
Older Adults Get Lost in Virtual Reality: Visuospatial Disorder Detection in Dementia Using a Voting Approach Based on Machine Learning Algorithms


Abstract
1. Introduction
- Designing the MVD Test as a VR environment along with MLAs, and using it to help physicians to identify behavioral and perceptual abnormalities associated with dementia.
- Examining the probability of identifying visuospatial and memory deficits using MLAs along with VR technology in dementia patients.
- Diagnosing cognitively impaired patients in a simulated environment that tests memory and visuospatial deficits.
- Classifying participants into three classes: older adults who have normal cognitive functioning, MCI, and early and moderately severe dementia.
- Analyzing data from real medical patients and measuring cognitive performance while patients perform real world tasks simulated in VR.
2. Literature Review
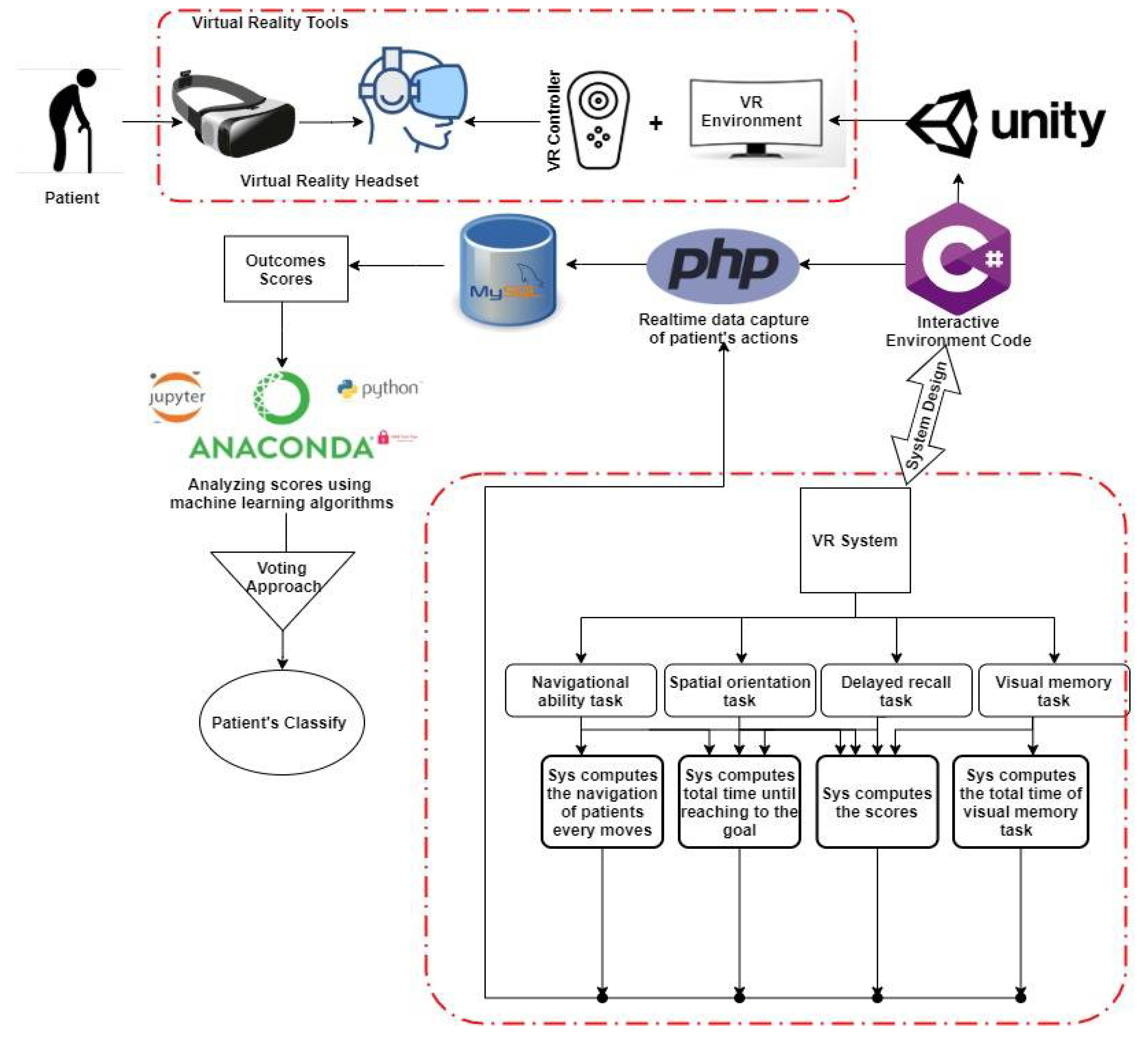
3. System Model
3.1. Patient’s History and Demographic
3.2. System Approach
3.3. Visuospatial Function
3.3.1. Navigational Task
- A simulation is shown by the system so that the patient can see the path from the starting point to the destination.
- To assess judgment of directions and to set points according to the response, the patient answers several questions.
- The system measures total time and the path coordinates of the patient during the task.
3.3.2. Visual Memory Task
3.4. Memory Function
Memory Registration and Delayed Recall Task
3.5. Outcomes Measurements
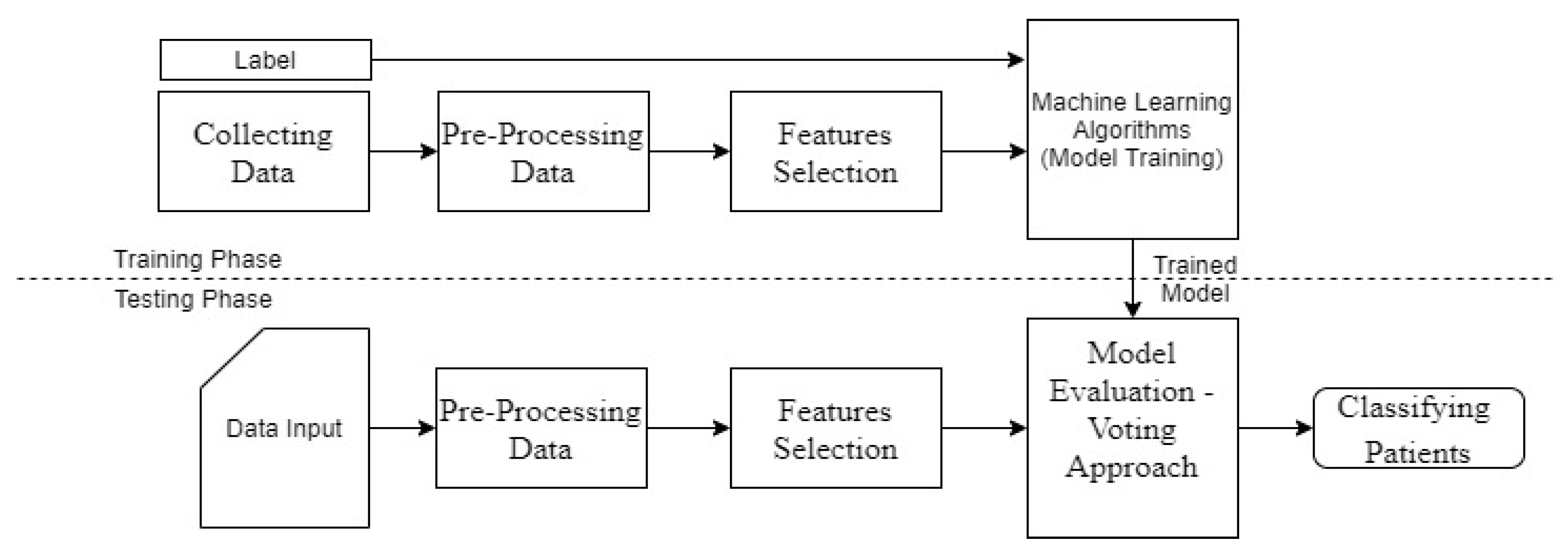
3.6. Machine Learning Algorithms
Pre-Processing Data
3.7. Classification Process
3.7.1. Decision Tree Classifier
3.7.2. Extra Trees Classifier
3.7.3. AdaBoost Classifier
3.7.4. Gradient Boosting Classifier
3.7.5. XGB Classifier
3.7.6. Random Forest Classifier
3.7.7. Multinomial Naive Bayes (NB)
3.7.8. Support Vector Classifier (SVC)
3.7.9. K-Neighbors Classifier
3.7.10. Multilayer Perceptron
4. Performance Evaluation and Discussion of Results
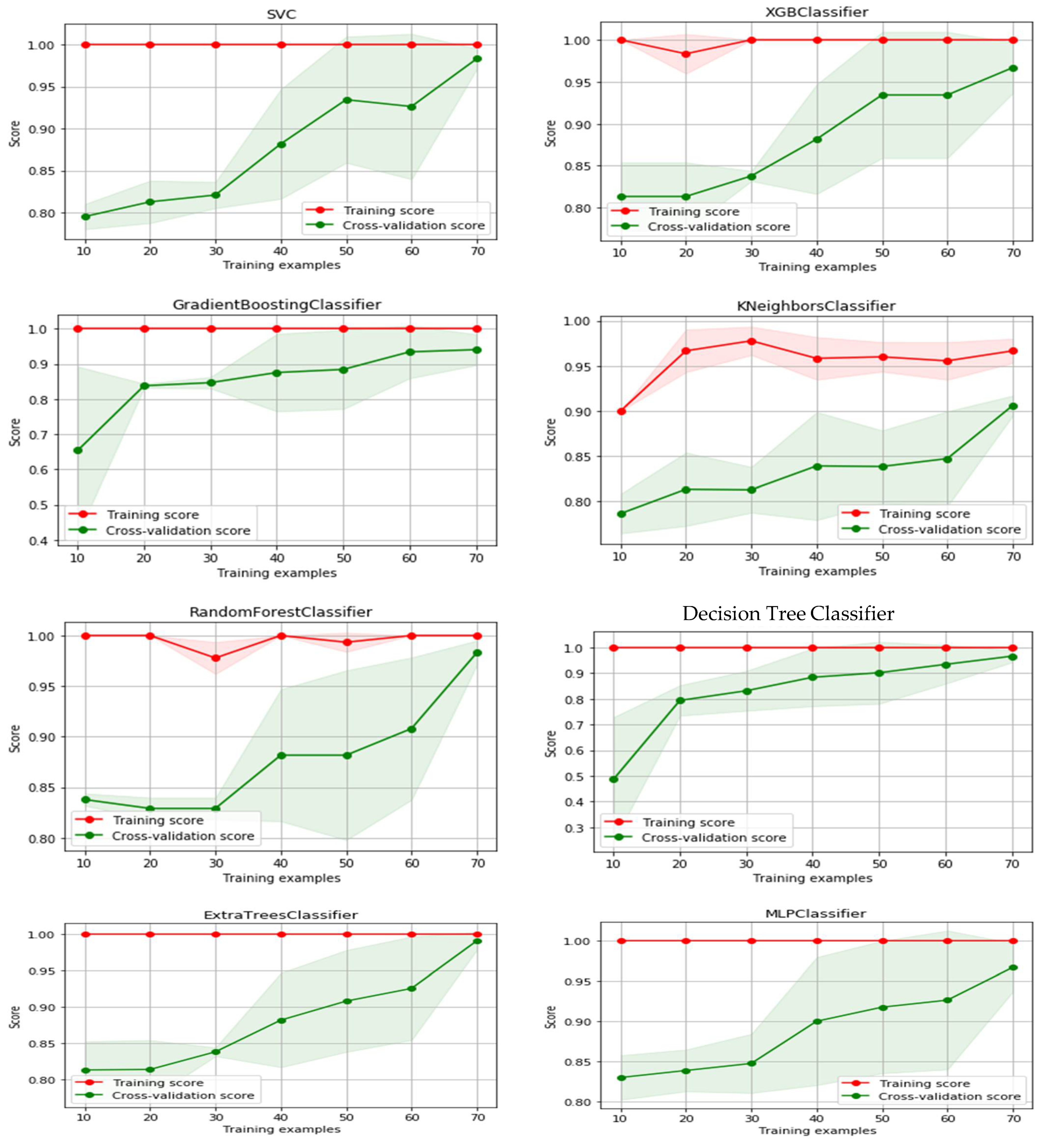
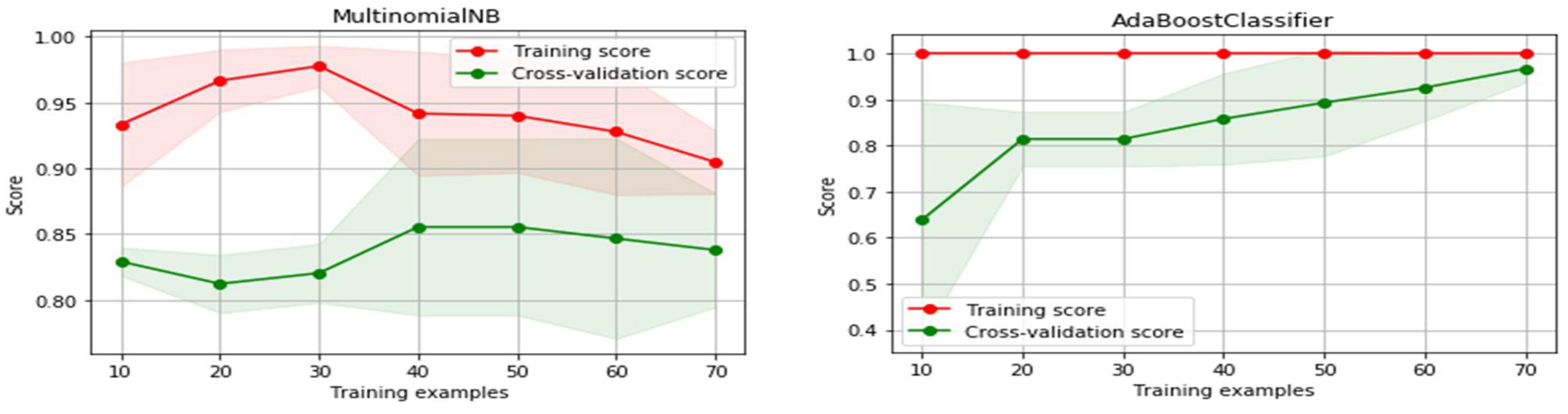
4.1. Training and Testing Phase
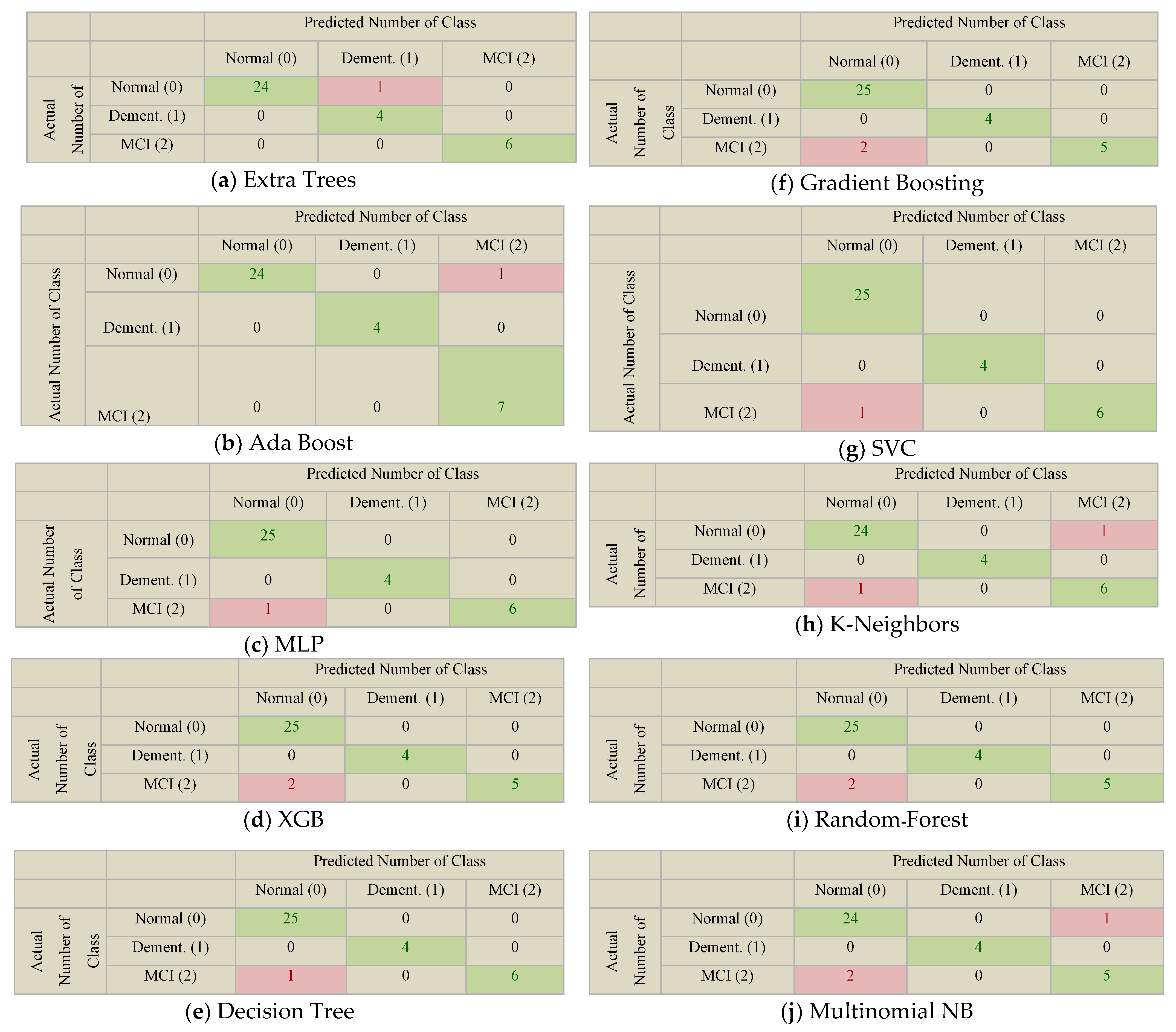
4.2. Evaluation Perfotrmance of ML Model
- TP for Dementia class in SVC = CM [1][1] = 4,
- FN for Dementia class in SVC = CM [1][0] + CM [1][2] = 0,
- TN for Dementia class in SVC = CM [0][0] + CM [2][2] + CM [0][2] + CM [2][0] = 32,
- FP for Dementia class in SVC = CM [0][1] + MC [2][1] = 0.
4.3. Generalized MLA Results Using the Voting Approach
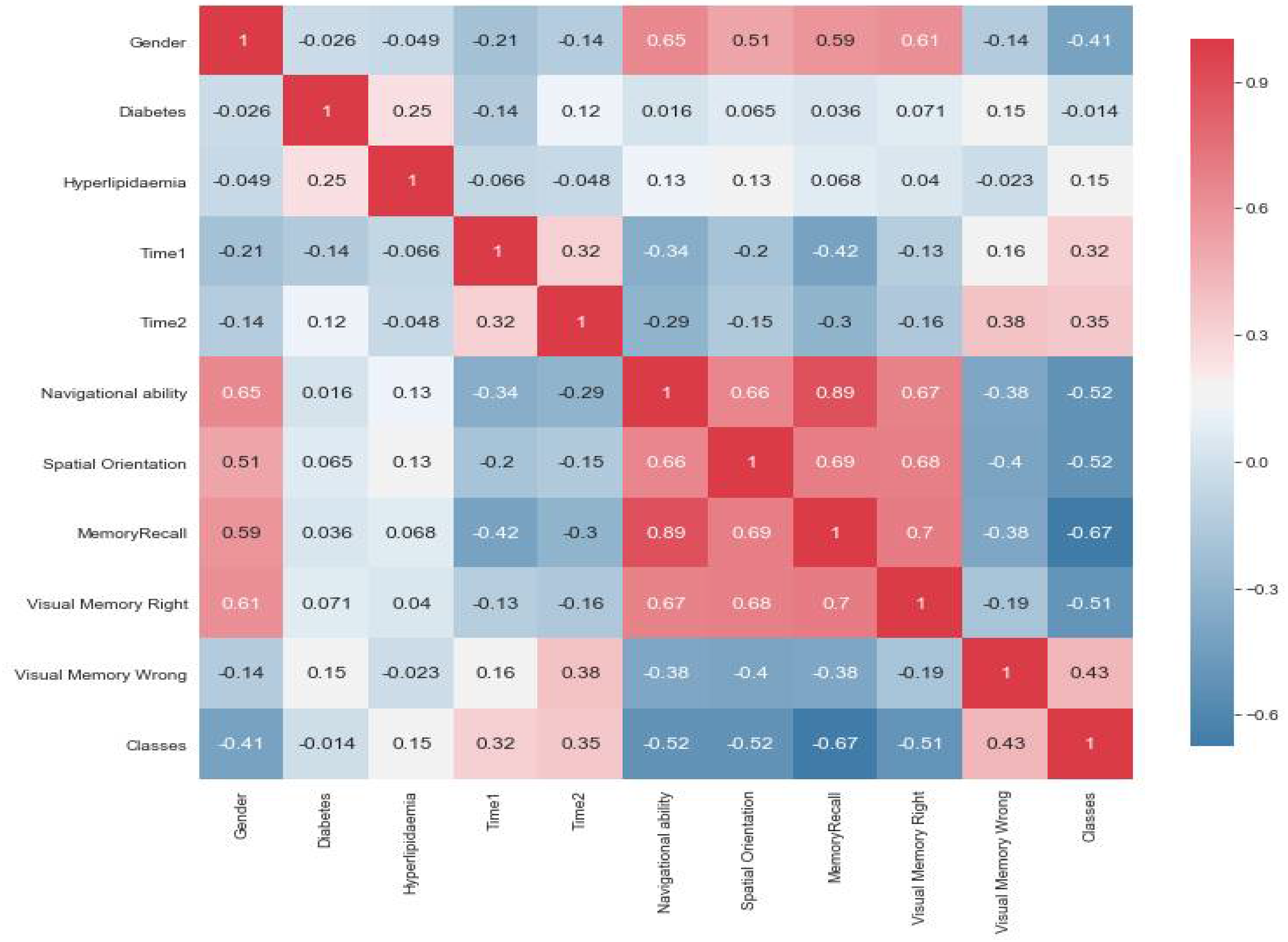
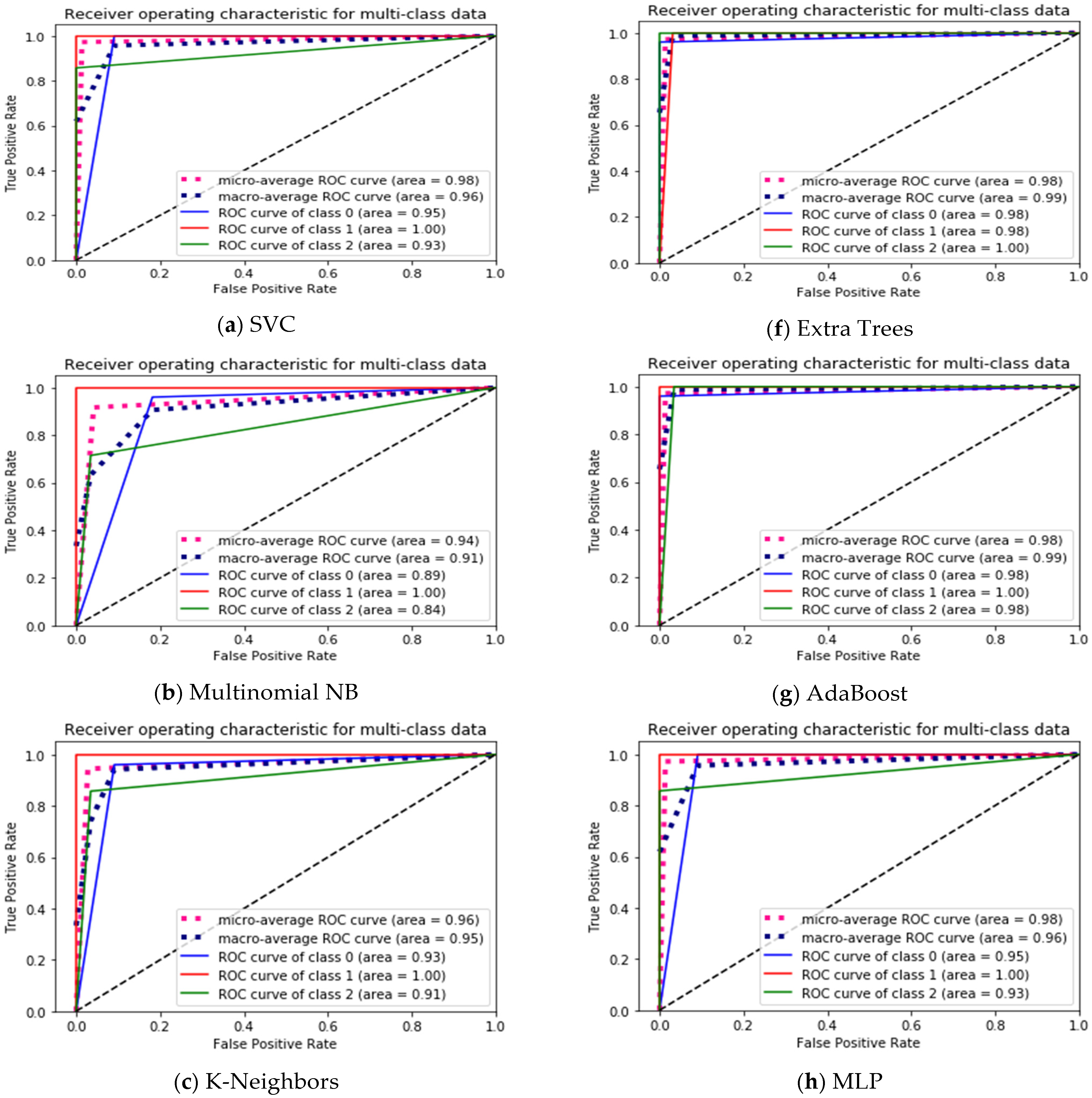
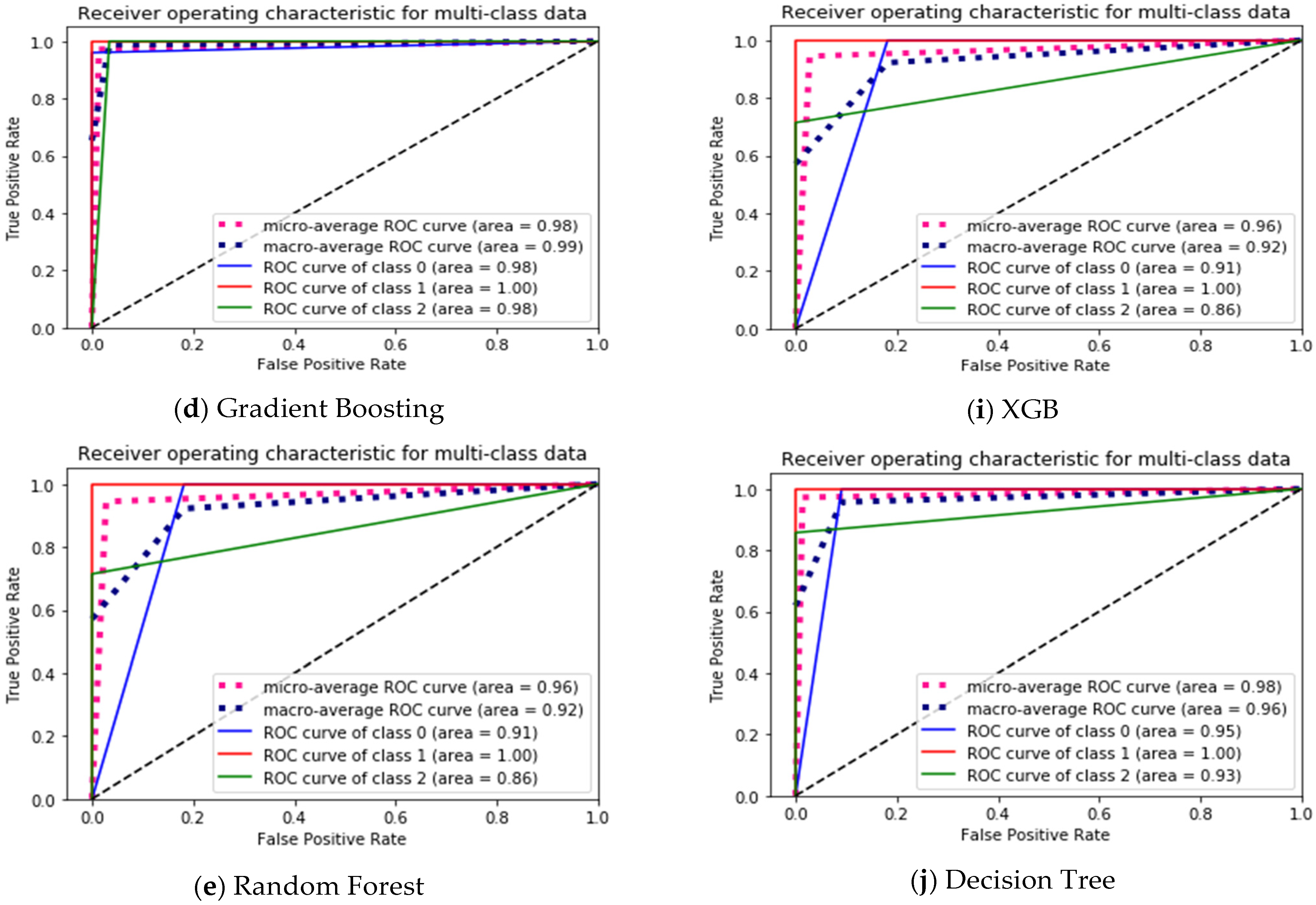
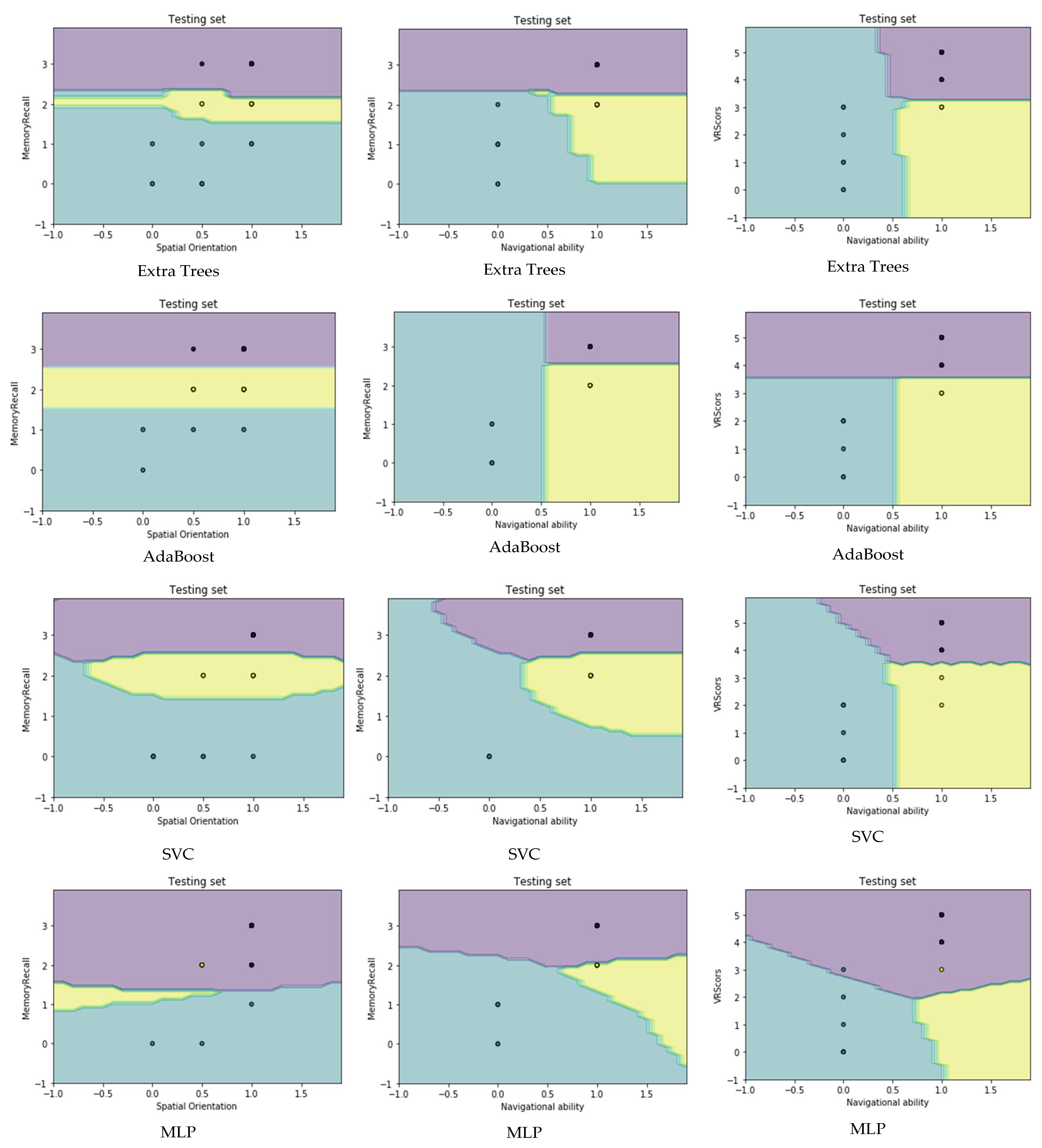
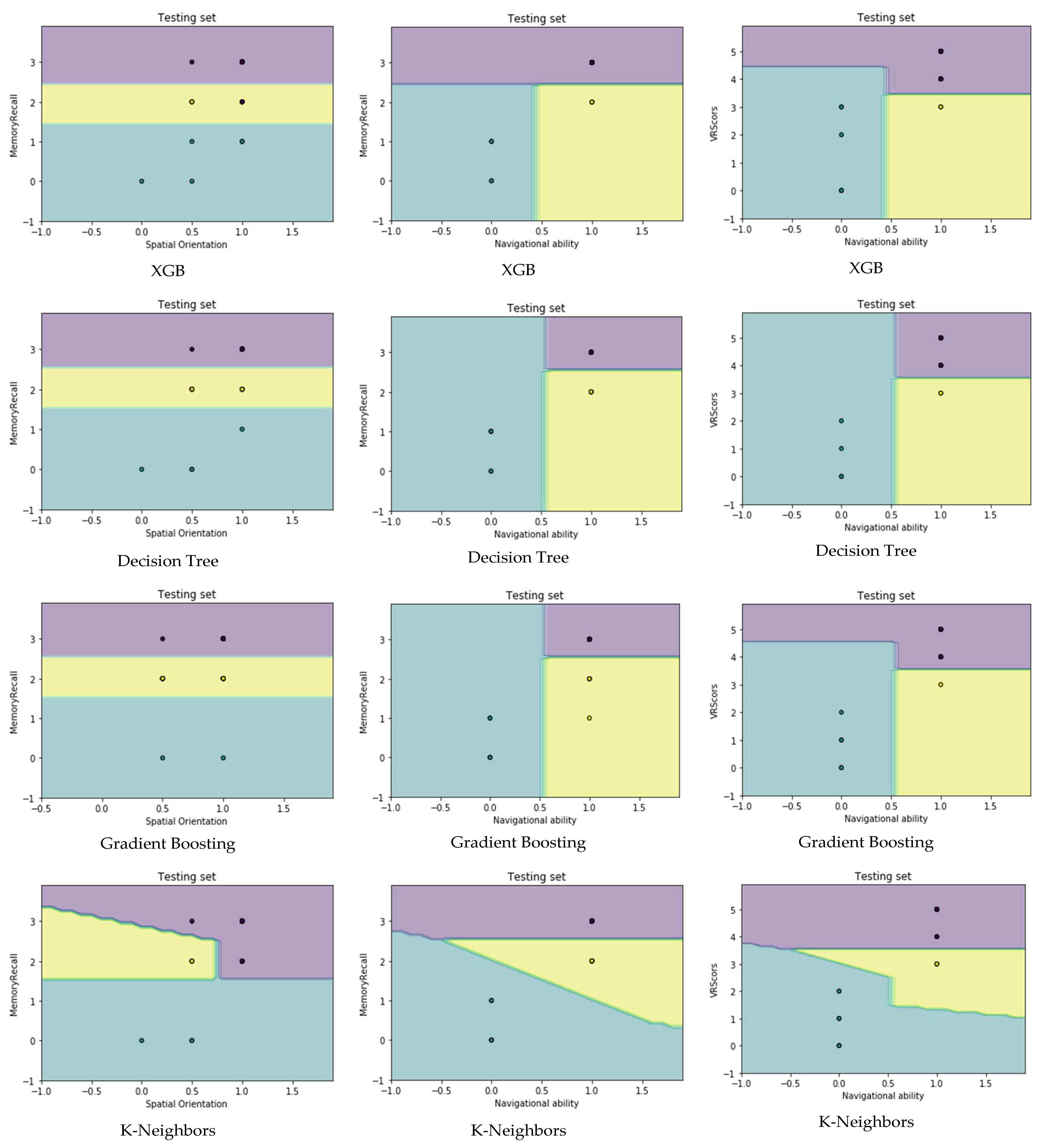
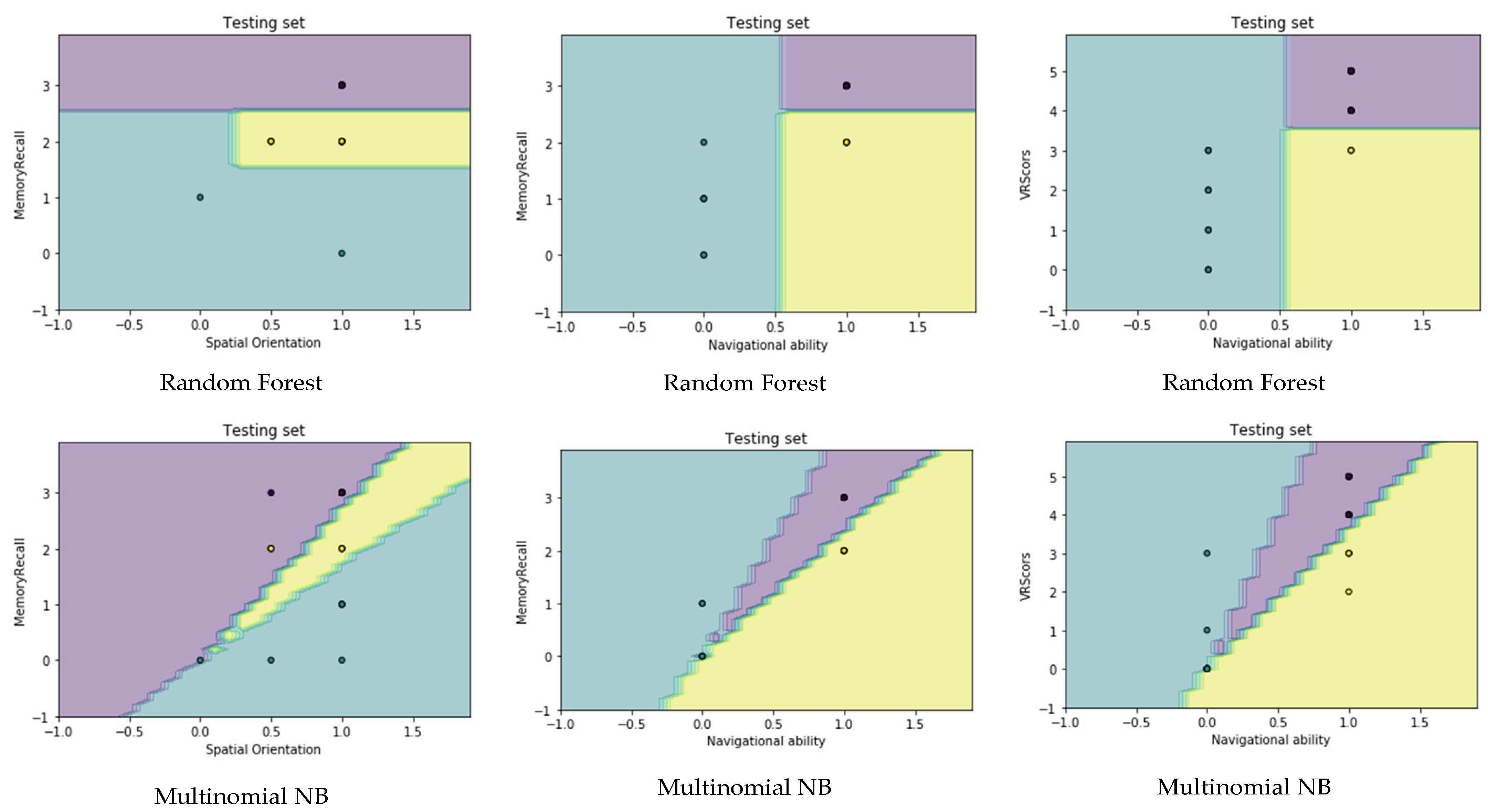
4.4. Visualization Data
5. Conclusions
- Transferring medically assessed tasks using paper and pencil to tasks that are electronically performed in a 3D virtual reality environment.
- Creating computer aided diagnosis (CAD) tools that are useful and easy to use for people who have a reduced cognitive ability and have limited use of technology;
- Dealing with elderly patients, especially when conducting tests;
- Execution of VR experiment in different hospitals and associations; and
- Analyzing real data from different hospitals and associations using the VR system.
6. Patents
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- García-Betances, R.I.; Jiménez-Mixco, V.; Arredondo, M.T.; Cabrera-Umpiérrez, M.F. Using virtual reality for cognitive training of the elderly. Am. J. Alzheimer’s Dis. Other Dement. 2015, 30, 49–54. [Google Scholar] [CrossRef] [PubMed]
- Alzheimer’s, A. 2015 Alzheimer’s disease facts and figures. Alzheimer’s Dement. J. Alzheimer’s Assoc. 2015, 11, 332. [Google Scholar] [CrossRef] [PubMed]
- Rowe, P. Kaplan & Sadock′s Concise Textbook of Clinical Psychiatry. J. Ment. Health 2009, 18, 360–361. [Google Scholar] [CrossRef]
- Salimi, S.; Irish, M.; Foxe, D.; Hodges, J.R.; Piguet, O.; Burrell, J.R. Can visuospatial measures improve the diagnosis of Alzheimer’s disease? Alzheimer’s Dement. Diagn. Assess. Dis. Monit. 2017, 10, 66–74. [Google Scholar] [CrossRef] [PubMed]
- Montenegro, J.M.F.; Argyriou, V. Cognitive evaluation for the diagnosis of Alzheimer’s disease based on Turing Test and Virtual Environments. Physiol. Behav. 2017, 173, 42–51. [Google Scholar] [CrossRef]
- Geldmacher, D.S.; Whitehouse, P.J. Evaluation of dementia. N. Engl. J. Med. 1996, 335, 330–336. [Google Scholar] [CrossRef]
- Weakley, A.; Williams, J.A.; Schmitter-Edgecombe, M.; Cook, D.J. Neuropsychological test selection for cognitive impairment classification: A machine learning approach. J. Clin. Exp. Neuropsychol. 2015, 37, 899–916. [Google Scholar] [CrossRef]
- Silverberg, N.B.; Ryan, L.M.; Carrillo, M.C.; Sperling, R.; Petersen, R.C.; Posner, H.B.; Snyder, P.J.; Hilsabeck, R.; Gallagher, M.; Raber, J.; et al. Assessment of cognition in early dementia. Alzheimer’s Dement. 2011, 7, e60–e76. [Google Scholar] [CrossRef]
- Taekman, J.M.; Shelley, K. Virtual environments in healthcare: Immersion, disruption, and flow. Int. Anesthesiol. Clin. 2010, 48, 101–121. [Google Scholar] [CrossRef]
- García-Betances, R.; Arredondo Waldmeyer, M.; Fico, G.; Cabrera-Umpiérrez, M. A succinct overview of virtual reality technology use in Alzheimer’s disease. ICT Assess. Rehabil. Alzheimer’s Dis. Relat. Disord. 2015, 7, 80. [Google Scholar]
- Mihelj, M.; Novak, D.; Beguš, S. Virtual Reality Technology and Applications. 2014. Available online: https://www.researchgate.net/publication/293273379_Virtual_Reality_Technology_and_Applications (accessed on 14 February 2022).
- Cushman, L.A.; Stein, K.; Duffy, C.J. Detecting navigational deficits in cognitive aging and Alzheimer disease using virtual reality. Neurology 2008, 71, 888–895. [Google Scholar] [CrossRef] [PubMed]
- Zakzanis, K.K.; Quintin, G.; Graham, S.J.; Mraz, R. Age and dementia related differences in spatial navigation within an immersive virtual environment. Med. Sci. Monit. 2009, 15, CR140–CR150. [Google Scholar] [PubMed]
- Plancher, G.; Tirard, A.; Gyselinck, V.; Nicolas, S.; Piolino, P. Using virtual reality to characterize episodic memory profiles in amnestic mild cognitive impairment and Alzheimer’s disease: Influence of active and passive encoding. Neuropsychologia 2012, 50, 592–602. [Google Scholar] [CrossRef] [PubMed]
- Shamsuddin, S.N.W.; Ugail, H.; Lesk, V.; Walters, E. VREAD: A virtual simulation to investigate cognitive function in the elderly. In Proceedings of the 2012 International Conference on Cyberworlds, Darmstadt, Germany, 25 September 2012; pp. 215–220. [Google Scholar]
- Bayahya, A.Y.; AlHalabi, W.; Al-Amri, S.H.; Albeshri, A.A.; El-Missiry, A.A. Computer Generated Environment Utilizing Machine Learning Algorithms to Evaluate Dementia Patients. Procedia Comput. Sci. 2019, 163, 275–282. [Google Scholar] [CrossRef]
- Kononenko, I. Machine learning for medical diagnosis: History, state of the art and perspective. Artif. Intell. Med. 2001, 23, 89–109. [Google Scholar] [CrossRef]
- Fatima, M.; Pasha, M. Survey of machine learning algorithms for disease diagnostic. J. Intell. Learn. Syst. Appl. 2017, 9, 1. [Google Scholar] [CrossRef]
- Abdullah, M.; Bayahya, A.Y.; Shammakh, E.S.B.; Altuwairqi, K.A.; Alsaadi, A.A. A novel adaptive e-learning model matching educator-student learning styles based on machine learning. In Communication, Management and Information Technology; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Yeh, S.-C.; Huang, M.-C.; Wang, P.-C.; Fang, T.-Y.; Su, M.-C.; Tsai, P.-Y.; Rizzo, A. Machine learning-based assessment tool for imbalance and vestibular dysfunction with virtual reality rehabilitation system. Comput. Methods Programs Biomed. 2014, 116, 311–318. [Google Scholar] [CrossRef]
- Tu, S.; Wong, S.; Hodges, J.R.; Irish, M.; Piguet, O.; Hornberger, M. Lost in spatial translation—A novel tool to objectively assess spatial disorientation in Alzheimer’s disease and frontotemporal dementia. Cortex 2015, 67, 83–94. [Google Scholar] [CrossRef]
- Lesk, V.E.; Shamsuddin, S.N.W.; Walters, E.R.; Ugail, H. Using a virtual environment to assess cognition in the elderly. Virtual Real. 2014, 18, 271–279. [Google Scholar] [CrossRef]
- Pengas, G.; Patterson, K.; Arnold, R.J.; Bird, C.M.; Burgess, N.; Nestor, P.J. Lost and found: Bespoke memory testing for Alzheimer’s disease and semantic dementia. J. Alzheimer’s Dis. 2010, 21, 1347–1365. [Google Scholar] [CrossRef]
- Tarnanas, I.; Schlee, W.; Tsolaki, M.; Müri, R.; Mosimann, U.; Nef, T. Ecological validity of virtual reality daily living activities screening for early dementia: Longitudinal study. JMIR Serious Games 2013, 1, e1. [Google Scholar] [CrossRef] [PubMed]
- Allain, P.; Foloppe, D.A.; Besnard, J.; Yamaguchi, T.; Etcharry-Bouyx, F.; Le Gall, D.; Nolin, P.; Richard, P. Detecting everyday action deficits in Alzheimer’s disease using a nonimmersive virtual reality kitchen. J. Int. Neuropsychol. Soc. 2014, 20, 468–477. [Google Scholar] [CrossRef] [PubMed]
- Zucchella, C.; Sinforiani, E.; Tassorelli, C.; Cavallini, E.; Tost-Pardell, D.; Grau, S.; Pazzi, S.; Puricelli, S.; Bernini, S.; Bottiroli, S. Serious games for screening pre-dementia conditions: From virtuality to reality? A pilot project. Funct. Neurol. 2014, 29, 153. [Google Scholar] [PubMed]
- Lezak, M.; Howieson, D.; Loring, D. Neuropsychological Assessment, 5th ed.; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Sathya, R.; Abraham, A. Comparison of supervised and unsupervised learning algorithms for pattern classification. Int. J. Adv. Res. Artif. Intell. 2013, 2, 34–38. [Google Scholar] [CrossRef]
- Kaur, G.; Chhabra, A. Improved J48 Classification Algorithm for the Prediction of Diabetes. Int. J. Comput. Appl. 2014, 98, 13–17. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13 August 2016; pp. 785–794. [Google Scholar]
- Ridgeway, G. The state of boosting. Comput. Sci. Stat. 1999, 172–181. [Google Scholar]
- Satyanarayana, N.; Ramalingaswamy, C.; Ramadevi, Y. Survey of Classification Techniques in Data Mining. In Proceedings of the International Multiconference of Engineers and Computer Scientists, Hong Kong, China, 18 March 2009. [Google Scholar]
- Pumpuang, P.; Srivihok, A.; Praneetpolgrang, P. Comparisons of classifier algorithms: Bayesian network, C4.5, decision forest and NBTree for Course Registration Planning model of undergraduate students. In Proceedings of the 2008 IEEE International Conference on Systems, Man and Cybernetics, Singapore, 12–15 October 2008; pp. 3647–3651. [Google Scholar]
- McCallum, A.; Nigam, K. A comparison of event models for naive bayes text classification. In Proceedings of the AAAI-98 Workshop on Learning for Text Categorization, Pittsburgh, PA, USA, 26 July 1998; pp. 41–48. [Google Scholar]
- Nurnberger, A.; Borgelt, C.; Klose, A. Improving naive Bayes classifiers using neuro-fuzzy learning. In Proceedings of the ANZIIS’99 & ANNES’99 & ACNN’99. 6th International Conference on Neural Information Processing, Perth, WA, Australia, 16 November 1999. [Google Scholar]
- Grother, P.J.; Candela, G.T.; Blue, J.L. Fast implementations of nearest neighbor classifiers. Pattern Recognit. 1997, 30, 459–465. [Google Scholar] [CrossRef]
- Windeatt, T. Ensemble MLP classifier design. In Computational Intelligence Paradigms; Springer: Berlin/Heidelberg, Germany, 2008; pp. 133–147. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in {P}ython. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Korting, T.S. C4. 5 Algorithm and Multivariate Decision Trees; Image Processing Division, National Institute for Space Research–INPE: Sao Jose dos Campos, SP, Brazil, 2006. [Google Scholar]
- Van Essen, B.; Macaraeg, C.; Gokhale, M.; Prenger, R. Accelerating a random forest classifier: Multi-core, GP-GPU, or FPGA? In Proceedings of the 2012 IEEE 20th International Symposium on Field-Programmable Custom Computing Machines, Toronto, ON, Canada, 29 April 2012; pp. 232–239. [Google Scholar]
- Pugazhenthi, D.; Rajagopalan, S. Machine learning technique approaches in drug discovery, design and development. Inf. Technol. J. 2007, 6, 718–724. [Google Scholar] [CrossRef][Green Version]
- Manliguez, C. Generalized Confusion Matrix for Multiple Classes. 2016. Available online: https://www.researchgate.net/publication/310799885_Generalized_Confusion_Matrix_for_Multiple_Classes (accessed on 14 February 2022).
- Altman, D.G.; Bland, J.M. Diagnostic tests. 1: Sensitivity and specificity. BMJ Br. Med. J. 1994, 308, 1552. [Google Scholar] [CrossRef] [PubMed]
- Vafeiadis, T.; Diamantaras, K.I.; Sarigiannidis, G.; Chatzisavvas, K.C. A comparison of machine learning techniques for customer churn prediction. Simul. Model. Pract. Theory 2015, 55, 1–9. [Google Scholar] [CrossRef]
- Hajian-Tilaki, K. Receiver Operating Characteristic (ROC) Curve Analysis for Medical Diagnostic Test Evaluation. Casp. J. Intern. Med. 2013, 4, 627–635. [Google Scholar]
- James, G. Majority Vote Classifiers: Theory and Applications; Stanford University: Stanford, CA, USA, 1998. [Google Scholar]
- Smolyakov, V. Ensemble Learning to Improve Machine Learning Results. 2017. Available online: https://dzone.com/articles/ensemble-learning-to-improve-machine-learning-resu (accessed on 14 February 2022).
- Bayahya, A.Y.; Alhalabi, W.; AlAmri, S.H. Smart Health System to Detect Dementia Disorders Using Virtual Reality. Healthcare 2021, 9, 810. [Google Scholar] [CrossRef]
- Migut, M.; Worring, M.; Veenman, C. Visualizing multi-dimensional decision boundaries in 2D. Data Min. Knowl. Discov. 2013, 29, 273–295. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Machine Learning Algorithms | Accuracy | Actual Error Rate (AER) | Cross Validation Accuracy |
|---|---|---|---|
| Extra Trees | 97.22% | 0.11 | 99.14% |
| AdaBoost | 97.22% | 0.11 | 97.43% |
| MLP | 97.22% | 0.11 | 96.58% |
| XGB | 94.44% | 0.22 | 97.43% |
| Decision Tree | 97.22% | 0.11 | 97.43% |
| Gradient Boosting | 97.22% | 0.11 | 98.29% |
| SVC | 97.22% | 0.11 | 98.29% |
| K-Neighbors | 94.44% | 0.22 | 89.74% |
| Random Forest | 94.44% | 0.22 | 99.14% |
| Multinomial NB | 91.66% | 0.33 | 85.47% |
| Machine Learning Algorithms | Percentage of Testing Data Based on Different Size of Training Data | |||||||
|---|---|---|---|---|---|---|---|---|
| 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | |
| Extra Trees | 83% | 84% | 85% | 88% | 93% | 93% | 97% | 86% |
| AdaBoost | 64% | 81% | 81% | 86% | 89% | 93% | 97% | 86% |
| MLP | 82% | 86% | 84% | 89% | 93% | 91% | 97% | 85% |
| XGB | 81% | 81% | 84% | 88% | 93% | 93% | 97% | 90% |
| Decision Tree | 49% | 79% | 83% | 88% | 90% | 93% | 97% | 85% |
| Gradient Boosting | 65% | 83% | 85% | 87% | 93% | 93% | 95% | 91% |
| SVC | 80% | 81% | 82% | 88% | 93% | 93% | 98% | 90% |
| K-Neighbors | 79% | 81% | 81% | 84% | 84% | 85% | 91% | 85% |
| Random Forest | 84% | 83% | 83% | 88% | 88% | 91% | 98% | 90% |
| Multinomial NB | 83% | 81% | 82% | 86% | 86% | 85% | 84% | 82% |
| MLA | Precision | Sensitivity | Specificity | ||||||
|---|---|---|---|---|---|---|---|---|---|
| H | D | M | H | D | M | H | D | M | |
| ET | 1.00 | 0.80 | 1.00 | 0.96 | 1.00 | 1.00 | 1.00 | 0.97 | 1.00 |
| AB | 1.00 | 1.00 | 0.88 | 0.96 | 1.00 | 1.00 | 1.00 | 1.00 | 0.97 |
| MLP | 0.96 | 1.00 | 1.00 | 1.00 | 1.00 | 0.86 | 0.91 | 1.00 | 1.00 |
| XGB | 0.93 | 1.00 | 1.00 | 1.00 | 1.00 | 0.71 | 0.82 | 1.00 | 1.00 |
| DT | 0.96 | 1.00 | 1.00 | 1.00 | 1.00 | 0.86 | 0.91 | 1.00 | 1.00 |
| GB | 1.00 | 1.00 | 0.88 | 0.96 | 1.00 | 1.00 | 1.00 | 1.00 | 0.97 |
| SVC | 0.96 | 1.00 | 1.00 | 1.00 | 1.00 | 0.86 | 0.91 | 1.00 | 1.00 |
| K-N | 0.96 | 1.00 | 0.86 | 0.96 | 1.00 | 0.86 | 0.91 | 1.00 | 0.97 |
| RF | 0.93 | 1.00 | 1.00 | 1.00 | 1.00 | 0.71 | 0.82 | 1.00 | 1.00 |
| MNB | 0.92 | 1.00 | 0.83 | 0.96 | 1.00 | 0.71 | 0.82 | 1.00 | 0.97 |
| MLA | Recall | Precision | F1-Score | |||||
|---|---|---|---|---|---|---|---|---|
| Classes | Mi | Mo | Mi | Mo | F1 | Mi | Mo | |
| ET | H | 0.97 | 0.99 | 0.93 | 0.99 | 0.98 | 0.97 | 0.96 |
| D | 0.89 | |||||||
| MCI | 1.00 | |||||||
| AB | H | 0.97 | 0.95 | 0.97 | 0.99 | 0.98 | 0.97 | 0.97 |
| D | 1.00 | |||||||
| MCI | 0.92 | |||||||
| MLP | H | 0.97 | 0.95 | 0.97 | 0.99 | 0.98 | 0.97 | 0.97 |
| D | 1.00 | |||||||
| MCI | 0.92 | |||||||
| XGB | H | 0.94 | 0.90 | 0.94 | 0.98 | 0.96 | 0.94 | 0.93 |
| D | 1.00 | |||||||
| MCI | 0.83 | |||||||
| DT | H | 0.97 | 0.95 | 0.97 | 0.99 | 0.98 | 0.97 | 0.97 |
| D | 1.00 | |||||||
| MCI | 0.92 | |||||||
| GB | H | 0.97 | 0.95 | 0.97 | 0.99 | 0.98 | 0.97 | 0.97 |
| D | 1.00 | |||||||
| MCI | 0.92 | |||||||
| SVC | H | 0.97 | 0.95 | 0.97 | 0.99 | 0.98 | 0.97 | 0.97 |
| D | 1.00 | |||||||
| MCI | 0.92 | |||||||
| K-N | H | 0.94 | 0.94 | 0.94 | 0.94 | 0.96 | 0.94 | 0.94 |
| D | 1.00 | |||||||
| MCI | 0.86 | |||||||
| RF | H | 0.94 | 0.90 | 0.94 | 0.98 | 0.96 | 0.94 | 0.93 |
| D | 1.00 | |||||||
| MCI | 0.83 | |||||||
| MNB | H | 0.92 | 0.92 | 0.92 | 0.91 | 0.94 | 0.92 | 0.91 |
| D | 1.00 | |||||||
| MCI | 0.77 | |||||||
| Voting Algorithm (Ensemble Vote) | |||
|---|---|---|---|
| Metrics | Cognitively Healthy | Dement. | MCI |
| Precision | 0.96 | 1.00 | 1.00 |
| Sensitivity | 1.00 | 1.00 | 0.86 |
| Specificity | 0.91 | 1.00 | 1.00 |
| F1-Score | 0.98 | 1.00 | 0.92 |
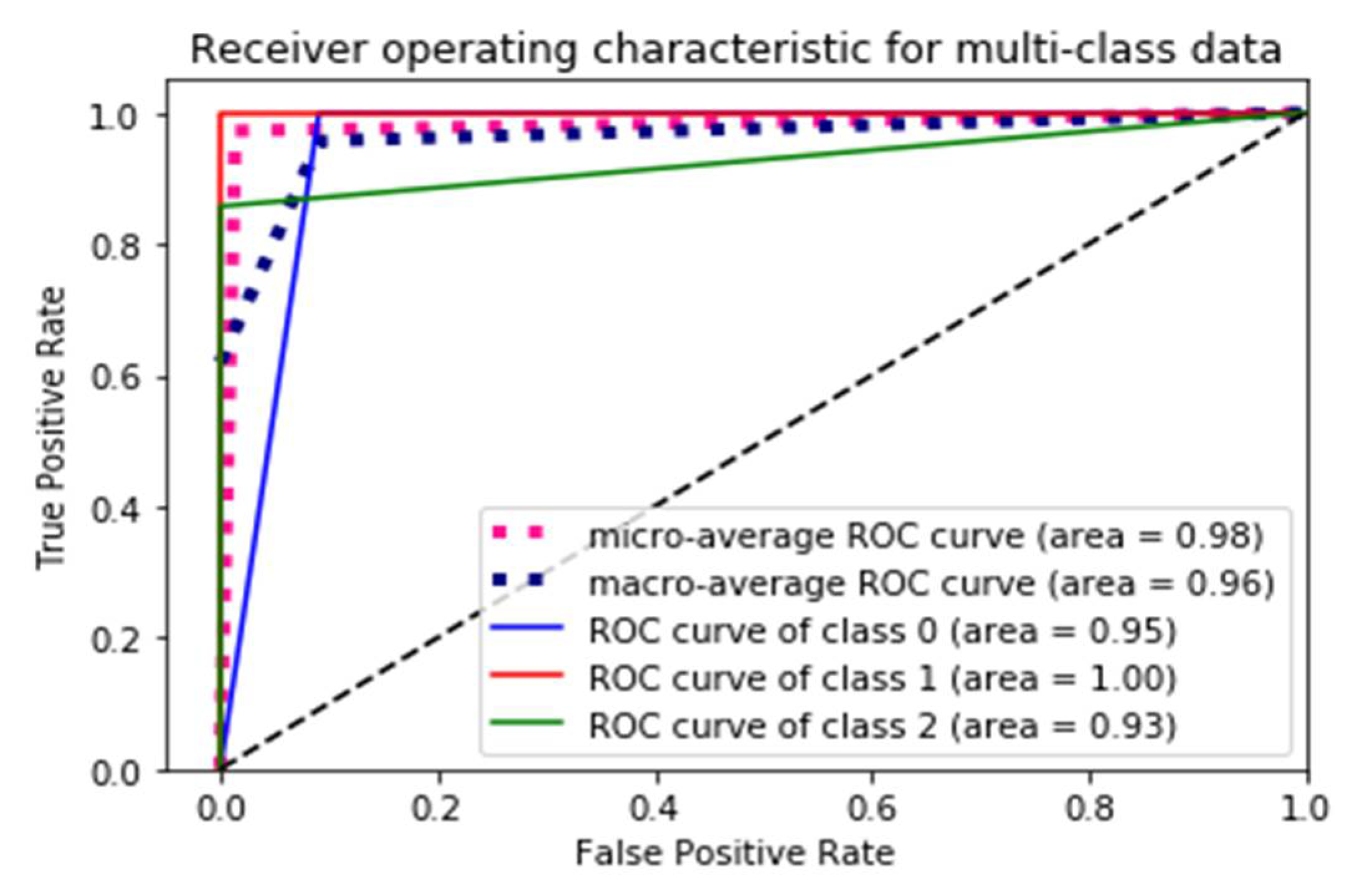
| ROC Curve | 0.95 | 1.00 | 0.93 |
| Micro-avg ROC curve | 0.98 | ||
| Macro-avg ROC curve | 0.96 | ||
| Accuracy | 97.22% | ||
| AER | 0.11 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bayahya, A.Y.; Alhalabi, W.; Alamri, S.H. Older Adults Get Lost in Virtual Reality: Visuospatial Disorder Detection in Dementia Using a Voting Approach Based on Machine Learning Algorithms. Mathematics 2022, 10, 1953. https://doi.org/10.3390/math10121953
Bayahya AY, Alhalabi W, Alamri SH. Older Adults Get Lost in Virtual Reality: Visuospatial Disorder Detection in Dementia Using a Voting Approach Based on Machine Learning Algorithms. Mathematics. 2022; 10(12):1953. https://doi.org/10.3390/math10121953
Chicago/Turabian StyleBayahya, Areej Y., Wadee Alhalabi, and Sultan H. Alamri. 2022. "Older Adults Get Lost in Virtual Reality: Visuospatial Disorder Detection in Dementia Using a Voting Approach Based on Machine Learning Algorithms" Mathematics 10, no. 12: 1953. https://doi.org/10.3390/math10121953
APA StyleBayahya, A. Y., Alhalabi, W., & Alamri, S. H. (2022). Older Adults Get Lost in Virtual Reality: Visuospatial Disorder Detection in Dementia Using a Voting Approach Based on Machine Learning Algorithms. Mathematics, 10(12), 1953. https://doi.org/10.3390/math10121953