1. Introduction
Nowadays, software reliability is always an important indicator for evaluating software quality and can be used as a basis to make an appropriate plan for software testing work. In modern software industries, software developers not only focus on the functionality of their developed software or systems but also ensure that software quality and stability are over an acceptable level. Once the software quality and stability cannot satisfy their clients’ or customers’ requirements, this will still cause the loss of sales or customer dissatisfaction no matter how superior the functionality and performance of software/system might be. However, due to the constraints of the project budget, human resources, and testing time, it is unrealistic for software developers to pursue a perfect and faultless software/system. Accordingly, in practice, most software developers will make a compromise plan instead of spending a huge budget pursuing a faultless software/system. Over the past few decades, various software reliability growth models (SRGMs) have been proposed, and most of them adopt a Non-Homogeneous Poisson Process (NHPP) to describe software testing and debugging phenomena [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21].
Generally, testing staff’s learning and experience will influence the debugging efficiency, and the velocity of error detection will increase in the mid to late testing phase. Therefore, the curve of the mean value function of a software reliability growth model (SRGM) will present an S-shaped form. Yamada et al. [
2] proposed an S-shaped reliability growth model for software error detection but they did not clearly point out which parameters are related to the learning factor in their proposed model. Li and Pham [
22] took failure intensity functions into consideration for presenting a learning effect during a testing process. Huang et al. [
23] developed an SRGM which considered testing effort. They believed that the efficiency of error detection may be lower in the early stage but that the growth rate of error detection will accelerate in the mid-stage. Therefore, the curve of the SRGM will present as S-shaped, indicating the learning effect that occurs in debugging works. Chiu et al. [
7] state that the learning effect should be considered a crucial parameter in SRGM, and the value of this parameter can be used to estimate the inflection point during a testing period. In their experiments, the curve of SRGM can adapt to concave or S-shape forms, reflecting the learning effect that exists in testing works. Moreover, due to the fact that the parameter of the learning effect might be hard to estimate if the related historical data are insufficient, the decision-maker needs to utilize other methods for evaluating the parameters’ value. In order to solve this issue, Chiu et al. [
24] extended their original model by utilizing a Bayesian method to reasonably estimate the parameters’ value regarding the learning effect. However, their research concerns perfect debugging SRGMs, and they did not take the testing staff’s negligence into consideration. Besides, they simply assumed that all software errors would be homogeneous, an unrealistic assumption because different error types will require different amounts of time to be rectified. Ahmad et al. [
25] proposed a testing-effort dependent inflection S-Shaped SRGM that includes the learning effect in the software testing process. Raju [
26] also proposed an inflection S-shaped software reliability model based on NHPP, and their model can be adapted to exponential and S-shaped data. Ramsamy et al. [
27] state that most SRGMs do not take the learning factors of testing staff into consideration. In order to improve the adaptability of various software testing projects, they utilized learning and debugging indices to develop an SRGM. Kim and Kim [
28] proposed SRGMs that were sensitive to learning effects by using Yamada and Ohba’s delayed S-shaped models. The study discussed the relationship between release time and testing efforts to minimize software development. Pachauri et al. [
29] took the S-shaped curve, imperfect debugging, and error reduction factors into consideration to develop a multi-stage SRGM. Jin and Jin [
30] extended the study of Huang et al. [
23] to propose an SRGM that included testing effort, and their model can accommodate exponential and S-shaped data patterns simultaneously. Chiu et al. [
31] extended their former model and assumed that the learning effect can be time-dependent and may grow linearly or exponentially with testing time. In addition, their extended model can describe the phenomenon of unstable debugging efficiency during the early testing stage. Based on the above discussion, it can be noted that although the learning effect has been taken into consideration in previous research, this work has not fully considered all possible factors regarding human resource issues, including the basic ability, learning efficacy, and negligent factor of testing staff. Accordingly, the present study will incorporate all of these elements to propose a software release decision model SRGM under multiple alternatives.
Moreover, most of the related studies only considered the scenario of perfect debugging. They simply assumed that the testing/debugging staff would not make mistakes again when they corrected the error codes. However, such an assumption might be unrealistic because humans are not perfect in nature, and it cannot be ruled out that testing/debugging staff’s carelessness may introduce new software defects. Therefore, recently, some studies have begun to investigate the issue of imperfect debugging SRGMs. Aktekin and Caglar [
32] proposed a multiplicative failure rate that varied randomly during the test phase, and the model could explain the phenomenon of imperfect debugging in practice. Peng et al. [
33] proposed an SRGM that considered testing-effort allocation for imperfect debugging processes. They designed three testing-effort functions (constant, Weibull, and logistic forms) to describe how the software developer allocates testing resources during a time horizon. Wang and Wu [
34] proposed an imperfect debugging SRGM by utilizing a fault content function with a log-logistic distribution. They assumed that testing/debugging staff’s skills, case tools, and testing resources are complex and uncertain factors that significantly influence the testing process. Therefore, these factors might cause new software faults, which were produced in the testing process. Zhu and Pham [
35] proposed a multi-release software reliability model that considered the remaining software faults from previous software releases and newly introduced faults different from those that existed earlier. Li and Pham [
36] also highlighted that debugging and test coverage might not be perfect, since the operating environment might be uncertain and varied for testing projects. Therefore, they proposed a model that used randomly distributed variables to simulate the uncertainty of the operating environment. Zhao et al. [
37] took the factors of perfect and imperfect debugging into consideration to propose a Bayesian SRGM to deal with the issue of the uncertainty of software reliability. Saraf and Iqbal [
38] developed an SRGM that incorporated two types of imperfect debugging and the change-point factor to deal with the issue of multiple versions for a software release. Li et al. [
39] proposed an NHPP-based SRGM that concerns testability growth effort, rectifying delays, and imperfect debugging. Within the above-mentioned studies, the common assumption is that new software errors are simply introduced with testing time. However, pure testing work is only used to discover errors in the system and should not produce any new errors because program codes are not changed during pure testing work. Therefore, in this study, the software error correction process and debugging staff’s negligence are considered, and our assessment of efficiency includes the results from the detected software error patterns. This is different from the idea of a traditional imperfect debugging SRGM.
It is easy to understand how the processing time for removing or correcting each error could be different, because different types of errors need different amounts of time to be corrected. Furthermore, the processing time for removing or correcting an error should be regarded as a random variable, which needs to be estimated in advance from the related historical data. However, most existing SRGMs simply assume that such processing time is constant and unitary. Obviously, this assumption might be unrealistic in practice. Accordingly, some related studies have begun to revise the former assumption and focus on the issue of multiple error types in order to improve the practicality of SRGMs. Kapur et al. [
9,
10] assumed that error detection rates are different for various error types. In their model, the errors can be classified as simple, difficult, and complex types. Jain et al. [
40] constructed an SRGM that considered simple and complex errors during the debugging process. Garmabaki et al. [
41] examined software version up-gradation and error conditions with different degrees of severity to construct software reliability models for different software versions, in which the number of error removals in each version included the detected errors in the current version and those left from the previous versions. Khatri and Chhillar [
42] classified software faults into three types (simple, difficult, and complex) to develop an imperfect SRGM. This classification was conducted according to the degree of error correction difficulty. Kaushal and Khullar [
43] proposed Neural Network Approaches to predict software errors for NASA’s public defect datasets. They classified software faults into different types according to the severity of the damage caused by the fault. Song and Rhew [
44] developed a method for identifying the types of software errors automatically. They roughly classified software errors into logic, data, interface, document, and computational problems. Wang et al. [
45] also took two types of faults into consideration to propose an SRGM and assumed that the two types of faults are mutually independent. Zhu and Pham [
46] proposed a two-phase SRGM that considered software error dependency and imperfect fault removal, and they assumed the occurrence of two types of software error during the two-phase debugging process. Huang et al. [
47] also considered two types of software error to develop an imperfect debugging SRGM. Based on the above discussion, previous studies have taken the issue of multiple error types into consideration because the correction for a complex error usually requires more time than a simple one does, and it is inappropriate to calculate the estimated time and cost for different error types by using a unified setting. Moreover, different errors require different processing time during a correction, and therefore the processing time for removing or correcting an error should be regarded as a random variable instead of a constant value. The decision-maker can reasonably estimate it by using the related operational data. However, most of the related studies have failed to recognize this factor. Accordingly, in order to increase practicability, our study assumes that the processing time for removing or correcting different error types follows specified probability distributions with different parameters.
In general, the testing environment might be changed due to increasing testing staff, upgrades to hardware, or changing case tools, and these factors will cause changes in debugging efficiency. The timing of changes in the testing environment is known as a change-point within the SRGM. Huang [
5] proposed an SRGM that considered both testing effort and change-points. Huang and Hung [
48] extended their former model to propose a model with multiple change-points based on the assumption that software developers will upgrade the developed software many times during a software’s life cycle in practice. Hu et al. [
49] proposed a modified adaptive testing model, and considered how a testing environment may be changed due to the change in a testing policy. Inoue et al. [
50] proposed an all-stage truncated multiple change-point model for assessing software reliability. They utilized a zero-truncated Poisson distribution to describe the counting process for software errors. Nagaraju et al. [
51] proposed an SRGM that incorporated heterogeneous change-points and an error detection process that can be characterized by different time segments. Ke and Huang [
52] highlighted that a development environment or method might be changed for some reason, and that such changes in the development process must be taken into consideration when adjusting the former analysis regarding software reliability. Pradhan et al. [
53] also took the change-point issue into consideration when they proposed a testing-effort-based NHPP software reliability growth model. Khurshid et al. [
54] proposed an imperfect debugging model, and they integrated testing effort, the fault-reduction factor, and change-point issues into their study. SRGMs that incorporate the change-point issue can bring more flexibility than the traditional models when the software developers face varied development or running environments. Accordingly, in this study, the change-point issue is taken into consideration, since, in practice, a software developer may increase manpower and resources within a testing system to accelerate testing tasks, and these changes might result in a change in software reliability. Thus, the current study incorporates these practical considerations within its model.
To sum up, this study considers the multiple issues of software testing in order to construct a software reliability growth model under multiple alternatives. Furthermore, the best timing for software release can be evaluated by considering reliability and cost. In addition, the parameters of the proposed model are more intuitive and can be more easily estimated or evaluated. Accordingly, we consider our study to be helpful to software industries aiming to release their software products or systems to the market. We identify three advantages of the present study, as follows: (1) The study integrates the issues of learning effect, human factors, imperfect debugging, multiple errors classification, change-point, etc., to construct a software reliability growth model under multiple alternatives. It is different from most of the related studies, which only take some of these factors into consideration. (2) The proposed model exhibits better performance with regards to goodness-of-fit compared with other existing models in statistical analyses. The estimation methods of the parameters’ values and confidence intervals are also developed in this study. (3) The model presented in this study is easier for practical applications. The optimal timing for software release can be obtained by the proposed model in terms of testing cost under the constraint of software reliability. The managers can evaluate all the feasible alternatives and decide on one of them before proceeding with software testing work. The rest of this paper is organized as follows:
Section 2 presents the development of the model, parameter estimation, and the optimal software release model.
Section 3 provides the model verification and comparison. The application and numerical analysis are presented in
Section 4. Finally,
Section 5 draws the concluding remarks and identifies topics for future studies.
2. Software Reliability Modeling
In recent years, NHPP has been widely and successfully used to examine reliability issues for a range of hardware and software applications. NHPP is a derivative of HPP; the major difference between these two stochastic processes is that the NHPP allows for the expected number of failures to vary with time. Since expected software faults decrease with testing time during the debugging process, it is suitable for application within software reliability growth models.
An implemented software system needs to be tested and debugged in advance to ensure quality when the system is released to the market. Several feasible alternatives can be designed and prepared for the software department or company, with the decision-maker selecting the best option for the software testing work. To balance system stability and related costs, the managers need to know the efficiency of any system reliability improvements under different resource allocations. Therefore, the managers will estimate the testing/debugging efficiency and the spending budget under several resource alternatives in advance. However, it is not easy to effectively estimate testing/debugging efficiency when the managers want to design and change input resources over time. Moreover, the environment of software testing might be changed or adjusted in practice due to changing testing staff, hardware, tools, or strategies midway through the testing process, and these changes may result in changes in testing/debugging efficiency. Accordingly, it is necessary to develop an effective SRGM that can deal with such issues of multiple testing alternatives or testing environment changes.
Generally, the process of software reliability growth can be described by mathematical functions as a counting process,
, where
follows an NHPP with the mean value function
, and this probability can be formulated as follows:
From another perspective, the mean value function can be expressed as the expected number of errors detected within the time period
:
Furthermore, software reliability
can be defined as the probability of no errors being detected within the time period
, and it can be formulated as follows:
The operating time
is for the requirements of stability in practice, and the decision-maker can give an adequate value for managerial requirements. Note that enlarging the operating time will decrease the value of reliability. In addition, the value of software reliability will finally approach one when testing time approaches infinity (
). The notations and terminologies are presented in
Table 1, and they will be used throughout the study:
2.1. Basic Model Development
In general, it is unrealistic to assume that testing work will be conducted under perfect debugging conditions because the debugging staff may always produce new errors or bugs when removing and correcting the detected ones. Therefore, some of the related studies have made the assumption that software errors may be increased by testing time, and this can be called the issue of imperfect debugging in SRGM. In our proposed model, the major influential factors include testing staffs’ autonomous errors-detected factor
, learning factor
, and negligent factor
. It should be noted that the values of the parameters
,
, and
must be greater than zero. In order to describe the concept of the proposed model, a causal loop diagram is used to illustrate the process of software reliability growth.
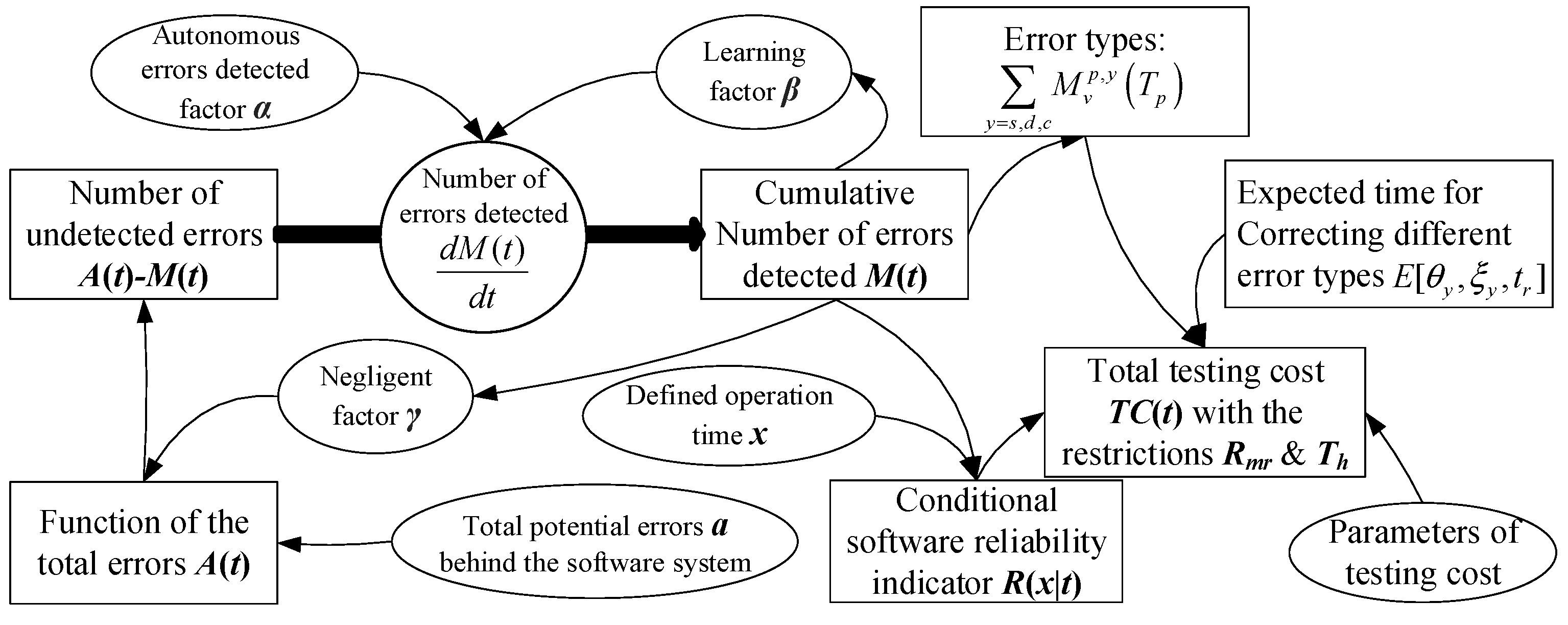
Figure 1 illustrates the logical concept of the process of the software testing/debugging task, and the total efficiency of error detection is associated with the three factors. The arrows indicate the direction of influence among these factors and/or components. The circles represent the factors regarding debugging works and testing costs. The rectangles represent the relevant components. Additionally, the meaning of the mean value function
can be regarded as the average of the cumulative number of errors detected. Therefore, the function
is used to estimate the expected cumulative number in practice. However, if we take the stochastic issue into consideration, the actual cumulative number will be influenced by random noise. Such a definition was often seen in similar studies.
In this causal loop diagram, the autonomous errors-detected factor
can be described as the rate at which testing staff can find errors by their original ability. In other words, these are software errors spontaneously found by testing staff without any reference to the previous error patterns. Therefore, this ability originates from the testing staff’s intelligence and previous training, and it is unrelated to the learning factor, i.e., knowledge acquired from the current project. Furthermore, the learning factor
indicates the testing staff’s learning ability, which is based on the previous error patterns. Therefore, the learning effect would increase with the testing time. Both factors can improve the efficiency of software debugging. However, the negligent factor
is the main cause of the phenomenon of imperfect debugging, and it can be regarded as the increased rate of new errors due to the debugging staff’s carelessness. In other words, the negligent factor negatively impacts on the efficiency of debugging, and it will increase the number of software errors. In this study, the number of the total software errors is set as a function of testing time, and we consider its increment to be related to the mean value function
. Therefore, the function of the total software errors can be defined as follows:
where
is the initial number of potential errors before the testing work started, and the new errors are those introduced along with the revised codes. The negligent factor
can be regarded as the rate of increase and is related to the accumulated number of software errors detected. In addition,
represents the cumulative fraction of the errors detected within the time range (0,
), and
signifies the undetected errors at time
. Accordingly, the process of the detection can be described using the following differential equation:
where the parameters
and
must be greater than or equal to zero to ensure the effect of debugging activity is positive in the testing process. Equations (4) and (5) imply that the learning effect and imperfect debugging exist in the testing process. Accordingly, the mean value function
can be derived by using differential equation methods; the following steps are the process for deducing the function
.
Since the cumulative fraction of the original detected pattern
is defined as
and the total errors increase with testing time, i.e.,
, Equation (5) can be rewritten as
. In order to deduce the math form of
, we arrange the equation in the following steps:
Taking the integral of both sides of the equation, we can obtain the result as follows:
Solving the above equation for
, we can obtain the math form of
with the unknown constant as the following equation:
Since the initial condition
is given (no error detected at testing time
), we can use it to solve the value of the unknown constant as follows:
Solving Equation (8) for the unknown constant, the constant can be obtained as follows:
Substituting the constant into Equation (8), we can obtain the complete form of
as follows:
Since
, the form of
can be simplified as follows:
Furthermore, the intensity function
, i.e., the number of the errors detected at time
, can be obtained as follows:
In order to handle the variation of the error detection rate per error at time
, the form of the error detection rate needs to be known and can be derived by Equations (4), (6), and (12), as follows:
The error detection rate is a strictly increasing function, which means that the testing staff’s efficiency is always improving in the process. Proposition A1 provides proof that the error detection rate is increasing at any testing time. Please see the proof in
Appendix A.
In general, testing staff’s learning effect will present an acceleration phenomenon in the testing process. Once the acceleration phenomenon is significant, the mean value function will present as S-shaped. However, the means by which to verify the S-shaped mean value function depends on whether the inflection point is greater than zero or not. By referring to Proposition A2, we can see that the mean value function will show the acceleration phenomenon as S-shaped if the condition
is supported. The existence of an inflection point implies that the learning effect is significant in the testing process, and the inflection time point can be given by the following:
The related proof of Proposition A2 can be seen in
Appendix A.
2.2. Parameter Estimation
The two estimation methods can be applied to estimate the model parameters in this study. These collected software failure data are used to demonstrate the fitting degrees among the proposed model and other existing ones.
(1) The least-square estimation method (LSE) is a standard approach in statistics for estimating model parameters by minimizing the sum of the squares of the residuals. A set of
pairs of observed data is taken into consideration, i.e.,
, to estimate all parameters of the proposed model. Here,
is the number of total detected errors within the period [
, and the calculation can be given by the following:
Taking the first-order derivative of Equation (16) with respect to each parameter and letting them be equal to zero, the simultaneous equations can be given as follows:
Since the closed-form expression of the solution cannot be obtained, numerical methods are employed to solve the simultaneous equations to obtain the estimated parameter values. However, if software testing managers use an error seeding method to estimate parameter according to the system scale, the estimation of the remaining parameters will be simplified by solving the simultaneous equations .
(2) The maximum likelihood estimation method (MLE) is another approach to estimate the parameters of an assumed probability distribution. Due to the operation of a Non-Homogeneous Poisson Process, the likelihood function can be given as follows:
Taking the natural logarithm of Equation (18), the likelihood function can be given as follows:
Likewise, taking the first-order derivative of Equation (19) with respect to each parameter and letting them be equal to zero, the simultaneous equations can be given as follows:
The estimated values of these parameters can be obtained by solving the log-likelihood function with numerical methods. However, if an error seeding method can be employed to estimate the initial number of all potential errors in advance, the estimation of the remaining parameters will be simplified by solving the simultaneous equations as .
In addition, the confidence interval for the parameters
can be derived from the variance–covariance matrix
for all the maximum likelihood estimators. The Fisher information matrix
F can be used to obtain the variance–covariance matrix
as follows:
The variance–covariance matrix
can be calculated by the inverse matrix of
F, and it can be given as follows:
The variance–covariance matrix can be used to measure the possible bias of the estimated parameters. The two-sided approximate 100 ×
CR% (Critical Region) for the estimated parameters can be obtained as follows:
where
is the critical value of a given area
of Student-
t distribution with
degrees of freedom.
2.3. Optimal Software Release with Consideration of Multiple Alternatives
In general, more than one feasible alternative is always prepared for the software department or company, and the testing manager will evaluate all the feasible alternatives and decide on one of them to proceed with the software testing work. However, the manager should consider not only savings in the related testing costs but also the need to meet the requirements of system reliability and release date. In order to balance these conflicting objectives, the manager needs to develop a decision model to evaluate which alternative is worthy to proceed with. According to historical data obtained from former testing projects and different arrangements of testing/debugging staff, the software testing engineers are able to devise multiple alternatives with the corresponding parameter values and costs. Accordingly, the proposed model can be presented as follows:
The objective function (24) is to minimize the total testing cost at the alternative
p’s testing time
from the designed alternatives under the minimal requirement of system reliability
and the restricted timeline of software release
. The values
,
, and
denote the estimated values of the model for testing alternative
.
is the defined reliability of no errors occurring within the operation time
under testing alternative
and it can be calculated by
. The objective function includes the five costs, which can be illustrated in the following descriptions. The setup cost of testing alternative
includes the initial cost in testing planning, equipment, and preparation works, which is given by
.
denotes the daily administrative cost per unit time during the testing period, which may include utility fees, office rental, and insurance.
denotes the cost of removing and correcting a simple, complex, or difficult error per unit time under testing alternative
.
denotes the total number of errors detected for alternative
with testing environment
. However, the error types should be categorized into simple, complex, and difficult, and the number of simple, complex, and difficult errors can be formulated as follows:
where
and
are the estimated ratios of the simple and difficult errors respectively.
In addition, it is necessary to estimate the time for removing and rectifying an error in advance, which will be assumed to follow a truncated exponential distribution (Huang et al. [
43]), as follows:
denotes the upper time limit for correcting an error, which is categorized into type
;
is a random variable corresponding to the processing time for correcting an error;
denotes the parameter for the expected time for correcting an error of type
, and a maximum likelihood estimation method can be used to evaluate the estimator
. In addition, complex errors always require more time to correct than simple ones because of the difficulty of the correction process. As a result, the upper time limit of difficult errors will be greater than for complex or simple ones (
). Based on the above, taking the natural logarithm for the likelihood function based on Equation (26), the result can be obtained as follows:
In Equation (27),
denotes the
ith sample of the correction time from historical data (
{
,
,…,
}). Taking the first-order derivative of the log-likelihood function with respect to
and allowing a value of 0, the value of the estimator
can be obtained as follows:
We can solve equation (28) for
by numerical methods to calculate the estimator
. Therefore, the expected time for correcting an error of type
with the parameters
and
can be estimated from the following equation:
Due to the lack of a closed-form solution to Equation (29), a numerical integration method will be needed to obtain the value. Based on the above-mentioned considerations, the total cost of error correction during the testing process can be given as .
The risk cost can be regarded as the loss if an error occurs after the software has been released to the market or implemented within an organization. In this study, can be a loss due to operational failure or damage to commercial reputation, and is the probability of the occurrence of failures after the software release. Therefore, the expected risk cost can be evaluated as . In addition, delaying the software release may result in both tangible and intangible losses. Accordingly, the time-dependent opportunity loss due to a delay in the software release must be considered, and this can be defined as . , , and denote the scale coefficient, the intercept value, and the increasing degree of opportunity loss over time, respectively. In this study, we take the power-law form as the opportunity cost. However, if decision-makers have other considerations, the math form of the opportunity cost can be redefined according to their needs.
Moreover, the managers might intend to accelerate the current testing work for some reason, and will therefore incorporate more manpower or resources to shorten the testing period. Once the manager decides to proceed with it, the change-point
will be shown in the curve of the mean value function. In such circumstances, the related parameters need to be re-estimated, and the mean value function should be redefined as follows:
where
and
denote the mean value functions before and after the change-point
.
,
, and
denote the estimated parameters for the changing environment.
3. Model Verification and Comparison
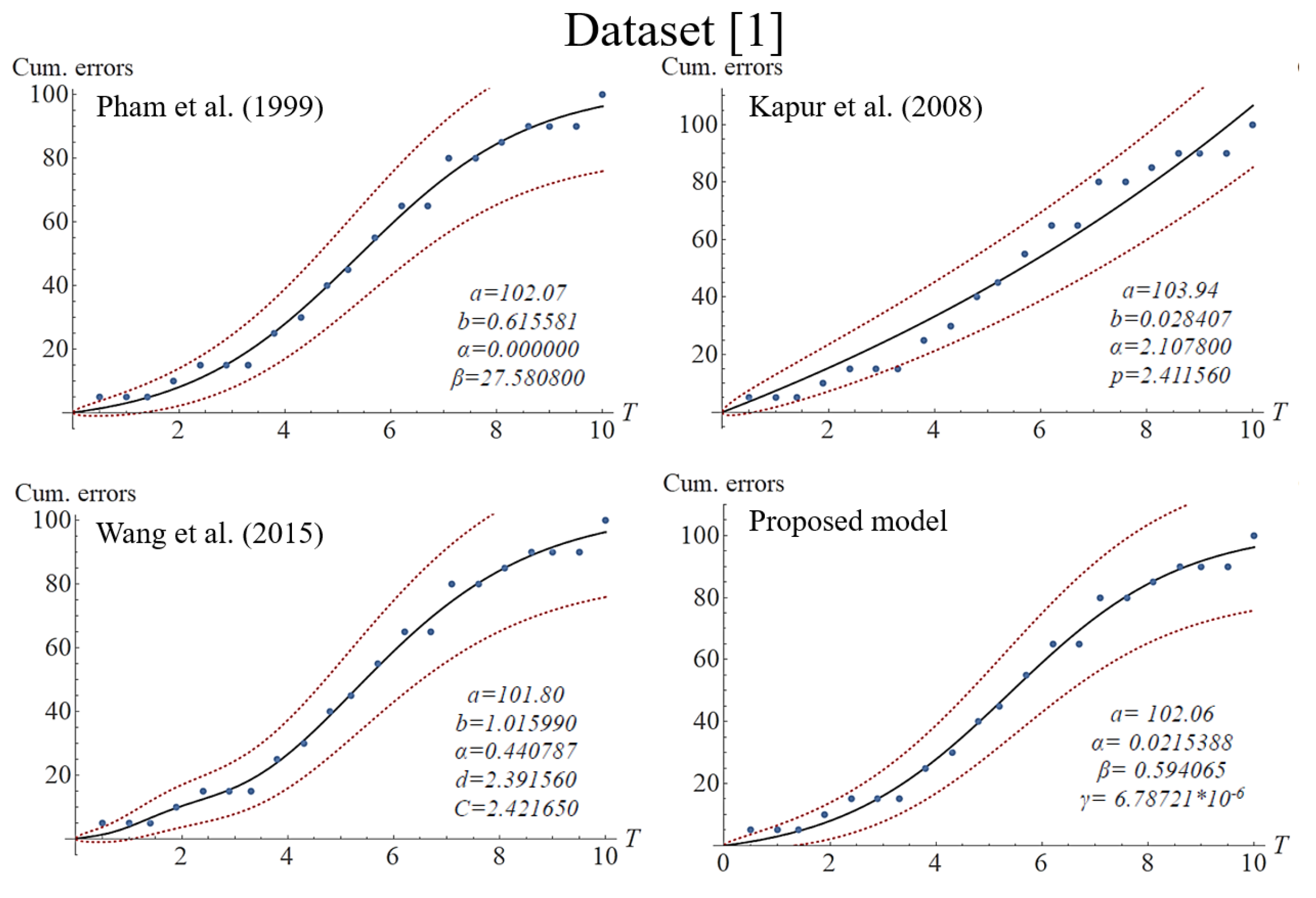
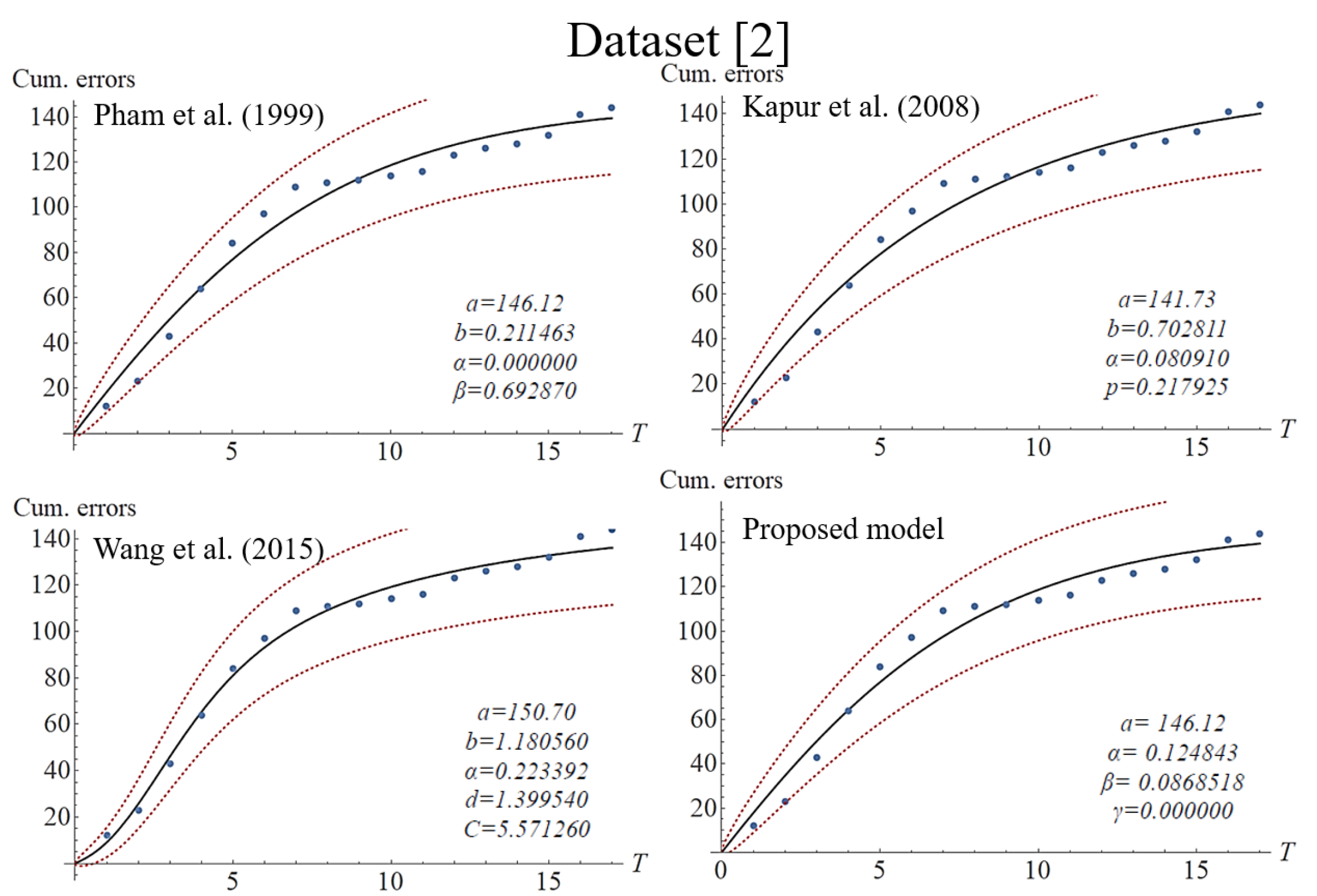
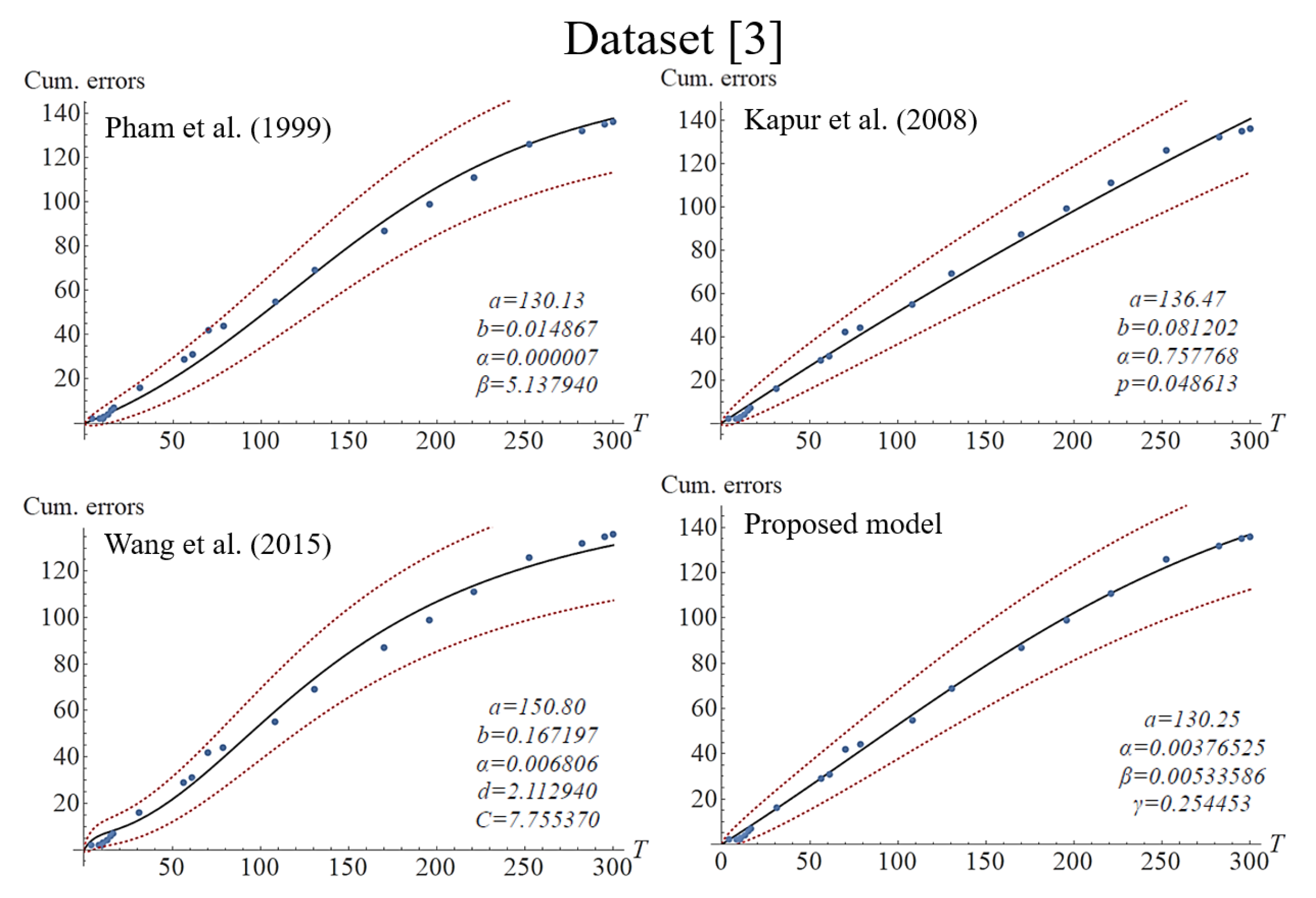
The section assesses the different SRGMs’ fitness ability to different datasets in practice. The datasets are available and were used by the related studies in the research field.
Table 2 presents the information of the datasets, and further details are provided in
Table 3. In order to verify the validity of the fitness of the proposed model, the study compared it with the three alternative classic SRGMs with imperfect debugging, and these can be seen in
Table 4.
Figure 1,
Figure 2,
Figure 3 and
Figure 4 present the fitting results of each imperfect debugging SRGM under the different datasets with the traditional CI. In order to fairly investigate the effectiveness of these models, the three most common criteria were chosen. These evaluation criteria were as follows:
- (1)
Mean square error (MSE) evaluates the difference between the estimated and true values, i.e., , where is the cumulative number of detected errors from time 0 to ; is the cumulative number of detected errors from o to estimated by using the mean value function; is the number of observations; and is the number of parameters.
- (2)
R-squared explains the variability of data in a model, with a greater value indicating the model has a better fit, and can be given by .
- (3)
Akaike information criterion (
AIC) [
55] is defined as the log-likelihood term penalized by the number of model parameters, which is given by
.
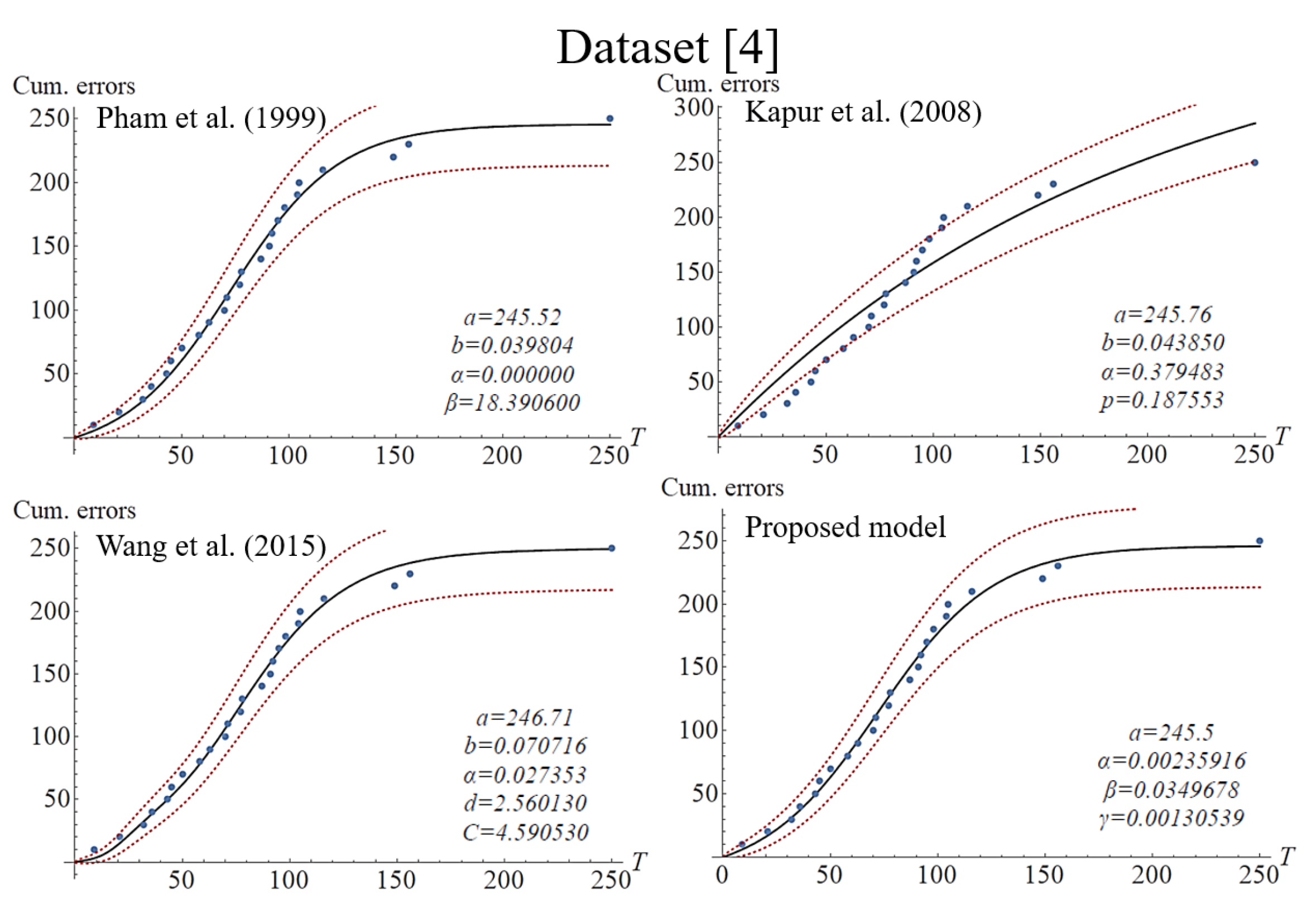
After the analysis of Goodness-of-Fit, it can be seen that the proposed model mostly outperforms the others in the criteria of MSE, R-squared, and AIC under datasets 3 and 4. Moreover, referring to the details in
Table 5 and
Figure 2 and
Figure 3, we can see that Wang’s model presents an extremely fitting ability for datasets 1 and 2, with R-squared values of 99.43% and 98.81%, respectively. In general, such indicators can measure a model’s performance in adapting to different data patterns, and decision-makers can utilize the applicability of different scenarios to accurately predict the future. However, the situation of overfitting should also be avoided. Examining the bottom-left corners of
Figure 2 and
Figure 4 for Wang’s model, we can observe the fluctuating curves to fit datasets 1 and 3, which might be due to the phenomenon of overfitting. Overfitting is as an error that occurs in data modeling, in which a particular function may align too closely to a specific dataset but not to other datasets. In other words, a model may overly learn the detail and noise in a specific training dataset. Obviously, the phenomenon of overfitting may negatively impact the performance of a model for new and future datasets. Although the performance of our model may not be superior to that of Wang’s, such overfitting did not show in our model because the proposed model did not show fluctuating curves to fit datasets. It is worth noting that the number of model parameters can influence the fitting ability. In practice, increasing the number of model parameters can effectively improve a model’s flexibility and adaptability. As can be seen in the mean value function of
Table 4, Wang’s model has five parameters, while the other models only used four parameters, and therefore Wang’s model can present more flexibility and adaptability than the other models. On the other hand, Kapur’s model shows weak adaptation to S-shaped datasets, perhaps having been developed for a specific scenario. Based on the data presented in
Figure 2 and
Figure 5, it can be seen that Kapur’s model could only present concave or exponential curves to the S-shaped datasets. Nonetheless, the Kapur model adapts well to the other datasets. In summary, our model presents a better validity of fitness in average cases. In other words, our model’s performance is not inferior to the others. Moreover, since it is easier to comprehend and evaluate our proposed model’s parameters, software testing managers can use them to adjust or modify the values, thereby more accurately predicting the efficiency of a testing scenario that might be changed in the future.
4. Application and Numerical Analysis
Suppose that a business application software provider has developed a commercial software product, and the development of the work is close to the last phase. Therefore, the product manager has to decide the best timing to release the software product. In general, numerous potential software bugs exist in the software, and the number can be estimated by using error seeding methods with consideration of the software scale. In this case, the number of software errors was estimated to be approximately 1650. However, in order to ensure the quality and stability of the software product, testing and debugging works are necessary to satisfy customers’ requirements. Although follow-up service packs can amend the defects of the developed software, customers’ minimal requirement for software reliability is 90%. Consequently, the product manager needs to arrange the appropriate software testing projects and schedules in advance to achieve the objectives of lower cost and higher reliability. However, due to the consideration of the company’s internal human resources, four software testing alternatives can be performed, with the manager choosing the most suitable. After investigation and evaluation by the company’s experts and senior engineers, the information and estimated parameters for the four candidate alternatives can be seen in
Table 6. Alternative P1 is devised for a project with low-intensity manpower. The testing team is composed of more junior staff. Even though the efficiency of such alternative testing work is inferior to the others, it can save the costs of removing and correcting different error types. On the contrary, alternative P4 can accelerate the testing work by using high-intensity manpower but it also costs more money due to the requirement of hiring senior staff with experience in testing. Furthermore, each testing staff member performs his/her job in rotation for 44 h per week. Every detected software bug will require different amounts of time to be corrected. The required time for removing bugs is assumed to follow a truncated exponential distribution, and the parameters of the distribution can be obtained by the proposed MLE method. After the calculation using MLE and historical data, the correct times for correcting simple, complex, and difficult errors are estimated to be approximately 1.5, 2.5, and 3.5 h. The manager can use this information to evaluate the related debugging cost. In addition, the risk cost and the opportunity loss are both taken into consideration. The expected risk cost per one percent loss in system reliability is about
$3500. The opportunity loss is devised as a time-dependent function, and the parameters are estimated to be
= 1800,
= 2.5, and
= 1.5. The other detailed information can be seen in
Table 6.
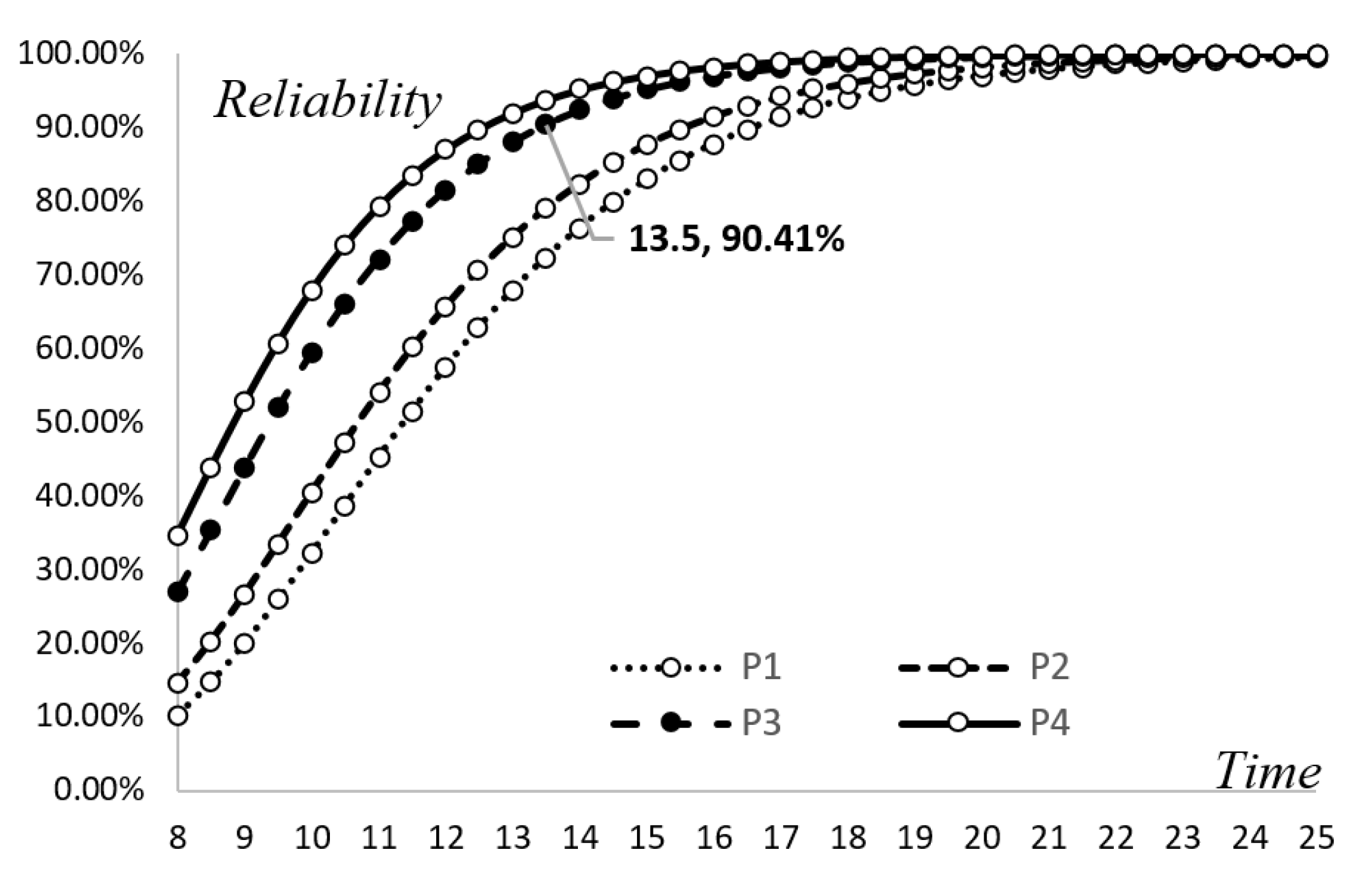
After calculation employing the proposed model, as shown in
Table 7 and
Figure 6, the curves of the four alternatives’ expected testing cost show convexity with testing time. Comparing the four alternatives, it can be seen that alternative P3 is more appropriate for the company since its expected testing cost is the lowest of all the other alternatives. Therefore, the manager should adopt alternative P3 and schedule the software release to occur after 13.5 weeks. The software reliability can reach 90.41% and the total expected cost is evaluated to be
$387,557. With regard to alternatives P1 and P2, the lowest costs are
$418,204 and
$427,751 at times 15.5 and 15 weeks according to
Table 7. However, despite the lower costs, these time points are not feasible solutions since the two alternatives’ software reliability can only reach 85.55% and 87.68% respectively, meaning they cannot satisfy the minimal requirement of software reliability for customers (90%). This minimal requirement would only be reached at 17 and 16 weeks of testing for these two alternatives, respectively. The growth of different alternatives can be seen in
Figure 7. Moreover, alternative P4 can rapidly raise the reliability but the related cost is higher than the other alternatives, by about 5–15%. Alternative P3 therefore offers a compromise between reliability and testing cost, and the manager should choose to proceed with the testing work as long as the testing time is within 13.5–18 weeks.
Furthermore, the manager may want to change his/her previous decision in order to release the software product as early as possible. Suppose that the testing work of alternative P3 has proceeded for 5 weeks, and then the manager decides to increase the manpower over the subsequent weeks in order to shorten the original testing schedule, for instance due to commercial competition. The estimated values of the new alternative’s parameters are presented in
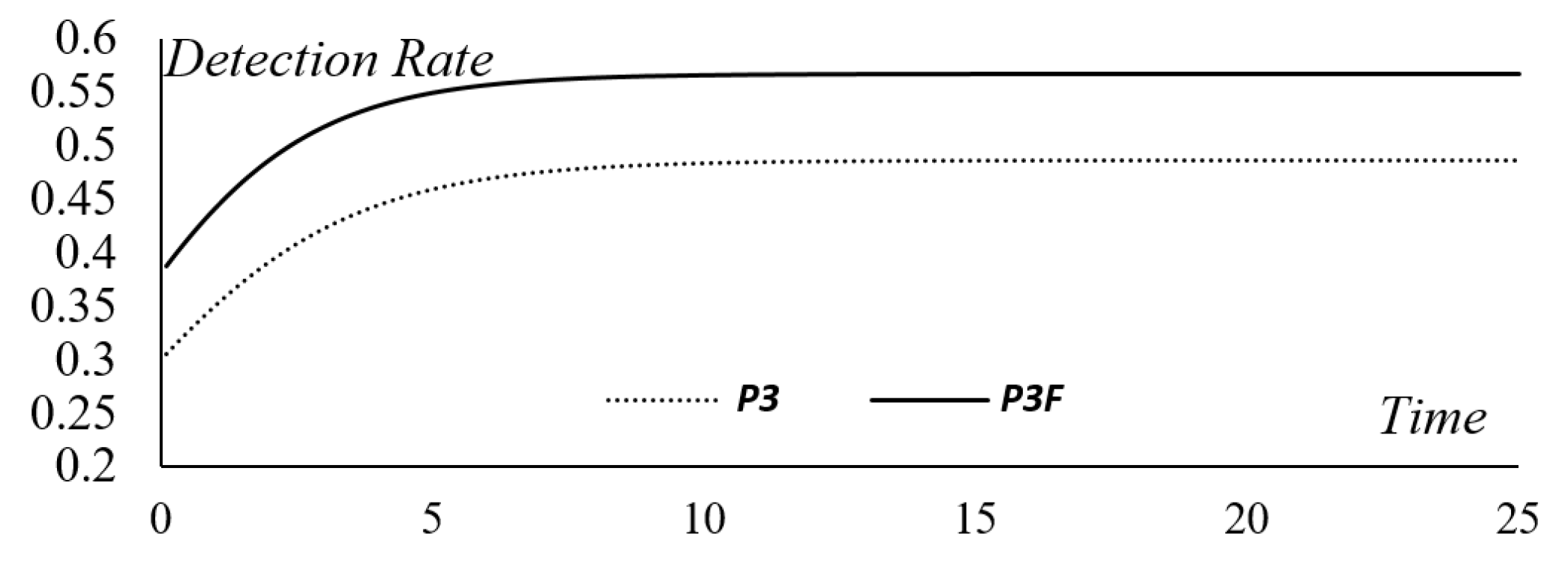
Table 8. The learning factor remains the same as before but both the autonomous errors-detected and negligent factors are higher than those in the previous setting. Since the detection rate can be used to investigate the efficiency of testing and debugging,
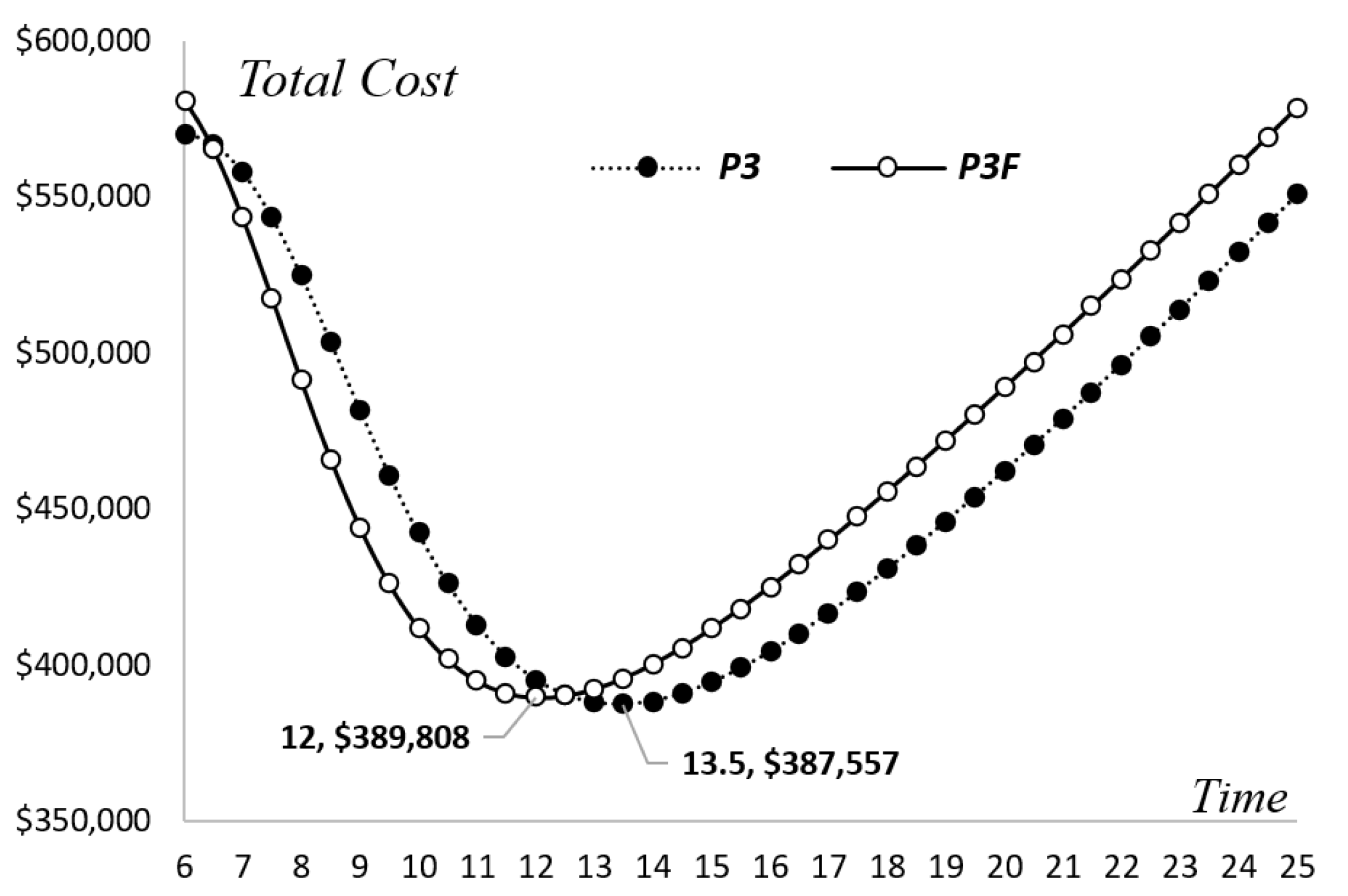
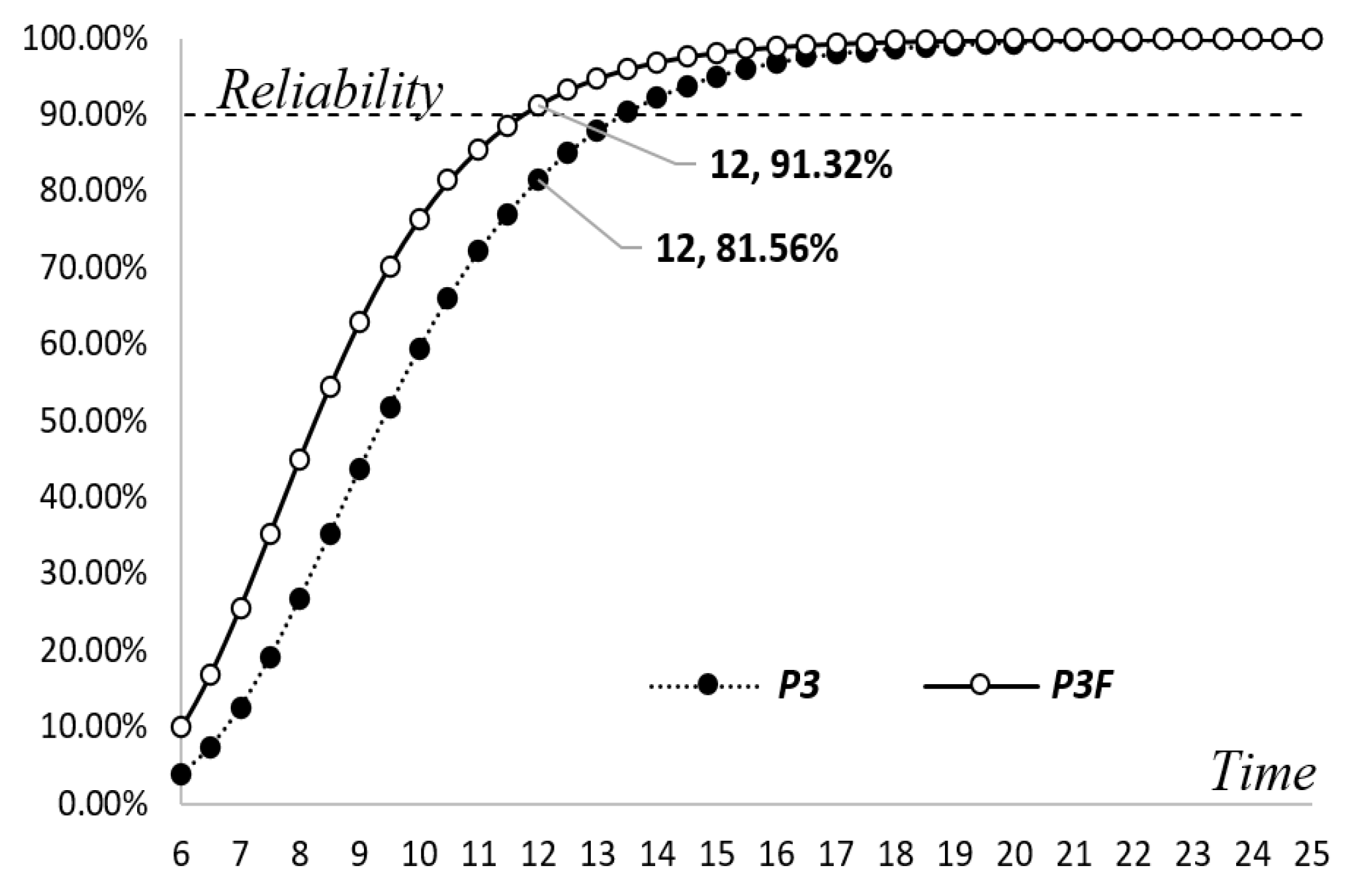
Figure 8 is presented to compare the new alternative with the original one. Although the detection rate of the new alternative is always higher than the original one, it can be seen that the two patterns are similar to each other because the increase in the detection rate with time depends on the size of the learning factor. By employing Equation (30) of the change-point model, the comparative results for the original and new alternatives can be obtained and are presented in
Table 9 and
Figure 9 and
Figure 10. The optimal timing of software release for the new alternative should be scheduled for the end of the 12th week. The estimated testing cost is approximately equal to
$389,808 with a reliability of 91.32%. Although the cost is slightly higher than that of the previous alternative, the duration of the testing can be shorter with no sacrifice in reliability. This is because the increase in the related debugging costs can be offset by the decrease in the opportunity loss. However, if the manager chose to follow the original alternative and did not increase the manpower to raise the testing efficiency, the reliability would only be 81.56% at the end of 12 weeks.
Some additional critical parameters were also considered by performing a sensitivity analysis to investigate their impacts on the total cost and the decision of software release time.
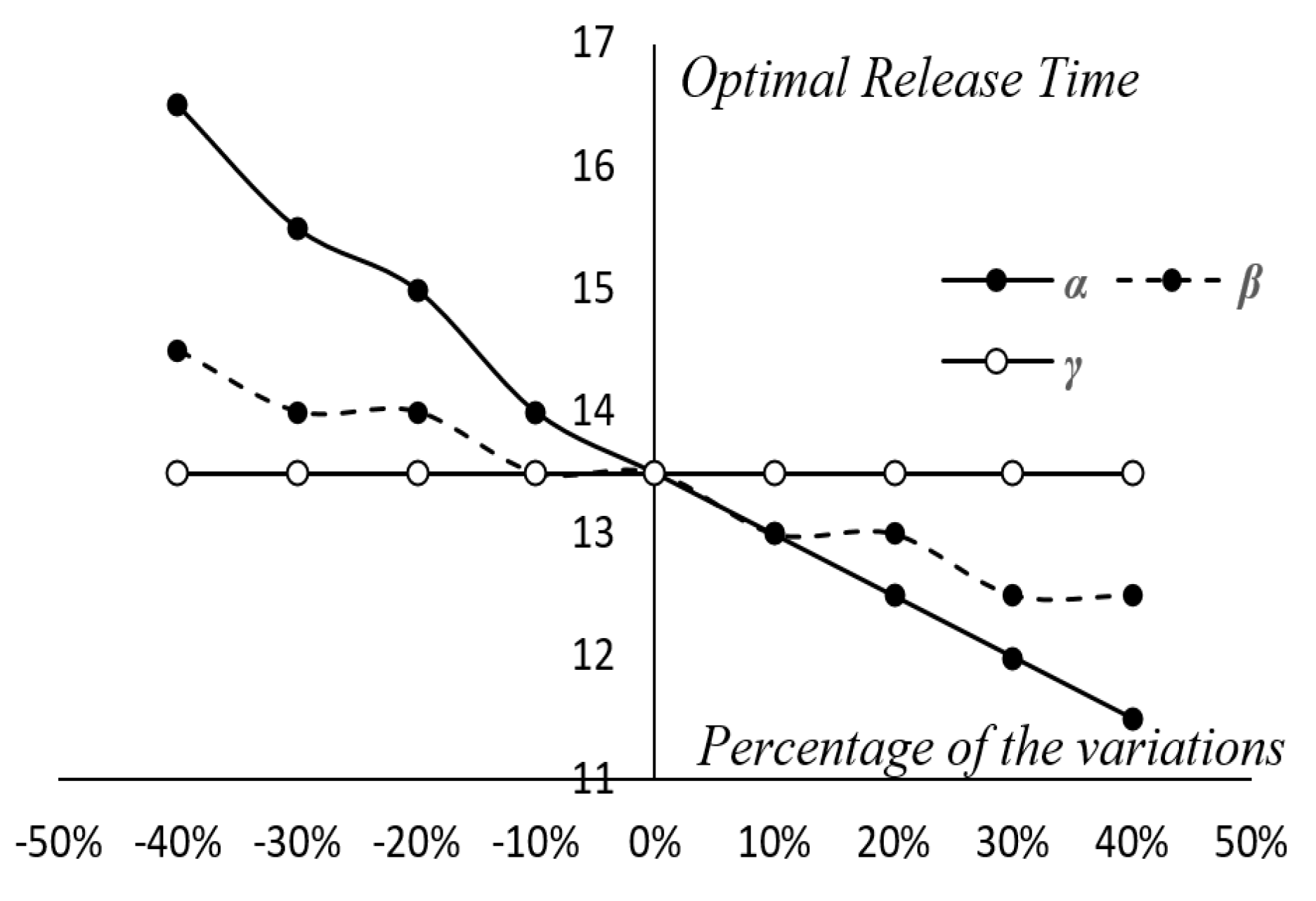
Figure 11 presents the impacts of related parameters
,
,
,
,
, and
on the total cost. As can be seen in
Figure 11, with regard to the model parameters, the cost is more sensitive to
and
. This means that misestimations of
and
will disturb the testing alternative’s budget plan. If the manager underestimated
and
, it might lead to the overestimation of the testing cost. Furthermore, the misestimation of
and
could also influence the company’s software release decision. As can be seen in
Figure 12, if the manager overestimated
and
, he/she will shorten the testing period and rush to release the software. In other words, such a situation may cause dissatisfaction of customers and damage the company’s reputation since the software was released to the market while still unreliable. Moreover, from a different perspective, if the manager wants to increase the efficiency of testing, he/she has to provide more job training to the testing staff in advance, which also increases the cost of educating the testing staff. Although the education investment can raise the values of
and
, the manager needs to consider the trade-off between any investment in the staff’s skills and the benefit of reducing the cost of reliability improvements. Additionally, the time-dependent administrative cost
and the error-correction cost
would also impact the testing cost. In this case, saving 10% of the error-correction cost can reduce the total testing cost by about 4.5%. The administrative cost is less impactful; saving 10% of the administrative cost may only reduce the total testing cost by about 1.5%. Accordingly, the manager might need to pay attention to how to improve the use of the expenditure for the error-correction works.
5. Conclusions
In this study, we proposed an imperfect debugging software reliability growth model with consideration of human factors and the nature of errors during the debugging process to estimate the related costs and the reliability indicator. Compared with previous models, the estimation of the learning and negligent factors in the proposed model is more intuitive and can be more easily evaluated by internal engineers or domain experts. Furthermore, this study also extended the issue of error classification by considering the impacts of different error types on the system. The expected time required to correct the different types of errors was assumed to obey different truncated exponential distributions. Moreover, in this study, the presented model enables software developers to produce multiple alternatives for a testing project, each with its distinct allocation of human resources. The best alternative can then be identified by utilizing the proposed software release model. These allocations consider debuggers’ learning and negligent factors, which influence the efficiency of software testing in practice. Furthermore, the change-point issue was taken into consideration, i.e., the fact that a software developer may increase manpower and resources so as to accelerate the testing work in practice.
With regard to analyzing the impact of the model parameters , , and on the testing cost, raising and can help improve debugging efficiency. However, the increase of and requires more on-the-job training or more senior manpower to achieve. In addition, decreasing the value of parameter depends on successfully reducing errors in correction work. On-the-job training and online case tools may also help reduce repetitions of the same mistakes. Although education investment is able to raise the values of and , the software developer has to consider the trade-off between any investment in staff’s skills and the given benefit in cost reduction due to reliability improvements. In addition, it should be noted that the optimal time to release a software product to the market is not only a matter of cost, because the software provider must also satisfy the minimal level of software reliability according to the contract or most customers’ requirements. In general, opportunity loss is related to the delay in the software release, and therefore the software developer should carefully estimate the parameters of the opportunity loss from marketing surveys.
Finally, two directions can be considered for future study: (1) The issue of multiple change-points could be taken into consideration since there are many environmental factors that may impact the debugging process at different times, resulting in the scenario of multiple change-points. Furthermore, error classification could also be extended to a function by considering the impacts of errors on the system. The testing staff can correct those errors that have more serious impacts on the system, and the probability distribution can be set to different forms in order to increase the flexibility of applications. (2) The time delay issue in developing a software reliability growth model could also be considered, i.e., the fact that software error correction will consume testing time and might therefore postpone the testing schedule. Most of the related studies have tended to ignore this factor and assume that the time required to correct software errors is zero, potentially leading to errors in the estimation of software reliability. Accordingly, future research might consider the time delay issue to make the model more realistic in practice.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}