
Intent-Controllable Citation Text Generation



Abstract
1. Introduction
- We introduce a new concept of intent-controllable citation text generation to generate various citation texts according to authors’ citation intent when the same cited paper is given.
- We extend the SciCite dataset for our defined task and the experiments with several models (Both the code and datasets are available at: https://github.com/BradLin0819/Automatic-Citation-Text-Generation-with-Citation-Intent-Control (accessed on 23 July 2021)).
- The model performance evaluated by humans and metrics shows that citation intents enhance the effectiveness and flexibility of authors when they write the citation texts at the beginning of paper writing.
2. Related Work
2.1. Generating Texts by Sequence-to-Sequence Models
2.2. Pre-Trained Sequence-to-Sequence Models in Natural Language Processing
2.3. Text Summarization
2.4. Citation Text Generation
2.5. Controllable Text Generation
3. Methodology
3.1. Dataset
- Removed data samples with duplicate citation texts;
- To ensure the reliability of our model, we removed data samples with duplicate citing paper and reference paper pairs between the training and validation (test) sets from the training set;
- We removed data samples with incomplete citation texts because our goal is to generate fluent sentences;
- Filtered out data samples without the abstract of the reference paper;
- To normalize the citation markers, we replaced the citation markers that have the current reference paper within them with #REF and other reference papers with #OTHERREF using regular expression operations.
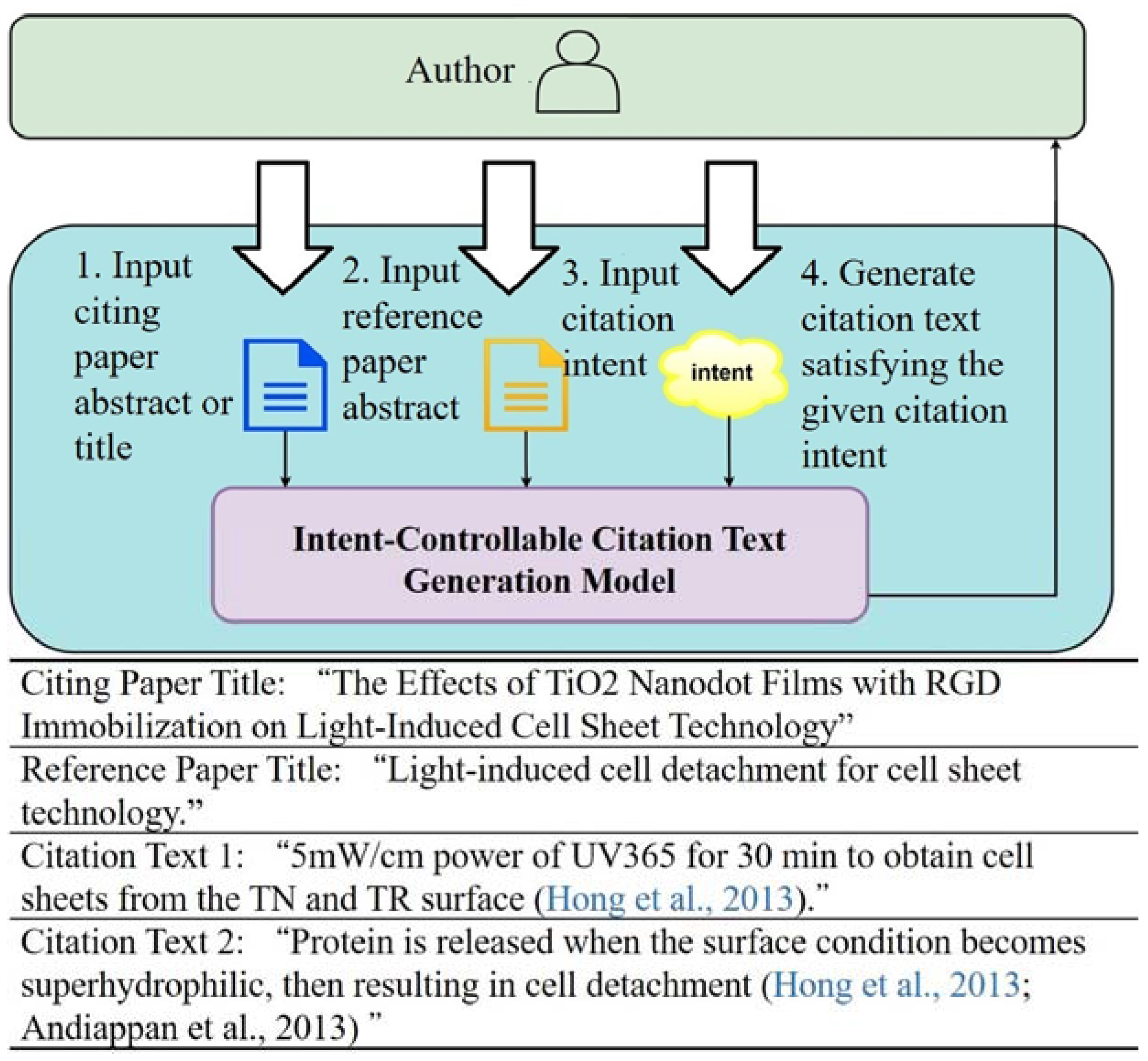
3.2. Overview
- The author provides the abstract or title of the paper draft;
- The author provides the abstract of the paper he/she wants to reference;
- The author specifies the desired citation intent;
- Generate the citation text with the given citation intent using our controllable citation text generation model.
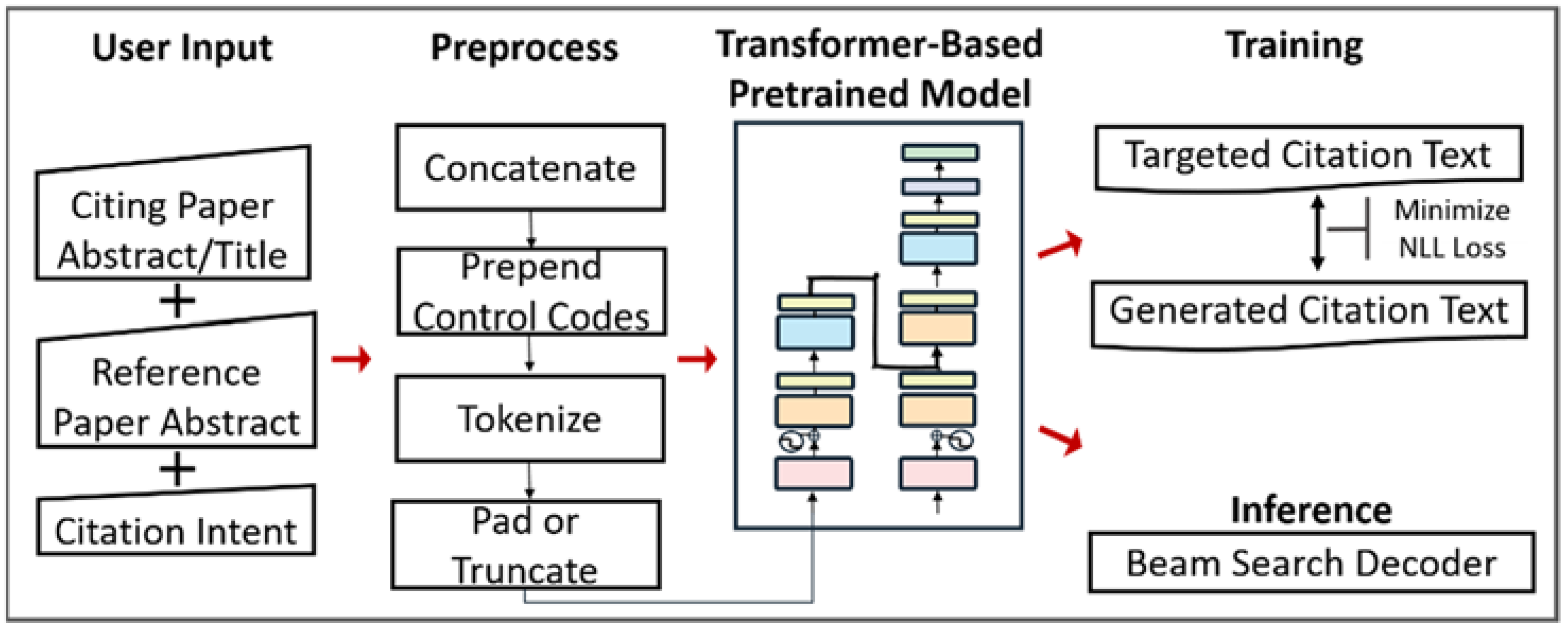
3.3. Controllable Citation Text Generation Model
- Concatenation: While generating citation texts, we take aCP/tCP and aRP as input documents. To feed multiple inputs into our model, we concatenated aCP/tCP and aRP into a flat sequence [aCP/tCP; aRP], where [.;.] denoted the concatenation.
- Prepend control codes: We assume that the model can discover the association between the input sequence and the output sequence. Accordingly, we employ a simple yet effective technique to enable controllable text generation [26,30,31,32]. We prepend the textual control codes c (e.g., citation intent for our case) to the concatenated input [aCP/tCP; aRP] and form the input sequence X of the model where X = [c; aCP/tCP; aRP]. Then, our model is expected to learn to generate the citation text with the desired citation intent. The representation of X is illustrated in Figure 2.
- Tokenization: Because the model can only input numerical values, we cannot directly feed the textual input into the model. Therefore, we need to tokenize the input sequence X into tokens (x1, x2, …, xm), and output sequence y into tokens (y1, y2, …, yn) where m, n is the length of the sequence. Then, we convert these tokens into indices using predefined vocabulary V, which consists of the most common tokens and the mapping between the token and the index.
- Pad or Truncate: To have the same input and output sequence size for the model, we fix the input and output sequence length. We set the maximal length of the input sequence to 1024 and the maximal length of the output sequence to 128. First, we add <s>, one special token, to the start of the sentence and </s>, the other special token, to the end of the sentence to make the model identify the start and the end of the sentence. Then, the sequence that is longer than the maximal length will be truncated. Furthermore, we pad sequences in the same batch with the special token <pad> to the longest sequence in the batch.

3.3.1. Pre-trained Text Generation Model
3.3.2. Model Training
3.3.3. Model Inference
4. Experiments
4.1. Evaluation Metrics
4.2. Implementation Detail
4.3. Human Evaluation
- (Correct) Does the citation sentence correctly express the factual relationship between the citing paper and the cited paper?
- (Specific) Does the citation sentence describe a specific relationship between the two papers, or is it vague enough to be used to cite many other papers?
- (Plausible) Does the citation sentence have the same topicality and tone in writing as the citing paper?
- (Intent) In which part of the paper does the citation sentence belong, introduction, method, or result?
5. Results and Discussion
6. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Santini, A. The importance of referencing. J. Crit. Care Med. 2018, 4, 3–4. [Google Scholar] [CrossRef]
- Boyack, K.W.; van Eck, N.J.; Colavizza, G.; Waltman, L. Characterizing in-text citations in scientific articles: A large-Scale analysis. J. Informetr. 2018, 12, 59–73. [Google Scholar] [CrossRef]
- Bornmann, L.; Mutz, R. Growth rates of modern science: A bibliometric analysis based on the number of publications and cited references. J. Assoc. Inf. Sci. Technol. 2015, 66, 2215–2222. [Google Scholar] [CrossRef]
- Hsiao, T.M.; Chen, K.-H. How authors cite references? A study of characteristics of in-text citations. Proc. Assoc. Inf. Sci. Technol. 2018, 55, 179–187. [Google Scholar] [CrossRef]
- Nicolaisen, J.; Frandsen, T.F. Number of references: A large-scale study of interval ratios. Scientometrics 2021, 126, 259–285. [Google Scholar] [CrossRef]
- Ucar, I.; López-Fernandino, F.; Rodriguez-Ulibarri, P.; Sesma-Sanchez, L.; Urrea-Micó, V.; Sevilla, J. Growth in the number of references in engineering journal papers during the 1972–2013 period. Scientometrics 2014, 98, 1855–1864. [Google Scholar] [CrossRef]
- Akin, I.; MurrellJones, M. Closing the Gap in Academic Writing Using the Cognitive Load Theory. Lit. Inf. Comput. Educ. J. 2018, 9, 2833–2841. [Google Scholar] [CrossRef]
- Xing, X.; Fan, X.; Wan, X. Automatic generation of citation texts in scholarly papers: A pilot study. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6181–6190. [Google Scholar]
- Luu, K.; Wu, X.; Koncel-Kedziorski, R.; Lo, K.; Cachola, I.; Smith, N.A. Explaining Relationships Between Scientific Documents. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Bangkok, Thailand, 2–4 August 2021; Volume 1, pp. 2130–2144. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Lo, K.; Wang, L.L.; Neumann, M.; Kinney, R.; Weld, D.S. S2ORC: The Semantic Scholar Open Research Corpus. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4969–4983. [Google Scholar]
- Abu-Jbara, A.; Ezra, J.; Radev, D. Purpose and polarity of citation: Towards nlp-based bibliometrics. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 596–606. [Google Scholar]
- Cohan, A.; Ammar, W.; van Zuylen, M.; Cady, F. Structural Scaffolds for Citation Intent Classification in Scientific Publications. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 3586–3596. [Google Scholar]
- Jha, R.; Abu-Jbara, A.; Qazvinian, V.; Radev, D.R. NLP-driven citation analysis for scientometrics. Nat. Lang. Eng. 2017, 23, 93–130. [Google Scholar] [CrossRef]
- Valenzuela, M.; Ha, V.; Etzioni, O. Identifying meaningful citations. In Proceedings of the Workshops at the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–26 January 2015. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Seattle, WA, USA, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get to the point: Summarization with pointer-generator networks. arXiv 2017, arXiv:1704.04368. [Google Scholar]
- sooftware/seq2seq. Available online: https://github.com/sooftware/seq2seq (accessed on 21 January 2022).
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Lapata, M. Text Summarization with Pretrained Encoders. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3730–3740. [Google Scholar]
- Zhong, M.; Liu, P.; Chen, Y.; Wang, D.; Qiu, X.; Huang, X. Extractive summarization as text matching. arXiv 2020, arXiv:2004.08795. [Google Scholar]
- Kobus, C.; Crego, J.M.; Senellart, J. Domain Control for Neural Machine Translation. In Proceedings of the International Conference Recent Advances in Natural Language Processing, Hissar, Bulgaria, 9–11 September 2013; pp. 372–378. [Google Scholar]
- Peng, N.; Ghazvininejad, M.; May, J.; Knight, K. Towards controllable story generation. In Proceedings of the First Workshop on Storytelling, New Orleans, LA, USA, 5–6 June 2018; pp. 43–49. [Google Scholar]
- Gupta, P.; Bigham, J.P.; Tsvetkov, Y.; Pavel, A. Controlling dialogue generation with semantic exemplars. arXiv 2020, arXiv:2008.09075. [Google Scholar]
- Wu, Z.; Galley, M.; Brockett, C.; Zhang, Y.; Gao, X.; Quirk, C.; Koncel-Kedziorski, R.; Gao, J.; Hajishirzi, H.; Ostendorf, M. A controllable model of grounded response generation. arXiv 2020, arXiv:2005.00613. [Google Scholar]
- Fan, A.; Grangier, D.; Auli, M. Controllable Abstractive Summarization. In Proceedings of the 2nd Workshop on Neural Machine Translation and Generation, Melbourne, Australia, 20 July 2018; pp. 45–54. [Google Scholar]
- He, J.; Kryściński, W.; McCann, B.; Rajani, N.; Xiong, C. Ctrlsum: Towards generic controllable text summarization. arXiv 2020, arXiv:2012.04281. [Google Scholar]
- Tan, B.; Qin, L.; Xing, E.; Hu, Z. Summarizing Text on Any Aspects: A Knowledge-Informed Weakly-Supervised Approach. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual Event, 16–20 November 2020; pp. 6301–6309. [Google Scholar]
- Lin, C.-Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating Text Generation with BERT. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: A Pretrained Language Model for Scientific Text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3615–3620. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Hayes, A.F.; Krippendorff, K. Answering the Call for a Standard Reliability Measure for Coding Data. Commun. Methods Meas. 2007, 1, 77–89. [Google Scholar] [CrossRef]
- Gabriel, S.; Bosselut, A.; Da, J.; Holtzman, A.; Buys, J.; Lo, K.; Celikyilmaz, A.; Choi, Y. Discourse Understanding and Factual Consistency in Abstractive Summarization. arXiv 2019, arXiv:1907.01272. [Google Scholar]
- Zhang, J.; Tang, J.; Liu, L.; Li, J. A mixture model for expert finding. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Osaka, Japan, 20–23 May 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 466–478. [Google Scholar]
- Buckley, C.; Voorhees, E.M. Retrieval evaluation with incomplete information. In Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Sheffield, UK, 25–29 July 2004; pp. 25–32. [Google Scholar]
- Woodard, J.L.; Seidenberg, M.; Nielson, K.A.; Miller, S.K.; Franczak, M.; Antuono, P.; Douville, K.L.; Rao, S.M. Temporally graded activation of neocortical regions in response to memories of different ages. J. Cogn. Neurosci. 2007, 19, 1113–1124. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Alwagait, E.; Shahzad, B.; Alim, S. Impact of social media usage on students academic performance in Saudi Arabia. Comput. Hum. Behav. 2015, 51, 1092–1097. [Google Scholar] [CrossRef]
- Ananthakrishnan, S.; Narayanan, S. Improved speech recognition using acoustic and lexical correlates of pitch accent in a n-best rescoring framework. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07, Honolulu, HI, USA, 15–20 April 2007; pp. IV-873–IV-876. [Google Scholar]
- Bošnjak, M.; Rocktäschel, T.; Naradowsky, J.; Riedel, S. Programming with a differentiable forth interpreter. Proc. Mach. Learn. Res. 2017, 70, 547–556. [Google Scholar]
- Bouachir, W.; Kardouchi, M.; Belacel, N. Fuzzy indexing for bag of features scene categorization. In Proceedings of the 2010 5th International Symposium On I/V Communications and Mobile Network, Rabat, Morocco, 30 September–2 October 2010; pp. 1–4. [Google Scholar]
- Bouker, M.A.; Hervet, E. Retrieval of images using mean-shift and gaussian mixtures based on weighted color histograms. In Proceedings of the 2011 Seventh International Conference on Signal Image Technology & Internet-Based Systems, Dijon, France, 28 November–1 December 2011; pp. 218–222. [Google Scholar]
- Chiang, C.-Y.; Siniscalchi, S.M.; Chen, S.-H.; Lee, C.-H. Knowledge integration for improving performance in LVCSR. In Proceedings of the INTERSPEECH, 2013 (14th Annual Conference of the International Speech Communication Association), Lyon, France, 25–29 August 2013; pp. 1786–1790. [Google Scholar]
- Dawelbait, G.; Mezher, T.; Woon, W.L.; Henschel, A. Taxonomy based trend discovery of renewable energy technologies in desalination and power generation. In Proceedings of the PICMET 2010 Technology Management for Global Economic Growth, Phuket, Thailand, 18–22 July 2010; pp. 1–8. [Google Scholar]
- Doleck, T.; Lajoie, S. Social networking and academic performance: A review. Educ. Inf. Technol. 2018, 23, 435–465. [Google Scholar] [CrossRef]
- Doleisch, H. SimVis: Interactive visual analysis of large and time-dependent 3D simulation data. In Proceedings of the 2007 Winter Simulation Conference, Washington, DC, USA, 9–12 December 2007; pp. 712–720. [Google Scholar]
- Henschel, A.; Casagrande, E.; Woon, W.L.; Janajreh, I.; Madnick, S. A unified approach for taxonomy-based technology forecasting. In Business Intelligence Applications and the Web: Models, Systems and Technologies; IGI Global: Hershey, PA, USA, 2012; pp. 178–197. [Google Scholar]
- Kelly, F.P. Charging and Accounting for Bursty Connections; Michigan Publishing, University of Michigan Library: Ann Arbor, MI, USA, 1996. [Google Scholar]
- Manhaeve, R.; Dumancic, S.; Kimmig, A.; Demeester, T.; De Raedt, L. Deepproblog: Neural probabilistic logic programming. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Piringer, H.; Tominski, C.; Muigg, P.; Berger, W. A multi-threading architecture to support interactive visual exploration. IEEE Trans. Vis. Comput. Graph. 2009, 15, 1113–1120. [Google Scholar] [CrossRef]
- Shahabuddin, J.; Chrungoo, A.; Gupta, V.; Juneja, S.; Kapoor, S.; Kumar, A. Stream-packing: Resource allocation in web server farms with a qos guarantee. In Proceedings of the International Conference on High-Performance Computing, Hyderabad, India, 17–20 December 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 182–191. [Google Scholar]
- Walhovd, K.B.; Fjell, A.M.; Dale, A.M.; Fischl, B.; Quinn, B.T.; Makris, N.; Salat, D.; Reinvang, I. Regional cortical thickness matters in recall after months more than minutes. Neuroimage 2006, 31, 1343–1351. [Google Scholar] [CrossRef]
- Van der Stoep, N.; Nijboer, T.C.; Van der Stigchel, S. Exogenous orienting of crossmodal attention in 3-D space: Support for a depth-aware crossmodal attentional system. Psychon. Bull. Rev. 2014, 21, 708–714. [Google Scholar] [CrossRef]
- Atchley, P.; Kramer, A.F.; Andersen, G.J.; Theeuwes, J. Spatial cuing in a stereoscopic display: Evidence for a “depth-aware” attentional focus. Psychon. Bull. Rev. 1997, 4, 524–529. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Intent Category | Definition |
|---|---|
| Background | “The citation states, mentions, or points to the background information giving more context about a problem, concept approach, topic, or importance of the problem in the field.” |
| Method | “Making use of a method, tool, approach or dataset” |
| ResultComparison | “Comparison of the paper’s results/findings with the results/findings of other work” |
| Train | Val | Test | ||
|---|---|---|---|---|
| Citing Paper | # words (std) | 242.58 (101.42) | 242.66 (112.14) | 250.59 (113.17) |
| # sentences (std) | 8.99 (3.81) | 9.17 (3.95) | 9.35 (4.39) | |
| Reference Paper | # words (std) | 227.30 (125.71) | 226.69 (106.84) | 223.99 (114.40) |
| # sentences (std) | 8.53 (4.78) | 8.44 (4.02) | 8.39 (4.12) | |
| Citation Text | # words (std) | 33.52 (15.35) | 33.38 (14.40) | 34.60 (15.31) |
| # sentences (std) | 1.03 (0.17) | 1.03 (0.18) | 1.03 (0.17) | |
| Intent (%) | Bg/Md/Rs | 50.76/34.54/14.51 | 57.52/29.34/13.12 | 52.79/33.90/13.30 |
| Notation | Definition |
|---|---|
| CP | Citing paper |
| RP | Reference paper |
| aCP | Abstract of the citing paper |
| tCP | Title of the citing paper |
| aRP | Abstract of the reference paper |
| D | Training dataset |
| C | Predefined citation intent set (control code set) |
| c | Specified citation intent (control code) |
| V | Predefined vocabulary |
| |V| | Predefined vocabulary size |
| X | Input sequence of the model |
| y | Target citation text |
| ŷ | Generated citation text |
| R-1 | R-2 | R-L | SciBS | Intent Acc. | |
|---|---|---|---|---|---|
| EXT-Oracle | 22.21 | 4.96 | 16.06 | 62.35 | |
| BART-no_intent | 22.74 | 3.03 | 15.85 | 63.16 | |
| BART-aCP + aRP | 23.64 | 3.45 | 16.96 | 63.81 | 88.34 |
| BART-tCP + aRP | 24.05 | 3.55 | 16.98 | 63.82 | 87.91 |
| T5-no_intent | 21.84 | 2.63 | 15.15 | 61.78 | |
| T5-aCP + aRP | 22.97 | 3.04 | 15.90 | 62.61 | 77.52 |
| T5-tCP + aRP | 23.85 | 3.44 | 16.59 | 63.37 | 82.99 |
| Background | R-1 | R-2 | R-L | SciBS |
|---|---|---|---|---|
| BART-aCP + aRP | 22.99 | 3.24 | 16.93 | 64.20 |
| BART-tCP + aRP | 23.38 | 3.30 | 16.83 | 64.13 |
| T5-aCP + aRP | 22.13 | 2.65 | 15.62 | 62.73 |
| T5-tCP + aRP | 23.10 | 3.08 | 16.32 | 63.49 |
| Method | R-1 | R-2 | R-L | SciBS |
| BART-aCP + aRP | 22.85 | 2.90 | 16.02 | 62.12 |
| BART-tCP + aRP | 22.90 | 3.16 | 15.90 | 62.09 |
| T5-aCP + aRP | 22.30 | 2.97 | 15.21 | 61.09 |
| T5-tCP + aRP | 23.20 | 3.34 | 15.79 | 61.75 |
| ResultCompare | R-1 | R-2 | R-L | SciBS |
| BART-aCP + aRP | 29.46 | 5.78 | 20.46 | 67.26 |
| BART-tCP + aRP | 29.57 | 5.63 | 20.42 | 67.13 |
| T5-aCP + aRP | 27.87 | 4.73 | 18.70 | 65.97 |
| T5-tCP + aRP | 28.51 | 5.04 | 19.62 | 66.99 |
| Plaus. | Spec. | Int. | Corr. | Cor&Spec. | Agr. | |
|---|---|---|---|---|---|---|
| B-aCP + aRP | 0.93 | 0.78 | 0.65 | 0.70 | 0.46 | 0.50 |
| B-tCP + aRP | 0.84 | 0.62 | 0.74 | 0.73 | 0.50 | 0.74 |
| T5-aCP + aRP | 0.98 | 0.68 | 0.60 | 0.70 | 0.51 | 0.61 |
| T5-tCP + aRP | 0.84 | 0.80 | 0.69 | 0.78 | 0.65 | 0.71 |
| Gold | 0.92 | 0.79 | 0.67 | 0.81 | 0.69 | 0.69 |
| Agr. | 0.69 | 0.71 | 0.71 | 0.77 | 0.71 |
| Input | Training Dataset | Best Model | Metrics | |
|---|---|---|---|---|
| Xing et al. [8] |
| ACL Anthology Network corpus
| Multi-Source Pointer-Generator Network with Cross Attention | R-1: 26.28 R-2: 7.05 R-L: 20.49 |
| Luu et al. [9] |
| S2-GORC
| Pritrained-GPT-2 | R-L-2: 12.3 |
| This work |
| Extended SciCite
| BART-tCP + aRP | R-1: 24.05 R-2: 3.55 R-L:16.98 |
| Citing paper title: “Exogenous orienting of crossmodal attention in 3-D space: Support for a depth-aware crossmodal attentional system” [58] |
| Citing paper abstract: “The aim of the present study was to investigate exogenous crossmodal orienting of attention in three-dimensional (3-D) space. Most studies in which the orienting of attention has been examined in 3-D space concerned either exogenous intramodal or endogenous crossmodal attention. Evidence for exogenous crossmodal orienting of attention in depth is lacking. Endogenous and exogenous attention are behaviorally different, suggesting that they are two different mechanisms. We used the orthogonal spatial-cueing paradigm and presented auditory exogenous cues at one of four possible locations in near or far space before the onset of a visual target. Cues could be presented at the same (valid) or at a different (invalid) depth from the target (radial validity), and on the same (valid) or on a different (invalid) side (horizontal validity), whereas we blocked the depth at which visual targets were presented. Next to an overall validity effect (valid RTs < invalid RTs) in horizontal space, we observed an interaction between the horizontal and radial validity of the cue: The horizontal validity effect was present only when the cue and the target were presented at the same depth. No horizontal validity effect was observed when the cue and the target were presented at different depths. These results suggest that exogenous crossmodal attention is depth-aware, and they are discussed in the context of the supramodal hypothesis of attention.” |
| Reference paper title: “Spatial cuing in a stereoscopic display: Evidence for a depth-aware attentional focus.” [59] |
| Reference paper abstract: “Two experiments were conducted to explore whether attentional selection occurs in depth, or whether attentional focus is depth blind, as suggested by Ghiradelli and Folk (1996). In Experiment 1, observers viewed stereoscopic displays in which one of four spatial locations was cued. Two of the locations were at a near-depth location and two were at a far-depth location, and a single target was presented along with three distractors. The results indicated a larger cost in reaction time for switching attention in x,y and depth than in x,y alone, supporting a depth-aware attentional spotlight. In Experiment 2, no distractors were present, similar to the displays used by Ghiradelli and Folk. In this experiment, no effect for switching attention in depth was found, indicating that the selectivity of attention in depth depends on the perceptual load imposed on observers by the tasks and displays.” |
| Original Citation Text: “Our findings are in line with the results from studies in which exogenous intramodal orienting of attention was investigated in 3-D space #REF.” |
| Generated Citation Texts |
| Intent: Background “It has been shown that attentional selection in depth depends on the perceptual load imposed on observers by the tasks and displays #REF.” |
| Intent: Method “We used the orthogonal spatial cueing paradigm #REF to investigate the spatial-cueing of attention in 3-D space.” |
| Intent: ResultComparison “Our findings are consistent with previous studies in which the orienting of attention in 3D space has been examined in 3-D space #REF.” |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, S.-Y.; Lin, T.-H.; Liao, C.-H.; Yuan, S.-M.; Sun, C.-T. Intent-Controllable Citation Text Generation. Mathematics 2022, 10, 1763. https://doi.org/10.3390/math10101763
Jung S-Y, Lin T-H, Liao C-H, Yuan S-M, Sun C-T. Intent-Controllable Citation Text Generation. Mathematics. 2022; 10(10):1763. https://doi.org/10.3390/math10101763
Chicago/Turabian StyleJung, Shing-Yun, Ting-Han Lin, Chia-Hung Liao, Shyan-Ming Yuan, and Chuen-Tsai Sun. 2022. "Intent-Controllable Citation Text Generation" Mathematics 10, no. 10: 1763. https://doi.org/10.3390/math10101763
APA StyleJung, S.-Y., Lin, T.-H., Liao, C.-H., Yuan, S.-M., & Sun, C.-T. (2022). Intent-Controllable Citation Text Generation. Mathematics, 10(10), 1763. https://doi.org/10.3390/math10101763