

An Evolving Fuzzy Neural Network Based on Or-Type Logic Neurons for Identifying and Extracting Knowledge in Auction Fraud †

 ,
,  ,
,  and
and
Abstract
1. Introduction
2. Literature Review
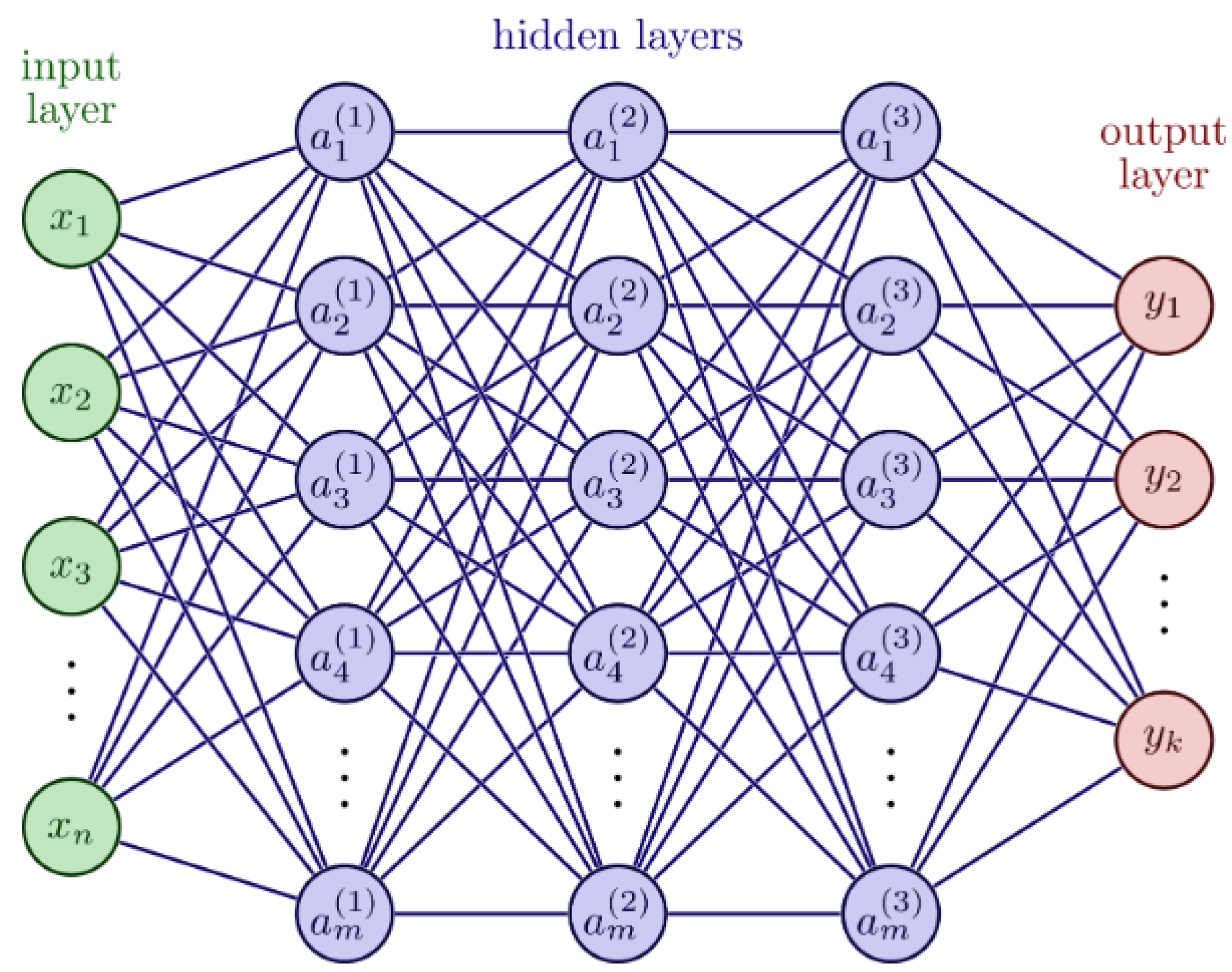
2.1. Artificial Neural Network and Applications
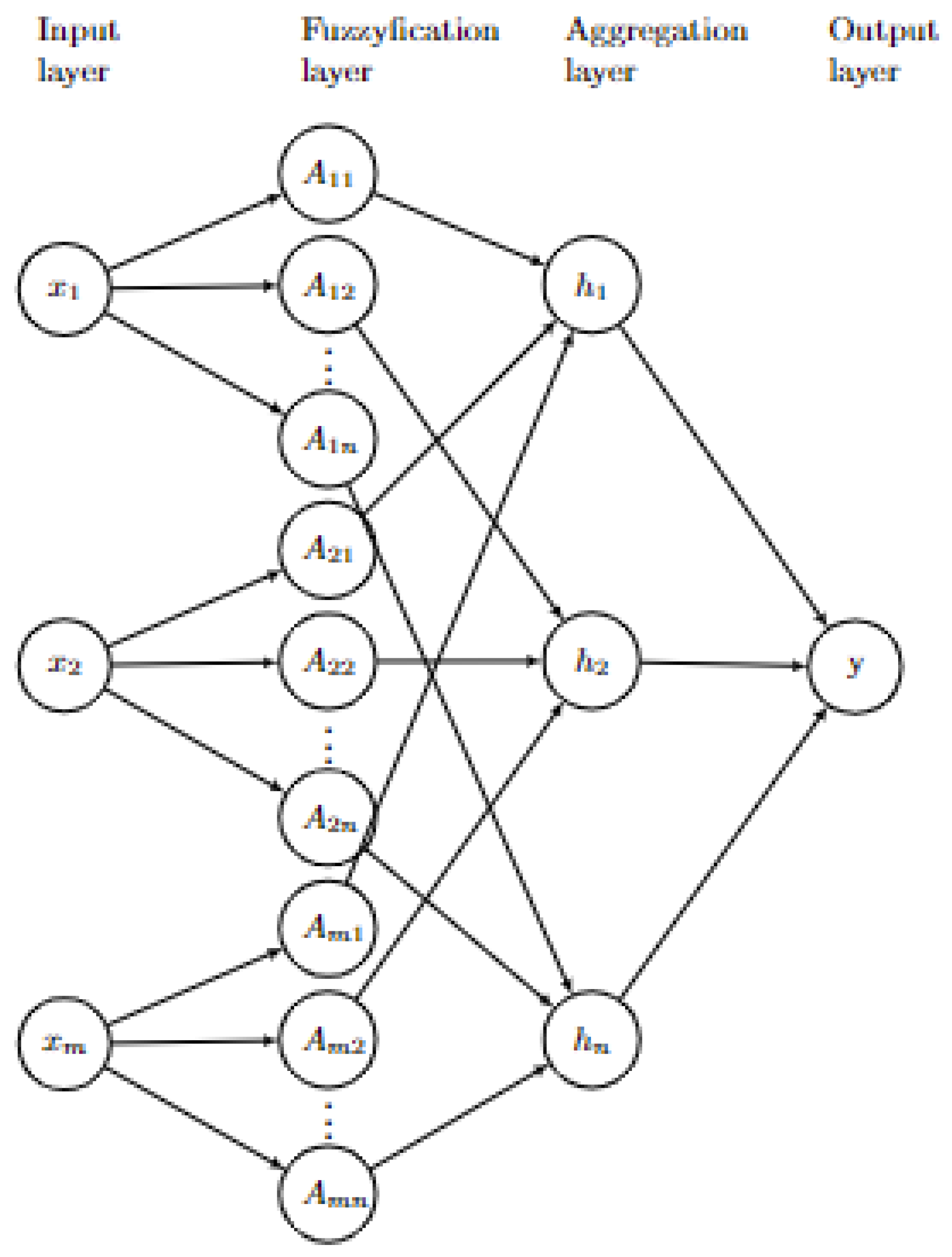
2.2. Fuzzy Neural Network
2.3. Fuzzy Natural Logic
2.4. Auction Fraud
- Advertising illegal (stolen) or black market goods;
- Fraud that happens during the bidding period, such as Shill Bidding;
- Post-auction fraud, such as the exaggerated collection of fees, insurance, and even the nondelivery of the purchased goods.
2.5. Evolving Fuzzy Systems and Interpretability
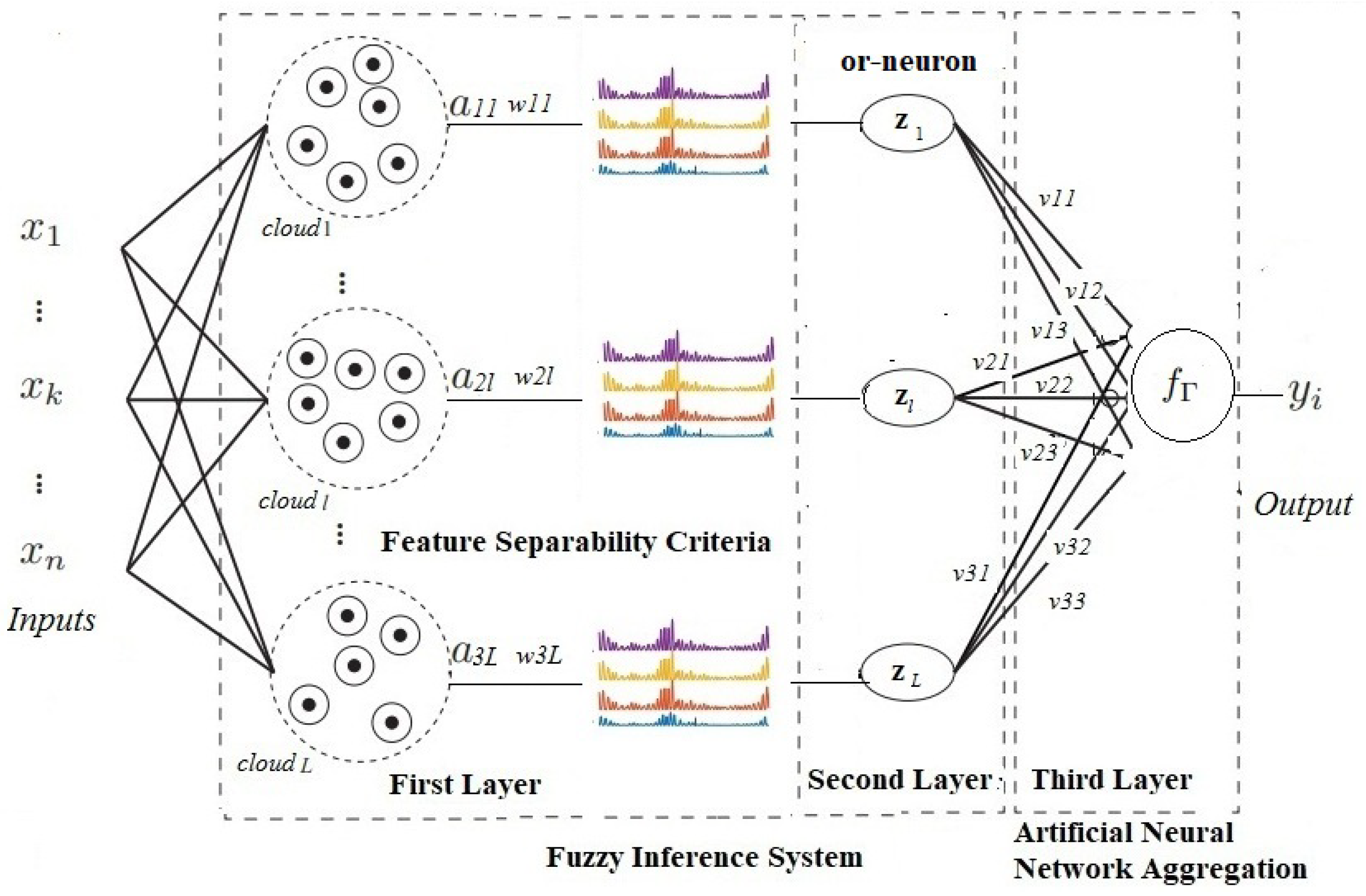
3. Evolving Fuzzy Neural Network Based on Self-Organizing Direction-Aware Data Partitioning (SODA) Approach and Or-Neurons-eFNN-SODA
3.1. First Layer
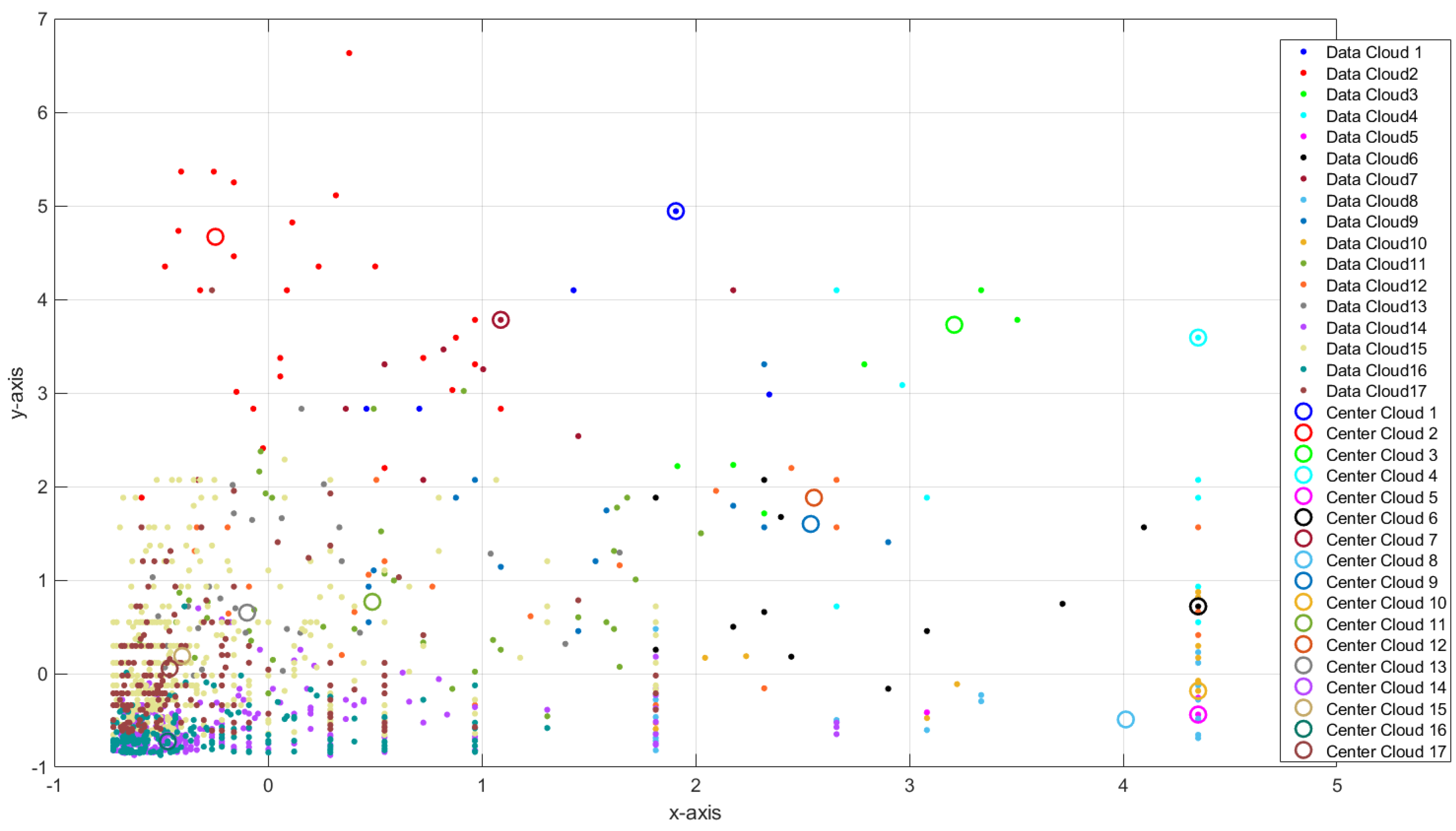
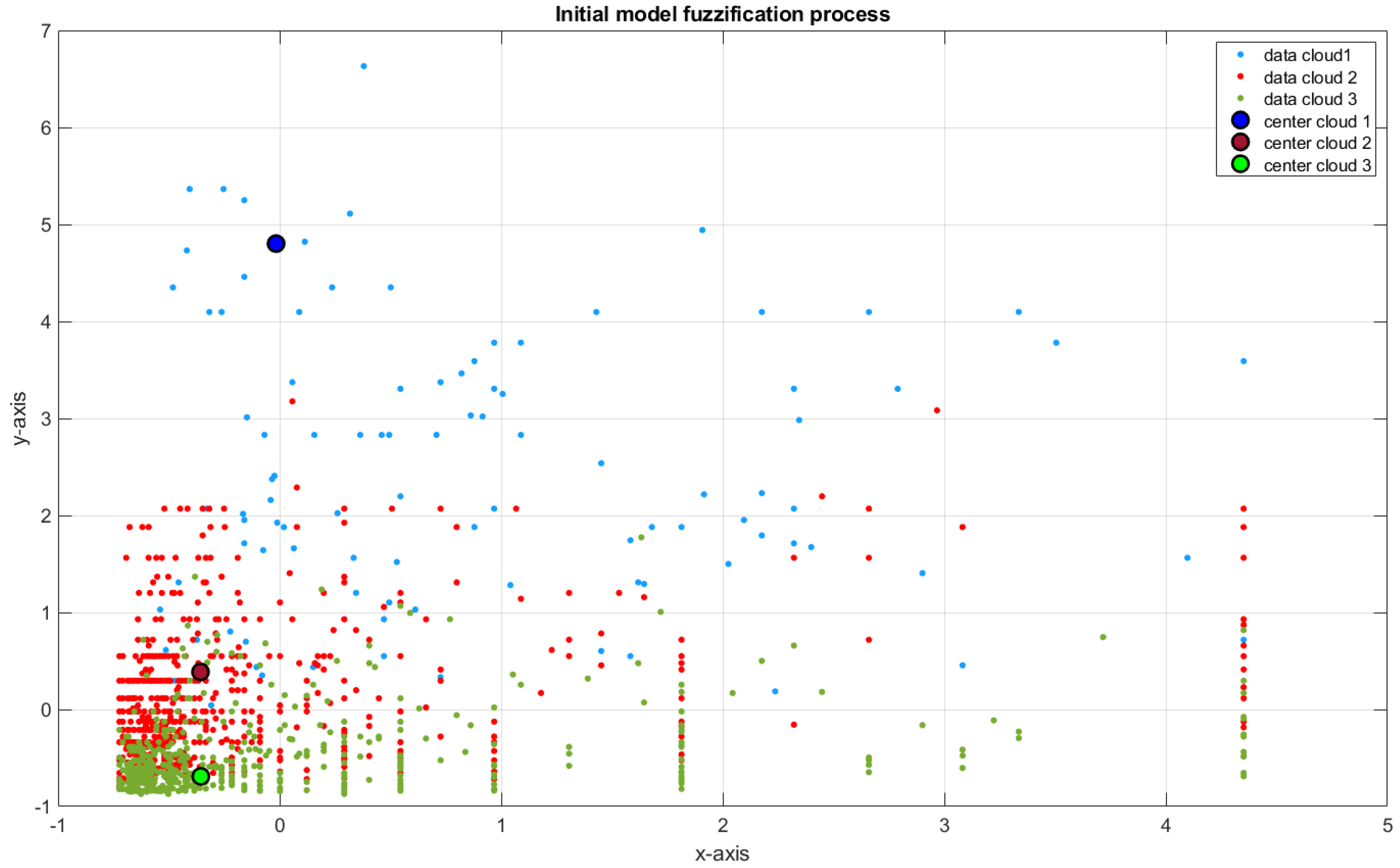
3.1.1. Self-Organizing Direction-Aware Data Partitioning
- -
- x = { } : Input variables (where the index k indicates the time instance at which the data point arrives).
- -
- un = {, , ..., } : Set of unique data point locations.
- -
- : Number of times that different data points occupy the same unique locations.
- -
- : The number of data samples belonging to the c-th class.
- -
- : The number of unique data samples belonging to the c-th class.
- -
- and .
3.1.2. Incremental Feature Weights Learning
3.2. Second Layer
3.3. Third Layer
3.4. Training
| Algorithm 1 eFNN-SODA Training and Update Algorithm |
| Initial Batch Learning Phase (Input: data matrix X): |
| (1) Define granularity of the cloud, . |
| (2) Extract L clouds in the first layer using the SODA approach (based on ). |
| (3) Construct L fuzzy neurons with Gaussian membership functions with and values derived from SODA. |
| (4) Calculate the combination (feature) weights for neuron construction using Equation (34). |
| (5) Construct L logic neurons on the second layer of the network by welding the L fuzzy neurons of the first layer, using or-neurons (Equation (37)) and the centers and widths . |
| (6) |
| for do |
| (6.1) Calculate the regression vector . |
| (6.2) Store it as one row entry into the activation level matrix z. |
| end for |
| (7) Extract activation level matrix z according to the L neurons. |
| (8) Estimate the weights of the output layer for all classes by Equation (42) using z and indicator vectors . |
| Update Phase (Input: single data sample ): |
| (11) Update L clouds and evolving new ones on demand (based on Stages 5, 6, and 7 of the SODA approach). |
| (12) Update the feature weights by updating the within- and between-class scatter matrix and recalculating Equation (34). |
| (13) Perform Steps (3) and (5). |
| (14) Calculate the interpretability criteria (Section 3.5). |
| (15) Calculate the regression vector . |
| (16) Update the output layer weights by Equation (45). |
- SODA algorithm: The complexity of (p is the dimensionality of the input space when updating with a single sample).
- Or-neurons: Complexity (constructing them from m clouds).
- Weights in the first-layer Gaussian neurons: Complexity (where K is the number of classes). That happens because the between- and within-class scatter matrices need to be updated for each class for each feature separately and independently, having a complexity of (matrices have a size of ).
- Neuron activation in the third-layer model: The complexity of (in each sample, the activation levels to all m neurons (with dimensionality p) require to be estimated).
- Output-layer neuron: The complexity of (because of the weighted method in each rule individually, demanding this complexity [55].)
3.5. Interpretability Criteria
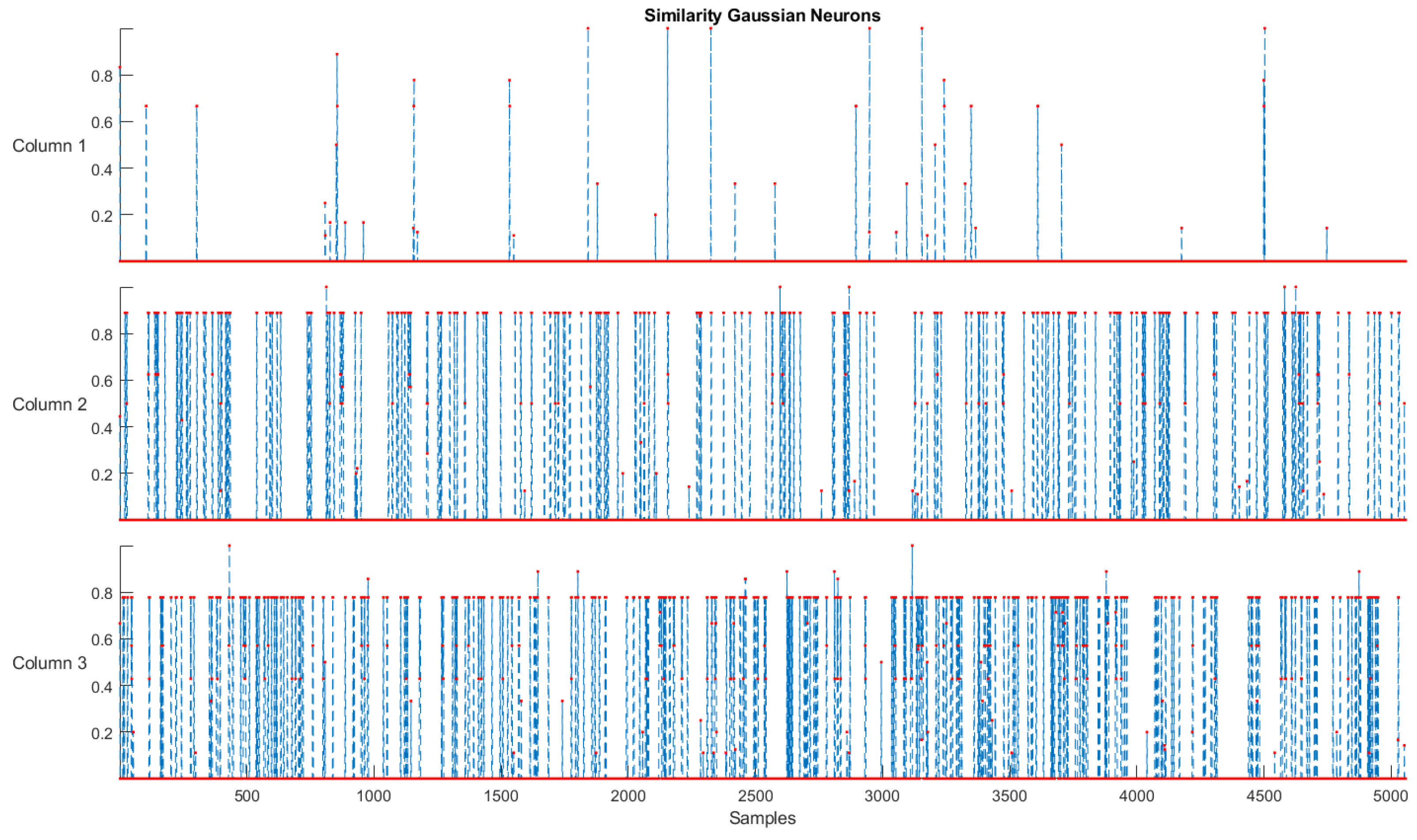
- Simplicity and Distinguishability: These two criteria verify whether the proposed model is the simplest and has its structures distinguishable during training. This means that the evaluation revolves around low complexity and high accuracy. Regarding the simplicity of the eFNN-SODA, the model is expected to have a more compact structure and a high degree of assertiveness. The criterion defined for the identification of model simplicity (in the comparison between models) can be expressed by:where and are, respectively, the number of fuzzy rules of the and .Regarding distinguishability, it is expected to assess whether there is an overlapping in the structures formed in the fuzzification process. The SODA approach uses an assessment of overlapping in the evolution process in its sixth stage, thus ensuring that this situation does not occur. For the evaluation of the distinguishability criterion, eFNN-SODA uses the comparison of similarity between the Gaussian neurons formed in the first layer (termed as and ) dimension-wise, and similarity () degree can be used for calculating an amalgamated value. The degree of change (⋉) is then presented by [11]:and , assuming that n new samples have passed the data-stream-based transformation phase with N samples operated so far for model training and adaptation [11].Therefore, it is feasible to conclude that two rules are only identical if all their antecedent parts are equivalent. The x coordinates of the points of intersection of two Gaussians used as fuzzy sets in the identical antecedent part of the Gaussian rule i (here for the jth) before and after its update can be estimated by [56]:with being the jth center coordinate and standard deviation of the Gaussian neuron before its update, and the jth center coordinate and standard deviation of the Gaussian neuron after its update [11].The maximal membership degree of the two Gaussian membership functions in the intersection coordinates is then used as overlap. Consequently, the similarity degree of the corresponding rules’ antecedent parts in the jth dimension is [11]:with being the membership degree of the jth fuzzy set in Rule i in the intersection point . The amalgamation of overall rule antecedent parts leads to the final similarity degree between the rule before and after its update:where T denotes a t-norm operator, and p is the number of inputs, as a robust nonoverlap along one single dimension is sufficient for the clouds to not overlap at all [56].
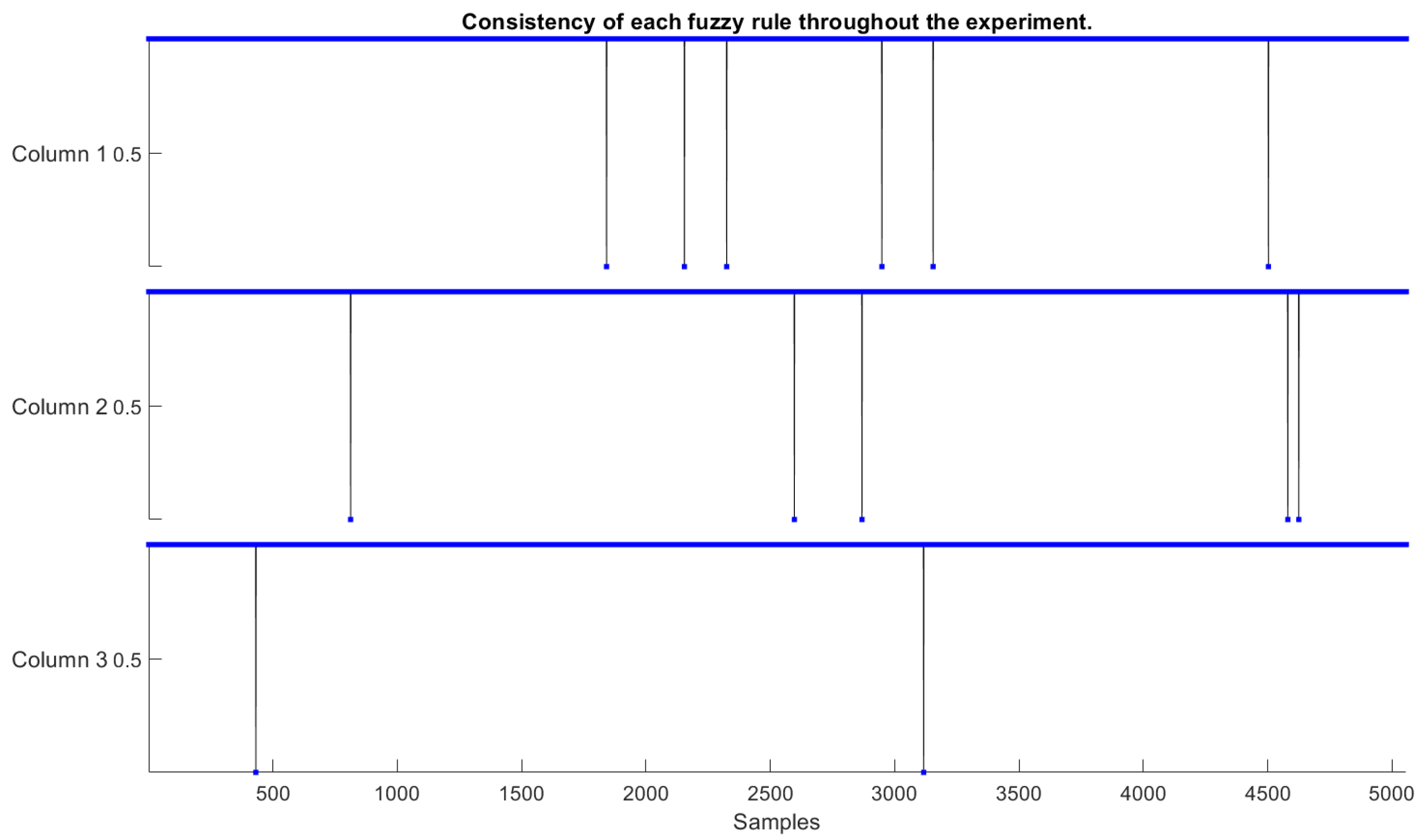
- Consistency, Coverage, and Completeness: The concept of consistency in evolving fuzzy systems is attending when their fuzzy rule-set does not deliver a high noise level or an inconsistently learned output behavior. Therefore, a set of fuzzy rules is considered inconsistent when two or more rules overlap in the antecedents, but not in the consequents. In this paper, the consistency of fuzzy rules (comparing a rule before and after its evolution) can be measured by evaluating the similarity involved in its rule antecedents ( and consequents (). In this case, they can be expressed by [37]:where and are close to 1 invariably can be assumed to indicate a heightened similarity, and when they are close to 0, a low similarity [37]. thr is a threshold value usually set at 0.8 or 0.9.
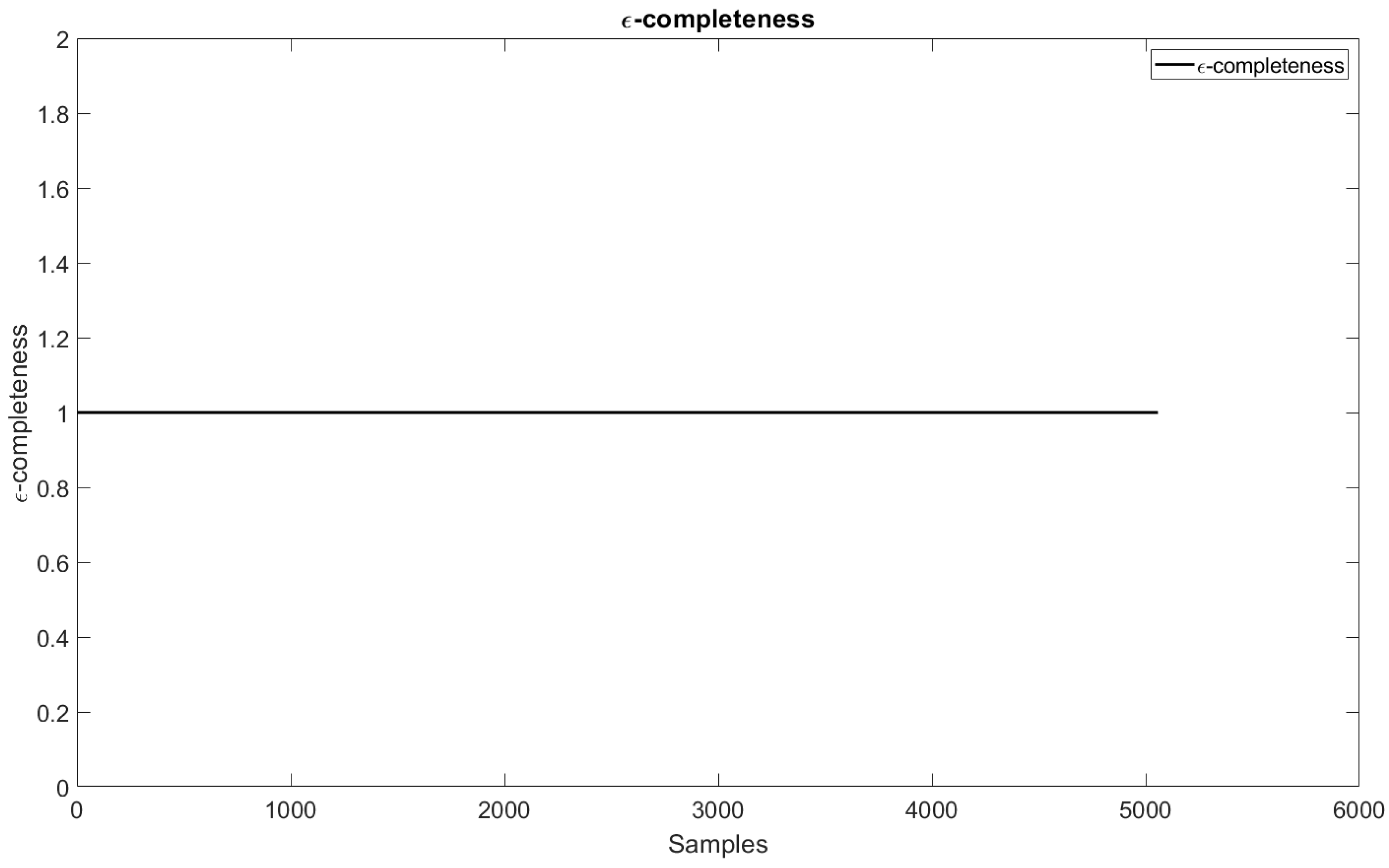
- The coverage criterion identifies whether there are holes in the resource space by generating undefined input states. This criterion can be solved by applying Gaussian functions, which have unlimited support. In this case, eFNN-SODA guarantees this criterion using this type of function throughout the model’s training [37].Finally, the -completeness criterion in the eFNN-SODA is defined by [37]:where is the membership degree of a fuzzy set appearing in the jth antecedent part of the ith rule, rl is the rule length, and = 0.135 according to definitions made in other research, which is considered an evaluation standard for this criterion [37].
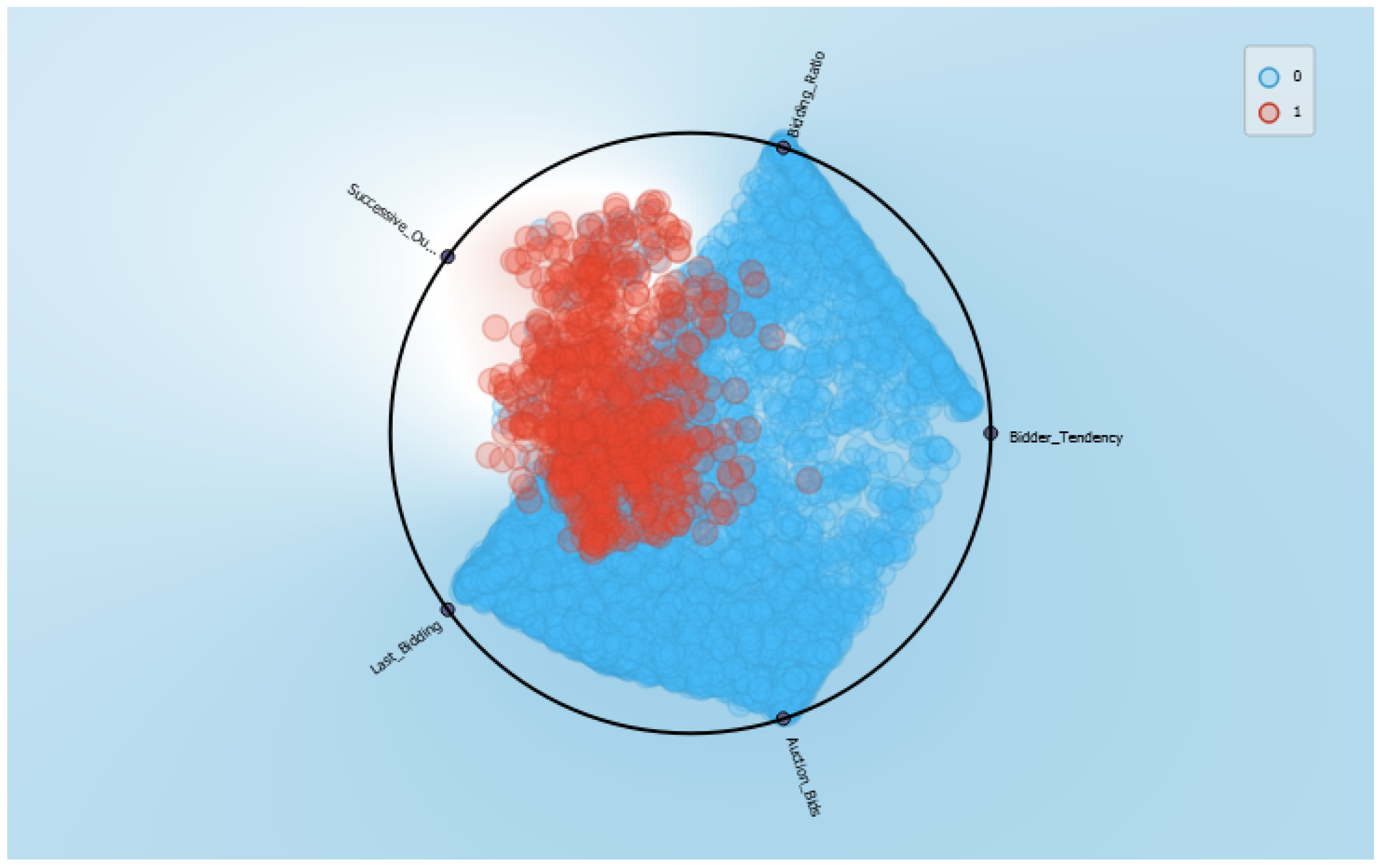
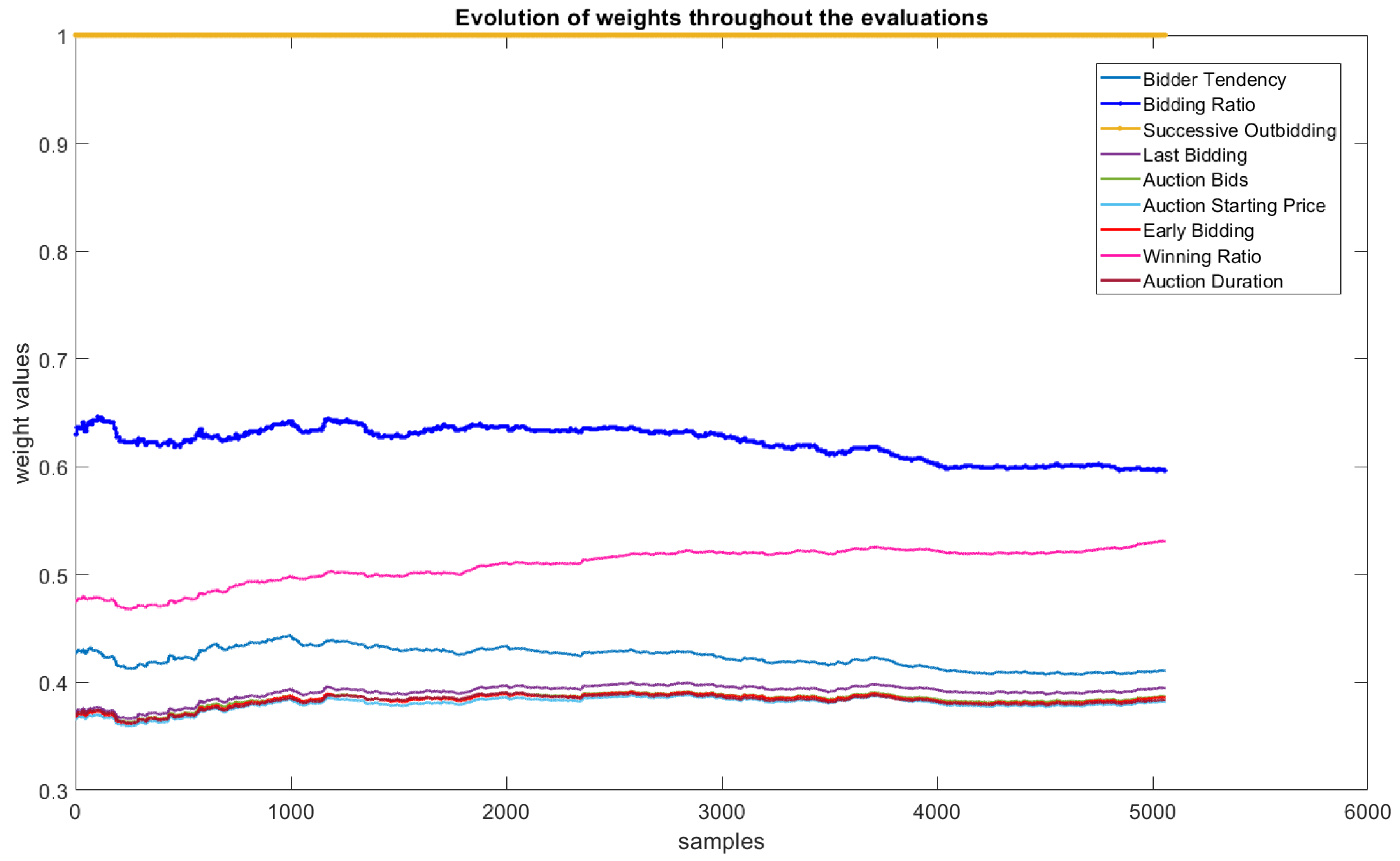
- Antecedent Interpretation: The evaluation of rule antecedents is also a fundamental part of interpreting and validating the results. In the case of eFNN-SODA, this evaluation is performed with the behavior of the evolution of the weights and the evaluation of the similarity of the Gaussian neurons formed in the first layer.
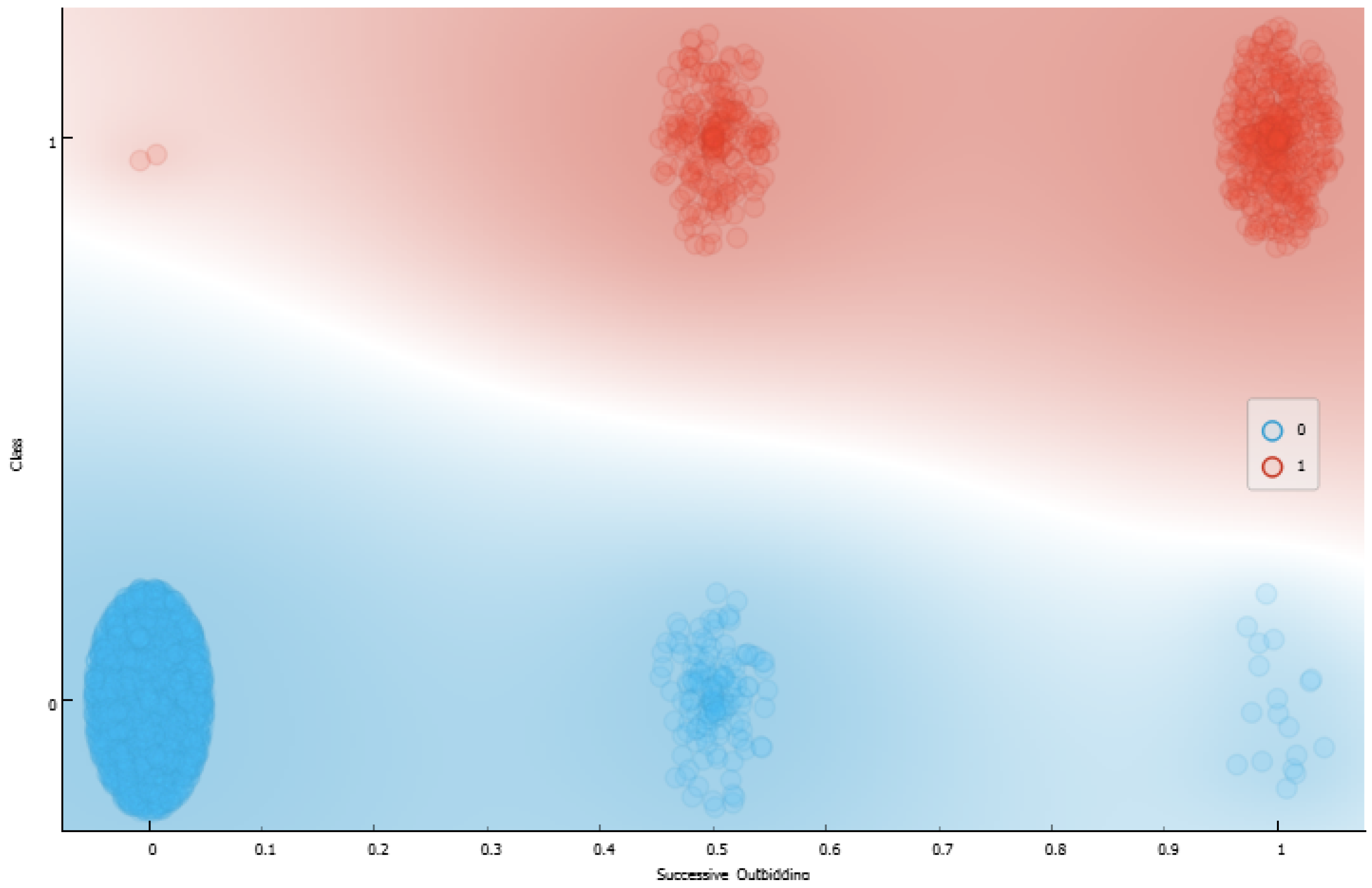
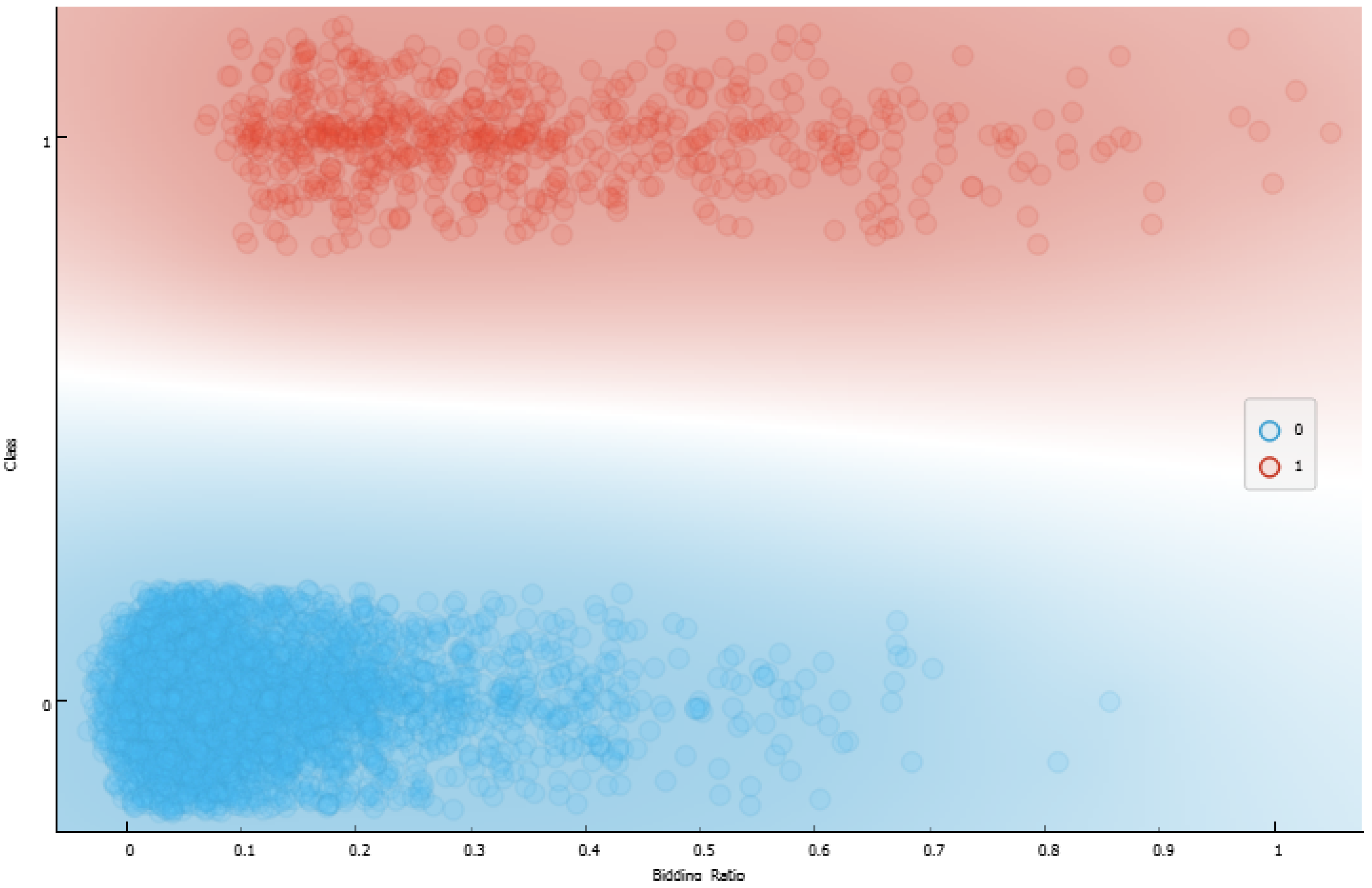
- Consequent Interpretation: The evaluation of rule consequents in eFNN-SODA is performed by graphically evaluating changes in the class to which the rule is connected. This is because the values of can change as the model evaluates new samples, and the consequent of the respective rule can be changed.
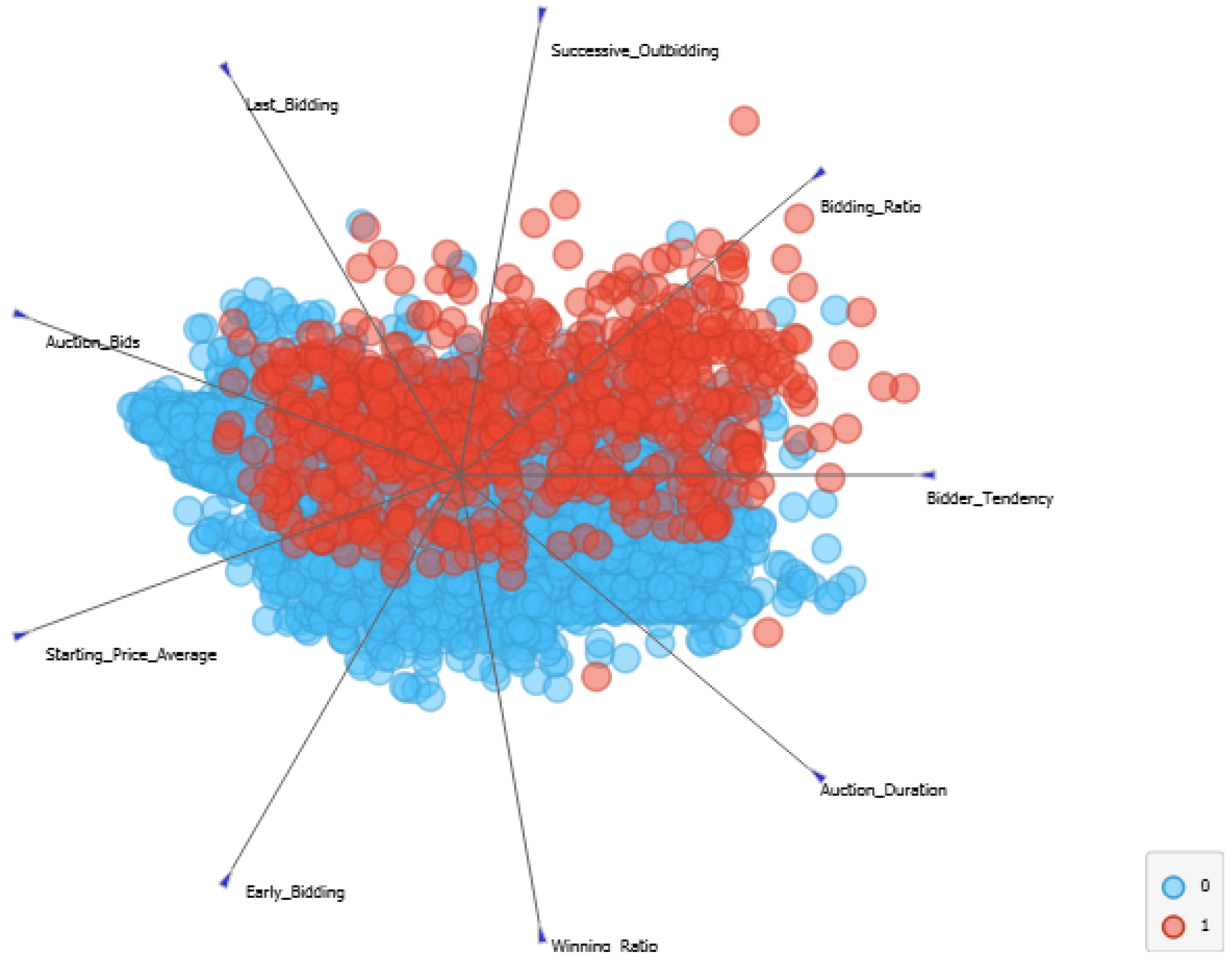
- Feature Importance Level: The evaluation of the features of the problem is also a fundamental part of understanding the model’s behavior. Graphical analyses of the variations generated by the weights in Equation (34) are obtained, allowing us to identify the behavior of the features throughout the experiment.
- Knowledge Expansion: The expansion of knowledge takes place by evaluating the evolution of fuzzy rules throughout the experiment. The SODA approach acts on the evolution and reduction in irrelevant rules. The eFNN-SODA model can also appreciate this behavior throughout the experiment.
4. Auction Fraud Testing
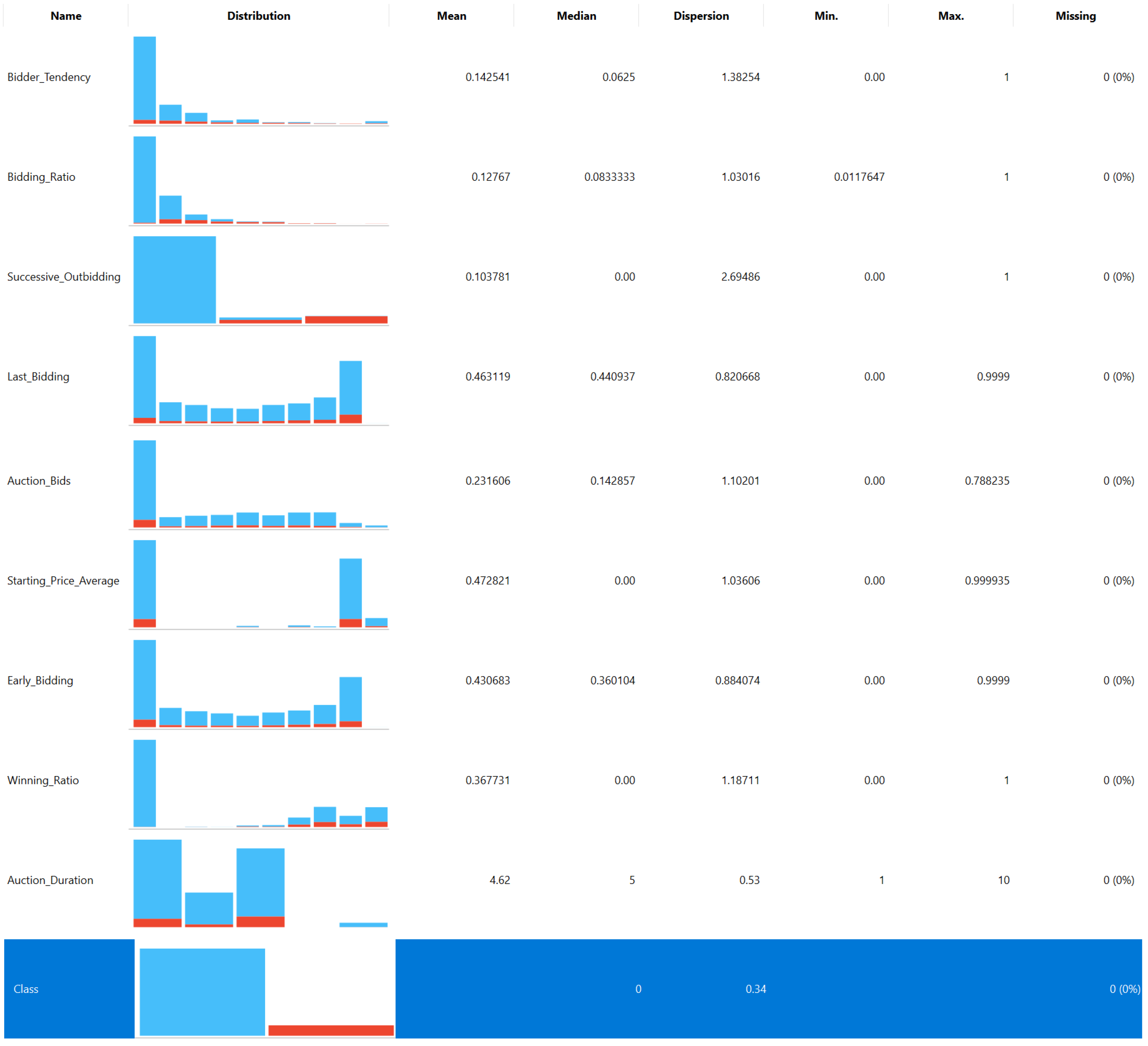
4.1. Data Set Features
4.2. Models and Hyperparameters
4.3. Evaluation Criteria of Experiments
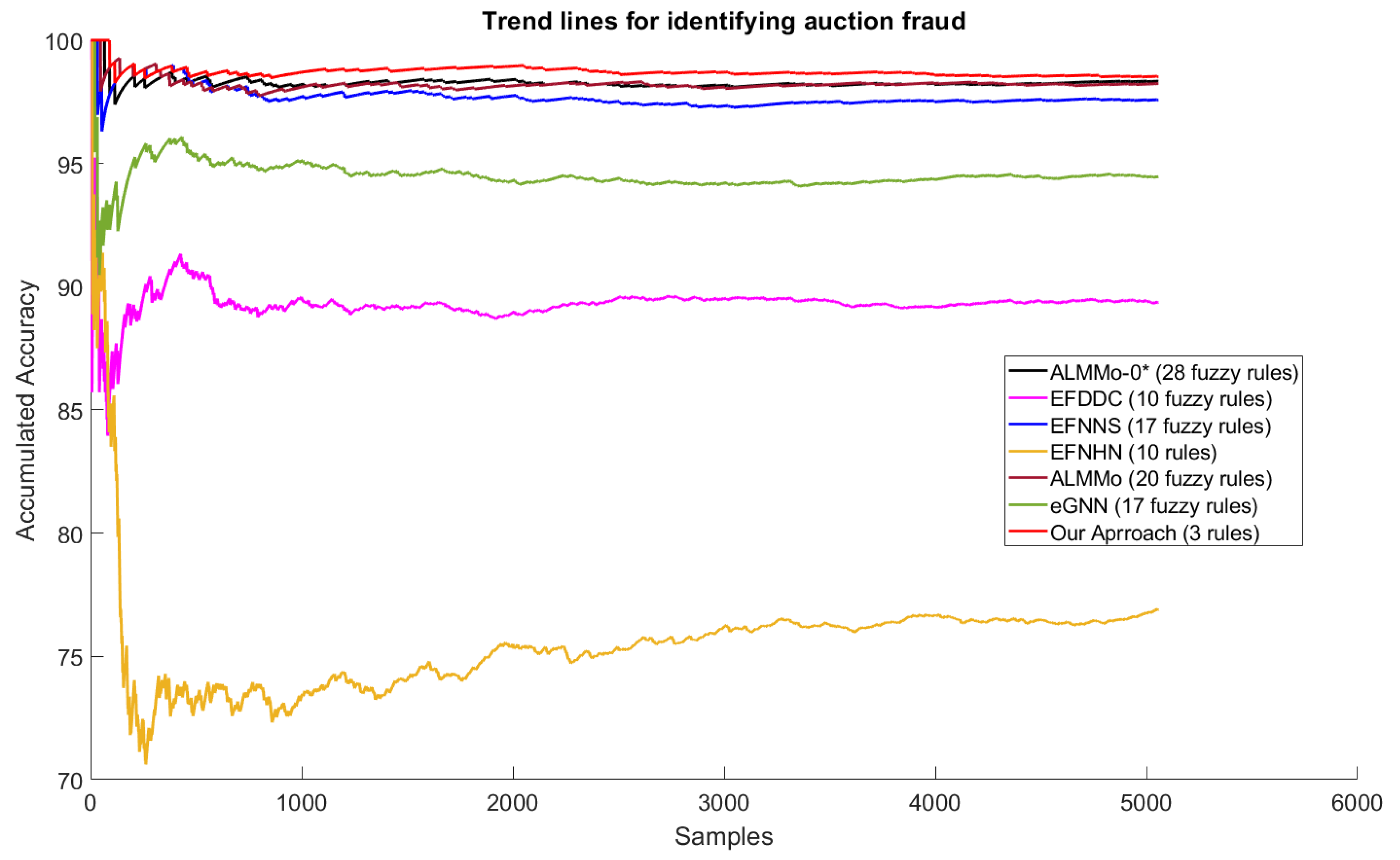
4.4. Results
5. Discussions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mitchell, R.; Michalski, J.; Carbonell, T. An Artificial Intelligence Approach; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Chua, C.E.H.; Wareham, J. Fighting internet auction fraud: An assessment and proposal. Computer 2004, 37, 31–37. [Google Scholar] [CrossRef]
- Button, M.; Nicholls, C.M.; Kerr, J.; Owen, R. Online frauds: Learning from victims why they fall for these scams. Aust. N. Z. J. Criminol. 2014, 47, 391–408. [Google Scholar] [CrossRef]
- Alzahrani, A.; Sadaoui, S. Scraping and preprocessing commercial auction data for fraud classification. arXiv 2018, arXiv:1806.00656. [Google Scholar]
- Alzahrani, A.; Sadaoui, S. Clustering and labeling auction fraud data. In Data Management, Analytics and Innovation; Springer: Berlin/Heidelberg, Germany, 2020; pp. 269–283. [Google Scholar]
- Buckley, J.; Hayashi, Y. Fuzzy neural networks: A survey. Fuzzy Sets Syst. 1994, 66, 1–13. [Google Scholar] [CrossRef]
- De Campos Souza, P.V. Fuzzy neural networks and neuro-fuzzy networks: A review the main techniques and applications used in the literature. Appl. Soft Comput. 2020, 92, 106275. [Google Scholar] [CrossRef]
- Novák, V. Fuzzy natural logic: Towards mathematical logic of human reasoning. In Towards the Future of Fuzzy Logic; Springer: Berlin/Heidelberg, Germany, 2015; pp. 137–165. [Google Scholar]
- Gu, X.; Angelov, P.; Kangin, D.; Principe, J. Self-Organised direction aware data partitioning algorithm. Inf. Sci. 2018, 423, 80–95. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- De Campos Souza, P.V.; Lughofer, E. An evolving neuro-fuzzy system based on uni-nullneurons with advanced interpretability capabilities. Neurocomputing 2021, 451, 231–251. [Google Scholar] [CrossRef]
- De Campos Souza, P.V.; Lughofer, E.; Guimaraes, A.J. Evolving Fuzzy Neural Network Based on Uni-nullneuron to Identify Auction Fraud. In Proceedings of the Joint Proceedings of the 19th World Congress of the International Fuzzy Systems Association (IFSA), the 12th Conference of the European Society for Fuzzy Logic and Technology (EUSFLAT), and the 11th International Summer School on Aggregation Operators (AGOP), Bratislava, Slovakia, 19–24 September 2021; pp. 314–321. [Google Scholar] [CrossRef]
- Haykin, S.S.; Haykin. Neural Networks and Learning Machines; Pearson Education Upper Saddle River: Hoboken, NJ, USA, 2009; Volume 3. [Google Scholar]
- Fausett, L.V. Fundamentals of Neural Networks: Architectures, Algorithms, and Applications; Prentice-Hall Englewood Cliffs: Hoboken, NJ, USA, 1994; Volume 3. [Google Scholar]
- Zhang, Z. Artificial neural network. In Multivariate Time Series Analysis in Climate and Environmental Research; Springer: Berlin/Heidelberg, Germany, 2018; pp. 1–35. [Google Scholar]
- Rumelhart, D.E.; Durbin, R.; Golden, R.; Chauvin, Y. Backpropagation: The basic theory. Backpropagation Theory Archit. Appl. 1995, 1–34. [Google Scholar]
- Pedrycz, W. Neurocomputations in relational systems. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 289–297. [Google Scholar] [CrossRef]
- Mithra, K.; Sam Emmanuel, W. GFNN: Gaussian-Fuzzy-Neural network for diagnosis of tuberculosis using sputum smear microscopic images. J. King Saud Univ.-Comput. Inf. Sci. 2021, 33, 1084–1095. [Google Scholar] [CrossRef]
- Hu, Q.; Gois, F.N.B.; Costa, R.; Zhang, L.; Yin, L.; Magaia, N.; de Albuquerque, V.H.C. Explainable artificial intelligence-based edge fuzzy images for COVID-19 detection and identification. Appl. Soft Comput. 2022, 123, 108966. [Google Scholar] [CrossRef]
- Salimi-Badr, A.; Ebadzadeh, M.M. A novel learning algorithm based on computing the rules’ desired outputs of a TSK fuzzy neural network with non-separable fuzzy rules. Neurocomputing 2022, 470, 139–153. [Google Scholar] [CrossRef]
- Nasiri, H.; Ebadzadeh, M.M. MFRFNN: Multi-Functional Recurrent Fuzzy Neural Network for Chaotic Time Series Prediction. Neurocomputing 2022, 507, 292–310. [Google Scholar] [CrossRef]
- Pan, Q.; Li, X.; Fei, J. Adaptive Fuzzy Neural Network Harmonic Control with a Super-Twisting Sliding Mode Approach. Mathematics 2022, 10, 1063. [Google Scholar] [CrossRef]
- Amirkhani, A.; Shirzadeh, M.; Molaie, M. An Indirect Type-2 Fuzzy Neural Network Optimized by the Grasshopper Algorithm for Vehicle ABS Controller. IEEE Access 2022, 10, 58736–58751. [Google Scholar] [CrossRef]
- Algehyne, E.A.; Jibril, M.L.; Algehainy, N.A.; Alamri, O.A.; Alzahrani, A.K. Fuzzy Neural Network Expert System with an Improved Gini Index Random Forest-Based Feature Importance Measure Algorithm for Early Diagnosis of Breast Cancer in Saudi Arabia. Big Data Cogn. Comput. 2022, 6, 13. [Google Scholar] [CrossRef]
- Novák, V.; Perfilieva, I.; Dvorak, A. Insight into Fuzzy Modeling; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Murinová, P.; Novák, V. The theory of intermediate quantifiers in fuzzy natural logic revisited and the model of “Many”. Fuzzy Sets Syst. 2020, 388, 56–89. [Google Scholar] [CrossRef]
- Novák, V.; Perfilieva, I. Forecasting direction of trend of a group of analogous time series using F-transform and fuzzy natural logic. Int. J. Comput. Intell. Syst. 2015, 8, 15–28. [Google Scholar] [CrossRef][Green Version]
- Nguyen, L. Integrating The Probabilistic Uncertainty to Fuzzy Systems in Fuzzy Natural logic. In Proceedings of the 2020 12th International Conference on Knowledge and Systems Engineering (KSE), Can Tho City, Vietnam, 12–14 November 2020; pp. 142–146. [Google Scholar]
- Xu, X.; Ding, X.; Qin, Z.; Liu, Y. Classification Models for Medical Data with Interpretative Rules. In Proceedings of the International Conference on Neural Information Processing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 227–239. [Google Scholar]
- Nemat, R. Taking a look at different types of e-commerce. World Appl. Program. 2011, 1, 100–104. [Google Scholar]
- Trevathan, J. Getting into the mind of an “in-auction” fraud perpetrator. Comput. Sci. Rev. 2018, 27, 1–15. [Google Scholar] [CrossRef]
- Abidi, W.U.H.; Daoud, M.S.; Ihnaini, B.; Khan, M.A.; Alyas, T.; Fatima, A.; Ahmad, M. Real-Time Shill Bidding Fraud Detection Empowered With Fussed Machine Learning. IEEE Access 2021, 9, 113612–113621. [Google Scholar] [CrossRef]
- Anowar, F.; Sadaoui, S. Detection of Auction Fraud in Commercial Sites. J. Theor. Appl. Electron. Commer. Res. 2020, 15, 81–98. [Google Scholar] [CrossRef]
- Anowar, F.; Sadaoui, S.; Mouhoub, M. Auction Fraud Classification Based on Clustering and Sampling Techniques. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 366–371. [Google Scholar] [CrossRef]
- De Campos Souza, P.V.; Lughofer, E. Evolving fuzzy neural classifier that integrates uncertainty from human-expert feedback. Evol. Syst. 2022, 1–23. [Google Scholar] [CrossRef]
- Škrjanc, I.; Iglesias, J.A.; Sanchis, A.; Leite, D.; Lughofer, E.; Gomide, F. Evolving fuzzy and neuro-fuzzy approaches in clustering, regression, identification, and classification: A survey. Inf. Sci. 2019, 490, 344–368. [Google Scholar] [CrossRef]
- Lughofer, E. On-line assurance of interpretability criteria in evolving fuzzy systems—Achievements, new concepts and open issues. Inf. Sci. 2013, 251, 22–46. [Google Scholar] [CrossRef]
- De Campos Souza, P.V.; Lughofer, E. An advanced interpretable Fuzzy Neural Network model based on uni-nullneuron constructed from n-uninorms. Fuzzy Sets Syst. 2020, 426, 1–26. [Google Scholar] [CrossRef]
- Lughofer, E. On-line incremental feature weighting in evolving fuzzy classifiers. Fuzzy Sets Syst. 2011, 163, 1–23. [Google Scholar] [CrossRef]
- Angelov, P.; Gu, X.; Príncipe, J. A generalized methodology for data analysis. IEEE Trans. Cybern. 2017, 48, 2981–2993. [Google Scholar] [CrossRef]
- Angelov, P.; Gu, X.; Kangin, D. Empirical data analytics. Int. J. Intell. Syst. 2017, 32, 1261–1284. [Google Scholar] [CrossRef]
- Gu, X.; Angelov, P.P. Self-organising fuzzy logic classifier. Inf. Sci. 2018, 447, 36–51. [Google Scholar] [CrossRef]
- Gu, X.; Angelov, P.P.; Príncipe, J.C. A method for autonomous data partitioning. Inf. Sci. 2018, 460, 65–82. [Google Scholar] [CrossRef]
- Watson, D.F. Computing the n-dimensional Delaunay tessellation with application to Voronoi polytopes. Comput. J. 1981, 24, 167–172. [Google Scholar] [CrossRef]
- Angelov, P.; Yager, R. A new type of simplified fuzzy rule-based system. Int. J. Gen. Syst. 2012, 41, 163–185. [Google Scholar] [CrossRef]
- De Campos Souza, P.V.; Lughofer, E.; Rodrigues Batista, H. An Explainable Evolving Fuzzy Neural Network to Predict the k Barriers for Intrusion Detection Using a Wireless Sensor Network. Sensors 2022, 22, 5446. [Google Scholar] [CrossRef]
- Dy, J.; Brodley, C. Feature Selection for Unsupervised Learning. J. Mach. Learn. Res. 2004, 5, 845–889. [Google Scholar]
- Qin, S.; Li, W.; Yue, H. Recursive PCA for Adaptive Process Monitoring. J. Process Control 2000, 10, 471–486. [Google Scholar]
- Klement, E.P.; Mesiar, R.; Pap, E. Triangular Norms; Springer Science & Business Media: Berlin, Germany, 2013; Volume 8. [Google Scholar]
- Hirota, K.; Pedrycz, W. OR/AND neuron in modeling fuzzy set connectives. IEEE Trans. Fuzzy Syst. 1994, 2, 151–161. [Google Scholar] [CrossRef]
- Pedrycz, W.; Reformat, M.; Li, K. OR/AND neurons and the development of interpretable logic models. IEEE Trans. Neural Netw. 2006, 17, 636–658. [Google Scholar] [CrossRef]
- Huang, G.B.; Chen, L.; Siew, C.K. Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Trans. Neural Netw. 2006, 17, 879–892. [Google Scholar] [CrossRef]
- Albert, A. Regression and the Moore-Penrose Pseudoinverse; Elsevier: Amsterdam, The Netherlands, 1972. [Google Scholar]
- Rosa, R.; Gomide, F.; Dovzan, D.; Skrjanc, I. Evolving neural network with extreme learning for system modeling. In Proceedings of the 2014 IEEE Conference on Evolving and Adaptive Intelligent Systems (EAIS), Linz, Austria, 2–4 June 2014; pp. 1–7. [Google Scholar]
- Lughofer, E. Evolving Fuzzy Systems—Methodologies, Advanced Concepts and Applications; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Lughofer, E.; Bouchot, J.L.; Shaker, A. On-line elimination of local redundancies in evolving fuzzy systems. Evol. Syst. 2011, 2, 165–187. [Google Scholar] [CrossRef]
- Demšar, J.; Leban, G.; Zupan, B. FreeViz—An intelligent multivariate visualization approach to explorative analysis of biomedical data. J. Biomed. Inform. 2007, 40, 661–671. [Google Scholar] [CrossRef]
- Hoffman, P.; Grinstein, G.; Marx, K.; Grosse, I.; Stanley, E. DNA visual and analytic data mining. In Proceedings of the Visualization ’97 (Cat. No. 97CB36155), Phoenix, AZ, USA, 19–24 October 1997; pp. 437–441. [Google Scholar] [CrossRef]
- de Campos Souza, P.V.; Torres, L.C.B.; Guimaraes, A.J.; Araujo, V.S.; Araujo, V.J.S.; Rezende, T.S. Data density-based clustering for regularized fuzzy neural networks based on nullneurons and robust activation function. Soft Comput. 2019, 23, 12475–12489. [Google Scholar] [CrossRef]
- Souza, P.; Ponce, H.; Lughofer, E. Evolving fuzzy neural hydrocarbon networks: A model based on organic compounds. Knowl.-Based Syst. 2020, 203, 106099. [Google Scholar] [CrossRef]
- De Campos Souza, P.V.; Rezende, T.S.; Guimaraes, A.J.; Araujo, V.S.; Batista, L.O.; da Silva, G.A.; Silva Araujo, V.J. Evolving fuzzy neural networks to aid in the construction of systems specialists in cyber attacks. J. Intell. Fuzzy Syst. 2019, 36, 6743–6763. [Google Scholar] [CrossRef]
- Soares, E.; Angelov, P.; Gu, X. Autonomous Learning Multiple-Model zero-order classifier for heart sound classification. Appl. Soft Comput. 2020, 94, 106449. [Google Scholar] [CrossRef]
- Angelov, P.; Gu, X. Autonomous learning multi-model classifier of 0-Order (ALMMo-0). In Proceedings of the 2017 Evolving and Adaptive Intelligent Systems (EAIS), Ljubljana, Slovenia, 31 May–2 June 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Leite, D.; Costa, P.; Gomide, F. Evolving granular neural network for semi-supervised data stream classification. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar] [CrossRef]
- Bifet, A.; Holmes, G.; Kirkby, R.; Pfahringer, B. MOA: Massive Online Analysis. J. Mach. Learn. Res. 2010, 11, 1601–1604. [Google Scholar]
- Ducange, P.; Marcelloni, F.; Pecori, R. Fuzzy Hoeffding Decision Tree for Data Stream Classification. Int. J. Comput. Intell. Syst. 2021, 14, 946–964. [Google Scholar] [CrossRef]
- Alonso, J.M.; Bugarín, A. ExpliClas: Automatic Generation of Explanations in Natural Language for Weka Classifiers. In Proceedings of the 2019 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Hyderabad, India, 7–10 July 2019; pp. 1–6. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
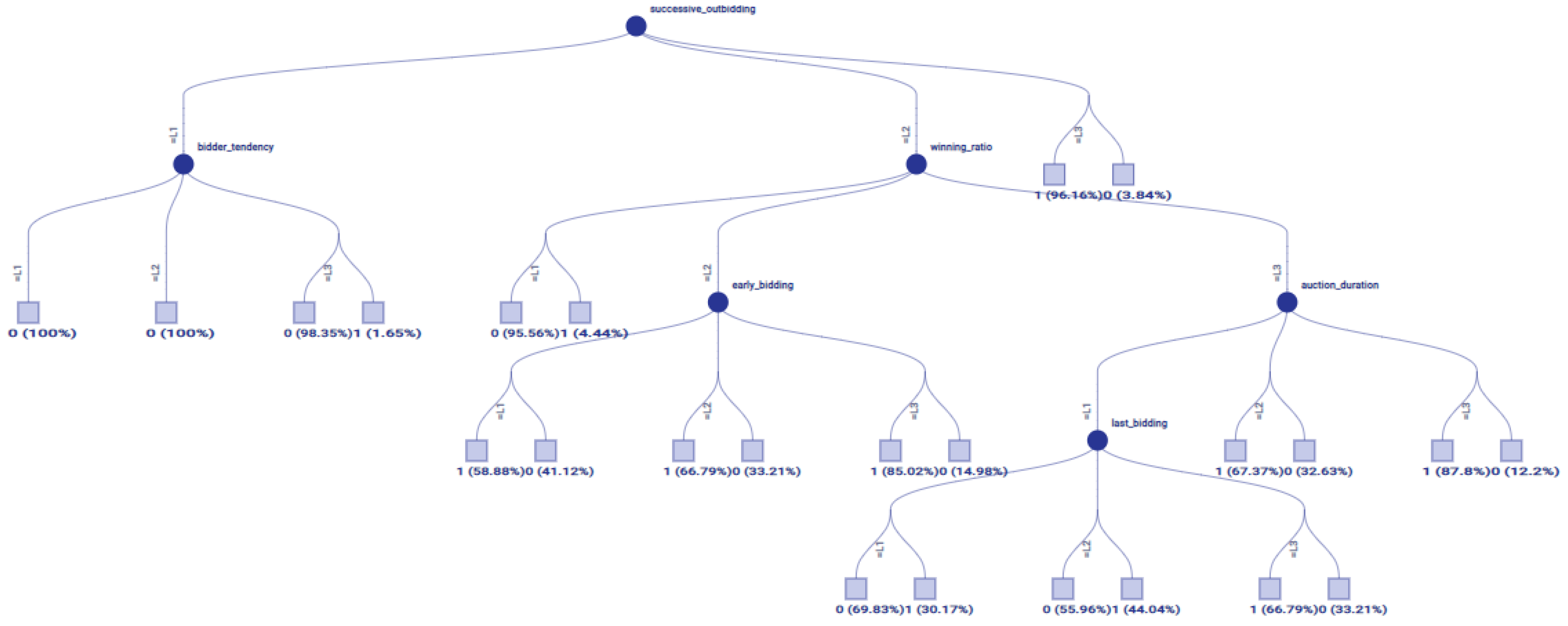
| Rule 1 changed with two membership functions, and this impacts changes in the consequent rule by a degree of 45%. |
| Rule 2 did not change. |
| Rule 3 changed with two membership functions, and this impacts changes in the consequent rule by a degree of 0.0003%. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Campos Souza, P.V.; Lughofer, E.; Batista, H.R.; Guimaraes, A.J. An Evolving Fuzzy Neural Network Based on Or-Type Logic Neurons for Identifying and Extracting Knowledge in Auction Fraud. Mathematics 2022, 10, 3872. https://doi.org/10.3390/math10203872
de Campos Souza PV, Lughofer E, Batista HR, Guimaraes AJ. An Evolving Fuzzy Neural Network Based on Or-Type Logic Neurons for Identifying and Extracting Knowledge in Auction Fraud. Mathematics. 2022; 10(20):3872. https://doi.org/10.3390/math10203872
Chicago/Turabian Stylede Campos Souza, Paulo Vitor, Edwin Lughofer, Huoston Rodrigues Batista, and Augusto Junio Guimaraes. 2022. "An Evolving Fuzzy Neural Network Based on Or-Type Logic Neurons for Identifying and Extracting Knowledge in Auction Fraud" Mathematics 10, no. 20: 3872. https://doi.org/10.3390/math10203872
APA Stylede Campos Souza, P. V., Lughofer, E., Batista, H. R., & Guimaraes, A. J. (2022). An Evolving Fuzzy Neural Network Based on Or-Type Logic Neurons for Identifying and Extracting Knowledge in Auction Fraud. Mathematics, 10(20), 3872. https://doi.org/10.3390/math10203872