1. Introduction
Due to the advantages of higher efficiency, safety and environmental friendliness, tunnel boring machines (TBMs) have been increasingly used in water conservancy, highway and railway tunnel construction [
1]. Once the special situation occurs or the operation is not timely for the TBMs, it may cause jamming, collapse, and other serious consequences. Therefore, the reasonable setting of TBM tunneling parameters is of vital significance to ensure tunneling security and efficiency. However, caused by complex geological conditions and numerous operating parameters, the prediction of key parameters of TBM is still challenging and has attracted the attention of many researchers. In practical tunnel construction, cutterhead torque and total thrust are the important operational parameters of TBMs, reflecting the obstruction degree of geological conditions and excavation behavior [
2]. There are many important works reported in recent decades. The methods for predicting the operational parameters can be typically categorized into two classes: physical model methods (combined with experiments) and data-driven methods (machine learning and deep learning).
Physical model methods mainly include empirical model methods, rock–soil mechanics analysis methods, and numerical simulation methods. Krause [
3] given the first empirical formula for calculating cutter torque and thrust, which has been widely used by designers of related enterprise. The quantitative relationship between cutterhead torque and other design parameters was established under different geological conditions by Ates et al. [
4]. Zhang et al. [
5] analyzed the influences of geological and operating parameters, and they proposed an approximate calculation method for the thrust and torque. The methodology to calculate thrust and torque was presented in the mixed-face ground [
6]. Faramarzi et al. [
7] established prediction models to estimate the torque and thrust by utilizing the discrete element method.
Those physical methods mentioned above give insights into the prediction of the cutterhead torque, which provides certain guidances for TBM design in practice. However, there are still obvious limits in practical applications because those methods commonly require prior knowledge of geological parameters and system parameters. With the advancement of data-driven techniques, physical methods were widely used in earlier research, but now, data-driven methods are more popular.
For data-driven methods, Sun et al. [
8] established a load prediction model for TBMs by using random forest (RF) to predict the operational parameters such as cutterhead torque and thrust based on the geological data and operational parameters. Subsequently, they employed three different recurrent neural network (RNN) models including traditional RNNs, long-short term memory (LSTM), and gated recurrent unit (GRU) to predict the TBM operation parameters in real time [
9]. Song et al. [
10] used a novel fuzzy c-means clustering-based time series segmentation method to segment operation parameter sequences, and they further used support vector machine regression (SVR) to predict the cutterhead thrust. Leng et al. [
11] proposed a hybrid data-mining approach to process the real-time monitoring data from TBM automatically. Using the change point detection method based on linear regression, Hong et al. [
12] segmented operation parameter sequences and established the separate prediction models for the cutter torque at each stage. Qin et al. [
13] presented a novel hybrid deep neural network (HDNN) for accurately predicting the cutterhead torque for shield tunneling machines based on the equipment operational and status parameters. A novel adaptive residual long short-term network was presented to predict cutterhead torque across domains under changeable geological conditions [
14]. Xu et al. [
15] established prediction methods for rotation speed, advance rate, and torque by comparing the different machine learning methods and deep neural networks.
It is seen that those data-driven methods have outperformed the physical models for the prediction of key operational parameters of TBM, but there are still some limitations. On the one hand, we noticed that the sampling period of data collection in the data acquisition system is usually 5 s, so the operating parameters fluctuate rapidly with 5 s intervals. If the specific predicted values are returned in real time with 5 s intervals, the values jump frequently, which will not assist the shield driver in adjusting the operating parameters as a guide. The main purpose of this paper is not simply to propose a prediction method but is aimed to assist the driver in the actual tunneling process. A large number of input parameters are needed in the above data-driven methods, so even if the real-time cutterhead torque is predicted, the operator cannot adjust the panel parameters to match the cutterhead torque in time, which may make some disturbance to the operators. On the other hand, for the deep learning algorithms, gradient disappearance and model degradation will occur as the number of layers increases, as well as the computational complexity will be large.
To solve the above-mentioned problems and better apply prediction models to assist intelligent tunneling, a novel hybrid prediction model combining Hidden Markov Model (HMM) and ensemble learning is proposed for the prediction of key parameters of TBM. The objective of this paper is to predict the interval of values rather than the specific values that were predicted in the above methods. One highlight of the proposed model is that the prediction of cutterhead torque and thrust is simplified to a classification problem by utilizing the HMM method, which makes it possible to use only seven panel parameters as input variables. From the perspective of engineering application, predicting interval values is more in line with the actual excavation needs, and it is more feasible for the driver to match the corresponding value interval of the cutterhead torque and thrust by adjusting only the seven parameters of the main panel, which not only ensures the excavation efficiency but also has more safety. In addition, it is more reasonable and scientific to describe the changes in geological conditions with value intervals rather than specific values of the cutterhead torque and thrust. Based on the value intervals, the coupling relationship between them and different geological conditions can be better established, which lays the foundation for the subsequent development of a unified model for different geological conditions. Therefore, it is essential to discretize the cutterhead torque and thrust and establish the correlation model between the value intervals and the panel parameters. First, HMM is used to mine the hidden states of the target variables in statistical terms; thus, the target variables are discretized, and the value intervals of each state are obtained. On this basis, three kinds of ensemble learning models, including AdaBoost, random forest (RF), and extreme random tree (ERT) are employed to predict the hidden states of cutterhead torque and total thrust under different forms of the same input parameters. The results show that the target variables after HMM discretization can be better predicted with fewer input variables, while other prediction models based on data-driven approaches have many input variables. Moreover, two excavation datasets from Beijing and Zhengzhou under different geological conditions are utilized to validate the effectiveness and superiority of the proposed method.
The rest of the paper is listed as follows. After the introduction,
Section 2 introduces the material data. Then, the proposed methods are presented in
Section 3.
Section 4 organizes the results and experimental verification. Thereafter, the discussion is drawn in
Section 5. Finally,
Section 6 gives the conclusion.
2. Materials
Two different geological cases, the data of Beijing and Zhengzhou from the actual projects, are utilized. The former is sandy gravel and the other is the fine sand stratum. The data are collected every day with a sampling period of 5 s and stored by the big data intelligent platform of the State Key Laboratory of Shield Machine and Boring Technology of China.
Consisting of the operational and status parameters, the original data included about 500 columns, and each column of data represents a physical quantity, such as cutterhead torque, propelling pressure of four groups of oil cylinders, rotation speed, advance velocity, etc. The data of Beijing is derived from Metro Line 2 in 350–360 rings that include approximately 68,000 rows, and the data of Zhengzhou are from Metro Line 4 in 550–566 rings that include approximately 123,000 rows. Affected by the data sensor and acquisition conditions, noise data including outliers and missing values may exist in the original data.
3. Methodology
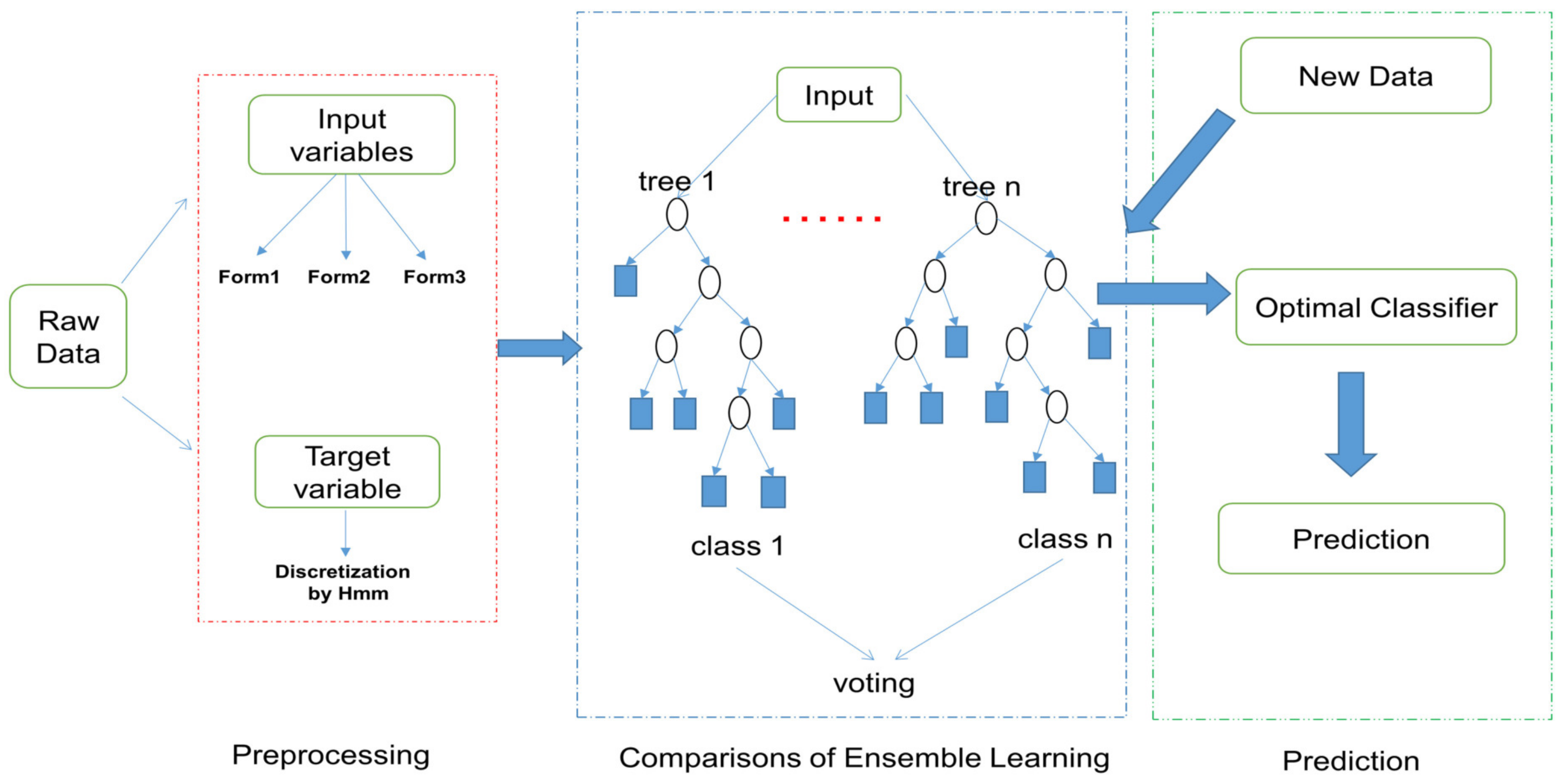
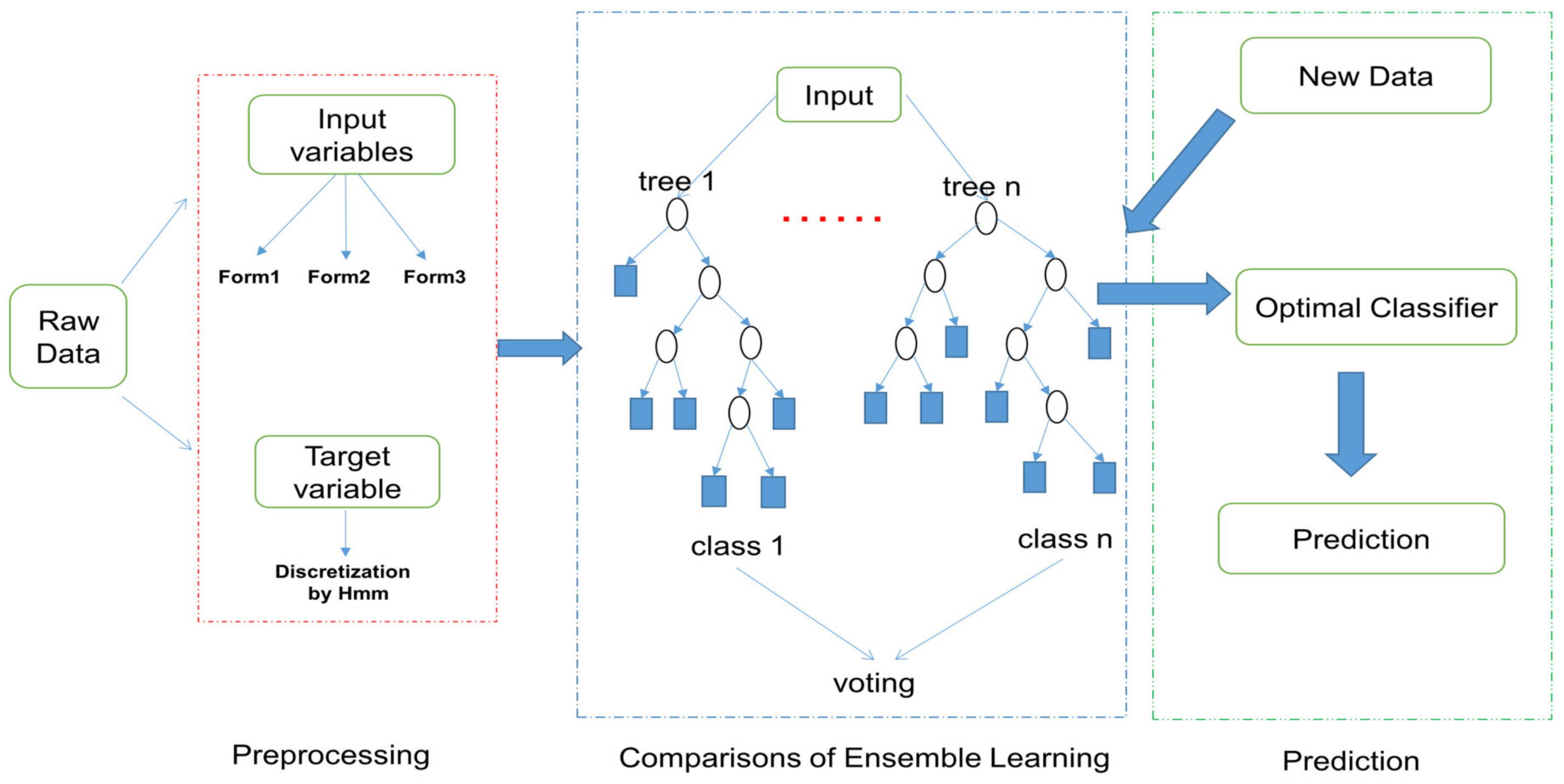
During the tunnel excavation process, predicting the value intervals provides more reliable safety and convenience for the driver and also lays the foundation for the subsequent development of a unified model for different geological conditions. With the aim of predicting the value intervals of cutterhead torque and total thrust, a hybrid prediction model combining HMM and ensemble learning is proposed. The architecture of the hybrid prediction model is shown in
Figure 1, and it mainly consists of three stages: data preprocessing, model comparisons, and prediction of target variables. To begin with, we preprocess the data to extract normal excavation data and select the input variables. Then, we discrete those parameters into different states by means of HMM encoding and record their corresponding value intervals. After that, we select the optimal model by comparing the performances of ensemble learning methods under different input forms. Finally, based on the optimal model, we predict the states of the target variables for the new data and extend to validation under different geologies. The detailed descriptions of each stage are presented as follows.
3.1. Data Preprocessing
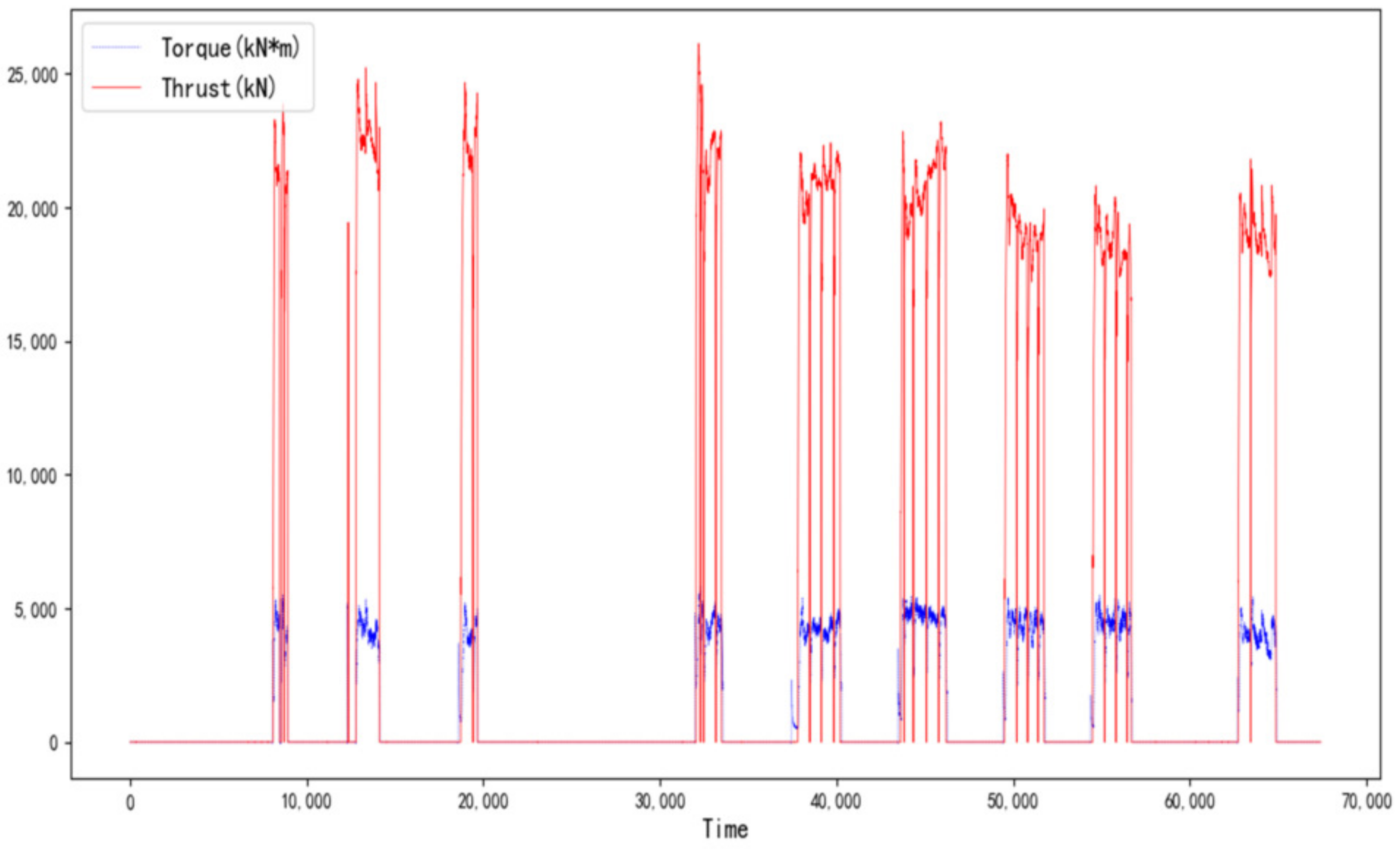
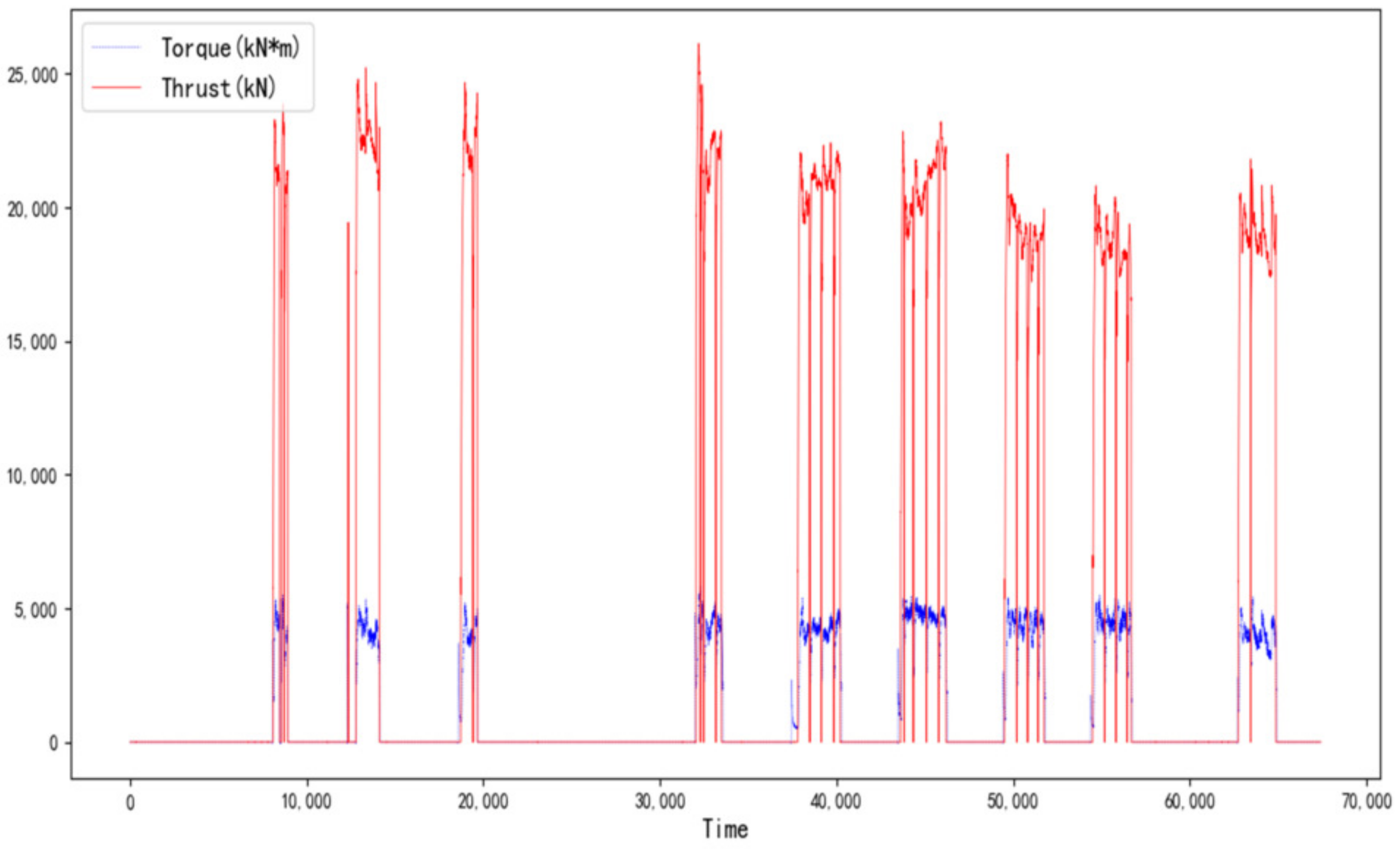
It is noteworthy that TBMs have complex systems including the trust hydraulic cylinder, propel system, other articulated systems, etc., but the boring process has a similar statistical pattern that consists of a series of tunneling cycles. The data in Beijing are plotted as an illustration in
Figure 2 to intuitively understand the TBM tunneling process.
As we can see in
Figure 2, TBM sequentially goes through the stages of starting, excavation, pause, ⋯, excavation, and stop during the construction process. In the pause or stop stage, the values of the operating parameters are 0 and they are invalid values in the raw data. In order to predict the cutter torque and thrust more accurately, it is necessary to extract the data of excavation stage from the raw data [
12,
16,
17]. It is noted that the data of the normal excavation stage are relatively smooth within a certain value range, which is significantly different from the starting and shutdown stages, where the starting stage has a clear upward trend and the shutdown stage has a downward trend. In this paper, the linear regression model of the change point detection method is used to find out the change point from one stage to the next based on the different features of the shield parameters in each stage [
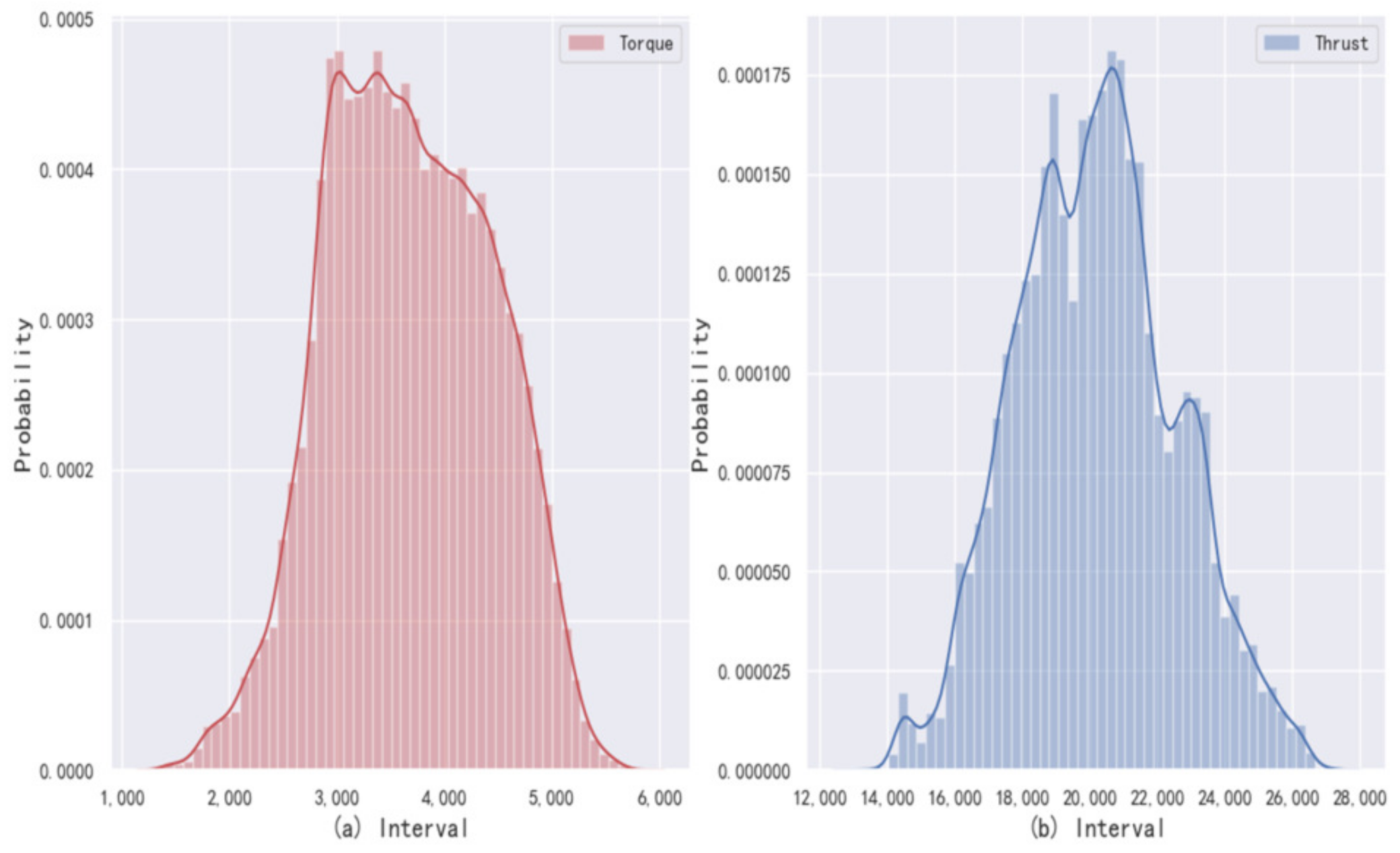
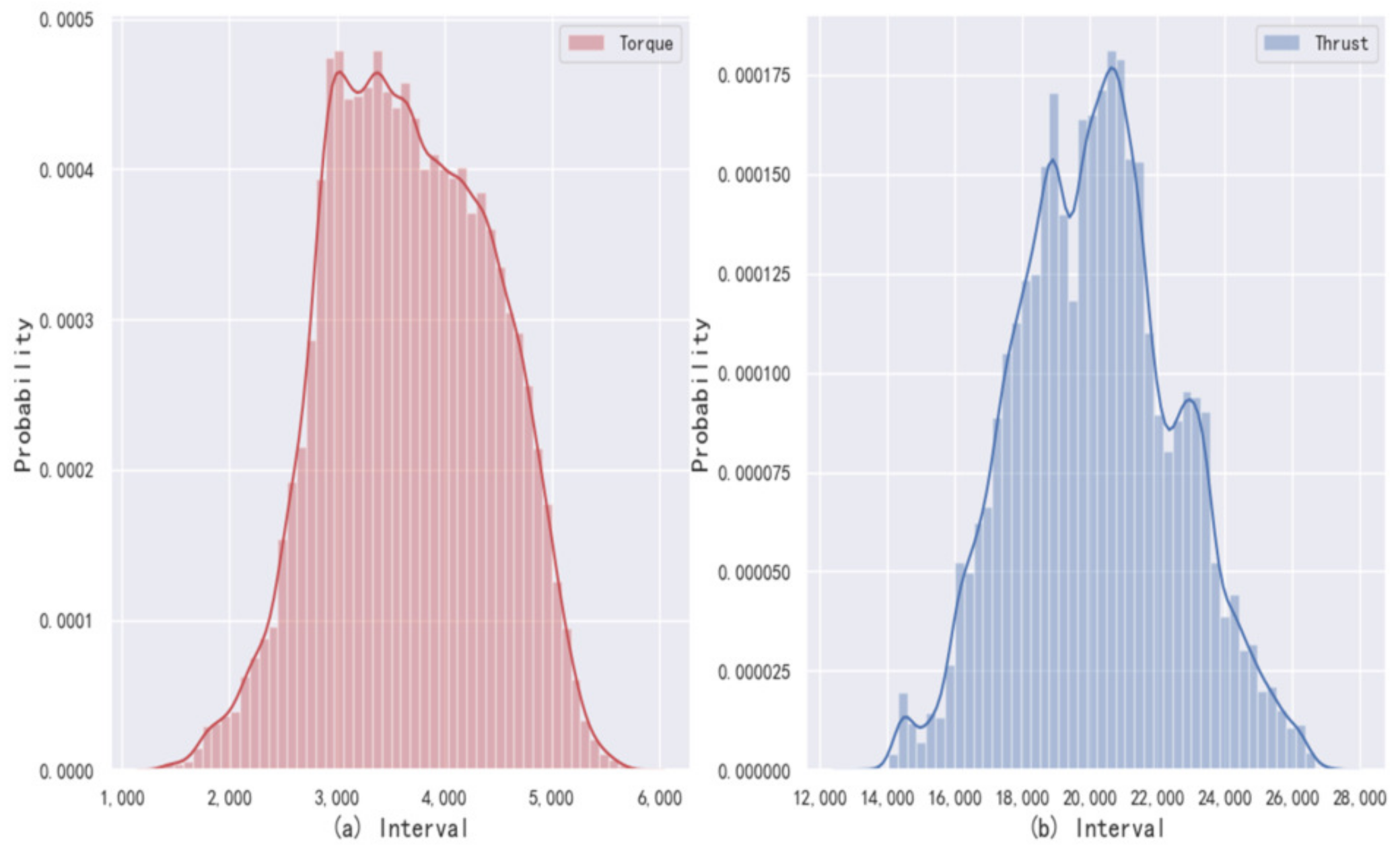
12]. Undeniably, in the above process, anomalous data can interfere with the determination of change points, but this interference is insignificant because change point detection is based on motion trends and a large number of data samples. Therefore, a limited amount of anomalous data do not have a significant impact. The statistical histograms of cutter torque and thrust in the excavation stage are shown in
Figure 3.
Most of the data in the pause stage and start-up stage are removed by using the change point detection.
Figure 3 shows that the data in the excavation stage are approximately subject to the normal distribution. The
principle is applied to remove the outlines to further improve the data quality.
With the objective of predicting the cutterhead torque and total thrust in this paper, the selection of input parameters is particularly important and directly affects the prediction effect. Generally speaking, the data patterns cannot be portrayed by a few variables, but in the case of redundant variables, it may cause over-fitting and affect the generalization ability of the model. Especially, the data in the excavation stage derived from the actual tunnel construction have about 500 attributes. Hence, it is particularly significant to select a few important variables as the input vector from those attributes. Fortunately, the prediction problem is simplified to a classification, and a large number of physical parameters are less relevant to the target parameters, which provides the possibility to efficiently select the input variables to control the dimension of the input vector. This paper aims to construct the prediction model of cutterhead torque and thrust with as few and essential parameters as possible. By comprehensive research on excavation sites and literature references, 7 variables including rotation speed of cutter, advance velocity, rotation speed of screw conveyor, and propelling pressure of four groups are selected as the input variables for the hybrid prediction model. They are all critical and essential for the tunneling stage of the TBMs regardless of the geological conditions. On the one hand, by observing the operation of the driver at the subway tunnel excavation site, these 7 parameters are the most direct and critical in the panel to adjust the tunneling process for the driver. On the other hand, according to the references mentioned in this paper, the input variables are selected in two ways: one is a manual subjective selection (such as Refs. [
8,
9,
10,
11,
12,
13,
14]), and the other uses dimensionality reduction methods such as principal component analysis (Ref. [
18]). Either way, these 7 parameters are the most frequently used in predicting the torque and thrust, which indicates their importance. Notice that cosine similarity was often used in the above papers to filter out variables that are closely related to the target variables. It should be noted that cosine similarity portrays a linear relationship between attributes of the TBM, but the TBM systems are complex, and it is not sufficient to consider only the linear correlation of attributes. The cosine similarities between those seven TBM attributes and torque are 0.72, 0.56, 0.61, 0.86, 0.87, 0.81, and 0.70, while their cosine similarity with thrust is 0.50, 0.77, 0.75, 0.96, 0.96, 0.96, and 0.85, respectively. Hence, ensemble learning models combined with HMM encoding are employed to mine the nonlinear relationships between those critical attributes of the TBM. On this basis, with the target parameters, cutterhead torque and total thrust as the output variables, a new data set with
is obtained, and the former seven are input variables. Moreover, three typical models based on the ensemble learning approach are compared.
3.2. Forms of the Model Comparisons
To compare the three kinds of representative ensemble learning models, the different forms of the input variables are designed below. Specifically, for the given dataset , where , is the number of input variables, and T is the length of each variable sequence. With this expression, the original input vector is , which indicates the values of input vector at time t, and is the corresponding output value. It is noteworthy that an HMM model is employed to extract the hidden states of the variables, and thus, the variables have been discretized. On this basis, all three different forms of the input variables are given as follows for this hybrid prediction model.
(1) The input vector is original , and the output is the hidden state of target variable that is obtained by HMM;
(2) The input vector is discretized by HMM , and the output is also discretized by HMM;
(3) The input vector is discretized and transformed into OneHot form , while the output is the same as above.
OneHot is a data preprocessing technique that converts categorical variables into binary vectors, which can extend the feature dimension and improve the learner to some extent. As a conclusion, the above different forms of the same seven attributes are used to validate the prediction models based on HMM and ensemble learning. The detailed descriptions of HMM and ensemble learning are presented as follows.
3.3. Hidden Markov Model
Hidden Markov Model (HMM) is a classical machine learning model that describes a Markov process with implicitly unknown parameters [
19]. Recently, HMMs have been used to analyze problems with uncertainty in transportation engineering and the prediction of tunnel geology [
20,
21,
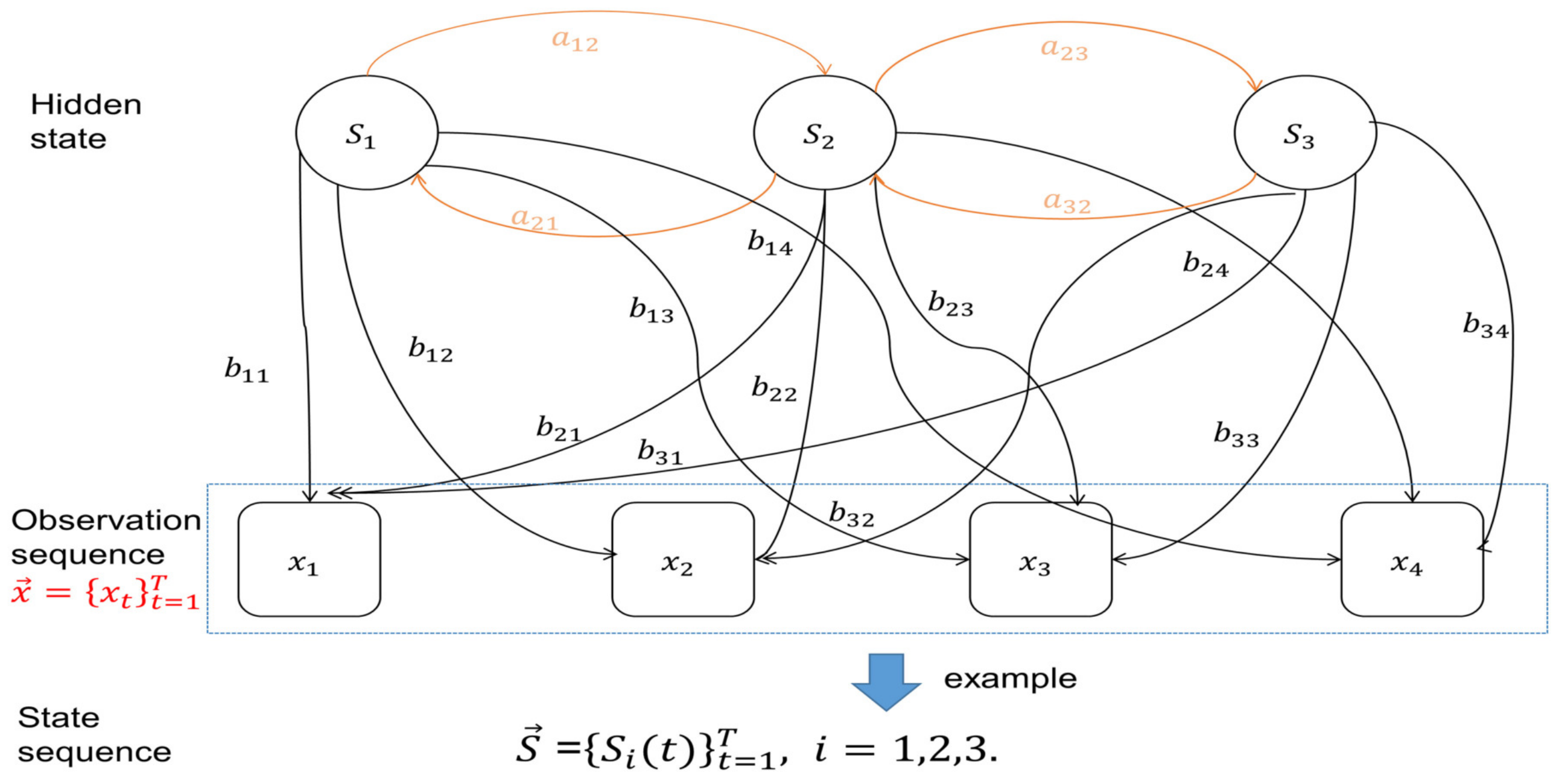
22], because it can capture the probability characteristics of the transitions between the underlying states. The HMM method in this paper is designed to encode variables into discrete states. The schematic of HMM is in
Figure 4 and the details are described as follows. For any HMM model, it is composed of three elements: the initial state probability distribution
, state sequence
, and observation sequence
, where
is the number of hidden state values
that can take at the state
i and
T is the length of the observation sequence. Under the assumption, the complete set of HMM parameters is described by a triplet
, where
is the prior initial probability matrix,
is the state transition probability matrix and
is the observation emission probability matrix where
is the emission probability, that is,
.
Our goal of using HMMs in this paper is to encode variables into discrete states, that is, find the optimal hidden state sequence
by regarding the operating parameters of TBM as given observation sequences. To achieve this, the Viterbi algorithm was a known method to solve the problem analytically by dynamic programming [
23] when the observation sequence
and model
were given. Therefore, model parameters should be estimated at first by using the Baum–Welch algorithm [
24] based on the given observation sequence
. For the given operating parameters of TBM, to better analyze their hidden states, an HMM model is designed, and the number of hidden state values
is set to different values in
Section 4.1.
3.4. Ensemble Learning
Ensemble learning, known as a multiple classifier system, trains and combines multiple learners to solve a learning problem [
25]. Nowadays, it is one of the most commonly used machine learning algorithms in engineering applications. Current ensemble learning methods can be roughly grouped into two categories according to the dependencies between multiple learners. One is represented by Boosting and the other is Bagging [
26]. AdaBoost is the most well-known Boosting algorithm with strong dependencies between its individual learners, while RF and ERT are Bagging algorithms with decision trees as basis weak learners, and each learner is independent. In order to understand the rules of the model proposed in this paper, the ideas of the AdaBoost, RF, and ERT algorithms are briefly described below.
3.4.1. AdaBoost
AdaBoost was first designed by Freund and Shapire to find a binary classifier [
27]. Its theoretical basis is sound and implementation is simple. Nowadays, it has been widely applied to the classification problems. The basic idea of AdaBoost is to learn a small number of weak classifiers
h by iteratively and then combining them into a strong one
H. Let
be the set of weak classifiers and a given dataset
, where
, and
T is the size of dataset. Let
be the sample weights that reflect the importance degrees of the samples. The technical details of AdaBoost are described as below.
(1) Normalize the weights satisfying
(2) For execute the following operations:
① The error
of a weak classifier
is the sum of the weighted classification errors,
where
. Choose the weak classifier
with the lowest error
,
② Calculate the sum of the weighted classification errors for the chosen weak classifier .
④ Update the weights by
where
is a normalization factor
(3) Output the strong classifier
In each iteration, the weights of the data misclassified are increased but the weights of the data correctly classified are decreased, which in turn changes the weights of the weak classifier. Finally, a linear combination of weak classifiers is combined to form a strong classifier, in which the classifier with a small error rate has a large weight and the classifier with a large classification error rate is given a small weight.
3.4.2. Random Forest (RF)
RF is an extension of Bagging based on bootstrap sampling, where randomized feature selection is introduced on top of Bagging [
28]. It is easy to implement and has surprisingly good performance in multi-classification applications. Therefore, it is honored as a representative ensemble learning method and is selected for predicting the key parameters of TBM in this paper. In RF, a decision tree, i.e., CART (classification and regression trees), is used as a weak learner. The implementation of the RF algorithm is summarized as the following 4 steps:
(1) Sample points from datasets in a put-back manner to generate the training set, and the remaining unsampled points are used as the test set;
(2) Randomly select m variables at each node to generate a CART;
(3) Repeat the above steps to form k CARTs;
(4) Integrate the above CARTs and vote the predicted values.
Specifically, traditional decision trees select an optimal split feature from the feature set of each node, whereas RF selects from a subset of
m features randomly generated from the feature set of the node [
29]. The parameter
m controls the randomness and it is given in advance by correlation analysis of the data set. The number of CART
k is considered as the key parameter of RF and influences the model performance. In this paper, the parameter
k is manually selected to predict the cutter torque and total thrust by the RF model.
3.4.3. Extreme Random Tree (ERT)
The ERT model is proposed by Geurts et al. [
30] and has been widely used for prediction problems as being computationally efficient. Similar to the RF, it is powerful for the multi-classification and is able to handle high-dimensional feature vectors. The algorithm has two key points:
(1) ERT uses all training samples to construct each tree with varying parameters rather than the bagging procedure used in RF;
(2) ERT randomly chooses the node split upon the construction of each tree, rather than the best split used in RF.
In general, AdaBoost improves the model accuracy by adjusting the weights of misclassified data points, and the weights of each weak classifier are different. In contrast, RF and ERF learn classifiers by random sampling with put-back, where the weights of each classifier are the same, and the final classification result is determined by voting. In conclusion, they all have a good ability to learn classifiers for classification problems and are easily implemented in Python. Therefore, for the prediction of the discrete state of cutterhead torque and total thrust, the three models mentioned above including AdaBoost, RF, and ERT are established after the cutterhead torque and thrust encoded by HMM. The generalization abilities of those models for the prediction are compared in
Section 4.2.
3.5. Performance Evaluation Metric
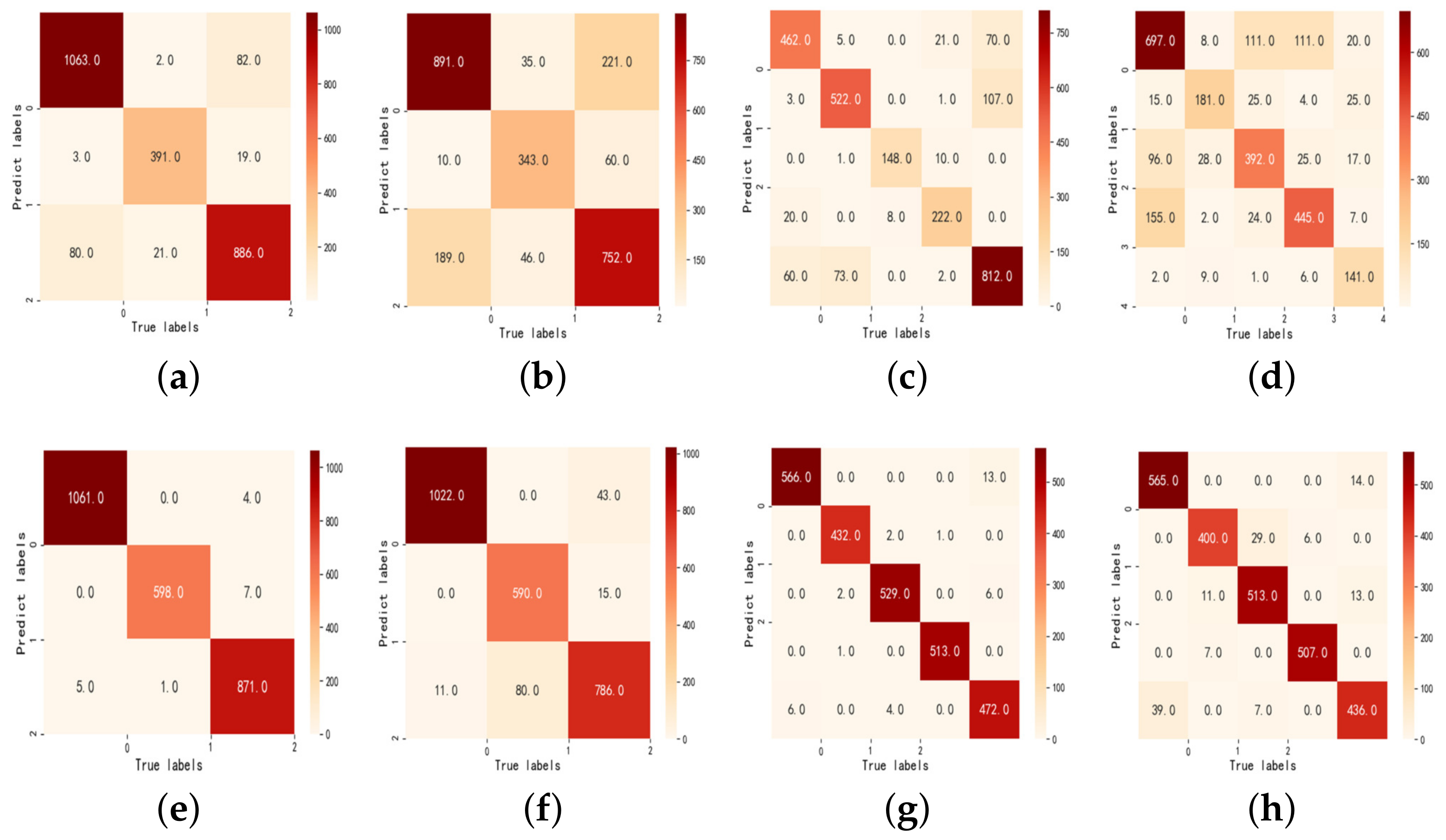
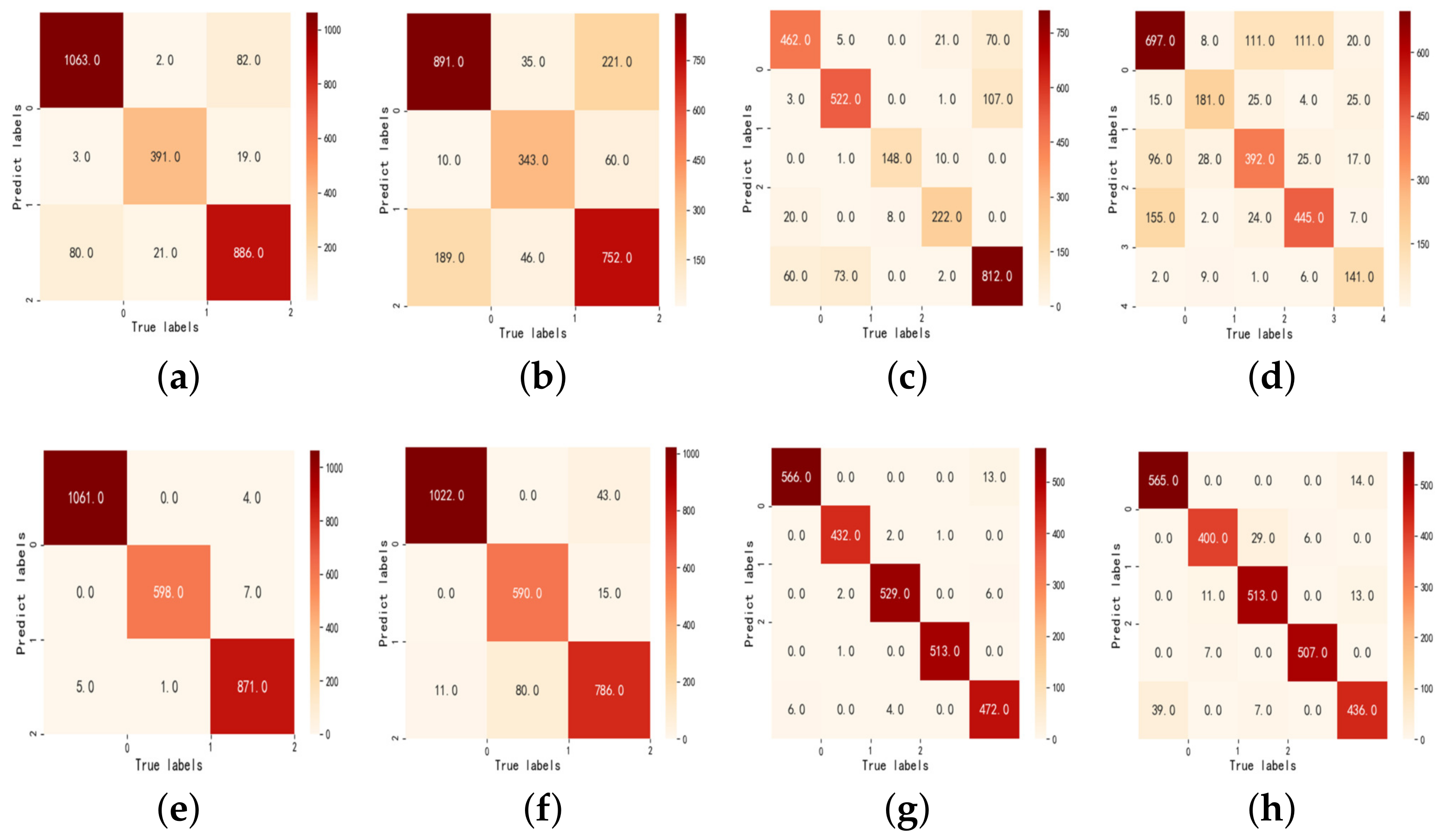
After the predicted models are established, some statistical metrics including confusion matrix, accuracy, precision, and recall are calculated to evaluate the performance of the prediction models. The definition of the confusion matrix for multiclass classification is shown in the following
Table 1.
where
indicates the number of predicted class
j when the true class is
i, and
n is the number of classes. The confusion matrix presents the number of predicted and true classes separately, and it visualizes the performance of predictions on each class. Based on this, the accuracy, precision, and recall of the classifier are calculated separately as shown below. The accuracy is defined as below:
The precision, recall are defined as follows, respectively:
where
represents the ratio of the number of samples with correct predictions in class
i to the samples whose predicted values are
i class, and
is the ratio of the number of samples predicted to be correct for class
i to the samples that are actually class
i. Unfortunately, precision and recall are contradictory. To eliminate this drawback, an alternative performance measure that considers precision and recall simultaneously is defined as:
5. Discussion
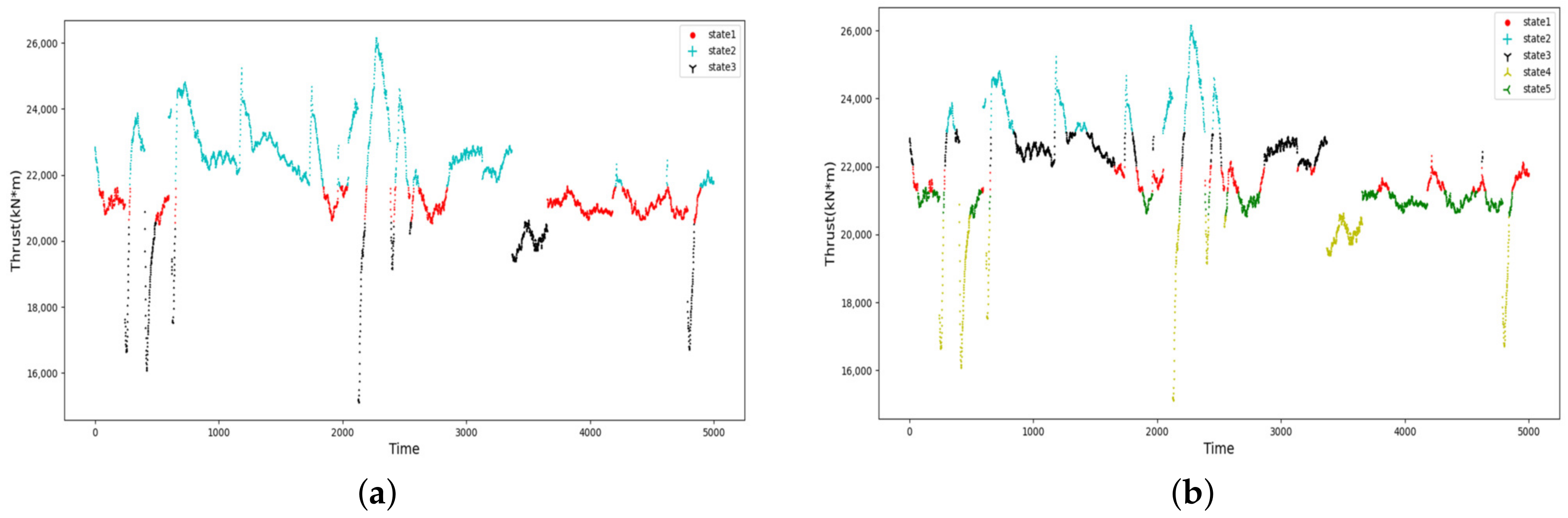
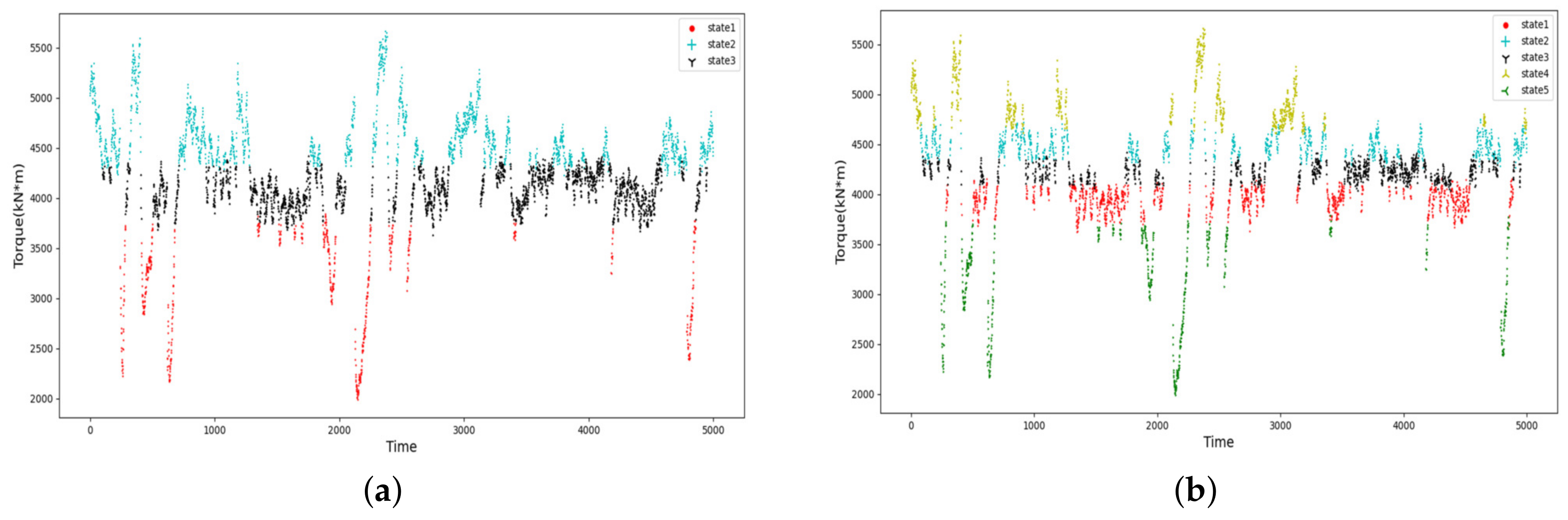
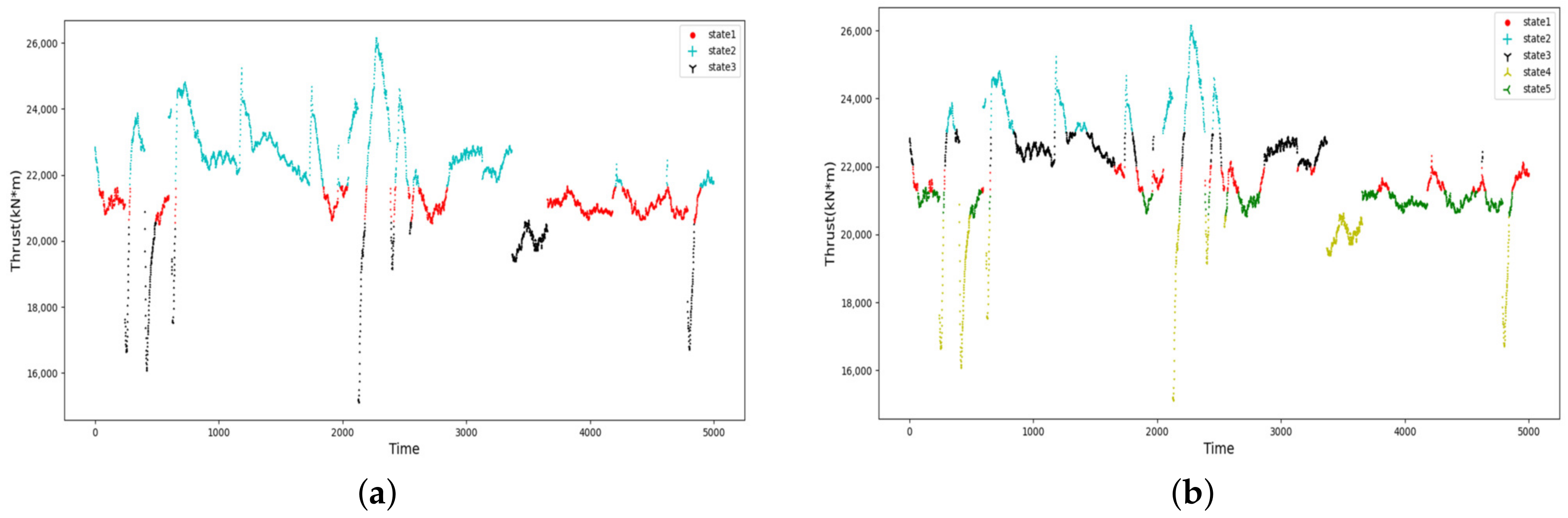
In this study, the data in the excavation stage are extracted firstly, and then, the thrust and torque of the excavation stage are discretized into hierarchical states by HMM.
Figure 5 and
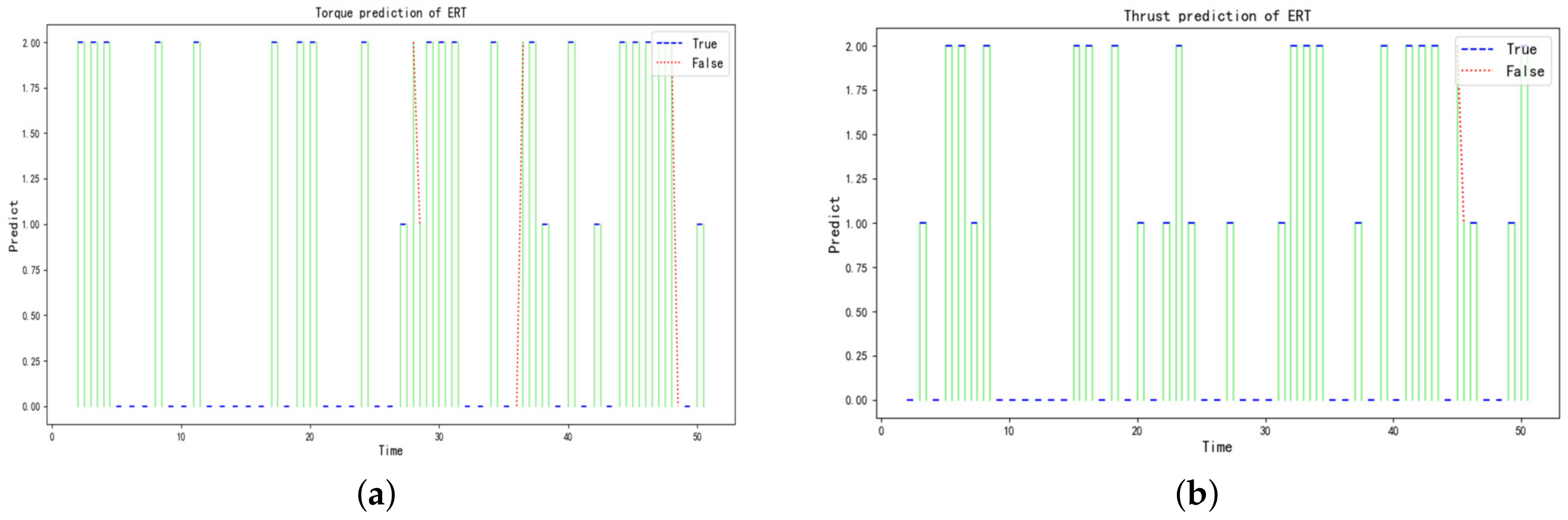
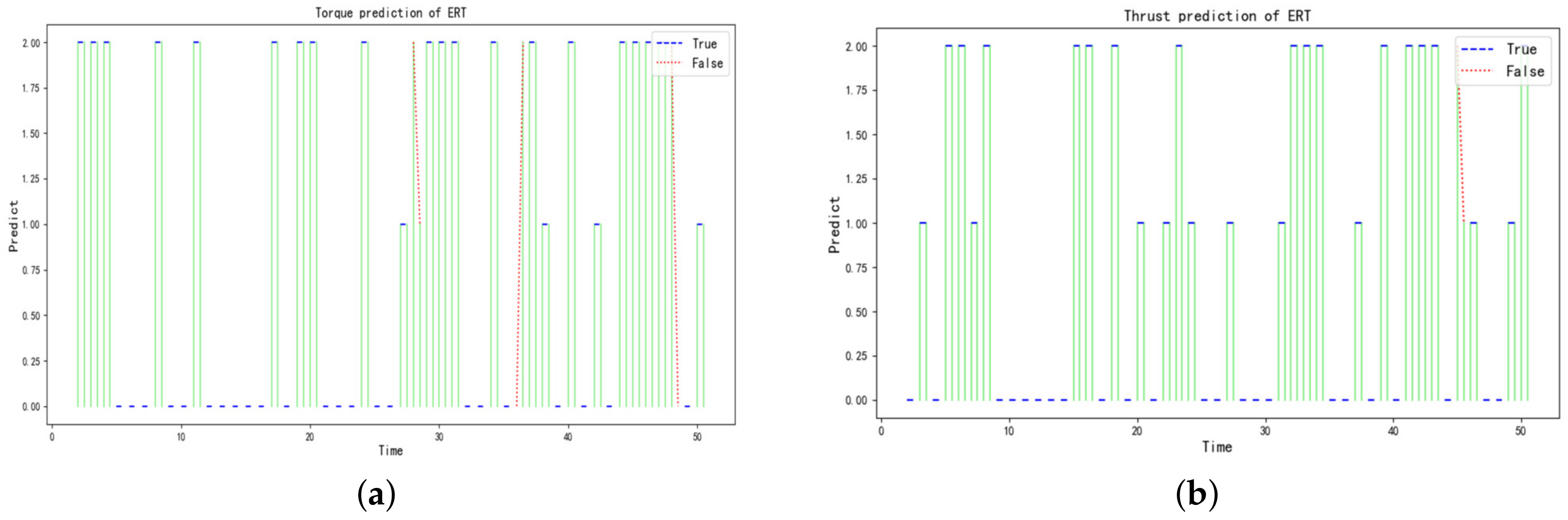
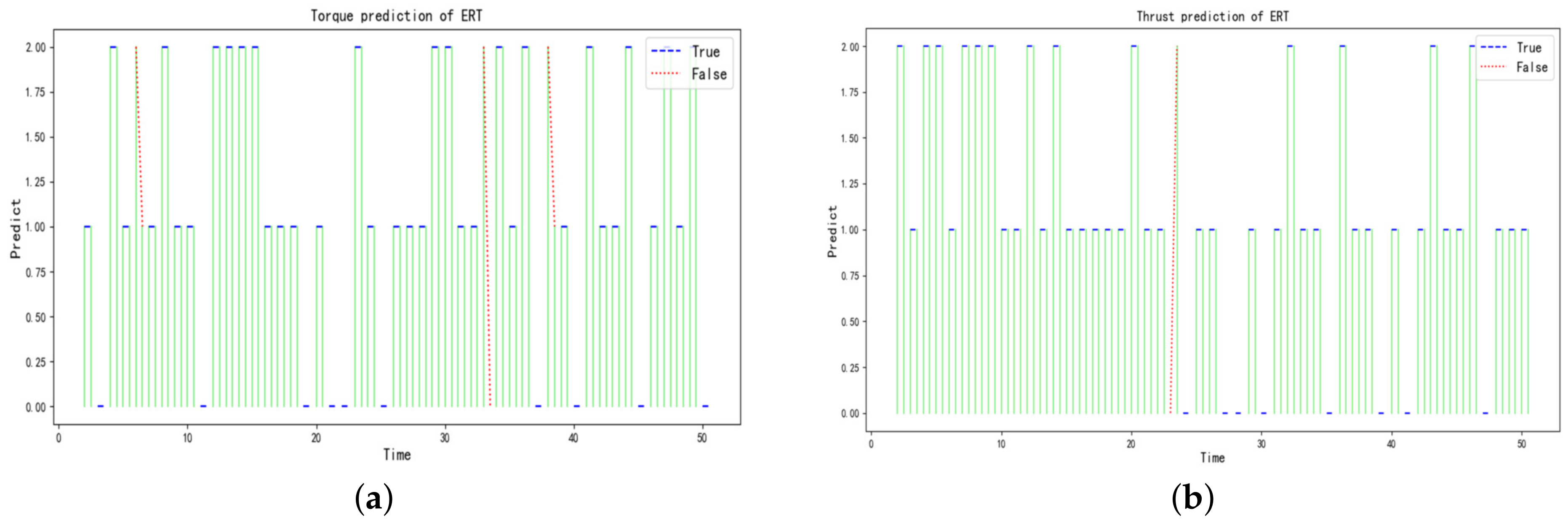
Figure 6 illustrate that the hidden states of the torque and thrust have a statistical pattern, i.e., the current state derives from the previous moment. This is consistent with the fact that the parameters are heavily influenced by their own inertia during the excavation stage. Therefore, the discretization of the torque and thrust by the HMM model is reasonable for discovering the hidden states of the variable themselves, and it is attributed to reducing the complexity of predicting the variables compared to deep learning algorithms. Meanwhile, it is worth noting that the outliers and noises, e.g., abrupt jump points, may negatively affect the discretization, and efforts are needed to identify those outliers and noises in further research.
For the excavation data in Zhengzhou,
Table 8 and
Table 9 show that the hybrid proposed models have a higher accuracy for the torque and thrust prediction compared with Beijing. The main reason may be that there are more training data and fewer noises in Zhengzhou, and the relationship between variables is relatively easy to learn. Although there is some difference in the accuracy of the predictions, there are some statistical laws that exist. When the input variables are in the Raw form, the prediction model performs more efficiently than the HMM form, and the prediction in the HMM form is approximated to the OneHot form. The main reason lies in that the input variables would lose some feature information in the process of discretization by HMM, and the OneHot form can not increase the effective information, although it formally extends the dimensionality of the input variables compared with the form of HMM.
In general, it is effective to encode the target variables into discrete states by HMM and transform the prediction into a classification problem. The results validate the prediction performance and the generalization ability of the proposed method under different geological conditions. The discretized intervals of cutter torque and thrust, although some information may be lost, still reflect the degree of obstruction and excavation behavior of geological conditions. It is worth noting that compared with the previous data-driven models, the proposed model with good performance has only seven parameters as input variables, and those seven parameters are panel set parameters that can be adjusted by the operator. Therefore, we aim to further match the corresponding geological conditions by establishing the coupling relationship between the value intervals of cutterhead torque, thrust and panel set parameters, which provides the basis for adjusting the panel operating parameters to geological conditions. It is of great meaning in the practical application of intelligent TBM tunneling, and efforts will be needed.
6. Conclusions
In this paper, to accomplish the mapping between essential parameters of TBMs and assist intelligent tunneling, a hybrid prediction model based on HMM and ensemble learning is applied to predicting intervals of the cutterhead torque and total thrust. For the data of the excavation stage, torque and thrust are discretized into different states by employing HMM, and the predictions become classification problems, which provides the basis for reducing the size of the model input to use the essential parameters only. Then, three representative ensemble learning models including AdaBoost, RF, and ERT are used to predict the classification problem, and comparisons have been conducted in three different forms of the same input variables. Two excavation datasets collected from different geological conditions are also used to validate the effectiveness and generalization of the proposed methods. By comparing the performances of the three representative models, ERT with the input parameters in Raw form has the highest accuracy and is selected to predict the torque and thrust. Meanwhile, the results show that (1) the torque and thrust can be efficiently divided into different intervals by HMM; (2) the ERT model outperforms RF and AdaBoost for the prediction of torque and thrust; (3) the input of Raw form is optimal for the prediction models based on the ensemble learning. Therefore, the ERT prediction method combined with HMM can accurately and effectively predict the cutterhead torque and thrust intervals in the practical tunnel boring application, which lays the foundation for subsequent adjustment of panel parameters according to geological conditions.
In the future, efforts will be made to identify outliers and noises in the excavation data and consider the geological conditions.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}