
Dynamic Model Selection Based on Demand Pattern Classification in Retail Sales Forecasting



Abstract
:1. Introduction
2. Literature Review
2.1. Demand Forecasting Method in Retailing
2.1.1. Individual Methods
2.1.2. Hybrid Methods
2.1.3. Combination Methods
2.2. Model Selection
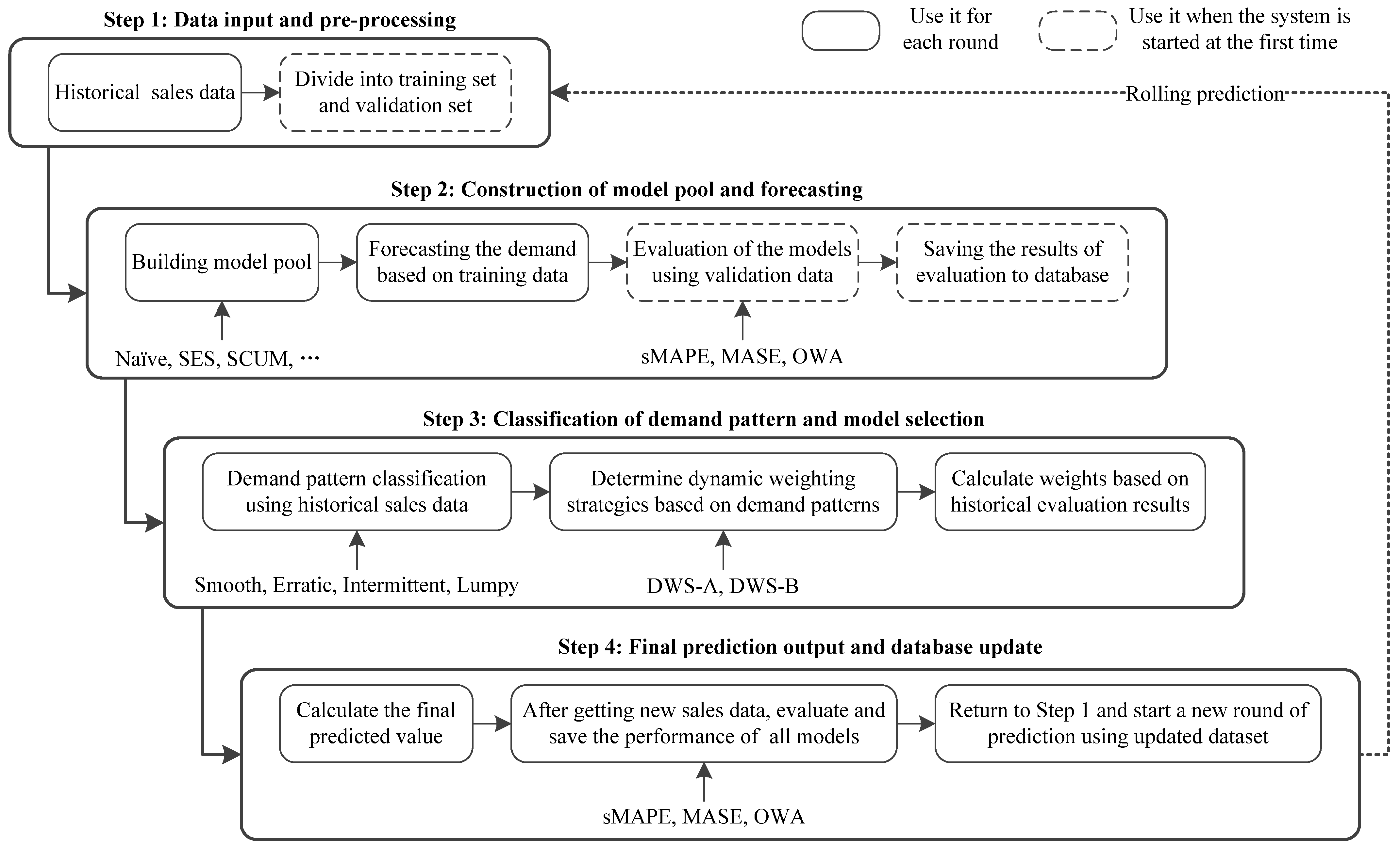
3. Methodology
3.1. Design of Forecasting Model Pool
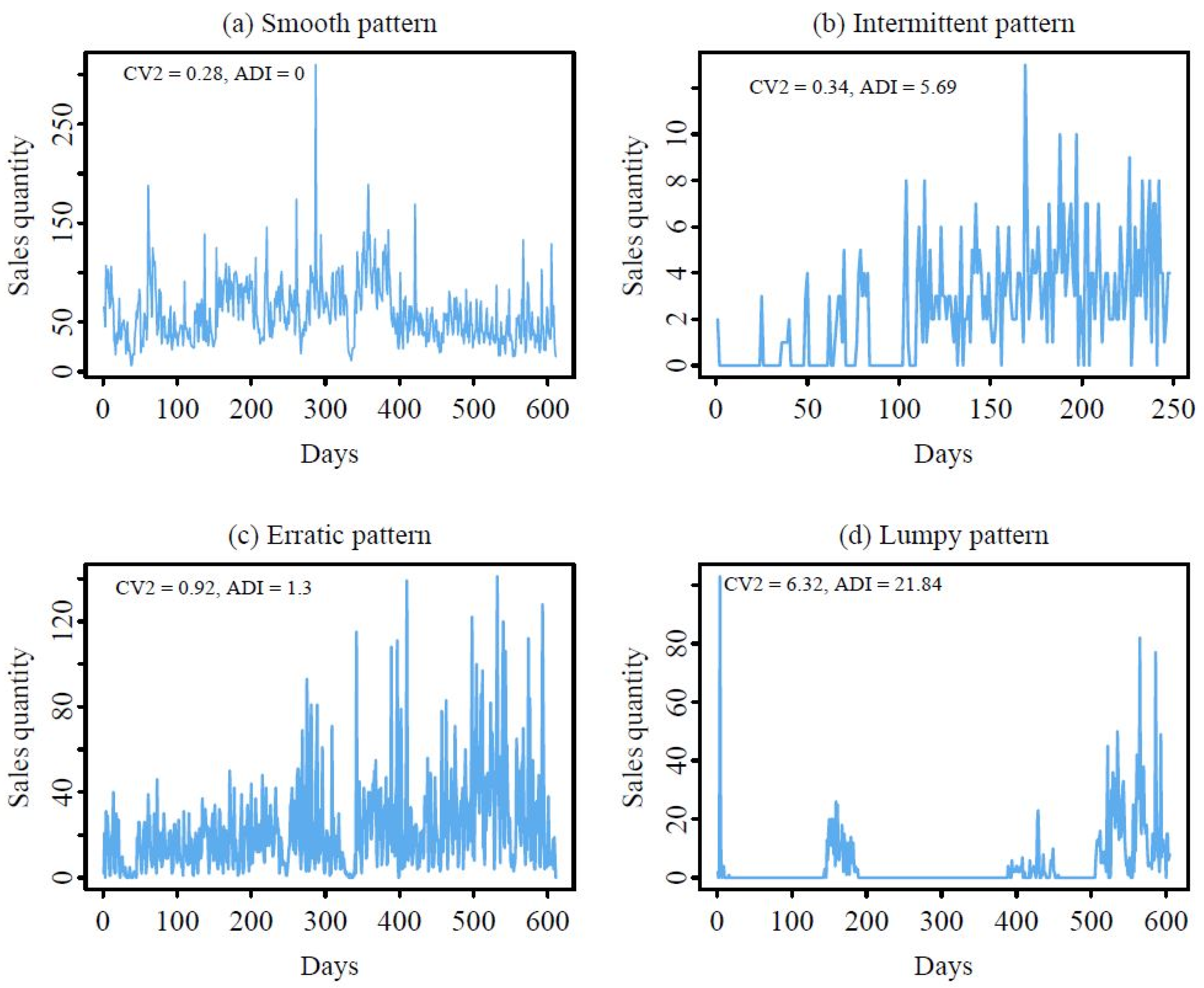
3.2. Demand Pattern Classification
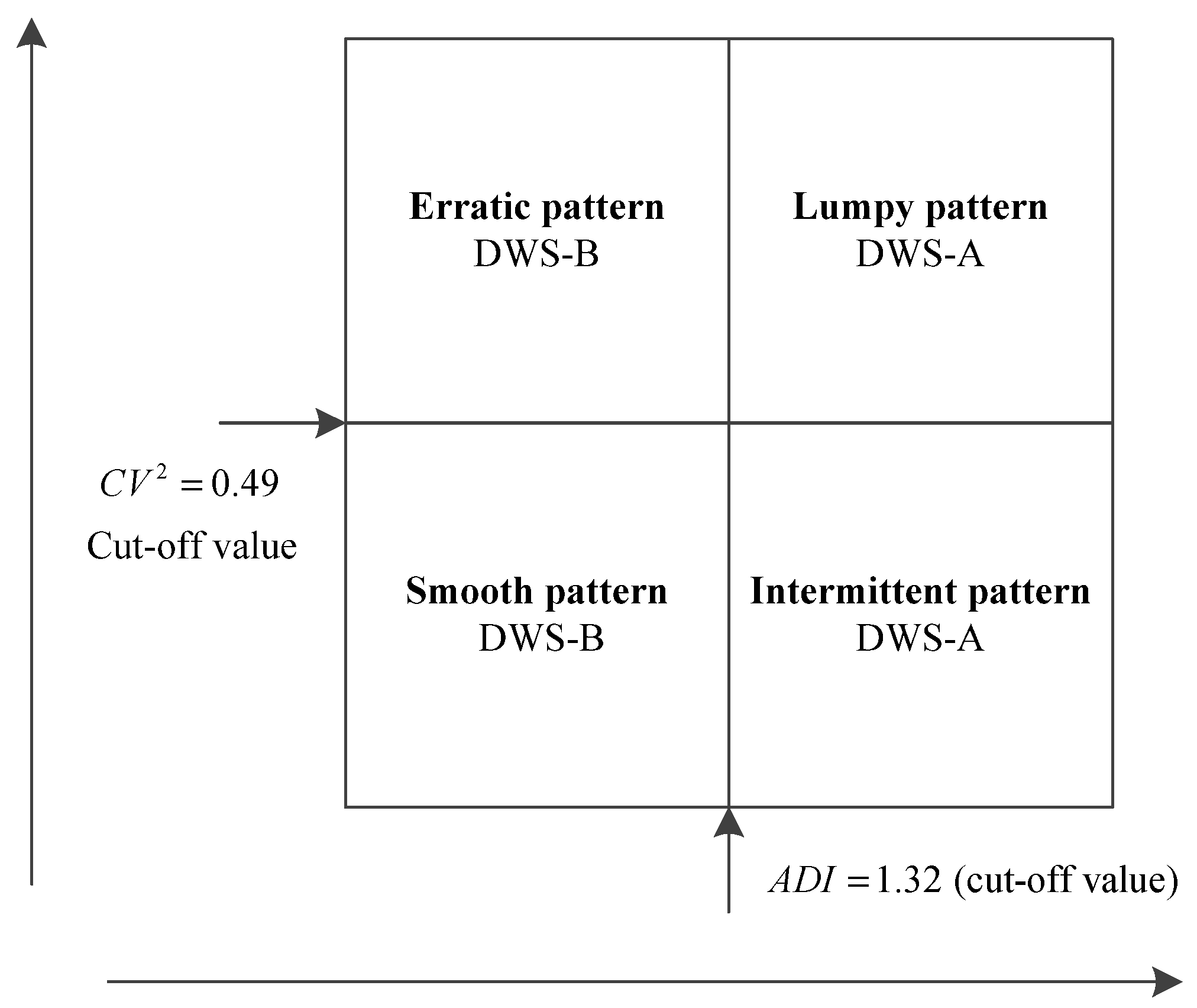
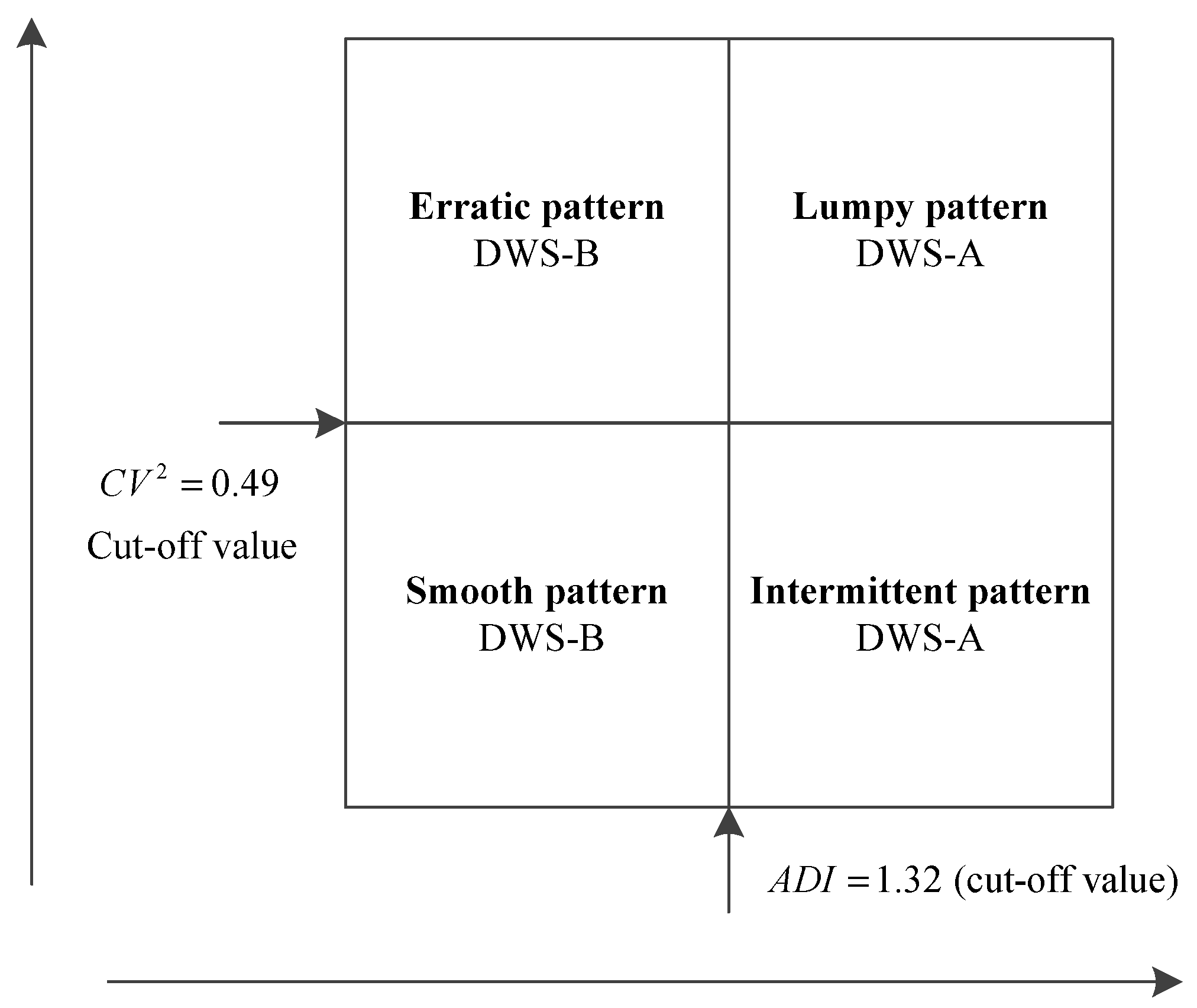
3.3. Design of Dynamic Weighting Strategy
3.4. Model Evaluation
4. Empirical Analysis
4.1. Empirical Data
4.2. Empirical Results
4.2.1. Smooth Pattern
4.2.2. Intermittent Pattern
4.2.3. Erratic Pattern
4.2.4. Lumpy Pattern
4.3. Optimal Dynamic Weighting Strategy for Each Demand Pattern
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Simchi-Levi, D.; Wu, M.X. Powering retailers′ digitization through analytics and automation. Int. J. Prod. Res. 2018, 56, 809–816. [Google Scholar] [CrossRef]
- Arunraj, N.S.; Ahrens, D. A hybrid seasonal autoregressive integrated moving average and quantile regression for daily food sales forecasting. Int. J. Prod. Econ. 2015, 170, 321–335. [Google Scholar] [CrossRef]
- Claeskens, G.; Magnus, J.R.; Vasnev, A.L.; Wang, W. The forecast combination puzzle: A simple theoretical explanation. Int. J. Forecast. 2016, 32, 754–762. [Google Scholar] [CrossRef]
- Ulrich, M.; Jahnke, H.; Langrock, R.; Pesch, R.; Senge, R. Classification-based model selection in retail demand forecasting. Int. J. Forecast. 2022, 38, 209–223. [Google Scholar] [CrossRef]
- Makridakis, S.; Andersen, A.; Carbone, R.; Fildes, R.; Hibon, M.; Lewandowski, R.; Newton, J.; Parzen, E.; Winkler, R. The accuracy of extrapolation (time series) methods: Results of a forecasting competition. J. Forecast. 1982, 1, 111–153. [Google Scholar] [CrossRef]
- Ching-Chin, C.; Ieng, A.I.K.; Ling-Ling, W.; Ling-Chieh, K. Designing a decision-support system for new product sales forecasting. Expert Syst. Appl. 2010, 37, 1654–1665. [Google Scholar] [CrossRef]
- Neelamegham, R.; Chintagunta, P.K. Modeling and Forecasting the Sales of Technology Products. Qme-Quant. Mark. Econ. 2004, 2, 195–232. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M4 Competition: Results, findings, conclusion and way forward. Int. J. Forecast. 2018, 34, 802–808. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice; OTexts: Melbourne, Australia, 2018. [Google Scholar]
- Brown, R.G. Smoothing, Forecasting and Prediction of Discrete Time Series; Courier Corporation: Chelmsford, MA, USA, 2004. [Google Scholar]
- Holt, C.C. Forecasting seasonals and trends by exponentially weighted moving averages. Int. J. Forecast. 2004, 20, 5–10. [Google Scholar] [CrossRef]
- Winters, P.R. Forecasting sales by exponentially weighted moving averages. Manag. Sci. 1960, 6, 324–342. [Google Scholar] [CrossRef]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Ali, Ö.G.; Sayın, S.; van Woensel, T.; Fransoo, J. SKU demand forecasting in the presence of promotions. Expert Syst. Appl. 2009, 36, 12340–12348. [Google Scholar] [CrossRef]
- Peng, B.; Song, H.; Crouch, G.I. A meta-analysis of international tourism demand forecasting and implications for practice. Tour. Manag. 2014, 45, 181–193. [Google Scholar] [CrossRef]
- Divakar, S.; Ratchford, B.T.; Shankar, V. Practice Prize Article—CHAN4CAST: A Multichannel, Multiregion Sales Forecasting Model and Decision Support System for Consumer Packaged Goods. Mark. Sci. 2005, 24, 334–350. [Google Scholar] [CrossRef]
- Kong, J.; Martin, G. A backpropagation neural network for sales forecasting. In Proceedings of Proceedings of ICNN′95-International Conference on Neural Networks, Perth, Australia, 27 November 1995; pp. 1007–1011.
- Lee, W.-I.; Chen, C.-W.; Chen, K.-H.; Chen, T.-H.; Liu, C.-C. Comparative study on the forecast of fresh food sales using logistic regression, moving average and BPNN methods. J. Mar. Sci. Technol. 2012, 20, 142–152. [Google Scholar] [CrossRef]
- Chen, F.; Ou, T. Gray relation analysis and multilayer functional link network sales forecasting model for perishable food in convenience store. Expert Syst. Appl. 2009, 36, 7054–7063. [Google Scholar] [CrossRef]
- Aburto, L.; Weber, R. Improved supply chain management based on hybrid demand forecasts. Appl. Soft Comput. 2007, 7, 136–144. [Google Scholar] [CrossRef]
- Liu, J.; Liu, C.; Zhang, L.; Xu, Y. Research on sales information prediction system of e-commerce enterprises based on time series model. Inf. Syst. E-Bus. Manag. 2019, 18, 1–14. [Google Scholar] [CrossRef]
- Rubio, L.; Alba, K. Forecasting Selected Colombian Shares Using a Hybrid ARIMA-SVR Model. Mathematics 2022, 10, 2181. [Google Scholar] [CrossRef]
- Wang, C.-C.; Chang, H.-T.; Chien, C.-H. Hybrid LSTM-ARMA Demand-Forecasting Model Based on Error Compensation for Integrated Circuit Tray Manufacturing. Mathematics 2022, 10, 2158. [Google Scholar] [CrossRef]
- Armstrong, J.S. Combining forecasts. In Principles of forecasting; Springer: Berlin/Heidelberg, Germany, 2001; pp. 417–439. [Google Scholar]
- Makridakis, S.; Hibon, M. The M3-Competition: Results, conclusions and implications. Int. J. Forecast. 2000, 16, 451–476. [Google Scholar] [CrossRef]
- Aye, G.C.; Balcilar, M.; Gupta, R.; Majumdar, A. Forecasting aggregate retail sales: The case of South Africa. Int. J. Prod. Econ. 2015, 160, 66–79. [Google Scholar] [CrossRef]
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Kuo, R. A sales forecasting system based on fuzzy neural network with initial weights generated by genetic algorithm. Eur. J. Oper. Res. 2001, 129, 496–517. [Google Scholar] [CrossRef]
- Fildes, R. Evaluation of Aggregate and Individual Forecast Method Selection Rules. Manag. Sci. 1989, 35, 1056–1065. [Google Scholar] [CrossRef]
- Taghiyeh, S.; Lengacher, D.C.; Handfield, R.B. Forecasting model selection using intermediate classification: Application to MonarchFx corporation. Expert Syst. Appl. 2020, 151, 113371. [Google Scholar] [CrossRef]
- Villegas, M.A.; Pedregal, D.J.; Trapero, J.R. A support vector machine for model selection in demand forecasting applications. Comput. Ind. Eng. 2018, 121, 1–7. [Google Scholar] [CrossRef]
- Gardner, E.S.; Mckenzie, E. Forecasting Trends in Time Series. Manag. Sci. 1985, 31, 1237–1246. [Google Scholar] [CrossRef]
- Assimakopoulos, V.; Nikolopoulos, K. The theta model: A decomposition approach to forecasting. Int. J. Forecast. 2000, 16, 521–530. [Google Scholar] [CrossRef]
- Spiliotis, E.; Assimakopoulos, V. 4Theta: Generalizing the Theta Method for Automatic Forecasting. Available online: https://github.com/M4Competition/M4-methods (accessed on 1 July 2022).
- Petropoulos, F.; Svetunkov, I. A simple combination of univariate models. Int. J. Forecast. 2020, 36, 110–115. [Google Scholar] [CrossRef]
- Syntetos, A.A.; Boylan, J.E.; Croston, J.D. On the categorization of demand patterns. J. Oper. Res. Soc. 2005, 56, 495–503. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef]
- Tian, X.; Wang, H. Forecasting intermittent demand for inventory management by retailers: A new approach. J. Retail. Consum. Serv. 2021, 62, 102662. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Article | Model Selection Strategy | Model Selection Criteria | Candidate Model |
|---|---|---|---|
| Fildes [29] | Aggregate selection | Out-of-sample performance | Filter model; Robust Trend Estimation |
| Taghiyeh, Lengacher, and Handfield [30] | Individual selection | In-sample performance. Out-of-sample performance | Naïve; Exponential Smoothing Models; ARIMA; Theta |
| Villegas, Pedregal, and Trapero [31] | Individual selection | Information criteria. In-sample performance | White Noise; Moving Average; Simple Exponential Smoothing; Mean; Median |
| Ulrich, Jahnke, Langrock, Pesch, and Senge [4] | Individual selection | Feature-based | Linear Regression; Generalized Additive Models; Quantile Regression; ARIMAX |
| Our study | Individual selection. Combination forecasts | Feature-based. Out-of-sample performance | Benchmark and winning models in M-Competitions |
| Characteristics | Haolinju | JD |
|---|---|---|
| Total items | ||
| No. of series | 4027 | 936 |
| Mean obs./series | 535.0 | 209.4 |
| Smooth pattern | ||
| No. of series | 1336 (33.2%) | 34 (3.6%) |
| % Zero values | 0.3 (2.2) | 2.1 (4.5) |
| Average of nonzero demand | 471.4 (1155.5) | 49.8 (50.9) |
| CV2 of nonzero demand | 0.223 (0.128) | 0.376 (0.084) |
| ADI | 0.096 (0.302) | 0.607 (0.554) |
| Intermittent pattern | ||
| No. of series | 713 (17.7%) | 40 (4.3%) |
| % Zero values | 56.8 (25.5) | 12.4 (14.9) |
| Average of nonzero demand | 38.7 (172.7) | 45.6 (121.6) |
| CV2 of nonzero demand | 0.315 (0.109) | 0.403 (0.059) |
| ADI | 6.949 (17.059) | 3.739 (3.986) |
| Erratic pattern | ||
| No. of series | 767 (19.0%) | 162 (17.3%) |
| % Zero values | 1.1 (3.4) | 2.9 (4.7) |
| Average of nonzero demand | 295.4 (667.4) | 91.7 (171.1) |
| CV2 of nonzero demand | 2.340 (4.124) | 2.641 (6.377) |
| ADI | 0.290 (0.476) | 0.781 (0.518) |
| Lumpy pattern | ||
| No. of series | 1211 (30.1%) | 700 (74.8%) |
| % Zero values | 45.8 (23.5) | 21.9 (18.4) |
| Average of nonzero demand | 34.0 (189.5) | 42.3 (102.1) |
| CV2 of nonzero demand | 1.586 (3.023) | 3.408 (7.795) |
| ADI | 7.096 (36.012) | 3.862 (6.421) |
| Model | sMAPE | MASE | OWA | % Improvement of Method over the Naïve |
|---|---|---|---|---|
| Haolinju: Horizon = 1 (Obs. = 1336 × 1 × 10) a | ||||
| Naïve | 19.948 (1.991) | 0.801 (0.152) | 1.000 (0.000) | - |
| Comb S-H-D | 17.366 (1.812) | 0.707 (0.126) | 0.883 (0.076) | 11.7% |
| SCUM | 17.714 (1.966) | 0.696 (0.128) | 0.885 (0.070) | 11.5% |
| DWS-A | 18.594 (1.961) | 0.763 (0.135) | 0.942 (0.069) | 5.8% |
| DWS-B | 17.387 (1.972) | 0.701 (0.133) | 0.873 (0.071) | 12.7% |
| Haolinju: Horizon = 7 (Obs. = 1336 × 7 × 4) b | ||||
| Naïve | 22.114 (0.967) | 0.926 (0.054) | 1.000 (0.000) | - |
| Comb S-H-D | 18.749 (0.135) | 0.811 (0.009) | 0.863 (0.043) | 13.7% |
| SCUM | 18.947 (0.216) | 0.796 (0.008) | 0.861 (0.043) | 13.9% |
| DWS-A | 17.588 (0.158) | 0.768 (0.020) | 0.813 (0.036) | 18.7% |
| DWS-B | 17.797 (0.334) | 0.764 (0.010) | 0.816 (0.038) | 18.4% |
| JD: Horizon = 1 (Obs. = 34 × 1 × 10) b | ||||
| Naïve | 49.071 (8.709) | 0.975 (0.161) | 1.000 (0.000) | - |
| Comb S-H-D | 42.648 (9.694) | 0.876 (0.158) | 0.897 (0.129) | 10.3% |
| SCUM | 41.644 (9.287) | 0.845 (0.144)) | 0.871 (0.119) | 12.9% |
| DWS-A | 45.632 (6.064) | 0.933 (0.234) | 0.975 (0.140) | 2.5% |
| DWS-B | 40.476 (8.104) | 0.819 (0.160) | 0.858 (0.118) | 14.2% |
| JD: Horizon = 7 (Obs. = 34 × 7 × 4) b | ||||
| Naïve | 52.739 (3.593) | 1.075 (0.121) | 1.000 (0.000) | - |
| Comb S-H-D | 41.531 (0.594) | 0.903 (0.027) | 0.841 (0.055) | 25.9% |
| SCUM | 40.942 (0.657) | 0.877 (0.024) | 0.821 (0.050) | 27.9% |
| DWS-A | 38.658 (1.515) | 0.838 (0.009) | 0.789 (0.033) | 31.1% |
| DWS-B | 38.707 (0.387) | 0.823 (0.004) | 0.782 (0.782) | 31.8% |
| Model | sMAPE | MASE | OWA | % Improvement of Method over the Naïve |
|---|---|---|---|---|
| Haolinju: Horizon = 1 (Obs. = 713 × 1 × 10) a | ||||
| Naïve | 78.516 (3.403) | 1.401 (0.142) | 1.000 (0.000) | - |
| Comb S-H-D | 123.704 (2.298) | 1.257 (0.088) | 1.241 (0.068) | −24.1% |
| SCUM | 125.214 (2.144) | 1.249 (0.091) | 1.248 (0.066) | −24.8% |
| DWS-A | 79.247 (3.445) | 1.349 (0.097) | 0.989 (0.035) | 1.1% |
| DWS-B | 111.481 (13.306) | 1.254 (0.090) | 1.164 (0.127) | -16.4% |
| Haolinju: Horizon = 7 (Obs. = 713 × 7 × 4) b | ||||
| Naïve | 82.682 (3.055) | 1.532 (0.127) | 1.000 (0.000) | - |
| Comb S-H-D | 124.918 (0.553) | 1.315 (0.017) | 1.175 (0.061) | −17.5% |
| SCUM | 126.654 (0.344) | 1.302 (0.016) | 1.181 (0.063) | −18.1% |
| DWS-A | 75.052 (1.303) | 1.361 (0.071) | 0.889 (0.029) | 11.1% |
| DWS-B | 120.953 (1.360) | 1.295 (0.029) | 1.146 (0.061) | −14.6% |
| JD: Horizon = 1 (Obs. = 40 × 1 × 10) a | ||||
| Naïve | 49.867 (7.385) | 1.094 (0.139) | 1.000 (0.000) | - |
| Comb S-H-D | 52.398 (9.005) | 1.057 (0.167) | 1.025 (0.193) | −2.5% |
| SCUM | 55.184 (8.113) | 1.037 (0.162) | 1.046 (0.171) | −4.6% |
| DWS-A | 47.535 (7.858) | 1.050 (0.157) | 0.960 (0.106) | 4.0% |
| DWS-B | 48.858 (7.067) | 0.994 (0.160) | 0.949 (0.118) | 5.1% |
| JD: Horizon = 7 (Obs. = 40 × 7 × 4) c | ||||
| Naïve | 56.265 (5.720) | 1.251 (0.044) | 1.000 (0.000) | - |
| Comb S-H-D | 55.036 (1.417) | 1.157 (0.037) | 0.955 (0.083) | 4.5% |
| SCUM | 57.666 (0.224) | 1.135 (0.038) | 0.974 (0.077) | 2.6% |
| DWS-A | 47.379 (0.724) | 1.058 (0.051) | 0.857 (0.074) | 14.3% |
| DWS-B | 52.147 (1.313) | 1.062 (0.020) | 0.903 (0.084) | 9.7% |
| Model | sMAPE | MASE | OWA | % Improvement of Method over the Naïve |
|---|---|---|---|---|
| Haolinju: Horizon = 1 (Obs. = 767 × 1 × 10) a | ||||
| Naïve | 32.220 (2.656) | 0.978 (0.686) | 1.000 (0.000) | - |
| Comb S-H-D | 31.539 (1.565) | 0.975 (0.670) | 1.007 (0.127) | −0.7% |
| SCUM | 29.752 (1.562) | 0.934 (0.667) | 0.956 (0.119) | 4.4% |
| DWS-A | 30.604 (2.485) | 0.976 (0.713) | 0.958 (0.116) | 4.2% |
| DWS-B | 28.731 (1.563) | 0.945 (0.720) | 0.915 (0.089) | 8.5% |
| Haolinju: Horizon = 7 (Obs. = 767 × 7 × 4) a | ||||
| Naïve | 36.492 (1.616) | 1.259 (0.293) | 1.000 (0.000) | - |
| Comb S-H-D | 35.613 (0.853) | 1.332 (0.253) | 1.025 (0.049) | −2.5% |
| SCUM | 33.380 (0.660) | 1.248 (0.208) | 0.969 (0.093) | 3.1% |
| DWS-A | 30.258 (1.428) | 1.058 (0.258) | 0.841 (0.069) | 15.9% |
| DWS-B | 31.030 (0.656) | 1.140 (0.326) | 0.886 (0.048) | 11.4% |
| JD: Horizon = 1 (Obs. = 162 × 1 × 10) b | ||||
| Naïve | 59.324 (8.485) | 1.451 (0.597) | 1.000 (0.000) | - |
| Comb S-H-D | 63.360 (11.363) | 1.407 (0.523) | 1.046 (0.191) | −4.6% |
| SCUM | 61.548 (10.980) | 1.343 (0.511) | 1.003 (0.171) | −0.3% |
| DWS-A | 56.958 (6.653) | 1.328 (0.482) | 0.956 (0.093) | 4.4% |
| DWS-B | 56.821 (8.354) | 1.298 (0.496) | 0.942 (0.097) | 5.8% |
| JD: Horizon = 7 (Obs. = 162 × 7 × 4) a | ||||
| Naïve | 63.030 (3.753) | 1.431 (1.115) | 1.000 (0.000) | - |
| Comb S-H-D | 62.366 (1.894) | 1.472 (0.070) | 1.022 (0.027) | −2.2% |
| SCUM | 60.903 (1.585) | 1.409 (0.090) | 0.983 (0.024) | 1.7% |
| DWS-A | 52.883 (2.642) | 1.303 (0.889) | 0.889 (0.020) | 11.1% |
| DWS-B | 54.516 (1.838) | 1.294 (0.898) | 0.898 (0.012) | 10.2% |
| Model | sMAPE | MASE | OWA | % Improvement of Method over the Naïve |
|---|---|---|---|---|
| Haolinju: Horizon = 1 (Obs. = 1211 × 1 × 10) a | ||||
| Naïve | 80.997 (3.429) | 1.176 (0.158) | 1.000 (0.000) | - |
| Comb S-H-D | 108.250 (1.737) | 1.072 (0.102) | 1.127 (0.061) | −12.7% |
| SCUM | 110.246 (1.581) | 1.059 (0.103) | 1.134 (0.062) | −13.4% |
| DWS-A | 81.301 (3.306) | 1.143 (0.141) | 0.983 (0.014) | 1.7% |
| DWS-B | 98.551 (9.256) | 1.078 (0.123) | 1.065 (0.073) | −6.5% |
| Haolinju: Horizon = 1 (Obs. = 1211 × 7 × 4) a | ||||
| Naïve | 86.245 (0.944) | 1.361 (0.112) | 1.000 (0.000) | - |
| Comb S-H-D | 110.943 (0.141) | 1.207 (0.035) | 1.078 (0.031) | −7.8% |
| SCUM | 113.245 (0.468) | 1.187 (0.034) | 1.084 (0.031) | −8.4% |
| DWS-A | 76.947 (0.515) | 1.218 (0.026) | 0.884 (0.033) | 11.6% |
| DWS-B | 106.015 (0.426) | 1.178 (0.027) | 1.038 (0.028) | −3.8% |
| JD: Horizon = 1 (Obs. = 700 × 1 × 10) b | ||||
| Naïve | 70.315 (4.558) | 1.487 (0.368) | 1.000 (0.000) | - |
| Comb S-H-D | 72.850 (8.011) | 1.384 (0.386) | 0.987 (0.083) | 1.3% |
| SCUM | 73.208 (7.767) | 1.352 (0.383) | 0.980 (0.079) | 2.0% |
| DWS-A | 68.414 (4.737) | 1.401 (0.348) | 0.969 (0.042) | 3.1% |
| DWS-B | 68.991 (6.494) | 1.316 (0.376) | 0.941 (0.055) | 5.9% |
| JD: Horizon = 7 (Obs. = 700 × 7 × 4) b | ||||
| Naïve | 75.817 (1.651) | 1.549 (0.041) | 1.000 (0.000) | - |
| Comb S-H-D | 74.057 (0.600) | 1.414 (0.079) | 0.945 (0.031) | 5.5% |
| SCUM | 74.092 (0.707) | 1.370 (0.075) | 0.931 (0.030) | 6.9% |
| DWS-A | 64.56 (0.387) | 1.341 (0.097) | 0.853 (0.033) | 14.7% |
| DWS-B | 69.691 (0.719) | 1.319 (0.085) | 0.880 (0.029) | 12.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
E, E.; Yu, M.; Tian, X.; Tao, Y. Dynamic Model Selection Based on Demand Pattern Classification in Retail Sales Forecasting. Mathematics 2022, 10, 3179. https://doi.org/10.3390/math10173179
E E, Yu M, Tian X, Tao Y. Dynamic Model Selection Based on Demand Pattern Classification in Retail Sales Forecasting. Mathematics. 2022; 10(17):3179. https://doi.org/10.3390/math10173179
Chicago/Turabian StyleE, Erjiang, Ming Yu, Xin Tian, and Ye Tao. 2022. "Dynamic Model Selection Based on Demand Pattern Classification in Retail Sales Forecasting" Mathematics 10, no. 17: 3179. https://doi.org/10.3390/math10173179
APA StyleE, E., Yu, M., Tian, X., & Tao, Y. (2022). Dynamic Model Selection Based on Demand Pattern Classification in Retail Sales Forecasting. Mathematics, 10(17), 3179. https://doi.org/10.3390/math10173179