
Meta-Heuristic Optimization and Keystroke Dynamics for Authentication of Smartphone Users

 ,
,  ,
,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
2. Literature Review
3. Keystroke Dynamics
3.1. Touch Information
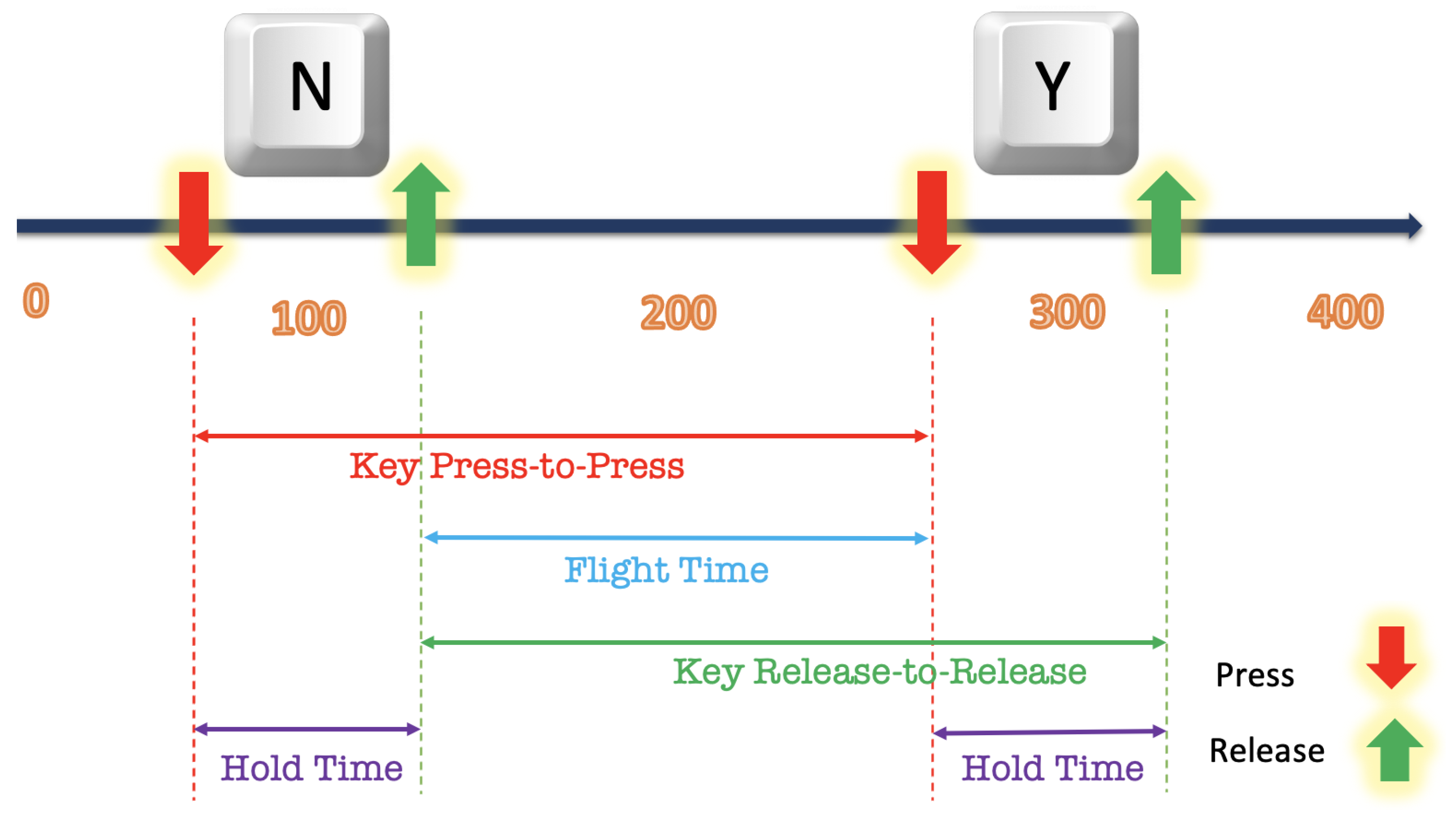
3.1.1. Dwell Time
3.1.2. Flight Time
3.1.3. Pressure
3.1.4. Coordinates
3.1.5. Motion Data
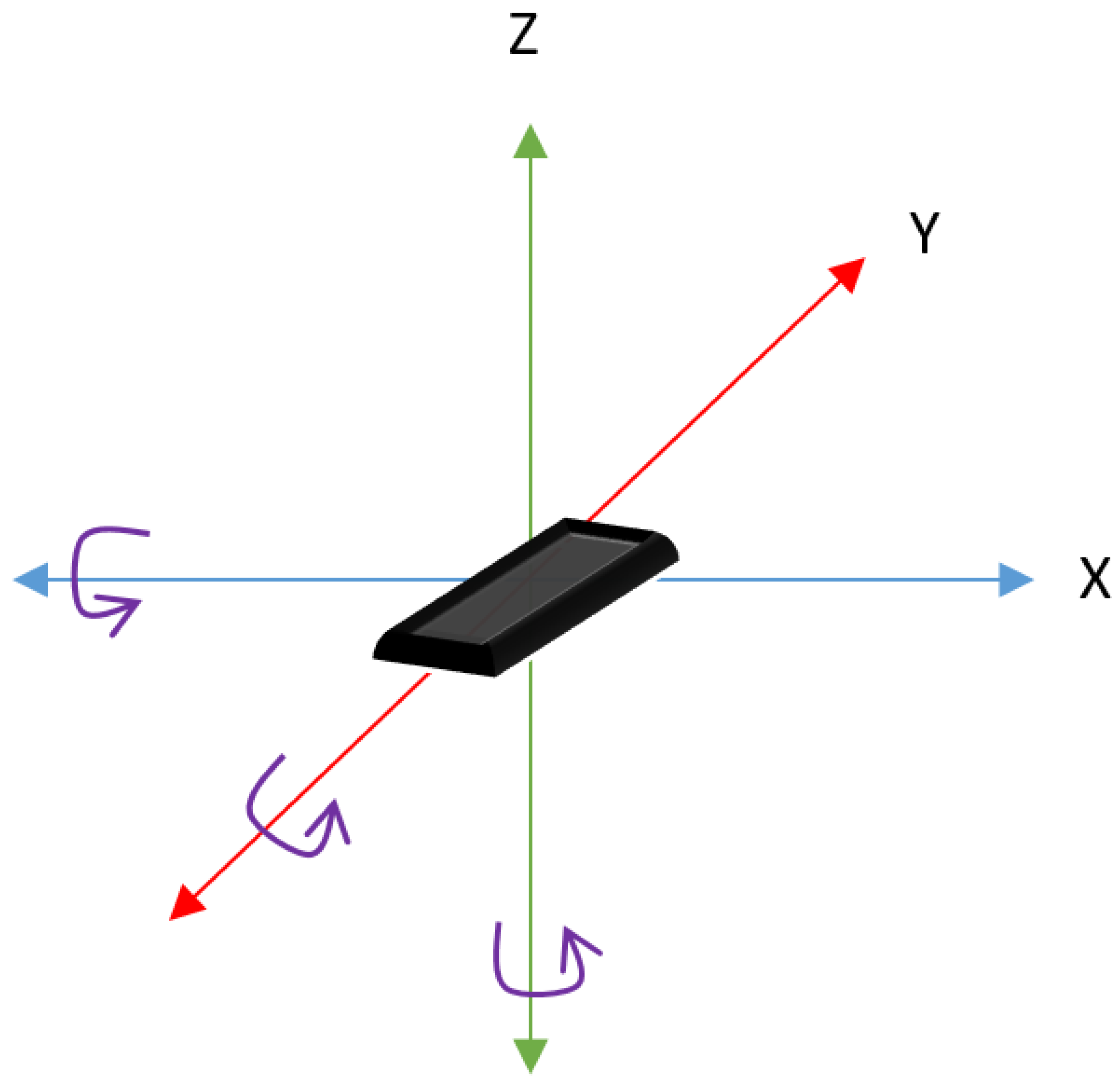
3.1.6. Accelerometer
3.1.7. Angular Velocity
3.1.8. Rotation Vector
4. The Proposed Methodology
4.1. Bidirectional Recurrent Neural Network (BRNN)
4.2. Dipper Throated Optimization (DTO)
| Algorithm 1 The Dipper Throated Optimization algorithm |
|
4.3. The Proposed Dynamic Weighted DTO Algorithm
| Algorithm 2 The Proposed DWDTO Algorithm |
|
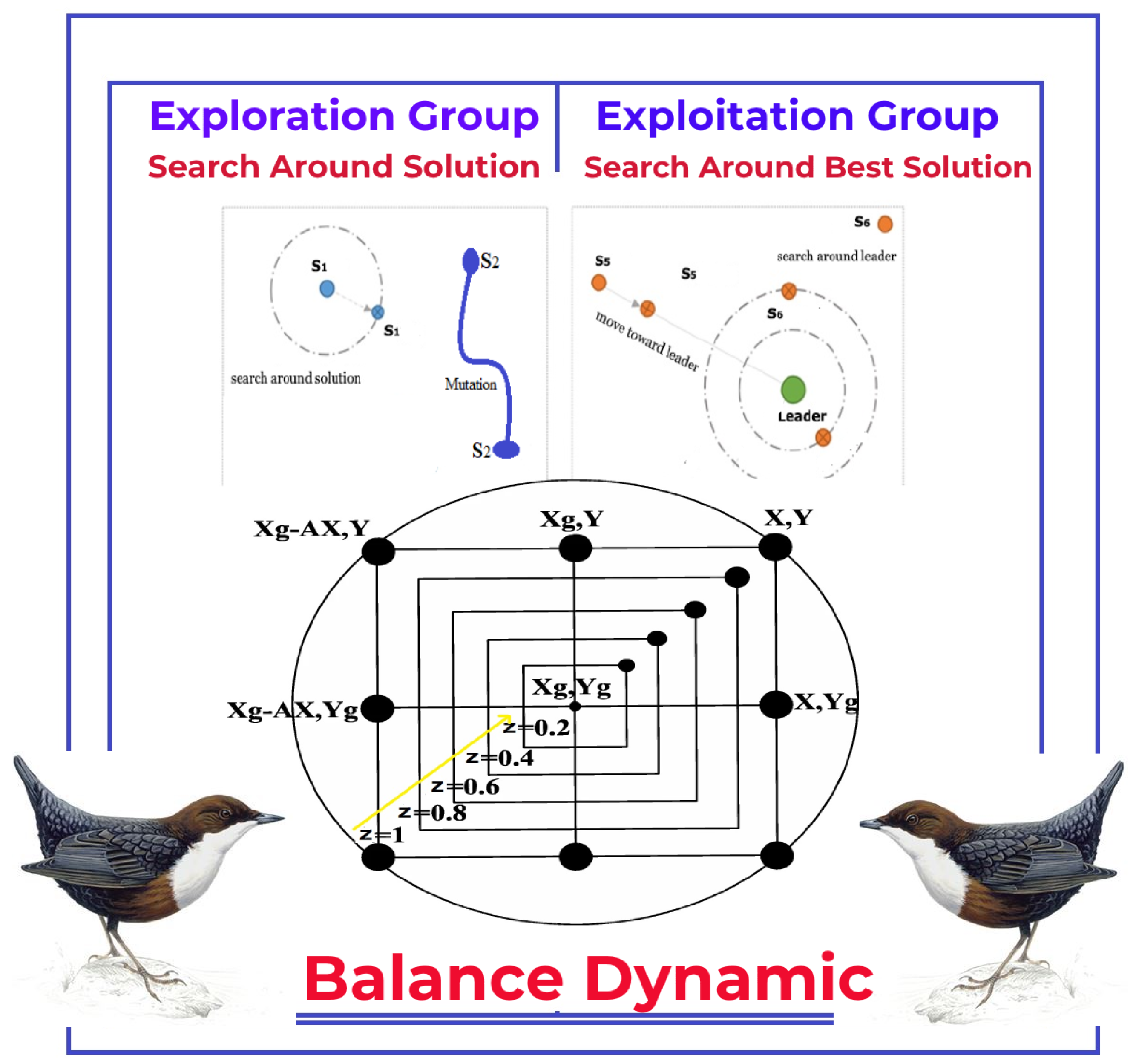
4.3.1. Exploration Group
4.3.2. Exploitation Group
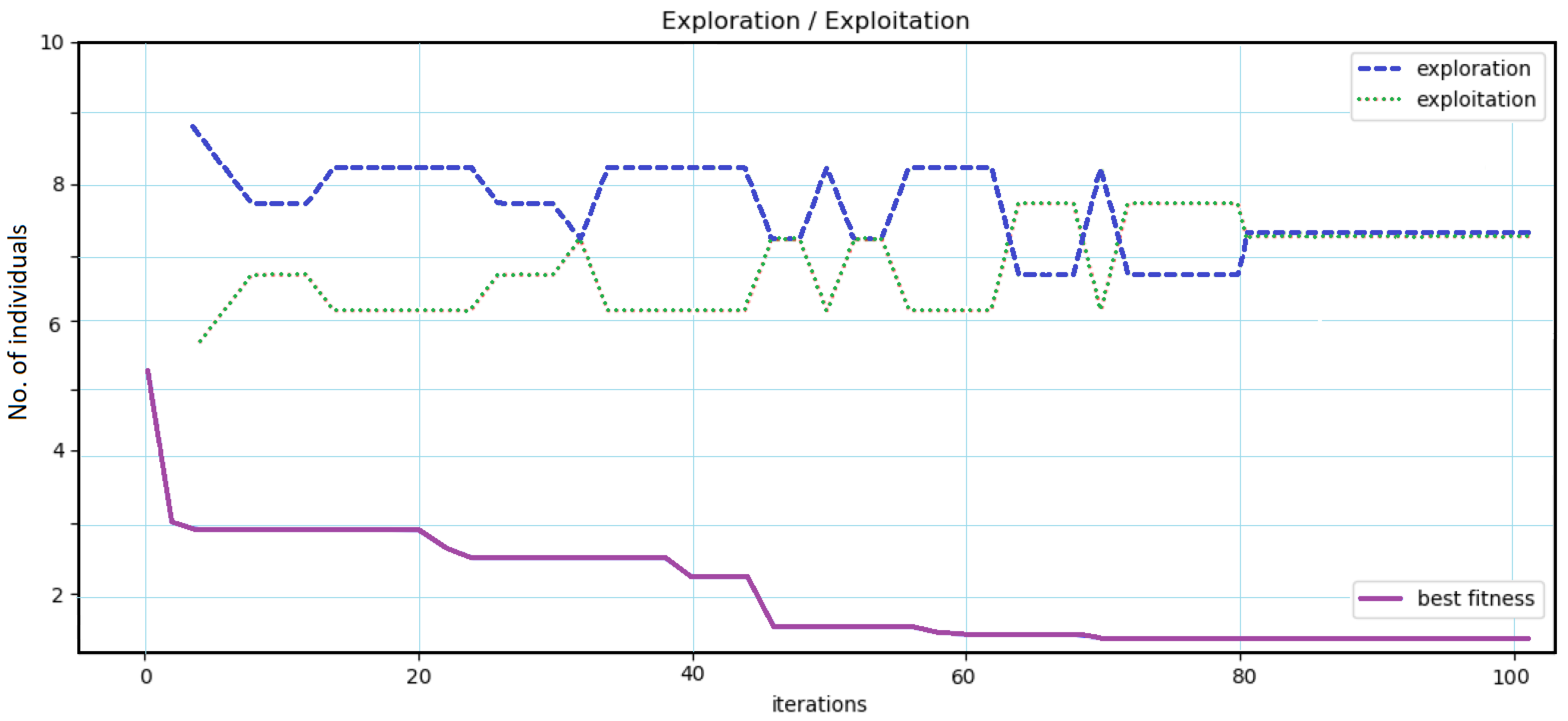
4.3.3. Balance between Exploration and Exploitation
4.3.4. Binary Optimizer
| Algorithm 3 The proposed feature selection algorithm (binary bDWDTO) |
|
5. Experimental Results
5.1. Evaluation Criteria
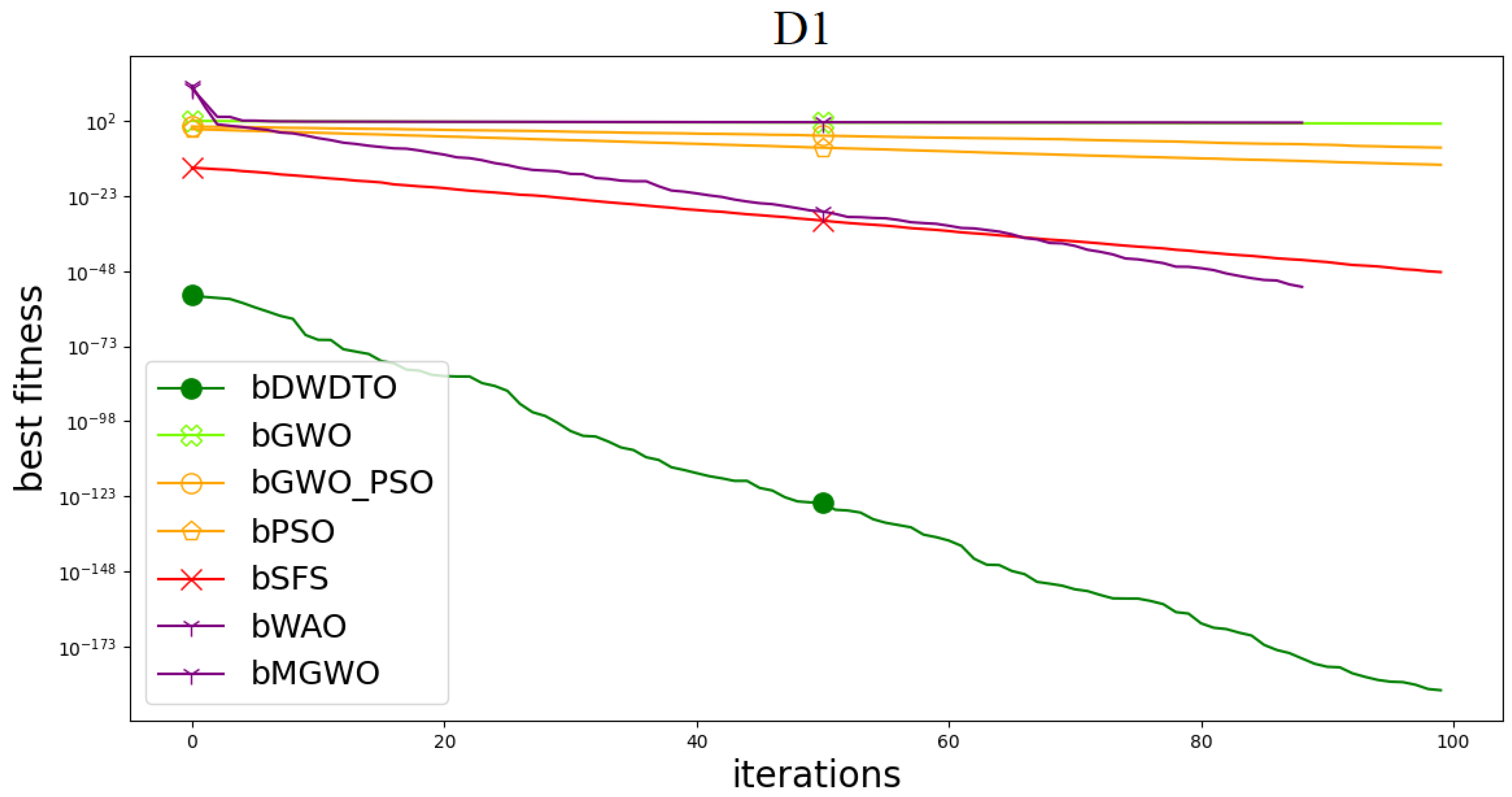
5.2. Results of the First Scenario
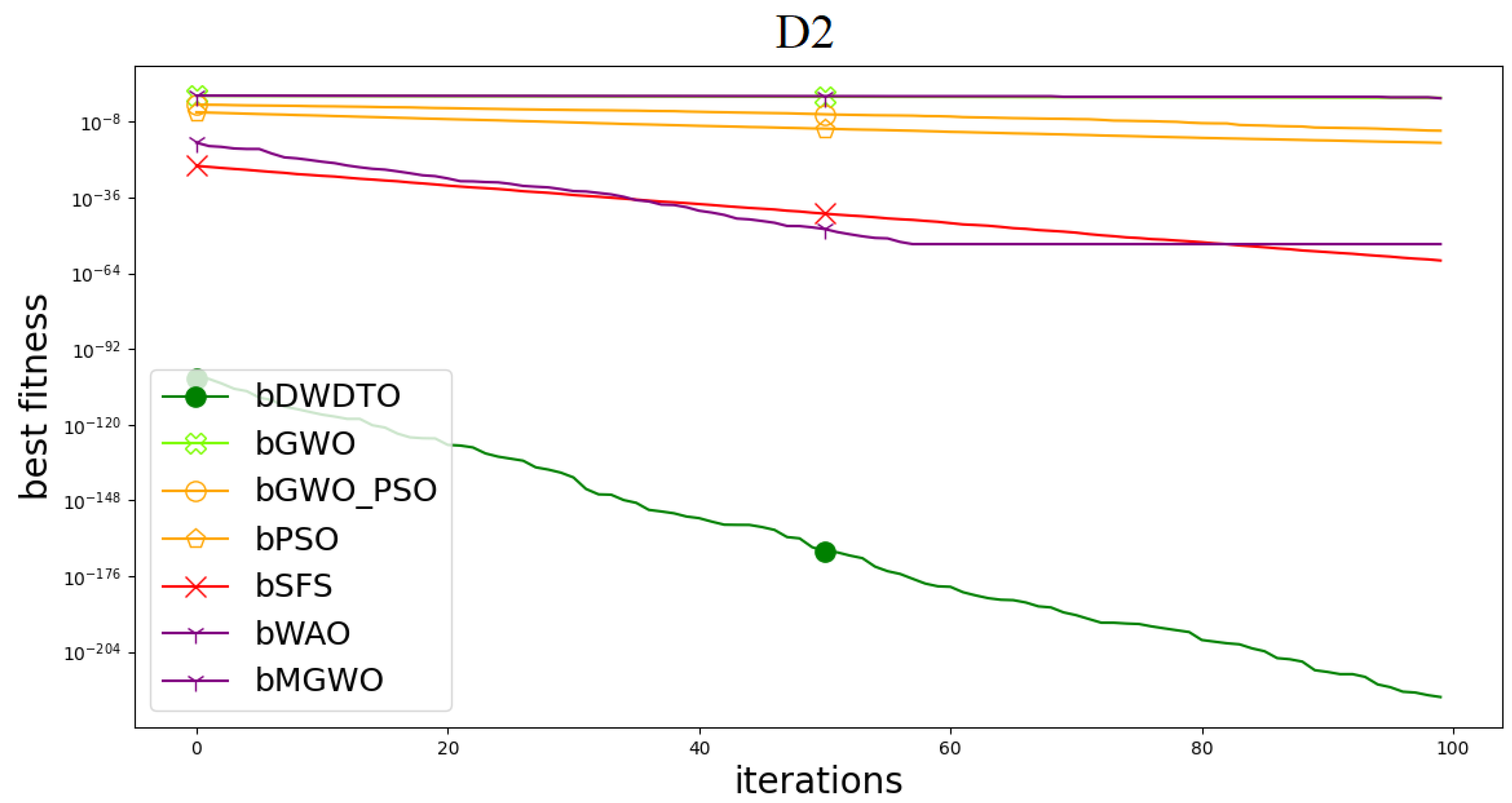
5.3. Results of the Second Scenario
5.4. Classification Results
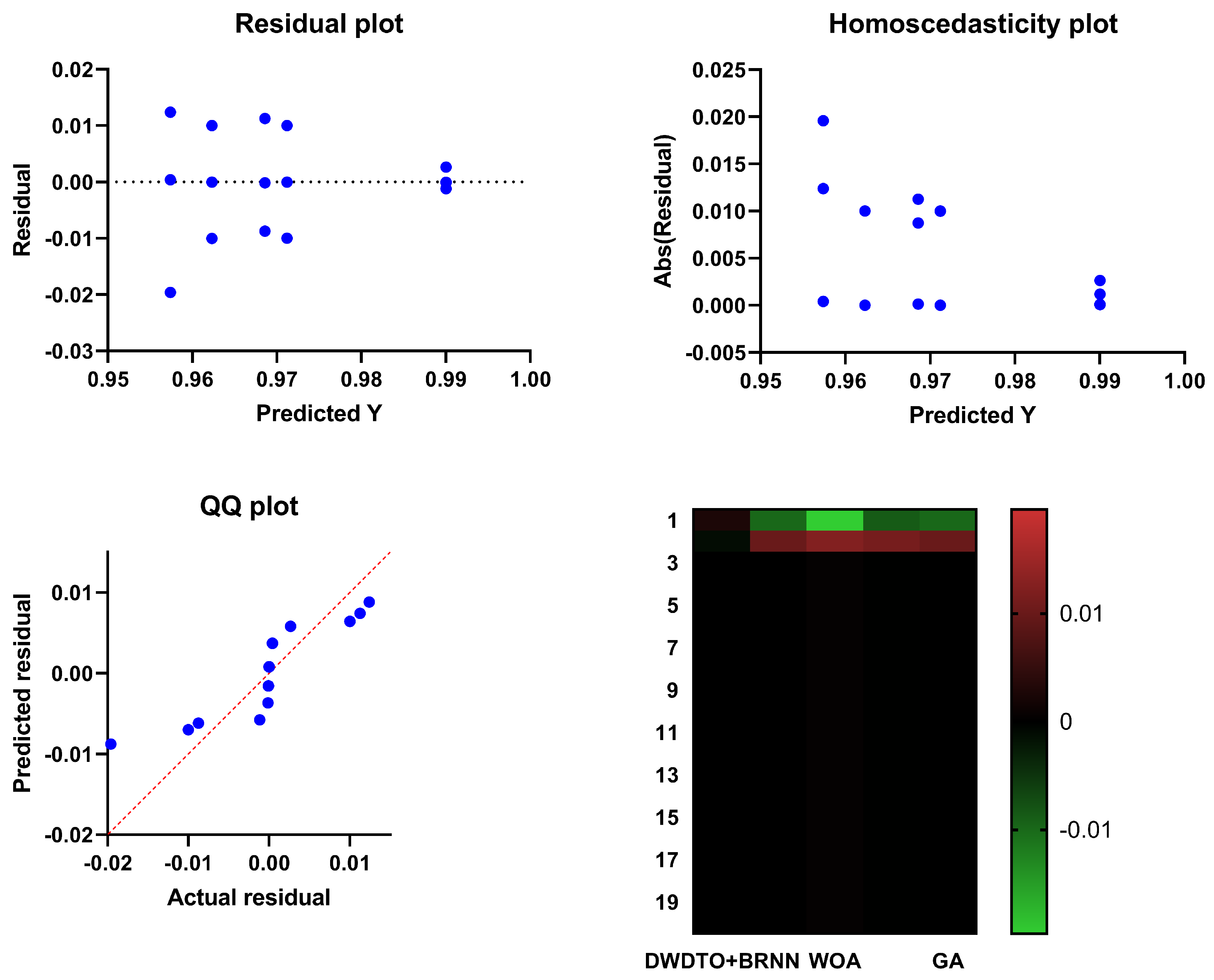
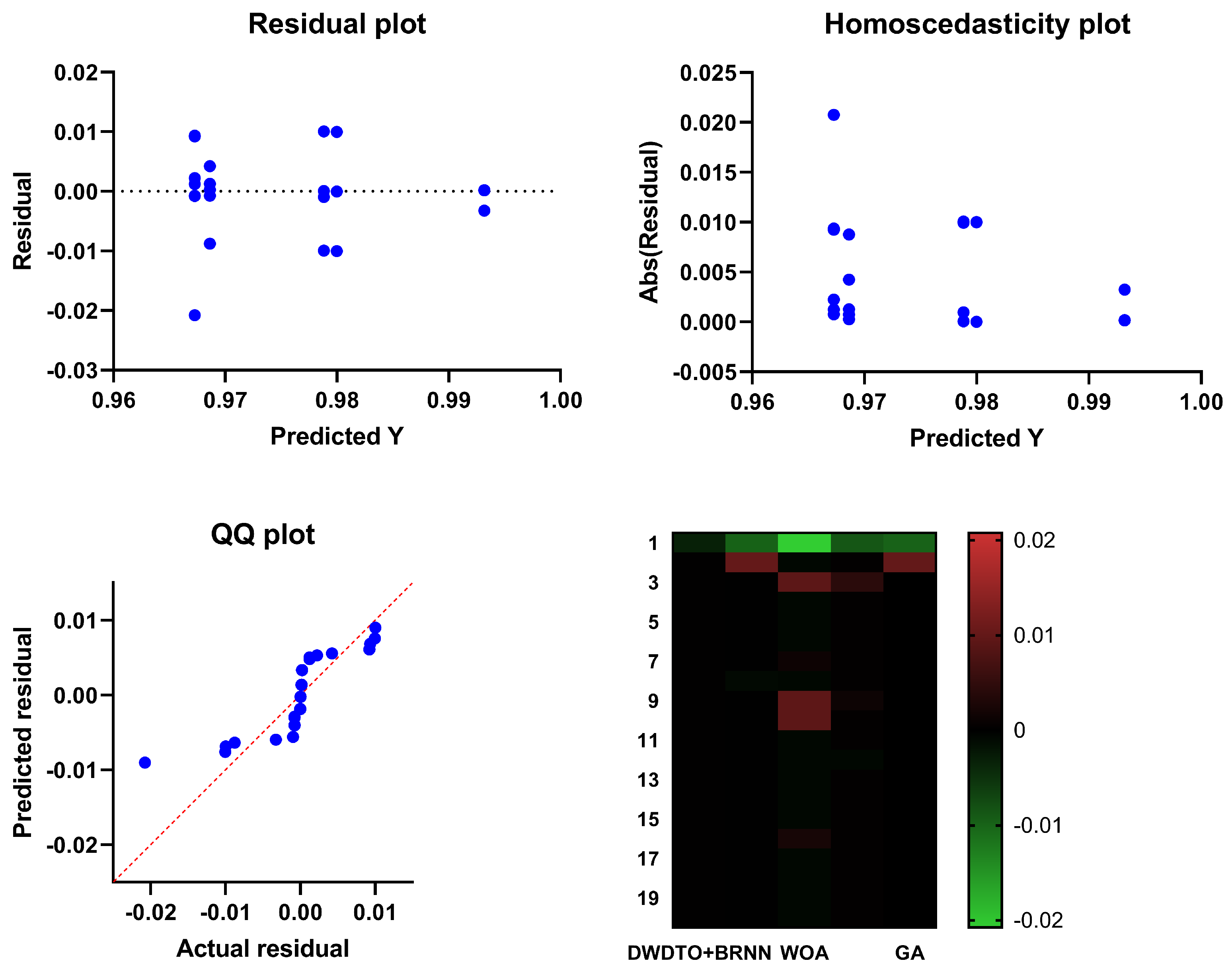
5.5. Comparison with Other Methods
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abualigah, L.; Elaziz, M.A.; Khodadadi, N.; Forestiero, A.; Jia, H.; Gandomi, A.H. Aquila Optimizer Based PSO Swarm Intelligence for IoT Task Scheduling Application in Cloud Computing. In Integrating Meta-Heuristics and Machine Learning for Real-World Optimization Problems; Springer: Berlin/Heidelberg, Germany, 2022; pp. 481–497. [Google Scholar]
- Sharma, R.; Sharma, V.K.; Singh, A. A Review Paper on Facial Recognition Techniques. In Proceedings of the 2021 Fifth International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 11–13 November 2021; pp. 617–621. [Google Scholar]
- Ali, M.M.; Mahale, V.H.; Yannawar, P.; Gaikwad, A.T. Overview of fingerprint recognition system. In Proceedings of the 2016 International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT), Chennai, India, 3–5 March 2016; pp. 1334–1338. [Google Scholar]
- Daniel, D.M.; Monica, B. Person authentication technique using human iris recognition. In Proceedings of the 2010 9th International Symposium on Electronics and Telecommunications, Timisoara, Romania, 11–12 November 2010; pp. 265–268. [Google Scholar]
- Kaveh, A.; Eslamlou, A.D.; Khodadadi, N. Dynamic water strider algorithm for optimal design of skeletal structures. Period. Polytech. Civ. Eng. 2020, 64, 904–916. [Google Scholar] [CrossRef]
- Kaveh, A.; Talatahari, S.; Khodadadi, N. Stochastic paint optimizer: Theory and application in civil engineering. Eng. Comput. 2022, 38, 1921–1952. [Google Scholar] [CrossRef]
- Kaveh, A.; Khodadadi, N.; Talatahari, S. A comparative study for the optimal design of steel structures using CSS and ACSS algorithms. Int. J. Optim. Civ. Eng 2021, 11, 31–54. [Google Scholar]
- Khodadadi, N.; Abualigah, L.; Mirjalili, S. Multi-objective Stochastic Paint Optimizer (MOSPO). Neural Comput. Appl. 2022, 2022, 1–24. [Google Scholar] [CrossRef]
- Khodadadi, N.; Mirjalili, S. Truss optimization with natural frequency constraints using generalized normal distribution optimization. Appl. Intell. 2022, 52, 10384–10397. [Google Scholar] [CrossRef]
- Kaveh, A.; Talatahari, S.; Khodadadi, N. The Hybrid Invasive Weed Optimization-Shuffled Frog-leaping Algorithm Applied to Optimal Design of Frame Structures. Period. Polytech. Civ. Eng. 2019, 63, 882–897. [Google Scholar] [CrossRef]
- Ryu, Y.S.; Koh, D.H.; Aday, B.L.; Gutierrez, X.A.; Platt, J.D. Usability Evaluation of Randomized Keypad. J. Usability Study 2010, 5, 65–75. [Google Scholar]
- Spillane, R. Keyboard apparatus for personal identification. IBM Tech. Discl. Bull. 1975, 17, 3346. [Google Scholar]
- Umphress, D.; Williams, G. Identity verification through keyboard characteristics. Int. J. Man-Mach. Stud. 1985, 23, 263–273. [Google Scholar] [CrossRef]
- Campisi, P.; Maiorana, E.; Lo Bosco, M.; Neri, A. User authentication using keystroke dynamics for cellular phones. IET Signal Process. 2009, 3, 333. [Google Scholar] [CrossRef]
- Lee, H.; Hwang, J.Y.; Kim, D.I.; Lee, S.; Lee, S.H.; Shin, J.S. Understanding Keystroke Dynamics for Smartphone Users Authentication and Keystroke Dynamics on Smartphones Built-In Motion Sensors. Secur. Commun. Netw. 2018, 2018, 2567463. [Google Scholar] [CrossRef]
- Cockell, R.; Halak, B. On the Design and Analysis of a Biometric Authentication System Using Keystroke Dynamics. Cryptography 2020, 4, 12. [Google Scholar] [CrossRef]
- Alsultan, A.; Warwick, K.; Wei, H. Non-conventional keystroke dynamics for user authentication. Pattern Recognit. Lett. 2017, 89, 53–59. [Google Scholar] [CrossRef]
- Kim, J.; Kang, P. Freely typed keystroke dynamics-based user authentication for mobile devices based on heterogeneous features. Pattern Recognit. 2020, 108, 107556. [Google Scholar] [CrossRef]
- Kiyani, A.T.; Lasebae, A.; Ali, K.; Rehman, M.U.; Haq, B. Continuous User Authentication Featuring Keystroke Dynamics Based on Robust Recurrent Confidence Model and Ensemble Learning Approach. IEEE Access 2020, 8, 156177–156189. [Google Scholar] [CrossRef]
- Porwik, P.; Doroz, R.; Wesolowski, T.E. Dynamic keystroke pattern analysis and classifiers with competence for user recognition. Appl. Soft Comput. 2021, 99, 106902. [Google Scholar] [CrossRef]
- Saini, B.S.; Singh, P.; Nayyar, A.; Kaur, N.; Bhatia, K.S.; El-Sappagh, S.; Hu, J.W. A Three-Step Authentication Model for Mobile Phone User Using Keystroke Dynamics. IEEE Access 2020, 8, 125909–125922. [Google Scholar] [CrossRef]
- Jalaly Bidgoly, A.; Jalaly Bidgoly, H.; Arezoumand, Z. A survey on methods and challenges in EEG based authentication. Comput. Secur. 2020, 93, 101788. [Google Scholar] [CrossRef]
- Ingale, M.; Cordeiro, R.; Thentu, S.; Park, Y.; Karimian, N. ECG Biometric Authentication: A Comparative Analysis. IEEE Access 2020, 8, 117853–117866. [Google Scholar] [CrossRef]
- Maiti, A.; Crager, K.; Jadliwala, M.; He, J.; Kwiat, K.; Kamhoua, C. RandomPad: Usability of Randomized Mobile Keypads for Defeating Inference Attacks. In Proceedings of the IEEE Euro Workshop on Innovations in Mobile Privacy & Security (IMPS), Paris, France, 29 April 2017; pp. 1–10. [Google Scholar]
- Benjapatanamongkol, N.; Bhattarakosol, P. A Preliminary Study of Finger Area and Keystroke Dynamics Using Numeric Keypad With Random Numbers on Android Phones. In Proceedings of the 2019 23rd International Computer Science and Engineering Conference (ICSEC), Phuket, Thailand, 30 October–1 November 2019; pp. 30–34. [Google Scholar]
- Yu, E.; Cho, S. GA-SVM wrapper approach for feature subset selection in keystroke dynamics identity verification. In Proceedings of the International Joint Conference on Neural Networks, 2003, Portland, OR, USA, 20–24 July 2003; Volume 3, pp. 2253–2257. [Google Scholar]
- Azevedo, G.L.F.B.G.; Cavalcanti, G.D.C.; Carvalho Filho, E.C.B. An approach to feature selection for keystroke dynamics systems based on PSO and feature weighting. In Proceedings of the 2007 IEEE Congress on Evolutionary Computation, Singapore, 25–28 September 2007; pp. 3577–3584. [Google Scholar]
- Karnan, M.; Muthuramalingam, A.; Kalamani, A. Feature subset selection in keystroke dynamics using ant colony optimization. J. Eng. Technol. Res. 2009, 1, 72–80. [Google Scholar]
- Karnan, M.; Akila, M. Personal Authentication Based on Keystroke Dynamics Using Soft Computing Techniques. In Proceedings of the 2010 Second International Conference on Communication Software and Networks, Singapore, 26–28 February 2010; pp. 334–338. [Google Scholar]
- Solami, E.A.; Boyd, C.; Clark, A.; Ahmed, I. User-representative feature selection for keystroke dynamics. In Proceedings of the 2011 5th International Conference on Network and System Security, Milan, Italy, 6–8 September 2011; pp. 229–233. [Google Scholar]
- El-Kenawy, E.S.M.; Mirjalili, S.; Alassery, F.; Zhang, Y.D.; Eid, M.M.; El-Mashad, S.Y.; Aloyaydi, B.A.; Ibrahim, A.; Abdelhamid, A.A. Novel Meta-Heuristic Algorithm for Feature Selection, Unconstrained Functions and Engineering Problems. IEEE Access 2022, 10, 40536–40555. [Google Scholar] [CrossRef]
- Abdelhamid, A.A.; El-Kenawy, E.S.M.; Alotaibi, B.; Amer, G.M.; Abdelkader, M.Y.; Ibrahim, A.; Eid, M.M. Robust Speech Emotion Recognition Using CNN+LSTM Based on Stochastic Fractal Search Optimization Algorithm. IEEE Access 2022, 10, 49265–49284. [Google Scholar] [CrossRef]
- Sami Khafaga, D.; Ali Alhussan, A.; El-kenawy, E.S.M.; Takieldeen, A.E.; Hassan, T.M.; Hegazy, E.A.; Eid, E.A.F.; Ibrahim, A.; Abdelhamid, A.A. Meta-heuristics for Feature Selection and Classification in Diagnostic Breast-Cancer. Comput. Mater. Contin. 2022, 73, 749–765. [Google Scholar]
- Choi, M.; Lee, S.; Jo, M.; Shin, J.S. Keystroke dynamics-based authentication using unique keypad. Sensors 2021, 21, 2242. [Google Scholar] [CrossRef] [PubMed]
- Sami Khafaga, D.; Ali Alhussan, A.; El-kenawy, E.S.M.; Ibrahim, A.; Abd Elkhalik, S.H.; El-Mashad, S.Y.; Abdelhamid, A.A. Improved Prediction of Metamaterial Antenna Bandwidth Using Adaptive Optimization of LSTM. Comput. Mater. Contin. 2022, 73, 865–881. [Google Scholar] [CrossRef]
- Abdel Samee, N.; El-Kenawy, E.S.M.; Atteia, G.; Jamjoom, M.M.; Ibrahim, A.; Abdelhamid, A.A.; El-Attar, N.E.; Gaber, T.; Slowik, A.; Shams, M.Y. Metaheuristic Optimization Through Deep Learning Classification of COVID-19 in Chest X-Ray Images. Comput. Mater. Contin. 2022, 73, 4193–4210. [Google Scholar]
- Nasser AlEisa, H.; El-kenawy, E.S.M.; Ali Alhussan, A.; Saber, M.; Abdelhamid, A.A.; Sami Khafaga, D. Transfer Learning for Chest X-rays Diagnosis Using Dipper Throated Algorithm. Comput. Mater. Contin. 2022, 73, 2371–2387. [Google Scholar]
- MEU-Mobile KSD Data Set. Available online: https://archive.ics.uci.edu/ml/datasets/MEU-Mobile+KSD (accessed on 28 June 2022).
- RHU KeyStroke Dynamics Benchmark Dataset. Available online: https://www.coolestech.com/rhu-keystroke/ (accessed on 28 June 2022).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Methodology | Result |
|---|---|---|
| [12] | Keystroke dynamics | False FRR = 12%, FAR = 6% |
| [15] | Keystroke dynamics | EER = 15% |
| [16] | Motion sensors | EER = 8.94% |
| [25] | Random keypad | EER = 10% |
| [34] | Unique Keypad | EER = 4.15% |
| Metric | Equation |
|---|---|
| Average fitness | |
| Worst Fitness | |
| Best fitness | |
| Average Error | |
| Average select size | |
| Standard deviation | |
| Accuracy | |
| N-value (NPV) | |
| p-value (PPV) | |
| Sensitivity (TPR) | |
| Specificity (TNR) | |
| F1-Score |
| Algorithm | Avg. Error | Avg. Select Size | Avg. Fitness | Best Fitness | Worst Fitness | Std Fitness |
|---|---|---|---|---|---|---|
| bDWDTO | 0.510 | 0.654 | 0.537 | 0.442 | 0.637 | 0.345 |
| bGWO | 0.523 | 0.718 | 0.573 | 0.462 | 0.656 | 0.364 |
| bGWO_PSO | 0.516 | 0.713 | 0.556 | 0.539 | 0.617 | 0.348 |
| bPSO | 0.514 | 0.848 | 0.560 | 0.462 | 0.675 | 0.372 |
| bSFS | 0.522 | 0.672 | 0.574 | 0.523 | 0.597 | 0.364 |
| bWAO | 0.511 | 0.943 | 0.561 | 0.500 | 0.675 | 0.359 |
| bMGWO | 0.520 | 0.764 | 0.539 | 0.490 | 0.656 | 0.355 |
| bMVO | 0.511 | 0.818 | 0.561 | 0.520 | 0.636 | 0.352 |
| bSBO | 0.528 | 0.833 | 0.568 | 0.520 | 0.636 | 0.360 |
| bGWO_GA | 0.532 | 0.793 | 0.532 | 0.520 | 0.636 | 0.357 |
| bFA | 0.517 | 0.853 | 0.567 | 0.500 | 0.695 | 0.363 |
| bGA | 0.511 | 0.813 | 0.561 | 0.462 | 0.636 | 0.363 |
| Algorithm | D1 | D2 |
|---|---|---|
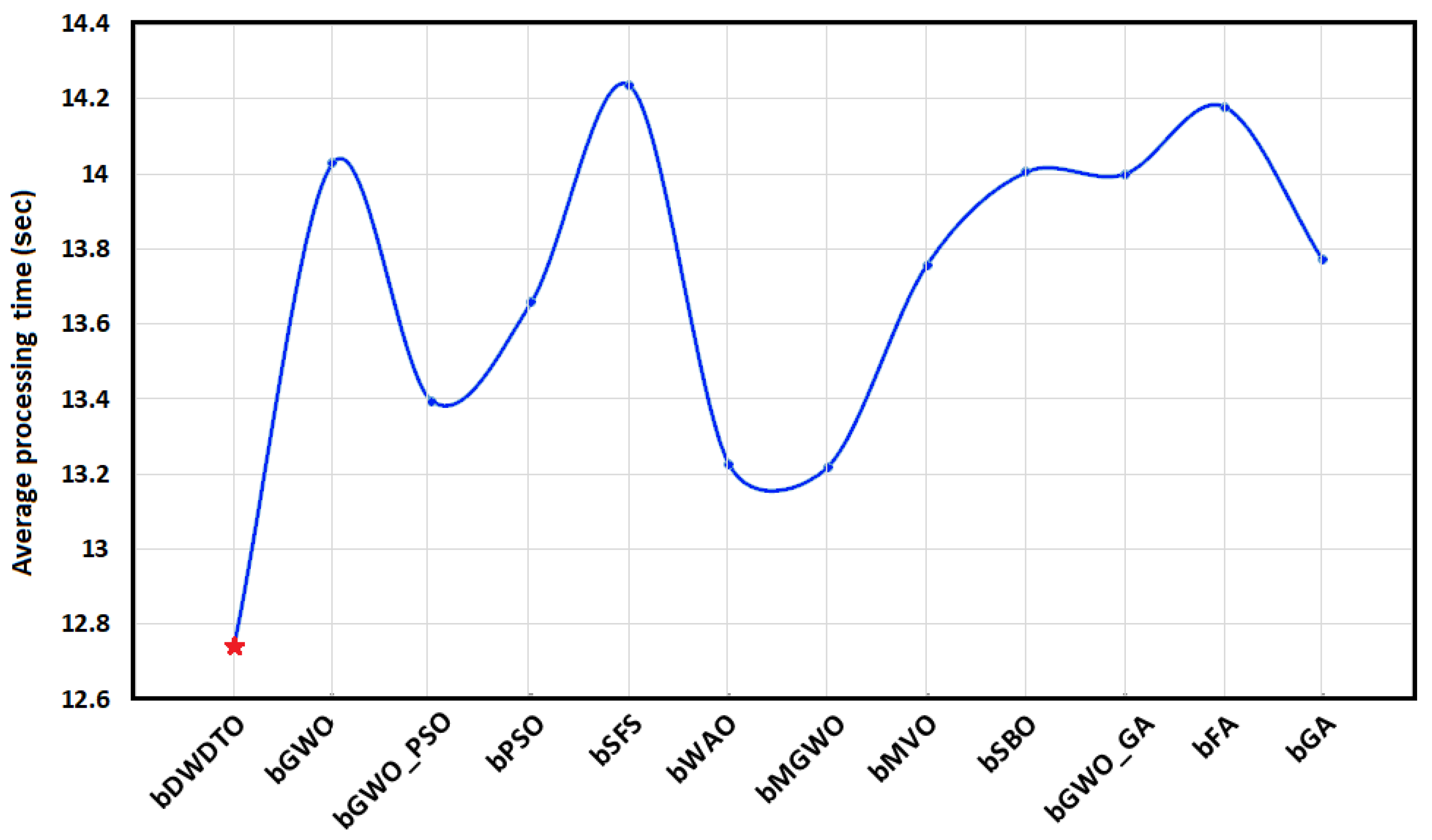
| bDWDTO | 12.534 | 12.952 |
| bGWO | 13.178 | 14.883 |
| bGWO_PSO | 12.77 | 14.02 |
| bPSO | 12.86 | 14.455 |
| bSFS | 14.26 | 14.21 |
| bWAO | 12.667 | 13.788 |
| bMGWO | 12.95 | 13.49 |
| bMVO | 13.121 | 14.395 |
| bSBO | 13.59 | 14.42 |
| bGWO_GA | 13.31 | 14.69 |
| bFA | 13.888 | 14.472 |
| bGA | 13.134 | 14.408 |
| Metric | NN | KNN | BRNN |
|---|---|---|---|
| Accuracy | 0.917 | 0.922 | 0.939 |
| Sensitivity (TPR) | 0.862 | 0.870 | 0.901 |
| Specificity (TNR) | 0.980 | 0.980 | 0.980 |
| Pvalue (PPV) | 0.980 | 0.980 | 0.980 |
| Nvalue (NPV) | 0.862 | 0.870 | 0.901 |
| F-score | 0.917 | 0.922 | 0.939 |
| Time (seconds) | 137 | 125 | 102 |
| Metric | DWDTO + BRNN | GWO | WOA | PSO | GA | GSA |
|---|---|---|---|---|---|---|
| Num. Values | 20 | 20 | 20 | 20 | 20 | 20 |
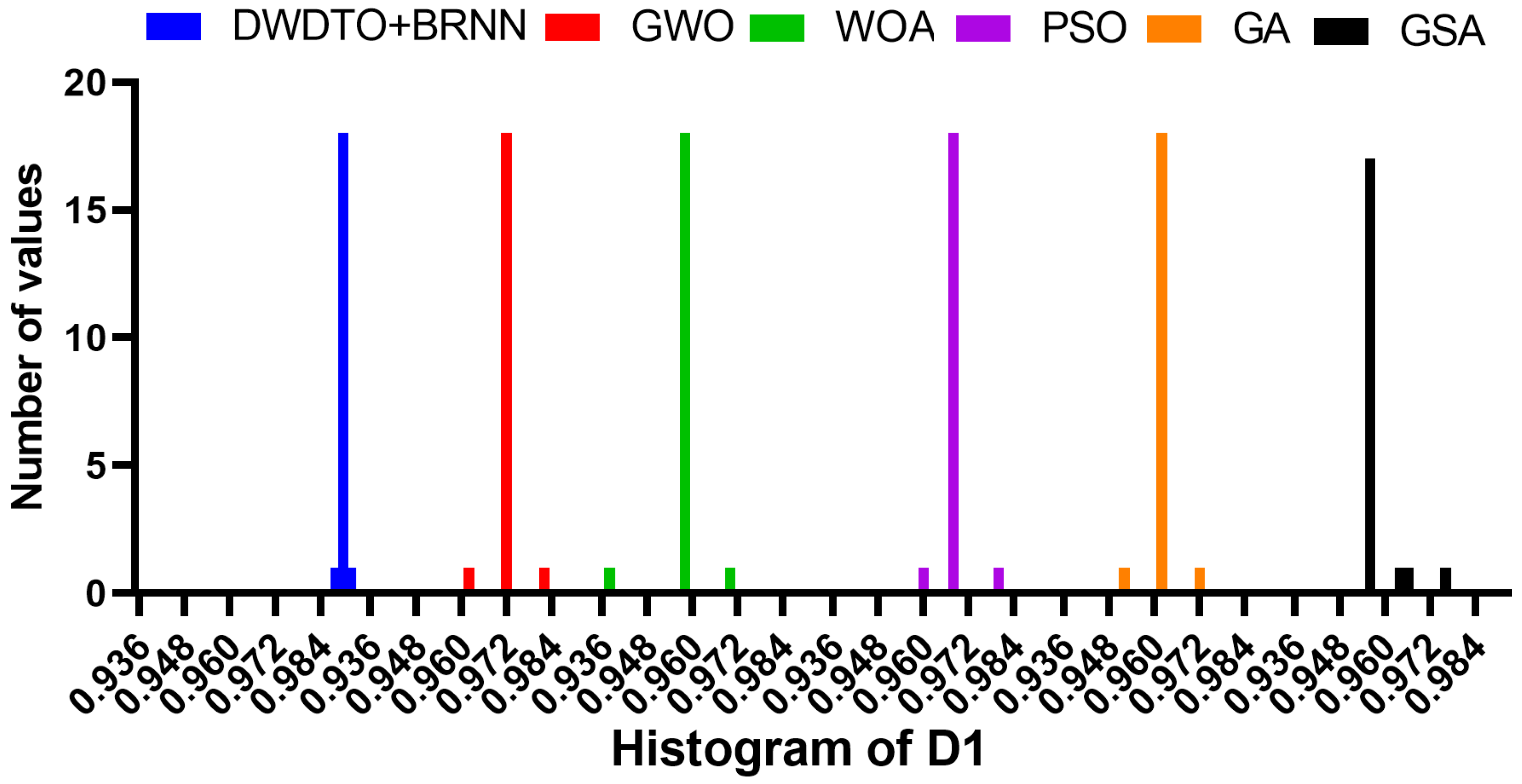
| Minimum | 0.9889 | 0.9612 | 0.9378 | 0.9598 | 0.9523 | 0.9563 |
| 25% | 0.9900 | 0.9712 | 0.9578 | 0.9685 | 0.9623 | 0.9563 |
| Median | 0.9900 | 0.9712 | 0.9578 | 0.9685 | 0.9623 | 0.9563 |
| 75% | 0.9900 | 0.9712 | 0.9578 | 0.9685 | 0.9623 | 0.9563 |
| Maximum | 0.9927 | 0.9812 | 0.9698 | 0.9798 | 0.9723 | 0.9763 |
| Range | 0.0038 | 0.0200 | 0.0320 | 0.0200 | 0.0200 | 0.0200 |
| Mean | 0.9901 | 0.9712 | 0.9574 | 0.9686 | 0.9623 | 0.9582 |
| Std. | 0.0007 | 0.0032 | 0.0053 | 0.0033 | 0.0032 | 0.0050 |
| Std. Error | 0.0001 | 0.0007 | 0.0012 | 0.0007 | 0.0007 | 0.0011 |
| Skewness | 3.289 | 5.703 × 10 | −2.171 | 1.263 | 0 | 3.014 |
| Kurtosis | 14.79 | 9.5 | 11.74 | 10.25 | 9.5 | 9.335 |
| Sum | 19.8 | 19.42 | 19.15 | 19.37 | 19.25 | 19.16 |
| Metric | DWDTO + BRNN | GWO | WOA | PSO | GA | GSA |
|---|---|---|---|---|---|---|
| Theo. median | 0 | 0 | 0 | 0 | 0 | 0 |
| Act. median | 0.99 | 0.9712 | 0.9578 | 0.9685 | 0.9623 | 0.9563 |
| Num. Values | 20 | 20 | 20 | 20 | 20 | 20 |
| Sum ranks | 210 | 210 | 210 | 210 | 210 | 210 |
| Sum +ranks | 210 | 210 | 210 | 210 | 210 | 210 |
| Sum −ranks | 0 | 0 | 0 | 0 | 0 | 0 |
| p value | <0.0001 | <0.0001 | <0.0001 | <0.0001 | <0.0001 | <0.0001 |
| Significance | Yes | Yes | Yes | Yes | Yes | Yes |
| Discrepancy | 0.99 | 0.9712 | 0.9578 | 0.9685 | 0.9623 | 0.9563 |
| SS | DF | MS | F (DFn, DFd) | p Value | |
|---|---|---|---|---|---|
| Treatment | 0.01246 | 4 | 0.003115 | F (4, 95) = 256.8 | p < 0.0001 |
| Residual | 0.001152 | 95 | 0.00001213 | ||
| Total | 0.01361 | 99 |
| Algorithm | Avg. Error | Avg. Select Size | Avg. Fitness | Best Fitness | Worst Fitness | Std Fitness |
|---|---|---|---|---|---|---|
| bDWDTO | 0.447 | 0.449 | 0.459 | 0.407 | 0.558 | 0.345 |
| bGWO | 0.460 | 0.579 | 0.494 | 0.424 | 0.568 | 0.355 |
| bGWO_PSO | 0.461 | 0.603 | 0.461 | 0.449 | 0.517 | 0.351 |
| bPSO | 0.488 | 0.803 | 0.521 | 0.458 | 0.576 | 0.346 |
| bSFS | 0.467 | 0.627 | 0.467 | 0.414 | 0.600 | 0.387 |
| bWAO | 0.473 | 0.644 | 0.507 | 0.433 | 0.593 | 0.355 |
| bMGWO | 0.449 | 0.567 | 0.491 | 0.457 | 0.576 | 0.350 |
| bMVO | 0.482 | 0.784 | 0.515 | 0.416 | 0.559 | 0.352 |
| bSBO | 0.468 | 0.743 | 0.468 | 0.441 | 0.543 | 0.350 |
| bGWO_GA | 0.507 | 0.737 | 0.507 | 0.492 | 0.602 | 0.359 |
| bFA | 0.478 | 0.800 | 0.512 | 0.407 | 0.610 | 0.360 |
| bGA | 0.468 | 0.703 | 0.502 | 0.441 | 0.619 | 0.360 |
| Metric | NN | KNN | BRNN |
|---|---|---|---|
| Accuracy | 0.932 | 0.941 | 0.955 |
| Sensitivity (TPR) | 0.857 | 0.895 | 0.895 |
| Specificity (TNR) | 0.989 | 0.989 | 0.993 |
| p-value (PPV) | 0.984 | 0.988 | 0.988 |
| N-value (NPV) | 0.900 | 0.900 | 0.938 |
| F-score | 0.916 | 0.939 | 0.939 |
| Time (seconds) | 118 | 107 | 97 |
| Metric | DWDTO + BRNN | GWO | WOA | PSO | GA | GSA |
|---|---|---|---|---|---|---|
| Num. Values | 20 | 20 | 20 | 20 | 20 | 20 |
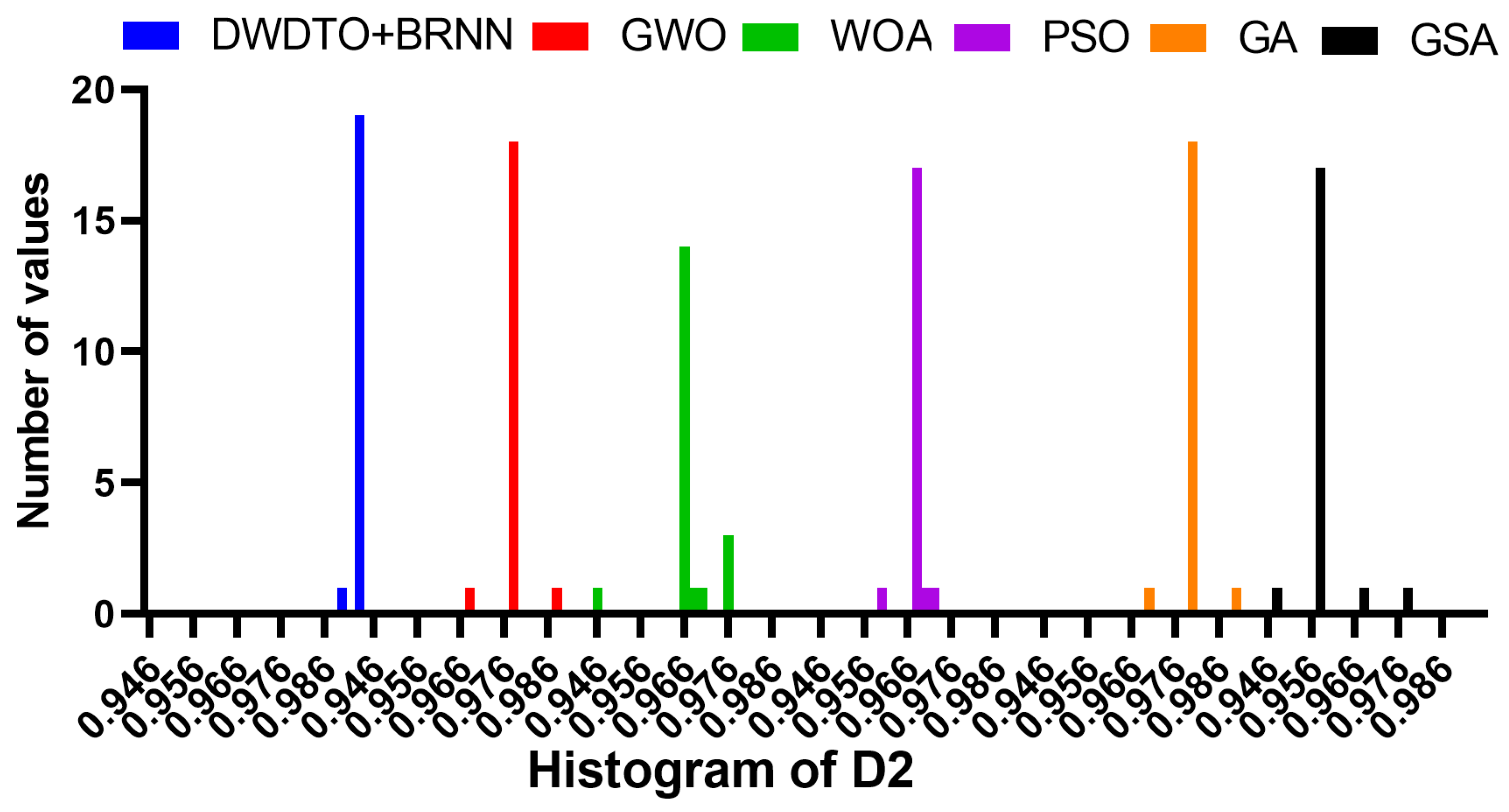
| Minimum | 0.9899 | 0.9689 | 0.9465 | 0.9599 | 0.9700 | 0.9471 |
| 25% | 0.9934 | 0.9789 | 0.9665 | 0.9689 | 0.9800 | 0.9571 |
| Median | 0.9934 | 0.9789 | 0.9665 | 0.9689 | 0.9800 | 0.9571 |
| 75% | 0.9934 | 0.9789 | 0.9680 | 0.9689 | 0.9800 | 0.9571 |
| Maximum | 0.9934 | 0.9889 | 0.9767 | 0.9729 | 0.9900 | 0.9771 |
| Range | 0.0034 | 0.0200 | 0.0301 | 0.0130 | 0.0200 | 0.0300 |
| Mean | 0.9932 | 0.9788 | 0.9673 | 0.9686 | 0.9800 | 0.9581 |
| Std. | 0.0008 | 0.0033 | 0.0061 | 0.0023 | 0.0032 | 0.0055 |
| Std. Error | 0.0002 | 0.0007 | 0.0014 | 0.0005 | 0.0007 | 0.0012 |
| Skewness | −4.472 | 0.0496 | −1.694 | −2.964 | −5.703 × 10 | 2.164 |
| Kurtosis | 20 | 9.379 | 7.402 | 13.36 | 9.5 | 8.21 |
| Sum | 19.86 | 19.58 | 19.35 | 19.37 | 19.6 | 19.16 |
| Metric | DWDTO + BRNN | GWO | WOA | PSO | GA | GSA |
|---|---|---|---|---|---|---|
| Theo. median | 0 | 0 | 0 | 0 | 0 | 0 |
| Act. median | 0.9934 | 0.9789 | 0.9665 | 0.9689 | 0.98 | 0.96 |
| Num. Values | 20 | 20 | 20 | 20 | 20 | 20 |
| Sum ranks | 210 | 210 | 210 | 210 | 210 | 210 |
| Sum +ranks | 210 | 210 | 210 | 210 | 210 | 210 |
| Sum −ranks | 0 | 0 | 0 | 0 | 0 | 0 |
| p-value | <0.0001 | <0.0001 | <0.0001 | <0.0001 | <0.0001 | <0.0001 |
| Significance | Yes | Yes | Yes | Yes | Yes | Yes |
| Discrepancy | 0.9934 | 0.9789 | 0.9665 | 0.9689 | 0.98 | 0.96 |
| SS | DF | MS | F (DFn, DFd) | p Value | |
|---|---|---|---|---|---|
| Treatment | 0.008733 | 4 | 0.002183 | F (4, 95) = 170.9 | p < 0.0001 |
| Residual | 0.001214 | 95 | 0.00001278 | ||
| Total | 0.009946 | 99 |
| Metric | D1 | D2 |
|---|---|---|
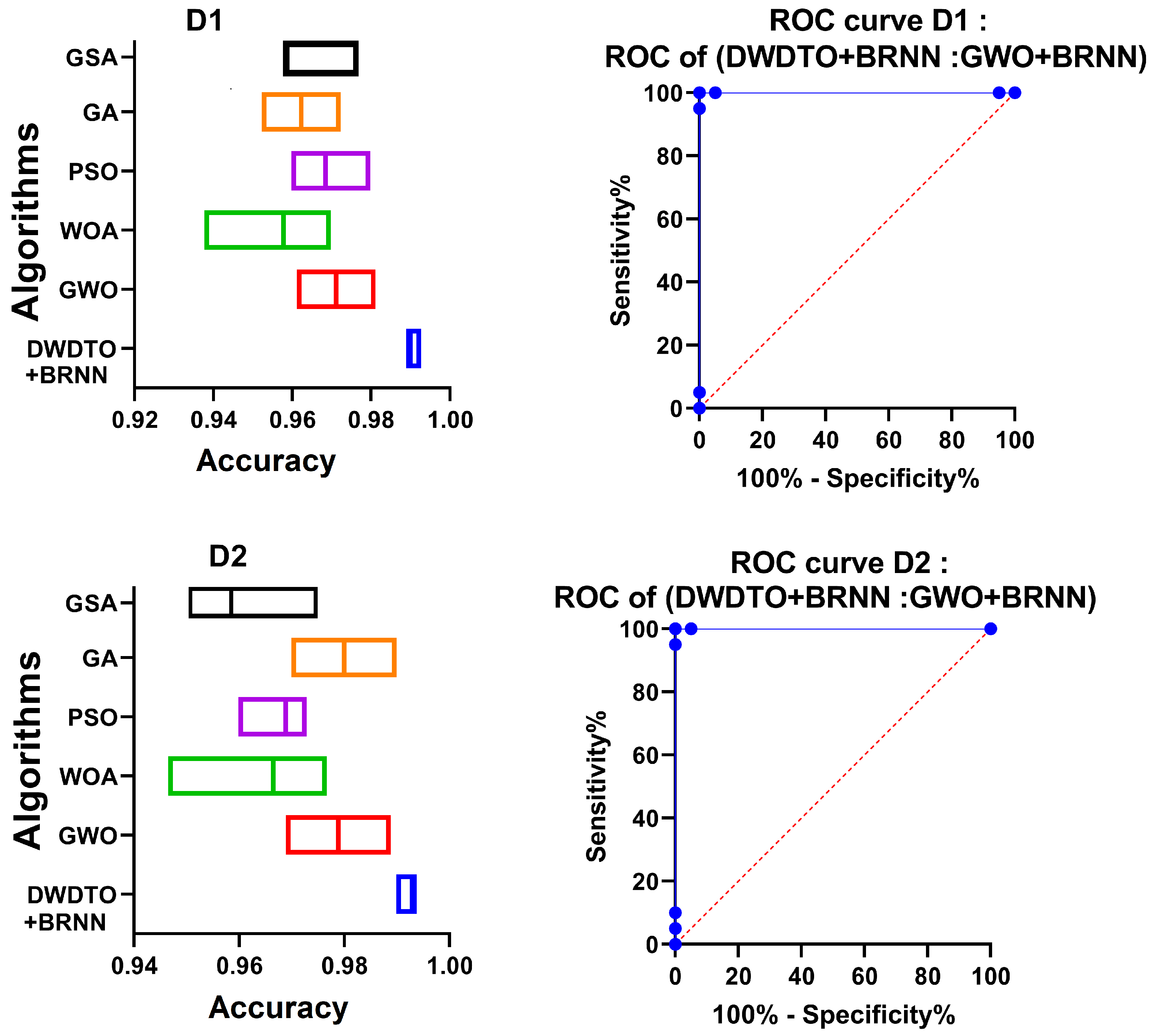
| Accuracy | 0.990182803 | 0.993208829 |
| Sensitivity (TRP) | 0.946547884 | 0.965909091 |
| Specificity (TNP) | 0.998003992 | 0.998003992 |
| p-value (PPV) | 0.988372093 | 0.988372093 |
| N-value (NPV) | 0.990491284 | 0.994035785 |
| F-Score | 0.967007964 | 0.977011494 |
| Time (seconds) | 77 | 59 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
El-Kenawy, E.-S.M.; Mirjalili, S.; Abdelhamid, A.A.; Ibrahim, A.; Khodadadi, N.; Eid, M.M. Meta-Heuristic Optimization and Keystroke Dynamics for Authentication of Smartphone Users. Mathematics 2022, 10, 2912. https://doi.org/10.3390/math10162912
El-Kenawy E-SM, Mirjalili S, Abdelhamid AA, Ibrahim A, Khodadadi N, Eid MM. Meta-Heuristic Optimization and Keystroke Dynamics for Authentication of Smartphone Users. Mathematics. 2022; 10(16):2912. https://doi.org/10.3390/math10162912
Chicago/Turabian StyleEl-Kenawy, El-Sayed M., Seyedali Mirjalili, Abdelaziz A. Abdelhamid, Abdelhameed Ibrahim, Nima Khodadadi, and Marwa M. Eid. 2022. "Meta-Heuristic Optimization and Keystroke Dynamics for Authentication of Smartphone Users" Mathematics 10, no. 16: 2912. https://doi.org/10.3390/math10162912
APA StyleEl-Kenawy, E.-S. M., Mirjalili, S., Abdelhamid, A. A., Ibrahim, A., Khodadadi, N., & Eid, M. M. (2022). Meta-Heuristic Optimization and Keystroke Dynamics for Authentication of Smartphone Users. Mathematics, 10(16), 2912. https://doi.org/10.3390/math10162912