
Estimating Value-at-Risk and Expected Shortfall: Do Polynomial Expansions Outperform Parametric Densities?


Abstract
1. Introduction
2. Statistical Models and Inference
2.1. General Framework
2.2. Distributions Based on Polynomial Expansions
2.2.1. Cornish-Fisher Expansion
2.2.2. Gram-Charlier Expansion
2.3. Parametric Distributions
2.3.1. Skewed-t Distribution
2.3.2. Johnson Distribution
3. Assessing the Performance of VaR and ES Estimates
3.1. Backtesting VaR and ES
3.2. Assessment of Performance with Loss Functions
4. Empirical Results
5. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Artzner, P.; Delbaen, F.; Eber, J.M.; Heath, D. Coherent measures of risk. Math. Financ. 1999, 9, 203–228. [Google Scholar] [CrossRef]
- Gneiting, T. Making and evaluating point forecasts. J. Am. Stat. Assoc. 2011, 106, 746–762. [Google Scholar] [CrossRef]
- Kratz, M.; Lok, Y.H.; McNeil, A.J. Multinomial VaR backtests: A simple implicit approach to backtesting expected shortfall. J. Bank. Financ. 2018, 88, 393–407. [Google Scholar] [CrossRef]
- Du, Z.; Escanciano, J.C. Backtesting expected shortfall: Accounting for tail risk. Manag. Sci. 2017, 63, 940–958. [Google Scholar] [CrossRef]
- Cornish, E.A.; Fisher, R.A. Moments and cumulants in the specification of distributions. Rev. De L’Institut Int. De Stat. 1938, 5, 307–322. [Google Scholar] [CrossRef]
- Maillard, D. A user’s guide to the Cornish-Fisher expansion. SSRN 2018. [Google Scholar] [CrossRef][Green Version]
- Chernozhukov, V.; Fernández-Val, I.; Galichon, A. Rearranging Edgeworth–Cornish–Fisher expansions. Econ. Theory 2010, 42, 419–435. [Google Scholar] [CrossRef]
- Amédée-Manesme, C.O.; Barthélémy, F.; Keenan, D. Cornish-Fisher expansion for commercial real estate value at risk. J. Real Estate Financ. Econ. 2015, 50, 439–464. [Google Scholar] [CrossRef][Green Version]
- Stuart, A.; Ord, K. Kendall’s Advanced Theory of Statistics, 4th ed.; Griffin: London, UK, 1977; Volume 1, pp. 166–171. [Google Scholar]
- Mauleón, I.; Perote, J. Testing densities with financial data: An empirical comparison of the Edgeworth-Sargan density to the Student’s t. Eur. J. Financ. 2000, 6, 225–239. [Google Scholar] [CrossRef]
- Jondeau, E.; Rockinger, M. Gram–Charlier densities. J. Econ. Dyn. Control 2001, 25, 1457–1483. [Google Scholar] [CrossRef]
- Ñíguez, T.M.; Perote, J. Forecasting heavy-tailed densities with positive Edgeworth and Gram-Charlier expansions. Oxf. Bull. Econ. Stat. 2012, 74, 600–627. [Google Scholar] [CrossRef]
- León, Á.; Ñíguez, T.M. The transformed Gram Charlier distribution: Parametric properties and financial risk applications. J. Empir. Financ. 2021, 63, 323–349. [Google Scholar] [CrossRef]
- Gallant, A.R.; Nychka, D.W. Semi-nonparametric maximum likelihood estimation. Econometrica 1987, 55, 363–390. [Google Scholar] [CrossRef]
- Gallant, A.R.; Tauchen, G. Seminonparametric estimation of conditionally constrained heterogeneous processes: Asset pricing applications. Econometrica 1989, 57, 1091–1120. [Google Scholar] [CrossRef]
- León, Á.; Mencía, J.; Sentana, E. Parametric properties of semi-nonparametric distributions, with applications to option valuation. J. Bus. Econ. Stat. 2009, 27, 176–192. [Google Scholar] [CrossRef]
- Hansen, B.E. Autoregressive conditional density estimation. Int. Econ. Rev. 1994, 35, 705–730. [Google Scholar] [CrossRef]
- Johnson, N.L. Systems of frequency curves generated by methods of translation. Biometrika 1949, 36, 149–176. [Google Scholar] [CrossRef]
- Simonato, J.G. The performance of Johnson distributions for computing value at risk and expected shortfall. J. Deriv. 2011, 19, 7–24. [Google Scholar] [CrossRef]
- Simonato, J.G. GARCH processes with skewed and leptokurtic innovations: Revisiting the Johnson-Su case. Financ. Lett. 2012, 9, 213–219. [Google Scholar] [CrossRef]
- Kupiec, P. Techniques for verifying the accuracy of risk measurement models. J. Deriv. 1995, 2, 73–84. [Google Scholar] [CrossRef]
- Christoffersen, P.F. Evaluating interval forecasts. Int. Econ. Rev. 1998, 39, 841–862. [Google Scholar] [CrossRef]
- Abad, P.; Muela, S.B.; López, C. The role of the loss function in value-at-risk comparisons. J. Risk Model Valid. 2015, 9, 1–19. [Google Scholar] [CrossRef]
- Christoffersen, P.F. Elements of Financial Risk Management, 2nd ed.; Amsterdam Elsevier/Academic Press: Amsterdam, The Netherlands, 2012; pp. 76–77. [Google Scholar]
- Aboura, S.; Maillard, D. Option pricing under skewness and kurtosis using a Cornish–Fisher expansion. J. Futur. Mark. 2016, 36, 1194–1209. [Google Scholar] [CrossRef]
- Liquet, B.; Nazarathy, Y. A dynamic view to moment matching of truncated distributions. Stat. Probab. Lett. 2015, 104, 87–93. [Google Scholar] [CrossRef]
- León, Á.; Ñíguez, T.M. Modeling asset returns under time-varying seminonparametric distributions. J. Banking Financ. 2020, 118, 105870. [Google Scholar] [CrossRef]
- Skoulakis, G. Simulating from polynomial-normal distributions. Commun. Stat.-Simul. Comput. 2009, 48, 472–477. [Google Scholar] [CrossRef]
- Zhu, D.; Galbraith, J.W. Modeling and forecasting expected shortfall with the generalized asymmetric Student-t and asymmetric exponential power distributions. J. Empir. Financ. 2011, 18, 765–778. [Google Scholar] [CrossRef]
- Choi, P.; Nam, K. Asymmetric and leptokurtic distribution for heteroscedastic asset returns: The SU-normal distribution. J. Empir. Financ. 2008, 15, 41–63. [Google Scholar] [CrossRef]
- Jorion, P. Value at Risk: The New Benchmark for Managing Financial Risk; McGraw-Hill: New York, NY, USA, 2007; pp. 139–157. [Google Scholar]
- Lopez, J.A. Methods for evaluating value-at-risk estimates. Econ. Rev. 1999, 2, 3–17. [Google Scholar] [CrossRef]
- Sarma, M.; Thomas, S.; Shah, A. Selection of value-at-risk models. J. Forecast. 2003, 22, 337–358. [Google Scholar] [CrossRef]
- Caporin, M. Evaluating value-at-risk measures in the presence of long memory conditional volatility. J. Risk 2008, 10, 79–110. [Google Scholar] [CrossRef]
- Hoga, Y.; Demetrescu, M. Monitoring value-at-risk and expected shortfall forecasts. Manag. Sci. 2022. [Google Scholar] [CrossRef]
- Zhu, D.; Galbraith, J.W. A generalized asymmetric Student-t distribution with application to financial econometrics. J. Econom. 2010, 157, 297–305. [Google Scholar] [CrossRef]
- Del Brio, E.; Mora-Valencia, A.; Perote, J. Risk quantification for commodity ETFs: Backtesting value-at-risk and expected shortfall. Int. Rev. Financ. Anal. 2020, 70, 101163. [Google Scholar] [CrossRef]
- León, Á.; Ñíguez, T.M. Polynomial adjusted Student-t densities for modeling asset returns. Eur. Financ. 2022, 28, 907–929. [Google Scholar] [CrossRef]
- Bagnato, L.; Potì, V.; Zoia, M.G. The role of orthogonal polynomials in adjusting hyperbolic secant and logistic distributions to analyse financial asset returns. Stat. Pap. 2015, 56, 1205–1234. [Google Scholar] [CrossRef]
- Meng, X.; Taylor, J.W. Estimating value-at-risk and expected shortfall using the intraday low and range data. Eur. J. Oper. Res. 2020, 280, 191–202. [Google Scholar] [CrossRef]



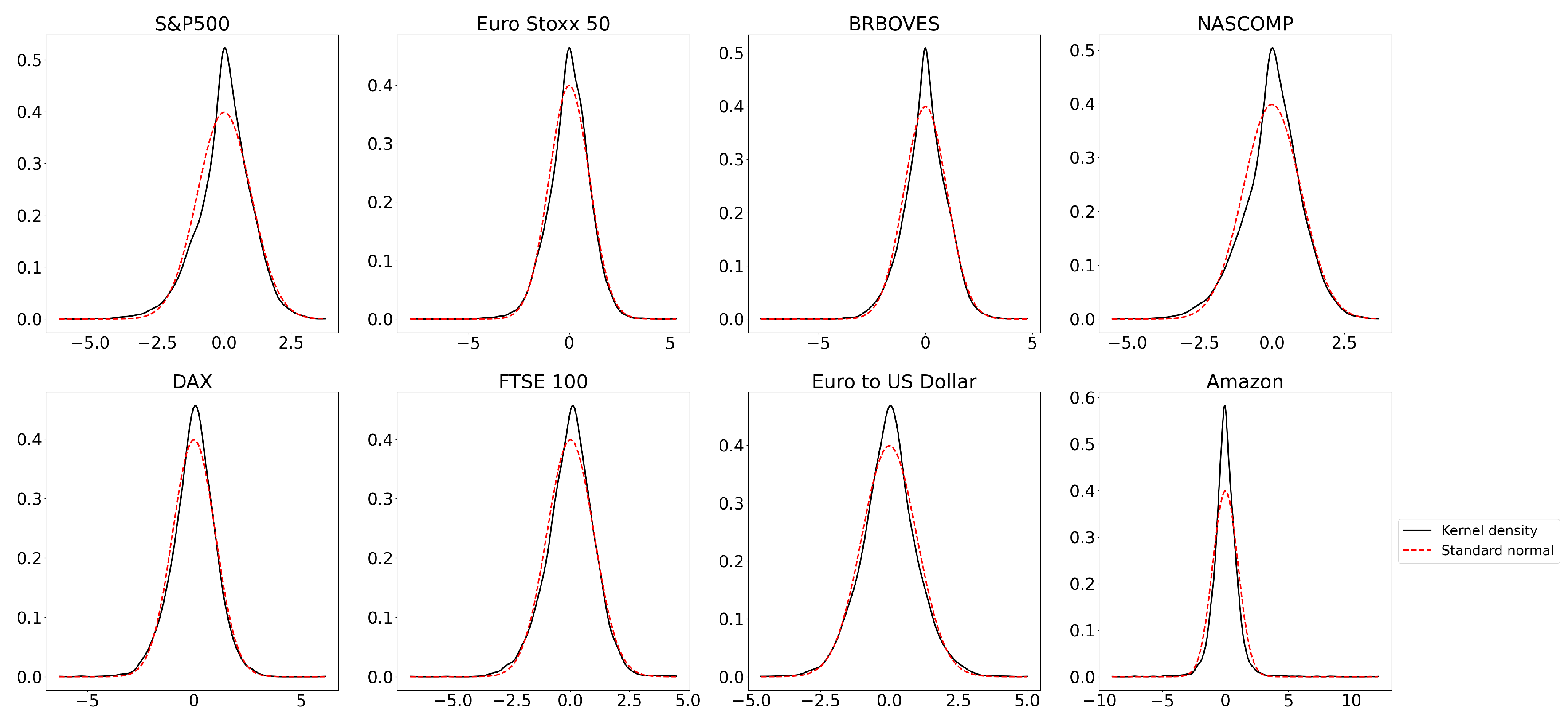{kind=link}
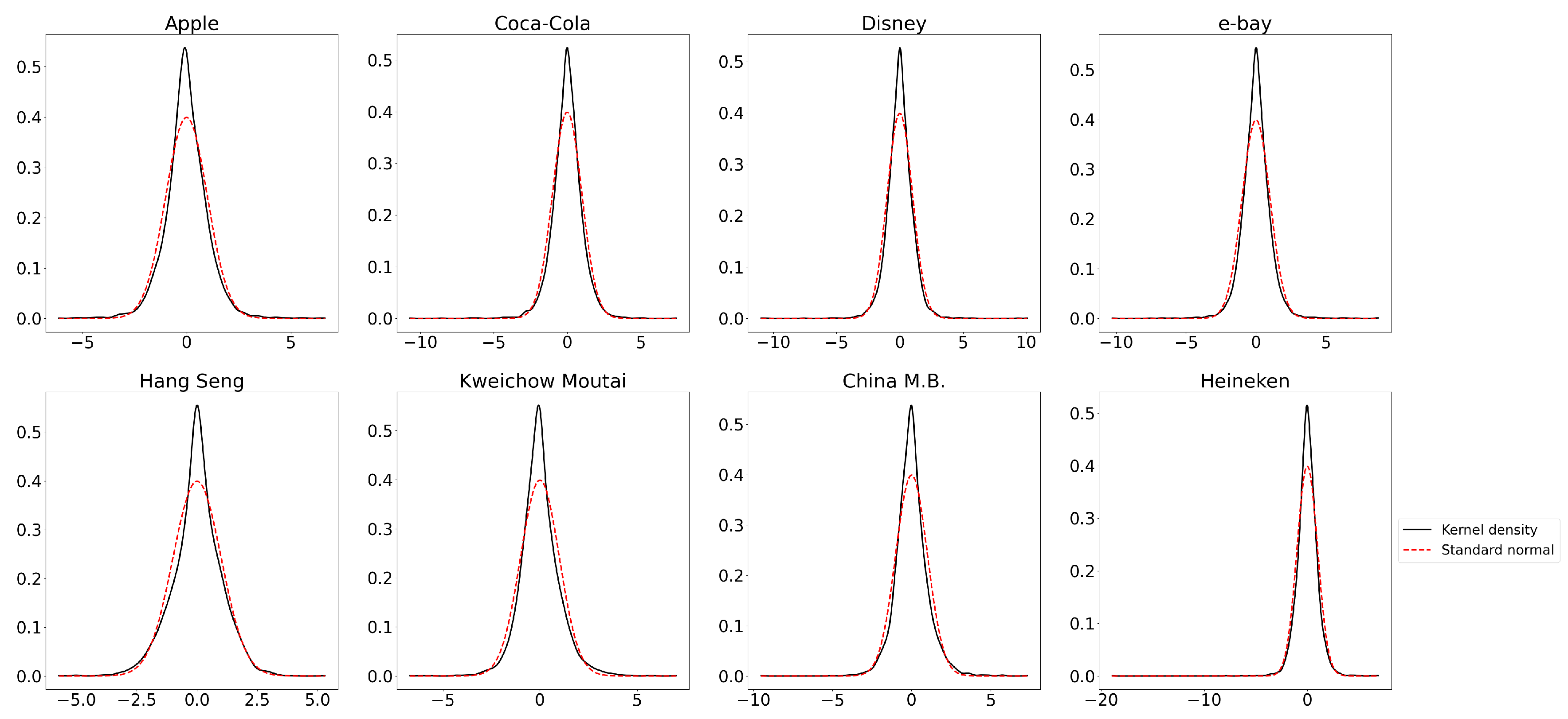{kind=link}
| Series | Mean | Std.Dev. | Max | Min | Skew. | Kurt. | Period | T |
|---|---|---|---|---|---|---|---|---|
| S&P500 | 0.02 | 1.16 | 10.96 | −9.47 | −0.23 | 9.48 | 11/10/2000–10/12/2019 | 5000 |
| Euro Stoxx 50 | −0.01 | 1.42 | 10.44 | −9.01 | −0.05 | 5.24 | 11/10/2000–10/12/2019 | 5000 |
| BRBOVES | 0.04 | 1.69 | 13.68 | −12.10 | −0.12 | 4.62 | 11/10/2000–10/12/2019 | 5000 |
| NASCOMP | 0.02 | 1.46 | 13.25 | −9.59 | 0.08 | 6.83 | 11/10/2000–10/12/2019 | 5000 |
| Hang Seng | 0.01 | 1.39 | 13.40 | −13.59 | −0.04 | 9.21 | 11/10/2000–10/12/2019 | 5000 |
| DAX | 0.02 | 1.56 | 12.37 | −9.60 | −0.11 | 5.39 | 11/10/2000–10/12/2019 | 5000 |
| FTSE100 | 0.00 | 1.33 | 12.22 | −11.51 | −0.25 | 9.95 | 11/10/2000–10/12/2019 | 5000 |
| Euro to US $ | 0.00 | 0.59 | 3.84 | −4.62 | −0.10 | 2.78 | 11/10/2000–10/12/2019 | 5000 |
| China Merch. Bank | 0.05 | 2.15 | 9.60 | −14.27 | 0.17 | 4.07 | 10/04/2002−10/12/2019 | 4353 |
| Kweichow Moutai | 0.12 | 2.05 | 9.56 | −15.21 | 0.34 | 3.60 | 02/01/2002−10/12/2019 | 4421 |
| Amazon.com | 0.08 | 2.28 | 29.62 | −28.46 | 0.54 | 14.83 | 11/10/2000–10/12/2019 | 5000 |
| Apple | 0.10 | 1.17 | 13.02 | −19.75 | −0.23 | 6.36 | 11/10/2000–10/12/2019 | 5000 |
| Coca−Cola | 0.01 | 1.79 | 13.00 | −10.60 | −0.14 | 11.02 | 11/10/2000–10/12/2019 | 5000 |
| Walt Disney | 0.03 | 1.79 | 14.82 | −20.29 | −0.21 | 11.00 | 11/10/2000–10/12/2019 | 5000 |
| e−bay | 0.03 | 2.50 | 26.53 | −23.04 | 0.10 | 12.74 | 11/10/2000–10/12/2019 | 5000 |
| Heineken | 0.01 | 1.44 | 9.57 | −21.53 | −0.74 | 14.39 | 29/06/2000–10/12/2019 | 5000 |
| CF | GC | Skewed-t | Johnson | Normal | |
|---|---|---|---|---|---|
| 0.0240 (0.0049) | 0.0239 (0.0064) | 0.0245 (0.0044) | 0.0239 (0.0086) | 0.0245 (0.0127) | |
| 0.7575 (0.0433) | 0.7548 (0.0444) | 0.7541 (0.0296) | 0.7577 (0.0473) | 0.7574 (0.1120) | |
| 0.0432 (0.0031) | 0.0427 (0.0031) | 0.0443 (0.0074) | 0.0432 (0.0031) | 0.0421 (0.0413) | |
| c | 2.0919 (0.2144) | 2.1235 (0.2214) | 2.0882 (0.2612) | 2.0926 (0.2588) | 2.1294 (1.1149) |
| −0.0184 (0.0248) | −0.0175 (0.0421) | −0.0244 (0.0219) | −0.0182 (0.0790) | −0.0234 (0.0350) | |
| −0.2613 (0.0593) | 0.3873 (0.1484) | 0.5695 (0.0158) | 1.6762 (3.2153) | ||
| 0.3093 (0.1664) | 0.1628 (0.0438) | 25.7810 (14.2877) | 4.2613 (4.0214) | ||
| Sample skewness of | −0.2933 | −0.2933 | −0.2941 | −0.2933 | −0.2923 |
| Estimated skewness based on | −0.2754 | −0.2423 | −0.2548 | −0.2776 | |
| Sample kurtosis of | 3.4112 | 3.4108 | 3.4152 | 3.4114 | 3.4070 |
| Estimated kurtosis based on | 3.3374 | 3.3301 | 3.3275 | 3.3434 |
| Coverage Level | Coverage Level | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CF | GC | Skewed-t | Johnson | Normal | CF | GC | Skewed-t | Johnson | Normal | |
| S&P500 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| Euro Stoxx 50 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| BRBOVES | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| NASCOMP | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| Hang Seng | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| DAX | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| FTSE100 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 |
| Euro to US $ | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| China Merch. Bank | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| Kweichow Moutai | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| Amazon.com | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| Apple | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| Coca-Cola | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 |
| Walt Disney | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| e-bay | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| Heineken | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 |
| Coverage Level | Coverage Level | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CF | GC | Skewed-t | Johnson | Normal | CF | GC | Skewed-t | Johnson | Normal | |
| S&P500 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 |
| Euro Stoxx 50 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 |
| BRBOVES | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| NASCOMP | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 |
| Hang Seng | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 |
| DAX | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 |
| FTSE100 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 |
| Euro to US $ | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| China Merch. Bank | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| Kweichow Moutai | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 |
| Amazon.com | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| Apple | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Coca-Cola | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| Walt Disney | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| e-bay | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Heineken | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 |
| VaR | VaR | |||||
|---|---|---|---|---|---|---|
| S&P500 | GC | Skewed-t | GC | Skewed-t | ||
| Euro Stoxx 50 | CF | Skewed-t | CF | Johnson | ||
| BRBOVES | CF | Johnson | CF | Johnson | ||
| NASCOMP | GC | Skewed-t | GC | Johnson | ||
| Hang Seng | GC | Johnson | CF | Johnson | ||
| DAX | CF | Johnson | CF | Johnson | ||
| FTSE100 | CF | Skewed-t | CF | Johnson | ||
| Euro to US $ | GC | Skewed-t | CF | Skewed-t | ||
| China Merch. Bank | GC | Johnson | CF | Johnson | ||
| Kweichow Moutai | CF | Johnson | CF | Johnson | ||
| Amazon.com | CF | — ** | — | CF | Johnson | |
| Apple | CF | Johnson | CF | Johnson | ||
| Coca-Cola | CF | — ** | — | — ** | Johnson | — |
| Walt Disney | CF | Johnson | CF | Johnson | ||
| e-bay | GC | Johnson | CF | Johnson | ||
| Heineken | CF | Johnson | CF | Johnson | ||
| ES | ES | |||||
|---|---|---|---|---|---|---|
| S&P500 | GC | Skewed-t | CF | Skewed-t | ||
| Euro Stoxx 50 | CF | Johnson | CF | Johnson | ||
| BRBOVES | CF | Johnson | CF | Johnson | ||
| NASCOMP | CF | Johnson | CF | Johnson | ||
| Hang Seng | CF | Johnson | CF | Johnson | ||
| DAX | CF | Johnson | CF | Johnson | ||
| FTSE100 | CF | Johnson | CF | Johnson | ||
| Euro to US $ | CF | Johnson | CF | Skewed-t | ||
| China Merch. Bank | CF | Skewed-t | GC | Skewed-t | ||
| Kweichow Moutai | CF | Skewed-t | CF | Skewed-t | ||
| Amazon.com | CF | Johnson | CF | Skewed-t | ||
| Apple | CF | Johnson | CF | Johnson | ||
| Coca-Cola | CF | Johnson | CF | Skewed-t | ||
| Walt Disney | CF | Johnson | GC | Johnson | ||
| e-bay | CF | Johnson | CF | Johnson | ||
| Heineken | CF | Skewed-t | CF | Skewed-t | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Castillo-Brais, B.; León, Á.; Mora, J. Estimating Value-at-Risk and Expected Shortfall: Do Polynomial Expansions Outperform Parametric Densities? Mathematics 2022, 10, 4329. https://doi.org/10.3390/math10224329
Castillo-Brais B, León Á, Mora J. Estimating Value-at-Risk and Expected Shortfall: Do Polynomial Expansions Outperform Parametric Densities? Mathematics. 2022; 10(22):4329. https://doi.org/10.3390/math10224329
Chicago/Turabian StyleCastillo-Brais, Brenda, Ángel León, and Juan Mora. 2022. "Estimating Value-at-Risk and Expected Shortfall: Do Polynomial Expansions Outperform Parametric Densities?" Mathematics 10, no. 22: 4329. https://doi.org/10.3390/math10224329
APA StyleCastillo-Brais, B., León, Á., & Mora, J. (2022). Estimating Value-at-Risk and Expected Shortfall: Do Polynomial Expansions Outperform Parametric Densities? Mathematics, 10(22), 4329. https://doi.org/10.3390/math10224329