
Tags’ Recommender to Classify Architectural Knowledge Applying Language Models


Abstract
1. Introduction
2. Related Work
2.1. Architectural Knowledge and Agile Global Software Engineering
2.2. Approaches to Address the Lack of Explicit Architectural Knowledge
3. Architectural Knowledge Condensation and the Slack Tagging Service
- Accessible UTEM logs. All the stakeholders involved in an agile GSE project must access the information contained in the UTEM log files to consult the AK that is shared among the development team.
- UTEM log classification mechanism to structure the shared information to ease the AK retrieval. This mechanism must be based on a semantic scheme representing the AK shared through UTEM.
- AK searching mechanism. All the stakeholders could use the semantic scheme to find valuable AK with less effort in the structured UTEM logs.
3.1. Accessible Messages of the UTEM Log Files
3.2. UTEM Log Files Classification Mechanism
3.3. Scenario of Architectural Knowledge Condensation
3.4. Potential Benefits of the Architectural Knowledge Condensation
- Reduction of interruptions. Since full implementation of this concept provides a search engine for AK, a team member who has a question about any AK topic could first use the search engine before interrupting one of their or her teammates to ask a question.
- Reduced time to find AK. AK condensation offers a common point to search for shared knowledge in different UTEM, in addition to offering search filters that most UTEM do not offer, such as search by period, by author, by the recipient, by UTEM source, and by tag.
- Reduction of development tasks time. As a consequence of the two previous points, it is expected that the time to complete development tasks will be reduced since the project’s AK will be more accessible through the AK search engine.
4. Language Models Development and Integration to Slack Tagging Service
4.1. Corpus Development
4.2. Language Models Development
- them. I am programming
- programming I am
- I do not like to design
- N-grams-2 (bigrams): the sequence of terms was determined after performing an analysis between N-grams of sizes 2, 4, and 6.
- We used Kneser–Ney discounting (kndiscount) as a smoothing method.
- Gtmin: specify the minimum counts for N-grams to be included in the language model, we used gt2min.
ver VMIP1S0 que CS el DA0FP0 historia NCFP000 de SP usuario NCMS000 estar VMIP3P0 enfocar VMP00PF a SP uno DI0MS0 asistente NCCS000 médico AQ0MS00
see VB that IN the DT user NN ’s story NN is VBZ focused VBN on IN a DT medical JJ assistant NN
4.3. Language Models and Slack Tagging Service Integration
- An user clicks the button to start tagging a message, and the Slack tagging service does an HTTP request to the recommendation service sending the message text.
- The recommendation service receives the text and sends it to each of the seven language models. Each model calculates a numerical value called perplexity, which expresses the confidence of the sentence tested in the language models. It is worth mentioning that the perplexity value is expressed between 0 and 1, where values close to zero indicate a powerful closeness. The measure used to compare the similarity in the language models was “average perplexity per word”.
- Once the recommendation service obtained the perplexity values of the seven language models; the values are ordered so that the first position represents the tag that fits better to the received text, according to the language models. Then, the service return to Slack an ordered list of tags, to be shown in the selection tag window (see Figure 2).
5. Materials and Methods
5.1. Objective
5.2. Planning
5.2.1. Context and Subjects Selection
5.2.2. Study Design, Variables Selection, Furthermore, Hypotheses Formulation
- . There is no significant difference in the number of correctly tagged messages by using the tags recommendation feature or the auto-completion feature.
- . There is no significant difference in time spent tagging a message by using the tags recommendation feature or the auto-completion feature.
5.2.3. Instrumentation
- Context scenario. This scenario was used in our past work [18], and it concerned two agile developers from different companies and locations working on the same project (medical appointments system), one of whom required information about a RESTful service that the other was developing. They had documentation debt, and consequently, they had to acquire the project AK by asking questions to each other. A complete description of this scenario is located at https://github.com/gborrego/autotagsakagsd (accessed on 16 November 2021).
- Chatting guides. Each pair of participants had to follow two guides (one per scenario role) to simulate a technical conversation using Slack regarding the context scenario. The guides had marks indicating when to tag using either the recommendation or auto-completion features. It is important to highlight that these guides were based on the chatting scripts used in our past work [18] and the interactions based on these scripts comprised the corpus with which we developed the language models of this study. Furthermore, it is worth remarking that using a chatting guide does not mean that we wrote exact phrases to be copied by the participants during their interactions. This chatting guide contained hints about what to request or respond to cause variations in the participants’ writing, but with the same hints’ semantic; in this way, we could test the robustness of the language models. Both chatting guides are located at https://github.com/gborrego/autotagsakagsd (accessed on 16 November 2021).
- Slack tagging service, and were presented in Section 3. The service also registers when it was activated and when it was closed to obtain the time spent tagging a message.
- Messages gathering program. It is a program developed in Node.js which uses the Slack API to extract the messages of public channels and then sends them to the Algolia repository.
- Extended TAM questionnaire. We prepared a questionnaire in Google Forms which was based on the Technology Acceptance Model [64] (TAM) using a Likert-7 scale. Just as in our previous work [18], we extended this questionnaire adding items such: how the Slack component integrates to the daily work, and another in which we asked about enhancements that the participants would consider adding to the component to answer the RQ3. Furthermore, this questionnaire collected the following demographic data: age, years of experience in agile development, years of experience in distributed/global software development. The complete questionnaire could be viewed at https://github.com/gborrego/autotagsakagsd (accessed on 16 November 2021).
5.3. Operation
5.3.1. Preparation
5.3.2. Execution
- Introduction (duration 10 min). We explained to the participants the study sessions along with their objectives. We organized the participants in pairs (to chat between them), and then we asked their email addresses to register them on the Slack workspace. We created a public channel for each pair of participants (to isolate the pairs’ conversations), and we helped them complete the Slack registration. We gave the participants a short training session regarding how to use the tagging service (3 min, approx.), and they quickly explored the available tags (2 min, approx.). Then, we described the scenario in which they would be located to carry out the tasks, and we assigned a role to each pair member: either the developer working on a RESTful service or the developer who wished to use it. We gave them the corresponding guides, and we explained to them that the guides had marks indicating when to use the recommendation feature. Each pair member sat in a different part of the session room, ensuring they had no visual contact as if they were geographically distributed. We asked them to avoid talking to each other to emulate an environment of geographic distribution better.
- Interacting through Slack (duration 25 min). Following the corresponding guide, the participants used Slack to chat, and the tagging service aided them. We explained that they could paraphrase the messages since we gave them only a guide, not a script. We also told the participants that they could write a new tag (unregistered/invalid tag) if they could not find one that fitted a certain message on the options shown by the tagging service.
- Finalization (duration 3 min). When the participants had finished chatting through Slack, they answered the TAM-based questionnaire. Finally, we executed the message-gathering program to send all the channel conversations to a common repository.
5.3.3. Data Collection and Data Validation
6. Results
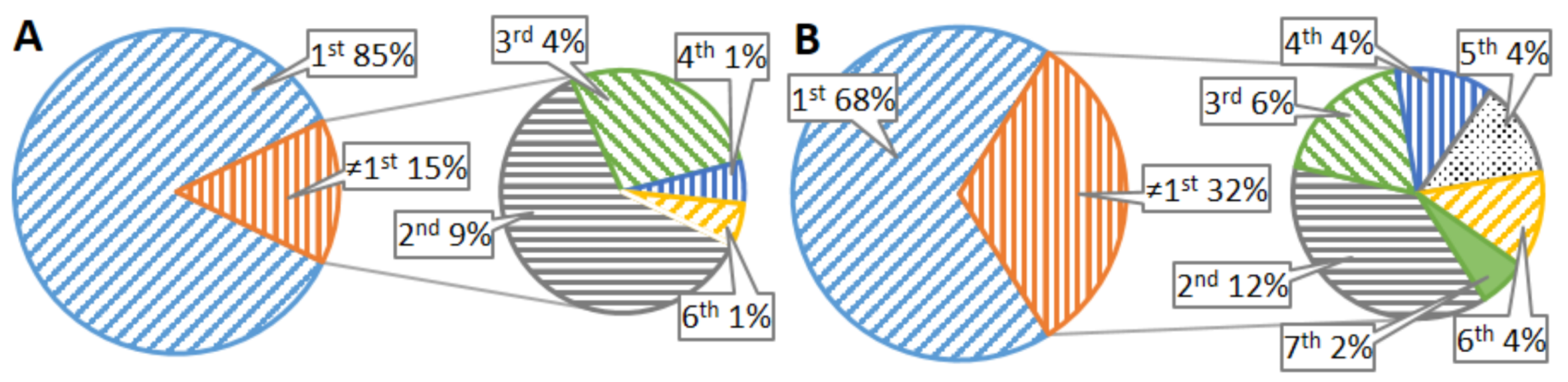
6.1. Tagging Correctness
6.2. Time Spent to Tag Messages
6.3. Additional Observations
6.4. Qualitative Results
7. Threats to Validity
7.1. Conclusion Validity
7.2. Internal Validity
7.3. Construct Validity
7.4. External Validity
8. Discussion
8.1. Implications about Architectural Knowledge Condensation in Agile Global Software Engineering
- We must implement a mechanism to determine how well a message was tagged. This implementation could run when developers look for projects’ AK, using the searching mechanism proposed by the AK condensation concept; thus, when they find AK, they also could qualify the tagging. It is important to notice that the searching mechanism has as a source a repository where the UTEM logs will be stored; thus, it can contain messages from email, code repositories (commit comments), instant messengers, etc.
- Another mechanism could take from the messages repository the tagged ones with a good qualification; thus, determining when is a good qualification would be crucial.
- The same mechanism could group the messages by tag, and finally, pass the grouped messages to a final process to update the current language models or generate new ones based on new tags.
8.2. Implications about Natural Language Models in Agile Global Software Engineering
8.3. Summary of Contributions
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AK | Architectural Knowledge |
| GSE | Global Software Engineering |
| NLP | Natural Language Processing |
| TAM | Technology Acceptance Model |
| UTEM | Unstructured Textual and Electronic Media |
References
- Vliet, H.V. Software architecture knowledge management. In Proceedings of the IEEE 19th Australian Conference on Software Engineering (ASWEC 2008), Perth, Australia, 25–28 March 2008; pp. 24–31. [Google Scholar] [CrossRef]
- Kruchten, P. Documentation of Software Architecture from a Knowledge Management Perspective—Design Representation. In Software Architecture Knowledge Management: Theory and Practice; Springer: Berlin/Heidelberg, Germany, 2009; Chapter 3; pp. 39–57. [Google Scholar] [CrossRef]
- Dalkir, K. Knowledge Management in Theory and Practice, 2nd ed.; MIT Press: Cambridge, MA, USA, 2011; p. 485. [Google Scholar]
- Holmstrom, H.; Conchuir, E.O.; Agerfalk, P.J.; Fitzgerald, B. Global Software Development Challenges: A Case Study on Temporal, Geographical and Socio-Cultural Distance. In Proceedings of the International Conference on Global Software Engineering (ICGSE ’06), Florianopolis, Brazil, 16–19 October 2006; pp. 3–11. [Google Scholar] [CrossRef]
- Zahedi, M.; Shahin, M.; Ali Babar, M. A systematic review of knowledge sharing challenges and practices in global software development. Int. J. Inf. Manag. 2016, 36, 995–1019. [Google Scholar] [CrossRef]
- Beck, K.; Beedle, M.; van Bennekum, A.; Cockburn, A.; Cunningham, W.; Fowler, M.; Grenning, J.; Highsmith, J.; Hunt, A.; Jeffries, R.; et al. Manifesto for Agile Software Development. Web. 2001. Available online: https://agilemanifesto.org/ (accessed on 20 October 2021).
- Cockburn, A.; Highsmith, J. Agile Software Development:The People Factor. Computer 2001, 34, 131–133. [Google Scholar] [CrossRef]
- Yanzer Cabral, A.R.; Ribeiro, M.B.; Noll, R.P. Knowledge Management in Agile Software Projects: A Systematic Review. J. Inf. Knowl. Manag. (JIKM) 2014, 13, 1450010. [Google Scholar] [CrossRef]
- Borrego, G.; Moran, A.A.L.; Palacio, R.R.; Rodriguez, O.M.O.; Morán, A.L.; Palacio, R.R.; Rodríguez, O.M.; Moran, A.A.L.; Palacio, R.R.; Rodriguez, O.M.O. Understanding architectural knowledge sharing in AGSD teams: An empirical study. In Proceedings of the 11th IEEE International Conference on Global Software Engineering, Irvine, CA, USA, 2–3 August 2016; pp. 109–118. [Google Scholar] [CrossRef]
- Clerc, V.; Lago, P.; Vliet, H.V. Architectural Knowledge Management Practices in Agile Global Software Development. In Proceedings of the IEEE Sixth International Conference on Global Software Engineering Workshop, Helsinki, Finland, 15–18 August 2011; pp. 1–8. [Google Scholar] [CrossRef]
- Tom, E.; Aurum, A.; Vidgen, R. An exploration of technical debt. J. Syst. Softw. 2013, 86, 1498–1516. [Google Scholar] [CrossRef]
- Bider, I.; Söderberg, O. Becoming Agile in a Non-Disruptive Way. In Proceedings of the 18th International Conference on Enterprise Information Systems (ICEIS 2016), Rome, Italy, 25–28 April 2016; SCITEPRESS—Science and Technology Publications, Lda.: Setubal, Portugal, 2016; pp. 294–305. [Google Scholar] [CrossRef]
- Bosch, J. Software Architecture: The Next Step; EWSA; Volume 3047, Lecture Notes in Computer Science; Oquendo, F., Warboys, B., Morrison, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 194–199. [Google Scholar]
- Holz, H.; Melnik, G.; Schaaf, M. Knowledge management for distributed agile processes: Models, techniques, and infrastructure. In Proceedings of the IEEE Enabling Technologies: Infrastructure for Collaborative Enterprises, Linz, Austria, 11 June 2003; pp. 291–294. [Google Scholar] [CrossRef]
- Uikey, N.; Suman, U.; Ramani, A. A Documented Approach in Agile Software Development. Int. J. Softw. Eng. 2011, 2, 13–22. [Google Scholar]
- Rios, N.; Mendes, L.; Cerdeiral, C.; Magalhães, A.P.F.; Perez, B.; Correal, D.; Astudillo, H.; Seaman, C.; Izurieta, C.; Santos, G.; et al. Hearing the Voice of Software Practitioners on Causes, Effects, and Practices to Deal with Documentation Debt. In Requirements Engineering: Foundation for Software Quality; Madhavji, N., Pasquale, L., Ferrari, A., Gnesi, S., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 55–70. [Google Scholar]
- Ryan, S.; O’Connor, R.V. Acquiring and sharing tacit knowledge in software development teams: An empirical study. Inf. Softw. Technol. 2013, 55, 1614–1624. [Google Scholar] [CrossRef]
- Borrego, G.; Morán, A.L.; Palacio, R.R.; Vizcaíno, A.; García, F.O. Towards a reduction in architectural knowledge vaporization during agile global software development. Inf. Softw. Technol. 2019, 112, 68–82. [Google Scholar] [CrossRef]
- Estler, H.; Nordio, M.; Furia, C.A.; Meyer, B.; Schneider, J. Agile vs. Structured Distributed Software Development: A Case Study. In Proceedings of the 2012 IEEE Seventh International Conference on Global Software Engineering, Porto Alegre, Brazil, 27–30 August 2012; pp. 11–20. [Google Scholar]
- Bagheri, E.; Ensan, F. Semantic tagging and linking of software engineering social content. Autom. Softw. Eng. 2016, 23, 147–190. [Google Scholar] [CrossRef]
- Nagwani, N.K.; Singh, A.K.; Pandey, S. TAGme: A topical folksonomy based collaborative filtering for tag recommendation in community sites. In Proceedings of the 4th Multidisciplinary International Social Networks Conference (MISNC ’17), Bangkok, Thailand, 17–19 July 2017. [Google Scholar] [CrossRef]
- Bailey, B.P.; Konstan, J.A. On the need for attention-aware systems: Measuring effects of interruption on task performance, error rate, and affective state. Comput. Hum. Behav. 2006, 22, 685–708. [Google Scholar] [CrossRef]
- Altmann, E.; Trafton, J.; Hambrick, Z. Momentary Interruptions Can Derail the Train of Thought. J. Exp. Psychol. Gen. 2014, 143, 215–226. [Google Scholar] [CrossRef]
- Czerwinski, M.; Horvitz, E.; Wilhite, S. A Diary Study of Task Switching and Interruptions. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’04), Vienna, Austria, 24–29 April 2004; Association for Computing Machinery: New York, NY, USA, 2004; pp. 175–182. [Google Scholar] [CrossRef]
- Bailey, B.P.; Iqbal, S.T. Understanding Changes in Mental Workload during Execution of Goal-Directed Tasks and Its Application for Interruption Management. ACM Trans. Comput.-Hum. Interact. 2008, 14, 1–28. [Google Scholar] [CrossRef]
- Nielsen, J. Usability Engineering; Interactive Technologies; Elsevier Science: Amsterdam, The Netherlands, 1994. [Google Scholar]
- Kruchten, P.; Lago, P.; Vliet, H.V. Building Up and Reasoning About Architectural Knowledge. In Proceedings of the Second International Conference on Quality of Software Architectures, Västerås, Sweden, 27–29 June 2006; pp. 43–58. [Google Scholar] [CrossRef]
- Bass, L.; Clements, P.; Kazman, R. Software Architecture in Practice, 2nd ed.; Addison-Wesley Professional: Boston, MA, USA, 2003; p. 560. [Google Scholar]
- ISO/IEC/IEEE. Systems and Software Engineering—Architecture Description. In ISO/IEC/IEEE 42010:2011(E); IEEE: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- Kruchten, P. The Rational Unified Process: An Introduction, 3rd ed.; Addison-Wesley Longman: Reading, MA, USA, 2003. [Google Scholar]
- Clements, P.; Kazman, R.; Klein, M. Evaluating Software Architectures: Methods and Case Studies; SEI Series in Software Engineering; Addison-Wesley: Boston, MA, USA, 2001. [Google Scholar]
- Vogel, O.; Arnold, I.; Chughtai, A.; Kehrer, T. Software Architecture: A Comprehensive Framework and Guide for Practitioners; Springer: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- Dorairaj, S.; Noble, J.; Malik, P. Knowledge Management in Distributed Agile Software Development. In Proceedings of the IEEE 2012 Agile Conference, Dallas, TX, USA, 13–17 August 2012; pp. 64–73. [Google Scholar] [CrossRef]
- Jiménez, M.; Piattini, M.; Vizcaíno, A. Challenges and Improvements in Distributed Software Development: A Systematic Review. Adv. Softw. Eng. 2009, 2009, 710971. [Google Scholar] [CrossRef]
- Awar, K.; Sameem, M.; Hafeez, Y. A model for applying Agile practices in Distributed environment: A case of local software industry. In Proceedings of the 2017 International Conference on Communication, Computing and Digital Systems (C-CODE 2017), Islamabad, Pakistan, 8–9 March 2017; pp. 228–232. [Google Scholar] [CrossRef]
- Sneed, H.M. Dealing with Technical Debt in agile development projects. In Proceeding of the 6th International Conference (SWQD 2014), Vienna, Austria, 14–16 January 2014; pp. 48–62. [Google Scholar] [CrossRef]
- Clear, T. Documentation and Agile Methods: Striking a Balance. SIGCSE Bull. 2003, 35, 12–13. [Google Scholar] [CrossRef]
- Souza, E.; Moreira, A.; Goulão, M. Deriving architectural models from requirements specifications: A systematic mapping study. Inf. Softw. Technol. 2019, 109, 26–39. [Google Scholar] [CrossRef]
- Mirakhorli, M.; Chen, H.M.; Kazman, R. Mining Big Data for Detecting, Extracting and Recommending Architectural Design Concepts. In Proceedings of the 1st International Workshop on Big Data Software Engineering, Florence, Italy, 23 May 2015; pp. 15–18. [Google Scholar] [CrossRef]
- Shahbazian, A.; Kyu Lee, Y.; Le, D.; Brun, Y.; Medvidovic, N. Recovering Architectural Design Decisions. In Proceedings of the 15th International Conference on Software Architecture, Seattle, WA, USA, 30 April–4 May 2018; pp. 95–104. [Google Scholar] [CrossRef]
- Sobernig, S.; Zdun, U. Distilling architectural design decisions and their relationships using frequent item-sets. In Proceedings of the 13th Working IEEE/IFIP Conference on Software Architecture, Venice, Italy, 5–8 April 2016; pp. 61–70. [Google Scholar] [CrossRef]
- Treude, C.; Storey, M.A. Work item tagging: Communicating concerns in collaborative software development. IEEE Trans. Softw. Eng. 2012, 38, 19–34. [Google Scholar] [CrossRef]
- Storey, M.A.; Ryall, J.; Singer, J.; Myers, D.; Cheng, L.T.; Muller, M. How software developers use tagging to support reminding and refinding. IEEE Trans. Softw. Eng. 2009, 35, 470–483. [Google Scholar] [CrossRef]
- Al-kofahi, J.M.; Tamrawi, A.; Nguyen, T.T.; Nguyen, H.A.; Nguyen, T.N. Fuzzy Set Approach for Automatic Tagging in Evolving Software. In Proceedings of the 2010 IEEE International Conference on Software Maintenance (ICSM), Timisoara, Romania, 12–18 September 2010; pp. 1–10. [Google Scholar] [CrossRef]
- Liu, J.; Zhou, P.; Yang, Z.; Liu, X.; Grundy, J. FastTagRec: Fast tag recommendation for software information sites. Autom. Softw. Eng. 2018, 25, 675–701. [Google Scholar] [CrossRef]
- Mushtaq, H.; Malik, B.H.; Shah, S.A.; Siddique, U.B.; Shahzad, M.; Siddique, I. Implicit and explicit knowledge mining of Crowdsourced communities: Architectural and technology verdicts. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 105–111. [Google Scholar] [CrossRef][Green Version]
- Parra, E.; Escobar-Avila, J.; Haiduc, S. Automatic tag recommendation for software development video tutorials. In Proceedings of the 2018 IEEE/ACM 26th International Conference on Program Comprehension (ICPC), Gothenburg, Sweden, 27 May–3 June 2018; pp. 222–232. [Google Scholar] [CrossRef]
- Jovanovic, J.; Bagheri, E.; Cuzzola, J.; Gasevic, D.; Jeremic, Z.; Bashash, R. Automated semantic tagging of textual content. IT Prof. 2014, 16, 38–46. [Google Scholar] [CrossRef]
- Wang, T.; Wang, H.; Yin, G.; Ling, C.X.; Li, X.; Zou, P. Tag recommendation for open source software. Front. Comput. Sci. 2014, 8, 69–82. [Google Scholar] [CrossRef]
- Alqahtani, S.S.; Rilling, J. An Ontology-Based Approach to Automate Tagging of Software Artifacts. In Proceedings of the International Symposium on Empirical Software Engineering and Measurement, Toronto, ON, Canada, 9–10 November 2017; pp. 169–174. [Google Scholar] [CrossRef]
- Zhou, P.; Liu, J.; Liu, X.; Yang, Z.; Grundy, J. Is deep learning better than traditional approaches in tag recommendation for software information sites? Inf. Softw. Technol. 2019, 109, 1–13. [Google Scholar] [CrossRef]
- Martins, E.F.; Belém, F.M.; Almeida, J.M.; Gonçalves, M.A. On cold start for associative tag recommendation. J. Assoc. Inf. Sci. Technol. 2016, 67, 83–105. [Google Scholar] [CrossRef]
- Soliman, M.; Galster, M.; Salama, A.R.; Riebisch, M. Architectural knowledge for technology decisions in developer communities: An exploratory study with StackOverflow. In Proceedings of the 13th Working IEEE/IFIP Conference on Software Architecture, Venice, Italy, 5–8 April 2016; pp. 128–133. [Google Scholar] [CrossRef]
- Musil, J.; Ekaputra, F.J.; Sabou, M.; Ionescu, T.; Schall, D.; Musil, A.; Biffl, S. Continuous Architectural Knowledge Integration: Making Heterogeneous Architectural Knowledge Available in Large-Scale Organizations. In Proceedings of the IEEE International Conference on Software Architecture, Gothenburg, Sweden, 3–7 April 2017; pp. 189–192. [Google Scholar] [CrossRef]
- Lin, B.; Zagalsky, A.E.; Storey, M.A.; Serebrenik, A. Why Developers Are Slacking Off: Understanding How Software Teams Use Slack. In Proceedings of the 19th ACM Conference on Computer Supported Cooperative Work and Social Computing Companion, San Francisco, CA, USA, 27 February–2 March 2016; pp. 333–336. [Google Scholar] [CrossRef]
- White, K.; Grierson, H.; Wodehouse, A. Using Slack for Asynchronous Communication in a Global Design Project. In Proceedings of the International Conference on Engineering and Product Design Education, Oslo, Norway, 7–8 September 2017; pp. 346–351. [Google Scholar]
- Chatterjee, P.; Damevski, K.; Pollock, L. Exploratory Study of Slack Q&A Chats as a Mining Source for Software Engineering Tools. In Proceedings of the 2019 IEEE/ACM 16th International Conference on Mining Software Repositories (MSR) (ICSE 2019), Montreal, QC, Canada, 26–27 May 2019; MSR 2019 MSR Technical Papers. pp. 490–501. [Google Scholar]
- Martínez-García, J.R.; Castillo-Barrera, F.E.; Palacio, R.R.; Borrego, G.; Cuevas-Tello, J.C. Ontology for knowledge condensation to support expertise location in the code phase during software development process. IET Softw. 2020, 14, 234–241. [Google Scholar] [CrossRef]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing, 2nd ed.; Prentice-Hall: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- González-López, S.; Borrego, G.; López-López, A.; Morán, A.L. Clasificando conocimiento arquitectónico a través de técnicas de minería de texto. Komput. Sapiens 2018, 1, 29–33. [Google Scholar]
- Vatanen, T.; Väyrynen, J.J.; Virpioja, S. Language Identification of Short Text Segments with N-gram Models. In Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10), Marseille, France, 11–16 May 2010; European Language Resources Association (ELRA): Valletta, Malta, 2010. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Wohlin, C.; Runeson, P.; Hst, M.; Ohlsson, M.C.; Regnell, B.; Wessln, A. Experimentation in Software Engineering; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Davis, F.D. Perceived Usefulness, Perceived Ease of Use, and User Acceptance of Information Technology. MIS Q. 1989, 13, 319–340. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tag/Meta-Tag | Number of Messages |
|---|---|
| UserStory | 88 |
| RESTResource | 61 |
| RESTTest | 43 |
| Documentation | 36 |
| Encryption | 26 |
| TestData | 23 |
| TechnologicalSupport | 16 |
| Students | Developers | |||||
|---|---|---|---|---|---|---|
| Usefulness | Ease of Use | Integration | Usefulness | Ease of Use | Integration | |
| Mode | 7 | 7 | 7 | 7 | 7 | 7 |
| Median | 6 | 6 | 6 | 6 | 7 | 6 |
| Q.75 | 7 | 7 | 7 | 7 | 7 | 7 |
| Q.50 | 6 | 6 | 6 | 6 | 7 | 6 |
| Q.25 | 5 | 5 | 5 | 5 | 6 | 4.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Borrego, G.; González-López, S.; Palacio, R.R. Tags’ Recommender to Classify Architectural Knowledge Applying Language Models. Mathematics 2022, 10, 446. https://doi.org/10.3390/math10030446
Borrego G, González-López S, Palacio RR. Tags’ Recommender to Classify Architectural Knowledge Applying Language Models. Mathematics. 2022; 10(3):446. https://doi.org/10.3390/math10030446
Chicago/Turabian StyleBorrego, Gilberto, Samuel González-López, and Ramón R. Palacio. 2022. "Tags’ Recommender to Classify Architectural Knowledge Applying Language Models" Mathematics 10, no. 3: 446. https://doi.org/10.3390/math10030446
APA StyleBorrego, G., González-López, S., & Palacio, R. R. (2022). Tags’ Recommender to Classify Architectural Knowledge Applying Language Models. Mathematics, 10(3), 446. https://doi.org/10.3390/math10030446