
Inferential Reading Skills in High School: A Study on Comprehension Profiles

 ,
,  , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Materials
2.3. Procedure
2.4. Data Analyses
3. Results
3.1. Descriptive Statistics
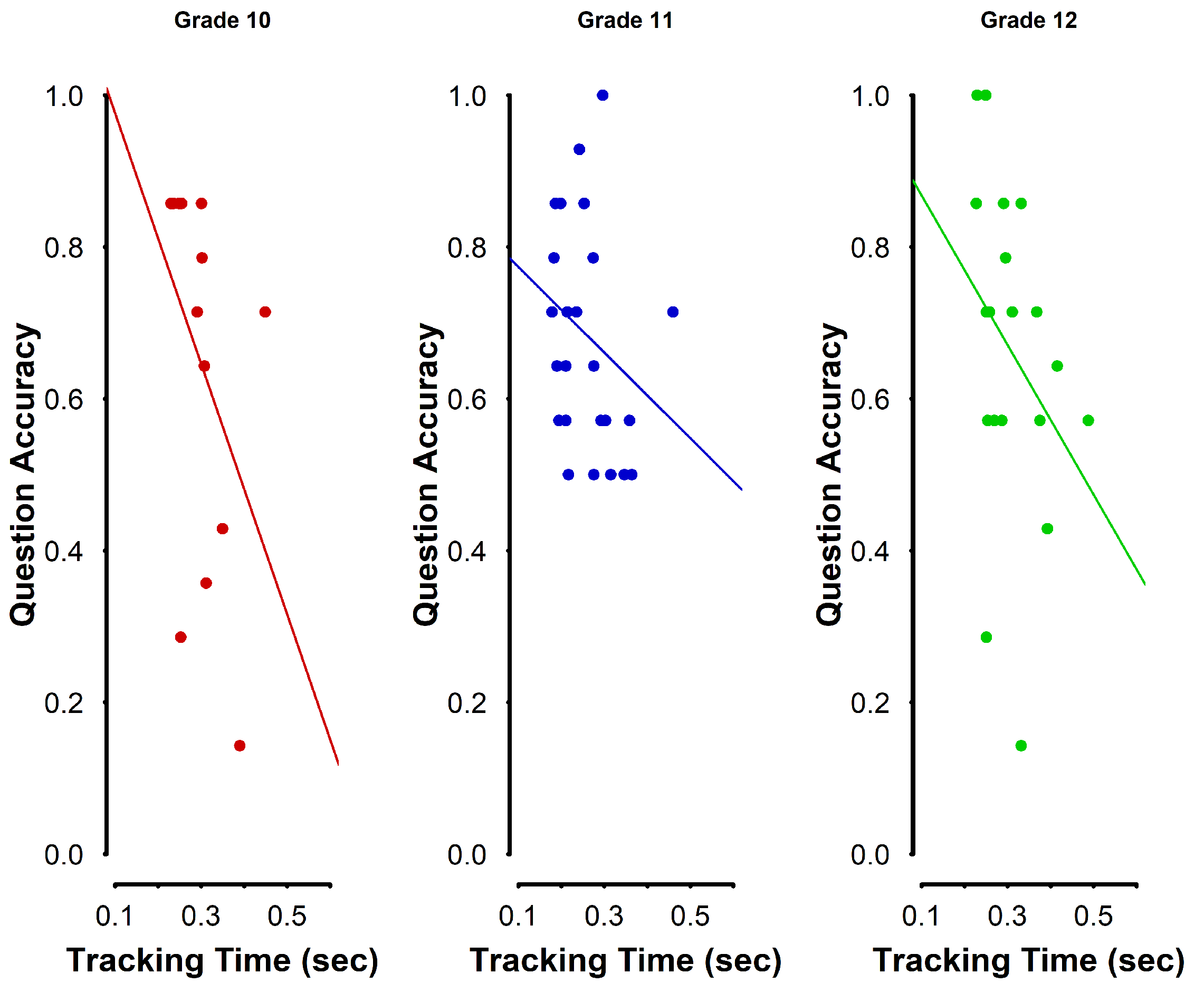
3.2. Reading Profiles (Tracking Times) by Grade Levels
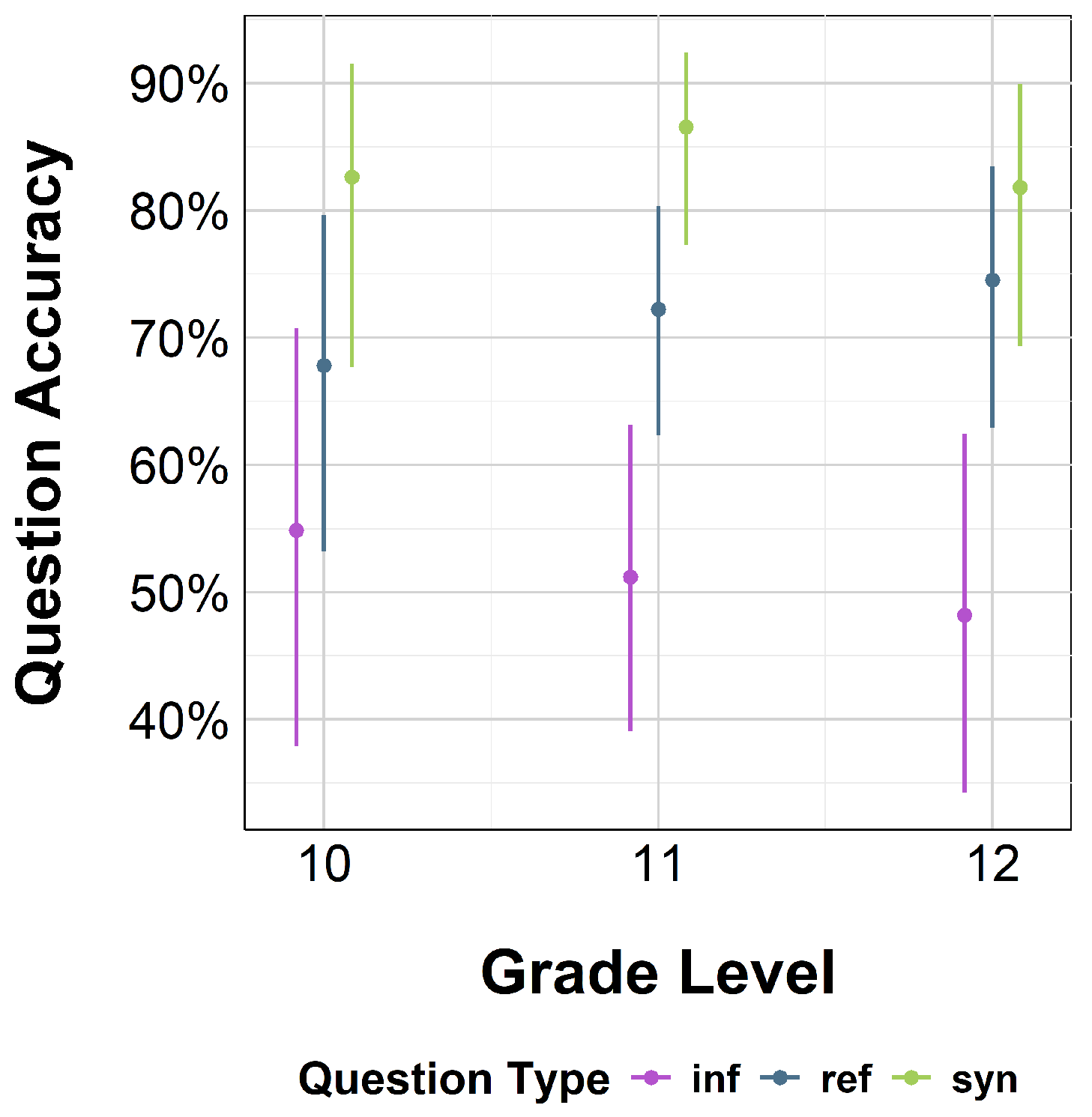
3.3. Reading Comprehension (Question Accuracy)
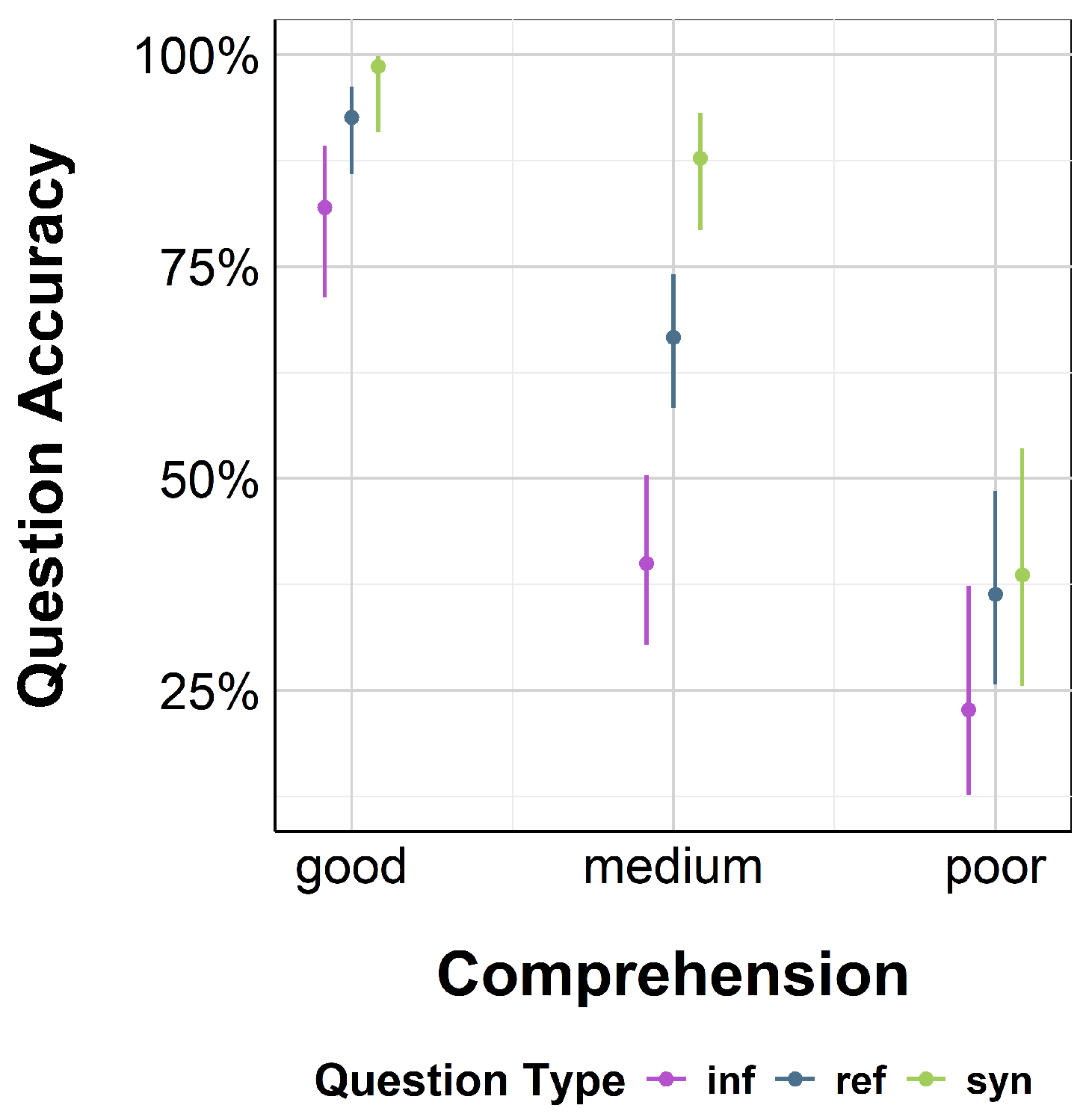
3.4. Results per Comprehension Proficiency
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Text 1 | Text 2 | |
|---|---|---|
| Text Length (words) | 226 | 218 |
| Mean Word Length (letters) | 5.0 | 5.0 |
| Mean Word Log Frequency | 4.1 | 4.1 |
| Type-Token Ratio | 0.63 | 0.60 |
| Lexical Density | 0.53 | 0.55 |
| Part-Of-Speech Type | 12 | 11 |
| Mean Sentence Length (words) | 16.14 | 16.77 |
| Readability index (Flesch Reading Ease) | 55.1 | 44.29 |
Appendix A.1. TEXT 1
Bees like playing with balls too
Even the most dedicated workers allow themselves a break when circumstances permit. We are referring to bumblebees, a particular species of bee. Provided with the opportunity, these insects engage in playing with marbles, appearing to derive great enjoyment from the activity. Play, in fact, seems to represent a beneficial behavior for bees, just as it does for other animals: children, for instance, play football, and young kittens wrestle with one another. But how exactly do these small, winged creatures entertain themselves? This behavior has been the object of scientific investigation, with researchers designing a dedicated arena for observation. On one end, there was the entrance, while on the opposite side stood a container filled with a mixture of pollen and sugar. To reach it, the bees could choose between two distinct paths. The paths were physically separated and both contained small balls. However, in one path, the balls were fixed to the ground, whereas in the other, they were free to roll. The researchers observed that the insects more often chose the path with the balls that could move. And they did it just for the sake of play. Indeed, they could have reached the food more quickly by taking the alternative route; nevertheless, they appeared to prefer grasping the balls with their tiny legs and rolling around with them.
- What does “bumblebees” mean in the text? [SYN]
- bees *
- animals
- beasts
- puppies
- Who or what does “dedicated workers” refer to? [REF]
- the bees *
- the scientists
- the workers
- the animals
- The sentence “Provided with the opportunity, these insects engage in playing with small balls, appearing to derive great enjoyment from the activity” suggests that: [INF]
- bees love to play with small balls *
- bees rarely play because they seldom take a break
- bumblebees, when they can, play marbles but prefer hide and seek
- insects play even if they don’t enjoy it
- In the text, besides the word “marbles,” another word is used to refer to them. Which one? [SYN]
- little balls *
- footballs
- bocce balls
- containers
- According to the text, which sentence best completes: “Bees like playing with the little balls” [INF]
- in fact, they choose the path where the balls roll *
- if they reach the sugar-pollen paste
- but they get bored flying over flowers
- however, they can’t manage to grab them with their legs
- In this sentence from the text, “The researchers observed that the insects more often chose the path with the balls that could move,” who or what is able to move? [REF]
- the balls *
- the researchers
- the insects
- the wheels
- What does “it” refer to in the sentence “And they did it just for the sake of playing”? [REF]
- choosing the path with the moving marbles *
- reaching the food faster
- having fun
- flying over garden flowers
Appendix A.2. TEXT 2
How do parrots talk?
Certain species of birds possess the remarkable ability to mimic the sounds or calls of other animals. Among them, parrots are for sure the most proficient, even imitating the human voice to such an extent that they appear to actually engage in speech. This exceptional ability can be attributed to two primary factors. First, parrots are highly intelligent birds. In addition, they possess a respiratory system that shares certain similarities with that of humans, facilitating their vocalizations. But how are they able to imitate the human voice? To produce their calls, parrots rely on a specialized organ located at the end of their vocal tract. By adjusting the position of their neck, they are able to modify the shape of this vocal channel, which, in turn, allows them to control both the duration and intensity of the sounds they produce, simulating human speech with remarkable accuracy. However, some species of these colorful birds go even further. The grey parrot, for example, is an excellent imitator and is able to associate meaning with the words it repeats in a given language. If trained properly, it can even manage to express full sentences within the context of a conversation. For instance, it can easily respond to a greeting or express gratitude after receiving its favorite food.
- What does “mimic” mean in the text? [SYN]
- simulate *
- modify
- follow
- thank
- What does “them” refer to in the sentence: “Among them, parrots are undoubtedly the most proficient, even imitating the human voice to such an extent that they appear to actually engage in speech”? [REF]
- the animals that have the ability to speak *
- the grey-feathered parrots
- the birds from warm countries
- the parrots that are very intelligent
- Based on the text, which sentence best completes “Parrots are able to imitate the human voice” [INF]
- because they are very intelligent birds *
- but they can’t imitate a whale’s song
- so they come into contact with humans
- even though they have a respiratory system
- In the sentence: “To produce their calls, parrots rely on a specialized organ located at the end of their vocal tract” who or what performs the action of producing? [REF]
- the parrots *
- the organ
- the calls
- the mouth
- In the text, besides the word “calls” another word is used in its place. What is it? [SYN]
- sounds *
- voice
- screeches
- words
- What does the expression “colorful birds” refer to in the text? [REF]
- the parrots *
- the robins
- human beings
- birds in general
- The sentence “If trained properly, it can even manage to express full sentences within the context of a conversation” suggests that: [INF]
- the grey parrot is better than others at imitating the human voice *
- all parrots can easily hold a conversation
- most parrots can be trained
- some birds prefer to sing rather than talk
References
- Albertin, G., Bongioanni, P., Dolciotti, C., Ferro, M., Gagliardi, G., Lento, A., Marzi, C., Nadalini, A., Pirrelli, V., & Tamburini, F. (2024, June 21). Early detection of prodromal stages of cognitive impairment in the Italian elderly population using NLP and AI technologies: The ReMind project. VII International Conference on Clinical Linguistics (CILC2024), Salamanca, Spain. [Google Scholar]
- Arrington, C. N., Kulesz, P. A., Francis, D. J., Fletcher, J. M., & Barnes, M. A. (2014). The contribution of attentional control and working memory to reading comprehension and decoding. Scientific Studies of Reading, 18(5), 325–346. [Google Scholar] [CrossRef]
- Barth, A. E., Barnes, M., Francis, D., Vaughn, S., & York, M. (2015). Inferential processing among adequate and struggling adolescent comprehenders and relations to reading comprehension. Reading and Writing, 28, 587–609. [Google Scholar] [CrossRef] [PubMed]
- Bates, D., Mächler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67(1), 1–48. [Google Scholar] [CrossRef]
- Borella, E., Carretti, B., & Pelegrina, S. (2010). The specific role of inhibition in reading comprehension in good and poor comprehenders. Journal of Learning Disabilities, 43(6), 541–552. [Google Scholar] [CrossRef]
- Brysbaert, M. (2019). How many words do we read per minute? A review and meta-analysis of reading rate. Journal of Memory and Language, 109, 104047. [Google Scholar] [CrossRef]
- Burani, C., Marcolini, S., De Luca, M., & Zoccolotti, P. (2008). Morpheme-based reading aloud: Evidence from dyslexic and skilled Italian readers. Cognition, 108(1), 243–262. [Google Scholar] [CrossRef]
- Cartwright, K. B. (2012). Insights from cognitive neuroscience: The importance of executive function for early reading development and education. Early Education & Development, 23(1), 24–36. [Google Scholar]
- Cartwright, K. B. (2023). Executive skills and reading comprehension: A guide for educators. Guilford publications. [Google Scholar]
- Castles, A., Rastle, K., & Nation, K. (2018). Ending the reading wars: Reading acquisition from novice to expert. Psychological Science in the Public Interest, 19(1), 5–51. [Google Scholar] [CrossRef]
- Catts, H. W. (2018). The simple view of reading: Advancements and false impressions. Remedial and Special Education, 39(5), 317–323. [Google Scholar] [CrossRef]
- Christiansen, M. H., & Chater, N. (2016). The now-or-never bottleneck: A fundamental constraint on language. Behavioral and Brain Sciences, 39, e62. [Google Scholar] [CrossRef]
- Christopher, M. E., Miyake, A., Keenan, J. M., Pennington, B., DeFries, J. C., Wadsworth, S. J., Willcutt, E., & Olson, R. K. (2012). Predicting word reading and comprehension with executive function and speed measures across development: A latent variable analysis. Journal of Experimental Psychology: General, 141(3), 470. [Google Scholar] [CrossRef] [PubMed]
- Clinton-Lisell, V. (2022). Listening ears or reading eyes: A meta-analysis of reading and listening comprehension comparisons. Review of Educational Research, 92(4), 543–582. [Google Scholar] [CrossRef]
- Crepaldi, D., Ferro, M., Marzi, C., Nadalini, A., Pirrelli, V., & Taxitari, L. (2022). Finger movements and eye movements during adults’ silent and oral reading. In Developing language and literacy: Studies in honor of dorit diskin ravid (pp. 443–471). Springer. [Google Scholar]
- Daugaard, H. T., Cain, K., & Elbro, C. (2017). From words to text: Inference making mediates the role of vocabulary in children’s reading comprehension. Reading and Writing, 30, 1773–1788. [Google Scholar] [CrossRef]
- De Luca, M., Barca, L., Burani, C., & Zoccolotti, P. (2008). The effect of word length and other sublexical, lexical and semantic variables on developmental reading deficit. Cognitive and Behavioral Neurology, 21(4), 227–235. [Google Scholar] [CrossRef]
- Elleman, A. M., & Oslund, E. L. (2019). Reading comprehension research: Implications for practice and policy. Policy Insights from the Behavioral and Brain Sciences, 6(1), 3–11. [Google Scholar] [CrossRef]
- Ferro, M., Cappa, C., Giulivi, S., Marzi, C., Nahli, O., Cardillo, F. A., & Pirrelli, V. (2018, October 21–27). Readlet: Reading for understanding. 2018 IEEE 5th International Congress on Information Science and Technology (CiSt) (pp. 1–6), Marrakech, Morocco. [Google Scholar]
- Ferro, M., Marzi, C., Nadalini, A., Taxitari, L., Lento, A., & Pirrelli, V. (2024, May 20–25). Readlet: A dataset for oral, visual and tactile text reading data of early and mature readers. 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) (pp. 13595–13609), Torino, Italy. [Google Scholar]
- Foorman, B. R., Petscher, Y., & Herrera, S. (2018). Unique and common effects of decoding and language factors in predicting reading comprehension in grades 1–10. Learning and Individual Differences, 63, 12–23. [Google Scholar] [CrossRef]
- Frost, R. (2012). Towards a universal model of reading. Behavioral and Brain Sciences, 35(5), 263–279. [Google Scholar] [CrossRef]
- García, J. R., & Cain, K. (2014). Decoding and reading comprehension: A meta-analysis to identify which reader and assessment characteristics influence the strength of the relationship in English. Review of Educational Research, 84(1), 74–111. [Google Scholar] [CrossRef]
- Hall, C., Vaughn, S., Barnes, M. A., Stewart, A. A., Austin, C. R., & Roberts, G. (2020). The effects of inference instruction on the reading comprehension of English learners with reading comprehension difficulties. Remedial and Special Education, 41(5), 259–270. [Google Scholar] [CrossRef]
- Hoover, W. A., & Gough, P. B. (1990). The simple view of reading. Reading and Writing, 2, 127–160. [Google Scholar] [CrossRef]
- Kendeou, P., Van Den Broek, P., Helder, A., & Karlsson, J. (2014). A cognitive view of reading comprehension: Implications for reading difficulties. Learning Disabilities Research & Practice, 29(1), 10–16. [Google Scholar]
- Kincaid, J. P., Fishburne, R. P., Jr., Rogers, R. L., & Chissom, B. S. (1975). Derivation of new readability formulas (automated readability index, fog count and Flesch Reading Ease formula) for navy enlisted personnel. Institute for Simulation and Training. [Google Scholar]
- Kintsch, W. (1988). The role of knowledge in discourse comprehension: A construction-integration model. Psychological Review, 95(2), 163. [Google Scholar] [CrossRef] [PubMed]
- Kuperman, V., Schroeder, S., & Gnetov, D. (2024). Word length and frequency effects on text reading are highly similar in 12 alphabetic languages. Journal of Memory and Language, 135, 104497. [Google Scholar] [CrossRef]
- Kuperman, V., & Van Dyke, J. A. (2011). Effects of individual differences in verbal skills on eye-movement patterns during sentence reading. Journal of Memory and Language, 65(1), 42–73. [Google Scholar] [CrossRef]
- Liu, Y., Reichle, E. D., & Gao, D.-G. (2013). Using reinforcement learning to examine dynamic attention allocation during reading. Cognitive Science, 37(8), 1507–1540. [Google Scholar] [CrossRef]
- Lo, S., & Andrews, S. (2015). To transform or not to transform: Using generalized linear mixed models to analyse reaction time data. Frontiers in Psychology, 6, 1171. [Google Scholar] [CrossRef]
- Lucisano, P., & Piemontese, M. E. (1988). Gulpease: Una formula per la predizione della leggibilita di testi in lingua italiana. Scuola e Città, 3, 110–124. [Google Scholar]
- Marzi, C., Narzisi, A., Milone, A., Masi, G., & Pirrelli, V. (2022). Reading behaviors through patterns of finger-tracking in Italian children with autism spectrum disorder. Brain Sciences, 12(10), 1316. [Google Scholar] [CrossRef]
- Nadalini, A., Marzi, C., Ferro, M., Taxitari, L., Lento, A., Crepaldi, D., & Pirrelli, V. (2023). Eye-voice and finger-voice spans in adults’ oral reading of connected texts: Implications for reading research and assessment. The Mental Lexicon, 18(3), 366–400. [Google Scholar] [CrossRef]
- Oslund, E. L., Clemens, N. H., Simmons, D. C., & Simmons, L. E. (2018). The direct and indirect effects of word reading and vocabulary on adolescents’ reading comprehension: Comparing struggling and adequate comprehenders. Reading and Writing, 31, 355–379. [Google Scholar] [CrossRef]
- Peng, P., Zhang, Z., Wang, W., Lee, K., Wang, T., Wang, C., Luo, J., & Lin, J. (2022). A meta-analytic review of cognition and reading difficulties: Individual differences, moderation, and language mediation mechanisms. Psychological Bulletin, 148(3-4), 227. [Google Scholar] [CrossRef]
- Perfetti, C., & Stafura, J. (2014). Word knowledge in a theory of reading comprehension. Scientific Studies of Reading, 18(1), 22–37. [Google Scholar] [CrossRef]
- Petscher, Y., Cabell, S. Q., Catts, H. W., Compton, D. L., Foorman, B. R., Hart, S. A., Lonigan, C. J., Phillips, B. M., Schatschneider, C., Steacy, L. M., Terry, N. P., & Wagner, R. K. (2020). How the science of reading informs 21st-century education. Reading Research Quarterly, 55, S267–S282. [Google Scholar] [CrossRef]
- Pérez, A. I., Paolieri, D., Macizo, P., & Bajo, T. (2014). The role of working memory in inferential sentence comprehension. Cognitive Processing, 15, 405–413. [Google Scholar] [CrossRef]
- Rayner, K. (1998). Eye movements in reading and information processing: 20 years of research. Psychological Bulletin, 124(3), 372. [Google Scholar] [CrossRef]
- Rayner, K., & Reichle, E. D. (2010). Models of the reading process. Wiley Interdisciplinary Reviews: Cognitive Science, 1(6), 787–799. [Google Scholar] [CrossRef] [PubMed]
- R Core Team. (2024). R: A language and environment for statistical computing [Computer software manual]. R Core Team. Available online: https://www.R-project.org/ (accessed on 13 May 2025).
- Rice, M., & Wijekumar, K. K. (2024). Inference skills for reading: A meta-analysis of instructional practices. Journal of Educational Psychology, 116(4), 569–589. [Google Scholar] [CrossRef]
- Royeras, J., & Sumayo, G. (2024). Vocabulary knowledge and inferential reading comprehension of senior high school students: A Descriptive-Correlational Inquiry. East Asian Journal of Multidisciplinary Research, 3(3), 10–55927. [Google Scholar] [CrossRef]
- Samuelson, L. K. (2021). Toward a precision science of word learning: Understanding individual vocabulary pathways. Child Development Perspectives, 15(2), 117–124. [Google Scholar] [CrossRef]
- Silagi, M. L., Radanovic, M., Conforto, A. B., Mendonça, L. I. Z., & Mansur, L. L. (2018). Inference comprehension in text reading: Performance of individuals with right-versus left-hemisphere lesions and the influence of cognitive functions. PLoS ONE, 13(5), e0197195. [Google Scholar] [CrossRef]
- Singer, M., & Leon, J. (2007). Psychological studies of higher language processes: Behavioral and empirical approaches. In Higher level language processes in the brain: Inference and comprehension processes (pp. 9–25). Lawrence Erlbaum Associates Publishers. [Google Scholar]
- Staub, A., & Rayner, K. (2007). Eye movements and on-line comprehension processes. The Oxford Handbook of Psycholinguistics, 327, 342. [Google Scholar]
- Taxitari, L., Cappa, C., Ferro, M., Marzi, C., Nadalini, A., & Pirrelli, V. (2021, June 5–12). Using mobile technology for reading assessment. 2020 6th IEEE congress on information science and technology (CiSt) (pp. 302–307), Agadir-Essaouira, Morocco. [Google Scholar]
- Tighe, E. L., & Schatschneider, C. (2016). Examining the relationships of component reading skills to reading comprehension in struggling adult readers: A meta-analysis. Journal of Learning Disabilities, 49(4), 395–409. [Google Scholar] [CrossRef] [PubMed]
- Tremblay, A., Derwing, B., Libben, G., & Westbury, C. (2011). Processing advantages of lexical bundles: Evidence from self-paced reading and sentence recall tasks. Language Learning, 61(2), 569–613. [Google Scholar] [CrossRef]
- Verhoeven, L., Reitsma, P., & Siegel, L. S. (2011). Cognitive and linguistic factors in reading acquisition. Reading and Writing, 24, 387–394. [Google Scholar] [CrossRef]
- Yeari, M., & Van den Broek, P. (2011). A cognitive account of discourse understanding and discourse interpretation: The landscape model of reading. Discourse Studies, 13(5), 635–643. [Google Scholar] [CrossRef]


| Text 1 | Text 2 | |
|---|---|---|
| Text Length (words) | 211 | 210 |
| Mean Word Length (letters) | 4.78 | 4.88 |
| Mean Word Log Frequency | 4.34 | 4.32 |
| Type-Token Ratio | 0.66 | 0.69 |
| Lexical Density | 0.52 | 0.58 |
| Part-Of-Speech Type | 11 | 10 |
| Mean Sentence Length (words) | 16.23 | 16.15 |
| Readability index (Gulpease) | 58.2 | 57.0 |
| Tracking Time ∼ GradeLevel * (poly(QuestionAccuracy, 2) + Length + Frequency) + (1|Token) + (1|Subject) | ||||
|---|---|---|---|---|
| Estimate | Std. Error | t-Value | p-Value | |
| Intercept | 4.81 | 0.22 | 21.75 | <0.001 |
| gradeLevel_11th | 0.59 | 0.22 | 2.67 | 0.008 |
| gradeLevel_12th | 0.03 | 0.26 | 0.14 | 0.893 |
| poly(question accuracy,2)1 | 32.50 | 6.28 | 5.18 | <0.001 |
| poly(question accuracy,2)2 | 14.04 | 6.68 | 2.10 | 0.036 |
| Estimate | Std. Error | t-Value | p-Value | |
| Length | −1.27 | 0.09 | −14.25 | <0.001 |
| Frequency | 0.25 | 0.10 | 2.48 | 0.013 |
| gradeLevel_11th: poly(question accuracy,2)1 | −1.86 | 8.81 | −0.21 | 0.832 |
| gradeLevel_12th: poly(question accuracy,2)1 | −14.43 | 7.40 | −1.95 | 0.050 |
| gradeLevel_11th: poly(question accuracy,2)2 | −43.26 | 7.46 | −5.80 | <0.001 |
| gradeLevel_12th: poly(question accuracy,2)2 | −18.79 | 8.17 | −2.30 | 0.021 |
| gradeLevel_11th:Length | −0.05 | 0.03 | −1.93 | 0.053 |
| gradeLevel_12th:Length | 0.08 | 0.03 | 3.22 | 0.001 |
| gradeLevel_11th:Frequency | −0.09 | 0.04 | −2.21 | 0.027 |
| gradeLevel_12th:Frequency | −0.07 | 0.03 | −2.17 | 0.030 |
| R2 = 0.989 | ||||
| Question Accuracy ∼ GradeLevel * QuestionType + (1|Subject) | ||||
|---|---|---|---|---|
| Estimate | Std. Error | z-Value | p-Value | |
| Intercept | 0.20 | 0.36 | 0.54 | 0.59 |
| gradeLevel_11th | −0.15 | 0.45 | −0.33 | 0.74 |
| gradeLevel_12th | −0.27 | 0.48 | −0.56 | 0.57 |
| questionType_ref | 0.55 | 0.41 | 1.33 | 0.18 |
| questionType_syn | 1.37 | 0.50 | 2.77 | 0.01 |
| gradeLevel_11th:questionType_ref | 0.36 | 0.51 | 0.70 | 0.48 |
| gradeLevel_12th:questionType_ref | 0.60 | 0.55 | 1.10 | 0.27 |
| gradeLevel_11th:questionType_syn | 0.45 | 0.62 | 0.73 | 0.46 |
| gradeLevel_12th:questionType_syn | 0.21 | 0.64 | 0.33 | 0.74 |
| R2 = 0.257 | ||||
| Tracking Time ∼ Comprehension * (Length + Frequency) + (1|Token) + (1|Subject) | ||||
|---|---|---|---|---|
| Estimate | Std. Error | z-Value | p-Value | |
| Intercept | 5.31 | 0.17 | 30.50 | <0.001 |
| Comprehension_medium | −0.46 | 0.20 | −2.34 | 0.019 |
| Comprehension_poor | −0.50 | 0.25 | −1.99 | 0.047 |
| Length | −1.18 | 0.08 | −14.93 | <0.001 |
| Frequency | 0.14 | 0.09 | 1.51 | 0.131 |
| Comprehension_medium:Length | 0.12 | 0.03 | 4.36 | <0.001 |
| Comprehension_poorLength | 0.19 | 0.03 | 5.77 | <0.001 |
| Comprehension_medium:Frequency | 0.01 | 0.04 | 0.18 | 0.85 |
| Comprehension_poorFrequency | 0.17 | 0.04 | 4.03 | <0.001 |
| R2 = 0.986 | ||||
| Question Accuracy ∼ Comprehension * QuestionType + (1|Subject) | ||||
|---|---|---|---|---|
| Estimate | Std. Error | z-Value | p-Value | |
| Intercept | 1.51 | 0.31 | 4.94 | <0.001 |
| Comprehension_medium | −1.91 | 0.37 | −5.12 | <0.001 |
| Comprehension_poor | −2.74 | 0.47 | −5.79 | <0.001 |
| questionType_ref | 1.01 | 0.48 | 2.12 | 0.034 |
| questionType_syn | 2.75 | 1.05 | 2.61 | 0.009 |
| Comprehension_medium:questionType_ref | 0.09 | 0.56 | 0.15 | 0.878 |
| Comprehension_poorquestionType_ref | −0.35 | 0.65 | −0.54 | 0.591 |
| Comprehension_medium:questionType_syn | −0.37 | 1.12 | −0.33 | 0.739 |
| Comprehension_poorquestionType_syn | −1.99 | 1.15 | −1.72 | 0.085 |
| R2 = 0.428 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nadalini, A.; Marzi, C.; Ferro, M.; Cinini, A.; Cutugno, P.; Chiarella, D. Inferential Reading Skills in High School: A Study on Comprehension Profiles. Educ. Sci. 2025, 15, 654. https://doi.org/10.3390/educsci15060654
Nadalini A, Marzi C, Ferro M, Cinini A, Cutugno P, Chiarella D. Inferential Reading Skills in High School: A Study on Comprehension Profiles. Education Sciences. 2025; 15(6):654. https://doi.org/10.3390/educsci15060654
Chicago/Turabian StyleNadalini, Andrea, Claudia Marzi, Marcello Ferro, Alessandra Cinini, Paola Cutugno, and Davide Chiarella. 2025. "Inferential Reading Skills in High School: A Study on Comprehension Profiles" Education Sciences 15, no. 6: 654. https://doi.org/10.3390/educsci15060654
APA StyleNadalini, A., Marzi, C., Ferro, M., Cinini, A., Cutugno, P., & Chiarella, D. (2025). Inferential Reading Skills in High School: A Study on Comprehension Profiles. Education Sciences, 15(6), 654. https://doi.org/10.3390/educsci15060654