1. Introduction
As the globe was shaken by the outbreak of COVID-19 in 2020, reports of the arrival of monkeypox in 2022 show yet another global virus [
1]. This virus is closely linked to cowpox and smallpox. Monkeys and rodents are the primary vectors of transmission, although human-to-human transmission is also widespread [
2]. In 1958, a laboratory in Copenhagen, Denmark, discovered the virus for the first time in a monkey [
3]. In 1970, amid an increased attempt to eliminate smallpox [
4,
5], the first human case of monkeypox was documented in the Democratic Republic of the Congo. It is common knowledge that many people who live in close proximity to tropical rainforests in Central and West Africa fall victim to the highly contagious monkeypox virus. Physical contact with an infected human, animal, or object is sufficient for the virus to spread. Transmission occurs by saliva, nasal secretions, or respiratory droplets [
5]. It can also be spread via animal bites. Patients infected with monkeypox experience a range of short-term symptoms, including fever, pains, weariness, and red bumps on the skin in the long run [
6,
7].
Despite the fact that the reported instances of monkeypox are on the rise, the disease is not nearly as infectious as COVID-19 has been. In 1990, only fifty people in West and Central Africa contracted monkeypox [
8]. However, by 2020, there were 5000 reported instances. Although it was previously believed that monkeypox exclusively occurred in Africa, numerous non-African nations, including Europe and the United States, reported identifying monkeypox infections in people in 2022. As a result, widespread panic and worry are rising; many individuals are airing their concerns on online platforms. According to CDC recommendations, no effective therapy exists for the monkeypox virus at the present time. Two oral medications, Brincidofovir and Tecovirimat, which were previously only used to treat the smallpox virus, have been licensed for treatment against the monkeypox virus by the Centers for Disease Control and Prevention [
9]. Nonetheless, the monkeypox virus may be effectively combated by immunization. Despite the availability of FDA-approved vaccinations against the monkeypox virus, none have been administered to humans in the United States. Treatment for monkeypox in other countries typically involves the use of smallpox vaccinations [
10]. Monkeypox is diagnosed using a combination of the patient’s medical history and the peculiarities of the skin lesions themselves. However, electron microscopy testing of skin lesions is the gold standard for confirming a viral infection. Moreover, the monkeypox virus can be validated by polymerase chain reaction (PCR) [
11], a technique that is already being widely employed in the diagnosis of COVID-19 patients [
12,
13,
14,
15].
Machine learning (ML) is a burgeoning field of AI that has shown great promise in a variety of settings, from decision-making assistance and industrial applications to medical imaging and illness detection. Medical professionals have found that the safe, accurate, and quick imaging solutions made possible by ML are invaluable resources for making informed decisions. For the purpose of breast cancer diagnosis, for instance, CAD systems based on fuzzy logic were created by the authors of [
16]. When compared to traditional ML, fuzzy logic is superior, since it can speed up computational tasks while mimicking the logic and approach of a trained radiologist. The cancer detection algorithm delivers a result based on the user’s selected method if they input information such as contour, density, and shape [
17]. The authors of [
18] used a small dataset of 108 patients with COVID-19 and 86 non-COVID-19 patients to assess ten different deep learning models and achieved 99.1% accuracy. Using 453 CT scan images, the authors of [
19] built a modified Inception-based model and improved its accuracy to 73.1%. Psoriasis, melanoma, lupus, and chickenpox are only a few of the skin illnesses that may be detected with the use of the low-complexity convolutional neural network (CNN) suggested by the authors of [
20]. They demonstrated that skin illness can be detected 71% of the time utilizing image analysis with an already-existing VGGNet. The proposed approach showed the best performance, with accuracy of about 78%. Using MobileNet and smartphones, the authors of [
21] developed a method for diagnosing skin diseases. They reported an accuracy of 94.4% when identifying individuals with chickenpox symptoms.
At the time of writing, few studies have been uncovered that show promise for the use of ML methods in the diagnosis of monkeypox using image processing. The lack of a framework developed for image-based diagnosis of monkeypox was due to the lack of a publicly available dataset for training and testing purposes, as the virus has just recently been substantially introduced in many countries.
In light of these opportunities, a significant conclusion was reached: that it is necessary to develop a new approach for robustly diagnosing monkeypox images and fill this gap. To fill it, this paper proposes two new algorithms for improving the selection of the best set of features and improving a classifier’s performance. These two algorithms are based on the Al-Biruni Earth radius (BER) algorithm, the sine cosine algorithm (SCA), and particle swarm optimization (PSO). The feature selection is based on a new hybrid of SCA and BER, whereas the optimization of the classifier’s parameters was based on a new hybrid of PSO and BER. To prove the effectiveness of the proposed algorithms, a set of experiments were conducted, and the results are compared to those of other competing feature selection and parameter optimization algorithms. Statistical tests were conducted to show the stability of the proposed algorithms, and the results confirmed the target outcome.
The remainder of the paper follows this outline: The literature review is presented in
Section 2, followed by the materials and methods employed in this paper in
Section 3. The proposed optimization algorithms are discussed in
Section 4. Then, the experiment results and their findings are described in
Section 5. Finally, the suggestions for future research are summarized and discussed in
Section 6.
2. Literature Review
Medical diagnoses and treatments are two areas where ML and deep learning have shown to be invaluable. Researchers have built a variety of models and systems that use ML and deep learning to make illness predictions. There is currently no reliable diagnostic test for Alzheimer’s disease. Diagnosis should involve the patient’s medical background, the results of cognitive and laboratory testing, and maybe an electroencephalogram (EEG). Consequently, innovative approaches are needed to guarantee earlier and more accurate diagnoses and to track treatment success. The authors of [
22] used a machine learning approach called support vector machine (SVM) to search EEG epochs for traits that might identify Alzheimer’s disease patients from controls. To automatically identify AD patients from healthy controls, a processing approach based on quantitative EEG (qEEG) was developed. Accuracy was good in the research because it accounted for how each patient was diagnosed.
Heart disease is one of the top five main causes of death worldwide today. The forecasting of cardiovascular illness is a major challenge in the field of clinical data analysis. Machine learning has shown itself to be capable of extracting useful information from the mountains of data produced by the healthcare industry. Several studies have merely scratched the surface of how machine learning may be used to forecast heart illness. The authors of [
23] suggested a novel method to enhance the accuracy of cardiovascular disease prediction by locating crucial features using machine learning methods. A number of different feature combinations and well-established classification algorithms were tested in the prediction model [
24,
25].
Diagnosis of Parkinson’s disease (PD) is often made after careful medical observation and study of clinical indicators. In many cases, a wide variety of motor symptoms must be defined in order to complete this examination. Traditional diagnostic procedures, however, rely on the subjective assessment of movements that might be difficult to detect. Machine learning also facilitates the integration of data from many modalities, such as MRI and SPECT, for PD diagnosis [
26]. Applying machine learning algorithms may help us find relevant qualities that are underutilized in the clinical diagnosis of PD and which might be relied on to diagnose PD in preclinical stages or atypical forms.
In the clinic, fatty liver disease is common and is associated with an increased risk of mortality (FLD). Early prediction of FLD patients offers the opportunity to create a workable plan for prevention, early diagnosis, and therapy. To aid in the detection of at-risk individuals, diagnosis itself, and the prevention and management of FLD, the authors of [
27] developed a machine-learning model to predict the onset and progression of the disease. A variety of classification models, such as logistic regression (LR), random forest (RF), Naive Bayes (NB), and an artificial neural network (ANN), were developed for FLD prediction. The receiver operating characteristic curve area was used to evaluate the efficacy of the four models (ROC). The authors of [
27] developed and studied four classification algorithms that reliably identify fatty liver disease. However, when compared to other classification strategies, the random forest model fared the best. Primary prevention, monitoring, early treatment, and care of patients with fatty livers might all benefit from the adoption of a random forest model in the clinical environment.
Chronic kidney disease (CKD) is a serious threat to health and well-being, and it affects an alarmingly growing number of individuals throughout the world. In its early stages, CKD typically presents no symptoms; hence, its presence is often overlooked. Medication that slows the course of CKD is most effective when given to patients soon after diagnosis. Machine-learning models can greatly assist therapists in achieving this objective because of their rapid and accurate identification capabilities. A machine-learning strategy for CKD diagnosis was proposed by the authors of [
28]. The CKD dataset, which is heavily skewed by missing values, was contributed from the machine learning repository at UCI [
29]. Patients may forget or be unable to provide some measures for several reasons. Therefore, it is common to find gaps in the data in clinical practice. In order to generate models, six machine-learning techniques were used when the missing data were added. The random forest model had the highest diagnostic accuracy (99.75%) compared to the others. After analyzing the mistakes of the preexisting models, it was proposed to use a combined model, including logistic regression and a random forest employing a perceptron, which could achieve an average accuracy of 99.83 percent after ten simulation repetitions. This led us to speculate that this approach can be used to analyze clinical data in order to diagnose more complicated diseases better.
In order to reliably identify coronary artery disease, the authors of [
30] introduced a revolutionary machine-learning technique (CAD). Ten time-tested approaches to machine learning were considered. The effectiveness of these strategies was improved by the application of data standardization and preprocessing. Particle swarm optimization, a form of genetic algorithm, was used in tandem with stratified ten-fold cross-validation to optimize feature selection and classifier parameters in concurrently. Experimental results showed that the suggested approach considerably enhanced the accuracy of the machine-learning models used in medical and scientific research.
Monkeypox has recently emerged as a significant global health concern; there are confirmed cases in 75 countries outside of Africa. Early clinical identification of monkeypox is challenging due to the virus’s similarity to chickenpox and measles. Where confirmatory polymerase chain reaction (PCR) tests are not readily available, computer-assisted detection of lesion morphology may aid in the monitoring and rapid diagnosis of individuals infected with monkeypox. Automatic skin lesion detection using deep-learning algorithms has been shown to be effective when sufficient training instances are provided. Due of monkeypox’s rarity, there was already a knowledge vacuum among medical specialists throughout the world before the current outbreak. Scientists are taking heart from the successes of supervised machine learning in the discovery of COVID-19 as they attempt to find a remedy for this perplexing issue. However, implementing machine learning to detect monkeypox from patient skin images is hampered by a lack of monkeypox skin photos.
The biggest monkeypox skin image database was given by the authors of [
31]. With the help of web scraping, now a comprehensive picture collection of both healthy and sick skin for anybody can be found and used. Images of infected skin show symptoms of measles, cowpox, chickenpox, smallpox, and monkeypox. Pictures of measles, chickenpox, and monkeypox skin lesions were compiled by the authors of [
32] to create the Monkeypox Skin Lesion Dataset (MSLD). The majority of these pictures came from publicly accessible sources, including websites, news portals, and case reports. Initial procedures involved augmenting the sample size with more data and conducting a 3-fold cross-validation trial. In the second stage, pre-trained deep learning models such as VGG-16, ResNet50, and InceptionV3 were used to classify illnesses into different categories (e.g., monkeypox). The maximum overall accuracy was reached by ResNet50. Using a modified version of VGG16, the authors of [
33] proposed a deep learning model for detecting monkeypox disease based on image data collection and implementation. It is safer to use and disseminate such data for constructing and implementing any machine-learning model because the dataset was assembled by collecting images from multiple open-source publications and websites. Two different investigations used the VGG16 model with the adjustments. The findings from both trials indicate that this model may reliably identify patients with monkeypox. More insight into the features of the monkeypox virus can be achieved due to the model’s ability to predict and extract such features.
3. Materials and Methods
The primary materials and methods employed in this work to implement the proposed approaches are detailed in this section. Achieving the greatest outcomes begins with feature engineering and continues with the iterative use of meta-heuristic optimization approaches. Therefore, the next sections start with presenting the methods used in feature engineering, followed by the utilized optimization methods.
3.1. Feature Engineering
Machine-learning approaches rely heavily on feature engineering methods. These methods involve picking and choosing features that machine-learning pipelines will need. In the literature, feature selection and feature extraction are often used interchangeably. The goal of a feature extraction procedure is to modify the raw data in order to derive new variables that can improve the performance of the machine-learning algorithm. In contrast, the goal of feature selection is to extract and identify the specific features in the dataset that are most useful for the classification tasks based on a set of criteria, such as originality, consistency, and meaningfulness. Binary values (both 0 and 1) are utilized to limit the search space in order to implement the feature selection procedure. As a result, the continuous values-based meta-heuristic optimizers will need to be updated so they can deal with the binary outputs corresponding to the selected features [
34,
35].
Feature selection is the most important part of feature engineering, since it determines which features will be used to optimize for performance. Each feature in the n-feature set can be assigned the value 1 or 0 to indicate whether or not it is part of the final solution in the feature selection job. In order to identify the best set of features, meta-heuristic algorithms often begin with a random population of vectors with random features and then conduct a sequence of exploration and exploitation. The coming sections briefly introduce the deep neural network employed for feature extraction using transfer learning. These deep networks include AlexNet, VGG, ResNet, and GoogleNet. As GoogleNet was the deep network adopted for feature extraction, it is presented in more detail in the next sections. On the other hand, the other deep networks are presented briefly, as they were used for comparison purposes.
3.1.1. AlexNet Deep Network
By achieving a top-5 test error rate of only 15.3% on a subset of the ImageNet dataset, AlexNet was declared the winner of ILSVRC-2012. Dropout was used in the model to prevent overfitting, and convolution operations were implemented using graphics processing units. AlexNet, when it was first released, was the biggest convolution neural network ever built [
36].
3.1.2. VGG Deep Network
When it came to localization and classification, the VGG models came out on top and in second place, respectively, in the 2014 ImageNet Challenge. With very deep convolutional networks (16 and 19 weight layers), the models achieved top-5 test error rates of 6.8% and 25.3% in the ILSVRS classification and localization tracks, respectively, by making efficient use of the smallest available filter sizes [
37].
3.1.3. ResNet Deep Network
The basic ResNet was developed in response to the degradation issue in deep neural networks; it was inspired by the VGG nets. In this context, “degradation” means that the network’s performance on test and training data declines as its depth grows. When it comes to identity mapping, the ResNet model takes the fast route by using a shortcut connection whose output is simply added to the stacked layer’s final result. With no need to worry about the network degrading over time, a deeper network may be created and trained. A considerably deeper ResNet, an ensemble (i.e., eight times deeper than VGG nets), led to reduced complexity, simple optimization, and an enhanced top-5 error rate in comparison to state-of-the-art models of 3.57% [
38].
3.1.4. GoogleNet Deep Network
GoogLeNet and the rest of the Inception model deep learning family are built on iterations of an Inception module [
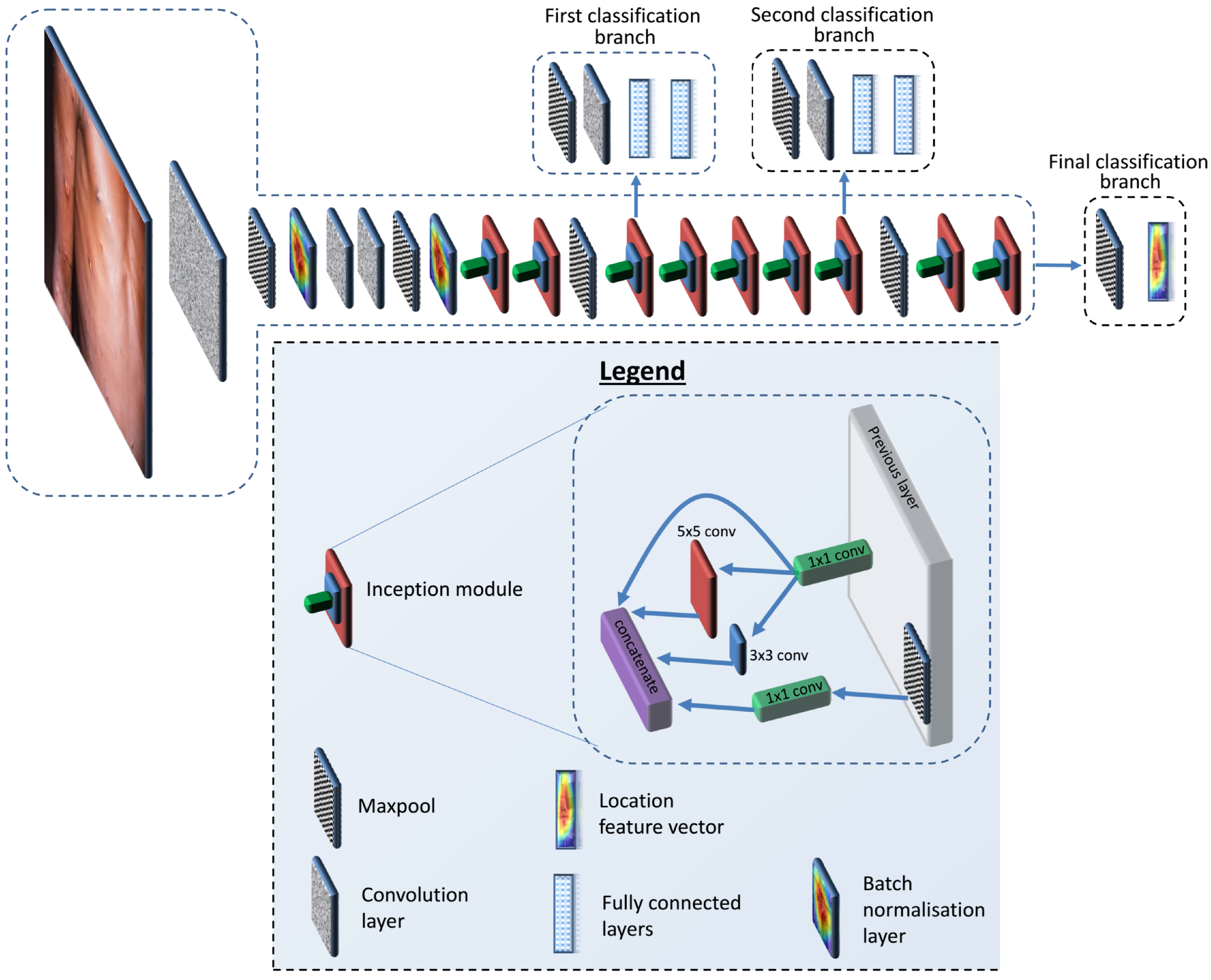
39]. Using a network-within-a-network strategy, the Inception module does its best to approximate the convolutional vision network’s local sparse structure. GoogLeNet, a model developed by Google, achieved top-5 error accuracy of 6.67%, making it the winner of the ILSVRC 2014 competition. Inception versions 1–4 and Inception–ResNet are two variants of GoogLeNet that may be accessed by the general public. As a network inside a network, Inception has a spatial repetition of the best local sparse structure of a visual network. Inception uses 11 inexpensive convolutions to compute reductions before resorting to the 33 or 55 more resource-intensive convolutions. An example of a high-capability architecture that served as a model for our own design is GoogleNet. New concepts, algorithms, and enhanced network topologies are just as important as more processing power, larger datasets, and more complex models when it comes to improving identification capabilities. The architecture of the GoogleNet deep network is shown in
Figure 1. In this work, the GoogleNet deep network was adopted for feature extraction based on the results achieved compared to those of other deep networks.
3.2. Multi-Layer Neural Network
In the neural network (NN) model known as the multi-layer perceptron [
40], the neurons in the interstitial spaces between the several hidden layers are interconnected [
41].
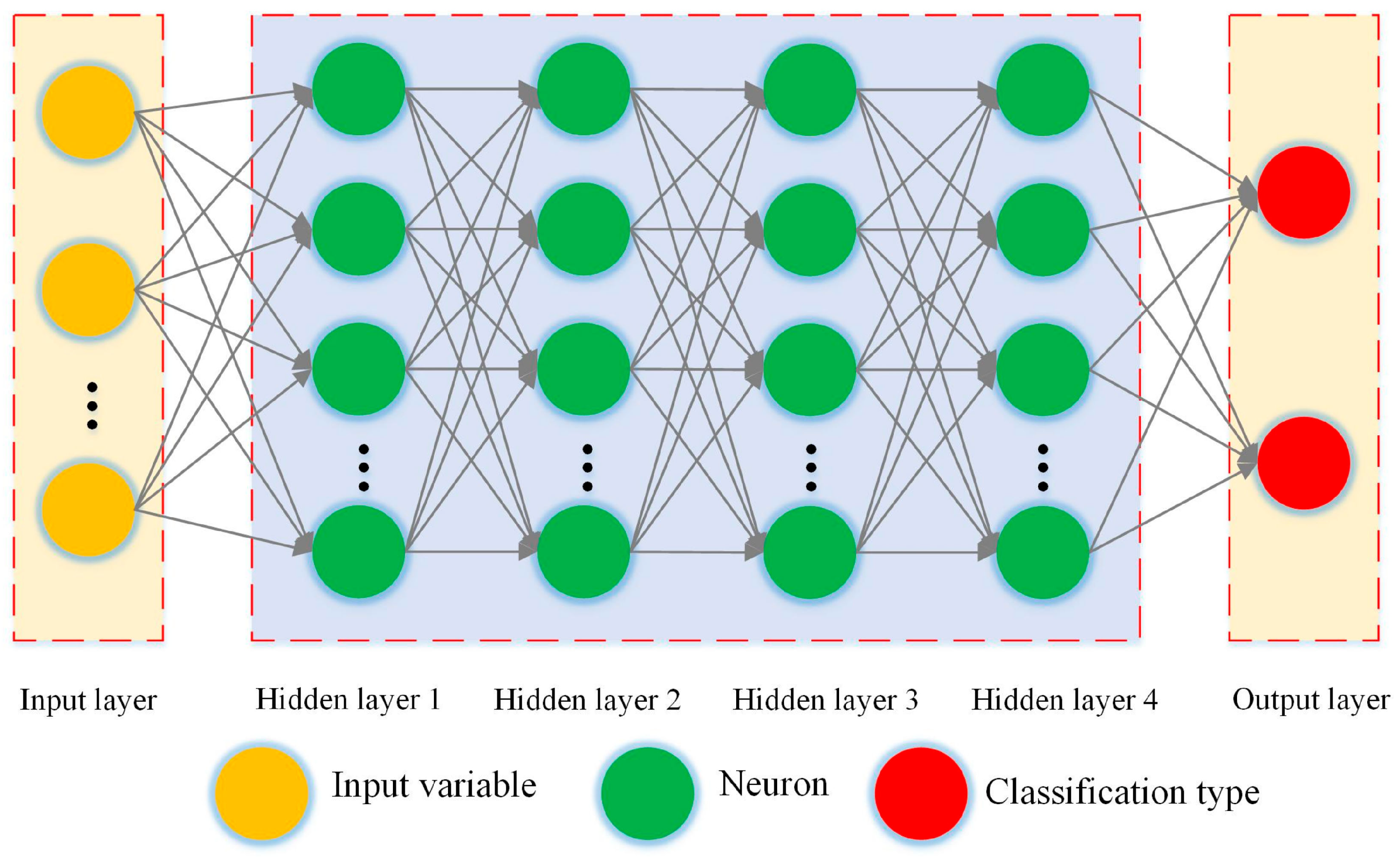
Figure 2 depicts the model architecture of the developed NN employed for classifying the selected features of the input images. The developed NN makes use of both practice and experimentation in its parameter selection. The parameters of this NN are optimized using the proposed meta-heuristic optimization algorithm. The details of the optimization algorithm and the optimized parameters are presented and discussed in the next sections.
3.3. Meta-Heuristic Optimization
In this paper, three optimization algorithms, namely, Al-Biruni Earth radius (BER), the sine cosine algorithm (SCA), and particle swarm optimization (PSO), were utilized. These algorithms were used to develop two new hybrid optimization algorithms for feature selection and NN parameter optimization. In this section, the basics of these algorithms are presented; then, the proposed hybrid optimization algorithms are explained in the next section.
3.3.1. Al-Biruni Earth Radius (BER) Optimization Algorithm
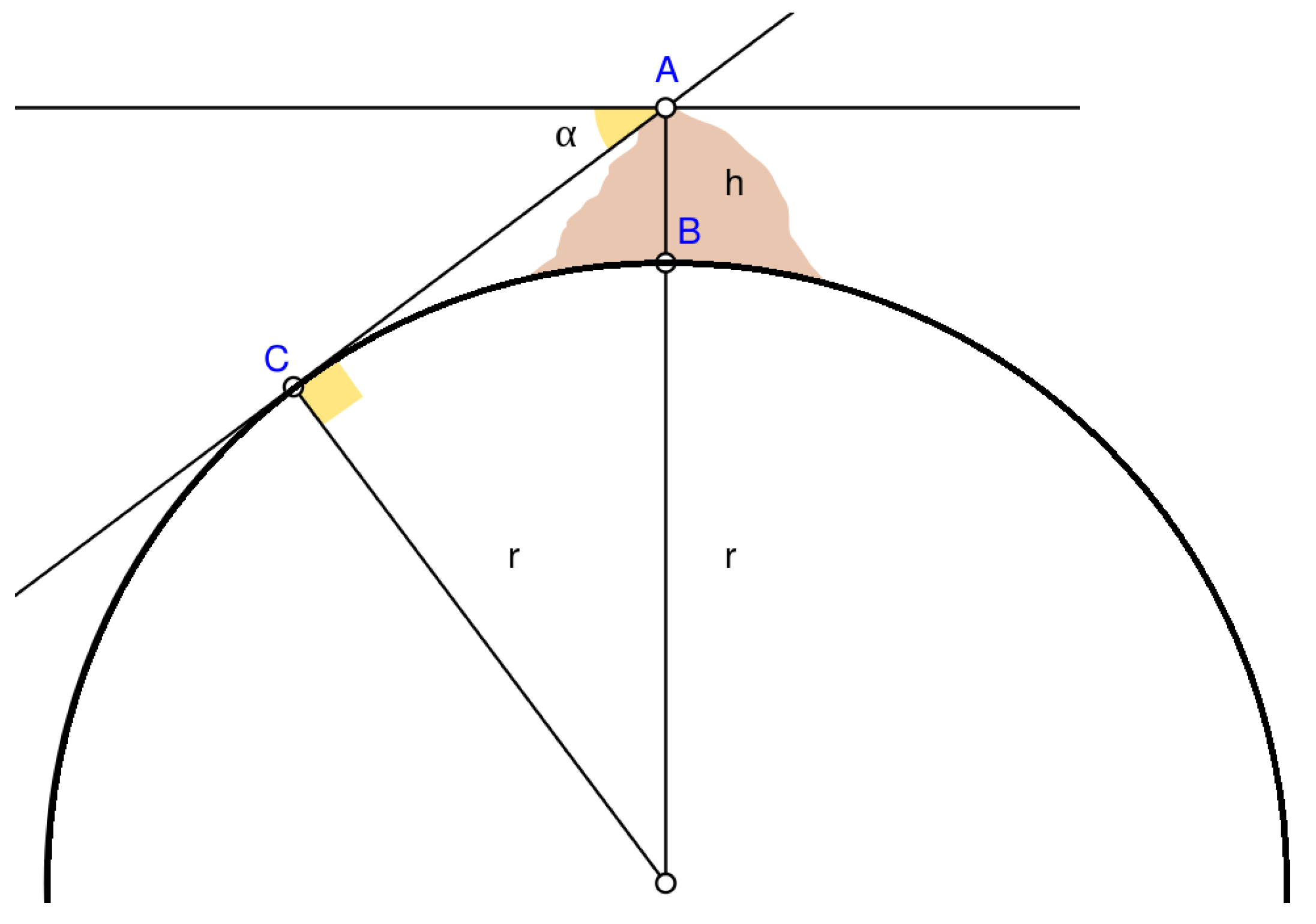
The calculation of earth radius based on Al-Biruni method is depicted in
Figure 3. This method forms the basis of Al-Biruni Earth Radius (BER) optimization algorithm. Finding the optimal solution within specified constraints is the work of optimization algorithms. Each member of the population can be represented by a
S vector in the BER algorithm:
, where
is the dimension of the search space and
d is the dimension of the parameter or feature being optimized. It is proposed that success up to some limit be measured using the fitness function
F. Using these stages of the optimization procedure, populations may be searched for a fitness-maximizing vector
. To begin, a sample of the population is chosen at random (solutions). Before BER can begin optimizing, a number of factors must be specified, including the fitness function, the minimum and maximum allowed solution sizes, the population size, the dimensions, and the number of solutions. Exploration and exploitation operations form the backbone of the BER algorithm as explained in the following.
Exploration Operation: This operation is responsible for locating promising areas of the search space and breaking through local optimum stasis on the way to the best possible solution.
- –
Moving towards the best solution: Using this strategy, the solitary explorer will scout out the immediate region around its current location for potentially fruitful new exploration sites. One way to accomplish this is by using an iterative process to search for a more optimal option (with respect to fitness) from the numerous available choices nearby. BER analysis uses the following formulas to accomplish this goal:
where
,
h is a number that is randomly selected from the range
,
and
are coefficient vectors whose values are measured by Equation (
1),
is the solution vector at iteration
t, and
D is the diameter of the circle in which the search agent will look for promising areas.
Exploitation Operation: The exploiting group is accountable for improving current solutions. When a cycle ends, the BER calculates the fitness of each participant and awards those with the best scores. The BER employs two unique strategies to achieve the aim of exploitation, both of which are outlined in the following.
- –
Moving towards the best solution: The following equation is employed to move in the direction of the best solution.
where
is a random vector calculated using Equation (2) that controls the movement steps towards the best solution,
is the solution vector at iteration
t,
is the best solution vector, and
D refers to the distance vector.
- –
Searching the area around the best solution Generally speaking, the region around the optimal response offers the most potential for success (leader). As a result, some people will hunt for ways to enhance the situation by investigating alternatives that are somewhat similar to the best one. To implement the aforementioned process, BER employs the following equation.
where the best solution is denoted bu
, which is selected after comparing
and
. The following equation is used to mutate the solution if the best fitness was not changed in the last two iterations.
where
z is a random number in the range
and
t is the iteration number.
Selection of the best solution: To ensure that the solutions are of excellent quality, the BER chooses the best ones to employ in the next cycle. While the elitism technique is more effective, it may lead multi-modal functions to converge too soon [
42,
43]. By taking a mutational approach and scanning the area surrounding the explorers, the BER is able to deliver cutting-edge exploration capabilities. With its robust exploration capabilities, the BER is able to stave off convergence. First, parameters such as population size, mutation frequency, and iteration count are input into the BER. The BER then assigns individuals to either the exploration group or the exploitation group. The BER method dynamically modifies the size of each group throughout the iterative process of locating the best solution. Two approaches are used by each group to complete their missions. The BER ensures diversity and thorough exploration by shuffling the order of responses between repetitions. In one iteration, a solution may be part of the exploration group, but by the next, it may be part of the exploitation group. Due to the BER’s exclusive nature, the leader will not be deposed during the procedure.
3.3.2. Sine Cosine Algorithm
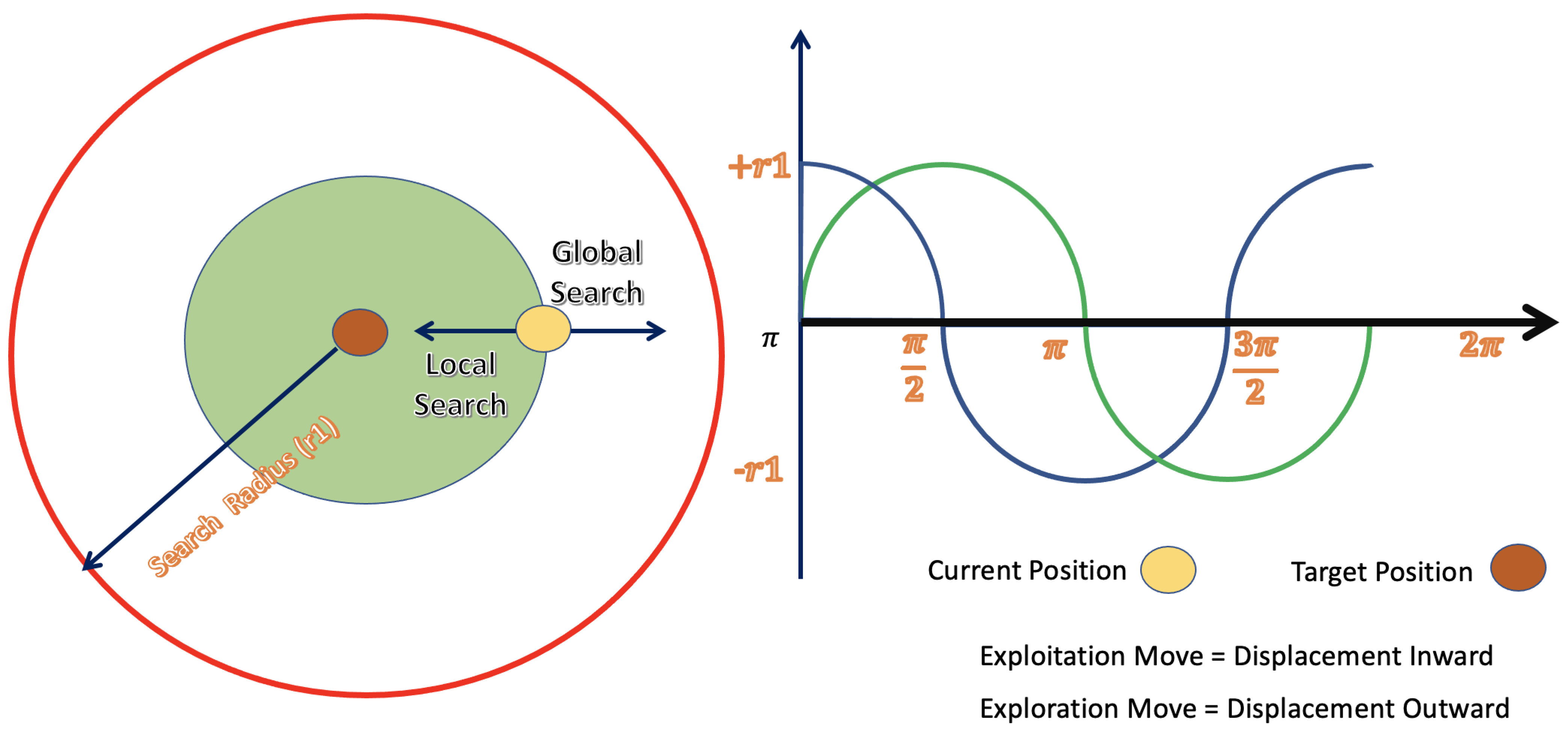
The sine cosine algorithm (SCA) was initially introduced in [
44]. Based on
Figure 4, it can be noted that the oscillation functions of sines (and cosines) have an important role in determining the optimal solution sites. To express the operations of SCA, a collection of random variables is employed [
45].
The update process of the candidate solutions is performed using the following equation.
in which
t is the number of search iterations. Current and best solutions are referred to as
S and
. The values of
are allocated to the random variables
,
, and
. For example, as can be seen from the equation, the locations of the best solutions influence the present solution’s position, making it easier to get to an ideal solution. The value of
is changed as follows during the running iterations of SCA.
where
a is a constant, and
t and
represent the current and maximum iterations, respectively.
The SCA algorithm is more resilient than a broad range of meta-heuristic approaches in the literature because it uses just one optimal solution to lead the other solutions. Compared to other algorithms, this algorithm’s convergence speed and memory usage are quite low [
45]. Nevertheless, as the number of local optimum solutions grows, the algorithm’s efficiency declines. Since the local optima can become stagnant, the SCA optimizer and the GWO algorithm are incorporated into the proposed algorithm to take advantage of their fast convergence rates and memory efficiency, and to ensure a healthy ratio of exploration to exploitation tasks during the optimization process.
3.3.3. Particle Swarm Optimization
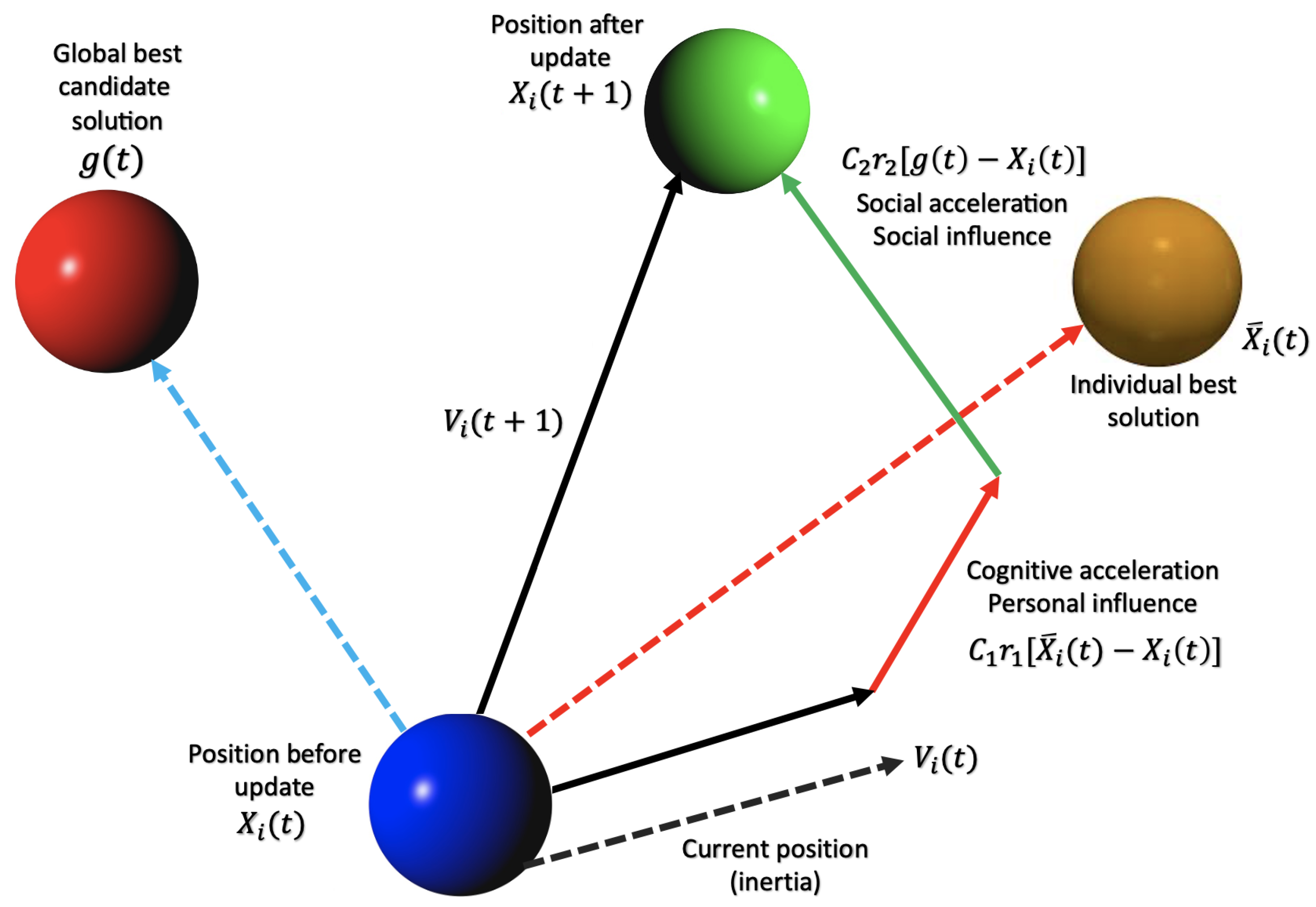
The particle swarm optimization (PSO) methodology is based on mimicking the foraging behavior of flocking animals such as birds using an optimization tool that outperforms the group intelligence approach. Some technical optimization issues can be solved with the PSO method, which was developed after observing this class of animal foraging patterns. All particles in the PSO algorithm have an adjustable value, and their search velocity and range are controlled by the speed at which they move, as shown in
Figure 5. Particles then conduct their solution space search from the optimal particle’s position in the population. Particles keep themselves current during the search process by monitoring two extreme values: the individual extremum
, which is the optimal solution discovered by an individual particle, and the global extremum
, which is the ideal solution currently found by the whole group. A scenario where the particles are looked for in a D-dimensional target space is considered, where a group of N particles live together. The i-th particle’s velocity throughout its journey is a D-dimensional vector:
Each particle’s particular extremum, defined as its best possible position in the solution space, is represented by the notation:
As long as the particle locates both the local and global extrema, it can modify its current velocity and position using the following formulas.
where the global extremum is denoted by
,
w refers to the inertia weight, and the learning factors
and
are selected arbitrarily in the range between 0 and 2.
refers to the particle velocity, and
and
are random numbers between 0 and 1.
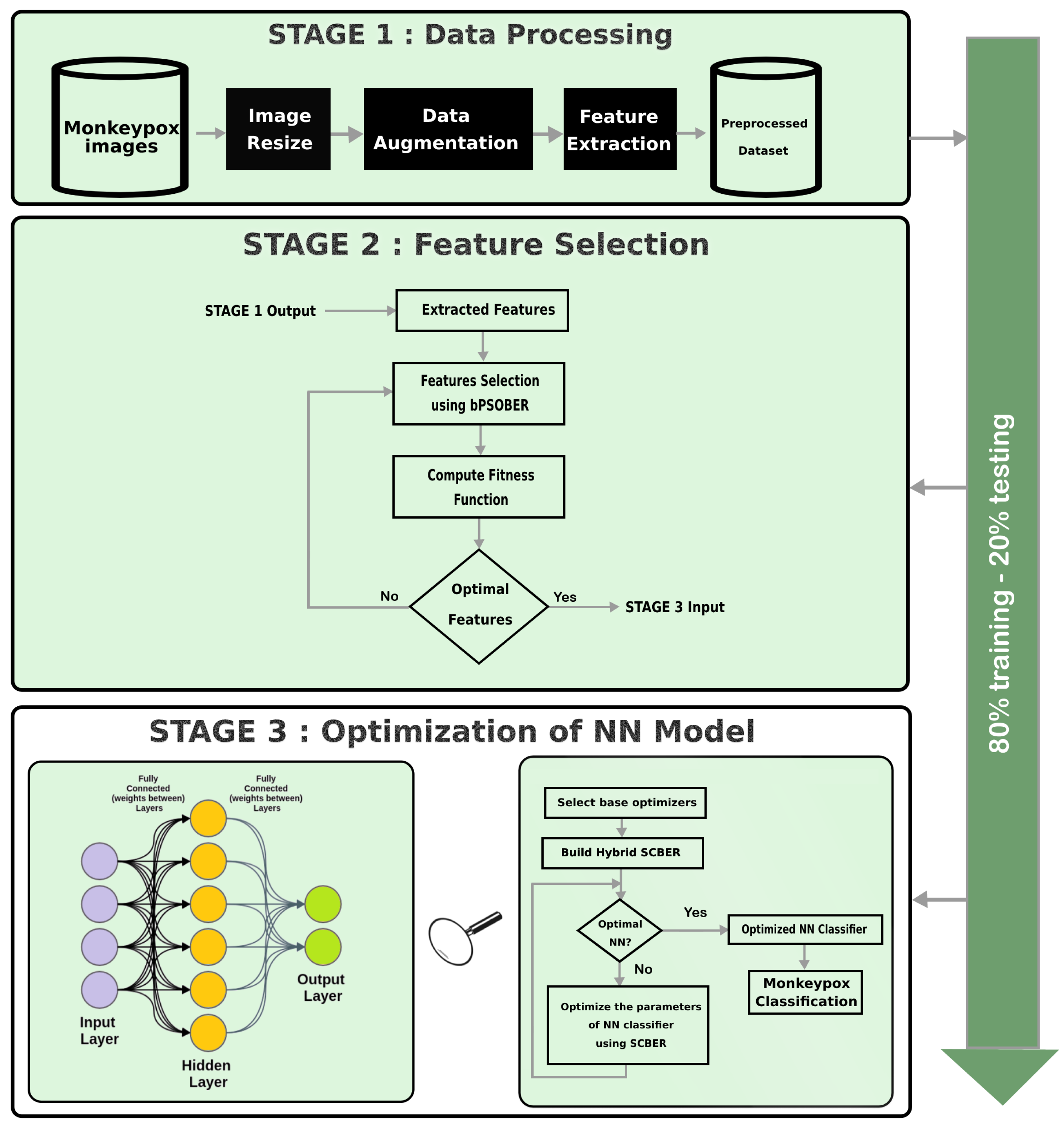
5. Experimental Results
Three sets of experiments were carried out in this paper to evaluate the proposed algorithms. The purpose of the first set of experiments was to determine which of the deep learning networks available for feature extraction performs the best, and then adopt the best performing deep network. The results of the best-adopted network werer then fed to the proposed feature selection algorithm (bPSOBER), which was evaluated using the second set of experiments. The selected features were classified using the optimized NN, which was optimized using the proposed SCBER, which was evaluated using the third set of experiments. In addition, a set of statistical experiments were conducted to assess the stability and significance of the proposed algorithms. In this section, the results of these experiments are presented and explained.
The hardware parameters of the platform that ran the experiments were: central processing unit (CPU) of type Intel Core i7, the graphics processing unit (GPU) was GeForce RTX2070 Super with 8 GB memory, and the main memory was of size 16 GB. On the other hand, the software parameters were: platform was Ubuntu 20.04 with CUDA9.0, Cudnn7.1, TensorFlow 1.15, and Spider IDE with Python3.7. Based on these parameters, the experiments were conducted in ≥16 batches, which enabled completing the model training process in a relatively short time.
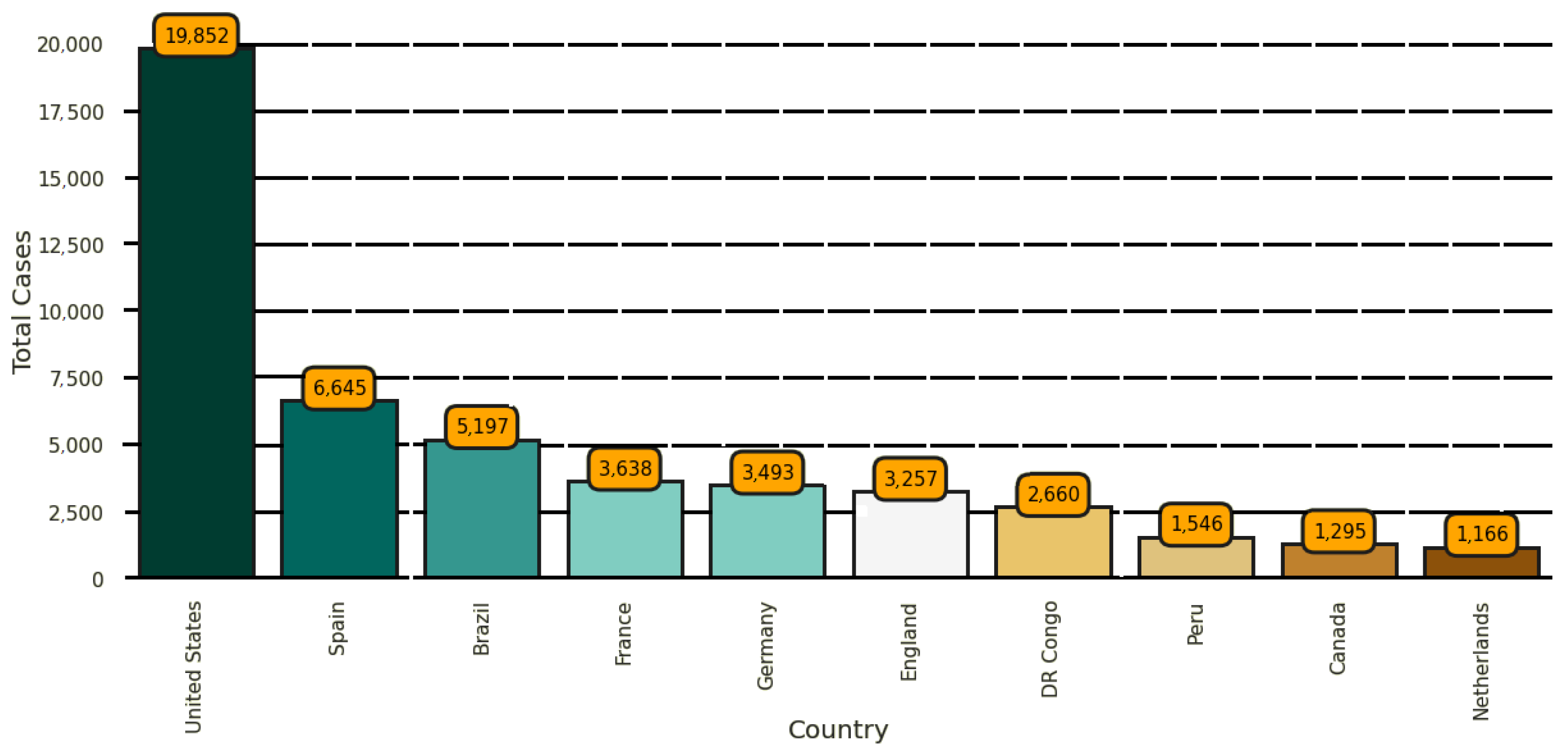
5.1. Monkeypox Dataset
The experiments conducted in this work were based on a freely available dataset on Kaggle [
46]. This dataset is composed of 279 images of monkeypox cases and 293 images of normal cases. Sample images of the dataset are shown in
Figure 7, and the spread of the contamination of the monkeypox infection is shown in
Figure 8. As the size of the dataset is small, data augmentation was applied to increase the number of images in the dataset to enable transfer learning for feature extraction.
5.2. Evaluation Criteria
The effectiveness of the proposed feature selection procedure is evaluated in terms of the metrics presented in
Table 1. These metrics include mean, worst fitness, best fitness, average fitness size, standard deviation, and average error. On the other hand, the effectiveness of the extracted features and the performance of the proposed optimized neural network are evaluated in terms of the metrics listed in
Table 2. These metrics include accuracy, n-value,
p-value, sensitivity, specificity, and F1-score. In these tables,
M represents the total number of optimization iterations,
stands for the best solution vector at iteration
j, and
indicates the size of the best solution. The number of data points in the test set is represented by
N, and the output label at data point
i is marked by
. The number of features is denoted by
D, and the label of the class of point
i is denoted by
. True positive, false positive, and false negative are abbreviated as
,
,
, and
, respectively [
47].
5.3. Configuration Parameters
Table 3 displays the proposed algorithms’ configuration parameters. These parameters include the population size, number of training iterations, mutation probability, and K factor for the BER parts of the proposed algorithms; the inertial factor of the SC algorithm; the exploration percentage; the numbers of runs and agents; the dimensions of the search space; and finally, the values of
and
, which were set as 0.99 and 0.01, respectively. On the other hand,
Table 4 displays the settings for the other competing algorithms used in the experiments.
5.4. Stage 1: Preprocessing Results
The preprocessing of the input dataset was applied through a set of steps, including resizing the input images, data augmentation, evaluation of the given deep networks to chose the best, and then feature extraction.
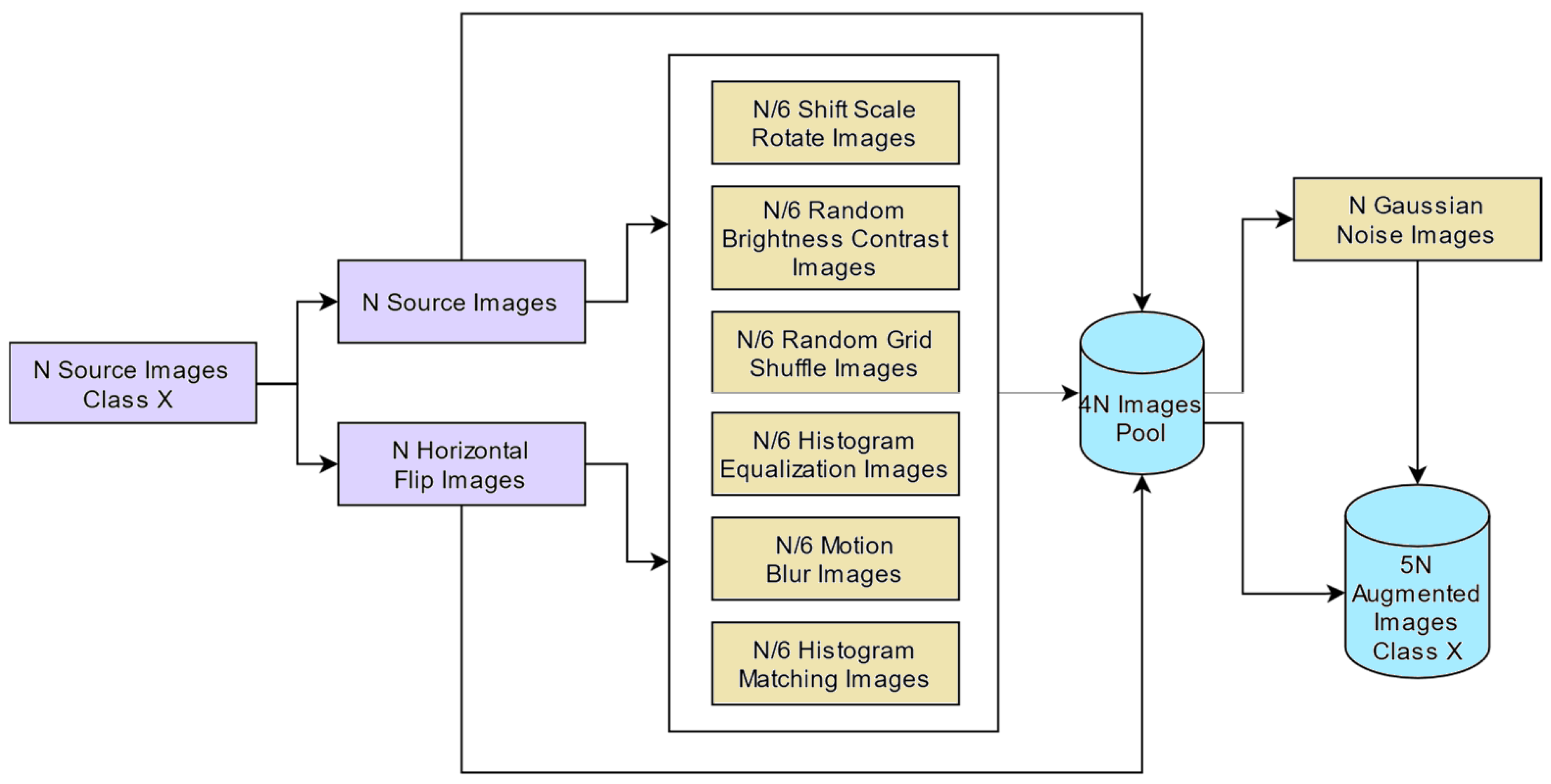
5.4.1. Data Augmentation
The term “data augmentation” refers to the method of changing the size and orientation of the dataset images to generate new image that can enrich the existing dataset. Data augmentation is used on both training and validation sets to boost the generalization capacity of deep learning-based image classification models. Various data augmentation techniques, such as geometric modification, kernel filters, picture mixing, random erasure, and transformations, were applied to increase the size of the dataset. The image augmentation pipeline was developed for monkeypox images using some selected augmentation methods. All images in the validation and training sets for each class were scaled to
before being augmented. The process of image augmentation is depicted in
Figure 9.
5.4.2. Evaluating the Deep Learning Networks
Machine-learning models rely heavily on the detection and extraction of key features from input images. Here, the outputs of four different deep neural networks, namely, AlexNet [
36], VGG-19 [
37], GoogleNet [
39], and ResNet-50 [
38], are compared based the same dataset. The outputs from these networks are presented in
Table 5. Using the default parameters, we first gathered the features of the images from the preceding layers of a deep neural network so that they could be used in the subsequent operations for feature selection and balancing. GoogleNet had the best performance, as seen in the results. Therefore, this was adopted by extracting the features that were then fed to the feature selection process.
5.5. Stage 2: Feature Selection Results
The selection of the most significant features of the features extracted by GoogleNet was essential. In this experiment, six optimization methods were employed—namely, the bPSOBER, binary BER (bBER), binary particle swarm optimizer (bPSO) [
48], binary whale optimization algorithm (bWOA) [
49], binary gray wolf optimizer (bGWO) [
50], binary firefly algorithm (bFA) [
51], and binary genetic algorithm (bGA) [
52]. The evaluation of results achieved by these feature selection methods is listed in
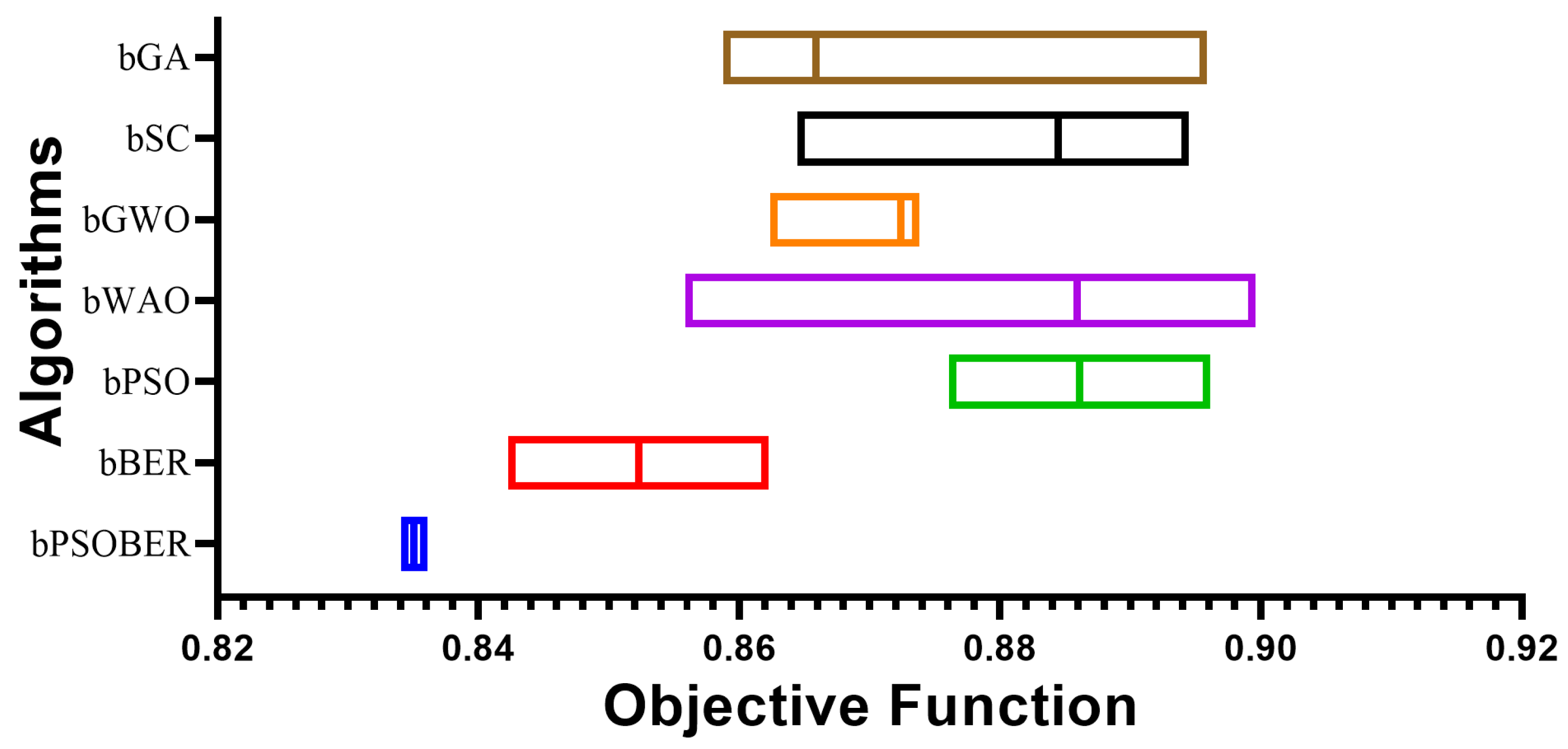
Table 6. It can be seen in this table that the results achieved by the proposed bPSOBER algorithm are superior to those achieved by the other feature selection methods.
To demonstrate that the proposed feature selection algorithm (bPSOBER) is statistically significantly superior, the
p-values were computed by comparing the outputs of each pair of algorithms. To conduct this study, Wilcoxon’s rank-sum test was employed. There are two major hypotheses at play here: the null and the alternative. The mean (
) values of the null hypothesis represented by
include
,
,
,
,
and
. However, the
hypothesis does not factor in the averages of the algorithms. The outcomes of the Wilcoxon rank-sum test are shown in
Table 7. Compared to the previous algorithms, the suggested one has a lower
p-value (
p < 0.005). The suggested feature selection approach was validated by these findings, demonstrating its statistical superiority. A one-way analysis of variance (ANOVA) test was performed to examine whether or not there were statistically significant differences between the suggested bPSOBER algorithm and the other algorithms. The mean (
) values of the null hypothesis, designated by
, include
.
Table 8 presents the measured results of the ANOVA test. The results recorded in these tables confirm the superiority, significance, and effectiveness of the proposed feature selection algorithm.
Another experiment was conducted to show the effectiveness of the feature selection process on the classification performance.
Table 9 shows classification results with and without feature selection. It can be easily noted in this table that feature selection is necessary to boost the accuracy of the classification results.
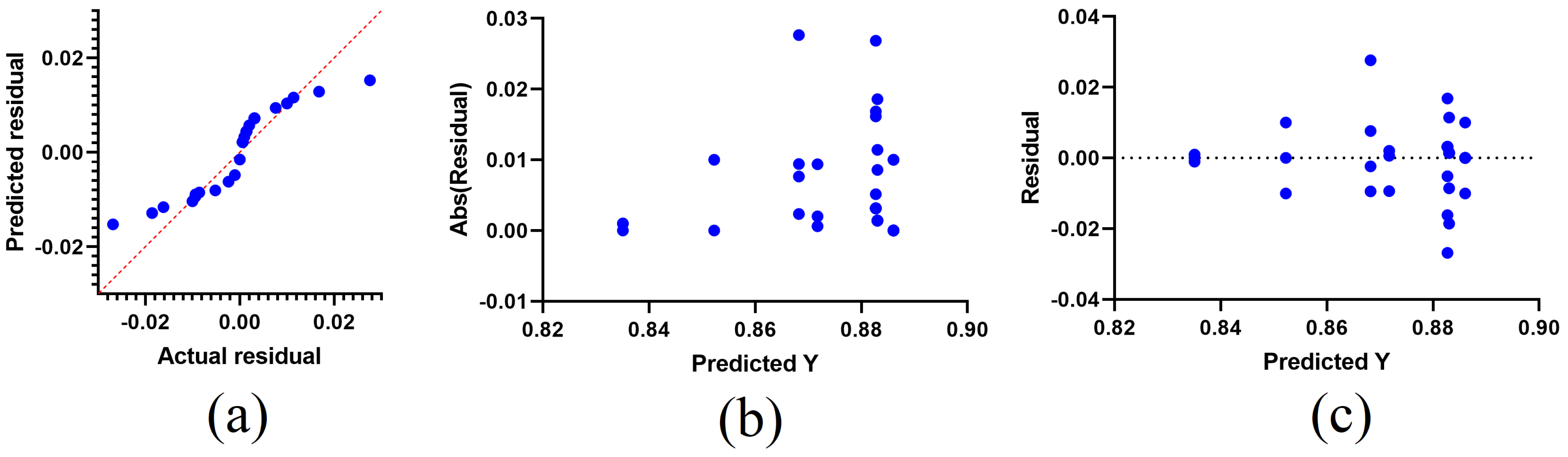
The results using the proposed feature selection method are illustrated by the plots shown in
Figure 10. In this figure, the quartile–quartile (QQ), homoscedasticity, and residual plots are used to show the effectiveness and robustness of the proposed method. The values shown in the QQ plot approximately fit a straight line, which reflects the robustness of the selected features in classifying the monkepox cases. In addition, the recorded results in the homoscedasticity and residual plots give more emphasis to these findings.
The average error of the proposed feature selection method compared to those of six other feature selection methods is shown in the plot depicted in
Figure 11. In this figure, it is shown that the proposed method achieved the lowest average error, which confirms the robustness of the proposed method. In addition, the heatmap shown in
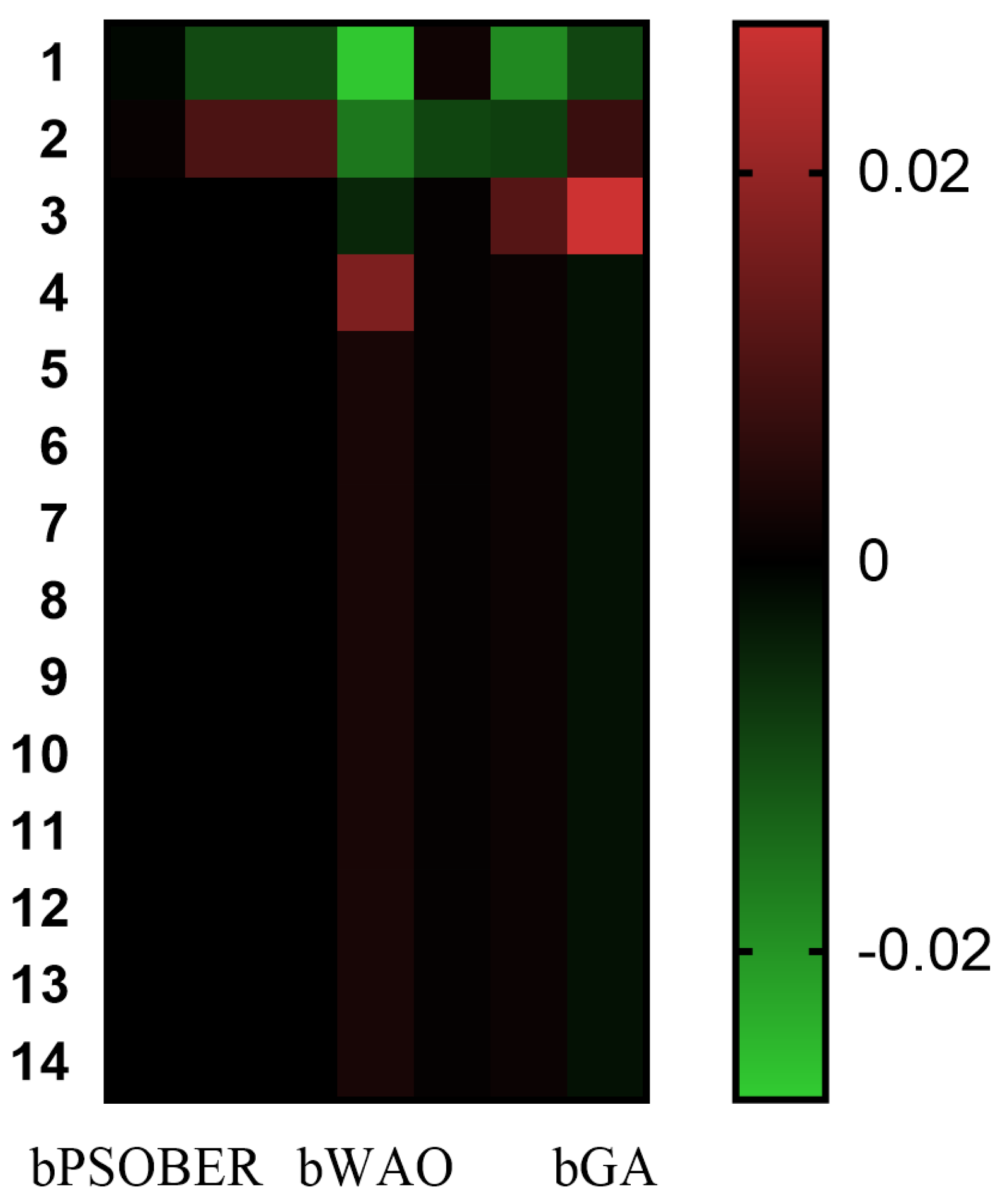
Figure 12 confirms the superiority of bPSOBER, as it achieved the best results when compared to bWAO and bGA feature selection algorithms.
5.6. Stage 3: Monkeypox Classification Results
The selected features based on the proposed bPSOBER were used to classify the input image through a machine-learning classifier. The classifier adopted in this work was the multi-layer neural network (NN). To achieve the best performance of this NN, the parameters of this network were optimized using SCBER. The optimized parameters are listed in
Table 10.
The effectiveness of the optimized NN classifier was evaluated using a set of experiments. SCBER’s results are compared to those of BER, PSO, PSOBER, and SC to demonstrate the superiority of the proposed NN optimization. Various optimizers were employed to fine-tune the NN’s parameters, and the outcomes were recorded and analyzed.
Table 11 presents a statistical analysis of the results achieved using SCBER compared to other optimization methods. Based on the results shown in this table, it is clear that the proposed optimization method yields superior results compared to the other methods.
The statistical significance of the proposed optimization of NN using SCBER was tested using the
p-values by comparing the outputs of each pair of algorithms. The Wilcoxon’s rank-sum test was performed, and results were recorded. There are two major hypotheses at play here: the null and the alternative. The mean (
) values of null hypothesis represented by
include
. However, the
hypothesis does not factor in the averages of the algorithms. The outcomes of the Wilcoxon rank-sum test are shown in
Table 12. Compared to the previous algorithms, the suggested one has a lower
p-value (
p < 0.005). The suggested feature selection approach was validated by these findings, demonstrating its statistical superiority. The ANOVA test was performed to examine whether or not there was a statistically significant difference between the suggested SCBER algorithm and the other algorithms. The mean (
) values of the null hypothesis, designated by
, include
=
. The measured values of the ANOVA test are presented in
Table 13. As presented in these tables, the results emphasize the superiority and effectiveness of the proposed approach in classifying monkeypox cases from images.
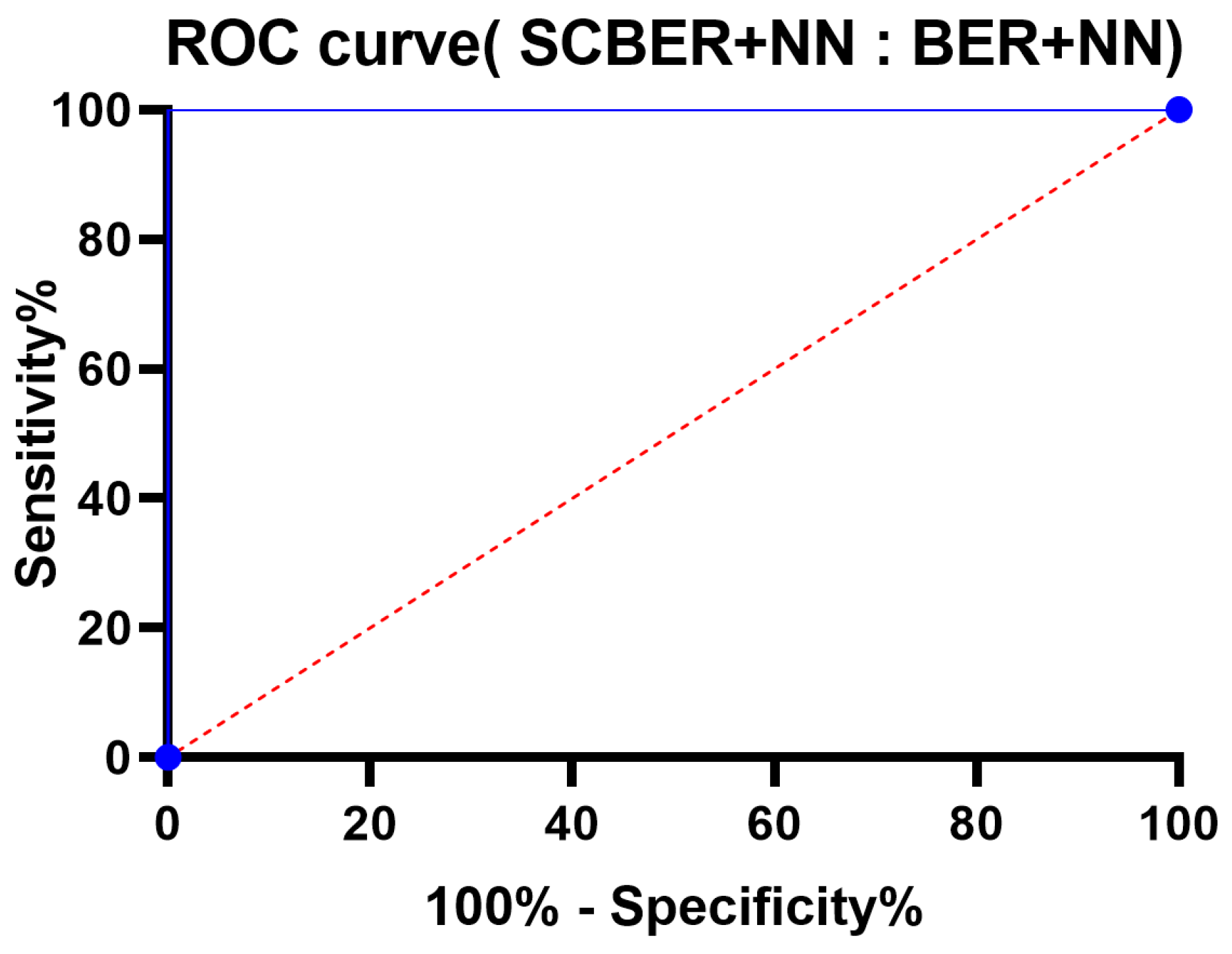
Figure 13 and
Figure 14 graphically depict the statistical analysis of the achieved classification results.
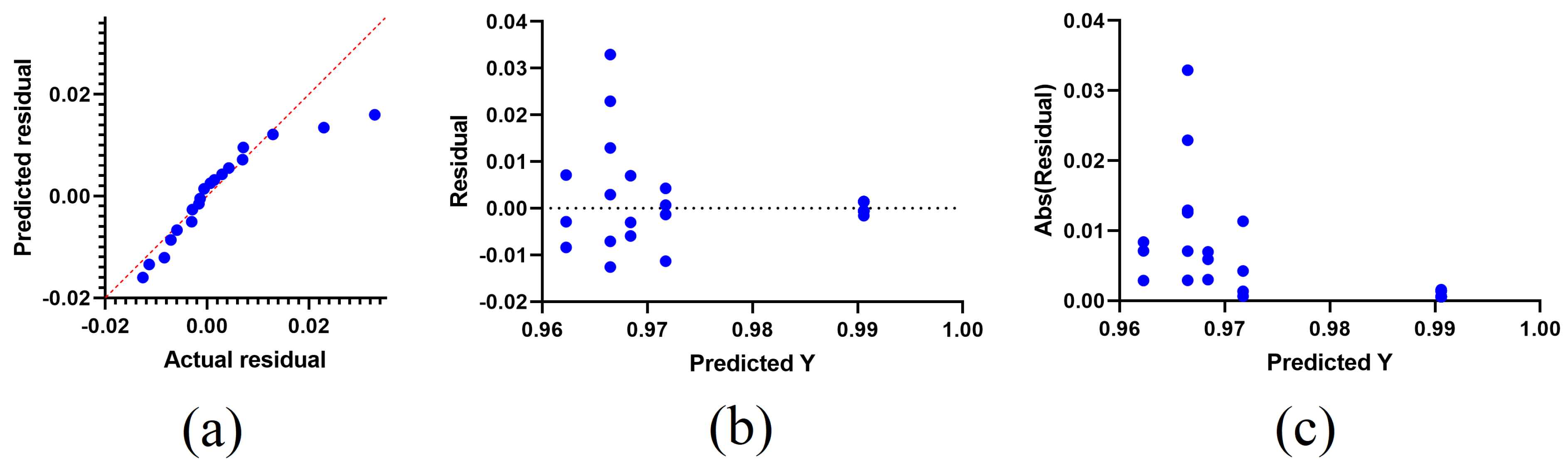
Figure 13 contains three plots, namely, a quartile–quartile (QQ) plot, a residual plot, and a homoscedasticity plot.
Figure 14 illustrates the ROC curve. It can be seen in these graphs that SCBER is stable, with residual errors ranging from −0.02 to +0.02 and homoscedasticity values from −0.01 to +0.04. The QQ plot further demonstrates that the anticipated outcomes are consistent with the observed values, providing more evidence for the validity of the proposed method.
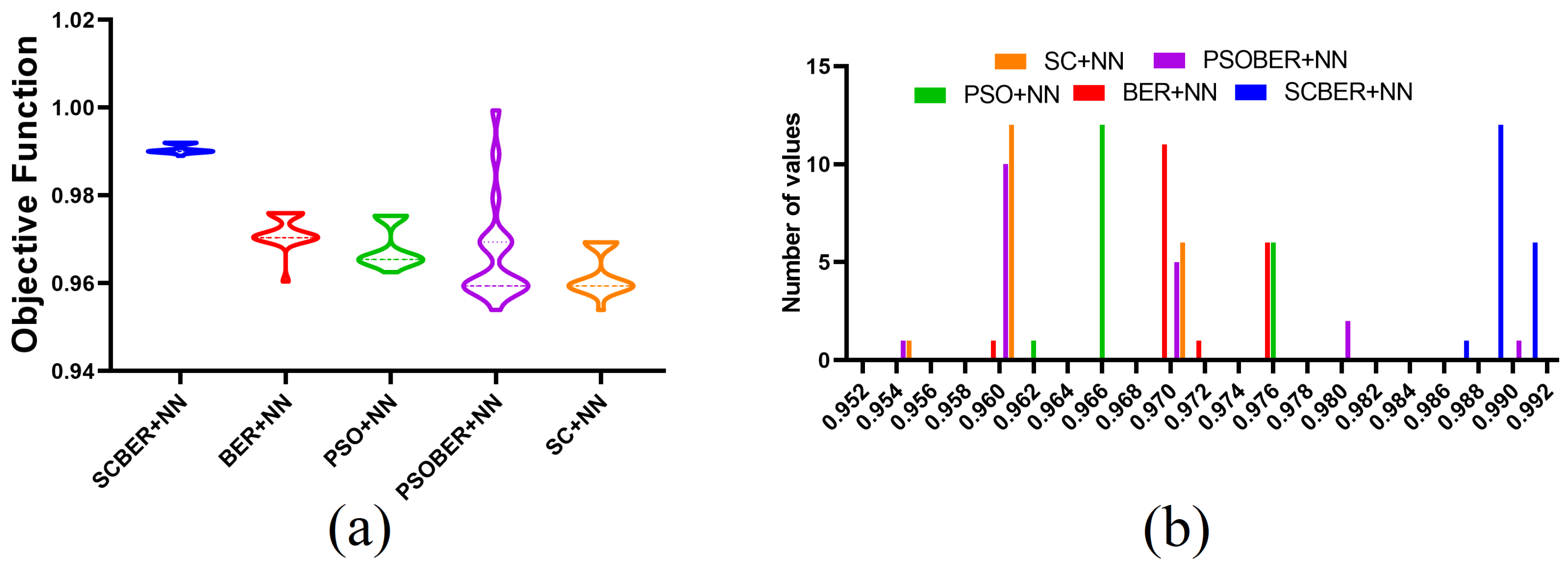
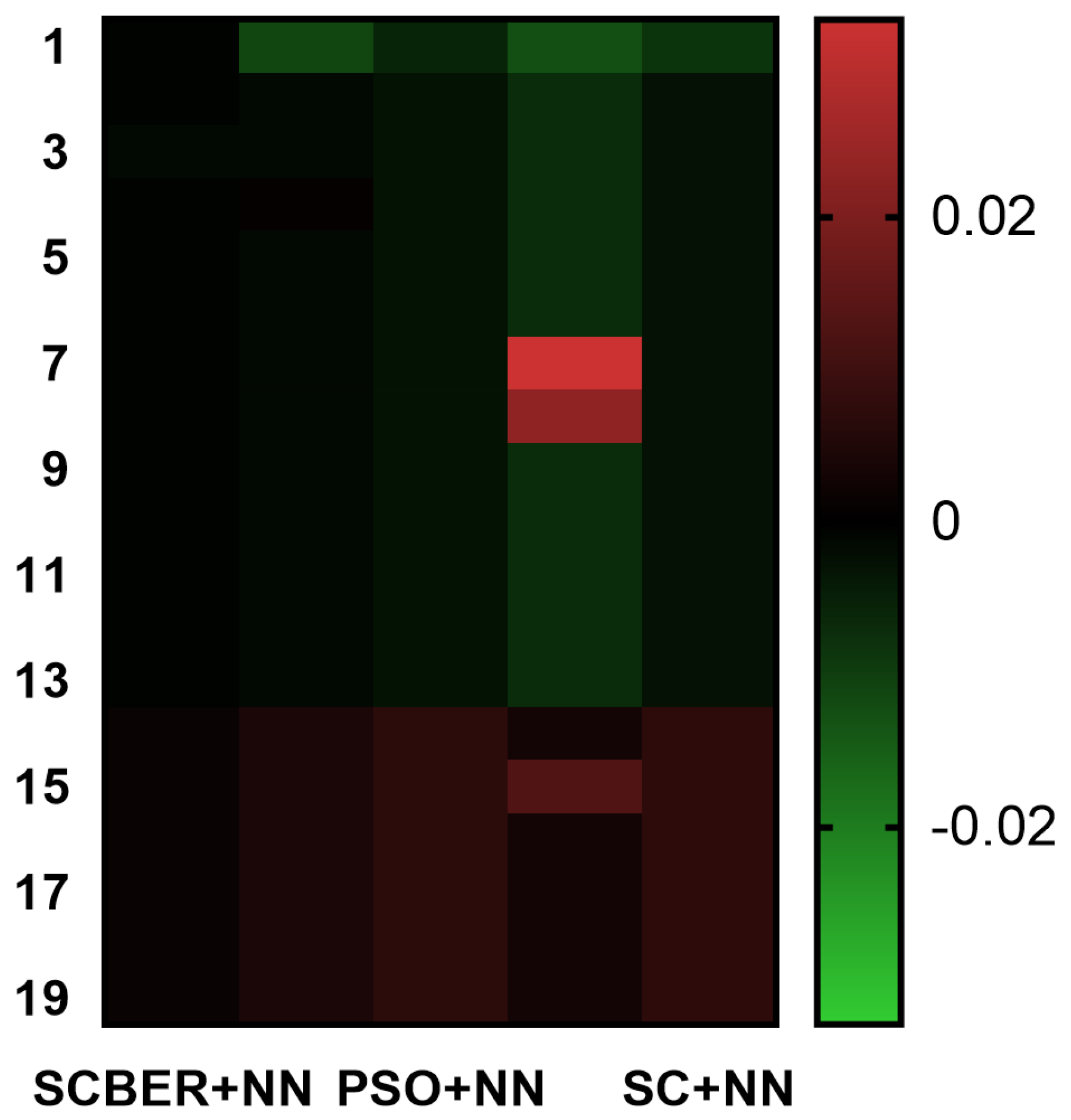
The accuracy plots depicted in
Figure 15 and the heatmap plot depicted in
Figure 16 show the accuracy and the histogram of the results achieved using SCBER. The accuracy plot shows that higher accuracy was achieved by the proposed algorithm compared to the other four optimization algorithm. In addition, the accuracy histogram plot emphasizes the superiority and stability of the proposed optimization algorithm in classifying the monkeypox cases in the input images.



 ,
, 





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}