Abstract
Bivariate continuous negatively correlated proportional data defined in the unit square often appear in many different disciplines, such as medical studies, clinical trials and so on. To model this type of data, the paper proposes two new bivariate continuous distributions (i.e., negatively correlated proportional inverse Gaussian (NPIG) and negatively correlated proportional gamma (NPGA) distributions) for the first time and provides corresponding distributional properties. Two mean regression models are further developed for data with covariates. The normalized expectation–maximization (N-EM) algorithm and the gradient descent algorithm are combined to obtain the maximum likelihood estimates of parameters of interest. Simulations studies are conducted, and a data set of cortical thickness for schizophrenia is used to illustrate the proposed methods. According to our analysis between patients and controls of cortical thickness in typical mutual inhibitory brain regions, we verified the compensatory of cortical thickness in patients with schizophrenia and found its negative correlation with age.
1. Introduction
In many aspects, experimental results or measurements are reported in the form of ratios, scores, proportions or percentages, which is frequently encountered in sociology, psychology, epidemiology and clinical trials. The characteristic of the data is that they are continuously valued within the unit interval ; thus, models focusing on this limited range are worthwhile. Researchers have developed different strategies for modeling such kinds of data. First, the beta distribution and beta regression models have been exhaustively studied by many authors, including [1,2,3]. Kieschnick and McCullough [4] summarized and compared different regression models for proportional data in the open interval. Next, the simplex distribution investigated by Zhang and Qiu [5] can also be utilized to model such continuous proportional data, and they further pointed out the simplex regression model is more robust than the beta model. By mimicking the construction of beta distributions with gamma variates, Lijoiu et al. [6] proposed a so-called normalized inverse Gaussian (IG) distribution by substituting the gamma variates with IG variates, as a new tool for modeling univariate proportional data. Later, Liu et al. [7] renamed it as the proportional inverse Gaussian (PIG) distribution and set up regression models. Due to the diversity and dimension enlarger of data, we need to generalize the univariate continuous proportional models to multivariate cases. Wang and Tu [8] considered the semiparametric tests for multigroup proportional data in a closed interval .
From the perspective of data structure, the multi-dimensional data limited in unit intervals can be divided into compositional data and multivariate proportional data according to their domains. For compositional data, which often appear in various fields, such as biology, medicine and economics, the summation of all components of data values equals one, also known as structure relative numbers reflecting the composition of objects. Thus, the corresponding models fitting for the compositional data are defined in the open hyperplane . Due to the constraint of , it leads to certain negative correlations between any two dimensions of compositional data. One of the well-known distributions is the Dirichlet distribution, which can be regarded as a generalization of the beta distribution to more than two components. It was first used to fit two compositional biological data in [9]. Campbell and Mosimann [10] considered a Dirichlet regression model by linking the parameters to a set of covariates via a polynomial function, and the models with applications to the analysis of psychiatric data are investigated in [11]. By the way, the beta distribution could be regarded as a two-dimensional Dirichlet distribution, and a beta variate X and its complement are also negatively correlated. Other research on related models can be found in recent literature [12,13].
For multivariate proportional data, it appears that each component of the data is valued between 0 and 1 with no direct constraint among components. The corresponding models for this type of data are defined in the unit cubic without restriction . There are many ways to construct appropriate models, such as beta distribution with copula linking functions. Cepeda-Cuervo et al. [14] defined a bivariate beta regression model from copulas and considered the Bayesian approach, in which the correlation could be positive or negative. Petterle et al. [15] proposed a multivariate generalized linear mixed model for modeling continuous bounded variables in the interval . Sun et al. [16] proposed a linear stochastic representation (SR) to construct multivariate positively correlated continuous models based on IG and gamma distributions, named as multivariate PIG and proportional gamma (PGA) distributions, respectively, which can only fit positively correlated continuous proportional data.
The cortical thickness of schizophrenia data used in [16] shows high correlations and compensation behaviors related to disease severity among different brain regions. Further, we find that a large number of negative covariant region pairs may occur in patients if the changes of compensations are reduced. This indicates the observations of negatively correlated regions in cortical thickness are of great significance for the study of schizophrenia and its prognosis. Motivated by the construction technique in multivariate PIG and PGA distributions, we will propose models to capture the negative correlation among components for multivariate proportional data. To the best of our knowledge, work considering the negative correlation of multivariate proportion data is quite scarce. Here, we focus on the bivariate situations; thus, the proposed models are expected to provide efficient tools in modeling negatively correlated proportional data.
By combining the construction of multivariate PIG/PGA distributions and the negative correlation structure in beta/Dirichlet distributions, we define a new random vector via the following SR:
where are independent random variables with the same support , and each can follow any same continuous distribution family but with possibly different parameters. In the following, for each (), we applied the IG and gamma distributions to construct bivariate negatively correlated PIG (NPIG) and negatively correlated proportional gamma (NPGA) distributions.
The rest of the paper is organized as follows. In Section 2 and Section 3, the bivariate NPIG and NPGA distributions are, respectively, proposed and related distributional properties (e.g., moments, joint densities) are provided. Moreover, the normalized expectation–maximization (N-EM) facilitated by the one-step gradient descent algorithms are established for calculating the maximum likelihood (ML) estimations of parameters of interest. In Section 4, simulations for the proposed methods are performed. A data set on the cortical thickness of schizophrenia is used to illustrate the proposed methods in Section 5. Finally, a discussion is provided in Section 6. Some technical details are put in the Appendix A and Appendix B, and others are shown in the Supplementary Material.
2. Bivariate Negatively Correlated PIG Models
First, we propose a new bivariate NPIG distribution based on equi-dispersed IG distributions and develop the corresponding NPIG mean regression model. The N-EM algorithms for calculating the ML estimators of parameters are also provided.
2.1. Bivariate NPIG Distribution
The IG distribution with location parameter (>0) and shape parameter (>0), denoted by , if it has the probability density function (pdf)
According to the results of [17], we have and . By setting , the general IG distribution reduces to the equi-dispersed as its mean equals the variance.
By adopting three independent equi-dispersed IG variates with for , the random vector defined by (1) is said to follow a bivariate NPIG distribution, denoted by with . Since the moment generating functions (MGF) of is , the expectations, variances and the covariance are computed based on (A1)–(A5) as
where is the incomplete gamma function. According to the numerical experiments in [16], the correlation coefficient is limited in the open interval . The joint pdf of the bivariate NPIG distribution is derived as
where
From the perspective of practice, usually, we would like to have intuitive interpretations of population means. Therefore, we re-parametrize the bivariate NPIG distribution in terms of the parameter vector according to (2) and (3) by making the following one-to-one mapping
The pdf of the re-parameterized bivariate NPIG distribution, denoted by , is
where ,
Figure 1 plots the bivariate NPIG distribution with two sets of different values of parameters. We note that a larger value of makes the distribution more concentrated, and it also influences the number of modes. When is large enough, the change in the values of affects the location of modes and the skewness of distributions. Thus, it is appropriate to regard as the dispersion parameter and as the two location parameters. Sometimes, while the distributions are dense and unimodal, the modes are very different from the expectations.
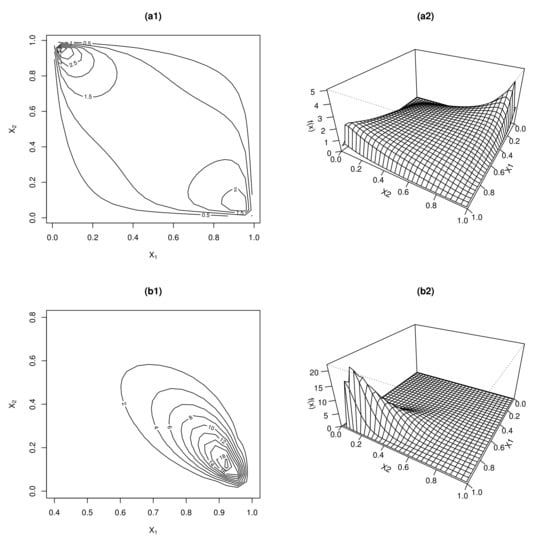
Figure 1.
The contour plots and 3D perspectives of the bivariate NPIG distribution with different values of parameters: (a1,a2) ; (b1,b2) .
2.2. ML Estimation of Parameters via the N-EM Algorithm
Let and denote the observed data, where is the realization of . The log-likelihood function of the parameter vector is given by
where is a constant free from the parameter vector . Due to the existence of the intractable integrals in (5), neither the Newton–Raphson nor the Fisher scoring algorithm is attainable in dealing with the above expression. Instead, we adopt the N-EM algorithm, which is composed of three steps:
- N-step:
- Establish the following normalized density function based on asso that is also a valid pdf defined on , where denotes the t-th approximation of .
- E-step:
- Construct a surrogate Q-function by utilizing the integral version of Jensen’s inequality aswhereis defined by (4), and is a constant not depending on . It can be proven that satisfiesindicating that it minorizes at .
- M-step:
- Maximize with respect to and obtain
However, it is difficult to obtain the unique explicit expression of in the M-step. Instead, it is recommended to separate the estimation procedures into two parts:
- M-step-1:
- Given , by solving , we have the -th approximation for aswhere
- M-step-2:
- The iteration for is obtained by adopting the gradient descent algorithm aswhereand is the step size at the t-th iteration of the algorithm, determined by
The stopping rule of the above loops under the proposed N-EM embedded with the gradient descent algorithm is controlled by
where is a pre-determined precision. The details of constructing the N-EM algorithm are shown in Appendix B.1, and other relevant calculations are given in Supplementary Material A.1 and A.2. Finally, the ML estimates of can be obtained by combining (7) and (8) when the algorithm stops.
2.3. Bivariate NPIG Mean Regression Model
We extend the re-parametrized distribution to the corresponding regression model for investigating the relationship between the mean vector with a set of covariates. The logit link function is adopted for with , then the resulting model can be formulated as
where is the vector of covariates associated with the i-th subject, and is the -vector of unknown regression coefficients. The log-likelihood function of the new parameter vector for the regression model given the observed data is written as
where is a constant free from the parameter vector ,
Similar to the construction of , we can obtain
where is a constant, denotes the t-th approximation of the ML estimator and
The procedure of obtaining the ML estimators of is similar to that in Section 2.2. First, for given , we set and find the positive root to obtain the -th approximation for , which is given by
with
Moreover, to obtain the ML estimator of , we first define
Using the one-step gradient descent algorithm, we have the iteration
where the step size is defined by
3. Bivariate Negatively Correlated PGA Models
To provide other candidates for flexibly modeling the above-mentioned negatively correlated continuous proportional data, in this section, we propose a new bivariate NPGA distribution based on equi-dispersed gamma distributions (see the first paragraph in Section 3.1) and develop a bivariate NPGA mean regression model.
3.1. Bivariate NPGA Distribution
Let , then it is an equi-dispersed gamma distribution with , and its pdf is , . Let with for be three independent equi-dispersed gamma variates, then the random vector defined by (1) is said to follow a bivariate NPGA distribution, denoted by with . The MGF of , in this case, is , with , from (A1)–(A5), we have
The correlation coefficient takes values within as well. The pdf of is
where is the realization of and .
For the purpose of modeling the population means in (12) and (13) directly, we also make a one-to-one transformation among parameter vectors and by
The pdf of re-parameterized bivariate NPGA distribution, denoted by , is
Figure 2 plots the bivariate NPGA distribution with two sets of different values of parameters. Similar to those findings in Figure 1, is regarded as the dispersion parameter and is the location vector.
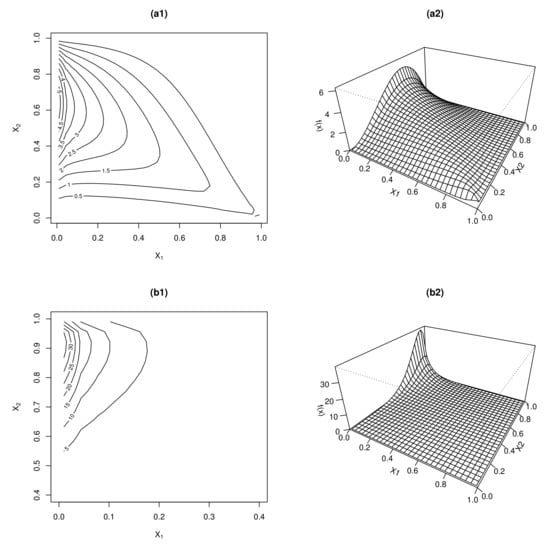
Figure 2.
The contour plots and 3D perspectives of the bivariate NPIG distribution with different values of parameters: (a1,a2) ; (b1,b2) .
3.2. ML Estimation of Parameters via the Gradient Descent Algorithm
Let and denote the observed data, where is the realization of . The log-likelihood function of the parameter vector is given by
where is a constant free from the parameter vector . Then, we adopt the gradient descent algorithm directly to find the ML estimator of by setting
Thus, the -th estimation is given by
where the step size at the t-th iteration is
We also provide another method in Appendix B.2 with the N-EM algorithm applied, which results in the same iteration shown in (14).
3.3. Bivariate NPGA Mean Regression Model
The bivariate NPGA mean regression model is formulated in a similar way as
where is the vector of covariates associated with the i-th subject, and is the -vector of unknown regression coefficients. The gradient descent algorithm still works for finding the ML estimators of in the NPGA mean regression model, which is similar to that stated in Section 3.2.
4. Simulation Experiments
For all above bivariate NPIG- and NPGA-related models, although no explicit expressions for the ML estimators of parameters, the bootstrap method is an efficient tool to approximately calculate the standard errors and the confidence intervals (CIs) for them, while the details of the bootstrap procedure are omitted due to its routines. Based on it, we conduct several numerical experiments in the section to investigate the performances of the above-proposed estimation methods for the bivariate NPIG and NPGA distributions with their corresponding mean regression models. We use R software to design parallel computing on 64 CPUs of the windows system for the time-consuming simulations. The impacts of other computational aspects on the simulations are not considered.
4.1. Experiment for NPIG Models
Firstly, for the bivariate NPIG distribution, we choose the parameter configurations as follows: sample size is ; true values of are set as , and , corresponding to a low, moderate and high correlations. In the regression model, the corresponding sample size is ; , , ; the covariates are , with , is randomly chosen from and for . For a given sample size n, experimental data are i.i.d. sampled from or each is generated from according to the regression model specified by (9), where SR (1) based on three IG variates can facilitate the sample generation. Parameters of interest are and , respectively.
For each generated sample group, parameters are estimated by the proposed N-EM embedded with the gradient descent algorithm, and the whole process is repeated K times. The value of K is chosen as 1000 and 500 for the distribution and regression model, respectively. To better express the quantitative values on evaluating the estimation accuracy, we use a general symbol to denote each component of parameters to be estimated, and is its true value. The obtained ML estimate for in each loop is denoted by , and the number of iterations is recorded as to the converged algorithm, where .
The averaged ML estimate (Ave-MLE), standard deviation (Std) and mean squared error (MSE) for the estimator and the averaged iterative number (it.no) are, respectively, computed as
The simulated results for of the bivariate NPIG distribution are summarized in Table 1. The simulated results for of the bivariate NPIG regression model are listed in Table 2. From the results, it is easy to find that the estimates of the parameters are well provided and are much closer to their true values as the sample size increases; more specifically, the estimation stability and accuracy are both improved, as indicated by the decreasing values of Stds and MSEs. The population correlation coefficient and the averaged estimated value calculated with the ML estimates of parameters are also presented, which shows the relationship is completely depicted.

Table 1.
ML estimate, Std and MSE for in bivariate NPIG distribution.
Table 2.
ML estimate, Std and MSE for in bivariate NPIG regression model.
4.2. Experiments for NPGA Models
For the bivariate NPGA distribution, the parameter settings are similar with those for the NPIG models. The choice of sample size n is the same. True values of are chosen as and for the NPGA distribution. In the NPGA regression model, , , ; the covariates are , with , and is randomly sampled from for . Data are generated from or according to the model specified by (15). To assess the estimation performances on parameters of interest and , we still adopt the measurements introduced in Section 4.1 for comparisons.
Table 3 and Table 4 summarize the results of simulation studies for the bivariate NPGA distribution and the corresponding mean regression model. The averaged ML estimates are provided, as well as the Stds and MSEs of the estimators. It is also observed that the estimation performance is satisfactory. The values of iterative numbers indicate that the computational efficiency and convergence rate are good. All averaged estimated values of the correlation calculated with the ML estimates of parameters are close to the population correlation coefficients.
Table 3.
ML estimate, Std and MSE for in bivariate NPGA distribution.
Table 4.
ML estimate, Std and MSE for in bivariate NPGA regression model.
4.3. Numerical Study on Means, Variances, Covariances and Correlations
In this subsection, we provide some numerical studies on the means, variances, covariances and correlations. For the bivariate NPIG distribution, we choose the values of mean parameters as , combined with the value of being and 20, respectively. The expectations, variances for two components, the covariances, and the correlation coefficients between them are presented in Table 5. For the bivariate NPGA distribution, we choose the values of the mean parameters as , combined with the value of being the same as that of . The corresponding properties are summarized in Table 6. Note that the expectation for each component is just or for in the two distributions. “Mean1” indicates the expectation for the first component, and “Mean2” indicates the expectation for the second component. Variances and covariances are computed based on the derived formulae in the Section 2.1 and Section 3.1, respectively, and “Var1” indicates the variance for the first component, “Var2” indicates the variance for the second component and “Cov” indicates the covariance between the two components. The correlation coefficient indicated by “Coef” is calculated according to its definition.
Table 5.
Means, variances, covariances and correlations for the bivariate NPIG distribution.
Table 6.
Means, variances, covariances and correlations for the bivariate NPGA distribution.
5. Applications
We obtain the cortical thickness of 41 patients with schizophrenia and 40 healthy controls from [18]. Structural magnetic resonance imaging scans obtained from the participants were processed using Freesurfer. Cortical thickness was parcellated by the Destrieux atlas [19] to provide 148 brain regions and estimated by the standard procedures described in [20]. Regional Ethics Committees (Nottinghamshire & Derbyshire) approved the study and all participants provided written informed consent. We aim to analyze the negative co-varying pairs of regions for investigating the influence of schizophrenia on the cortical thickness between controls and patients. The negative correlation pairs among 148 dimensions of data based on Pearson correlation coefficients are shown in Figure 3. The locations of squares marked with red circles are our following examples in subsections. The descriptions of used data are given in the Supplementary Material.
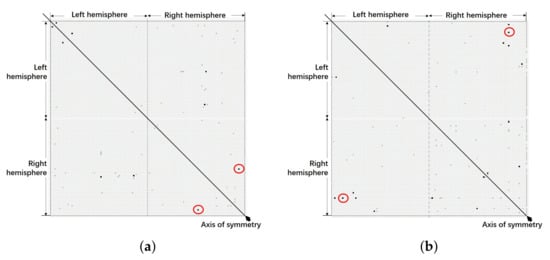
Figure 3.
Negative correlations between the thickness of 74 different sulco-gyral cortical units in each hemisphere of (a) patients; (b) controls. (Each square represent a negative correlation of corresponding units under the Spearman significance test, where the p-values of black ones are and gray ones are ).
5.1. Lateral and Suborbital Sulcus
We take the thickness difference of the horizontal ramus of the anterior segment of the lateral sulcus () and suborbital sulcus () in the right hemisphere as . Based on the significant, negative correlation between and in patients and a positive correlation in controls, we fit the patient and control groups data into the four different distributions, where bivariate PIG and PGA models are derived from [16]. The CIs and Stds of parameters (Par.) are calculated by bootstrap re-samplings.
The results are shown in Table 7. We note that the bivariate PGA and NPGA distributions perform better under the model selection criterion. The ML estimates of the mean parameters in two distributions between the patient and control groups fall on the boundary of the corresponding parameters’ confidence intervals of the other group, respectively. This implies the different cortical thinness between the two groups. Although the two regions inhibited each other, their thicknesses in the patients were significantly reduced compared with the control group. With the weakening of the compensatory behaviors of the patients’ cortical thickness in these areas, the negatively correlated pair different from the control group was produced, which is consistent with the clinical manifestations of changes in the cerebral cortex of schizophrenia.
Table 7.
ML estimates (MLEs), stds and CIs for the thickness of and (Section 5.1) between controls and patients in two distributions with model selection criterion AIC and BIC.
To further study the thickness changes in patients, we introduce two common covariates for the two groups: , are the logarithm transformation of the age in years, and , are gender (male=0, female=1). Based on (9) and (15), we have the following regression models:
where , and . Table 8 listed the results by fitting the data of patients and controls with the four corresponding regression models. From the bootstrap CIs, we know that there are significantly negative relationships between and log(age) only in controls. The other difference is focused on the influence of gender to , which is significantly positive to in controls and indicates irrelevant to in patients. Based on the results, we see that the mutual inhibition between and is mainly due to the opposite compensation of with gender and with age in patients.
Table 8.
ML estimates (MLEs), stds and CIs for the thickness of and (Section 5.1) between controls and patients in two regression models with selection criterion AIC and BIC.
5.2. Cingulate Gyrus and Lateral Occipito-Temporal Sulcus
In this subsection, we analyze regions in different hemispheres. The left posterior-dorsal part of the cingulate gyrus () and right lateral occipito-temporal sulcus () are taken as . Based on the significant negative correlation between and in controls and a positive correlation in patients, we fit the data of patients and controls into the four distributions, respectively. Similar to Section 5.1, we also consider covariates in four corresponding mean regression models. The correlation information from the samples implies that the data are not related to gender, so we only consider one covariate log(age). The results are summarized in Table 9 and Table 10.
Table 9.
ML estimates (MLEs), stds and CIs for the thickness of and (Section 5.2) between controls and patients in two distributions with model selection criterion AIC and BIC.
Table 10.
ML estimates (MLEs), stds and CIs for the thickness of and (Section 5.2) between controls and patients in two regression models with selection criterion AIC and BIC.
Based on the selection criterion, bivariate PGA and NPGA distributions and models show better performance. The mean cortical thickness differences between the two groups are significant. Similar to the results of medical research, the thicknesses in patients were consistently smaller than those of the controls. In the mean regression models, the influences of log(age) to are quite similar in the two groups, which is obviously different from the results shown in the previous subsection. The slight difference between the two groups is the influence of log(age) to , which is not significant in controls.
Combining the results in the two tables, we find the thickness difference between the two groups due to the loss of compensatory behaviors in the patients and raise a reasonable doubt that the duration of patients may cause the loss.
6. Conclusions, Limitations, and Future Research
In this paper, we proposed models that fit bivariate negatively correlated continuous proportional data for the first time. Based on the equal-dispersed IG distribution and the gamma distribution with a single parameter, we developed the bivariate NPIG and NPGA distributions. Models with covariates are also considered by formulating the mean regression models based on the two new distributions. Moreover, we provide efficient methods for parameter estimations of the four different models, respectively. The N-EM algorithm aided by the gradient descent algorithms based on Jensen’s inequality is used to overcome the difficulties in calculating ML estimates of parameters. For readers interested in algorithms, we recommend reading [21,22]. In Section 5, we used two different criteria to evaluate the models. We study the negative correlation pairs that increase with the decrease in compensation behaviors, and the information obtained from the main research is consistent with our previous findings with the same dataset [23]. Moreover, we propose the hypotheses of the causes of them based on the results, which needs further medical exploration. According to our analysis of the cortical thickness of schizophrenic patients and the control group, we verified the compensatory nature of cortical thickness in schizophrenic patients and found that it was negatively correlated with age. If you want to use the original data and R code of this article for your research, please contact the corresponding author by email. In addition, the use of original data should be agreed with the data collection team.
There are other topics worthy of further research beyond this paper. We only considered the mean regression models for the proposed distributions and did not consider the mode regressions as there are no closed forms for their modes. Similarly, there are quantile regressions. To better interpret the data, we hope to explore the mode regression models and have already constructed a new model with an explicit expression of the mode. The construction structure is similar to (1). Moreover, linear constructions, such as SR (1), to set models with arbitrary positive or negative correlations are difficult to achieve. We consider changing independent to a bivariate correlated vector and then the correlation structure between components based on the construction (1) more flexible. Moreover, the Copula method may be one feasible way, or mixture models could be considered by combining PIG with NPIG and PGA with NPGA. Finally, the exact tests in the bivariate NPIG and NPGA models for one sample and multiple samples are also our interests. They can help us research the significance of differences.
Supplementary Materials
The following are available at https://www.mdpi.com/article/10.3390/math10030353/s1, A.1: Solution to , A.2: Calculations for , A.3: Calculations for , A.4: Calculations for , A.5: Calculations for , A.6: Calculations for , B.1: Lateral and suborbital sulcus, B.2: Cingulate gyrus and lateral occipito-temporal sulcus.
Author Contributions
Y.S. contributed to the methodology, data curation, visualization and writing—original draft preparation; G.T. contributed to the conceptualization and supervision; S.G. contributed to the data curation; L.S. contributed to the validation; C.Z. contributed to the software, visualization and writing—original draft preparation. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China grant numbers 11771199, 11801380, 12071124 and 12171225. Prof. Shu’s work was funded in part by the Science and Technology Development Fund, Macau SAR (File No. FDCT/0033/2020/A1), and by the Research Committee under the grant MYRG2020-00081-FBA.
Institutional Review Board Statement
For ethics recruitment of participants and data collection has been described previously (and was approved by National Research Ethics Committee, Nottinghamshire (NHS REC Ref: 10/H0406/49).
Informed Consent Statement
All participants provided written informed consent.
Data Availability Statement
The use of original data should be agreed with the data collection team.
Acknowledgments
The authors wish to express their sincere appreciation to all those who made suggestions for improvements to this paper. We acknowledge the Centre for Translational Neuroimaging in Mental Health, University of Nottingham (Peter F Liddle, Lena Palaniyappan) and the Sir Peter Mansfield Imaging Centre, University of Nottingham (Penny Gowland) who provided the imaging data.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Some Properties of New Distributions[
Similar to [16], when the (MGF) of and () exist, we obtain the expectation and variance of with the SR (1) as follows:
respectively, where denotes the MGF of Y. The covariance of and is given by
where . It is easy to verify that .
Appendix B. The Construction of the N-EM Algorithm
Appendix B.1. ML Estimation of Parameters in the Bivariate NPIG Distribution
We develop the N-EM algorithm by introducing the integral version of Jensen’s inequality:
where is a concave function, is a real-valued function and is a pdf defined on [7]. Then, we have
where are constants free from . Based on (A7), we derive the surrogate function shown in (6). By the MM principle [24,25,26], given , the -th approximation is updated by . Obviously, minorizes at .
Appendix B.2. ML Estimation of Parameters in the Bivariate NPGA Distribution
To apply the N-EM algorithm, we need to construct the surrogate function . By using Jensen’s inequality, we obtain
where is the pdf of , is a constant and . In addition, by the supporting hyperplane inequality, we have
With the two inequalities we obtained, the surrogate function is
where is a constant.
References
- Ferrari, S.; Cribari-Neto, F. Beta regression for modelling rates and proportions. J. Appl. Stat. 2004, 31, 799–815. [Google Scholar] [CrossRef]
- Simas, A.B.; Barreto-Souza, W.; Rocha, A.V. Improved estimators for a general class of beta regression models. Comput. Stat. Data Anal. 2010, 54, 348–366. [Google Scholar] [CrossRef] [Green Version]
- Ferrari, S.L.P.; Pinheiro, E.C. Improved likelihood inference in beta regression. J. Stat. Comput. Simul. 2011, 81, 431–443. [Google Scholar] [CrossRef]
- Kieschnick, R.; McCullough, B.D. Regression analysis of variates observed on (0, 1): Percentages, proportions and fractions. Stat. Model. 2003, 3, 193–213. [Google Scholar] [CrossRef] [Green Version]
- Zhang, P.; Qiu, Z.G. Regression analysis of proportional data using simplex distribution. Sci. Sin. Math. 2014, 44, 89–104. (In Chinese) [Google Scholar] [CrossRef] [Green Version]
- Lijoi, A.; Mena, R.H.; Prünster, I. Hierarchical mixture modeling with normalized inverse–Gaussian priors. J. Am. Stat. Assoc. 2005, 100, 1278–1291. [Google Scholar] [CrossRef]
- Liu, P.Y.; Tian, G.L.; Yuen, K.C.; Zhang, C.; Tang, M.L. Proportional inverse Gaussian distribution: A new tool for analyzing continuous proportional data. Aust. N. Z. J. Stat. 2021, (in press). [Google Scholar] [CrossRef]
- Wang, C.; Tu, D. A bootstrap semiparametric homogeneity test for the distributions of multigroup proportional data, with applications to analysis of quality of life outcomes in clinical trials. Stat. Med. 2020, 39, 1715–1731. [Google Scholar] [CrossRef]
- Connor, R.J.; Mosimann, J.E. Concepts of independence for proportions with a generalization of the Dirichlet distribution. J. Am. Stat. Assoc. 1969, 64, 194–206. [Google Scholar] [CrossRef]
- Campbell, G.; Mosimann, J.E. Multivariate methods for proportional shape. ASA Proc. Sect. Stat. Graph. 1987, 1, 10–17. [Google Scholar]
- Gueorguieva, R.; Rosenheck, R.; Zelterman, D. Dirichlet component regression and its applications to psychiatric data. Comput. Stat. Data Anal. 2008, 52, 5344–5355. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, B. On Compositional Data Modeling and Its Biomedical Applications. Ph.D. Dissertation, Columbia University, New York, NY, USA, 2013. [Google Scholar]
- Morais, J.; Thomas-Agnan, C.; Simioni, M. Using compositional and Dirichlet models for market share regression. J. Appl. Stat. 2018, 45, 1670–1689. [Google Scholar] [CrossRef] [Green Version]
- Cepeda-Cuervo, E.; Achcar, J.A.; Lopera, L.G. Bivariate beta regression models: Joint modeling of the mean, dispersion and association parameters. J. Appl. Stat. 2014, 41, 677–687. [Google Scholar] [CrossRef]
- Petterle, R.R.; Laureano, H.A.; da Silva, G.P.; Bonat, W.H. Multivariate generalized linear mixed models for continuous bounded outcomes: Analyzing the body fat percentage data. Stat. Methods Med. Res. 2021, 30, 2619–2633. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Tian, G.L.; Guo, S.X.; Liu, P.Y. New models for analyzing positively correlated continuous proportional data: A cortical thickness study for schizophrenia. Biometrics 2021. (submitted). [Google Scholar]
- Tweedie, M.C.K. Statistical properties of inverse Gaussian distributions. I. Ann. Math. Stat. 2018, 28, 362–377. [Google Scholar] [CrossRef]
- Palaniyappan, L.; Liddle, P.F. Diagnostic discontinuity in psychosis: A combined study of cortical gyrification and functional connectivity. Schizophr. Bull. 2014, 40, 675–684. [Google Scholar] [CrossRef]
- Destrieux, C.; Fischl, B.; Dale, A.; Halgren, E. Automatic parcellation of human cortical gyri and sulci using standard anatomical nomenclature. NeuroImage 2010, 53, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Fischl, B.; Dale, A.M. Measuring the thickness of the human cerebral cortex from magnetic resonance images. Proc. Natl. Acad. Sci. USA 2000, 97, 11050–11055. [Google Scholar] [CrossRef] [Green Version]
- McLachlan, G.J.; Krishnan, T. The EM Algorithm and Extensions, 2nd ed.; John Wiley & Sons: New York, NY, USA, 2007. [Google Scholar]
- Lange, K. MM Optimization Algorithms; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2016. [Google Scholar]
- Guo, S.X.; Palaniyappan, L.; Liddle, F.P.; Feng, J.F. Dynamic cerebral reorganization in the pathophysiology of schizophrenia: A MRI-derived cortical thickness study. Psychol. Med. 2016, 46, 2201–2214. [Google Scholar]
- Lange, K.; Hunter, D.R.; Yang, I. Optimization transfer using surrogate objective functions (with discussions). J. Comput. Graph. Stat. 2000, 9, 1–20. [Google Scholar]
- Hunter, D.R.; Lange, K. A tutorial on MM algorithms. Am. Stat. 2004, 58, 30–37. [Google Scholar] [CrossRef]
- Tian, G.L.; Huang, X.F.; Xu, J.F. An assembly and decomposition approach for constructing separable minorizing functions in a class of MM algorithms. Stat. Sin. 2004, 29, 961–982. [Google Scholar] [CrossRef] [Green Version]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).