
Exemplar-Based Sketch Colorization with Cross-Domain Dense Semantic Correspondence





Abstract
:1. Introduction
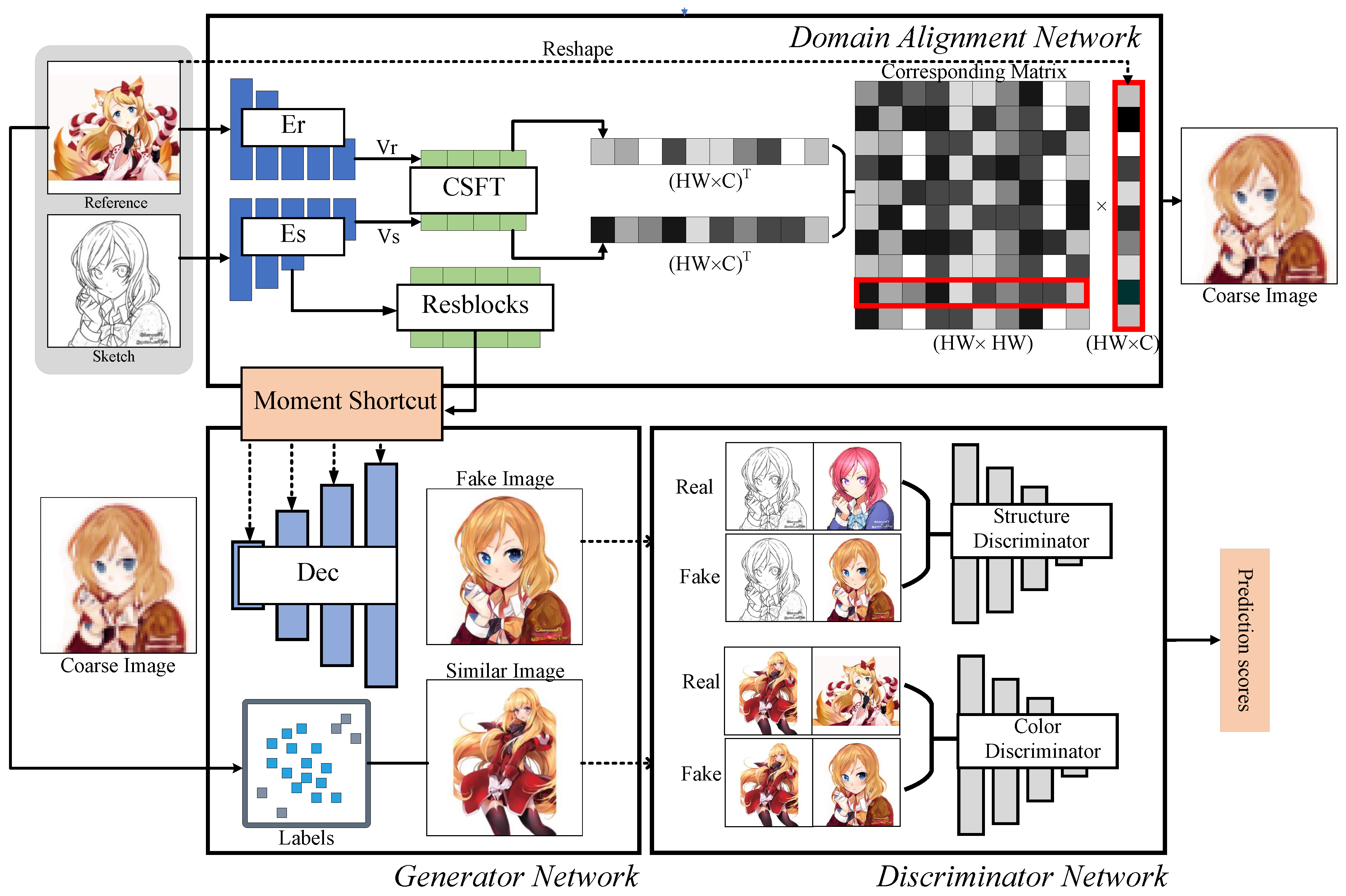
- The cross-domain alignment module is proposed for imposing the distinct domain to a shared, embedded space for progressively aligning and outputting the warped image in a coarse-to-fine manner.
- To facilitate the establishment of dense correspondence, we proposed an explicit style transfer module utilizing self attention-based pixel-wise feature transfer mechanism, which we term the cross-domain spatially feature transfer module (CSFT).
- We proposed a specific adversarial strategy for exemplar-based sketch colorization to facilitate the imaging quality and stabilize the adversarial training.
2. Related Work
2.1. Image-to-Image Translation
2.2. Sketch-Based Tasks
2.3. Exemplar-Based Image Synthesis
3. Proposed Method
3.1. Domain Alignment Network
3.1.1. Domain Alignment
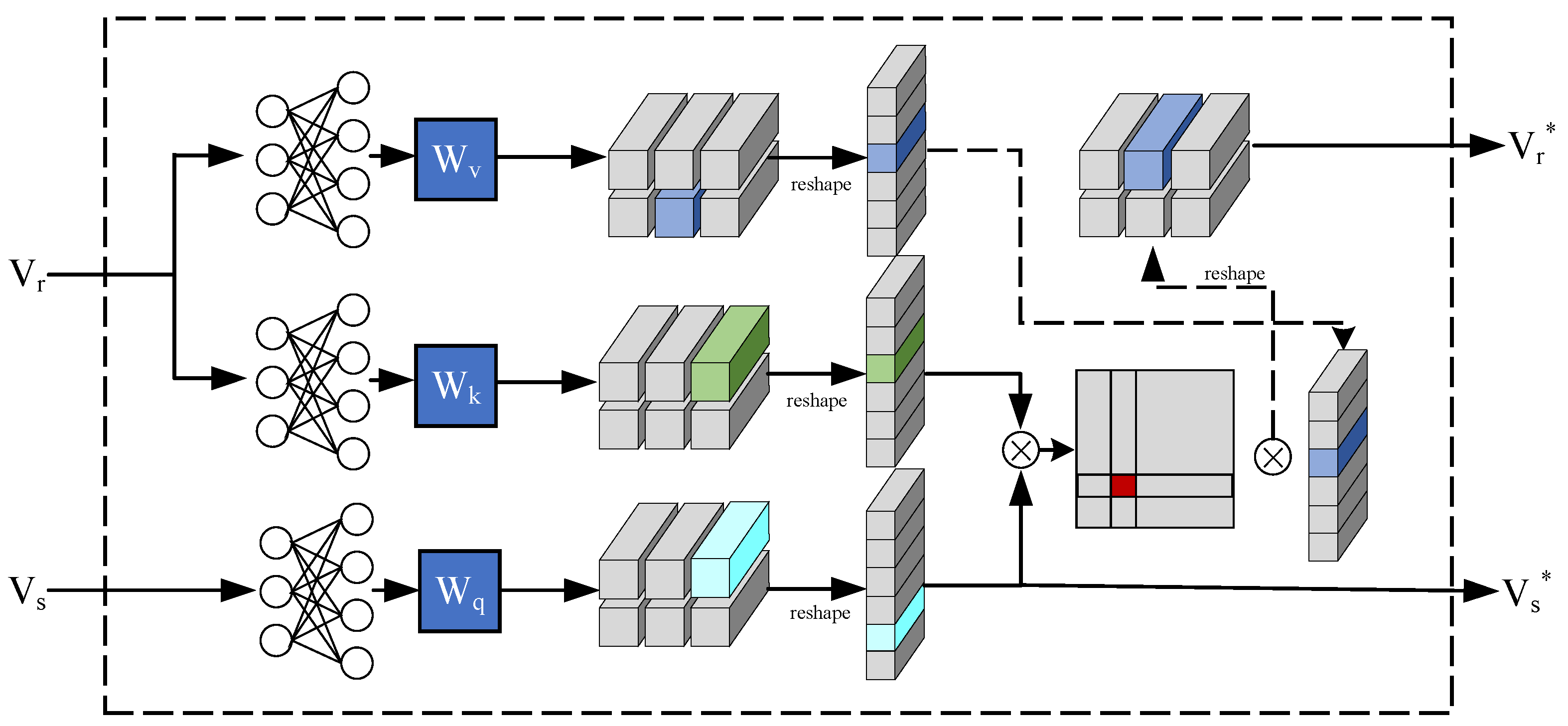
3.1.2. Dense Correspondence
3.1.3. Cross-Domain Spatially Feature Transfer
3.2. Coarse-to-Fine Generator
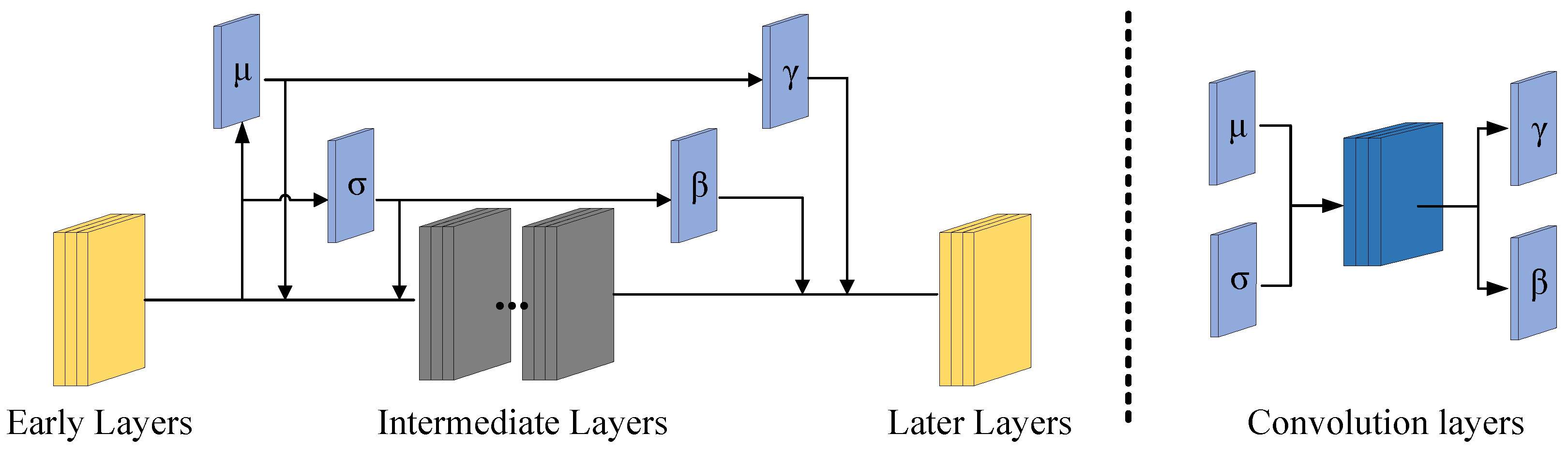
Dynamic Moment Shortcut
3.3. Structural and Colorific Strategy
3.3.1. Structural Condition
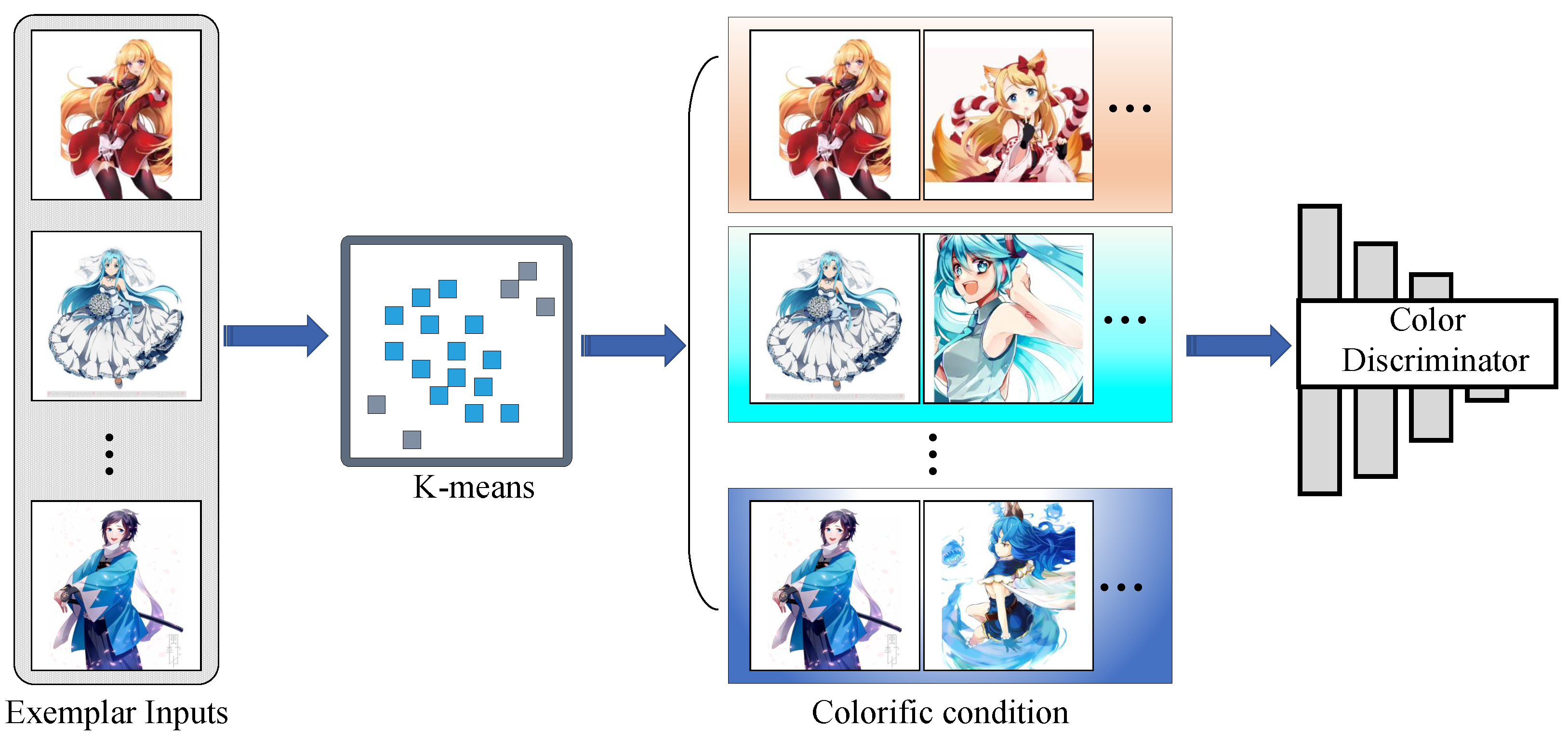
3.3.2. Colorific Condition
3.3.3. Structural and Colorific Discriminators
3.4. Loss for Exemplar-Based Sketch Colorization
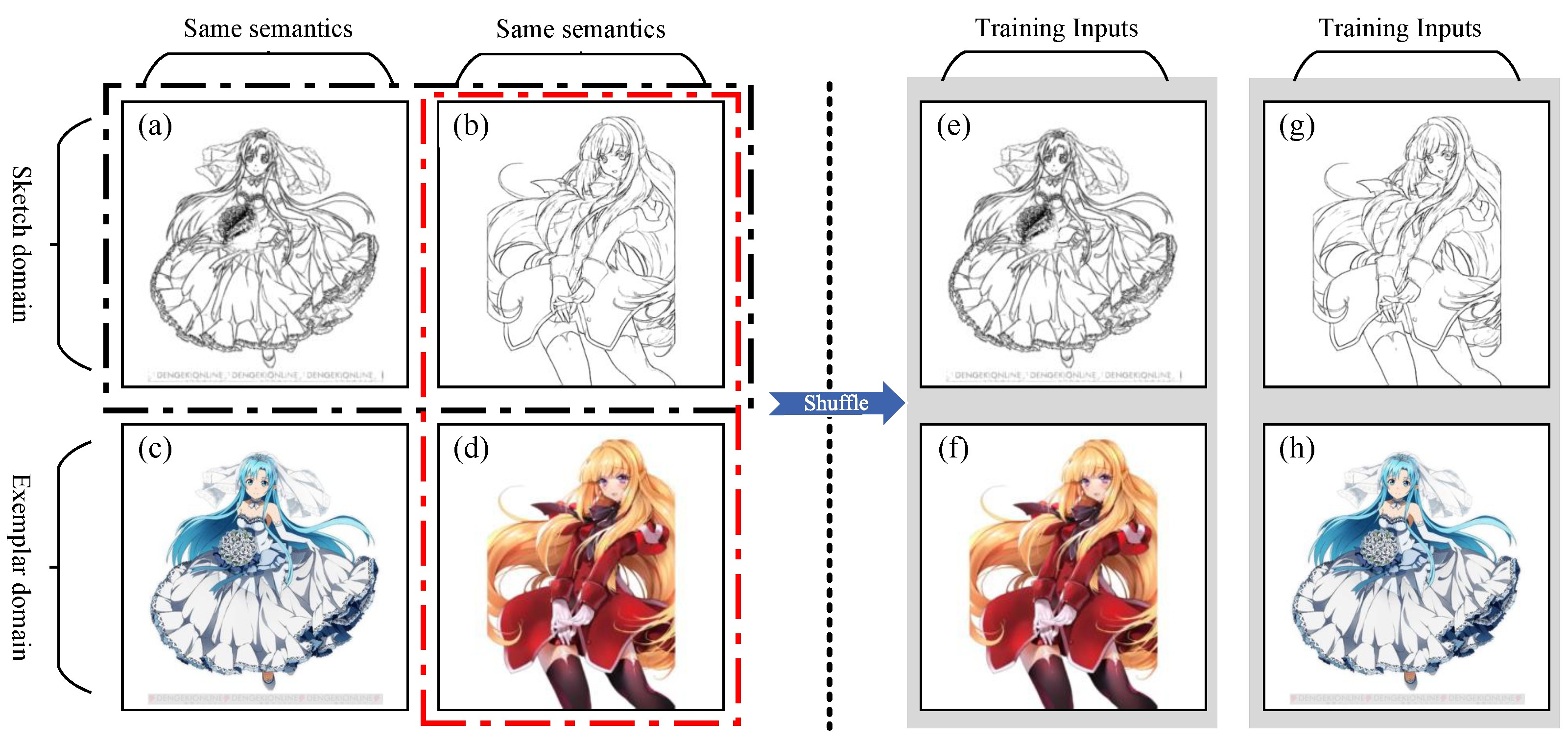
3.4.1. Loss for Exemplar Translation
3.4.2. Loss for Pseudo Reference Pairs
3.4.3. Loss for Domain Alignment
3.4.4. Loss for Adversarial Network
4. Experiments
4.1. Implementation
4.2. Dataset
4.2.1. Anime-Sketch-Colorization-Pair Dataset
4.2.2. Animal Face Dataset
4.2.3. Edge2Shoe Dataset
4.3. Comparisons to Baselines
4.4. Quantitative Evaluation
- Firstly, we use Fréchet Inception Distance (FID) [61] to measure the distance between the synthetic image and the natural image distribution. FID calculated the Wasserstein-2 distance between the two Gaussian distributions in line with the features representation of a pre-trained convolution network InceptionV3 [66]. As Table 2 shows, compared with other excellent models, our proposed model has the best score in FID.
- Peak Signal to Noise Ratio (PSNR) is an engineering term representing the ratio between a signal’s maximum power and the destructive noise power that affects its fidelity. We also evaluate the PSNR index of the models on different datasets, as shown in Table 3, and our model has achieved good performance.
- NDB [68] and JSD [69]. To measure the similarity of the distribution between the real and generated images, we used two bin-based metrics, NDB (Number of Statistically-Different Bins) and JSD (Jensen-Shannon Divergence). These metrics evaluate the degree of pattern missing in the generated model. Our model has achieved good performance, as shown in Table 5.
4.5. Qualitative Comparison
4.6. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| GAN | Generative Adversarial Networks |
| CSFT | Cross-domain Spatially Feature Transfer Module |
References
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A neural algorithm of artistic style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- Gatys, L.; Ecker, A.S.; Bethge, M. Texture synthesis using convolutional neural networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2414–2423. [Google Scholar]
- Wen, J.; Xu, Y.; Li, Z.; Ma, Z.; Xu, Y. Inter-class sparsity based discriminative least square regression. Neural Netw. 2018, 102, 36–47. [Google Scholar] [CrossRef] [PubMed]
- Gatys, L.A.; Ecker, A.S.; Bethge, M.; Hertzmann, A.; Shechtman, E. Controlling perceptual factors in neural style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3985–3993. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Ci, Y.; Ma, X.; Wang, Z.; Li, H.; Luo, Z. User-guided deep anime line art colorization with conditional adversarial networks. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 1536–1544. [Google Scholar]
- Zhang, L.; Li, C.; Simo-Serra, E.; Ji, Y.; Wong, T.-T.; Liu, C. User-guided line art flat filling with split filling mechanism. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Event, 19–25 June 2021; pp. 9889–9898. [Google Scholar]
- Hati, Y.; Jouet, G.; Rousseaux, F.; Duhart, C. Paintstorch: A user-guided anime line art colorization tool with double generator conditional adversarial network. In Proceedings of the European Conference on Visual Media Production, London, UK, 17–18 December 2019; pp. 1–10. [Google Scholar]
- Yuan, M.; Simo-Serra, E. Line art colorization with concatenated spatial attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Event, 19–25 June 2021; pp. 3946–3950. [Google Scholar]
- Zhang, R.; Zhu, J.-Y.; Isola, P.; Geng, X.; Lin, A.S.; Yu, T.; Efros, A.A. Real-time user-guided image colorization with learned deep priors. arXiv 2017, arXiv:1705.02999. [Google Scholar] [CrossRef]
- Xiao, Y.; Zhou, P.; Zheng, Y.; Leung, C.-S. Interactive deep colorization using simultaneous global and local inputs. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1887–1891. [Google Scholar]
- Chen, J.; Shen, Y.; Gao, J.; Liu, J.; Liu, X. Language-based image editing with recurrent attentive models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8721–8729. [Google Scholar]
- Kim, H.; Jhoo, H.Y.; Park, E.; Yoo, S. Tag2pix: Line art colorization using text tag with secat and changing loss. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9056–9065. [Google Scholar]
- Zou, C.; Mo, H.; Gao, C.; Du, R.; Fu, H. Language-based colorization of scene sketches. ACM Trans. Graph. (TOG) 2019, 38, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Kim, E.; Lee, Y.; Kim, D.; Chang, J.; Choo, J. Reference-based sketch image colorization using augmented-self reference and dense semantic correspondence. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 5801–5810. [Google Scholar]
- Bugeau, A.; Ta, V.-T.; Papadakis, N. Variational exemplar-based image colorization. IEEE Trans. Image Process. 2013, 23, 298–307. [Google Scholar] [CrossRef] [Green Version]
- Charpiat, G.; Hofmann, M.; Schölkopf, B. Automatic image colorization via multimodal predictions. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 126–139. [Google Scholar]
- Liu, X.; Wan, L.; Qu, Y.; Wong, T.-T.; Lin, S.; Leung, C.-S.; Heng, P.-A. Intrinsic colorization. In Proceedings of the ACM SIGGRAPH Asia 2008 Papers, Singapore, 10–13 December 2008; pp. 1–9. [Google Scholar]
- Tomasi, C.; Manduchi, R. Bilateral filtering for gray and color images. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No. 98CH36271), Bombay, India, 1 January 1998; pp. 839–846. [Google Scholar]
- Winnemöller, H.; Olsen, S.C.; Gooch, B. Real-time video abstraction. ACM Trans. Graph. (TOG) 2006, 25, 1221–1226. [Google Scholar] [CrossRef]
- Zhao, M.; Zhu, S.-C. Portrait painting using active templates. In Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Non-Photorealistic Animation and Rendering, Vancouver, BC, Canada, 5–7 August 2011; pp. 117–124. [Google Scholar]
- He, M.; Chen, D.; Liao, J.; Sander, P.V.; Yuan, L. Deep exemplar-based colorization. ACM Trans. Graph. (TOG) 2018, 37, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Jia, X.; Georgoulis, S.; Tuytelaars, T.; Gool, L.V. Exemplar guided unsupervised image-to-image translation with semantic consistency. arXiv 2018, arXiv:1805.11145. [Google Scholar]
- Park, T.; Liu, M.-Y.; Wang, T.-C.; Zhu, J.-Y. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2337–2346. [Google Scholar]
- Qi, X.; Chen, Q.; Jia, J.; Koltun, V. Semi-parametric image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8808–8816. [Google Scholar]
- Zhang, B.; He, M.; Liao, J.; Sander, P.V.; Yuan, L.; Bermak, A.; Chen, D. Deep exemplar-based video colorization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8052–8061. [Google Scholar]
- Hertzmann, A.; Jacobs, C.E.; Oliver, N.; Curless, B.; Salesin, D.H. Image analogies. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 12–17 August 2001; pp. 327–340. [Google Scholar]
- Liao, J.; Yao, Y.; Yuan, L.; Hua, G.; Kang, S.B. Visual attribute transfer through deep image analogy. arXiv 2017, arXiv:1705.01088. [Google Scholar] [CrossRef] [Green Version]
- Sun, T.-H.; Lai, C.-H.; Wong, S.-K.; Wang, Y.-S. Adversarial colorization of icons based on contour and color conditions. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 683–691. [Google Scholar]
- Wang, M.; Yang, G.-Y.; Li, R.; Liang, R.-Z.; Zhang, S.-H.; Hall, P.M.; Hu, S.-M. Example-guided style-consistent image synthesis from semantic labeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1495–1504. [Google Scholar]
- Wen, J.; Zhang, Z.; Xu, Y.; Zhang, B.; Fei, L.; Liu, H. Unified embedding alignment with missing views inferring for incomplete multi-view clustering. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, Hawail, USA, 27 January–1 February 2019; Volume 33, pp. 5393–5400. [Google Scholar]
- Li, B.; Wu, F.; Weinberger, K.Q.; Belongie, S. Positional normalization. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Wang, T.-C.; Liu, M.-Y.; Zhu, J.-Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8798–8807. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1857–1865. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Liu, M.-Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.-W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8789–8797. [Google Scholar]
- Yelamarthi, S.K.; Reddy, S.K.; Mishra, A.; Mittal, A. A zero-shot framework for sketch based image retrieval. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 300–317. [Google Scholar]
- Dutta, A.; Akata, Z. Semantically tied paired cycle consistency for zero-shot sketch-based image retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5089–5098. [Google Scholar]
- Chen, W.; Hays, J. Sketchygan: Towards diverse and realistic sketch to image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9416–9425. [Google Scholar]
- Lu, Y.; Wu, S.; Tai, Y.-W.; Tang, C.-K. Image generation from sketch constraint using contextual gan. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 205–220. [Google Scholar]
- Liu, F.; Deng, X.; Lai, Y.-K.; Liu, Y.-J.; Ma, C.; Wang, H. Sketchgan: Joint sketch completion and recognition with generative adversarial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5830–5839. [Google Scholar]
- Frans, K. Outline colorization through tandem adversarial networks. arXiv 2017, arXiv:1704.08834. [Google Scholar]
- Zhang, L.; Ji, Y.; Lin, X.; Liu, C. Style transfer for anime sketches with enhanced residual u-net and auxiliary classifier gan. In Proceedings of the 2017 4th IAPR Asian Conference on Pattern Recognition (ACPR), Nanjing, China, 26–29 November 2017; pp. 506–511. [Google Scholar]
- Lian, J.; Cui, J. Anime style transfer with spatially-adaptive normalization. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Liu, M.; Ding, Y.; Xia, M.; Liu, X.; Ding, E.; Zuo, W.; Wen, S. Stgan: A unified selective transfer network for arbitrary image attribute editing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Huang, X.; Liu, M.-Y.; Belongie, S.; Kautz, J. Multimodal unsupervised image-to-image translation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 172–189. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Lee, J.; Kim, D.; Ponce, J.; Ham, B. Sfnet: Learning object-aware semantic correspondence. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2278–2287. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Chen, T.; Lucic, M.; Houlsby, N.; Gelly, S. On self modulation for generative adversarial networks. arXiv 2018, arXiv:1810.01365. [Google Scholar]
- Kim, T.; Song, I.; Bengio, Y. Dynamic layer normalization for adaptive neural acoustic modeling in speech recognition. arXiv 2017, arXiv:1707.06065. [Google Scholar]
- Winnemöller, H.; Kyprianidis, J.E.; Olsen, S.C. Xdog: An extended difference-of-gaussians compendium including advanced image stylization. Comput. Graph. 2012, 36, 740–753. [Google Scholar] [CrossRef] [Green Version]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.; Ebrahimi, M. Edgeconnect: Structure guided image inpainting using edge prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Sajjadi, M.S.; Scholkopf, B.; Hirsch, M. Enhancenet: Single image super-resolution through automated texture synthesis. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4491–4500. [Google Scholar]
- Zhang, P.; Zhang, B.; Chen, D.; Yuan, L.; Wen, F. Cross-domain correspondence learning for exemplar-based image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Sealttle, WA, USA, 16–18 June 2020; pp. 5143–5153. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Kim, T. Anime Sketch Colorization Pair. Available online: https://www.kaggle.com/datasets/ktaebum/anime-sketch-colorization-pair (accessed on 1 June 2019).
- Choi, Y.; Uh, Y.; Yoo, J.; Ha, J.-W. Stargan v2: Diverse image synthesis for multiple domains. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Sealttle, WA, USA, 16–18 June 2020. [Google Scholar]
- Yu, A.; Grauman, K. Fine-Grained Visual Comparisons with Local Learning. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mao, Q.; Lee, H.-Y.; Tseng, H.-Y.; Ma, S.; Yang, M.-H. Mode seeking generative adversarial networks for diverse image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1429–1437. [Google Scholar]
- Fuglede, B.; Topsoe, F. Jensen-shannon divergence and hilbert space embedding. In Proceedings of the IEEE International Symposium onInformation Theory, ISIT 2004. Proceedings, Chicago, IL, USA, 27 June–2 July 2004; p. 31. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | FID ↓ | PSNR ↑ | SSIM ↑ | NDB ↓ | JSD ↓ | |
|---|---|---|---|---|---|---|
| Animal Faces | Cat | 25.64 | 11.90 | 0.53 | 2.21 | 0.018 |
| Dog | 26.65 | 12.77 | 0.62 | 2.54 | 0.021 | |
| Wild | 27.41 | 11.96 | 0.64 | 3.12 | 0.028 | |
| Comics | Anime-pair | 19.14 | 16.44 | 0.83 | 2.00 | 0.016 |
| Hand-drawn | Edge2shoe | 15.69 | 16.72 | 0.83 | 2.01 | 0.015 |
| Animal Face | Comics | Hand-Drawn | |||
|---|---|---|---|---|---|
| Methods | Cat | Dog | Wild | Anime-Pair | edge2shoe |
| SPADE | 42.52 | 37.39 | 47.41 | 58.62 | 32.55 |
| MUINT | 33.48 | 32.45 | 42.54 | 37.45 | 29.47 |
| CycleGAN | 70.44 | 80.54 | 88.19 | 106.45 | 70.96 |
| Sun et al. | 48.45 | 45.45 | 55.69 | 67.65 | 38.46 |
| Cocos Net | 29.47 | 30.11 | 27.56 | 24.93 | 19.64 |
| Ours(w/o ) | 28.12 | 26.42 | 29.13 | 28.13 | 18.77 |
| Ours(w/o ) | 30.34 | 30.58 | 33.65 | 24.95 | 22.98 |
| Ours(w/o CSFT) | 33.54 | 36.21 | 34.21 | 30.96 | 24.16 |
| Ours() | 25.64 | 26.65 | 27.41 | 19.14 | 15.69 |
| Animal Face | Comics | Hand-Drawn | |||
|---|---|---|---|---|---|
| Methods | Cat | Dog | Wild | Anime-Pair | edge2shoe |
| SPADE | 9.89 | 7.68 | 9.54 | 11.57 | 10.15 |
| MUINT | 10.32 | 10.45 | 9.59 | 12.96 | 12.11 |
| CycleGAN | 8.47 | 8.21 | 7.68 | 10.11 | 10.01 |
| Sun et al. | 9.36 | 10.45 | 10.42 | 12.41 | 13.34 |
| Cocos Net | 11.21 | 11.44 | 11.69 | 14.65 | 16.73 |
| Ours | 11.90 | 12.77 | 11.96 | 16.44 | 16.72 |
| Animal Face | Comics | Hand-Drawn | |||
|---|---|---|---|---|---|
| Methods | Cat | Dog | Wild | Anime-Pair | edge2shoe |
| SPADE | 0.42 | 0.44 | 0.42 | 0.40 | 0.40 |
| MUINT | 0.62 | 0.60 | 0.66 | 0.71 | 0.70 |
| CycleGAN | 0.51 | 0.51 | 0.52 | 0.50 | 0.50 |
| Sun et al. | 0.52 | 0.61 | 0.59 | 0.70 | 0.71 |
| Cocos Net | 0.53 | 0.62 | 0.63 | 0.81 | 0.82 |
| Ours | 0.53 | 0.62 | 0.64 | 0.83 | 0.83 |
| Animal Face | Comics | Hand-Drawn | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Methods | Cat | Dog | Wild | Anime-Pair | edge2shoe | |||||
| NDB | JSD | NDB | JSD | NDB | JSD | NDB | JSD | NDB | JSD | |
| SPADE | 4.14 | 0.035 | 3.14 | 0.030 | 3.68 | 0.032 | 4.34 | 0.041 | 4.00 | 0.033 |
| MUINT | 2.25 | 0.020 | 3.01 | 0.029 | 3.01 | 0.029 | 3.51 | 0.029 | 2.54 | 0.019 |
| CycleGAN | 4.45 | 0.041 | 4.56 | 0.041 | 4.51 | 0.040 | 5.12 | 0.048 | 4.87 | 0.047 |
| Sun et al. | 4.41 | 0.040 | 4.11 | 0.039 | 3.47 | 0.035 | 3.41 | 0.030 | 3.28 | 0.020 |
| Cocos Net | 2.20 | 0.018 | 2.59 | 0.022 | 3.01 | 0.024 | 2.36 | 0.018 | 2.01 | 0.015 |
| Ours | 2.21 | 0.018 | 2.54 | 0.021 | 3.12 | 0.028 | 2.00 | 0.016 | 2.01 | 0.015 |
| Animal Face | Comics | Hand-Drawn | |||
|---|---|---|---|---|---|
| Loss Function | Cat | Dog | Wild | Anime-Pair | edge2shoe |
| w/o | 40.68 | 52.65 | 50.52 | 33.51 | 32.69 |
| w/o | 25.87 | 26.85 | 28.65 | 19.14 | 15.77 |
| w/o | 40.74 | 37.37 | 46.49 | 51.62 | 42.55 |
| w/o | 42.51 | 38.39 | 47.44 | 58.68 | 44.55 |
| 25.64 | 26.65 | 27.41 | 19.14 | 15.69 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, J.; Zhong, H.; Liu, H.; Fu, Y. Exemplar-Based Sketch Colorization with Cross-Domain Dense Semantic Correspondence. Mathematics 2022, 10, 1988. https://doi.org/10.3390/math10121988
Cui J, Zhong H, Liu H, Fu Y. Exemplar-Based Sketch Colorization with Cross-Domain Dense Semantic Correspondence. Mathematics. 2022; 10(12):1988. https://doi.org/10.3390/math10121988
Chicago/Turabian StyleCui, Jinrong, Haowei Zhong, Hailong Liu, and Yulu Fu. 2022. "Exemplar-Based Sketch Colorization with Cross-Domain Dense Semantic Correspondence" Mathematics 10, no. 12: 1988. https://doi.org/10.3390/math10121988
APA StyleCui, J., Zhong, H., Liu, H., & Fu, Y. (2022). Exemplar-Based Sketch Colorization with Cross-Domain Dense Semantic Correspondence. Mathematics, 10(12), 1988. https://doi.org/10.3390/math10121988