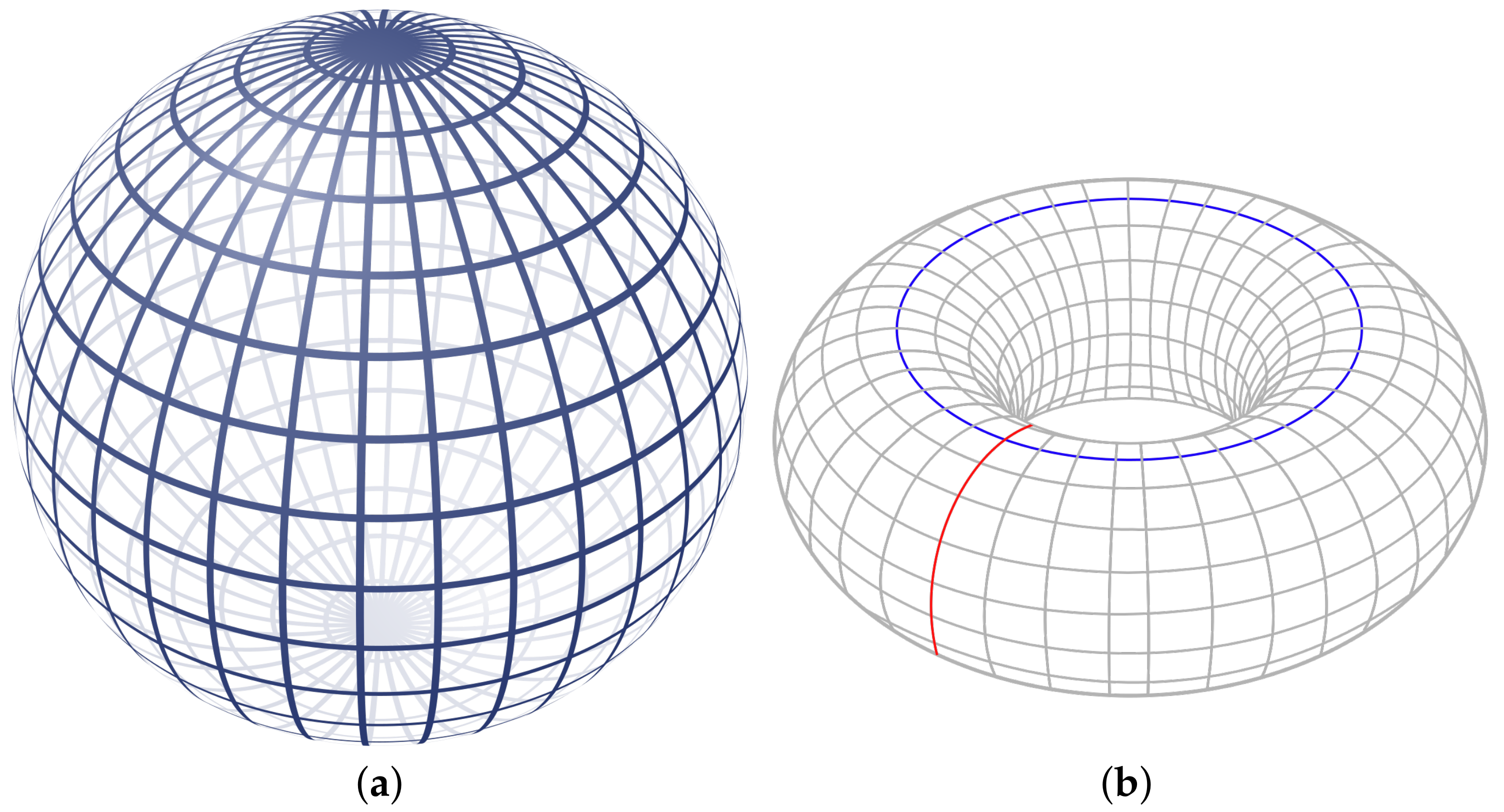
Figure 1.
The sphere (a) bounds a 2-dimensional void. The torus (b) bounds a 2-dimensional void and two 1-dimensional holes. Images: Geek3 and YassinMrabet via Wikipedia.
Figure 1.
The sphere (a) bounds a 2-dimensional void. The torus (b) bounds a 2-dimensional void and two 1-dimensional holes. Images: Geek3 and YassinMrabet via Wikipedia.
Figure 2.
The pipeline for a topological study of digital data in a Machine Learning context. A filtration associates a persistence diagram to the digital data. The persistence diagram is then vectorized by means of various vectorization methods. Finally, the vector is fed to a Machine Learning classifier.
Figure 2.
The pipeline for a topological study of digital data in a Machine Learning context. A filtration associates a persistence diagram to the digital data. The persistence diagram is then vectorized by means of various vectorization methods. Finally, the vector is fed to a Machine Learning classifier.
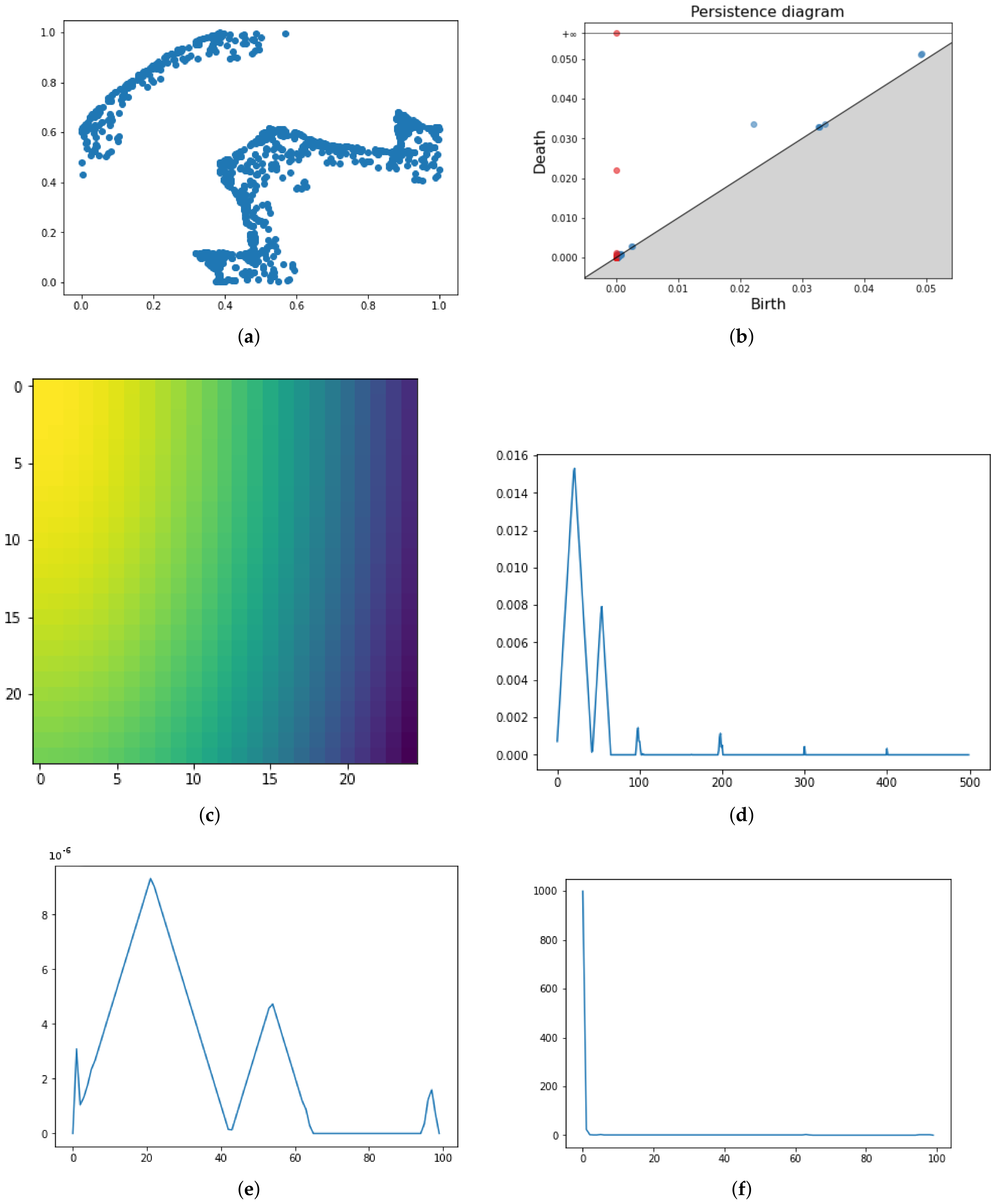
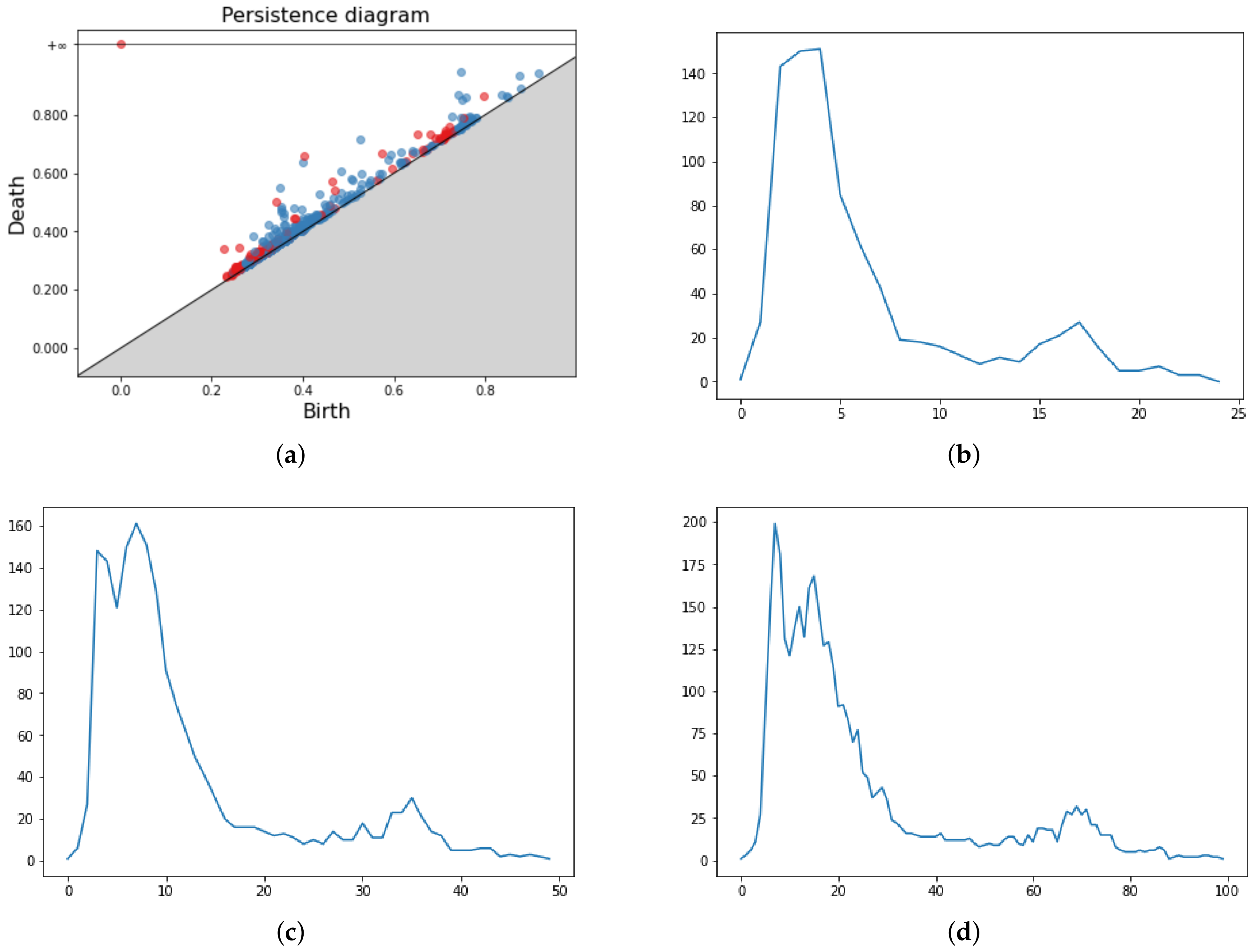
Figure 3.
Pipeline application for point cloud data (a). The persistence diagram associated (b). In the second and third rows, four different vectorization methods for the same PD, namely Persistence Images (c), Persistence Landscapes (d), Persistence Silhouette (e) and Betti Curves (f).
Figure 3.
Pipeline application for point cloud data (a). The persistence diagram associated (b). In the second and third rows, four different vectorization methods for the same PD, namely Persistence Images (c), Persistence Landscapes (d), Persistence Silhouette (e) and Betti Curves (f).
Figure 4.
Pixel connection in cubical complexes.
Figure 4.
Pixel connection in cubical complexes.
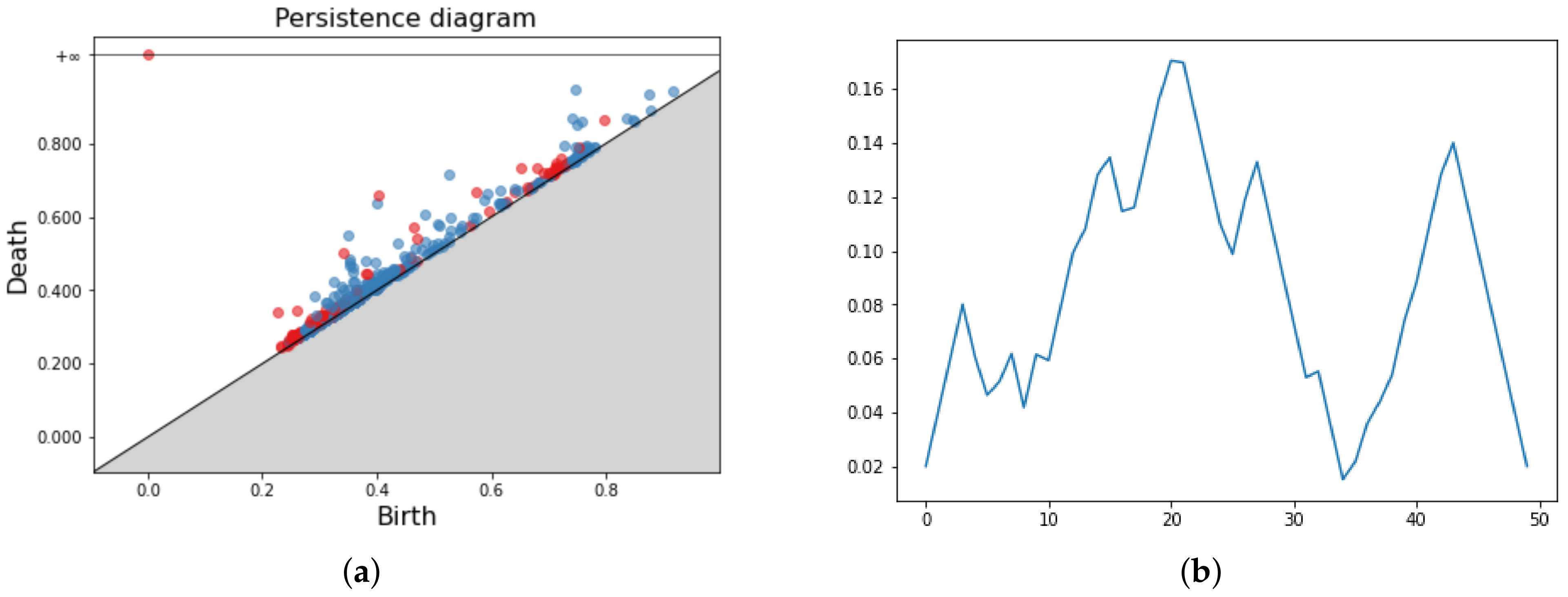
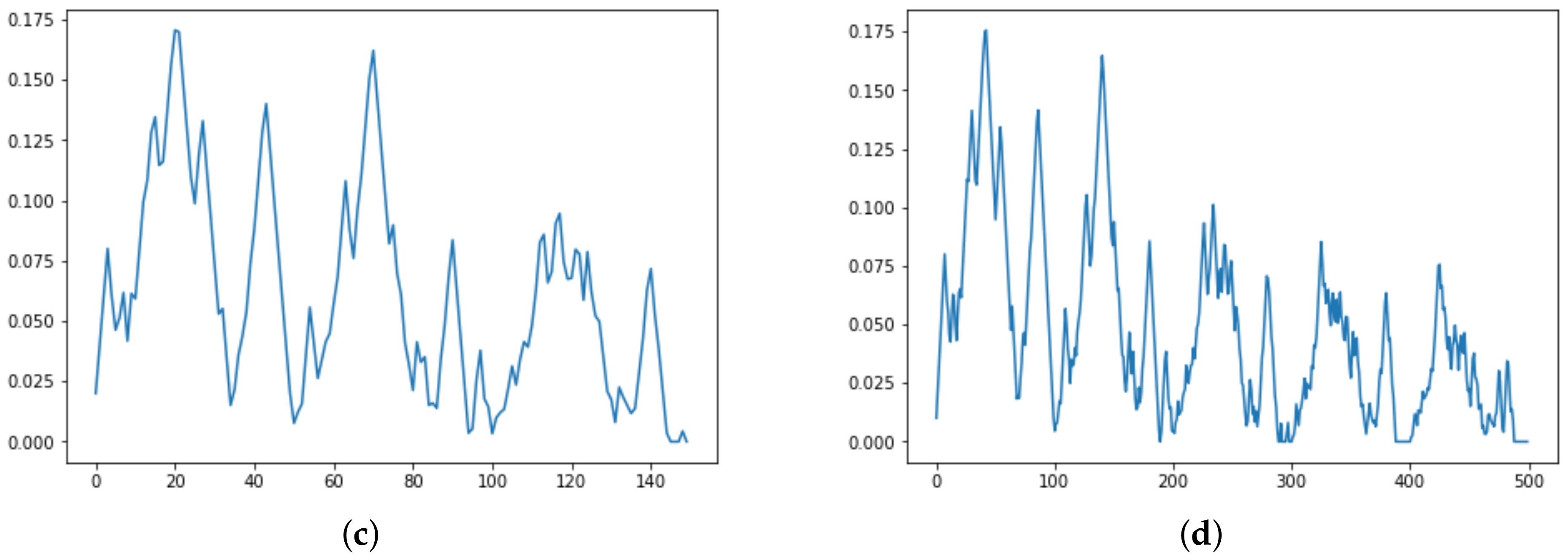
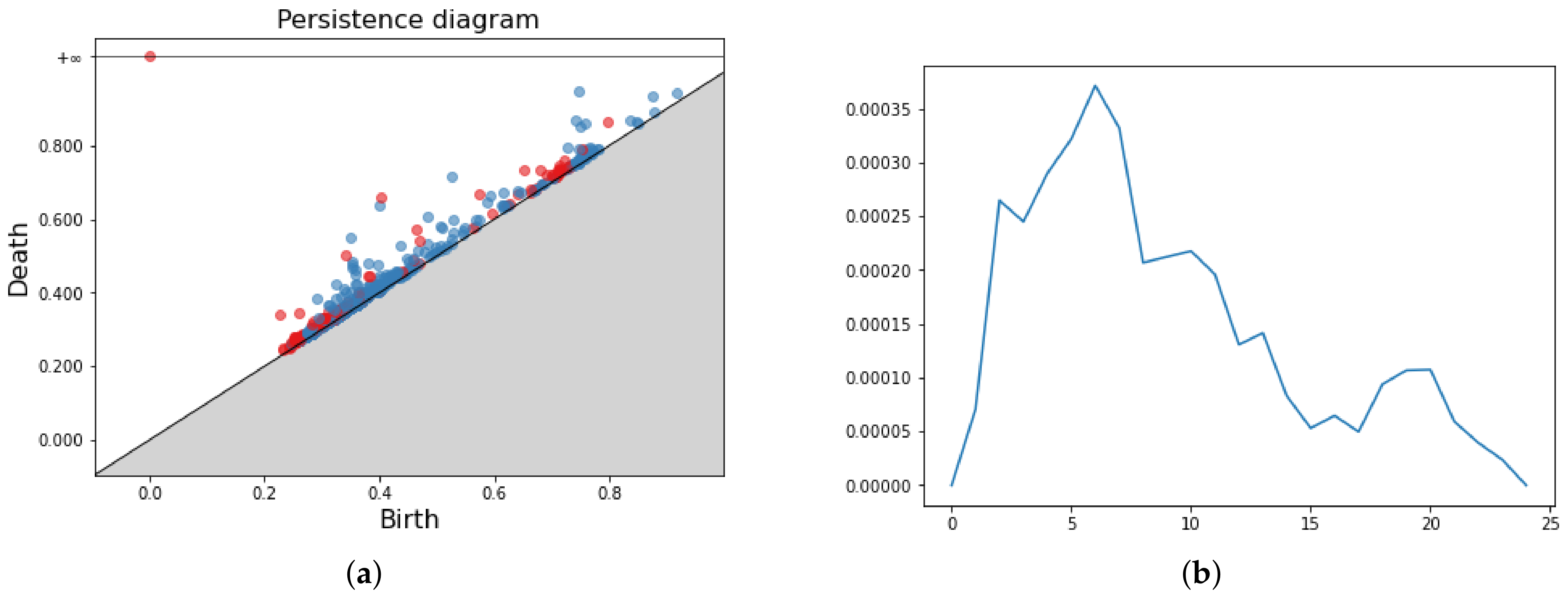
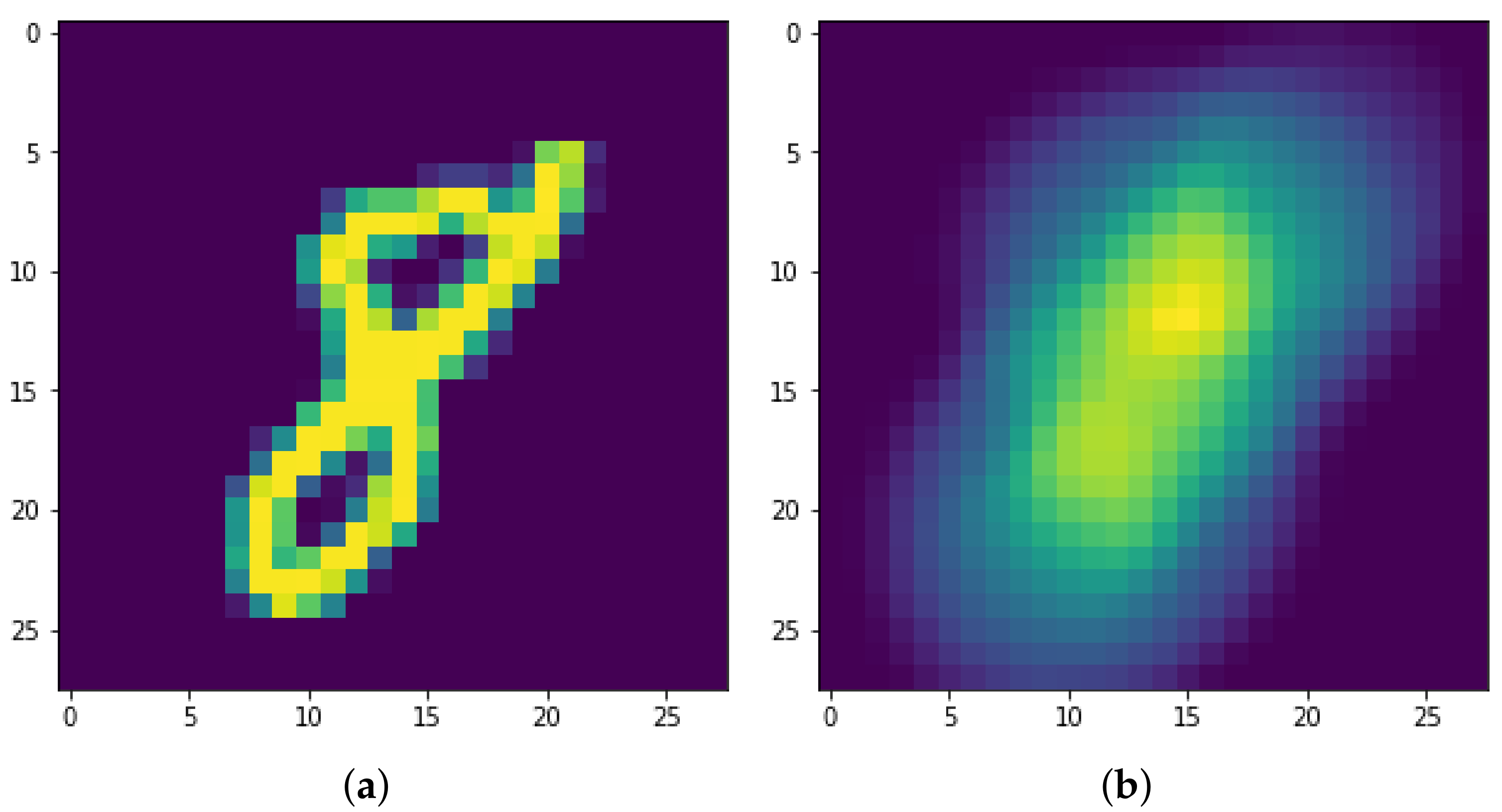
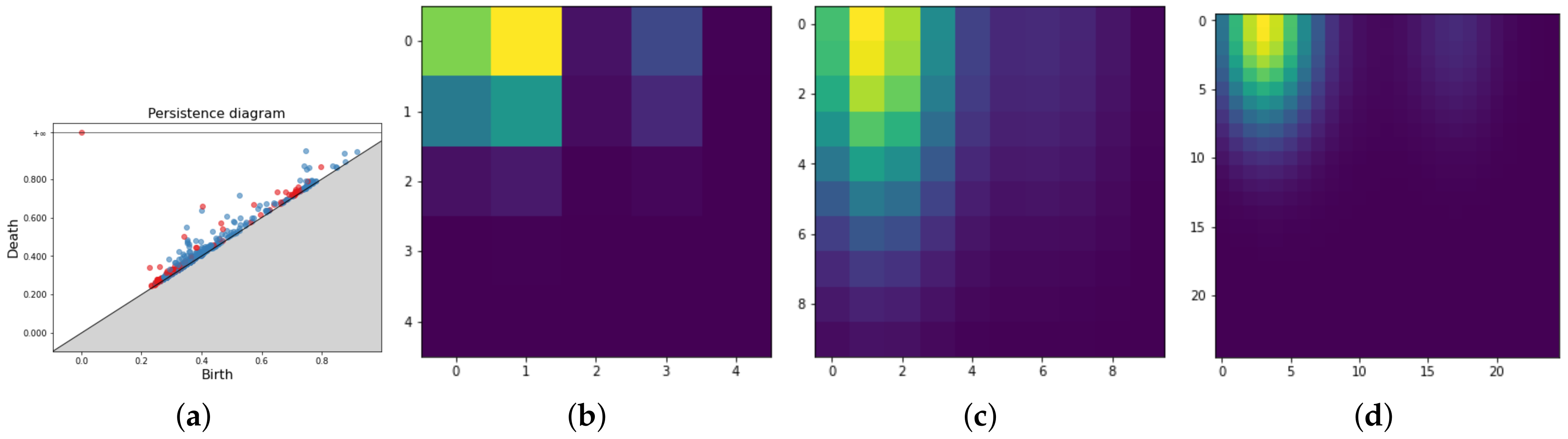
Figure 5.
Persistence Diagram (a) and three Persistence Images for respectively in (b–d).
Figure 5.
Persistence Diagram (a) and three Persistence Images for respectively in (b–d).
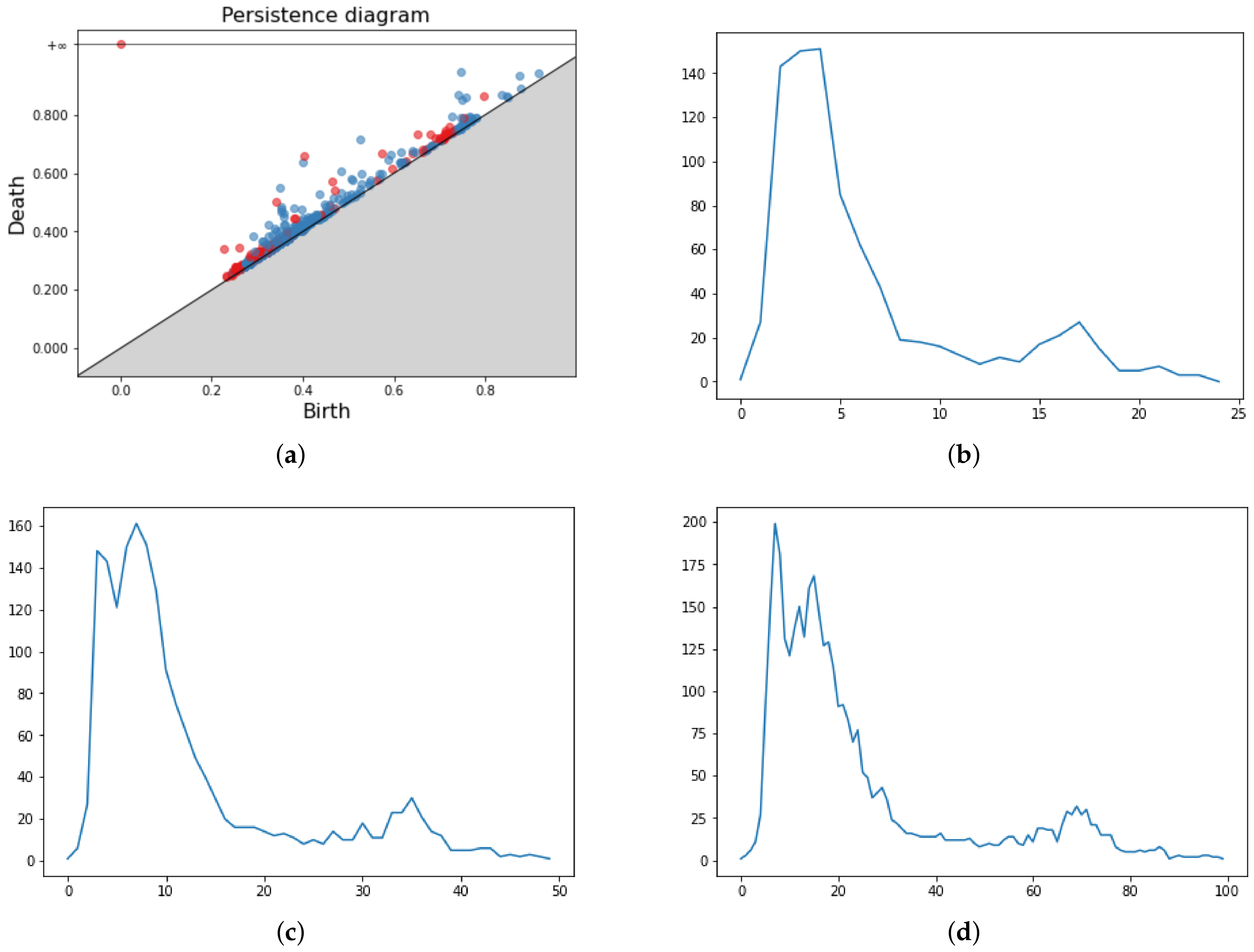
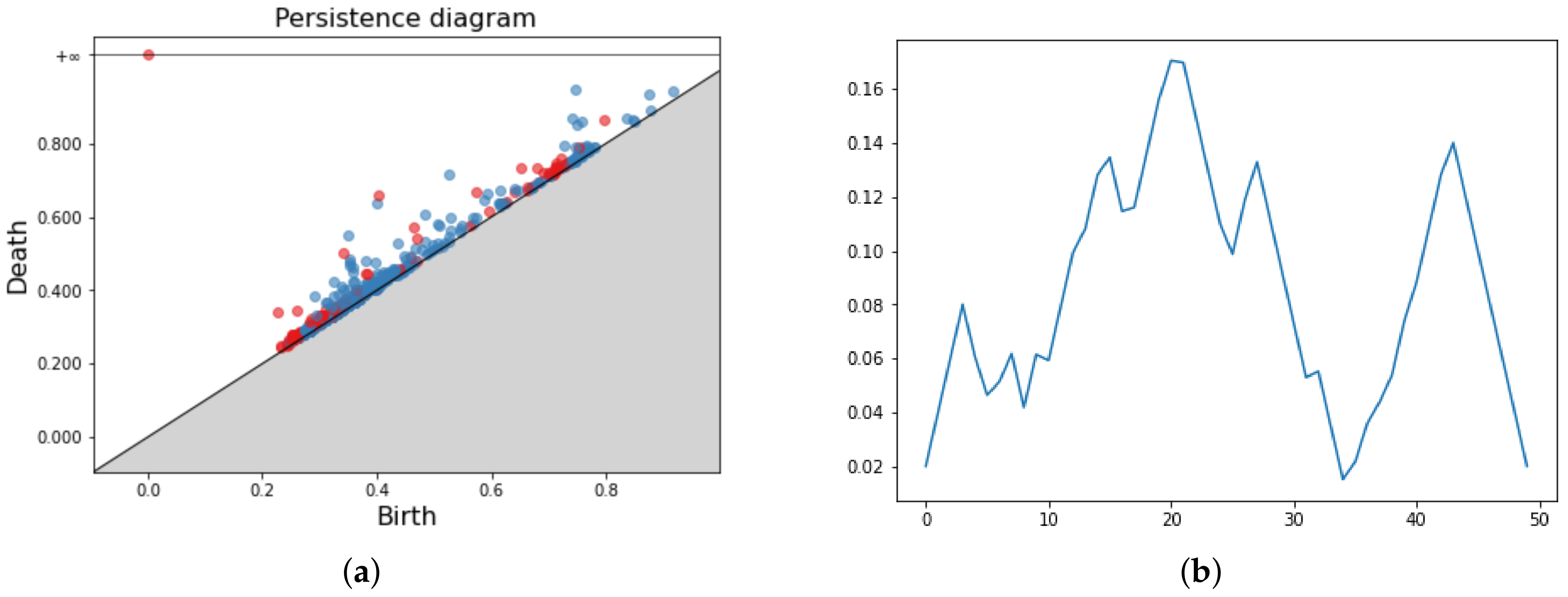
Figure 6.
Persistence Diagram (a) and three Persistence Landscapes for respectively in (b–d).
Figure 6.
Persistence Diagram (a) and three Persistence Landscapes for respectively in (b–d).
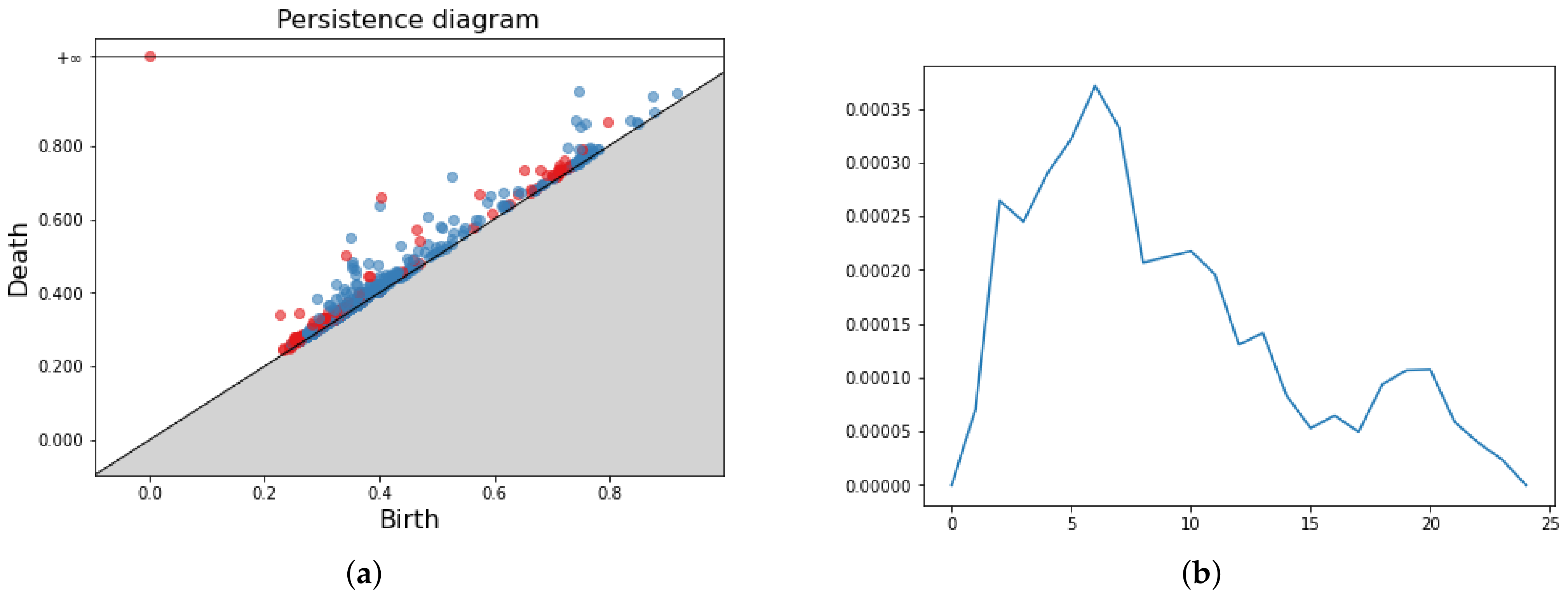
Figure 7.
Persistence Diagram (a) and three Persistence Silhouettes for and , respectively in (b–d).
Figure 7.
Persistence Diagram (a) and three Persistence Silhouettes for and , respectively in (b–d).
Figure 8.
Persistence Diagram (a) and three Betti curves for and , respectively, in (b–d).
Figure 8.
Persistence Diagram (a) and three Betti curves for and , respectively, in (b–d).
Figure 9.
Example of truncated orbits for the first 1000 iterations of the linked twisted map for different r. From (a) to (e) r is, respectively, and .
Figure 9.
Example of truncated orbits for the first 1000 iterations of the linked twisted map for different r. From (a) to (e) r is, respectively, and .
Figure 10.
Example of truncated orbits for the first 1000 iterations of the linked twisted map for and five different starting points (a–e).
Figure 10.
Example of truncated orbits for the first 1000 iterations of the linked twisted map for and five different starting points (a–e).
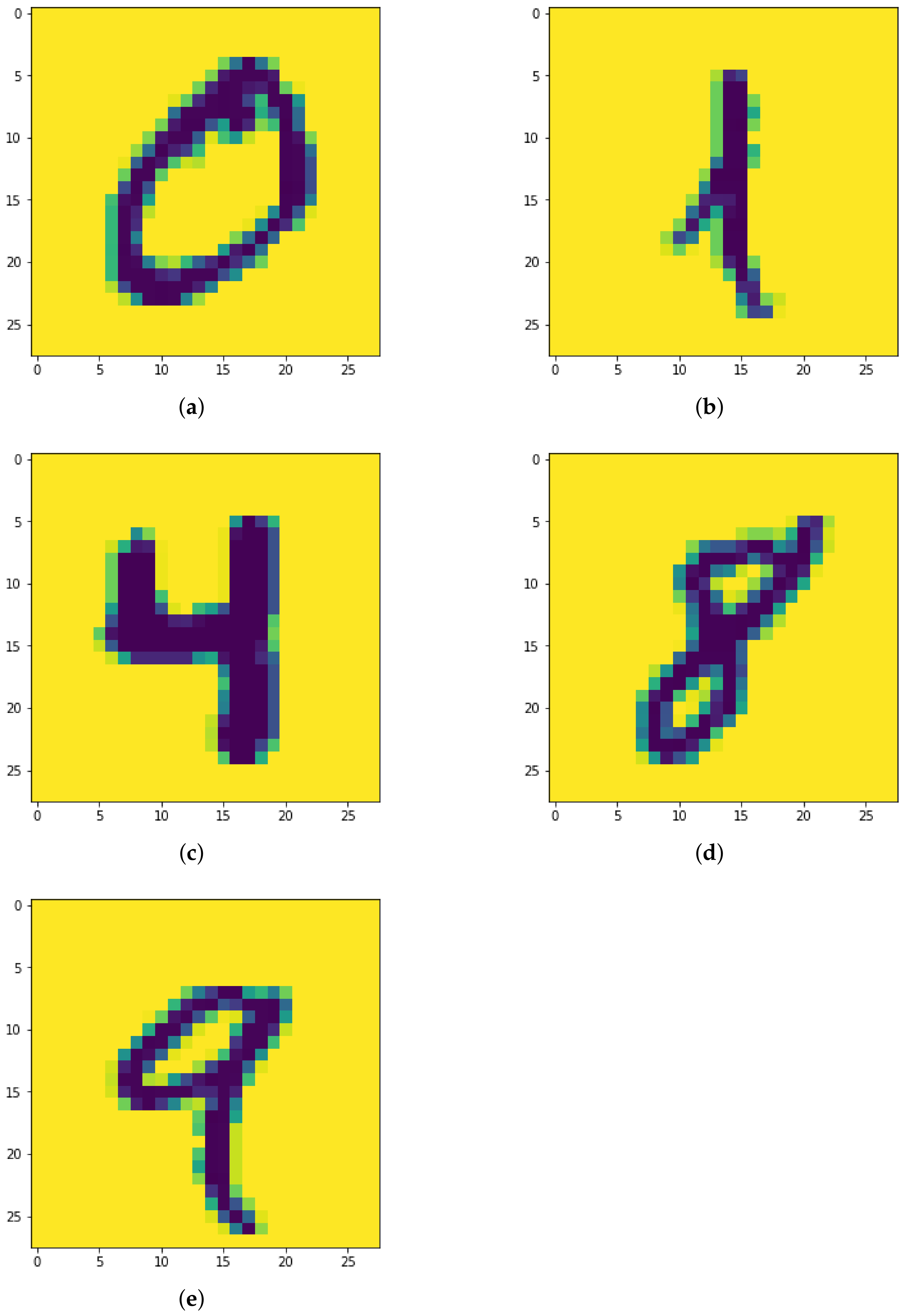
Figure 11.
Sample images from MNIST dataset. It can be seen at a glance that the homology of different digits is almost always trivial (for (b,c)) or close to trivial (for (a,d,e)).
Figure 11.
Sample images from MNIST dataset. It can be seen at a glance that the homology of different digits is almost always trivial (for (b,c)) or close to trivial (for (a,d,e)).
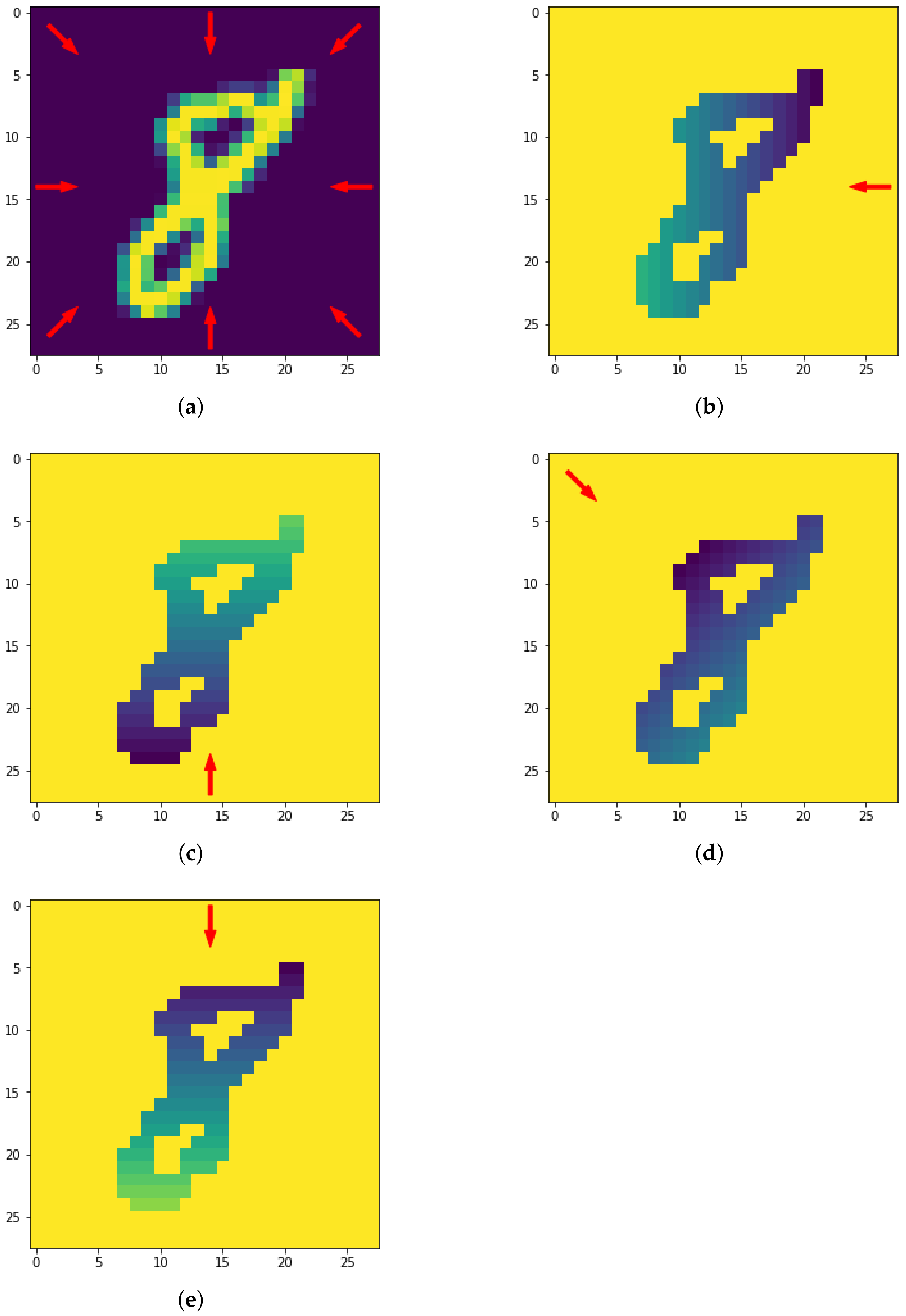
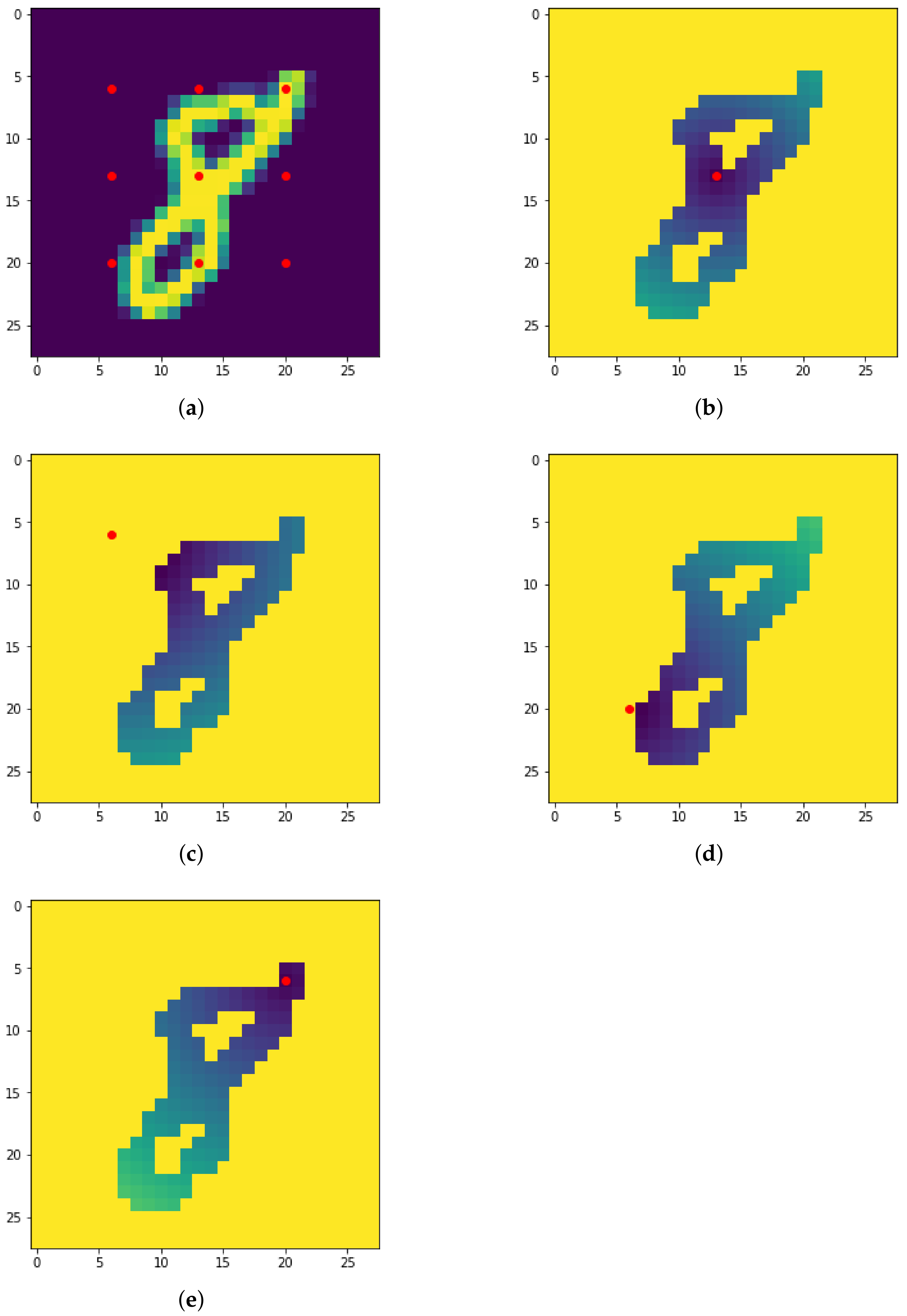
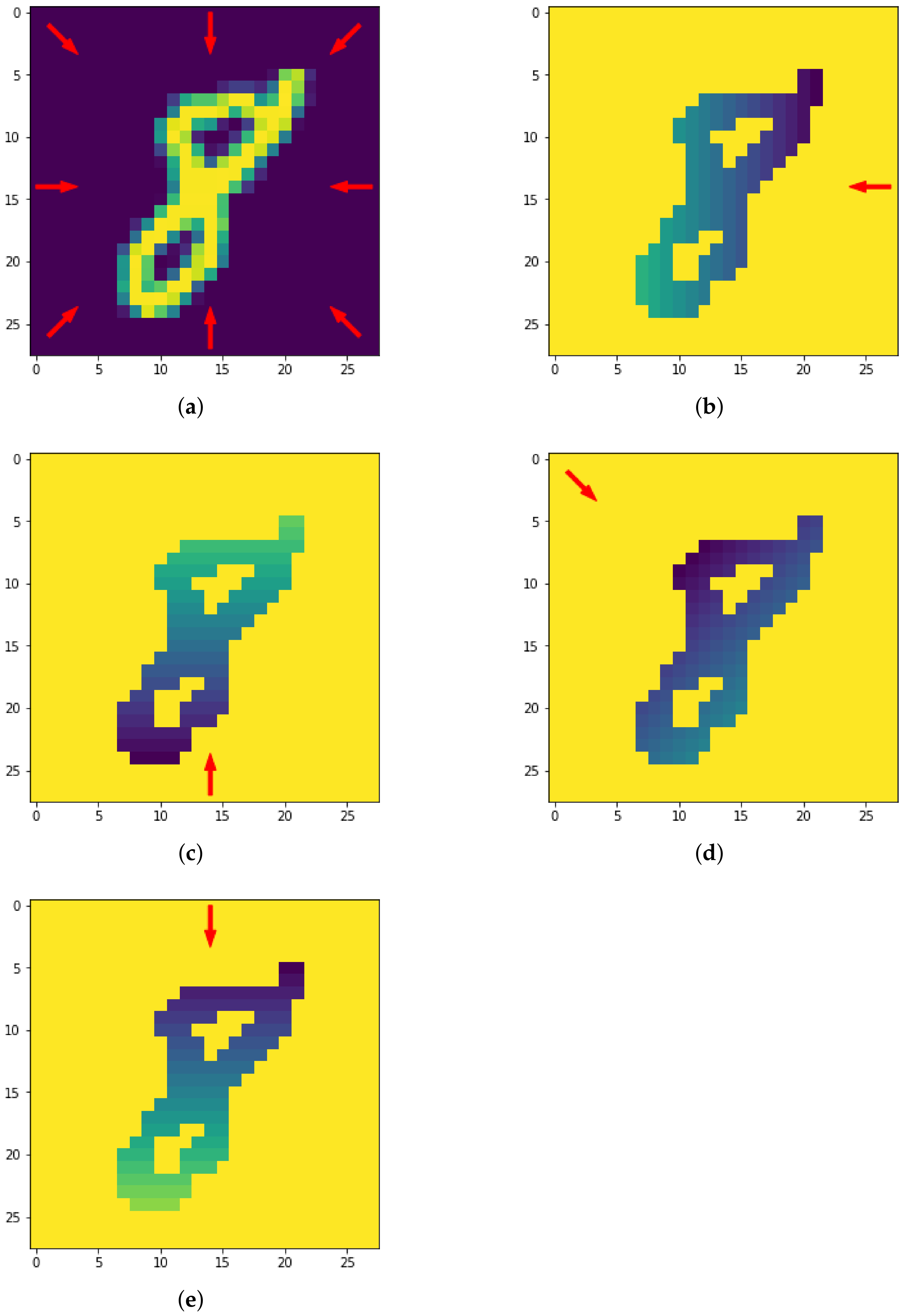
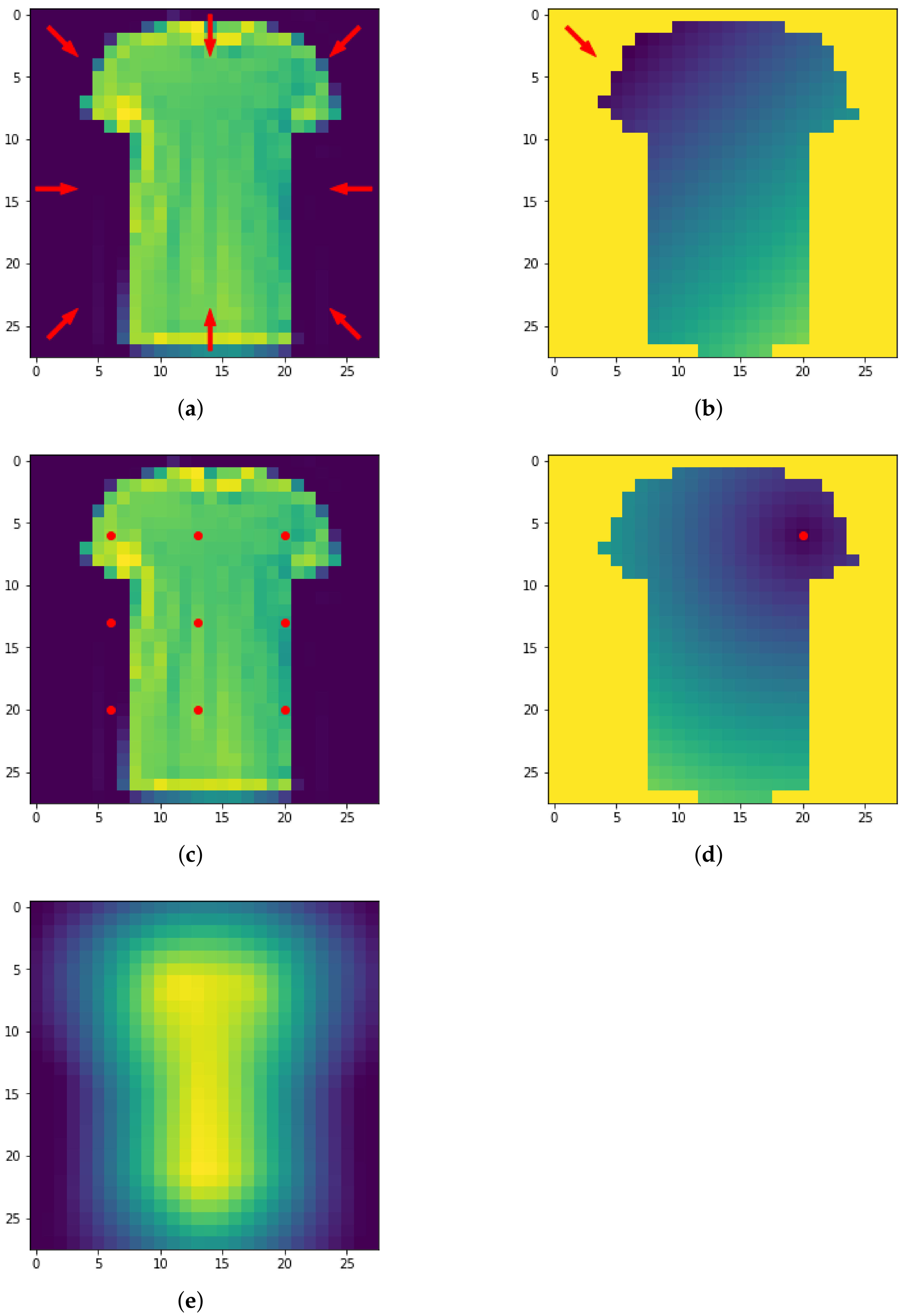
Figure 12.
The eight directions used for the height filtration (a) and resulting filtrated images along four directions (b–e).
Figure 12.
The eight directions used for the height filtration (a) and resulting filtrated images along four directions (b–e).
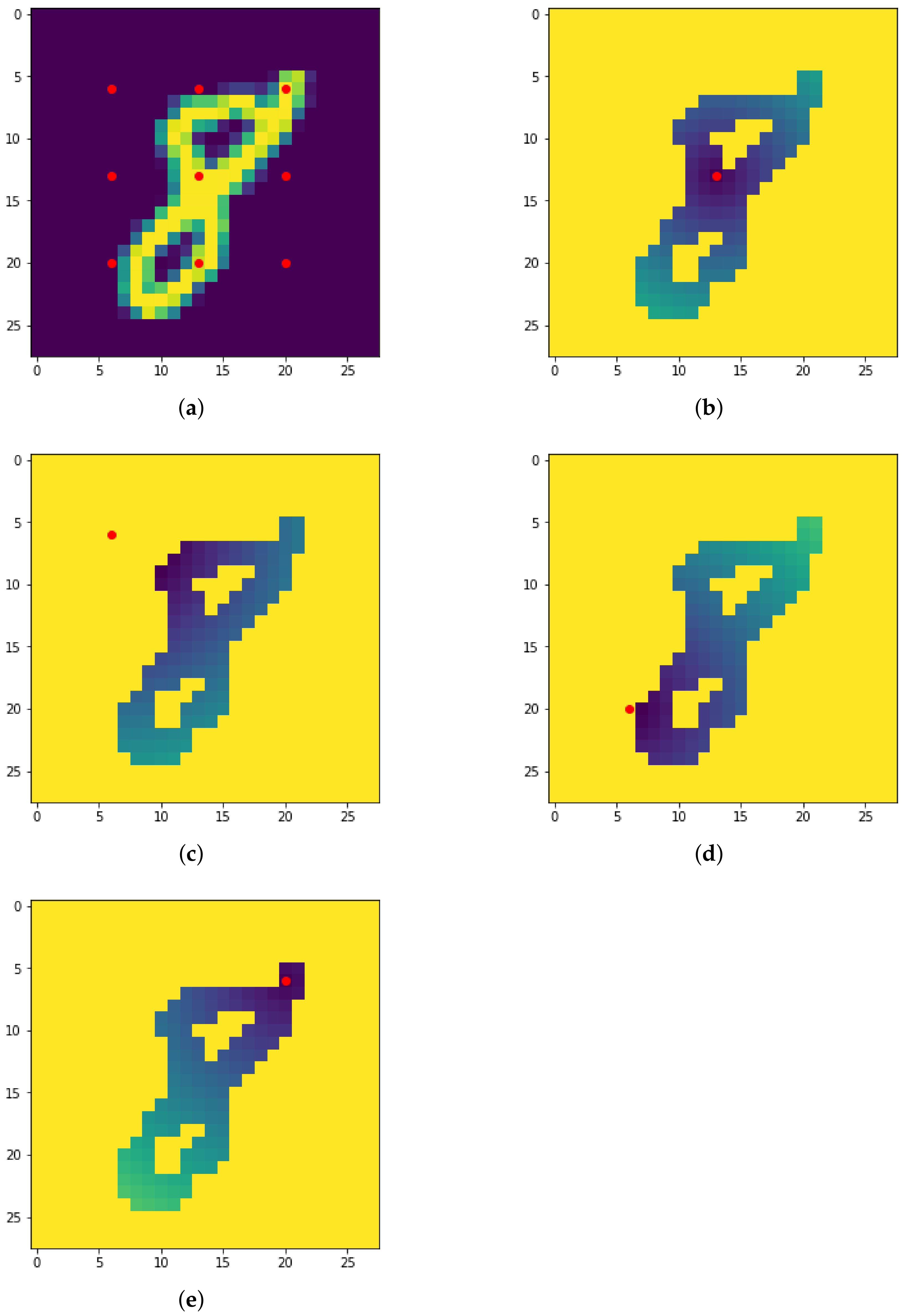
Figure 13.
The nine centers used for the radial filtration (a) and resulting filtrated images with respect to four different centers (b–e).
Figure 13.
The nine centers used for the radial filtration (a) and resulting filtrated images with respect to four different centers (b–e).
Figure 14.
The original digit “8” (a) and the resulting filtered image with respect to the density filtration with radius (b).
Figure 14.
The original digit “8” (a) and the resulting filtered image with respect to the density filtration with radius (b).
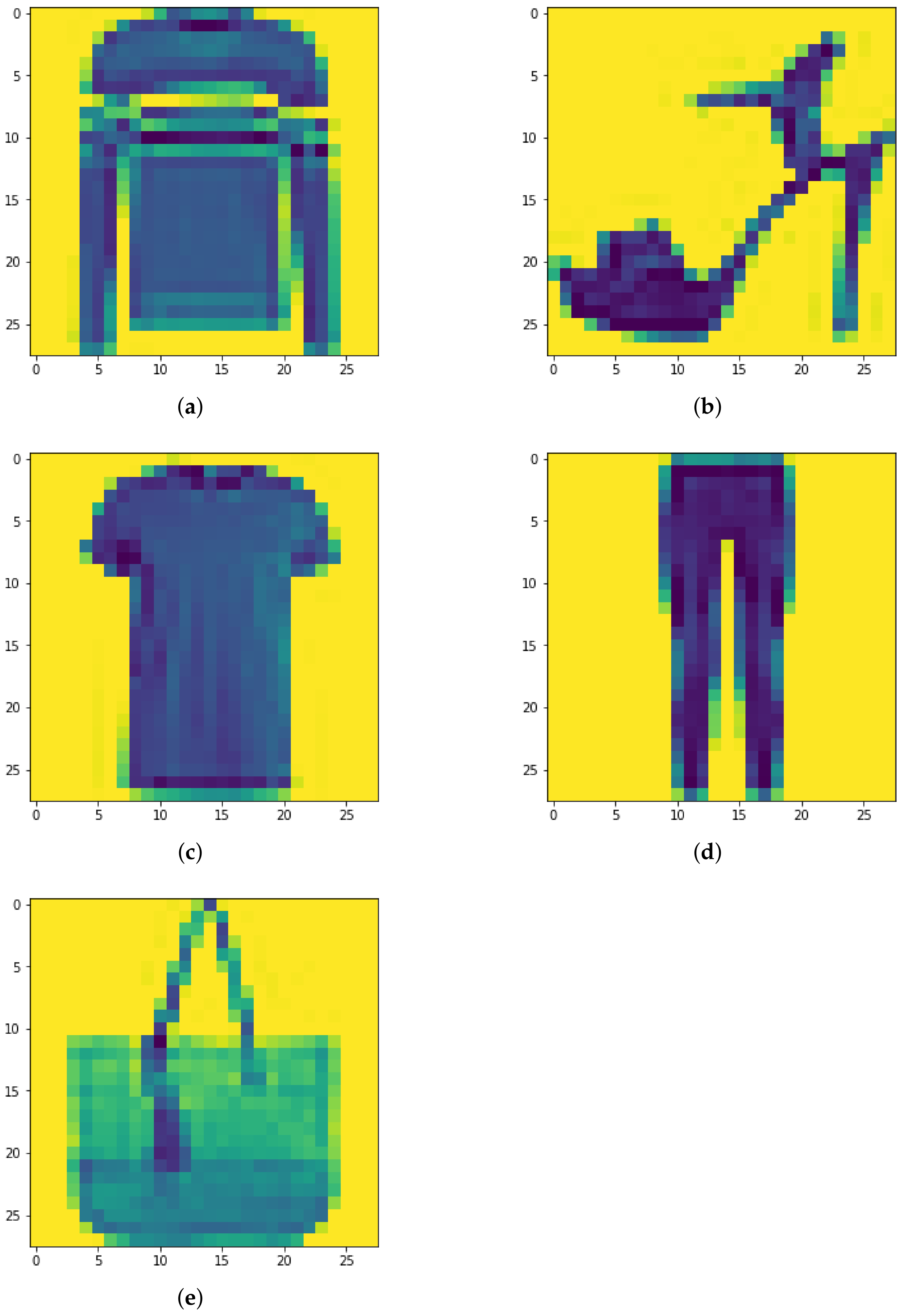
Figure 15.
(a–e) Sample images from FMNIST dataset. Classifying these images is clearly more difficult than with the MNIST dataset.
Figure 15.
(a–e) Sample images from FMNIST dataset. Classifying these images is clearly more difficult than with the MNIST dataset.
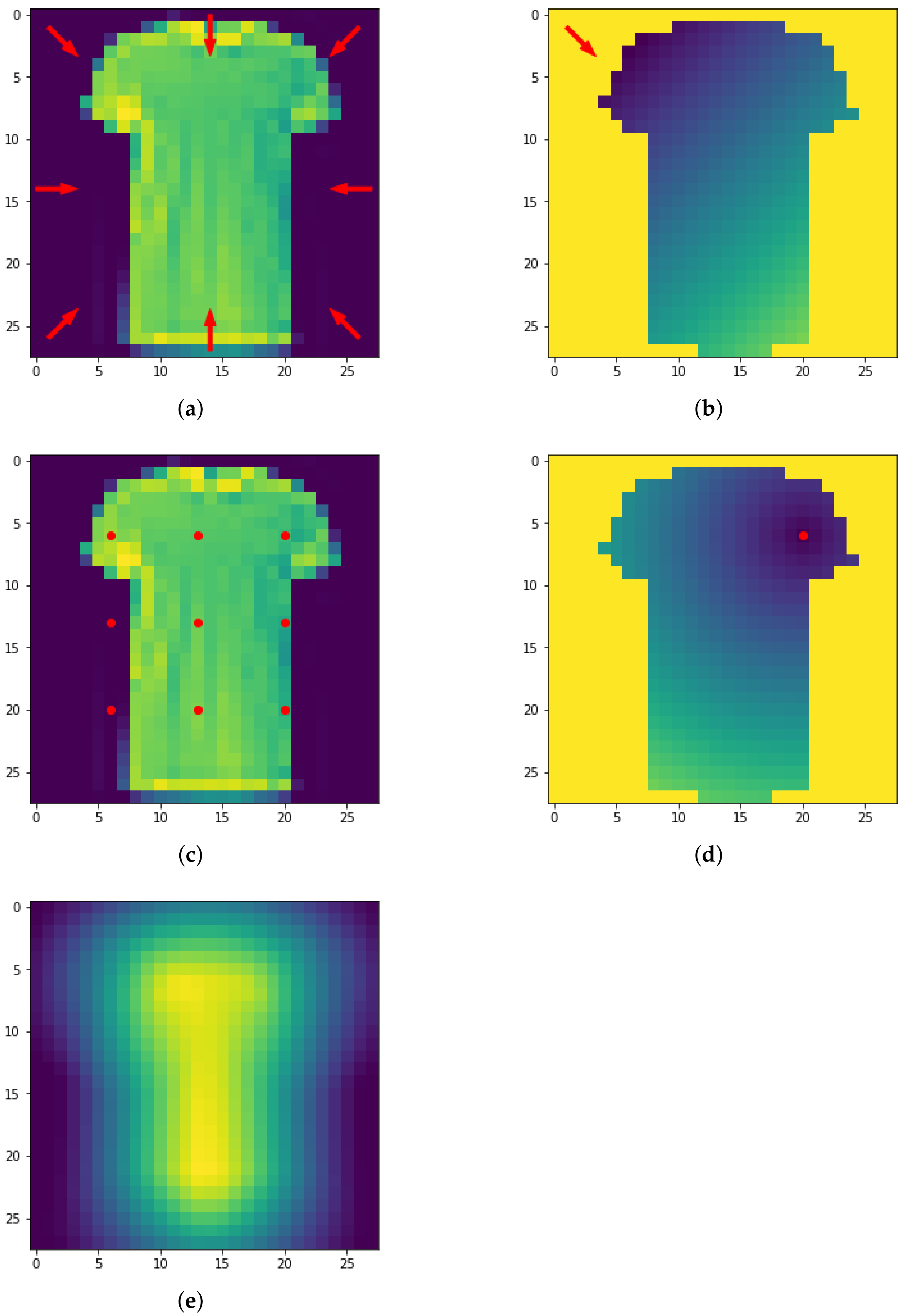
Figure 16.
The eight directions used for the height filtration (a) and resulting filtrated image (b). The nine centers used for the radial filtration (c,d). Density filtered image (e).
Figure 16.
The eight directions used for the height filtration (a) and resulting filtrated image (b). The nine centers used for the radial filtration (c,d). Density filtered image (e).
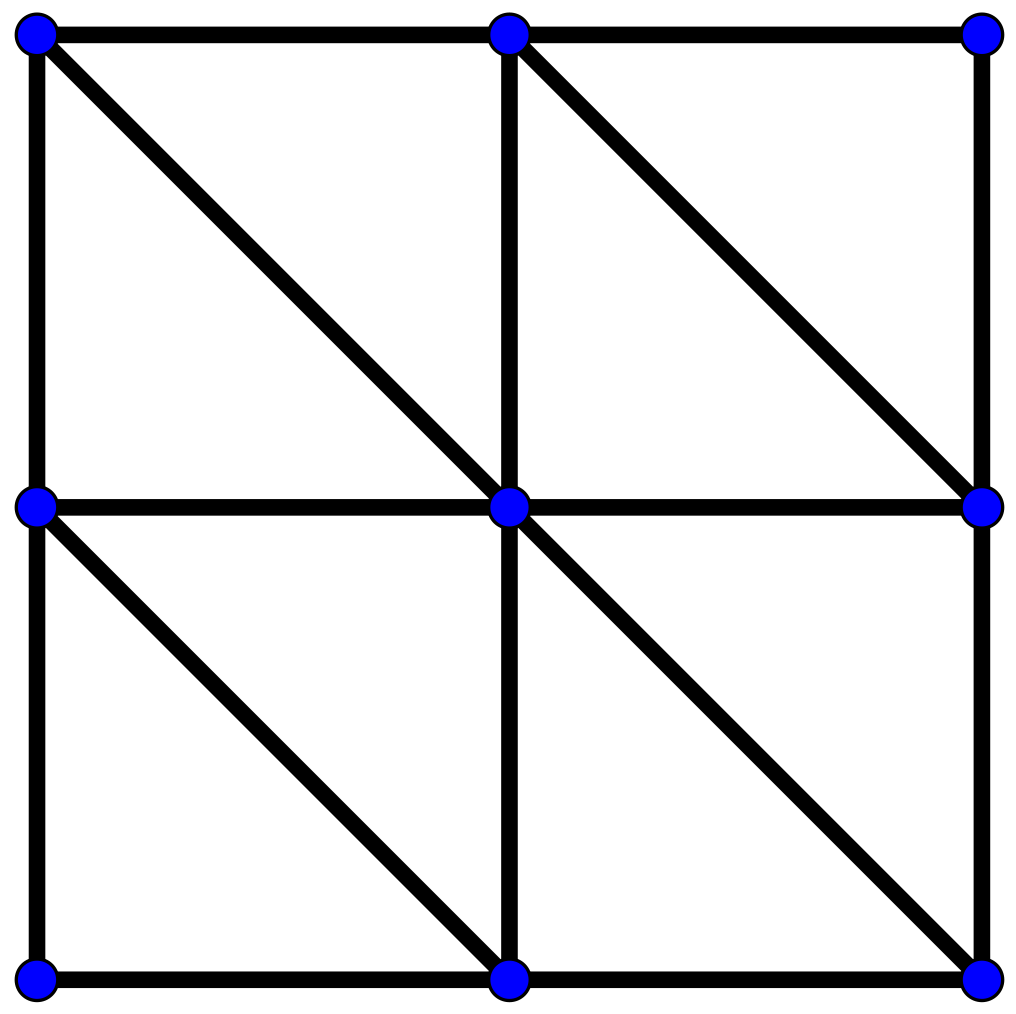
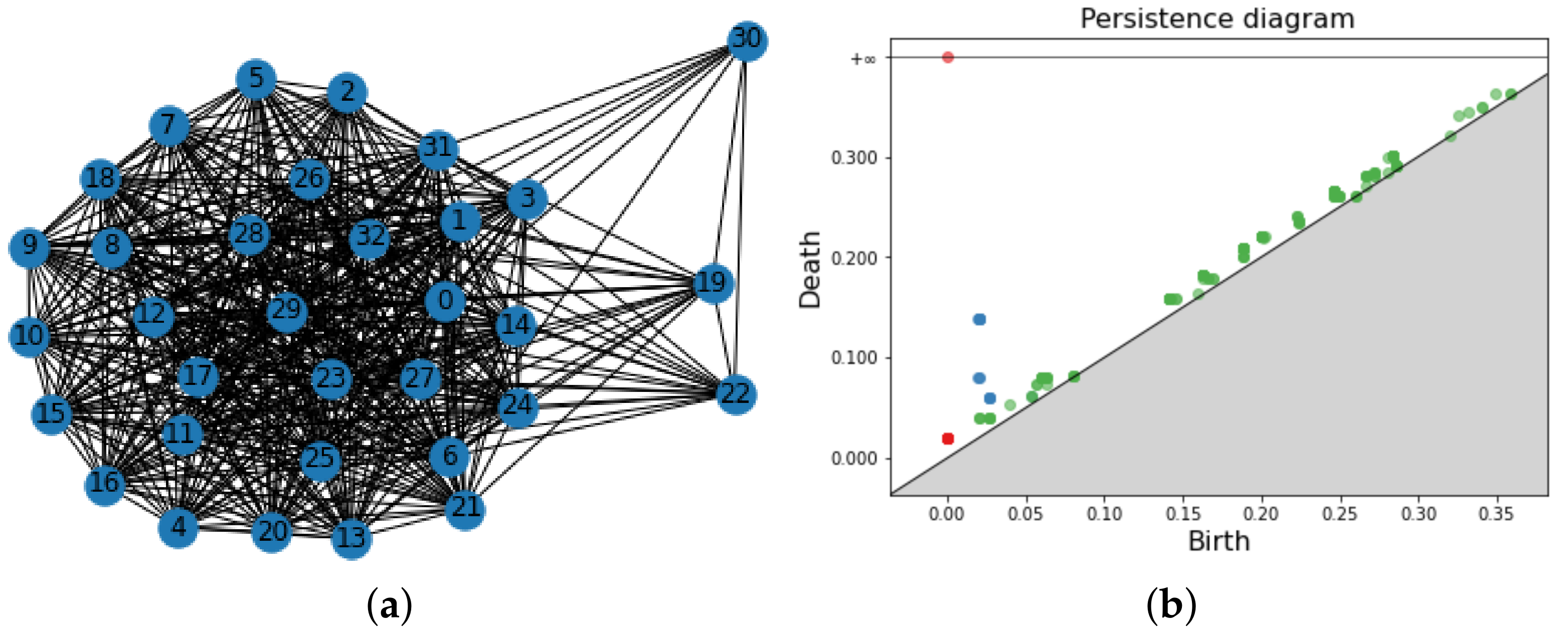
Figure 17.
A graph of COLLAB (a) and the corresponding PD (b). For aesthetic reasons, only a small sample of 2-simplexes are shown and the edge weight is not displayed. In figure (b) the PD in dimension 0–2 are visualized in the same plot: points are red for PD in dimension 0, blue for PD in dimension 1 and green for dimension 2.
Figure 17.
A graph of COLLAB (a) and the corresponding PD (b). For aesthetic reasons, only a small sample of 2-simplexes are shown and the edge weight is not displayed. In figure (b) the PD in dimension 0–2 are visualized in the same plot: points are red for PD in dimension 0, blue for PD in dimension 1 and green for dimension 2.
Table 1.
Accuracy for the dynamical system dataset. (PI: persistent image; PL: persistent landscape; BC: Betti curve).
Table 1.
Accuracy for the dynamical system dataset. (PI: persistent image; PL: persistent landscape; BC: Betti curve).
| Accuracy | | | (Fused) | (Concat) |
|---|
| Run 1 | (PI) | (PL) | (PI) | (PL) |
| Run 2 | (PI) | (PL) | (PI) | (PL) |
| Run 3 | (PI) | (PL) | (PI) | (PL) |
| Run 4 | (PI) | (BC) | (PI) | (BC) |
| Run 5 | (PI) | (PL) | (PI) | (PL) |
| Run 6 | (PI) | (PL) | (PI) | (PL) |
| Run 7 | (PI) | (PL) | (PI) | (PL) |
| Run 8 | (PI) | (PL) | (PI) | (PL) |
| Run 9 | (PI) | (PL) | (PI) | (BC) |
| Run 10 | (PI) | (PL) | (PI) | (PL) |
| Mean: | | | | |
Table 2.
Best method for the dynamical system dataset.
Table 2.
Best method for the dynamical system dataset.
| Homology | Accuracy | Vectorization | Classifier |
|---|
| | Persistence Images | RandomForestClassifier |
| | Persistence Landscapes | SVC(kernel = ‘rbf’, C = 10) |
| (fused) | | Persistence Images | RandomForestClassifier |
| (concat) | | Persistence Landscapes | RandomForestClassifier |
Table 3.
Accuracy for MNIST dataset. (PI: persistent image; PL: persistent landscape; PS: persistent silhouette; BC: Betti curve).
Table 3.
Accuracy for MNIST dataset. (PI: persistent image; PL: persistent landscape; PS: persistent silhouette; BC: Betti curve).
| Accuracy | | | (Fused) | (Concat) |
|---|
| Run 1 | (PI) | (PL) | (PI) | (PL) |
| Run 2 | (PI) | (PL) | (PI) | (PL) |
| Run 3 | (PI) | (PL) | (PI) | (PS) |
| Run 4 | (PI) | (PL) | (PI) | (PL) |
| Run 5 | (PS) | (PL) | (PI) | (PL) |
| Run 6 | (PI) | (PL) | (PI) | (PL) |
| Run 7 | (PI) | (PL) | (PI) | (PL) |
| Run 8 | (PS) | (PL) | (PI) | (PL) |
| Run 9 | (PI) | (PL) | (PI) | (BC) |
| Run 10 | (PI) | (PL) | (PI) | (PL) |
| Mean: | | | | |
Table 4.
Accuracy for MNIST dataset of the collapse approach. (PI: persistent image; PL: persistent landscape).
Table 4.
Accuracy for MNIST dataset of the collapse approach. (PI: persistent image; PL: persistent landscape).
| Accuracy | | | (Fused) | (Concat) |
|---|
| Run 1 | (PI) | (PL) | (PI) | (PI) |
| Run 2 | (PI) | (PI) | (PI) | (PI) |
| Run 3 | (PI) | (PI) | (PI) | (PI) |
| Run 4 | (PI) | (PL) | (PI) | (PI) |
| Run 5 | (PI) | (PI) | (PI) | (PI) |
| Run 6 | (PL) | (PL) | (PI) | (PI) |
| Run 7 | (PI) | (PL) | (PI) | (PL) |
| Run 8 | (PI) | (PL) | (PI) | (PI) |
| Run 9 | (PL) | (PL) | (PI) | (PI) |
| Run 10 | (PI) | (PI) | (PI) | (PL) |
| Mean: | | | | |
Table 5.
Accuracy for MNIST dataset of the multivector approach. (PI: persistent image; PL: persistent landscape; PS: persistent silhouette; BC: Betti curve).
Table 5.
Accuracy for MNIST dataset of the multivector approach. (PI: persistent image; PL: persistent landscape; PS: persistent silhouette; BC: Betti curve).
| Accuracy | | | (Fused) | (Concat) |
|---|
| Run 1 | (PL) | (PL) | (PI) | (PL) |
| Run 2 | (PL) | (PL) | (BC) | (PL) |
| Run 3 | (PL) | (PS) | (BC) | (PL) |
| Run 4 | (PL) | (PL) | (BC) | (PS) |
| Run 5 | (PL) | (PL) | (BC) | (PL) |
| Run 6 | (PL) | (PL) | (BC) | (PL) |
| Run 7 | (PL) | (PL) | (PI) | (PL) |
| Run 8 | (PL) | (PL) | (BC) | (PS) |
| Run 9 | (PL) | (PL) | (PL) | (PL) |
| Run 10 | (PL) | (PL) | (BC) | (PL) |
| Mean: | | | | |
Table 6.
Best method for MNIST dataset.
Table 6.
Best method for MNIST dataset.
| Homology | Accuracy | Vectorization | Classifier | Approach |
|---|
| | PI | SVC(kernel = ‘rbf’, C = 10) | Multivector |
| | PL | SVC(kernel = ‘rbf’, C = 20) | Collapse |
| (fused) | | PI | SVC(kernel = ‘rbf’, C = 20) | Multivector |
| (concat) | | PI | SVC(kernel = ‘rbf’, C = 20) | Multivector |
Table 7.
Accuracy for MNIST dataset of [
38] pipeline and [
41] pipeline. (TF: tent function; PI: persistent image).
Table 7.
Accuracy for MNIST dataset of [
38] pipeline and [
41] pipeline. (TF: tent function; PI: persistent image).
| Accuracy | [38] Pipeline | [41] Pipeline |
|---|
| Run 1 | | (TF) |
| Run 2 | | (TF) |
| Run 3 | | (TF) |
| Run 4 | | (PI) |
| Run 5 | | (TF) |
| Run 6 | | (TF) |
| Run 7 | | (TF) |
| Run 8 | | (PI) |
| Run 9 | | (TF) |
| Run 10 | | (TF) |
| Mean: | | |
Table 8.
Accuracy for FMNIST dataset. (PI: persistent image).
Table 8.
Accuracy for FMNIST dataset. (PI: persistent image).
| Accuracy | | | (Fused) | (Concat) |
|---|
| Run 1 | (PI) | (PI) | (PI) | (PI) |
| Run 2 | (PI) | (PI) | (PI) | (PI) |
| Run 3 | (PI) | (PI) | (PI) | (PI) |
| Run 4 | (PI) | (PI) | (PI) | (PI) |
| Run 5 | (PI) | (PI) | (PI) | (PI) |
| Run 6 | (PI) | (PI) | (PI) | (PI) |
| Run 7 | (PI) | (PI) | (PI) | (PI) |
| Run 8 | (PI) | (PI) | (PI) | (PI) |
| Run 9 | (PI) | (PI) | (PI) | (PI) |
| Run 10 | (PI) | (PI) | (PI) | (PI) |
| Mean: | | | | |
Table 9.
Accuracy for FMNIST dataset of the collapse approach. (PI: persistent image; PL: persistent landscape).
Table 9.
Accuracy for FMNIST dataset of the collapse approach. (PI: persistent image; PL: persistent landscape).
| Accuracy | | | (Fused) | (Concat) |
|---|
| Run 1 | (PL) | (PI) | (PL) | (PL) |
| Run 2 | (PL) | (PI) | (PL) | (PL) |
| Run 3 | (PL) | (PI) | (PL) | (PL) |
| Run 4 | (PL) | (PL) | (PL) | (PL) |
| Run 5 | (PL) | (PI) | (PL) | (PL) |
| Run 6 | (PL) | (PI) | (PL) | (PL) |
| Run 7 | (PL) | (PI) | (PL) | (PL) |
| Run 8 | (PL) | (PI) | (PL) | (PL) |
| Run 9 | (PL) | (PL) | (PI) | (PL) |
| Run 10 | (PL) | (PL) | (PL) | (PL) |
| Mean: | | | | |
Table 10.
Accuracy for FMNIST dataset of the multivector approach. (PL: persistent landscape; PS: persistent silhouette).
Table 10.
Accuracy for FMNIST dataset of the multivector approach. (PL: persistent landscape; PS: persistent silhouette).
| Accuracy | | | (Fused) | (Concat) |
|---|
| Run 1 | (PL) | (PL) | (PL) | (PL) |
| Run 2 | (PL) | (PS) | (PL) | (PL) |
| Run 3 | (PL) | (PL) | (PL) | (PL) |
| Run 4 | (PL) | (PL) | (PL) | (PL) |
| Run 5 | (PL) | (PL) | (PL) | (PL) |
| Run 6 | (PL) | (PL) | (PL) | (PL) |
| Run 7 | (PL) | (PL) | (PL) | (PL) |
| Run 8 | (PL) | (PL) | (PL) | (PL) |
| Run 9 | (PL) | (PL) | (PL) | (PL) |
| Run 10 | (PL) | (PL) | (PL) | (PL) |
| Mean: | | | | |
Table 11.
Accuracy for FMNIST dataset of [
38] pipeline and [
41] pipeline. (PI: persistent image; TF: tent function).
Table 11.
Accuracy for FMNIST dataset of [
38] pipeline and [
41] pipeline. (PI: persistent image; TF: tent function).
| Accuracy | [38] Pipeline | [41] Pipeline |
|---|
| Run 1 | | (PI) |
| Run 2 | | (PI) |
| Run 3 | | (TF) |
| Run 4 | | (PI) |
| Run 5 | | (PI) |
| Run 6 | | (PI) |
| Run 7 | | (PI) |
| Run 8 | | (PI) |
| Run 9 | | (PI) |
| Run 10 | | (PI) |
| Mean: | | |
Table 12.
Best method for FMNIST dataset.
Table 12.
Best method for FMNIST dataset.
| Homology | Accuracy | Vectorization | Classifier | Approach |
|---|
| | PL | RFC | Multivector |
| | PI | RFC | Collapse |
| (fused) | | PL | RFC | Multivector |
| (concat) | | PL | RFC | Multivector |
Table 13.
Accuracy for COLLAB dataset. (PI: persistent image; PL: persistent landscape; PS: persistent silhouette; BC: Betti curve).
Table 13.
Accuracy for COLLAB dataset. (PI: persistent image; PL: persistent landscape; PS: persistent silhouette; BC: Betti curve).
| Accuracy | | | | (Fused) | (Concat) |
|---|
| Run 1 | (PI) | (PS) | (PI) | (PI) | (PI) |
| Run 2 | (PI) | (PS) | (PI) | (PI) | (PI) |
| Run 3 | (PI) | (PS) | (PI) | (PI) | (PI) |
| Run 4 | (BC) | (PL) | (PI) | (PI) | (PI) |
| Run 5 | (BC) | (PS) | (PI) | (PI) | (PI) |
| Run 6 | (PI) | (PS) | (PI) | (PI) | (PI) |
| Run 7 | (PI) | (PS) | (PI) | (PI) | (PI) |
| Run 8 | (BC) | (PS) | (PI) | (PI) | (PI) |
| Run 9 | (PS) | (PS) | (PI) | (PI) | (PI) |
| Run 10 | (PS) | (PS) | (PI) | (PI) | (PI) |
| Mean: | | | | | |
Table 14.
Best method for COLLAB dataset.
Table 14.
Best method for COLLAB dataset.
| Homology | Accuracy | Vectorization | Classifier |
|---|
| | Betti Curves | RandomForestClassifier |
| | Persistence Silhouette | RandomForestClassifier |
| | Persistence Images | RandomForestClassifier |
| (fused) | | Persistence Images | RandomForestClassifier |
| (concat) | | Persistence Images | RandomForestClassifier |
Table 15.
p-value statistic for the dynamical system dataset.
Table 15.
p-value statistic for the dynamical system dataset.
| p-Value | | | Fused | Concat |
|---|
| PI vs. PL | 2.03 × | | | |
| PI vs. PS | | | | |
| PI vs. BC | | | | |
| PL vs. PS | Null | | | |
| PL vs. BC | Null | | Null | |
| PS vs. BC | Null | | | |
Table 16.
p-value statistic for the MNIST dataset.
Table 16.
p-value statistic for the MNIST dataset.
| p-Value | | | Fused | Concat |
|---|
| PI vs. PL | 4.55 × | | | |
| PI vs. PS | | | | |
| PI vs. BC | | | | |
| PL vs. PS | | | | |
| PL vs. BC | | | | |
| PS vs. BC | | | | |
Table 17.
p-value statistic for the FMNIST dataset.
Table 17.
p-value statistic for the FMNIST dataset.
| p-Value | | | Fused | Concat |
|---|
| PI vs. PL | 2.02 × | | | |
| PI vs. PS | | | | |
| PI vs. BC | | | | |
| PL vs. PS | | | | |
| PL vs. BC | | | | |
| PS vs. BC | | | | |
Table 18.
p-value statistic for the COLLAB dataset.
Table 18.
p-value statistic for the COLLAB dataset.
| p-Value | | | | Fused | Concat |
|---|
| PI vs. PL | 3.73 × | | | | |
| PI vs. PS | | | | | |
| PI vs. BC | | | | | |
| PL vs. PS | | | | | |
| PL vs. BC | | | | | |
| PS vs. BC | | | | | |
Table 19.
p-value statistic for the homology dimensions.
Table 19.
p-value statistic for the homology dimensions.
| p-Value | Dynamical | MNIST | FMNIST | COLLAB |
|---|
| vs. | 5.71 × | | | |
| vs. | - | - | - | |
| vs. fused | | | | |
| vs. concat | | | | |
| vs. | - | - | - | |
| vs. fused | | | | |
| vs. concat | | | | |
| vs. fused | - | - | - | |
| vs. concat | - | - | - | |
| fused vs. concat | | | | |












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}