
A Review of the Modification Strategies of the Nature Inspired Algorithms for Feature Selection Problem


 , ,
, ,  , and
, and 
Abstract
1. Introduction
- What is the current status of modified NIAs-FS research?
- What are the important aspects and design issues regarding building NIA for tackling FS?
- What are the modifications that were applied on NIA for tackling FS and in what domains were they applied?
- Are there current open-source software systems that apply a modified NIA-FS?
- Theoretical aspects of modified NIAs-FS provide detailed coverage for three main subjects: Meta-heuristic optimization, the FS problem, and modifications on meta-heuristic to enhance meta-heuristics for FS;
- Applied aspects of modified NIAs-FS presents different applications of modified NIAs-FS;
- Technical aspects of modified NIAs-FS presents a new developed FS tool, named Evolopy-FS.
2. Feature Selection as a Task of Disentangling the Symmetry of Feature Space
3. Meta-Heuristic Optimization
3.1. Trajectory-Based Optimization
3.2. Population-Based Optimization
3.2.1. Evolution-Based Optimization (EA)
3.2.2. Swarm-Based Optimization (SI)
3.3. Challenges of Meta-Heuristic Optimization
4. Feature Selection
4.1. Dimensionality Problem
4.2. FS Preliminaries
4.3. NIAs for Feature Selection
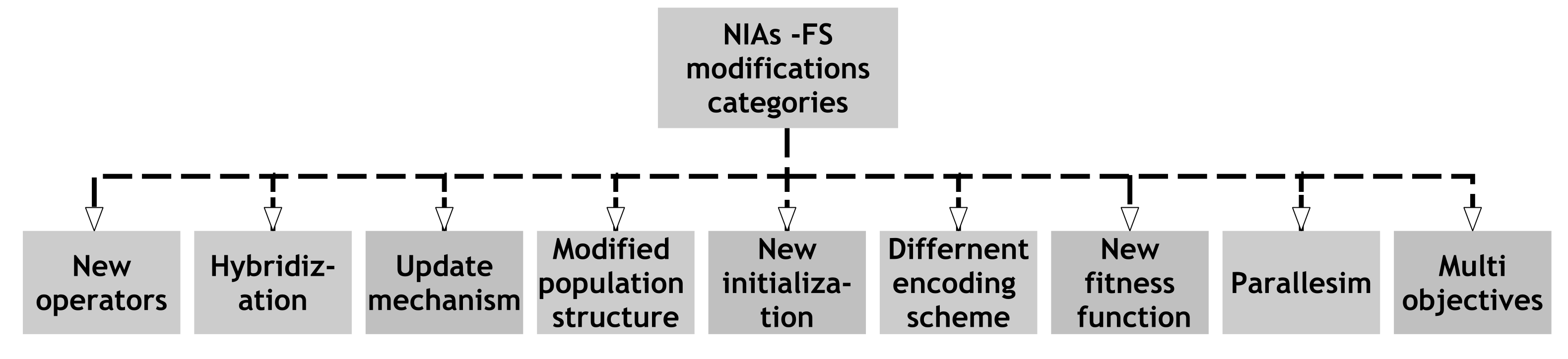
5. NIAs FS Modifications
5.1. New Operators
5.1.1. Chaotic Maps
5.1.2. Rough Set
5.1.3. Selection Operators
5.1.4. Sigmoidal Function
5.1.5. Transfer Functions
5.1.6. Crossover
5.1.7. Mutation
5.1.8. Levy Flight
5.1.9. Other Operators
5.2. Hybridization
5.2.1. NIA-NIA Hybridization
5.2.2. NIA-Classifier Hybridization
5.2.3. NIA-Filter (Wrapper-Filter) Hybridization
5.3. Update Mechanism
5.4. Modified Population Structure
5.5. Different Encoding Scheme
5.6. New Initialization
5.7. New Fitness Function
5.8. Multi Objective
5.9. Parallelism
6. NIAs FS Applications
6.1. Microarray Gene Expression Classification
6.2. Facial Expression Recognition
6.3. Medical Applications
6.4. Handwritten Letter Recognition
6.5. Hyper Spectral Images Processing
6.6. Protein and Related Genome Annotation
6.7. Biochemistry and Drug Design
6.8. Electroencephalogram (EEG) Application
6.9. Financial Prediction
6.10. Software Product Line Estimation
6.11. Spam Detection in Emails
6.12. Other Various Applications
6.13. An Open Source Evolopy-FS Framework
7. Assessment and Evaluation of NIAs FS Modification Techniques
8. Conclusions and Future Research Directions
- Until now, there are few works in the binary optimization field. Many new operators can be proposed to enhance the performance of binary optimizers in a binary space. This is an interesting research direction;
- The proposed enhanced binary versions of optimizers can be used as a data mining tool in various applications. There are some applications where the usage of modified NIAs-FS in them is still limited;
- It would also be interesting to look at the dimensionality and number of instances in data sets. Nowadays, the majority of FS works to address problems with dimensionality up to several thousand but the question that may arise is what will happen if the data sets scaled up to millions of features? There is a scalability gap that should be addressed in the future;
- There is still room for improvement through parallel NIAs-FS. This might be a fruitful direction for research;
- Hyper volume Pareto optimal dominance and many-objective optimization need further crucial investigation.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, H.; Yu, L. Toward integrating feature selection algorithms for classification and clustering. IEEE Trans. Knowl. Data Eng. 2005, 17, 491–502. [Google Scholar]
- Hawkins, D.M. The problem of overfitting. J. Chem. Inf. Comput. Sci. 2004, 44, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Chen, H.; Yang, B.; Zhao, X.; Hu, L.; Cai, Z.; Huang, H.; Tong, C. Toward an optimal kernel extreme learning machine using a chaotic moth-flame optimization strategy with applications in medical diagnoses. Neurocomputing 2017, 267, 69–84. [Google Scholar] [CrossRef]
- Zawbaa, H.M.; Emary, E.; Grosan, C.; Snasel, V. Large-dimensionality small-instance set feature selection: A hybrid bio-inspired heuristic approach. Swarm Evol. Comput. 2018, 42, 29–42. [Google Scholar] [CrossRef]
- Tubishat, M.; Abushariah, M.A.; Idris, N.; Aljarah, I. Improved whale optimization algorithm for feature selection in Arabic sentiment analysis. Appl. Intell. 2018, 49, 1–20. [Google Scholar] [CrossRef]
- Medjahed, S.A.; Saadi, T.A.; Benyettou, A.; Ouali, M. Gray wolf optimizer for hyperspectral band selection. Appl. Soft Comput. 2016, 40, 178–186. [Google Scholar] [CrossRef]
- Makhadmeh, S.N.; Al-Betar, M.A.; Alyasseri, Z.A.A.; Abasi, A.K.; Khader, A.T.; Damaševičius, R.; Mohammed, M.A.; Abdulkareem, K.H. Smart home battery for the multi-objective power scheduling problem in a smart home using grey wolf optimizer. Electronics 2021, 10, 447. [Google Scholar] [CrossRef]
- Faris, H.; Abukhurma, R.; Almanaseer, W.; Saadeh, M.; Mora, A.M.; Castillo, P.A.; Aljarah, I. Improving financial bankruptcy prediction in a highly imbalanced class distribution using oversampling and ensemble learning: A case from the Spanish market. Prog. Artif. Intell. 2019, 9, 1–23. [Google Scholar] [CrossRef]
- Al-Madi, N.; Faris, H.; Abukhurma, R. Cost-Sensitive Genetic Programming for Churn Prediction and Identification of the Influencing Factors in Telecommunication Market. Int. J. Adv. Sci. Technol. 2018, 13–28. [Google Scholar]
- Pourzangbar, A.; Losada, M.A.; Saber, A.; Ahari, L.R.; Larroudé, P.; Vaezi, M.; Brocchini, M. Prediction of non-breaking wave induced scour depth at the trunk section of breakwaters using Genetic Programming and Artificial Neural Networks. Coast. Eng. 2017, 121, 107–118. [Google Scholar] [CrossRef]
- Okewu, E.; Misra, S.; Maskeliunas, R.; Damasevicius, R.; Fernandez-Sanz, L. Optimizing green computing awareness for environmental sustainability and economic security as a stochastic optimization problem. Sustainability 2017, 9, 1857. [Google Scholar] [CrossRef]
- Xue, B.; Zhang, M.; Browne, W.N.; Yao, X. A survey on evolutionary computation approaches to feature selection. IEEE Trans. Evol. Comput. 2016, 20, 606–626. [Google Scholar] [CrossRef]
- Alweshah, M.; Al Khalaileh, S.; Gupta, B.B.; Almomani, A.; Hammouri, A.I.; Al-Betar, M.A. The monarch butterfly optimization algorithm for solving feature selection problems. Neural Comput. Appl. 2020, 2020, 1–15. [Google Scholar] [CrossRef]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef]
- Dash, M.; Liu, H. Feature selection for classification. Intell. Data Anal. 1997, 1, 131–156. [Google Scholar] [CrossRef]
- Tabakhi, S.; Moradi, P.; Akhlaghian, F. An unsupervised feature selection algorithm based on ant colony optimization. Eng. Appl. Artif. Intell. 2014, 32, 112–123. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, G.; Chen, H.; Dong, H.; Zhu, X.; Wang, S. An improved particle swarm optimization for feature selection. J. Bionic Eng. 2011, 8, 191–200. [Google Scholar] [CrossRef]
- Yang, C.H.; Chuang, L.Y.; Yang, C.H. IG-GA: A hybrid filter/wrapper method for feature selection of microarray data. J. Med Biol. Eng. 2010, 30, 23–28. [Google Scholar]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature selection: A data perspective. ACM Comput. Surv. (CSUR) 2018, 50, 94. [Google Scholar] [CrossRef]
- Brezočnik, L.; Fister, I.; Podgorelec, V. Swarm Intelligence Algorithms for Feature Selection: A Review. Appl. Sci. 2018, 8, 1521. [Google Scholar] [CrossRef]
- Diao, R.; Shen, Q. Nature inspired feature selection meta-heuristics. Artif. Intell. Rev. 2015, 44, 311–340. [Google Scholar] [CrossRef]
- Oliveira, A.L.; Braga, P.L.; Lima, R.M.; Cornélio, M.L. GA-based method for feature selection and parameters optimization for machine learning regression applied to software effort estimation. Inf. Softw. Technol. 2010, 52, 1155–1166. [Google Scholar] [CrossRef]
- Khushaba, R.N.; Al-Ani, A.; AlSukker, A.; Al-Jumaily, A. A combined ant colony and differential evolution feature selection algorithm. In Proceedings of the International Conference on Ant Colony Optimization and Swarm Intelligence; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–12. [Google Scholar]
- Tran, B.; Xue, B.; Zhang, M. Improved PSO for feature selection on high-dimensional datasets. In Proceedings of the Asia-Pacific Conference on Simulated Evolution and Learning; Springer: Berlin/Heidelberg, Germany, 2014; pp. 503–515. [Google Scholar]
- Kanan, H.R.; Faez, K.; Taheri, S.M. Feature selection using ant colony optimization (ACO): A new method and comparative study in the application of face recognition system. In Proceedings of the Industrial Conference on Data Mining; Springer: Berlin/Heidelberg, Germany, 2007; pp. 63–76. [Google Scholar]
- Hancer, E.; Xue, B.; Karaboga, D.; Zhang, M. A binary ABC algorithm based on advanced similarity scheme for feature selection. Appl. Soft Comput. 2015, 36, 334–348. [Google Scholar] [CrossRef]
- Balázs, K.; Botzheim, J.; Kóczy, L.T. Comparative Investigation of Various Evolutionary and Memetic Algorithms. In Computational Intelligence in Engineering; Springer: Berlin/Heidelberg, Germany, 2010; pp. 129–140. [Google Scholar] [CrossRef]
- Sahlol, A.T.; Elaziz, M.A.; Jamal, A.T.; Damaševičius, R.; Hassan, O.F. A novel method for detection of tuberculosis in chest radiographs using artificial ecosystem-based optimisation of deep neural network features. Symmetry 2020, 12, 1146. [Google Scholar] [CrossRef]
- Sahlol, A.T.; Yousri, D.; Ewees, A.A.; Al-qaness, M.A.A.; Damasevicius, R.; Elaziz, M.A. COVID-19 image classification using deep features and fractional-order marine predators algorithm. Sci. Rep. 2020, 10, 15–36. [Google Scholar] [CrossRef]
- Polap, D.; Woźniak, M. Polar bear optimization algorithm: Meta-heuristic with fast population movement and dynamic birth and death mechanism. Symmetry 2017, 9, 203. [Google Scholar] [CrossRef]
- Połap, D.; Woźniak, M. Red fox optimization algorithm. Expert Syst. Appl. 2021, 166, 114107. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl.-Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Jouhari, H.; Lei, D.; Al-qaness, M.A.A.; Abd Elaziz, M.; Damaševičius, R.; Korytkowski, M.; Ewees, A.A. Modified Harris Hawks optimizer for solving machine scheduling problems. Symmetry 2020, 12, 1460. [Google Scholar] [CrossRef]
- Ksiazek, K.; Połap, D.; Woźniak, M.; Damaševičius, R. Radiation heat transfer optimization by the use of modified ant lion optimizer. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence, Honolulu, HI, USA, 27 November–1 December 2017; Volume 2018, pp. 1–7. [Google Scholar]
- Damaševičius, R.; Maskeliūnas, R. Agent state flipping based hybridization of heuristic optimization algorithms: A case of bat algorithm and krill herd hybrid algorithm. Algorithms 2021, 14, 358. [Google Scholar] [CrossRef]
- Faris, H.; Aljarah, I.; Al-Betar, M.A.; Mirjalili, S. Grey wolf optimizer: A review of recent variants and applications. Neural Comput. Appl. 2018, 30, 413–435. [Google Scholar] [CrossRef]
- Hira, Z.; Gillies, D. A Review of Feature Selection and Feature Extraction Methods Applied on Microarray Data. Adv. Bioinform. 2015, 2015, 198363. [Google Scholar] [CrossRef] [PubMed]
- Somol, P.; Grim, J.; Novovičová, J.; Pudil, P. Improving feature selection process resistance to failures caused by curse-of-dimensionality effects. Kybernetika 2011, 47, 401–425. [Google Scholar]
- von Luxburg, U.; Bousquet, O. Distance-Based Classification with Lipschitz Functions. In Learning Theory and Kernel Machines; Springer: Berlin/Heidelberg, Germany, 2003; pp. 314–328. [Google Scholar] [CrossRef]
- Higgins, I.; Amos, D.; Pfau, D.; Racaniere, S.; Matthey, L.; Rezende, D.; Lerchner, A. Towards a Definition of Disentangled Representations. arXiv 2018, arXiv:cs.LG/1812.02230. [Google Scholar]
- Brank, J.; Mladenić, D.; Grobelnik, M.; Liu, H.; Mladenić, D.; Flach, P.A.; Garriga, G.C.; Toivonen, H.; Toivonen, H. Feature Selection. In Encyclopedia of Machine Learning; Springer: Boston, MA, USA, 2011; pp. 402–406. [Google Scholar] [CrossRef]
- Achille, A.; Soatto, S. Emergence of Invariance and Disentanglement in Deep Representations. In Proceedings of the 2018 Information Theory and Applications Workshop (ITA), San Diego, CA, USA, 11–16 February 2018. [Google Scholar] [CrossRef]
- Ratner, A.J.; Ehrenberg, H.R.; Hussain, Z.; Dunnmon, J.; Ré, C. Learning to Compose Domain-Specific Transformations for Data Augmentation. arXiv 2017, arXiv:stat.ML/1709.01643. [Google Scholar]
- Khaire, U.M.; Dhanalakshmi, R. Stability of feature selection algorithm: A review. J. King Saud Univ. Comput. Inf. Sci. 2019, 2019. [Google Scholar] [CrossRef]
- Gheyas, I.A.; Smith, L.S. Feature subset selection in large dimensionality domains. Pattern Recognit. 2010, 43, 5–13. [Google Scholar] [CrossRef]
- Mafarja, M.M.; Mirjalili, S. Hybrid Whale Optimization Algorithm with simulated annealing for feature selection. Neurocomputing 2017, 260, 302–312. [Google Scholar] [CrossRef]
- Glover, F. Tabu search-part I. ORSA J. Comput. 1989, 1, 190–206. [Google Scholar] [CrossRef]
- Mirjalili, S.Z.; Mirjalili, S.; Saremi, S.; Faris, H.; Aljarah, I. Grasshopper optimization algorithm for multi-objective optimization problems. Appl. Intell. 2018, 48, 805–820. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A.; Mostaghim, S. Confidence measure: A novel metric for robust meta-heuristic optimisation algorithms. Inf. Sci. 2015, 317, 114–142. [Google Scholar] [CrossRef]
- Lu, H.; Wang, X.; Fei, Z.; Qiu, M. The effects of using Chaotic map on improving the performance of multiobjective evolutionary algorithms. Math. Probl. Eng. 2014, 2014, 924652. [Google Scholar] [CrossRef]
- Chuang, L.Y.; Yang, C.H.; Li, J.C. Chaotic maps based on binary particle swarm optimization for feature selection. Appl. Soft Comput. 2011, 11, 239–248. [Google Scholar] [CrossRef]
- Chuang, L.Y.; Yang, C.S.; Wu, K.C.; Yang, C.H. Gene selection and classification using Taguchi chaotic binary particle swarm optimization. Expert Syst. Appl. 2011, 38, 13367–13377. [Google Scholar] [CrossRef]
- Bharti, K.K.; Singh, P.K. Opposition chaotic fitness mutation based adaptive inertia weight BPSO for feature selection in text clustering. Appl. Soft Comput. 2016, 43, 20–34. [Google Scholar] [CrossRef]
- Ahmed, S.; Mafarja, M.; Faris, H.; Aljarah, I. Feature selection using salp swarm algorithm with chaos. In Proceedings of the 2nd International Conference on Intelligent Systems, Metaheuristics & Swarm Intelligence; ACM: New York, NY, USA, 2018; pp. 65–69. [Google Scholar]
- Sayed, G.I.; Khoriba, G.; Haggag, M.H. A novel chaotic salp swarm algorithm for global optimization and feature selection. Appl. Intell. 2018, 48, 1–20. [Google Scholar] [CrossRef]
- Ewees, A.A.; El Aziz, M.A.; Hassanien, A.E. Chaotic multi-verse optimizer-based feature selection. Neural Comput. Appl. 2017, 31, 991–1006. [Google Scholar] [CrossRef]
- Sayed, G.I.; Darwish, A.; Hassanien, A.E. A New Chaotic Whale Optimization Algorithm for Features Selection. J. Classif. 2018, 35, 300–344. [Google Scholar] [CrossRef]
- Sayed, G.I.; Hassanien, A.E.; Azar, A.T. Feature selection via a novel chaotic crow search algorithm. Neural Comput. Appl. 2017, 31, 171–188. [Google Scholar] [CrossRef]
- Qasim, O.S.; Al-Thanoon, N.A.; Algamal, Z.Y. Feature selection based on chaotic binary black hole algorithm for data classification. Chemom. Intell. Lab. Syst. 2020, 15, 104104. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough sets. Int. J. Comput. Inf. Sci. 1982, 11, 341–356. [Google Scholar] [CrossRef]
- Zainal, A.; Maarof, M.A.; Shamsuddin, S.M. Feature selection using Rough-DPSO in anomaly intrusion detection. In Proceedings of the International Conference on Computational Science and Its Applications; Springer: Berlin/Heidelberg, Germany, 2007; pp. 512–524. [Google Scholar]
- Inbarani, H.H.; Azar, A.T.; Jothi, G. Supervised hybrid feature selection based on PSO and rough sets for medical diagnosis. Comput. Methods Programs Biomed. 2014, 113, 175–185. [Google Scholar] [CrossRef]
- Alia, A.F.; Taweel, A. Feature selection based on hybrid Binary Cuckoo Search and rough set theory in classification for nominal datasets. Algorithms 2017, 14, 65. [Google Scholar] [CrossRef][Green Version]
- El Aziz, M.A.; Hassanien, A.E. Modified cuckoo search algorithm with rough sets for feature selection. Neural Comput. Appl. 2018, 29, 925–934. [Google Scholar] [CrossRef]
- Mafarja, M.M.; Mirjalili, S. Hybrid binary ant lion optimizer with rough set and approximate entropy reducts for feature selection. Soft Comput. 2018, 23, 6249–6265. [Google Scholar] [CrossRef]
- Chen, Y.; Zhu, Q.; Xu, H. Finding rough set reducts with fish swarm algorithm. Knowl.-Based Syst. 2015, 81, 22–29. [Google Scholar] [CrossRef]
- Hassanien, A.E.; Gaber, T.; Mokhtar, U.; Hefny, H. An improved moth flame optimization algorithm based on rough sets for tomato diseases detection. Comput. Electron. Agric. 2017, 136, 86–96. [Google Scholar] [CrossRef]
- Tawhid, M.A.; Ibrahim, A.M. Hybrid binary particle swarm optimization and flower pollination algorithm based on rough set approach for feature selection problem. In Nature-Inspired Computation in Data Mining and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2020; pp. 249–273. [Google Scholar]
- Ropiak, K.; Artiemjew, P. On a Hybridization of Deep Learning and Rough Set Based Granular Computing. Algorithms 2020, 13, 63. [Google Scholar] [CrossRef]
- Dennett, D.C. Darwinś dangerous idea. Science 1995, 35, 34–40. [Google Scholar]
- Tanaka, M.; Watanabe, H.; Furukawa, Y.; Tanino, T. GA-based decision support system for multicriteria optimization. Systems, Man and Cybernetics. In Proceedings of the Intelligent Systems for the 21st Century; Springer: Berlin/Heidelberg, Germany, 1995; Volume 2, pp. 1556–1561. [Google Scholar]
- Mafarja, M.; Aljarah, I.; Heidari, A.A.; Hammouri, A.I.; Faris, H.; AlaḾ, A.Z.; Mirjalili, S. Evolutionary population dynamics and grasshopper optimization approaches for feature selection problems. Knowl.-Based Syst. 2018, 145, 25–45. [Google Scholar] [CrossRef]
- Mafarja, M.; Mirjalili, S. Whale optimization approaches for wrapper feature selection. Appl. Soft Comput. 2018, 62, 441–453. [Google Scholar] [CrossRef]
- Khushaba, R.N.; Al-Ani, A.; Al-Jumaily, A. Feature subset selection using differential evolution and a statistical repair mechanism. Expert Syst. Appl. 2011, 38, 11515–11526. [Google Scholar] [CrossRef]
- Leibowitz, N.; Baum, B.; Enden, G.; Karniel, A. The exponential learning equation as a function of successful trials results in sigmoid performance. J. Math. Psychol. 2010, 54, 338–340. [Google Scholar] [CrossRef]
- Aneesh, M.; Masand, A.A.; Manikantan, K. Optimal feature selection based on image pre-processing using accelerated binary particle swarm optimization for enhanced face recognition. Procedia Eng. 2012, 30, 750–758. [Google Scholar] [CrossRef][Green Version]
- Pereira, L.; Rodrigues, D.; Almeida, T.; Ramos, C.; Souza, A.; Yang, X.S.; Papa, J. A binary cuckoo search and its application for feature selection. In Cuckoo Search and Firefly Algorithm; Springer: Berlin/Heidelberg, Germany, 2014; pp. 141–154. [Google Scholar]
- Rodrigues, D.; Pereira, L.A.; Nakamura, R.Y.; Costa, K.A.; Yang, X.S.; Souza, A.N.; Papa, J.P. A wrapper approach for feature selection based on bat algorithm and optimum-path forest. Expert Syst. Appl. 2014, 41, 2250–2258. [Google Scholar] [CrossRef]
- Mafarja, M.; Aljarah, I.; Faris, H.; Hammouri, A.I.; AlaḾ, A.Z.; Mirjalili, S. Binary grasshopper optimisation algorithm approaches for feature selection problems. Expert Syst. Appl. 2019, 117, 267–286. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. S-shaped versus V-shaped transfer functions for binary particle swarm optimization. Swarm Evol. Comput. 2013, 9, 1–14. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R.C. A discrete binary version of the particle swarm algorithm. Systems, Man, and Cybernetics. In Proceedings of the Computational Cybernetics and Simulation, Orlando, FL, USA, 12–15 October 1997; Volume 5, pp. 4104–4108. [Google Scholar]
- Faris, H.; Mafarja, M.M.; Heidari, A.A.; Aljarah, I.; AlaḾ, A.Z.; Mirjalili, S.; Fujita, H. An efficient binary Salp Swarm Algorithm with crossover scheme for feature selection problems. Knowl.-Based Syst. 2018, 154, 43–67. [Google Scholar] [CrossRef]
- Mafarja, M.; Aljarah, I.; Heidari, A.A.; Faris, H.; Fournier-Viger, P.; Li, X.; Mirjalili, S. Binary dragonfly optimization for feature selection using time-varying transfer functions. Knowl.-Based Syst. 2018, 161, 185–204. [Google Scholar] [CrossRef]
- Emary, E.; Zawbaa, H.M.; Hassanien, A.E. Binary grey wolf optimization approaches for feature selection. Neurocomputing 2016, 172, 371–381. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, S.; Phillips, P.; Ji, G. Binary PSO with mutation operator for feature selection using decision tree applied to spam detection. Knowl.-Based Syst. 2014, 64, 22–31. [Google Scholar] [CrossRef]
- Sihwail, R.; Omar, K.; Ariffin, K.A.Z.; Tubishat, M. Improved Harris Hawks Optimization Using Elite Opposition-Based Learning and Novel Search Mechanism for Feature Selection. IEEE Access 2020, 8, 121127–121145. [Google Scholar] [CrossRef]
- Sims, D.W.; Humphries, N.E.; Bradford, R.W.; Bruce, B.D. Lévy flight and Brownian search patterns of a free-ranging predator reflect different prey field characteristics. J. Anim. Ecol. 2012, 81, 432–442. [Google Scholar] [CrossRef]
- Khurmaa, R.A.; Aljarah, I.; Sharieh, A. An intelligent feature selection approach based on moth flame optimization for medical diagnosis. Neural Comput. Appl. 2020, 33, 7165–7204. [Google Scholar] [CrossRef]
- Oh, I.S.; Lee, J.S.; Moon, B.R. Hybrid genetic algorithms for feature selection. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1424–1437. [Google Scholar] [PubMed]
- Vieira, S.M.; Mendonça, L.F.; Farinha, G.J.; Sousa, J.M. Modified binary PSO for feature selection using SVM applied to mortality prediction of septic patients. Appl. Soft Comput. 2013, 13, 3494–3504. [Google Scholar] [CrossRef]
- Zhang, Y.; Gong, D.; Hu, Y.; Zhang, W. Feature selection algorithm based on bare bones particle swarm optimization. Neurocomputing 2015, 148, 150–157. [Google Scholar] [CrossRef]
- Yang, C.S.; Chuang, L.Y.; Ke, C.H.; Yang, C.H. Boolean binary particle swarm optimization for feature selection. In Proceedings of the Evolutionary Computation 2008, Hong Kong, China, 1–6 June 2008; pp. 2093–2098. [Google Scholar]
- Danyadi, Z.; Foldesi, P.; Koczy, L.T. Solution of a fuzzy resource allocation problem by various evolutionary approaches. In Proceedings of the 2013 Joint IFSA World Congress and NAFIPS Annual Meeting (IFSA/NAFIPS), Edmonton, AB, Canada, 24–28 June 2013. [Google Scholar] [CrossRef]
- Chuang, L.Y.; Tsai, S.W.; Yang, C.H. Improved binary particle swarm optimization using catfish effect for feature selection. Expert Syst. Appl. 2011, 38, 12699–12707. [Google Scholar] [CrossRef]
- Xue, B.; Zhang, M.; Browne, W.N. Single feature ranking and binary particle swarm optimisation based feature subset ranking for feature selection. In Proceedings of the Thirty-fifth Australasian Computer Science Conference; Australian Computer Society, Inc.: Darlinghurst, Australia, 2012; Volume 122, pp. 27–36. [Google Scholar]
- Lane, M.C.; Xue, B.; Liu, I.; Zhang, M. Gaussian based particle swarm optimisation and statistical clustering for feature selection. In Proceedings of the European Conference on Evolutionary Computation in Combinatorial Optimization; Springer: Berlin/Heidelberg, Germany, 2014; pp. 133–144. [Google Scholar]
- Krisshna, N.A.; Deepak, V.K.; Manikantan, K.; Ramachandran, S. Face recognition using transform domain feature extraction and PSO-based feature selection. Appl. Soft Comput. 2014, 22, 141–161. [Google Scholar] [CrossRef]
- Banka, H.; Dara, S. A Hamming distance based binary particle swarm optimization (HDBPSO) algorithm for high dimensional feature selection, classification and validation. Pattern Recognit. Lett. 2015, 52, 94–100. [Google Scholar] [CrossRef]
- Moradi, P.; Gholampour, M. A hybrid particle swarm optimization for feature subset selection by integrating a novel local search strategy. Appl. Soft Comput. 2016, 43, 117–130. [Google Scholar] [CrossRef]
- Xi, M.; Sun, J.; Liu, L.; Fan, F.; Wu, X. Cancer Feature Selection and Classification Using a Binary Quantum-Behaved Particle Swarm Optimization and Support Vector Machine. Comput. Math. Methods Med. 2016, 2016, 3572705. [Google Scholar] [CrossRef] [PubMed]
- Mistry, K.; Zhang, L.; Neoh, S.C.; Lim, C.P.; Fielding, B. A micro-GA embedded PSO feature selection approach to intelligent facial emotion recognition. IEEE Trans. Cybern. 2017, 47, 1496–1509. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Song, X.F.; Gong, D.W. A return-cost-based binary firefly algorithm for feature selection. Inf. Sci. 2017, 418, 561–574. [Google Scholar] [CrossRef]
- Lin, K.C.; Hung, J.C.; Wei, J.T. Feature selection with modified lionś algorithms and support vector machine for high-dimensional data. Appl. Soft Comput. 2018, 68, 669–676. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Prado-Cumplido, M.; Pérez-Cruz, F.; Bousoño-Calzón, C. Feature selection via genetic optimization. In Proceedings of the International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2002; pp. 547–552. [Google Scholar]
- Zeng, X.P.; Li, Y.M.; Qin, J. A dynamic chain-like agent genetic algorithm for global numerical optimization and feature selection. Neurocomputing 2009, 72, 1214–1228. [Google Scholar] [CrossRef]
- Guo, J.; White, J.; Wang, G.; Li, J.; Wang, Y. A genetic algorithm for optimized feature selection with resource constraints in software product lines. J. Syst. Softw. 2011, 84, 2208–2221. [Google Scholar] [CrossRef]
- Blum, C.; Puchinger, J.; Raidl, G.R.; Roli, A. Hybrid metaheuristics in combinatorial optimization: A survey. Appl. Soft Comput. 2011, 11, 4135–4151. [Google Scholar] [CrossRef]
- Sayed, S.A.F.; Nabil, E.; Badr, A. A binary clonal flower pollination algorithm for feature selection. Pattern Recognit. Lett. 2016, 77, 21–27. [Google Scholar] [CrossRef]
- Alweshah, M.; Alkhalaileh, S.; Albashish, D.; Mafarja, M.; Bsoul, Q.; Dorgham, O. A hybrid mine blast algorithm for feature selection problems. Soft Comput. 2020, 25, 17–534. [Google Scholar] [CrossRef]
- Ibrahim, R.A.; Ewees, A.A.; Oliva, D.; Elaziz, M.A.; Lu, S. Improved salp swarm algorithm based on particle swarm optimization for feature selection. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 3155–3169. [Google Scholar] [CrossRef]
- Sayed, G.I.; Hassanien, A.E. A hybrid SA-MFO algorithm for function optimization and engineering design problems. Complex Intell. Syst. 2018, 4, 195–212. [Google Scholar] [CrossRef]
- Zhang, L.; Mistry, K.; Neoh, S.C.; Lim, C.P. Intelligent facial emotion recognition using moth-firefly optimization. Knowl.-Based Syst. 2016, 111, 248–267. [Google Scholar] [CrossRef]
- Li, S.; Wu, X.; Tan, M. Gene selection using hybrid particle swarm optimization and genetic algorithm. Soft Comput. 2008, 12, 1039–1048. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Ding, W.; El-Shahat, D. A hybrid Harris Hawks optimization algorithm with simulated annealing for feature selection. Artif. Intell. Rev. 2020, 54, 593–637. [Google Scholar] [CrossRef]
- Ibrahim, A.M.; Tawhid, M.A. A New Hybrid Binary Algorithm of Bat Algorithm and Differential Evolution for Feature Selection and Classification. In Applications of Bat Algorithm and Its Variants; Springer: Berlin/Heidelberg, Germany, 2020; pp. 1–18. [Google Scholar]
- Nemati, S.; Basiri, M.E.; Ghasem-Aghaee, N.; Aghdam, M.H. A novel ACO–GA hybrid algorithm for feature selection in protein function prediction. Expert Syst. Appl. 2009, 36, 12086–12094. [Google Scholar] [CrossRef]
- Wan, Y.; Wang, M.; Ye, Z.; Lai, X. A feature selection method based on modified binary coded ant colony optimization algorithm. Appl. Soft Comput. 2016, 49, 248–258. [Google Scholar] [CrossRef]
- Mafarja, M.; Qasem, A.; Heidari, A.A.; Aljarah, I.; Faris, H.; Mirjalili, S. Efficient hybrid nature-inspired binary optimizers for feature selection. Cogn. Comput. 2020, 12, 150–175. [Google Scholar] [CrossRef]
- Li, Q.; Chen, H.; Huang, H.; Zhao, X.; Cai, Z.; Tong, C.; Liu, W.; Tian, X. An Enhanced Grey Wolf Optimization Based Feature Selection Wrapped Kernel Extreme Learning Machine for Medical Diagnosis. Comput. Math. Methods Med. 2017, 2017, 9512741. [Google Scholar] [CrossRef]
- Kihel, B.K.; Chouraqui, S. Firefly optimization using artificial immune system for feature subset selection. Int. J. Intell. Eng. Syst 2019, 12, 337–347. [Google Scholar] [CrossRef]
- Faris, H.; Hassonah, M.A.; AlaḾ, A.Z.; Mirjalili, S.; Aljarah, I. A multi-verse optimizer approach for feature selection and optimizing SVM parameters based on a robust system architecture. Neural Comput. Appl. 2018, 30, 2355–2369. [Google Scholar] [CrossRef]
- Aljarah, I.; AlaḾ, A.Z.; Faris, H.; Hassonah, M.A.; Mirjalili, S.; Saadeh, H. Simultaneous feature selection and support vector machine optimization using the grasshopper optimization algorithm. Cogn. Comput. 2018, 10, 478–495. [Google Scholar] [CrossRef]
- Yang, C.S.; Chuang, L.Y.; Ke, C.H.; Yang, C.H. A Hybrid Feature Selection Method for Microarray Classification. IAENG Int. J. Comput. Sci. 2008, 35, 285–290. [Google Scholar]
- Unler, A.; Murat, A.; Chinnam, R.B. mr2PSO: A maximum relevance minimum redundancy feature selection method based on swarm intelligence for support vector machine classification. Inf. Sci. 2011, 181, 4625–4641. [Google Scholar] [CrossRef]
- Cervante, L.; Xue, B.; Zhang, M.; Shang, L. Binary particle swarm optimisation for feature selection: A filter based approach. In Proceedings of the Evolutionary Computation (CEC), Brisbane, Australia, 10–15 June 2012; pp. 1–8. [Google Scholar]
- Moghadasian, M.; Hosseini, S.P. Binary cuckoo optimization algorithm for feature selection in high-dimensional datasets. In Proceedings of the International Conference on Innovative Engineering Technologies (ICIET014), Bangkok, Thailand, 28–29 December 2014; pp. 18–21. [Google Scholar]
- Zhang, C.K.; Hu, H. Feature selection using the hybrid of ant colony optimization and mutual information for the forecaster. Machine Learning and Cybernetics. In Proceedings of the 2005 International Conference on Machine Learning and Cybernetics, Guangzhou, China, 18–21 August 2005; Volume 3, pp. 1728–1732. [Google Scholar]
- Huang, J.; Cai, Y.; Xu, X. A hybrid genetic algorithm for feature selection wrapper based on mutual information. Pattern Recognit. Lett. 2007, 28, 1825–1844. [Google Scholar] [CrossRef]
- Uğuz, H. A two-stage feature selection method for text categorization by using information gain, principal component analysis and genetic algorithm. Knowl.-Based Syst. 2011, 24, 1024–1032. [Google Scholar] [CrossRef]
- Wang, L.; Xu, G.; Wang, J.; Yang, S.; Guo, L.; Yan, W. GA-SVM based feature selection and parameters optimization for BCI research. Natural Computation (ICNC). In Proceedings of the 2011 Seventh International Conference on Natural Computation, Shanghai, China, 26–28 July 2011; Volume 1, pp. 580–583. [Google Scholar]
- Zainudin, M.; Sulaiman, M.; Mustapha, N.; Perumal, T.; Nazri, A.; Mohamed, R.; Manaf, S. Feature selection optimization using hybrid relief-f with self-adaptive differential evolution. Int. J. Intell. Eng. Syst 2017, 10, 21–29. [Google Scholar] [CrossRef]
- Guha, R.; Ghosh, M.; Mutsuddi, S.; Sarkar, R.; Mirjalili, S. Embedded chaotic whale survival algorithm for filter-wrapper feature selection. arXiv 2020, arXiv:2005.04593. [Google Scholar] [CrossRef]
- Hassonah, M.A.; Al-Sayyed, R.; Rodan, A.; AlaḾ, A.Z.; Aljarah, I.; Faris, H. An efficient hybrid filter and evolutionary wrapper approach for sentiment analysis of various topics on Twitter. Knowl.-Based Syst. 2020, 192, 105353. [Google Scholar] [CrossRef]
- Ahmed, N.; Rafiq, J.I.; Islam, M.R. Enhanced human activity recognition based on smartphone sensor data using hybrid feature selection model. Sensors 2020, 20, 317. [Google Scholar] [CrossRef]
- Kanan, H.R.; Faez, K. An improved feature selection method based on ant colony optimization (ACO) evaluated on face recognition system. Appl. Math. Comput. 2008, 205, 716–725. [Google Scholar] [CrossRef]
- Chuang, L.Y.; Chang, H.W.; Tu, C.J.; Yang, C.H. Improved binary PSO for feature selection using gene expression data. Comput. Biol. Chem. 2008, 32, 29–38. [Google Scholar] [CrossRef] [PubMed]
- Martinez, E.; Alvarez, M.M.; Trevino, V. Compact cancer biomarkers discovery using a swarm intelligence feature selection algorithm. Comput. Biol. Chem. 2010, 34, 244–250. [Google Scholar] [CrossRef] [PubMed]
- Mohamad, M.S.; Omatu, S.; Deris, S.; Yoshioka, M. A modified binary particle swarm optimization for selecting the small subset of informative genes from gene expression data. IEEE Trans. Inf. Technol. Biomed. 2011, 15, 813–822. [Google Scholar] [CrossRef]
- Xue, B.; Zhang, M.; Browne, W.N. Novel initialisation and updating mechanisms in PSO for feature selection in classification. In Proceedings of the European Conference on the Applications of Evolutionary Computation; Springer: Berlin/Heidelberg, Germany, 2013; pp. 428–438. [Google Scholar]
- Mafarja, M.; Sabar, N.R. Rank based binary particle swarm optimisation for feature selection in classification. In Proceedings of the 2nd International Conference on Future Networks and Distributed Systems, Amman, Jordan, 26–27 June 2018; pp. 1–6. [Google Scholar]
- Mafarja, M.; Jarrar, R.; Ahmad, S.; Abusnaina, A.A. Feature selection using binary particle swarm optimization with time varying inertia weight strategies. In Proceedings of the 2nd International Conference on Future Networks and Distributed Systems; ACM: New York, NY, USA, 2018; p. 18. [Google Scholar]
- Aljarah, I.; Mafarja, M.; Heidari, A.A.; Faris, H.; Zhang, Y.; Mirjalili, S. Asynchronous accelerating multi-leader salp chains for feature selection. Appl. Soft Comput. 2018, 71, 964–979. [Google Scholar] [CrossRef]
- Hammouri, A.I.; Mafarja, M.; Al-Betar, M.A.; Awadallah, M.A.; Abu-Doush, I. An improved Dragonfly Algorithm for feature selection. Knowl.-Based Syst. 2020, 203, 106131. [Google Scholar] [CrossRef]
- Faris, H.; Heidari, A.A.; AlaḾ, A.Z.; Mafarja, M.; Aljarah, I.; Eshtay, M.; Mirjalili, S. Time-varying hierarchical chains of salps with random weight networks for feature selection. Expert Syst. Appl. 2020, 140, 112898. [Google Scholar] [CrossRef]
- Ouadfel, S.; Abd Elaziz, M. Enhanced Crow Search Algorithm for Feature Selection. Expert Syst. Appl. 2020, 159, 113572. [Google Scholar] [CrossRef]
- Gholami, J.; Pourpanah, F.; Wang, X. Feature selection based on improved binary global harmony search for data classification. Appl. Soft Comput. 2020, 93, 106402. [Google Scholar] [CrossRef]
- Khurma, R.A.; Aljarah, I.; Sharieh, A. Rank based moth flame optimisation for feature selection in the medical application. In Proceedings of the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Khurma, R.A.; Castillo, P.A.; Sharieh, A.; Aljarah, I. Feature Selection using Binary Moth Flame Optimization with Time Varying Flames Strategies. In Proceedings of the 12th International Joint Conference on Computational Intelligence; SciTePress: Setubal, Portugal, 2020; pp. 17–27. [Google Scholar] [CrossRef]
- Galbally, J.; Fierrez, J.; Freire, M.R.; Ortega-Garcia, J. Feature selection based on genetic algorithms for on-line signature verification. In Proceedings of the IEEE Workshop on Automatic Identification Advanced Technologies, Alghero, Italy, 7–8 June 2007; pp. 198–203. [Google Scholar]
- Lu, J.; Zhao, T.; Zhang, Y. Feature selection based-on genetic algorithm for image annotation. Knowl.-Based Syst. 2008, 21, 887–891. [Google Scholar] [CrossRef]
- Li, R.; Lu, J.; Zhang, Y.; Zhao, T. Dynamic Adaboost learning with feature selection based on parallel genetic algorithm for image annotation. Knowl.-Based Syst. 2010, 23, 195–201. [Google Scholar] [CrossRef]
- Hans, R.; Kaur, H. Quasi-opposition-Based Multi-verse Optimization Algorithm for Feature Selection. In Proceedings of the First International Conference on Computing, Communications, and Cyber-Security (IC4S 2019); Springer: Berlin/Heidelberg, Germany, 2020; pp. 345–359. [Google Scholar]
- Chakraborty, B. Feature subset selection by particle swarm optimization with fuzzy fitness function. In Proceedings of the 2008 International Conference on Intelligent System and Knowledge Engineering ISKE, Xiamen, China, 17–19 November 2008; Volume 1, pp. 1038–1042. [Google Scholar]
- De Stefano, C.; Fontanella, F.; Marrocco, C.; Di Freca, A.S. A GA-based feature selection approach with an application to handwritten character recognition. Pattern Recognit. Lett. 2014, 35, 130–141. [Google Scholar] [CrossRef]
- Khurma, R.A.; Castillo, P.A.; Sharieh, A.; Aljarah, I. New Fitness Functions in Binary Harris Hawks Optimization for Gene Selection in Microarray Datasets. In Proceedings of the 12th International Joint Conference on Computational Intelligence; SciTePress: Setubal, Portugal, 2020; Volume 1, pp. 139–146. [Google Scholar] [CrossRef]
- Zio, E.; Baraldi, P.; Pedroni, N. Selecting features for nuclear transients classification by means of genetic algorithms. IEEE Trans. Nucl. Sci. 2006, 53, 1479–1493. [Google Scholar] [CrossRef]
- Mandal, M.; Mukhopadhyay, A.; Maulik, U. Prediction of protein subcellular localization by incorporating multiobjective PSO-based feature subset selection into the general form of Chous PseAAC. Med Biol. Eng. Comput. 2015, 53, 331–344. [Google Scholar] [CrossRef]
- Aljarah, I.; Habib, M.; Faris, H.; Al-Madi, N.; Heidari, A.A.; Mafarja, M.; Abd Elaziz, M.; Mirjalili, S. A Dynamic Locality Multi-Objective Salp Swarm Algorithm for Feature Selection. Comput. Ind. Eng. 2020, 147, 106628. [Google Scholar] [CrossRef]
- Niu, B.; Yi, W.; Tan, L.; Geng, S.; Wang, H. A multi-objective feature selection method based on bacterial foraging optimization. Nat. Comput. 2019, 120, 63–76. [Google Scholar] [CrossRef]
- Habib, M.; Aljarah, I.; Faris, H. A Modified Multi-objective Particle Swarm Optimizer-Based Lévy Flight: An Approach Toward Intrusion Detection in Internet of Things. Arab. J. Sci. Eng. 2020, 45, 6081–6108. [Google Scholar] [CrossRef]
- Al-Tashi, Q.; Abdulkadir, S.J.; Rais, H.M.; Mirjalili, S.; Alhussian, H. Approaches to Multi-Objective Feature Selection: A Systematic Literature Review. IEEE Access 2020, 8, 125076–125096. [Google Scholar] [CrossRef]
- Punch, W.F., III; Goodman, E.D.; Pei, M.; Chia-Shun, L.; Hovland, P.D.; Enbody, R.J. Further Research on Feature Selection and Classification Using Genetic Algorithms. ICGA J. 1993, 93, 557–564. [Google Scholar]
- Ghamisi, P.; Couceiro, M.S.; Benediktsson, J.A. A novel feature selection approach based on FODPSO and SVM. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2935–2947. [Google Scholar] [CrossRef]
- Frohlich, H.; Chapelle, O.; Scholkopf, B. Feature selection for support vector machines by means of genetic algorithm. In Proceedings of the 2003 15th IEEE International Conference, Sacramento, CA, USA, 3–5 November 2003; pp. 142–148. [Google Scholar]
- Robbins, K.; Zhang, W.; Bertrand, J.; Rekaya, R. The ant colony algorithm for feature selection in high-dimension gene expression data for disease classification. Math. Med. Biol. A J. IMA 2007, 24, 413–426. [Google Scholar] [CrossRef] [PubMed]
- Kabir, M.M.; Shahjahan, M.; Murase, K. A new local search based hybrid genetic algorithm for feature selection. Neurocomputing 2011, 74, 2914–2928. [Google Scholar] [CrossRef]
- Kabir, M.M.; Shahjahan, M.; Murase, K. A new hybrid ant colony optimization algorithm for feature selection. Expert Syst. Appl. 2012, 39, 3747–3763. [Google Scholar] [CrossRef]
- Ibrahim, H.T.; Mazher, W.J.; Ucan, O.N.; Bayat, O. A grasshopper optimizer approach for feature selection and optimizing SVM parameters utilizing real biomedical data sets. Neural Comput. Appl. 2018, 31, 5965–5974. [Google Scholar] [CrossRef]
- Sreedharan, N.P.N.; Ganesan, B.; Raveendran, R.; Sarala, P.; Dennis, B. Grey Wolf optimisation-based feature selection and classification for facial emotion recognition. IET Biom. 2018, 7, 490–499. [Google Scholar] [CrossRef]
- Handels, H.; Roß, T.; Kreusch, J.; Wolff, H.H.; Poeppl, S.J. Feature selection for optimized skin tumor recognition using genetic algorithms. Artif. Intell. Med. 1999, 16, 283–297. [Google Scholar] [CrossRef]
- Zheng, B.; Chang, Y.H.; Wang, X.H.; Good, W.F.; Gur, D. Feature selection for computerized mass detection in digitized mammograms by using a genetic algorithm. Acad. Radiol. 1999, 6, 327–332. [Google Scholar] [CrossRef]
- Li, T.S. Feature selection for classification by using a GA-based neural network approach. J. Chin. Inst. Ind. Eng. 2006, 23, 55–64. [Google Scholar] [CrossRef]
- Babaoglu, İ.; Findik, O.; Ülker, E. A comparison of feature selection models utilizing binary particle swarm optimization and genetic algorithm in determining coronary artery disease using support vector machine. Expert Syst. Appl. 2010, 37, 3177–3183. [Google Scholar] [CrossRef]
- Ahmad, F.; Isa, N.A.M.; Hussain, Z.; Osman, M.K.; Sulaiman, S.N. A GA-based feature selection and parameter optimization of an ANN in diagnosing breast cancer. Pattern Anal. Appl. 2015, 18, 861–870. [Google Scholar] [CrossRef]
- Sheikhpour, R.; Sarram, M.A.; Sheikhpour, R. Particle swarm optimization for bandwidth determination and feature selection of kernel density estimation based classifiers in diagnosis of breast cancer. Appl. Soft Comput. 2016, 40, 113–131. [Google Scholar] [CrossRef]
- Sayed, G.I.; Hassanien, A.E.; Nassef, T.M.; Pan, J.S. Alzheimerś Disease Diagnosis Based on Moth Flame Optimization. In Proceedings of the International Conference on Genetic and Evolutionary Computing; Springer: Berlin/Heidelberg, Germany, 2016; pp. 298–305. [Google Scholar]
- Sayed, G.I.; Hassanien, A.E. Moth-flame swarm optimization with neutrosophic sets for automatic mitosis detection in breast cancer histology images. Appl. Intell. 2017, 47, 397–408. [Google Scholar] [CrossRef]
- Daelemans, W.; Hoste, V.; De Meulder, F.; Naudts, B. Combined optimization of feature selection and algorithm parameters in machine learning of language. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2003; pp. 84–95. [Google Scholar]
- Aghdam, M.H.; Ghasem-Aghaee, N.; Basiri, M.E. Text feature selection using ant colony optimization. Expert Syst. Appl. 2009, 36, 6843–6853. [Google Scholar] [CrossRef]
- Ewees, A.A.; Sahlol, A.T.; Amasha, M.A. A Bio-inspired moth-flame optimization algorithm for Arabic handwritten letter recognition. Control, Artificial Intelligence, Robotics & Optimization (ICCAIRO). In Proceedings of the 2017 International Conference, Brussels, Belgium, 13–17 July 2017; pp. 154–159. [Google Scholar]
- Tackett, W.A. Genetic Programming for Feature Discovery and Image Discrimination. ICGA J. 1993, 1993, 303–311. [Google Scholar]
- Bhanu, B.; Lin, Y. Genetic algorithm based feature selection for target detection in SAR images. Image Vis. Comput. 2003, 21, 591–608. [Google Scholar] [CrossRef]
- Jarvis, R.M.; Goodacre, R. Genetic algorithm optimization for pre-processing and variable selection of spectroscopic data. Bioinformatics 2004, 21, 860–868. [Google Scholar] [CrossRef] [PubMed]
- Zhuo, L.; Zheng, J.; Li, X.; Wang, F.; Ai, B.; Qian, J. A genetic algorithm based wrapper feature selection method for classification of hyperspectral images using support vector machine. In Proceedings of the Geoinformatics 2008 and Joint Conference on GIS and Built Environment: Classification of Remote Sensing Images; International Society for Optics and Photonics: Bellingham, WA, USA, 2008; Volume 7147, p. 71471. [Google Scholar]
- Li, S.; Wu, H.; Wan, D.; Zhu, J. An effective feature selection method for hyperspectral image classification based on genetic algorithm and support vector machine. Knowl.-Based Syst. 2011, 24, 40–48. [Google Scholar] [CrossRef]
- Ghamisi, P.; Benediktsson, J.A. Feature selection based on hybridization of genetic algorithm and particle swarm optimization. IEEE Geosci. Remote Sens. Lett. 2015, 12, 309–313. [Google Scholar] [CrossRef]
- Raymer, M.L.; Punch, W.F.; Goodman, E.D.; Kuhn, L.A.; Jain, A.K. Dimensionality reduction using genetic algorithms. IEEE Trans. Evol. Comput. 2000, 4, 164–171. [Google Scholar] [CrossRef]
- Palaniappan, R.; Raveendran, P. Genetic Algorithm to select features for Fuzzy ARTMAP classification of evoked EEG. In Proceedings of the 2002 Asia-Pacific Conference, Taipei, Taiwan, China, 8 August 2002; Volume 2, pp. 53–56. [Google Scholar]
- Garrett, D.; Peterson, D.A.; Anderson, C.W.; Thaut, M.H. Comparison of linear, nonlinear, and feature selection methods for EEG signal classification. IEEE Trans. Neural Syst. Rehabil. Eng. 2003, 11, 141–144. [Google Scholar] [CrossRef]
- Noori, F.M.; Qureshi, N.K.; Khan, R.A.; Naseer, N. Feature selection based on modified genetic algorithm for optimization of functional near-infrared spectroscopy (fNIRS) signals for BCI. In Proceedings of the 2016 2nd International Conference on IEEE, Chengdu, China, 26–27 October 2016; pp. 50–53. [Google Scholar]
- Chen, L.H.; Hsiao, H.D. Feature selection to diagnose a business crisis by using a real GA-based support vector machine: An empirical study. Expert Syst. Appl. 2008, 35, 1145–1155. [Google Scholar] [CrossRef]
- Huang, C.F.; Chang, B.R.; Cheng, D.W.; Chang, C.H. Feature Selection and Parameter Optimization of a Fuzzy-based Stock Selection Model Using Genetic Algorithms. Int. J. Fuzzy Syst. 2012, 14, 1. [Google Scholar]
- Temitayo, F.; Stephen, O.; Abimbola, A. Hybrid GA-SVM for efficient feature selection in e-mail classification. Comput. Eng. Intell. Syst. 2012, 3, 17–28. [Google Scholar]
- Faris, H.; AlaḾ, A.Z.; Heidari, A.A.; Aljarah, I.; Mafarja, M.; Hassonah, M.A.; Fujita, H. An intelligent system for spam detection and identification of the most relevant features based on evolutionary random weight networks. Inf. Fusion 2019, 48, 67–83. [Google Scholar] [CrossRef]
- Saidala, R.K. Variant of Northern Bald Ibis Algorithm for Unmasking Outliers. Int. J. Softw. Sci. Comput. Intell. (IJSSCI) 2020, 12, 15–29. [Google Scholar] [CrossRef]
- Yu, E.; Cho, S. GA-SVM wrapper approach for feature subset selection in keystroke dynamics identity verification. In Proceedings of the International Joint Conference on IEEE, Portland, OR, USA, 20–24 July 2003; Volume 3, pp. 2253–2257. [Google Scholar]
- Rodrigues, D.; Pereira, L.A.; Almeida, T.; Papa, J.P.; Souza, A.; Ramos, C.C.; Yang, X.S. BCS: A binary cuckoo search algorithm for feature selection. In Proceedings of the 2013 IEEE International Symposium on IEEE, Beijing, China, 19–23 May 2013; pp. 465–468. [Google Scholar]
- Hajnayeb, A.; Ghasemloonia, A.; Khadem, S.; Moradi, M. Application and comparison of an ANN-based feature selection method and the genetic algorithm in gearbox fault diagnosis. Expert Syst. Appl. 2011, 38, 10205–10209. [Google Scholar] [CrossRef]
- Khurma, R.A.; Aljarah, I.; Sharieh, A.; Mirjalili, S. EvoloPy-FS: An Open-Source Nature-Inspired Optimization Framework in Python for Feature Selection. In Evolutionary Machine Learning Techniques; Springer: Berlin/Heidelberg, Germany, 2020; pp. 131–173. [Google Scholar]
- Faris, H.; Aljarah, I.; Mirjalili, S.; Castillo, P.A.; Guervós, J.J.M. EvoloPy: An Open-source Nature-inspired Optimization Framework in Python. IJCCI (ECTA) 2016, 1, 171–177. [Google Scholar]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Unler, A.; Murat, A. A discrete particle swarm optimization method for feature selection in binary classification problems. Eur. J. Oper. Res. 2010, 206, 528–539. [Google Scholar] [CrossRef]
- Nakamura, R.Y.; Pereira, L.A.; Costa, K.; Rodrigues, D.; Papa, J.P.; Yang, X.S. BBA: A binary bat algorithm for feature selection. In Proceedings of the 2012 25th SIBGRAPI Conference on Graphics, Patterns and Images, Ouro Preto, Brazil, 22–25 August 2012; pp. 291–297. [Google Scholar]
- Taha, A.M.; Mustapha, A.; Chen, S.D. Naive bayes-guided bat algorithm for feature selection. Sci. World J. 2013, 2013, 325973. [Google Scholar] [CrossRef]
- Huang, C.L. ACO-based hybrid classification system with feature subset selection and model parameters optimization. Neurocomputing 2009, 73, 438–448. [Google Scholar] [CrossRef]
- Lin, K.C.; Chien, H.Y. CSO-based feature selection and parameter optimization for support vector machine. In Proceedings of the 2009 Joint Conferences on IEEE, Tamsui, Taiwan, China, 3–5 December 2009; pp. 783–788. [Google Scholar]
- ElAlami, M.E. A filter model for feature subset selection based on genetic algorithm. Knowl.-Based Syst. 2009, 22, 356–362. [Google Scholar] [CrossRef]
- Huang, C.L.; Wang, C.J. A GA-based feature selection and parameters optimizationfor support vector machines. Expert Syst. Appl. 2006, 31, 231–240. [Google Scholar] [CrossRef]
- Zhang, Y.; Gong, D.W.; Cheng, J. Multi-objective particle swarm optimization approach for cost-based feature selection in classification. IEEE/ACM Trans. Comput. Biol. Bioinform. (TCBB) 2017, 14, 64–75. [Google Scholar] [CrossRef] [PubMed]
- Kashef, S.; Nezamabadi-pour, H. An advanced ACO algorithm for feature subset selection. Neurocomputing 2015, 147, 271–279. [Google Scholar] [CrossRef]
- Kashef, S.; Nezamabadi-pour, H. A new feature selection algorithm based on binary ant colony optimization. In Proceedings of the 2013 5th Conference on IEEE, Kuala Lumpur, Malaysia, 4–5 December 2013; pp. 50–54. [Google Scholar]
- Zhao, T.; Lu, J.; Zhang, Y.; Xiao, Q. Feature selection based on genetic algorithm for cbir. In Proceedings of the Image and Signal Processing, 2008. CISP’08, Congress on IEEE, Sanya, China, 27–30 May 2008; Volume 2, pp. 495–499. [Google Scholar]
- Xue, B.; Zhang, M.; Browne, W.N. New fitness functions in binary particle swarm optimisation for feature selection. In Proceedings of the 2012 IEEE Congress on IEEE, Brisbane, QLD, Australia, 10–15 June 2012; pp. 1–8. [Google Scholar]
- Emary, E.; Zawbaa, H.M.; Ghany, K.K.A.; Hassanien, A.E.; Parv, B. Firefly optimization algorithm for feature selection. In Proceedings of the 7th Balkan Conference on Informatics Conference, ACM, Craiova, Romania, 2–4 September 2015; p. 26. [Google Scholar]
- Xue, B.; Zhang, M.; Browne, W.N. Particle swarm optimization for feature selection in classification: A multi-objective approach. IEEE Trans. Cybern. 2013, 43, 1656–1671. [Google Scholar] [CrossRef]
- Xue, B.; Cervante, L.; Shang, L.; Browne, W.N.; Zhang, M. Binary PSO and rough set theory for feature selection: A multi-objective filter based approach. Int. J. Comput. Intell. Appl. 2014, 13, 1450009. [Google Scholar] [CrossRef]
- Doerner, K.; Gutjahr, W.J.; Hartl, R.F.; Strauss, C.; Stummer, C. Pareto ant colony optimization: A metaheuristic approach to multiobjective portfolio selection. Ann. Oper. Res. 2004, 131, 79–99. [Google Scholar] [CrossRef]




{kind=link}
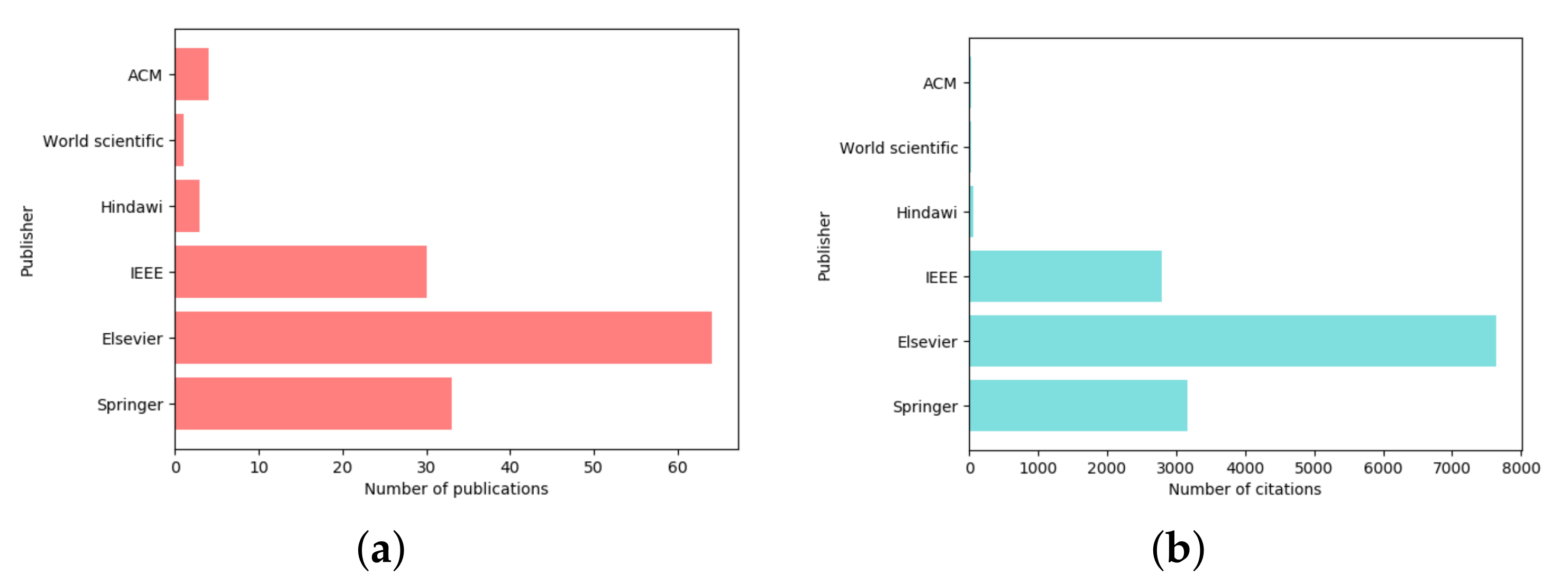{kind=link}
{kind=link}
| New Operator | NIA Wrapper and No. of Publications | References | Total NIAs |
|---|---|---|---|
| Chaotic maps | PSO(4), SSA(2), MVO(1), CSA(1) WOA(1), MFO(1) | [3,51,52,53,54,55,56,57,58] | 10 |
| Rough set | PSO(2), CS(2), FA(1), MFO(1) | [61,62,63,64,66,67] | 6 |
| Selection operators (RWS,TS) | GOA(1), WOA(2), ABC(1), DE(1) | [26,46,72,73,74] | 5 |
| Sigmoidal function | PSO(1), GWO(1), CS(1), BA(1), GOA(1) | [6,76,77,78,79] | 5 |
| S-shaped and V-shaped TFs | PSO(1), SSA(1), DA(1), GOA(1) | [79,80,82,83] | 4 |
| Crossover | GWO(1), SSA(1), WOA(1), GOA(1) | [73,79,82,84] | 4 |
| Mutation | PSO(2), GOA(1) | [53,79,85] | 3 |
| Uniform Combination (UC) | PSO(2) | [80,91] | 2 |
| Local search | PSO(2) | [24,90] | 2 |
| DE evolutionary operators | WOA(1), ABC(1) | [5,26] | 2 |
| Boolean algebra operation | PSO(1) | [92] | 1 |
| Logistic regression | PSO(1) | [202] | 1 |
| Catfish strategy | PSO(1) | [94] | 1 |
| Feature subset ranking | PSO(1) | [95] | 1 |
| Statistical clustering | PSO(1) | [96] | 1 |
| Threshold | PSO(1) | [97] | 1 |
| Gaussian sampling | PSO(1) | [91] | 1 |
| Reinforced memory strategy | PSO(1) | [91] | 1 |
| XOR operator | PSO(1) | [98] | 1 |
| Correlation information | PSO(1) | [99] | 1 |
| Binary quantum | PSO(1) | [100] | 1 |
| Reinitialization strategy | PSO(1) | [101] | 1 |
| Non replaceable memory | PSO(1) | [101] | 1 |
| Levy flight | CS(1) | [64] | 1 |
| Return cost indicator | FFA(1) | [102] | 1 |
| Pareto dominance based | FFA(1) | [102] | 1 |
| Movement operator and adaptive jump | FFA(1) | [102] | 1 |
| Greedy search | ALO(1) | [103] | 1 |
| Evolutionary Population Dynamics (EPD) | GOA(1) | [72] | 1 |
| DE-based neighborhood mechanism | ABC(1) | [26] | 1 |
| Repair mechanism | DE(1) | [74] | 1 |
| m-features operator (OR operator) | GA(1) | [104] | 1 |
| Dynamic neighboring genetic | GA(1) | [105] | 1 |
| Repair operator | GA(1) | [106] | 1 |
| Target | Type | Strategy | Model | References | Total |
|---|---|---|---|---|---|
| Enhance the exploitation | NIA-NIA (Population-trajectory (mimetic) SI-EA, SI-SI) | Global search followed by local search | GWO-ALO, WOA-SA, CSA-FPA, SSA-PSO, PSO-mGA, ACO-DE, MFO-SA, MFO-LFA | [4,23,46,101,108,110,111,112] | 8 |
| Refine the best solutions | NIA-NIA | Implementing NIAs sequentially as a pipeline. Apply operators of 1st algorithm then apply operators of the 2nd algorithm sequentially | WOA-SA, PSO-GA | [46,113] | 2 |
| Speed up the search process | NIA-NIA | Perform parallel exploration | ACO-GA | [116,117] | 2 |
| Enhance the initialization process | NIA-NIA | Generate initial solutions by one algorithm then update them using the other algorithm | GA-IGWO | [119] | 1 |
| Improve the training process. Improve the evaluation process. Reduce the computation complexity. Investigate the capability of different classifiers. Simultaneous parameters optimization and feature reduction. Study the influence of different evaluation strategies on wrappers performance. | NIA-Classifier | For the simultaneous parameter and FS optimization, NIA works as a tuner to optimize the training parameters set up, selecting the optimal feature subset by making new representations of an individual, in such a way the length of the individual equals the number of parameters and number of features and adjusts the values of genes by either doing real or binary conversion. | PSO-KDE, GA-IGWO-KELM, GWO-NN, CS-OPF, CSA-FPA-OPF, BBA-OPF, BBA-NaiveBayes, {MVO-RF, MVO-J48, MVO-Kstar, MVO-LMT}, MVO-SVM, GOA-SVM, ACO-SVM, ACO-NN, CMFO-KELM, CSO-SVM, GA-KNN, {GA-NN, GA-BNN, GA-MLP, GA-BP-NN, GA-RBF-NN, GA-LQV-NN, GAANN-RP, GAANN-LM, GAANN-GD, GA-RWN}, GA-C4.5, GA-SVM, GA-Bayesian, GA-FKNN, GA-adaboost, GA-SVR, | [3,18,22,56,77,78,108,117,119,121,122,128,130,151,156,164,166,167,168,169,171,172,173,174,175,182,185,188,189,190,191,194,196,197,198,203,204,205,206,207,208,151,22] | 49 |
| Minimize the dimensionality of the large datasets, eliminate the redundant/ irrelevant features, evaluate the generated features subsets | NIA-Filter (Wrapper-Filter) | Classically applied in two steps: Filtering of the features applied first then a wrapper is applied on the reduced dataset. Other studies tried to embed the filter in the structure of a wrapper in order to evaluate the generated features subsets | {IG-IBPSO, CFS-IBPSO}, MSPSO-F-Score, MI-PSO, {BPSO-G (Intropy-PSO), BPSO-P (MI-PSO)}, CS-MI-Entropy, LA-QuickReduct-CEBARKCC, IWOA-IG, ACO-MI, ACO-Multivariate filter, GA-MI, IG-GA, GA-Entropy | [5,16,17,18,64,65,124,125,126,127,128,129,130] | 14 |
| Modification | NIA Wrapper and No. Publications | References | Total Works |
|---|---|---|---|
| Update mechanism | PSO(10), SSA(1), DA(1), ACO(5) | [24,25,53,83,90,96,135,136,137,138,139,141,142,179,209,210,211] | 17 |
| Modified population structure | PSO(1), SSA(1), GA(1) | [101,105,142] | 3 |
| Different encoding scheme | PSO(3), GA(4) | [17,90,91,105,149,150,212] | 7 |
| New initialization | PSO(2), GWO(1) | [53,84,139] | 3 |
| New fitness function | PSO(2), GWO(1), FFA(1), WOA(1), GA(4) | [5,6,106,153,154,182,183,213,214] | 9 |
| Multi objective | PSO(4), ACO(1), GA(1) | [156,157,209,215,216,217] | 6 |
| Parallelism | PSO(2), GA(2) | [17,151,162,163] | 4 |
| Modification | PSO | GWO | SSA | CS | DA | FFA | LA | BA | MVO | GOA | WOA | ACO | MFO | GA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| New operator | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ |
| Hybridization | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Update mechanism | ✓ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ |
| Modified population structure | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| Different encoding scheme | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| New initialization | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| New fitness function | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ |
| Multi objective | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ |
| Parallelism | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| Modification | PSO | GWO | SSA | CS | DA | FFA | LA | BA | MVO | GOA | WOA | ACO | MFO | GA | Total Studies/Modification |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| New operator | 21 | 2 | 3 | 3 | 1 | 1 | 1 | 1 | 1 | 2 | 4 | 0 | 2 | 6 | 48 |
| Hybridization | 11 | 2 | 1 | 3 | 0 | 0 | 1 | 3 | 2 | 2 | 2 | 7 | 3 | 38 | 75 |
| Update mechanism | 10 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 0 | 0 | 17 |
| Modified population structure | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 3 |
| Different encoding scheme | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4 | 7 |
| New initialization | 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 |
| New fitness function | 2 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 4 | 9 |
| Multi objective | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 6 |
| Parallelism | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 4 |
| Total studies/FS-NIA | 56 | 6 | 6 | 6 | 2 | 2 | 2 | 4 | 3 | 4 | 7 | 13 | 5 | 56 | 172 |
| FS Application | NIA Wrapper and No. of Publications | References | Total NIAs |
|---|---|---|---|
| Microarray gene expression classification. (DNA micro array classification) | PSO(9), GWO(1), CS(1), GOA(1), ACO(2), GA(4) | [4,18,24,52,98,100,123,126,128,136,137,138,164,165,166,167,168] | 18 |
| Facial expression recognition | PSO(3), GWO(1), ACO(2), FO(1) | [25,76,97,101,112,135,169] | 7 |
| Medical applications (SONAR, tumor, mass and various disease detection, medical diagnosis, medical data, and bio signal analysis) | PSO(4), GWO(1), WOA(1), ACO(1), MFO(3), GA(6) | [3,57,62,113,119,153,172,173,174,175,176,177,211] | 16 |
| Handwritten letter recognition, sentiment analysis, language processing, signature verification system, and text categorization | PSO(1), WOA(1), ACO(1), MFO(1), GA(6) | [5,53,89,105,129,149,154,178,179,180] | 10 |
| Hyper spectral images processing and classification. | PSO(3), GWO(2), GA(9) | [4,6,150,151,163,181,182,183,184,185,186,212] | 13 |
| Intrusion detection | PSO(1) | [61] | 1 |
| Protein and related genome annotation. | PSO(1), ACO(1) | [116,157] | 2 |
| Meteorology weather forecasting | ACO(1) | [127] | 1 |
| Biological application | GA(1) | [162] | 1 |
| Biochemistry and drug design | GA(2) | [104] | 2 |
| Electroencephalogram (EEG) signals application/Brain Computer Interface (BCI) system | ACO(1), GA(2) | [23,130,188,189,190] | 5 |
| Design an automatic FS model that can choose the most relevant features from password typing | GA(1) | [196] | 1 |
| Transient diagnosis system for nuclear power plants | GA(1) | [156] | 1 |
| Financial diagnosis /business crisis detection/stock price prediction | PSO(1), GA(3) | [191,192,202] | 4 |
| Diagnose different types of fault in a gearbox | GA(1) | [198] | 1 |
| Software Product Line (SPLs) and sw effort estimation | GA(2) | [22,106] | 2 |
| Theft detection in power distribution systems | CS(1) | [197] | 1 |
| Spam detection in emails | PSO(1), GA(2) | [85,193,194] | 3 |
| Transient diagnosis system for nuclear power plants | GA(1) | [156] | 1 |
| Automatic tomato disease detection system based | MFO(1) | [67] | 1 |
| App | Modification | Model | Classifier | Datasets | Dimension | Year | Ref. |
|---|---|---|---|---|---|---|---|
| Microarray gene expression | Hybridization | GA-SVM | SVM | 2 | 2000 | 2003 | [164] |
| Hybridization | GA-MI | SVM | 13 | 2000 | 2007 | [128] | |
| Update mechanism | IPSO | 1-KNN | 11 | 15,009 | 2008 | [136] | |
| Update mechanism | BPSO | 1-KNN | 6 | 10,509 | 2008 | [92] | |
| Hybridization | IBPSO-IG, IBPSO-CFS | 1-KNN | 6 | 11,225 | 2008 | [123] | |
| Update mechanism | cuPSO | 1-KNN | 11 | 15,009 | 2010 | [137] | |
| Hybridization | GA-IG | 1-KNN | 11 | 15,009 | 2010 | [18] | |
| Hybridization New operator/chaotic | TCBPSO-CFC | 1-KNN | 10 | 9868 | 2011 | [52] | |
| Update mechanism | IBPSO | SVM | 10 | 12,600 | 2011 | [138] | |
| Hybridization | GA-NN-MI | NN-BP | 11 | 7129 | 2011 | [166] | |
| Hybridization | ACOFS | NN | 9 | 2000 | 2012 | [167] | |
| Hybridization | CS-MI-Entropy | ANN | 6 | 15,009 | 2014 | [126] | |
| Update mechanism | PSO-LSRG | 1-KNN | 5 | 12,600 | 2014 | [24] | |
| New operator/XOR | HDBPSO | 1-KNN, 3-KNN, 5-KNN | 3 | 7129 | 2015 | [98] | |
| New operator/binaryquantum | BQPSO-SVM | SVM | 5 | 12,600 | 2016 | [100] | |
| Hybridization | GWO-ALO | 5-KNN | 7 | 49151 | 2018 | [4] | |
| Hybridization | GOA-SVM | SVM | 3 | 17,678 | 2018 | [168] | |
| Medical application | Hybridization | GABPNN, GARBFNN, GALQVNN | BPNN, RBFNN, LQVNN | 1 | 30 | 2006 | [172] |
| Hybridization | PSO-GA | SVM | 3 | 7129 | 2008 | [113] | |
| New fitness function | PSO-MLP | MLP | 3 | 16 | 2008 | [153] | |
| Hybridization | BPSO-FST, GA-FST | SVM | 1 | 23 | 2010 | [173] | |
| New operator/rough set | PSO-RR, PSO-QR | Naive Bayes, BayesNet, KStar | 4 | 45 | 2014 | [62] | |
| Hybridization | GAANNRP, GAANNLM, GAANNGD, | NNRP, NNLM, NNGD | 1 | 10 | 2015 | [174] | |
| Hybridization | PSO-KDE | KDE | 2 | 32 | 2016 | [175] | |
| Hybridization | IGWO-GA-KELM | KELM | 2 | 32 | 2017 | [119] | |
| New operator/chaotic maps | CMFOFS-KELM | KELM | 1 | 22 | 2017 | [3] | |
| Hyper spectral images processing | New fitness function hybridization | GA-MDLP-Bayesian | Bayesian | 3 | 20 | 2003 | [182] |
| New fitness function | GA-DFA | Validation by projection | 1 | 882 | 2004 | [183] | |
| Hybridization | GA-SVM | SVM | 1 | 198 | 2008 | [184] | |
| Different encoding schemes | GA-KNN | KNN | 1 | 25 | 2008 | [150] | |
| Different encoding schemes | GA-KNN | KNN | 1 | 25 | 2008 | [212] | |
| Hybridization parallelism | Parallel-GA-Adaboost | Adaboost ensemble, KNN | 1 | 25 | 2010 | [151] | |
| Different encoding schemes | BGAFS, BCGAFS | Adaboost ensemble, KNN | 1 | 25 | 2010 | [151] | |
| Hybridization | MI-GA-SVM-BB | SVM, BB | 2 | 202 | 2011 | [185] | |
| Parallelism | FODPSO-SVM | SVM | 2 | 220 | 2015 | [163] | |
| Hybridization | HGAPSO-SVM | SVM | 1 | 220 | 2015 | [186] | |
| New fitness function | GWO-KNN | 7-KNN | 3 | 224 | 2016 | [6] | |
| Hybridization | GWO-ALO | 5-KNN | 5 | 10,304 | 2018 | [4] | |
| Arabic HR | New operator/local search | HGA | 1-KNN | 1 | 16 | 2004 | [89] |
| Different encoding schemes | GA | No classifier | 1 | 100 | 2007 | [149] | |
| Update mechanism | ACO | KNN | 1 | 7542 | 2009 | [179] | |
| New population structure | CAGA | NN-BP | 1 | 16 | 2009 | [105] | |
| Hybridization | IG-GA-PCA | KNN, C4.5 | 4 | 7542 | 2011 | [129] | |
| New fitness function | GA-FLD | KNN, MLP, SVM (RBF, Poly, Sigm) | 4 | 780 | 2014 | [154] | |
| New initialization+New operator/mutation | BPSO | No classifier/clustering problem | 3 | 8830 | 2016 | [53] | |
| Hybridization new operator/DE evolutionary | IWOA-IG-SVM | SVM | 4 | 8057 | 2018 | [5] | |
| Face recognition | Update mechanism | ACO | KNN | 1 | 400 | 2007 | [25] |
| Update mechanism | ACO | KNN | 1 | 400 | 2008 | [135] | |
| New operator/intelligent acceleration | ABPSO | Euclidean classifier | 2 | 2204 | 2012 | [76] | |
| New operator/threshold | BPSO | Euclidean classifier | 7 | 16,380 | 2014 | [97] | |
| Hybridization new operator update | PSO-mGA | NN-BP, SVM-RBF, ensembles | 2 | 1280 | 2017 | [101] | |
| Hybridization | GWO-NN | NN | 2 | 486 | 2018 | [169] | |
| New operators/return-cost | Rc-BBFA | 1-KNN | 10 | 1280 | 2016 | [112] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abu Khurma, R.; Aljarah, I.; Sharieh, A.; Abd Elaziz, M.; Damaševičius, R.; Krilavičius, T. A Review of the Modification Strategies of the Nature Inspired Algorithms for Feature Selection Problem. Mathematics 2022, 10, 464. https://doi.org/10.3390/math10030464
Abu Khurma R, Aljarah I, Sharieh A, Abd Elaziz M, Damaševičius R, Krilavičius T. A Review of the Modification Strategies of the Nature Inspired Algorithms for Feature Selection Problem. Mathematics. 2022; 10(3):464. https://doi.org/10.3390/math10030464
Chicago/Turabian StyleAbu Khurma, Ruba, Ibrahim Aljarah, Ahmad Sharieh, Mohamed Abd Elaziz, Robertas Damaševičius, and Tomas Krilavičius. 2022. "A Review of the Modification Strategies of the Nature Inspired Algorithms for Feature Selection Problem" Mathematics 10, no. 3: 464. https://doi.org/10.3390/math10030464
APA StyleAbu Khurma, R., Aljarah, I., Sharieh, A., Abd Elaziz, M., Damaševičius, R., & Krilavičius, T. (2022). A Review of the Modification Strategies of the Nature Inspired Algorithms for Feature Selection Problem. Mathematics, 10(3), 464. https://doi.org/10.3390/math10030464