
A New Method for Reconstructing Data Considering the Factor of Selected Provider Nodes Set in Distributed Storage System


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Work
3. Description and Modeling of Single Node Failure Repair Problem
3.1. Repair Principle of Erasure Code
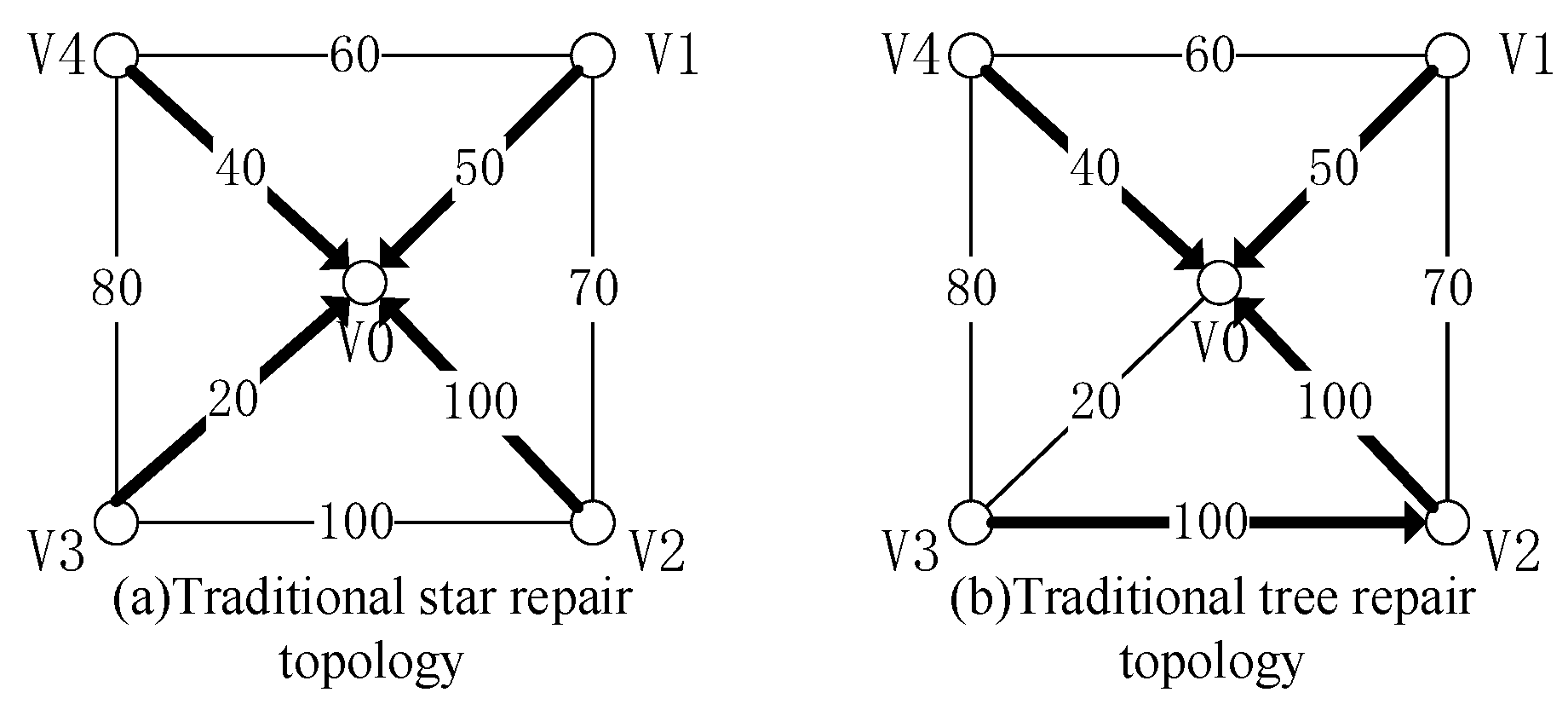
3.2. Influence of Network Topology on Repair Delay
3.3. Repair Flow
3.3.1. Repair Flow
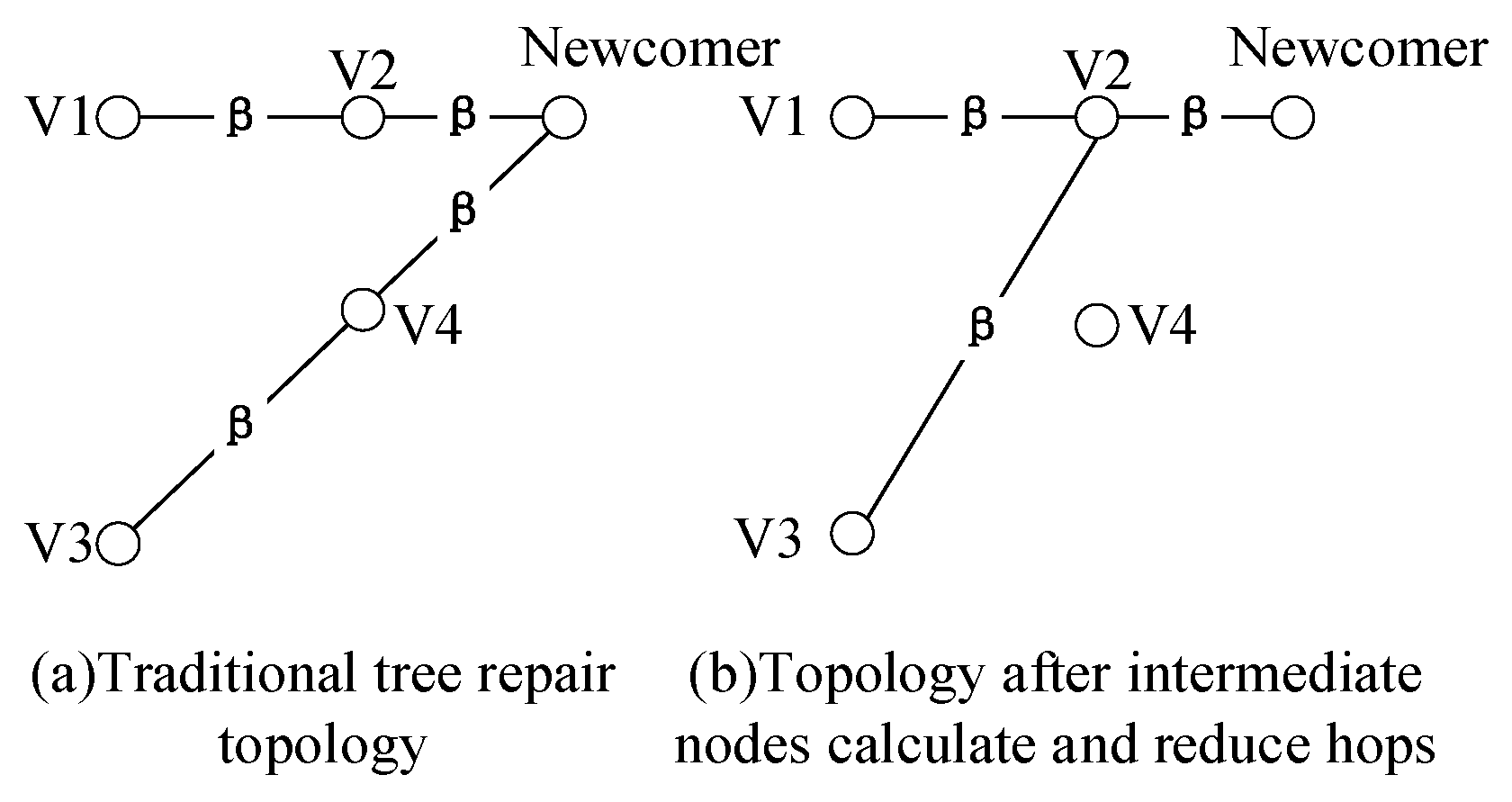
3.3.2. Minimum Hops
3.4. Node Selection for Single Node Fault Repair
3.5. The Optimal Repair Tree Construction Problem after Repairing the Node-Set Is Determined
4. Considering the Single Node Fault Repair Method Based on SDN and Genetic Algorithm after Repairing the Node-Set
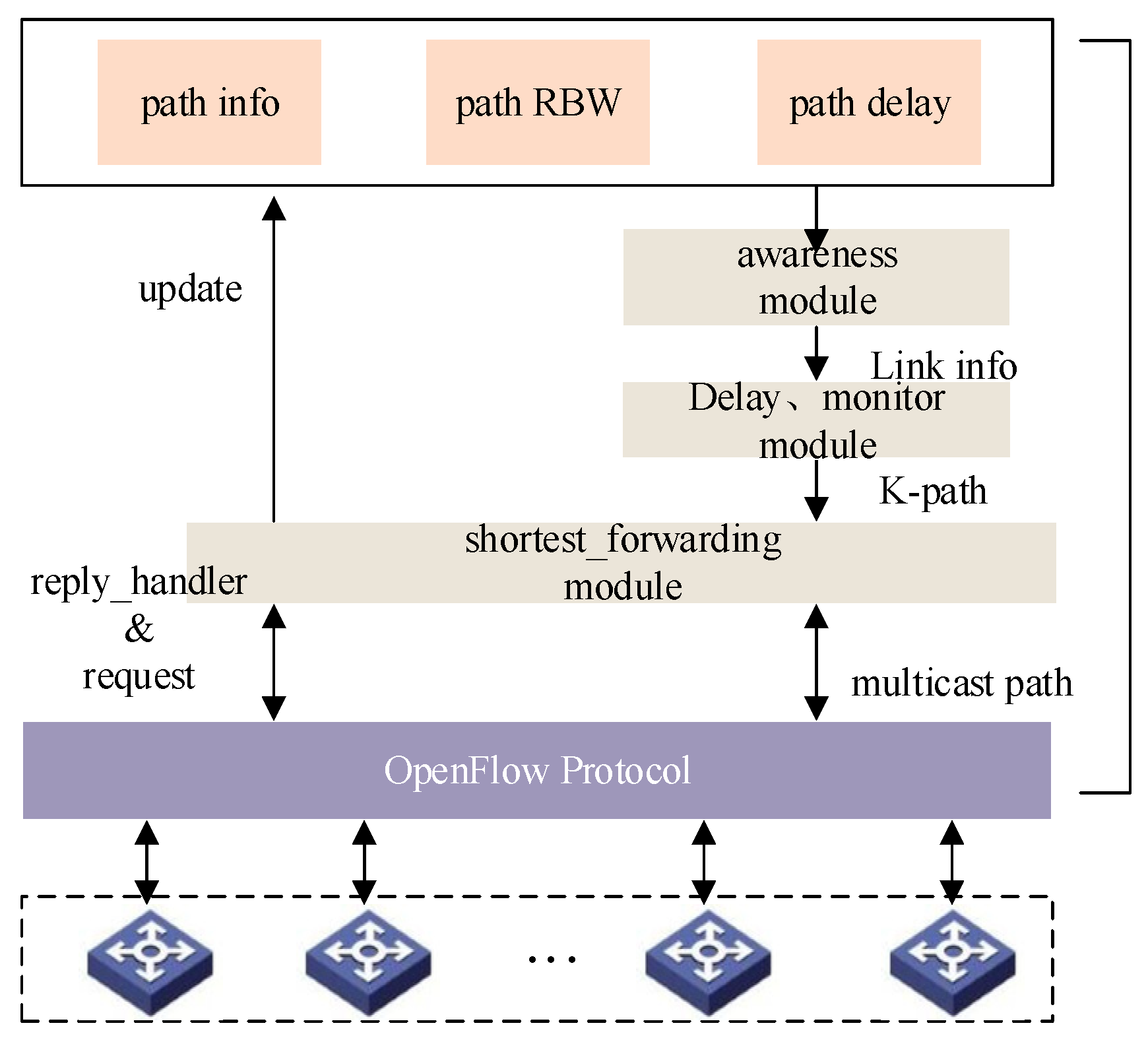
4.1. SDN Network Measurement
4.2. Node Selection Strategy
4.2.1. Newcomer Node Selection Based on the Multi-Attribute Decision
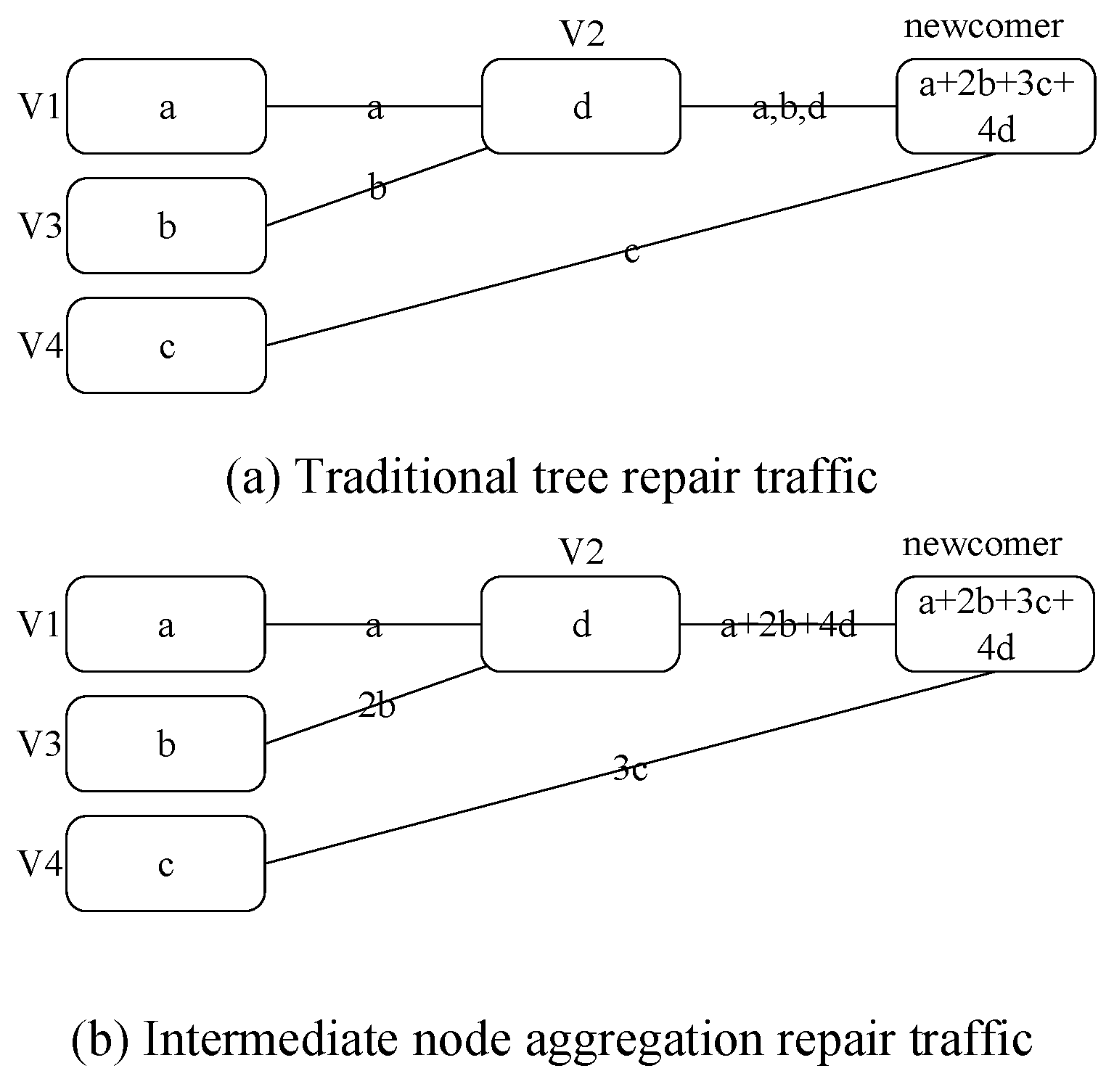
4.2.2. Provider Nodes Selection Based on Bandwidth Ranking among Node Sets
| Algorithm 1 Providers node selection based on bandwidth sorting between node sets |
| Input: Nn node-set and Np node-set. |
| Output: provider nodes. |
| 1: SDN get bandwidth from Nn and Np. |
| 2: Bandwidth = {} |
| 3: for bandwidth of ni in Nn and nj in Np do |
| 4: if bandwidth is true then Bandwidth.set((ni,nj),bandwidth) |
| 5: else pass |
| 6: end if |
| 7: end for |
| 8: Sort edge.bandwidth from Bandwidth. |
| 9: for edge in Bandwidth do |
| 10: Get (ni,nj) from Bandwidth, Provider.append(nj); |
| 11: end for |
| 12: return Provider |
4.3. Solution of Optimal Repair Tree Based on Genetic Algorithm
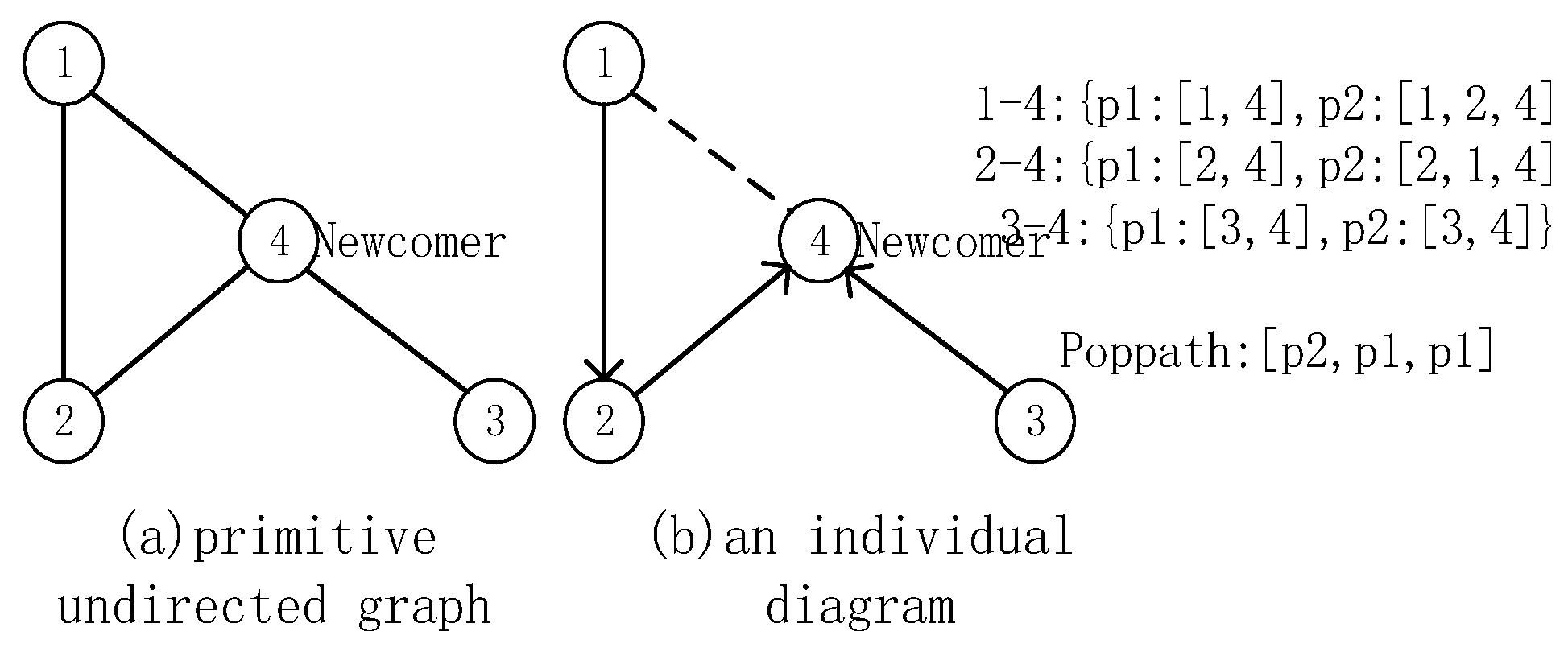
4.3.1. k-Path Encoding, Decoding, Population Initialization, and Fitness Function
| Algorithm 2 Initial population |
| Input: population size popsize, provider nodes and the newcomer node. Output: population. |
| 1: Popsize = {} |
| 2: Get all k-paths between the provider nodes and the newcomer node. |
| 3: while Popsize does not meet the requirements do |
| 4: for node in Providers do |
| 5: individual append the i-path between the node and newcomer; |
| 6: end for |
| 7: Popsize append the individual; |
| 8: end while |
| 9: return Popsize |
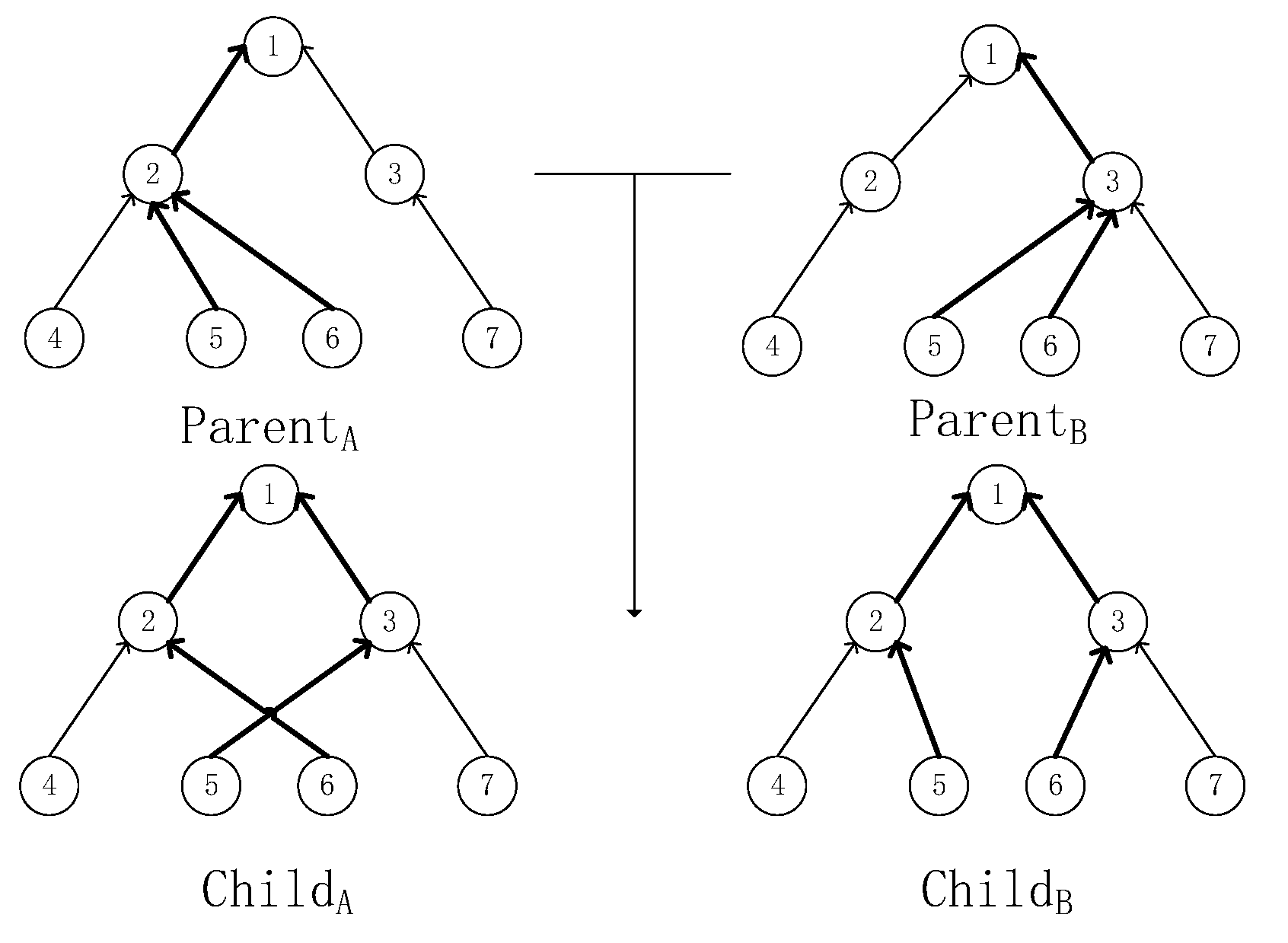
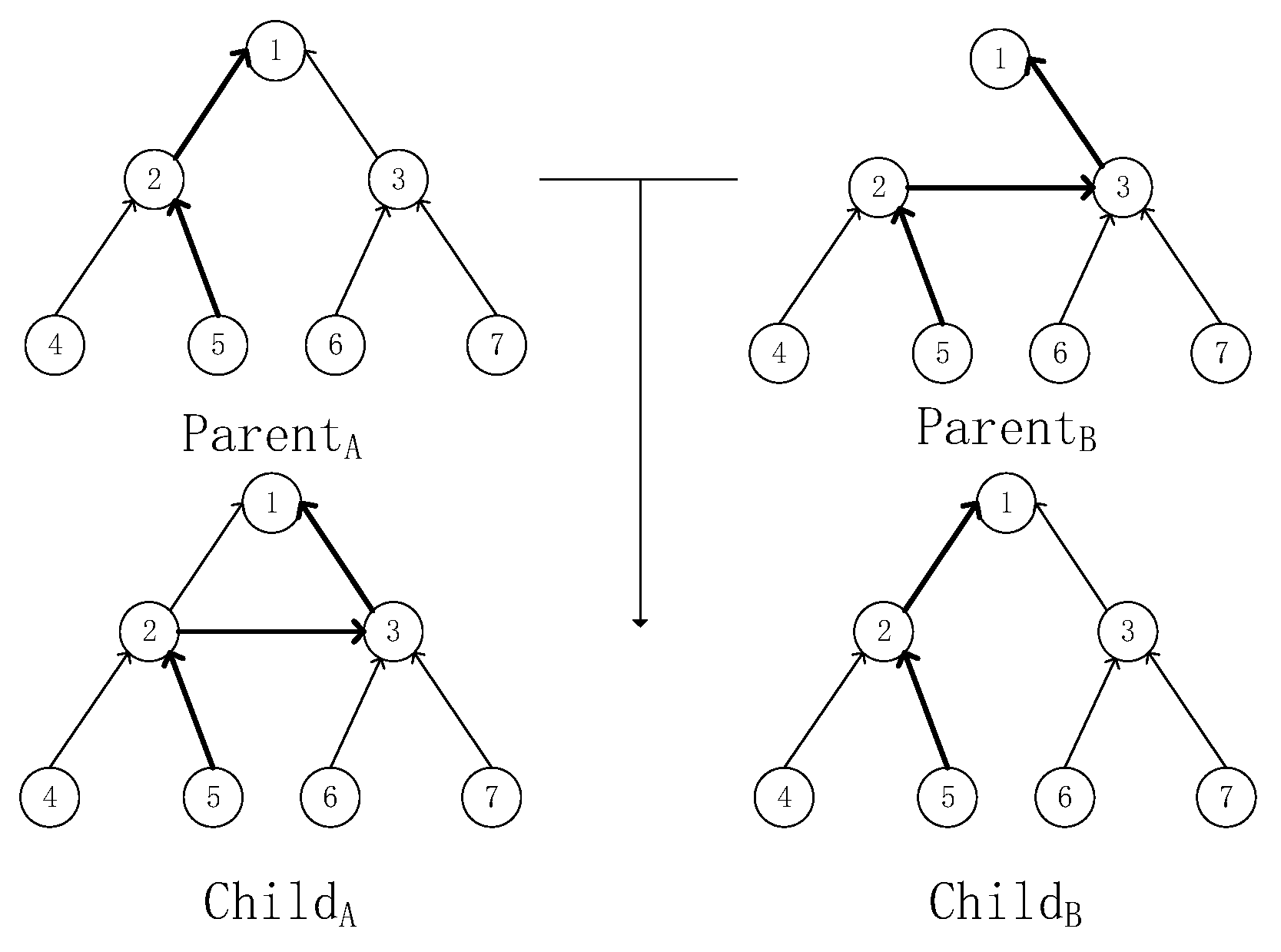
4.3.2. Crossover Operator
| Algorithm 3 Crossover operation |
| Input: old population, cross probability Pc. |
| Output: new population. |
| 1: newPopsize= {} |
| 2: for i in len(oldPopsize) do |
| 3: Get parent x and parent y: randomly selected two individuals without crossover; |
| 4: if Random.Random<Pc then |
| 5: Get the gene fragments of the parent: x[i:j] and y[i:j]; |
| 6: Change x[i:j] and y[i:j]; |
| 7: Get child1 [x1,…,y1,…,yj,…,xd] and child2 [y1,…,xi,…,yj,…,yd]; |
| 8: newPopsize.append(child1,child2); |
| 9: else newPopsize.append(x,y) |
| 10: end if |
| 11: end for |
| 12: return newPopsize |
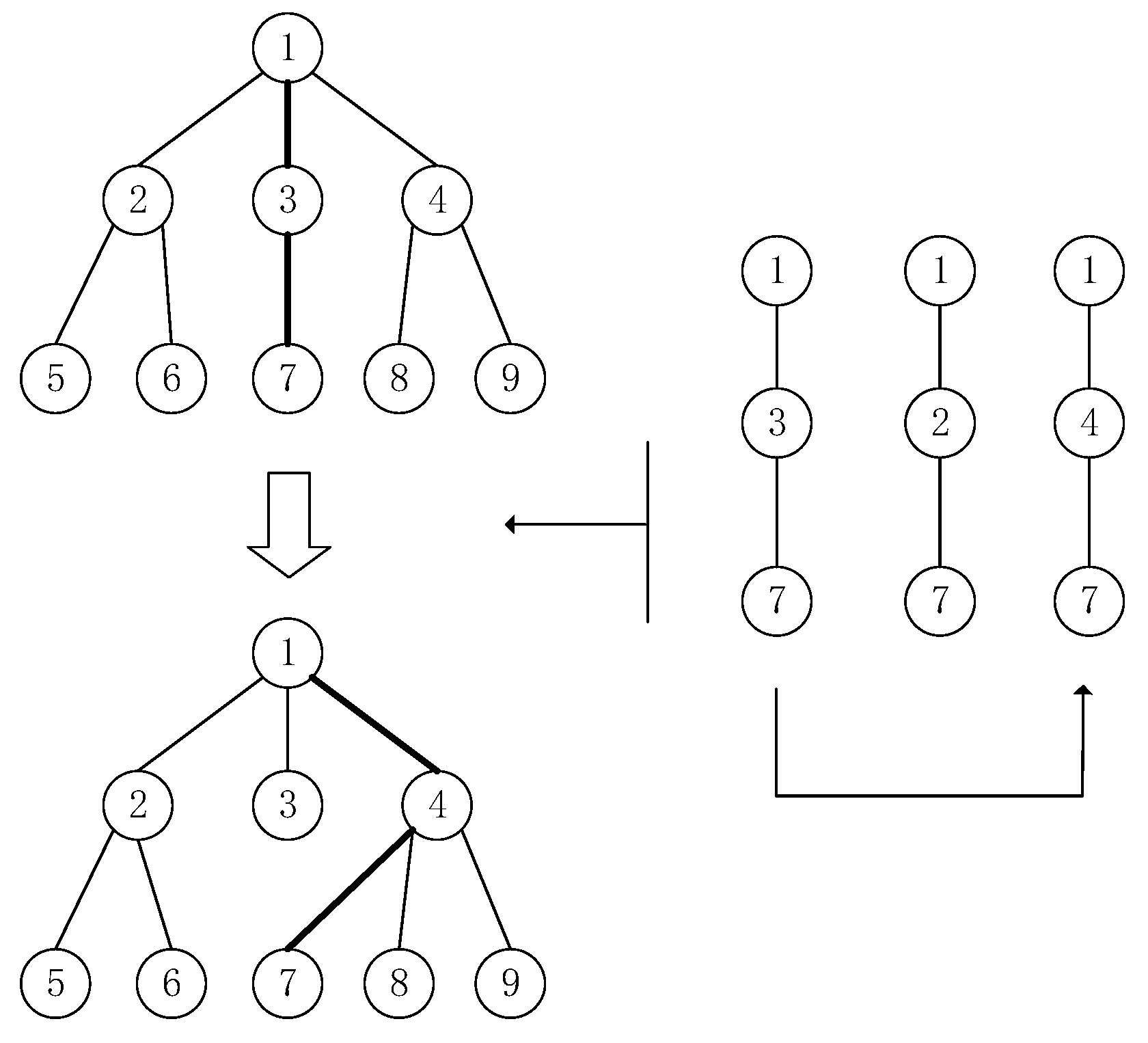
4.3.3. Remove Loop Operation
| Algorithm 4 Loop removal operation |
| Input: population with infeasible solution |
| Output: new population of fully feasible solutions |
| 1: Get oldPopsize from the previous step. |
| 2: newPopsize = {} |
| 3: treePopsize = {} |
| 4: for Poppath in oldPopsize do |
| 5: if Poppath has a loop then |
| 6: Get kruskalTree from creating Newcomer-rooted kruskal Tree for Poppath; |
| 7: Convert tree attribute paths to graph paths and get newPoppath from kruskalTree; |
| 8: treePopsize.append(newPoppath); |
| 9: else newPopsize.append(newPoppath); |
| 10: end if |
| 11: end for |
| 12: return newPopsize, treePopsize |
4.3.4. Mutation Operator
4.3.5. Selection Operator
| Algorithm 5 Select operator |
| Input: population from the previous step, old population |
| Output: next generation population |
| 1: pm = random [0,1]. |
| 2: if pm < 0.5 then go to step 5 |
| 3: else go to step 10 |
| 4: end if |
| 5: allPopsize = newPopsize + oldPopsize |
| 6: Function (select operator 1) |
| 7: sort(allPopsize) and go straight to the top 20 |
| 8: then the rest of individuals are randomly selected. |
| 9: EndFunction |
| 10: Function (select operator 2) |
| 11: sort(allPopsize) Individuals with higher population fitness values were given higher selection probability and selected only until the population size was reached |
| 12: EndFunction |
4.3.6. Optimal Topology Construction Method Based on Hybrid Genetic Algorithm
| Algorithm 6 Optimal topology construction method based on Hybrid Genetic Algorithm |
| Input: population size as popsize, the maximum number of evolutionary genera-tions G and cross probability PC, mutation probability PM. |
| Output: the optimal individual, which can be used to repair process of the optimal tree repair topology. |
| 1: execute algorithm 2 to obtain the initialization population P(0) with the number of popsize. |
| 2: for individual∈ p(0) do |
| 3: calculate the fitness value of each individual according to Formula (15). |
| 4: end for |
| 5: while current number of evolutionary generations t < G do |
| 6: clear crossed offspring, mutant offspring. |
| 7: while crossed offspring number < popsize do |
| 8: ifPC > Random value then |
| 9: two individuals are randomly selected from the current population P(t), and algorithm 3 is executed with probability PC to generate individuals to join cross offspring. |
| 10: else |
| 11: parent individuals directly join the cross offspring. |
| 12: end if |
| 13: end while |
| 14: the set of crossed individuals is marked as O1. |
| 15: if the topology containing loop then |
| 16: use Kruskal minimum spanning tree search to create a new topology. |
| 17: end if |
| 18: if the individual set is marked as O1 then |
| 19: while mutant offspring number < popsize do |
| 20: if PM > Random value then |
| 21: from an individual randomly in the current population P(t), execute Section 4.3.4 with probability PM to generate individual to join mutation offspring. |
| 22: else |
| 23: the parent individual will directly join the mutation offspring |
| 24: end if |
| 25: the return value treepopsize skips the mutation operation and saves it, and the remaing individuals form newpopsize to replace the original individual set for subsequent operations. |
| 26: end while |
| 27: else |
| 28: the individual set is marked as O2. |
| 29: execute algorithm 5 on the set newpopsize∪oldpopsize, obtain the selection method according to the probability PM. |
| 30: select the number of individuals with the population as the population P(t + 1) of the next generation, so that t = t + 1. |
| 31: newpopsize = treepopsize (O1) + treepopsize (O2). |
| 32: end while |
| 33: output the individual with the lowest fitness function value in the traversal population. |
5. Experiment and Evaluation
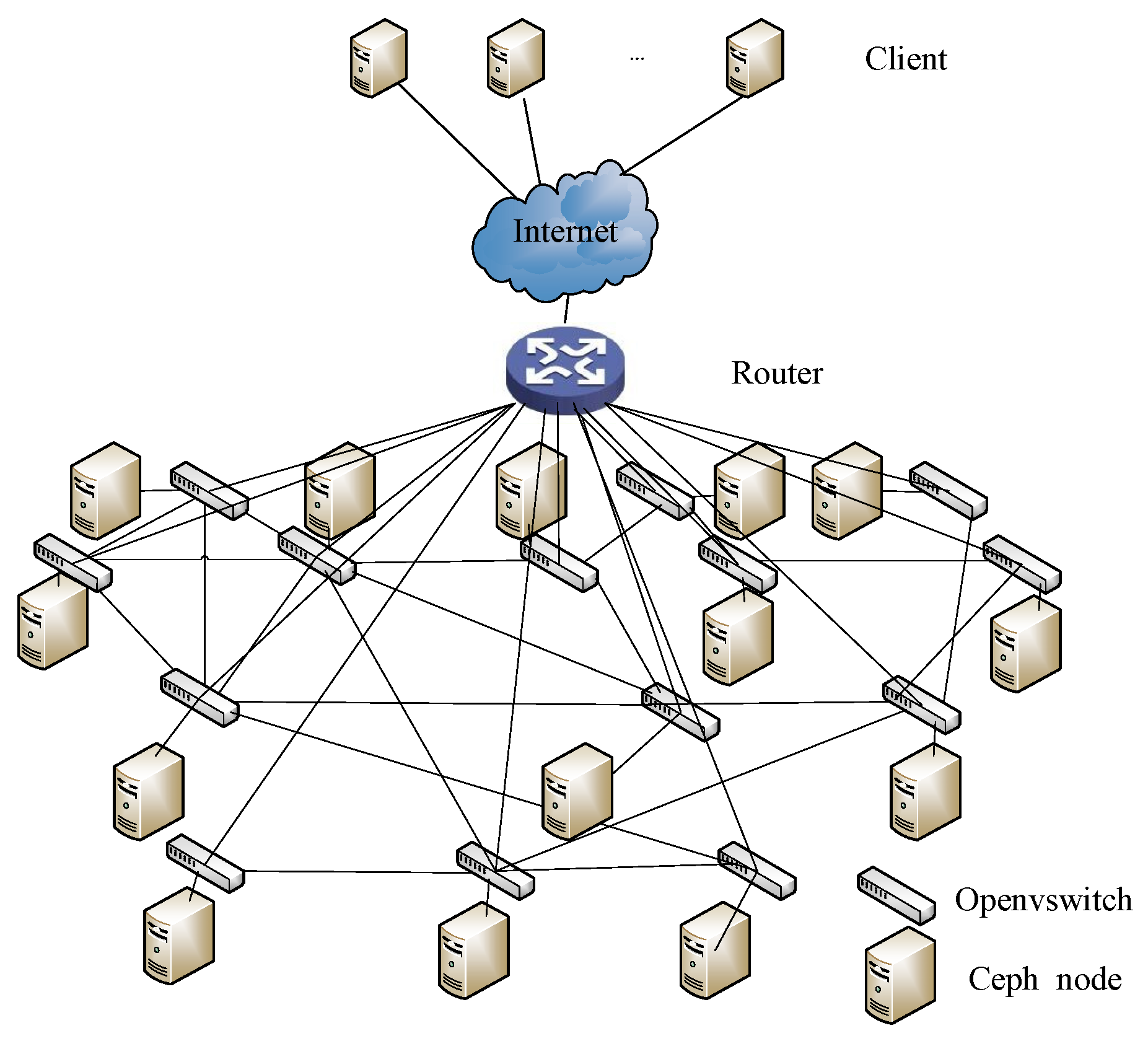
5.1. Experimental Environment
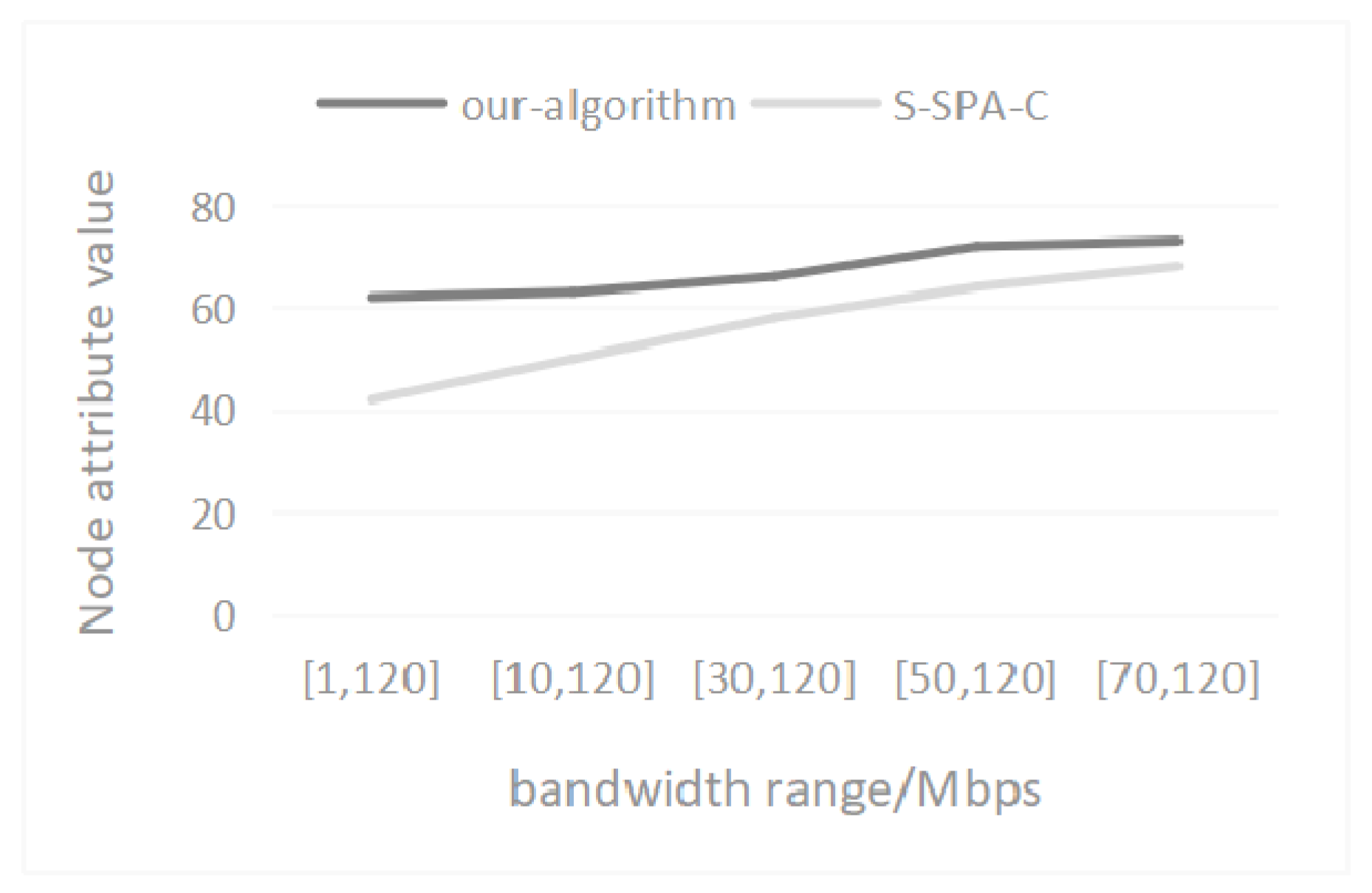
5.2. Node Attribute
5.3. Algorithm Parameters
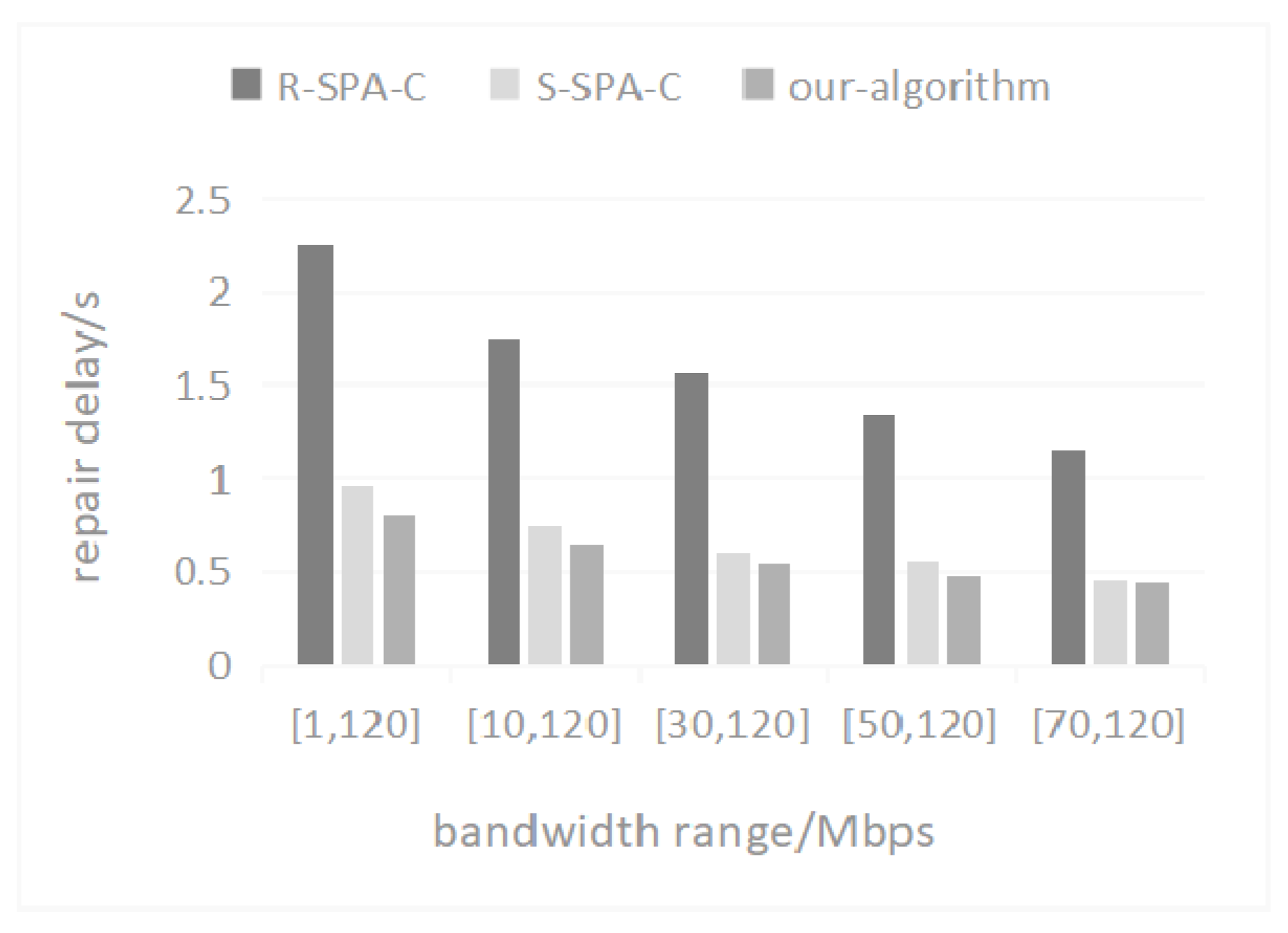
5.4. Repair Rate
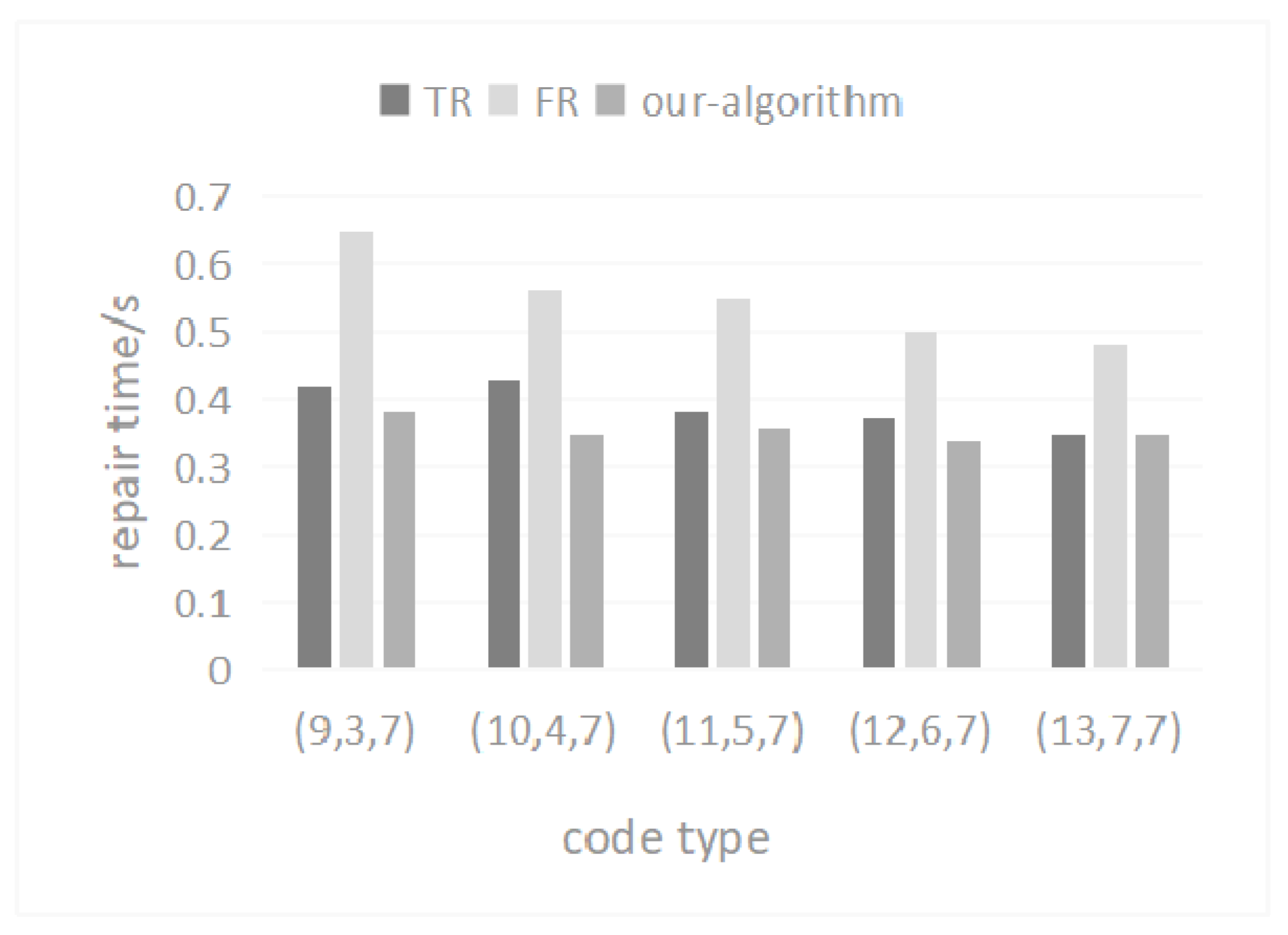
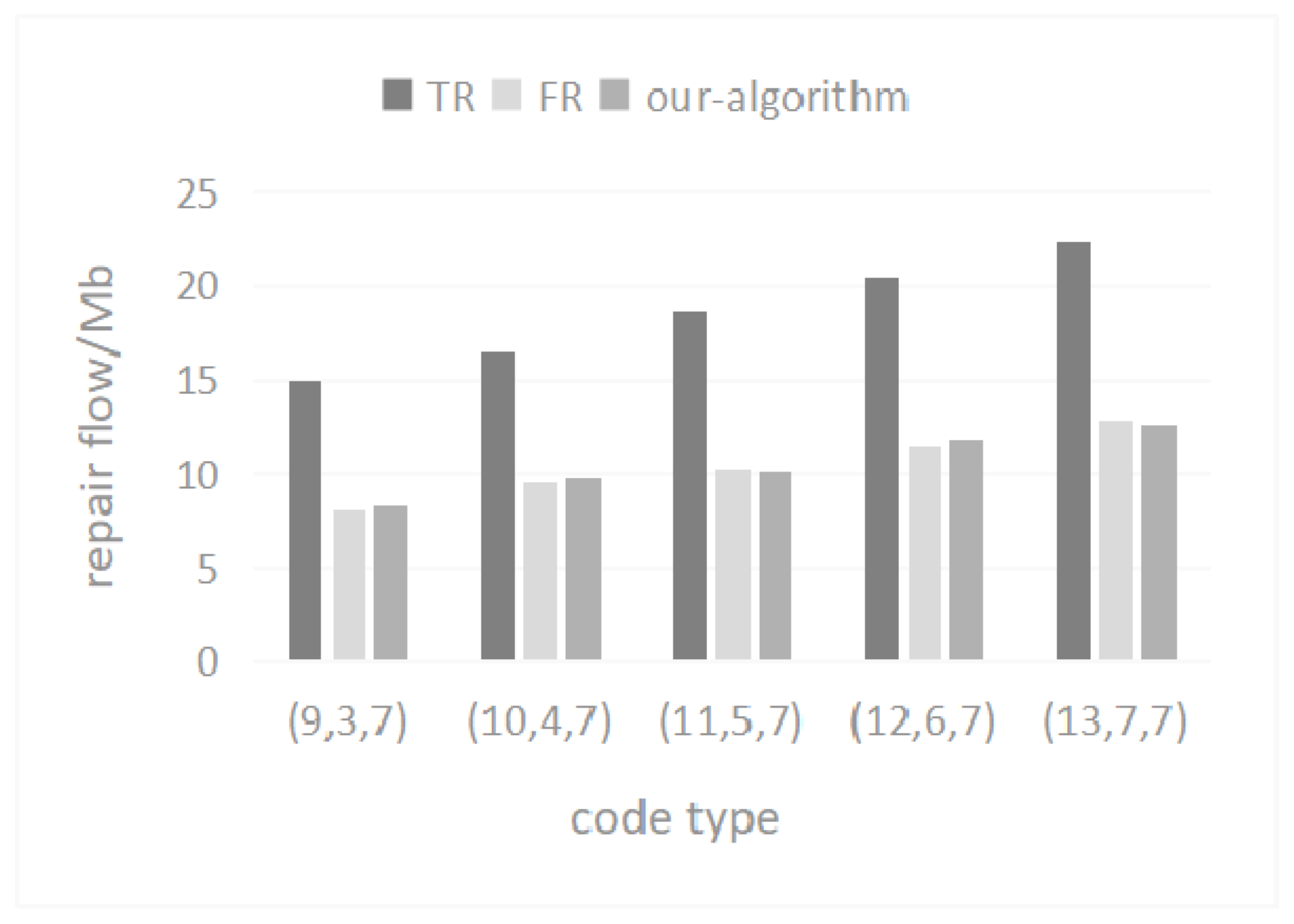
5.5. Repair Flow
6. Summary and Prospects
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huang, J.; Cao, Q.; Huang, S.; Xie, C. Concurrent Node Reconstruction for Erasure-Coded Storage Clusters. J. Comput. Res. Dev. 2016, 53, 1918–1929. (In Chinese) [Google Scholar]
- Wang, Y.; Sun, W.; Zhou, S.; Pei, X.; Li, X. Key Technologies of Distributed Storage for Cloud Computing. J. Softw. 2012, 4, 232–256. (In Chinese) [Google Scholar] [CrossRef]
- Wang, Y.; Li, S. Research and performance evaluation of data replication technology in distributed storage systems. Comput. Math. Appl. 2006, 51, 1625–1632. [Google Scholar] [CrossRef][Green Version]
- Luo, X.; Xu, S. Summary of Research for Erasure Code in Storage System. J. Comput. Res. Dev. 2012, 49, 1–11. (In Chinese) [Google Scholar]
- Rao, K.; Hafner, J.; Golding, R. Reliability for networked storage nodes. IEEE Trans. Dependable Secur. Comput. 2011, 8, 404–418. [Google Scholar] [CrossRef]
- Caruso, G.; Gattone, S.A.; Fortuna, F.; Di Battista, T. Cluster Analysis as a Decision-Making Tool: A Methodological Review. In Proceedings of the International Symposium on Distributed Computing and Artificial Intelligence, Toledo, Spain, 20–22 June 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- D’Adamo, I.; Gastaldi, M.; Morone, P. The impact of a subsidized tax deduction on residential solar photovoltaic-battery energy storage systems. Util. Policy 2022, 75, 101358. [Google Scholar] [CrossRef]
- Zhang, S.; Zou, F. Survey on software-defined network research. Appl. Res. Comput. 2013, 30, 2246–2251. (In Chinese) [Google Scholar]
- Zhong, F.; Wang, Y.; Li, N. Survey of heterogeneous-based data repair strategies for erasure codes. Appl. Res. Comput. 2019, 6, 2241–2249. (In Chinese) [Google Scholar]
- Zhang, Y.; Chu, J.; Weng, C. Survey on Data Updating in Erasure-Coded Storage Systems. J. Comput. Res. Dev. 2020, 57, 2419–2431. (In Chinese) [Google Scholar]
- Rizzo, L. On the Feasibility of Software FEC; University di Pisa: Pisa, Italy, 1997. [Google Scholar]
- Zheng, Q. Research on Erasure Code for Secure Storage System; Shanghai Jiao Tong University: Shanghai, China, 2009. [Google Scholar]
- Lin, X.; Wang, Y.; Pei, X.; Xu, F.; Fu, Y. GRC: A High Fault-Tolerance and Low Recovery-Overhead Erasure Code for Multiple Losses. J. Comput. Res. Dev. 2014, 51, 172–181. [Google Scholar]
- Zhou, Y.; Li, G.; Jiang, X.; Li, H.; Han, H. Piggyback Code Based on Distributed Storage Systems. J. Chin. Comput. Syst. 2020, 41, 1091–1097. [Google Scholar]
- Wang, Z.; Wang, H.; Shao, A.; Wang, D. A Local Reconstruction Code and Hitchhiker Code Mixing Storage Scheme. Chin. J. Comput. 2020, 43, 618–630. (In Chinese) [Google Scholar]
- Zhang, X.; Xu, J.; Hu, Y. Proactive Locally Repairable Codes for Cloud Storage System. J. Comput. Res. Dev. 2019, 56, 1988–2000. [Google Scholar]
- Wang, J.; Liang, W.; Liu, X.; Yang, Y. Locally Repairable Codes Based on MSR Codes in Cloud Storage System. J. Beijing Univ. Posts Telecommun. 2016, 39, 60–66. (In Chinese) [Google Scholar]
- Jiang, X.; Li, G.; Zhou, Y.; Hu, J.; Li, H. Repair Pipelining for Erasure-Coded Storage Based on Load-Balanced. Acta Elect. R Onica Sin. 2020, 48, 930–936. (In Chinese) [Google Scholar]
- Zhong, F.; Wang, Y.; Li, N. Node Selection Scheme for Data Repair in Heterogeneous Distributed Storage Systems. Comput. Sci. 2019, 46, 35–41. (In Chinese) [Google Scholar]
- Qiu, L.; Wang, F.; Li, C. EDS: A Novel Scheme for Boosting Single-Disk Failure Recovery of Triple-Erasure-correcting Code Storage Systems. Chin. J. Comput. 2013, 36, 2041–2052. [Google Scholar] [CrossRef]
- Huang, J. Design and Optimization of Erasure-Coded Clustered Storage Systems; Science Press: Beijing, China, 2016; pp. 91–125. [Google Scholar]
- Xie, X.; Huang, Q.; Wang, L.S. Collaboration coding to multi-node repair program under the twin-MDS codes framework in cloud storage systems. J. Commun. 2015, 36, 1–8. (In Chinese) [Google Scholar]
- Wang, Y.; Wei, D.; Yin, X.; Wang, X. Heterogeneity-Aware Data Regeneration in Distributed Storage Systems. In Proceedings of the IEEE Annual Conference on Computer Communications (IEEE INFOCOM), Toronto, ON, Canada, 27 April–2 May 2014. [Google Scholar]
- Wan, X. The Research on Optimization of Topology Sensitive Repair Technology in Distributed Storage System; Nanjing University: Nanjing, China, 2015. [Google Scholar]
- Zhang, H.; Li, H.; Li, S.Y.R. Repair Tree: Fast Repair for Single Failure in Erasure-Coded Distributed Storage Systems. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 1728–1739. [Google Scholar] [CrossRef]
- Xue, Y.; Zhu, H.; Liang, J.; Słowik, A. Adaptive crossover operator based multi-objective binary genetic algorithm for feature selection in classification. Knowl. Based Syst. 2021, 227, 107218. [Google Scholar] [CrossRef]
- Xue, Y.; Xue, B.; Zhang, M. Self-Adaptive Particle Swarm Optimization for Large-Scale Feature Selection in Classification. ACM Trans. Knowl. Discov. Data 2019, 13, 1–27. [Google Scholar] [CrossRef]
- Xue, Y.; Tang, T.; Pang, W.; Liu, A. Self-adaptive parameter and strategy based particle swarm optimization for large-scale feature selection problems with multiple classifiers. Appl. Soft Comput. 2020, 88, 106031. [Google Scholar] [CrossRef]
- Lan, G.; Tomczak, J.; Roijers, D.; Eiben, A.E. Time efficiency in optimization with a bayesian-evolutionary algorithm. Swarm Evol. Comput. 2022, 69, 100970. [Google Scholar] [CrossRef]
- Zivkovic, M.; Bacanin, N.; Djordjevic, A.; Antonijevic, M.; Strumberger, I.; Rashid, T.A. Hybrid Genetic Algorithm and Machine Learning Method for COVID-19 Cases Prediction. In Proceedings of International Conference on Sustainable Expert Systems; Springer: Singapore, 2021. [Google Scholar]
- Wei, G.; Wu, Q.; Zhou, M. A hybrid probabilistic multiobjective evolutionary algorithm for commercial recommendation systems. IEEE Trans. Comput. Soc. Syst. 2021, 8, 589–598. [Google Scholar] [CrossRef]
- Seo, K.; Hyun, S.; Kim, Y. An Edge-Set Representation Based on a Spanning Tree for Searching Cut Space. IEEE Trans. Evol. Comput. 2015, 19, 465–473. [Google Scholar] [CrossRef]
- Niu, S.; Wu, W.; Zhang, X.; Cai, Y.; Xu, X. Jump hashing-based data placement algorithm. Ruan Jian Xue Bao J. Softw. 2017, 28, 1929–1939. (In Chinese) [Google Scholar]
- Xing, Y.; Xiao, N.; Liu, F.; Fu, Y.; Li, F.; Wu, X. A History-Based Consistent Hashing Routing Policy for Cluster Deduplication System. J. Comput. Res. Dev. 2014, 51, 182–188. (In Chinese) [Google Scholar]
- Hong, W.; Wang, K.; Hsu, Y. Application-Aware Resource Allocation for SDN-based Cloud Datacenters. In Proceedings of the International Conference on Cloud Computing and Big Data, Fuzhou, China, 16–19 December 2013. [Google Scholar]
- Miao, Y.; Hongbing, Q.; Yong, W.; Zou, Z.; Fei, Z.; Tianxin, M. A method of repairing single node failure in the distributed storage system based on the regenerating-code and a hybrid genetic algorithm. Neurocomputing 2021, 458, 566–578. [Google Scholar]
- Reed, I.; Solomon, G. Polynomial codes over certain finite fields. J. Soc. Ind. Appl. Math. 1960, 8, 300–304. [Google Scholar] [CrossRef]
- Ke, W.; Wang, Y.; Ye, M. A Priority Based Multicast Flow Scheduling Method for a Collaborative Edge Storage Datacenter Network. IEEE Access 2021, 9, 79793–79805. [Google Scholar] [CrossRef]
- Qi, F.; Gong, Q.; Zhou, Y.; Wang, X. Heterogeneity-Aware Node Selection for Data Repair in Distributed Storage Systems. J. Comput. Res. Dev. 2015, 52, 68–74. (In Chinese) [Google Scholar]













Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, M.; Zhang, Q.; Wei, R.; Wang, Y.; Deng, X. A New Method for Reconstructing Data Considering the Factor of Selected Provider Nodes Set in Distributed Storage System. Mathematics 2022, 10, 1739. https://doi.org/10.3390/math10101739
Ye M, Zhang Q, Wei R, Wang Y, Deng X. A New Method for Reconstructing Data Considering the Factor of Selected Provider Nodes Set in Distributed Storage System. Mathematics. 2022; 10(10):1739. https://doi.org/10.3390/math10101739
Chicago/Turabian StyleYe, Miao, Qinghao Zhang, Ruoyu Wei, Yong Wang, and Xiaofang Deng. 2022. "A New Method for Reconstructing Data Considering the Factor of Selected Provider Nodes Set in Distributed Storage System" Mathematics 10, no. 10: 1739. https://doi.org/10.3390/math10101739
APA StyleYe, M., Zhang, Q., Wei, R., Wang, Y., & Deng, X. (2022). A New Method for Reconstructing Data Considering the Factor of Selected Provider Nodes Set in Distributed Storage System. Mathematics, 10(10), 1739. https://doi.org/10.3390/math10101739