1. Introduction
With the vigorous development of E-commerce and the continuous expansion of Internet users, Taobao, Amazon and other online shopping platforms continue to provide a large number of products and services to meet the potential diversified needs, which will bring the problem of “information overload”. How to find appropriate services and effective information has become a difficult problem in front of us. As a way to solve the “information overload” of the Internet, recommendation systems can directly connect users and items, better promote products and reduce the burden of users. Recommendation systems, due to their multi-domain applicability, are among the main topics of scientific interest in recent years [
1,
2].
As a new business model, community E-commerce focuses on serving relatively stable local consumer groups [
3]. It is also faced with endless choices and decisions when shopping online. Community E-commerce is mainly divided into two categories, one refers to the E-commerce that provides the living needs of the regional groups within a certain area, mainly in the way of combining online and offline commerce. The degree of overlap between the activity range and trajectory of the user group is higher than that of traditional E-commerce. The other type is the group of users with the same hobbies, with similar needs forming a community circle, and their hobbies overlap more than ordinary E-commerce. In daily life, consumers are more willing to trust the recommendations of friends or influential people, rather than a lack of unconvincing advertisements. Trust, as the core concept of interpersonal relationships, will directly affect the user’s decision-making process [
4]. Compared with traditional E-commerce users, community E-commerce has more communication and mutual trust, which makes it easier to tap the trust relationship between users. Therefore, there is an urgent need to develop a trust-based recommender system for communities E-commerce platforms establishing trust relationships based on users’ purchase history is an important dimension of recommender systems to predict items that users may purchase in the near future [
5].
Personalized recommendation is generally divided into content-based [
6], collaborative filtering recommendation [
7] and the increasingly popular social network-based recommendation [
8,
9]; however, there are some problems, such as cold start, data sparsity, recommendation accuracy and so on. With the development of social networks, the trust relationship between users is used in recommendation systems. Trust-based recommendation systems are widely studied and have become an extension of traditional recommendations. Many scholars have added social networks or user trust relationships on the basis of traditional algorithms to improve the accuracy of recommendations [
10,
11,
12].
Existing studies have proven that trust between users can improve the accuracy of recommendation, but the existing trust information is very sparse, and there is a lack of research on the implicit trust relationship between users. For the above problems, this paper proposes a novel recommendation approach called Implicit Trust-Probabilistic Matrix Factorization (IT-PMF) for community E-commerce based on implicit trust relationships and in-group membership. The main contributions of this paper are as follows:
The study generates a user commodity rating matrix based on cumulative purchases for items according to their historical purchase records.
The study mines users’ local implicit trust information through the users’ similarities and the interactions between users, and the users are soft clustered to calculate the degree of membership to a user category. The local implicit trust relationship and the user’s in-group membership were adjusted by the adaptive weight to determine the degree of each part’s influence.
The study integrates rating trust and trust information into the probability matrix factorization model, so that the final result is not only affected by its own rating value but also by the recommendations of neighboring users.
The experiment was carried out on a real community E-commerce data set, and the constructed rating matrix performed well on the traditional PMF algorithm. At the same time, the influence of parameters on the experimental results was evaluated, and the results showed the efficiency of the algorithm.
The rest of the paper is organized as follows.
Section 2 summarizes the related work.
Section 3 proposes the community E-commerce recommendation algorithm based on trust, including implicit trust relationship and in-group membership.
Section 4 presents experimental results and analysis.
Section 5 concludes the paper.
2. Literature Review
2.1. Traditional Recommendation Algorithms
The rapid development of information technology and the Internet has facilitated the explosive growth of information, which has exacerbated the problem of information overload. In response to this problem, recommender systems emerge as the times require that systems help users find the content they are interested in. Traditional recommendation algorithms are mainly divided into content-based recommendation algorithms, collaborative filtering recommendation algorithms and hybrid recommendation algorithms. The content-based recommendation algorithm is the earliest recommendation algorithm used. Its idea is relatively simple. It labels users and products and recommends items that are highly similar to historically favorite items to users. The user-based collaborative filtering algorithm was originally proposed by the Groupslens research group [
7], followed by a commodity-based collaborative filtering algorithm [
13] and a matrix-factorization-based collaborative filtering algorithm [
14]. Hybrid recommendation algorithms can overcome the limitations brought by a single recommendation algorithm and combine different algorithms to obtain better recommendation results.
However, with the continuous development of information technology and the advent of the intelligent era, the data of users and commodities are growing rapidly, resulting in typical problems such as sparsity, cold start and long tail. In order to solve the above problems, two commonly used methods are as follows: (1) matrix factorization technology: the rating matrix is decomposed in order to predict the user’s non rated items. The most classic examples are singular-value decomposition technology [
15], and the Matrix Factorization method (MF). The MF method is mainly divided into basic Matrix Factorization (basic MF), regularization matrix factorization, Probabilistic Matrix Factorization (PMF), Non-negative Matrix Factorization (NMF), orthogonal nonnegative matrix factorization and so on. (2) Data filling method: other useful information is used to supplement data sparsity and cold start user information, so as to alleviate sparsity. With the gradual rise of social media and social networks, integrating trust into recommendation algorithms can effectively solve common problems such as data sparsity and user cold start.
In order to effectively alleviate the problems of data sparsity and cold starts, the data sparsity is reduced by introducing context information [
16,
17,
18], clustering [
19,
20,
21,
22] and other methods, and the user’s own needs are considered to make the algorithm more efficient. Accuracy is greatly improved. The main difference between a social recommendation and a traditional recommendation algorithm is that the former mines users’ social relations, establishes trust relations between users and establishes social relationship network. With the gradual entry of social media into public life, the social network and trust relationship data between users has also become one of the data sources to fill the sparsity of the matrix.
2.2. Recommendation Algorithm Based on Social Network and Trust
With the continuous enrichment of social network information, scholars at home and abroad have opened up new ideas based on trust relationships in social networks and mining trust relationships. For example, the EigenTrust model is a peer-to-peer network reputation management algorithm proposed by Kamvar et al. [
8]. The topic model and Markov model integrate user preferences and location information into the model, which greatly improves the prediction accuracy. TidalTrust was proposed by Golbeck et al. [
9]. They integrated trust into the social network, and the algorithm refers to the source node when predicting the score. All trusted neighbors rate the items and analyze how the trust level and the length of the trust chain affect the trust agreement between other nodes. Scholars such as Wang et al. [
23] proposed a semantic-based social network recommendation system. The idea is to use sensor data from mobile phone users to mine potential friends who are similar to the target user through contextual information, so that the recommendation results more accurately reflect user preferences, as online comments will have an impact on consumers’ purchase behavior. Gong et al. [
24] explored the potential of using explicit and implicit information to mine the potential information of the meta-path in recommendation. Ma et al. [
25] proposed a recommendation model that comprehensively considers local information and global information. Li et al. [
26] proposed a novel RHRM recommendation framework that filters only helpful reviews and reflects them in the personalized recommendation service. Wang et al. [
27] explored the credibility of online reviews and verified that deceptive reviews can affect consumers’ purchasing decisions. Zhang et al. [
28] proposed the ImDetector method for the imbalance in comment data, which has advantages in detecting fraudulent reviewers.
In the social network environment, the research on recommendation algorithms has also achieved certain breakthrough results, and good progress has been made in the recommendation that integrates trust into the matrix factorization model. For example, Jamali m et al. [
11] proposed a social network recommendation algorithm SocialMF based on matrix factorization technology, which connects users’ social relations with recommendation and solves the problem of users’ cold start. Qiu j et al. significantly improved DeepWalk and Line, proposed NetMF and laid a theoretical foundation for the network embedding method based on skip-gram [
29]. PMF [
30] was first proposed by the University of Toronto, Canada, and was gradually applied in recommendation. It solved the problems of data sparsity and prediction accuracy by using user social network information and user rating records. Chen Ting et al. [
4] integrated global trust and local trust to calculate the user’s trust weight value, added the influence of trust weight to the PMF algorithm and proposed the Trust-PMF algorithm. Xu et al. [
31] incorporated the social trust relationship of users in social networks into the loss function to improve recommendation accuracy.
In a word, in the recommendation algorithms for the integration of trust, most of the research [
4,
9,
32,
33] aims to further dig into the basis of the explicit trust relationship, but there is a lack of research on the implicit trust relationship between users. Often, the unmined implicit trust relationships that users have contain richer information, and the existing trust-based recommendation algorithms cannot be used for datasets without obvious social relationships. Therefore, considering the above problems, this paper proposes an IT-PMF recommendation algorithm on a dataset without explicit social relations. Preferences, purchasing habits and category affiliation affect the strength of trust among users, and trust is incorporated into the probability matrix factorization recommendation algorithm. Experiments show that the algorithm can significantly improve the accuracy of recommendation on community E-commerce data sets without obvious trust relationship.
3. Relevant Work
3.1. Trust Calculation
In order to improve the sparsity of data sets, scholars have made constant efforts to introduce user information in addition to ratings, such as user location, user context and trust relations, aiming at more accurate recommendations. As a complicated social network relation, trust is distinct, fuzzy, transferable, non-symmetrical, combinable and dynamic in nature. The trust relations between users are primarily backed by user social networks. Two forms of social trust relations are commonly found: the trust type and friend type. The main differences between them are described below:
- (1)
A trust relation is unidirectional, whereas a friend relation is bidirectional.
- (2)
Construction of a trust relation is based on certain similar taste, whereas such similarity may or may not exist in a friend relation.
With the continuous enrichment of social network relationships, trust relationships are also divided into local trust and global trust. Global trust mainly refers to the degree of influence and prestige of users in the entire social network, while local trust is related to the target user. Influencing factors between groups of users have direct interaction. The recommendation algorithms incorporating trust relations enjoy the following advantages over traditional recommendation algorithms. First, the recommendation accuracy is greatly improved. Compared with algorithms based merely on user ratings, the algorithms using trust relations are able to identify user preferences more precisely. Second, the issue of user cold starts can be effectively addressed. Third, the inclusion of user social trust relations leads to more convincing recommendation results. Therefore, with the booming community E-commerce nowadays, trust relations are becoming a more and more influential factor. However, the use of explicit trust relationships is often greatly restricted due to the user’s personal privacy and difficulty in obtaining them, and certain behaviors and preferences of users often contain rich potential trust relationships. Therefore, potential implicit trust relationships begin to appear to fill the gap of explicit trust.
3.2. PMF Algorithm
PMF (probabilistic matrix factorization) is a collaborative filtering recommendation algorithm based on matrix decomposition. It is superior to previously proposed recommendation algorithms when used for traditional rating data. It proves highly effective for Netflix with massive and sparse data. Its underlying concept is that a relation between users and films (i.e., users’ film preferences) can be determined by combining a limited number of factors linearly.
Assume that we have M films, N users, and integer rating values from 1 to
. Let
represents the rating of user
for movie
j. U and V are used to denote a user matrix and a film matrix, respectively, and the column vectors
and
represent user-specific and movie-specific latent feature vectors, respectively. The predictive rating is defined in Equation (1):
where
is a probability density function of the Gaussian distribution with mean
and variance
, and
is an index function (if User
has given a rating of Film
,
, otherwise it is equal to 0). The potential eigenvectors of users and films are defined in Equation (2):
The logarithmic posterior distribution function of users and films is shown in Equation (3):
where
C is a constant independent of any variable. Maximizing the above formula is equivalent to minimizing Equation (4):
3.3. Trust-PMF Recommendation Algorithm Based on Trust Network
On the basis of the PMF algorithm, Chen Ting [
4] brought forward a recommendation algorithm based on trust in social network environments, namely, the Trust-PMF recommendation algorithm. It combines known user trust relations with user similarity data. With both global trust and local trust taken into consideration, the trust weight of users can be derived with trust propagation mechanism. Through the incorporation of the collaborative filtering technique into the matrix factorization process and the use of segmented adaptive weight computing, more accurate recommendation results can be obtained. The basic computational formula is shown in Equation (5):
It is assumed that potential user eigenvectors and potential commodity eigenvectors both follow Gaussian prior distribution with an average of 0, as shown in Equation (6):
After extending the PMF model, deriving the posterior probability with Bayes’ theorem, and calculating the logarithm, the Equation (7) can be achieved:
where
Con is a constant that does not depend on the parameters. Maximizing the logarithmic function in the formula is equivalent to minimizing the loss function. The loss function is shown in Equation (8):
where
and
.
4. Community E-Commerce Recommendation Algorithm Based on Trust
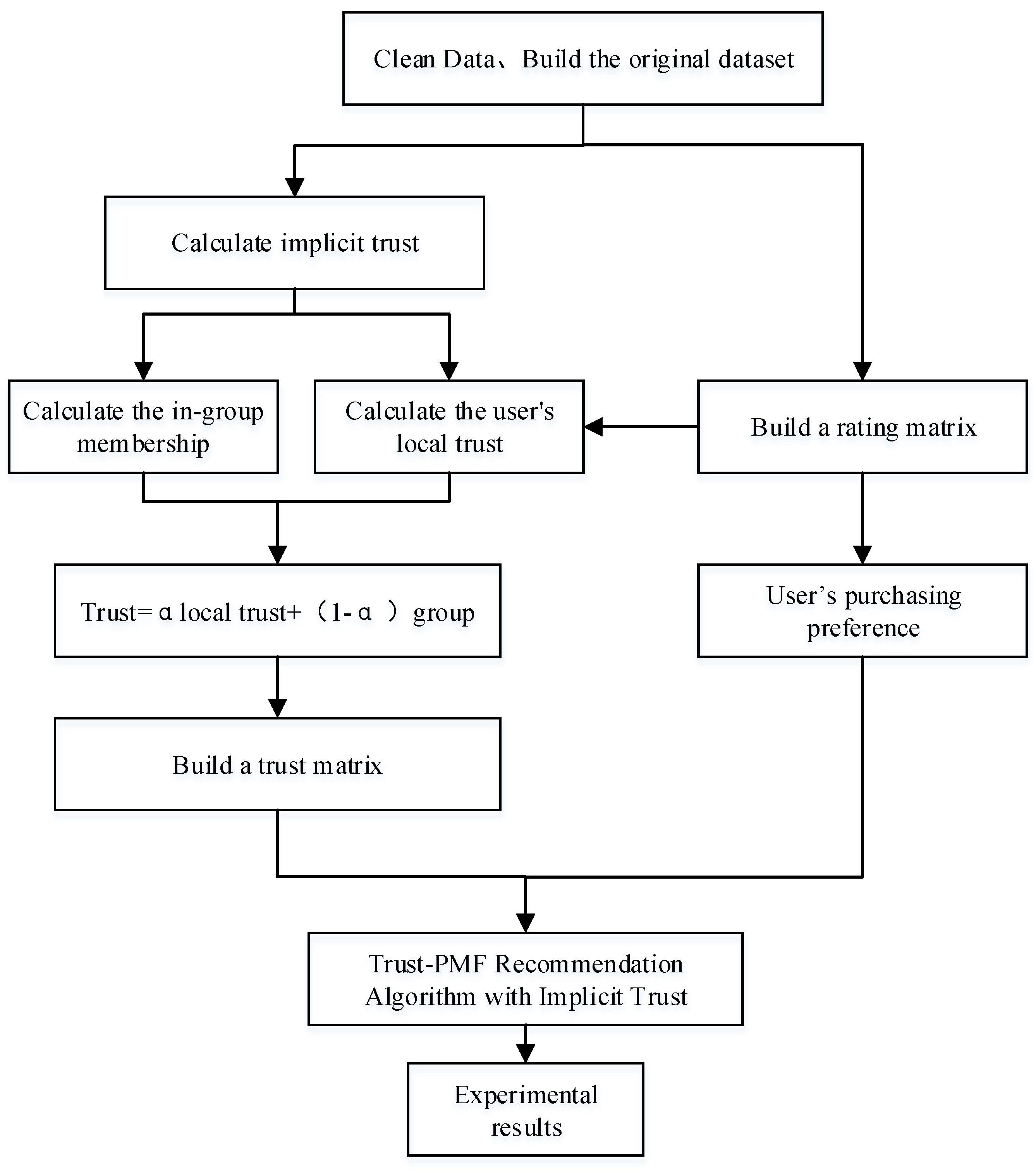
This study’s proposed IT-PMF method consists of local implicit trust relationships and in-group membership. It should be noted that, in general, data sets contain scoring information, while for data sets without scoring information, we proposed the use of the number of cumulative purchases of goods by users as the users’ ratings of goods. The local implicit trust relationship was calculated based on the similarity of purchase behaviors and the number of successful interactions between users. The user group attribute value was calculated through the fuzzy c-means clustering algorithm to obtain the user’s in-group membership. The local implicit trust relationship and the user’s in-group membership were adjusted by the adaptive weight to determine the degree of each part’s influence. To form recommendation weight based on trust and to use neighbor interaction to make up for the inaccurate prediction score caused by data sparseness, the trust information and rating information are integrated into the probability matrix factorization model, so that the user’s rating of the item not only depends on the interaction of the potential factor vectors between the user and the item but is also affected by the score of the neighbor set. The algorithm flow is shown in
Figure 1.
Table 1 is the main symbols used in the formulas in this paper and detailed description.
4.1. Implicit Trust Modeling
4.1.1. Local Implicit Trust Modeling
Two types of trust should be distinguished from each other: local trust and global trust. Local trust mainly refers to the trust between two individual users, while global trust generally indicates the dependability of a user throughout a social network, which is related to the qualities of the user such as creditability and capabilities.
In this paper, local trust is measured with user purchase similarity, user rating preference and successful interactions between users, as shown in Equation (9):
where
is the user purchase similarity expressed as a value of Jaccard Mean squared differences (JMSD) similarity [
34], as given in Equation (10):
where
represents the common rating collection of Users
u and
v, and max and min indicate maximum rating and minimum rating, respectively. However, since JMSD does not reflect the interaction between user rating preferences and users, Equation (11) calculations are adopted for further dependability derivation:
where
denotes the rating similarity between User
and User
.
and
represent the average and variance of the ratings of User u, respectively. It can be seen from the above formulas that a significant difference between Users u and v in terms of rating average or variance will lead to low rating similarity between them.
In real life, a user tends to put more trust in users with successful interaction with him/her, and less in those failing to interact with him/her. In order to introduce this tendency into our calculations, we first divide user ratings into two categories: positive and negative. Positive ratings are higher than average, while negative ones are lower than average. If the ratings of the same commodity given by two users fall into the same category, their interaction is deemed successful; otherwise, their interaction is deemed failed. This relation is expressed with Equation (12):
The posterior trust value between two users is expressed as the ratio of successful interactions to total interactions.
4.1.2. In-Group Membership
Social groups can be divided into in-groups and out-groups based on the users’ sense of belonging. In-groups refer to groups in which a user often participates and can be viewed by the user as “our groups”. Groups other than in-groups are regarded as out-groups, or “their groups”. The concept of the in-group was brought forward by American sociologist W. G. Sumner in 1906. With this concept, he intended to describe users’ group belonging, group awareness and influence of groups on individuals. For the degree of in-group membership, the fuzzy clustering c-Means technique is used in this paper for the purpose of clustering. Some scholars have studied cluster analysis for mixed data [
35]. The fuzzy clustering c-Means algorithm was first proposed by Dunn and then further promoted by Bezdek [
36]. Users are not classified directly into established types. The membership degree of users is calculated instead. The main calculation steps include the following: (1) Clustering users based on fuzzy c-means clustering algorithm, where the degrees of user membership in different types of groups are calculated; (2) the user in-group membership is calculated based on Cosine similarity.
- (1)
Clustering users based on fuzzy c-means clustering algorithm
Fuzzy c-means clustering algorithm is used to calculate the membership of users for each commodity category. A membership matrix between users and category can therefore be obtained, as shown in
Table 2.
The columns in the matrix refer to user types, while the rows refer to users. represents the membership degree of User in Type .
- (2)
Calculate In-group membership
Cosine similarity is used to calculate in-group membership degree between users, as shown in Equation (13):
where
and
denote membership degree of Users
and
in Type
.
4.2. Model of IT-PMF
The local trust and the membership degree of the in-group membership obtained above are linearly added through Formula (14) to obtain the user’s trust matrix:
After the user trust matrix is derived, the TOP–N neighboring users are extracted based on user trust weight. User ratings and trust information are then incorporated into the PMF model. In this way, the predictive ratings of specific commodities given by users are not only dependent on previous user rating records but are also affected by neighboring users. In addition, adaptive weight
is adopted to dynamically determine the impact of in-group membership degree and user local trust, thereby obtaining more practical calculation results. After the introduction of user trust relations, the user predictive rating can be defined in Equation (15):
where
is the user trust weight derived from trust calculation. The conditional probability distribution of users’ rating
in relation to eigenvectors
is given below in Equation (16):
5. Experimental Results and Analysis
The experiments were conducted on a computer with 1.70 GHZ Intel Core i5, 8 GB memory and the Windows 10 operation system. The proposed algorithm and other comparative algorithms were all realized in a python 3.8 programming environment. Two indices widely employed in academia were used to evaluate performance of the recommendation algorithms—Mean Absolute Error (MAE) and Root Mean Square Error (RMSE). The experiments were completed with real-life community E-commerce user purchase data.
The data set used contained 89,525 user purchase records from August 2019 to 21 September 2020 in T-APP software (hereinafter abbreviated as T-APP). The original data were subject to a cleaning process to eliminate data generated during APP test stage and data corresponding to abnormal purchase orders. By merging repeated commodity IDs, we concluded that the data set involved 3321 users, 3245 commodities and 77,258 normal purchase records. The data-cleaning process is shown in the
Figure 2 below.
The description of some commodities is given in
Table 3. Every data entry has basic attributes such as user ID, commodity ID, purchase time, purchase amount and payment method. Four attributes are mainly used in this paper: User ID, commodity ID, commodity name and purchase amount.
Since the data set consists of user purchase records, it is first necessary to generate user-commodity rating data. A rating indicates how much a user likes a commodity, while a purchase frequency can be said to reflect a user purchase preference (preferred commodities are purchased more frequently than less preferred ones). Hence, we take a user’s purchase frequency of a commodity as his/her rating of the commodity, thus building a “pseudo rating” matrix, i.e., a predictive rating data set. In order to normalize the rating range, the ratings in the data set were converted into the interval [0, 1] with the ratio . The number of neighboring users is set at three.
5.1. Impact of Parameters
In this section, the dependence () of the number of iterations and predictive ratings on user preferences is analyzed, together with the impact of the proportion () of local trust in total trust on the recommendation results of the proposed algorithm. Ten dimensions are assumed for the eigenvectors.
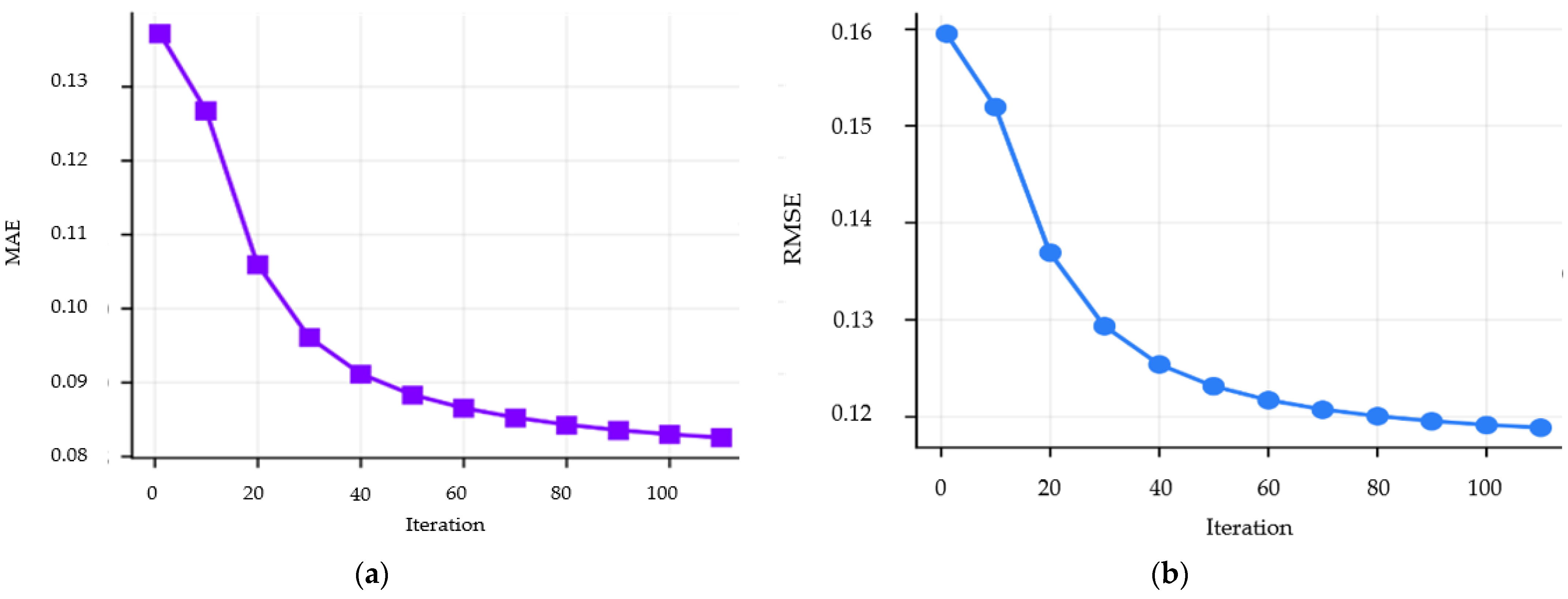
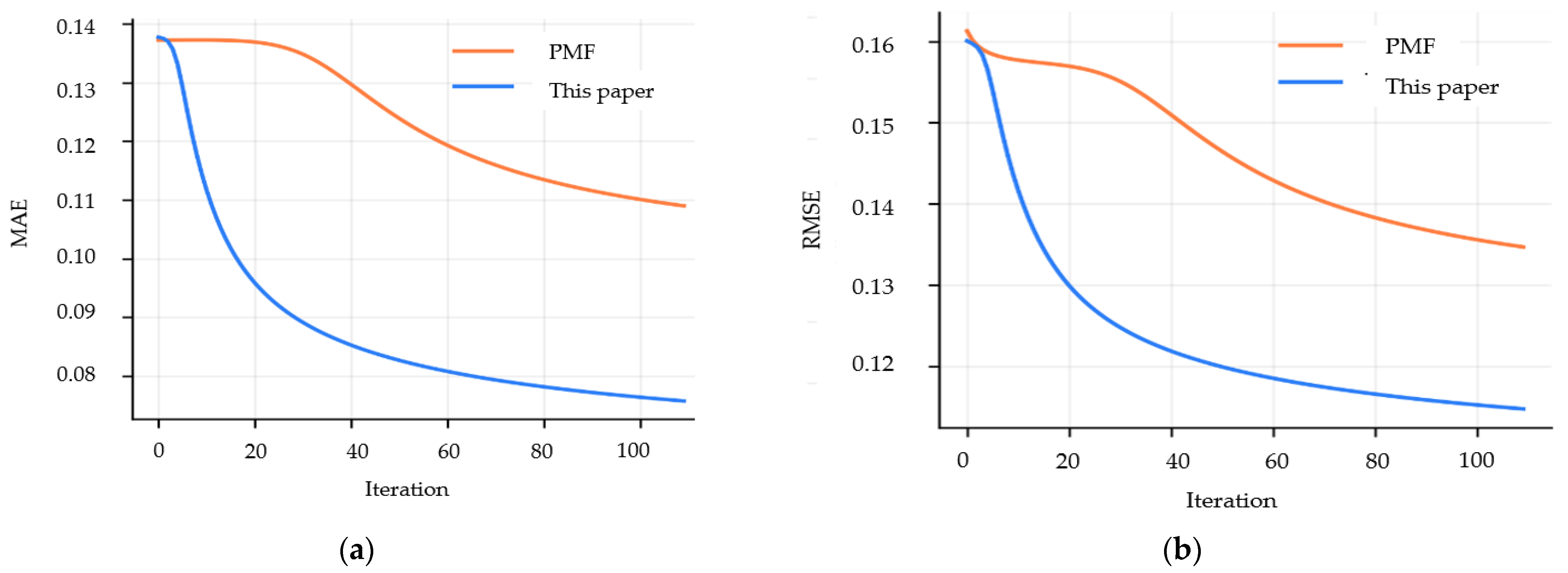
It can be seen from
Figure 3 that both MAE and RMSE vary with the number of iterations. The recommendation error first decreases with the increasing number of iterations and then gradually converges.
Figure 4a,b depict the impact of
on MAE and RMSE, respectively, and
indicates the dependence of a predictive rating on a user preference.
should be in the interval [0, 1]. In the experiments, the values in the sequence 0.1, 0.3, … are taken in turn for
. When
, both indices reach an optimal value. At this point, the dependence of the final predictive rating on preference of friends is 10%, while its dependence on the preference of the user is 90%.
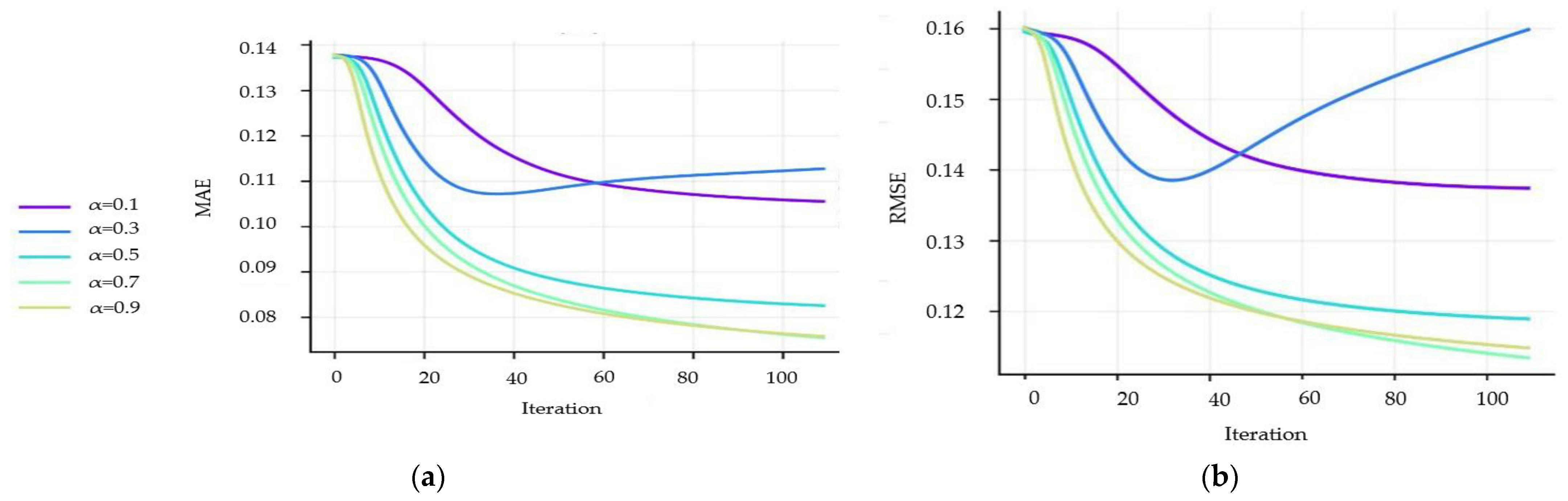
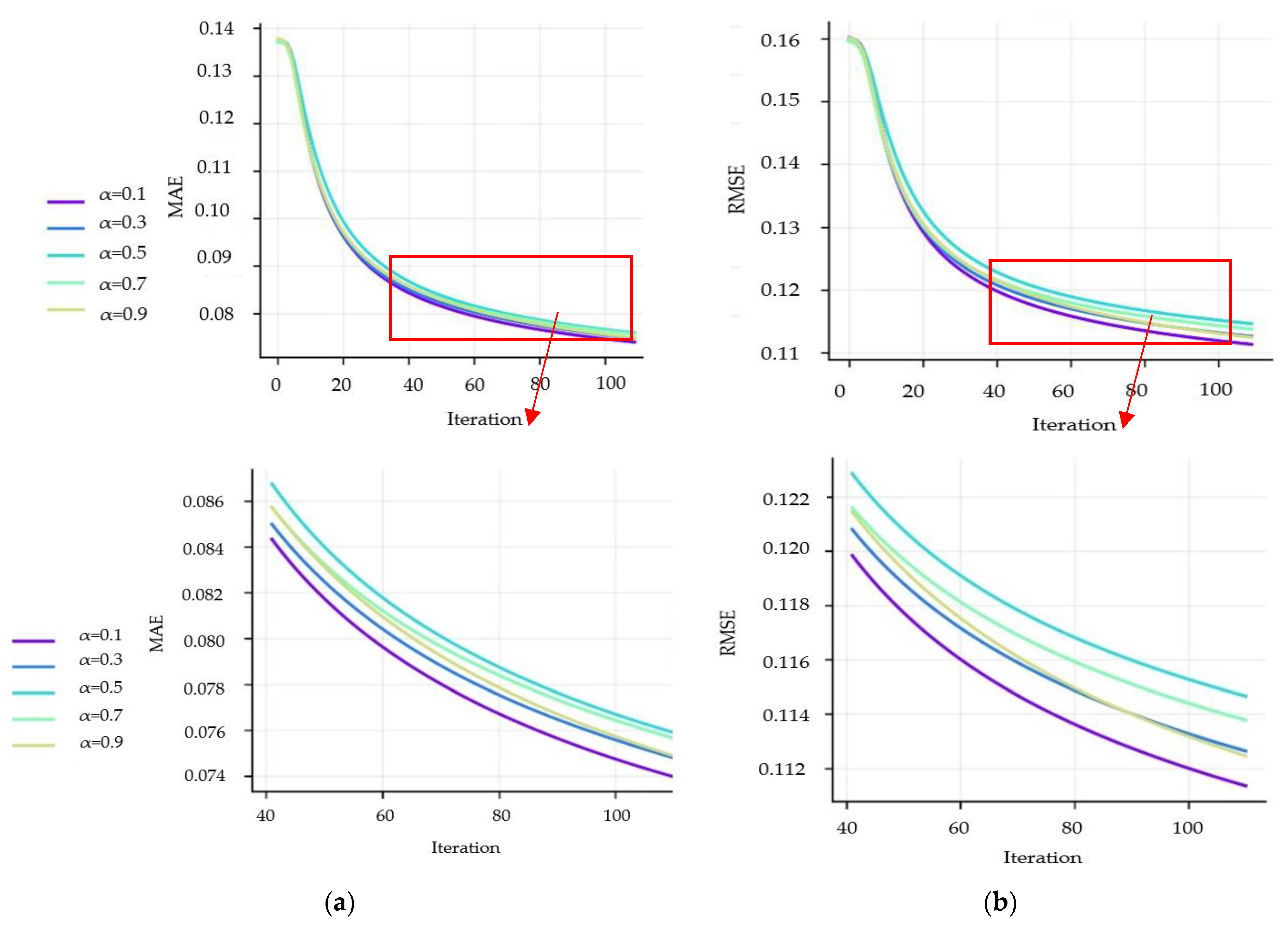
Figure 5a,b depict the impact of
on MAE and RMSE, respectively. Different values of
correspond to different proportions of local trust and global trust in the calculation of overall trust. In this paper, the algorithm leads to the minimum prediction error if
. This suggest that, in the research context of this paper, most users have limited trusted friends, and consequently, it is difficult for target users to gain subjective knowledge and understanding of other users. As a result, the overall trust can only be largely determined with the impact of trusted friends.
5.2. Experiment Results and Analysis
Comparison with traditional PMF algorithm without trust information: The PMF algorithm only makes use of user ratings without considering user trust weight information. The algorithm proposed in this paper makes recommendations on the basis of user ratings and implicit user trust relations generated. It can be seen from
Figure 6 that this algorithm is significantly superior to the traditional PMF algorithm, meaning that the addition of trust relations leads to more accurate prediction of user needs.
Table 4 shows the comparison between the proposed IT-PMP approach with the baseline matrix factorization algorithms (e.g., SVD (Single Value Decomposition), SVD++ and NMF), the regular PMF algorithm and the PMF algorithm based on 0–1 trust matrix, and we named it the Traditional Trust Probabilistic Matrix Factorization (TTPMF). It can be seen that the algorithm proposed in this paper is superior than the above algorithms in the MAE and RMSE indices. The reason for the poor performance of the comparison algorithms may be that PMF, SVD, SVD++ and NMF only use rating information without introducing trust information, and TTPMF only stays on the surface information of trust without fully mining the deep trust relationship between users. It shows that the introduction of implicit trust information can make up for the problem of low recommendation accuracy caused by data sparseness in collaborative filtering.
In the process of trust matrix generation using the algorithm proposed in this paper, the values in the interval [0, 1] are derived by means of weighted calculation. Most traditional trust matrices, on the other hand, take the form of a 0–1 matrix. It is obvious that, compared with TTPMF and PMF, the MAE and RMSE obtained by the algorithm proposed in this paper are lower, and the prediction error is smaller and closer to the actual value.
The experiment results show that the “pseudo-rating” matrix and user trust similarity matrix constructed in this paper are suitable for recommendations for community E-commerce users without rating and trust information. In addition, the implicit trust information for user mining proposed by us can reduce existing recommendation errors and can be used for trust-based recommendation methods. It leads to smaller recommendation errors compared with other PMF algorithms and consequently results in more accurate recommendations.
6. Conclusions
This study proposed a new recommendation method named IT-PMF based on implicit trust relationships consisting of local implicit trust relationships and in-group membership. The local implicit trust relationship was calculated based on the similarity of purchase behaviors and the number of successful interactions between users. The new algorithm established a user’s preference model to generate the target user’s neighbors. Combined with the user’s purchasing preference and the influence from his or her neighbors, the algorithm could predict the target user’s scoring on certain commodities, which provides a new perspective for trust-based recommendation research.
The IT-PMF was verified by extensive experiments, in which the dataset was collected from a real community E-commerce platform. The proposed method was trained in the training set and evaluated in the test set. Two indicators, namely, MAE and RMSE, were adopted to assess the algorithm’s performance. The result showed that the IT-PMF method had a better performance in both MAE and RMSE indices compared with baseline algorithms, such as PMF and SVD.
This study founded that, in T-app dataset, the final prediction score was mostly affected by the user’s purchasing preference (90%) and partly affected by his or her friends’ preferences (10%). This conclusion was deduced through the experiment of the IT-PMF’s parameters’ sensitivity, namely, α and β. In the experiment, when the value of β was assigned as 0.1, the error of the algorithm was the smallest. The value range of α was set to [0, 1], and the experimental results showed that when the value of α was 0.9, the evaluation indicators were all optimal.
The algorithm proposed in this paper can provide decision-making support for enterprises to implement precision recommendation strategies to improve the efficiency of marketing on community E-commerce platform. Although the proposed IT-PMF method performed well in this study, there are still some gaps to be explored in the future.
First, the amount of data that T-app could provide at this time is limited. In this research, the author only analyzed the data of 12 months, starting from August 2019. In the future, with the accumulation of consumption data, the author will work on a dynamic model of trust relationship, which takes the time factor into account.
Second, the dataset analyzed in this paper was limited to users’ purchase data. This means that the results of the experiment might be limited, too. Future research could integrate the user’s social, location and other contextual information into the establishment of trust relationship, which will further improve the accuracy of the recommendation.
Author Contributions
Conceptualization, J.W. and X.S.; methodology, X.S. and X.N.; software, X.S.; validation, X.S. and X.N.; formal analysis, J.W. and X.S.; investigation, L.S. and D.W.; resources, J.W. and L.S.; data curation, X.S. and X.N.; writing—original draft preparation, X.S. and X.N.; writing—review and editing, X.S. and X.N.; visualization, X.S.; supervision, J.W.; project administration, J.W., L.G. (Lu Gao), L.G. (Liping Geng) and D.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Cabrera-Sánchez, J.P.; Ramos-de-Luna, I.; Carvajal-Trujillo, E.; Villarejo-Ramos, Á.F. Online recommendation systems: Factors influencing use in e-commerce. Sustainability 2020, 12, 8888. [Google Scholar] [CrossRef]
- Xiao, L.; Mao, H.; Wang, S. Research on mobile marketing recommendation method incorporating layout aesthetic preference for sustainable m-commerce. Sustainability 2020, 12, 2496. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Li, Y.; Shi, L.; Yang, L.; Niu, X.; Zhang, W. ReRec: A Divide-and-Conquer Approach to Recommendation Based on Repeat Purchase Behaviors of Users in Community E-Commerce. Mathematics 2022, 10, 208. [Google Scholar] [CrossRef]
- Chen, T.; Zhu, Q.; Zhou, M.X.; Wang, S. Trust-based recommendation algorithm in social network. J. Softw. 2017, 28, 721–731. [Google Scholar] [CrossRef]
- Zhang, W.; Du, Y.; Yang, Y.; Yoshida, T. DeRec: A data-driven approach to accurate recommendation with deep learning and weighted loss function. Electron. Commer. Res. Appl. 2018, 31, 12–23. [Google Scholar] [CrossRef]
- Belkin, N.J.; Croft, W.B. Information filtering and information retrieval: Two sides of the same coin? Commun. ACM 1992, 35, 29–38. [Google Scholar] [CrossRef]
- Resnick, P.; Iacovou, N.; Suchak, M.; Bergstrom, P.; Riedl, J. Grouplens: An open architecture for collaborative filtering of netnews. In Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work, Chapel Hill, NC, USA, 22–26 October 1994; pp. 175–186. [Google Scholar] [CrossRef]
- Kamvar, S.D.; Schlosser, M.T.; Garcia-Molina, H. The eigentrust algorithm for reputation management in p2p networks. In Proceedings of the 12th International Conference on World Wide Web, Budapest, Hungary, 20–24 May 2003; pp. 640–651. [Google Scholar] [CrossRef]
- Golbeck, J.A. Computing and Applying Trust in Web-Based Social Networks. Ph.D. Thesis, University of Maryland, College Park, MD, USA, 2005. [Google Scholar]
- Ma, H.; Yang, H.; Lyu, M.R.; King, I. Sorec: Social recommendation using probabilistic matrix factorization. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 931–940. [Google Scholar] [CrossRef]
- Jamali, M.; Ester, M. A matrix factorization technique with trust propagation for recommendation in social networks. In Proceedings of the Fourth ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; pp. 135–142. [Google Scholar] [CrossRef]
- Jamali, M.; Ester, M. Trustwalker: A random walk model for combining trust-based and item-based recommendation. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 397–406. [Google Scholar] [CrossRef]
- Deshpande, M.; Karypis, G. Item-based top-n recommendation algorithms. ACM Trans. Inf. Syst. 2004, 22, 143–177. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Koenigstein, N.; Paquet, U. Xbox movies recommendations: Variational Bayes matrix factorization with embedded feature selection. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 129–136. [Google Scholar] [CrossRef]
- Kurashima, T.; Iwata, T.; Irie, G.; Fujimura, K. Travel route recommendation using geotags in photo sharing sites. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, Toronto, ON, Canada, 26–30 October 2010; pp. 579–588. [Google Scholar] [CrossRef]
- Li, X.; Chen, C.H.; Zheng, P.; Jiang, Z.; Wang, L. A context-aware diversity-oriented knowledge recommendation approach for smart engineering solution design. Knowl.-Based Syst. 2021, 215, 106739. [Google Scholar] [CrossRef]
- Hu, B.; Ester, M. Spatial topic modeling in online social media for location recommendation. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 25–32. [Google Scholar] [CrossRef]
- Shinde, S.K.; Kulkarni, U. Hybrid personalized recommender system using centering-bunching based clustering algorithm. Expert Syst. Appl. 2012, 39, 1381–1387. [Google Scholar] [CrossRef]
- Cheng, Y.; Church, G.M. Biclustering of expression data. In Proceedings of the 8th International Conference on Intelligent Systems for Molecular Biology, La Jolla, CA, USA, 19–23 August 2000; pp. 93–103. [Google Scholar]
- Hu, L.; Chan, K.C. Fuzzy clustering in a complex network based on content relevance and link structures. IEEE Trans. Fuzzy Syst. 2015, 24, 456–470. [Google Scholar] [CrossRef]
- Shepitsen, A.; Gemmell, J.; Mobasher, B.; Burke, R. Personalized recommendation in social tagging systems using hierarchical clustering. In Proceedings of the 2008 ACM Conference on Recommender Systems, Lausanne, Switzerland, 23–25 October 2008; pp. 259–266. [Google Scholar] [CrossRef]
- Wang, Z.; Liao, J.; Cao, Q.; Qi, H.; Wang, Z. Friendbook: A semantic-based friend recommendation system for social networks. IEEE Trans. Mob. Comput. 2014, 14, 538–551. [Google Scholar] [CrossRef]
- Gong, J.; Zhang, X.; Li, Q.; Wang, C.; Song, Y.; Zhao, Z.; Wang, S. A Top-N Movie Recommendation Framework Based on Deep Neural Network with Heterogeneous Modeling. Appl. Sci. 2021, 11, 7418. [Google Scholar] [CrossRef]
- Ma, P.; Wang, L.; Qin, J. A Low-Rank Tensor Factorization Using Implicit Similarity in Trust Relationships. Symmetry 2020, 12, 439. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Li, X.; Lee, B.; Kim, J. A hybrid CNN-based review helpfulness filtering model for improving e-commerce recommendation Service. Appl. Sci. 2021, 11, 8613. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, W.; Li, J.; Mai, F.; Ma, Z. Effect of online review sentiment on product sales: The moderating role of review credibility perception. Comput. Human Behav. 2022, 133, 107272. [Google Scholar] [CrossRef]
- Zhang, W.; Xie, R.; Wang, Q.; Yang, Y.; Li, J. A novel approach for fraudulent reviewer detection based on weighted topic modelling and nearest neighbors with asymmetric Kullback–Leibler divergence. Decis. Support Syst. 2022, 157, 113765. [Google Scholar] [CrossRef]
- Qiu, J.; Dong, Y.; Ma, H.; Li, J.; Wang, K.; Tang, J. Network embedding as matrix factorization: Unifying deepwalk, line, pte, and node2vec. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina del Rey, CA, USA, 5–9 February 2018; pp. 459–467. [Google Scholar] [CrossRef] [Green Version]
- Mnih, A.; Salakhutdinov, R.R. Probabilistic matrix factorization. Adv. Neural Inf. Process. Syst. 2007, 20, 1257–1264. [Google Scholar]
- Xu, B.; Lin, H.; Yang, L.; Lin, Y.; Xu, K. Cognitive Knowledge-aware Social Recommendation via Group-enhanced Ranking Model. Cogn. Comput. 2022, 14, 1055–1067. [Google Scholar] [CrossRef]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 426–434. [Google Scholar] [CrossRef]
- Tang, J.; Hu, X.; Gao, H.; Liu, H. Exploiting local and global social context for recommendation. In Proceedings of the 23rd International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 2712–2718. [Google Scholar]
- Bobadilla, J.; Serradilla, F.; Bernal, J. A new collaborative filtering metric that improves the behavior of recommender systems. Knowl.-Based Syst. 2010, 23, 520–528. [Google Scholar] [CrossRef]
- Caruso, G.; Gattone, S.A. Waste management analysis in developing countries through unsupervised classification of mixed data. Soc. Sci. 2019, 8, 186. [Google Scholar] [CrossRef] [Green Version]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}