All articles published by MDPI are made immediately available worldwide under an open access license. No special
permission is required to reuse all or part of the article published by MDPI, including figures and tables. For
articles published under an open access Creative Common CC BY license, any part of the article may be reused without
permission provided that the original article is clearly cited. For more information, please refer to
https://www.mdpi.com/openaccess.
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature
Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for
future research directions and describes possible research applications.
Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive
positive feedback from the reviewers.
Editor’s Choice articles are based on recommendations by the scientific editors of MDPI journals from around the world.
Editors select a small number of articles recently published in the journal that they believe will be particularly
interesting to readers, or important in the respective research area. The aim is to provide a snapshot of some of the
most exciting work published in the various research areas of the journal.
In this paper, we propose a deep wavelet neural network (DWNN) model to approximate the natural phenomena that are described by some classical PDEs. Concretely, we introduce wavelets to deep architecture to obtain a fine feature description and extraction. That is, we constructs a wavelet expansion layer based on a family of vanishing momentum wavelets. Second, the Gaussian error function is considered as the activation function owing to its fast convergence rate and zero-centered output. Third, we design the cost function by considering the residual of governing equation, the initial/boundary conditions and an adjustable residual term of observations. The last term is added to deal with the shock wave problems and interface problems, which is conducive to rectify the model. Finally, a variety of numerical experiments are carried out to demonstrate the effectiveness of the proposed approach. The numerical results validate that our proposed method is more accurate than the state-of-the-art approach.
Partial differential equations (PDEs) play an important role in modeling of various disciplines, especially in physics, chemistry, engineering, economics, etc., [1,2]. However, it is difficult to find the analytical solution of PDEs. Thus, traditional numerical methods, such as finite volume method (FVM) [3], finite difference method (FDM) [4], and finite element method (FEM) [5], are applied to obtain the approximated solution. A typical implementation of mesh-based numerical methods follows three steps: (1) grid generation; (2) discretization of governing equation; and (3) solving by some iterative methods. The advantages of traditional methods lie in their reliability and sufficient mathematical support. Although these methods are powerful and rigorous, there may exist “dimension explosion” when the dimension of independent variable grows. Moreover, the computational complexity may increase exponentially with grid refinement.
In recent decades, neural networks have made remarkable achievements in various fields, such as natural language processing [6], image recognition [7], and sequential actions processing [8,9], etc. Since neural networks have excellent performance in dealing with high-dimensional data, it is natural to consider the neural network as the solver for PDEs. There are four aspects support this view. First, being a universal approximator, the neural network can represent natural phenomena that are described by classical PDEs. Second, the approximated solution obtained by the neural network is continuous over the whole domain of integration. Third, computational complexity does not increase exponentially with the increase of sampling points. Finally, the neural network is a meshfree algorithm, which means it is able to overcome the dimension explosion and solve the equation of complex geometries well. Based on these properties, neural network have been used to solve partial differential equations in recent years. For example, Lagaris et al. [10] use an artificial neural network to solve differential equations (DEs). The trial solution of DEs is decomposed into two parts, where one part satisfies initial/boundary conditions and the other part is the product of a mapping parameterized as a neural network and a defined function that vanishes on the boundary. Further, they propose a method to solve partial differential equations with irregular boundary via multi-layer perceptron (MLP) and radial basis function (RBF) neural network [11]. Mai-Duy and Tran-Cong [12] obtain numerical solution of DEs using multiquadric radial basis function neural network. Then, they propose direct radial basis function network (DRBFN) and indirect radial basis function network (IRBFN) to solve differential equations [13].
In order to reduce the scale of network parameter set and improve the computational efficiency, the Functional Link Artificial Neural Network (FLANN) model was introduced [14]. In this model, the actual hidden layer in the neural network is eliminated. The input pattern is transformed to higher-dimensional pattern by using orthogonal polynomials. In 2016, Mall and Chakraverty [15] solved ordinary differential equations via Legendre neural network. They removed the hidden layer and extend the original input pattern to an higher dimensional by Legendre polynomials. Later, they proposed the Chebyshev neural network (ChNN) model to solve partial differential equations; to be more specific, elliptic PDEs [16]. The hidden layer is replaced by a functional extension block and this block is based on Chebyshev polynomial. Then, Sun et al. [17] used Bernstein neural network (BeNN) to solve elliptic PDEs as well, replacing Chebyshev polynomial with Bernstein basis function. These single-layer models have fewer parameters but they rely on the trial solution. Actually, the trial solution is very hard to construct when the boundary conditions are complicated. Meanwhile, gradient calculations are quite computationally expensive due to the inability to use automatic differential.
Recently, to address the above-mentioned issues, E and Han [18,19,20,21] proposed a deep learning-based method to solve various types of high-dimensional PDEs. Sirignano et al. [22] present deep Galerkin method which combines deep learning and Galerkin method to solve high-dimensional free-boundary PDEs. Zang et al. [23] solved high-dimensional PDEs with irregular domains using a weak adversarial network. Raissi et al. [24] developed a PDE solver named physics-informed neural network (PINN). In PINNs, the cost function is enriched by adding residuals from the governing equation, which serves as regularization constraints limiting the space of acceptable solutions to a manageable size. Meng et al. [25] solved time-dependent PDEs via parareal physics-informed neural network, which decomposes the long-time problem into lots of short-time problems. Jagtap et al. [26] applied conservative physics-informed neural networks to forward and inverse problems. While the PINNs algorithm is now recognized as an effective approach, they are not equipped with bulit-in data processing mechanism, which may restrict their robustness and generalization capability. In addition, the different scenarios, such as interface and shock wave, may not be accurately handled. It should be pointed out that wavelet transform is a kind of signal analysis methods, which has localization properties in both the time domain and the frequency domain. It is an efficient approach to analyze local features [27,28]. Therefore, our method constructs a deep wavelet neural network on the basis of PINNs to make use of the remarkable ability of wavelets to extract multi-scale features and detailed features, which has a better performance.
In this paper, we propose a new numerical method based on DWNN to solve partial differential equations. First, we introduce wavelets to PINNs to obtain a fine feature description and extraction because wavelets offer an effective way to process non-stationary signal [29,30]. In DWNN, the input data primarily flows through a functional expansion layer based on a family of vanishing momentum wavelets for enhancement and then fed into a deep feedforward neural network. Second, in order to improve the rate of convergence, we use Gaussian activation function instead of conventional activation functions. Third, to handle the shock wave problems and interface problems, we add the residual of a few observations into the cost function to rectify models according to article [31]. Finally, a variety of numerical experiments validate the effectiveness of the proposed method. The main contributions are the following:
Introducing wavelet transforms to a deep learning architecture, which is able to obtain a fine feature description and extraction.
Considering the residual of observations into cost function to handle the problems with shock wave and interface.
Utilizing Gaussian error function as the activation function to improve the rate of convergence.
The remainder of this paper is organized as follows. In Section 2, we introduce the basic architecture and learning algorithm of DWNN. In Section 3, we present a series of experimental results on benchmark problems in mathematical physics. Finally, conclusions are incorporated in Section 4.
2. Deep Wavelet Neural Network Model (DWNN)
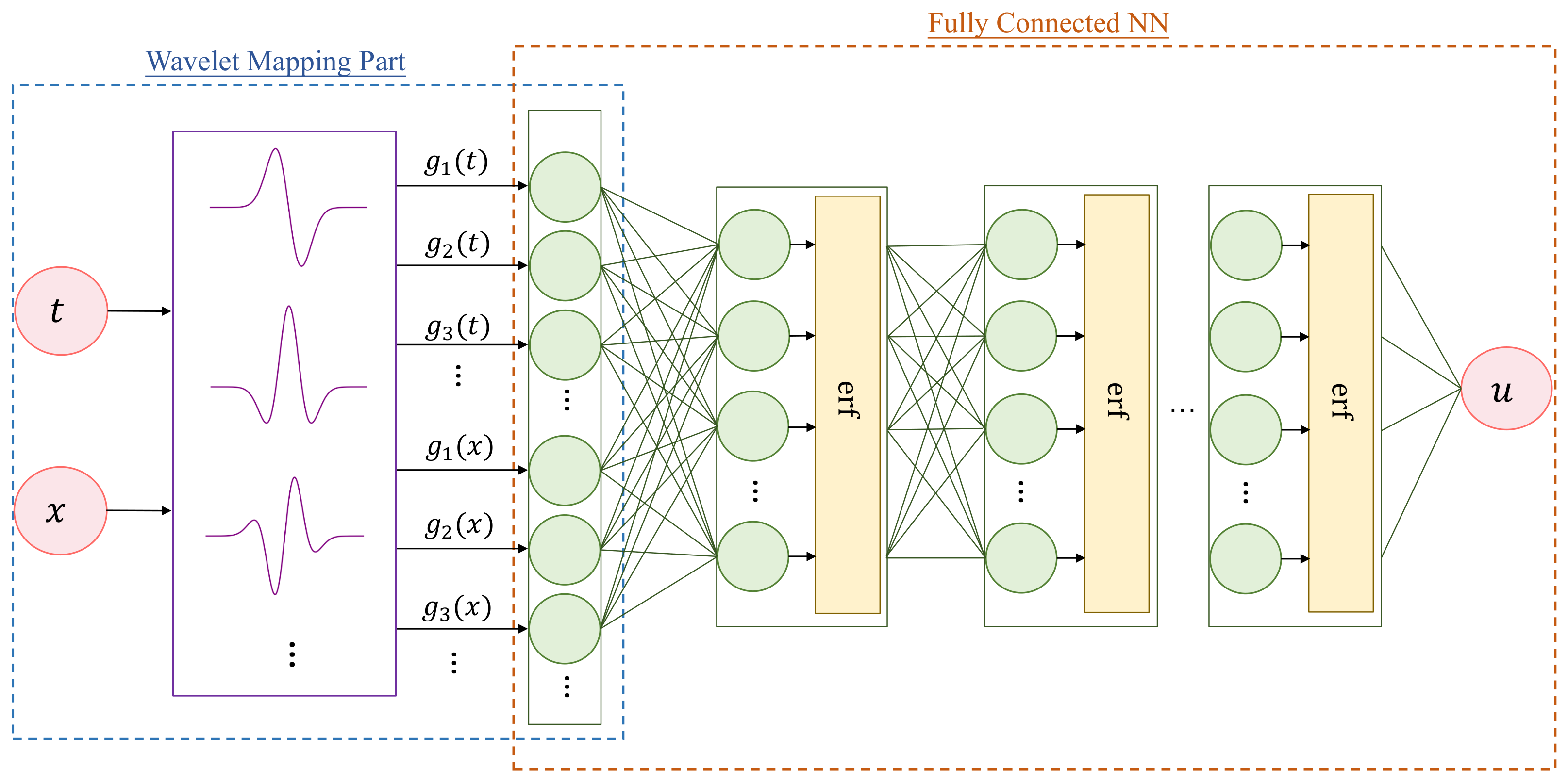
In this section, the basic architecture and the proposed algorithm for solving PDEs are described in detail. Figure 1 shows the structure of DWNN, which is composed of input layer, wavelet expansion layer, fully connected layers and output layer. Specifically, the number of nodes in the input layer is determined by the number of variables. The functional expansion layer is based on a family of wavelets. This is followed by a fully connected neural network. The DWNN model is composed of two modules: one is the wavelet-mapping part and the other is the fully connected part.
2.1. Wavelet Mapping Part
In first part, we map the input data to a higher-dimensional feature space using the family of wavelets. Then, the enhanced pattern is fed into the deep feedforward neural network as new input vectors.
Here, we choose the family of vanishing momentum wavelets (VMWs) [32] for expanding:
where denotes the n-th wavelets. The first two of VMWs are known as
The higher-order VMWs can be calculated by Formula (1):
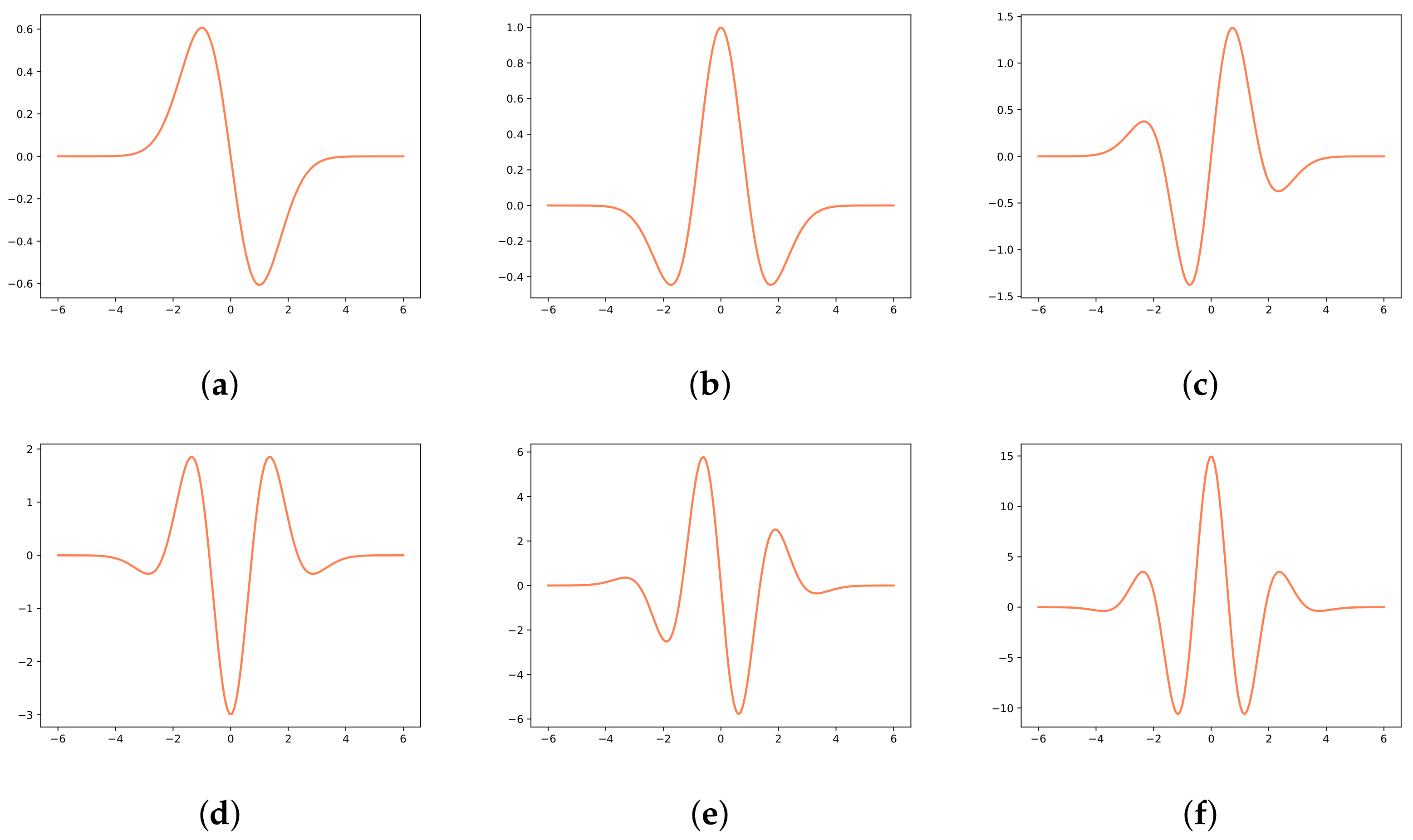
Vanishing momentum wavelets possess a number of significant properties, such as being continuous and differentiable. Moreover, odd-order derivative is an odd function while the even-order derivative is an even function. Both of them are smooth wavelets. Figure 2 presents the waveforms of vanishing momentum wavelets. In practice, the intricate nonlinear behavior of some equations is hard to capture accurately [24]. Hence, we introduce wavelets to deep architecture because wavelet transform can effectively extract more details from the input data and fully highlight some features of the data. Then, around singularities or jumps, the proposed method will make more accurate approximations.
Let as the input pattern, then the enhanced pattern is obtained by using the family of vanishing momentum wavelets as
Thus, the m-dimensional input pattern is mapped to the enhanced n-dimensional pattern (). Figure 1 presents the architecture of DWNN model, where , .
2.2. Fully Connected Neural Network
A fully connected neural network is a kind of fundamental artificial neural network. In this network, all neurons are fully connected between adjacent layers. Supposing an L-layer fully connected neural network, the first layer is the input layer and the last layer is the output layer. Several layers, , are called hidden layers. Each hidden layer in the neural network receives the output from the previous layer:
Then, the nonlinear activation is imposed to the above vector to become a new input sending to the next layer:
Therefore, the information from the input layer is transmitted to the last layer through forward propagation. The final representation of neural network is as follows
where is the parameter set and operator ∘ denotes composition operator.
The optimal approximation performance of the network is obtained by minimizing the cost function to a certain tolerance or up to a specified iterations to find the optimum of weights (w) and biases (b). Specifically, we aim to obtain
where is the cost function. Any optimization method can be used to try to solve this minimization problem. The Newton method is a common optimization method that needs to calculate the second derivative of the objective function, that is, the Hessian matrix. If the Hessian matrix is dense, each iteration requires a large amount of computation and storage space. Moreover, the Newton method is not really robust since the Hessian matrix cannot be guaranteed to always be positive definite. The quasi-Newton method introduces the approximate matrix of the Hessian matrix. The approximate matrix is positive definite, so the algorithm always searches in the direction of the optimal value. However, the computational and storage overhead is still large when the approximate matrix becomes dense. The L-BFGS-B algorithm [33] is an improvement of the quasi-Newton algorithm, which has a small overhead per iteration and fast execution speed. The basic idea is to only save and use the curvature information of the most recent m iterations to construct an approximate matrix of the Hessian matrix. After each iteration, the oldest curvature information is deleted and the newest curvature information is saved. Here, we use L-BFGS-B method [33] to iteratively update the parameter set.
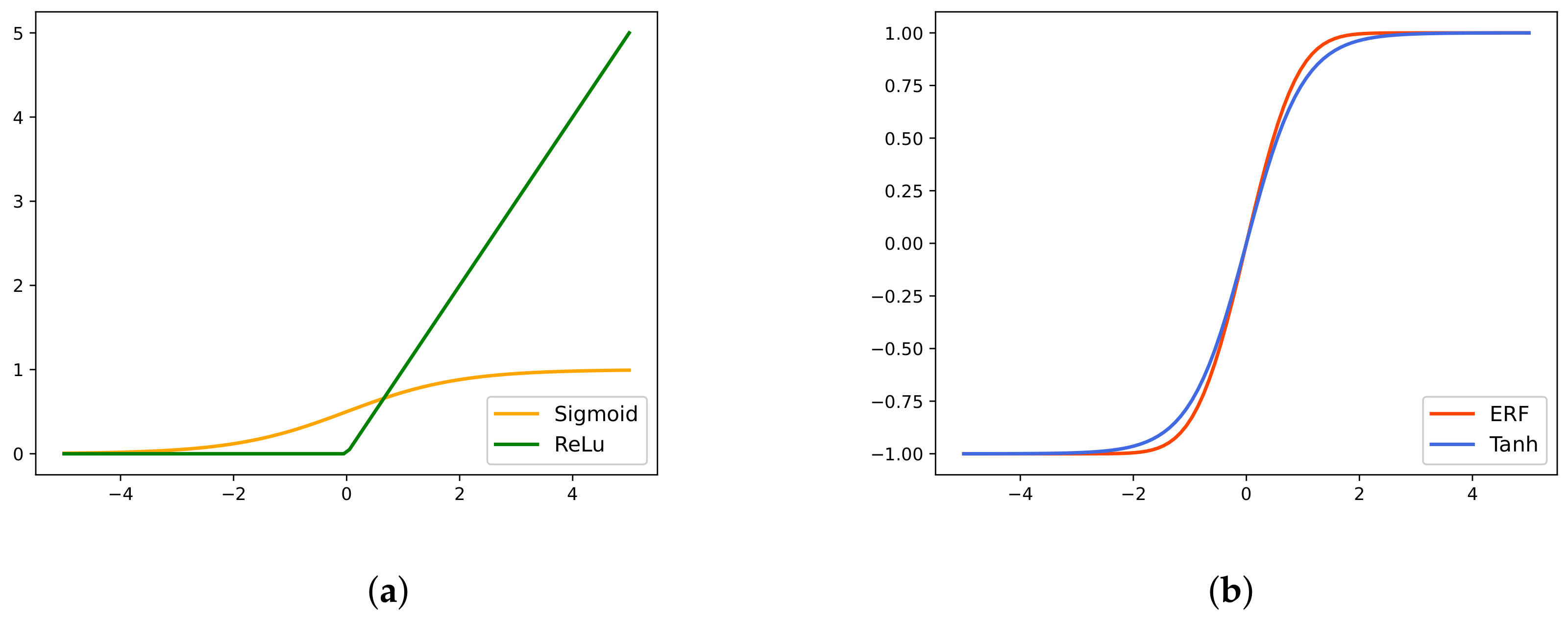
Actually, in the training process of network, the activation function is of great importance because the optimization parameter set depends on the derivative of cost function, which in turn relies on the activation function. The most common activation functions include sigmoid, ReLu, tanh, etc. Figure 3a presents a schematic diagram of sigmoid and ReLu function, from which we see that the output value of sigmoid and ReLu function is not symmetrical about the zero point. Here, we obviously do not want the value obtained by the next neuron to be positive at all times. Figure 3b presents a schematic diagram of tanh and Gaussian error function. The output value of tanh function is symmetric about zero, but the gradient is smooth. Therefore, we find a function whose output value is symmetric about zero, continuous, differentiable, and has a steeper gradient, namely, the Gaussian error function, as the activation function. Under this setting, the convergence rate of the model is accelerated. Gaussian error function is derived from measure theory, which is a special function and broadly applied in probability theory, statistics, etc. [34]. The Gaussian error function with independent variable x is defined as
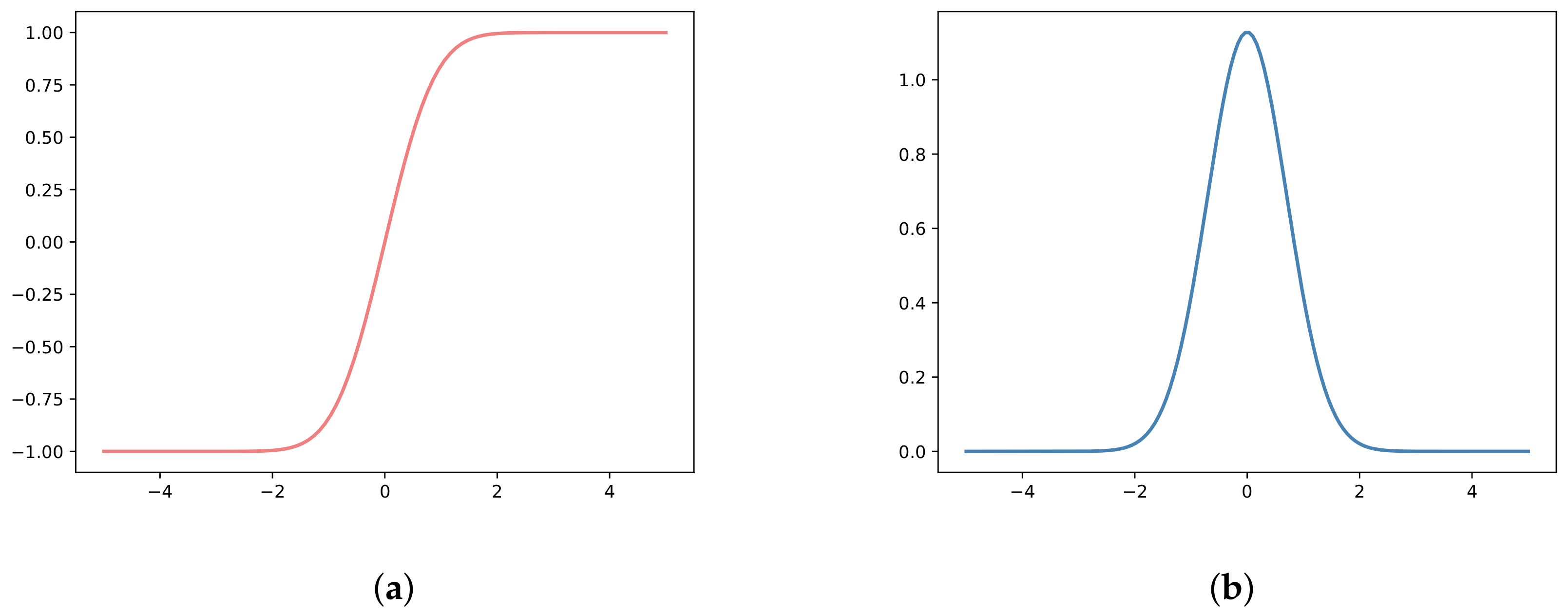
Figure 4a shows a schematic of the Gaussian error function separately. The derivative of Gaussian error function is presented in Figure 4b. It is obvious that the output of Gaussian error function is zero-centered, and the gradient is steep, which accelerates the convergence rate of the model.
The universal approximation theorem [35] states that, for any given tolerance , a DWNN model can be trained such that the resulting approximation error is less than that tolerance . George et al. [36,37] generalize this theorem and present the systematic study of quantitative error bounds. In DWNN model, we apply the wavelet transform to the input coordinates of the input side before fully connected network for multi-scale projection. Then, the lower-dimensional input is mapped to higher-dimensional feature space with no demands on the data. Therefore, the error is still bound by optimization error.
2.3. Loss Function and Algorithm
Assume a PDE given by
where represents differential operator and denotes the boundary of computational domain . Initial and boundary conditions are already known. What we need to approximate is . In PINN [24], is defined by the left-hand-side of Equation (15):
and we can obtain using automatic differentiation [38]. The parameters between and are shared. We seek to approximate the unknown function utilizing the defined model with parameters. The goal is to find the optimum of parameter set that minimizes the properly defined cost function. To be more specific, the cost function is written as
where MSE is defined as
Here, denotes the residual training points on , represents the initial points on , denotes the boundary points on , and denotes the interior training points in the domain of . refers to the number of collocation points, / corresponds to the number of initial/boundary data, and represents the number of observations. The coefficient depends on the governing equation itself and is usually set to 0 or 1. evaluates the degree of inconsistency between the network model and the true value. Concretely, the first term serves as a penalty constraining the solution space, the second and third terms are regarded as the constraints of initial and boundary conditions, respectively. The last depicts the deviation between the output of neural network and ground truth. We usually set to 1 to rectify the model by utilizing the last term when dealing with the problems with shock wave and interface. If the solution of equation is continuous, this term degenerates, which means equals zero. In this paper, we use L-BFGS-B method [33] that has faster convergence speed and less memory cost to optimize all target loss functions. The resulting algorithm, termed as deep wavelet neural network, is summarized in Algorithm 1.
Algorithm 1 Deep Wavelet Neural Network (DWNN) for solving partial differential equations.
Input: Collocation points ; Initial training data ; Boundary training data ; Observations .
Output: Neural network predicted solution .
1:
Construct the architecture of neural network with wavelet layer and parameter set ;
2:
Specify the training set ,,, for collocation points, initial, boundary and domain points;
3:
Make DWNN wavelet-based expansion layer of input data as
4:
Specity the loss function with the coefficient by adjusting the sum of PDEs residuals, initial/boundary conditions and observations residuals;
5:
Train the neural network to find the best parameters by minimizing the loss function with L-BFGS-B optimization method;
6:
return ;
3. Numerical Results
We consider various forms of partial differential equations to illustrate the validity and robustness of the proposed method in this section. We evaluate the accuracy of numerical solution by relative error and error. The results demonstrate that the predicted result of deep wavelet neural network is more accurate. In Section 3.1, five equations are shown to validate the effectiveness of the proposed algorithm in one-dimensional space, and in Section 3.2, three examples are given to verify the correctness of our method in two-dimensional space. Lastly, in Section 3.3, two equations are shown to demonstrate the reliability and generalization ability of the proposed method in high-dimensional space.
3.1. One-Dimensional Equations
In this subsection, we take five different one-dimensional equations, these being the Schrödinger equation, carburizing equation, Klein-Gordon equation, Burgers equation and Allen-Cahn equation, to show the stability and reliability of our method.
3.1.1. Schrödinger Equation
In order to demonstrate the validity of our method for handling periodic boundary conditions, complex-valued functions and diverse kinds of nonlinearities in the PDEs [39], the Schrödinger equation is introduced in this subsection. The Schrödinger equation is a fundamental assumption in quantum mechanics proposed by the Austrian physicist Schrodinger [40]. It describes the motion of microscopic particles and each microscopic system has a corresponding equation. In one-dimensional space, the Schrödinger equation with periodic boundary conditions reads as
In this case, we use seven wavelets in the wavelet expansion layer and the following fully connected neural network is considered to be four hidden layers with 100 neurons per hidden layer. Gaussian error function is taken for the activation function. The is obtained from the left-hand-side of Equation (22)
Actually, is the complex-valued solution that contains a real part and imaginary part. Supposing represents the real part and denotes the imaginary part, the complexed-valued solution is rewritten as . Therefore, the neural network is multi-output because two units are needed to completely represent the entire solution. The cost function is composed of three terms:
where
Here, specifies the unsupervised points on , specifies the initial points on , and specifies the boundary points on .
The training set consists of initial points , boundary points , and collocation points = 20,000. All randomly sampled point locations are generated using a Latin Hypercube Sampling strategy [41]. To evaluate the accuracy of this model, we use the dataset from PINN [24]. They used traditional spectral method to simulate this problem. Specifically, Equation (22) is integrated from the initial time to the final time using the Chebfun package [42] under the set boundary conditions.
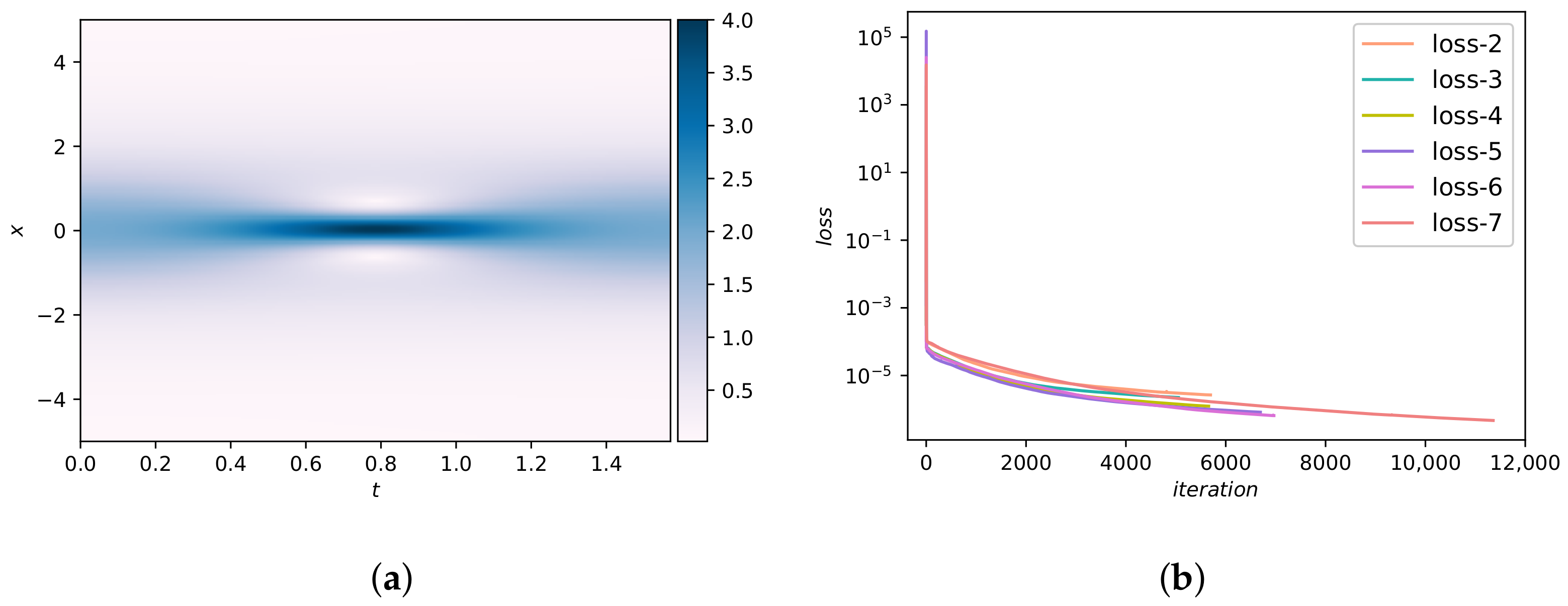
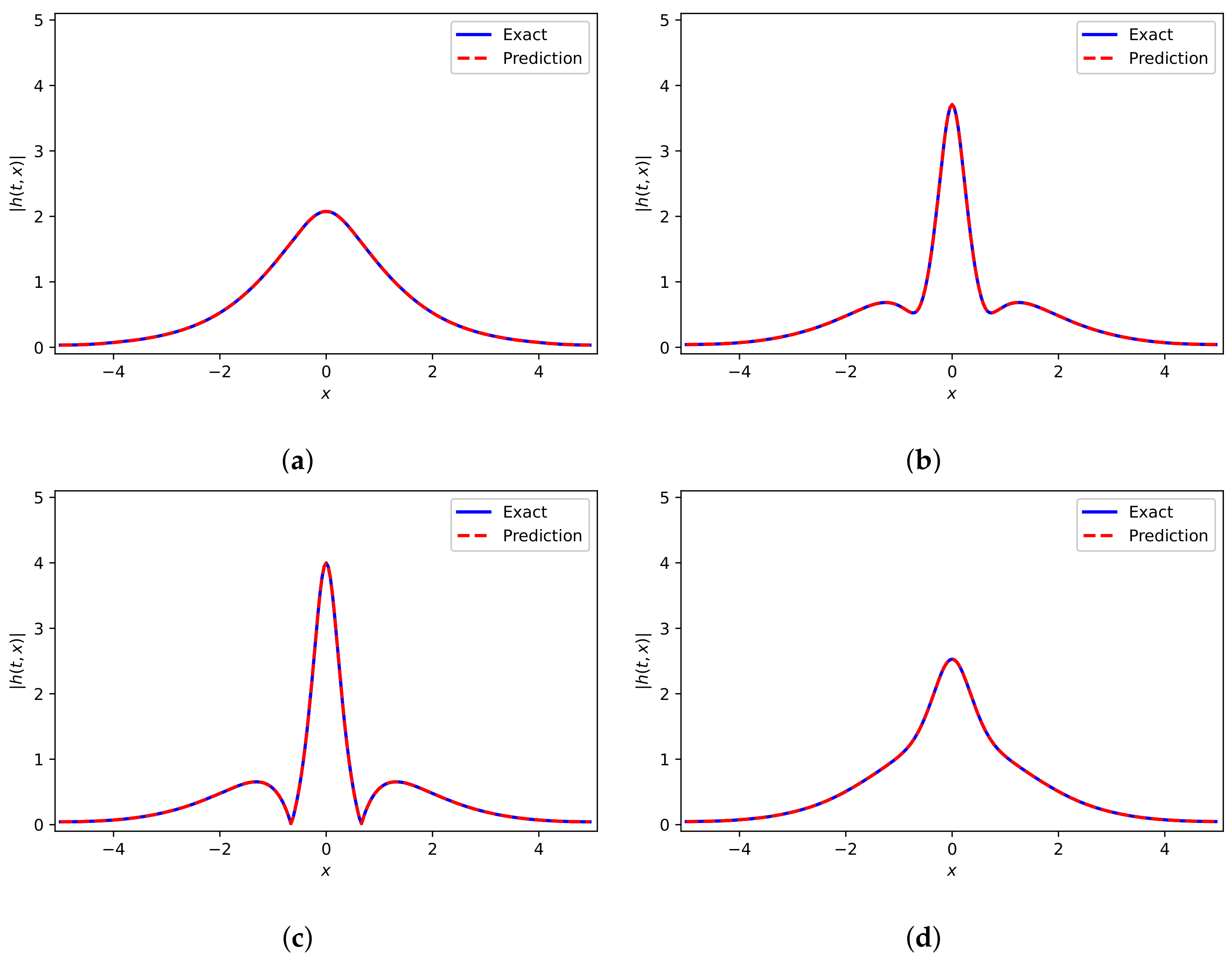
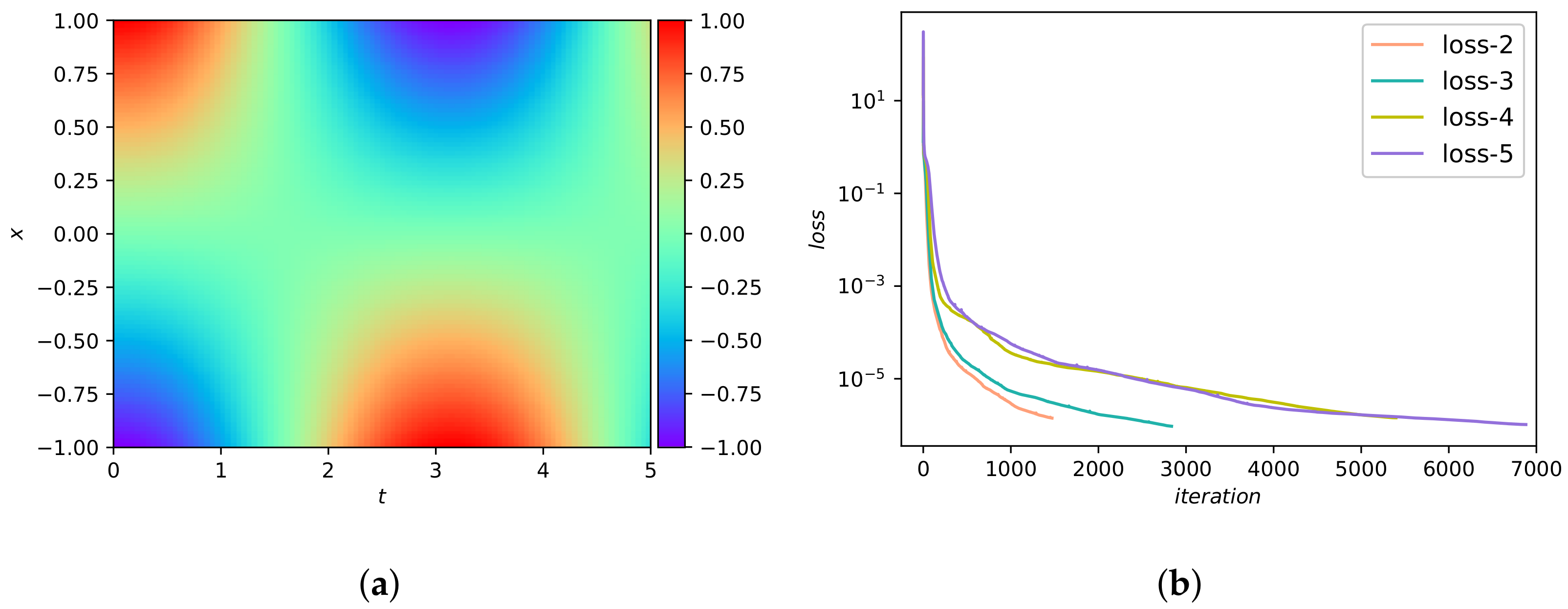
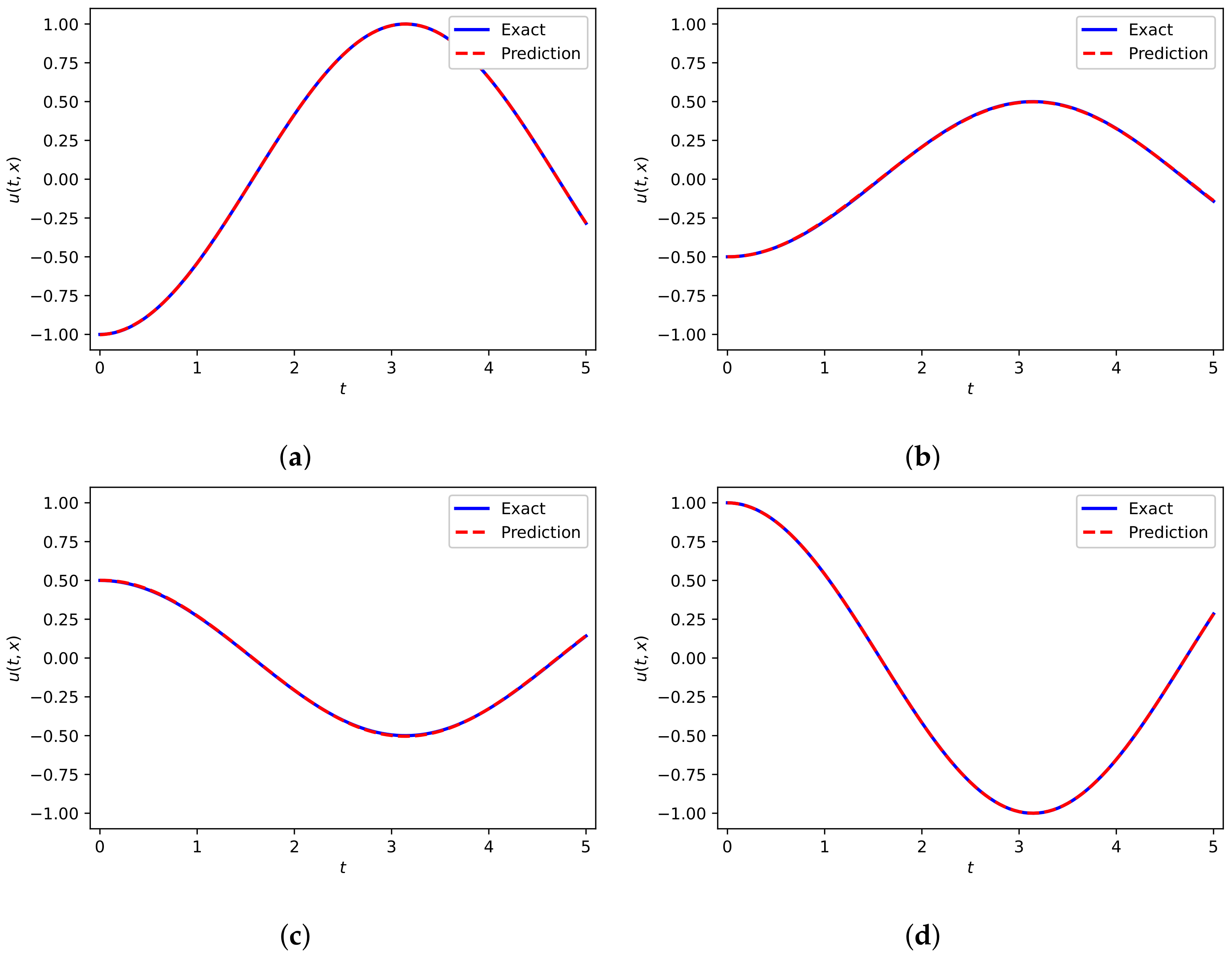
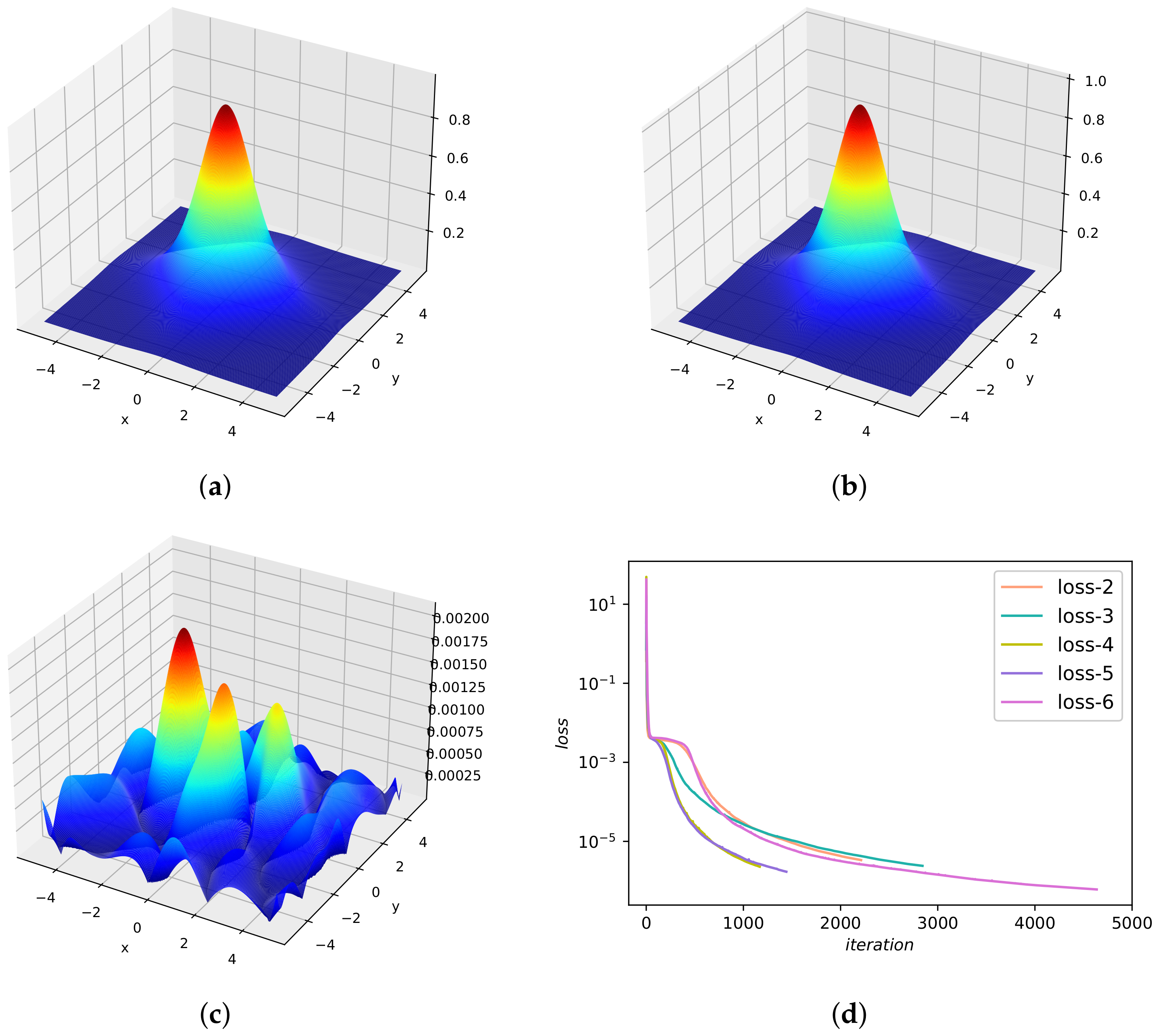
In this example, we first use Adam [43] for 50,000 iterations and then use L-BFGS-B method for optimization. Figure 5a presents the DWNN model predicted solution . It seems that the predicted sulution is coincident with analytical solution. Furthermore, a presentation with regard to the convegence rate of DWNN model for different number of wavelets is shown in Figure 5b. It is seen that the DWNN model using seven wavelets keeps converging until the least, while training is terminated prematurely in other cases to prevent overfitting. The prediction error for this case calculated in the end is in the relative -norm. It is noted that this prediction error is an order of magnitude smaller than the error previously described using PINN [24]. A detailed assessment of the neural network solution at different temporal snapshots is reflected in Figure 6. We find that there is a satisfactory agreement of the predicted DWNN solution and exact solution.
To further investigate the capability of the proposed method, the following systematic studies are carried out to quantify the predictive accuracy for different number of wavelets as well as for different hidden layers. Table 1 summarizes the errors and errors with respect to different numbers of wavelets (VMWs) and different numbers of hidden layers (l), while keeping 100 hidden neurons fixed in each hidden layer. As expected, the predictive accuracy increases as the number of wavelets and hidden layers increase. To illustrate the insensitivity of the DWNN model to noise, we perform a systematic study with respect to the noise corruption levels in one-dimensional Schrödinger experiment. The results are listed in Table 2, from which we observe that the proposed approach is robust.
3.1.2. Carburizing Diffusion Equation
To demonstrate the ability of the method presented in this paper to solve realistic problems, we consider the carburzing diffusion model. Carburizing is a chemical heat-treatment process, which is widely used in low carbon/alloy steel. The specific method is to put the workpiece into the active carburizing medium and obtain the high carbon in surface layer by heating and holding. The carburizing process can make the surface of a carburized workpiece obtain higher hardness, so as to improve the wear resistance [44,45]. The form of the nonlinear carburizing diffusion equation is
where c denotes the carbon concentration and denotes the diffusion coefficient that depends on the concentration. The diffusion coefficient dynamically varies due to external factors such as temperature in practical problems. In this experiment, we consider a variable coefficient . A source term added is given by
Then the corresponding exact solution is . The computing domain is set to , . The case . We compute the above problem with homogeneous Dirichlet boundary condition. The network structure consists of a wavelet expansion layer with five wavelets and a fully connected part with four hidden layers. Each hidden layer contains 20 neurons and a Gaussian error function. The is obtained from Equation (28)
The cost function is composed of three parts: , , . For brevity, we use to characterize the initial and boundary conditions. Therefore, the cost function is given by
where
Given a set of 100 initial/boundary data and 10,000 collocation points, we obtain the latent solution by training the DWNN model. The predicted solution of deep wavelet neural network is shown in Figure 7a, and we observe that our results show great agreement with the exact results [46]. The curves of loss functions associated to the number of wavelets are plotted in Figure 7b. From Figure 7b, we find that employing five wavelets can achieve the minimum loss with fewer iterations. The relative error measured is . Figure 8 provides a more detailed visual comparison at unequal temporal snapshots , respectively. It is clearly seen that the experimental solution coincides with the analytical solution.
To further verify the validity of the proposed method, we carry out a systematic study with regard to different number of VMWs and different number of hidden layers, while the number of hidden neurons are fixed to 20 per hidden layer. The resulting errors and errors are given in Table 3. We easily find that the prediction error reduces when the number of wavelets increase in general. It seems that the proposed methodology effectively improves the predictive accuracy. Additionally, by using wavelet expansions, the system becomes fairly stable so that the prediction error can remain at levels of with fewer hidden layers.
3.1.3. Klein-Gordon Equation
In this part, we consider a Klein-Gordon equation that is second order in both time and space. The Klein-Gordon equation is a fundamental equation in relativistic quantum mechanics and quantum field theory. It is a special relativistic form of the Schrodinger equation used to describe particles with zero spin. Moreover, the Klein-Gordon equation arises in many scientific areas, such as condensed matter physics [47], nonlinear wave equations [48], quantum field theory [49], etc. The form of an inhomogeneous Klein-Gordon equation is as follows
where the initial and boundary conditions are both derive from analytical solution . denotes the Laplacian operator which acts on the space variables only. and , , are all constants.
We set the computational domain . In addition, we consider , and to −1, 0, 1, respectively. k is set to 2. Further, the term is given by . The deep architecture used for the computation contains wavelet expansion layer with five VMWs and five hidden layers with 50 neurons per layer. Gaussian error function is assumed to the activation function. The is obtained from the left-hand side of Equation (34)
The optimal parameters are trained by minimizing the cost function
where
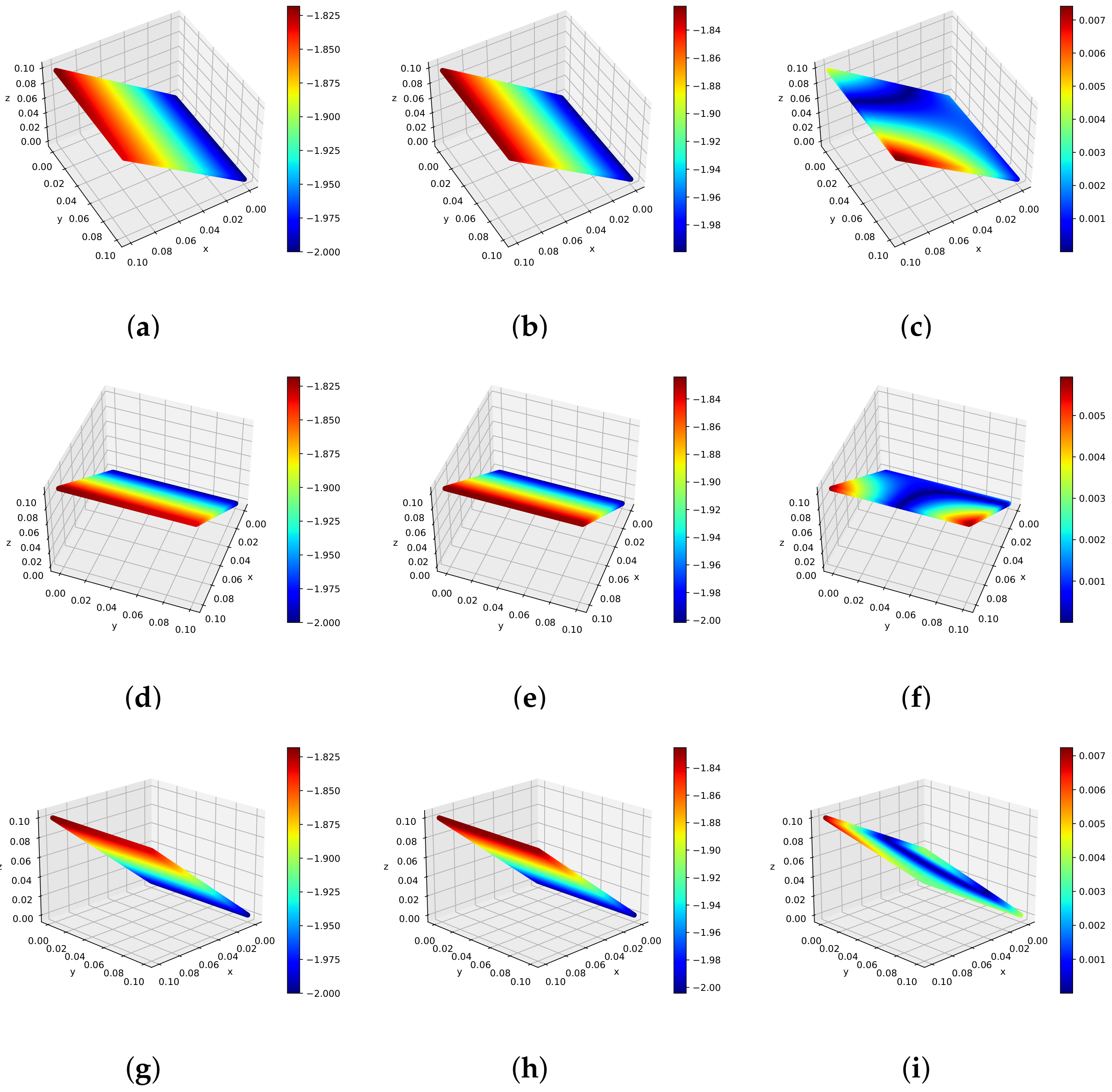
We give a set of 100 randomly chosen initial/boundary data and 10,000 collocation points to train all parameters of neural network. The prediction error is calculated at in the relative -norm. Figure 9a presents the predicted DWNN solution . There is little substantial difference between the predicted results and theorized results [50]. Figure 9b shows the optimization process for the parameters of deep wavelet neural network under a different number of VMWs. We see that using five wavelets has the best performance. A more intuitive assessment of the predicted solution corresponding to four different space points is plotted in Figure 10. Coming to the comparison of results, we observe that the simulation results are in great agreement with the exact solution. The errors and errors according to different number of VMWs and different number of hidden layers are summarized in Table 4, where the hidden neurons are fixed to 50. From this table, we find that the prediction error declines with increasing number of VMWs until it becomes stable.
3.1.4. Burgers Equation
The Burgers equation is a basic equation in various fields of applied mathematics, such as gas dynamics, fluid mechanics [51], and traffic flow [52]. In 1915, the Burgers equation was first proposed by Harry Bateman [53]. It is a nonlinear partial differential equation that simulates the propagation and reflection of shock waves. Since it is hard for traditional numerical methods to capture strong shock waves, we solve this equation with our method. In one-dimensional space, the Burgers equation with Dirichlet boundary conditions is given by
We use DWNN model to solve this equation. Therein, five wavelets are used in wavelet expansion layer. The following fully connected neural network is fixed to 8 hidden layers and each hidden layer contains 20 neurons. The is obtained from the left-hand side of Equation (39)
The value of can be obtained with autodifferentiation. The complicated nonlinear behaviour of the Burgers equation results in the formation of a acuminate internal layer. It is notoriously difficult to solve with traditional numerical methods accurately. So, we add the residual of a handful of observations into cost function. To be specific, the loss function is expressed as
where
Here, specifies the collocaction points on , denotes the initial/boundary points on , and represents the interior training points in the domain.
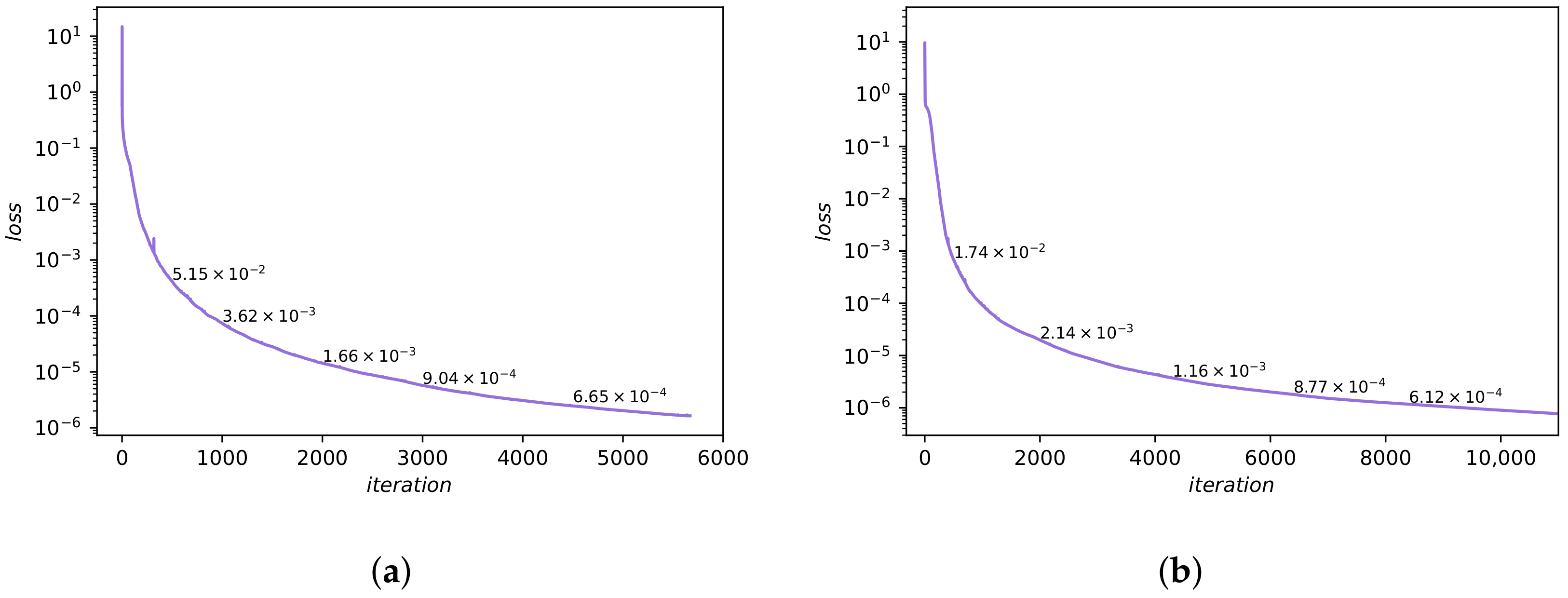
The training set contains collocaction points = 10,000, initial/boundary points , and inner points . Figure 11a shows the predicted DWNN solution, while the exact solution is recorded in article [54]. Compared with the analytical results, we see that there is no difference between the predicted DWNN solution and the exact solution. Figure 11b shows the change processes of objective functions over the number of iterations under different number of wavelets, from which we find that using four wavelets has the fastest convergence rate but using five works best. In order to display the change process of test error simultaneously, Figure 12a draws the loss curve when the number of wavelets is five separately, and marks the test errors (black text) under different iterations. From this we see that as the number of iterations increases, the loss and test error both decrease. The relative error measured in the end is . Moreover, a detailed comparison between the predicted solution and analytical result at unequal temporal snapshots is presented in Figure 13. It is seen that the predicted DWNN solution is indistinguishable from the analytical solution.
To further prove the effectiveness of the proposed method, we carry out the following experimental study to quantify its accuracy. Table 5 summarizes the errors and errors from three perspectives. First, we show the performance of DWNN model whose cost function contains three terms according to Equation (41). Second, we present the results of DWNN model, which only contains wavelets, and do not add (we briefly named it WTNN). Lastly, we give the results of other state-of-the-art methods such as PINN. The prediction errors are listed with regard to different number of VMWs and different number of hidden layers, while keeping 20 hidden neurons fixed in each hidden layer. It is clearly seen that considering the residual of a handful of observations into cost function not only achieves the most accuracy but also gives a relatively stable approximation for the solution. Moreover, the DWNN model can achieve high predictive accuracy with fewer hidden layers, which undoubtedly reduces the computational cost. Therefore, the third term of the cost function degenerates when solving the continuous problem, but it is really effective when solving the shock wave problem.
3.1.5. Allen-Cahn Equation
We consider the Allen-Cahn quation with periodic boundary conditions in this subsection. Allen and Cahn jointly introduced this equation to describe the antiphase boundary motion in crystals in 1979 [55]. The Allen–Cahn equation is important to describe fluid dynamics and reaction-diffusion problems in material science. Moreover, the Allen-Cahn equation is generally applied to deal with various problems such as image analysis [56,57], mean curvature flow rate [58], crystal growth [59], and so on. In one-dimensional space, Allen-Cahn equation reads as
We use the DWNN model which employs five wavelets in wavelet expansion layer and five hidden layers in fully connected part to solve this problem. Each hidden layer contains 60 neurons and a Gaussian error function. The is obtained from Equation (45)
An interesting feature of this equation is the phenomenon of metastable state. The areas of solution close to are flat, and the interface between these areas remain unchanged for a long period of time until a sudden change occurs. Therefore, we use the advantage of inner points to rectify the model and randomly choose a few inner points to better deal with the discontinuity of the Allen-Cahn equation. The loss function is written as
where
Here, specifies the unsupervised collocation points on , denotes the initial data, denotes the boundary data and corresponds to internal sample points in the domain.
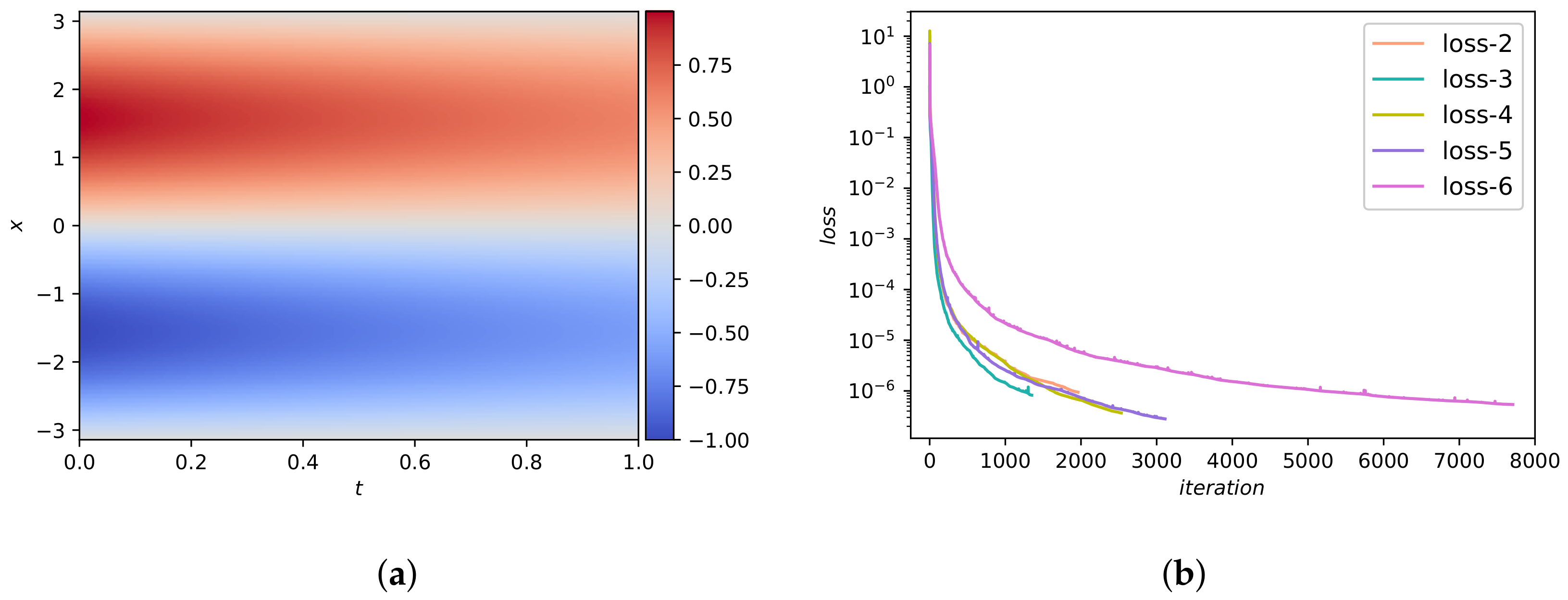
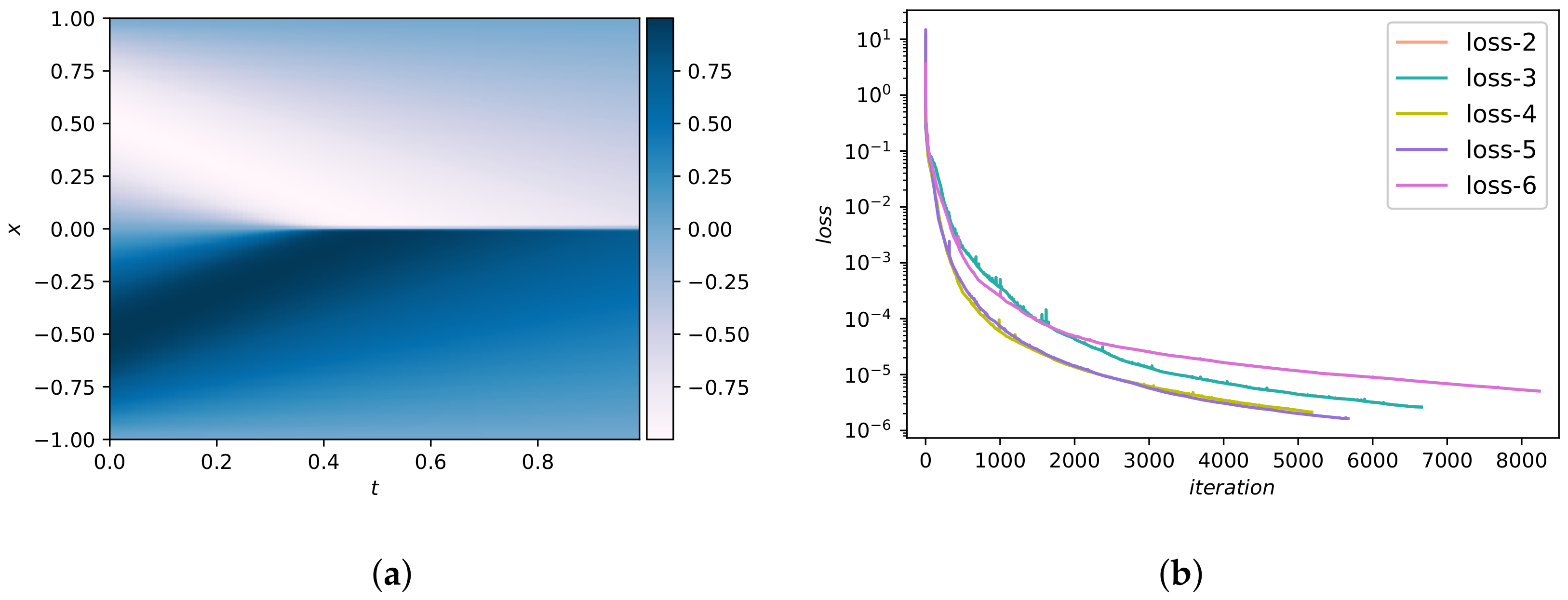
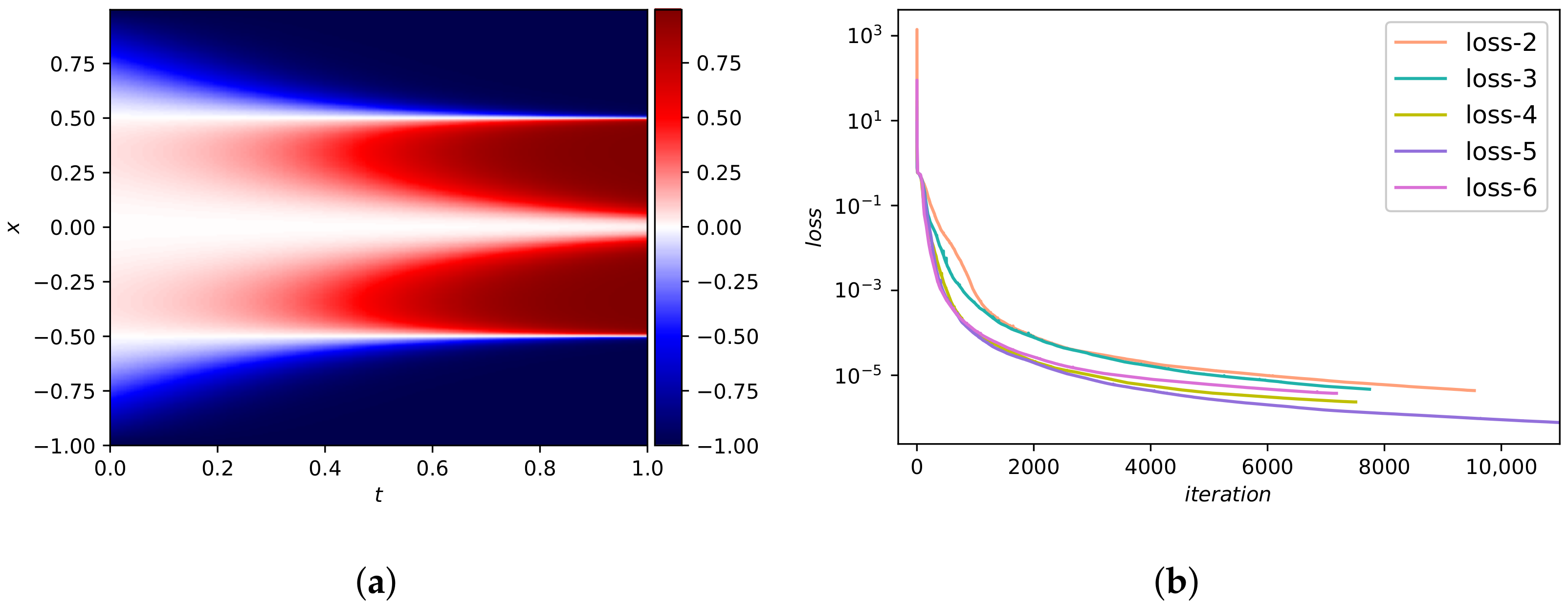
We select 200 inner points in addition to 100 initial/boundary points and 10,000 collocation points to form the training set. The dataset we used was reported in a previous work [24]. They used convolutional spectral methods to simulate an Allen-Cahn equation. Concretely, Equation (45) has integrated from the initial state to the final time using the Chebfun package [42]. Figure 14a shows the predicted value obtained from DWNN model. The predicted value and analytical value are basically the same. The comparison of loss functions for the DWNN model is pictured in Figure 14b. From Figure 14b, we see that the loss function drops quickly when we use five wavelets. Figure 12b shows the loss curve and test errors (black text) using five wavelets. From Figure 12b, we observe that both loss and test errors decrease as the number of iterations increases, as we expected. The error in relative -norm is measured at . In particular, this prediction error is almost three orders of magnitude smaller than the method offered by PINN using continuous time model [24].
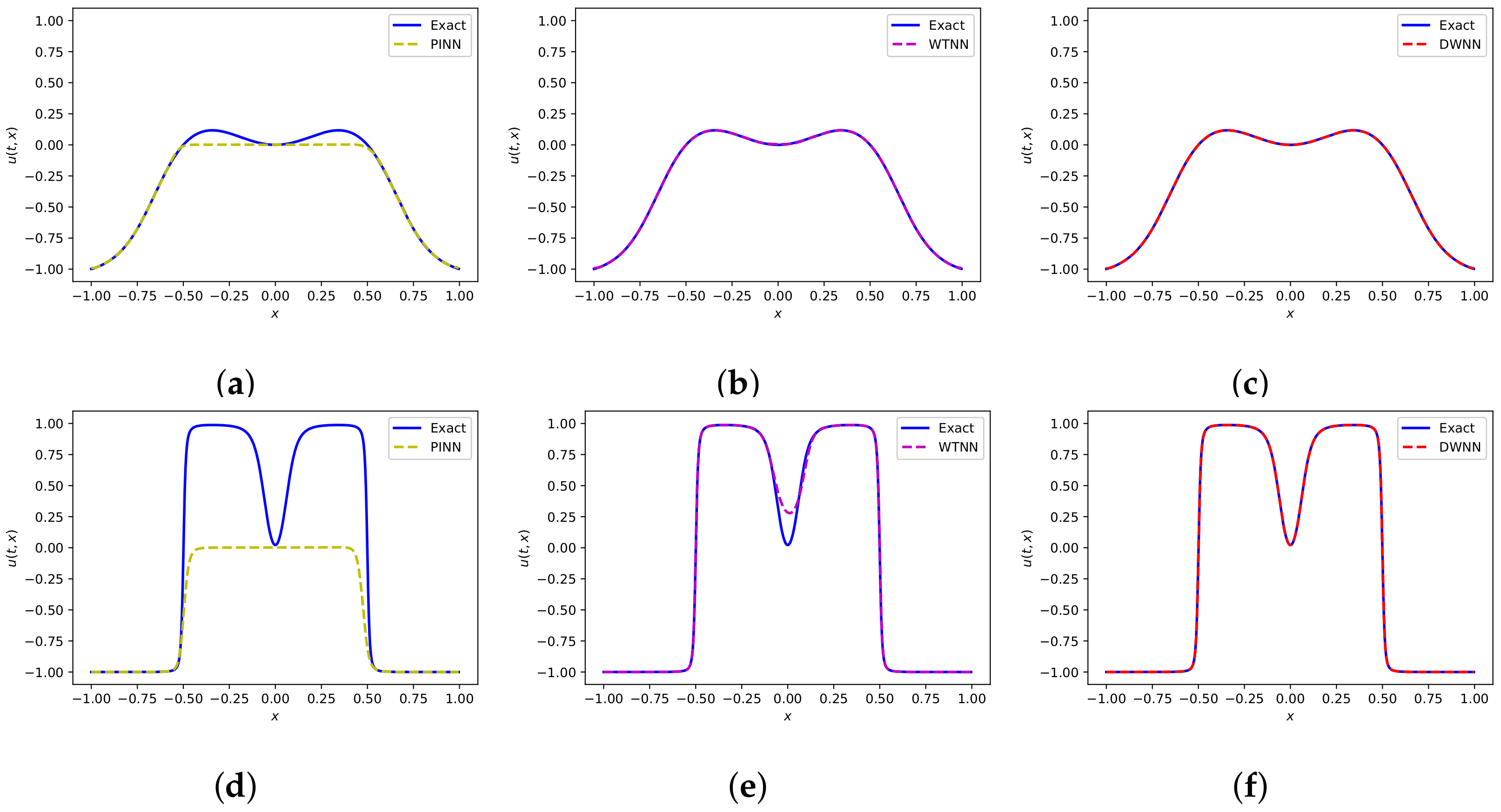
Figure 15 presents the predicted solution based on three methods. Figure 15a,d present the PINN solution at and , severally. It is obvious that the PINN solution is not so consistent with the exact solution. Correspondingly, Figure 15b,e display the neural network model which only contains wavelet transform at and . It is seen that the predicted solution is better than PINN, but there still exists gaps in some point locations. Figure 15c,f show the DWNN solution at the same time points. We see that the predicted DWNN solution is in perfect agreement with the exact solution. As we can find from Figure 15, the experimental results of DWNN model are closer to the analytical results. Furthermore, we report the errors and errors based on PINN, WTNN and DWNN for different number of VMWs, and different number of hidden layers. Here, the number of neurons are fixed to 60 in each hidden layer. The results are listed in Table 6. Apparently, when dealing with interface problems, adding the residual term of observation points can improve the predictive accuracy significantly.
3.2. Two-Dimensional Equations
In this subsecion, three two-dimensional equations are presented so as to further demonstrate the perfomance of the proposed method.
3.2.1. Burgers Equation
In two-dimensional space, the form of Burgers equation [54] is
where the initial/boundary conditions are extracted from analytical solution given by
In this part, we exploit the deep wavelet neural network which consists of wavelet expansional layer with six wavelets and a fully connected neural network with seven hidden layers. Each hidden layer contains 20 hidden neurons. The activation function remains the same. The is obtained from Equation (52)
The target parameters of neural network are trained by minimizing the loss function
where
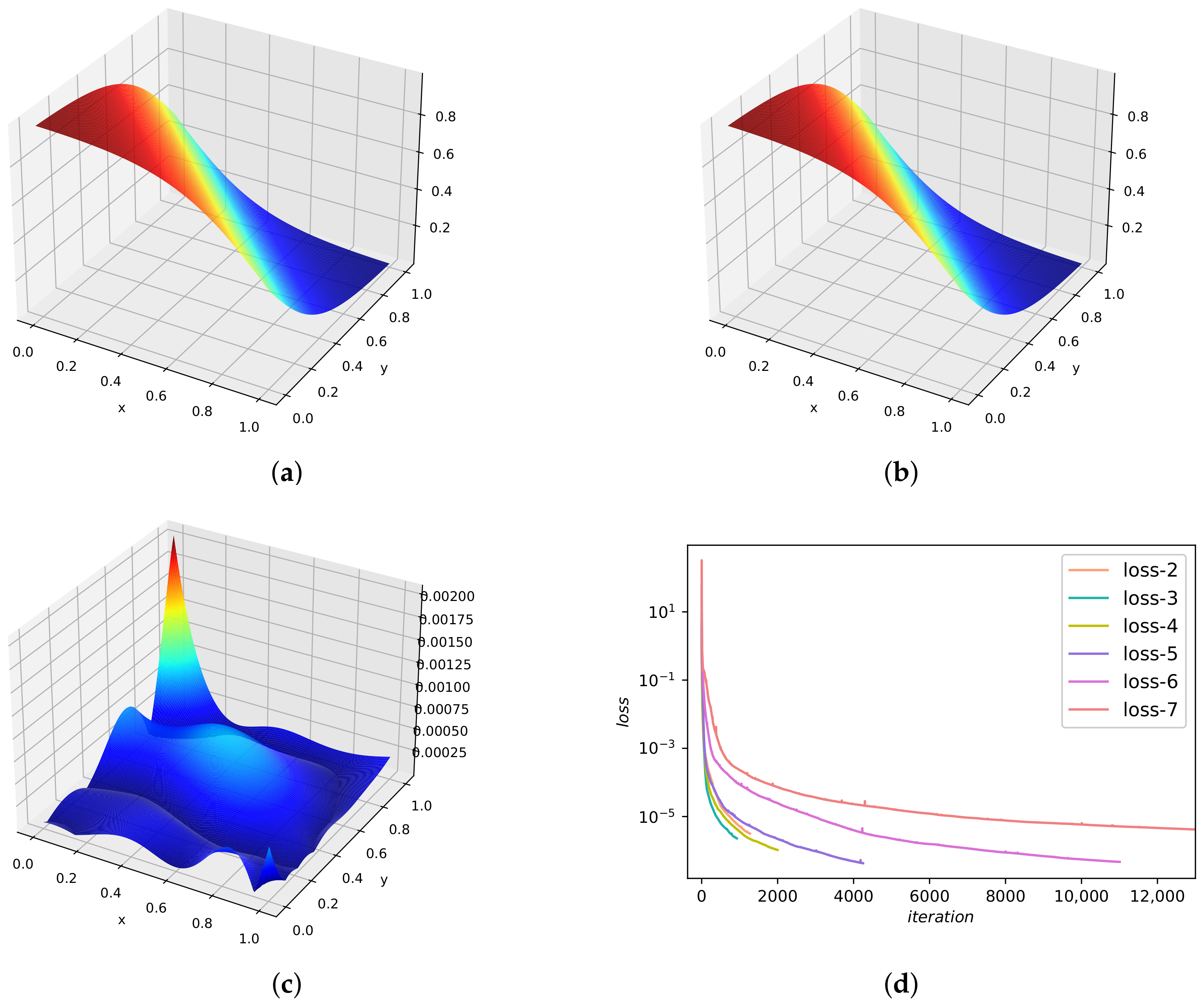
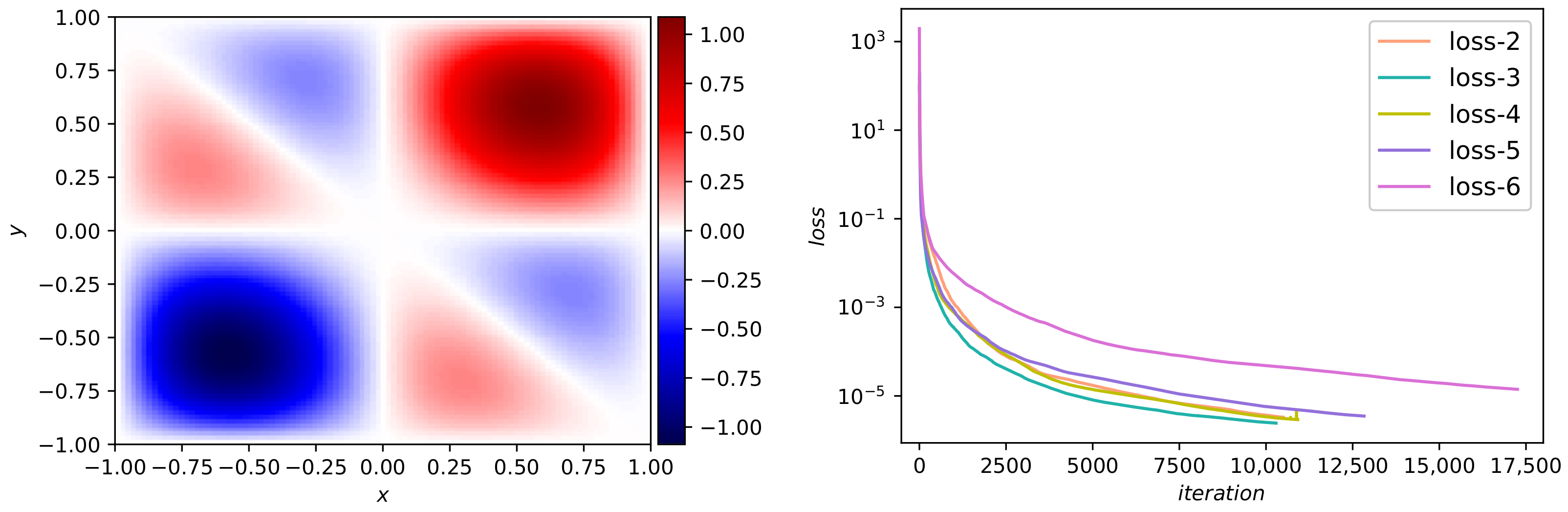
The collocation points are 20,000 whereas the initial/boundary points are 150. The predicted DWNN solution at time instant is presented in Figure 16b. To see it more precisely, we show the analytical solution at time instant in Figure 16a. It is hard to see any difference between them. The relative error calculated is . Figure 16c depicts the error visually at . As we can see, the error is so small in most areas except for a few points. The progresses of the loss functions versus iterations are plotted in Figure 16d. The objective function reaches the minimum value in the case of six wavelets. We give a systematic research on the errors and errors with regard to different number of VMWs and different number of hidden layers when the neurons are set to 20 per hidden layer. The results are displayed in Table 7. It can be seen from the table that it tends to be stable starting from the use of five wavelets.
3.2.2. Schrödinger Equation
In two-dimensional space, we consider Schrödinger equation with the Dirichlet boundary conditions
where the potential function . The analytical solution for this equation is
We adopt six wavelets and a followed fully connected neural network with 4 hidden layers. Each hidden layer has 50 hidden neurons. The is obtained from the left-hand-side of Equation (58)
Similar to the previous case in Section 3.1.1, the entire solution is rewritten as , which means the network is also multi-output. The DWNN parameters are obtained by minimizing the mean squared error loss
where
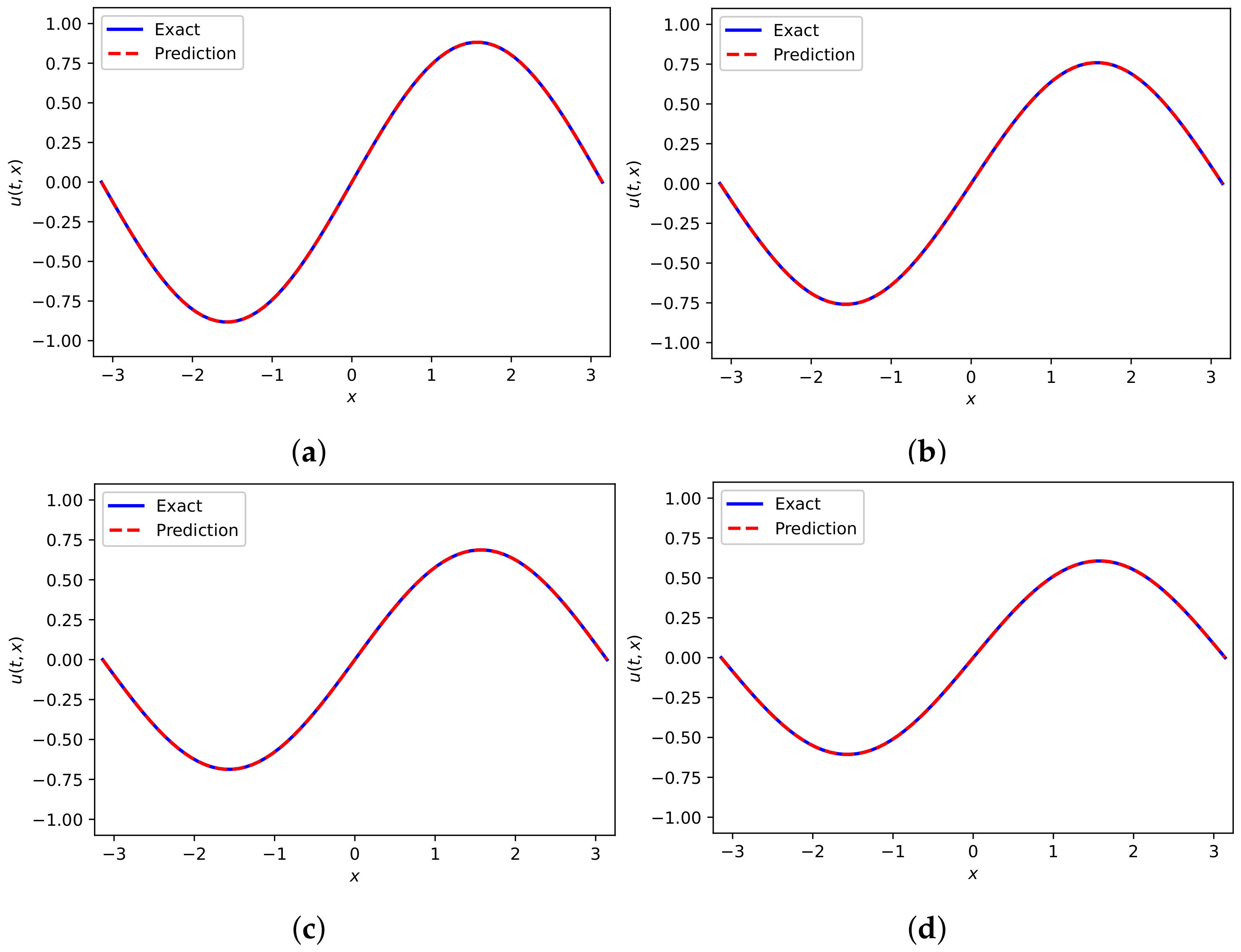
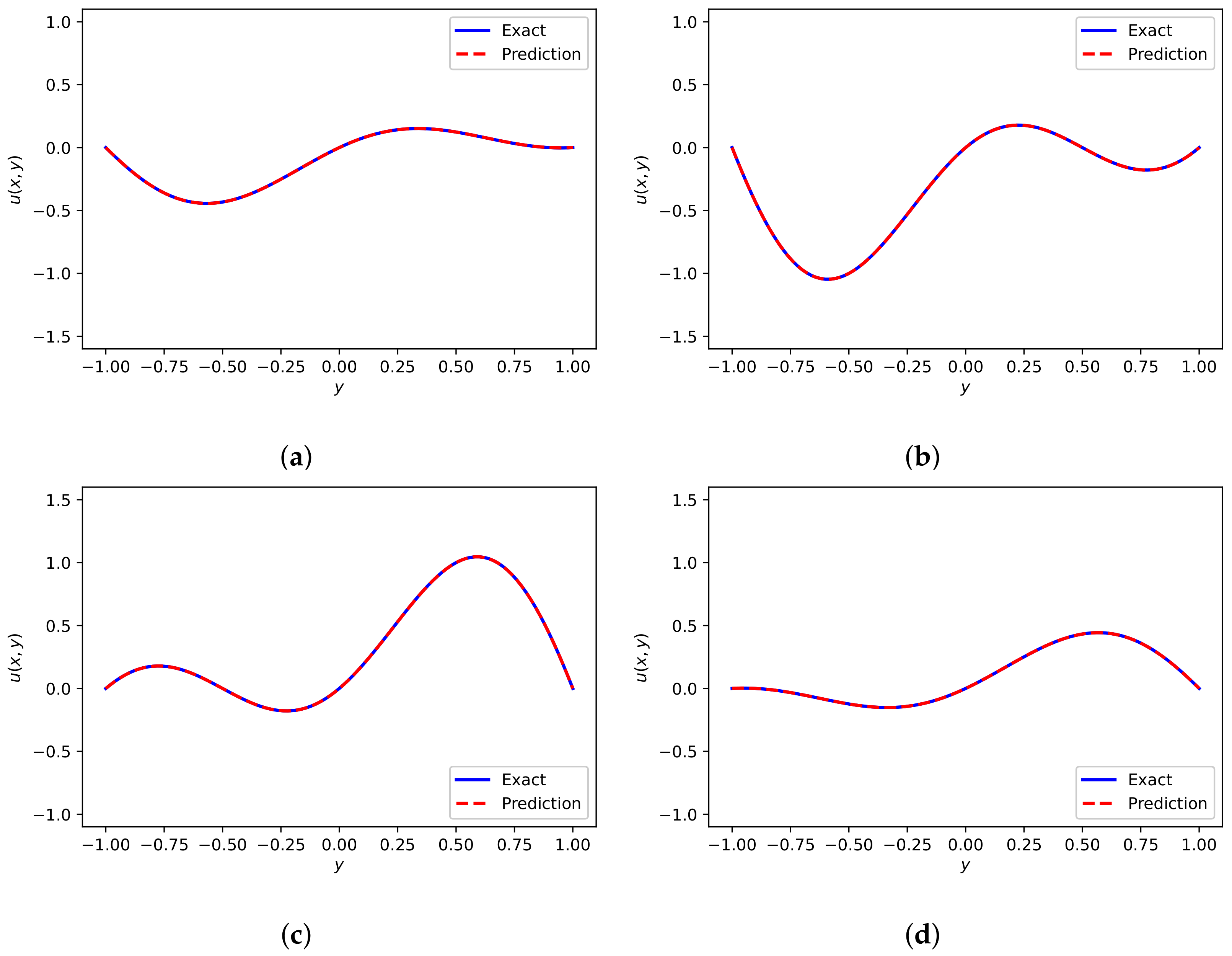
The number of collocation points is 20,000, and the number of training data on the initial/boundary is 150. The entire solution at time instant obtained from analytical solution [39] and DWNN model are shown in Figure 17a,b, respectively. Coming to the comparison of them, we can observe similar results. Figure 17c presents the absolute error for at and the relative error calculated for this instance is . It suggests that the simulation result is consistent with the theoretical result. The trends of loss functions versus iterations are presented in Figure 17d, from which we find that the loss function is continuously reduced to the minimum under six wavelets. In Table 8, we list the resulting prediction errors in -norm and -norm for different number of VMWs and different number of hidden layers. The number of neurons are fixed to 50 in each hidden layer. The results show that as the number of VMWs increases, the predictive accuracy improves in general.
3.2.3. Helmholtz Equation
In two dimensions, we consider the Helmholtz equation with homogeneous Dirichlet boundary conditions
where the forcing term is given by
In this case, we consider and the corresponding exact solution is . Here, five wavelets are used in wavelet expansion layer. There are six following hidden layers and each layer contains 40 neurons. The is obtained from Equation (64)
The optimal parameters are learned by minimizing the loss function
where
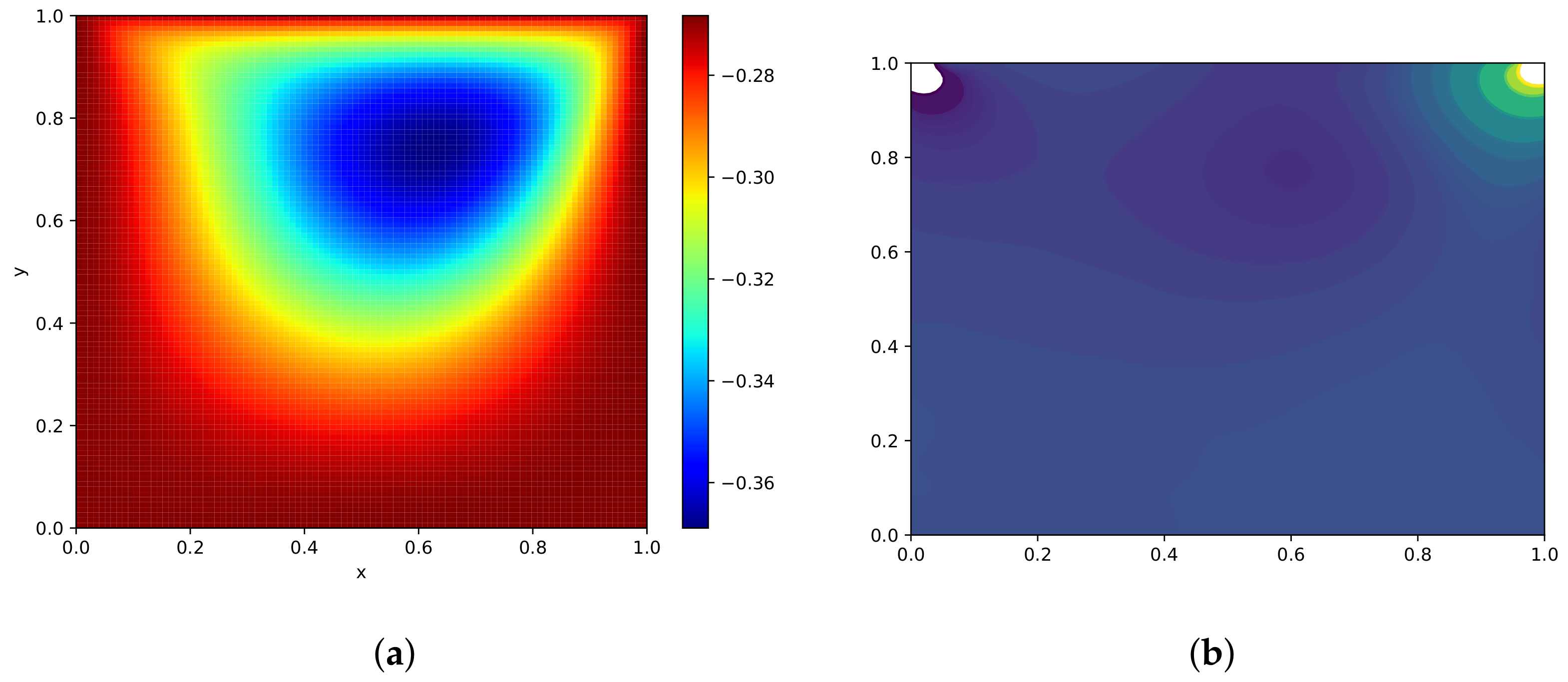
The training data, , are 400, whereas the residual training data, , are 16,000. Figure 18a presents the contour plot of predicted result of Helmholtz equation. This prediction seems to be identical to the theoretical solution [50]. Figure 18b presents the change trends of loss functions versus iterations, from which we see the best convergence of five wavelets. The relative error measured in the end is . We plot the comparison of DWNN results and analytical results at as shown in Figure 19. In these figures we find that the simulation solution is in consistent with the law of physics and the analytical solution. A detailed experimental study to quantify the impact of unequal number of VMWs and different layers of network is presented in Table 9. By fixing the number of neurons in each hidden layer to 40, we vary the number of wavelets and hidden layers, and monitor the resulting errors and errors for the predicted solution. The general trend shows that the predictive accuracy is improved obviously by the addition of wavelet extension layer.
3.2.4. Flow in a Lid-Driven Cavity
In this subsection, we consider the steady-state flow in a two-dimensional lid-driven cavity, which is a typical incompressible viscous fluid model in computational fluid mechanics. The system is governed by the incompressible Navier-Stokes equations, which can be written as [60]
Here, is the velocity field and p is the pressure field. represents the x-component of the velocity vector field and represents the y-component. The computational domain . denotes the top boundary of the 2-D square cavity and denotes the other three sides. Reynolds number (Re) is a non-dimensional number used to characterize fluid flow and we consider . We make an assumption according to Wang et al. [60] that
Under this assumption, the incompressibility constraint is automatically satisfied. The is obtained from Equation (70)
where . Therefore, the neural network is multi-output because two units are needed to represent and p, respectively. The cost function is given by
where
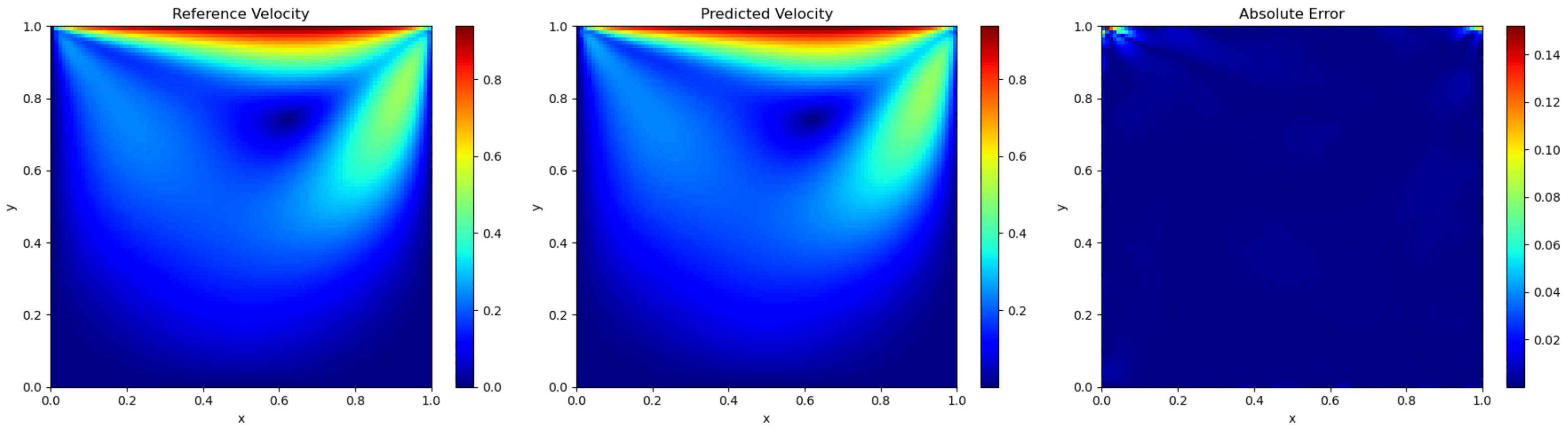
In this example, we use three wavelets in the wavelet-mapping layer. The followed fully connected neural network consists of three layers with 50 neurons in each layer. The training dataset contains , . We first use the Adam method for 40,000 iterations and then use L-BFGS-B method for optimization. The relative error of velocity calculated in the end is . Figure 20 presents the reference velocity [60], predicted velocity and numerical error, respectively. It seems that the experimental result is in good agreement with reference result. Figure 21 shows the stream function and pressure p. A large vortex in the center of the square cavity can be observed.
3.3. High-Dimensional Equations
In this subsection, we consider two high-dimensional equations including Burgers equation and Poisson equation to show the validity and generalization ability of the proposed method.
3.3.1. Burgers Equation
We consider the three-dimensional time-dependent Burgers’ equation [54] as follows
The initial and boundary conditions are extracted from exact solutions, and the exact solutions are given by
In this experiment, we set , , and . To speed up the training process, we only use two wavelets in wavelet expansion layer and fed the enhanced pattern to a fully connected neural network with four hidden layers. Each hidden layer has 40 hidden neurons. It is noted that, three output nodes are needed to output u, v, w, respectively. The is obtained from Equation (Section 3.3.1)
Therefore, is consist of three parts. The parameters are learned by minimizing the loss function
where
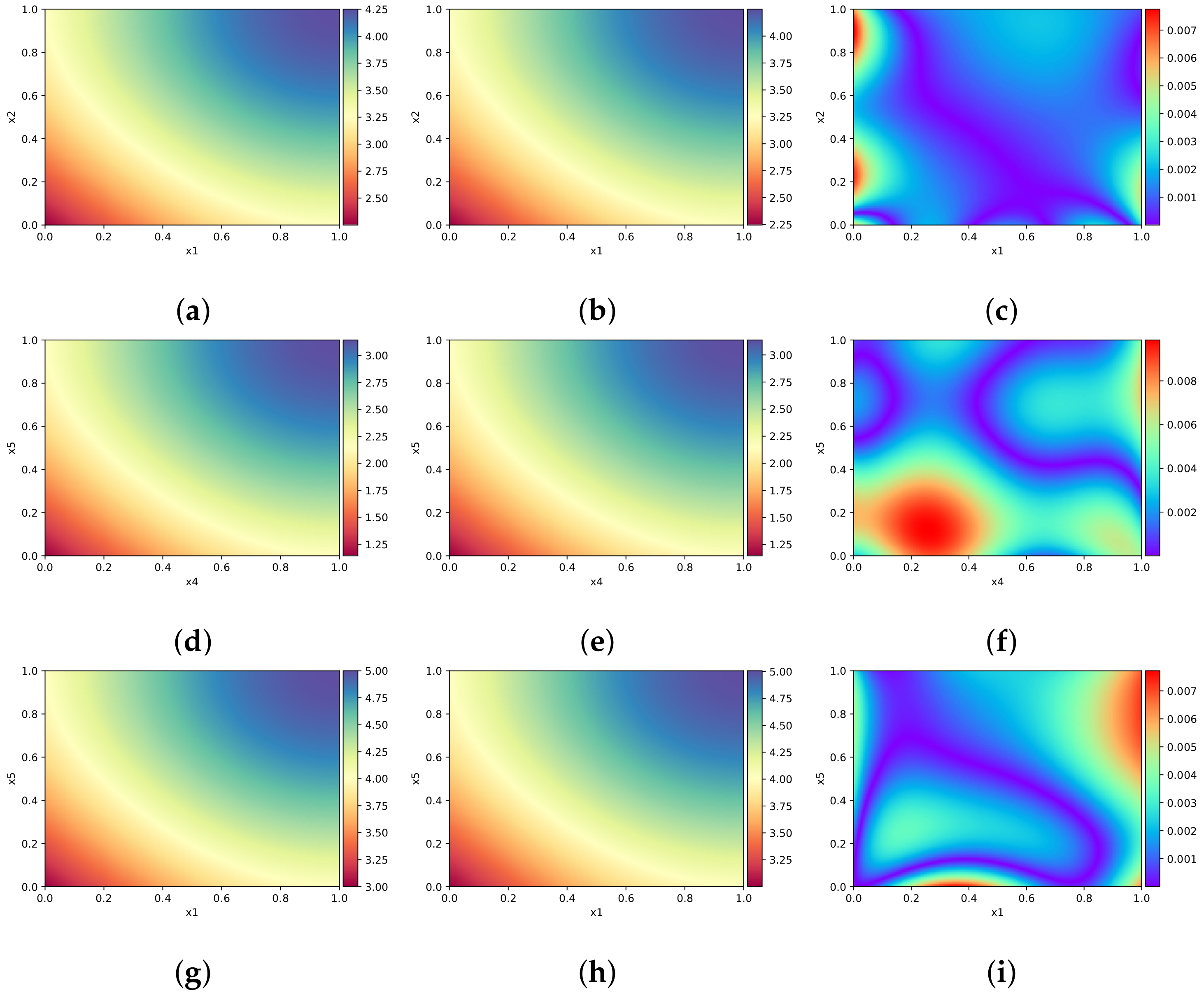
We randomly chose 200 initial/boundary training data points, 200 observations and 20,000 collocation points. The relative error was measured at -norm is . We present the predicted result from different perspectives. Figure 22 shows the exact solutions, predicted solutions, and absolute errors at different time instants. Figure 22a–c present the results at time . Figure 22d–f present the results at time . Finally, Figure 22g–i present the results at time . From Figure 22, we see that the prediction solutions are in satisfactory agreement with exact solutions.
3.3.2. Poisson Equation
We consider a Poisson equation with Dirichlet boundary condion [61]
with problem dimension . The classical solution for this problem is .
We also use two wavelets in wavelet expansion layer in this part. The followed fully connected network is considered to five hidden layers, and each hidden layer uses 40 neurons. The is obtained from Equation (82)
The optimal parameters are trained by minimizing loss function
where
The training data set includes initial/boundary points and collocation points = 20,000, respectively. The relative error calculated is . Figure 23 shows the analytical solutions, numerical solutions and absolute errors in the different planes. Figure 23a–c shows the plane , when , , . Figure 23d–f shows the plane , when , , . Finally, Figure 23g–i shows the plane , when , , . From the Figure 23, we observe that the simulation results are in excellent agreement with the exact solutions.
3.4. Comparison of DWNN and Others
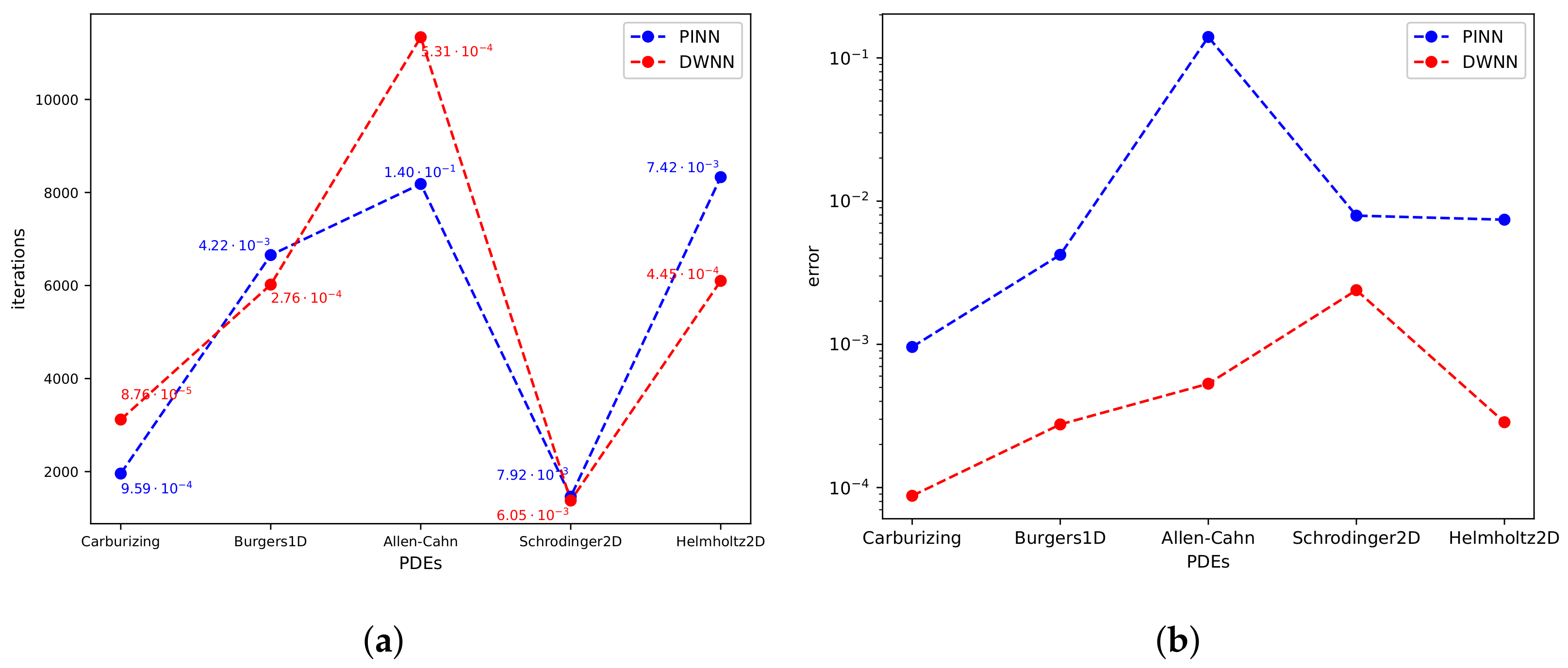
To demonstrate the merit of the proposed DWNN model, we present the number of iterations and the relative errors of PINN and DWNN for five numerical examples including the carburizing diffusion equation, 1D Burgers equation, Allen-Cahn equation, 2D Schrödinger equation, and 2D Helmholtz equation. Figure 24a shows the number of iterations of PINN and DWNN, and the corresponding relative error is marked near each data point. First, we use five wavelets to solve the carburizing diffusion equation and Burgers equation. As we can see from Figure 24a, there is little difference in the number of iterations between PINN and DWNN for these two cases. However, the relative error of DWNN model is one order of magnitude lower than that of PINN. Second, we solve the Allen-Cahn equation using five wavelets and add a small sample of observations to the training set; finally, the DWNN model has 3155 more iterations than PINN. However, meanwhile, the relative error of DWNN is almost three orders of magnitude lower than PINN. Lastly, we use three wavelets to solve the Helmholtz equation in two-dimensions. Because fewer wavelets are used, the number of features increases slightly. Therefore, the results show that in the training process of two-dimensional Helmholtz equation, the DWNN model has fewer iterations and higher predictive accuracy. Figure 24b shows the comparison of relative errors between PINN and DWNN for five examples, from which we observe that DWNN model achieves a higher predictive accuracy. The more intuitive relative error results for DeLISA [62], Deep learning-based method coupled with SSL [31] (For brevity, denoted as SSL), and DWNN are listed in Table 10. For the cases in Table 10, we show the optimal solution with respect to the different methods. The results suggest that DWNN model performs better overall.
4. Discussion
In this work, we propose a deep wavelet neural network to tackle a series of partial differential equations. To gain further insight, we record and compare the experimental results of DWNN model and other state-of-the-art algorithms respectively. We also present experiments to validate the effectiveness of each part of the proposed model. Taken together, the development of this work provides a new architecture and training algorithm to improve the generalization ability and predictive accuracy significantly. Moreover, the proposed model is also good at solving shock-wave problems and interface problems. Despite these advances, we must acknowledge that one limitation of the proposed architecture is that we must carefully choose the number of appropriate wavelet mappings. At present, our system tends to be stable when the number of wavelets is near five. There are also many open questions worth considering as future research directions. Can we strictly establish a universal optimal design and its theory? Can we design other useful feature embedding to handle different scenarios? We believe that answering these questions not only leads to a better understanding of network models, but also opens a new door for developing interpretable machine learning algorithms that are necessary for many key applications in science and engineering.
5. Conclusions
In this paper, we propose a deep wavelet neural network model to solve partial differential equations. We introduce wavelets to the deep architecture to obtain a fine feature description and extraction. Then we use Gaussian error activation function instead of other traditional activation functions. Moreover, we add a tunable residual term of a few sample data points into the cost function to rectify the model. To investigate the performance of the proposed method, we carry out a variety of numerical experiments including Schrödinger equation, carburizing equation, Klein-Gordon equation, Burgers equation, Allen-Cahn equation, Helmholtz equation, and Poisson equation. In all cases, the relative error and error in solution are shown to be smaller than the state-of-the-art approach. We also present ablation experiments to validate the effectiveness of each part of the proposed model. The numerical results verify that the proposed method improves the predictive accuracy, robustness, and generalization ability.
Author Contributions
Conceptualization, Y.L. and S.Y.; Funding acquisition, Y.L. and S.Y.; Methodology, Y.L. and L.X.; Resources, L.X.; Supervision, Y.L. and S.Y.; Visualization, L.X.; Writing—original draft, L.X.; Writing—review & editing, Y.L. and S.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research work was funded by NSFC (11971296), and National Key Research and Development Program of China (No. 2021YFA1003004).
Conflicts of Interest
The authors declare no conflict of interest.
References
Ricardo, H.J. A Modern Introduction to Differential Equations; Academic Press: Cambridge, MA, USA, 2020. [Google Scholar]
Eymard, R.; Gallouët, T.; Herbin, R. Finite volume methods. In Handbook of Numerical Analysis; Elsevier: Amsterdam, The Netherlands, 2000; Volume 7, pp. 713–1018. [Google Scholar]
Zhang, Y. A finite difference method for fractional partial differential equation. Appl. Math. Comput.2009, 215, 524–529. [Google Scholar] [CrossRef]
Taylor, C.A.; Hughes, T.J.; Zarins, C.K. Finite element modeling of blood flow in arteries. Comput. Methods Appl. Mech. Eng.1998, 158, 155–196. [Google Scholar] [CrossRef]
Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision And Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar]
Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
Lagaris, I.E.; Likas, A.C.; Papageorgiou, D.G. Neural-network methods for boundary value problems with irregular boundaries. IEEE Trans. Neural Netw.2000, 11, 1041–1049. [Google Scholar] [CrossRef] [Green Version]
Mai-Duy, N.; Tran-Cong, T. Numerical solution of differential equations using multiquadric radial basis function networks. Neural Netw.2001, 14, 185–199. [Google Scholar] [CrossRef] [Green Version]
Mai-Duy, N.; Tran-Cong, T. Approximation of function and its derivatives using radial basis function networks. Appl. Math. Model.2003, 27, 197–220. [Google Scholar] [CrossRef] [Green Version]
Pao, Y.H.; Phillips, S.M. The functional link net and learning optimal control. Neurocomputing1995, 9, 149–164. [Google Scholar] [CrossRef]
Mall, S.; Chakraverty, S. Application of Legendre neural network for solving ordinary differential equations. Appl. Soft Comput.2016, 43, 347–356. [Google Scholar] [CrossRef]
Mall, S.; Chakraverty, S. Single layer Chebyshev neural network model for solving elliptic partial differential equations. Neural Process. Lett.2017, 45, 825–840. [Google Scholar] [CrossRef]
Sun, H.; Hou, M.; Yang, Y.; Zhang, T.; Weng, F.; Han, F. Solving partial differential equation based on Bernstein neural network and extreme learning machine algorithm. Neural Process. Lett.2019, 50, 1153–1172. [Google Scholar] [CrossRef]
Weinan, E.; Han, J.; Jentzen, A. Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations. Commun. Math. Stat.2017, 5, 349–380. [Google Scholar]
Han, J.; Weinan, E. Deep learning approximation for stochastic control problems. arXiv2016, arXiv:1611.07422. [Google Scholar]
Han, J.; Jentzen, A.; Weinan, E. Solving high-dimensional partial differential equations using deep learning. Proc. Natl. Acad. Sci. USA2018, 115, 8505–8510. [Google Scholar] [CrossRef] [Green Version]
Han, J.; Zhang, L.; Weinan, E. Solving many-electron Schrödinger equation using deep neural networks. J. Comput. Phys.2019, 399, 108929. [Google Scholar] [CrossRef] [Green Version]
Sirignano, J.; Spiliopoulos, K. DGM: A deep learning algorithm for solving partial differential equations. J. Comput. Phys.2018, 375, 1339–1364. [Google Scholar] [CrossRef] [Green Version]
Zang, Y.; Bao, G.; Ye, X.; Zhou, H. Weak adversarial networks for high-dimensional partial differential equations. J. Comput. Phys.2020, 411, 109409. [Google Scholar] [CrossRef] [Green Version]
Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys.2019, 378, 686–707. [Google Scholar] [CrossRef]
Jagtap, A.D.; Kharazmi, E.; Karniadakis, G.E. Conservative physics-informed neural networks on discrete domains for conservation laws: Applications to forward and inverse problems. Comput. Methods Appl. Mech. Eng.2020, 365, 113028. [Google Scholar] [CrossRef]
Mallat, S.; Zhong, S. Characterization of signals from multiscale edges. IEEE Trans. Pattern Anal. Mach. Intell.1992, 14, 710–732. [Google Scholar] [CrossRef] [Green Version]
Zainuddin, Z.; Pauline, O. Modified wavelet neural network in function approximation and its application in prediction of time-series pollution data. Appl. Soft Comput.2011, 11, 4866–4874. [Google Scholar] [CrossRef]
Liu, H.; Mi, X.w.; Li, Y.f. Wind speed forecasting method based on deep learning strategy using empirical wavelet transform, long short term memory neural network and Elman neural network. Energy Convers. Manag.2018, 156, 498–514. [Google Scholar] [CrossRef]
Wang, C.; Gao, R.X. Wavelet transform with spectral post-processing for enhanced feature extraction. In Proceedings of the 19th IEEE Instrumentation and Measurement Technology Conference (IEEE Cat. No. 00CH37276) IMTC/2002, Anchorage, AK, USA, 21–23 May 2002; Volume 1, pp. 315–320. [Google Scholar]
Li, Y.; Mei, F. Deep learning-based method coupled with small sample learning for solving partial differential equations. Multimed. Tools Appl.2021, 80, 17391–17413. [Google Scholar] [CrossRef]
Ososkov, G.; Shitov, A. Gaussian wavelet features and their applications for analysis of discretized signals. Comput. Phys. Commun.2000, 126, 149–157. [Google Scholar] [CrossRef]
Berkani, M.S.; Giurgea, S.; Espanet, C.; Coulomb, J.L.; Kieffer, C. Study on optimal design based on direct coupling between a FEM simulation model and L-BFGS-B algorithm. IEEE Trans. Magn.2013, 49, 2149–2152. [Google Scholar] [CrossRef]
Andrews, L.C. Special Functions of Mathematics for Engineers; Spie Press: Bellingham, WA, USA, 1998; Volume 49. [Google Scholar]
Chen, T.; Chen, H. Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems. IEEE Trans. Neural Netw.1995, 6, 911–917. [Google Scholar] [CrossRef] [Green Version]
Lanthaler, S.; Mishra, S.; Karniadakis, G.E. Error estimates for deeponets: A deep learning framework in infinite dimensions. Trans. Math. Its Appl.2022, 6, tnac001. [Google Scholar] [CrossRef]
Lu, L.; Jin, P.; Pang, G.; Zhang, Z.; Karniadakis, G.E. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nat. Mach. Intell.2021, 3, 218–229. [Google Scholar] [CrossRef]
Baydin, A.G.; Pearlmutter, B.A.; Radul, A.A.; Siskind, J.M. Automatic differentiation in machine learning: A survey. J. Mach. Learn. Res.2018, 18, 1–43. [Google Scholar]
Sun, Z. A meshless symplectic method for two-dimensional nonlinear Schrödinger equations based on radial basis function approximation. Eng. Anal. Bound. Elem.2019, 104, 1–7. [Google Scholar] [CrossRef]
Schrödinger, E. An undulatory theory of the mechanics of atoms and molecules. Phys. Rev.1926, 28, 1049. [Google Scholar] [CrossRef]
Stein, M. Large sample properties of simulations using Latin hypercube sampling. Technometrics1987, 29, 143–151. [Google Scholar] [CrossRef]
Platte, R.B.; Trefethen, L.N. Chebfun: A new kind of numerical computing. In Progress in Industrial Mathematics at ECMI 2008; Springer: Berlin/Heidelberg, Germany, 2010; pp. 69–87. [Google Scholar]
Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv2014, arXiv:1412.6980. [Google Scholar]
Maisuradze, M.V.; Kuklina, A.A. Numerical solution of the differential diffusion equation for a steel carburizing process. In Solid State Phenomena; Trans Tech Publications Ltd.: Freienbach, Switzerland, 2018; Volume 284, pp. 1230–1234. [Google Scholar]
Kula, P.; Pietrasik, R.; Dybowski, K. Vacuum carburizing—Process optimization. J. Mater. Process. Technol.2005, 164, 876–881. [Google Scholar] [CrossRef]
Xia, C.; Li, Y.; Wang, H. Local discontinuous Galerkin methods with explicit Runge-Kutta time marching for nonlinear carburizing model. Math. Methods Appl. Sci.2018, 41, 4376–4390. [Google Scholar] [CrossRef]
Caudrey, P.; Eilbeck, J.; Gibbon, J. The sine-Gordon equation as a model classical field theory. Il Nuovo Cimento B (1971–1996)1975, 25, 497–512. [Google Scholar] [CrossRef]
Dodd, R.K.; Morris, H.C.; Eilbeck, J.; Gibbon, J. Soliton and nonlinear wave equations. London and New York. 1982. Available online: https://www.osti.gov/biblio/6349564 (accessed on 25 April 2022).
Wazwaz, A.M. New travelling wave solutions to the Boussinesq and the Klein-Gordon equations. Commun. Nonlinear Sci. Numer. Simul.2008, 13, 889–901. [Google Scholar] [CrossRef]
Jagtap, A.D.; Kawaguchi, K.; Karniadakis, G.E. Adaptive activation functions accelerate convergence in deep and physics-informed neural networks. J. Comput. Phys.2020, 404, 109136. [Google Scholar] [CrossRef] [Green Version]
Basdevant, C.; Deville, M.; Haldenwang, P.; Lacroix, J.; Ouazzani, J.; Peyret, R.; Orlandi, P.; Patera, A. Spectral and finite difference solutions of the Burgers equation. Comput. Fluids1986, 14, 23–41. [Google Scholar] [CrossRef]
Bateman, H. Some recent researches on the motion of fluids. Mon. Weather Rev.1915, 43, 163–170. [Google Scholar] [CrossRef]
Yang, X.; Ge, Y.; Zhang, L. A class of high-order compact difference schemes for solving the Burgers’ equations. Appl. Math. Comput.2019, 358, 394–417. [Google Scholar] [CrossRef]
Allen, S.M.; Cahn, J.W. A microscopic theory for antiphase boundary motion and its application to antiphase domain coarsening. Acta Metall.1979, 27, 1085–1095. [Google Scholar] [CrossRef]
Beneš, M.; Chalupeckỳ, V.; Mikula, K. Geometrical image segmentation by the Allen-Cahn equation. Appl. Numer. Math.2004, 51, 187–205. [Google Scholar] [CrossRef]
Dobrosotskaya, J.A.; Bertozzi, A.L. A wavelet-Laplace variational technique for image deconvolution and inpainting. IEEE Trans. Image Process.2008, 17, 657–663. [Google Scholar] [CrossRef]
Feng, X.; Prohl, A. Numerical analysis of the Allen-Cahn equation and approximation for mean curvature flows. Numer. Math.2003, 94, 33–65. [Google Scholar] [CrossRef]
Wheeler, A.A.; Boettinger, W.J.; McFadden, G.B. Phase-field model for isothermal phase transitions in binary alloys. Phys. Rev. A1992, 45, 7424. [Google Scholar] [CrossRef]
Wang, S.; Teng, Y.; Perdikaris, P. Understanding and mitigating gradient flow pathologies in physics-informed neural networks. SIAM J. Sci. Comput.2021, 43, A3055–A3081. [Google Scholar] [CrossRef]
Yu, B. The deep Ritz method: A deep learning-based numerical algorithm for solving variational problems. Commun. Math. Stat.2018, 6, 1–12. [Google Scholar]
Li, Y.; Zhou, Z.; Ying, S. DeLISA: Deep learning based iteration scheme approximation for solving PDEs. J. Comput. Phys.2022, 451, 110884. [Google Scholar] [CrossRef]
Figure 1.
Architecture of deep wavelet neural network.
Figure 1.
Architecture of deep wavelet neural network.
Figure 3.
The comparison of activation function. (a) Sigmoid and ReLu. (b) ERF and Tanh.
Figure 3.
The comparison of activation function. (a) Sigmoid and ReLu. (b) ERF and Tanh.
Figure 4.
Diagram of Gaussian error function and its derivative. (a) Gaussian error function. (b) The derivative of the Gaussian error function.
Figure 4.
Diagram of Gaussian error function and its derivative. (a) Gaussian error function. (b) The derivative of the Gaussian error function.
Figure 5.
Results of Equation (22). (a) The predicted solution . (b) The change process of the objective function versus iteration number.
Figure 5.
Results of Equation (22). (a) The predicted solution . (b) The change process of the objective function versus iteration number.
Figure 6.
Comparison of predicted solution and exact solution of Equation (22) corresponding to different temporal snapshots. (a) ; (b) ; (c) ; (d) .
Figure 6.
Comparison of predicted solution and exact solution of Equation (22) corresponding to different temporal snapshots. (a) ; (b) ; (c) ; (d) .
Figure 7.
Results of Equation (28). (a) The predicted solution . (b) The change process of the objective function versus iteration number.
Figure 7.
Results of Equation (28). (a) The predicted solution . (b) The change process of the objective function versus iteration number.
Figure 8.
Comparison of predicted solution and exact solution of Equation (28) corresponding to different temporal snapshots. (a) ; (b) ; (c) ; (d) .
Figure 8.
Comparison of predicted solution and exact solution of Equation (28) corresponding to different temporal snapshots. (a) ; (b) ; (c) ; (d) .
Figure 9.
Results of Equation (34). (a) The predicted solution . (b) The change process of the objective function versus iteration number.
Figure 9.
Results of Equation (34). (a) The predicted solution . (b) The change process of the objective function versus iteration number.
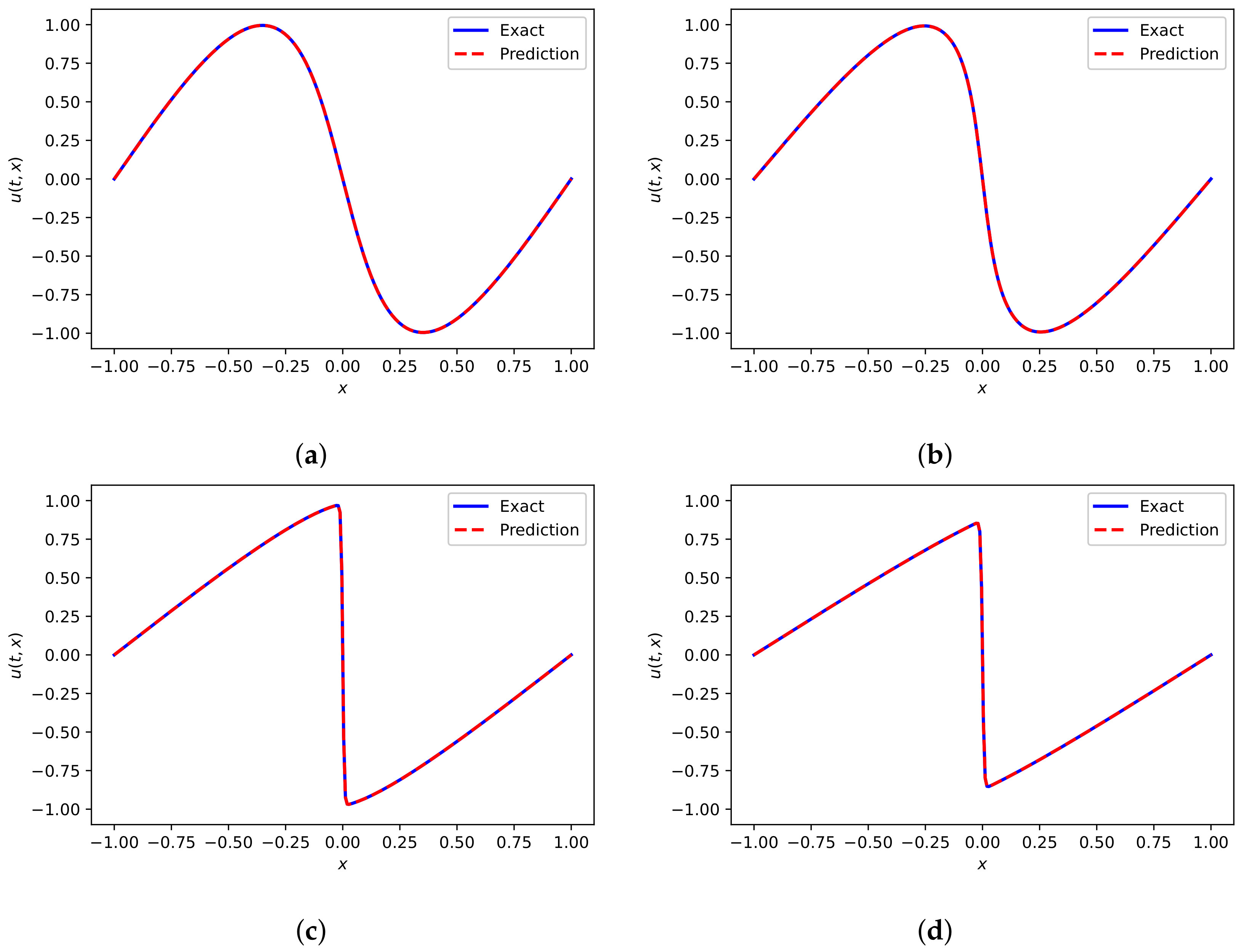
Figure 10.
Comparison of predicted solution and exact solution of Equation (34) corresponding to different x. (a) ; (b) ; (c) ; (d) .
Figure 10.
Comparison of predicted solution and exact solution of Equation (34) corresponding to different x. (a) ; (b) ; (c) ; (d) .
Figure 11.
Results of Equation (39). (a) The predicted solution . (b) The change process of the objective function versus iteration number.
Figure 11.
Results of Equation (39). (a) The predicted solution . (b) The change process of the objective function versus iteration number.
Figure 12.
The Loss and error of Burgers and Allen-Cahn. (a) 1D Burgers. (b) Allen-Cahn.
Figure 12.
The Loss and error of Burgers and Allen-Cahn. (a) 1D Burgers. (b) Allen-Cahn.
Figure 13.
Comparison of predicted solution and exact solution of Equation (39) corresponding to different temporal snapshots. (a) ; (b) ; (c) ; (d) .
Figure 13.
Comparison of predicted solution and exact solution of Equation (39) corresponding to different temporal snapshots. (a) ; (b) ; (c) ; (d) .
Figure 14.
Results of Equation (45). (a) The predicted solution . (b) The change process of the objective function versus iteration number.
Figure 14.
Results of Equation (45). (a) The predicted solution . (b) The change process of the objective function versus iteration number.
Figure 15.
Comparison of predicted solution and exact solution of Equation (45) based on PINN, WTNN and DWNN. (a–c) the comparison of predicted PINN solution, WTNN solution, DWNN solution and exact solution at , respectively. (d–f) the comparison of predicted PINN solution, WTNN solution, DWNN solution and exact solution at , respectively.
Figure 15.
Comparison of predicted solution and exact solution of Equation (45) based on PINN, WTNN and DWNN. (a–c) the comparison of predicted PINN solution, WTNN solution, DWNN solution and exact solution at , respectively. (d–f) the comparison of predicted PINN solution, WTNN solution, DWNN solution and exact solution at , respectively.
Figure 16.
Results of Equation (52). (a) Exact solution at time . (b) Predicted solution at time . (c) Numerical error at time . (d) The change process of the objective function versus iteration number.
Figure 16.
Results of Equation (52). (a) Exact solution at time . (b) Predicted solution at time . (c) Numerical error at time . (d) The change process of the objective function versus iteration number.
Figure 17.
Results of Equation (58). (a) Exact solution at time . (b) Predicted solution at time . (c) Numerical error at time . (d) Loss vs. iterations.
Figure 17.
Results of Equation (58). (a) Exact solution at time . (b) Predicted solution at time . (c) Numerical error at time . (d) Loss vs. iterations.
Figure 18.
Results of Equation (64). (a) The predicted solution . (b) The change process of the objective function versus iteration number.
Figure 18.
Results of Equation (64). (a) The predicted solution . (b) The change process of the objective function versus iteration number.
Figure 19.
Comparison of predicted solution and exact solution of Equation (64) at different x. (a) ; (b) ; (c) ; (d) .
Figure 19.
Comparison of predicted solution and exact solution of Equation (64) at different x. (a) ; (b) ; (c) ; (d) .
Figure 21.
The stream function and pressure field p. (a) The stream function . (b) Pressure field p.
Figure 21.
The stream function and pressure field p. (a) The stream function . (b) Pressure field p.
Figure 22.
Results of Equation (Section 3.3.1) at different time instants. (a–c) Exact solution, numerical solution, and numerical error at . (d–f) Exact solution, numerical solution, and numerical error at . (g–i) Exact solution, numerical solution, and numerical error at .
Figure 22.
Results of Equation (Section 3.3.1) at different time instants. (a–c) Exact solution, numerical solution, and numerical error at . (d–f) Exact solution, numerical solution, and numerical error at . (g–i) Exact solution, numerical solution, and numerical error at .
Figure 23.
Results of Equation (82) in the different planes. (a–c) Exact solution, numerical solution and numerical error in the plane , . (d–f): Exact solution, numerical solution and numerical error in the plane , . (g–i) Exact solution, numerical solution and numerical error in the plane , .
Figure 23.
Results of Equation (82) in the different planes. (a–c) Exact solution, numerical solution and numerical error in the plane , . (d–f): Exact solution, numerical solution and numerical error in the plane , . (g–i) Exact solution, numerical solution and numerical error in the plane , .
Figure 24.
The comparison of iterations and errors. (a) Iteration comparison. (b) Error comparison.
Figure 24.
The comparison of iterations and errors. (a) Iteration comparison. (b) Error comparison.
Table 1.
The errors and errors for 1D Schrödinger.
Table 1.
The errors and errors for 1D Schrödinger.
Li, Y.; Xu, L.; Ying, S.
DWNN: Deep Wavelet Neural Network for Solving Partial Differential Equations. Mathematics2022, 10, 1976.
https://doi.org/10.3390/math10121976
AMA Style
Li Y, Xu L, Ying S.
DWNN: Deep Wavelet Neural Network for Solving Partial Differential Equations. Mathematics. 2022; 10(12):1976.
https://doi.org/10.3390/math10121976
Chicago/Turabian Style
Li, Ying, Longxiang Xu, and Shihui Ying.
2022. "DWNN: Deep Wavelet Neural Network for Solving Partial Differential Equations" Mathematics 10, no. 12: 1976.
https://doi.org/10.3390/math10121976
APA Style
Li, Y., Xu, L., & Ying, S.
(2022). DWNN: Deep Wavelet Neural Network for Solving Partial Differential Equations. Mathematics, 10(12), 1976.
https://doi.org/10.3390/math10121976
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.
Article Metrics
No
No
Article Access Statistics
For more information on the journal statistics, click here.
Multiple requests from the same IP address are counted as one view.
Li, Y.; Xu, L.; Ying, S.
DWNN: Deep Wavelet Neural Network for Solving Partial Differential Equations. Mathematics2022, 10, 1976.
https://doi.org/10.3390/math10121976
AMA Style
Li Y, Xu L, Ying S.
DWNN: Deep Wavelet Neural Network for Solving Partial Differential Equations. Mathematics. 2022; 10(12):1976.
https://doi.org/10.3390/math10121976
Chicago/Turabian Style
Li, Ying, Longxiang Xu, and Shihui Ying.
2022. "DWNN: Deep Wavelet Neural Network for Solving Partial Differential Equations" Mathematics 10, no. 12: 1976.
https://doi.org/10.3390/math10121976
APA Style
Li, Y., Xu, L., & Ying, S.
(2022). DWNN: Deep Wavelet Neural Network for Solving Partial Differential Equations. Mathematics, 10(12), 1976.
https://doi.org/10.3390/math10121976
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}