1. Introduction
Project-Based Learning (PBL) is a constructivist pedagogical approach in which students acquire knowledge and skills through the active exploration of problems and the execution of meaningful projects. Unlike traditional teaching methods, where information is presented in a fragmented way and with a predominantly theoretical focus, PBL suggests that students work on projects that reflect real-life situations, promoting contextualized and applied learning (
Vogler et al., 2018). In this model, students are not passive recipients of information, but active agents who develop competencies through research, experimentation, and the application of concepts in concrete contexts. This approach aligns with the theory of meaningful learning (
Ausubel, 1968), which emphasizes the importance of connecting new information with prior knowledge to facilitate deeper and more lasting understanding.
Designing a project-based course requires careful planning to guarantee that students not only gain disciplinary knowledge but also develop transversal skills such as problem-solving, critical thinking, effective communication, and teamwork (
Ngereja et al., 2020). Clear learning objectives must be defined, and the project should revolve around an open-ended question or challenge, complex enough to require the application of multiple concepts and methodologies. As students progress through the project, they are required to investigate, analyze data, synthesize information, and make informed decisions, fostering active and autonomous learning. A key aspect of PBL is assessment, which must go beyond traditional exams to incorporate methods such as formative assessment, self-assessment, and peer assessment. These strategies enable students to reflect on their own learning process and receive continuous feedback, contributing to the improvement of their competencies. The final project deliverable—which can take various forms such as technical reports, prototypes, presentations, or simulations—not only serves as evidence of learning but can also have an impact beyond the classroom by addressing real problems and proposing innovative solutions (
Alves et al., 2016).
In engineering and applied science education, PBL has proven particularly effective, as it allows students to tackle complex technical problems that simulate challenges found in professional environments (
Bédard et al., 2012). The integration of computational tools, the use of simulations, and the implementation of agile methodologies in project development have been shown to improve both academic performance and students’ preparedness for the job market. One of the main benefits of PBL in the training of electronic engineers is that it promotes the integration of theoretical and practical knowledge, enabling students to better understand the fundamentals of the discipline and their application in the development of electronic devices and systems (
Etchepareborda et al., 2018). In a traditional approach, concepts such as electrical circuits, digital systems, microcontroller programming, and communications are usually taught in isolation, which can hinder the perception of their interrelation. With PBL, the designed projects require the combination of these areas, forcing students to apply principles from different branches of engineering to solve a specific problem. This improves their synthesis ability and fosters deeper and more meaningful learning (
de Sales & Boscarioli, 2021).
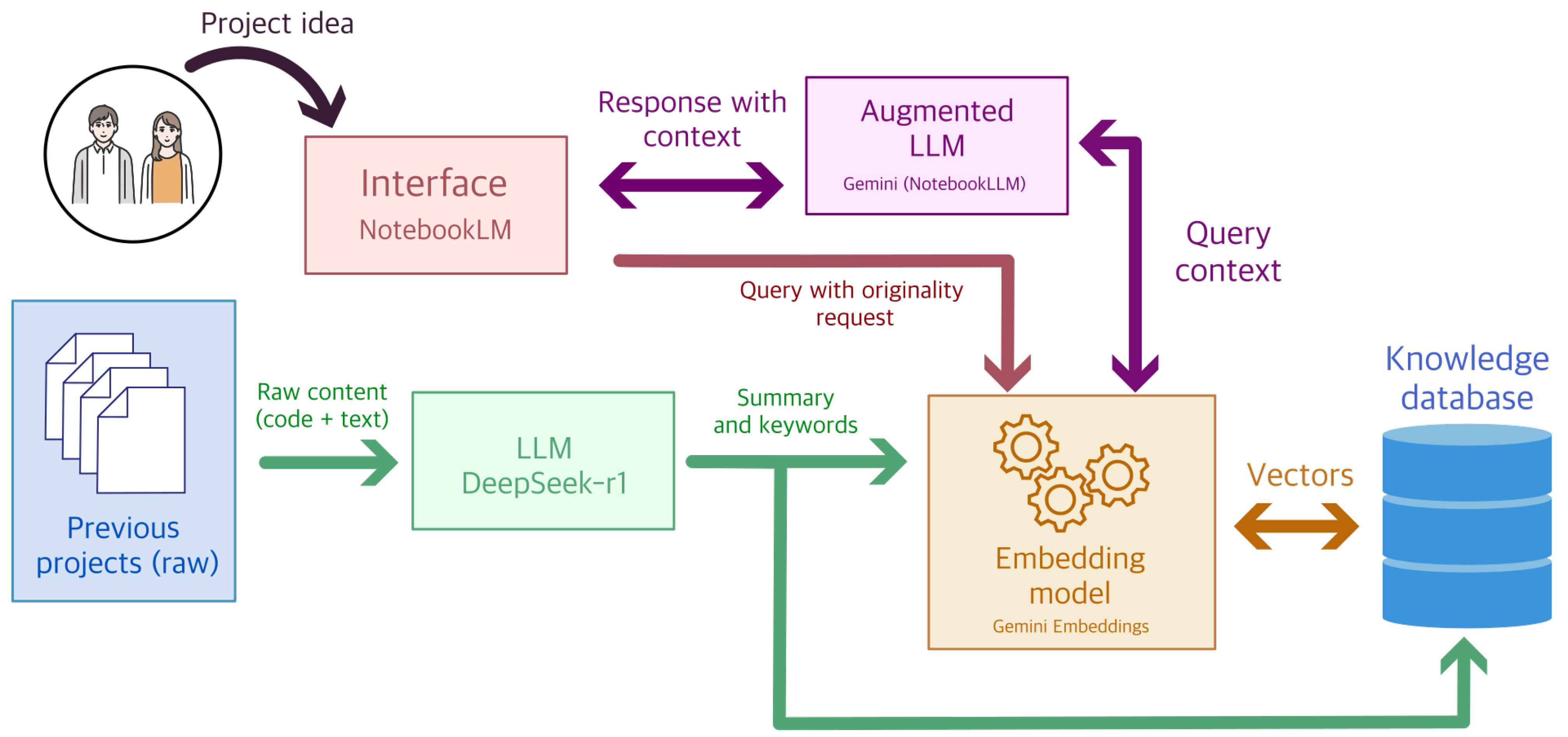
In this paper, we present the case of the course *Advanced Digital Systems and Applications* (SDAA), part of the Master’s Degree in Electronic, Robotic and Automation Engineering at the University of Seville. This course brings together students from various engineering backgrounds, such as electronics, computer science, and telecommunications among others. The course is designed for students to develop a research project in which they apply the knowledge acquired during the course. This knowledge includes the Internet of Things (IoT), Artificial Intelligence, and the design of electronic and software applications using a Raspberry Pi 4 (RPi4) (
Balon & Simić, 2019). The RPi4 system is a low-cost, small-form-factor microcomputer that has gained popularity in educational and professional settings due to its versatility and processing capabilities (see
Figure 1). Throughout the course, students must design a project that integrates these skills and concepts, using the RPi4 as the core platform. The topic of the projects is open, but must focus on the knowledge covered in the course. This means students can choose an area of application that interests them, as long as it relates to the use of the RPi4 and the concepts of IoT, AI, and electronic systems. This thematic freedom encourages student creativity and motivation, as they can explore areas they are passionate about and apply their knowledge in real-world contexts (
Fitrah et al., 2025). The only requirement is that the project must be validated by the instructor, who will ensure that the chosen topic is relevant and feasible within the course framework. This validation process is essential to guarantee that students are working on projects that meet the course objectives and that they have the necessary resources and support to carry them out successfully. The proposed system expected to be useful for the instructors because it serves as a automatic validation tool for such validation process. This can prevent issues such as lecturers forgetting past projects or even changes in faculty within the department. Even, if lecturers were new to the class, they could be ”easily misled” because they would not know what has been done previously.
To evaluate the projects, the assessment criteria should focus on the originality and innovation of the proposals, as well as the technical quality and the presentation of the final work. Students must demonstrate their ability to research, design, and develop a project that not only meets technical requirements but also provides added value in terms of originality and creativity. This last aspect is critical, as one of the indicators of project quality is its capacity to offer novel solutions to existing problems or to address challenges in an innovative way. Originality refers not only to the novelty of the approach or proposed solution but also to how students articulate their idea and endow it with practical utility and relevance in the current context.
Students, in order to carry out their projects, have access to a knowledge base that includes previous works done by other students in prior years. In the field of application and software development, it is common to reuse code from public repositories such as GitHub to accelerate the development process. This practice is valid and accepted in the developer community, as long as the usage licenses are respected and appropriate credit is given to the original authors. This methodology is motivated also because it encourages the reproducibility of the results. However, in the academic context, the reuse of previous works raises an ethical and pedagogical dilemma. On one hand, it allows students to learn from past experiences and benefit from the work done by others. On the other hand, it can lead to the temptation to copy or plagiarize ideas without adding value or offering an original perspective (
Chu et al., 2021). This dilemma is exacerbated by the pressure students feel to meet deadlines and quality expectations, which can lead to unethical decisions in the pursuit of quick solutions.
Regarding this, over the years, the teaching team has observed that students tend to be inspired by previous works, which can lead to the creation of projects that, although technically correct, lack originality and creativity. Evaluating these works becomes a challenge, as the line between inspiration and plagiarism can be blurred (
McIntire et al., 2024). Additionally, the instructor must assess year after year whether the work presents an original research line or if it is simply an adaptation of previous works. This task becomes unfeasible when the number of prior works is high (the SDAA course already has 100 previous works), which can lead to subjective evaluations. Furthermore, it must be considered that students do not always have the ability to identify which previous works are relevant to their project and which are not. This can lead to an information overload and difficulty in discerning what is useful and what is not. Additionally, students may feel overwhelmed by the amount of available information and may have trouble integrating the knowledge acquired into their own project.
This paper proposes a framework to address the evaluation of the originality of projects. This framework allows (1) students to identify relevant prior works for their project to reduce similarity, and (2) instructors to evaluate the originality of projects in an objective and verified manner. To achieve this, a project originality assessment system based on information retrieval techniques (RAG) is proposed. The use of large language models (LLMs) is suggested to serve as a semantic foundation to understand the content and idea of prior works. Due to the context window limitation of LLMs, it is necessary to use an information retrieval system to identify relevant prior works for the project. The instructor will provide reports and codes of previous projects as a knowledge base and open a communication channel with the LLM so that students can ask questions about the previous works. The LLM, in turn, will generate a summary of the relevant prior works and provide an evaluation of the originality of the new project. This approach not only facilitates the identification of relevant works but also allows students to reflect on their own learning process and improve their skills in research and project development. Additionally, by using an information retrieval system based on LLMs, it is expected that the cognitive load on students will be reduced, improving their ability to integrate prior knowledge into their own projects.
The main contribution of this paper lies in the development and evaluation of a framework that combines information retrieval techniques and language models to assess the originality of projects in an educational context. This approach not only addresses the issue of plagiarism and lack of originality but also promotes more meaningful and contextualized learning, aligned with the principles of PBL.
The paper is structured as follows:
Section 2 presents a state of the art review on the use of LLMs in education and the evaluation of originality.
Section 3 describes the proposed framework, including the methodology and the results obtained from its implementation. Finally,
Section 4 presents the conclusions and the implications for future research.
4. Results
This section presents the evaluation results of the RAG system for assessing the originality of student projects. The evaluation is divided into two parts. First, the ability of the system to recover and assess the originality of 91 prior works from previous academic years (2019–2022) is evaluated. These works naturally span a range of originality, as students are encouraged to develop new ideas but are not prevented from building on past projects. Second, the evaluation focuses on 10 test cases created specifically for this study to assess the system’s ability to assign originality scores to unseen project proposals.
To construct the test set, a third instructor—who was not involved in the blind scoring phase—reviewed the entire historical corpus of projects and created 10 new project descriptions with controlled levels of originality. These were designed to span the full originality scale and were labeled based on the official originality criterion used in the course and communicated to students. According to this criterion, a project with a score of 0 is one that closely replicates an existing work, with the same modules, objectives, and technical structure. A project with a score of 10 introduces a novel concept, implementation, or application scenario that has not been seen in any previous work, while still respecting the course constraints (in this case, the development of an IoT application based on a Raspberry Pi 4). During the experiment, the two primary instructors rated each test case independently, without access to each other’s scores or to the output of the RAG system. Their scores were then averaged to obtain the final instructor score per case, which was compared against the RAG-assigned score. This evaluation setting was chosen to reflect real teaching conditions, where originality evaluation is inherently subjective but guided by shared pedagogical criteria. By averaging the scores, we reduce the impact of individual bias and provide a fairer ground for comparison with the system’s output.
4.1. Structured Summaries Generation
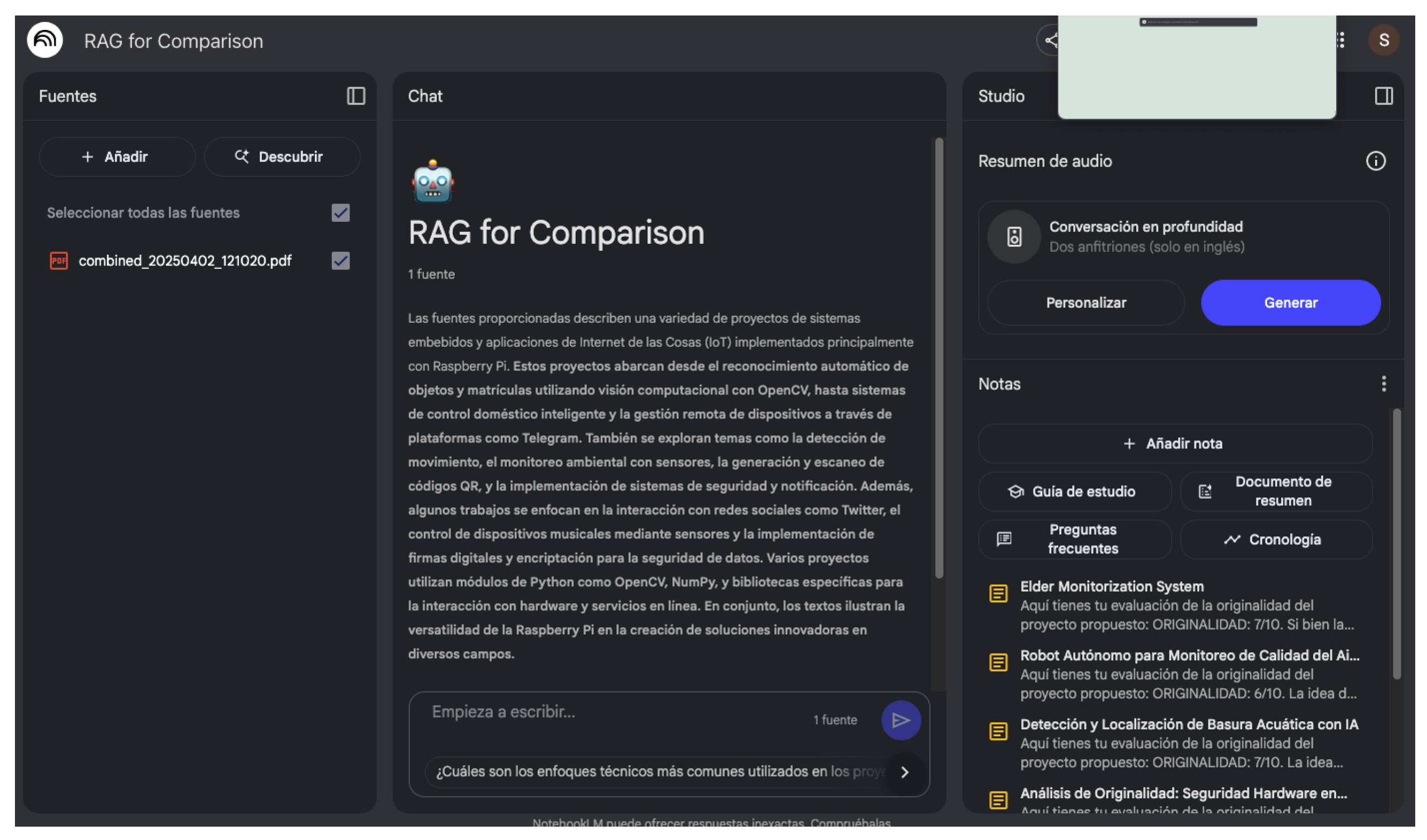
For the generation of summaries, the DeepSeek-R1 model with 14 trillion parameters was used, which generated a structured summary of the previous works. All summaries were compiled into a single PDF and uploaded to the NotebookLM database. This platform supports up to 50 PDF documents, so the limit of works is well beyond the number of previous works (see
Figure 6). The input prompt described in the previous section was used for generating the summaries. The summaries were generated using an Nvidia RTX 4090 graphics card in a processor AMD Ryzen 9 7950X3D. The model was run on a local machine with 128 GB of RAM and a 2 TB NVMe SSD hard drive. The average generation time for the summaries is 3.5 s per work, which allows for the creation of the summaries of the previous works in less than 5 min. Although the computing system is powerful, the DeepSeek-R1 model, which only takes up 9GB, is optimized to be efficient in computational resources, making it suitable for inference on a laptop or desktop computer.
In
Figure 7, an example of a structured summary generated by the DeepSeek-R1 model is presented. In this case, the model has generated a summary of a previous work that meets the course requirements. The summary includes the project metadata, project description, project objectives, modules and code libraries used, hardware used, and contextual keywords.
It can be seen that the model is capable of generating a summarized description of the previous work, which contains more than 200 lines of raw code and a 10-slide presentation. The summary includes the project metadata, which is important for indexing: file names and project description. Additionally, it includes the code modules and libraries used, the hardware utilized, and contextual keywords. This information is relevant for indexing the previous works and helps the LLM understand the content of the work. Furthermore, it provides the student or the instructor with a reference to relevant previous works for their project without having to read the entire work or delve into the code.
4.2. Examples of Proposal Originality Evaluation
Once all the works were summarized and the knowledge base was created with NotebookLM, the originality of the previous works was evaluated. For this purpose, three types of previous works were manually created: (1) works very similar to the previous works, (2) inspired works, and (3) completely original works never seen before. These works were generated manually by observing the knowledge base. In
Table 1, two examples for each type of idea are presented, which were used to evaluate the RAG. In
Table 2, the responses of each of the previous works are shown when simulating them as new project proposals with the prompt described in
Figure 5. The model was able to evaluate the originality of the previous works and returned an originality score between 0 and 10, where 0 represents a work very similar to the previous ones and 10 represents a completely original work. It can be observed that the model successfully evaluated the originality of the previous works and provided a consistent originality score.
The system effectively identifies the closest semantic case with ease. In the cases of inspired works, the model returned an originality score between 5 and 7, indicating that the work is original but has similarities with previous works. In the cases of completely original works, the model returned an originality score between 8 and 10, indicating that the work is fully original and does not resemble the previous works. In the latter range, the model references previous works with superficial similarities, such as those using a Raspberry Pi.
4.3. Comparative Evaluation of Originality
To validate this system, 10 ad-hoc works were processed with the RAG tool. These 10 works were specifically designed to cover the full range of originality. A professor of the course was asked to propose 10 works with varied originality characteristics. These 10 proposals were processed using the RAG tool (see
Table 2), and two professors from the course were asked to evaluate the originality of the works. These two evaluator-instructors involved in this study have taught the SDAA course since its inception and possess a detailed recollection of past student projects. Their evaluations are therefore based on this accumulated internal dataset, which reflects years of exposure to project work in the course. This memory-driven assessment is, in practice, how originality is evaluated in real classrooms: instructors compare new proposals against what they remember having seen before. The results of the RAG evaluation have been compared with the assessments provided by the professors to check for alignment and consistency in the evaluation of originality.
The RAG-based system is specifically designed to address this issue. By building a semantically indexed and explorable memory of all prior works, it ensures that all instructors—regardless of tenure or recollection—can operate with access to the same complete and objective context. The system not only identifies the most similar past works but justifies its judgment and provides suggestions for improvement when originality is low. In this sense, it functions as a cognitive prosthesis for evaluators, not a replacement, but a correction mechanism for memory limitations and subjective gaps.
Rather than reproducing instructor bias, the system serves to expose it. By comparing human-assigned originality scores with those generated by the RAG tool, discrepancies can be analyzed to understand where instructor evaluations may have overlooked significant similarity. This not only improves the fairness of the assessment process but also contributes to the standardization of evaluation criteria in project-based learning environments.
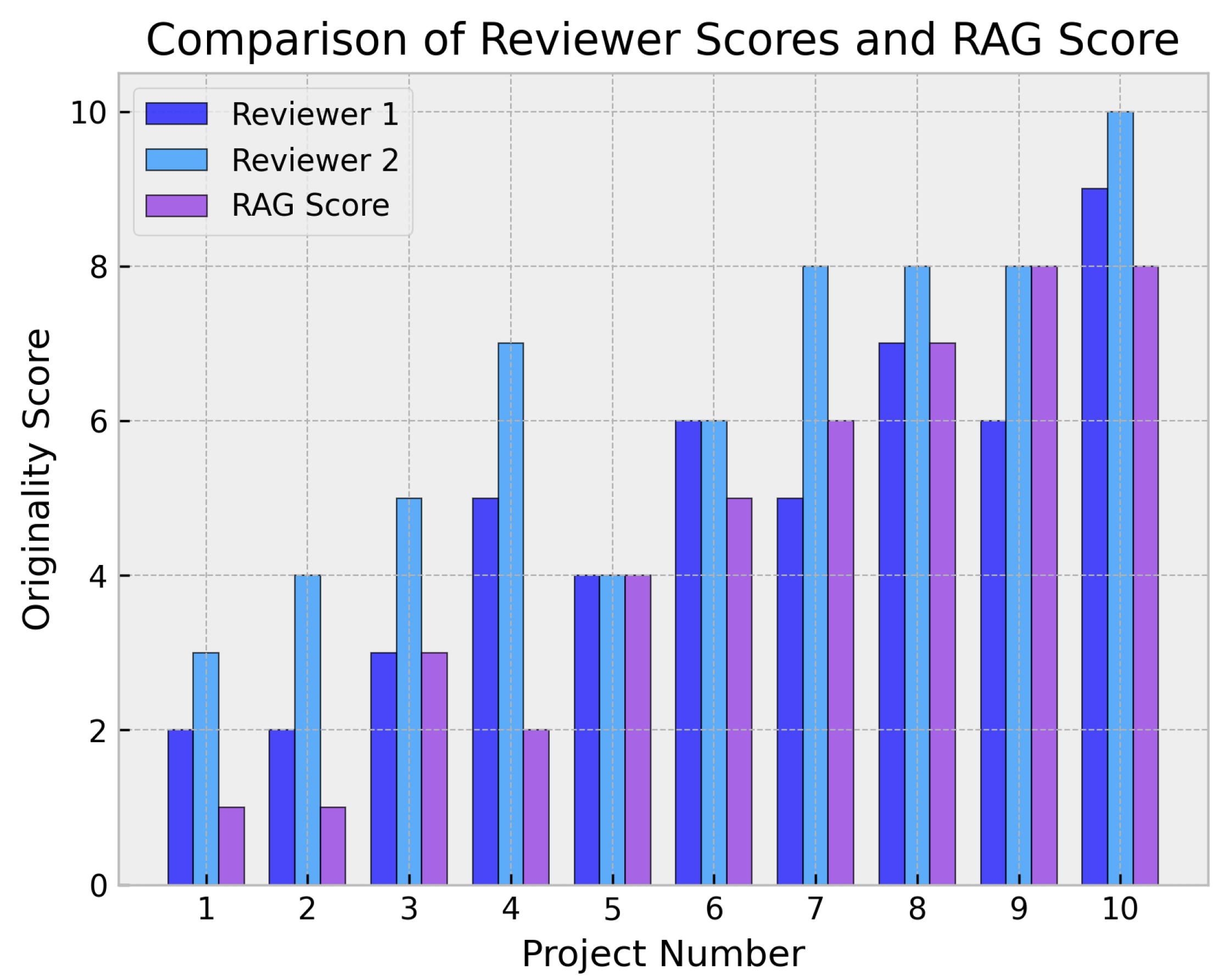
In
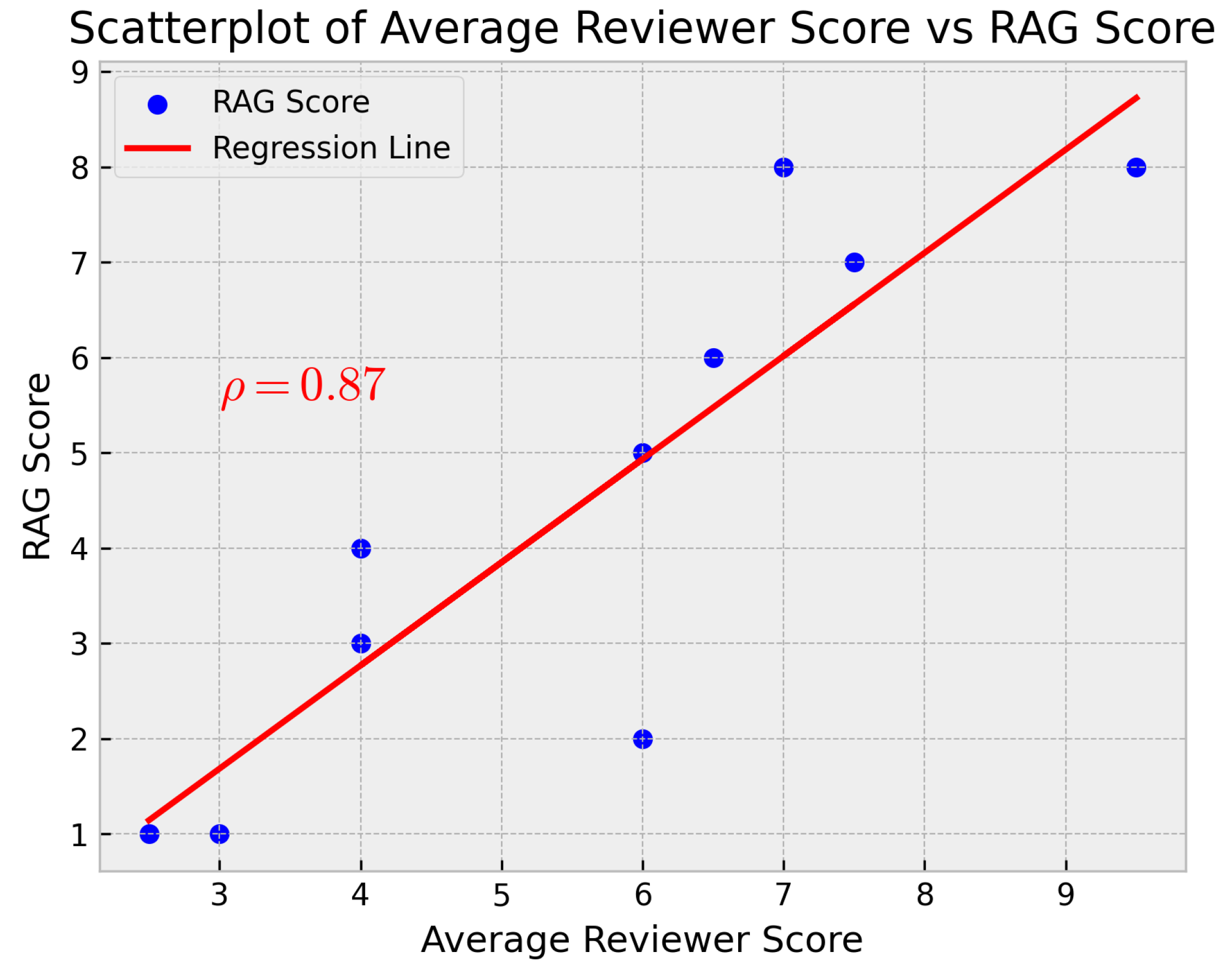
Figure 8, the results of each processed project and the originality scores assigned by the instructors and the proposed RAG system are presented. It can be observed that the RAG system shows a good correlation with the instructors’ evaluations. In
Figure 9, the correlation between the originality scores assigned by the instructors and the RAG system is also presented. To support the statistical validity of this correlation, we computed the Pearson correlation coefficient between the originality scores assigned by the RAG system and the mean score of the two instructors. The result was
with a
p-value of
, indicating that the correlation is statistically significant at the 95% confidence level. This correlation indicates that the RAG system is capable of evaluating the originality of previous works in a way that is consistent with the instructors’ evaluations.
Regarding the differences between the originality scores given by the instructors and the RAG system, it can be observed that the RAG system tends to be stricter in evaluating the originality of previous works. The average discrepancy between the RAG score and the instructors’ scores is −1.1. This discrepancy is due to several reasons: (1) the RAG system considers the originality of previous works and their similarity to prior works. It only takes into account originality based on previous ideas. Instructors, on the other hand, may forget that some previous works may have been influenced by others, which can lead to a less strict evaluation. (2) the RAG system tends to underestimate works because most of them contain latent ideas related to the course content. Every work proposed by a student inevitably shares common foundations with previous works. Therefore, the RAG system tends to evaluate the originality of previous works more strictly than the instructors.
An example of this divergence can be found in the work titled “IoT Predictive Maintenance System”. It was evaluated by the RAG system with a score of 8/10, while the instructors rated the originality of the work with a score of 10/10. This work incorporates a novel system that has not been implemented before, and the instructors recognize it as such. However, the RAG system evaluated the originality of the work with a lower score because the work deals with topics such as “monitoring” and “sensing”, which are core themes in all the projects. It has been observed that it is difficult to come up with a project that the RAG identifies with a 10/10 score. Nevertheless, the RAG system does identify this proposal as the most original.
A particular situation is that of the work titled “Connected Perimeter Alarm”. This work was evaluated by the RAG system with a score of 4/10, while the instructors evaluated the originality of the work with an average score of 6/10, as they do not particularly remember any work that dealt with home security and alarm systems based on magnetic sensors. The RAG system evaluated the originality of the work with a lower score (2/10) because it appears to find a significant number of matches with previous works. This work seems to be an adaptation of a previous project titled “Automated Surveillance System with Raspberry Pi and Sensors (2020)”, which uses PIR motion sensors instead of magnetic sensors. This type of similarity detection capability is a desirable feature because it moderates the bias effect in the grading of the student by the instructor. In a real scenario, the student could use this system and reframe their objectives to achieve a higher grade.
4.4. User Feedback and Perceived Utility
To complement the technical evaluation, we conducted a small-scale qualitative survey to assess the perceived usefulness and usability of the system among stakeholders. Two instructors who participated in the originality rating process and eight students who had previously completed the SDAA course were invited to interact with the system and provide open-ended feedback. All participants were asked to identify the most valuable and most limiting aspects of the tool from their perspective.
This exploratory feedback reinforces the utility of the system as both a pedagogical aid and an evaluation support tool. It also points to areas for refinement, such as balancing the strictness of the scoring function and improving prompt engineering support for novice users.
4.5. Generalization to Other Courses and Disciplines
The RAG framework presented in this study was developed and evaluated in the context of a master’s course in electronic engineering. However, the design of the system is intentionally modular and domain-agnostic. Its capacity to evaluate the originality of student work does not depend on the specific technical content of the projects, but on the ability to semantically compare new proposals against a corpus of previously completed works.The core premise of this system is simple: originality is always defined relative to prior knowledge. Consequently, the framework can be deployed in any context where a collection of previous student outputs is available, regardless of discipline. The key adaptation step required for generalization is the design of an appropriate summarization prompt that reflects the instructional objectives and originality criteria relevant to the target course.
Preparing a new course or domain for RAG deployment involves two main steps:
Definition of Originality Criteria: The instructor must define what constitutes originality in their specific context. This may include novel combinations of methods, application to previously unaddressed problems, creative re-interpretation of known tools, or any domain-specific marker of innovation.
Prompt Engineering for Summarization: Once these criteria are defined, the summarization prompt must be adapted to extract and structure the relevant information from prior works. This includes metadata (e.g., project title, year), descriptive elements (objectives, methodology, implementation), and any features relevant to originality (e.g., design decisions, thematic scope). The summarization LLM—such as DeepSeek—can be instructed via prompt alone, with no retraining required.
The summaries generated using this process are then compiled into a PDF (or multiple PDFs) and uploaded into the retrieval platform—in this study, NotebookLM. At this point, no further customization is needed. The contextualization engine of the RAG system operates over the provided summaries, and its behavior does not change across disciplines. Whether the indexed documents describe engineering systems, social science interventions, or literary analyses, the mechanism for similarity detection, explanation generation, and originality scoring remains unchanged.While the semantic features extracted from the documents are course-specific, the RAG evaluation mechanism itself is fully general. Its modularity, reliance on prompt-based customization, and decoupled summarization–retrieval architecture make it highly transferable across domains. The only requirement is that the corpus of prior works be sufficiently documented and structured so that meaningful summaries can be produced.
5. Discussion
Project-Based Learning has established itself as a highly valuable pedagogical approach, especially in disciplines like engineering, where it encourages the acquisition of knowledge and skills through the active resolution of problems and the completion of meaningful tasks that simulate real professional challenges. This method fosters contextualized and applied learning, aligned with constructivist theories and theories of meaningful learning. However, PBL presents an inherent challenge in assessment, particularly when it comes to originality. In environments where students have access to prior work or vast repositories of code and ideas, it becomes crucial, both from an ethical and pedagogical perspective, to distinguish between legitimate inspiration and genuine innovation, as opposed to mere reuse or plagiarism. Ensuring that students develop novel solutions and demonstrate a deep understanding, rather than superficially assembling pre-existing components, is essential for validating the learning objectives of PBL. Solving this problem is critical for maintaining academic integrity and ensuring that student effort translates into real competencies. Here, an important distinction should be made between plagiarism detection and originality evaluation. While existing tools like Turnitin are effective in identifying exact or near-exact matches in text or code, they are not suitable for assessing whether a student project introduces a novel idea or solution—especially in project-based engineering education where the reuse of libraries or hardware configurations is often legitimate and necessary. Our framework addresses this gap by providing instructors and students with a transparent and explainable assessment of conceptual similarity, including contextualized reasoning and improvement suggestions.
Thus, this article presents and validates a framework based on Retrieval-Augmented Generation (RAG) and Large Language Models (LLMs) as a viable and effective solution to address this originality assessment challenge in the context of the Advanced Digital Systems and Applications course. The implementation demonstrated that the system can efficiently process the documentation of previous projects (reports, code, presentations) to generate structured summaries and create an indexed knowledge base. When querying this base, the RAG system provided originality evaluations for new project proposals that showed a notable correlation (0.87) with the assessments of expert instructors, also identifying the most relevant previous works and justifying the evaluation. A significant aspect of the proposal is its accessibility; the use of an efficient open-source language model such as DeepSeek for summarization, combined with a platform like NotebookLM by Google for knowledge base management and RAG interaction, means that the implementation of this system does not necessarily require a massive investment in proprietary computational resources. This makes it a feasible option for educational institutions that may not have dedicated high-performance computing infrastructure, democratizing access to advanced evaluation support tools.
5.1. Practical Implications
The proposed framework has immediate and specific implications for educational practice, particularly in courses where students are expected to produce original project-based work. Instructors frequently face the challenge of assessing whether a student project genuinely introduces a new idea or merely reuses known structures. This task becomes increasingly difficult as the number of prior works grows and institutional memory becomes fragmented. The RAG-based system presented here provides a scalable and explainable support tool that makes the historical context of a course explicit and accessible. By indexing prior works and contextualizing new proposals semantically, the system allows instructors to make more informed and consistent originality judgments. It is particularly helpful for reducing variability between instructors and for assisting those who are new to a course and lack full exposure to past student work.
From the student perspective, the tool functions as a formative assistant during the ideation phase. It provides feedback about the novelty of an idea, retrieves similar previous projects, and suggests refinements. This promotes self-assessment and iteration, and aligns well with pedagogical models that emphasize autonomy and reflection. Integration into the course workflow is lightweight. The summarization pipeline requires minimal preparation once the summarization prompt has been tailored to the domain, and systems like NotebookLM enable direct interaction without complex setup. For institutions concerned with platform dependency, open-source alternatives exist that allow the same logic to be reproduced locally, as discussed in the Future Lines section.
Ultimately, the system does not replace the human evaluator but augments their capacity to reason with the full historical context. It contributes to a fairer and more transparent originality evaluation process and offers a structured path toward scalable co-evaluation in project-based learning environments.
5.2. Limitations
Although the RAG-based originality evaluation system shows strong alignment with instructor judgment overall, a closer inspection of divergence cases and user feedback reveals important limitations, both conceptual and practical.
A first class of failure involves mismatches between the RAG score and the instructors’ perception of novelty. In one case, a project focused on predictive maintenance was scored 10/10 by instructors, who considered it an entirely novel proposal. However, the RAG system assigned it a score of 8/10, likely due to the presence of thematic overlap with many prior projects involving sensor monitoring and diagnostics. This suggests that the system tends to penalize projects that share vocabulary or components with common patterns in the corpus, even when the conceptual framing is new. Conversely, in the case of a perimeter alarm system using magnetic sensors, the instructors gave a moderate originality score (6/10), seeing no clear precedent, while the RAG system rated it much lower (2/10). The system retrieved a similar prior project based on PIR sensors, interpreting the structural similarity as significant, despite the difference in sensor technology. This shows the system’s capacity to recall structural analogies that instructors may miss, but also exposes its limitation in recognizing meaningful technical distinctions.
These cases illustrate a general pattern: the system is conservative near the upper end of the scale and sensitive to recurring terminology or architectures, sometimes underestimating pedagogically novel work. Qualitative feedback from users reinforces these observations. Several students reported that the tool was useful for shaping ideas but noted that its performance strongly depended on how explicitly the idea was described. If the proposal was vague or underspecified, the system often failed to interpret it meaningfully. Others pointed out that when asked for highly original ideas, the system occasionally responded with suggestions that were too complex or impractical for the scope of the course. These behaviors suggest that the system is effective when properly guided, but may not be well-suited to early-stage ideation without support. Instructors, on the other hand, highlighted that the interface was simple and accessible, and praised the system’s ability to explain its scores via contextual comparisons with past work. However, they also noted that the system tended to be overly strict, rarely assigning top scores even to projects they considered outstanding. These observations point to three key limitations: (1) the system’s reliance on surface-level similarity may obscure recognition of conceptual novelty, (2) its suggestions and evaluations are highly sensitive to input precision, and (3) the scoring model lacks adaptability to the pedagogical goals of each specific course. While these constraints do not invalidate its usefulness, they define the boundary conditions under which the tool should be interpreted as a co-evaluation aid rather than an autonomous assessor.
5.3. Ethical Implications
The use of artificial intelligence in evaluative educational settings raises valid ethical concerns that must be addressed explicitly. In the context of originality assessment, these concerns include transparency of the evaluation criteria, explainability of the decision process, and the potential for incorrect judgments—either in the form of false positives (flagging a n ovel project as derivative) or false negatives (failing to identify unoriginal work). The system described in this work is not intended to operate autonomously, nor to replace human evaluators. It is designed as a human-in-the-loop co-evaluation tool. For students, it functions as a formative assistant: it offers feedback on project ideas during the proposal phase, allowing students to iteratively improve and refine their work. It is not used for grading or ranking, but for guidance.
For instructors, the system provides a second opinion: it retrieves potentially similar past projects and explains its judgment, including rationale and suggestions. However, the final decision about originality remains entirely with the human instructor. This mitigates the risk of unjustified automation and places the tool in a support role, rather than a prescriptive one. In terms of explainability, the system provides not only a similarity score, but also specific comparisons and contextual comments that justify its assessment. This transparency allows users to understand why a score was assigned, challenge its validity, or disregard it if it lacks relevance.
Concerning false judgments, it is important to highlight that such misclassifications can and do occur in human-only assessments as well. The novelty of this system lies in making the basis for the evaluation explicit and reviewable. In cases where the system is overly strict or lenient, its outputs can be compared with instructor judgment, and the discrepancy analyzed. This dual-track approach helps to identify biases, blind spots, and inconsistencies on both sides.
Thus, the ethical design of the system hinges on three pillars:
Non-autonomy: The system should never makes binding decisions on its own.
Explainability: All judgments should be accompanied by transparent justification.
Support for fairness: The system reduces dependence on fallible human memory and helps newcomers to evaluate with the same context as experienced instructors.
We believe that maintaining a human-in-the-loop design, together with full transparency and optionality, allows this system to be used ethically and responsibly in educational environments.
6. Conclusions and Future Work
Regarding future work, there is still much lines to explore. A key aspect is the technical improvement of the system. This includes further fine-tuning of the evaluation models to better align with specific pedagogical criteria, as well as integrating source code similarity analysis tools to complement the textual semantic analysis and gain a more comprehensive view of originality. Additionally, an important strategic objective would be to evolve towards a fully open-source RAG system. While DeepSeek is already open-source, replacing proprietary elements such as NotebookLM with open-source alternatives (e.g., using libraries like LangChain or LlamaIndex along with vector databases such as ChromaDB or FAISS, and open LLMs) would give institutions greater control, transparency, customization, and long-term sustainability, eliminating dependencies on external platforms.
Another fundamental expansion line concerns enriching the knowledge base used by the RAG system. It is crucial to go beyond simply adding more projects from previous years. The proposal is to integrate core course materials, such as lecture notes, fundamental theoretical concepts, and even solutions or statements from mandatory lab practices and exercises. This would transform the RAG system: it would no longer only compare a new proposal to previous final projects, but could also help check if a student is improperly reusing fragments from mandatory practices or if, on the contrary, they are correctly applying the theoretical concepts and techniques learned in class to build their original solution. Evaluating originality in this broader context would allow for valuing not only novelty compared to other projects but also the student’s ability to integrate and apply the core knowledge taught in the course in a creative and independent manner.
Another promising direction for future development is the reimplementation of the retrieval and interaction component using open-source tools. While the current system relies on Google NotebookLM due to its ease of use and integration with institutional infrastructure (licensed through the University of Seville), this dependency may limit long-term reproducibility and cross-institutional deployment. Alternative solutions based on LlamaIndex, ChromaDB, or other local vector database frameworks could be used to replicate the RAG workflow in a fully self-hosted environment. In this setup, the summarization would continue to be performed locally using DeepSeek via Ollama, and a minimal interface layer could be developed to replace the proprietary frontend. Although this would require additional computational infrastructure and engineering effort, it would provide a more sustainable and adaptable foundation for future applications in other educational contexts.
Finally, it remains essential to investigate the actual pedagogical impact of these tools. Longitudinal studies are needed to understand how students interact with the RAG system, whether it modifies their ideation and development strategies, and its real impact on the quality and originality of student projects. The development of more intuitive user interfaces adapted to the academic workflow, as well as the exploration of the applicability of this framework across different courses, educational levels, and disciplines that employ PBL, are necessary steps to validate its robustness and maximize its potential as a tool that supports fairer, more efficient, and formative assessment, driving true innovation in project-based learning.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}