Abstract
In recent years, continuous metaheuristics have been a trend in solving binary-based combinatorial problems due to their good results. However, to use this type of metaheuristics, it is necessary to adapt them to work in binary environments, and in general, this adaptation is not trivial. The method proposed in this work evaluates the use of reinforcement learning techniques in the binarization process. Specifically, the backward Q-learning technique is explored to choose binarization schemes intelligently. This allows any continuous metaheuristic to be adapted to binary environments. The illustrated results are competitive, thus providing a novel option to address different complex problems in the industry.
Keywords:
combinatorial problems; metaheuristics; binarization scheme; backward Q-learning; machine learning MSC:
90C27
1. Introduction
The resolution of real problems can be approached through mathematical modeling to find a solution with an optimization algorithm [1]; under this scheme, it is increasingly common for different industries to solve combinatorial problems for their normal operation to minimize costs and times, as well as maximize profits. Such is the case of the forestry industry [2], flight planning for unmanned aircraft [3], or the detection of cracks in pavements [4]. Combinatorial problems are mostly NP-hard, which makes it difficult to find solutions with polynomial-time algorithms [5], which is why the use of intelligent optimization algorithms, mainly metaheuristics (MHs) [6], have considerably supported the growth of combinatorial problem solving; through their search processes, they manage to intelligently explore the search space, finding quasi-optimal solutions in reasonable computational times.
MHs are general-purpose algorithms widely used to solve optimization problems. Talbi in [7] indicated that metaheuristics can be classified according to how they perform the search process. Single-solution metaheuristics transform a single solution during the search process. Some classic examples of this type of metaheuristics are simulated annealing [8] and tabu search [9]. On the other hand, population-based metaheuristics are a set of solutions that are evolved as the optimization process progresses. Some classic examples of this type of metaheuristics are particle swarm optimization [10], cuckoo search [11], and the generic algorithm [12]. In the literature, population-based metaheuristics are more widely used than single-solution metaheuristics.
The no-free-lunch (NFL) theorem [13] tells us that there is no optimization algorithm that is good at all optimization problems. This theorem motivates researchers to keep developing new innovative algorithms. Thanks to this theorem, new metaheuristics have been created with very good performance. These good metaheuristics are grey wolf optimization [14], the whale optimization algorithm [15], and the sine–cosine algorithm (SCA) [16].
The grey wolf optimizer has been used for example in feature selection [17], training neural networks [18], optimizing support vector machines [19], designing and tuning controllers [20], economic dispatch problems [21], robotics and path planning [22], and scheduling [23].
The whale optimization algorithm has been used for example in optimal power flow problem [24], the economic dispatch problem [25], the electric vehicle charging station locating problem [26], image segmentation [27], feature selection [28], drug toxicity prediction [29], and emissions prediction and forecasting [30].
The sine–cosine algorithm has been used for example in the trajectory controller problem [31], feature selection [32], power management [33], network integration [34], engineering problems [35], and Image processing [36].
The grey wolf optimizer, sine–cosine algorithm, and whale optimization algorithm have been developed to perform in continuous domains; however, there are a small number of techniques that are capable of operating in binary and continuous domains, as is the case of genetic algorithms [37] and some variations of ant colony optimization (ACO) [38]. However, they have not been able to obtain the performance obtained by continuous metaheuristic techniques that use an operator capable of transforming their continuous solutions to binary space. In recent years, there has been an increase in the literature on new and novel binarization operators, such as those based on machine learning, specifically clustering techniques such as K-means [39] and DB-scan [40], based on reinforcement learning, such as Q-learning [41] and SARSA [42], among other inspirations, such as quantum [43], logical operators [44], crossovers [45], and percentiles [46]. Among the most-common and -used operators is the two-step operator, which consists of normalizing the continuous values through a transfer function (Step 1) to be subsequently binarized an approximation rule, finally obtaining a value of 0 or 1 (Step 2) [47]. In this context, it is necessary to continue the search for new variations of binarization techniques, since it has been proven that they directly influence the performance of the MHs [48,49,50,51,52].
In this work, we propose a new intelligent operator using a binarization scheme selection (BSS) capable of adapting any continuous MHs to work in the binary domain. BSS is based on the two-step technique, where employing an intelligent operator, the transfer function, and the binarization rules to be used are chosen; this scheme was first proposed in [53]. BSS has been previously used with reinforcement learning techniques within the machine learning umbrella: Q-learning and SARSA; in this case, a new intelligent operator called backward Q-learning (BQSA) [54] is presented, which is a combination between Q-learning and SARSA, updating the Q-values by SARSA and in a delayed way with Q-learning. On the other hand, the set of schemes of this proposal is more extensive, going from 40 possible combinations to 80. All of the above points to the need to investigate hybrid methods to improve the algorithm’s performance. The contributions made as a result of this work are presented below:
- The implementation of a BSS, as a binarization operator capable of operating in any continuous MH.
- The use of the BQSA as an smart operator in BSS.
- A larger set of transfer functions obtained from the literature, which generates an increase from 40 to 80 possible binarization schemes to be used.
Experimental tests were carried out against multiple state-of-the-art binarization strategies that solve the set covering problem. Among the results obtained, there are considerably competitive performances for the proposed work, but not having statistically significant differences, although the difference with static versions is validated. In these quantitative comparisons, we can observe differences in the convergence behavior between the 80 and 40 actions versions, as well as the balance between exploration and exploitation.
The rest of the paper is structured as follows: Section 2 presents the work related to metaheuristic techniques, machine learning, and their hybridization. Section 3 presents the proposal for the incorporation of the BQSA in BSS, while in Section 4, its implementation is validated with the results obtained and the respective statistical tests, ending with the analysis and conclusions in Section 5.
2. Related Work
In the following subsections, we present some of the concepts necessary to internalize the work.
2.1. Reinforcement Learning
Machine learning (ML) aims to analyze data in the search of patterns and to develop predictions obtaining future results [55]; when decomposing ML, we can find four main types (Figure 1): supervised, unsupervised, semi-supervised, and reinforcement learning (RL). In RL, an agent receives a set of instructions, actions, or guidelines with which it will then make its own decisions based on a process of reward and penalty to guide the agent toward the optimal solution to the problem.

Figure 1.
Machine learning classification.
Under this basis, an RL agent is constituted by four sub-elements: policy; value function; reward function; the environment model; however, the latter is usually optional [56]. As a definition of these elements, we give the following:
- A policy defines the agent’s behavior at each instant of time, i.e., it is a mapping from the set of perceived states to the set of actions to be performed when the agent is in those states.
- The value function allows the agent to maximize the sum of total rewards in the long run. It calculates the value of a state–action pair as the total amount of rewards that the agent can expect to accumulate in the future, starting from the state it is in. Thus, the agent selects the action based on value judgments. Indeed, while the reward determines the immediate and intrinsic desirability of a state–action pair, the value indicates the long-term desirability of a state–action pair considering likely future state–action pairs and their rewards.
- A reward function represents the agent’s goal, i.e., it translates each perceived state–action pair into a single number. In other words, a reward indicates the intrinsic desirability of that state–action pair. It is a way of communicating to the agent what the agent wants to obtain, but not how to achieve it.
- An environment model is intended to reproduce the behavior of the environment, i.e., the model that directs the agent to the next state and the subsequent reward based on the current state–action pair. The environment model is not always available and is therefore an optional element.
Among the existing RL classifications, we find the temporal difference techniques [57], where the Q-learning (QL) algorithm is the most popular for its contributions in several areas [58]. Still, there are other algorithms, such as SARSA [59] and the BQSA [54], which are variations of QL, but have obtained different performances for different problems.
2.2. Q-Learning
Among the algorithms present in RL, we find the QL algorithm first proposed in [60], which provides agents with the ability to learn to act optimally without the need to build domain maps. Having several possible s states, where from the “environment”, we obtain the current s in which the agent interacts and performs decisions. The agent has a set of possible actions which affect the reward and the next state. Once an action is performed, the state changes. When changing state, the agent receives a reward for the decision made. Where the rewards received by the agent consequently generate learning in the agent. To solve the problem, the agent learns the best course of action it can take, which has a maximum cumulative reward. The sequence of actions from the first state to the terminal state is called an episode. The transition of states is given by the Equation (1).
where is nominating the reward of the action taken in state and is the reward received when action is taken, is the maximum value of the action for the next state, the value of must be and corresponds to the learning factor. On the other hand, the value of must be and corresponds to the discount factor. If reaches the value of 0, only the immediate reward will be considered, while as it approaches 1, the future reward receives greater emphasis relative to the immediate reward. QL is algorithmically presented with the following Algorithm 1:
| Algorithm 1 Q-learning. |
|
2.3. State-Action-Reward-State-Action
This is a method of RL that uses generalized policy iteration patterns, which consists of two processes that are performed simultaneously and interact with each other, where one performs the value function with the current policy, and at the same time, the other one improves the current policy. These two processes complement each other in each iteration, but each one does not need to be completed before the next one begins.
The learning agent learns the current value function derived from the policy currently in use. To understand how it works, the first step is to learn an action-value function instead of a state-value function. In particular, for the on-policy method, we must estimate for the current policy and all states s and actions a.
To understand the algorithm, let us consider the transitions as a pair of values, state–action to state–action, where the values of the state–action pairs are learned. These cases are identical: both are Markov chains with a rewarding process. The theorems that ensure convergence of state values also apply to the corresponding algorithm for action values, with Equation (2).
After each transition the state is updated, until a terminal state is reached. When a state is terminal then , is defined as zero. Each transition process is composed of five events: (State-Action-Reward-State-Action), giving the name to the SARSA algorithm. The following is the Algorithm 2:
| Algorithm 2 SARSA. |
|
2.4. Backward Q-Learning
Backward Q-learning is another RL technique, although its name is similar to QL, it is not an ordinary Q-function update function (Equation (1)), this time, a backward update is added, hence the name backward Q-learning.
In this structure, action is directly affected, while the policy is indirectly affected. As the agent increases interaction with the environment, the agent’s precise knowledge also increases. Due to its structure, the agent can improve the learning speed, balance the explore–exploit dilemma and converge to the global minimum by using those previous states, actions, and information in an episode. Then, it is recorded that agents went through states, chose actions, and acquired rewards in an episode, and then this information will be used to update the Q-function again.
When the agent reaches the target state in the current episode, the produced data is used to update the Q-function backward. For example, state is defined as an initial state, and state is defined as a terminal state. The agent updates the Q-function N times from the initial state to the terminal state in an episode thanks to the recorded events: “s, a, r, s”. Therefore, we redefine Equation (1) of a step as:
where is the number of times the Q-function will be updated in the current episode. In turn, the agent simultaneously records the four events in , represented mathematically with the Equation (4):
Once the agent reaches the terminal state, the agent will backward update the Q-function based on the information obtained from Equation (4) as follows (Equation (5)).
where , and are the learning and discount factors respectively for the backward update of Q-function. Algorithm 3 is added for a better understanding of the above.
| Algorithm 3 Backward Q-learning. |
|
2.5. Metaheuristics
MHs are used to solve optimization problems, which can be considered a strategy that guides and modifies other heuristics to produce solutions beyond those normally generated in a search for local optimality [61]. Blum and Roli [6] mention two main components of any metaheuristic algorithm, which are: diversification and intensification, also known as exploration and exploitation. Exploration means generating diverse solutions to explore the search space on a global scale, while exploitation is to focus the search on a local region, knowing that a good solution is found in this neighborhood. Global optimization can be achieved with a good combination of these two main components, as a good balance while selecting the best solutions will improve the convergence rate of the algorithms. Choosing the best solutions can ensure that the solutions converge to the optimum. At the same time, diversification through randomization allows the search from the local optimum to the whole search space, causing the diversity of the solutions to grow.
The great advantage of MHs is that they are able to generate near-optimal solutions in reduced computational times as opposed to exact methods and, in addition, they are able to adapt to the problem in contrast to heuristic methods [7].
A high percentage of MHs are nature-based; this is mainly because their development is based on some abstraction of nature. The existing taxonomy can be defined in various ways and in various sections of the MH if one wanted to dissect; at first, they can be classified as those based on the trajectory or based on population. A popular classification can be those presented by [62,63], decomposing the population-based ones into 4 main categories: physics-based, human-based, evolutionary-based and swarm-based (Figure 2). Furthermore, the taxonomy presented in [64] deepens in the main components that conform to these algorithms: the solution evaluation, parameters, encoding, initialization of the agents or the population, management of the population, operators, and finally, local search.

Figure 2.
Nature-inspired metaheuristics.
Along this regard, and going deeper into the metaheuristic components and behavior, a metaheuristic can be represented algorithmically as a triple nested cycle. The first cycle corresponds to the iterations performed during the optimization process, the second cycle corresponds to the solutions obtained from the agents and finally, the third cycle corresponds to the dimensions associated with the problem. It is necessary to mention that within the third cycle, there is a that is characteristic of each MH. In the Algorithm 4 the above mentioned is presented.
| Algorithm 4 Discrete general scheme of metaheuristics. |
|
2.6. Hybridizations
Hybridizations between MHs and other approaches have been thoroughly studied in the literature, among these approaches is ML including RL. Various authors propose taxonomies and types of interactions such as [65,66,67,68]. Optimization and ML approaches according to Song et al. [65] interact in four ways:
- Optimization supports ML.
- The ML supports the optimization.
- ML supports ML.
- Optimization supports optimization.
Interaction number 2 is also structured in the classification presented in [66,67], where the way it supports ML is at the problem level, replacing, for example, objective functions or constraints that are costly; at a low level, i.e., in the components or operators of the MH; and finally at a high level, where ML techniques can be used to choose between different MHs or components of an MH.
2.7. Binarization
As mentioned above, a high percentage of population-based metaheuristics are continuous in nature. Therefore, they are not suitable for solving binary optimization problems directly. Due to this reason, an adaptation to the context of the 0 and 1 domain is necessary. The two-step sequential mechanism and the BSS used in other works are detailed below [41,42].
Two-Step
Within the literature, the transfer from continuous to binary through the two-step mechanism is one of the most common. Its characteristic name is due to its sequential mechanism, where the first step consists of transferring from the reals to a bounded interval through transfer functions, i.e., , then in the second step, by means of binarization rules, the bounded interval is transformed to a value of . In the last few years, several transfer functions have been presented, among the most common ones are the S and V type functions [49], others exist such as the X [69,70], Z [71], U [72,73], Q [74], in the literature we can find versions that change during the iterative process by means of a decreasing parameter [75,76,77,78]
2.8. Binarization Scheme Selector
As mentioned in Section 1, other works proposed the idea of combining RL with MHs, following the framework proposed by Talbi et al. in [66,67], being born from this combination an intelligent selector based on the two-step technique mentioned above, called BSS. The breakthrough of this smart selector is that it is able to learn autonomously through trial and error which transfer function (first step) and binarization rule (second step) best fit in the binarization when obtaining the solutions of the optimization process. In the proposals [42], there are S-type and V-type transfer functions, and as binarization rules there are standard, static, complement, elitist and elitist roulette, resulting in a total of 40 possible combinations, combinations that the intelligent selector is able to determine which one to use in each iteration. Figure 3 shows in general how the BSS is applied, and the Algorithm 5 explains the operation of the BSS.
| Algorithm 5 Binarization scheme selector. |
|
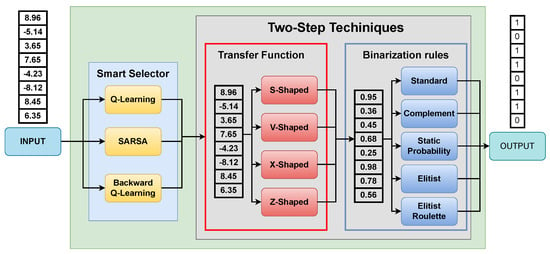
Figure 3.
Binarization scheme selector.
3. The Proposal: Binarization Scheme Selector
As mentioned above, this work proposes to apply and integrate a new intelligent operator called the BQSA [54] integrated into the BSS. This time, it is necessary to modify the original BSS operation related to the way the BQSA operates, i.e., memory. We detail the modification in question in the Algorithm 6. Algorithm 6 is very similar to Algorithm 5 except for some differences, which are highlighted in black (Lines 14–17). First, we initialize the Q-table, M (where the events are recorded), N (the number of times the Q-function will be updated), and randomly the swarm. Then, at each iteration, a binarization scheme for the “exploration” or “exploitation” state is selected from the Q-table and then applied. Subsequently, we obtain the reward by applying the binarization scheme to then update the Q-values in the Q-table. Finally, as explained in Section 2.4, we record the four events , once the iterations reach the same value as N, we start to perform the backward update of the Q-table.
| Algorithm 6 Binarization scheme selector modified. |
|
Another modification made to the BSS is the number of transfer functions with which it operates; in its original version, it has implemented eight functions in total, four transfer functions type S-shaped [49] and V-shaped [79] (see Figure 4a,b). The new ones added are the so-called X-shaped [69,70] and Z-shaped [71,80] types. Figure 4c,d and Table 1 show the details of the new transfer functions and the originals.
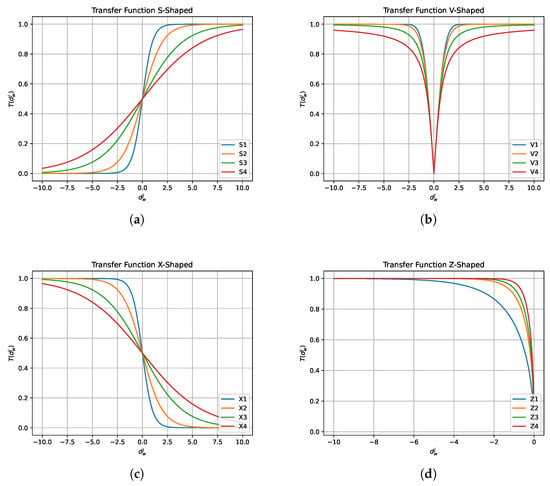
Figure 4.
Transfer functions. (a) S-shaped; (b) V-shaped; (c) X-shaped; (d) Z-shaped.

Table 1.
Transfer functions.
4. Experimental Results
To validate the performance of our proposal, a comparison of eight different versions of GWO, SCA, and WOA was carried out. Three of these versions incorporate BQSA, QL, and SARSA, where 80 binarization schemes were selected (80aBQSA, 80aQL, 80aSA). The other three versions of the final refer to incorporating BQSA, QL, and SARSA, where 40 binarization schemes were selected (40aBQSA,40aQL,40aSA). Finally, the last two use fixed binarization schemes. Regarding the binarization schemes and versions, it is necessary to mention that the schemes or also called actions are composed of the multiplication of the ; in this case, we have four families of transfer functions with 4 functions each, 16 in total and 5 binarization rules: . Regarding the versions mentioned and performed, 40aQL and 40aSA are the original versions of 40 actions (families S and V) applied to QL [41] and SARSA [42], respectively, in order to see the performance of our proposal, we replicated QL and SARSA, but this time in 80 actions and BQSA in both 40 and 80 actions. Finally, the versions in the middle, the first, BCL, uses the V4-Elitist [48]. The second, called MIR, uses the V4-Complement [49].
The benchmark instances of the set covering problem solved are those proposed in Beasley’s OR-Library [81]. In particular, we solved 45 instances delivered in this library.
The programming language used in the construction of the algorithms was Python 3.7, and it was executed with the free services of Google Colaboratory [82]. The results were stored and processed from databases provided by the Google Cloud Platform. The authors at [48] suggest making 40,000 calls to the objective function. To this end, we used 40 individuals from the population and 1000 iterations for all GWO, SCA, and WOA execution instances. 31 independent executions were performed for each executed instance. All parameters used for GWO, SCA, WOA, BQSA, QL, and SARSA are detailed in Table 2.
Table 2.
Parameters’ setting.
The results obtained from the experimentation process are summarized in the Table 3, Table 4 and Table 5, where the results are presented for each of the eight versions, and the 45 benchmark instances, wherein the first row the names of the versions are presented, in the second row, the titles that go as follows, the first column names the OR-Library instances used (Inst.), the second column the optimal value known for each of these instances (Opt.), while the following columns are titled in three columns the best result obtained in the 31 independent runs (Best), the average of these 31 runs (Avg), and finally the relative percentage deviation (RPD), which is defined in Equation (6). While in the last row, each column’s average results are presented to facilitate the comparison between versions.
Table 3.
Comparison of the metaheuristics’ GWO.
Table 4.
Comparison of the metaheuristics SCA.
Table 5.
Comparison of the metaheuristics’ WOA.
4.1. Convergence and Exploration–Exploitation Charts
During the experimentation, several data from the optimization process were recorded, such as the fitness obtained in iteration and the diversity among individuals as presented in [41,42], in order to analyze their behavior during the iterations. A graphical representation is the convergence graphs shown in Figure 5, Figure 6 and Figure 7, where the X axis corresponds to the 1000 iterations, while the Y axis presents the best fitness obtained up to that iteration. The graphs correspond to the best runs for representative instances, and the fitness value found is recorded in the subtitle of each graph, while in the graph set title, the known optimum is presented in order to make a simpler comparison. Other representations are the exploration and exploration graphs, presented in Figure 8, Figure 9 and Figure 10, where on the X-axis, the iterations are presented while on the Y-axis, the exploration (XPL) and exploitation (XPLT) are displayed.
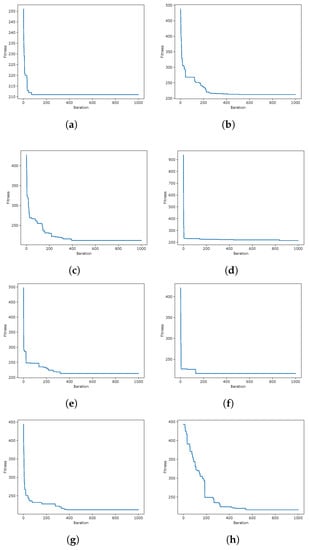
Figure 5.
GWO instances coverage when resolving the scp55 instance of the SCP. Instance Optimum: 211. (a) 80aBQSA—fitness obtained 211—Instance 55; (b) 80aQL—fitness obtained 212—Instance 55 (c) 80aSA—fitness obtained 212—Instance 55; (d) 40aBQSA—fitness obtained 212—Instance 55; (e) 40aQL—fitness obtained 213—Instance 55; (f) 40aSA—fitness obtained 212—Instance 55; (g) BCL—fitness obtained 212—Instance 55; (h) MIR—fitness obtained 216—Instance 55.
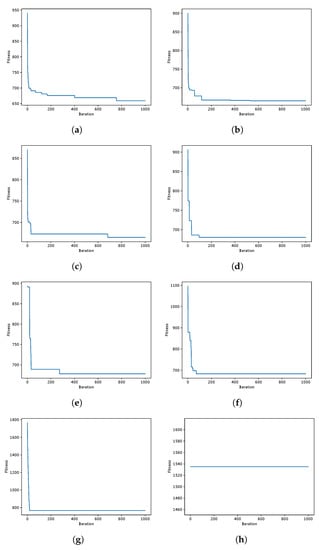
Figure 6.
SCA instances coverage when resolving the scp49 instance of the SCP. Instance Optimum: 641. (a) 80aBQSA—fitness obtained 659—Instance 49; (b) 80aQL—fitness obtained 665—Instance 49; (c) 80aSA—fitness obtained 665—Instance 49; (d) 40aBQSA—fitness obtained 664—Instance 49; (e) 40aQL—fitness obtained 667—Instance 49; (f) 40aSA—fitness obtained 663—Instance 49; (g) BCL—fitness obtained 766—Instance 49; (h) MIR—fitness obtained 1535—Instance 49.
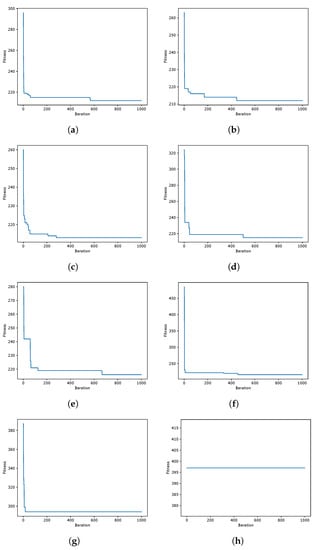
Figure 7.
WOA instances coverage when resolving the scp55 instance of the SCP. Instance Optimum: 211. (a) 80aBQSA—fitness obtained 212—Instance 55; (b) 80aQL—fitness obtained 212—Instance 55; (c) 80aSA—fitness obtained 213—Instance 55; (d) 40aBQSA—fitness obtained 212—Instance 55; (e) 40aQL—fitness obtained 212—Instance 55; (f) 40aSA—fitness obtained 212—Instance 55; (g) BCL—fitness obtained 294—Instance 55; (h) MIR—fitness obtained 397—Instance 55.
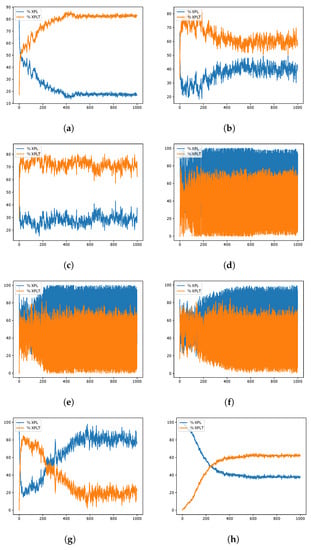
Figure 8.
GWO instances exploration–exploitation percentages when resolving the scp51 instance of the SCP. Instance Optimum: 253. (a) 80aBQSA—fitness obtained 255; (b) 80aQL—fitness obtained 256; (c) 80aSA—fitness obtained 256; (d) 40aBQSA—fitness obtained 254; (e) 40aQL—fitness obtained 258; (f) 40aSA—fitness obtained 257; (g) BCL—fitness obtained 259; (h) MIR—fitness obtained 262.
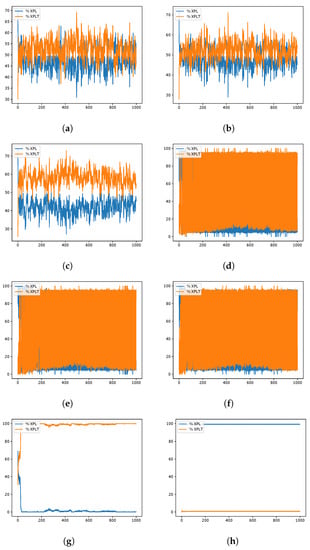
Figure 9.
SCA instances exploration–exploitation percentages when resolving the scp51 instance of the SCP. Instance Optimum: 494. (a) 80aBQSA—fitness obtained 496; (b) 80aQL—fitness obtained 503; (c) 80aSA—fitness obtained 502; (d) 40aBQSA—fitness obtained 502; (e) 40aQL—fitness obtained 503; (f) 40aSA—fitness obtained 504; (g) BCL—fitness obtained 564; (h) MIR—fitness obtained 962.
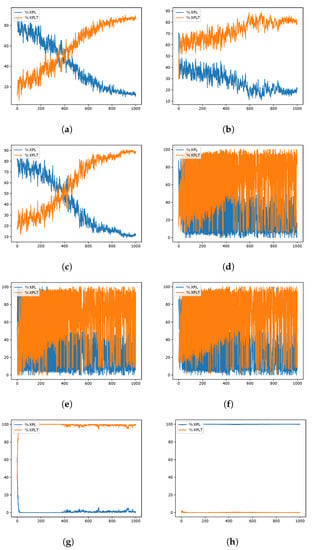
Figure 10.
WOA instances exploration–exploitation percentages when resolving the scp41 instance of the SCP. Instance Optimum: 429. (a) 80aBQSA—fitness obtained 430; (b) 80aQL—fitness obtained 431; (c) 80aSA—fitness obtained 430; (d) 40aBQSA—fitness obtained 430; (e) 40aQL—fitness obtained 430; (f) 40aSA—fitness obtained 431; (g) BCL—fitness obtained 489; (h) MIR—fitness obtained 638.
4.2. Statistical Results
To validate the comparison between averages, it is necessary to define by means of the corresponding statistical test if the difference between the results is significant, for which we use the Wilcoxon–Mann–Whitney test [83], making a comparison between all the versions, with a significance level of 0.05, for each of the MH used, where these results are represented in Table 6, Table 7 and Table 8. These tables are structured as follows; the first column presents the techniques used, the following columns present the average p-values of the 45 instances compared with the version indicated in the column title; if the value of this comparison is greater than 0.05 it is presented as “0.05”, when the comparison is against the same version the symbol “-” is presented and the values have been approximated to the second decimal place.
Table 6.
Average p-value of GWO compared to others algorithm.
Table 7.
Average p-value of SCA compared to others algorithm.
Table 8.
Average p-value of WOA compared to others algorithm.
5. Conclusions
The increase in computing capacity at more accessible costs has allowed the democratization of the use of machine learning, which has generated an increase in research in different areas, where we can see that every day, the use of these techniques is more common in both academia and industry. The use of machine learning in the improvement of the metaheuristics search process is a field in constant development, where several researches seek to validate the use of ML as a process improvement. The literature presents two explicit schemes for these hybridizations, the high-level ones, where we can observe the hyperheuristics, and the low-level ones, as is the case of this research, where the ML technique is a further operator of the MH.
In this paper, a new intelligent operator is presented in the use of binarization scheme selection (BSS), able to adapt any continuous MH to work in the binary domain. The main contributions are the implementation of a BSS capable of operating in any MH, using a new intelligent operator such as BQSA, and the increase of the possible actions of the intelligent operator from 40 to 80. The increase in these actions comes from the incorporation of two novel families that are rarely used in binarization schemes, such as Z-shaped and X-shaped.
The two-step binarization schemes are the most-used binarization methods in the literature [47], both for their versatility in programming and their low computational cost; for this, it is necessary to choose a transfer function (Step 1) and binarization rule (Step 2), but in the literature, there are many different ways to binarize, since there is a combinatorial problem between the options of Step 1 and Step 2, reaching the extreme of having infinite alternatives [75,78], having so many options, it is necessary to choose intelligently among all the possible options.
In the literature, to solve the problem of choosing the binarization scheme, in most cases, a combination that has presented good performance is chosen, while in some more exhaustive works, the combination is validated against an extensive experimental analysis, as is the case in [48,49], but these only confirm a good two-step combinatorial problem, for a given problem and instances, which is not necessarily replicable to other problems in the same domain. Under this context, an intelligent scheme was proposed in [41] to select among different actions (two-step combinatorics), where by means of QL, an action is chosen for each iteration, which is rewarded or penalized according to their performance, this being a hybridization where a machine learning technique supports metaheuristics. There are other works where BSS is used, which present different intelligent selectors such as QL [41] and SARSA [42], but always with the most-used set of 40 actions (8 choices of V-shaped and S-shaped transfer functions and five binarizations), which have presented diverse favorable performances, but in this work, besides replicating these experiments, we analyzed the performance of 80 actions (16 options of V-shaped, S-shaped, X-shaped, and Z-shaped transfer functions, and 5 binarizations), with the objective of validating that, by having a wider range of actions, the intelligent selector will be able to choose in a better way, avoiding biases by having reduced actions, besides directing the research so that the intelligent selector has more options to choose from.
In response to this proposal, an extensive set of experiments was carried out, which were detailed in Section 4, where eight different versions were compared between 3 MHs, solving 45 different instances of the set covering problem, all of them executed in 31 independent runs, in order to perform the respective statistical tests. The versions containing 80 actions (80aBQSA, 80aQL, and 80aSA) presented competitive performances, obtaining a similar average RPD and, in some cases, better, but having differences that were not significant in front of the respective statistical tests; therefore, we cannot conclude that they have a better performance compared to the versions with 40 actions (40aBQSA, 40aQL, and 40aSA), but for the MHs’ WOA and SCA, there were significant differences when compared to the static version MIR (v4-Complement), which had the worst performance of the eight versions. After analyzing the convergence plots, we can observe that, although the results are diverse, we can assume that the static schemes present early convergences, compared to the dynamic versions (40 and 80 actions), which is related to a good search process without getting trapped early in local optima. Along with this, the exploration and exploitation graphs give us a different perspective of the behavior during the search process, which gives us information on the diversity between individuals, as defined in [84]; from these graphs, we can conclude that the versions with 80 shares tend to have a more predominant tendency to exploit, On the other hand, we confirmed that the recommendations of the literature will not necessarily be applicable for any problem, as is the case of using the MIR combination, which was validated for another problem, confirming what is stated in the no-free-lunch theorem [13].
During the theoretical and experimental development of this work, new research questions have arisen, which remain as possible future works based on the work implemented in this paper, where we can highlight the need to advance in addressing the use of variable transfer functions [75,78]. This is in order to take advantage of the richness of being able to vary the transfer function under a continuous parameter, but which in turn generates a problem to solve, which is that BQSA, SARSA, QL, and other temporal difference techniques are defined to choose between a discrete set of actions, not allowing directly choosing actions in continuous domains. It is also necessary to study the influence of transfer functions against binarization rules, i.e., to use a variety of actions, either individual transfer functions or individual binarization rules. Along with answering the above questions, the option of evaluating other MHs in the literature in other binary domain problems is contemplated in order to confirm that the incorporation of reinforcement learning techniques generates the same effect on them. Another area to investigate is the behavior of this hybridization under smaller subsets in order to evaluate the impact of each of the combinatorics.
Author Contributions
M.B.-R., J.L.-R. and F.C.-C.: conceptualization, investigation, methodology, writing—review and editing, project administration, resources, formal analysis. B.C., R.S. and J.G.: writing—review and editing, investigation, validation, funding acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
Crawford and Ricardo Soto are supported by Grant ANID/FONDECYT/REGULAR/1210810. Marcelo Becerra-Rozas is supported by the National Agency for Research and Development (ANID)/Scholarship Program/DOCTORADO NACIONAL/2021-21210740. Felipe Cisternas-Caneo is supported by Beca INF-PUCV.
Data Availability Statement
The code used can be found in: https://github.com/imaberro/BSS-BQSA-80-40-actions, accessed on 12 November 2022.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| Acronyms | |
| MH | Metaheuristics |
| NFL | No-free-lunch theorem |
| SCA | Sine-cosine algorithm |
| ACO | Ant colony optimization |
| BSS | Binarization scheme selection |
| BQSA | Backward Q-learning |
| ML | Machine learning |
| RL | Reinforcement learning |
| QL | Q-learning |
| 80aBQSA | Version of backward Q-learning with 80 actions |
| 80aQL | Version of Q-learning with 80 actions |
| 80aSA | Version of SARSA with 80 actions |
| 40aBQSA | Version of backward Q-learning with 40 actions |
| 40aQL | Version of Q-learning with 40 actions |
| 40aSA | Version of SARSA with 40 actions |
| MIR | Static version of two-step, using V4 and complement |
| BCL | Static version of two-step, using V4 and elitist |
| S1 | S-shaped Type 1 |
| S2 | S-shaped Type 2 |
| S3 | S-shaped Type 3 |
| S4 | S-shaped Type 4 |
| V1 | V-shaped Type 1 |
| V2 | V-shaped Type 2 |
| V3 | V-shaped Type 3 |
| V4 | V-shaped Type 4 |
| X1 | X-shaped Type 1 |
| X2 | X-shaped Type 2 |
| X3 | X-shaped Type 3 |
| X4 | X-shaped Type 4 |
| Z1 | Z-shaped Type 1 |
| Z2 | Z-shaped Type 2 |
| Z3 | Z-shaped Type 3 |
| Z4 | Z-shaped Type 4 |
| XPL | Exploration |
| XPLT | Exploitation |
| RPD | Relative percentage deviation |
| Symbol | |
| New Q-value obtained for state and action | |
| Old Q-value obtained for state and action | |
| State at time t | |
| Reward at time t | |
| Action at time t | |
| Learning factor | |
| Max Q-value obtained for state and action | |
| Discount factor | |
| Q-value obtained for state s and action a | |
| s | State |
| Last status | |
| a | Action |
| r | Reward |
| Next state | |
| Policy | |
| New Q-value obtained for state and action , at iteration i | |
| Reward at iteration i and | |
| Memory of backward Q-learning | |
| Action on t at iteration i | |
| Q-value obtained for state and action , at iteration j | |
| N | Number of times the Q-function will be updated |
| Population X in iteration , individual i and dimension d | |
| Population X in iteration t, individual i and dimension d | |
| Perturbation or dimensional movement, which depends on | |
| each metaheuristic | |
| Transfer function result calculated for population d, at iteration | |
| j for individual w |
References
- Hanaka, T.; Kiyomi, M.; Kobayashi, Y.; Kobayashi, Y.; Kurita, K.; Otachi, Y. A Framework to Design Approximation Algorithms for Finding Diverse Solutions in Combinatorial Problems. arXiv 2022, arXiv:2201.08940. [Google Scholar]
- Sun, Y.; Jin, X.; Pukkala, T.; Li, F. Two-level optimization approach to tree-level forest planning. For. Ecosyst. 2022, 9, 100001. [Google Scholar] [CrossRef]
- Ait Saadi, A.; Soukane, A.; Meraihi, Y.; Benmessaoud Gabis, A.; Mirjalili, S.; Ramdane-Cherif, A. UAV Path Planning Using Optimization Approaches: A Survey. Arch. Comput. Methods Eng. 2022, 29, 4233–4284. [Google Scholar] [CrossRef]
- Hoang, N.D.; Huynh, T.C.; Tran, X.L.; Tran, V.D. A Novel Approach for Detection of Pavement Crack and Sealed Crack Using Image Processing and Salp Swarm Algorithm Optimized Machine Learning. Adv. Civ. Eng. 2022, 2022, 9193511. [Google Scholar] [CrossRef]
- Guo, T.; Han, C.; Tang, S.; Ding, M. Solving combinatorial problems with machine learning methods. In Nonlinear Combinatorial Optimization; Springer: Cham, Switzerland, 2019; pp. 207–229. [Google Scholar]
- Blum, C.; Roli, A. Metaheuristics in combinatorial optimization: Overview and conceptual comparison. Acm Comput. Surv. 2003, 35, 268–308. [Google Scholar] [CrossRef]
- Talbi, E.G. Metaheuristics: From Design to Implementation; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 74. [Google Scholar]
- Van Laarhoven, P.J.; Aarts, E.H. Simulated annealing. In Simulated Annealing: Theory and Applications; Springer: Berlin/Heidelberg, Germany, 1987; pp. 7–15. [Google Scholar]
- Glover, F.; Laguna, M. Tabu search. In Handbook of Combinatorial Optimization; Springer: Berlin/Heidelberg, Germany, 1998; pp. 2093–2229. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Yang, X.S.; Deb, S. Cuckoo search via Lévy flights. In Proceedings of the 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009; pp. 210–214. [Google Scholar]
- Holland, J.H. Genetic algorithms. Sci. Am. 1992, 267, 66–73. [Google Scholar] [CrossRef]
- Ho, Y.C.; Pepyne, D.L. Simple explanation of the no-free-lunch theorem and its implications. J. Optim. Theory Appl. 2002, 115, 549–570. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl.-Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Emary, E.; Zawbaa, H.M.; Grosan, C.; Hassenian, A.E. Feature subset selection approach by gray-wolf optimization. In Proceedings of the Afro-European Conference for Industrial Advancement; Springer: Cham, Switzerland, 2015; pp. 1–13. [Google Scholar]
- Mosavi, M.R.; Khishe, M.; Ghamgosar, A. Classification of sonar data set using neural network trained by gray wolf optimization. Neural Netw. World 2016, 26, 393. [Google Scholar] [CrossRef]
- Eswaramoorthy, S.; Sivakumaran, N.; Sekaran, S. Grey wolf optimization based parameter selection for support vector machines. COMPEL—Int. J. Comput. Math. Electr. Electron. Eng. 2016, 35, 1513–1523. [Google Scholar] [CrossRef]
- Li, S.X.; Wang, J.S. Dynamic modeling of steam condenser and design of PI controller based on grey wolf optimizer. Math. Probl. Eng. 2015, 2015, 120975. [Google Scholar] [CrossRef]
- Wong, L.I.; Sulaiman, M.; Mohamed, M.; Hong, M.S. Grey Wolf Optimizer for solving economic dispatch problems. In Proceedings of the 2014 IEEE International Conference on Power and Energy (PECon), Kuching, Malaysia, 1–3 December 2014; pp. 150–154. [Google Scholar]
- Tsai, P.W.; Nguyen, T.T.; Dao, T.K. Robot path planning optimization based on multiobjective grey wolf optimizer. In Proceedings of the International Conference on Genetic and Evolutionary Computing; Springer: Cham, Switzerland, 2016; pp. 166–173. [Google Scholar]
- Lu, C.; Gao, L.; Li, X.; Xiao, S. A hybrid multi-objective grey wolf optimizer for dynamic scheduling in a real-world welding industry. Eng. Appl. Artif. Intell. 2017, 57, 61–79. [Google Scholar] [CrossRef]
- Bentouati, B.; Chaib, L.; Chettih, S. A hybrid whale algorithm and pattern search technique for optimal power flow problem. In Proceedings of the 2016 8th International Conference on Modelling, Identification and Control (ICMIC), Algiers, Algeria, 15–17 November 2016; pp. 1048–1053. [Google Scholar]
- Touma, H.J. Study of the economic dispatch problem on IEEE 30-bus system using whale optimization algorithm. Int. J. Eng. Technol. Sci. 2016, 3, 11–18. [Google Scholar] [CrossRef]
- Yin, X.; Cheng, L.; Wang, X.; Lu, J.; Qin, H. Optimization for hydro-photovoltaic-wind power generation system based on modified version of multi-objective whale optimization algorithm. Energy Procedia 2019, 158, 6208–6216. [Google Scholar] [CrossRef]
- Abd El Aziz, M.; Ewees, A.A.; Hassanien, A.E. Whale optimization algorithm and moth-flame optimization for multilevel thresholding image segmentation. Expert Syst. Appl. 2017, 83, 242–256. [Google Scholar] [CrossRef]
- Mafarja, M.M.; Mirjalili, S. Hybrid whale optimization algorithm with simulated annealing for feature selection. Neurocomputing 2017, 260, 302–312. [Google Scholar] [CrossRef]
- Tharwat, A.; Moemen, Y.S.; Hassanien, A.E. Classification of toxicity effects of biotransformed hepatic drugs using whale optimized support vector machines. J. Biomed. Inform. 2017, 68, 132–149. [Google Scholar] [CrossRef]
- Zhao, H.; Guo, S.; Zhao, H. Energy-related CO2 emissions forecasting using an improved LSSVM model optimized by whale optimization algorithm. Energies 2017, 10, 874. [Google Scholar] [CrossRef]
- Banerjee, A.; Nabi, M. Re-entry trajectory optimization for space shuttle using sine-cosine algorithm. In Proceedings of the 2017 8th International Conference on Recent Advances in Space Technologies (RAST), Istanbul, Turkey, 19–22 June 2017; pp. 73–77. [Google Scholar]
- Sindhu, R.; Ngadiran, R.; Yacob, Y.M.; Zahri, N.A.H.; Hariharan, M. Sine–cosine algorithm for feature selection with elitism strategy and new updating mechanism. Neural Comput. Appl. 2017, 28, 2947–2958. [Google Scholar] [CrossRef]
- Mahdad, B.; Srairi, K. A new interactive sine cosine algorithm for loading margin stability improvement under contingency. Electr. Eng. 2018, 100, 913–933. [Google Scholar] [CrossRef]
- Padmanaban, S.; Priyadarshi, N.; Holm-Nielsen, J.B.; Bhaskar, M.S.; Azam, F.; Sharma, A.K.; Hossain, E. A novel modified sine-cosine optimized MPPT algorithm for grid integrated PV system under real operating conditions. IEEE Access 2019, 7, 10467–10477. [Google Scholar] [CrossRef]
- Gonidakis, D.; Vlachos, A. A new sine cosine algorithm for economic and emission dispatch problems with price penalty factors. J. Inf. Optim. Sci. 2019, 40, 679–697. [Google Scholar] [CrossRef]
- Abd Elfattah, M.; Abuelenin, S.; Hassanien, A.E.; Pan, J.S. Handwritten arabic manuscript image binarization using sine cosine optimization algorithm. In Proceedings of the International Conference on Genetic and Evolutionary Computing; Springer: Cham, Switzerland, 2016; pp. 273–280. [Google Scholar]
- Shreem, S.S.; Turabieh, H.; Al Azwari, S.; Baothman, F. Enhanced binary genetic algorithm as a feature selection to predict student performance. Soft Comput. 2022, 26, 1811–1823. [Google Scholar] [CrossRef]
- Ma, W.; Zhou, X.; Zhu, H.; Li, L.; Jiao, L. A two-stage hybrid ant colony optimization for high-dimensional feature selection. Pattern Recognit. 2021, 116, 107933. [Google Scholar] [CrossRef]
- García, J.; Crawford, B.; Soto, R.; Castro, C.; Paredes, F. A k-means binarization framework applied to multidimensional knapsack problem. Appl. Intell. 2018, 48, 357–380. [Google Scholar] [CrossRef]
- García, J.; Moraga, P.; Valenzuela, M.; Crawford, B.; Soto, R.; Pinto, H.; Peña, A.; Altimiras, F.; Astorga, G. A Db-Scan binarization algorithm applied to matrix covering problems. Comput. Intell. Neurosci. 2019, 2019, 3238574. [Google Scholar] [CrossRef]
- Crawford, B.; Soto, R.; Lemus-Romani, J.; Becerra-Rozas, M.; Lanza-Gutiérrez, J.M.; Caballé, N.; Castillo, M.; Tapia, D.; Cisternas-Caneo, F.; García, J.; et al. Q-learnheuristics: Towards data-driven balanced metaheuristics. Mathematics 2021, 9, 1839. [Google Scholar] [CrossRef]
- Lemus-Romani, J.; Becerra-Rozas, M.; Crawford, B.; Soto, R.; Cisternas-Caneo, F.; Vega, E.; Castillo, M.; Tapia, D.; Astorga, G.; Palma, W.; et al. A novel learning-based binarization scheme selector for swarm algorithms solving combinatorial problems. Mathematics 2021, 9, 2887. [Google Scholar] [CrossRef]
- Lai, X.; Hao, J.K.; Fu, Z.H.; Yue, D. Diversity-preserving quantum particle swarm optimization for the multidimensional knapsack problem. Expert Syst. Appl. 2020, 149, 113310. [Google Scholar] [CrossRef]
- Aytimur, A.; Babayigit, B. Binary Artificial Bee Colony Algorithms for {0–1} Advertisement Problem. In Proceedings of the 2019 6th International Conference on Electrical and Electronics Engineering (ICEEE), Istanbul, Turkey, 16–17 April 2019; pp. 91–95. [Google Scholar]
- Abdel-Basset, M.; Mohamed, R.; Elkomy, O.M.; Abouhawwash, M. Recent metaheuristic algorithms with genetic operators for high-dimensional knapsack instances: A comparative study. Comput. Ind. Eng. 2022, 166, 107974. [Google Scholar] [CrossRef]
- Jorquera, L.; Valenzuela, P.; Causa, L.; Moraga, P.; Villavicencio, G. A Percentile Firefly Algorithm an Application to the Set Covering Problem. In Proceedings of the Computer Science On-Line Conference; Springer: Cham, Switzerland, 2021; pp. 750–759. [Google Scholar]
- Crawford, B.; Soto, R.; Astorga, G.; García, J.; Castro, C.; Paredes, F. Putting continuous metaheuristics to work in binary search spaces. Complexity 2017, 2017, 8404231. [Google Scholar] [CrossRef]
- Lanza-Gutierrez, J.M.; Crawford, B.; Soto, R.; Berrios, N.; Gomez-Pulido, J.A.; Paredes, F. Analyzing the effects of binarization techniques when solving the set covering problem through swarm optimization. Expert Syst. Appl. 2017, 70, 67–82. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. S-shaped versus V-shaped transfer functions for binary particle swarm optimization. Swarm Evol. Comput. 2013, 9, 1–14. [Google Scholar] [CrossRef]
- Mafarja, M.; Eleyan, D.; Abdullah, S.; Mirjalili, S. S-shaped vs. V-shaped transfer functions for ant lion optimization algorithm in feature selection problem. In Proceedings of the International Conference on Future Networks and Distributed Systems, Cambridge, UK, 19–20 July 2017; pp. 1–7. [Google Scholar]
- Ghosh, K.K.; Guha, R.; Bera, S.K.; Kumar, N.; Sarkar, R. S-shaped versus V-shaped transfer functions for binary Manta ray foraging optimization in feature selection problem. Neural Comput. Appl. 2021, 33, 11027–11041. [Google Scholar] [CrossRef]
- Agrawal, P.; Ganesh, T.; Oliva, D.; Mohamed, A.W. S-shaped and v-shaped gaining-sharing knowledge-based algorithm for feature selection. Appl. Intell. 2022, 52, 81–112. [Google Scholar] [CrossRef]
- Cisternas-Caneo, F.; Crawford, B.; Soto, R.; Tapia, D.; Lemus-Romani, J.; Castillo, M.; Becerra-Rozas, M.; Paredes, F.; Misra, S. A data-driven dynamic discretization framework to solve combinatorial problems using continuous metaheuristics. In Innovations in Bio-Inspired Computing and Applications; Springer: Cham, Switzerland, 2020; pp. 76–85. [Google Scholar]
- Wang, Y.H.; Li, T.H.S.; Lin, C.J. Backward Q-learning: The combination of Sarsa algorithm and Q-learning. Eng. Appl. Artif. Intell. 2013, 26, 2184–2193. [Google Scholar] [CrossRef]
- Burns, E. In-Depth Guide to Machine Learning in the Enterprise. Techtarget 2021, 17. Available online: https://www.techtarget.com/searchenterpriseai/In-depth-guide-to-machine-learning-in-the-enterprise (accessed on 12 November 2022).
- Lo, A.W. Reconciling efficient markets with behavioral finance: The adaptive markets hypothesis. J. Investig. Consult. 2005, 7, 21–44. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Clifton, J.; Laber, E. Q-learning: Theory and applications. Annu. Rev. Stat. Appl. 2020, 7, 279–301. [Google Scholar] [CrossRef]
- Rummery, G.A.; Niranjan, M. On-Line Q-Learning Using Connectionist Systems; Citeseer: Cambridge, UK, 1994; Volume 37. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Glover, F.W.; Kochenberger, G.A. Handbook of Metaheuristics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006; Volume 57. [Google Scholar]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Cuevas, E.; Fausto, F.; González, A. New Advancements in Swarm Algorithms: Operators and Applications; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Jourdan, L.; Dhaenens, C.; Talbi, E.G. Using datamining techniques to help metaheuristics: A short survey. In Proceedings of the International Workshop on Hybrid Metaheuristics; Springer: Berlin/Heidelberg, Germany, 2006; pp. 57–69. [Google Scholar]
- Song, H.; Triguero, I.; Özcan, E. A review on the self and dual interactions between machine learning and optimisation. Prog. Artif. Intell. 2019, 8, 143–165. [Google Scholar] [CrossRef]
- Talbi, E.G. Machine Learning into Metaheuristics: A Survey and Taxonomy of Data-Driven Metaheuristics; ffhal-02745295f; HAL: Lyon, France, 2020. [Google Scholar]
- Talbi, E.G. Machine learning into metaheuristics: A survey and taxonomy. ACM Comput. Surv. 2021, 54, 1–32. [Google Scholar] [CrossRef]
- Karimi-Mamaghan, M.; Mohammadi, M.; Meyer, P.; Karimi-Mamaghan, A.M.; Talbi, E.G. Machine Learning at the service of Meta-heuristics for solving Combinatorial Optimization Problems: A state-of-the-art. Eur. J. Oper. Res. 2022, 296, 393–422. [Google Scholar] [CrossRef]
- Ghosh, K.K.; Singh, P.K.; Hong, J.; Geem, Z.W.; Sarkar, R. Binary social mimic optimization algorithm with x-shaped transfer function for feature selection. IEEE Access 2020, 8, 97890–97906. [Google Scholar] [CrossRef]
- Beheshti, Z. A novel x-shaped binary particle swarm optimization. Soft Comput. 2021, 25, 3013–3042. [Google Scholar] [CrossRef]
- Guo, S.-S.; Wang, J.-S.; Guo, M.-W. Z-shaped transfer functions for binary particle swarm optimization algorithm. Comput. Intell. Neurosci. 2020, 2020, 6502807. [Google Scholar] [CrossRef]
- Awadallah, M.A.; Hammouri, A.I.; Al-Betar, M.A.; Braik, M.S.; Abd Elaziz, M. Binary Horse herd optimization algorithm with crossover operators for feature selection. Comput. Biol. Med. 2022, 141, 105152. [Google Scholar] [CrossRef] [PubMed]
- Mirjalili, S.; Zhang, H.; Mirjalili, S.; Chalup, S.; Noman, N. A novel U-shaped transfer function for binary particle swarm optimisation. In Soft Computing for Problem Solving 2019; Springer: Singapore, 2020; pp. 241–259. [Google Scholar]
- Jain, S.; Dharavath, R. Memetic salp swarm optimization algorithm based feature selection approach for crop disease detection system. J. Ambient. Intell. Humaniz. Comput. 2021, 1–19. [Google Scholar] [CrossRef]
- Kahya, M.A.; Altamir, S.A.; Algamal, Z.Y. Improving whale optimization algorithm for feature selection with a time-varying transfer function. Numer. Algebra Control Optim. 2021, 11, 87. [Google Scholar] [CrossRef]
- Islam, M.J.; Li, X.; Mei, Y. A time-varying transfer function for balancing the exploration and exploitation ability of a binary PSO. Appl. Soft Comput. 2017, 59, 182–196. [Google Scholar] [CrossRef]
- Mafarja, M.; Aljarah, I.; Heidari, A.A.; Faris, H.; Fournier-Viger, P.; Li, X.; Mirjalili, S. Binary dragonfly optimization for feature selection using time-varying transfer functions. Knowl.-Based Syst. 2018, 161, 185–204. [Google Scholar] [CrossRef]
- Chantar, H.; Thaher, T.; Turabieh, H.; Mafarja, M.; Sheta, A. BHHO-TVS: A binary harris hawks optimizer with time-varying scheme for solving data classification problems. Appl. Sci. 2021, 11, 6516. [Google Scholar] [CrossRef]
- Rajalakshmi, N.; Padma Subramanian, D.; Thamizhavel, K. Performance enhancement of radial distributed system with distributed generators by reconfiguration using binary firefly algorithm. J. Inst. Eng. India Ser. B 2015, 96, 91–99. [Google Scholar] [CrossRef]
- Sun, W.Z.; Zhang, M.; Wang, J.S.; Guo, S.S.; Wang, M.; Hao, W.K. Binary Particle Swarm Optimization Algorithm Based on Z-shaped Probability Transfer Function to Solve 0–1 Knapsack Problem. IAENG Int. J. Comput. Sci. 2021, 48, 294–303. [Google Scholar]
- Beasley, J.; Jörnsten, K. Enhancing an algorithm for set covering problems. Eur. J. Oper. Res. 1992, 58, 293–300. [Google Scholar] [CrossRef]
- Bisong, E. Google Colaboratory. In Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners; Apress: Berkeley, CA, USA, 2019; pp. 59–64. [Google Scholar] [CrossRef]
- Mann, H.B.; Whitney, D.R. On a test of whether one of two random variables is stochastically larger than the other. Ann. Math. Stat. 1947, 18, 50–60. [Google Scholar] [CrossRef]
- Morales-Castañeda, B.; Zaldivar, D.; Cuevas, E.; Fausto, F.; Rodríguez, A. A better balance in metaheuristic algorithms: Does it exist? Swarm Evol. Comput. 2020, 54, 100671. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).