Hyperparameter optimization is to find, among all the models, those hyperparameters that return the best performance measure with the validation dataset. In this study, simple grid optimization was applied for hyperparameter optimization. The optimization parameters used were:
C = 50,
= 0.0075 and
= 1 × 10
−5. These parameters were used for all models. The ML supervised classification algorithm SVR was used to predict PM levels. In detail, to evaluate the performance of the models used and establish improvements in their predictions, two new datasets were derived from the baseline and extended datasets with the same characteristics as the original datasets, but for the hourly range between 05:00 to 11:00 p.m. These new datasets were created due to the trends observed in
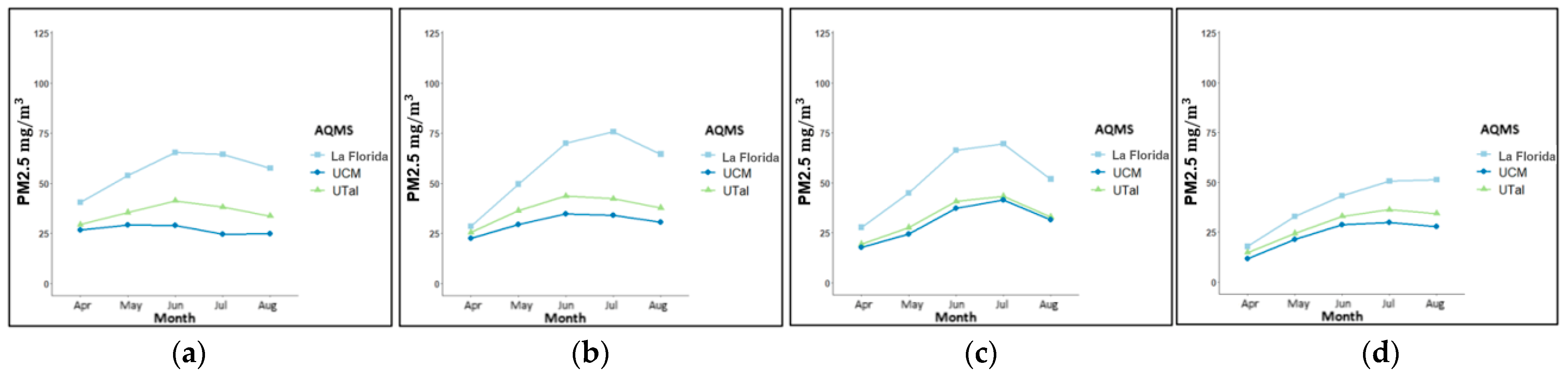
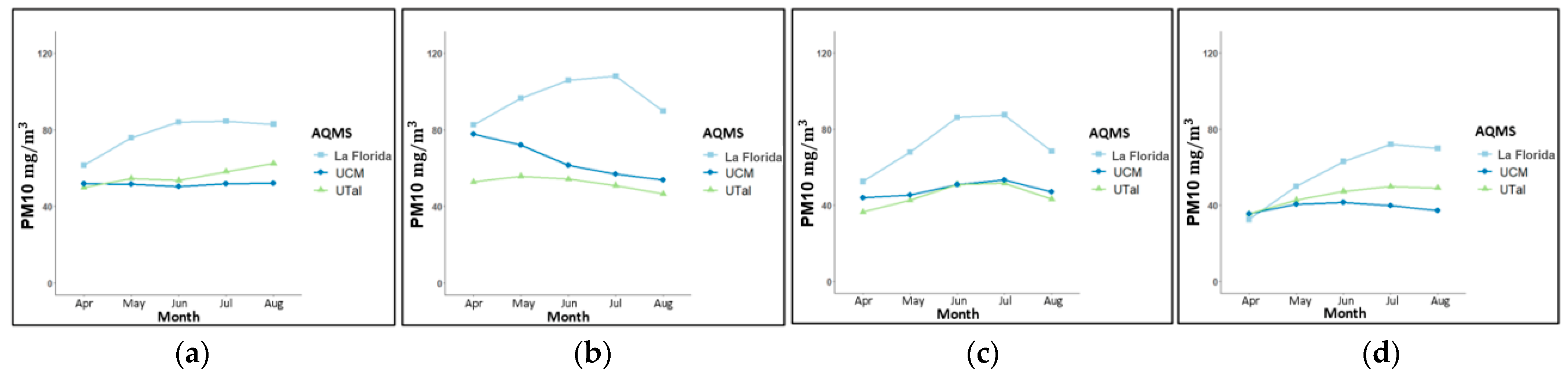
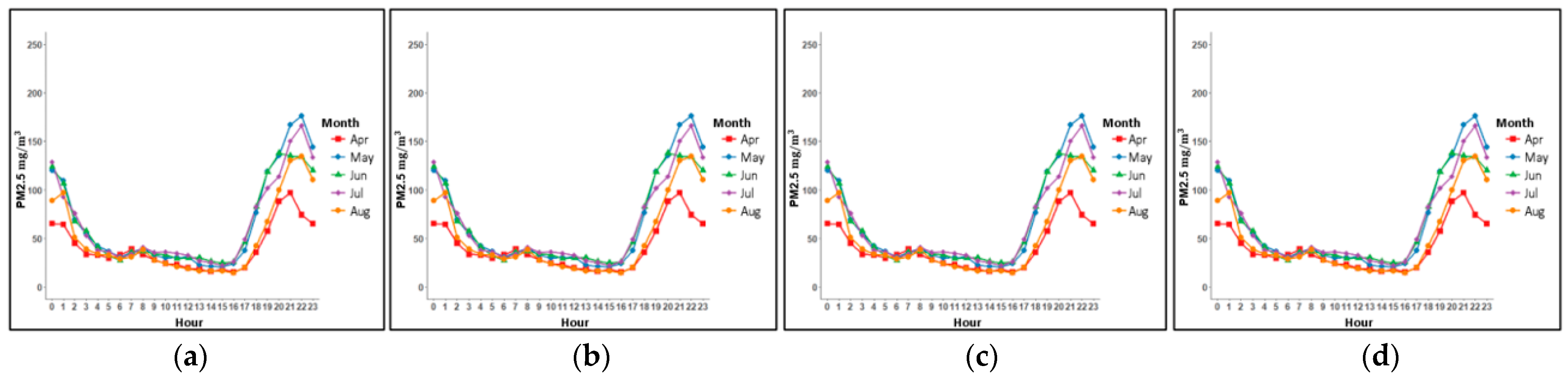
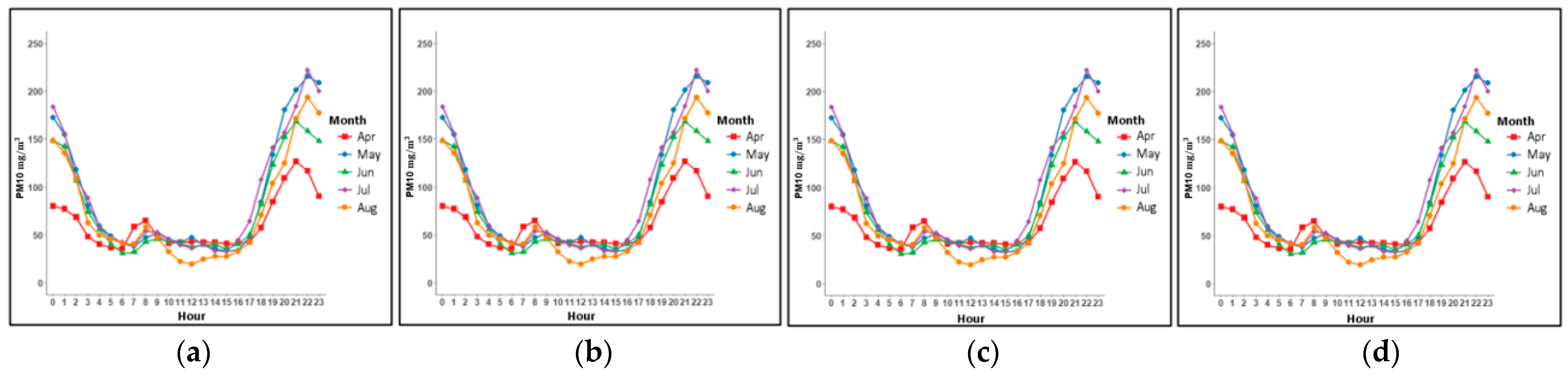
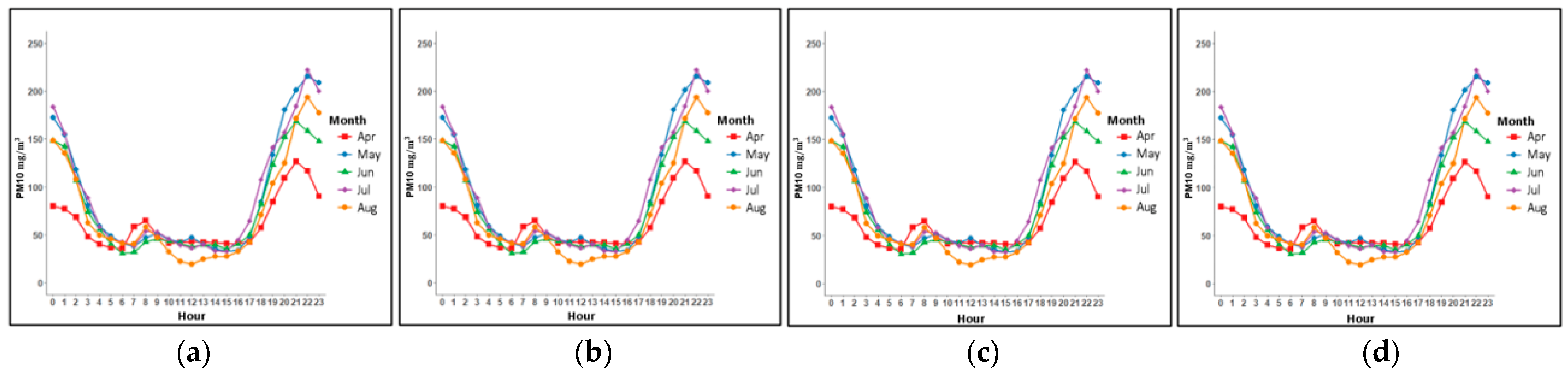
Figure 6 and
Figure 7, where an increase in PM concentrations was observed within this interval in the three AQMSs. Therefore, we carried out the training of 24 models to predict PM2.5 and PM10 levels in the three AQMSs of Talca city, considering the 24-h average and the average between 05:00 to 11:00 p.m. In this way, for each AQMS (UCM, UTAL and La Florida), eight models were implemented, for example, for UCM AQMS we have: UCM_baseline_PM2.5, UCM_baseline_PM10, UCM_extended_PM2.5, UCM_extended_PM10, UCM_baseline_PM2.5_5-11pm, UCM_baseline_PM10_5-11pm, UCM_extended_PM2.5_5-11pm and UCM_ extended _PM10_5-11pm.
Model Performance and Evaluation
The following tables show the results obtained during the training phase with data from 2014 to 2017 for La Florida AQMS, and from 2014 to 2016 for the UCM and UTAL AQMSs. For the evaluation of model performance, we use the determination coefficient R
2 and RMSE. For forecast accuracy evaluation, we use the MASE [
18].
We separated the results for the training predictive models where the 24-h averages and the averages between 05:00 to 11:00 p.m. were used.
Table 5 and
Table 6 show the model performance results for the 24-h average and average between 05:00 to 11:00 p.m., respectively.
According to the results of
Table 5, it is possible to note that, for each AQMS, the model performance, for the prediction of PM2.5 and PM10 concentrations, was improved for the extended datasets. In general, the determination coefficients obtained by the adjusted SVR models indicate a good fit in the 12 scenarios shown in
Table 5. The R
2 were between 0.66 and 0.88, evidencing a good performance, especially in the adjusted models for the UTAL and La Florida AQMSs. Moreover, the RMSE values were smaller in models for the UCM and UTAL AQMS. In addition, the MASE values indicate that the forecast level of the models is good (MASE < 1), especially in the UTAL AQMS.
The training results shown in
Table 6 indicate that for all AQMSs the performance of the model based on R
2 was between 0.67 and 0.88, which implies a good fit of the SVR model. Furthermore, as in the previous case, the RMSE values were smaller in models for the UCM and UTAL AQMS and better performance was observed for the extended database. When comparing the results of
Table 5 and
Table 6, we can observe that the R
2 were higher in the adjusted models for averages between 05:00 to 11:00 p.m. While the MASE values indicate a higher forecast level for the models for averages between 05:00 to 11:00 p.m. Subsequently, an external validation of the best models obtained in the training phase was made with year 2017 for the UCM and UTAL AQMS, and with year 2018 for the La Florida AQMS.
Table 7 and
Table 8 show the model´s performance for predicted PM10 and PM2.5 levels, based on statistics R
2, RMSE and MASE, for 24-h average data and average between 05:00 to 11:00 p.m., respectively.
According to the results of
Table 7, the R
2 of the adjusted model for prediction of PM10 levels varied from 0.80 to 0.91 and from 0.81 to 0.92 for PM2.5 prediction. In
Table 8, the R
2 of the adjusted model for PM10 prediction varied from 0.85 to 0.93 and from 0.86 to 0.94 for PM2.5 prediction. The RMSE values were smaller in models for the UCM and UTAL AQMS than in the training stage. In addition, according to
Table 8, the MASE values indicates a higher forecast level in the models for averages between 05:00 to 11:00 p.m.
In general, the determination coefficients obtained by the adjusted SVR models indicate a good fit in the 24 scenarios shown in
Table 7 and
Table 8. However, the results obtained to predict PM10 and PM2.5 were better with the model for the extended dataset and averages between 05:00 to 11:00 p.m.
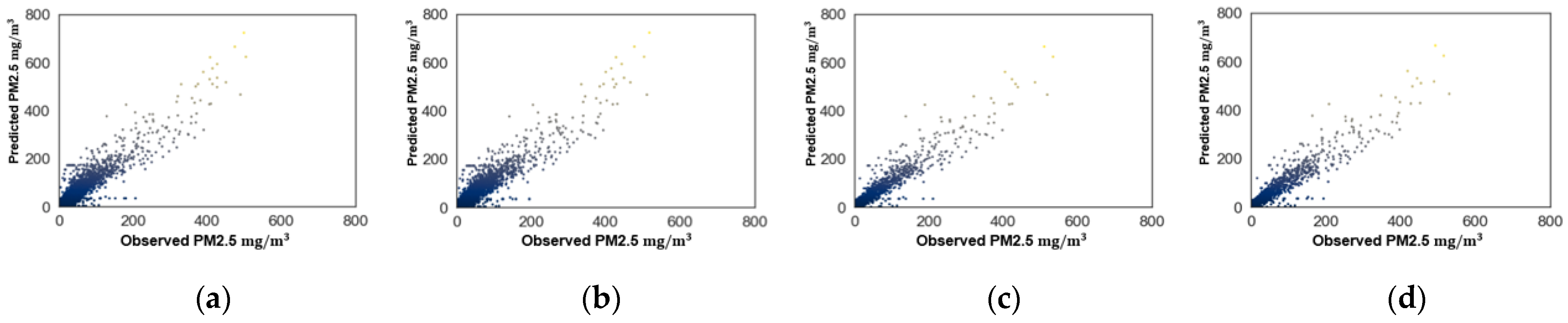
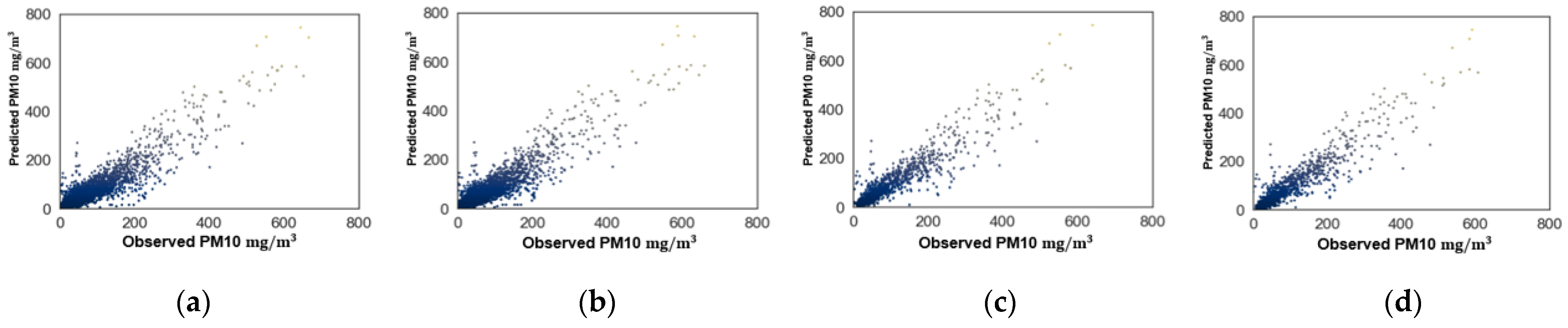
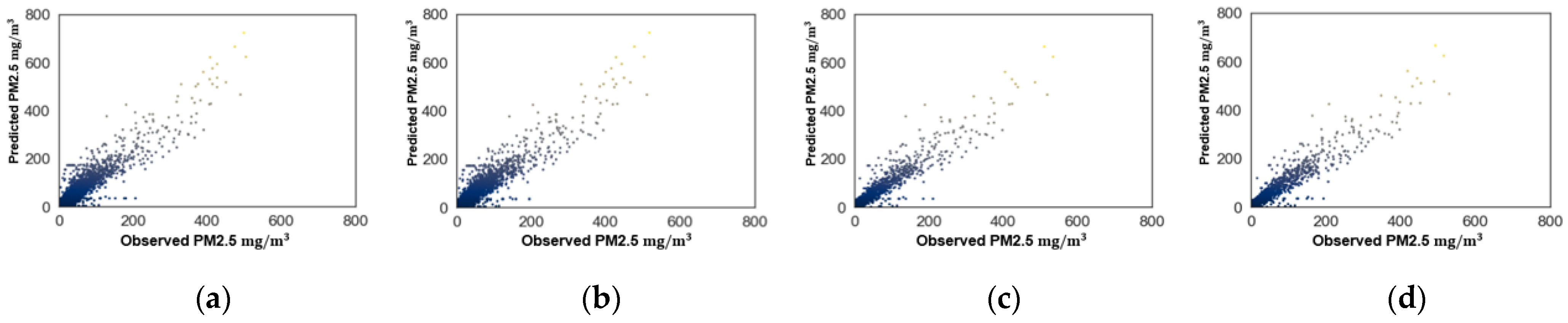
Finally, plots of the predicted versus observed PM10 and PM2.5 levels are shown in
Figure 8 and
Figure 9 for La Florida AQMS, respectively. Plots for the other AQMSs show similar behavior and are omitted here. In
Figure 8 and
Figure 9, predictively, the SVR model followed the trend of the observed data. However, a better level of prediction was observed in the plots for the extended dataset using the averages between 05:00 to 11:00 p.m. These predictions are shown in
Figure 8 and
Figure 9c,d.
Table 9 shows the Chilean primary quality guidelines for PM2.5 and PM10 levels in 24-h. Next, the prediction capacity of the proposed models with respect to the primary quality guidelines for PM2.5 and PM10 were analyzed, based on which the degree of precision to detect critical episodes was determined.
Table 10 and
Table 11 contain the categorization of the observed and predicted concentrations according to the primary air quality regulations for each category (i.e., good, regular, alert, pre-emergency and emergency) for averages between 05:00 to 11:00 p.m. and PM2.5 and PM10 levels. Note that, in
Table 10 and
Table 11, we categorize the observed and predicted levels according to the categories indicated in
Table 9; for example, in the La Florida AQMS there were 64 concentrations of PM2.5 in good condition, of which 61 were correctly predicted. The objective of these tables is to evaluate the predictive capacity of the proposed models.
As can be seen, in
Table 10 and
Table 11, the predicted values have a high accuracy; if we observe the alert, pre-emergency and emergency conditions, the model developed achieved a high prediction accuracy for these classes, which represented a minority in the CEM period. This is of great relevance, since, for the lifting of citizen restrictions in a timely manner, it is crucial to efficiently predict these minority classes due to their relevance to alert and manage critical episodes during the months of April to August.
Table 12,
Table 13,
Table 14,
Table 15,
Table 16 and
Table 17 show the data correctly classified for each of the air quality categories (
Table 9) and those that were misclassified in other categories. For each table, we also provide the respective percentages of correct classification. In detail, the contingency
Table 12,
Table 13 and
Table 14 show the predicted air quality categories for PM2.5 levels in the case of La Florida, UCM and UTAL AQMSs. Meanwhile contingency
Table 15,
Table 16 and
Table 17 show the predicted categories for PM10 levels for each AQMS.
In
Table 12,
Table 13 and
Table 14, it is possible to observe that our models are capable of predicting PM2.5 levels for each category with high precision. In the case of La Florida AQMS, the prediction of each category was: good equals to 91.9%, regular equals to 50.9%, alert equals to 34.9%, pre-emergency equals to 58.4% and emergency equals to 69.9%. For UCM AQMS, prediction values were as follow: good equals to 96.0%, regular equals to 61.2%, alert equals to 64.8%, pre-emergency equals to 80.5% and emergency equals to 91.4%. Finally, in the case of UTAL AQMS, our model gave prediction values for each category as follows: good equals to 89.4%, regular equals to 68.9%, alert equals to 55.4%, pre-emergency equals to 81.3% and emergency equals to 100%. Specifically, we note that the prediction is good in the minority categories (i.e., alert, pre-emergency and emergency). These categories are very important due their relevance in the monitoring of critical episodes.
For PM10 prediction,
Table 15,
Table 16 and
Table 17 show the values and percentage of successes for each category. In the case of La Florida AQMS, the prediction of each category was: good equals to 94.7%, regular equals to 48.9%, alert equals to 37.9%, pre-emergency equals to 52.3% and emergency equals to 75%. For UCM AQMS, prediction values were as follows: good equals to 99.4%, regular equals to 51.6%, alert equals to 73.7%, pre-emergency equals to 70% and emergency equals to 100%. Finally, in the case of UTAL AQMS, our model gave prediction values for each category as follows: good equals to 99.7%, regular equals to 56.4%, alert equals to 44.4%, pre-emergency equals to 60% and emergency equals to 57.1%.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}