

Multisensor Fusion Estimation for Systems with Uncertain Measurements, Based on Reduced Dimension Hypercomplex Techniques


Abstract
:1. Introduction
2. Tessarine Processing
3. Problem Statement
- For each , they must satisfy that or at every instant of time, i.e., if one of them takes the value 0, the other one is 1, or both are 0.
- , for every .
- For each sensor , and , and are independent for , and also and are independent for .
- is independent of , and , for any .
4. -Proper Distributed Fusion LS Linear Estimation
4.1. Local -Proper LS Linear Estimation Algorithms
4.2. Distributed -Proper LS Linear Estimation Algorithms
4.3. Computational Complexity
5. -Proper Centralized Fusion LS Linear Estimation
6. Numerical Example
6.1. Example 1
- -
- in the -proper scenario, , for all , , , and
- -
- in the -proper scenario, , and , for , .
- In the -proper scenario:
- -
- Case 1: , ;
- -
- Case 2: , ;
- -
- Case 3: , ;
- -
- Case 4: , ;
- -
- Case 5: , ;
- -
- Case 6: , .
- In the -proper scenario:
- -
- Case 1: , , ;
- -
- Case 2: , , ;
- -
- Case 3: , , ;
- -
- Case 4: , , ;
- -
- Case 5: , , ;
- -
- Case 6: , , .
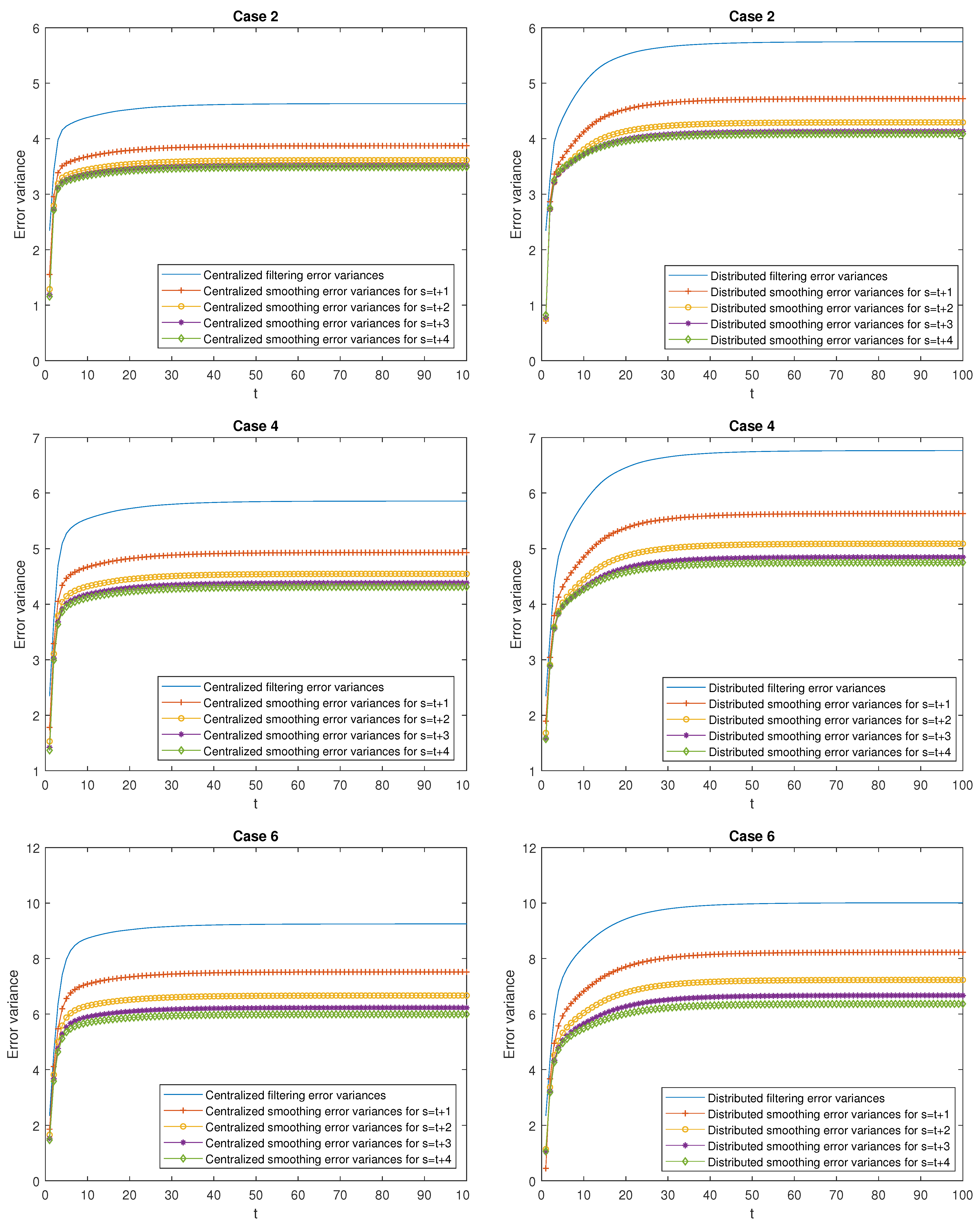
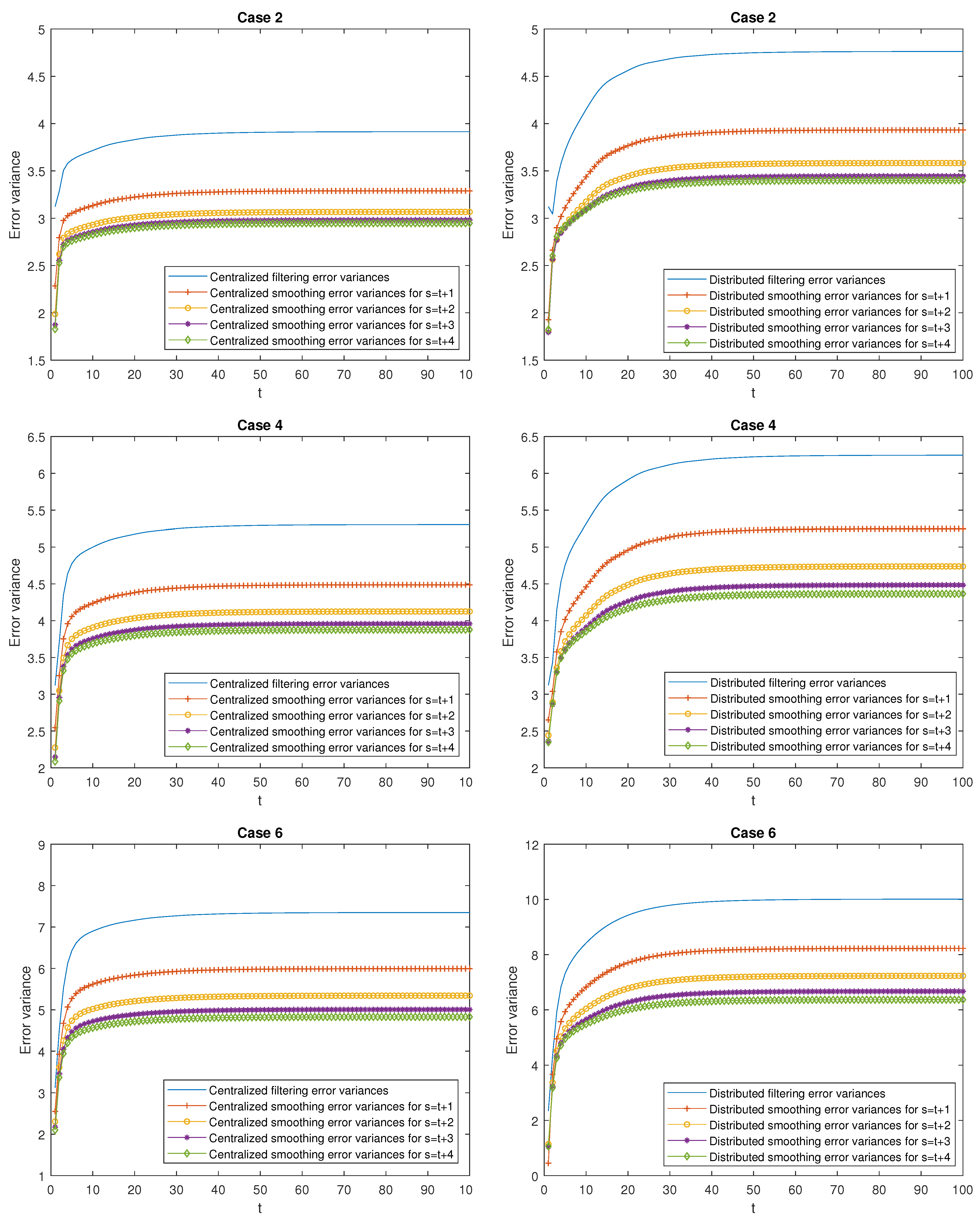
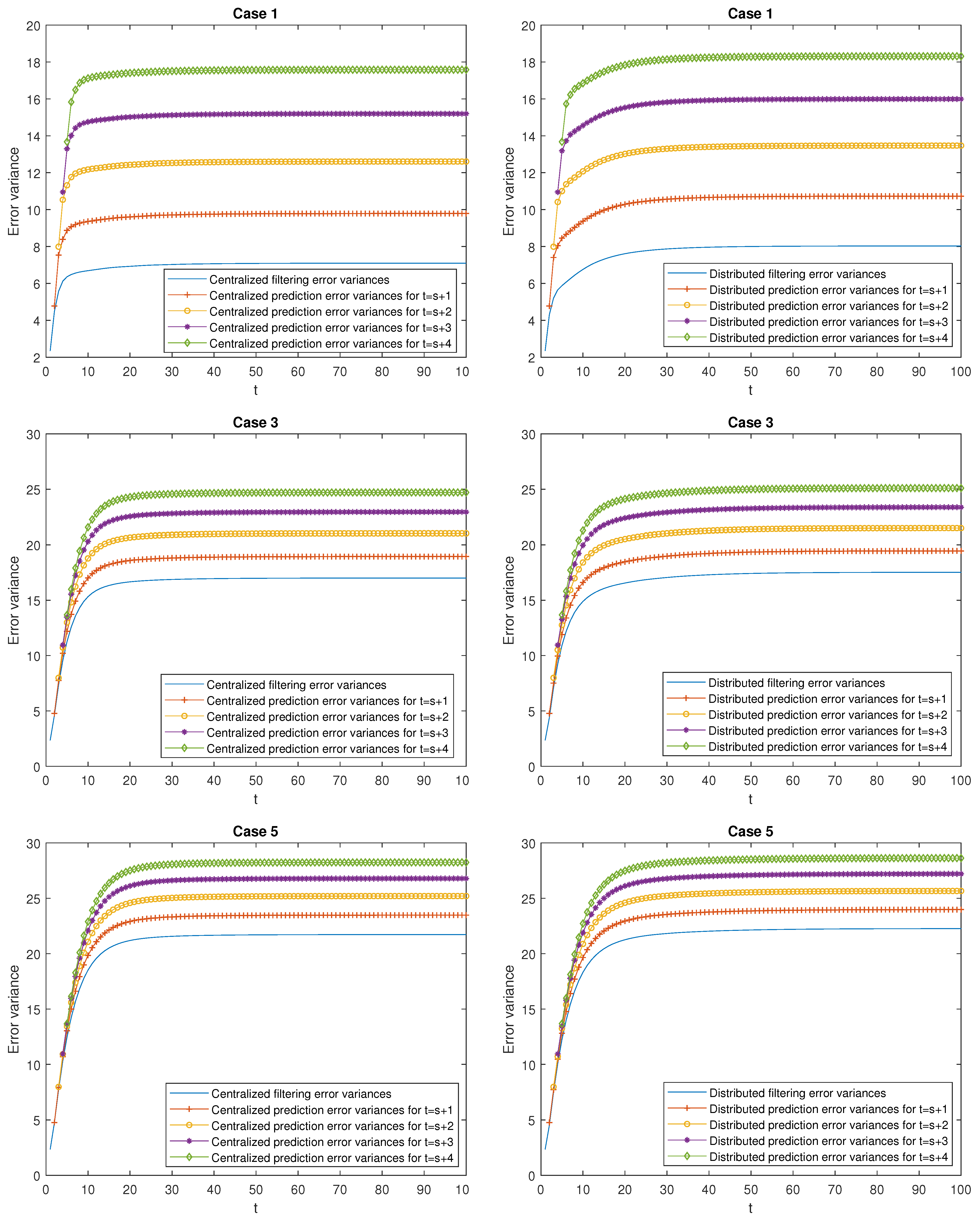
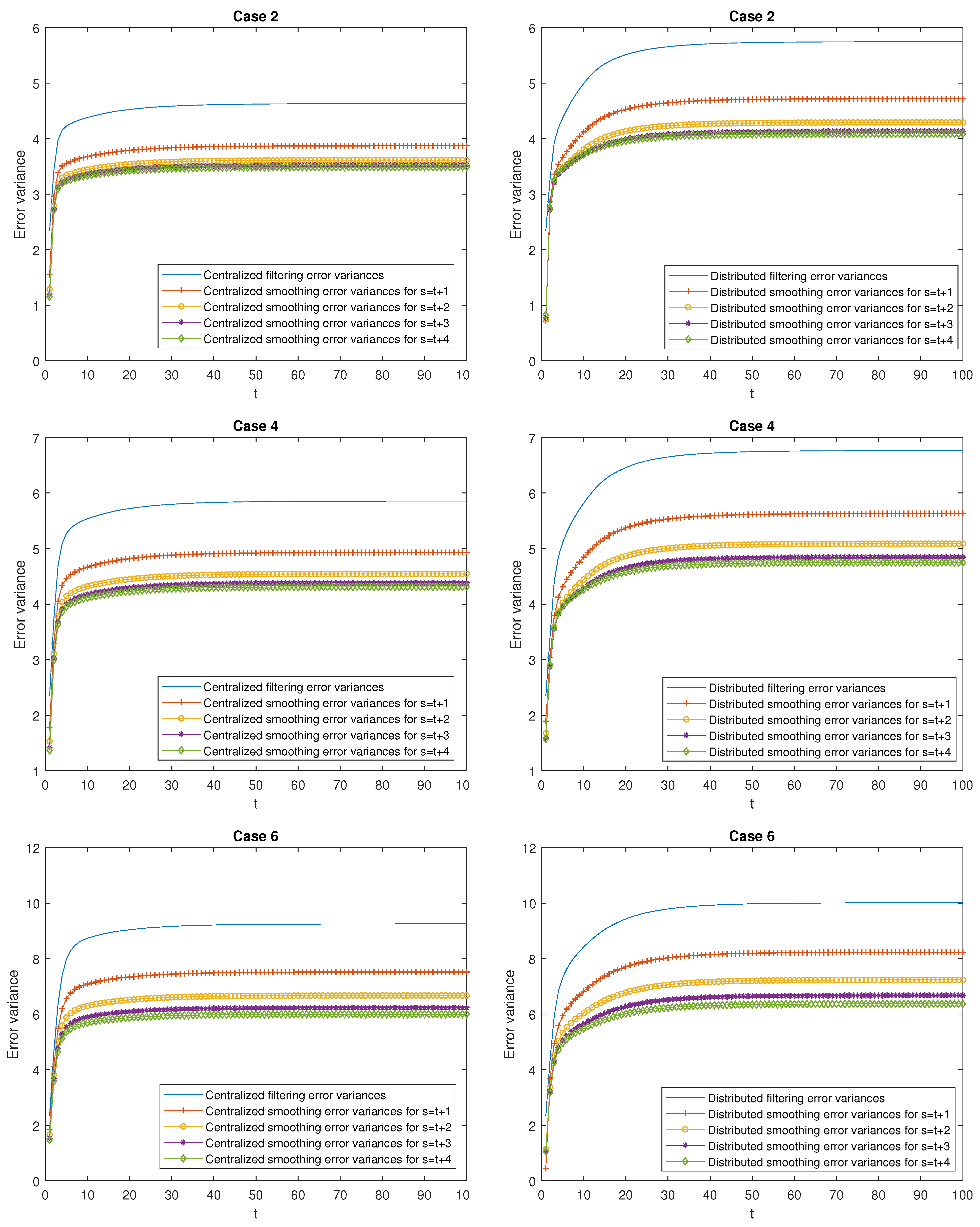
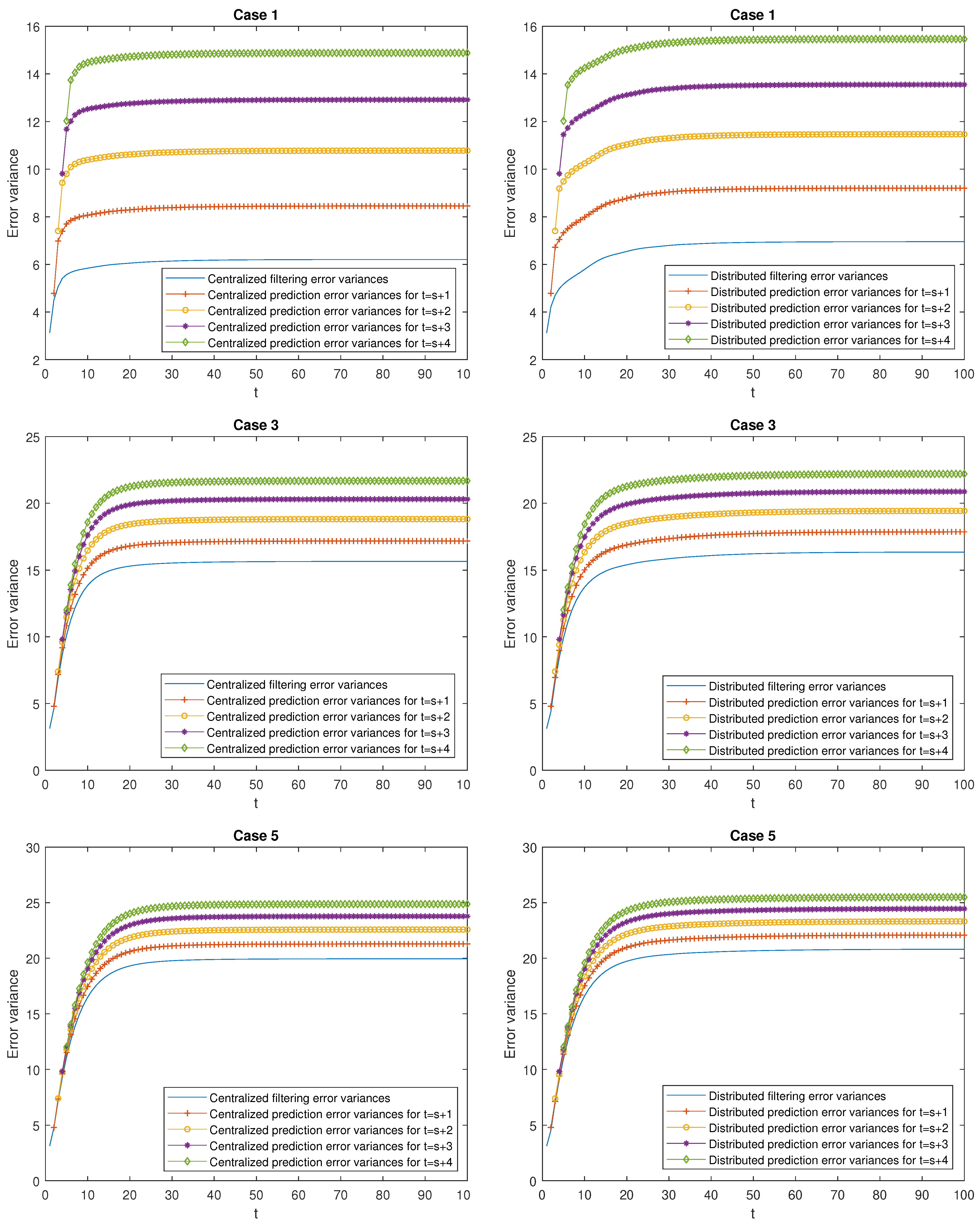
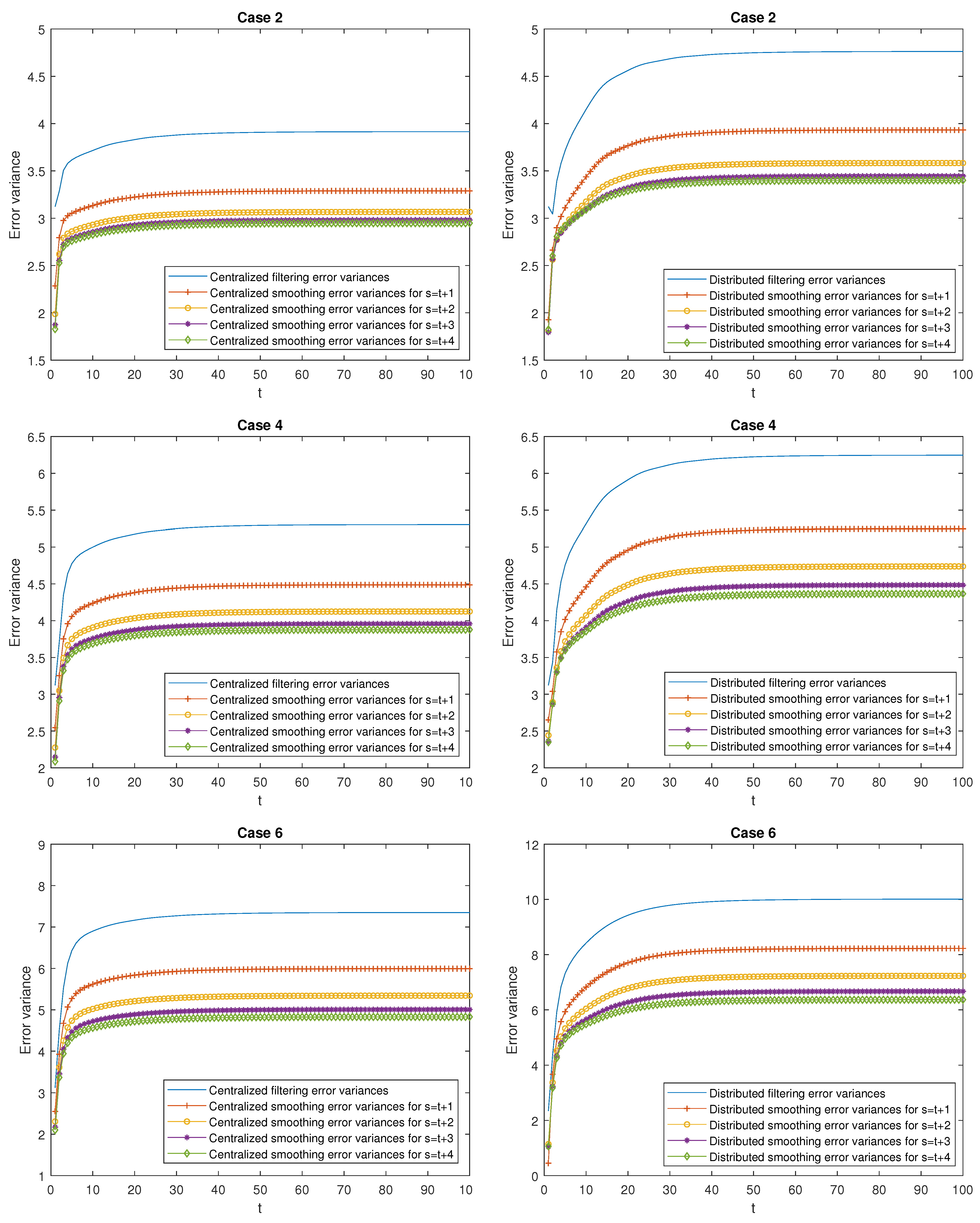
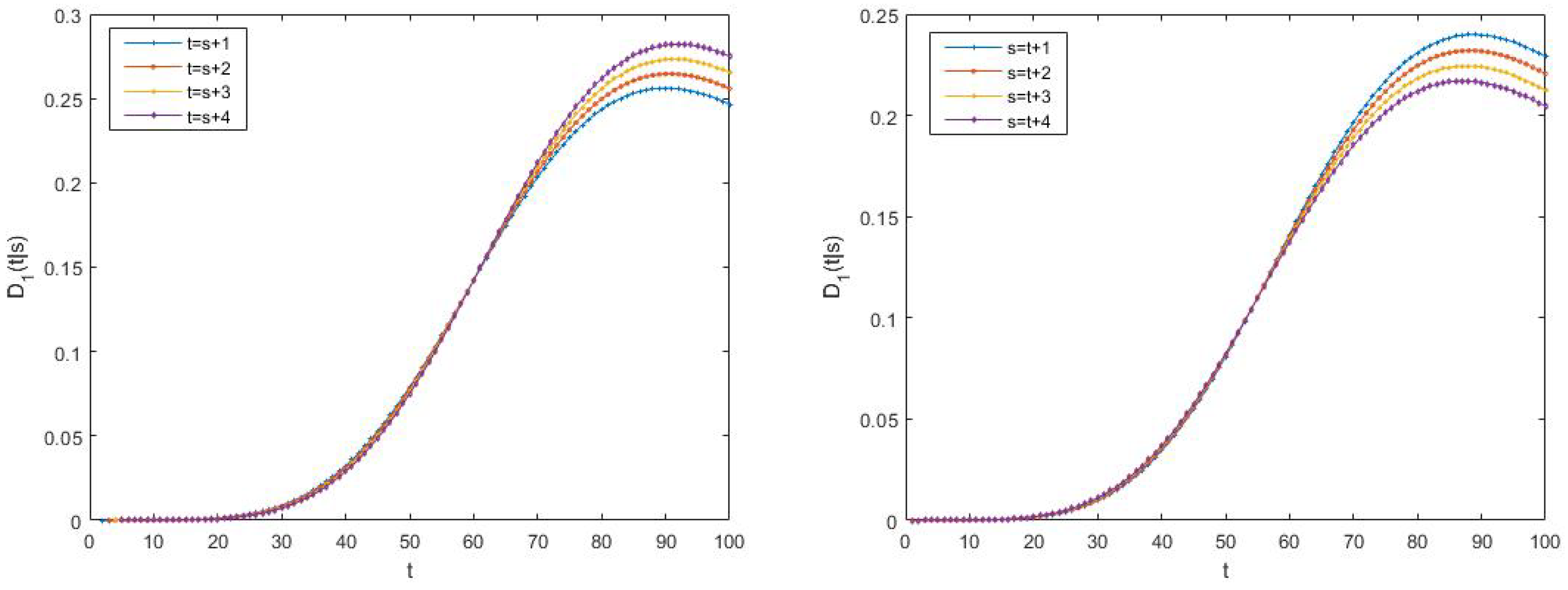
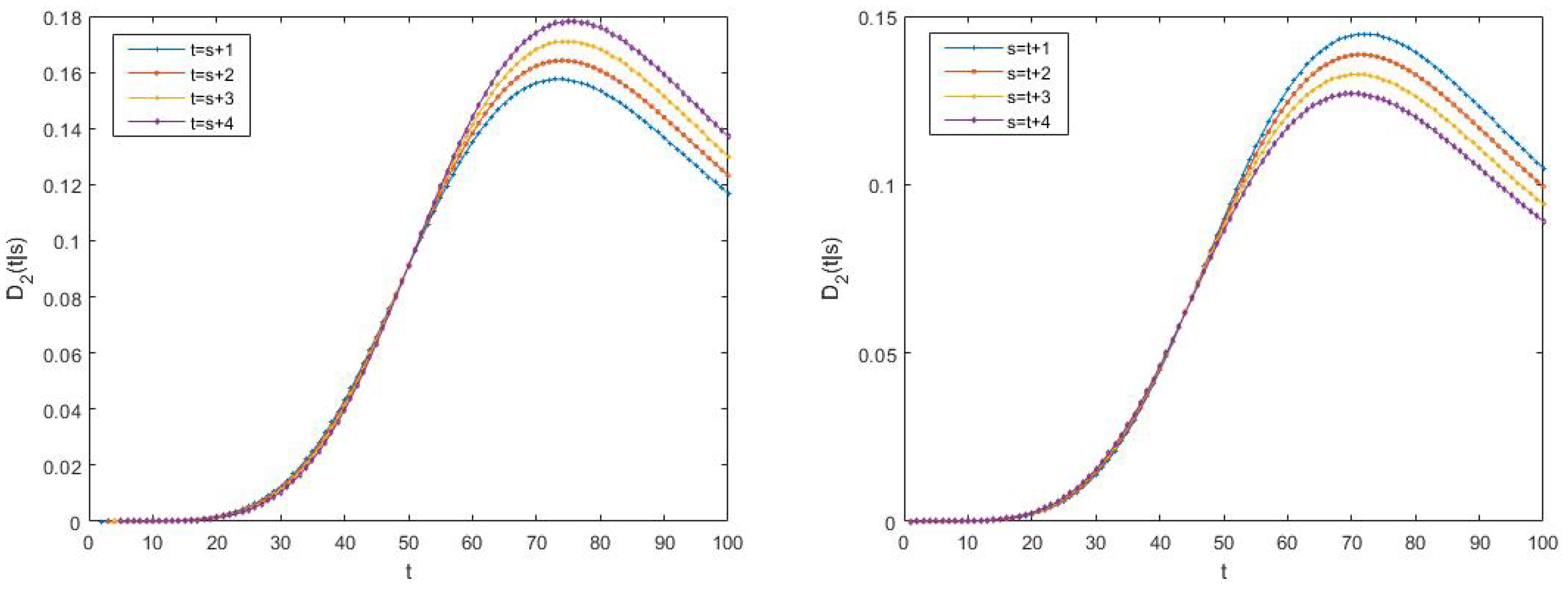
- Better performance of the centralized estimators over the distributed ones. Effectively, in Case 1, it can be observed that the mean of the centralized and distributed filtering error variances, and , takes the values and , respectively, which indicate a better performance of the centralized filters over the distributed ones. The same conclusion can be deduced when comparing the means of the prediction and smoothing error variances at the same stage . As an example, observe that the mean of the centralized and distributed prediction error variances for , denoted by and , respectively, take the values and , and the one corresponding to the mean of the centralized and distributed smoothing error variances at stage are given by , and . Similar considerations can be made for all the cases.
- Better performance of the smoothing estimators over the filtering ones and both, in turn, over the prediction ones. Effectively, in Case 1, the following relation is true: . Similar conclusions are obtained in all the cases and for any .
- Worse performance of the prediction estimators as the stage τ increases (the opposite consideration for the smoothing estimators). As an example, in Case 1, it is observed that (for the prediction errors) and (for the smoothing errors). Similar considerations can be made for all the cases.
- In the delay situation: For Cases 1 and 2, it can be observed that the estimations obtained in Case 2 outperform the ones obtained in Case 1, due to the fact that in this case, the probability that the measurements are updated is greater than that of Case 1.
- In the situation of missing measurements: For Cases 3 and 4, the probability that the measurements contain only noise is smaller in Case 4 than in Case 3; hence, better estimations are obtained.
- In the situation of mixed uncertainties: For Cases 5 and 6, better estimations are obtained in Case 6 versus Case 5 since there is a greater probability that the measurements are updated or delayed and a lower probability that they contain only noise.
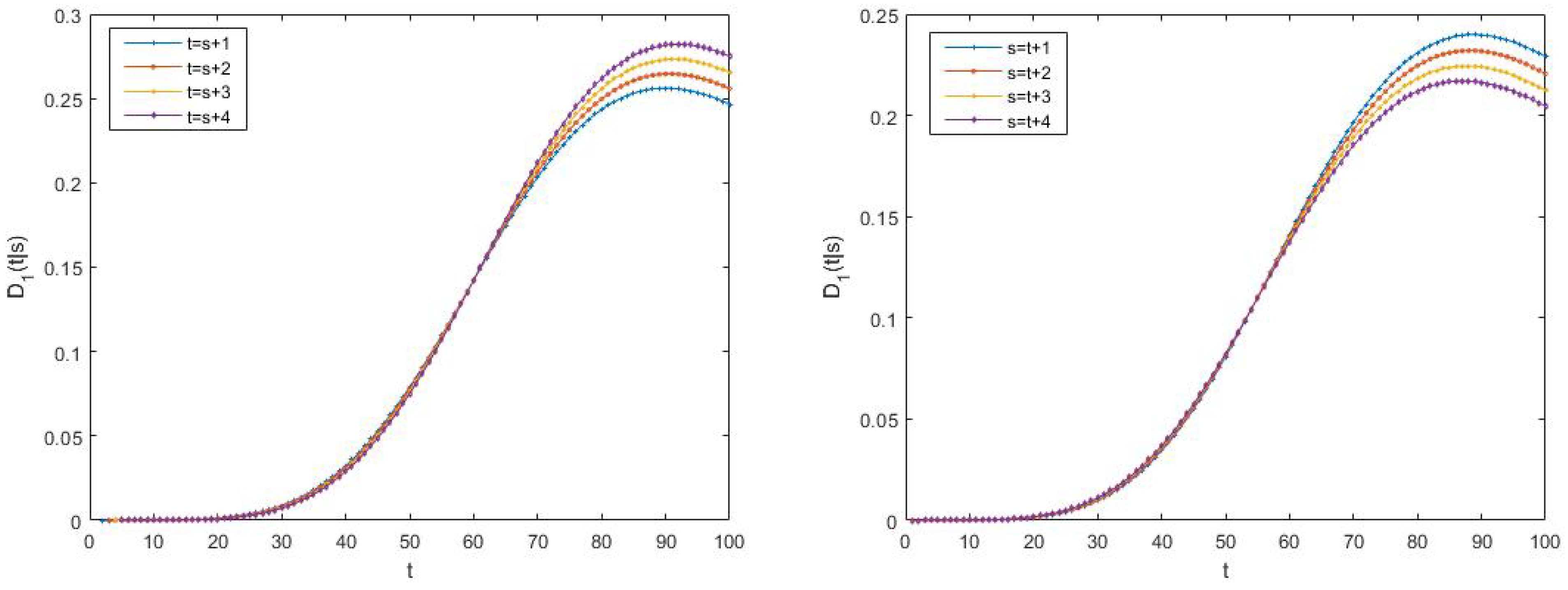
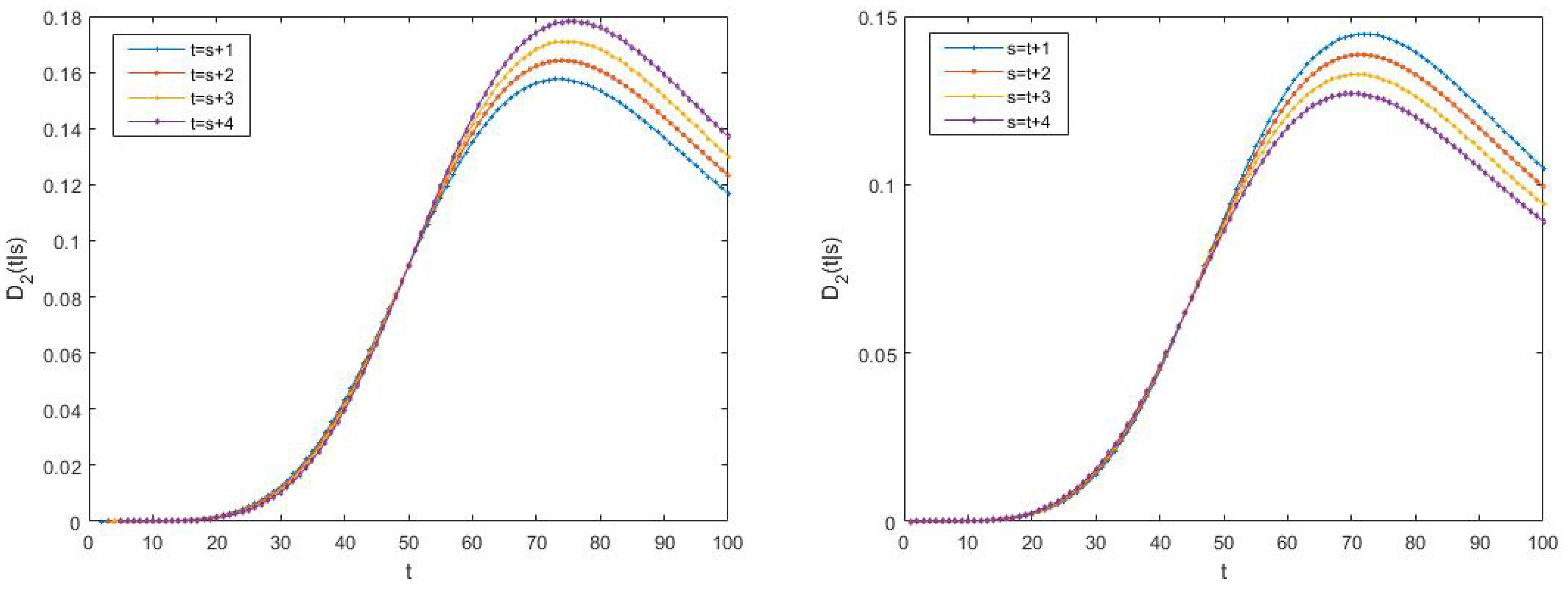
6.2. Example 2
- -
- -proper scenario: , , and , for all , and
- -
- -proper scenario: and , and , and , and and .
- -
- -proper scenario: .
- -
- -proper scenario: .
7. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Proof of Theorem 2
Appendix B. Proof of Theorem 3
Appendix C. Proof of Theorem 5
Appendix D. Proof of Theorem 6
References
- Kurkin, A.A.; Tyugin, D.Y.; Kuzin, V.D.; Chernov, A.G.; Makarov, V.S.; Beresnev, P.O.; Filatov, V.I.; Zeziulin, D.V. Autonomous mobile robotic system for environment monitoring in a coastal zone. Procedia Comput. Sci. 2017, 103, 459–465. [Google Scholar] [CrossRef]
- Hsu, Y.-L.; Chou, P.-H.; Chang, H.-C.; Lin, S.-L.; Yang, S.-C.; Su, H.-Y.; Chang, C.-C.; Cheng, Y.-S.; Kuo, Y.-C. Design and Implementation of a Smart Home System Using Multisensor Data Fusion Technology. Sensors 2017, 17, 1631. [Google Scholar] [CrossRef]
- Gao, B.; Hu, G.; Gao, S.; Zhong, Y.; Gu, C.; Beresnev, P.O.; Filatov, V.I.; Zeziulin, D.V. Multi-sensor optimal data fusion for INS/GNSS/CNS integration based on unscented Kalman filter. Int. J. Control Autom. Syst. 2018, 16, 129–140. [Google Scholar] [CrossRef]
- Huang, S.; Chou, P.; Jin, X.; Zhang, Y.; Jiang, Q.; Yao, S. Multi-Sensor image fusion using optimized support vector machine and multiscale weighted principal component analysis. Electronics 2020, 9, 1531. [Google Scholar] [CrossRef]
- Gao, B.; Hu, G.; Zhong, Y.; Zhu, X. Cubature rule-based distributed optimal fusion with identification and prediction of kinematic model error for integrated UAV navigation. Aerosp. Sci. Technol. 2021, 109, 1106447. [Google Scholar] [CrossRef]
- Yukun, C.; Xicai, S.; Zhigang, L. Research on Kalman-filter based multisensor data fusion. J. Syst. Eng. Electron. 2007, 18, 497–502. [Google Scholar] [CrossRef]
- Ding, F. Combined state and least squares parameter estimation algorithms for dynamic systems. Appl. Math. Model. 2014, 38, 403. [Google Scholar] [CrossRef]
- Shenglun, Y.; Mattia, Z. Robust Kalman Filtering under Model Uncertainty: The Case of Degenerate Densities. IEEE Trans. Automat. Contr. 2021. [Google Scholar] [CrossRef]
- Ma, J.; Sun, S. Centralized fusion estimators for multisensor systems with random sensor delays, multiple packet dropouts and uncertain observations. IEEE Sens. J. 2013, 13, 1228–1235. [Google Scholar] [CrossRef]
- Chen, D.; Xu, L. Optimal filtering with finite-step autocorrelated process noises, random one-step sensor delay and missing measurements. Commun. Nonlinear Sci. Numer. Simul. 2016, 32, 211–224. [Google Scholar] [CrossRef]
- Liu, W.-Q.; Wang, X.-M.; Deng, Z.-L. Robust centralized and weighted measurement fusion Kalman estimators for uncertain multisensor systems with linearly correlated white noises. Inf. Fusion 2017, 35, 11–25. [Google Scholar] [CrossRef]
- Lin, H.; Sun, S. Distributed fusion estimator for multi-sensor asynchronous sampling systems with missing measurements. IET Signal Process. 2016, 10, 724–731. [Google Scholar] [CrossRef]
- Tian, T.; Sun, S.; Li, N. Multi-sensor information fusion estimators for stochastic uncertain systems with correlated noises. Inf. Fusion 2016, 27, 126–137. [Google Scholar] [CrossRef]
- Xing, Z.; Xia, Y.; Yan, L.; Lu, K.; Gong, Q. Multisensor distributed weighted Kalman filter fusion with network delays, stochastic uncertainties, autocorrelated, and cross-correlated noises. IEEE Trans. Syst. Man Cyber. Syst. 2018, 48, 716–726. [Google Scholar] [CrossRef]
- Zhang, J.; Gao, S.; Li, G.; Xia, J.; Qi, X.; Gao, B. Distributed recursive filtering for multi-sensor networked systems with multi-step sensor delays, missing measurements and correlated noise. Signal Process. 2021, 181, 107868. [Google Scholar] [CrossRef]
- Yuan, X.; Yu, S.; Zhang, S.; Wang, G.; Liu, S. Quaternion-Based Unscented Kalman Filter for Accurate Indoor Heading Estimation Using Wearable Multi-Sensor System. Sensors 2015, 15, 10872–10890. [Google Scholar] [CrossRef]
- Talebi, S.; Kanna, S.; Mandic, D. A distributed quaternion Kalman filter with applications to smart grid and target tracking. IEEE Trans. Signal Inf. Process. Netw. 2016, 2, 477–488. [Google Scholar]
- Tannous, H.; Istrate, D.; Benlarbi-Delai, A.; Sarrazin, J.; Gamet, D.; Ho Ba Tho, M.C.; Dao, T.T. A new multi-sensor fusion scheme to improve the accuracy of knee flexion kinematics for functional rehabilitation movements. J. Sens. 2016, 16, 1914. [Google Scholar] [CrossRef] [Green Version]
- Navarro-Moreno, J.; Fernández-Alcalá, R.M.; Jiménez López, J.D.; Ruiz-Molina, J.C. Widely linear estimation for multisensor quaternion systems with mixed uncertainties in the observations. J. Frankl. Inst. 2019, 356, 3115–3138. [Google Scholar] [CrossRef]
- Wu, J.; Zhou, Z.; Fourati, H.; Li, R.; Liu, M. Generalized linear quaternion complementary filter for attitude estimation from multi-sensor observations: An optimization approach. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1330–1343. [Google Scholar] [CrossRef]
- Talebi, S.P.; Werner, S.; Mandic, D.P. Quaternion-valued distributed filtering and control. IEEE Trans. Autom. Control. 2020, 65, 4246–4256. [Google Scholar] [CrossRef]
- Fernández-Alcalá, R.M.; Navarro-Moreno, J.; Ruiz-Molina, J.C. T-proper hypercomplex centralized fusion estimation for randomly multiple sensor delays systems with correlated noises. Sensors 2021, 21, 5729. [Google Scholar] [CrossRef]
- Jiménez-López, J.D.; Fernández-Alcalá, R.M.; Navarro-Moreno, J.; Ruiz-Molina, J.C. The distributed and centralized fusion filtering problems of tessarine signals from multi-sensor randomly delayed and missing observations under Tk-properness conditions. Mathematics 2021, 9, 2961. [Google Scholar] [CrossRef]
- Zanetti de Castro, F.; Eduardo Valle, M. A broad class of discrete-time hypercomplex-valued Hopfield neural networks. Neural Netw. 2020, 122, 54–67. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alfsmann, D. On families of 2N-dimensional hypercomplex algebras suitable for digital signal processing. In Proceedings of the 14th European Signal Processing Conference, 14th European Signal Processing Conference (EUSIPCO 2006), Florence, Italy, 4–8 September 2006; pp. 1–4. [Google Scholar]
- Alfsmann, D.; Göckler, H.G.; Sangwine, S.J.; Ell, T.A. Hypercomplex algebras in digital signal processing: Benefits and drawbacks. In Proceedings of the 15th European Signal Processing Conference, Poznan, Poland, 3–7 September 2007; pp. 1322–1326. [Google Scholar]
- Hahn, S.L.; Snopek, K.M. Complex and Hypercomplex Analytic Signals: Theory and Applications; Artech House: Norwood, MA, USA, 2016. [Google Scholar]
- Catoni, F.; Boccaletti, D.; Cannata, R.; Catoni, V.; Nichelatti, E.; Zampetti, P. The Mathematics of Minkowski Space-Time: With an Introduction to Commutative Hypercomplex Numbers; Birkhaüser Verlag: Basel, Switzerland, 2008. [Google Scholar]
- Navarro-Moreno, J.; Ruiz-Molina, J.C. Wide-sense Markov signals on the tessarine domain. A study under properness conditions. Signal Process. 2021, 183, 108022. [Google Scholar] [CrossRef]
- Nitta, T.; Kobayashi, M.; Mandic, D.P. Hypercomplex widely linear estimation through the lens of underpinning geometry. IEEE Trans. Signal Process. 2019, 67, 3985–3994. [Google Scholar] [CrossRef]
- Grassucci, E.; Comminiello, D.; Uncini, A. An information-theoretic perspective on proper quaternion variational autoencoders. Entropy 2021, 23, 856. [Google Scholar] [CrossRef]
- Navarro-Moreno, J.; Fernández-Alcalá, R.M.; Jiménez-López, J.D.; Ruiz-Molina, J.C. Tessarine signal processing under the T-properness condition. J. Frankl. Inst. 2020, 357, 10100. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fusion Method | Filtering | Prediction | Smoothing |
|---|---|---|---|
| Centralized | |||
| Distributed |
| Cases | Filtering | Prediction: | Smoothing: | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 6.9234 7.6676 | 9.6168 10.3765 | 12.4458 13.1431 | 15.0486 15.6886 | 17.4433 18.0306 | 5.3697 5.9197 | 4.7648 5.1388 | 4.5051 4.7790 | 4.3921 4.6328 |
| 2 | 4.5390 5.5281 | 6.7719 7.8469 | 9.8292 10.8171 | 12.6421 13.5498 | 15.2299 16.0640 | 3.7946 4.5354 | 3.5424 4.1401 | 3.4435 3.9973 | 3.4212 3.9622 |
| 3 | 16.2548 16.5213 | 18.2474 18.5119 | 20.3810 20.6221 | 22.3444 22.5641 | 24.1511 24.3512 | 14.9311 15.1552 | 13.9736 14.1378 | 13.2796 13.3827 | 12.7753 12.8245 |
| 4 | 5.7176 6.4844 | 7.9889 8.8057 | 10.9485 11.7014 | 13.6715 14.3629 | 16.1767 16.8116 | 4.8191 5.4013 | 4.4473 4.8981 | 4.2898 4.6787 | 4.2218 4.5968 |
| 5 | 20.5823 20.9046 | 22.4152 22.7121 | 24.2120 24.4833 | 25.8656 26.1134 | 27.3876 27.6139 | 19.1857 19.5125 | 18.1108 18.4190 | 17.2780 17.5536 | 16.6324 16.8704 |
| 6 | 8.9821 9.5247 | 11.5869 12.0809 | 14.2575 14.7101 | 16.7147 17.1292 | 18.9754 19.3550 | 7.3064 7.7961 | 6.4887 6.8709 | 6.0641 6.3559 | 5.8423 6.0840 |
| Cases | Filtering | Prediction: | Smoothing: | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 6.0702 6.6500 | 8.3156 8.9052 | 10.6490 11.1900 | 12.7959 13.2922 | 14.7711 15.2263 | 4.7329 5.1555 | 4.1974 4.4732 | 3.9544 4.1470 | 3.8409 4.0052 |
| 2 | 3.8564 4.6005 | 5.6914 6.5058 | 8.2355 8.9830 | 10.5761 11.2629 | 12.7295 13.3605 | 3.2399 3.7966 | 3.0210 3.4710 | 2.9380 3.3482 | 2.9049 3.3127 |
| 3 | 14.9522 15.3920 | 16.5263 16.9481 | 18.1980 18.5837 | 19.7363 20.0890 | 21.1520 21.4744 | 13.8800 14.3013 | 13.0793 13.4627 | 12.4797 12.8189 | 12.0298 12.3261 |
| 4 | 5.1916 5.9890 | 7.0810 7.9173 | 9.5134 10.2815 | 11.7514 12.4568 | 13.8103 14.4581 | 4.3965 5.0333 | 4.0439 4.5557 | 3.8817 4.3248 | 3.8049 4.2216 |
| 5 | 18.7493 19.4711 | 20.1627 20.8326 | 21.5402 22.1542 | 22.8080 23.3709 | 23.9750 24.4909 | 17.6607 18.4132 | 16.8025 17.5593 | 16.1205 16.8643 | 15.5780 16.2995 |
| 6 | 7.1621 7.9999 | 9.3053 10.1092 | 11.5591 12.2969 | 13.6328 14.3097 | 15.5406 16.1617 | 5.8434 6.5764 | 5.2147 5.8134 | 4.8912 5.3839 | 4.7212 5.1533 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fernández-Alcalá, R.M.; Jiménez-López, J.D.; Navarro-Moreno, J.; Ruiz-Molina, J.C. Multisensor Fusion Estimation for Systems with Uncertain Measurements, Based on Reduced Dimension Hypercomplex Techniques. Mathematics 2022, 10, 2495. https://doi.org/10.3390/math10142495
Fernández-Alcalá RM, Jiménez-López JD, Navarro-Moreno J, Ruiz-Molina JC. Multisensor Fusion Estimation for Systems with Uncertain Measurements, Based on Reduced Dimension Hypercomplex Techniques. Mathematics. 2022; 10(14):2495. https://doi.org/10.3390/math10142495
Chicago/Turabian StyleFernández-Alcalá, Rosa M., José D. Jiménez-López, Jesús Navarro-Moreno, and Juan C. Ruiz-Molina. 2022. "Multisensor Fusion Estimation for Systems with Uncertain Measurements, Based on Reduced Dimension Hypercomplex Techniques" Mathematics 10, no. 14: 2495. https://doi.org/10.3390/math10142495
APA StyleFernández-Alcalá, R. M., Jiménez-López, J. D., Navarro-Moreno, J., & Ruiz-Molina, J. C. (2022). Multisensor Fusion Estimation for Systems with Uncertain Measurements, Based on Reduced Dimension Hypercomplex Techniques. Mathematics, 10(14), 2495. https://doi.org/10.3390/math10142495