Scanning Signatures: A Graph Theoretical Model to Represent Visual Scanning Processes and A Proof of Concept Study in Biology Education


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Methods: Construction of the Network Model
2.1. Data: Gathering and Preparation
2.2. Basic Definitions and Idealizations
- we keep a record of how many instances or occurrences there are of each arc,
- if we keep a record of how many times a vertex is “visited” in our walk,
- and if we keep information about the order in which arcs are traversed along our walk in some way.
2.3. Arc and Vertex Weights
Average and Idealized Position of An Arc, and Idealized Walk Sets
2.4. Comparability of Graphs Obtained from Different Data Sequences
3. Results: A Proof of Concept
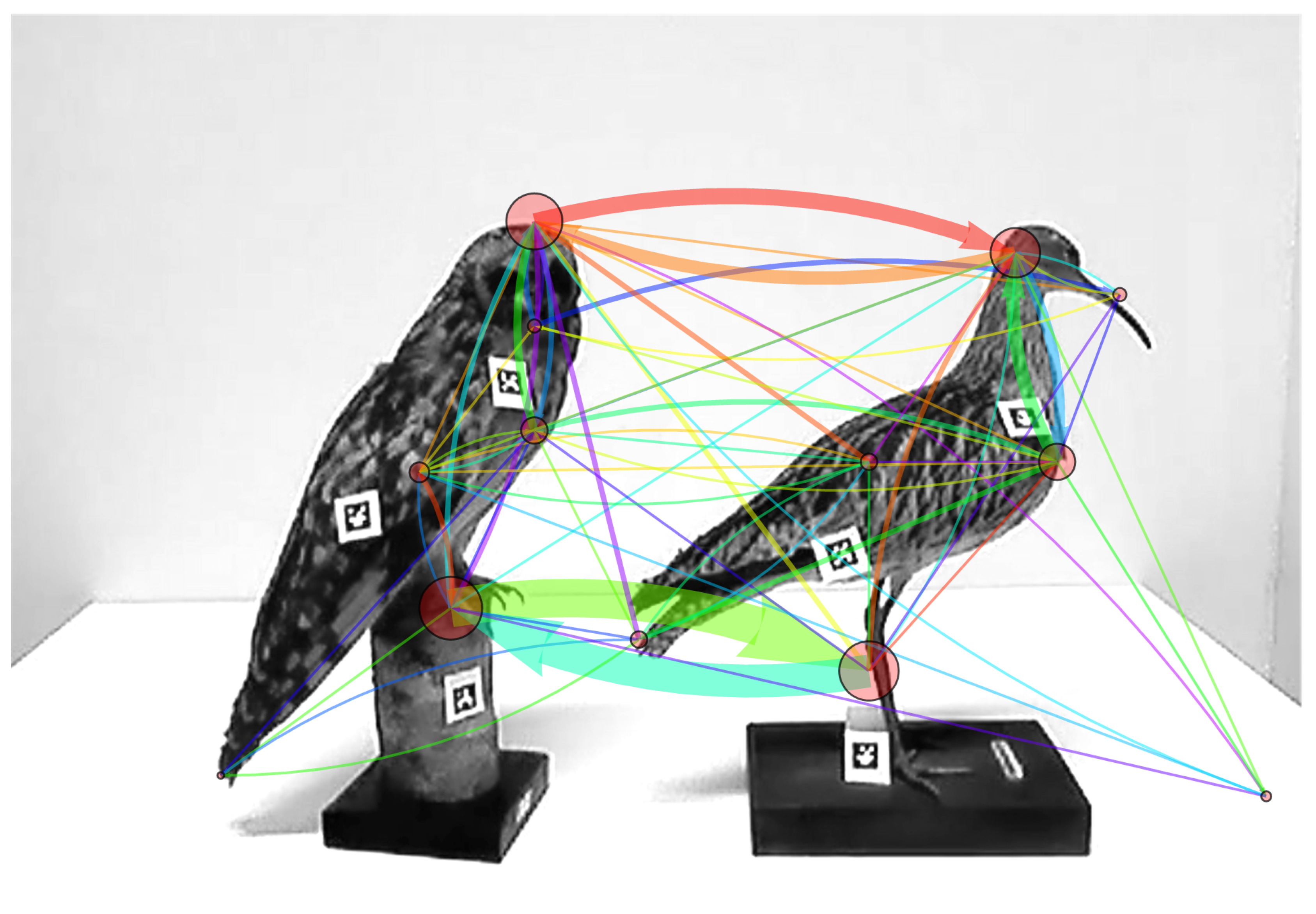
3.1. The Constructed Network, a Scanning Signature
3.2. Analyzing the Temporal Dimension
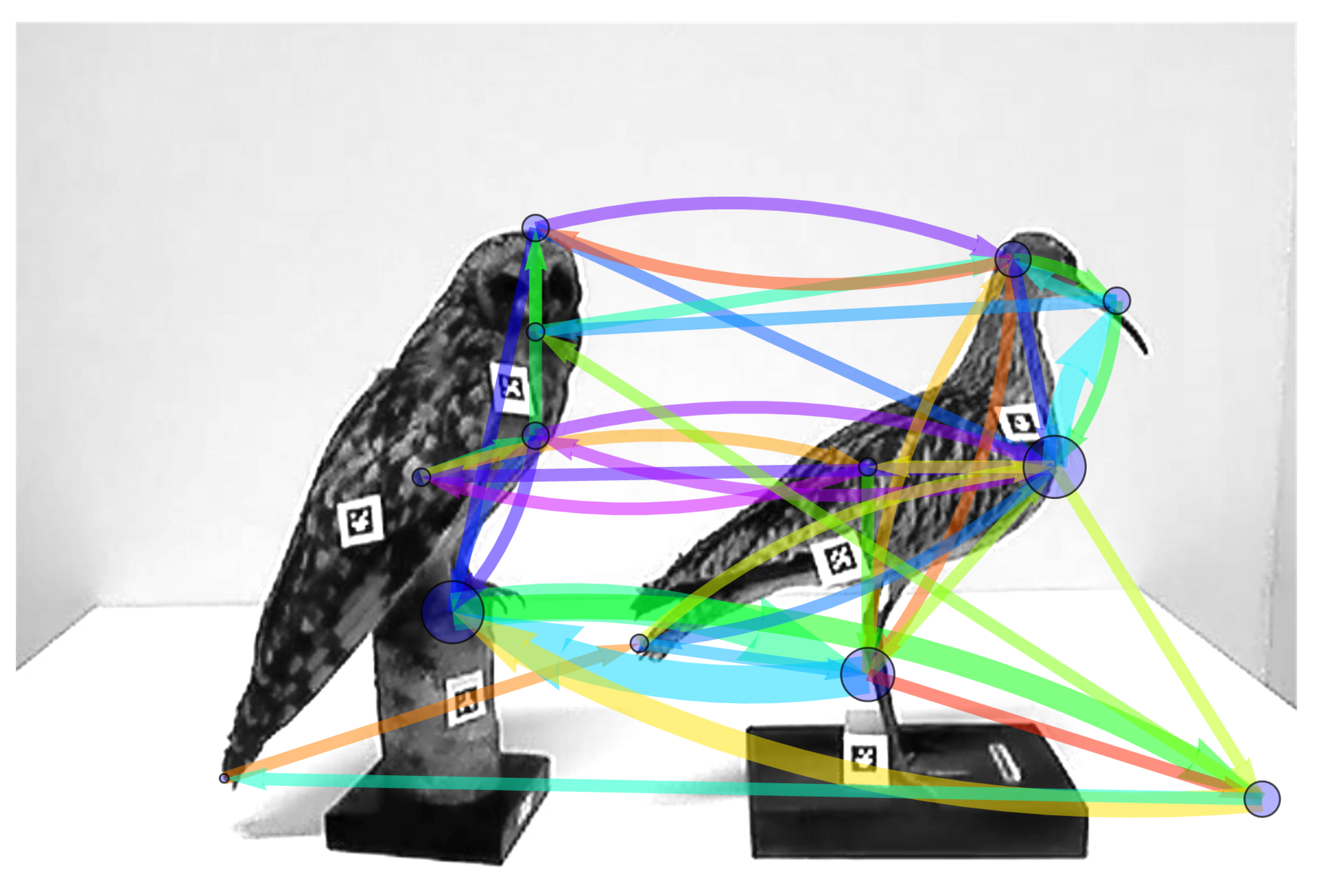
3.3. Comparing and Combining Scanning Signatures
3.3.1. Combining Vertex and Arc Weights of Two Sequences into a Single Scanning Signature
3.3.2. Combining the Temporal Structure of Two Sequences into a Single Scanning Signature
4. Discussion and Conclusions
4.1. Extensions of the Model
4.1.1. Using Fixations—Loops and Pseudographs
4.1.2. Combining the Data from Many Scanning Signatures and Using It as a Combined Signature
4.1.3. Vertex Weights
4.1.4. Temporal Information for the Vertices
4.1.5. Standard Deviations besides Means in the Temporal Information of Arcs and Vertices
4.2. Conclusions and Directions for Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Jarodzka, H.; Holmqvist, K. Eye tracking in educational science: Theoretical frameworks and research agendas. J.Eye Mov. Res. 2017, 10, 1–18. [Google Scholar]
- Was, C.; Sansosti, F.; Morris, B. (Eds.) Eye-Tracking Technology Applications in Educational Research; IGI Global: Hershey, PA, USA, 2017. [Google Scholar]
- Lukander, K.; Toivanenm, M.; Puolumäki, K. Inferring Intent and Action from Gaze in Naturalistic Behavior, A Review. Int. J. Mobil. Hum. Comp. Interact 2017, 9, 41–57. [Google Scholar] [CrossRef]
- Toivanen, M.; Lukander, K.; Puolumäki, K. Probabilistic Approach to Robust Wearable Gaze Tracking. J. Eye Mov. Res. 2017, 10, 1–26. [Google Scholar]
- Homqvist, K.; Nyström, M.; Andersson, R.; Dewhurst, R.; Jarodzka, H.; van der Weijer, J. Eye-Tracking: A Comprehensive Guide to Methods and Measures; Oxford University Press: Oxford, UK, 2011. [Google Scholar]
- Goldberg, J.H.; Helfman, J.I. Scanpath clustering and aggregation. In Proceedings of the 2010 Symposium on Eye-Tracking Research and Applications, Austin, TX, USA, 22–24 March 2010; pp. 227–234. [Google Scholar]
- Schneider, B.; Pea, R. Towards collaboration sensing. Int. J. Comput.-Support. Collab. Learn. 2014, 9, 371–395. [Google Scholar] [CrossRef]
- Anderson, N.; Anderson, F.; Kingstone, A.; Bischof, W.F. A comparison of scanpath comparison methods. Behav. Res. 2015, 47, 1377–1392. [Google Scholar] [CrossRef] [PubMed]
- Dewhurst, R.; Nyström, M.; Jarodzka, H.; Foulsham, T.; Johansson, R.; Holmqvist, K. It depends on how you look at it: Scanpath comparison in multiplel dimensions wth MultiMatch, a vector-based approach. Behav. Res. 2012, 44, 1079–1100. [Google Scholar] [CrossRef] [PubMed]
- Foulsham, T.; Dewhurst, R.; Nyström, M.; Jarodzka, H.; Johansson, R.; Underwood, G.; Holmqvist, K. Comparing scanpaths during scene encoding and recognition: A multidimensional approach. J. Eye Mov. Res. 2016, 5, 1–14. [Google Scholar]
- Jarodzka, H.; Holmqvist, K.; Nyström, M. A vector-based multidimensional scanpath similarity measure. In Proceedings of the 2010 Symposium on Eye Tracking Research and Its Applications, Austin, TX, USA, 22–24 March 2010; pp. 211–218. [Google Scholar]
- Just, M.A.; Carpenter, P. A theory of reading: From eye fixations to comprehension. Psychol. Rev. 1980, 87, 329–354. [Google Scholar] [CrossRef] [PubMed]
- Jarodzka, H.; Scheiter, K.; Gerjets, P.; Van Gog, T. In the eyes of the beholder: How experts and novices interpret dynamic stimuli. Learn. Instruct. 2010, 22, 146–154. [Google Scholar] [CrossRef]
- Eberbach, C.; Crowley, K. From everyday to scientific observation: How children learn to observe the biologist’s world. Rev. Educ. Res. 2009, 79, 39–68. [Google Scholar] [CrossRef]
- Roth, W.M.; McRobbie, C.J.; Lucas, K.B.; Boutonné, S. Why students fail to learn from demonstrations? A social practice perspective on learning in physics. J. Res. Sci. Teach. 1997, 34, 509–533. [Google Scholar] [CrossRef]
- Trumbull, D.J.; Bonney, R.; Grudens-Schuck, N. Developing materials to promote inquiry: Lessons learned. Sci. Educ. 2005, 89, 879–900. [Google Scholar] [CrossRef]
- Finnish National Board of Education (FNBE). The National Core Curriculum for Basic Education, 2014; Finnish National Board of Education (FNBE): Helsinki, Finland, 2016. [Google Scholar]
- Palmberg, I.; Berg, I.; Jeronen, E.; Kärkkäinen, S.; Norrgård-Sillanpää, P.; Persson, C.; Vilkonis, R.; Yli-Panula, E. Nordic–Baltic student teachers’ identification of and interest in plant and animal species: The importance of species identification and biodiversity for sustainable development. J. Sci. Teach. Educ. 2015, 26, 549–571. [Google Scholar] [CrossRef]
- Kaasinen, A. Plant Species Recognition Skills in Finnish Students and Teachers. Educ. Sci. 2019, 9, 85. [Google Scholar] [CrossRef]
- Chartrand, G.; Zhang, P. A First Course in Graph Theory; Dover Publications: Mineola, NY, USA, 2012. [Google Scholar]
- Bondy, J.A.; Murty, U.S.R. Graph Theory with Applications; Elsevier Science Publishing Co.: Amsterdam, The Netherlands, 1976. [Google Scholar]





© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Garcia Moreno-Esteva, E.; Kervinen, A.; Hannula, M.S.; Uitto, A. Scanning Signatures: A Graph Theoretical Model to Represent Visual Scanning Processes and A Proof of Concept Study in Biology Education. Educ. Sci. 2020, 10, 141. https://doi.org/10.3390/educsci10050141
Garcia Moreno-Esteva E, Kervinen A, Hannula MS, Uitto A. Scanning Signatures: A Graph Theoretical Model to Represent Visual Scanning Processes and A Proof of Concept Study in Biology Education. Education Sciences. 2020; 10(5):141. https://doi.org/10.3390/educsci10050141
Chicago/Turabian StyleGarcia Moreno-Esteva, Enrique, Anttoni Kervinen, Markku S. Hannula, and Anna Uitto. 2020. "Scanning Signatures: A Graph Theoretical Model to Represent Visual Scanning Processes and A Proof of Concept Study in Biology Education" Education Sciences 10, no. 5: 141. https://doi.org/10.3390/educsci10050141
APA StyleGarcia Moreno-Esteva, E., Kervinen, A., Hannula, M. S., & Uitto, A. (2020). Scanning Signatures: A Graph Theoretical Model to Represent Visual Scanning Processes and A Proof of Concept Study in Biology Education. Education Sciences, 10(5), 141. https://doi.org/10.3390/educsci10050141