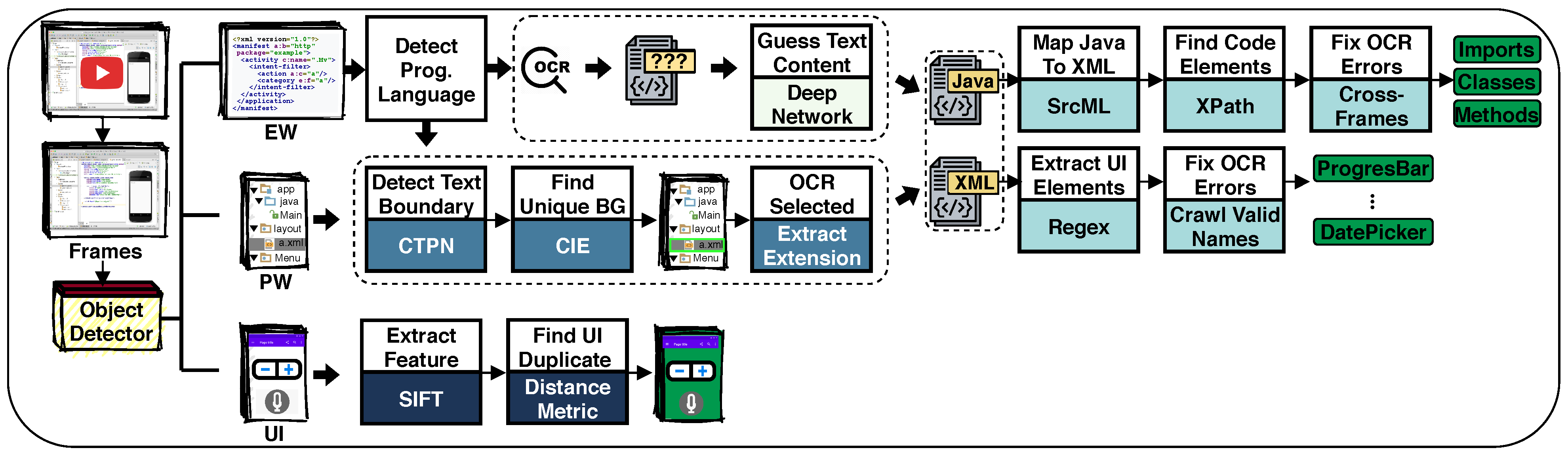
In this section, VID2META is introduced, which aims to complement the metadata of Android screencasts by analyzing their video frames to extract meaningful Java and GUI elements, as well as entire GUIs.
2.2. Localizing Code-Editing Windows, Project Windows, and GUIs
A mobile programming screencast consists of n frames where each frame is typically divided into windows/regions with different sizes (e.g., a frame shows an IDE could have several regions such as an editing window, a project window, a GUI layout, etc.). To extract Java and GUI elements from those frames, we need to locate the bounding box of the code-editing windows precisely. Thereby, we are assured that when we apply OCR on only those windows, we are only extracting the code information (i.e., to avoid extracting other irrelevant information from other windows in an IDE such as a project window, an output window, etc.). The windows that are located are defined as follows.
Code-Editing Window (CEW): This window contains Java or XML texts.
Project window (PW): A project window is typically displayed on the left side of an IDE and includes resource files of a project in the form of a tree view.
Graphical user interface (GUI): Visual GUI elements are placed on GUIs where users can interact with the app.
Formally, given a video V = where is a frame captured at the ith second and n is the total number of seconds in video . I aim to detect the location of each window in , if any. Note that this problem is considered as a multi-window detection and localization problem in video frames, in which each frame could have all possible combinations of the pre-identified windows. For example, in a mobile programming screencast, the screen of a narrator could show an IDE where the project window, an XML, and one or more GUI previews are displayed at the same time. Regardless of the number of windows displayed at the same time, all windows must be located accurately.
To recognize the windows in a frame, we need first to obtain each window’s features and feed them into a learning model. For this task, a convolutional neural network (CNN), called Inception-Resnet V2 [
11], with a region-based object detector, called Faster RCNN [
12], are utilized. Note that a pre-trained CNN is successfully adapted in analyzing video programming frames [
13,
14,
15], and Faster R-CNN has shown promising results in detecting mobile GUI components [
16,
17]. The choice of the Inception-Resnet V2 network with Faster R-CNN is based on the empirical evaluation performed by [
18] who found that this combination outperformed several other object detectors that used various CNN architectures. Several parameters impact the network’s performance during the training process. The choice of the
optimizer plays an essential role in updating the weights after each epoch by back-propagation (one forward and backward pass of every training sample through the neural network). Based on the recommended optimizer by Faster R-CNN,
momentum is used, which is a version of the stochastic gradient descent (SGD) [
19]. The default values for the network layers’ hyperparameters are used, such as a stride value of 16.
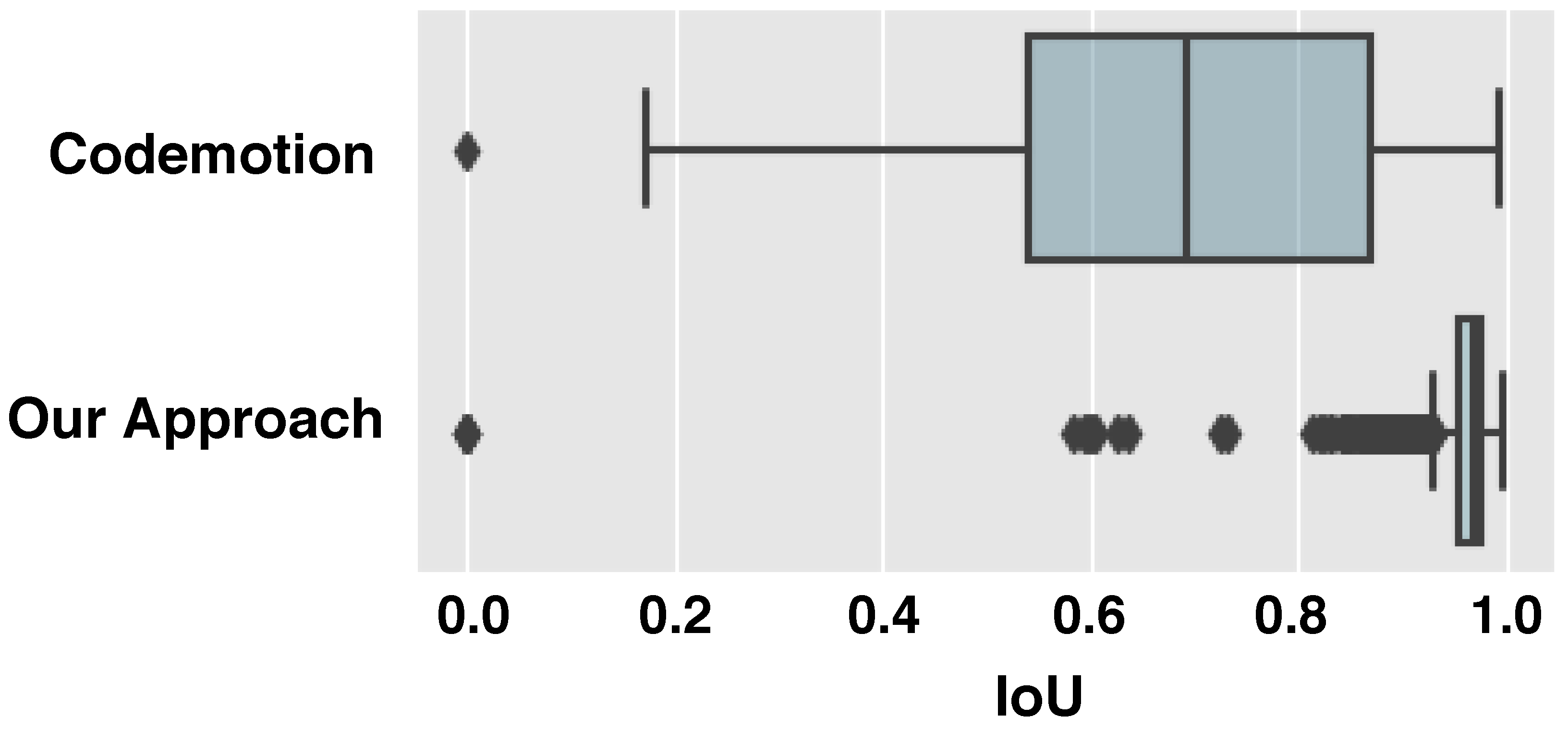
To train the object detector, we need to manually collect videos and annotate code-editing windows with their coordinates. Next, the data collection and annotation processes are explained.
2.2.1. Datasets: Mobile Programming Screencasts
To prepare the data for the object detector’s training, I used 20 videos manually chosen from YouTube. To select the videos, I searched for various topics using the keyword
Android, combining it with words such as
Google Map, game development, or
ListView. The final selection was limited to a maximum of three videos from each topic. A total of 11 different categories were collected. Most importantly, I ensured diversity by selecting a maximum of one video from each playlist. A total of 18 unique authors produced the videos. Concerning the visual content of the video datasets, I ensured that there was a variety of (i) regions presented in the video (two GUI previews shown at the same time, XML with UI, and others) and (ii) IDE background colors (15 white and five dark greys). After the videos were chosen, they were downloaded to the server with the highest available quality using the youtube-dl (
https://github.com/rg3/youtube-dl, accessed on 10 June 2021) tool. The mean and median length of the collected videos were 608 s and 592 s, respectively.
2.2.2. Annotating Code-Editing Windows, Project Windows, and GUIs
To train a model to locate a specific window/region, we have to collect several images that contain those regions and feed them into a neural network with their coordinates. Because the regions are spatially located within an image, the neural network learns to extract the relevant spatial features (through convolutional layers) for each region, which maps to its coordinates.
The mobile programming screencast dataset was used to annotate three windows. Note that a video frame containing an IDE could have none to several windows (e.g., a project window, an editing window, and a GUI preview displayed simultaneously).
Two annotators annotated each window belonging to one of the categories with bounding box information (e.g., coordinates) and a label (e.g., CEW, PW, or GUI). Previous works that analyzed programming screencasts extracted a frame per second and classified each frame individually [
13,
15,
20]. They also found that the manual labeling task requires time-intensive human efforts (i.e., required 100 students for the annotation process in [
13]). In our case, we classified a frame, defined the bounding box of each window, and labelled its class, which adds more time efforts to the manual annotation process. Based on the study that found that programming screencasts are more static than other types of videos [
21], we found that annotating the entire video while playing instead of extracting and annotating each of its individual frames is much more effective. On average, annotating a single region on a frame takes about seven seconds.
To facilitate the process of video annotation, we used a cloud-based web tool called DataTurks (
https://dataturks.com/, accessed on 15 June 2021) and uploaded the 20 videos. Next, we initiated the class names with the labels. Note that since we need to evaluate the proposed approach (explained in
Section 2.3) in distinguishing between Java and XML, we labeled the CEW with either Java or XML. Yet, when the network was trained, Java and XML were considered as one class that belongs to CEW. We played each video and paused it once a region of interest (RoI) appeared. We labeled each region with a class name and drew a corresponding bounding box around each region (i.e., there could be more than one region in each snapshot). The video was played while our regions and class names were still drawn. Thus, we did not need to annotate each snapshot/frame individually. We paused the video when our ROIs were no longer shown to remove them accordingly.
After annotating all videos, we downloaded the annotated datasets in the JSON format. This file included all information we needed to create a PASCAL VOC [
22] format file for each image, including the ground-truth annotation information. This file is required when training an object detector. We parsed the JSON file and extracted the annotation information for each window:
StartTime,
EndTime,
className, and
BoundingBox. Then, for each second between the start and end time, we (i) extracted a frame from the corresponding video such that the
frameNumber = fps * currentSecond, (ii) saved the
frameNumber,
className, the bounding box, and the
currentSecond information. Once this process was finished, we grouped different regions based on the
currentSecond and saved them in the PASCAL VOC format file. Using this step, a single PASCAL VOC format for each image could have multiple regions/windows. To confirm that our annotation was accurate, we drew a bounding box with a class label on each region based on the ground-truth information. A second annotator checked each frame, and we revised the ones that did not have an accurate annotation. The Cohen’s Kappa coefficient was 0.95, which indicated a high agreement between the annotators.
Table 1 shows the number of collected images and the total number of windows/regions in each image. Because not all images contained only one region (RoI), the table was divided into multi-region (ROIs) and single-region systems. The majority of the annotated images contain a project window (PW) and Java regions. There are few cases in which more than one GUI was displayed simultaneously, which makes the total number of annotated GUI reached to 7390 regions. The GUI regions could be displayed with other regions, such as (PW and XML), together with 1138 images. There are few cases where a single region was displayed on the screen, such as Java. In total, the number of annotated images and regions was 7798 and 16,085, respectively.
2.3. Detecting Programming Language
The approach proposed above locates the bounding box of code-editing window regardless of its content that could be a Java or XML file. Two different approaches were followed to the extract code or UI elements; therefore, we needed first to predict the editing window’s content. Two different approaches were proposed to predict the content of the editing window as follows. First, the selected file was located from the project window with its file extension (e.g., .java or .xml). This approach cannot be applied in several cases, such as when the project window is hidden, or if there is no selected file in the project window. Thus, a second approach was proposed based on the textual content of the editing window. More specifically, a deep learning model was employed to predict the text’s programming language written in the editing window. Let us first explain the approach that locates the selected file in the project window using a pipeline of three main steps.
First, the background color of the selected file was typically different from other files. Based on this, we needed to accurately find the background color (BG) of each file listed on the project window (PW). To detect the BG, we needed to first detect the bounding box of each text in PW. The problem of text detection is different from object detection such that for the first one, the region of interest (ROI) is a text composed of different sizes of characters, numbers, or symbols, whereas for the latter, the (ROI) has a well-defined closed boundary [
23], such as the entire PW region in our case. Thus, in this task, a fine-grained text-based detection approach [
24,
25] was utilized. In particular, I leveraged the architecture of a connectionist text proposal network (CTPN) [
26] to detect the position of each text entry (file or directory) presented in the PW as follows. First, the input images (PWs) were fed into a CNN-based feature extractor, called VGG-16 [
27], to extract the feature maps. Second, to produce a fine-scale text proposal, the CTPN detector densely slid a
window in the map to detect the text line and then produced text proposals. Last, to further increase the accuracy of the text proposal and find meaningful context information, the CTPN connected sequential text proposals in the feature map using a recurrence mechanism. It has been shown that using sequential context information on words improves the recognition performance [
28]. Ultimately, a
predicted by
(explained in
Section 2.2) was fed into a (
CTPN) that outputs a set of closed bounding boxes for each textual entry (e.g., the names of files, images, or directory) presented in the
.
Second, this step’s input is the output of the previous step, which is a set of predicted bounding boxes for each textual entry presented in . Each predicted bounding box is considered as a candidate that might or might not have the region of interest (selected file). An abjectness score was defined to either zero (entry was not selected) or one (entry was selected). To detect the objectness score, I based the approach on assuming that the selected entry’s BG color is different from others. Note that the detected bounding box covers only the presented text, whereas the background color spans over the PW’s width.
For this reason, each predicted bounding box was expanded to the full width of the PW (i.e., refined bounding box (RBB)). Note that the bounding box of each
was automatically detected using the previous approach (explained in the previous
Section 2.2). For each
, the dominant color was obtained by computing the (RGB) color of each pixel and count the frequency of each color.
Last, the dominant color of each
was compared to that of
where
j ≥
i + 1 and
j ≤
n (total number =
). One trivial solution is to compute the similarity between two RGB colors based on a distance metric (e.g., euclidean distance). However, two RGB colors might look very similar to the human, but they might have a large euclidean distance, and this is due to the fact that they are represented in RGB color space which led to the flaw. Thus,
CIE Lab color space was designed to approximate human vision based on the color’s lightness [
29]. For this reason, the color differences between two
were quantified by computing the Δ
E and following the guidelines of the International Commission on Illumination (CIE), as shown in Equation (
1). Formally, the dominant background color for each
was converted into (L*a*b*) where (i)
L represents the lightness value and ranges from zero (dark black) to 100 (bright white), (ii)
a represents the green (negative direction) and red (positive direction) components, and (iii)
b represents the blue (negative direction) and yellow (positive direction) components. To detect whether the background color of
was similar to that of
, Δ
E has to be ≤ a threshold. By the end of this comparison, there should only be one unique
which embodies the selected file or directory.
The second approach, to detect the code-editing window’s content, is based on DL text classifier. I leveraged GuessLang (
https://github.com/yoeo/guesslang, accessed on 20 June 2021), which is a deep neural network with three classification layers and a customized linear classifier. I opted to employ GuessLang as it has been successfully used in the field of SE [
30,
31]. GuessLang has already been trained on 30 programming languages. The list of programming languages that the model was trained on did not include Android development (e.g., Java and XML). For this reason, I fine-tuned the architecture of GuessLang and trained it on a new dataset. The new dataset contains a total of 15,000 Java and 15,000 XML files extracted from 675 open-source Android projects found in the play store and collected by [
32]. During the training, the source code files were transformed into features vectors in which bigrams and trigrams were computed before they were fit into the network.
2.4. Extracting Java and UI Elements
To extract Java and UI elements from videos, I applied OCR on the predicted editing window and predicted its content using the approaches proposed above. Next, I present the approaches that extract Java and UI elements.
2.4.1. Java Elements
SrcML [
33] is utilized to map the extracted Java code to an XML document. This document contains syntactic information about the source code as it wraps the text with meaningful tag names such as imports, classes, and methods. Although srcML has been successfully used in the field of SE where the entire code is available in the text format [
34,
35], it has never been used to the source code embedded in video frames. This poses two main limitations: (i) the OCRed code typically contains several errors since most OCR engines are sensitive to image quality and does not work well with images that contain source code [
5,
36,
37] and (ii) each video frame contains only part of the Java element (i.e., incomplete element) since the code in programming screencasts is typically written on the fly. To detect OCR errors, I devised several steps to fix issues as follows.
First, Java elements are not recognized by srcML due to errors in the syntax of the OCRed code. There are several cases where this could occur such as if (i) the class name is not detected if the semicolon is missing before class definition, (ii) there is illegal space in the definition of a Java element (e.g., import statement), (iii) open and/or close curly brackets are missing. To solve this, I wrote a script to pre-process all OCRed codes and fix syntax errors as follows. First, I removed illegal extra spaces in import statements, class names, method names, and method calls. Second, I added a semicolon at the end of each statement if they do not exist or changed a colon to a semicolon where appropriate. Third, I fixed missing curly brackets or parentheses (i.e., some curly brackets are extracted as squares).
Second, most modern IDEs feature code suggestion where a popup window appears when developers write code to help them save time, and as such srcML extracts method names and calls from a popup window which are not part of the transcribed code. To detect if an extracted method name or call was part of the transcribed code, I checked if the full definition matches the correct format (i.e., syntactically correct). For example, a method name must have a modifier, return value, name, and parenthesis. Otherwise, it is considered as a method extracted from a popup window. It is worth mentioning that this step is essential as the extracted Java elements must be part of the transcribed code; otherwise, irrelevant Java elements are displayed and indexed.
Last, Java elements are incorrectly extracted due to OCR errors, which is very common when OCR is applied to an IDE to extract source code [
5,
36,
37,
38]. This is due to the fact that OCR is very sensitive to (i) the colorful background of the IDE, (ii) the low resolution of video frames, and (iii) the low quality of video frames. Let us denote the initial set of the extracted Java elements from a video as V =
, in which
is the
jth extracted element from the
ith frame (to be precise, the cropped editing window). As import statements, class names, method names, and method calls are extracted, I create one set for each element type (i.e., four different sets for each video). Each set contains unique elements and their counts. For example, if the same method name (e.g.,
onOptionsItemSelected) was extracted from a total of
k frames, this means it has a count of
k. The
k value determines the confidence score of whether an element was correctly extracted or not. The similarity between each pair of elements was computed using a character-level similarity metric. Specifically, The normalized Levenshtein distance NLD (as described in Equation (
2)) was used, and if the similarity between two elements is greater than a threshold, I discarded the element that was extracted fewer times (based on the percentage change). The rationale is that an incorrect (or incomplete) element is typically extracted fewer times than a similar correct element because OCR is less likely to confuse some characters. For example, if an element
onOptionsLtemSelected was incorrectly extracted, appeared only
k times, and was very similar to
onOptionsItemSelected which appeared more times than
k, the first term was assumed to be incorrectly extracted.
2.4.2. UI Elements
An android app contains a layout that has an invisible container such as
RelativeLayout that defines visible UI elements to the users in which they can view or interact with the app. The UI elements can be declared based on (i) a list of pre-built UI elements provided by Android such as
TextView,
DatePicker,
ProgressBar, and several others; (ii) third-party API libraries in which a user must import the required package and/or create a dependency entry in the
build.gradle file; and (iii) a customized class in which a developer must create a custom Java code and define the behavior of the element. Fortunately, we can create a list of valid UI elements and check if an OCRed UI element is in that list to detect incorrectly extracted UI elements. I created a list of valid UI elements as follows. First, I utilized the official online Android documentation (
https://developer.android.com/, accessed on 30 June 2021) to crawl all UI elements. Second, I used all import statements defined in Java files using the approach that extracts import statements, as well as a regular expression to find all third-party dependencies defined in the
build.gradle file. Note that this file’s content was written on a code-editing window, and thereby we could easily extract its content and find UI elements defined as a dependency. Last, I applied OCR on the predicted project window to extract a list of file names, which contains names of potential user-defined UI elements. Ultimately, if an OCRed UI element was incomplete (e.g.,
Imagevie) or incorrect (e.g.,
viewelipper), it would not exist in a list of valid UI elements, and thereby it would be marked as an incorrect element.
2.5. Eliminating Duplicate GUI Screens
Extracting one frame per second from each video would result in duplicate frames, especially when it comes to video programming tutorials as the displayed contents in these videos are more static than other types [
21]. The trained model locates and crops GUI screens from each frame, which results in redundant GUI screens. To detect redundant GUI screens, I adapted the mature image descriptor, the scale-invariant feature transform (SIFT) [
39], to extract the robust features that are invariant to rotation, transformation, and scaling features. The key points are detected using a Hessian matrix approximation, in which SIFT assigns a distinctive descriptor (feature vector) to each keypoint.
To demonstrate the proposed approach for selecting unique UI frames, consider an input video as V =
, in which each
is processed through the first phase (see
Section 2.2) to output the cropped
, if any. Note that for each
there could be many GUI screens or none at all. For each video, there is a new set that contains a list of the extracted GUIs denoted as UI =
, where
m indicates the total number of extracted UIs from a video. Duplicate frames were detected and removed as follows. First, the feature vector was extracted from each
and saved in memory (to extract the features only once). Second, the euclidean distance between each extracted feature from
to that of
was computed, in which
j ≥
i + 1 and
j ≤
m. The two UIs were considered similar if the percentage of the matched descriptor was above a pre-defined threshold.
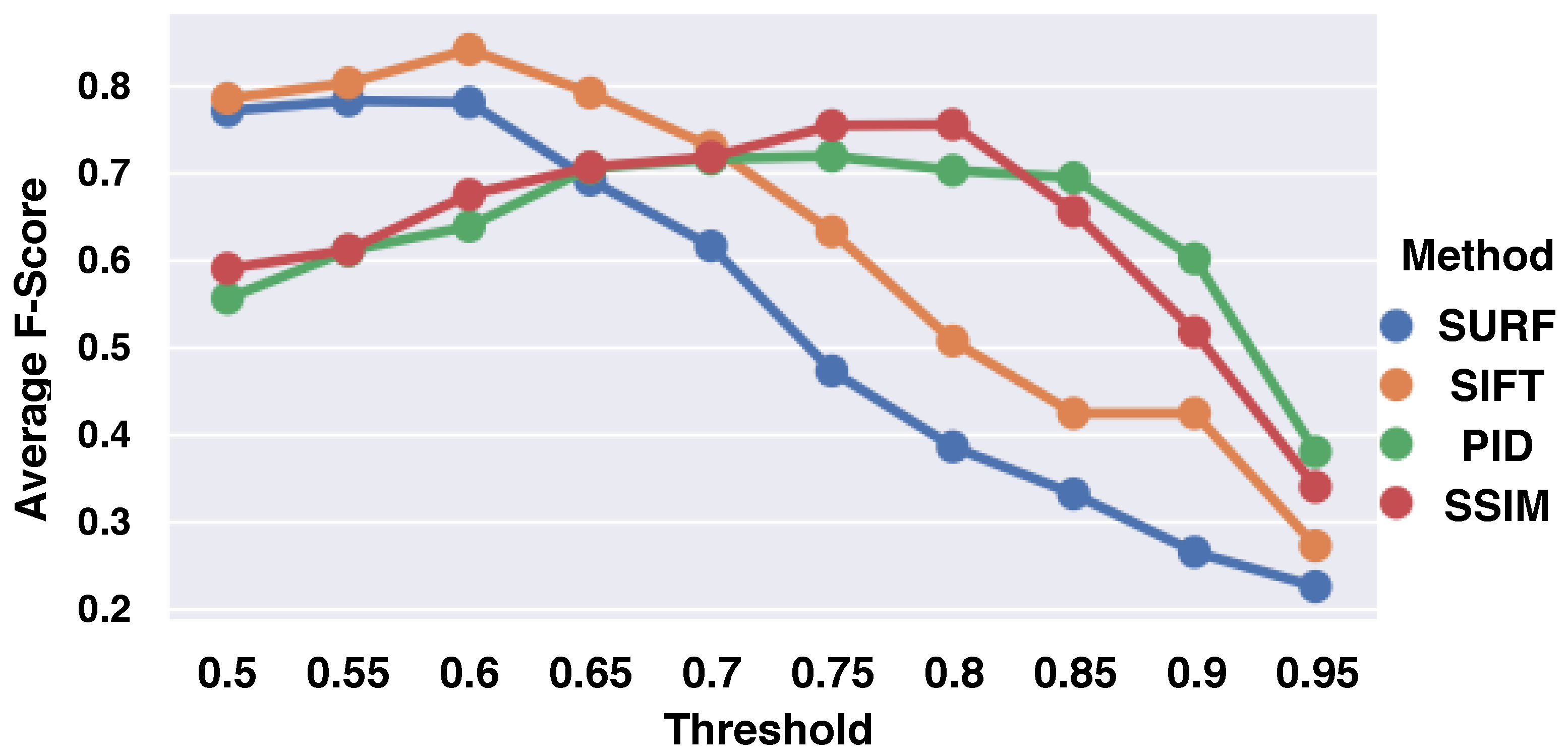
To assist the claim that SIFT performs the best in terms of removing duplicate UI frames from video programming tutorials, an empirical evaluation was performed on four different methods. In particular, I compared SIFT to another image descriptor, speeded-up robust features (SURFs) [
39], and two other pixel-wise algorithms. I utilized two of the most popular pixel-wise comparisons (i) to detect mobile GUI changes using perceptual image differences (PIDs) [
40,
41], and (ii) to detect changes between programming video frames using the structural similarity index (SSIM) [
14]. PID compares two images based on models of the human visual system [
42], whereas SSIM compares the pixel intensities of two images [
43]. The four methods removed duplicates based on a similarity threshold, and to ensure a fair comparison, I experimented with each method with different thresholds that range from 0.5 to 0.95 with a step size of 0.05.









{kind=link}
{kind=link}
{kind=link}