Harnessing Entropy via Predictive Analytics to Optimize Outcomes in the Pedagogical System: An Artificial Intelligence-Based Bayesian Networks Approach



Abstract
1. Introduction
2. Research Problem and Research Questions
3. Definition of Entropy in the Pedagogical System in the Context of This Study
4. Rationale for Using the Bayesian Network Analytical Approach for Educational Research
- “What has already happened?” descriptive analytics in Section 5:
- Purpose: To use descriptive analytics to discover from the collected data, the baseline state of the students, and the underlying contributing attributes which drive it.
- “What-If?” predictive analytics to explore the spread of energy in a pedagogical system in Section 6:
- Purpose: to use predictive analytics to perform in-silico experiments with fully controllable parameters to predict future entropic outcomes (how “energy” could spread from one part of a pedagogical system to different parts) to better inform educators and policy makers about the key drivers of the attributes that could contribute to conditions required for favorable outcomes, and conversely, become aware of the “at-risk” signals which could prevent unfavorable and worst-case scenarios from happening in the students’ formative assessments.
5. Descriptive Analytics to Find Out “What Has Happened?” in The Pedagogical System
5.1. The Dataset from the School
5.2. Codebook of the Dataset
5.3. Software Used: Bayesialab
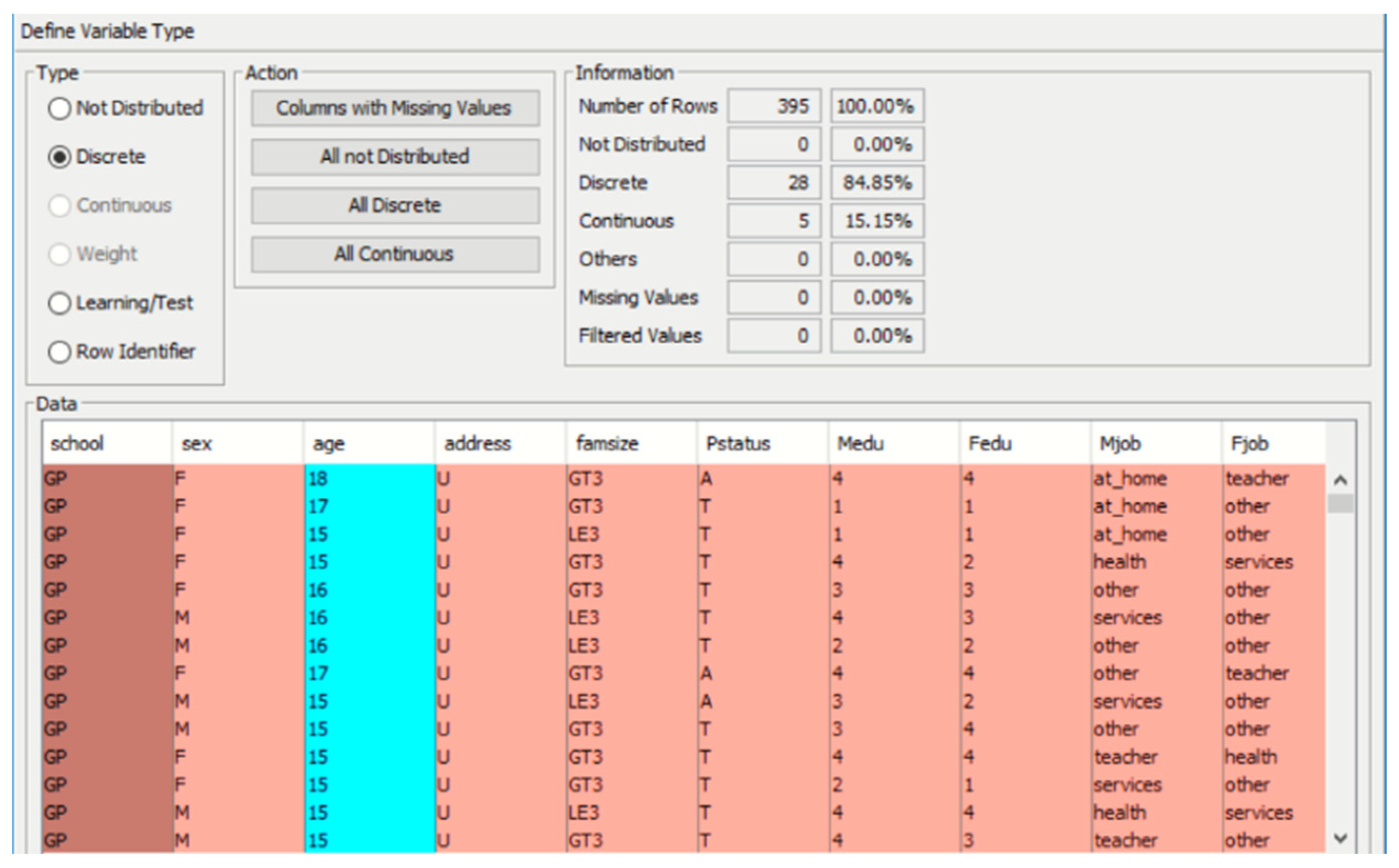
5.4. Pre-Processing: Checking for Missing Values or Errors in the Data
5.5. Discretization of the Dataset
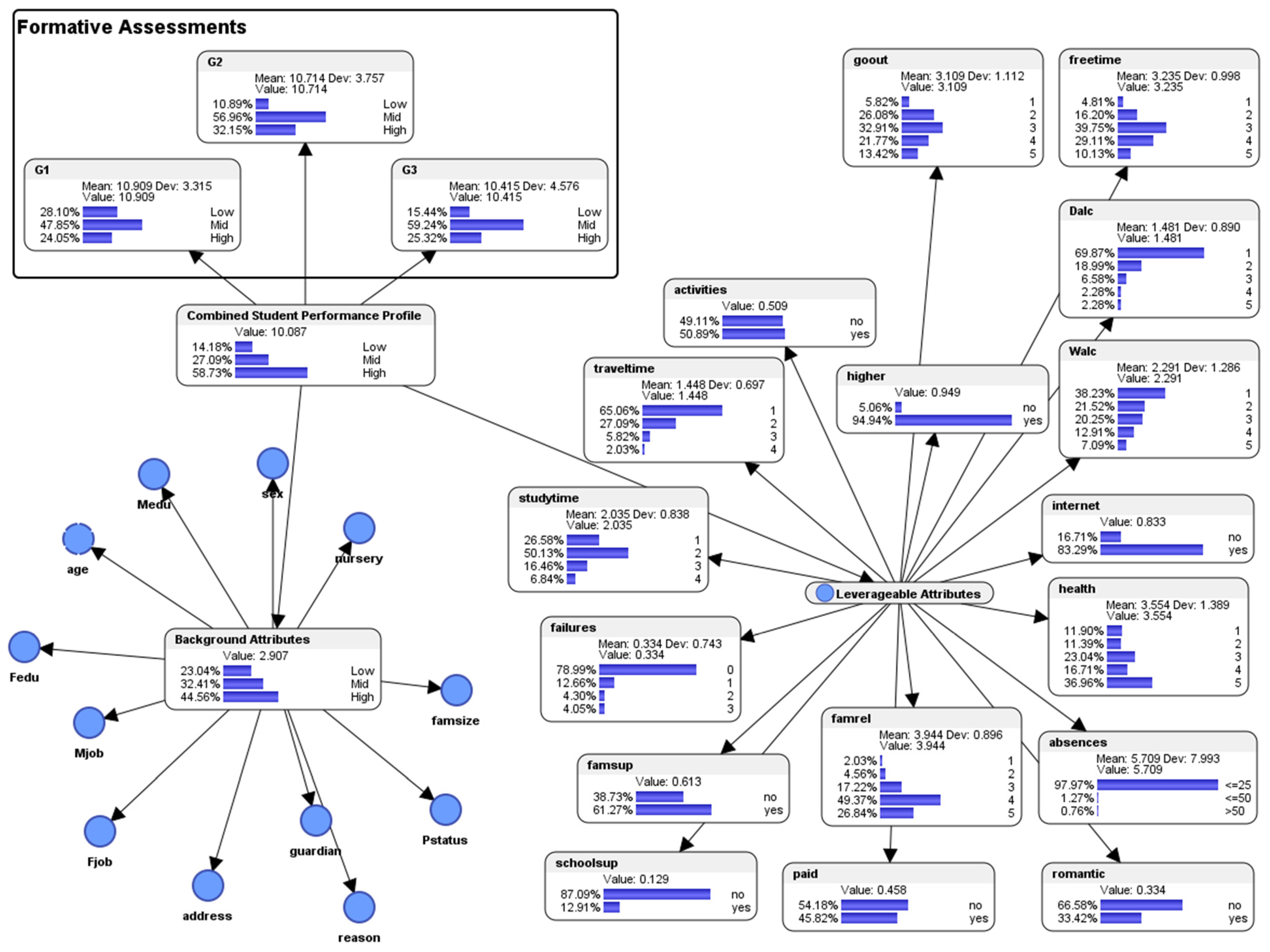
5.6. Descriptive Analytics: Overview of the Bayesian Network Model
- For the attribute (activities) extra-curricular activities, 49.11% responded with “no”; 50.89% responded with “yes.” About half of the students had participated in extra-curricular activities.
- For the attribute (traveltime) home to school travel time, category 1 represents <15 min., category 2 represents 15 to 30 min., category 3 represents 30 min. to 1 h, and category 4 represents >1 h. 65.06% of the students responded with category 1 (<15 min.); 27.09% responded with category 2 (15 to 30 min.); 5.82% responded with category 3 (30 min. to 1 h); and 2.03% responded with category 4 (> 1 h). A majority of the students (65.06%) spent less than 15 minutes to travel from their homes to school.
- For the attribute (studytime) weekly study time, category 1 represents <2 h, category 2 represents 2 to 5 h, category 3 represents 5 to 10 h, and category 4 represents >10 h. 26.58% responded with category 1 (< 2 h); 50.13% responded with category 2 (2 to 5 h); 16.46% responded with category 3 (5 to 10 h); and 6.84% responded with category 4 (>10 h). Half of the students spent 2 to 5 hours per week studying, while a quarter spent less than 2 hours per week.
- For the attribute (failures) number of past class failures, 70.99% of the students had experienced 0 failure; 12.66% had experienced 1 failure; 4.3% had experienced 2 failures; and 4.05% had experienced more than 2 failures. Seven out of ten students did not experience any failure in the past.
- For the attribute (famsup) family educational support, 38.73% responded with “no”; 61.27% responded with “yes.” Most of the students (61.27%) received educational support from their families.
- For (schoolsup) extra educational support by the school, 87.09% responded with “no”; 12.91% responded with “yes.” A majority of the students (87.09%) received extra educational support from the school.
- For the attribute (famrel) quality of family relationships (from 1 which represents “very bad” to 5 which represents “excellent”), 2.03% responded with category 1 (very bad); 4.56% responded with category 2 (bad); 17.22% responded with category 3 (moderate); 49.37% responded with category 4 (good); and 26.84% responded with category 5 (excellent). Nearly half of the students (49.37%) had good relationships with their families, while more than a quarter (26.84%) had excellent relationships.
- For the attribute (paid) extra paid classes within the course subject, 54.18% responded with “no,” and 45.82% responded with “yes.” More than half (54.18%) of the students did not receive extra paid classes.
- For the attribute (romantic) with a romantic relationship, 66.58% responded with “no,” and 33.42% responded with “yes.” One-third of the students (33.42%) were in romantic relationships.
- For the attribute (absences) number of school absences, 97.97% responded with <=25 times; 1.27% responded with <=50 times; and 0.76% responded with >50 times. Almost all the students (except for about 2%) had regular class attendances.
- For the attribute (health) current health status (from 1 which represents “very bad” to 5 which represents “very good”), 11.90% responded with category 1 (very bad); 11.39% responded with category 2 (bad); 23.04% responded with category 3 (moderate); 16.71% responded with category 4 (good); and 36.96% responded with category 5 (very good). More than one-third of the students reported having very good health.
- For the attribute (internet) Internet access at home, 16.71% responded with “no,” and 83.29% responded with “yes.” A majority of the students (83.29%) had Internet access at home.
- For the attribute (Walc) weekend alcohol consumption (from 1 which represents “very low” to 5 which represents “very high”), 38.23% responded with category 1 (very low); 21.52% responded with category 2 (low); 20.25% responded with category 3 (moderate); 12.91% responded with category 4 (high); and 7.09% responded with category 5 (very high). More than one-third (38.23%) of the students consumed a very low level of alcohol during the weekends.
- For the attribute (Dalc) weekday alcohol consumption (from 1 which represents “very low” to 5 which represents “very high”), 69.87% responded with category 1 (very low); 18.99% responded with category 2 (low); 6.58% responded with category 3 (moderate); 2.28% responded with category 4 (high); and 2.28% responded with category 5 (very high). More than two-thirds (69.87%) of the students consumed a very low level of alcohol during the weekdays.
- For the attribute (freetime) free time after school (from 1 which represents “very low” to 5 which represents “very high”), 4.81% responded with category 1 (very low); 16.20% responded with category 2 (low); 39.75% responded with category 3 (moderate); 29.11% responded with category 4 (high); and 2.28% responded with category 5 (very high). Almost four in ten students (39.75%) had moderate amount of free time after school.
- For the attribute (goout) going out with friends, (from 1 which represents “very low” to 5 which represents “very high”), 5.82% responded with category 1 (very low); 26.08% responded with category 2 (low); 32.91% responded with category 3 (moderate); 21.77% responded with category 4 (high); and 13.42% responded with category 5 (very high). Almost one-third of the students (32.91%) had moderate amount of time to go out with their friends.
- For the attribute (higher) which asked whether the student wished to pursue higher education, 49.11% responded with “no,” and 50.89% responded with “yes.” Slightly more than half of the students (50.89%) wished to pursue higher education.
5.7. Descriptive Analytics: Entropy in the Bayesian Network Model
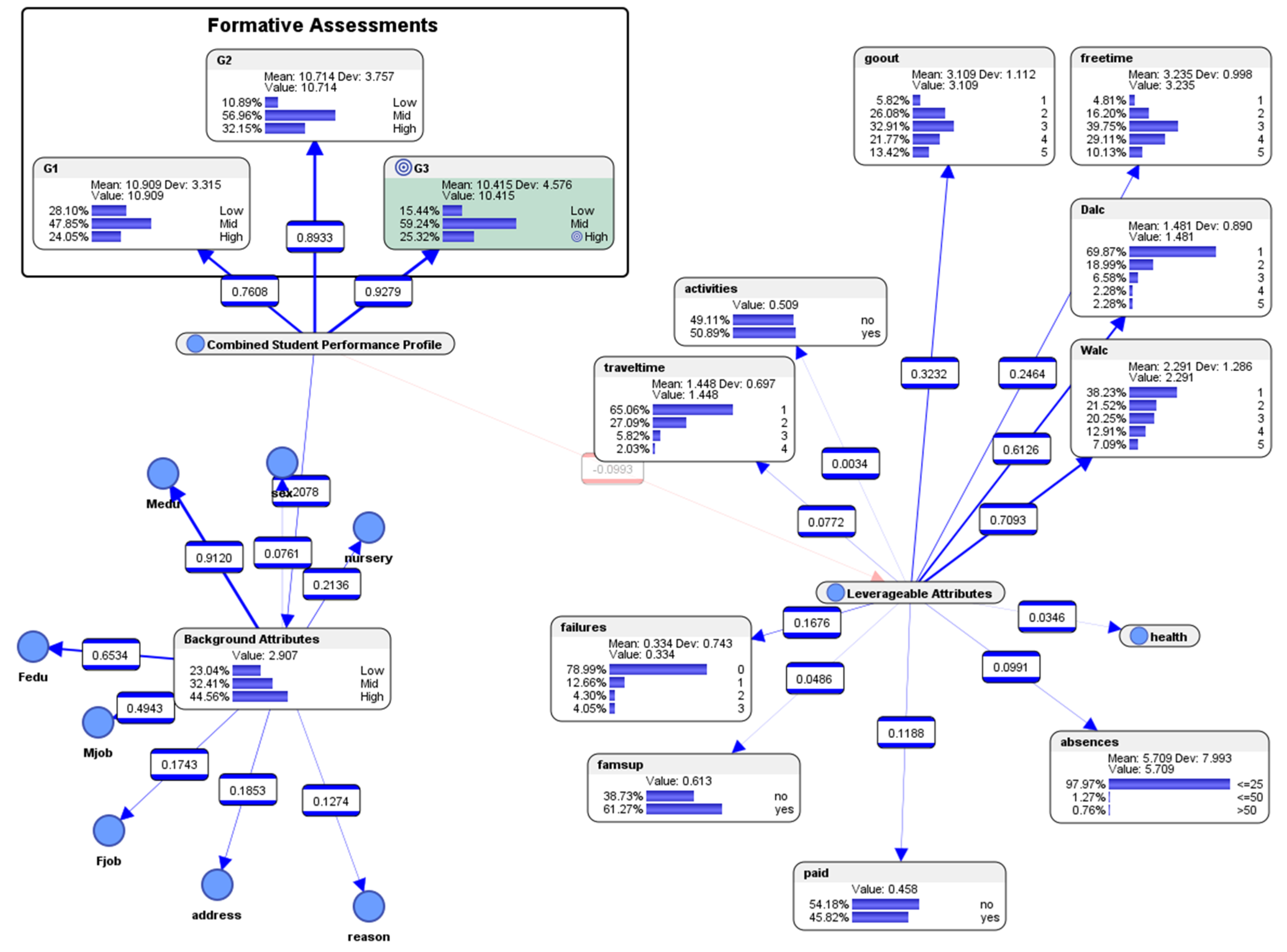
5.8. Descriptive Analytics: Mutual Information in the Bayesian Network Model
- Normalized Mutual Information (with respect to the child)
- Normalized Mutual Information (with respect to the parent)
- Symmetric Normalized Mutual Information
- Relative Mutual Information (with respect to the child)
- Relative Mutual Information (with respect to the parent)
- Symmetric Relative Mutual Information
5.9. Descriptive Analytics: Pearson Correlation Analysis
5.10. Organization of the Rest of the Paper
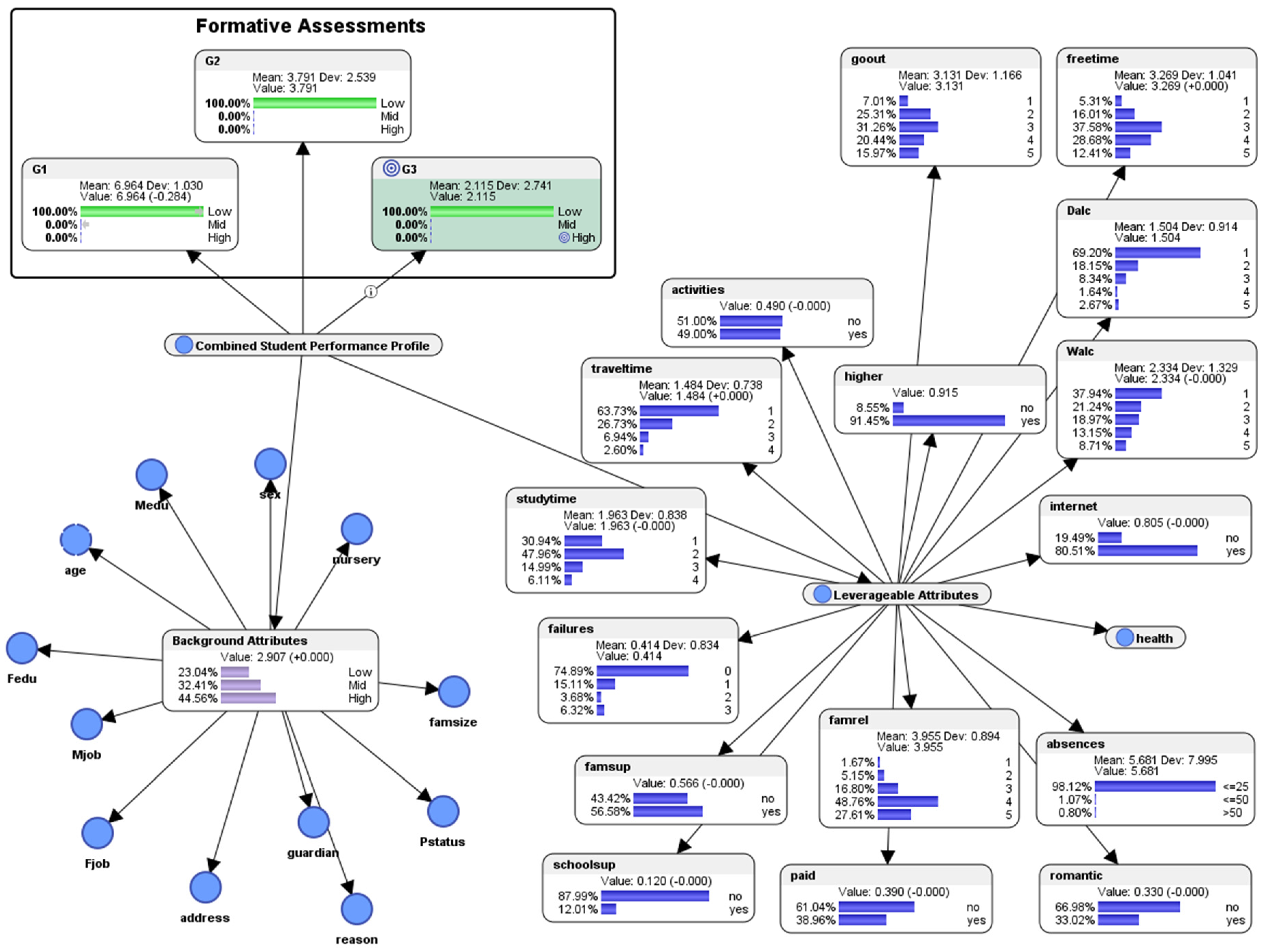
6. Predictive Analytics: Simulation of “What-If?” Scenarios to Visualize the “Spread of Energy” (Entropy) in a Pedagogical System
7. Evaluation of the Predictive Performance of the Bayesian Network Machine Learning Model
7.1. Gains Curve
7.2. Lift Curve
7.3. Receiver Operating Characteristic Curve
7.4. Target Evaluation Cross-Validation by K-Fold
8. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Clausius, R. The Mechanical Theory of Heat, with Its Applications to the Steam-Engine and to the Physical Properties of Bodies; John van Voorst: London, UK, 1867. [Google Scholar]
- Larson, R. Improving the Odds: A Basis for Long-Term Change; Rowman & Littlefield Education: Lanham, MD, USA, 2009. [Google Scholar]
- Levina, E.Y.; Voronina, M.V.; Rybolovleva, A.A.; Sharafutdinova, M.M.; Zhandarova, L.F. The Concepts of Informational Approach to the Management of Higher Education’s Development. Sci. Educ. 2016, 11, 9913–9922. [Google Scholar]
- Yeh, H.-C.; Chen, Y.-C.; Chang, C.-H.; Ho, C.-H.; Wei, C. Rainfall Network Optimization Using Radar and Entropy. Entropy 2017, 19, 553. [Google Scholar] [CrossRef]
- Karevan, Z.; Suykens, J. Transductive Feature Selection Using Clustering-Based Sample Entropy for Temperature Prediction in Weather Forecasting. Entropy 2018, 20, 264. [Google Scholar] [CrossRef]
- Liang, X. A Study of the Cross-Scale Causation and Information Flow in a Stormy Model Mid-Latitude Atmosphere. Entropy 2019, 21, 149. [Google Scholar] [CrossRef]
- Men, B.; Long, R.; Li, Y.; Liu, H.; Tian, W.; Wu, Z. Combined Forecasting of Rainfall Based on Fuzzy Clustering and Cross Entropy. Entropy 2017, 19, 694. [Google Scholar] [CrossRef]
- Cheewaprakobkit, P. Study of Factors Analysis Affecting Academic Achievement of Undergraduate Students in International Program. In Proceedings of the International MultiConference of Engineers and Computer Scientists 2013, Hong Kong, China, 13–15 March 2013. [Google Scholar]
- Shahiri, A.M.; Husain, W.; Rashid, N.A. A Review on Predicting Student’s Performance Using Data Mining Techniques. Procedia Comput. Sci. 2015, 72, 414–422. [Google Scholar] [CrossRef]
- Hox, J.; van de Schoot, R.; Matthijsse, S. How few countries will do? Comparative survey analysis from a Bayesian perspective. Surv. Res. Methods 2012, 6, 87–93. [Google Scholar]
- Friston, K.; Kiebel, S. Predictive coding under the free-energy principle. Philos. Trans. R. Soc. B: Biol. Sci. 2009, 364, 1211–1221. [Google Scholar] [CrossRef]
- Friston, K.; Daunizeau, J.; Kilner, J.; Kiebel, S. Action and behavior: A free-energy formulation. Biol. Cybern. 2010, 102, 227–260. [Google Scholar] [CrossRef]
- Cowell, R.G.; Dawid, A.P.; Lauritzen, S.L.; Spieglehalter, D.J. Probabilistic Networks and Expert Systems: Exact Computational Methods for Bayesian Networks; Springer: New York, NY, USA, 1999; ISBN 978-0-387-98767-5. [Google Scholar]
- Jensen, F.V. An Introduction to Bayesian Networks; Springer: New York, NY, USA, 1999; ISBN 0-387-91502-8. [Google Scholar]
- Korb, K.B.; Nicholson, A.E. Bayesian Artificial Intelligence; Chapman & Hall/CRC: London, UK, 2010; ISBN 978-1-4398-1591-5. [Google Scholar]
- Bayes, T. A Letter from the Late Reverend Mr. Thomas Bayes, F.R.S. to John Canton, M.A. and F. R. S. Philos. Trans. R. Soc. Lond. 1763, 53, 269–271. [Google Scholar]
- Pearl, J. Fusion, propagation, and structuring in belief networks. Artif. Intell. 1986, 29, 241–288. [Google Scholar] [CrossRef]
- Pearl, J. Causality: Models, Reasoning, and Inference, 2nd ed.; Cambridge University Press: Cambridge, UK, 2010; ISBN 978-0-521-89560-6. [Google Scholar]
- Pearl, J. Causes of Effects and Effects of Causes. Sociol. Methods Res. 2015, 44, 149–164. [Google Scholar] [CrossRef]
- Sloman, S.A. Counterfactuals and causal models: Introduction to the special issue. Cogn. Sci. 2013, 37, 969–976. [Google Scholar] [CrossRef] [PubMed]
- How, M.-L.; Hung, W.L.D. Educational Stakeholders’ Independent Evaluation of an Artificial Intelligence-Enabled Adaptive Learning System Using Bayesian Network Predictive Simulations. Educ. Sci. 2019, 9, 110. [Google Scholar] [CrossRef]
- Lockwood, J.R.; Castellano, K.E.; Shear, B.R. Shear Flexible Bayesian Models for Inferences from Coarsened, Group-Level Achievement Data. J. Educ. Behav. Stat. 2018, 43, 663–692. [Google Scholar] [CrossRef]
- Levy, R. Advances in Bayesian Modeling in Educational Research. Educ. Psychol. 2016, 51, 368–380. [Google Scholar] [CrossRef]
- Kaplan, D. Causal inference with large-scale assessments in education from a Bayesian perspective: A review and synthesis. Large Scale Assess. Educ. 2016, 4, 7. [Google Scholar] [CrossRef]
- Muthén, B.; Asparouhov, T. Bayesian structural equation modeling: A more flexible representation of substantive theory. Psychol. Methods 2012, 17, 313–335. [Google Scholar] [CrossRef]
- Yajuan, S.; Jerome, P. Reiter Nonparametric Bayesian Multiple Imputation for Incomplete Categorical Variables in Large-Scale Assessment Surveys. J. Educ. Behav. Stat. 2013, 38, 499–521. [Google Scholar]
- Button, K.S.; Ioannidis, J.P.; Mokrysz, C.; Nosek, B.A.; Flint, J.; Robinson, E.S.; Munafao, M.R. Power failure: Why small sample size undermines the reliability of neuroscience. Nat. Rev. Neurosci. 2013, 14, 365–376. [Google Scholar] [CrossRef]
- Lee, S.-Y.; Song, X.-Y. Evaluation of the Bayesian and maximum likelihood approaches in analyzing structural equation models with small sample sizes. Multivar. Behav. Res. 2004, 39, 653–686. [Google Scholar] [CrossRef] [PubMed]
- Cortez, P.; Silva, A. Using Data Mining to Predict Secondary School Student Performance. In Proceedings of the 5th Future Business Technology Conference (FUBUTEC 2008), Porto, Portugal, 9–11 April 2008; Brito, A., Teixeira, J., Eds.; EUROSIS: Ostend, Belgium, 2008; pp. 5–12. [Google Scholar]
- Cortez, P. Student Performance Data Set. Available online: https://archive.ics.uci.edu/mL/datasets/student+performance (accessed on 28 April 2019).
- Bayesia, S.A.S. BayesiaLab: Missing Values Processing. Available online: http://www.bayesia.com/bayesialab-missing-values-processing (accessed on 2 June 2019).
- Conrady, S.; Jouffe, L. Bayesian Networks & BayesiaLab: A Practical Introduction for Researchers; Bayesia: Franklin, TN, USA, 2015; ISBN 0-9965333-0-3. [Google Scholar]
- Bayesia, S.A.S. R2-GenOpt* Algorithm. Available online: https://library.bayesia.com/pages/viewpage.action?pageId=35652439#6c939073de75493e8379c0fff83e1384 (accessed on 19 March 2019).
- Lauritzen, S.L.; Spiegelhalter, D.J. Local computations with probabilities on graphical structures and their application to expert systems. J. R. Stat. Soc. 1988, 50, 157–224. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Latham, P.E.; Roudi, Y. Mutual information. Scholarpedia 2009, 4, 1658. [Google Scholar] [CrossRef]
- Cole, R. Estimating the impact of private tutoring on academic performance: Primary students in Sri Lanka. Educ. Econ. 2017, 25, 142–157. [Google Scholar] [CrossRef]
- Huang, M.-H. After-School Tutoring and the Distribution of Student Performance. Comp. Educ. Rev. 2013, 57, 689–710. [Google Scholar] [CrossRef]
- Pai, H.-J.; Ho, H.-Z.; Lam, Y.W. It Takes a Village: An Indigenous Atayal After-School Tutoring Program in Taiwan. Child. Educ. 2017, 93, 280–288. [Google Scholar] [CrossRef]
- Rickard, B.; Mills, M. The effect of attending tutoring on course grades in Calculus I. Int. J. Math. Educ. Sci. Technol. 2018, 49, 341–354. [Google Scholar] [CrossRef]
- Robinson, C.; Lee, M.; Dearing, E.; Rogers, T. Reducing Student Absenteeism in the Early Grades by Targeting Parental Beliefs. Am. Educ. Res. J. 2018, 55, 1163–1192. [Google Scholar] [CrossRef]
- Bayesia, S.A.S. Gains Curve. Available online: https://library.bayesia.com/display/BlabC/Gains+Curve (accessed on 3 June 2019).
- Bayesia, S.A.S. Lift Curve. Available online: https://library.bayesia.com/display/BlabC/Lift+Curve (accessed on 3 June 2019).
- Bayesia, S.A.S. Receiver Operating Characteristic Curve. Available online: https://library.bayesia.com/display/BlabC/ROC+Curve (accessed on 3 June 2019).
- Forushani, N.Z.; Besharat, M.A. Relation between emotional intelligence and perceived stress among female students. Procedia Soc. Behav. Sci. 2011, 30, 1109–1112. [Google Scholar] [CrossRef][Green Version]
- McGeown, S.P.; St Clair-Thompson, H.; Clough, P. The study of non-cognitive attributes in education: Proposing the mental toughness framework. Educ. Rev. 2016, 68, 96–113. [Google Scholar] [CrossRef]
- Panerai, A.E. Cognitive and noncognitive stress. Pharmacol. Res. 1992, 26, 273–276. [Google Scholar] [CrossRef]
- Pau, A.K.H. Emotional Intelligence and Perceived Stress in Dental Undergraduates. J. Dent. Educ. 2003, 67, 6. [Google Scholar]
- Schoon, I. The impact of non-cognitive skills on outcomes for young people 2013. Educ. Endow. Found. 2013, 59, 2019. [Google Scholar]
- Al-Mutawah, M.A.; Fateel, M.J. Students’ Achievement in Math and Science: How Grit and Attitudes Influence? Int. Educ. Stud. 2018, 11, 97. [Google Scholar] [CrossRef]
- Chamberlin, S.A.; Moore, A.D.; Parks, K. Using confirmatory factor analysis to validate the Chamberlin affective instrument for mathematical problem solving with academically advanced students. Br. J. Educ. Psychol. 2017, 87, 422–437. [Google Scholar] [CrossRef]
- Egalite, A.J.; Mills, J.N.; Greene, J.P. The softer side of learning: Measuring students’ non-cognitive skills. Improv. Sch. 2016, 19, 27–40. [Google Scholar] [CrossRef]
- Lipnevich, A.A.; MacCann, C.; Roberts, R.D. Assessing Non-Cognitive Constructs in Education: A Review of Traditional and Innovative Approaches. In Oxford Handbook of Child Psychological Assessment; Oxford University Press Inc.: New York, NY, USA, 2013. [Google Scholar]
- Mantzicopoulos, P.; Patrick, H.; Strati, A.; Watson, J.S. Predicting Kindergarteners’ Achievement and Motivation from Observational Measures of Teaching Effectiveness. J. Exp. Educ. 2018, 86, 214–232. [Google Scholar] [CrossRef]
- Bayesia, S.A.S. Bayesialab. Available online: https://www.bayesialab.com/ (accessed on 18 March 2019).
- Bayes Fusion LLC. GeNie. Available online: https://www.bayesfusion.com/genie/ (accessed on 18 March 2019).
- University of Brasilia (UnB). Framework & GUI for Bayes Nets and Other Probabilistic Models. Available online: https://sourceforge.net/projects/unbbayes/ (accessed on 18 March 2019).
- Norsys Software Corp. Netica. Available online: https://www.norsys.com/netica.html (accessed on 18 March 2019).
- Bayes Server LLC. Bayes Server. Available online: https://www.bayesserver.com/ (accessed on 18 March 2019).





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Leverageable? | Attribute | Description |
|---|---|---|
| No | school | student’s school (nominal) |
| No | sex | student’s sex (“F”—female or “M”—male) |
| No | address | student’s home address type (“U”—urban or “R”—rural) |
| No | famsize | family size (“LE3”—less or equal to 3 or “GT3”—greater than 3) |
| No | Pstatus | parent’s cohabitation status (“T”—living together or “A”—apart) |
| No | Medu | mother’s education (from 0 to 4 a) |
| No | Fedu | father’s education (from 0 to 4 a) |
| No | Mjob | mother’s job (nominal b) |
| No | Fjob | father’s job (nominal b) |
| No | reason | reason for choice of school (nominal: close to “home”, “reputation”, “course”, or “other”) |
| No | guardian | student’s guardian (nominal: “mother,” “father” or “other”) |
| Yes | traveltime | home to school travel time (numeric: “1” — less than 15 min., “2” — 15 min. to 30 min., “3” — 30 min. to 1 h, or “4” — more than 1 h) |
| Yes | studytime | weekly study time (numeric: “1”— less than 2 h, “2”— 2 h to 5 h, “3” — 5 h to 10 h, or “4” — more than 10 h) |
| Yes | failures | number of past class failures (n if 1<= n < 3, else 4) |
| Yes | schoolsup | extra educational support (yes or no) |
| Yes | famsup | family educational support (yes or no) |
| Yes | paid | extra paid classes within the course subject (yes or no) |
| Yes | activities | extra-curricular activities (yes or no) |
| Yes | higher | wants to pursue higher education (yes or no) |
| Yes | internet | Internet access at home (yes or no) |
| Yes | romantic | with a romantic relationship (yes or no) |
| Yes | famrel | quality of family relationships (numeric: from 1—very bad to 5—excellent) |
| Yes | freetime | free time after school (numeric: from 1—very low to 5—very high) |
| Yes | goout | going out with friends (numeric: from 1—very low to 5—very high) |
| Yes | Dalc | workday alcohol consumption (numeric: from 1—very low to 5—very high) |
| Yes | Walc | weekend alcohol consumption (numeric: from 1—very low to 5—very high) |
| Yes | health | current health status (numeric: from 1—very bad to 5—very good) |
| Yes | absences | number of school absences (numeric: from 0 to 93) |
| Yes | G1 | score of formative assessment G1 (numeric: from 0 to 20) |
| Yes | G2 | score of formative assessment G2 (numeric: from 0 to 20) |
| Yes | G3 | score of final exam G3 (numeric: from 0 to 20) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
HOW, M.-L.; HUNG, W.L.D. Harnessing Entropy via Predictive Analytics to Optimize Outcomes in the Pedagogical System: An Artificial Intelligence-Based Bayesian Networks Approach. Educ. Sci. 2019, 9, 158. https://doi.org/10.3390/educsci9020158
HOW M-L, HUNG WLD. Harnessing Entropy via Predictive Analytics to Optimize Outcomes in the Pedagogical System: An Artificial Intelligence-Based Bayesian Networks Approach. Education Sciences. 2019; 9(2):158. https://doi.org/10.3390/educsci9020158
Chicago/Turabian StyleHOW, Meng-Leong, and Wei Loong David HUNG. 2019. "Harnessing Entropy via Predictive Analytics to Optimize Outcomes in the Pedagogical System: An Artificial Intelligence-Based Bayesian Networks Approach" Education Sciences 9, no. 2: 158. https://doi.org/10.3390/educsci9020158
APA StyleHOW, M.-L., & HUNG, W. L. D. (2019). Harnessing Entropy via Predictive Analytics to Optimize Outcomes in the Pedagogical System: An Artificial Intelligence-Based Bayesian Networks Approach. Education Sciences, 9(2), 158. https://doi.org/10.3390/educsci9020158