give a different set of values for . The regression model on elements would have different parameter estimates under varied data order. Furthermore, even the model assumption may vary according to the data order. In that sense, we say the current HPC method is order dependent. As the conclusion, under both interpretations, the HPC method is permutation variate both in terms of the matrix and models for variance components.
7. Real Data Analysis
In this section, we analyze a set of weather data by HPC and AHPC. We focus on comparing the estimators of the correlation matrix. Furthermore, there is no natural order in this weather data set. In this section,
jmcm package in
R [
5] is used for estimations of the HPC method. Function
lm is applied in
R to do the linear regression for AHPC. These weather data are collected from the UK government public web page,
Met Office. We select
different weather stations in the UK. They are allocated in Ballypartick Forest, Cambridge, Lewick, Leuchars and Sheffield. We cut off the data before 1962 and make this data set balance, leaving us with
sample size. There is no missing value in this data set. The average minimum temperature in each month is recorded in Celsius degrees.
For comparison between HPC and AHPC, our interest is on the estimator of correlation matrices. Thus, sample variance
is used as the estimator of the variance for station
i. We set the initial order alphabetically: Ballypartick Forest, Cambridge, Lewick, Leuchars and Sheffield. Then we shift this initial order by relocating the Sheffield station to the beginning. Meanwhile, based on the non-parametric analysis of
under both methods with respect to distances
between climate stations
i and
j, solid lines are plotted in
Figure 8. Combined with the consideration of
AIC and
BIC, we assume three different polynomial models for
in HPC and AHPC under two orders, respectively.
For s of the HPC method, we assume a linear model under the initial order and a quadratic one under the shifted order. On the other hand, to keep the model monotonic decreasing, we model angle parameters s in AHPC instead of s. We assume a linear model under both orders.
Under both orders, by applying HPC and AHPC, we can get four regression results. The fitted models are plotted with dot lines in
Figure 8. Cross comparison of these results with the sample correlation matrices under these two orders, by their relative errors defined as
, where
is Euclidean norm, and
and
are the sample and estimated correlation matrix, respectively. We should notice that the norm of sample correlations remains the same,
, and the norm of the difference between sample correlation matrices under both is order
.
Observing the results in
Table 2 and
Table 3, it is obvious that the estimator of HPC depends on the order of the data, while AHPC presents a consistent estimating result. Even redoing the modeling process from the model selecting stage, we observe from the relative errors in
Table 2 that the relative errors between sample and estimated correlation generated on
are different in HPC. As one conclusion, under different permutations, the estimating results of HPC would vary. Consequentially, it is improper to use the HPC method to model the covariance matrices of data without a natural order for its failure to offer a permutation consistent estimator.
On the other hand, for AHPC,
Table 3 shows the consistency of these estimators under different orders. Moreover, there is an interpretation advantage in AHPC comparing to HPC. For example, in this real data analysis, the interpretation of the relationship between correlation
and the distance between stations
j and
k are not obvious in the HPC model. Meanwhile, the AHPC model for
is monotonic decreasing, suggesting
increases with distance
. Moreover,
is a monotonic decreasing function. Thus
decreases with respect to the distance between stations.
8. Conclusions and Discussion
In this paper, we addressed the permutation variation of HPC through its geometrical interpretations. Then AHPC for covariance modeling was proposed. AHPC was proven to improve the order-dependence issue of HPC. Furthermore, the direct relation between and R in AHPC provides an advantage in making model assumptions, parameter estimations and statistical interpretations. However, due to the limitation of the relation between angles, the model assumption for angles in AHPC must satisfy an extra constraint.
Both HPC and AHPC can only guarantee semi-positive definiteness. The reason behind this drawback of both methods is the same. From the geometrical interpretations above, we can see that the definition of angles in both methods can only ensure the symmetry and diagonal elements being 1s in the correlation matrix R. By changing the inequality constraint on angles in AHPC to strict less, we can simultaneously make sure the correlation matrix is positive definite.
These four covariance modeling methods we mentioned in this paper have their advantages. For the most accurate estimator, an appropriate model assumption is essential. Thus we may use a certain decomposition method based on the data, since different methods would generate their pattern against coefficients. Under an appropriate model assumption, estimators in all four methods are consistent. AHPC, MCD and ACD can do the model selection visually, while in some cases, model selection in HPC can only be based on statistical criteria.
There are some potential researches available on this AHPC method. As we see in simulation examples, sometimes the pattern is too complicated to fit with the linear model; the non-parametric and semi-parametric model could be applied in the AHPC method, similar to the studies of [
14,
15].



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}