
Real-Time Assembly Support System with Hidden Markov Model and Hybrid Extensions

 ,
,  ,
,  ,
,  and
and
Abstract
:1. Introduction
2. Related Work
2.1. Assembly Assistance Systems
2.2. Prediction Techniques
3. Next Assembly Step Prediction through Hidden Markov Models
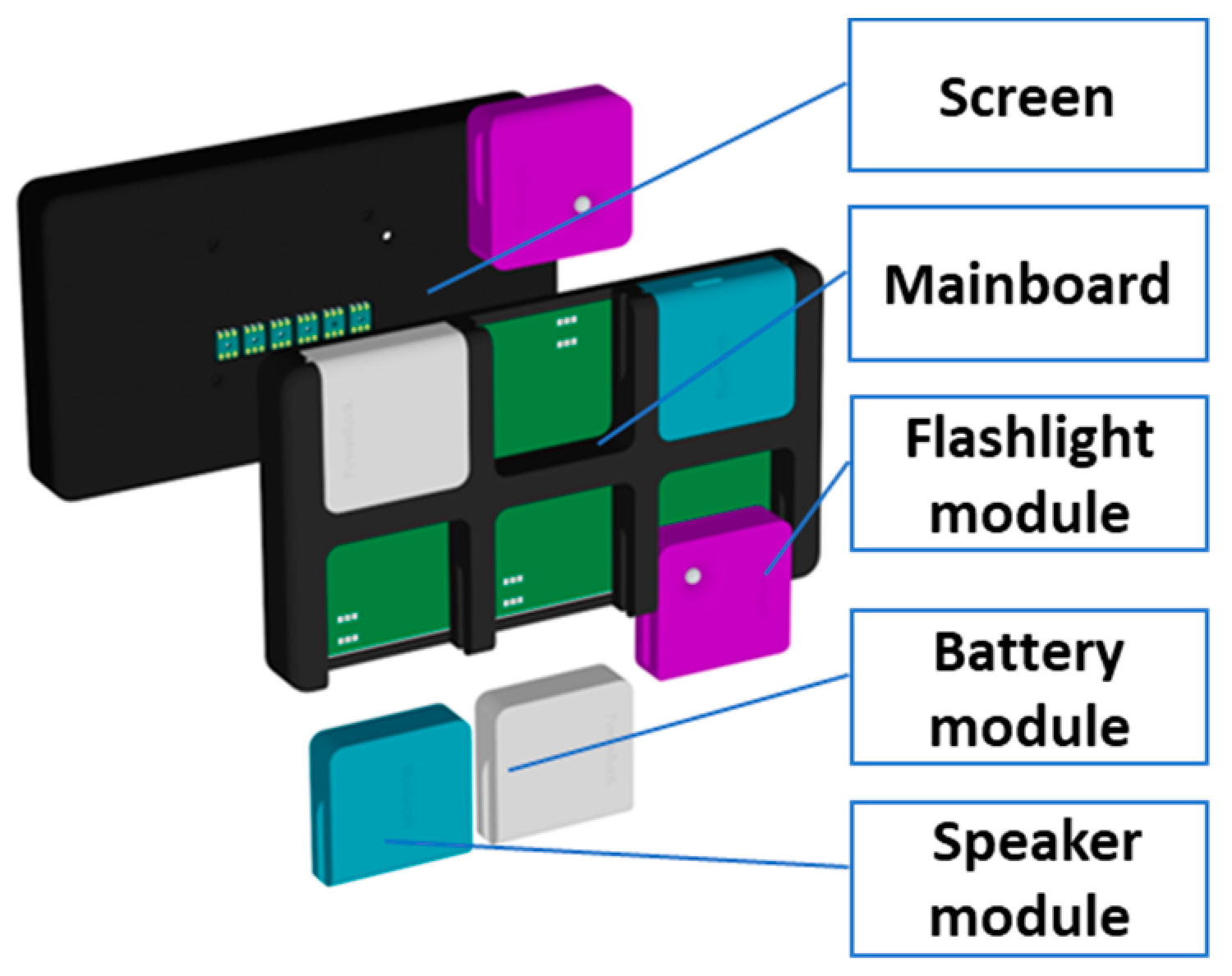
3.1. Assembly Support System
- Tabletop height adjustment: performed manually by the user or automatically by software using the front facing camera.
- Object detection: identifies the position of each object within each image during the training.
- Depth camera streaming: provides control to the depth camera, exposing all of its capabilities such as RGB, point cloud, depth.
- Object position: establishes the 3D position of objects relying on information from the previous two services. It detects if the component was assembled correctly, and if not, it prompts the user.
- Face mimics detection: detects emotions from pictures with the user’s face during training.
- Human characteristic detection: age and gender are identified from image processing of the user’s picture during assembly. This service with the face mimicking service can be utilized to detect the user’s state/mood.
- Predictor service: has the goal to assist the user throughout the training, providing the next best-suitable instructions depending on the user’s previous and on-going performance. This is done by collecting and aggregating information from the service above with various algorithms.
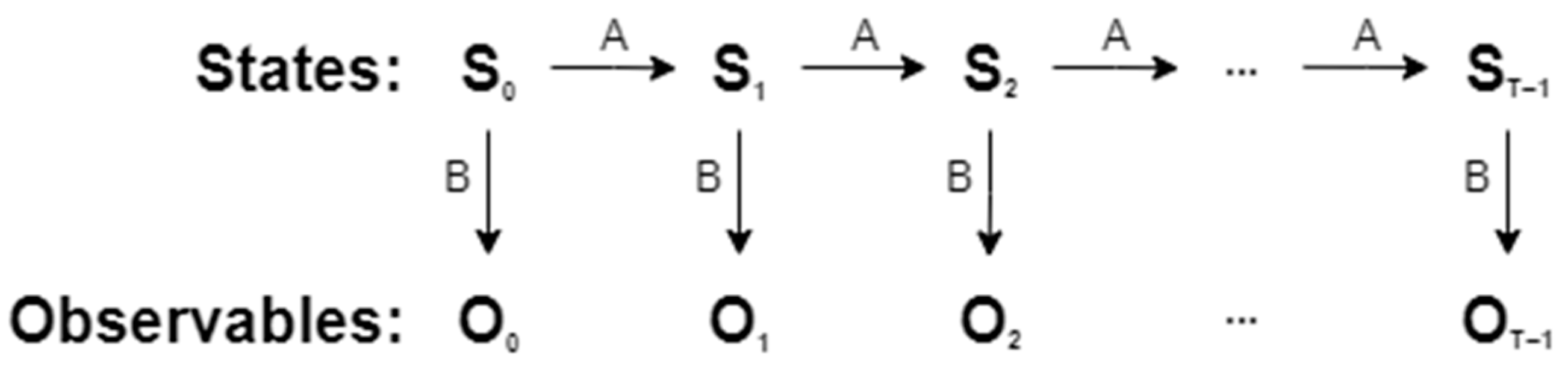
3.2. The HMM-Based Prediction Algorithm
3.3. Hybrid Prediction
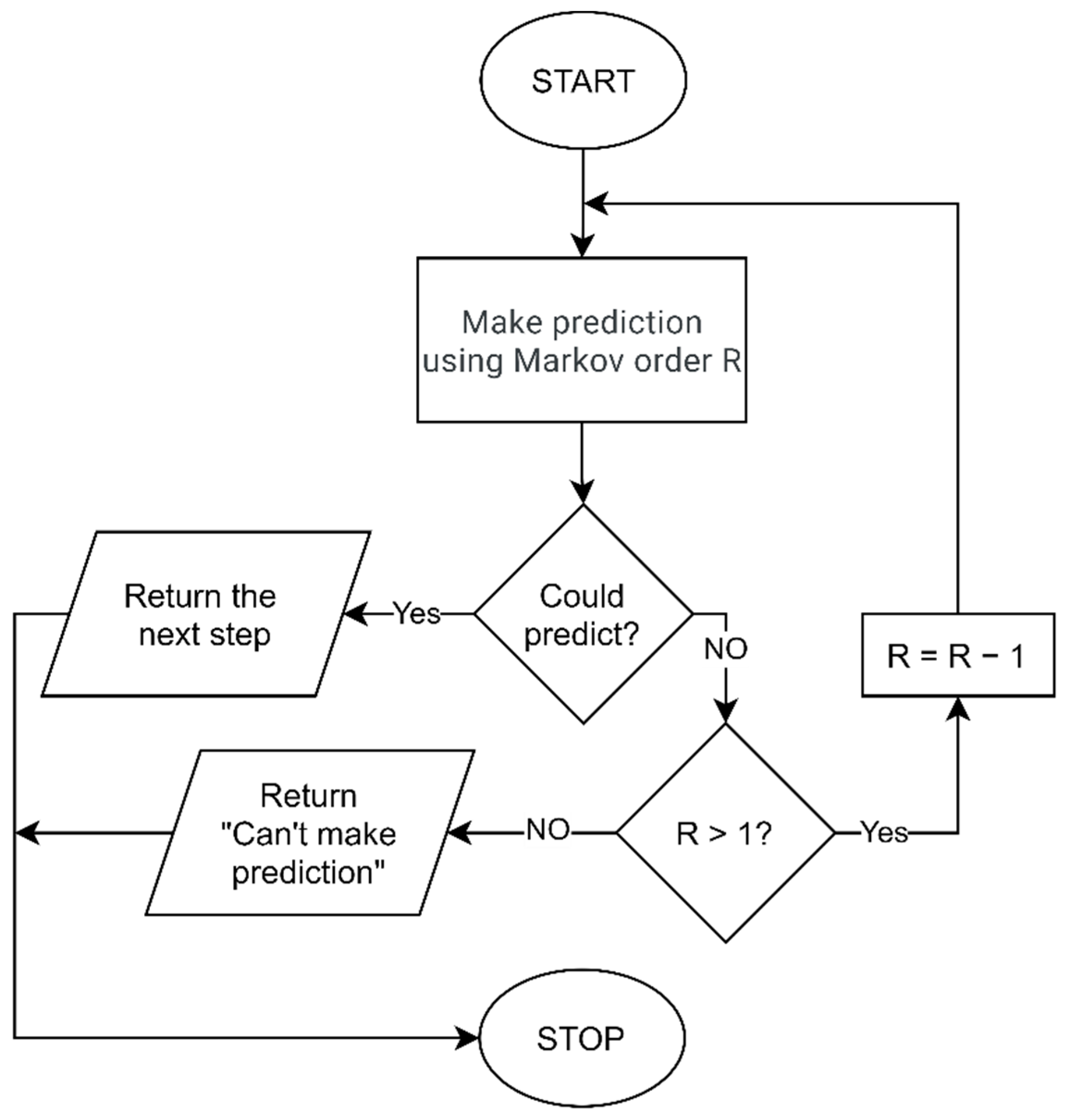
3.3.1. Prediction by Partial Matching
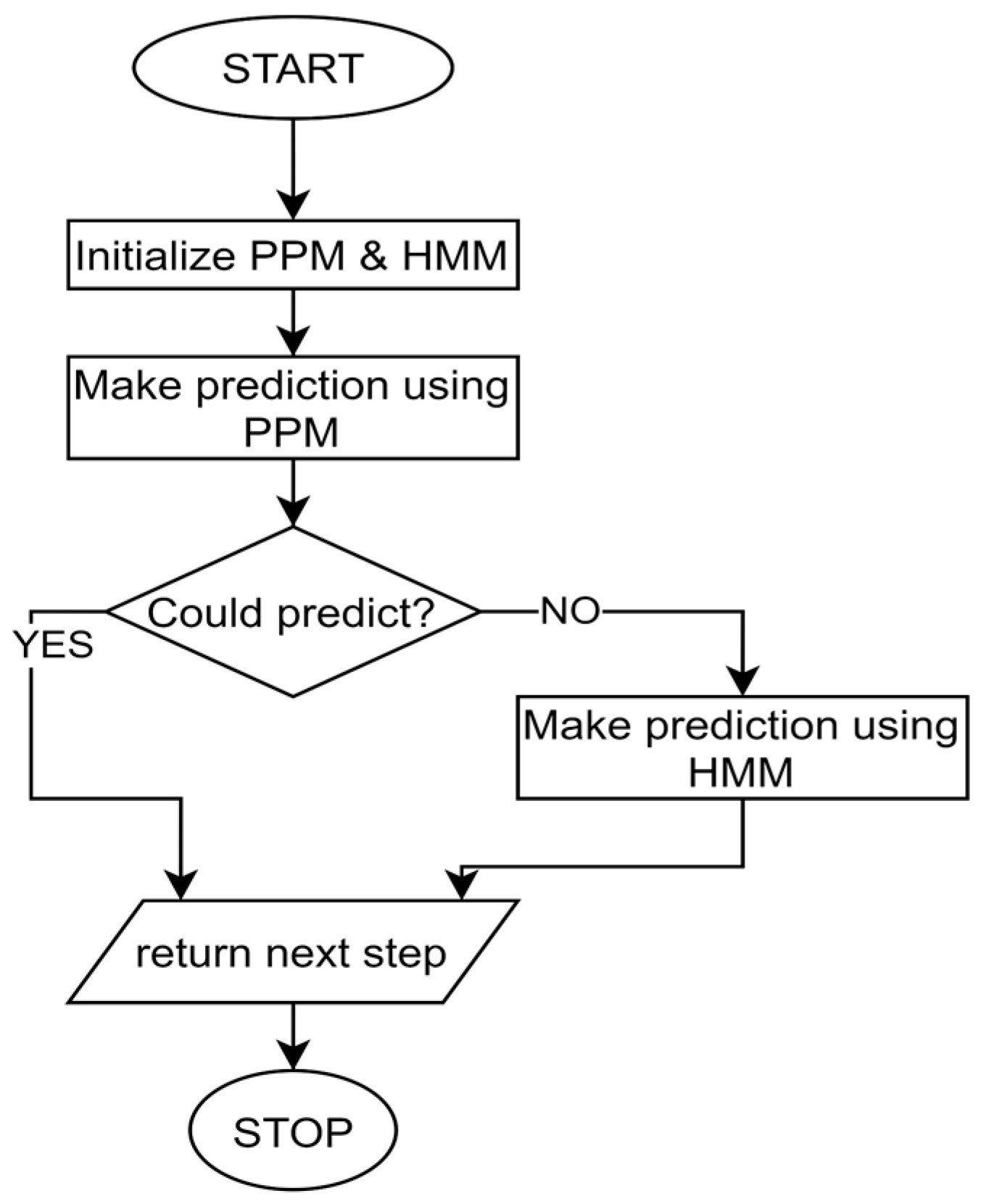
3.3.2. Hybrid Predictor with Prioritization
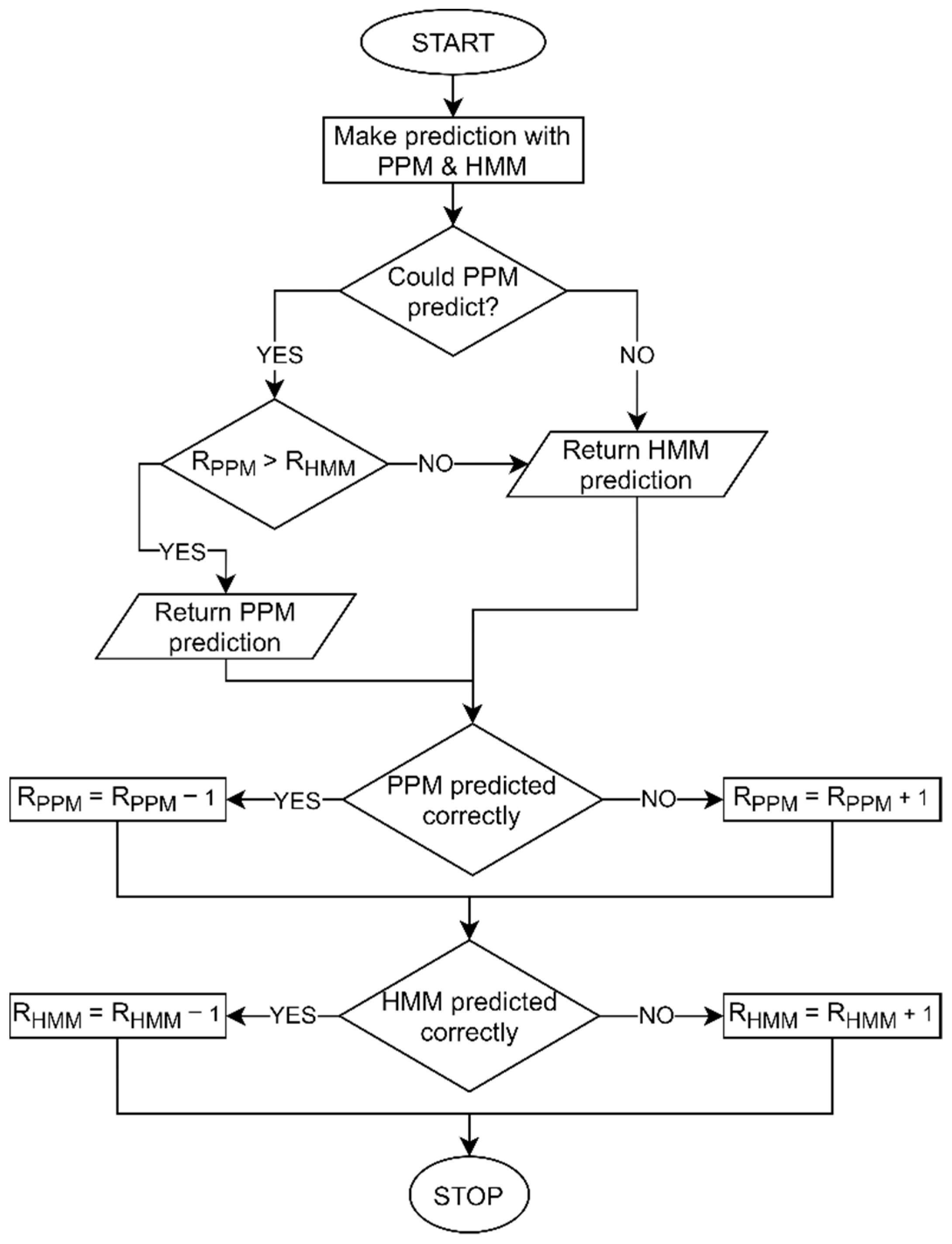
3.3.3. Reputation-Based Hybrid Prediction
- initialize predictors;
- set reputation for each predictor to 0;
- each predictor makes a prediction;
- if only one predictor could predict, return that prediction;
- else, select prediction based on maximum reputation;
- receive feedback on prediction;
- foreach predictor, if the prediction was correct, increase the reputation by 1, else decrease it by 1;
- clamp the reputation in the reputation interval.
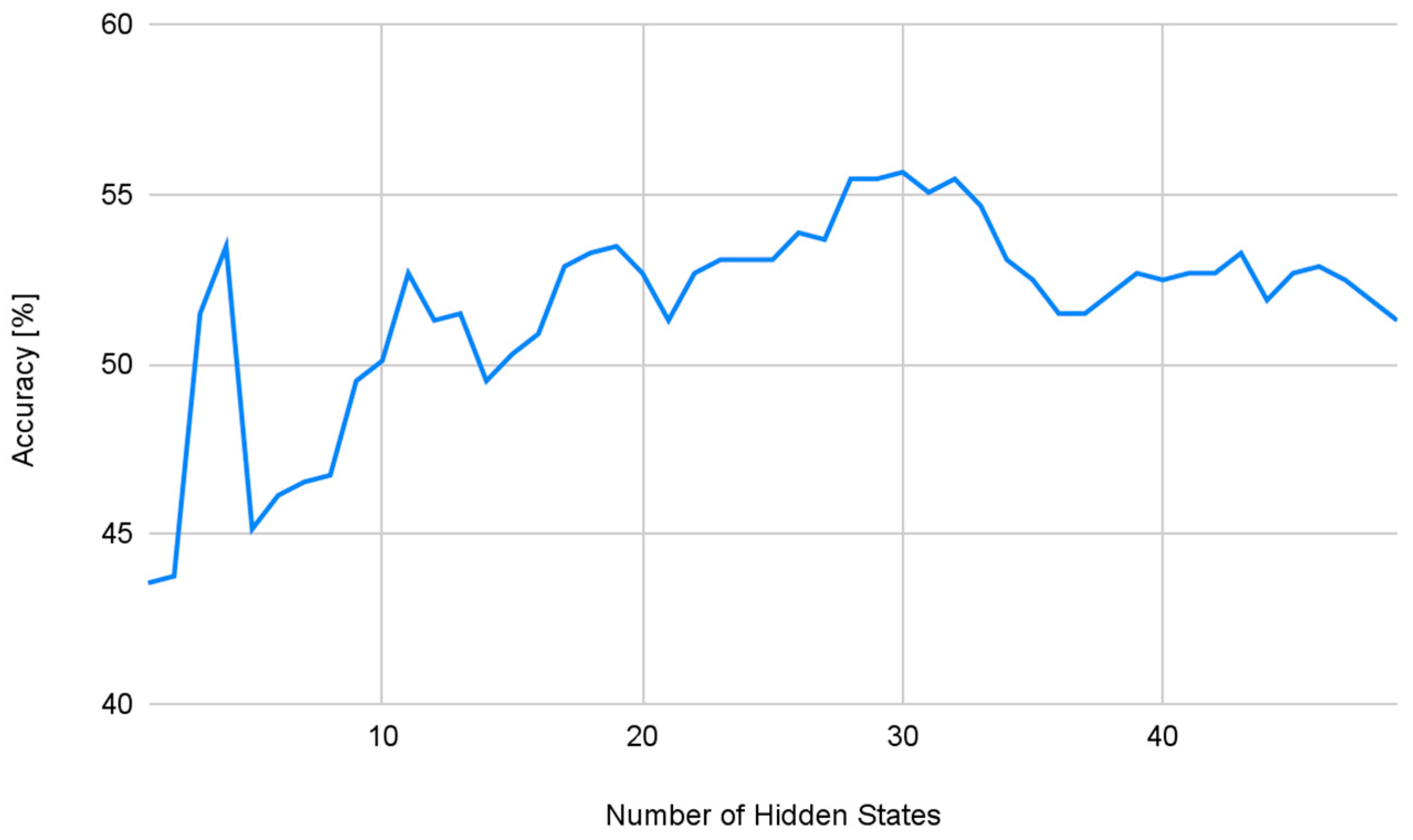
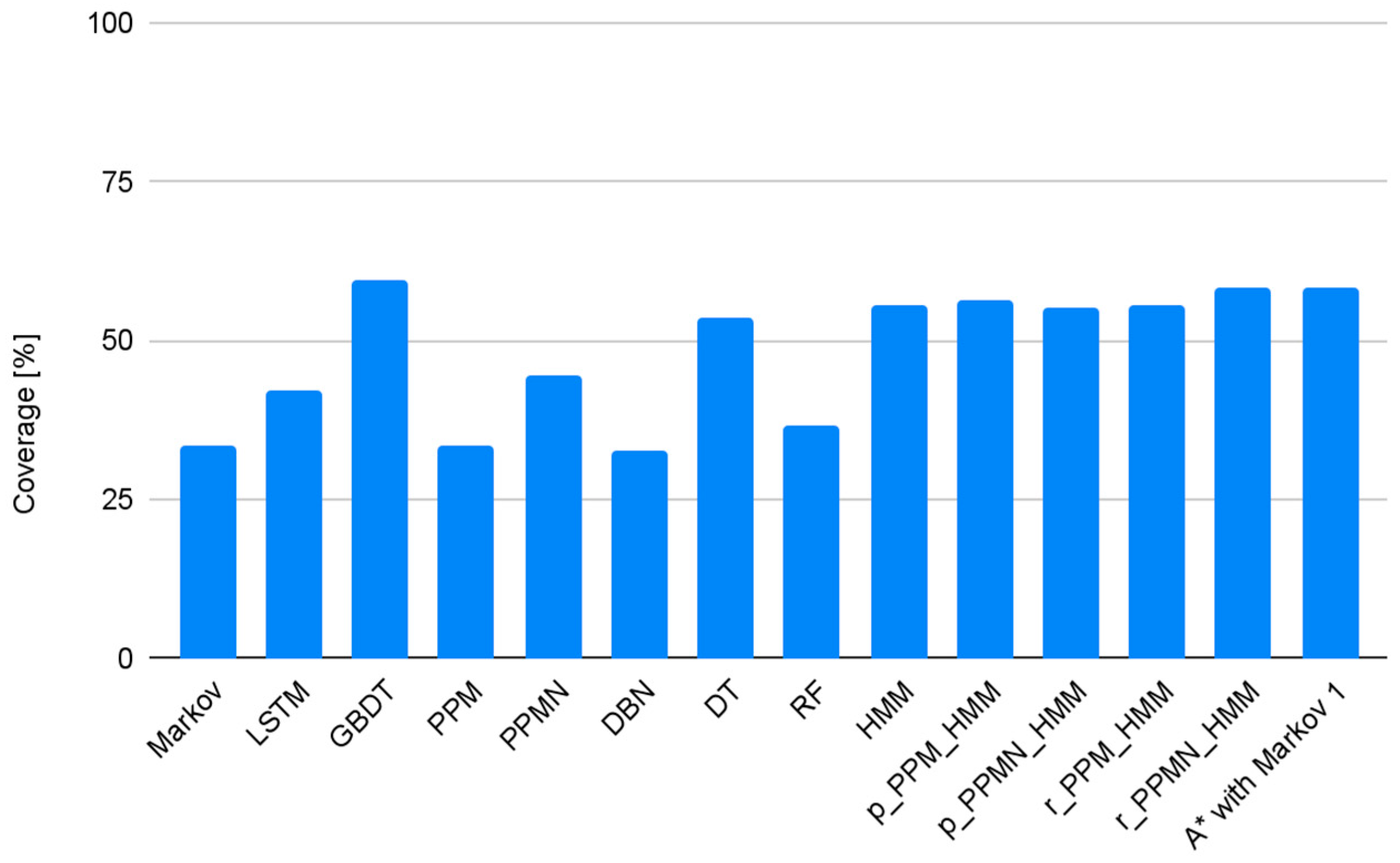
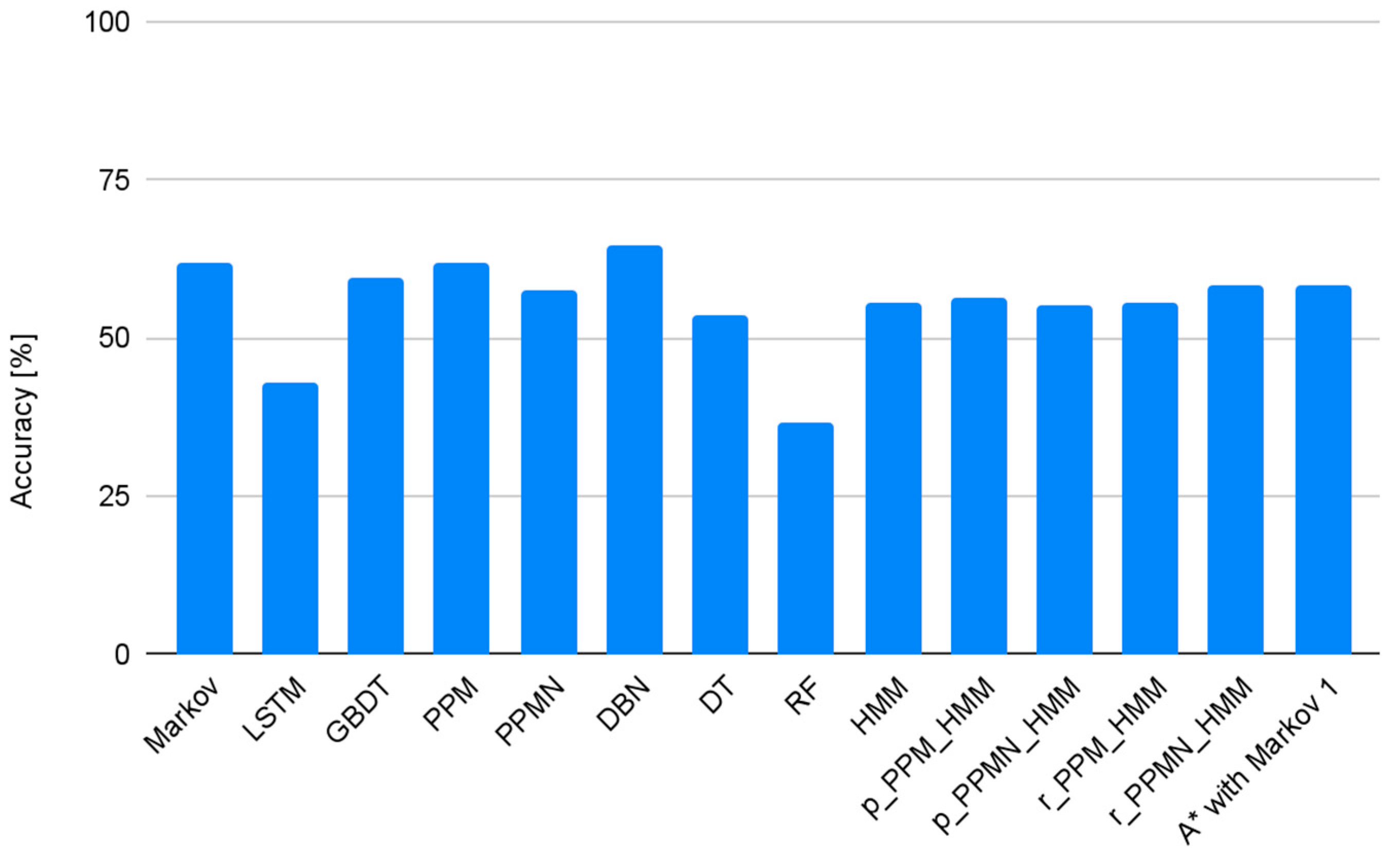
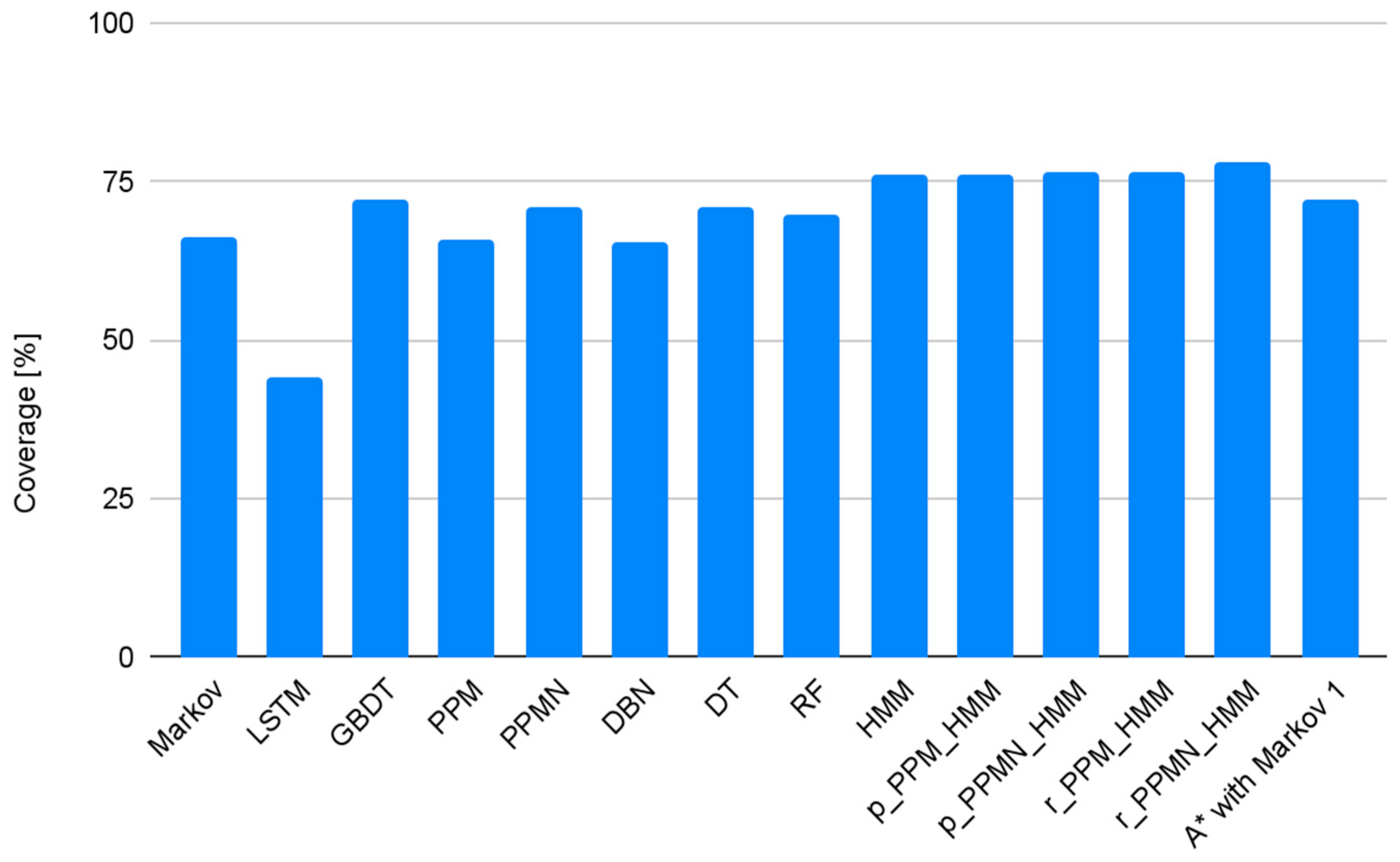
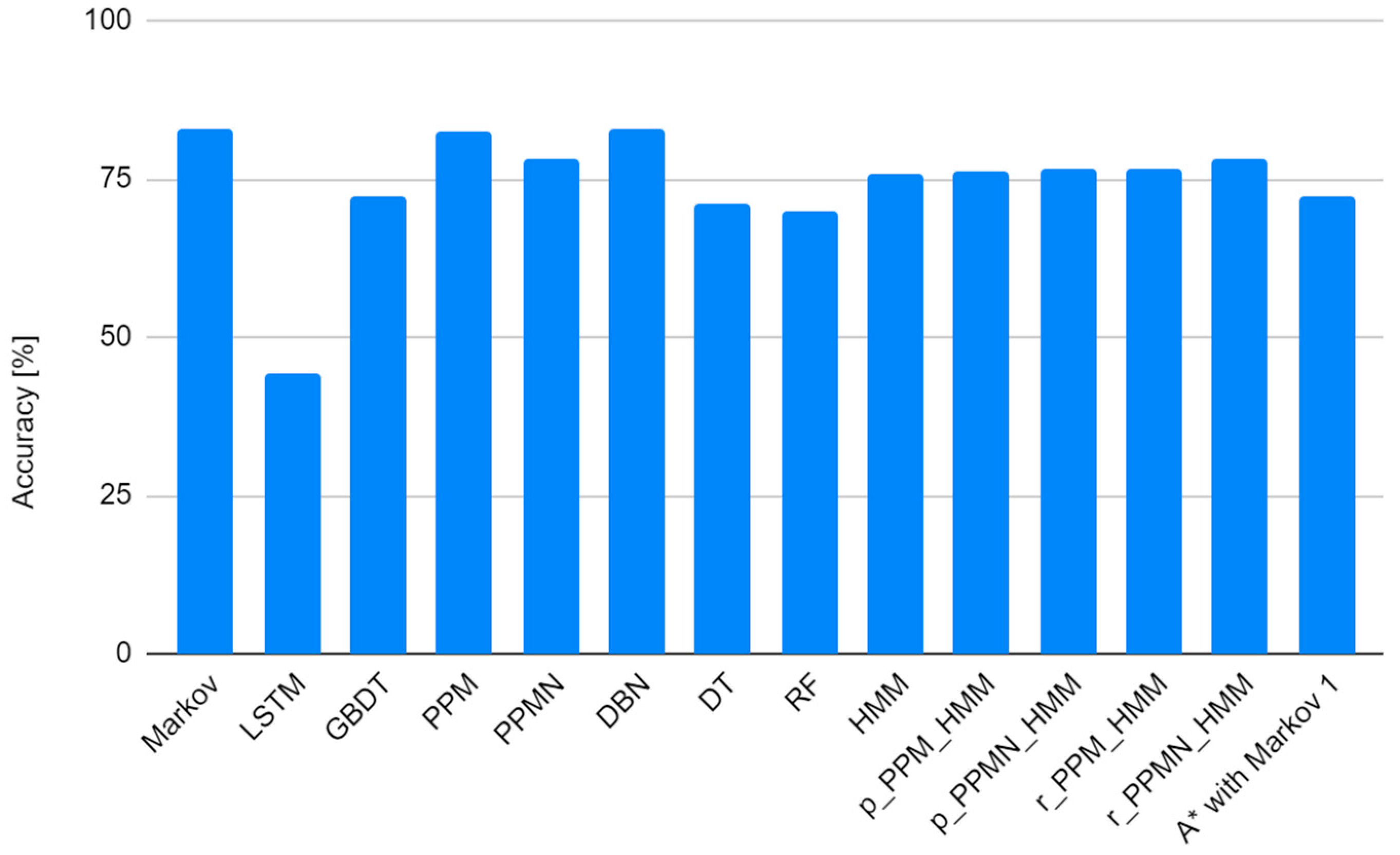
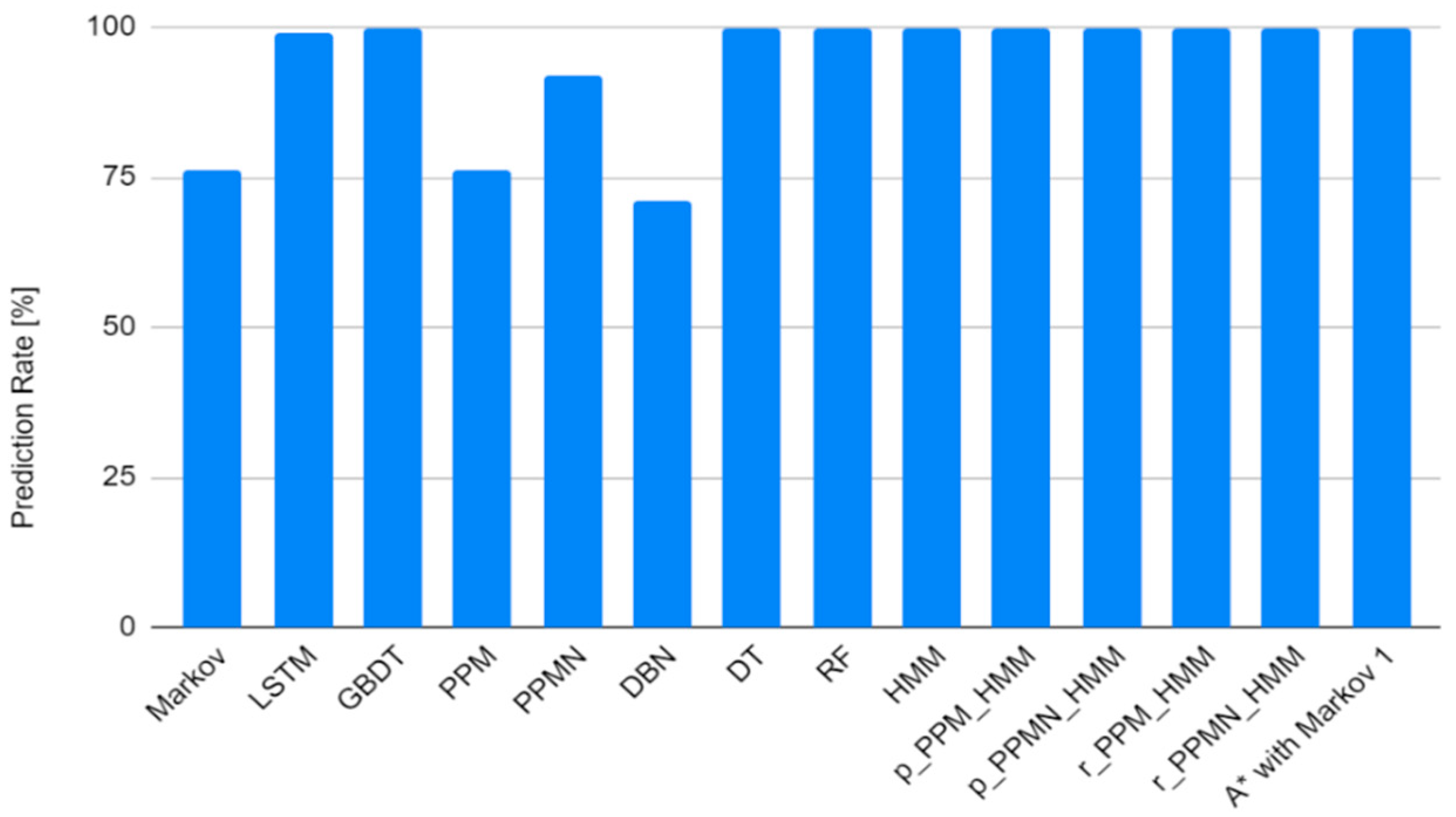
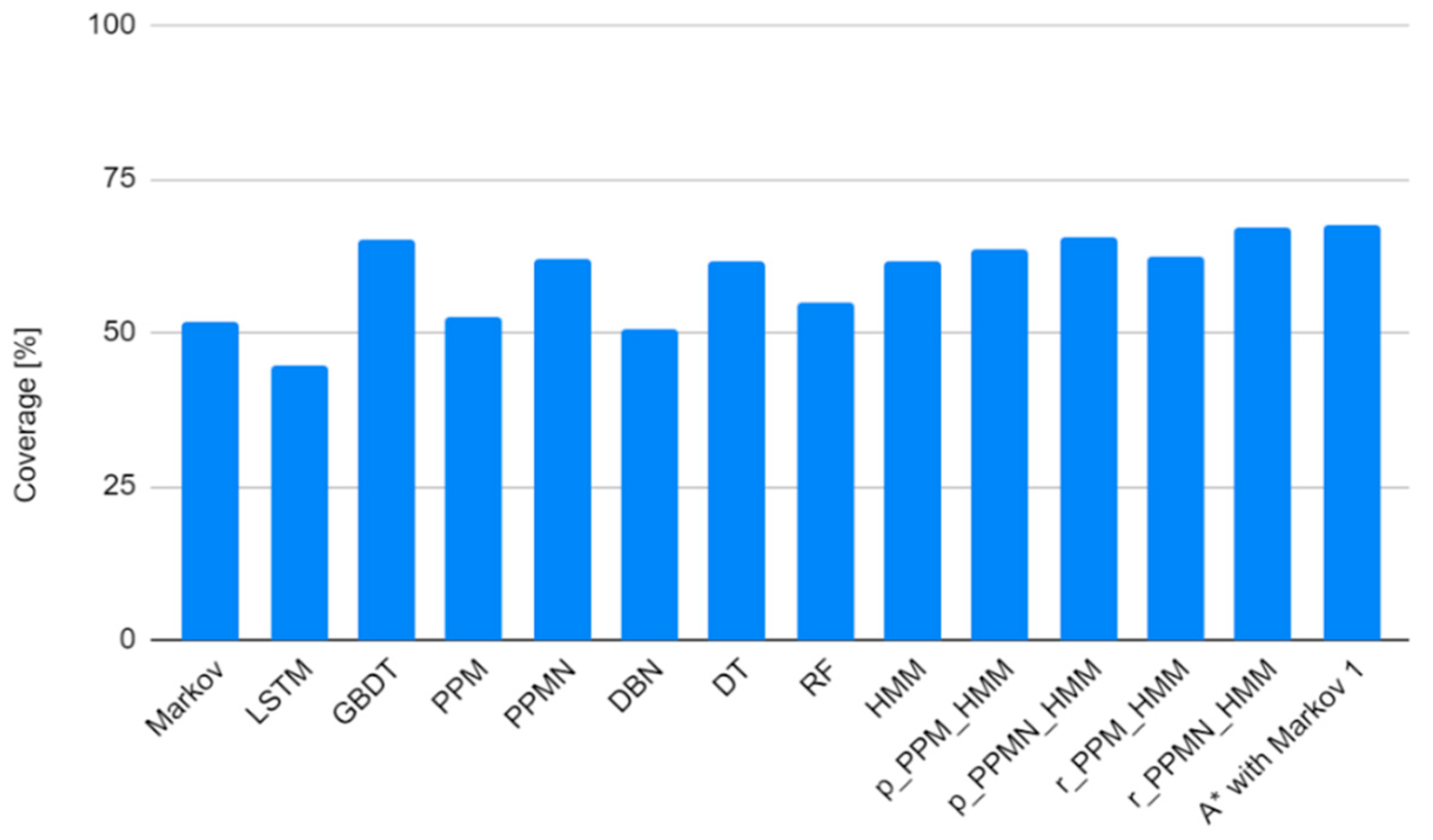
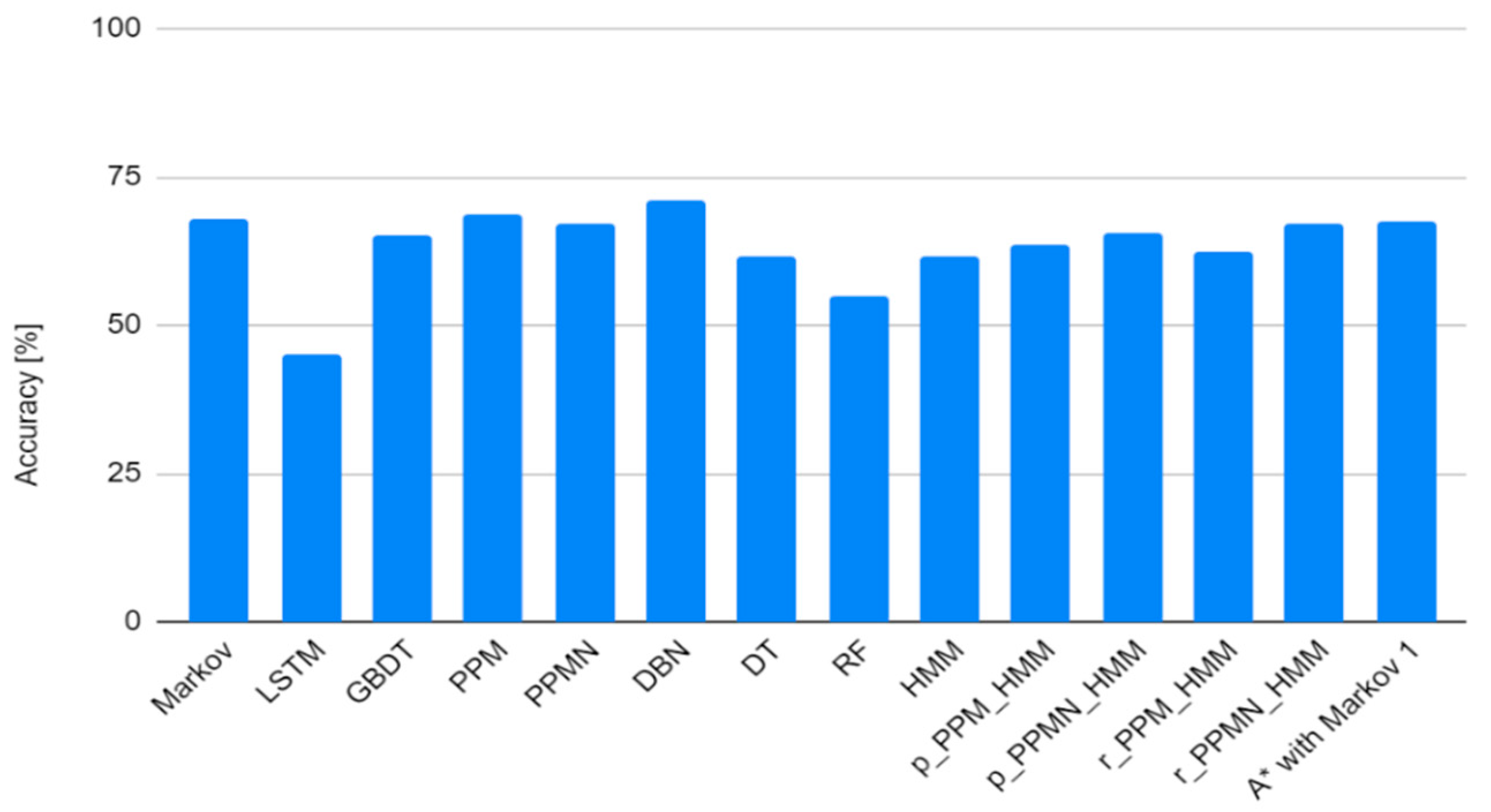
4. Experimental Results
5. Conclusions and Further Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Serger, S.; Tataj, D.; Morlet, A.; Isaksson, D.; Martins, F.; Mir Roca, M.; Hidalgo, C.; Huang, A.; Dixson-Declève, S.; Balland, P.; et al. Industry 5.0, a Transformative Vision for Europe: Governing Systemic Transformations Towards a Sustainable Industry; Publications Office of the European Union: Luxembourg, 2022. [Google Scholar] [CrossRef]
- Maddikunta, P.K.R.; Pham, Q.-V.; Prabadevi, B.; Deepa, N.; Dev, K.; Gadekallu, T.R.; Ruby, R.; Liyanage, M. Industry 5.0: A Survey on Enabling Technologies and Potential Applications. J. Ind. Inf. Integr. 2022, 26, 100257. [Google Scholar] [CrossRef]
- Deguchi, A.; Hirai, C.; Matsuoka, H.; Nakano, T.; Oshima, K.; Tai, M.; Tani, S. What Is Society 5.0? In Society 5.0: A People-Centric Super-Smart Society; Springer Singapore: Singapore, 2020; pp. 1–23. [Google Scholar] [CrossRef]
- Chiacchio, F.; Petropoulos, G.; Pichler, D. The Impact of Industrial Robots on EU Employment and Wages—A Local Labour Market Approach; Bruegel: Brussels, Belgium, 2018. [Google Scholar]
- Bisello, M.; Fernández-Macías, E.; Eggert Hansen, M. New Tasks in Old Jobs: Drivers of Change and Implications for Job Quality; Publications Office of the European Union: Luxembourg, 2018. [Google Scholar] [CrossRef]
- Romero, D.; Bernus, P.; Noran, O.; Stahre, J.; Fast-Berglund, Å. The Operator 4.0: Human Cyber-Physical Systems & Adaptive Automation Towards Human-Automation Symbiosis Work Systems. In Advances in Production Management Systems. Initiatives for a Sustainable World; Nääs, I., Vendrametto, O., Mendes Reis, J., Gonçalves, R.F., Silva, M.T., von Cieminski, G., Kiritsis, D., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 677–686. [Google Scholar] [CrossRef] [Green Version]
- Sorostinean, R.; Gellert, A.; Pirvu, B.-C. Assembly Assistance System with Decision Trees and Ensemble Learning. Sensors 2021, 21, 3580. [Google Scholar] [CrossRef] [PubMed]
- Gellert, A.; Zamfirescu, C.-B. Using Two-Level Context-Based Predictors for Assembly Assistance in Smart Factories. In Intelligent Methods in Computing, Communications and Control. ICCCC 2020. Advances in Intelligent Systems and Computing; Dzitac, I., Dzitac, S., Filip, F., Kacprzyk, J., Manolescu, M.J., Oros, H., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 167–176. [Google Scholar] [CrossRef]
- Gellert, A.; Zamfirescu, C.-B. Assembly support systems with Markov predictors. J. Decis. Syst. 2020, 29, 63–70. [Google Scholar] [CrossRef]
- Gellert, A.; Precup, S.-A.; Pirvu, B.-C.; Zamfirescu, C.-B. Prediction-Based Assembly Assistance System. In Proceedings of the 25th IEEE International Conference on Emerging Technologies and Factory Automation, Vienna, Austria, 8–11 September 2020; pp. 1065–1068. [Google Scholar] [CrossRef]
- Rabiner, L.R. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef] [Green Version]
- Gellert, A.; Precup, S.-A.; Pirvu, B.-C.; Fiore, U.; Zamfirescu, C.-B.; Palmieri, F. An Empirical Evaluation of Prediction by Partial Matching in Assembly Assistance Systems. Appl. Sci. 2021, 11, 3278. [Google Scholar] [CrossRef]
- Mark, B.G.; Rauch, E.; Matt, D.T. Worker Assistance Systems in Manufacturing: A Review of the State of the Art and Future Directions. J. Manuf. Syst. 2021, 59, 228–250. [Google Scholar] [CrossRef]
- Peron, M.; Sgarbossa, F.; Strandhagen, J.O. Decision Support Model for Implementing Assistive Technologies in Assembly Activities: A Case Study. Int. J. Prod. Res. 2022, 60, 1341–1367. [Google Scholar] [CrossRef]
- Knoke, B.; Thoben, K.-D. Training Simulators for Manufacturing Processes: Literature Review and systematisation of Applicability Factors. Comput. Appl. Eng. Educ. 2021, 29, 1191–1207. [Google Scholar] [CrossRef]
- Miqueo, A.; Torralba, M.; Yagüe-Fabra, J.A. Lean Manual Assembly 4.0: A Systematic Review. Appl. Sci. 2020, 10, 8555. [Google Scholar] [CrossRef]
- Pilati, F.; Faccio, M.; Gamberi, M.; Regattieri, A. Learning Manual Assembly through Real-Time Motion Capture for Operator Training with Augmented Reality. Procedia Manuf. 2020, 45, 189–195. [Google Scholar] [CrossRef]
- Rossi, M.; Papetti, A.; Germani, M.; Marconi, M. An Augmented Reality System for Operator Training in the Footwear Sector. Comput. Aided Des. Appl. 2020, 18, 692–703. [Google Scholar] [CrossRef]
- Fu, M.; Fang, W.; Gao, S.; Hong, J.; Chen, Y. Edge Computing-Driven Scene-Aware Intelligent Augmented Reality Assembly. Int. J. Adv. Manuf. Technol. 2022, 119, 7369–7381. [Google Scholar] [CrossRef]
- Lai, Z.-H.; Tao, W.; Leu, M.C.; Yin, Z. Smart Augmented Reality Instructional System for Mechanical Assembly towards Worker-Centered Intelligent Manufacturing. J. Manuf. Syst. 2020, 55, 69–81. [Google Scholar] [CrossRef]
- Neb, A.; Brandt, D.; Rauhöft, G.; Awad, R.; Scholz, J.; Bauernhansl, T. A Novel Approach to Generate Augmented Reality Assembly Assistance Automatically from CAD Models. Procedia CIRP 2021, 104, 68–73. [Google Scholar] [CrossRef]
- Baroroh, D.K.; Chu, C.-H.; Wang, L. Systematic Literature Review on Augmented Reality in Smart Manufacturing: Collaboration between Human and Computational Intelligence. J. Manuf. Syst. 2021, 61, 696–711. [Google Scholar] [CrossRef]
- Hirt, C.; Holzwarth, V.; Gisler, J.; Schneider, J.; Kunz, A. Virtual Learning Environment for an Industrial Assembly Task. In Proceedings of the 2019 IEEE 9th International Conference on Consumer Electronics (ICCE-Berlin), Berlin, Germany, 8–11 September 2019; pp. 337–342. [Google Scholar] [CrossRef] [Green Version]
- Gorecky, D.; Khamis, M.; Mura, K. Introduction and Establishment of Virtual Training in the Factory of the Future. Int. J. Comput. Integr. Manuf. 2017, 30, 182–190. [Google Scholar] [CrossRef]
- Manns, M.; Tuli, T.B.; Schreiber, F. Identifying Human Intention during Assembly Operations Using Wearable Motion Capturing Systems Including Eye Focus. Procedia CIRP 2021, 104, 924–929. [Google Scholar] [CrossRef]
- Pratticò, F.G.; Lamberti, F. Towards the Adoption of Virtual Reality Training Systems for the Self-Tuition of Industrial Robot Operators: A Case Study at KUKA. Comput. Ind. 2021, 129, 103446. [Google Scholar] [CrossRef]
- Turk, M.; Resman, M.; Herakovič, N. The Impact of Smart Technologies: A Case Study on the Efficiency of the Manual Assembly Process. Procedia CIRP 2021, 97, 412–417. [Google Scholar] [CrossRef]
- Turk, M.; Šimic, M.; Pipan, M.; Herakovič, N. Multi-Criterial Algorithm for the Efficient and Ergonomic Manual Assembly Process. Int. J. Environ. Res. Public. Health 2022, 19, 3496. [Google Scholar] [CrossRef] [PubMed]
- Vanneste, P.; Huang, Y.; Park, J.Y.; Cornillie, F.; Decloedt, B.; Van den Noortgate, W. Cognitive Support for Assembly Operations by Means of Augmented Reality: An Exploratory Study. Int. J. Hum. Comput. Stud. 2020, 143, 102480. [Google Scholar] [CrossRef]
- Petzoldt, C.; Keiser, D.; Beinke, T.; Freitag, M. Requirements for an Incentive-Based Assistance System for Manual Assembly. In Dynamics in Logistics; Freitag, M., Haasis, H.-D., Kotzab, H., Pannek, J., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 541–553. [Google Scholar] [CrossRef]
- Petzoldt, C.; Keiser, D.; Beinke, T.; Freitag, M. Functionalities and Implementation of Future Informational Assistance Systems for Manual Assembly. In Subject-Oriented Business Process Management. The Digital Workplace—Nucleus of Transformation; Freitag, M., Kinra, A., Kotzab, H., Kreowski, H.-J., Thoben, K.-D., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 88–109. [Google Scholar] [CrossRef]
- Gräßler, I.; Roesmann, D.; Pottebaum, J. Traceable Learning Effects by Use of Digital Adaptive Assistance in Production. Procedia Manuf. 2020, 45, 479–484. [Google Scholar] [CrossRef]
- ElKomy, M.; Abdelrahman, Y.; Funk, M.; Dingler, T.; Schmidt, A.; Abdennadher, S. ABBAS: An Adaptive Bio-Sensors Based Assistive System. In Proceedings of the 2017 CHI Conference Extended Abstracts on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 2543–2550. [Google Scholar] [CrossRef]
- Wang, Z.; Bai, X.; Zhang, S.; Wang, Y.; Han, S.; Zhang, X.; Yan, Y.; Xiong, Z. User-Oriented AR Assembly Guideline: A New Classification Method of Assembly Instruction for User Cognition. Int. J. Adv. Manuf. Technol. 2021, 112, 41–59. [Google Scholar] [CrossRef]
- Baum, L.E.; Petrie, T. Statistical inference for probabilistic functions of finite state Markov chains. Ann. Math. Stat. 1966, 37, 1554–1563. [Google Scholar] [CrossRef]
- Houpt, J.W.; Frame, M.E.; Blaha, L.M. Unsupervised parsing of gaze data with a beta-process vector auto-regressive hidden Markov model. Behav. Res. 2018, 50, 2074–2096. [Google Scholar] [CrossRef]
- Wang, Y.; Kong, Y.; Tang, X.; Chen, X.; Xu, Y.; Chen, J.; Sun, S.; Guo, Y.; Chen, Y. Short-Term Industrial Load Forecasting Based on Ensemble Hidden Markov Model. IEEE Access 2020, 8, 160858–160870. [Google Scholar] [CrossRef]
- Li, J.; Zhang, X.; Zhou, X.; Lu, L. Reliability assessment of wind turbine bearing based on the degradation-Hidden-Markov model. Renew. Energy 2019, 132, 1076–1087. [Google Scholar] [CrossRef]
- Ullah, I.; Ahmad, R.; Kim, D. A Prediction Mechanism of Energy Consumption in Residential Buildings Using Hidden Markov Model. Energies 2018, 11, 358. [Google Scholar] [CrossRef] [Green Version]
- Simões, A.; Viegas, J.M.; Farinha, J.T.; Fonseca, I. The state of the art of hidden markov models for predictive maintenance of diesel engines. Qual. Reliab. Eng. Int. 2017, 33, 2765–2779. [Google Scholar] [CrossRef]
- Park, S.; Lim, W.; Sunwoo, M. Robust Lane-Change Recognition Based on An Adaptive Hidden Markov Model Using Measurement Uncertainty. Int. J. Automot. Technol. 2019, 20, 255–263. [Google Scholar] [CrossRef]
- Eddy, S. What is a hidden Markov model? Nat. Biotechnol. 2004, 22, 1315–1316. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yoon, B.J. Hidden Markov Models and their Applications in Biological Sequence Analysis. Curr. Genom. 2009, 10, 402–415. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tamposis, I.A.; Tsirigos, K.D.; Theodoropoulou, M.C.; Kontou, P.I.; Bagos, P.G. Semi-supervised learning of Hidden Markov Models for biological sequence analysis. Bioinformatics 2019, 35, 2208–2215. [Google Scholar] [CrossRef] [PubMed]
- Qin, B.; Xiao, T.; Ding, C.; Deng, Y.; Lv, Z.; Su, J. Genome-Wide Identification and Expression Analysis of Potential Antiviral Tripartite Motif Proteins (TRIMs) in Grass Carp (Ctenopharyngodon idella). Biology 2021, 10, 1252. [Google Scholar] [CrossRef]
- Karplus, K.; Sjölander, K.; Barrett, C.; Cline, M.; Haussler, D.; Hughey, R.; Holm, L.; Sander, C. Predicting protein structure using hidden Markov models. Proteins Struct. Funct. Bioinform. 1997, 29, 134–139. [Google Scholar] [CrossRef]
- Lasfar, M.; Bouden, H. A method of data mining using Hidden Markov Models (HMMs) for protein secondary structure prediction. Procedia Comput. Sci. 2018, 127, 42–51. [Google Scholar] [CrossRef]
- Kirsip, H.; Abroi, A. Protein Structure-Guided Hidden Markov Models (HMMs) as A Powerful Method in the Detection of Ancestral Endogenous Viral Elements. Viruses 2019, 11, 320. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yin, X.; Jiang, X.T.; Chai, B.; Li, L.; Yang, Y.; Cole, J.R.; Tiedje, J.M.; Zhang, T. ARGs-OAP v2.0 with an expanded SARG database and Hidden Markov Models for enhancement characterization and quantification of antibiotic resistance genes in environmental metagenomes. Bioinformatics 2018, 34, 2263–2270. [Google Scholar] [CrossRef] [Green Version]
- Xie, G.; Fair, J.M. Hidden Markov Model: A shortest unique representative approach to detect the protein toxins, virulence factors and antibiotic resistance genes. BMC Res. Notes 2021, 14, 122. [Google Scholar] [CrossRef]
- Emdadi, A.; Eslahchi, C. Auto-HMM-LMF: Feature selection based method for prediction of drug response via autoencoder and hidden Markov model. BMC Bioinform. 2021, 22, 33. [Google Scholar] [CrossRef]
- Li, J.; Lee, J.Y.; Liao, L. A new algorithm to train hidden Markov models for biological sequences with partial labels. BMC Bioinform. 2021, 22, 162. [Google Scholar] [CrossRef]
- Sagayam, K.M.; Hemanth, D.J. ABC algorithm based optimization of 1-D hidden Markov model for hand gesture recognition applications. Comput. Ind. 2018, 99, 313–323. [Google Scholar] [CrossRef]
- Chen, Z.; Li, Y.; Xia, T.; Pan, E. Hidden Markov model with auto-correlated observations for remaining useful life prediction and optimal maintenance policy. Reliab. Eng. Syst. Saf. 2019, 184, 123–136. [Google Scholar] [CrossRef]
- Cheng, P.; Chen, M.; Stojanovic, V.; He, S. Asynchronous fault detection filtering for piecewise homogenous Markov jump linear systems via a dual hidden Markov model. Mech. Syst. Signal Processing 2021, 151, 107353. [Google Scholar] [CrossRef]
- Kouadri, A.; Hajji, M.; Harkat, M.F.; Abodayeh, K.; Mansouri, M.; Nounou, H.; Nounou, M. Hidden Markov model based principal component analysis for intelligent fault diagnosis of wind energy converter systems. Renew. Energy 2020, 150, 598–606. [Google Scholar] [CrossRef]
- Ding, K.; Lei, J.; Chan, F.T.; Hui, J.; Zhang, F.; Wang, Y. Hidden Markov model-based autonomous manufacturing task orchestration in smart shop floors. Robot. Comput.-Integr. Manuf. 2020, 61, 101845. [Google Scholar] [CrossRef]
- Berg, J.; Reckordt, T.; Richter, C.; Reinhart, G. Action recognition in assembly for human-robot-cooperation using hidden Markov models. Procedia CIRP 2018, 76, 205–210. [Google Scholar] [CrossRef]
- Liu, T.; Lyu, E.; Wang, J.; Meng, M.Q.H. Unified Intention Inference and Learning for Human-Robot Cooperative Assembly. IEEE Trans. Autom. Sci. Eng. 2021, 19, 2256–2266. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Trevizan, B.; Chamby-Diaz, J.; Bazzan, A.L.; Recamonde-Mendoza, M. A comparative evaluation of aggregation methods for machine learning over vertically partitioned data. Expert Syst. Appl. 2020, 152, 113406. [Google Scholar] [CrossRef]
- Feng, C.; Zhang, J. Assessment of aggregation strategies for machine-learning based short-term load forecasting. Electr. Power Syst. Res. 2020, 184, 106304. [Google Scholar] [CrossRef]
- Tornede, A.; Gehring, L.; Tornede, T.; Wever, M.; Hüllermeier, E. Algorithm selection on a meta level. Mach. Learn. 2022, 1–34. [Google Scholar] [CrossRef]
- Alattas, K.A.; Mohammadzadeh, A.; Mobayen, S.; Abo-Dief, H.M.; Alanazi, A.K.; Vu, M.T.; Chang, A. Automatic Control for Time Delay Markov Jump Systems under Polytopic Uncertainties. Mathematics 2022, 10, 187. [Google Scholar] [CrossRef]
- Chiputa, M.; Zhang, M.; Ali, G.G.M.N.; Chong, P.H.J.; Sabit, H.; Kumar, A.; Li, H. Enhancing Handover for 5G mmWave Mobile Networks Using Jump Markov Linear System and Deep Reinforcement Learning. Sensors 2022, 22, 746. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, H.; Stojanovic, V.; Cheng, P.; He, S.; Luan, X.; Liu, F. Asynchronous fault detection for interval type-2 fuzzy nonhomogeneous higher-level Markov jump systems with uncertain transition probabilities. IEEE Trans. Fuzzy Syst. 2021, 30, 2487–2499. [Google Scholar] [CrossRef]
- Vadivel, R.; Ali, M.S.; Joo, Y.H. Drive-response synchronization of uncertain Markov jump generalized neural networks with interval time varying delays via decentralized event-triggered communication scheme. J. Frankl. Inst. 2020, 357, 6824–6857. [Google Scholar] [CrossRef]
- Pîrvu, B.-C. Conceptual Overview of an Anthropocentric Training Station for Manual Operations in Production. Balk. Reg. Conf. Eng. Bus. Educ. 2019, 1, 362–368. [Google Scholar] [CrossRef]
- Govoreanu, V.C.; Neghină, M. Speech Emotion Recognition Method Using Time-Stretching in the Preprocessing Phase and Artificial Neural Network Classifiers. In Proceedings of the 2020 IEEE 16th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 3–5 September 2020; pp. 69–74. [Google Scholar] [CrossRef]
- Gellert, A.; Sorostinean, R.; Pirvu, B.-C. Robust Assembly Assistance Using Informed Tree Search with Markov Chains. Sensors 2022, 22, 495. [Google Scholar] [CrossRef]
- Stamp, M. A Revealing Introduction to Hidden Markov Models. In Introduction to Machine Learning with Applications in Information Security, 1st ed.; Chapman and Hall/CRC: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Precup, S.-A.; Gellert, A.; Dorobantiu, A.; Zamfirescu, C.-B. Assembly Process Modeling through Long Short-Term Memory. In Proceedings of the 13th Asian Conference on Intelligent Information and Database Systems, Phuket, Thailand, 7–10 April 2021. [Google Scholar]
- Precup, S.-A.; Gellert, A.; Matei, A.; Gita, M.; Zamfirescu, C.B. Towards an Assembly Support System with Dynamic Bayesian Network. Appl. Sci. 2022, 12, 985. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Specifications |
|---|---|
| Display | 43-inch 4K touchscreen |
| CPU | Intel i7-7700 |
| GPU | NVIDIA GeForce GTX 1060 |
| RAM | 16 GB |
| SSD | 250 GB |
| Operating System | Windows 10 |
| HMM Seed | Prediction Rate [%] | Accuracy [%] | Coverage [%] |
|---|---|---|---|
| 197,706 | 100 | 51.49 | 51.49 |
| 20,612 | 100 | 53.47 | 53.47 |
| 930,364 | 100 | 56.44 | 56.44 |
| 938,425 | 100 | 58.42 | 58.42 |
| 973,051 | 100 | 58.42 | 58.42 |
| Average | 100 | 55.64 | 55.64 |
| Reputation Interval | Students [%] | Workers [%] | Mixed [%] |
|---|---|---|---|
| [−1, 1] | 55.45 | 76.45 | 63.32 |
| [−2, 2] | 55.64 | 76.09 | 62.67 |
| [−3, 3] | 55.25 | 76.69 | 62.45 |
| [−4, 4] | 55.64 | 76.69 | 62.24 |
| [−5, 5] | 55.45 | 76.69 | 62.31 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gellert, A.; Precup, S.-A.; Matei, A.; Pirvu, B.-C.; Zamfirescu, C.-B. Real-Time Assembly Support System with Hidden Markov Model and Hybrid Extensions. Mathematics 2022, 10, 2725. https://doi.org/10.3390/math10152725
Gellert A, Precup S-A, Matei A, Pirvu B-C, Zamfirescu C-B. Real-Time Assembly Support System with Hidden Markov Model and Hybrid Extensions. Mathematics. 2022; 10(15):2725. https://doi.org/10.3390/math10152725
Chicago/Turabian StyleGellert, Arpad, Stefan-Alexandru Precup, Alexandru Matei, Bogdan-Constantin Pirvu, and Constantin-Bala Zamfirescu. 2022. "Real-Time Assembly Support System with Hidden Markov Model and Hybrid Extensions" Mathematics 10, no. 15: 2725. https://doi.org/10.3390/math10152725
APA StyleGellert, A., Precup, S.-A., Matei, A., Pirvu, B.-C., & Zamfirescu, C.-B. (2022). Real-Time Assembly Support System with Hidden Markov Model and Hybrid Extensions. Mathematics, 10(15), 2725. https://doi.org/10.3390/math10152725