


A Vehicular Edge Computing-Based Architecture and Task Scheduling Scheme for Cooperative Perception in Autonomous Driving

Abstract
:1. Introduction
- We propose a hybrid time slot-based VEC architecture consisting of AVs and RSUs for cooperative perception, in which some real conditions of AVs are considered, e.g., the involvement of multiple types of resources, heterogeneity of tasks and AV resources and transmission constraint of every participating AV.
- We formulate the task scheduling problem in the proposed architecture as a multitask multitarget scheduling problem with assignment restrictions. We show that the problem is a multidimensional multiple knapsack problem with assignment restrictions, and its NP-hardness is proven in the paper.
- We design a two-stage heuristic scheme (TSHS) for the formulated scheduling problem, which aims at better utilization of the resources of AVs for a better cooperative perception. We compare the result of TSHS with optimum results and the results of some basic benchmarks, and its effectiveness is validated after extensive simulations.
2. Related Works
2.1. Vehicular Edge Computing and Cooperative Perception
2.2. Task Scheduling among CAVs
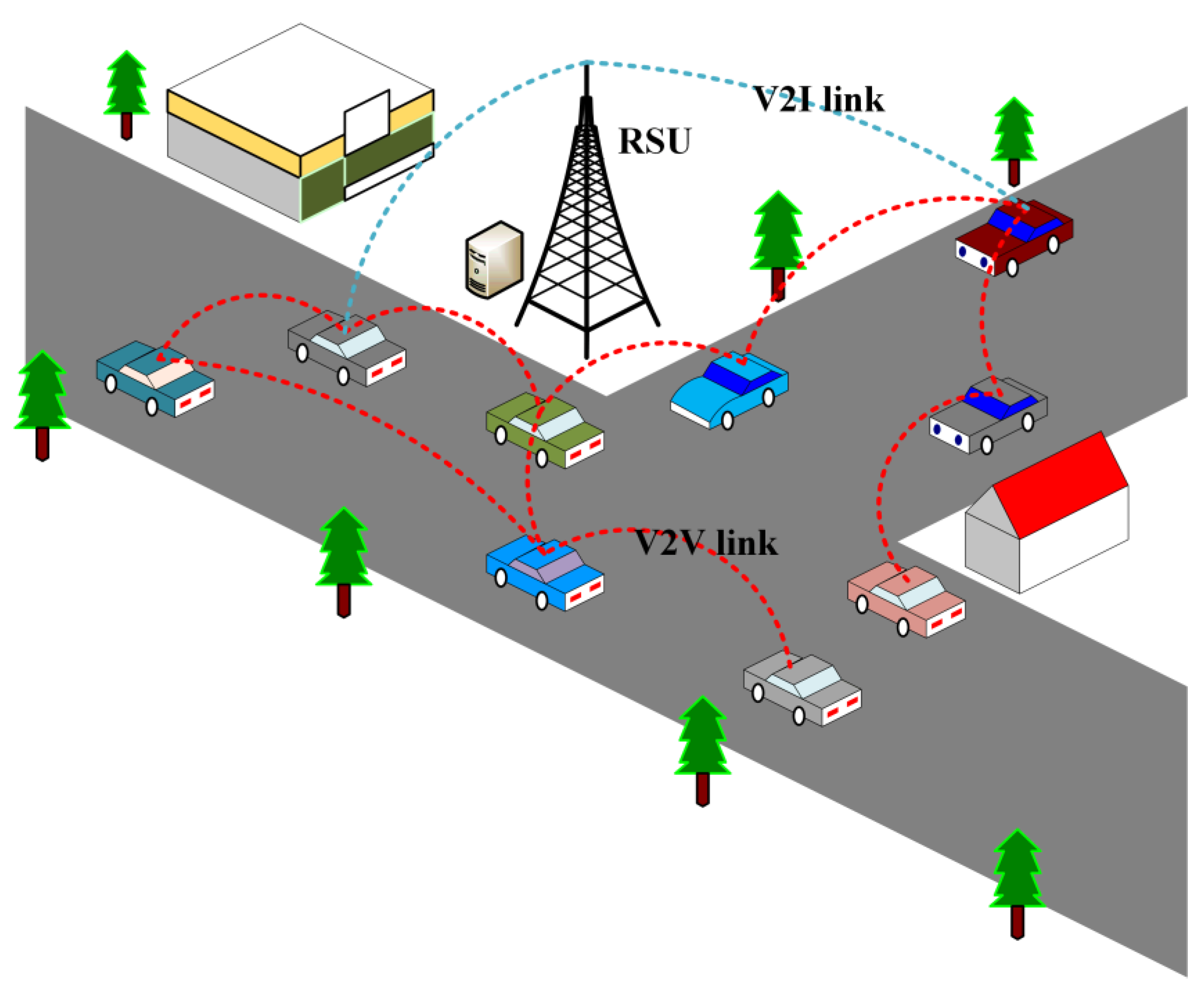
3. System Model and Problem Formulation
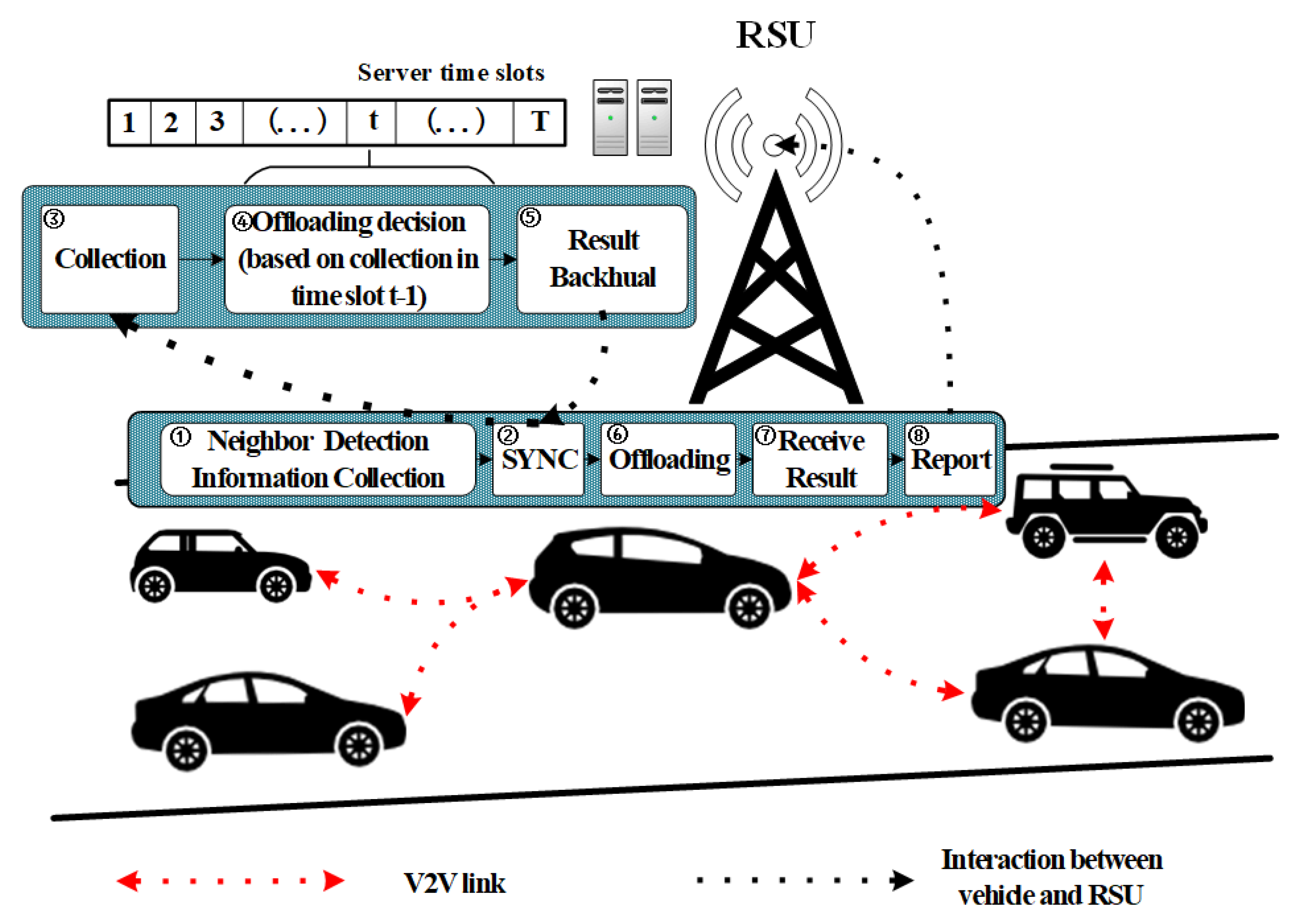
3.1. Hybrid VEC-Based Architecture for Cooperative Perception
- First, vehicles conduct neighbor detection via V2V links. A vehicle sends detection packets to other vehicles, and vehicles without packet loss and with low round-trip time are regarded as neighbors. We assume that the neighbors detected in a time slot will not change because of the short length of the time slot, but neighbors in different time slots can change because of vehicle mobility. For vehicle ; means that vehicles are mutual neighbors; otherwise, . We use to denote the neighbor vector of AV and to denote the neighbor matrix of all vehicles in the region in a time slot. In addition to the neighbor vector, the available resources possessed by AVs and the task vector produced by vehicles need to be reported to the RSU in every time slot. Here, ; denotes the number of -type tasks produced by AV , and denotes the task matrix of all vehicles in the region. These correspond to procedures 1–2 in the block diagram.
- Second, the RSU makes scheduling decisions according to the collected information in a time slot and sends the results back to vehicles in the region. These correspond to procedures 3–5 in the block diagram.
- Finally, AVs conduct task offloading according to the decision result and report the task results to the RSU after completion for further acquisition of other vehicles. These correspond to procedures 6–8 in the block diagram.
3.2. Problem Formulation
3.3. Optimal Solution
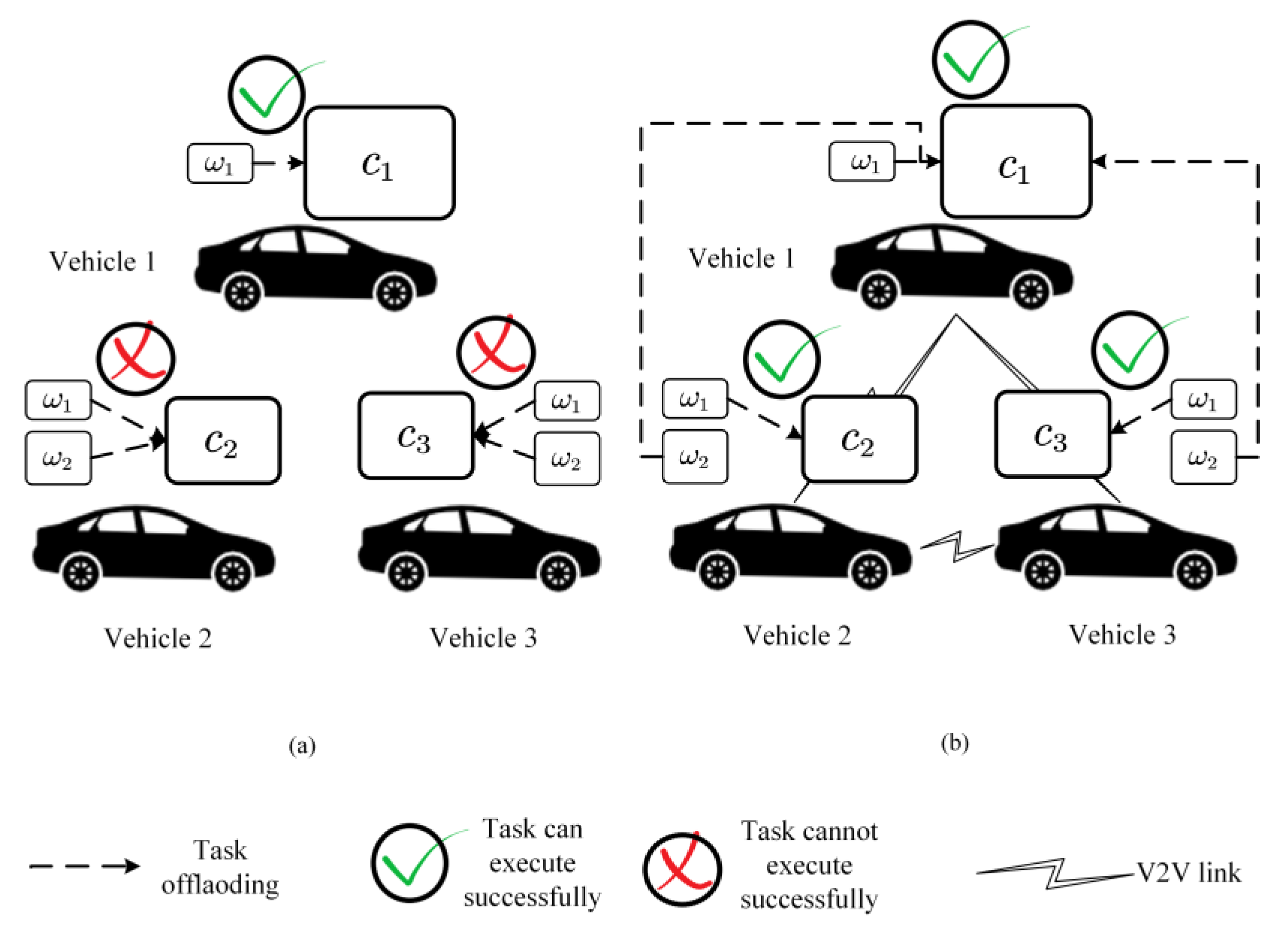
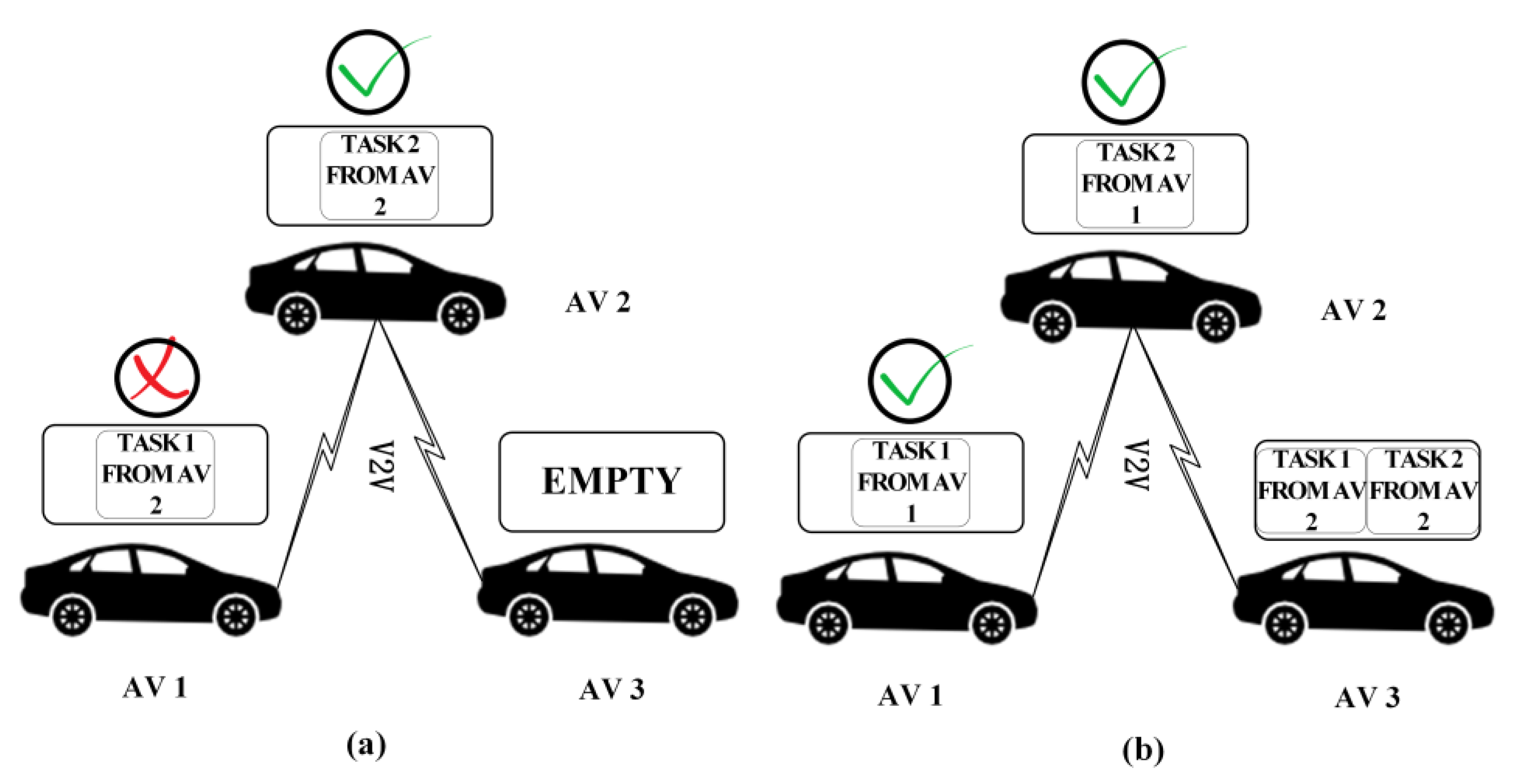
4. Two-Stage Heuristic Scheme (TSHS)
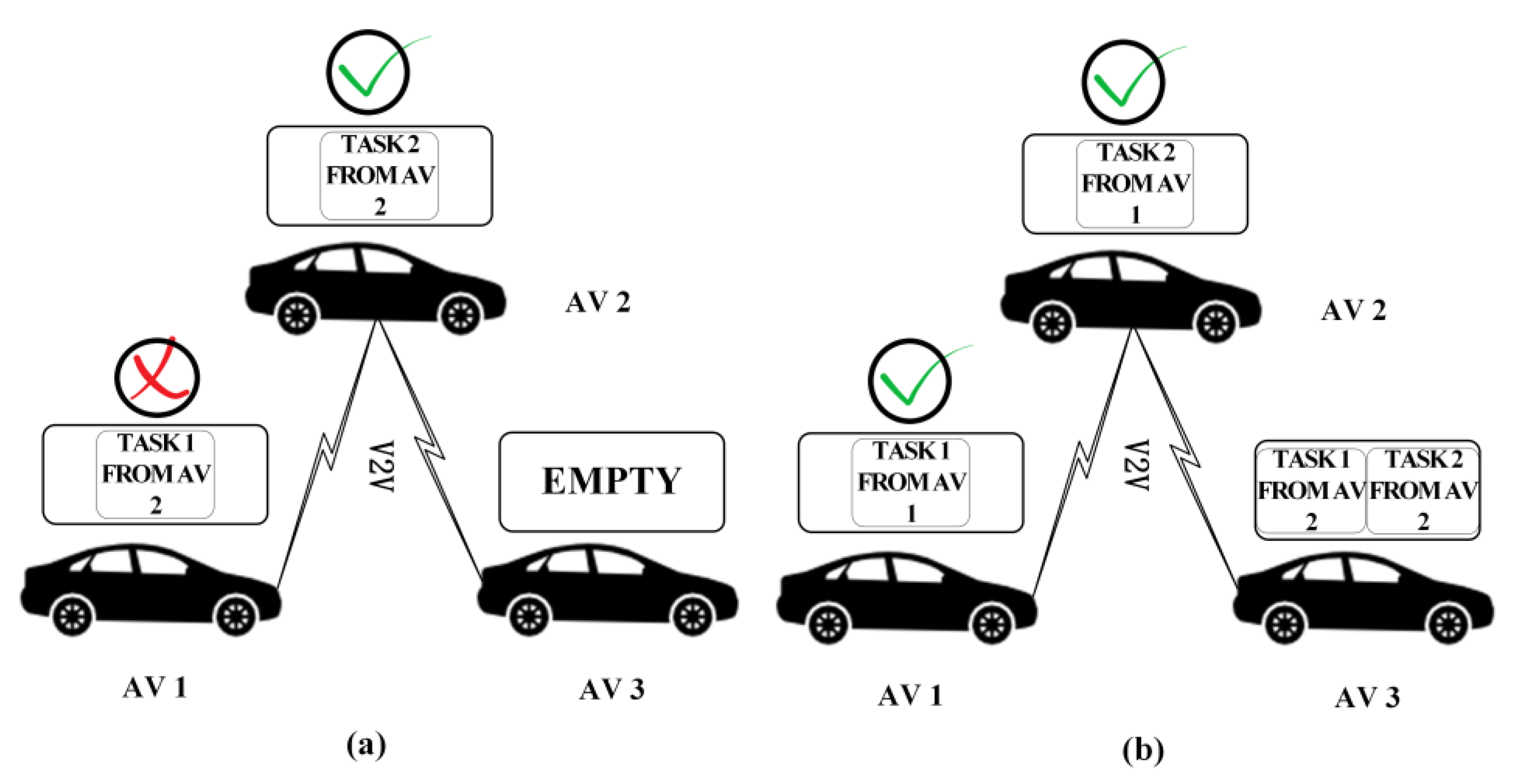
- Determination of the priority of participating AVs in cooperative perception. In this stage, the priority of AVs that need task scheduling is determined based on the status of the vehicles, e.g., produced tasks, available resources and neighbors.
- Determination of execution target vehicles of tasks produced by participating AVs. In this stage, target vehicles of tasks are determined, i.e., which neighbors hold that task is confirmed.
4.1. Highlighted Ideas
4.1.1. Stage of Determination of AV Priorities
4.1.2. Determination of the Target Vehicle of Tasks
4.2. Algorithm
| Algorithm 1 | |
| 1: | ) |
| 2: | ) |
| 3: | /* schedule tasks from origin vehicle to target vehicle for execution */ |
| 4: | /* integrate results and transmit them to RSU */ |
| Algorithm 2) | |
| 1: | |
| 2: | : |
| 3: | : |
| 4: | |
| 5: | |
| 6: | |
| 7: | |
| 8: | : |
| 9: | |
| 10: | sort in decreasing order of di |
| 11: | return |
| Algorithm 3) | |
| 1: | : |
| 2: | True |
| 3: | |
| 4: | |
| 5: | : |
| 6: | |
| 7: | for each : |
| 8: | False |
| 9: | for each : |
| 10: | : |
| 11: | |
| 12: | |
| 13: | |
| 14: | |
| 15: | success_flag ← True |
| 16: | break |
| 17: | if success_flag = False: |
| 18: | |
| 19: | |
| 20: | break |
| 21: | if success_flag = False: |
| 22: | break |
| 23: | if success_flag = True: |
| 24: | |
| 25: | else: |
| 26: | |
| 27: | |
4.3. Properties
5. Experiment and Discussion
5.1. Experimental Setup
- For all participating AVs, three types of resources are needed. Although some mainstream AVs can possess 30 CPU cores or more, utilizing parts of cores to conduct cooperative perception is more rational because of the unreliability of communication and the demands of other users’ and AV applications. The available resources of different vehicles should be diverse because of price differences. We can divide participating vehicles into high-level vehicles and medium-level vehicles. Furthermore, the available number of CPU cores of AVs at the same level could be slightly different due to different users’ habits. We set the resource domains of the three types of resources to (7–10, 37–43, 58–64) for high-level vehicles and (4–6, 18–23, 28–32) for medium-level vehicles: an AVs’ possessed available resources are randomly generated from the domain’s scope based on its level. The randomness reflects the fact that the available resources of different vehicles of the same level can still be slightly different. Meanwhile, the fact that the number of high-level vehicles is less than the number of medium-level vehicles needs to be considered, and the ratio is set to 30%.
- As stated in Section 1, cameras, LiDAR and radar can be installed on AVs for environmental perception, and the resource requirements corresponding to the LiDAR, camera and radar data processing tasks are different. We can regard them as different tasks. For a more realistic scenario, we consider three types of tasks that can be profiled by a triple tuple. The needed CPU cores of a task are determined according to its corresponding sensors’ data production rate in our paper, i.e., the larger the data production rate is, the more CPU cores used to process those data are needed. The resource requirements corresponding to the LiDAR, camera and radar data processing tasks are , and , respectively. The settings of the three types of profiles mainly consider the relationship of the resource requirements among the tasks from LiDAR, cameras and radar and the maximum number of CPU cores of an AV. The absolute resource requirement of each task is related to the specific machine and the length of the time slot, which are not considered in this paper. There are indeed more specific and scientific descriptions for tasks’ computation intensity, e.g., the amount of computation, latency/energy consumption for finishing a workload or needed instruction cycles of CPU. For simplicity and ease of calculation, we define the resource requirement of tasks (computationally intensive) as a triple tuple that includes the number of CPU cores. We assume that every CPU core needed by a task runs with full loads in our model.
- Neighbors are determined by sending detection packets by V2V links (DSRC). The results of neighbor detection can be represented by a neighbor vector. We can generate these neighbor vectors. Two facts should be considered. First, a vehicle cannot connect to too many other vehicles. Second, the distribution of AV numbers of neighbors is almost normal distribution. We set the generating rules as follows: An AV should have at least two neighbors. The number of participating vehicles is referred to as the cluster scale, and the two terms are used interchangeably. When the scale is 5–10, an AV can have up to five neighbors; when the scale is 10–20, the maximum number of neighbors of the AV is half of the scale; and when the scale exceeds 20, the maximum number of neighbors is 10. The number of neighbors of each vehicle is randomly chosen between the maximum and minimum values according to a normal distribution.
- Determining the number of every vehicle’s generated tasks is slightly complex. For participating vehicles, the distribution of the proportion of the number of AVs whose available resources cannot meet the requirement of tasks generated by themselves to the total number of participating vehicles is unknown. We assume that the probability of every proportion is the same. We use the resource satisfaction degree (RSD), i.e., the proportion of vehicles whose tasks can be completed by themselves, in the cluster to denote the distribution in a discrete manner. The value of RSD ranges from 90% to 10%. For a particular value of RSD, we randomly generate task requests of each AV, which guarantees that the proportion of vehicles whose tasks can be completed by itself in the cluster is equal to the value of RSD. Each RSD value of each cluster scale generates 25 groups of data, and each group contains the task requests of each participating vehicle in cooperative perception.
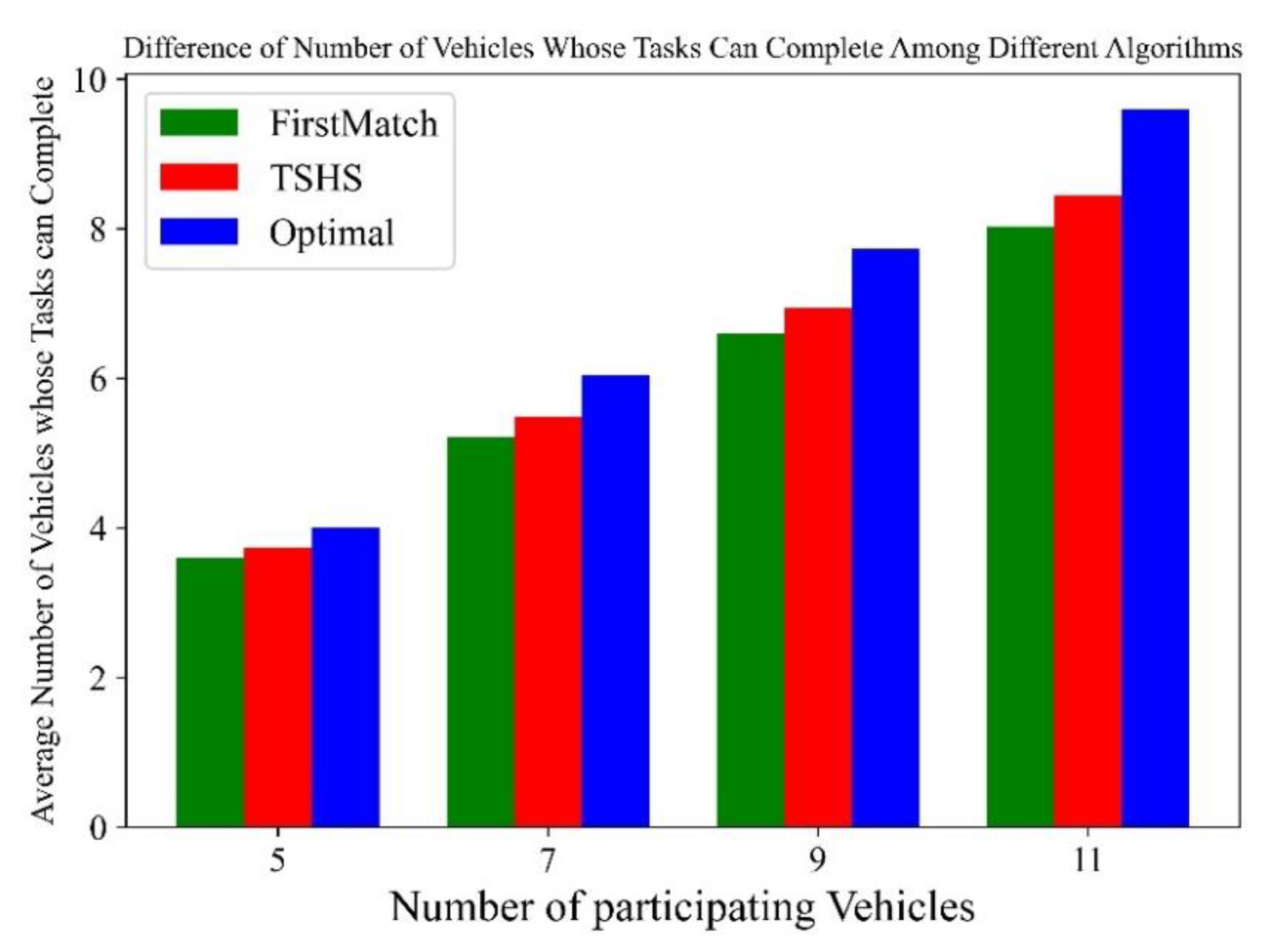
- Optimal: optimal tasks scheduling scheme, which is solved by CPLEX.
- FirstMatch (FM): Vehicles are numbered starting from 0, and FM selects vehicles in order from small to large for task scheduling determination. For the selected vehicle, a neighbor is also selected from the neighbor set according to the number from small to large, and as many tasks as possible are scheduled. If the vehicle cannot schedule its tasks in this way, it fails; otherwise, it succeeds.
5.2. Results and Discussion
5.2.1. Performance over Time
5.2.2. Improvement in Road Safety in the VEC-Based Architecture with Scheduling
5.2.3. Resource Utilization
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Eskandarian, A.; Wu, C.X.; Sun, C.Y. Research Advances and Challenges of Autonomous and Connected Ground Vehicles. IEEE Trans. Intell. Transp. Syst. 2021, 22, 683–711. [Google Scholar] [CrossRef]
- Caillot, A.; Ouerghi, S.; Vasseur, P.; Boutteau, R.; Dupuis, Y. Survey on Cooperative Perception in an Automotive Context. IEEE Trans. Intell. Transp. Syst. 2022, 1–20. [Google Scholar] [CrossRef]
- Kenney, J.B. Dedicated Short-Range Communications (DSRC) Standards in the United States. Proc. IEEE 2011, 99, 1162–1182. [Google Scholar] [CrossRef]
- Liu, L.K.; Lu, S.D.; Zhong, R.; Wu, B.F.; Yao, Y.T.; Zhang, Q.Y.; Shi, W.S. Computing Systems for Autonomous Driving: State of the Art and Challenges. IEEE Internet Things 2021, 8, 6469–6486. [Google Scholar] [CrossRef]
- Hafner, B.; Bajpai, V.; Ott, J.; Schmitt, G.A. A Survey on Cooperative Architectures and Maneuvers for Connected and Automated Vehicles. IEEE Commun. Surv. Tutor. 2022, 24, 380–403. [Google Scholar] [CrossRef]
- Shen, Z.P.; Liu, Y.G.; Li, Z.M.; Nabin, M.H. Cooperative Spacing Sampled Control of Vehicle Platoon Considering Undirected Topology and Analog Fading Networks. IEEE Trans. Intell. Transp. Syst. 2022, 1–14. [Google Scholar] [CrossRef]
- Kim, S.W.; Qin, B.X.; Chong, Z.J.; Shen, X.T.; Liu, W.; Ang, M.H.; Frazzoli, E.; Rus, D. Multivehicle Cooperative Driving Using Cooperative Perception: Design and Experimental Validation. IEEE Trans. Intell. Transp. Syst. 2015, 16, 663–680. [Google Scholar] [CrossRef]
- Zhou, P.Y.; Kortoci, P.; Yau, Y.P.; Finley, B.; Wang, X.J.; Braud, T.; Lee, L.H.; Tarkoma, S.; Kangasharju, J.; Hui, P. AICP: Augmented Informative Cooperative Perception. IEEE Trans. Intell. Transp. Syst. 2022, 1–14. [Google Scholar] [CrossRef]
- Lin, L.; Liao, X.F.; Jin, H.; Li, P. Computation Offloading Toward Edge Computing. Proc. IEEE 2019, 107, 1584–1607. [Google Scholar] [CrossRef]
- Amadeo, M.; Campolo, C.; Molinaro, A. Information-Centric Networking for Connected Vehicles: A Survey and Future Perspectives. IEEE Commun. Mag. 2016, 54, 98–104. [Google Scholar] [CrossRef]
- Feng, J.Y.; Liu, Z.; Wu, C.; Ji, Y.S. AVE: Autonomous Vehicular Edge Computing Framework with ACO-Based Scheduling. IEEE Trans. Veh. Technol. 2017, 66, 10660–10675. [Google Scholar] [CrossRef]
- Zhu, C.; Chiang, Y.H.; Xiao, Y.; Ji, Y.S. FlexSensing: A QoI and Latency-Aware Task Allocation Scheme for Vehicle-Based Visual Crowdsourcing via Deep Q-Network. IEEE Internet Things 2021, 8, 7625–7637. [Google Scholar] [CrossRef]
- Lai, Y.X.; Xu, Y.F.; Mai, D.J.; Fan, Y.; Yang, F. Optimized Large-Scale Road Sensing Through Crowdsourced Vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 3878–3889. [Google Scholar] [CrossRef]
- Hui, Y.L.; Huang, Y.H.; Su, Z.; Luan, T.H.; Cheng, N.; Xiao, X.; Ding, G.R. BCC: Blockchain-Based Collaborative Crowdsensing in Autonomous Vehicular Networks. IEEE Internet Things 2022, 9, 4518–4532. [Google Scholar] [CrossRef]
- Zhao, H.Y.; Zhang, Y.B.; Meng, P.F.; Shi, H.; Li, L.E.R.; Lou, T.C.; Zhao, J.S. Safety Score: A Quantitative Approach to Guiding Safety-Aware Autonomous Vehicle Computing System Design. In Proceedings of the 31st IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 23–26 June 2020; pp. 1479–1485. [Google Scholar]
- Tissljaric, L.; Vrbanic, F.; Ivanjko, E.; Caric, T. Motorway Bottleneck Probability Estimation in Connected Vehicles Environment Using Speed Transition Matrices. Sensors 2022, 22, 20. [Google Scholar] [CrossRef]
- Shan, M.; Narula, K.; Wong, Y.F.; Worrall, S.; Khan, M.; Alexander, P.; Nebot, E. Demonstrations of Cooperative Perception: Safety and Robustness in Connected and Automated Vehicle Operations. Sensors 2021, 21, 31. [Google Scholar] [CrossRef]
- Gani, S.M.O.; Fallah, Y.P.; Bansal, G.; Shimizu, T. A Study of the Effectiveness of Message Content, Length, and Rate Control for Improving Map Accuracy in Automated Driving Systems. IEEE Trans. Intell. Transp. Syst. 2019, 20, 405–420. [Google Scholar] [CrossRef]
- Higuchi, T.; Giordani, M.; Zanella, A.; Zorzi, M.; Altintas, O. Value-Anticipating V2V Communications for Cooperative Perception. In Proceedings of the 30th IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1947–1952. [Google Scholar]
- Thandavarayan, G.; Sepulcre, M.; Gozalvez, J. Cooperative Perception for Connected and Automated Vehicles: Evaluation and Impact of Congestion Control. IEEE Access 2020, 8, 197665–197683. [Google Scholar] [CrossRef]
- Rohani, M.; Gingras, D.; Vigneron, V.; Gruyer, D. A New Decentralized Bayesian Approach for Cooperative Vehicle Localization Based on Fusion of GPS and VANET Based Inter-Vehicle Distance Measurement. IEEE Intell. Transp. Syst. Mag. 2015, 7, 85–95. [Google Scholar] [CrossRef]
- Miller, A.; Rim, K.; Chopra, P.; Kelkar, P.; Likhachev, M. Cooperative Perception and Localization for Cooperative Driving. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–15 June 2020; pp. 1256–1262. [Google Scholar]
- Krämmer, A.; Schöller, C.; Gulati, D.; Knoll, A. Providentia—A Large Scale Sensing System for the Assistance of Autonomous Vehicles. 2019. Available online: https://mediatum.ub.tum.de/1510403 (accessed on 6 July 2021).
- Liu, X.; Li, W.D.; Zhang, X.J. Strategy-Proof Mechanism for Provisioning and Allocation Virtual Machines in Heterogeneous Clouds. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 1650–1663. [Google Scholar] [CrossRef]
- Zhang, J.X.; Yang, X.T.; Xie, N.; Zhang, X.J.; Vasilakos, A.V.; Li, W.D. An online auction mechanism for time-varying multidimensional resource allocation in clouds. Future Gener. Comp. Syst. 2020, 111, 27–38. [Google Scholar] [CrossRef]
- Zhang, J.X.; Xie, N.; Zhang, X.J.; Li, W.D. Strategy-Proof Mechanism for Online Time-Varying Resource Allocation with Restart. J. Comput. 2021, 19, 20. [Google Scholar] [CrossRef]
- Zhang, J.X.; Xie, N.; Yang, X.T.; Zhang, X.J.; Li, W.D. Strategy-proof mechanism for time-varying batch virtual machine allocation in clouds. Clust. Comput. 2021, 24, 3709–3724. [Google Scholar] [CrossRef]
- Zhang, J.X.; Xie, N.; Zhang, X.J.; Li, W.D. An online auction mechanism for cloud computing resource allocation and pricing based on user evaluation and cost. Future Gener. Comp. Syst. 2018, 89, 286–299. [Google Scholar] [CrossRef]
- Zhang, J.X.; Xie, N.; Zhang, X.J.; Yue, K.; Li, W.D.; Kumar, D. Machine Learning Based Resource Allocation of Cloud Computing in Auction. CMC-Comput. Mat. Contin. 2018, 56, 123–135. [Google Scholar] [CrossRef]
- Zhang, J.X.; Chi, L.X.; Xie, N.; Yang, X.T.; Zhang, X.J.; Li, W.D. Strategy-proof mechanism for online resource allocation in cloud and edge collaboration. Computing 2022, 104, 383–412. [Google Scholar] [CrossRef]
- Zhang, J.X.; Lou, W.L.; Sun, H.; Su, Q.; Li, W.D. Truthful auction mechanisms for resource allocation in the Internet of Vehicles with public blockchain networks. Future Gener. Comp. Syst. 2022, 132, 11–24. [Google Scholar] [CrossRef]
- Liwang, M.H.; Wang, J.X.; Gao, Z.B.; Du, X.J.; Guizani, M. Game Theory Based Opportunistic Computation Offloading in Cloud-Enabled IoV. IEEE Access 2019, 7, 32551–32561. [Google Scholar] [CrossRef]
- Chen, X.; Thomas, N.; Zhan, T.M.; Ding, J. A Hybrid Task Scheduling Scheme for Heterogeneous Vehicular Edge Systems. IEEE Access 2019, 7, 117088–117099. [Google Scholar] [CrossRef]
- Wan, S.H.; Li, X.; Xue, Y.; Lin, W.M.; Xu, X.L. Efficient computation offloading for Internet of Vehicles in edge computing-assisted 5G networks. J. Supercomput. 2020, 76, 2518–2547. [Google Scholar] [CrossRef]
- Liu, Y.; Yu, H.M.; Xie, S.L.; Zhang, Y. Deep Reinforcement Learning for Offloading and Resource Allocation in Vehicle Edge Computing and Networks. IEEE Trans. Veh. Technol. 2019, 68, 11158–11168. [Google Scholar] [CrossRef]
- Zhou, Z.Y.; Feng, J.H.; Chang, Z.; Shen, X.M. Energy-Efficient Edge Computing Service Provisioning for Vehicular Networks: A Consensus ADMM Approach. IEEE Trans. Veh. Technol. 2019, 68, 5087–5099. [Google Scholar] [CrossRef]
- Xu, X.L.; Xue, Y.; Qi, L.Y.; Yuan, Y.; Zhang, X.Y.; Umer, T.; Wan, S.H. An edge computing-enabled computation offloading method with privacy preservation for internet of connected vehicles. Future Gener. Comp. Syst. 2019, 96, 89–100. [Google Scholar] [CrossRef]
- Jansen, K. A Fast Approximation Scheme for the Multiple Knapsack Problem. In International Conference on Current Trends in Theory and Practice of Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7147, pp. 313–324. [Google Scholar]
- Available online: https://www.ibm.com/products/ilog-cplex-optimization-studio (accessed on 2 June 2021).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acronym | Phrase |
|---|---|
| AV | autonomous vehicle |
| VEC | vehicular edge computing |
| RSU | roadside unit |
| TSHS | two-stage heuristic scheme |
| CAVs | connected and autonomous vehicles |
| DSRC | dedicated short-range communication |
| V2V | vehicle-to-vehicle |
| V2I | vehicle-to-infrastructure |
| EC | edge computing |
| NoN | number of neighbors |
| BDR | balance degree of resources |
| RRAT | resource requirements of all tasks |
| RSD | satisfaction degree |
| Term | Description |
|---|---|
| Number and set of AVs in cooperative perception | |
| Number and set of task types | |
| Number and set of resource types | |
| Task request vector of vehicle and task request matrix of all AVs in a time slot | |
| Resource requirement vector of task type , and the resource requirement matrix of all types of tasks | |
| Available resources of AV used in cooperative perception and those resources of all vehicles in a time slot | |
| Neighbor vector of AV and those of all vehicles | |
| Decision variable of AV , which indicates whether its tasks are completed with assistance from other vehicles. . | |
| Latent decision variable of -type tasks that are transmitted to AV from AV for execution.. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, Y.; Zhang, J. A Vehicular Edge Computing-Based Architecture and Task Scheduling Scheme for Cooperative Perception in Autonomous Driving. Mathematics 2022, 10, 3328. https://doi.org/10.3390/math10183328
Wei Y, Zhang J. A Vehicular Edge Computing-Based Architecture and Task Scheduling Scheme for Cooperative Perception in Autonomous Driving. Mathematics. 2022; 10(18):3328. https://doi.org/10.3390/math10183328
Chicago/Turabian StyleWei, Yuankui, and Jixian Zhang. 2022. "A Vehicular Edge Computing-Based Architecture and Task Scheduling Scheme for Cooperative Perception in Autonomous Driving" Mathematics 10, no. 18: 3328. https://doi.org/10.3390/math10183328
APA StyleWei, Y., & Zhang, J. (2022). A Vehicular Edge Computing-Based Architecture and Task Scheduling Scheme for Cooperative Perception in Autonomous Driving. Mathematics, 10(18), 3328. https://doi.org/10.3390/math10183328