
Topic Level Visualization of Student Enrollment Records in a Computer Science Curriculum



Abstract
1. Introduction
2. Background
- Show topic level detail of how courses contribute to a complete program of study
- Enable individual students’ course enrollment to be visualized and compared
- Be flexible enough to accommodate changes in course offerings or different curriculum maps
- Perform the mapping and visualization in a way that is largely automated to reduce the manual burden of producing the visualizations
- What can topic level visualizations show when plotted over a complete program of study?
- How can topic level visualizations be combined with student registration data to create individualized maps of topic coverage?
3. Materials and Methods
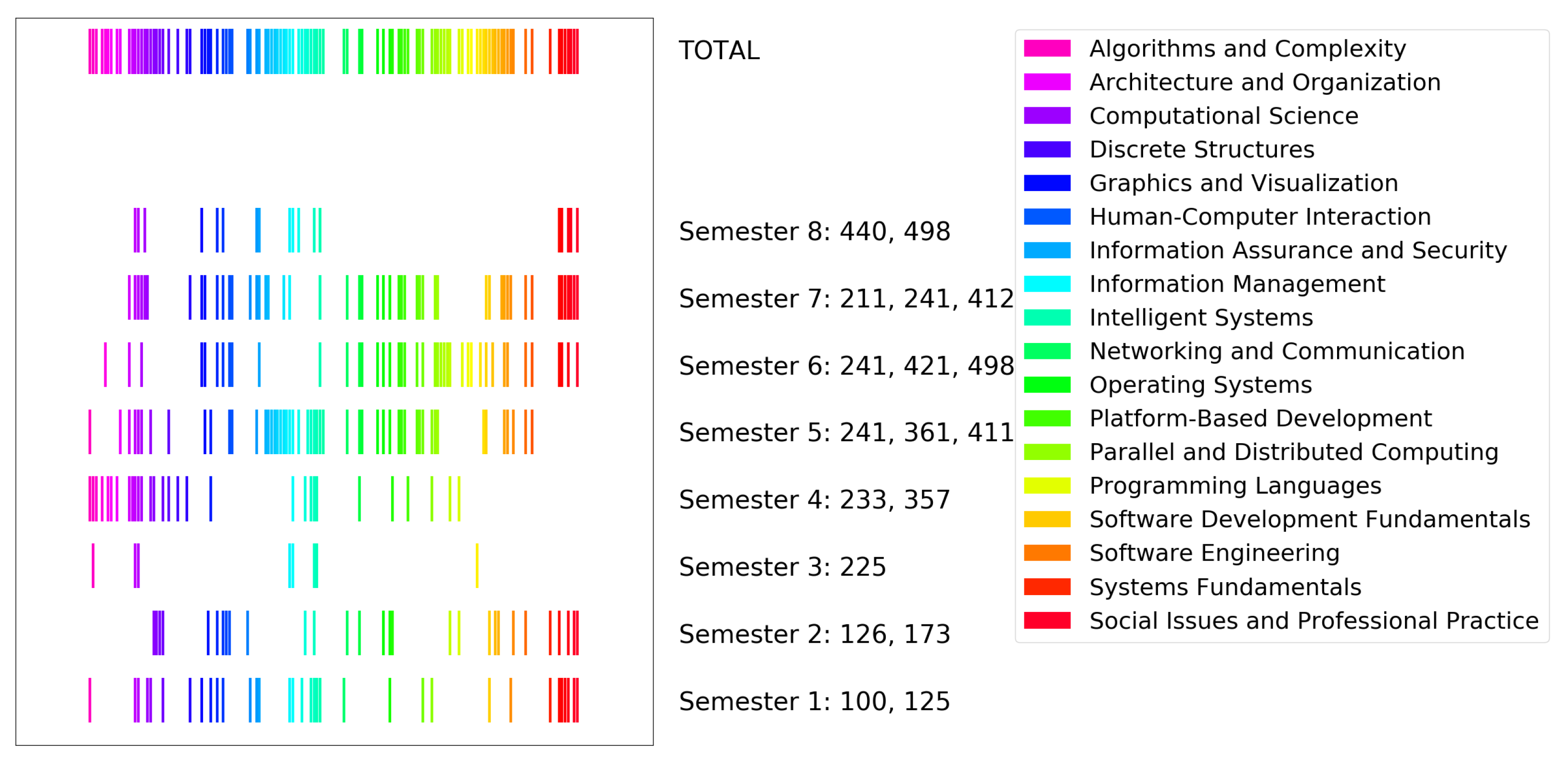
3.1. CS2013 Data
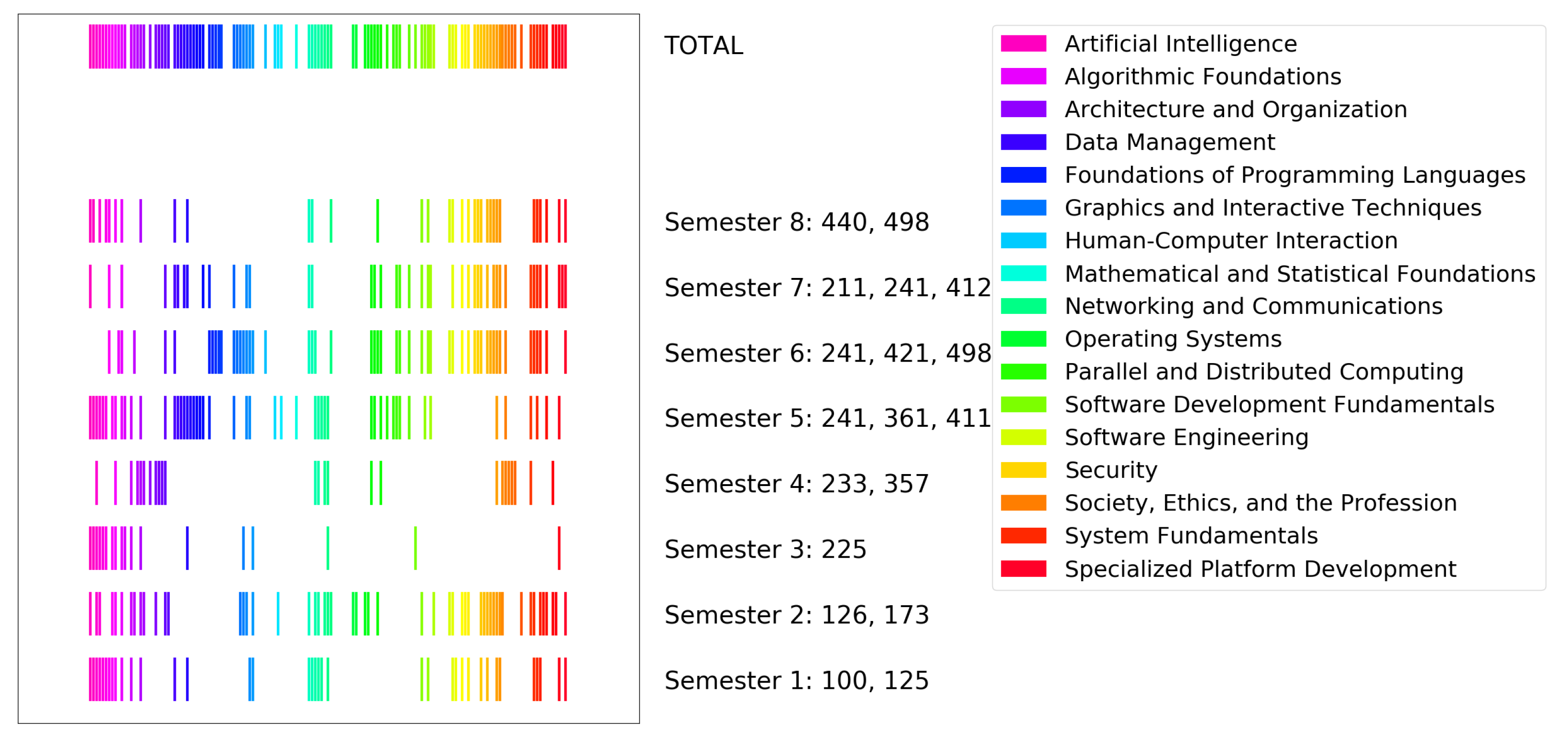
3.2. CS2023 Data
3.3. Course Description and Enrollment Data
3.4. Computational Approach
| Algorithm 1: Map preprocessing. |
 |
| Algorithm 2: Align courses to map. |
 |
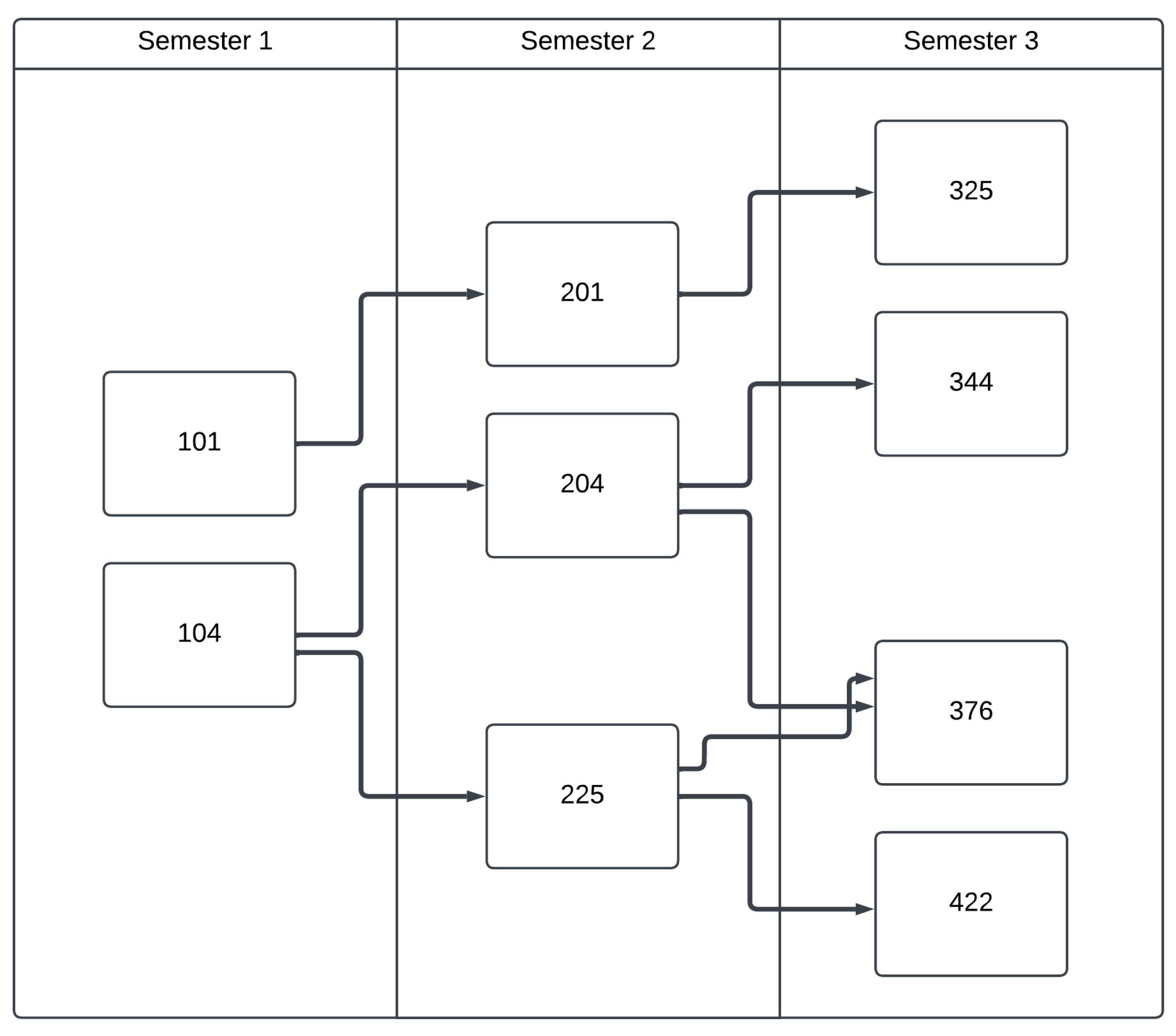
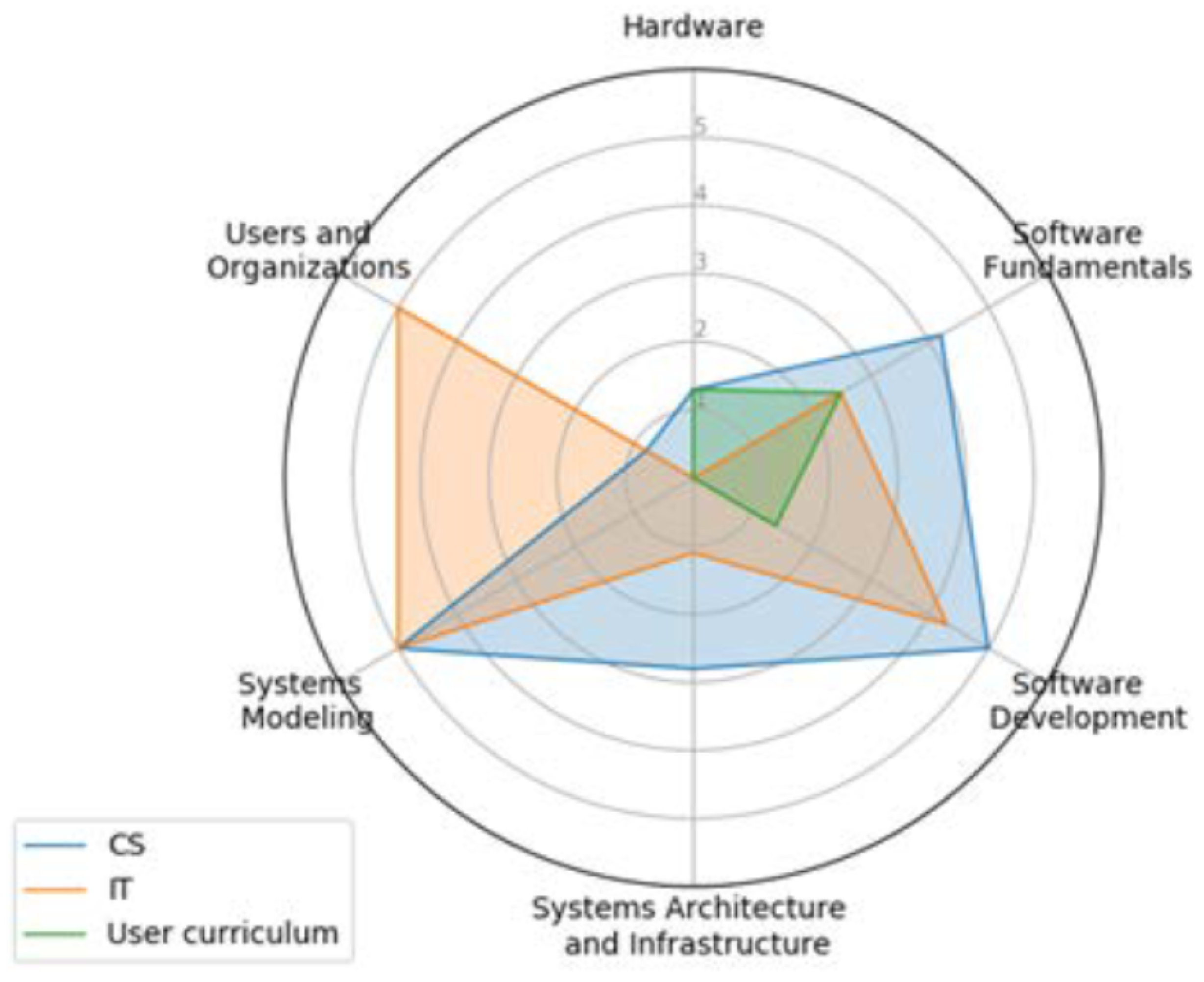
3.5. Visualization
4. Results
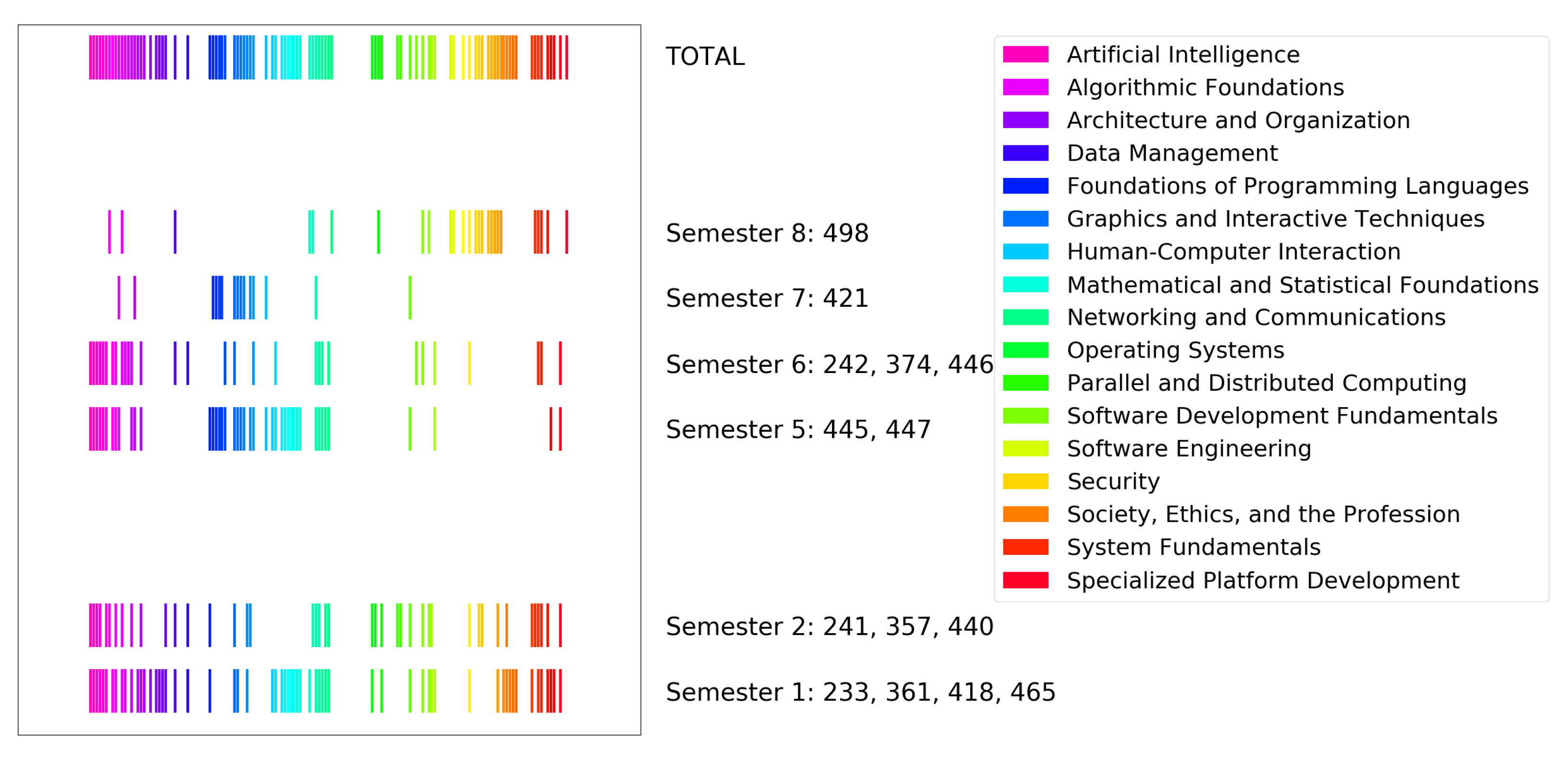
4.1. Visualization
4.2. Quality of Alignment
4.3. Potential Mapping Using LLM’s
“Given the attached list of topics, could you please try and tell me which topics match the following text? ‘Fundamentals of computer architecture: digital logic design, working up from the logic gate level to understand the function of a simple computer; machine-level programming to understand implementation of high-level languages; performance models of modern computer architectures to enable performance optimization of software; hardware primitives for parallelism and security.’”
5. Discussion
Limitations
6. Conclusions
Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ACM | Association of Computing Machinery |
| NLP | Natural Language Processing |
| LLM | Large Language Model |
| HPK | High Prior Knowledge |
| LPK | Low Prior Knowledge |
| ILO | Illustrative Learning Outcome |
| W2V | Word2Vec |
| OOV | Out of Vocabulary |
| WMD | Word Mover Distance |
Appendix A
Appendix A.1. CS2013 Topic Map
Appendix A.2. CS2023 Topic Map
Appendix B. Claude 3.5 Sonnet Mapping Computer Architecture Course Description Text to the CS2023 Topic Map
- “digital logic design, working up from the logic gate level” matches:
- -
- Digital Logic and Digital Systems
- “understand the function of a simple computer” and “machine-level programming” matches:
- -
- Assembly Level Machine Organization
- -
- Machine-Level Data Representation
- -
- Functional Organization
- “performance models of modern computer architectures to enable performance optimization” matches:
- -
- Performance and Energy Efficiency
- -
- Systems Execution and Memory Model
- “hardware primitives for parallelism and security” matches:
- -
- Parallel and Distributed Computing
- -
- Secure Processor Architectures
- -
- Memory Hierarchy
- -
- Interfacing and Communication
- Digital Logic and Digital Systems
- Machine-Level Data Representation
- Assembly Level Machine Organization
- Functional Organization
- Performance and Energy Efficiency
- Secure Processor Architectures
- Memory Hierarchy
- Interfacing and Communication
References
- Amadieu, F., van Gog, T., Paas, F., Tricot, A., & Mariné, C. (2009). Effects of prior knowledge and concept-map structure on disorientation, cognitive load, and learning. Learning and Instruction, 19(5), 376–386. [Google Scholar] [CrossRef]
- Anthropic. (2024). Claude. (Large Language Model). Available online: https://anthropic.com/claude (accessed on 4 December 2024).
- Arvai, K. (2018). kneed: Knee-point detection in Python. Available online: https://github.com/arvkevi/kneed (accessed on 5 May 2024).
- Assiri, A., AL-Malaise, A., & Brdesee, H. (2020). From traditional to intelligent academic advising: A systematic literature review of e-academic advising. IJACSA, 11(4), 507–517. [Google Scholar] [CrossRef]
- Asudani, D. S., Nagwani, N. K., & Singh, P. (2023). Impact of word embedding models on text analytics in deep learning environment: A review. Artificial Intelligence Review, 56(9), 10345–10425. [Google Scholar] [CrossRef]
- Bird, S., Klein, E., & Loper, E. (2009). Natural language processing with Python. O’Reilly. [Google Scholar]
- Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. Journal of Machine Learning Research, 3, 993–1022. [Google Scholar]
- CC2020 Task Force. (2020a). Computing curricula 2020: Paradigms for global computing education. ACM. [Google Scholar] [CrossRef]
- CC2020 Task Force. (2020b). Computing curricula 2020: Paradigms for global computing education. Appendix G. [Google Scholar]
- Clemmons, A. W., Donovan, D. A., Theobald, E. J., & Crowe, A. J. (2022). Using the intended–enacted–experienced curriculum model to map the vision and change core competencies in undergraduate biology programs and courses. LSE, 21(1), ar6. [Google Scholar] [CrossRef] [PubMed]
- Efstathiou, V., Chatzilenas, C., & Diomidis, S. (2018, March). Word embeddings for the software engineering domain. Zenodo. [Google Scholar] [CrossRef]
- Ervin, L., Carter, B., & Robinson, P. (2013). Curriculum mapping: Not as straightforward as it sounds. Journal of Vocational Education and Training, 65(3), 309–318. [Google Scholar] [CrossRef]
- Falegnami, A., Romano, E., & Tomassi, A. (2024). The emergence of the GreenSCENT competence framework: A constructivist approach: The GreenSCENT theory. In The european green deal in education (p. 13). Routledge. [Google Scholar]
- Francis, W. N., & Kucera, H. (1979). Brown corpus manual. Available online: http://clu.uni.no/icame/manuals/BROWN/INDEX.HTM (accessed on 5 May 2024).
- Ikuta, T., & Gotoh, Y. (2014). Development of visualization of learning outcomes using curriculum mapping. In D. G. Sampson, D. Ifenthaler, J. M. Spector, & P. Isaias (Eds.), Digital systems for open access to formal and informal learning (pp. 69–82). Springer International Publishing. [Google Scholar] [CrossRef]
- Isenberg, T., Isenberg, P., Chen, J., Sedlmair, M., & Möller, T. (2013). A systematic review on the practice of evaluating visualization. IEEE Transactions on Visualization and Computer Graphics, 19(12), 2818–2827. [Google Scholar] [CrossRef] [PubMed]
- Jelodar, H., Wang, Y., Yuan, C., Feng, X., Jiang, X., Li, Y., & Zhao, L. (2019). Latent Dirichlet allocation (LDA) and topic modeling: Models, applications, a survey. Multimedia Tools and Applications, 78(11), 15169–15211. [Google Scholar] [CrossRef]
- Kantrowitz, M. (1995). Names corpus. Available online: http://www.cs.cmu.edu/afs/cs/project/ai-repository/ai/areas/nlp/corpora/names/readme.txt (accessed on 5 May 2024).
- Kinariwala, S., & Deshmukh, S. (2023). Short text topic modelling using local and global word-context semantic correlation. Multimedia Tools and Applications, 82(17), 26411–26433. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A. N., Raj, R. K., Aly, S. G., Anderson, M. D., Becker, B. A., Blumenthal, R. L., Eaton, E., Epstein, S. L., Goldweber, M., Jalote, P., Lea, D., Oudshoorn, M., Pias, M., Reiser, S., Servin, C., Simha, R., Winters, T., & Xiang, Q. (2024). Computer science curricula 2023. ACM. [Google Scholar] [CrossRef]
- Lam, B. H., & Tsui, K. T. (2016). Curriculum mapping as deliberation—Examining the alignment of subject learning outcomes and course curricula. Studies in Higher Education, 41(8), 1371–1388. [Google Scholar] [CrossRef]
- Levy, O., & Goldberg, Y. (2014, June). Linguistic Regularities in Sparse and Explicit Word Representations. In R. Morante, & S. W.-t. Yih (Eds.), Proceedings of the eighteenth conference on computational natural language learning (pp. 171–180). Association for Computational Linguistics. [Google Scholar] [CrossRef]
- Newman-Griffis, D., & Fosler-Lussier, E. (2017). Second-order word embeddings from nearest neighbor topological features. arXiv. [Google Scholar] [CrossRef]
- Nooralahzadeh, F., Øvrelid, L., & Lønning, J. T. (2018). Evaluation of Domain-specific Word Embeddings using Knowledge Resources. In N. Calzolari, K. Choukri, C. Cieri, T. Declerck, S. Goggi, K. Hasida, H. Isahara, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, S. Piperidis, & T. Tokunaga (Eds.), Proceedings of the eleventh international conference on language resources and evaluation (LREC 2018) (pp. 1438–1445). European Language Resources Association (ELRA). Available online: https://aclanthology.org/L18-1228/ (accessed on 14 January 2025).
- OpenAI. (2024). Chatgpt: A conversational AI model. Available online: https://openai.com/chatgpt (accessed on 4 December 2024).
- Rawle, F., Bowen, T., Murck, B., & Hong, R. (2017). Curriculum mapping across the disciplines: Differences, approaches, and strategies. CELT, 10, 75–88. [Google Scholar] [CrossRef]
- Rehurek, R., & Sojka, P. (2011). Gensim–python framework for vector space modelling. NLP Centre, Faculty of Informatics, Masaryk University, Brno, Czech Republic, 3(2), 45–50. [Google Scholar]
- Řehůřek, R., & Sojka, P. (2010). Software framework for topic modelling with large corpora. University of Malta. Available online: https://is.muni.cz/publication/884893/en/Software-Framework-for-Topic-Modelling-with-Large-Corpora/Rehurek-Sojka (accessed on 10 June 2022).
- Schutte, K., Line, D., & McCullick, C. (2019). Using curriculum mapping and visualization to maximize effective change. AIJ, 8(2), 81–93. [Google Scholar] [CrossRef]
- Su, M. T., Tempero, E., Hosking, J., & Grundy, J. (2012, August 20–24). A study of architectural information foraging in software architecture documents [Conference session]. 2012 Joint Working IEEE/IFIP Conference on Software Architecture and European Conference on Software Architecture (pp. 141–150), Helsinki, Finland. [Google Scholar] [CrossRef]
- Takada, S., Cuadros-Vargas, E., Impagliazzo, J., Gordon, S., Marshall, L., Topi, H., van der Veer, G., & Waguespack, L. (2020). Toward the visual understanding of computing curricula. Education and Information Technologies, 25(5), 4231–4270. [Google Scholar] [CrossRef]
- The Joint Task Force on Computing Curricula & Association for Computing Machinery and IEEE Computer Society. (2013). Computer science curricula 2013: Curriculum guidelines for undergraduate degree programs in computer science. Association for Computing Machinery. [Google Scholar]
- Zhao, G., Liu, Y., Zhang, W., & Wang, Y. (2018, January 13–15). TFIDF based feature words extraction and topic modeling for short text [Conference session]. 2018 2nd International Conference on Management Engineering, Software Engineering and Service Sciences (pp. 188–191), Wuhan, China. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Element | Description | Example Item |
|---|---|---|
| CS Core | Must know topics; kept to a minimum | Complexity |
| KA Core | Topics for in-depth study | Formal Recursive Analysis |
| Non-core | Elective topics | Quantum Computation |
| ILOs | Descriptive student activities, results, or values | Explain examples of NP–complete problems. |
| Trend | Explanation |
|---|---|
| Special topics and independent study courses produce spurious map | Thesis research, Seminar courses, Individual study etc. … cannot be mapped without better data |
| More detailed descriptions yield better results | The more specific the language (eigenvalues, vertex, combinatorics, …) vs. (algorithm, topics, methods, …) |
| WMD scores tended to be lower (0.3–0.7) for better matches | e.g., Course: “Probability and Statistics” top 2: Statistics (0.52), Probability (0.55) vs. “Special Topics” top 2: Teamwork (0.85), Evaluating the Design (0.86) |
| Some matches appear logical without direct evidence | For example, course “Database Systems” matched to topic “NoSQL Systems” which is reasonable but may not actually be covered as it was not listed explicitly in the course description |
| Several topics over- or under-matched courses | e.g., Topic: “Quantum Architectures” matched 40% of courses, likely because it was defined using many generic terms like: “principle, axiom, measurement, computation, state, theorem” and few specific terms like: “qubit, entanglement, quantum” |
| Model | Topics Identified |
|---|---|
| Chat-GPT 4 | None (did not compute) |
| Claude 3.5 Sonnet | Digital Logic and Digital Systems |
| Machine-Level Data Representation | |
| Assembly Level Machine Organization | |
| Functional Organization | |
| Performance and Energy Efficiency | |
| Secure Processor Architectures | |
| Memory Hierarchy | |
| Interfacing and Communication | |
| Our Method | Heterogeneous Architectures |
| System Fundamentals: Basic Concepts | |
| Overview of Computer Systems | |
| Performance and Energy Efficiency | |
| Assembly Level Machine Organization | |
| Performance Evaluation | |
| Embedded Platforms | |
| Functional Organization | |
| Principles of Operating Systems | |
| Common Aspects/Shared Concerns | |
| Sustainability Issues | |
| Computing History | |
| Resource Management | |
| System Performance | |
| Scheduling | |
| Digital Logic and Digital Systems | |
| Interfacing and Communication |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bethke, E.; Amos, J.R. Topic Level Visualization of Student Enrollment Records in a Computer Science Curriculum. Educ. Sci. 2025, 15, 614. https://doi.org/10.3390/educsci15050614
Bethke E, Amos JR. Topic Level Visualization of Student Enrollment Records in a Computer Science Curriculum. Education Sciences. 2025; 15(5):614. https://doi.org/10.3390/educsci15050614
Chicago/Turabian StyleBethke, Eliot, and Jennifer R. Amos. 2025. "Topic Level Visualization of Student Enrollment Records in a Computer Science Curriculum" Education Sciences 15, no. 5: 614. https://doi.org/10.3390/educsci15050614
APA StyleBethke, E., & Amos, J. R. (2025). Topic Level Visualization of Student Enrollment Records in a Computer Science Curriculum. Education Sciences, 15(5), 614. https://doi.org/10.3390/educsci15050614