
Sequence Analysis-Enhanced AI: Transforming Interactive E-Book Data into Educational Insights for Teachers




Abstract
1. Introduction
2. Literature Review
2.1. Potential of Generative AI in Education
2.2. Sequence Analysis as a Visualization Tool
3. Methodology
3.1. Overall Approach: Co-Design
3.2. Design of CustomGPT
3.3. Description of Opiq Environment
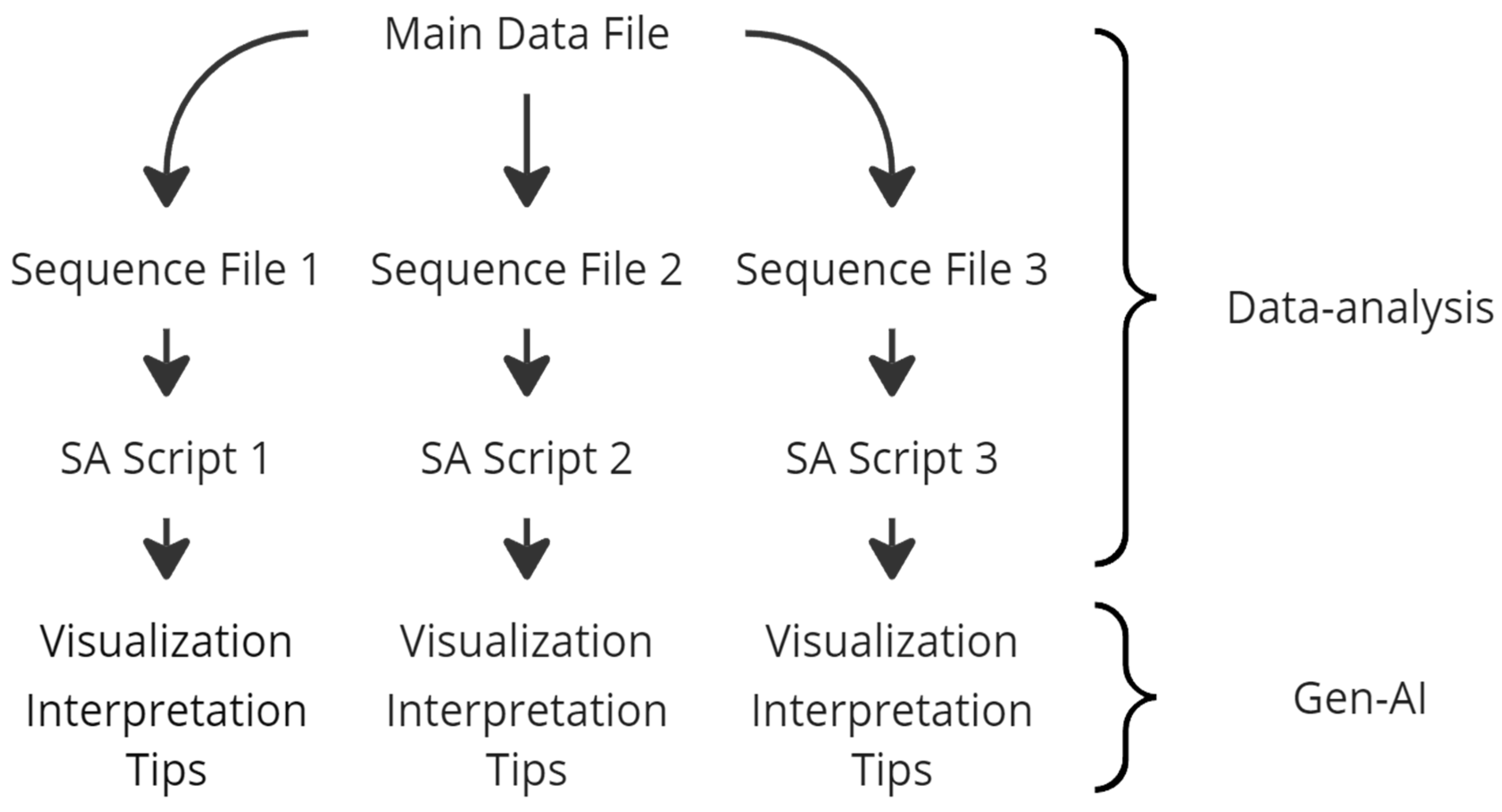
3.4. Data Collection and Analysis
4. Results
4.1. Opinions on the Interactive E-Books’ Environment
4.2. Opinions on the Process of Students’ Interaction
4.3. Opinions on the Design and Functionality of the Developed CustomGPT
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Features of the Test-Data
- Student ID: A unique identifier for each student, allowing for the tracking of individual interaction patterns over time;
- TimeCode: A timestamp indicating the exact date and time when each interaction occurred. This column is crucial for analyzing temporal patterns in Opiq usage;
- Action: Describes the type of activity the student engaged in, such as watching videos, reading materials, completing exercises, or taking tests. This information is important for deriving typical sessions based on dominant activities and their order;
- Score: The results of assessments, representing the correctness of students’ answers. Scores range from 0 to 100 as it is in the Opiq environment.
Appendix B. Features of the Scripts for Sequence Analysis
- pandas: for data manipulation and analysis;
- numpy: for numerical operations;
- matplotlib.pyplot: for plotting and visualization;
- scipy.cluster.hierarchy: for performing hierarchical clustering;
- scipy.spatial.distance: for calculating pairwise distances between sequences.

Appendix C. Description of Various Analysis Options Available in the CustomGPT and Examples of Interpretation and Tips Provided by the CustomGPT
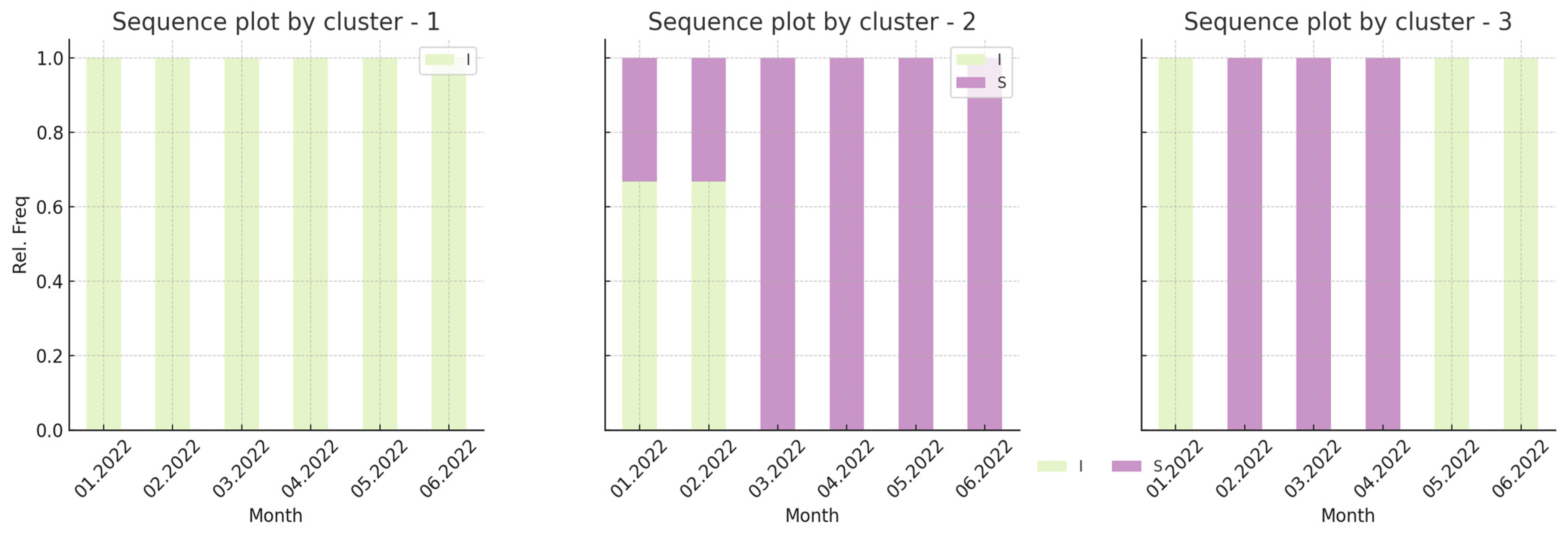
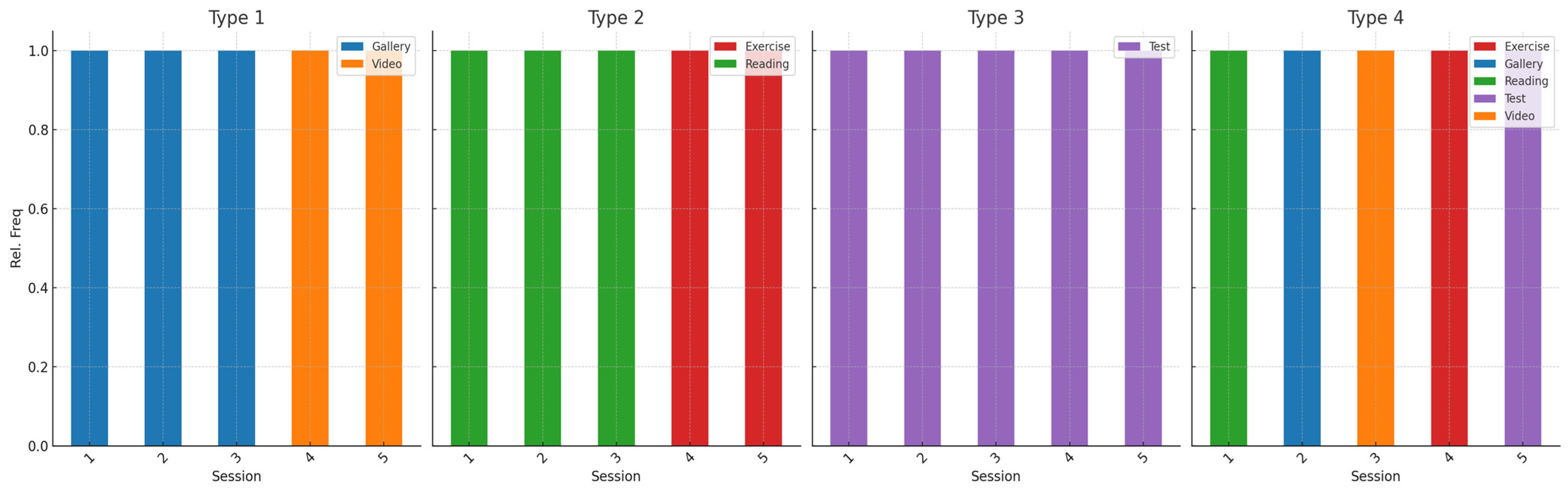
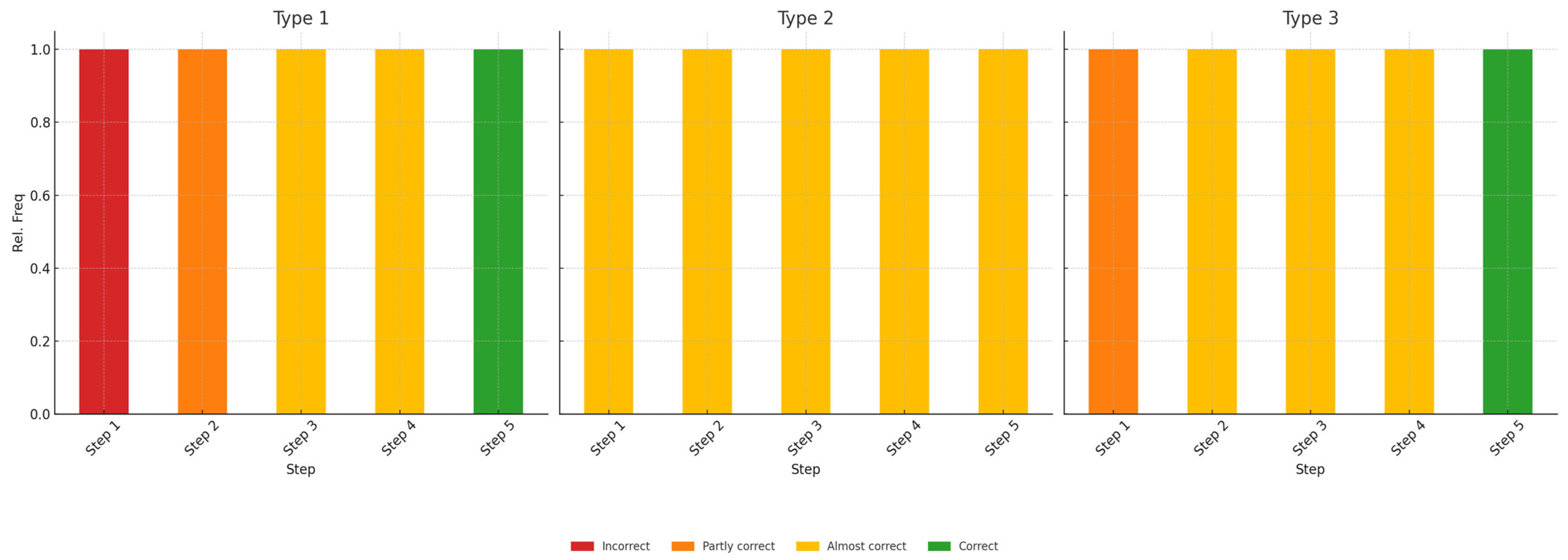
Appendix D. Requirements, Evaluation Criteria and Possibilities for CustomGPT Development Process

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Requirements | Evaluation Criteria | Possibilities |
|---|---|---|---|
| Educational log-data gathering and processing | Define the information to collect (e.g., actions and timestamps that may be of interest), determine granularity for adequate representation of the learning process | Are all important actions and timestamps, including omissions or subtle events, considered? Can the level of detail in the data be adjusted after collection for specific analytical tasks? Are there artifacts in the data, and if so, can they be neutralized during further analysis? | Ability to track micro-behaviors of students, including actions tied to specific content (e.g., reading, completing exercises, testing). Flexibility in log-file granularity—allowing a single log file to be used for analyses at different levels. |
| Ensure data protection and anonymity during collection, processing, and usage in CustomGPT | Does the system eliminate the possibility of data leakage at various stages of analysis? Are well-defined access levels provided for different users (teachers, administrators, etc.)? | A flexible anonymity system allows for sharing aggregated data for research or product improvements while maintaining participant anonymity. It also enables personalized information for a limited audience (e.g., teachers and parents). | |
| Define directions for analysis (e.g., activity trends, interaction strategies, test completion patterns), write analysis code, and test it in Python and R | Do the analysis results reflect trends that are easy to interpret and of interest to teachers? Do Python script results match those obtained in R, confirming accuracy? | Wide variability in analysis allows teachers to focus on what matters to them. The analysis can target students (class trends) or content (trends in studying a specific textbook) and can also be generalized or personalized. | |
| Visualizations | Define appropriate visualization methods for sequences based on analysis goals (state plot, distribution plot, etc.) | Do the graphs represent real data without distortion, ensuring accurate understanding of patterns? | Develop a dynamic visualization system that automatically selects the most appropriate type of graph (e.g., state plot for sequence analysis, distribution plot for frequency evaluation) based on input data and analysis goals. |
| Ensure intuitive visualizations—a color palette that allows clear differentiation of patterns; include a legend to define key visualization elements | Are the colors contrasting and easily distinguishable for different categories (e.g., actions, states, or test results)? Can teachers or analysts without technical training understand the visualization results? | Create a visualization interface where teachers or analysts can choose color schemes and customize legends to simplify pattern understanding, allowing individualization of data representation for various audiences (e.g., teachers, parents, researchers). | |
| Interpretation | Provide CustomGPT instructions to train the model for understanding results, highlighting key trends (e.g., high relative frequency of a specific action during a session) and presenting them in interpretations | Are the interpretations consistently aligned with the highlighted trends across multiple scenarios or datasets? Can the model adapt to variations in input data (e.g., different formats, levels of detail) without losing interpretation quality? | Interpretation might be based not only on developers’ instructions, but also on users’ interaction, which means the focus of interpretation might be more personalized |
| Ensure practice-oriented interpretation of results for teachers, where numerical metrics are translated into insights useful for understanding the learning process | Do the insights align with teachers’ needs and can teachers implement changes or interventions based on the insights provided? Is there a feedback mechanism for teachers to refine the interpretation process and improve the relevance of insights over time? | Further training of the chatbot could focus on highlighting key metrics that are of practical interest to teachers. For example, attention could be drawn to the absence of specific actions in patterns or, conversely, the dominance of a certain action at the beginning, middle, or end of a session. | |
| Tips | Generated tips should be based on results in each particular case and their interpretation, so Interpretation + Tips become related to each other | Are the tips closely aligned with the specific results and interpretations for each case? | Subsequent outputs can also build upon previous ones, forming a sort of portfolio for each student or class. This creates an opportunity for comparative analysis of interaction dynamics over time. |
| DLE specifications and interaction context should be taken into account while generating tips | Are the tips adapted to the context of the student’s learning behavior? | The system could provide aggregated action plans for educators or administrators, summarizing the tips for multiple students or groups. This feature would allow educators to implement data-driven interventions at scale. |
Appendix E. Interview Analysis
| Informative Potential | Question in the Interview |
|---|---|
| Background | What are the main strengths of Opiq? |
| What disadvantages of Opiq have you noted? | |
| RQ1 | Do you think that the process of students’ interaction with Opiq may vary? For example, students may use different strategies when learning material. |
| Do you think that different activities in Opiq (reading, video, gallery, practice, etc.) may vary depending on the context (task, age, subject, etc.)? Share your observations and thoughts on this matter. | |
| Do you think certain combinations of interactions (e.g., reading + watching videos, or practicing in preparation for obligatory tests) can be effective in the learning process? Share your observations and thoughts on this matter. | |
| Do you think that the order of studying content in Opiq matters? | |
| Would you as a teacher benefit from more detailed information about student interaction with Opiq? | |
| RQ2 | What information can you extract from graphs without explanation? |
| Is the textual interpretation of the graphs clear? Did it expand your understanding? | |
| Do you find the tips the bot gives you based on current information useful? | |
| RQ3 | What is your overall impression of the custom GPT? |
| What other statistics on your students’ use of Opiq would you like to know? |
| Dimension | Category | Code |
|---|---|---|
| Opinions on the Opiq environment | Positive features | Using material from Opiq to create own content (tests) |
| Showing some content from Opiq | ||
| Showing different strategies for studying material | ||
| Collaboration with students | ||
| Saving time | ||
| Automatic assessment | ||
| Sustainability | ||
| Negative features | Limited access | |
| Less effectiveness in comparison to classic books | ||
| Technical issues | ||
| Outdated information | ||
| Opinions on the process of students’ interaction | Variety of students’ interaction process | Test-taking strategies |
| General learning strategies | ||
| Order of interactions | ||
| Certain combinations | ||
| Factors influencing students’ strategies | Subject | |
| Quality of material | ||
| Motivation | ||
| Grade | ||
| Personal preferences | ||
| Platform flexibility | ||
| Information of interaction and ways of its application | Process of preparation for tests | |
| How much time students spend on different activities | ||
| Process of test-taking | ||
| Using the information for additional support | ||
| Using the information to plan the workload | ||
| Check if some content is avoided | ||
| Opinions on the design and functionality of the Custom GPT | Visualizations | Pictures are clear |
| Legend ambiguity | ||
| Additional info needed | ||
| Related frequency concept | ||
| Pictures aren’t clear | ||
| Descriptions | Descriptions are needed | |
| Descriptions can expand the understanding | ||
| Descriptions aren’t needed | ||
| Tips | Can be useful | |
| Different from teacher’s opinion on the case | ||
| Repeating description | ||
| Too general | ||
| Overall thoughts and ideas about the chatbot | Uncertainty about application | |
| Group analysis | ||
| Individual analysis | ||
| Flexibility to expand the analysis | ||
| Using a tool for diagnostic at some specific moments | ||
| Privacy concerns | ||
| Wider application | ||
| Other ways of visualization |
References
- Abbott, A. (1995). Sequence analysis: New methods for old ideas. The Annual Review of Sociology, 21, 93–113. [Google Scholar] [CrossRef]
- Aisenbrey, S., & Fasang, A. E. (2010). New life for old ideas: The “second wave” of sequence analysis bringing the “course” back into the life course. Sociological Methods & Research, 38, 420–462. [Google Scholar] [CrossRef]
- Alfirević, N., Praničević, D. G., & Mabić, M. (2024). Custom-trained large language models as open educational resources: An exploratory research of a business management educational chatbot in croatia and bosnia and herzegovina. Sustainability, 16, 4929. [Google Scholar] [CrossRef]
- Algarni, A. (2016). Data mining in education. International Journal of Advanced Computer Science and Applications, 7, 70659. [Google Scholar] [CrossRef]
- Almasre, M. (2024). Development and evaluation of a custom GPT for the assessment of students’ designs in a typography course. Education Sciences, 14, 148. [Google Scholar] [CrossRef]
- Ampadu, Y. B. (2023). Handling Big Data in Education: A Review of Educational Data Mining Techniques for Specific Educational Problems. IntechOpen. [Google Scholar] [CrossRef]
- Baker, R. S. J. D., & Inventado, P. S. (2014). Educational data mining and learning analytics. In Learning analytics (pp. 61–75). Springer. [Google Scholar]
- Bostock, M., & Heer, J. (2009). Protovis: A graphical toolkit for visualization. IEEE Transactions on Visualization and Computer Graphics, 15, 1121–1128. [Google Scholar] [CrossRef]
- Bürgin, R., & Ritschard, G. (2014). A decorated parallel coordinate plot for categorical longitudinal data. The American Statistical Association, 68, 98–103. [Google Scholar] [CrossRef]
- Chiarello, F., Giordano, V., Spada, I., Barandoni, S., & Fantoni, G. (2024). Future applications of generative large language models: A data-driven case study on ChatGPT. Technovation, 133, 103002. [Google Scholar] [CrossRef]
- Chukhlomin, V. (2024). Exploring the use of custom GPTs in higher education strategic planning: A preliminary field report. SSRN. [Google Scholar] [CrossRef]
- Collins, B. R., Black, E. W., & Rarey, K. E. (2024). Introducing anatomyGPT: A customized artificial intelligence application for anatomical sciences education. Clinical Anatomy, 37(6), 661–669. [Google Scholar] [CrossRef] [PubMed]
- Elzinga, C. H., & Liefbroer, A. C. (2007). De-standardization of family-life trajectories of young adults: A cross-national comparison using sequence analysis. The European Journal of Population, 23, 225–250. [Google Scholar] [CrossRef]
- Fasang, A. E., & Liao, T. F. (2014). Visualizing sequences in the social sciences: Relative frequency sequence Plots. Sociological Methods & Research, 43, 643–676. [Google Scholar] [CrossRef]
- Fonseca, D., García-Peñalvo, F. J., & Camba, J. D. (2021). New methods and technologies for enhancing usability and accessibility of educational data. Universal Access in the Information Society, 20, 421–427. [Google Scholar] [CrossRef] [PubMed]
- Fuller, K. A., Morbitzer, K. A., Zeeman, J. M., Persky, A. M., & Savage, A. C. (2024). Exploring the use of ChatGPT to analyze student course evaluation comments. BMC Medical Education, 24, 423. [Google Scholar] [CrossRef]
- Gaete Cruz, M., Ersoy, A., Czischke, D., & van Bueren, E. (2022). Towards a framework for urban landscape co-design: Linking the participation ladder and the design cycle. CoDesign, 19(3), 233–252. [Google Scholar] [CrossRef]
- García-Peñalvo, F., & Vázquez-Ingelmo, A. (2023). What do we mean by GenAI? A systematic mapping of the evolution, trends, and techniques involved in generative AI. The International Journal of Interactive Multimedia and Artificial Intelligence, 8, 7–16. [Google Scholar] [CrossRef]
- Guo, Y., Guo, S., Jin, Z., Kaul, S., Gotz, D., & Cao, N. (2022). Survey on visual analysis of event sequence data. IEEE Transactions on Visualization and Computer Graphics, 28, 5091–5112. [Google Scholar] [CrossRef]
- Haas, C. (2022). Applying Sequence Analysis in Higher Education Research: A Life Course Perspective on Study Trajectories. Theory and Method in Higher Education Research, 8, 127–147. [Google Scholar]
- Healy, K., & Moody, J. (2014). Data visualization in sociology. The Annual Review of Sociology, 40, 105–128. [Google Scholar] [CrossRef]
- Helske, J., Helske, S., Saqr, M., López-Pernas, S., & Murphy, K. (2024). A modern approach to transition analysis and process mining with Markov models in education. In M. Saqr, & S. López-Pernas (Eds.), Learning analytics methods and tutorials: A practical guide using R (pp. 381–427). Springer. [Google Scholar] [CrossRef]
- Honig, C. D. F., Desu, A., & Franklin, J. (2024). GenAI in the classroom: Customized GPT roleplay for process safety education. Education for Chemical Engineers, 49, 55–66. [Google Scholar] [CrossRef]
- Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Yan, X., Ishii, E., Bang, Y., Madotto, A., & Fung, P. (2022). Survey of Hallucination in Natural Language Generation. ACM Computing Surveys, 55(12), 1–38. [Google Scholar] [CrossRef]
- Kabir, A., Shah, S., Haddad, A., & Raper, D. M. S. (2024). Introducing our custom GPT: An example of the potential impact of personalized GPT builders on scientific writing. World Neurosurgery, 193, 461–468. [Google Scholar] [CrossRef]
- Kleinman, E., Shergadwala, M., Teng, Z., Villareale, J., Bryant, A., Zhu, J., & Seif El-Nasr, M. (2022). Analyzing students’ problem-solving sequences: A human-in-the-loop approach. Journal of Learning Analytics, 9, 138–160. [Google Scholar] [CrossRef]
- Koedinger, K. R., D’Mello, S. K., McLaughlin, E. A., Pardos, Z. A., & Rosé, C. P. (2015). Data mining and education. Wiley Interdisciplinary Reviews: Cognitive Science, 6, 333–353. [Google Scholar] [CrossRef]
- Kotsis, K. T. (2024). ChatGPT as teacher assistant for physics teaching. EIKI Journal of Effective Teaching Methods, 2(4), 18–27. [Google Scholar] [CrossRef]
- Macmillan, R., & Copher, R. (2005). Families in the life course: Interdependency of roles, role configurations, and pathways. The Journal of Marriage and Family, 67, 858–879. [Google Scholar] [CrossRef]
- Malik, S., Shneiderman, B., Du, F., Plaisant, C., & Bjarnadottir, M. (2016). High-volume hypothesis testing: Systematic exploration of event sequence comparisons. ACM Transactions on Interactive Intelligent Systems, 6, 1–23. [Google Scholar] [CrossRef]
- McIntosh, T. R., Liu, T., Susnjak, T., Watters, P., Ng, A., & Halgamuge, M. N. (2024). A culturally sensitive test to evaluate nuanced GPT hallucination. The IEEE Transactions on Artificial Intelligence, 5, 2739–2751. [Google Scholar] [CrossRef]
- Opanasenko, Y., Pedaste, M., & Siiman, L. A. (2023). Students’ patterns of interaction with e-books in Estonian basic schools: A sequence analysis study. In Innovative technologies and learning: Proceedings of the 6th international conference, ICITL 2023, Porto, Portugal, 28–30 August 2023 (pp. 451–460). Springer. [Google Scholar] [CrossRef]
- Opanasenko, Y., Pedaste, M., & Siiman, L. A. (2024). Sequence analysis as a tool for visualizing students’ patterns of taking tests in interactive e-book environment. In Innovative technologies and learning: Proceedings of the 7th international conference, ICITL 2024, Tartu, Estonia, 26–28 August 2024 (pp. 120–128). Springer. [Google Scholar] [CrossRef]
- OpenAI. (2024). ChatGPT. (June 15 Version) [Large Language Model]. OpenAI.
- Pandya, K., & Tatikonda, N. (2023). QuizMasterGPT: CustomGPT for education. Preprint. [Google Scholar]
- Pechenizkiy, M., Trčka, N., Vasilyeva, E., van der Aalst, W., & De Bra, P. (2009, July 1–3). Process mining online assessment data. The 2nd International Conference on Educational Data Mining (EDM 2009) (pp. 279–287), Córdoba, Spain. [Google Scholar]
- Plaisant, C., Milash, B., Rose, A., Widoff, S., & Shneiderman, B. (1996, April 13–18). Lifelines: Visualizing personal histories. ACM CHI (pp. 221–227), Vancouver, BC, Canada. [Google Scholar]
- Raab, M., & Struffolino, E. (2022). Sequence analysis. SAGE Publications. [Google Scholar]
- Riehmann, P., Hanfler, M., & Froehlich, B. (2005, October 23–25). Interactive Sankey diagrams. IEEE Symposium on Information Visualization (InfoVis 05) (pp. 233–240), Minneapolis, MN, USA. [Google Scholar] [CrossRef]
- Romero, C., & Ventura, S. (2020). Educational data mining and learning analytics: An updated survey. WIREs Data Mining and Knowledge Discovery, 10, e1355. [Google Scholar] [CrossRef]
- Sanders, E., & Stappers, P. J. (2008). Co-Creation and the New Landscapes of Design. CoDesign, 4(1), 5–18. [Google Scholar] [CrossRef]
- Schulhoff, S., Ilie, M., Balepur, N., Kahadze, K., Liu, A., Si, C., Li, Y., Gupta, A., Han, H., Schulhoff, S., Dulepet, P. S., Vidyadhara, S., Ki, D., Agrawal, S., Pham, C., Kroiz, G., Li, F., Tao, H., Srivastava, A., … Resnik, P. (2024). The Prompt Report: A Systematic Survey of Prompting Techniques. arXiv, arXiv:2406.06608. [Google Scholar]
- Siemens, G., & Long, P. (2011). Penetrating the fog: Analytics in learning and education. EDUCAUSE Review, 46, 30. [Google Scholar]
- Tan, T. K., & Samavedham, L. (2022). The learning process matter: A sequence analysis perspective of examining procrastination using learning management system. Computers & Education Open, 3, 100112. [Google Scholar] [CrossRef]
- Tian, H., Lu, W., Li, T. O., Tang, X., Cheung, S. C., Klein, J., & Bissyandé, T. F. (2023). Is ChatGPT the ultimate programming assistant—How far is it? arXiv, arXiv:2304.11938. [Google Scholar]
- Valle Torre, M., Oertel, C., & Specht, M. (2023). The sequence matters: A systematic literature review of using sequence analysis in Learning Analytics. arXiv, arXiv:2308.01218. [Google Scholar]
- Van Poucke, M. (2024). ChatGPT, the perfect virtual teaching assistant? Ideological bias in learner-chatbot interactions. Computers and Composition, 73, 102871. [Google Scholar] [CrossRef]
- Wang, J., Shimada, A., Oi, M., Ogata, H., & Tabata, Y. (2020). Development and evaluation of a visualization system to support meaningful E-Book learning. Interactive Learning Environments, 31, 836–853. [Google Scholar] [CrossRef]
- Wang, T. D., Plaisant, C., Quinn, A. J., Stanchak, R., Murphy, S., & Shneiderman, B. (2008, April 5–10). Aligning temporal data by sentinel events: Discovering patterns in electronic health records. ACM CHI (pp. 457–466), Florence, Italy. [Google Scholar]
- Weller, M. (2022). The Rise and Development of Digital Education. In Handbook of Open, Distance and Digital Education. Springer. [Google Scholar] [CrossRef]
- Wongsuphasawat, K., Guerra Gomez, J. A., Plaisant, C., Wang, T. D., Taieb-Maimon, M., & Shneiderman, B. (2011, May 7–12). Lifeflow: Visualizing an overview of event sequences. ACM CHI (pp. 1747–1756), Vancouver, BC, Canada. [Google Scholar]
- Yao, J. Y., Ning, K. P., Liu, Z. H., Ning, M. N., & Yuan, L. (2023). Llm lies: Hallucinations are not bugs, but features as adversarial examples. arXiv, arXiv:2310.01469. [Google Scholar]
- Zhao, J., Liu, Z., Dontcheva, M., Hertzmann, A., & Wilson, A. (2015, April 18–23). Matrixwave: Visual comparison of event sequence data. ACM CHI (pp. 259–268), Seoul, Republic of Korea. [Google Scholar]
- Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., Du, Y., Yang, C., Chen, Y., Chen, Z., Jiang, J., Ren, R., Li, Y., Tang, X., Liu, Z., Liu, P., … Wen, J. -R. (2023). A survey of large language models. arXiv, arXiv:2303.18223. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Opanasenko, Y.; Bardone, E.; Pedaste, M.; Siiman, L.A. Sequence Analysis-Enhanced AI: Transforming Interactive E-Book Data into Educational Insights for Teachers. Educ. Sci. 2025, 15, 28. https://doi.org/10.3390/educsci15010028
Opanasenko Y, Bardone E, Pedaste M, Siiman LA. Sequence Analysis-Enhanced AI: Transforming Interactive E-Book Data into Educational Insights for Teachers. Education Sciences. 2025; 15(1):28. https://doi.org/10.3390/educsci15010028
Chicago/Turabian StyleOpanasenko, Yaroslav, Emanuele Bardone, Margus Pedaste, and Leo Aleksander Siiman. 2025. "Sequence Analysis-Enhanced AI: Transforming Interactive E-Book Data into Educational Insights for Teachers" Education Sciences 15, no. 1: 28. https://doi.org/10.3390/educsci15010028
APA StyleOpanasenko, Y., Bardone, E., Pedaste, M., & Siiman, L. A. (2025). Sequence Analysis-Enhanced AI: Transforming Interactive E-Book Data into Educational Insights for Teachers. Education Sciences, 15(1), 28. https://doi.org/10.3390/educsci15010028