This section introduces basic concepts related to the proposed CARP-ABC algorithm to help to understand how it works. The concepts are introduced only briefly, for a more detailed description the corresponding works are referred to.
3.1. The CARP
In the existing works, as the input graph, some assume an undirected graph [
7], others assume a directed graph [
8,
49], and other ones a mixed graph [
6,
34]. In this work, a directed graph is assumed, in which undirected edges are regarded as two oppositely directed edges.
The (directed) graph of the CARP can be described the following way: , with a set of vertices V and a set of arcs (directed edges) A. A set of tasks is also given, which defines the arcs that have tasks assigned to them. If the graph of a CARP instance contains (undirected) edges, then an edge is added to A as a pair of arcs, one for each direction. For instance, if is an edge and , then the arcs and are added to A. Similarly, if is an edge with tasks assigned to it and , then the arcs and are added to T. The graph also has a special vertex (), the depot, and a dummy task , the significance of which is explained later.
The tasks are performed by a fleet of w homogeneous vehicles of capacity q. Every vehicle starts and ends its route at the depot (). Each task must be performed in a single operation, and each vehicle can satisfy at most as many demands as its maximum capacity.
The graph can be mapped to a road network where the arcs are road segments. Some of the road segments have tasks. To fulfill the tasks, different amounts but the same type of demand must be served. Each arc is characterized by the following functions:
: the head vertex of the arc;
: the tail vertex of the arc;
: the dead-heading or traversing cost, the cost of crossing the arc.
In addition, each task is characterized by the following functions:
: the unique identifier of the task, which is a positive integer;
: (positive) demand, which indicates the load necessary to serve the task;
: service cost, which is the cost of executing the task and crossing the arc (i.e., is included in ).
Although an edge is regarded as two oppositely directed arcs, if a task is assigned to it, then the task should be executed only once, in either direction. Let be a task of one of the arcs of an edge, then let denote the inversion of t, the other task of the edge. If and are the head and the tail vertexes of t, then and are the head and the tail vertexes of . The , and values are the same for t and .
Let the total number of tasks that have to be executed by at least one of the vehicles be denoted by n. The value of n depends on the composition of T: if T only contains arc tasks from edges, then , if T only contains arc tasks from arcs then .
The minimal total dead-heading cost between two vertices is provided by the function, which uses Dijkstra’s algorithm as the search algorithm. For instance, denotes the minimal total dead-heading cost traversing from vertex to vertex , where .
A CARP instance (
I) is defined as follows:
3.1.1. Solution Representation
A solution for a CARP instance is expressed as a set of route plans. The route plans are sequences of the
tasks that need to be executed in the given order. The consecutive tasks are connected by the shortest paths, which is provided by the
function. Therefore, a solution
S for a CARP instance can be expressed the following way:
where
is the number of route plans and
(
) is the
k-th route plan within the solution
S. The
k-th route plan can be expressed the following way:
where
is the number of (not dummy) tasks and
is the
i-th task within the
k-th route plan. It must be noted that here,
k is an index, which is only used to identify a specific route plan in the solution. The order of the route plans within the solution has no effect on the quality of the solution.
Since every route starts and ends in the depot, the dummy task – which represents the vehicle being in the depot – is added also as the first and the last element of the route plan sequences. Its , , and are set to 0, and both the head and the tail vertexes are the depot vertex.
For the solution representation of the CARP, a natural encoding approach can be used, just like in most vehicle routing problems. This means that all route plans can be encoded as an ordered list of ids of the tasks, so a solution can be represented as the concatenation of these lists. However, every route plan starts and ends with the dummy task
, so if the encoded route plans are concatenated, then there are consecutive dummy tasks in the resulting list. For the sake of simplicity, only one of each consecutive dummy task is kept in the encoded solution.
Figure 1 shows an example of a solution representation.
3.1.2. Objective and Constraints
The objective of the CARP is to minimize the total cost of the solution
S subject to some constraints, which are defined in this section. The total cost of a solution
S (i.e.,
) is calculated with the following formula (Equations (
4)–(
6)):
where
and
are the total dead-heading and service cost of the route plan
.
The solution
S has to satisfy the following constraints. First, each route plan starts and ends at the depot. Second, each task is executed exactly once. Therefore, the total number of tasks executed on each route plan (excluding the dummy task
) is equal to
n:
Moreover, a task cannot be executed more than once, neither in the same route nor in another route:
where
and
are route plans within
S,
is the
i-th task in the route plan
, and
is the
j-th task in the route plan
. If a task
t has an inverse (i.e.,
), then either
t or
is executed. Both cannot be executed in the same solution. Third, the total demand served each route plan does not exceed the capacity (
q) of the vehicle:
3.2. The Data-driven DCARP
There are various approaches for DCARP, but in this work, the data-driven version of DCARP is considered, which was recently formulated in [
20].
In this problem, instead of one static CARP instance, there is a series of DCARP instances (i.e., a DCARP scenario [
21]) that needs to be solved. A DCARP scenario is denoted by
, where
m is the number of DCARP instances within the scenario (i.e., the number of dynamic events that occurred and changed the previous DCARP instance is
). Each
(
) DCARP instance contains all the information about the current problem. The previous DCARP instance
, the execution of the accepted solution for
and the occurred event(s) define the next DCARP instance
, where
. The initial instance (
) can be viewed as a static (data-driven) CARP instance, since initially every vehicle is in the depot (in good state) and no task has been executed yet.
For a data-driven DCARP instance, information needs to be stored about all the vehicles and route plans. For each vehicle, the current location and state have to be known. Furthermore, identifiers are needed to be used for the vehicles and the route plans, since a vehicle may follow multiple route plans (one after another) and it is important to know for each route plan whether a vehicle already executed it, its execution is still in progress, or a vehicle still needed to be assigned to it to start its execution.
Instead of the number of vehicles (w), a set of identifiers of all the vehicles is needed to be defined, which is denoted by H. The set of the identifiers of the (currently) free vehicles is denoted by (), which is initially equal to H. The identifier of a vehicle is added to , if the vehicle finishes the execution of a route plan, and the identifier is removed, when a new route plan is assigned to the vehicle. If the execution of all the tasks is finished and all the vehicles are returned to the depot (i.e., there are no broken down vehicles outside on the roads), then , otherwise .
The set of identifiers of all the route plans is denoted by R, and the set of identifiers of the route plans that currently cannot be modified and not executed by any vehicle is denoted by (). When a new route plan is created, its identifier is added to R, and when the execution of it is finished or suspended (due to vehicle breakdown), its identifier is added to . If the execution of all the route plans is finished and there are no more tasks to execute, then , otherwise . The identifier is removed from only if the vehicle which is assigned to it was broken, but got fixed and can continue the execution of the plan. The function that defines which vehicle is assigned to a specific route plan is denoted by .
To store the current location of the vehicles in the instance, the virtual task strategy introduced in [
21] is used, which replaces the executed tasks in each route plan with “virtual tasks”. A “virtual task” is an arc whose
is the depot vertex
and
is the current location of the vehicle, vertex
v (
). For the sake of simplicity, it is assumed that when an unexpected event occurs, every vehicle is located exactly at a vertex. Since this task is “virtual”, it cannot be traversed, for this reason, it has an infinite traversing cost (i.e.,
). Furthermore, since it is a “task”, there is a demand and a service cost assigned to it, which are calculated according to the provided data: the service cost is the total cost produced by the vehicle so far (i.e., it is the sum of traversing and serving cost of the arcs that were crossed or served by the vehicle), and the demand is the total demand served by the vehicle so far. A route plan can have at most one virtual task. Therefore, if a route plan already has a virtual task, then it is updated taking into account the arcs traversed and the tasks executed since then by the corresponding vehicle. The set of all virtual tasks is denoted by
(
), and the function that defines which virtual task belongs to a specific route plan is denoted by
.
The set of arc tasks that need to be executed is denoted by T. If according to the gathered information a task t () was executed by the vehicle h (), then in the new DCARP instance t needs to be removed from T. Furthermore, the virtual task of the route plan of the vehicle (e.g., , where and ) needs to be updated. The new virtual task is generated in such a way that t is included in it (along with the other tasks the vehicle executed and arcs the vehicle traversed). If t has an inverse (i.e., ), then it is removed from T as well. Accordingly, the total number of tasks that have to be executed (n) is decreased by one or two.
The initial DCARP instance (
) is similar to a static CARP instance. The sets of the route plan identifiers (
R) and the function
are created and filled only after the solution is found for
. The set
is initially equal to
H, then based on
, all the vehicle identifiers that are assigned to a route plan are removed from
. At this stage, the sets
and
are empty sets, therefore the function
is an empty function as well. According to these, the initial DCARP instance (
) is defined as follows:
The subsequent DCARP instances (
, where
) are defined as follows:
3.2.1. Structure of a Scenario
A new DCARP instance is constructed and added to the DCARP scenario, when an unexpected event happens that changes the current problem to such an extent that it has effect on the currently executed solution. In [
21] all the possible events (based on realistic assumptions) were collected and analyzed based on their effect.
It is assumed that the roadmap, the number of vehicles, and the maximum capacity of the vehicles cannot change (at least during the execution of the solution). Therefore, V, , A, , , , q and H are the same in all the DCARP instances of a DCARP scenario.
It is assumed that roads can become closed/opened (it changes , thus , too), the traffic can decrease/increase (it changes and in some cases , thus , too), tasks can get cancelled/added (it changes T, n, , and ) and vehicles can breakdown/restart (it changes ), which are unexpected events. The expected events are the events that normally occur during the execution of the solution: a task is executed (it changes T), a vehicle moves (it changes , thus , too), or a vehicle returns to the depot (it changes and in some cases ). The affected components are updated only when a new instance is constructed. If rerouting is performed, then R and may change, but the changes are visible only in the next DCARP instance. Therefore, T, , n, , R, , , , , , , and may be different among the DCARP instances of a DCARP scenario.
Since due to the unexpected events some components of the DCARP instance change, the optimal solution may change, too. It is one’s choice to construct a new DCARP instance and reroute when there might be a better solution available, but the current solution is still feasible. However, constructing a new DCARP instance and rerouting is necessary when the current solution is not feasible anymore.
3.2.2. Solution Representation
For each DCARP instance, the solution representation is mainly the same as for static CARP instances. The only difference is that if the route plan has a virtual task assigned to it, then the virtual task is the second task within the route plan (since the first task is always the dummy task ). For instance, if the route plan has an identifier k () and there is a virtual task assigned to it (i.e., ), then .
3.2.3. Objective and Constraints
For each DCARP instance, the objective and the constraints are mainly the same, as well as for static CARP instances. The only difference is at the second constraint, which requires that the total number of tasks in the solution
S (excluding the dummy task
) is equal to the sum of the number of tasks that still need to be executed (
n) and the total number of virtual tasks (
):
The attributes of a virtual task guarantee that a solver will always place the virtual task right after the dummy task within a route plan of a (nearly optimal) solution, so there is no need to add a constraint regarding it.
3.2.4. Finding a Solution
The data-driven DCARP framework allows rerouting when a critical event (i.e., an unexpected event that may change the feasibility of the current solution) occurs. These events are the task appearance, the demand increased and the vehicle breakdown.
The data-driven DCARP framework allows the use of static CARP solvers by converting the current data-driven DCARP instance into a static CARP instance. After a (sufficiently good) solution is found by the CARP solver, the solution is converted into a data-driven DCARP solution.
Converting a data-driven DCARP instance into a static CARP instance works as follows: the sets of vehicle and route plan identifiers (i.e., H, , R, and ) are omitted, along with the related functions ( and ). Furthermore, all virtual tasks related to finished and suspended route plans are removed from T. For instance, if () is the virtual task of the route plan with identifier k () and , then is removed from T (i.e., ).
Converting a static CARP solution into a data-driven DCARP solution works as follows: the virtual tasks that are related to finished and suspended route plans are added to the solution in separate route plans to keep track the total cost of the DCARP scenario. Furthermore, if there are any new route plans within the solution, the framework gives them identifiers and also attempts to assign each of them to a free vehicle. For the other route plans, it can be easily determined which route plan identifier belongs to which route plan, based on the virtual task within them.
3.3. The Basic ABC Algorithm
This section introduces the basic ABC algorithm for combinatorial problems, based on [
16]. Just like in the original ABC algorithm [
13], the artificial bees are classified into the three groups:
employed bees, who are exploiting the food sources;
onlooker bees, who are making the decision about which food source to select;
scout bees, who are randomly choosing a new food source.
In the ABC algorithm, a food source is corresponded to a solution and the nectar amount of a food source is corresponded to the fitness of a solution.
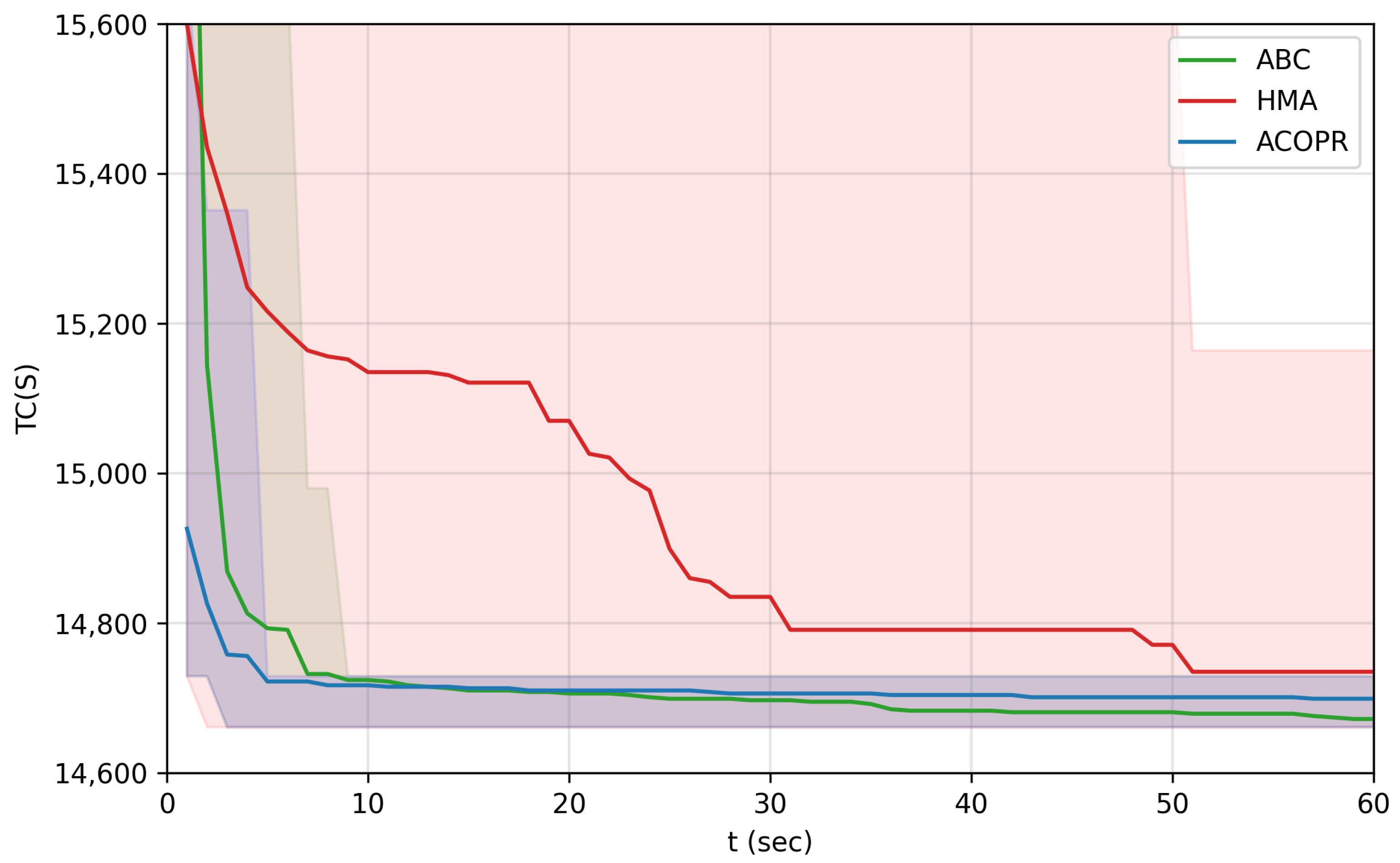
The ABC algorithm is an iterative process with four phases in total. It begins with the initial phase, then it iterates three bee phases (always in the same order) until a predefined termination criterion is met. In the initial phase, the population is initialized with randomly generated food sources. In the first phase, the employed bee phase, the employed bees are sent to the food sources, where they determine the nectar amounts of the food sources. In the second phase, the onlooker bee phase, the probability value of the sources are calculated based on their nectar amount, then the onlooker bees are sent to the preferred food source to find neighboring food sources and determine their nectar amount. In the third phase, the scout bee phase, the exploitation process of the sources exhausted by the bees are stopped and the scout bees are sent out to randomly discover new food sources within the search area. In each phase, the best food source found so far is memorized. The phases are described in more detail in the subsections below.
3.3.1. Initialization Phase
In the initialization phase, the parameters and the population are initialized. The parameters of the ABC algorithm can be defined as follows:
: the number of food sources, which is also the number of the employed bees and onlooker bees (i.e., for every food source, there is only one employed bee);
: the number of trials after which a food source is assumed to be abandoned;
a termination criterion.
The population is initialized by randomly generating number of food sources and assigning one employed bees to each of them. The employed bees evaluate the fitness of these solutions.
3.3.2. Employed Bee Phase
At this phase, each employed bee generates a new food source in the neighborhood of its current position. Once is obtained, it will be evaluated and compared to . If the nectar amount of is equal to or higher than that of , replaces and becomes a new member of the population, otherwise is retained. In other words, a greedy selection mechanism is employed between the old and the new candidate solutions.
3.3.3. Onlooker Bee Phase
An onlooker bee evaluates the nectar information taken from all the employed bees and selects a food source
depending on its probability value
calculated by the following expression:
where
is the nectar amount (i.e., the fitness value) of the
i-th food source
. The higher the value of
is, the higher the probability of that the
i-th food source is selected.
Once the onlooker has selected her food source , she produces a modification on by using a local search operator. The local search operator randomly selects a position in the neighborhood of . As in the case of the employed bees, if the modified food source has a better or equal nectar amount than , the modified food source replaces and becomes a new member in the population.
3.3.4. Scout Bee Phase
If a food source cannot be further improved through a predetermined number of trials limit, the food source is assumed to be abandoned, and the corresponding employed bee becomes a scout. The scout produces a food source randomly.
In the basic ABC algorithm, in each cycle, at most one scout bee goes outside to search for a new food source.
3.4. Move Operators for the CARP
In population-based evolutionary algorithms, to enrich the diversity of the population, move operators with different levels of step-size are utilized to generate new, neighboring solutions. These move operators can be divided into two main categories: small step-size operators and large step-size operators. Small step-size operators can modify the position and/or the direction of the tasks within one or two route plans. In contrast, large step-size operators are able to modify more than two route plans. The most commonly used small step-size operators in the literature, which are used in this work as well, are inversion, (single) insertion, swap, and two-opt operators [
6,
7,
8]. In this work, a novel small step-size operator is used as well, the sub-route plan operator, which is introduced in this work, in
Section 5. The only large step-size operator used in this work is merge-split, which was introduced in [
6]. It is called a large-step-size operator, since it is able to modify more than two route plans.
The inversion and the sub-route operators can only change the direction and the order of the tasks within one route plan, so they do not change the feasibility of the solution. In contrast, the insertion, the swap, and the two-opt operators may change the amount of demand that needs to be served in some of the route plans, so the feasibility of the solution may change, too. For this reason, based on the settings, the output solution of these operators could be different. If infeasible solutions are not accepted and the calculated output solution is infeasible, then the operator returns the original, input solution instead (assuming that the input solution is a feasible solution).
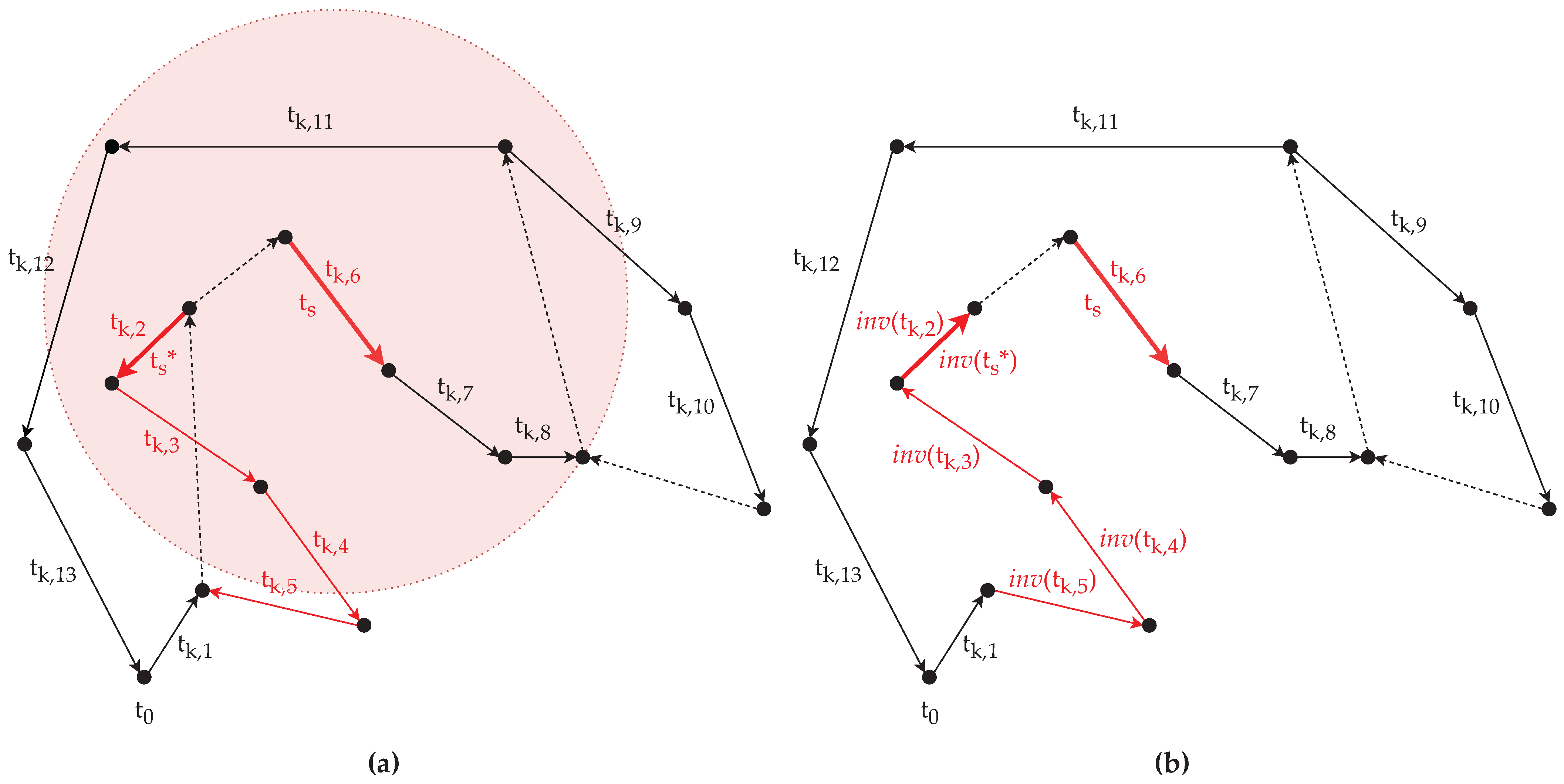
3.4.1. Inversion Operator
The inversion operator randomly selects a task within the input solution. If this task has an inverse (i.e., ), then the operator replaces t with within the solution, else it returns the input solution.
3.4.2. Insertion Operator
The insertion operator randomly selects a task , then replaces (inserts) it before or after another randomly selected task within the input solution. The selected tasks can be in different route plans or in the same route plan, but they cannot be the same tasks (i.e., ).
It creates two potential output solutions, based on where is inserted (before or after ). If has an inverse, then the operator creates other potential output solutions, which contains the inverse task of the task (i.e., ) instead of . It selects the solution as the output solution which has the smallest total cost among the potential output solutions.
3.4.3. Swap Operator
The swap operator randomly selects two tasks ( and , where ), then replaces them with each other (i.e., swaps them). Similarly to the insertion operator, the selected tasks can be from the same route plan or different route plans, but they cannot be the same tasks.
It creates potential output solutions, which contain one or two inverse task(s) of the selected tasks instead of the task(s). All the four possible combinations are considered. It selects the solution as the output solution which has the smallest total cost among the potential output solutions.
3.4.4. Two-Opt Operator
The two-opt operator randomly selects two route plans (e.g., and ) of the solution. Based on the selected two route plans, two cases exist for this move operator. If the selected two route plans are the same (i.e., ), then a sub-route plan (i.e., a part of the route plan) is selected randomly and its direction is reversed. If the selected two route plans are different (i.e., ), then these two route plans are randomly cut into four sub-route plans, and then two new potential output solutions are generated by reconnecting the four sub-route plans and the best one from them is selected. For example, and are cut into sub-route plans and , respectively. Two new solutions are generated by connecting them in the following ways: (1) with and with and (2) with reversed and reversed with .
3.4.5. Merge-split Operator
As it was mentioned before, the merge-split operator can make large changes in the solution (e.g., it can modify the order of all the tasks within one or more route plans), so it is considered a large step-size operator. This operator randomly selects
x number of different route plans in the input solution, where
x is a random number (
). It obtains an unordered list of tasks by merging the tasks of the selected route plans into one list, and then sorts this unordered list with a path scanning heuristic (e.g., [
22], which is used in this work as well). The obtained ordered list is then optimally split into new route plans using Ulusoy’s splitting procedure [
24].
The ordered list is constructed by the path scanning heuristic the following way. First, an empty path is initialized, then, the affected tasks are added one by one into the current path, until no tasks are left in the unordered list. In each iteration, only those tasks are taken into account that can be added to the current path without breaking the capacity constraint. If there are no any tasks like that, then the depot is added to the current path and a new path is initialized (that becomes the current path). When a task or the depot is added to the current path, the task/depot is connected to the end of the current path with the shortest path between them. If there are multiple tasks that can be added, the one that is closest to the end of the current path is added. If there are multiple tasks that are closest to the end of the current path, then one of the following rules are applied to determine which task should be added next:
- 1.
maximize the distance between and ;
- 2.
minimize the distance between and ;
- 3.
maximize the term ;
- 4.
minimize the term ;
- 5.
use rule 1, if the vehicle is less than half-full, otherwise use rule 2.
In the rules above, t () is a task and () is the depot. In one run, only one of the rules can be used. Therefore, the path scanning heuristic is ran five times, which results in five ordered lists.
The Ulusoy’s splitting procedure creates five new candidate output solutions from the five ordered lists by splitting the lists into route plans. How the procedure works is best summarized in [
50]. The procedure starts with constructing the Directed Acyclic Graph (DAG) from the ordered list. A DAG is a graph with arcs that represent feasible sub-tours of one giant tour. Next, the shortest path through the graph is calculated, which gives the optimal partition of the giant tour into feasible route plans. As the final step, a new candidate solution is created from the untouched route plans of the input solution and the route plans returned by the procedure. From the five candidate solutions the best one is chosen and returned by the operator.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









