Abstract
Training of neural networks requires large amounts of data. Simulated data sets can be helpful if the data required for the training is not available. However, the applicability of simulated data sets for training neuronal networks depends on the quality of the simulation model used. A simple and fast approach for the simulation of ground and honed surfaces with predefined properties is being presented. The approach is used to generate a diverse data set. This set is then applied to train a neural convolution network for surface type recognition. The resulting classifier is validated on the basis of a series of real measurement data and a classification rate of >85% is achieved. A possible field of application of the presented procedure is the support of measurement technicians in the standard-compliant evaluation of measurement data by suggestion of specific data processing steps, depending on the recognized type of manufacturing process.
1. Introduction
Production metrology deals with all of the measuring and inspection tasks that arise during the creation of products. Usually, function-related characteristics of workpieces are measured. In addition to the measurement, the procedure for evaluating surface roughness (e.g., 3D) as a quality criterion includes the steps of data preprocessing (e.g., filtering [1]) and parameter calculation [2] (cf. Figure 1). A large number of parameters exist for standard-compliant data preprocessing, as well as for standard-compliant roughness parameters calculation [2,3,4]. The selection of standard-compliant parameters has to be done manually and can be a challenge. In the case of recurring, identical measurement tasks, an expert defines the data processing steps once for all similar measurements. However, since a measuring device is usually used for a large number of different and changing measuring tasks, the parameterization of the measurement data processing steps must be adapted by the operator repeatedly. In the case of unknown or incorrectly assumed boundary conditions (e.g., due to communication errors, when measurements and evaluations are carried out by different persons), there is a risk that steps of the measurement data processing will be changed or incorrectly parameterized, and that the determined parameters are thus incorrect or no longer comparable.
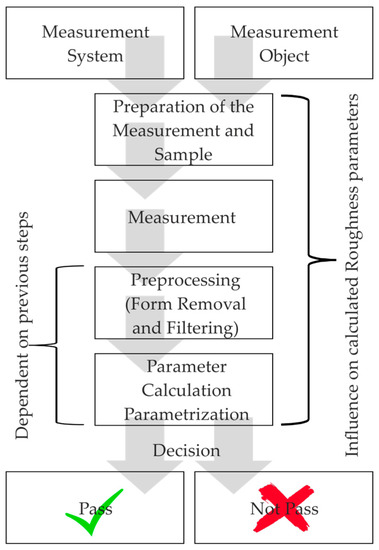
Figure 1.
Illustration of steps in roughness parameter calculation.
Assistance software, developed for example in the project “OptAssyst—User-oriented assistance systems for the safe use of optical distance sensors” funded by the German Federal Ministry of Education and Research (BMBF) [5] supports the user in the selection of the measuring principle, as well as in the parameterization of the data processing [6,7]. However, for the standard-compliant evaluation of surface roughness, the complete measuring task must be known, which includes knowledge of the manufacturing process. As an example, the surface filter must be selected in such a way that the surface details like e.g., grooves are not distorted—i.e., linear filters [3] for ground surfaces and robust filters for plateau-honed surfaces [4].
In order to support the user, it is therefore useful to automatically classify the measurement object and the related manufacturing process in order to suggest a standard-compliant procedure for measurement data processing and evaluation.
Signal processing approaches, which are usually used for the characterization of technical surfaces, such as radon transformation [8] or the watershed transformation [9], offer a solution for realizing classifiers. Parameters derived from these transformations, such as the number and location of peaks in the radon transformation, can be used for classification. However, the implementation of such approaches can be impractical for a non-expert user, as it requires extensive knowledge of both signal processing and the process. Another challenge is the extension of pre-selected transformational-based classifiers to other surface types.
Artificial neural networks (ANN) are an approach to the implementation of classifiers based only on measurement data sets and are therefore an alternative to signal processing approaches. Specifically convolutional neural networks (CNN) are successfully used to classify images, for example for the recognition of handwriting [10] or for recognizing objects in images [11]. On the one hand, this success leads to further research and new discoveries, such as Generative Adversarial Networks [12], for manipulating neuronal networks or the “deconvnet” for visualizing neuronal networks [13]. On the other hand, the success results in tools that make the application of CNN easier. Since surfaces measured with topography measuring instruments (such as Confocal microscopy, Coherence scanning interferometry), which deliver 2.5D elevation maps can be interpreted as grayscale images, the transfer of these techniques is evident. However, since the training of CNN requires a large amount of data (>1000 measurements), which is not always available, artificially generated measurement data sets with specific properties of technical surfaces are of interest. Therefore, an approach for generating two different classes of technical surfaces with predefined properties is presented (ground and honed surfaces). This artificial data is then used to train a simple convolutional neuronal network for surface classification. In the next step, the classifier that was trained with artificial data is verified by means of real measurement data sets (honed cylinder liners of different car manufacturers and a selection of ground surfaces).
The classification task with only two classes was deliberately chosen in such a way that the proposed procedure can be tested easily. Future work, which is excluded from this paper, focuses on the generation of optimal input data for artificial surface models based on time series models estimation from small sets of actual measurement data, and the application of more advanced or complex neuronal networks.
2. Approach for the Generation of Artificial Ground and Honed Surfaces
Real technical surfaces often have stochastically distributed features. The structure of those features depends on the chosen manufacturing process. In grinding or honing processes, geometrically indefinite cutting edges are used. Plasma-coated surfaces contain stochastically distributed pores. In many different applications, mathematical models for the simulation of such surfaces already exist.
The probability distribution of the topography heights is often assumed as Gaussian [14,15,16]. For honed surfaces, this assumption is invalid. Their probability distribution is often strongly asymmetric [17,18,19,20,21,22,23]. Existing models for the simulation of honed surfaces aim to produce surfaces with identical properties (e.g., roughness parameters) as given real surfaces. For the approach chosen in this paper, the objective is different: The aim is to simulate many different surfaces with the same (default) character, but the exact properties should be distributed stochastically.
A honing process can be seen as a modification of a grinding process. The movement of the honing stones relative to the surface leads to the characteristic cross-structure with the honing angle α. The probability distribution of the topography heights in a grinding process can be assumed as Gaussian. With multi-step honing processes (e.g., plateau honing), surfaces with a shallow peak area and a distinct valley area can be created. Hence, the different honing steps can be simulated as Gaussian topographies [24,25]. The combination of those topographies results in the final surface. A comparable approach was chosen in [21]. The model for the simulation of the Gaussian topographies is based on the approaches of [18,26]. The 2.5D topographies can be described as matrices of the form:
The point distance in direction of the x-axis is referred to as Δx and in y as Δy. The lateral properties of the surface are described with the circular autocorrelation function:
With for m + k > M – 1 n + l ≤ N – 1, analogous for n + l > N – 1 and combinations. The discrete power spectral density is the Fourier transform of the autocorrelation function:
The aim is to generate a discrete 3D-Topography of the form:
With , , , . The input data for the simulation is: A circular autocorrelation function , respectively its Fourier transform (the discrete power spectral density) , a matrix with standard normal distributed entries and the variance of the target surface. The given autocorrelation function must not contain phases; the corresponding discrete power spectral density must be real. Otherwise, is set for the simulation. This changes the shape of the autocorrelation function. The Fourier transform of the matrix g is G = F(g), so that:
The 2.5D-topography is generated from the input data with:
The Fourier transform of g is convoluted with the square root of the given power spectral density in the frequency domain. To achieve the requested variance , the power spectral density has to be normalized. The simulation method used here is similar to the one presented by Wu [26]. Wu uses a complex vector with uniformly distributed phases and constant amplitude instead of the Fourier transform G of a normal distributed matrix g. With such an approach, the given autocorrelation function is exactly mapped into the simulated topographies e.g., it does not contain any stochastic variations as in the approach chosen for this paper (cf. Figure 2b,d)). The difference in the generated artificial surfaces is subtle (cf. Figure 2a,c).
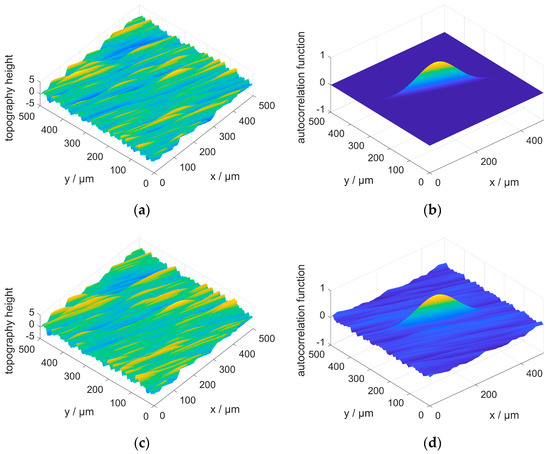
Figure 2.
(a,b): ground surface and its corresponding autocorrelation function simulated with the method of Wu (c,d): ground surface and corresponding autocorrelation function simulated with the proposed method.
However, since the model presented here is intended to simulate the stochastic properties of real surface topographies, this aspect should also be taken into account. In order to illustrate the difference between the two methods, definitions from the next paragraph are already used here. The autocorrelation function used in this example is the function R(x,y), defined in the next paragraph with parameters l1 = 100 µm, l2 = 5 µm, a = 2, and = 1 µm. Δx and Δy are chosen as 0.5 µm, the size of the simulated surface is 1000 × 1000 points.
3. Simulation of Directional Structures (Grinding Surfaces)
The autocorrelation function of real technical surfaces is approximately an exponential function [6]. A more general model is chosen for the simulation:
Here, the exponent a determines the character of the autocorrelation function. For a = 1, its shape is exponential and for a = 2 it is Gaussian. The autocorrelation function is not necessarily orthogonal to the axes of coordinates, therefore the angle is introduced. It specifies the rotation of the autocorrelation function around the origin and corresponds to the main direction of the structures respectively. the honing angle. The parameters l1 and l2 are the correlation lengths in direction and . The correlation length describes the distance, where the standardized autocorrelation function falls to h = e−1. In literature, other definitions for h exist, e.g., h = 0.2 [1]. The continuous autocorrelation function is discretized and used as a circular autocorrelation function. Depending on the parameter selection, non-differentiable points and discontinuities might occur, and the associated power spectral density may not be real. In the simulation, this leads to deviations from the requested autocorrelation function. Those deviations become smaller, as the simulated topography becomes larger in relation to the chosen autocorrelation length. The parameters for the simulation of a Gaussian distributed surface are the expectation value µ, the variance , the correlation lengths l1 and l2, the exponent a and the angle (cf. Figure 3).
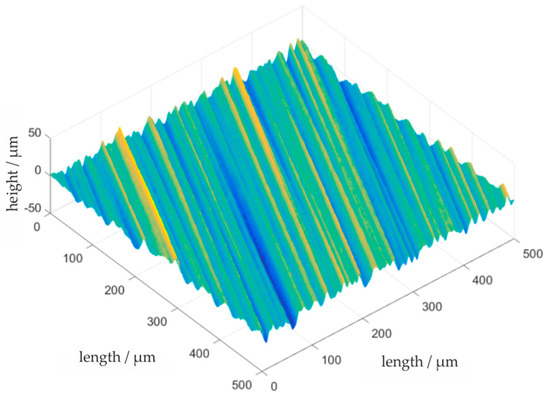
Figure 3.
Simulation of a grinding surface. Parameters: Δx = Δy = 0.5 µm; l1 = 500 µm; l2 = 5 µm; ϕ = 25°; σ = 5.68 µm; µ = 3.2 µm; Measurement field: 4000 × 4000 points; Field of view: 1000 × 1000 points.
4. Simulation of Honed Structures in Multiple Steps
4.1. One-Step Honing Process
A one-step honing process can be seen as a combination of two grinding processes. The up- and downward movement of the honing tool generates directional structures with an angle and . Together they generate the characteristic cross-structure. Both processes remove material, so the result for a one-step honing process is:
where and are two simulated, Gaussian distributed topographies with the same simulation parameters. The angles are for and for . The exponent, a, is chosen as 2 (Gaussian), if not marked otherwise (see Figure 4a). It should be considered that µ and are parameters of the two Gaussian distributed topographies and do not represent the expectation value and the standard distribution of the simulated honing process. The probability distribution of the honing process is the probability distribution of the minimum of two Gaussian distributed random variables and therefore not a Gaussian distribution.
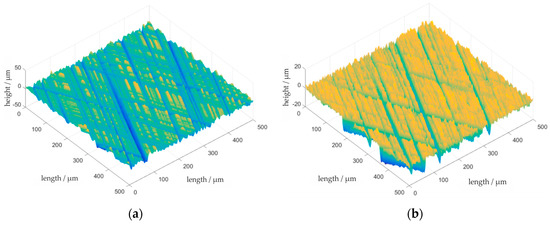
Figure 4.
(a) Simulation of a one-step honed surface as the minimum of two simulated grinding surfaces. Parameters: As in Figure 3; (b) Simulation of a plateau honed surface (Δx = Δy = 0.5 µm). Parameters step 1: l1 = 500 µm; l2 = 5 µm; ϕ = 25°; σ = 5.68 µm; µ = 3.2 µm. Parameters step 2: l1 = 20 µm; l2 = 2 µm; ϕ = 25°; σ = 1.8 µm; µ = 2.01 µm.
4.2. Multi-Step Honing Processes
For the simulation of a multi-step honing process, multiple simulated one-step honing processes are combined. One process virtually removes material from the topography resulting from the previous steps. Mathematically, the resulting topography is the minimum of multiple one-step honing topographies
The different processes are differently parameterized. In general, two simulated honing processes are sufficient to reproduce the structure of a plateau honed surface (cf. Figure 4b).
5. Approach for the Classification of Simulated Ground and Honed Surfaces Using Machine Learning
The techniques described above can be used for the fast generation of artificial data sets with defined characteristics. Here, a total of 2000 ground and honed surfaces were simulated, of which 1000 were selected for training the network and 1000 as test data sets. The parameters used for generation are given in Table 1. The measurement field size (500 × 500 pixels) was selected in such a way that it is in the range of typical confocal microscopes (e.g., NanoFocus µSurf explorer: measurement field 512 × 512 pixels). For the grinding structures, the lateral point distances Δx and Δy, and the autocorrelation lengths l1 and l2 were selected in order to create the process-specific directed structures. The angle, , varies freely. For honed structures, the correlation lengths l1 and l2 and variances and were chosen in such a way that they correspond to a coarse and a fine process step, similar to plateau honing. The honing angle was varied in a wide range. The simulated data was converted into grayscale images and compressed to 50 × 50 pixels to reduce the computational effort. Examples of the simulated ground and honed surfaces used for training can be found in Figure 5.

Table 1.
Selected parameters for generating the training and test data. For parameters with a range, a uniform distribution over the range is assumed.
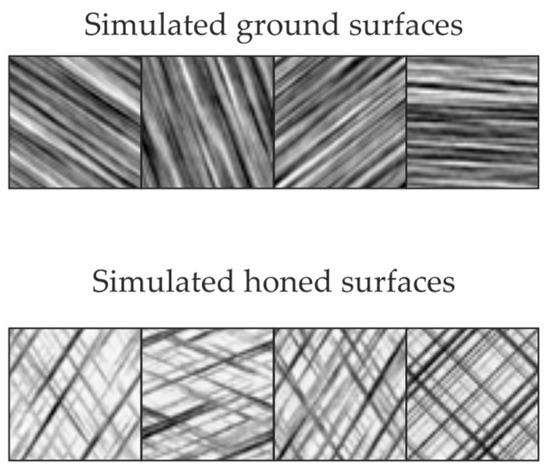
Figure 5.
Examples of simulated ground (top) and honed (bottom) surfaces as compressed grayscale images.
The Convolutional Neural Networks (CNNs) were implemented with The Mathworks’ Neural Network Toolbox to classify the simulated test data [27,28,29]. Two architectures, each with two different configurations were tested:
- A two-layer CNN with 8 filters of the size 5 × 5 in the first layer and 4 filters of the size 10 × 10.
- A two-layer CNN with 6 filters of the size 5 × 5 in the first layer and 6 filters of the size 5 × 5.
- A three-layer CNN with 8 filters of the size 5 × 5 in the first layer and 4 filters of the size 5 × 5 in the 2nd and third layer.
- A three-layer CNN with 6 filters of size 5 × 5 in the first, second and third layer.
The convolutional filters that form the core in the CNNs are convolutional operators of a given size (5 × 5 or 10 × 10) similar to edge detectors in image processing. Their weights are initialized randomly and iteratively changed (trained) over multiple epochs. The filter sizes are chosen small, since the structures to be learned by the CNN are expected to be small and primitive (straight lines or edges). The low number of layers (two or three) is due to the fact that the structures occurring in the data are of a periodic nature and do not have to be assembled into more complex structures.
The overall architecture of the investigated neural networks is as follows: An image input layer is used as the first layer to map the input data to the following neurons, followed by the convolutional layers, which consist of the convolution filters, followed by a ReLU layer (rectified linear unit, threshold value operator that assumes the function of an activation function), and a pooling layer, which folds the image with a maximum filter. The combination of convolution, ReLU layer and pooling is expected to preserve important information while reducing the overall data volume, resulting in a reduction of computation time [30]. Following the convolutional layers, a fully connected layer, a softmax layer, and a classification layer is selected (Figure 6).
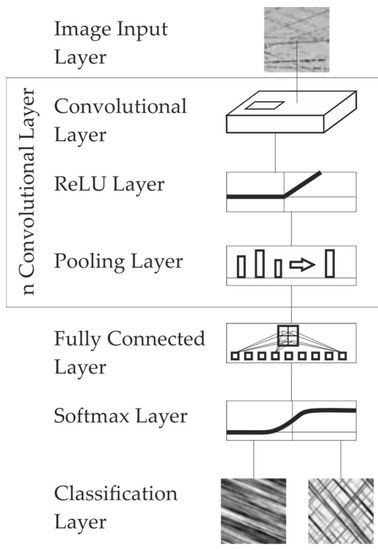
Figure 6.
Architecture of the considered Convolutional Neural Networks (CNNs).
To train the CNN, the Stochastic Gradient Descend with Momentum [31] is selected. The learning rate is chosen to be 0.01 for the first four epochs and then reduced by 1/10 for every four epochs. For each iteration, 100 simulated surfaces are entered and the maximum number of epochs is limited to eight.
The accuracy of the classification (detection rate) is calculated with:
With N+ being the number of correct classified data and N = 2000 the overall data set size.
Both the two-layer CNNs, as well as both three-layer CNNs, are able to distinguish grinded from honed surfaces with decent accuracy after training. For CNN number 1, the accuracy of classification with the artificially generated test set is 96.32%, for case 2 92.55%, for case 3 99.15%, and 99.05% for case 4. Thus, the two three-layer CNNs show a slightly higher classification rate for the artificially generated test data than the two-layer CNNs (see Table 2).
Table 2.
Comparison of the classification performance of the different CNN architectures.
Looking at the weights for the two-layer CNN in the first layer, it is noticeable that edge detection-like structures are visible in the first layer, but they are not directly interpretable (cf. Figure 7, left, 1st row, green). Some of the weights in the first layer, and multiple weights in the 2nd layer appear to be untrained, hence containing noise (cf. Figure 7, left, red). For the three-layer CNN, all of the neurons in the first layer appear to be trained. Three filters appear to have a similar structure (cf. Figure 7, right, 1st row, green). The interpretation of the weights in the 2nd layer is more difficult. Again, some filters appear to be untrained (cf. Figure 7, right, red), while others appear to have a structure. (cf. Figure 5, right, 2nd row, green) The third layer seems to contain mostly trained filters (Figure 7, right, 3rd row, green). A generally visual interpretation of the filter weights is hardly possible.

Figure 7.
Visualization of CNN weights for CNN architecture 1 (left) and 3 (right). Eventually untrained weights are marked in red, trained or interesting weights are marked green.
Generally speaking, the number of untrained filters in CNN structures 1. to 4. indicates that the CNN structure may have been selected too complex for the simple classification task. By adding further surface-types and extending the training set, it can be assumed that these filters will be trained for future characteristics.
6. Verification of the Classifier Using Real Ground and Honed Surfaces
All measurement data used for the verification was acquired as 2.5D-topographies (height maps) during the course of several completed projects not related to this work, using a confocal microscope as measurement device (Nanofocus µSurf explorer, NanoFocus AG, Oberhausen, Germany). This ensures that the existing data is independent of the methodology proposed in the Section 2, Section 3 and Section 4. A selection of honed samples of differently manufactured cylinder liners from various automotive manufacturers from the truck and car sector is used (in total 50 different surfaces, measured in each case at up to 11 different locations, in total 400 records). These are kindly provided by the members of the working group “Arbeitskreis 3D-Rauheitsmesstechnik”. Measured data from real ground surfaces is obtained from the institute’s data archive (in total 400 different measurement data sets) from completed measurement tasks. The real ground surfaces contain data sets with grinding defects.
Measurements of the classification performance according to formula 10 of the four different CNN architectures used to distinguish ground and honed surfaces are given in Table 2. The 3-layer CNNs showed better results than the 2-layer CNNs. Both 3-layer CNN architectures classified the same 31 grinding and 74 honing samples incorrectly. What is striking about the incorrectly classified grinding samples is the fact that all of the grinding structures run at an angle of 90°, which hints at a difficulty in learning this specific feature for the classification (cf. Figure 8, top). The wrongly classified honed samples differ in part largely from the average honed surface. Generally, they differ in appearance. There is no obviously visible systematics (cf. Figure 8, bottom). One possible explanation for part of the incorrectly classified data sets is the fact that structures such as pores, which are not considered for the model, occur in the real data sets.
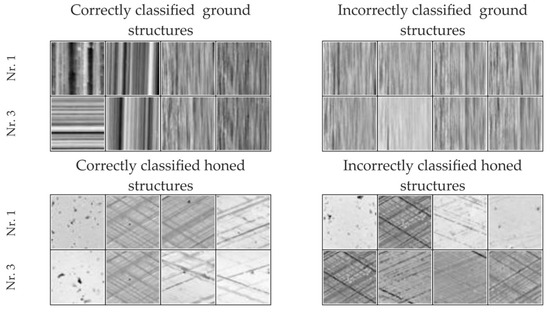
Figure 8.
Examples of correctly and incorrectly classified datasets.
In summary, it can be concluded that the classification rates of over 85% for real measured surfaces are satisfactory as a first result (see Table 2), especially since the verification set contained unmodelled characteristics. However, the detection rate is far from the performance of modern neural networks for more complex tasks [10,30]. Further work is therefore required.
7. Summary and Outlook
A simple approach to the simulation of artificial topographies with the characteristics of ground and honed surfaces was presented. In a second step, the two classes of artificially created surfaces were used to train CNNs in order to recognize the type of surface. It has been shown that simple, modern CNN architectures are suitable for classifying the two simulated surface types. In a third step, the CNNs were used to classify real ground and honed surfaces. The three-layer CNNs showed better results than the two-layer CNNs with a classification rate of above 85%. However, the performance is still below that of state-of-the-art CNNs. The classification task with only two recognizable classes was deliberately chosen as simple in order to test how well neural networks can be implemented and trained.
For the upcoming steps, both the approach to artificial creation of structured surfaces and the CNN for classification will be extended: the input data for the surface creation can be generated from actual measurement data based on stochastic time series models. Based on an optimization approach, ideal models can be chosen that provide the best possible stochastic description of surface properties. The suitability and versatility of this approach will be examined in further studies. It is intended that the resulting CNN can be used to support users in the standard-compliant characterization of technical surfaces through proposals for standard-compliant data processing steps, for example in the calculation of roughness parameters.
Acknowledgments
This research was funded by the German Research Foundation (DFG) within the Collaborative Research Center 926 “Microscale Morphology of Component Surfaces”. We thank the work group “Arbeitskreis 3D-Rauheitsmesstechnik” for the support of the work.
Author Contributions
Sebastian Rief, Matthias Eifler and Jörg Seewig conceived and implemented the approach for the generation of artificial ground and honed surfaces. Felix Ströer and Simon Kieß conceived and designed the ANNs for surface classification, generated test data, applied the ANN to the test and evaluated results. Sebastian Rief and Jörg Seewig helped in providing measurement data from real technical surfaces
Conflicts of Interest
The authors declare no conflict of interest.
References
- ISO 25178-3: 2012-11. Geometrical Product Specifications (GPS)—Surface Texture: Areal—Part 3: Specification Operators (ISO 25178-3:2012); ISO: Geneva, Switzerland, 2012. [Google Scholar]
- ISO 25178-2: 2012-09. Geometrical Product Specifications (GPS)—Surface Texture: Areal—Part 2: Terms, Definitions and Surface Texture Parameters (ISO 25178-2:2012); ISO: Geneva, Switzerland, 2012. [Google Scholar]
- ISO 16610-61: 2015-07. Geometrical Product Specification (GPS)—Filtration—Part 61: Linear Areal Filters—Gaussian Filters; ISO: Geneva, Switzerland, 2015. [Google Scholar]
- ISO 16610-71: 2014-09. Geometrical Product Specifications (GPS)—Filtration—Part 71: Robust Areal Filters: Gaussian Regression Filters; ISO: Geneva, Switzerland, 2014. [Google Scholar]
- Böttner, T.; Mauch, F.; Osten, W.; Riedel, J.; Schmitt, R.; Schmidt, H.; Hausotte, T.; Wiehr, C.; Seewig, J. Helfer ohne Fehl und Tadel—Assistenzsysteme für den sicheren Einsatz optischer Abstandssensoren. Inspect 2014, 15, 74–75. (In German) [Google Scholar]
- Wiehr, C. Hilfe aus dem Rechner—Assistent für die optische Oberflächenmesstechnik. QZ Qual. Zuverlässigk. 2013, 58, 40–42. (In German) [Google Scholar]
- Mauch, F.; Lyda, W.; Osten, W. Model-based assistance system for confocal measurements of rough surfaces. Proc. SPIE Opt. Meas. Syst. Ind. Insp. VIII 2013, 8788, 87880U. [Google Scholar] [CrossRef]
- Arnecke, P. A Measurement Method for Characterising Micro Lead on Ground Shaft Surfaces. Ph.D. Thesis, Technische Universität Kaiserslautern, Kaiserslautern, Germany, 2017. [Google Scholar]
- ISO 16610-85: 2013-02. Geometrical Product Specifications (GPS)—Filtration—Part 85: Morphological Areal Filters: Segmentation (ISO 16610-85:2013); ISO: Geneva, Switzerland, 2013. [Google Scholar]
- Ciregan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3642–3649. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 2672–2680. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Nayak, P.R. Random process model of rough surfaces. J. Lubr. Technol. 1971, 93, 398–407. [Google Scholar] [CrossRef]
- Whitehouse, D.J.; Archard, J.F. The Properties of random surfaces of significance in their contact. Proc. R. Soc. A Math. Phys. Eng. Sci. 1970, 316, 97–121. [Google Scholar] [CrossRef]
- Sayles, R.S.; Thomas, T.R. A stochastic explanation of some structural properties of a ground surface. Int. J. Prod. Res. 1976, 14, 641–655. [Google Scholar] [CrossRef]
- Patir, N. A numerical procedure for random generation of rough surfaces. Wear 1978, 47, 263–277. [Google Scholar] [CrossRef]
- Hu, Y.Z.; Tonder, K. Simulation of 3-D random rough surface by 2-D digital filter and fourier analysis. Int. J. Mach. Tools Manuf. 1992, 32, 83–90. [Google Scholar] [CrossRef]
- Bakolas, V. Numerical generation of arbitrarily oriented non-Gaussian three-dimensional rough surfaces. Wear 2003, 254, 546–554. [Google Scholar] [CrossRef]
- Wu, J.-J. Simulation of non-Gaussian surfaces with FFT. Tribol. Int. 2004, 37, 339–346. [Google Scholar] [CrossRef]
- Pawlus, P. Simulation of stratified surface topographies. Wear 2008, 264, 457–463. [Google Scholar] [CrossRef]
- Uchidate, M.; Yanagi, K.; Yoshida, I.; Shimizu, T.; Iwabuchi, A. Generation of 3D random topography datasets with periodic boundaries for surface metrology algorithms and measurement standards. Wear 2011, 271, 565–570. [Google Scholar] [CrossRef]
- Wang, T.; Wang, L.; Zheng, D.; Zhao, X.; Gu, L. Numerical simulation method of rough surfaces based on random switching system. J. Tribol. 2015, 137, 021403. [Google Scholar] [CrossRef]
- Malburg, M.C.; Raja, J.; Whitehouse, D.J. Characterization of surface texture generated by plateau honing process. CIRP Ann. Manuf. Technol. 1993, 637–639. [Google Scholar] [CrossRef]
- DIN EN ISO 13565-3: 2000-08. Oberflächenbeschaffenheit: Tastschnittverfahren; Oberflächen MIT Plateauartigen Funktionsrelevanten Eigenschaften—Teil 3: Beschreibung der Höhe von Oberflächen mit der Wahrscheinlichkeitsdichtekurve (ISO 13565-3: 2000-08); ISO: Geneva, Switzerland, 2000. [Google Scholar]
- Wu, J.-J. Simulation of rough surfaces with FFT. Tribol. Int. 2000, 33, 47–58. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Handwritten digit recognition with a back-propagation network. Adv. Neural Inf. Process. Syst. 1990, 2, 396–404. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; The MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).