

Anomaly Detection Algorithm Based on Broad Learning System and Support Vector Domain Description


Abstract
:1. Introduction
2. Related Work
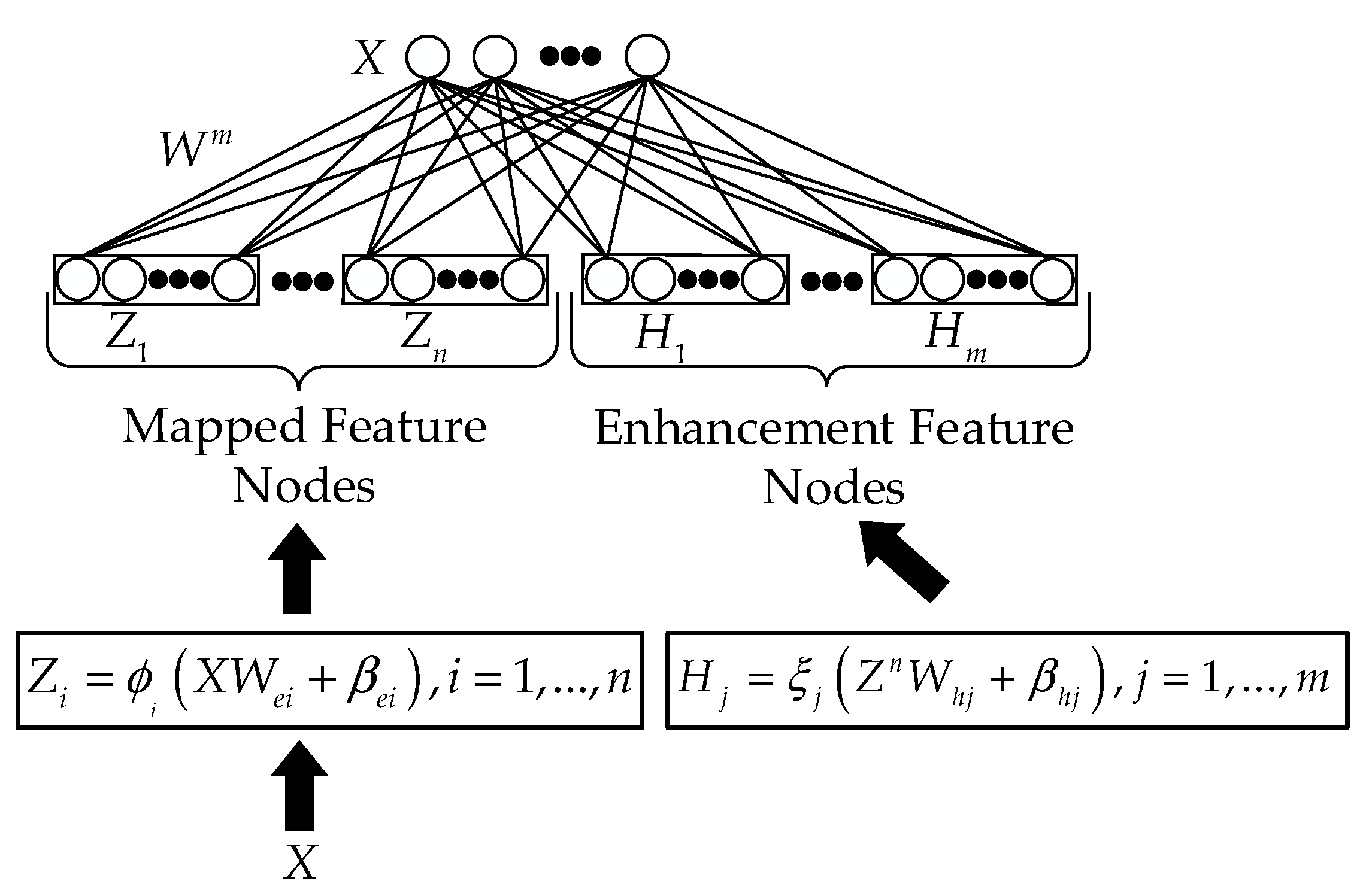
2.1. Overview of the Broad Learning System
2.2. Broad Learning System (BLS)
2.3. Support Vector Domain Description (SVDD)
- (1)
- Interior points (IP): , the corresponding sample lies within the hypersphere.
- (2)
- Support vectors (SV): , the corresponding sample lies on the boundary of the hypersphere.
- (3)
- Boundary support vector (BSV): , the corresponding sample lies outside the hypersphere.
3. Fundamentals of Anomaly Detection Model Based on BLS and SVDD
3.1. Data Reconstruction Model Based on BLS
- (1)
- Suppose the original input dataset is ; and denote the number and feature dimension of the data samples, respectively. According to Equations (1) and (2), we calculate to get the corresponding mapped feature nodes and enhancement feature nodes , respectively. By connecting the mapped feature nodes and enhancement feature nodes horizontally, we obtain the output feature matrix of the BLS, represented as .
- (2)
- Construct the data reconstruction model. Let , and be the data matrix after reconstruction. We can then obtain the output expression as follows:
- (3)
- Similar to the solution method described above, Equation (15) can be expressed as , where is the pseudo-inverse matrix of the matrix . Subsequently, by introducing parametric regularization, the problem of solving the pseudo-inverse of a matrix can be expressed as the following optimization problem.
3.2. Data Reconstruction Error Weights
3.3. Reconstruction Error Weighting-Based SVDD Algorithm
3.4. Framework of the BLSW_SVDD Model
- (1)
- Training the data-reconstruction model. First, the dataset is divided into a normal dataset and an abnormal dataset. The normal dataset is utilized for training the reconstruction error weight matrix of the BLS network. Subsequently, the reconstruction data matrix of the normal data and the abnormal data ( and ) can be obtained using Equation (15).
- (2)
- The reconstruction error weights are calculated. The normal dataset and the abnormal dataset are partitioned with 70% of the data for training the SVDD model and the remaining 30% of the data for testing the SVDD model (i.e., and ). Correspondingly, 70% of the normal reconstructed data and 70% of the abnormal reconstructed data are removed to obtain the reconstructed error matrix of the training set , and the remaining 30% of the normal reconstructed data and abnormal reconstructed data are used as the reconstructed error matrix of the test set . The reconstruction error value of each training data point can be obtained using Equation (18).
- (3)
- Training the SVDD. The SVDD model is trained by assigning a weight based on the reconstruction error to each training data point in the and replacing the penalty parameter to obtain the center of the minimum hypersphere and the minimum hypersphere radius .
- (4)
- Testing and anomaly detection. The distance from the data point Z in the test dataset to the center of the hypersphere is calculated using Equation (14). If , then the test data point Z is within the hypersphere and is a normal class sample, otherwise, it is an abnormal class sample.
4. Experiment and Analysis
4.1. Experimental Setup and Datasets
4.2. Model Evaluation Metrics
- (1)
- Precision represents the proportion of samples identified as normal by the model that are actually normal.
- (2)
- Recall represents the ratio of the number of samples correctly identified as normal by the model to the total number of samples in the normal class.
- (3)
- Accuracy is the most commonly used classification performance metric and can represent a model’s accuracy. This represents the number of correct model identifications as a proportion of the total sample size.
- (4)
- F1 value, also known as the balanced F-score, is defined as the summed average of the accuracy and recall, which integrates the results of precision and recall, and expresses the robustness of the model.
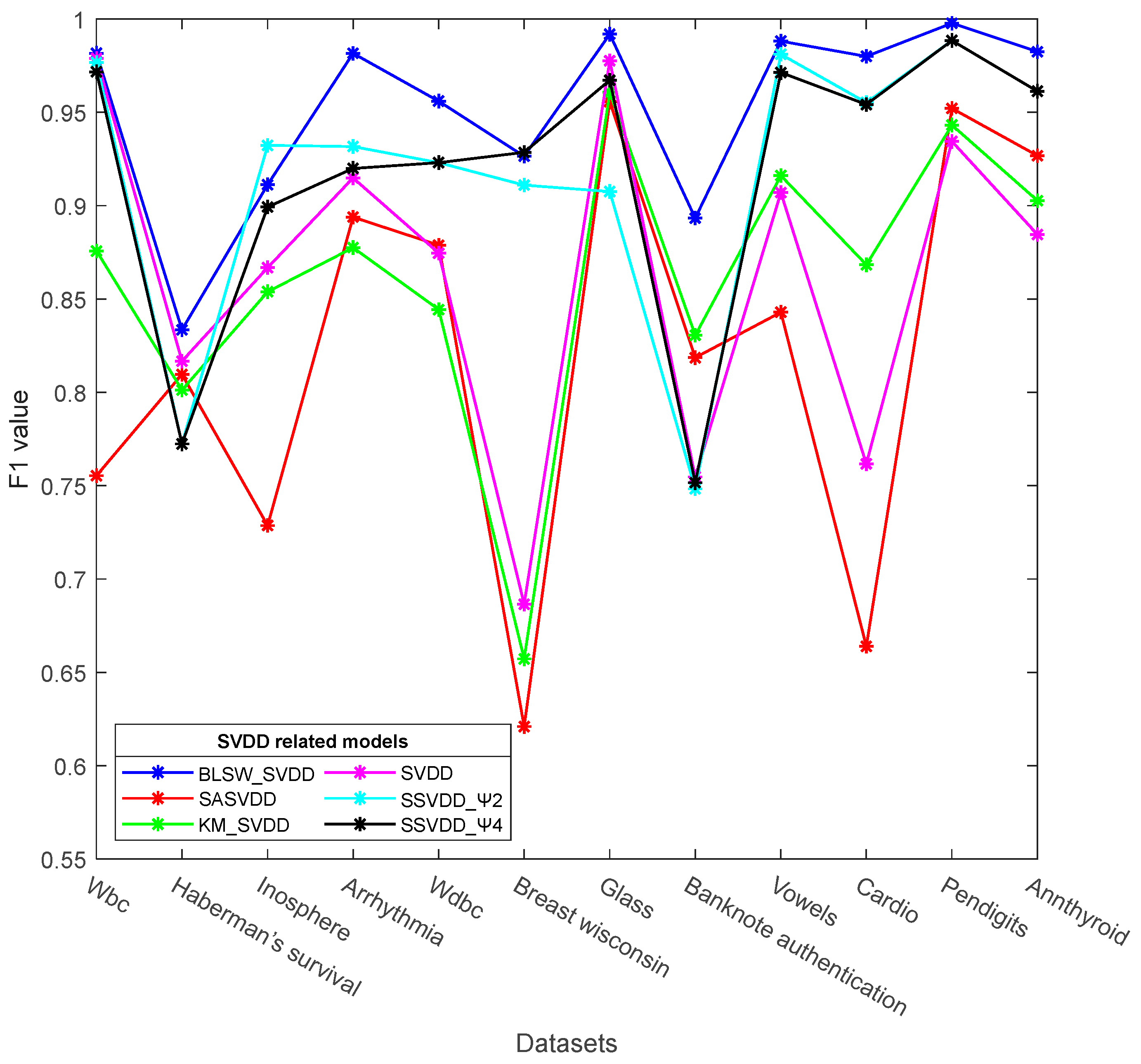
4.3. Comparison Results and Analysis with Other SVDD Models
5. Conclusions
- (1)
- The kernel function used in the BLSW_SVDD model in this study is a Gaussian function, and the parameter to be optimized is . However, when using kernel tricks, the SVDD algorithm faces difficulty selecting the kernel function and parameters. Therefore, in subsequent work, multiple kernel functions should be considered, which can mitigate the difficulty of selecting the kernel function and more fully portray the feature information of the original data.
- (2)
- The BLSW_SVDD model is ineffective on some datasets with a large proportion of abnormal data. Hence, we intend to continuously optimize the performance of the BLSW_SVDD model on datasets with a large proportion of anomaly data and continuously improve the performance of the BLSW_SVDD model to develop BLSW_SVDD model as a multi-classifier.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tax, D.M.; Duin, R.P. Support vector domain description. Pattern Recognit. Lett. 1999, 20, 1191–1199. [Google Scholar] [CrossRef]
- Tax, D.M.; Duin, R.P. Support vector data description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef]
- Qiu, K.; Song, W.; Wang, P. Abnormal data detection for industrial processes using adversarial autoencoders support vector data description. Meas. Sci. Technol. 2022, 33, 55–110. [Google Scholar] [CrossRef]
- Karsaz, A. A modified convolutional neural network architecture for diabetic retinopathy screening using SVDD. Appl. Soft Comput. 2022, 125, 102–109. [Google Scholar] [CrossRef]
- Lee, K.; Kim, D.-W.; Lee, D.; Lee, K.H. Improving support vector data description using local density degree. Pattern Recognit. 2005, 38, 1768–1771. [Google Scholar] [CrossRef]
- Lee, K.; Kim, D.-W.; Lee, K.H.; Lee, D. Density-induced support vector data description. IEEE Trans. Neural Netw. 2007, 18, 284–289. [Google Scholar] [CrossRef]
- Wang, C.-D.; Lai, J. Position regularized support vector domain description. Pattern Recognit. 2013, 46, 875–884. [Google Scholar] [CrossRef]
- Cha, M.; Kim, J.S.; Baek, J.-G. Density weighted support vector data description. Expert Syst. Appl. 2014, 41, 3343–3350. [Google Scholar] [CrossRef]
- Tao, H.; Yun, L.; Ke, W.; Jian, X.; Fu, L. A new weighted SVDD algorithm for outlier detection. In Proceedings of the 2016 Chinese Control and Decision Conference (CCDC), Yinchuan, China, 28–30 May 2016; pp. 5456–5461. [Google Scholar]
- Xu, J.; Yao, J.; Ni, L. Fault detection based on SVDD and custer algorithm. In Proceedings of the 2011 International Conference on Electronics, Communications and Control (ICECC), Ningbo, China, 9–11 September 2011; pp. 2050–2052. [Google Scholar]
- Wu, T.; Liang, Y.; Varela, R.; Wu, C.; Zhao, G.; Han, X. Self-adaptive SVDD integrated with AP clustering for one-class classification. Pattern Recognit. Lett. 2016, 84, 232–238. [Google Scholar] [CrossRef]
- Sohrab, F.; Raitoharju, J.; Gabbouj, M.; Iosifidis, A. Subspace support vector data description. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 722–727. [Google Scholar]
- Ruff, L.; Vandermeulen, R.; Goernitz, N.; Deecke, L.; Siddiqui, S.A.; Binder, A.; Müller, E.; Kloft, M. Deep one-class classification. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4393–4402. [Google Scholar]
- Hojjati, H.; Armanfard, N. Dasvdd: Deep autoencoding support vector data descriptor for anomaly detection. arXiv 2021, arXiv:2106.05410. [Google Scholar]
- Manoharan, P.; Walia, R.; Iwendi, C.; Ahanger, T.A.; Suganthi, S.; Kamruzzaman, M.; Bourouis, S.; Alhakami, W.; Hamdi, M. SVM-based generative adverserial networks for federated learning and edge computing attack model and outpoising. Expert Syst. 2022, e13072. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA; London, England, 2016. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Salakhutdinov, R.; Larochelle, H. Efficient learning of deep boltzmann machines. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 693–700. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Pao, Y.-H.; Takefuji, Y. Functional-link net computing: Theory, system architecture, and functionalities. Computer 1992, 25, 76–79. [Google Scholar] [CrossRef]
- Pao, Y.-H.; Park, G.-H.; Sobajic, D.J. Learning and generalization characteristics of the random vector functional-link net. Neurocomputing 1994, 6, 163–180. [Google Scholar] [CrossRef]
- Kumpati, S.N.; Kannan, P. Identification and control of dynamical systems using neural networks. IEEE Trans. Neural Netw. 1990, 1, 4–27. [Google Scholar]
- Chen, C.P.; Liu, Z. Broad learning system: A new learning paradigm and system without going deep. In Proceedings of the 2017 32nd Youth Academic Annual Conference of Chinese Association of Automation (YAC), Hefei, China, 19–21 May 2017; pp. 1271–1276. [Google Scholar]
- Chen, C.P.; Liu, Z. Broad learning system: An effective and efficient incremental learning system without the need for deep architecture. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 10–24. [Google Scholar] [CrossRef]
- Chu, F.; Liang, T.; Chen, C.P.; Wang, X.; Ma, X. Weighted broad learning system and its application in nonlinear industrial process modeling. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 3017–3031. [Google Scholar] [CrossRef]
- Zheng, Y.; Chen, B.; Wang, S.; Wang, W. Broad learning system based on maximum correntropy criterion. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3083–3097. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Li, J.; Lu, G.; Shen, P.; Bennamoun, M.; Shah, S.A.A.; Miao, Q.; Zhu, G.; Li, P.; Lu, X. Analysis and variants of broad learning system. IEEE Trans. Syst. Man Cybern. Syst. 2020, 52, 334–344. [Google Scholar] [CrossRef]
- Huang, P.; Chen, B. Bidirectional broad learning system. In Proceedings of the 2020 IEEE 7th International Conference on Industrial Engineering and Applications (ICIEA), Bangkok, Thailand, 19–21 April 2020; pp. 963–968. [Google Scholar]
- Xu, L.; Chen, C.P. Comparison and combination of activation functions in broad learning system. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 3537–3542. [Google Scholar]
- Pu, X.; Li, C. Online semisupervised broad learning system for industrial fault diagnosis. IEEE Trans. Ind. Inform. 2021, 17, 6644–6654. [Google Scholar] [CrossRef]
- Huang, J.; Vong, C.-M.; Chen, C.P.; Zhou, Y. Accurate and Efficient Large-Scale Multi-Label Learning With Reduced Feature Broad Learning System Using Label Correlation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Zeng, X.; Tian, F.; Zhang, S.; Zhao, L. Domain transfer broad learning system for long-term drift compensation in electronic nose systems. IEEE Access 2019, 7, 143947–143959. [Google Scholar] [CrossRef]
- Fan, J.; Wang, X.; Wang, X.; Zhao, J.; Liu, X. Incremental Wishart broad learning system for fast PolSAR image classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1854–1858. [Google Scholar] [CrossRef]
- Tsai, C.-C.; Hsu, C.-F.; Wu, C.-W.; Tai, F.-C. Cooperative localization using fuzzy DDEIF and broad learning system for uncertain heterogeneous omnidirectional multi-robots. Int. J. Fuzzy Syst. 2019, 21, 2542–2555. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.-A.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Gong, M.; Liu, J.; Li, H.; Cai, Q.; Su, L. A multiobjective sparse feature learning model for deep neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 3263–3277. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Sample Points | Dimensionality | Outliers (%) |
|---|---|---|---|
| Wbc | 378 | 30 | 21 (5.6%) |
| Haberman’s survival | 306 | 3 | 81 (26.4%) |
| Inosphere | 351 | 34 | 126 (36%) |
| Arrhythmia | 452 | 274 | 66 (15%) |
| Wdbc | 569 | 30 | 212 (27.1%) |
| Breast Wisconsin | 683 | 9 | 239 (35%) |
| Glass | 214 | 9 | 9 (4.2%) |
| Banknote authentication | 1372 | 4 | 610 (45%) |
| Vowels | 1456 | 12 | 50 (3.4%) |
| Cardio | 1831 | 21 | 176 (9.6%) |
| Pendigits | 6870 | 16 | 156 (2.27%) |
| Annthyroid | 7200 | 6 | 534 (7.42%) |
| Predicted as a Target Class | Predicted as Anomaly Class | |
|---|---|---|
| Real as a target class | ) | ) |
| Real as anomaly class | ) | ) |
| SVDD | KM_SVDD | SA_SVDD | SSVDD | BLSW_SVDD | ||||
|---|---|---|---|---|---|---|---|---|
| Ψ1 | Ψ2 | Ψ3 | Ψ4 | |||||
| Wbc | 0.9600 | 0.7913 | 0.8452 | 0.9391 | 0.9130 | 0.9478 | 0.9391 | 0.9652 |
| Haberman’s survival | 0.7011 | 0.6796 | 0.6806 | 0.6559 | 0.6774 | 0.6344 | 0.6559 | 0.7297 |
| Inosphere | 0.8330 | 0.8396 | 0.8340 | 0.8113 | 0.8774 | 0.8491 | 0.9151 | 0.8896 |
| Arrhythmia | 0.8478 | 0.7956 | 0.8309 | 0.8824 | 0.8971 | 0.8750 | 0.8456 | 0.9691 |
| Wdbc | 0.8215 | 0.7703 | 0.7919 | 0.8953 | 0.8953 | 0.8953 | 0.8953 | 0.9209 |
| Breast Wisconsin | 0.6431 | 0.6180 | 0.6900 | 0.7820 | 0.9336 | 0.7630 | 0.8294 | 0.9431 |
| Glass | 0.9569 | 0.9262 | 0.9169 | 0.8923 | 0.9077 | 0.8000 | 0.8154 | 0.9846 |
| Banknote authentication | 0.6400 | 0.7840 | 0.8049 | 0.6384 | 0.6384 | 0.6384 | 0.6165 | 0.8884 |
| Vowels | 0.8780 | 0.8654 | 0.9153 | 0.9474 | 0.9542 | 0.9497 | 0.9497 | 0.9771 |
| Cardio | 0.7382 | 0.7789 | 0.8104 | 0.9018 | 0.9164 | 0.9273 | 0.9164 | 0.9636 |
| Pendigits | 0.9233 | 0.9347 | 0.9455 | 0.9772 | 0.9772 | 0.9772 | 0.9772 | 0.9937 |
| Annthyroid | 0.8563 | 0.8756 | 0.9023 | 0.9255 | 09255 | 0.9255 | 0.9255 | 0.9727 |
| SVDD | KM_SVDD | SA_SVDD | SSVDD | BLSW_SVDD | ||||
|---|---|---|---|---|---|---|---|---|
| Ψ1 | Ψ2 | Ψ3 | Ψ4 | |||||
| Wbc | 0.9789 | 0.8757 | 0.7554 | 0.9680 | 0.9767 | 0.9717 | 0.9717 | 0.9817 |
| Haberman’s survival | 0.8167 | 0.8013 | 0.8097 | 0.7867 | 0.7724 | 0.7724 | 0.7724 | 0.8335 |
| Inosphere | 0.8668 | 0.8539 | 0.7287 | 0.8529 | 0.9323 | 0.8806 | 0.8993 | 0.9112 |
| Arrhythmia | 0.9149 | 0.8776 | 0.8939 | 0.9163 | 0.9317 | 0.9224 | 0.9200 | 0.9816 |
| Wdbc | 0.8746 | 0.8443 | 0.8788 | 0.9231 | 0.9231 | 0.9231 | 0.9231 | 0.9560 |
| Breast Wisconsin | 0.6865 | 0.6573 | 0.6210 | 0.8678 | 0.9110 | 0.9110 | 0.9286 | 0.9265 |
| Glass | 0.9776 | 0.9607 | 0.9557 | 0.9421 | 0.9076 | 0.8850 | 0.9672 | 0.9919 |
| Banknote authentication | 0.7548 | 0.8306 | 0.8186 | 0.7410 | 0.7483 | 0.7483 | 0.7517 | 0.8933 |
| Vowels | 0.9070 | 0.9161 | 0.8430 | 0.9763 | 0.9811 | 0.9784 | 0.9713 | 0.9882 |
| Cardio | 0.7617 | 0.8683 | 0.6640 | 0.9473 | 0.9553 | 0.9604 | 0.9542 | 0.9800 |
| Pendigits | 0.9344 | 0.9432 | 0.9521 | 0.9885 | 0.9885 | 0.9885 | 0.9885 | 0.9977 |
| Annthyroid | 0.8846 | 0.9027 | 0.9268 | 0.9613 | 0.9613 | 0.9613 | 0.9613 | 0.9825 |
| SVDD | KM_SVDD | SA_SVDD | SSVDD | BLSW_SVDD | ||||
|---|---|---|---|---|---|---|---|---|
| Ψ1 | Ψ2 | Ψ3 | Ψ4 | |||||
| Inosphere | 0.0122 | 0.005 | 0.0067 | 0.0026 | 0.0017 | 0.0018 | 0.0016 | 0.002 |
| Arrhythmia | 0.013 | 0.012 | 0.0152 | 0.0178 | 0.0122 | 0.0103 | 0.0101 | 0.0023 |
| Breast Wisconsin | 0.0034 | 0.0137 | 0.014 | 0.0177 | 0.0087 | 0.0079 | 0.0079 | 0.0022 |
| Vowels | 0.4157 | 0.0252 | 0.0384 | 0.1508 | 0.1422 | 0.1367 | 0.1603 | 0.0062 |
| Annthyroid | 15.5247 | 10.3347 | 11.3567 | 19.0395 | 18.9802 | 19.0092 | 19.0057 | 0.0699 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Q.; Zheng, Z.; Zhu, W.; Fang, X.; Fang, R.; Sun, W. Anomaly Detection Algorithm Based on Broad Learning System and Support Vector Domain Description. Mathematics 2022, 10, 3292. https://doi.org/10.3390/math10183292
Huang Q, Zheng Z, Zhu W, Fang X, Fang R, Sun W. Anomaly Detection Algorithm Based on Broad Learning System and Support Vector Domain Description. Mathematics. 2022; 10(18):3292. https://doi.org/10.3390/math10183292
Chicago/Turabian StyleHuang, Qun, Zehua Zheng, Wenhao Zhu, Xiaozhao Fang, Ribo Fang, and Weijun Sun. 2022. "Anomaly Detection Algorithm Based on Broad Learning System and Support Vector Domain Description" Mathematics 10, no. 18: 3292. https://doi.org/10.3390/math10183292
APA StyleHuang, Q., Zheng, Z., Zhu, W., Fang, X., Fang, R., & Sun, W. (2022). Anomaly Detection Algorithm Based on Broad Learning System and Support Vector Domain Description. Mathematics, 10(18), 3292. https://doi.org/10.3390/math10183292