
Text Mining in Education—A Bibliometrics-Based Systematic Review


Abstract
:1. Introduction
- What has been the state of the art in application of text mining methods in the field of education?
- What are the main themes in using Text mining in education in the 21st century and how have they evolved?
2. Methodology
Selection Criteria and Data Collection
- Scopus search term: (TITLE (“text mining” OR “text analytics” OR “text analysis” OR “natural language processing” OR “NLP” OR “writing analytics” OR “writing analysis” OR “language model” OR “computational linguistics”) AND TITLE-ABS-KEY (“teach*” OR “learn*” OR “educat*” OR “university" OR “college” OR “institution” OR “school” OR “student”)) AND PUBYEAR > 1999 AND (EXCLUDE (DOCTYPE, “re”)) AND (LIMIT-TO (LANGUAGE, “English”))
- Web of Science search term: (TI = (“text mining” OR “text analytics” OR “text analysis” OR “natural language processing” OR “NLP” OR “writing analytics” OR “writing analysis” OR “language model” OR “computational linguistics”)) AND TS = (“teach*” OR “learn*” OR “educat*” OR “university” OR “college” OR “institution” OR “school” OR “student”) and Review Articles (Exclude–Document Types) and English (Languages)
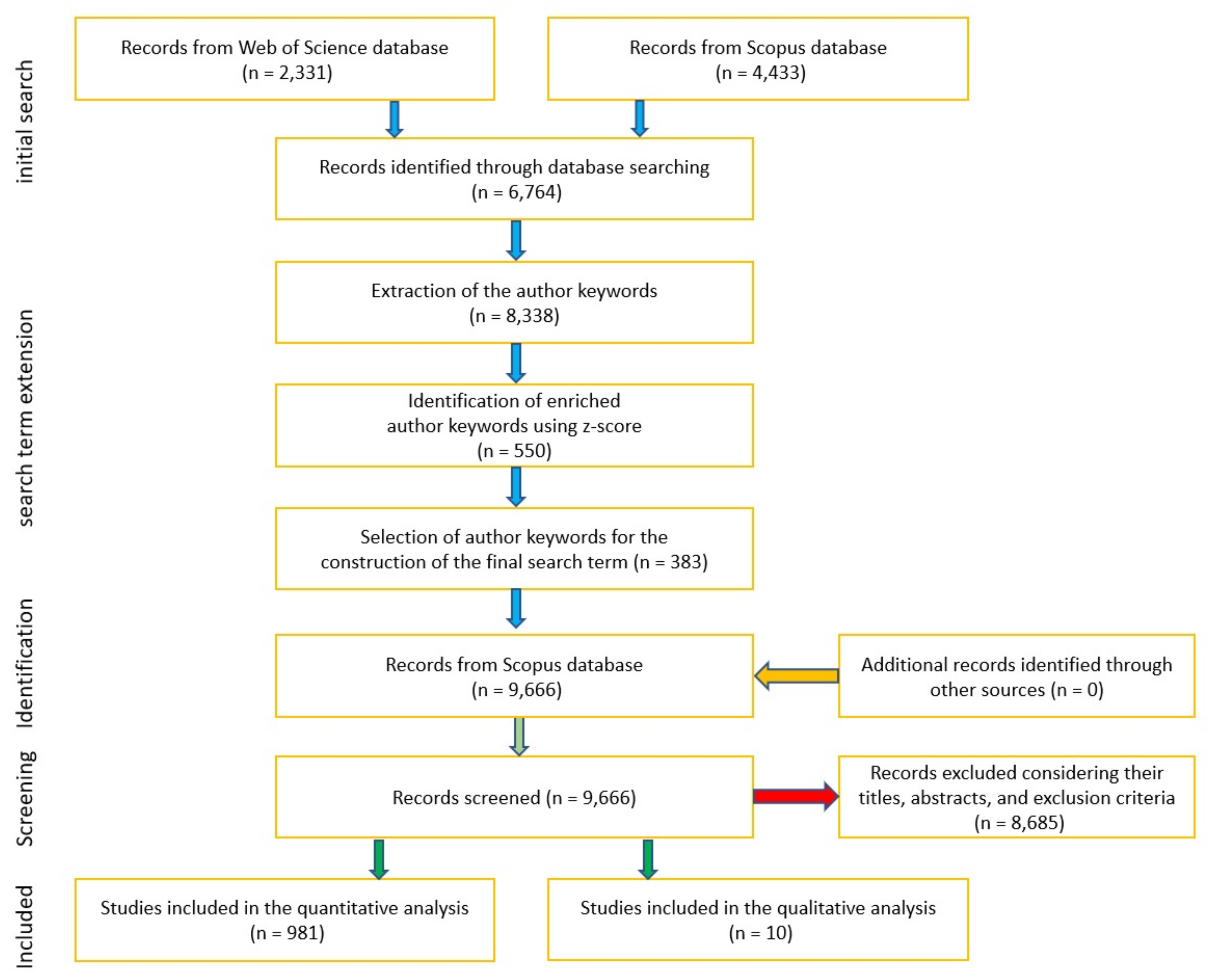
- Education related terms (Group A): words that represent education, teaching, or learning (e.g., “distance learning”, “MOOCs”)
- Text related jargon (Group B): terms that deal with preparing, processing, presenting or analysing text data (e.g., “word embedding”, “sentiment analysis”)
- Data analysis technique, jargon or discipline (Group C): terms that represent the name of a technique or part of a process that is concerned with the analysis of the data (e.g., “support vector machine”, “neural networks”)
- Publications that have:
- −
- a text related jargon (Group B) as well as an education related term (Group A) in their title
- Publications that have
- −
- a data analysis related technique, jargon or discipline (Group C) in their title, and
- −
- a text related jargon (Group B) in their title, abstract or author keywords and
- −
- an education related term (Group A) in their title

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author Keyword | Group | Frequency |
|---|---|---|
| Natural language processing | B | 1502 |
| Machine learning | C | 1031 |
| Text mining | B | 1005 |
| Deep learning | C | 401 |
| NLP | B | 294 |
| Sentiment analysis | B | 206 |
| Artificial intelligence | C | 167 |
| Language model | B | 165 |
| Information extraction | C | 128 |
| Text analysis | B | 125 |
| Text classification | B | 124 |
| Classification | C | 119 |
| Social media | C | 115 |
| Data mining | C | 109 |
| Natural language | B | 102 |
| Learning | A | 99 |
| Text analytics | B | 95 |
| Big data | C | 89 |
| Neural networks | C | 85 |
| Information retrieval | C | 78 |
| Electronic health records | NA | 77 |
| Speech recognition | C | 76 |
| Transfer learning | C | 74 |
| Natural language processing (nlp) | B | 73 |
| Topic modelling | B | 73 |
| Processing | C | 71 |
| Ontology | B | 68 |
| BERT | B | 67 |
| C | 66 | |
| Computational linguistics | B | 65 |
| COVID-19 | NA | 64 |
| Natural | C | 62 |
| Language models | B | 60 |
| Language processing | B | 60 |
| Word embeddings | B | 60 |
| Language modelling | B | 58 |
| Named entity recognition | B | 58 |
| Clustering | C | 57 |
| Text | C | 57 |
| LSTM | B | 53 |
| Neural network | C | 52 |
3. Results
3.1. Descriptive Analysis
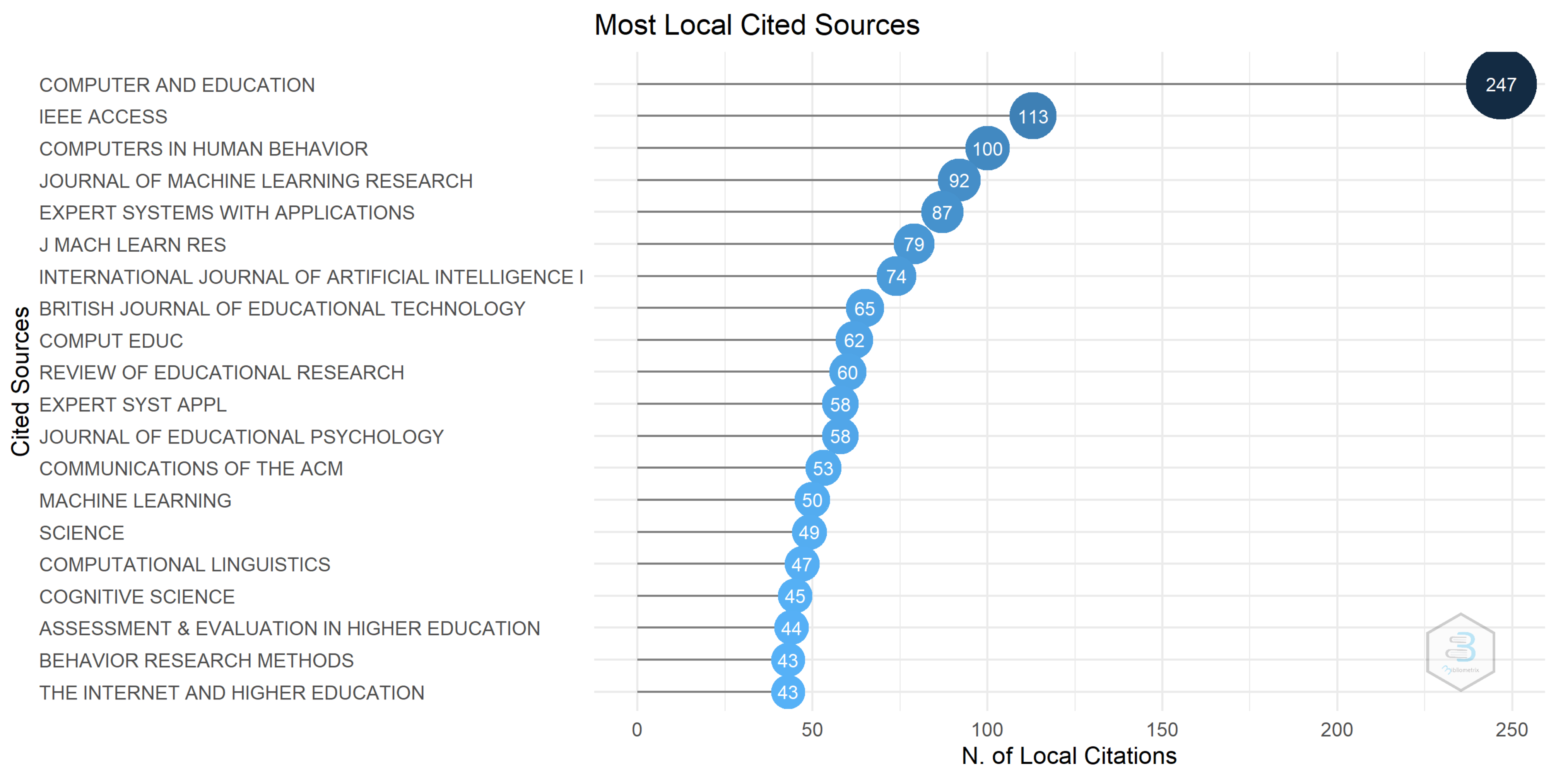
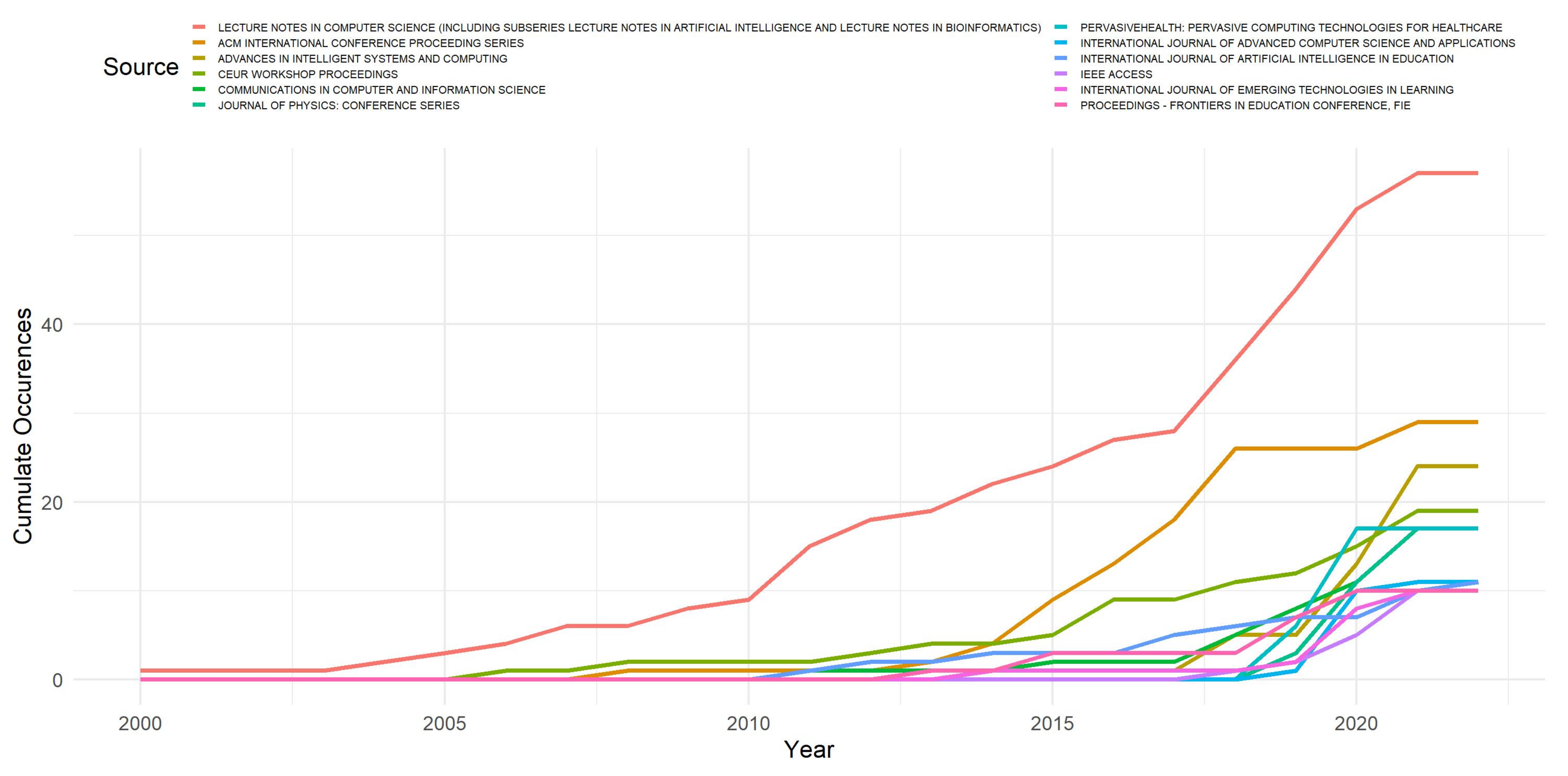
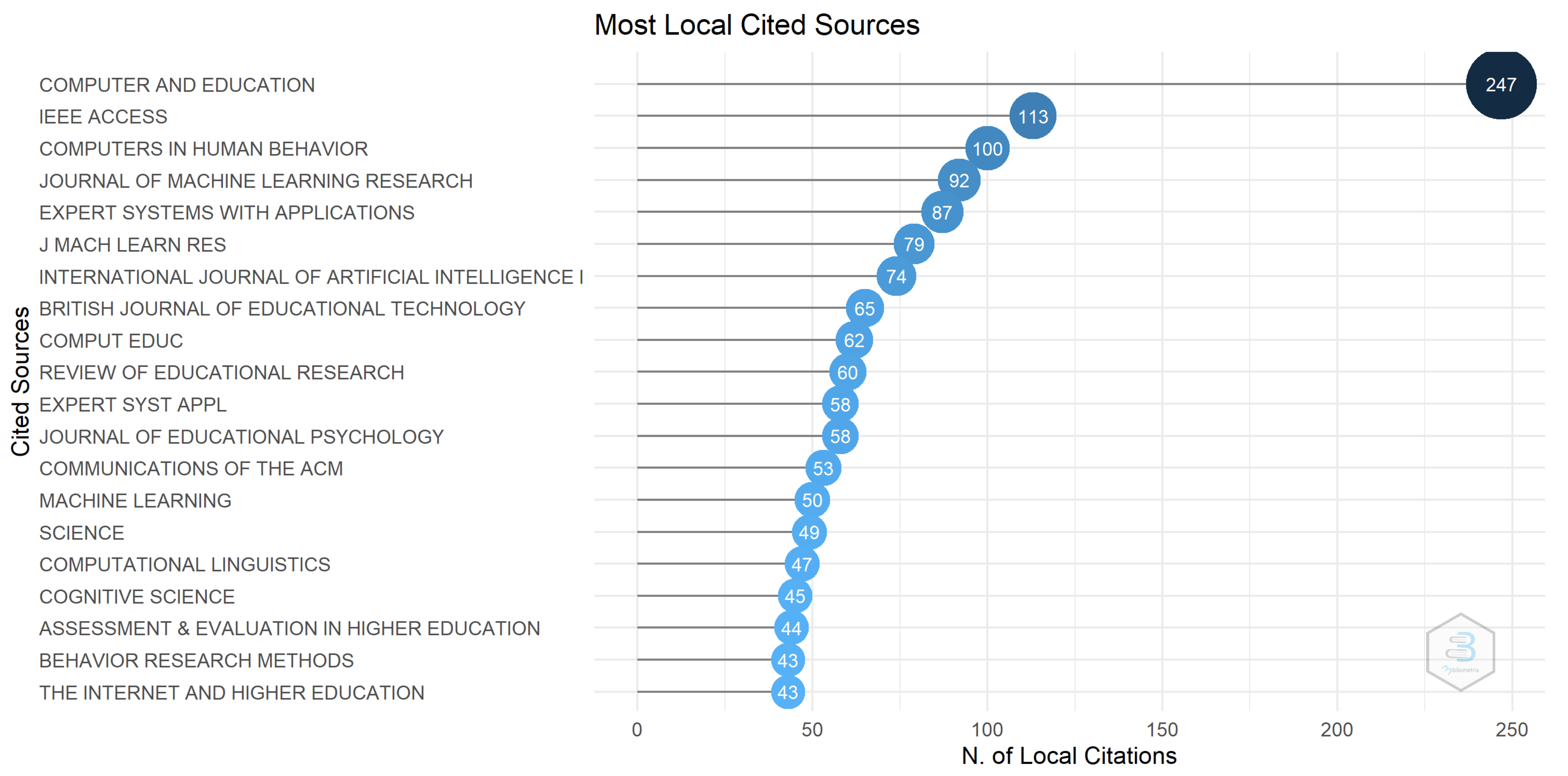
3.2. Source Analysis
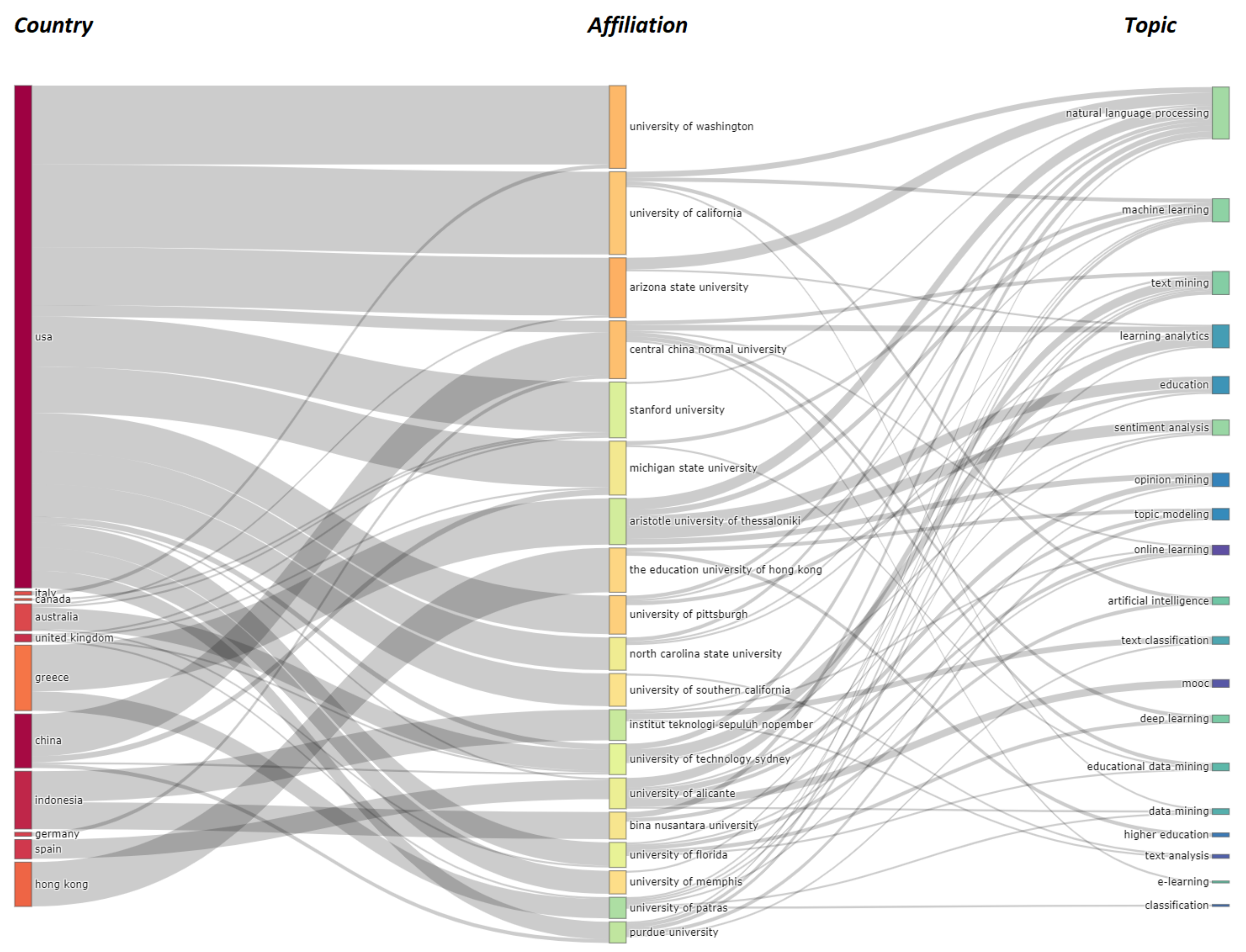
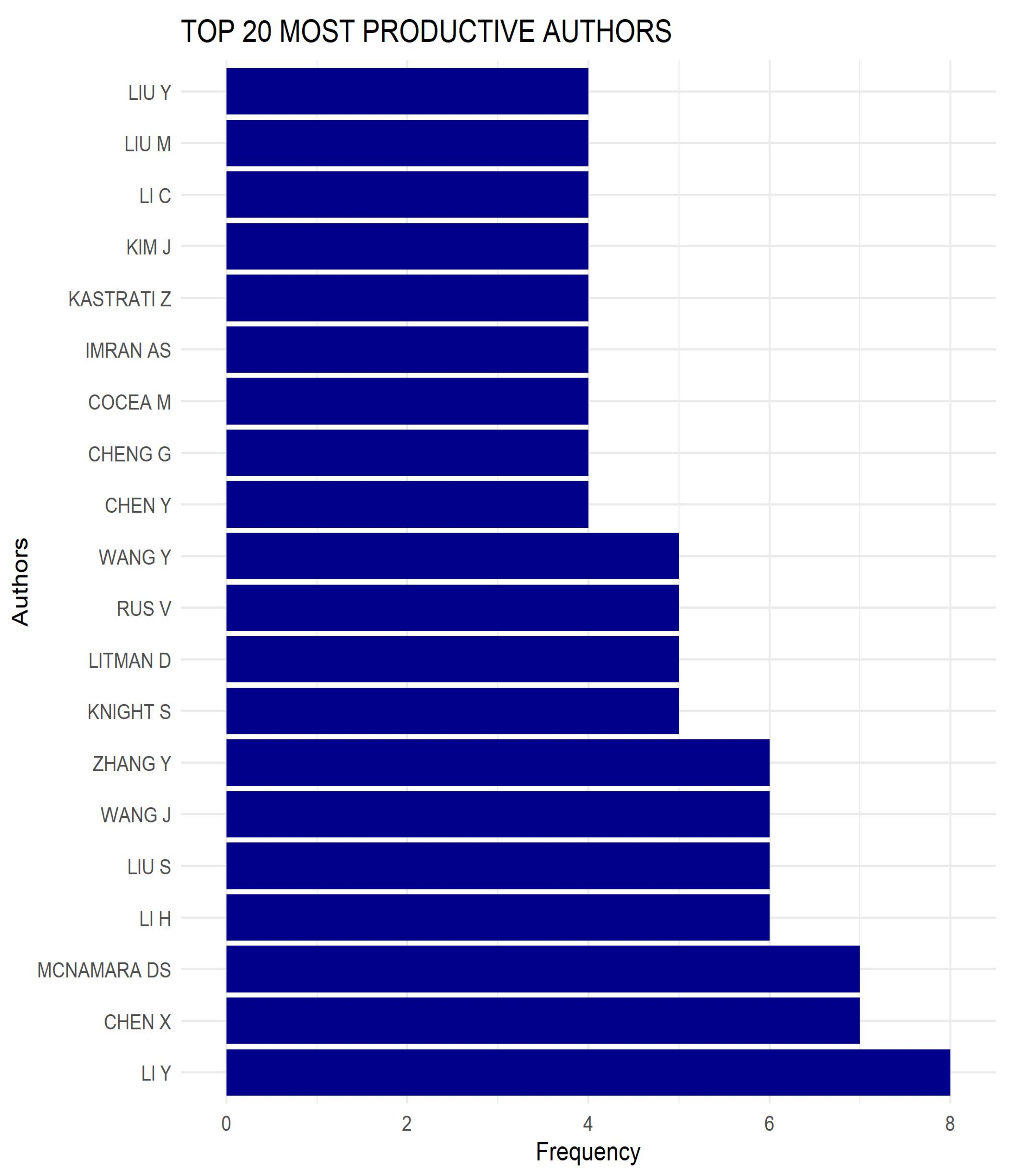
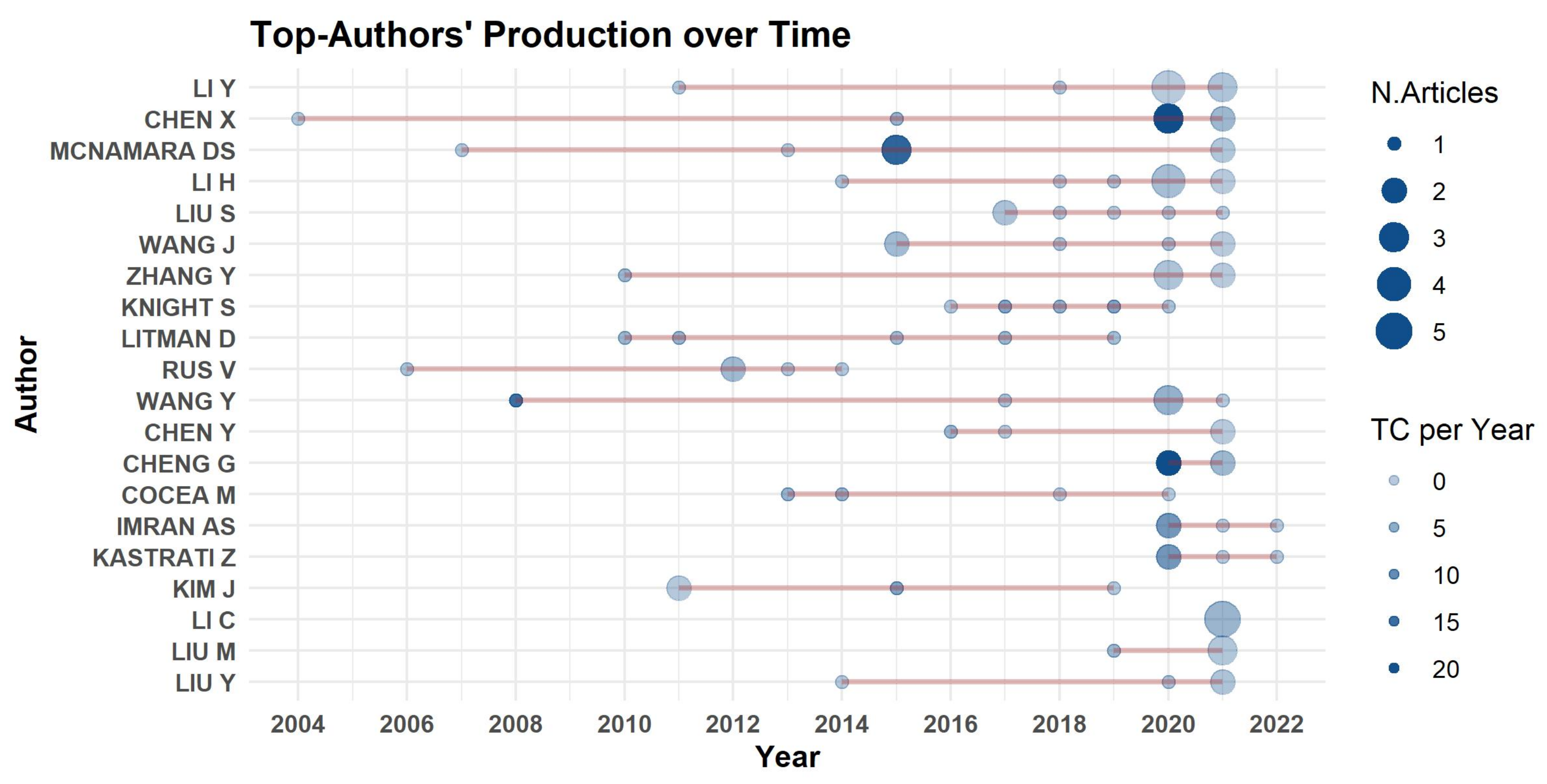
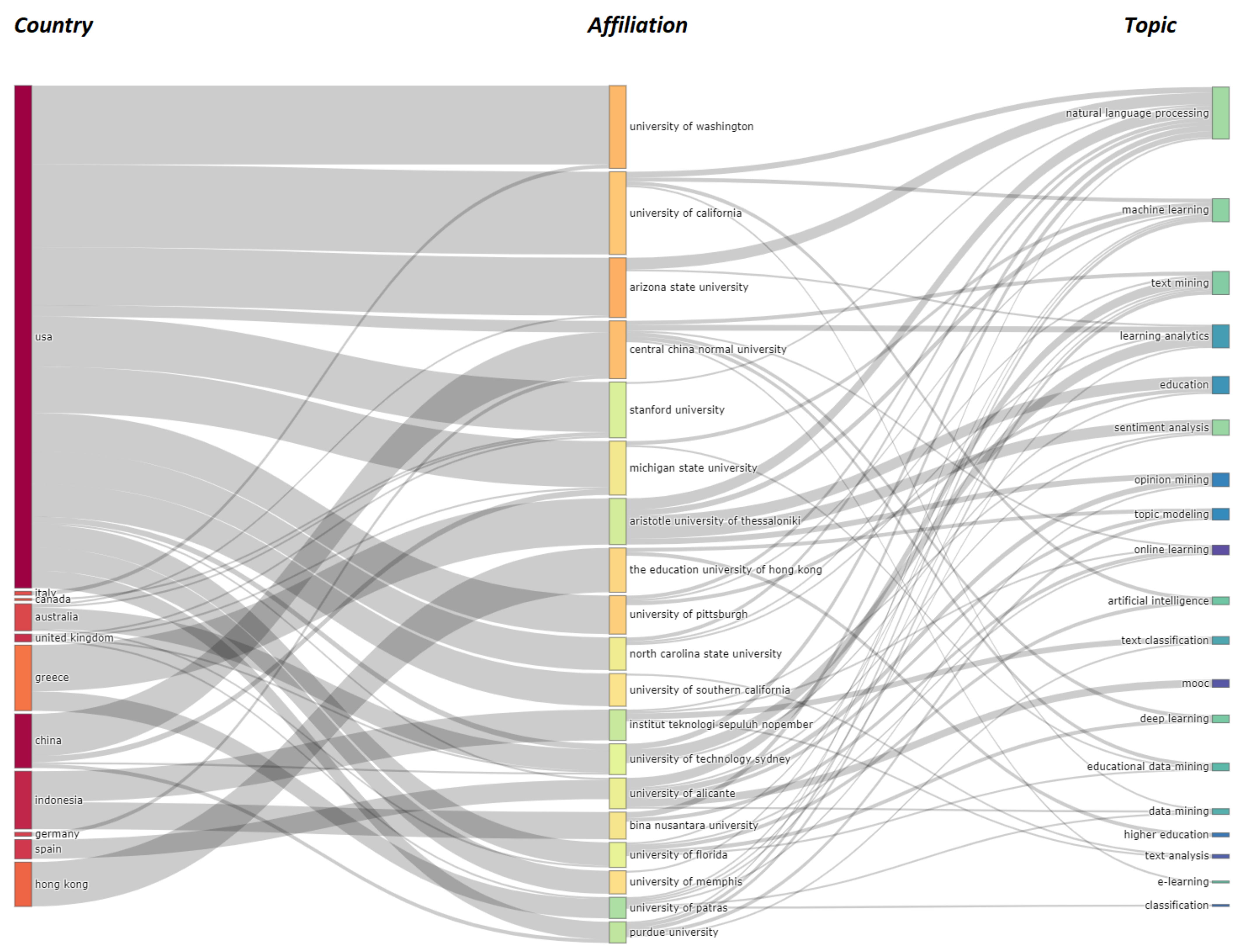
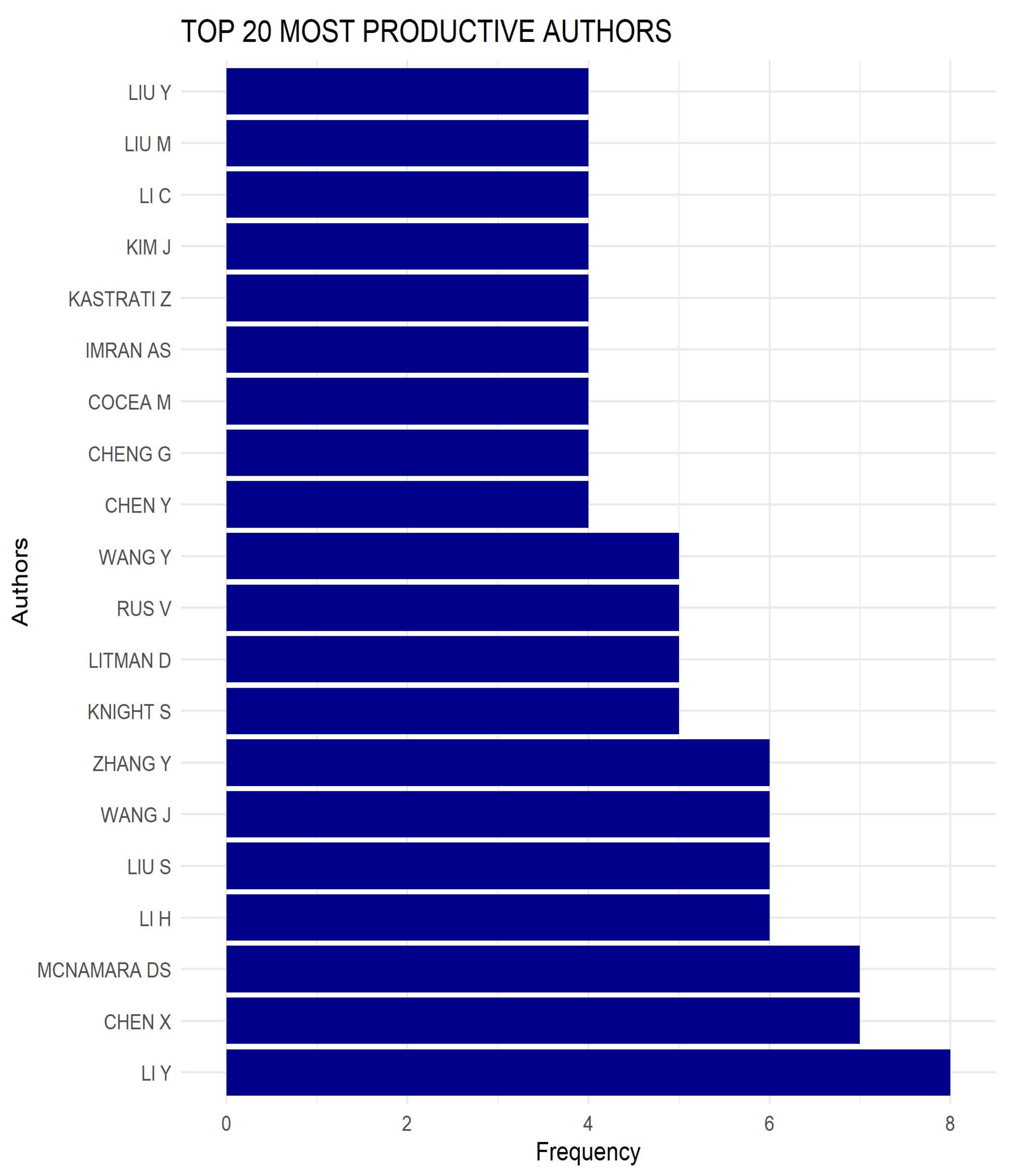
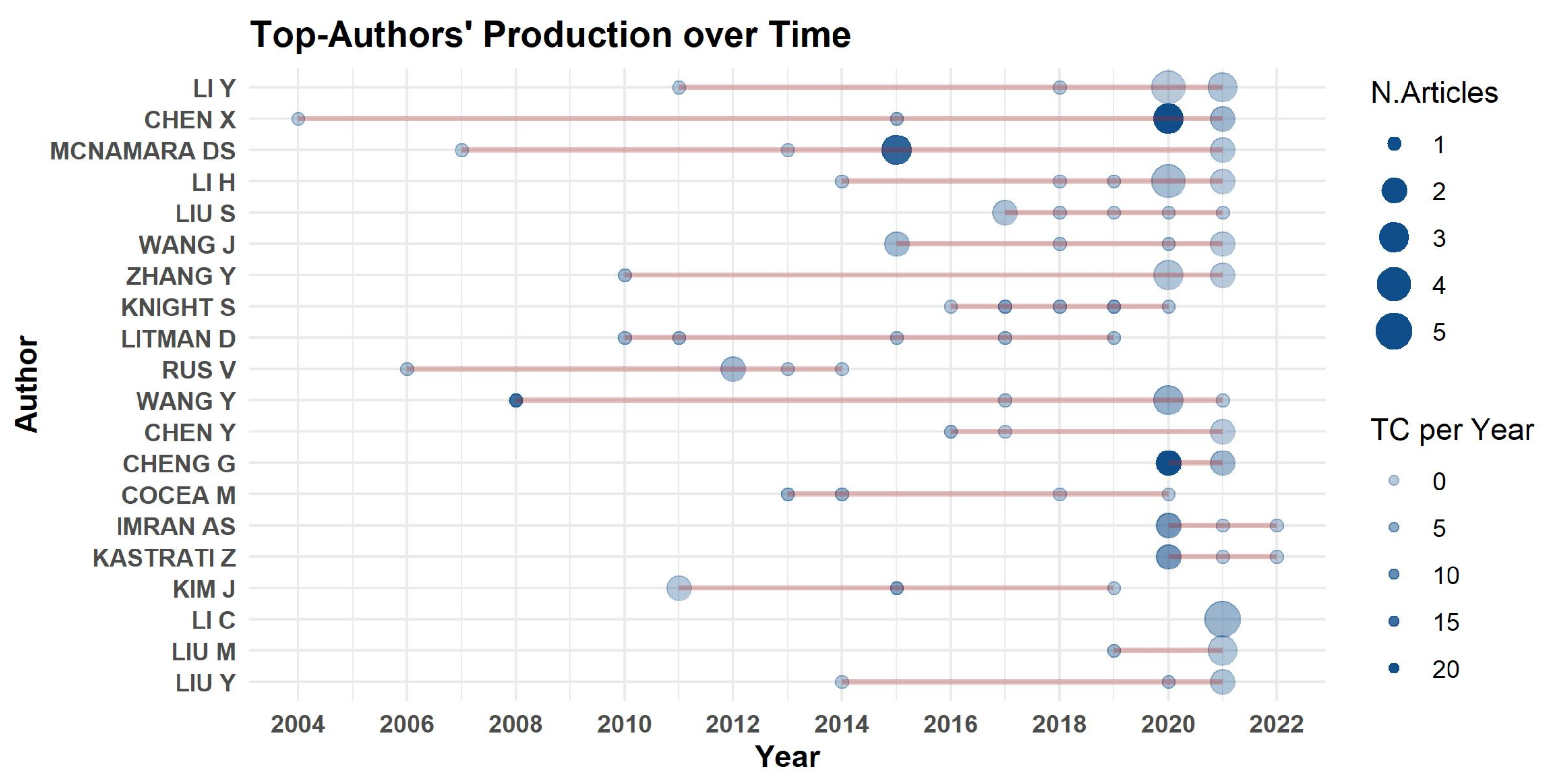
3.3. Author Analysis
3.4. Document Analysis
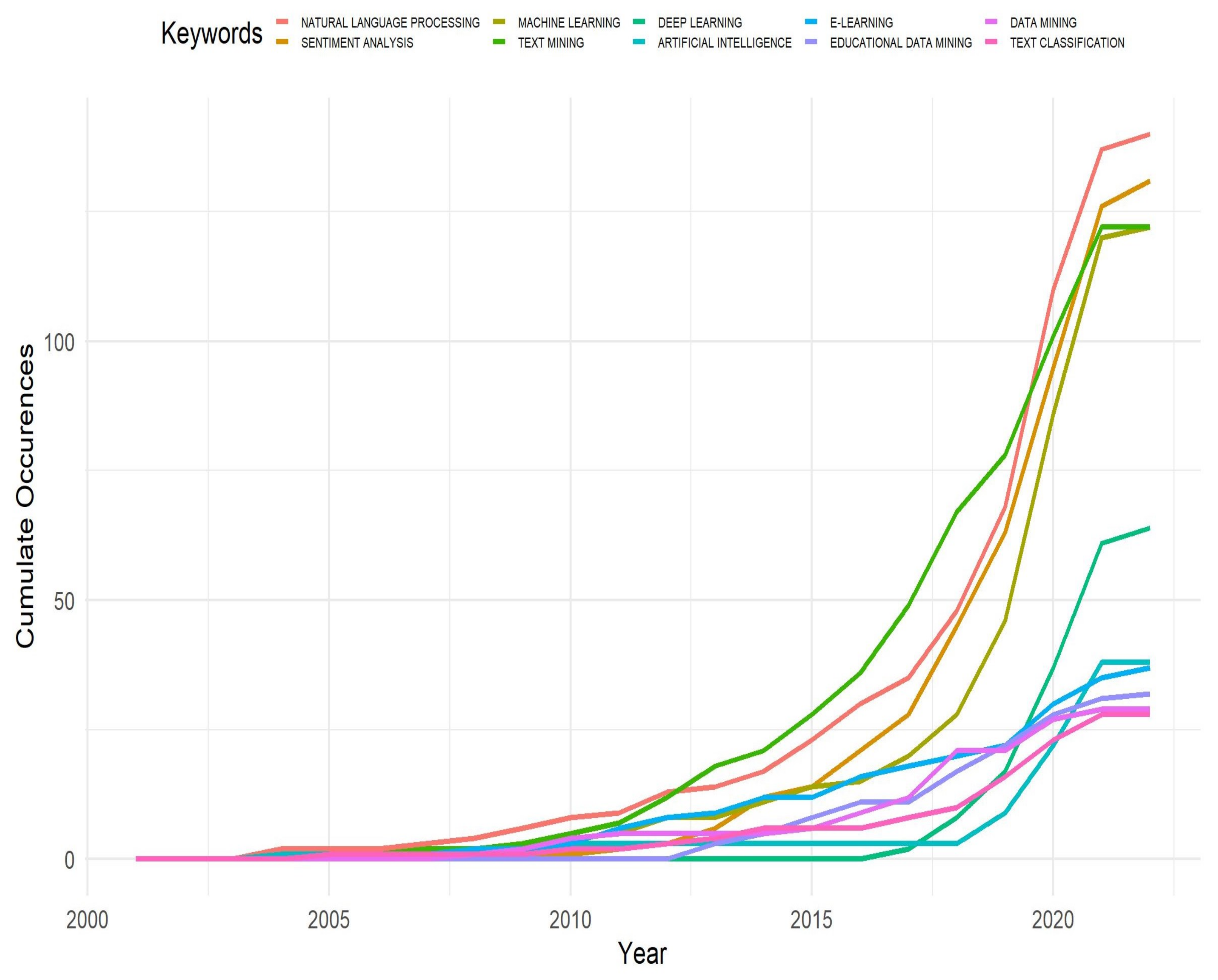
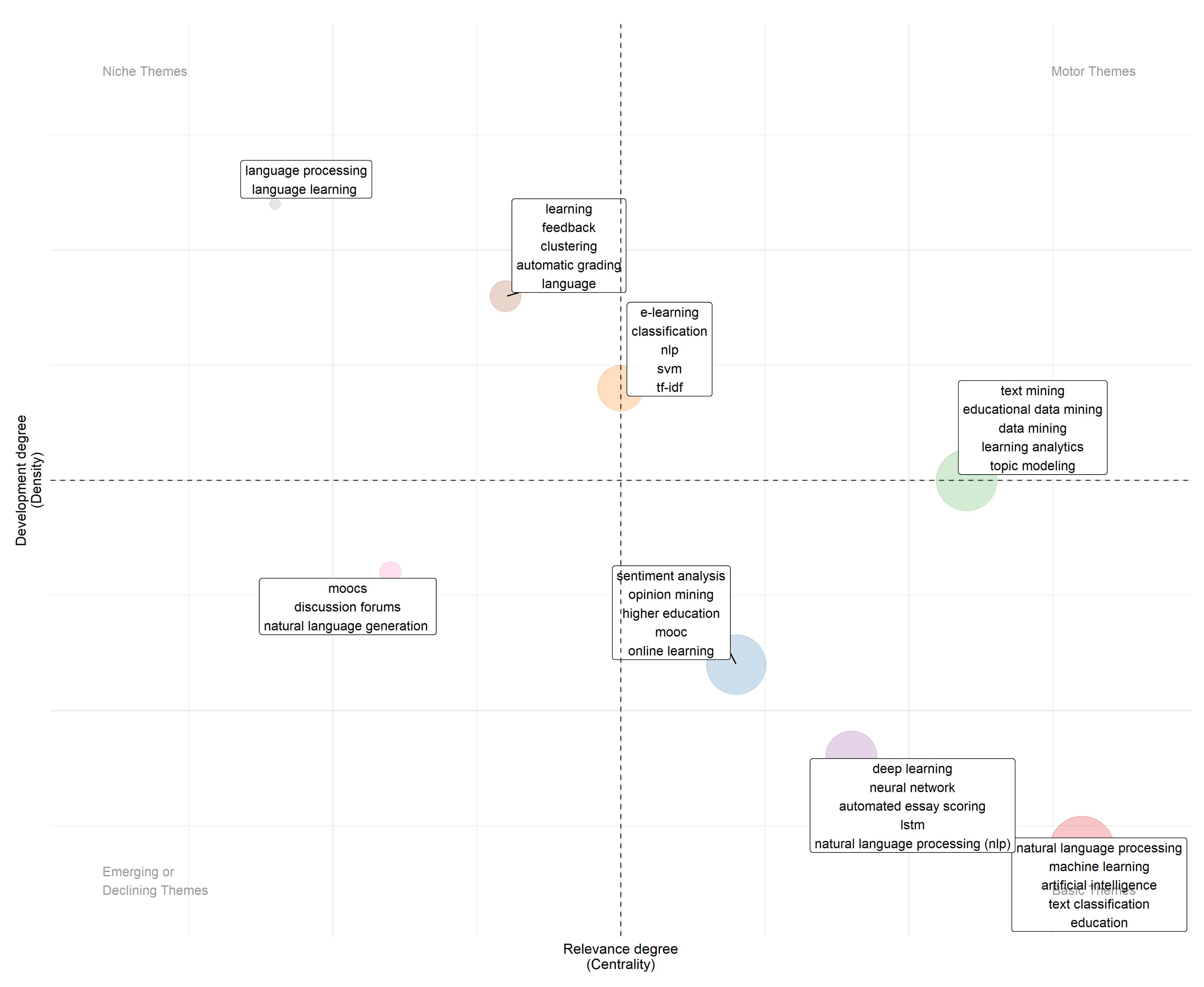
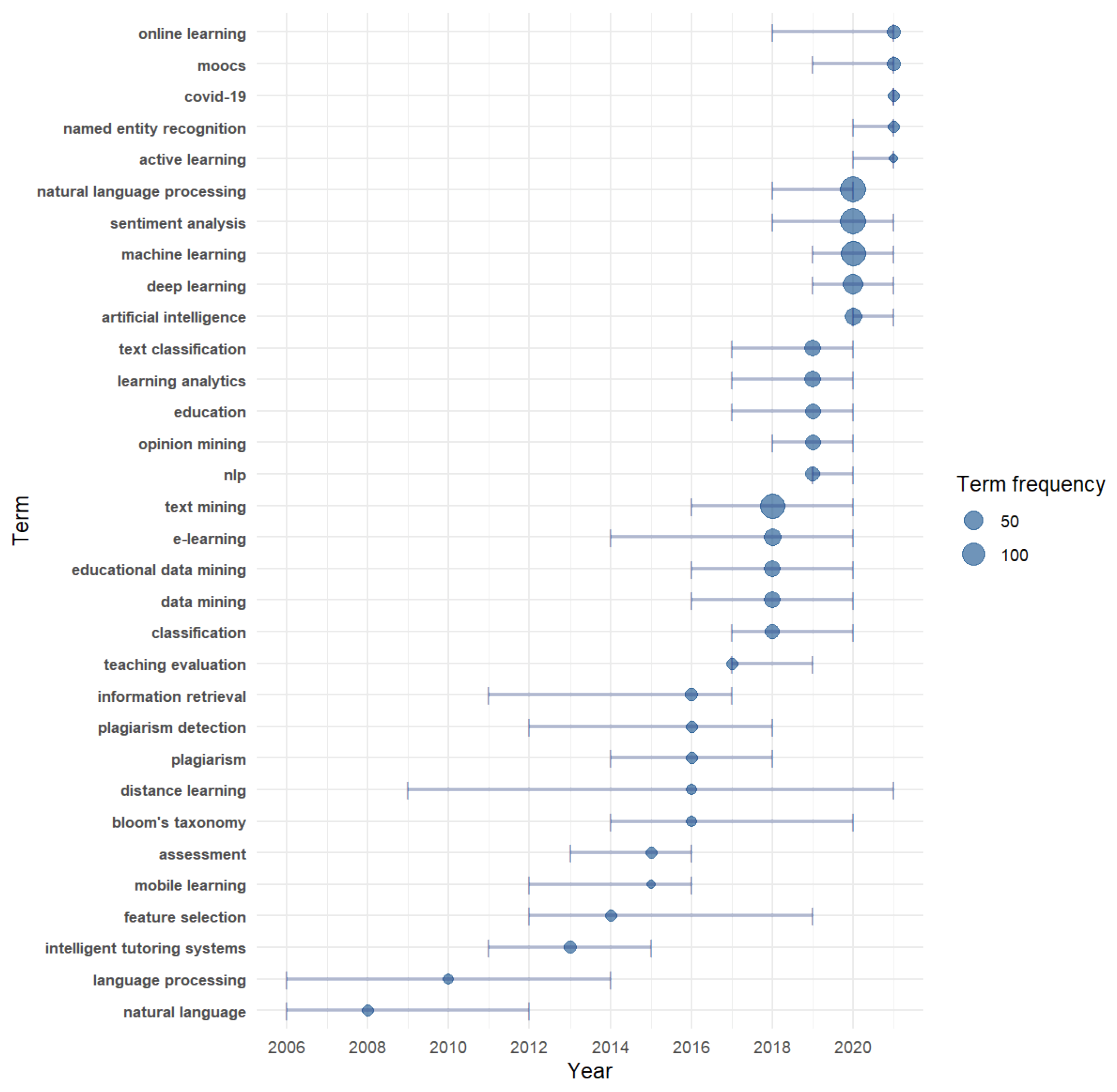
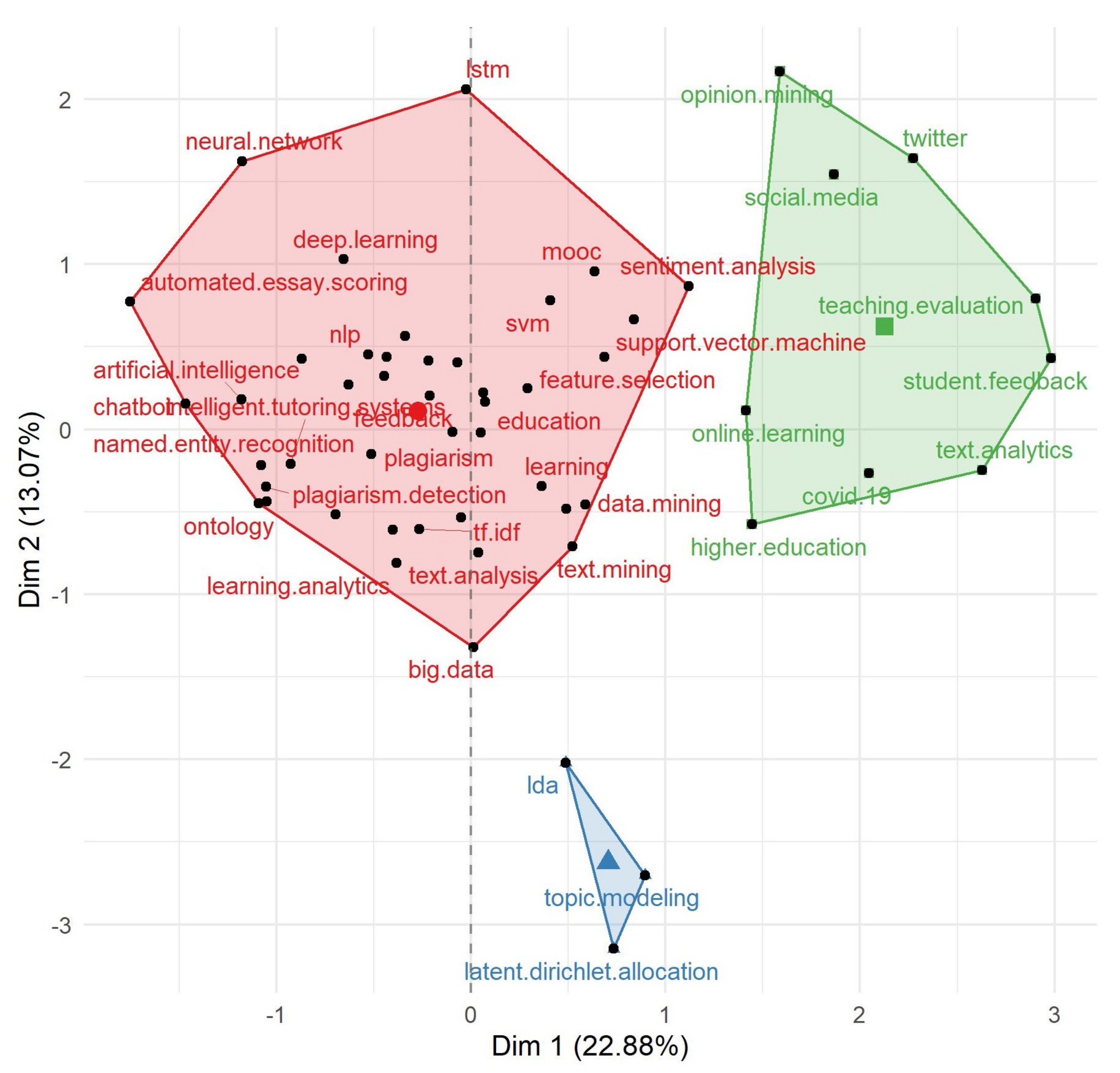
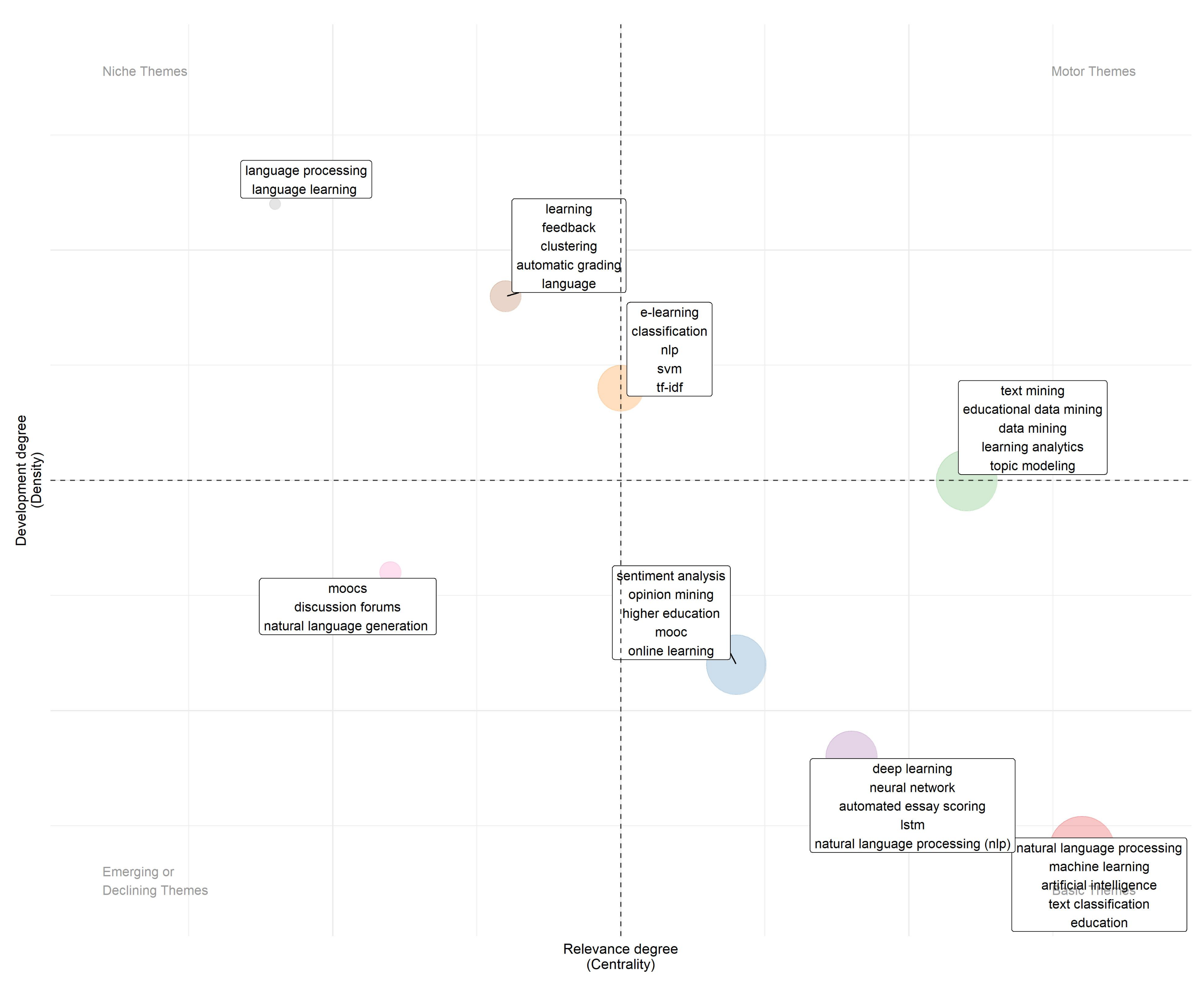
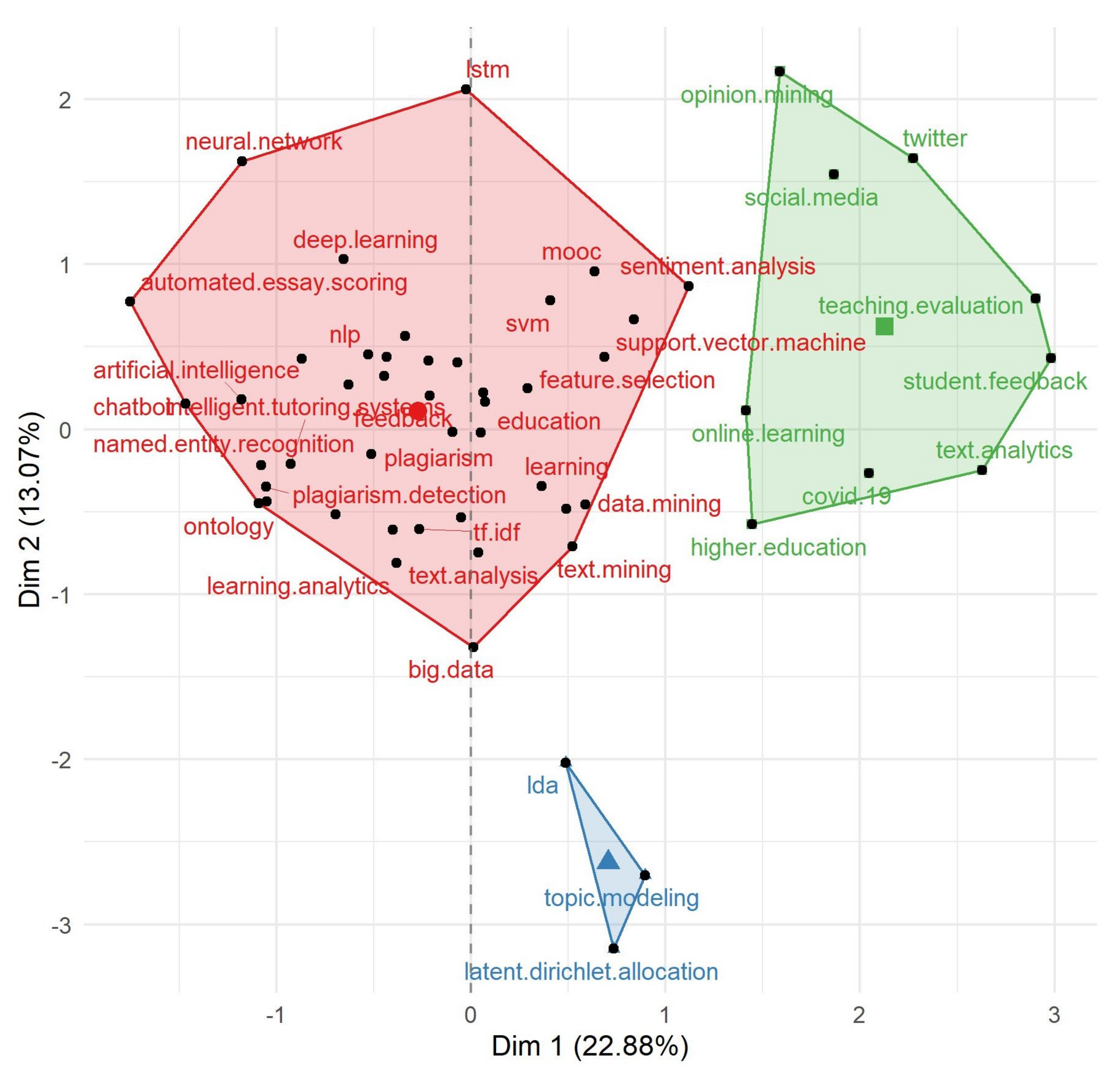
3.5. Conceptual Structure Analysis
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Liddy, E.D. Natural language processing. In Encyclopedia of Library and Information Science, 2nd ed.; Marcel Decker, Inc.: New York, NY, USA, 2001. [Google Scholar]
- Tan, A.H.; Ridge, K.; Labs, D.; Terrace, H.M.K. Text mining: The state of the art and the challenges. In Proceedings of the Pakdd 1999 Workshop on Knowledge Disocovery from Advanced Databases, Beijing, China, 26–28 April 1999; Volume 8, pp. 65–70. [Google Scholar]
- Denyer, D.; Tranfield, D. Producing a systematic review. In The Sage Handbook of Organizational Research Methods; Buchanan, D.A., Bryman, A., Eds.; Sage Publications Ltd.: Thousand Oaks, CA, USA, 2009; pp. 671–689. [Google Scholar]
- Battal, A.; Afacan Adanır, G.; Gülbahar, Y. Computer Science Unplugged: A Systematic Literature Review. J. Educ. Technol. Syst. 2021, 50, 24–47. [Google Scholar] [CrossRef]
- Shin, D.; Shim, J. A Systematic Review on Data Mining for Mathematics and Science Education. Int. J. Sci. Math. Educ. 2021, 19, 639–659. [Google Scholar] [CrossRef]
- Ferreira-Mello, R.; André, M.; Pinheiro, A.; Costa, E.; Romero, C. Text mining in education. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1332. [Google Scholar] [CrossRef]
- Kerkhof, R. Natural Language Processing for Scoring Open-Ended Questions: A Systematic Review. Master’s Thesis, University of Twente, Enschede, The Netherlands, 2020. [Google Scholar]
- Soni, S.; Kumar, P.; Saha, A. Automatic Question Generation: A Systematic Review. In Proceedings of the International Conference on Advances in Engineering Science Management & Technology (ICAESMT)-2019, Dehradun, India, 14–15 March 2019. [Google Scholar]
- Dos Santos, V.; de Souza, É.F.; Felizardo, K.R.; Watanabe, W.M.; Vijaykumar, N.L.; Aluizio, S.M.; Júnior, A.C. Conceptual Map Creation from Natural Language Processing: A Systematic Mapping Study. Rev. Bras. De Inform. Na Educ. Ao 2019, 27, 150–176. [Google Scholar] [CrossRef]
- Higgins, J.P.; Thomas, J.; Chandler, J.; Cumpston, M.; Li, T.; Page, M.J.; Welch, V.A. Cochrane Handbook for Systematic Reviews of Interventions; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef] [PubMed]
- Singh, V.K.; Singh, P.; Karmakar, M.; Leta, J.; Mayr, P. The journal coverage of Web of Science, Scopus and Dimensions: A comparative analysis. Scientometrics 2021, 126, 5113–5142. [Google Scholar] [CrossRef]
- Stahlschmidt, S.; Stephen, D. Comparison of Web of Science, Scopus and Dimensions databases. In KB Forschungspoolprojekt; DZHW: Hannover, Germany, 2020. [Google Scholar]
- Linnenluecke, M.K.; Marrone, M.; Singh, A.K. Conducting systematic literature reviews and bibliometric analyses. Aust. J. Manag. 2020, 45, 175–194. [Google Scholar] [CrossRef]
- Aria, M.; Cuccurullo, C. bibliometrix: An R-tool for comprehensive science mapping analysis. J. Inf. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- He, W. Examining students’ online interaction in a live video streaming environment using data mining and text mining. Comput. Hum. Behav. 2013, 29, 90–102. [Google Scholar] [CrossRef]
- Hung, J.L.; Zhang, K. Examining mobile learning trends 2003–2008: A categorical meta-trend analysis using text mining techniques. J. Comput. High. Educ. 2012, 24, 1–17. [Google Scholar] [CrossRef]
- McNamara, D.S.; Crossley, S.A.; Roscoe, R. Natural language processing in an intelligent writing strategy tutoring system. Behav. Res. Methods 2013, 45, 499–515. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Crossley, S.; Paquette, L.; Dascalu, M.; McNamara, D.S.; Baker, R.S. Combining click-stream data with NLP tools to better understand MOOC completion. In Proceedings of the 6th International Conference on Learning Analytics & Knowledge, Edinburgh, UK, 25–29 April 2016; pp. 6–14. [Google Scholar]
- Robinson, C.; Yeomans, M.; Reich, J.; Hulleman, C.; Gehlbach, H. Forecasting student achievement in MOOCs with natural language processing. In Proceedings of the 6th International Conference on Learning Analytics & Knowledge, Edinburgh, UK, 25–29 April 2016; pp. 383–387. [Google Scholar]
- Yim, S.; Warschauer, M. Web-based collaborative writing in L2 contexts: Methodological insights from text mining. Lang. Learn. Technol. 2017, 21, 146–165. [Google Scholar]
- Wang, F.; Ngo, C.W.; Pong, T.C. Structuring low-quality videotaped lectures for cross-reference browsing by video text analysis. Pattern Recognit. 2008, 41, 3257–3269. [Google Scholar] [CrossRef]
- Gibson, A.; Aitken, A.; Sándor, Á.; Buckingham Shum, S.; Tsingos-Lucas, C.; Knight, S. Reflective writing analytics for actionable feedback. In Proceedings of the 7th International Learning Analytics & Knowledge Conference, Vancouver, BC, Canada, 13–17 March 2017; pp. 153–162. [Google Scholar]
- Shum, S.B.; Sándor, Á.; Goldsmith, R.; Wang, X.; Bass, R.; McWilliams, M. Reflecting on reflective writing analytics: Assessment challenges and iterative evaluation of a prototype tool. In Proceedings of the 6th International Conference on Learning Analytics & Knowledge, Edinburgh, UK, 25–29 April 2016; pp. 213–222. [Google Scholar]
- Allen, L.K.; Snow, E.L.; McNamara, D.S. Are you reading my mind? Modeling students’ reading comprehension skills with Natural Language Processing techniques. In Proceedings of the 5th International Conference on Learning Analytics and Knowledge, Poughkeepsie, NY, USA, 16–20 March 2015; pp. 246–254. [Google Scholar]
- Cobo, M.; López-Herrera, A.; Herrera-Viedma, E.; Herrera, F. An approach for detecting, quantifying, and visualizing the evolution of a research field: A practical application to the Fuzzy Sets Theory field. J. Inf. 2011, 5, 146–166. [Google Scholar] [CrossRef]
- Callon, M.; Courtial, J.P.; Laville, F. Co-word analysis as a tool for describing the network of interactions between basic and technological research: The case of polymer chemsitry. Scientometrics 1991, 22, 155–205. [Google Scholar] [CrossRef]



| Year | Number of Publications |
|---|---|
| 2000–2004 | 18 |
| 2005–2019 | 67 |
| 2010–2014 | 136 |
| 2015–2019 | 346 |
| 2020–January 2022 | 414 |
| Author Keywords | Articles | Keywords-Plus (ID) | Articles |
|---|---|---|---|
| Natural language processing | 140 | Students | 306 |
| Sentiment analysis | 131 | Natural language processing systems | 223 |
| Machine learning | 122 | Data mining | 195 |
| Text mining | 122 | Learning systems | 171 |
| Deep learning | 64 | Sentiment analysis | 160 |
| Artificial intelligence | 38 | Natural language processing | 152 |
| E-learning | 37 | E-learning | 123 |
| Educational data mining | 32 | Teaching | 110 |
| Data mining | 29 | Text mining | 102 |
| Text classification | 28 | Education | 94 |
| Name | Number of Publications |
|---|---|
| Lecture Notes in Computer Science | 57 |
| ACM International Conference Proceedings Series | 29 |
| Advances in Intelligent Systems and Computing | 24 |
| CEUR Workshop Proceedings | 19 |
| Communication in Computer and Information Science | 17 |
| Journal of Physics: Conference Series | 17 |
| Pervasive Health: Pervasive Computing Technologies for Healthcare | 17 |
| International Journal of Advanced Computer Science and Applications | 11 |
| International Journal of Artificial Intelligence in Education | 11 |
| IEEE Access | 10 |
| First Author and Year | Digital Object Identifier | Total Citation (TC) | TC per Year | Ref |
|---|---|---|---|---|
| He W., 2013 | 10.1016/j.chb.2012.07.020 | 120 | 13 | [16] |
| Hung J.L., 2012 | 10.1007/s12528-011-9044-9 | 106 | 11 | [17] |
| Mcnamara D., 2013 | 10.3758/s13428-012-0258-1 | 70 | 8 | [18] |
| Crossley D., 2016 | 10.1145/2883851.2883931 | 61 | 10 | [19] |
| Robinson C., 2016 | 10.1145/2883851.2883932 | 42 | 7 | [20] |
| Yim S., 2017 | 10125/44599 | 37 | 7.4 | [21] |
| Wang F., 2008 | 10.1016/j.patcog.2008.03.024 | 31 | 2 | [22] |
| Gibson A., 2017 | 10.1145/3027385.3027436 | 27 | 5 | [23] |
| BuckinghamShum S., 2016 | 10.1145/2883851.2883955 | 23 | 2 | [24] |
| Allen L., 2015 | 10.1145/2723576.2723617 | 23 | 3 | [25] |
| Rank | Keyword | Frequency | Rank | Keyword | Frequency |
|---|---|---|---|---|---|
| 1 | Natural language processing | 140 | 26 | Neural network | 12 |
| 2 | Sentiment analysis | 131 | 27 | Student feedback | 12 |
| 3 | Machine learning | 122 | 28 | Automated essay scoring | 11 |
| 4 | Text mining | 122 | 29 | Feedback | 11 |
| 5 | Deep learning | 64 | 30 | Intelligent tutoring systems | 11 |
| 6 | Artificial intelligence | 38 | 31 | LSTM | 11 |
| 7 | E-learning | 37 | 32 | Natural language processing (NLP) | 11 |
| 8 | Educational data mining | 32 | 33 | Support vector machine | 11 |
| 9 | Data mining | 29 | 34 | BERT | 10 |
| 10 | Text classification | 28 | 35 | Feature selection | 9 |
| 11 | Learning analytics | 27 | 36 | Natural language | 9 |
| 12 | Education | 26 | 37 | Teaching evaluation | 9 |
| 13 | Topic modelling | 24 | 38 | Text analytics | 9 |
| 14 | Opinion mining | 23 | 39 | Word embedding | 9 |
| 15 | Higher education | 19 | 40 | Word2vec | 9 |
| 16 | Classification | 18 | 41 | Assessment | 8 |
| 17 | NLP | 18 | 42 | Big data | 8 |
| 18 | Text analysis | 18 | 43 | COVID-19 | 8 |
| 19 | MOOC | 16 | 44 | IDA | 8 |
| 20 | Online learning | 15 | 45 | Plagiarism detection | 8 |
| 21 | Chatbot | 13 | 46 | SVM | 8 |
| 22 | Latent dirichlet allocation | 13 | 47 | 8 | |
| 23 | Learning | 13 | 48 | Named entity recognition | 7 |
| 24 | MOOCs | 13 | 49 | Natural language understanding | 7 |
| 25 | Information retrieval | 12 | 50 | Ontology | 7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahadi, A.; Singh, A.; Bower, M.; Garrett, M. Text Mining in Education—A Bibliometrics-Based Systematic Review. Educ. Sci. 2022, 12, 210. https://doi.org/10.3390/educsci12030210
Ahadi A, Singh A, Bower M, Garrett M. Text Mining in Education—A Bibliometrics-Based Systematic Review. Education Sciences. 2022; 12(3):210. https://doi.org/10.3390/educsci12030210
Chicago/Turabian StyleAhadi, Alireza, Abhay Singh, Matt Bower, and Michael Garrett. 2022. "Text Mining in Education—A Bibliometrics-Based Systematic Review" Education Sciences 12, no. 3: 210. https://doi.org/10.3390/educsci12030210
APA StyleAhadi, A., Singh, A., Bower, M., & Garrett, M. (2022). Text Mining in Education—A Bibliometrics-Based Systematic Review. Education Sciences, 12(3), 210. https://doi.org/10.3390/educsci12030210