1. Introduction
This paper is concerned with the approximate solution of a large-scale linear system of equations of the form
where
need to be determined. If
, the linear systems (
1) with such thin (or tall) coefficient matrices
A are overdetermined and are often inconsistent. In this case, we are interested in the computation of the least-squares solution of systems (
1) by
where
denotes the Euclidean norm. If
, the linear system (
1) with such a fat (or flat) matrix
A is underdetermined. If the linear system is consistent and has many solutions, then the least Euclidean-norm solution
will often be considered. In this paper, we focus on the approximate of the least-norm solution when (
1) is consistent.
The Kaczmarz method in [
1] is a popular algorithm for solving the linear system (
1), which is called
the algebraic reconstruction technique (ART), and has a large range of fields of applications, such as image reconstruction in computerized tomography [
2,
3], signal processing [
4], and distributed computing [
5,
6]. In the classical Kaczmarz method [
1], all rows of the matrix
A are circularly passed according to the given order, and the current iteration point is orthogonally projected to the hyperplane formed by the index row for the next iteration. For a given initial solution
, the iteration scheme of the Kaczmarz method can be presented as
where
,
,
denotes the
ith row of
A,
presents the
ith element of
b, and
denotes the transpose of
A.
For the consistent linear system (
1), Strohmer and Vershynin [
7] in 2009 presented a randomized Kaczmarz algorithm (RK) with expected exponential convergence. The RK algorithm selects each iteration row with the row index
. A theoretical analysis showed that, compared with the selection of a row in the natural order, randomly selecting a row of iterations can greatly improve the convergence speed. In [
8], Bai and Wu designed a greedy randomized Kaczmarz (GRK) algorithm. GRK uses a greedy probability strategy, which is derived from the maximum distance rule, to grasp larger entries of the residual vector, and the work row with a larger residual error is determined. The theoretical analysis shows that the GRK converges to the least norm solution with the expected exponential, and the numerical experiments illustrate that GRK converges much faster than RK. In [
9], De Loera proposed a sampling Kaczmarz–Motzkin (SKM) for linear feasibility problems by combining the RK method with the Motzkin method [
10]. This method mainly consists of two stages. The row index set
of matrix
A is divided into multiple subsets
for the first stage, and the second stage involves determining the working row
by uniformly extracting one (
) in each iteration, and then updating
by (
4). In particular, the SKM method overcomes the weakness of the RK and Motzkin methods. For example, the RK method may be slow to converge because it does not utilize a greedy strategy, and the calculations of all residual vectors are expensive for the Motzkin method. However, the convergence rate of the SKM method may be slow since it enforces only one constraint for the current iteration.
The block Kaczmarz methods, which utilize the multi-row constraints, have received extensive attention for their fast convergence properties. The block iterative methods were first presented by Elfving [
11] and Eggermont et al. [
12] to solve (
1). Then, Needell et al. [
13] proposed a randomized block Kaczmarz (RBK) algorithm to solve the least-squares problem by selecting a subsystem from the predetermined partition at random, which linearly converges to the least-norm solution in expectation. The randomized block Kaczmarz algorithm iterates the form
where
and
are the submatrix and subvector of
A and
b, respectively,
and
represent the Moore–Penrose pseudoinverse of subsystem matrix
. Although the existence of this “good” paving of all rows is theoretically guaranteed, it is not always effortless to find it. Liu and Gu in [
14] designed a randomized greedy block Kaczmarz method to choose a “good” target block by embedding a greedy strategy in the predetermined subsystems, which was derived from the probability criterion proposed by Bai and Wu in [
8]. The convergence theory of GRBK shows that the iterative solution sequence linearly converges to the least-norm solution in expectation. In addition, the partitioning method may not be a good partition since it only focuses on the average partitioning of the row index set. Many variants of the block Kaczmarz have recently received extensive attention. For example, literature studies [
15,
16,
17,
18,
19,
20,
21] and references therein.
By exploring the structural properties of the coefficient matrix
A, some criteria can be used to determine the row partitions (see [
13,
14,
16,
22]). In the context of data science, the mean shift clustering (MS) is an iterative algorithm based on kernel density estimation [
23], which is widely used for data clustering. So, the combination of the clustering algorithm and greedy technique is extremely meaningful. Inspired by this, to improve the efficiency of block Kaczmarz, we constructed a novel block Kaczmarz–Motzkin method (BKMS(
,
)) by determining the largest residual block, and then introducing an almost maximum distance criterion for the current block to collect the row indices, close to the largest entry (absolute value), as the iteration index set. The row partitions were divided based on MS clustering, and the row correlation coefficient of the system matrix
A was considered the clustering criterion. Moreover, unlike k-means clustering [
16,
24], it only needs to initialize the bandwidth’s
automatic partitions instead of pre-specifying the number of partitions
, which depends on the initialized cluster centers.
This paper is organized as follows. The RBK method in [
13] and the GRBK method in [
14] are summarized in
Section 2.
Section 3 introduces the MS clustering briefly, and then the BKMS method is proposed and its convergence theory is constructed when (
1) is consistent.
Section 4 reports several examples and applications. We complete this work with some conclusions and discuss future work in
Section 5.
4. Numerical Examples
In this section, the numerical performances of the RK, Motzkin, GRK, RBK, SKM, GRBK, and BKMS algorithms are compared in different settings of the least-squares problem (
1). The operating environment of all experiments is the MATLAB 2020b version on a private computer with AMD Ryzen 5 4600H and 16 GB of memory. The
relative solution error is denoted by
which is used to measure the efficiency of all methods.
The initial vector is set as
for BKMS and other methods. We terminate the iteration process of each method once RSE
. The concept of a random partition sampling in [
13,
14] is sampling
randomly from row partition
at the
k-th iteration, and for each
i, the subset
can be denoted as
The iterative least-squares solver CGLS in [
14] is utilized to solve the underdetermined linear subsystem at each iteration since it requires fewer floating-point numbers between matrix–vector products than the MATLAB function “
pinv”.
This section consists of three parts. In the first part (Examples 1–3), we implement MS clustering to visualize the row partition of the coefficient matrix
A and verify that BKMS is more competitive than other methods to solve consistent linear systems (
1) with different
A. In the second part (Example 4), we consider the effects of parameters
and
on the performance of BKMS. In the last part (Examples 5 and 6), we provide two practical applications of the BKMS method.
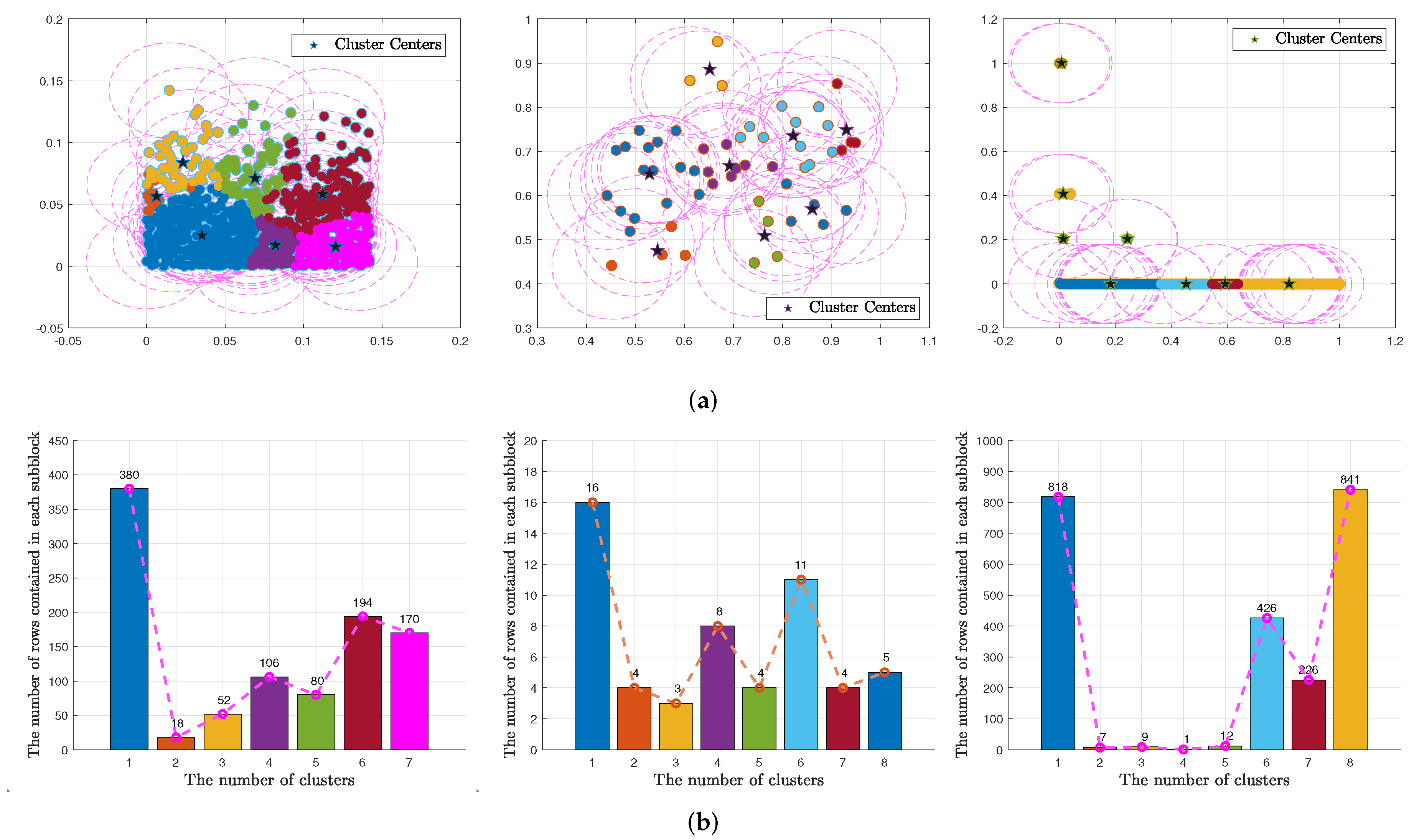
Example 1. This example implements the partitions of different system matrices by adopting the MS Algorithm 3. It is known that an ill-conditioned matrix means a high linear correlation between the rows of the matrix [16]. In the left graph of Figure 1a, we tested a dense matrix with the condition number (cond(A)) being , in the middle graph of Figure 1b, we tested a sparse matrix named “Cities” with cond(A) being 207.15, and in the right graph of Figure 1c, we tested an ill-conditioned sparse matrix named “relat6” with the cond(A) being 4.03 × 1016. Figure 1b plots the number of rows contained in each block of the matrices above, respectively. As shown in
Figure 1a, the rows with similar correlation coefficients
are likely to be allocated in a block. This may lead to the considerable control index set
in the BKMS method being very large, which is verified in
Figure 1b. To alleviate this problem, we continue to partition the current block, so it is reasonable to introduce an almost-maximum distance rule in BKMS.
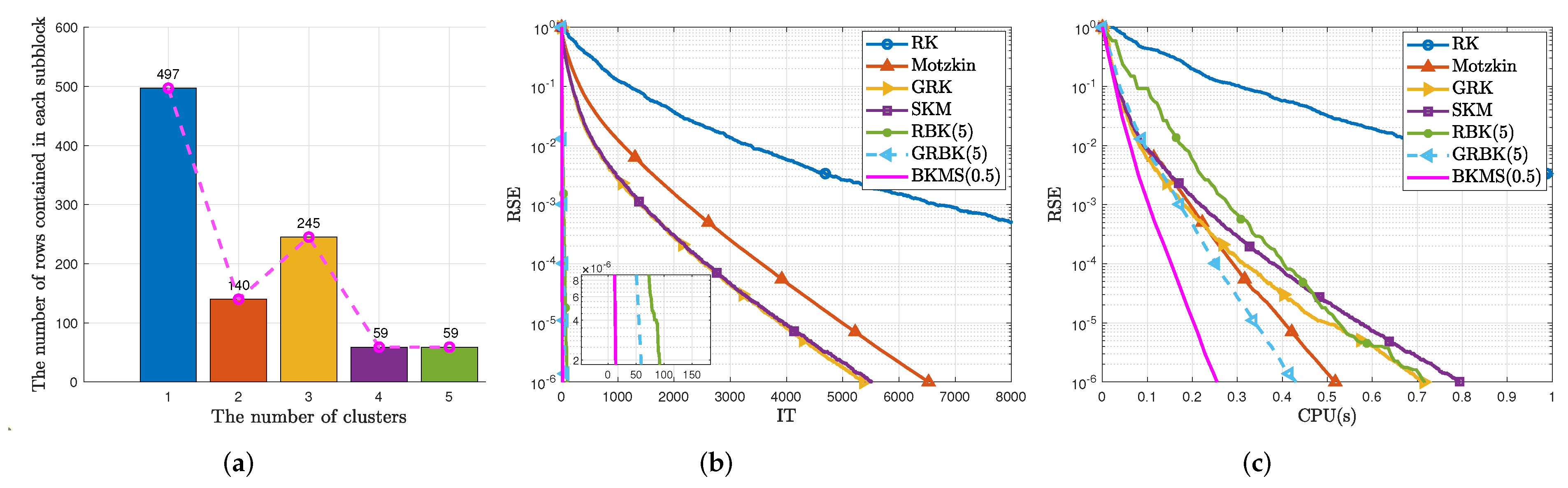
Example 2. This example considers a linear system (1) with a tall (or fat) coefficient matrix , i.e., (or ). Its elements are pseudorandom numbers from a standard normal distribution generated by the MATLAB function . Table 1 reports the iteration steps (IT) and CPU time in seconds (CPU(s)) of RK, Motzkin, GRK, SKM, RBK(p), and GRBK(p) with the same number of blocks and BKMS (). The refers to the numerical optimum parameter rather than a theoretical one. We will further discuss the in Example 4. Figure 2 shows the numerical performance of all methods, in particular, we control RBK(p), GRBK(p), and BKMS(0.5, 0.1) to have the same number of blocks . Figure 2a shows the number of rows contained in each subblock of BKMS. Figure 2b,c depict the curves of RSE versus IT and RSE versus CPU(s) of Algorithm 4, applied to solve (1) with the coefficient matrix . In addition, we default for BKMS(δ) in all examples unless otherwise specified. It is observed from
Table 1 that RBK(
p), GRBK(
p), and BKMS(
) are almost superior to RK, Motzkin, GRK, and SKM in terms of iteration steps and CPU time, thanks to the fact that block iteration takes multiple constraints. In addition, in block Kaczmarz methods, we find that BKMS(
) is more competitive than RBK(
p) and GRBK(
p). For example, the CPU time speed-up of the BKMS(
) over GRBK(
p) ranges from 1.206 to 1.610. Specifically, the value 1.610 is calculated by a ratio of 2.790 (CPU time consumed by GRBK(5) with the size of
A is 30,000 × 5000) over 1.733 (CPU time used by BKMS(
) for the same size of
A). Furthermore, from
Figure 2, BKMS(
) converges in less iterations and CPU time than other methods.
Example 3. This example executes the RK, Motzkin, GRK, SKM, RBK, GRBK, and BKMS methods to solve the sparse linear Equation (1). Table 2 summarizes different sparse matrices with different properties, which are taken from the Florida sparse matrix collection in [27]. The density
of a matrix A means the percentage of nonzero elements of A. The IT and CPU times for all methods are reported in Table 2. Similar to Example 2, Figure 3a shows the number of rows contained in each subblock of BKMS(), Figure 3b,c display the plots of RSE versus IT and RSE versus the CPU times of all methods, which are applied to solve a sparse linear system (1) named “WorldCities”. From
Table 2, RBK(
p), GRBK(
p), and BKMS(
) require fewer iteration steps and CPU times. Similar to the block Kaczmarz methods above, we believe that the BKMS method has better performance. For example, we calculate the CPU time speed-up of the BKMS(
) over GRBK(
p) ranges from 1.692 to 3.493 for solving the (
1) with a different sparse matrix
A listed in
Table 2. From
Figure 3, we can see that BKMS converges faster than other methods. By carefully comparing
Figure 3c, it is not difficult to find that SKM and RBK have similar time efficiencies. The reason is that calculating the Moore–Penrose pseudoinverse of large blocks reduces the efficiency of RBK. So, the number of coefficient matrix partitions affects the convergence speed of RBK, GRBK, and BKMS. Based on this, in Example 4, we will analyze the sensitivity of the parameters (
) in BKMS.
Example 4. This example investigates the effects of the parameters δ and η on the BKMS method. We use BKMS to solve system (1) with and the sparse system (1) named “abtaha1”, respectively. Table 3 and Table 4 list the iteration steps and CPU time of BKMS() once the RSE . The “- -” means abandoning the introduction of the almost maximum distance rule (i.e., removing steps 5 and 6 in Algorithm 4). In fact, we usually care more about the CPU time, so we use enumeration to select optimal parameters δ and η. This tuning method is also called the grid search in machine learning. That is, find the corresponding different parameter values by locking the optimal value. For example, we select initialization seeds and for BKMS(δ, η) in Table 3. As depicted in
Table 3, fix
, for the different
; although the number of iteration steps increases, the CPU time shows a trend of first falling and then rising. For each column, this law is roughly the same. Finding a suitable
is crucial. When
becomes larger, the number of blocks becomes smaller, which requires computing the Moore–Penrose pseudoinverse of a large block to be time-consuming. On the contrary, when
becomes smaller, the number of blocks increases. Considering an extreme case, when
A is row-normalized and there is only one row index in each block, BKMS is mathematically equivalent to the Motzkin method. A similar result also occurs in
Table 4. The initialization seeds
and
can be selected for BKMS(
,
) in
Table 4.
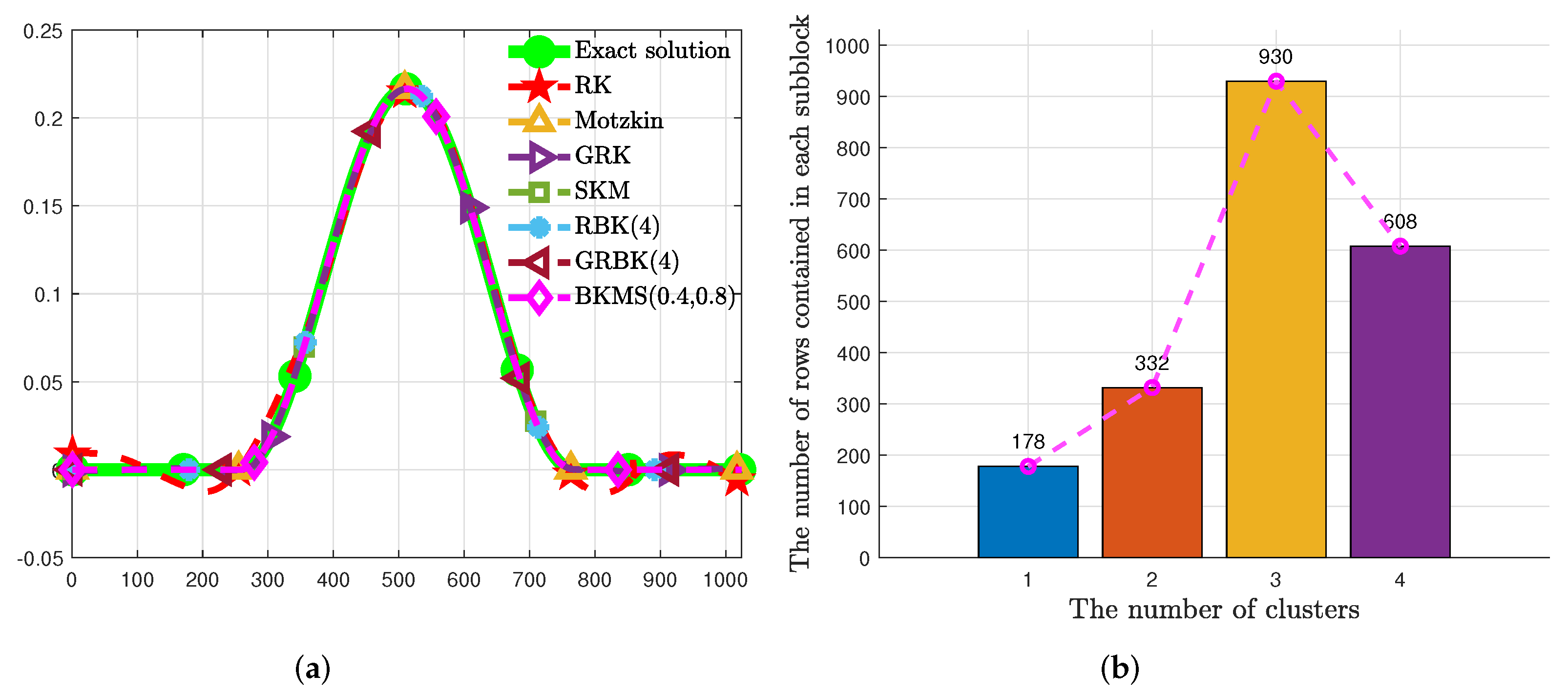
Example 5 (Discrete ill-posed problem)
. This example uses the BKMS method to the solution of Phillips
ill-posed problem in [28] and compares it with RK, Motzkin, GRK, SKM, RBK, and GRBK methods. The linear systems (1) are obtained by the discretization of the Fredholm integral equation of the first kind,on the square , where the kernel function is presented by withand the right-hand sidewhich is often severely ill-conditioned. In fact, ordinary linear systems (2) may yield poor approximate solutions in this case, then one of the effective ways to overcome this issue is ridge regression, also called the Tikhonov regularization, namelywhich can be restated aswhere and is a regularization parameter. The measurement matrix , exact solution , and are all calculated by the MATLAB function in [28].Set and . Then the size of the square matrix A is and the condition number of A is while is . In Figure 4, the (a) reports the approximation solution calculated by RK, Motzkin, GRK, SKM, RBK(4), GRBK(4), and BKMS(0.4, 0.8) together with the exact solution for the phillips test problem when the maximum number of iteration steps is 100. The (b) shows the partition performance of BKMS(). Table 5 lists the RSE, CPU time, and iteration of BKMS(0.4, 0.8) compared with RK, Motzkin, GRK, SKM, RBK(4), and GRBK(4) for the “phillips” problem when . Figure 4 shows that the recovered solutions by RBK(4), GRBK(4), and BKMS(0.4, 0.8) are much closer to the exact solution than RK, Motzkin, GRK, and SKM do. It can be seen from
Table 5 that BKMS obtains less RSE than other methods. In addition, BKMS needs less CPU time and iterations to reach the stop rule.
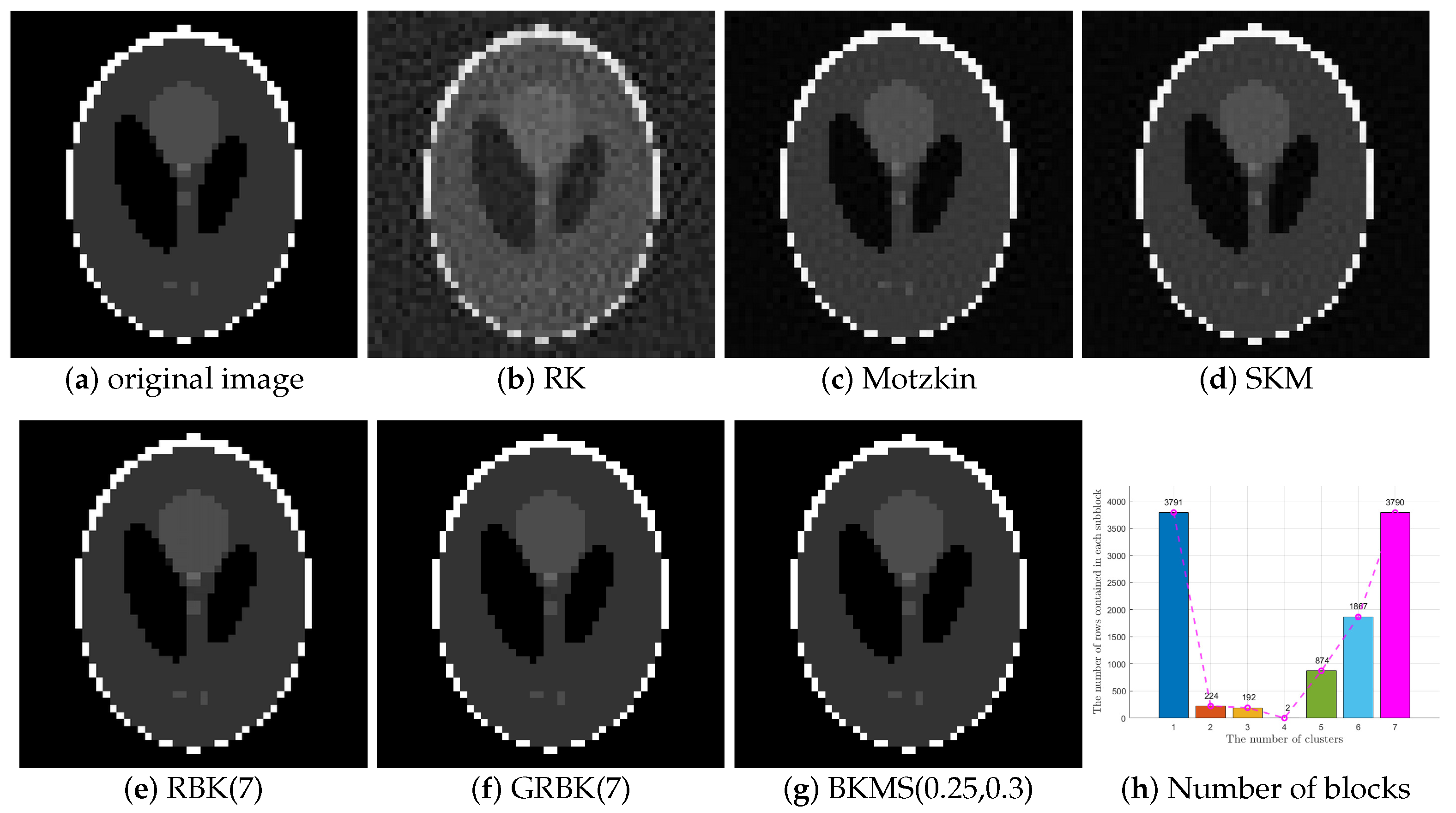
Example 6 (CT reconstruction problem)
. This example implements the reconstruction of a computer tomography (CT) image. This test problem can be implemented by the MATLAB function in the ART Tools package in [29]. We set , and , then resulting in the size of A is 10,740 × 2500, the exact solution (See the (a) of Figure 5) and the b we obtained by . The BKMS(0.25, 0.3) is applied to reconstruct from b and compared with the RK, SKM, RBK(7), and GRBK(7) methods. Figure 5 shows the recovered images by RK, SKM, RBK(7), GRBK(7), and BKMS(0.25, 0.3) together with the original image.
Table 6 reports the RSE, the CPU time, and iteration steps of BKMS(0.25, 0.3) compared with RK, SKM, RBK(7), and GRBK(7) once
. We set the maximum iterative number (
) to 8000.
It is shown from
Figure 5 that all methods obtained well-restored images above. It can be seen from
Table 6 that BKMS(0.25, 0.3) needs less CPU time and iteration steps than other methods for restoring images.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}