1. Introduction
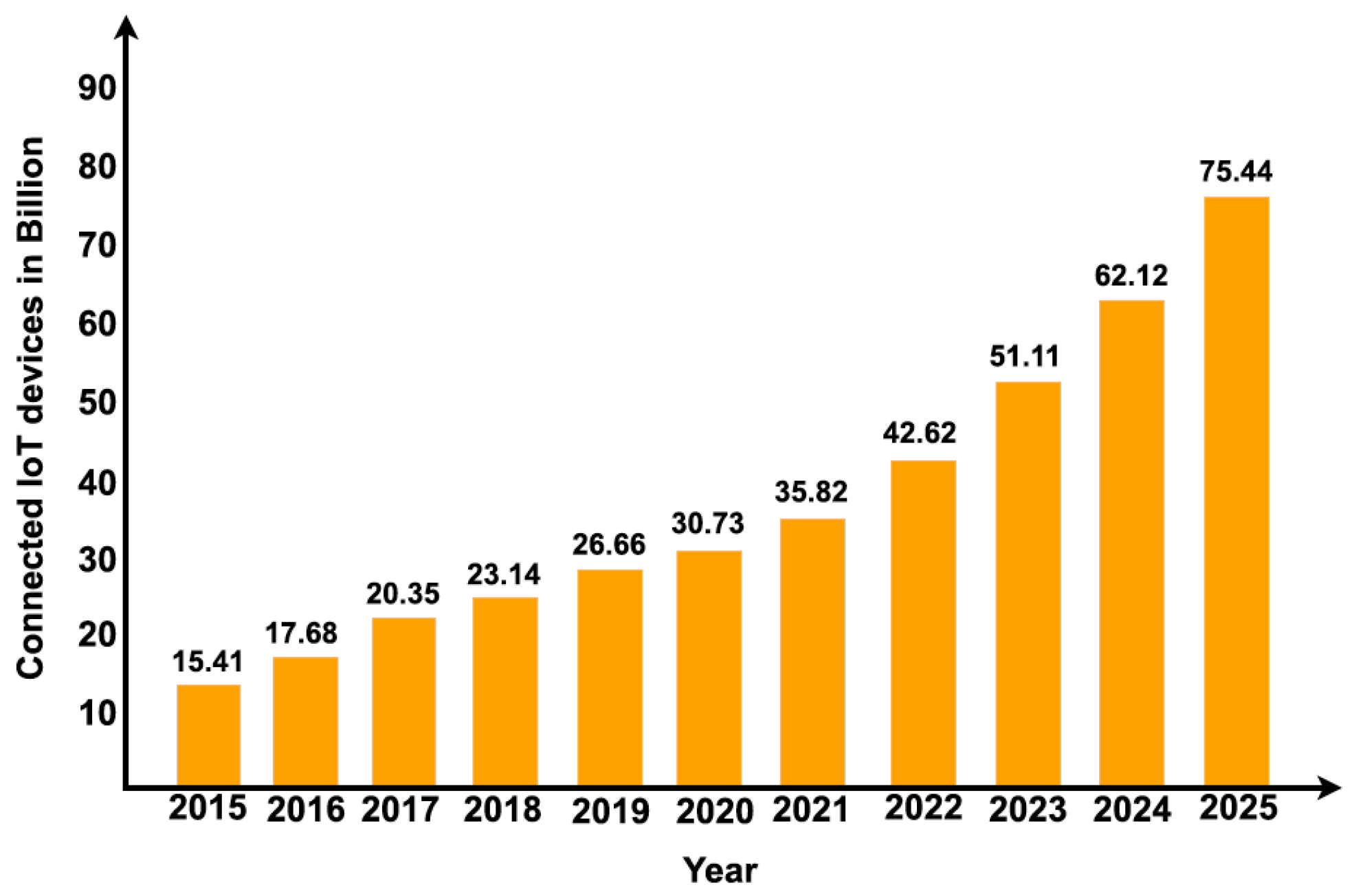
The Internet of Things (IoT) has the potential to change our way of life and work by providing its fundamental services to all connected smart devices. IoT solves several wireless network problems, such as a large number of smart devices with reliable internet access, energy-constrained portable edge devices, quick data transfers, efficient bandwidth use, and improved data collection accuracy at the receiver. To accomplish these goals, the devices must be effectively connected so that they can exchange sensed data rapidly and make wise decisions to regulate physical phenomena, which will lead to the creation of a smart ecosystem. Numerous studies predict that the Internet of Things will be crucial to a wide range of commercial and social applications in the years to come, such as smart buildings, utilities, consumer electronics, smart cities, smart transportation, smart healthcare, security, logistics, climate-smart agriculture, asset tracking, and waste management systems. Over 75 billion connected devices are expected to exist, as seen in
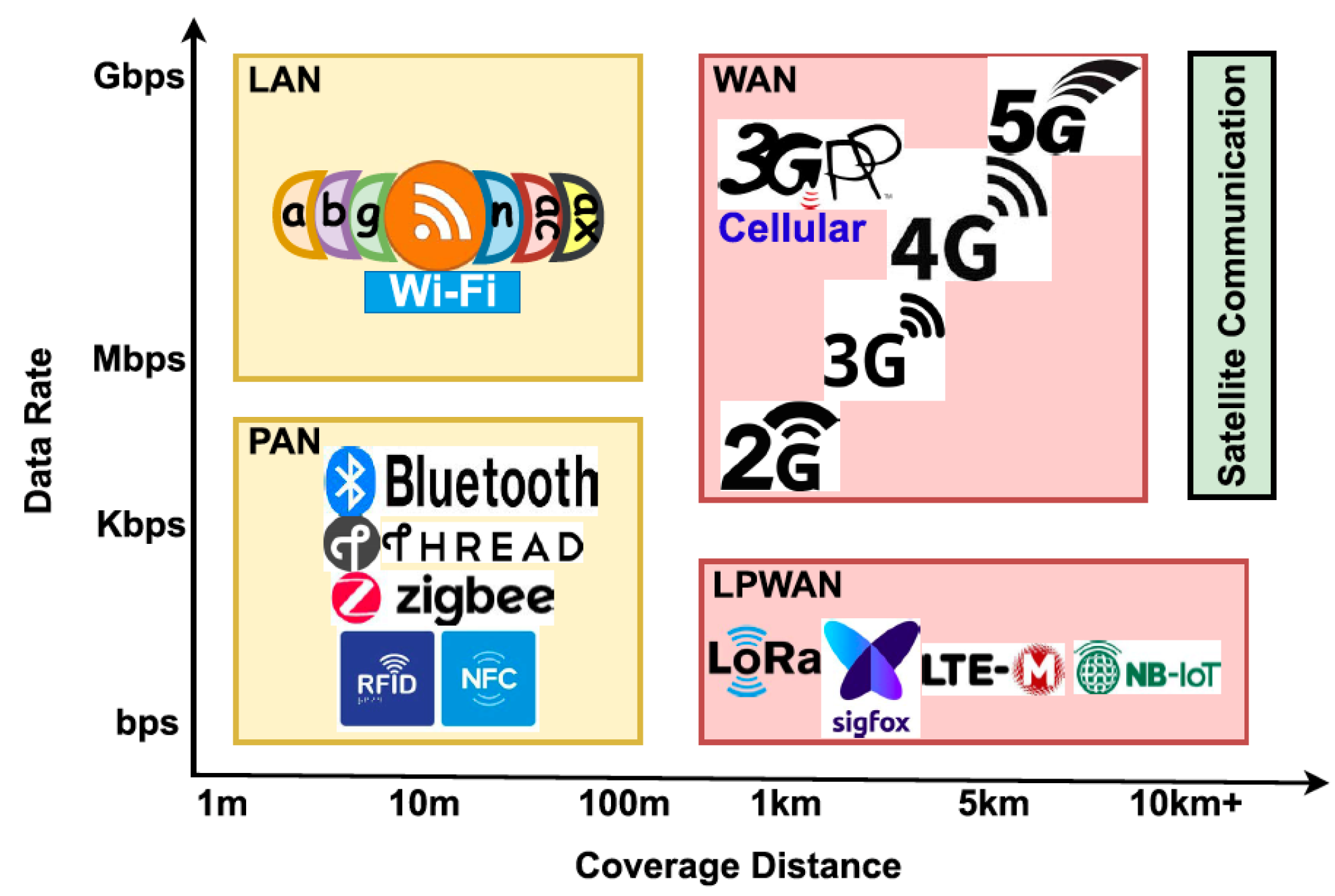
Figure 1, based on an analysis by the Statista Research Department (SRD). Numerous wireless technologies, including long-range cellular networks and short-range Wireless Sensor Networks (WSNs), have been developed to assist the Internet of Things. Short-range wireless technology is a subset of wireless technologies used on the Internet of Things. However, there are some challenges with short-range wireless solutions for IoT networks, including weak network resilience, restricted network scalability, and increased network development costs. In contrast, the Internet of Things, which depends on cellular networks, has a complex infrastructure, a short network lifetime, and a high cost of network development. Long-range and short-range wireless communication methods for Internet of Things applications face the aforementioned difficulties, which have resulted in the development of Low Power Wide Area Networks (LPWANs). The IoT goal is met by the widely used and leading LPWAN wireless Wide Area Network (WAN) technology, which has wide coverage, low-energy consumption, effective bandwidth utilization, and low implementation costs for networks. Several wireless communication technologies are compared for their energy effectiveness and implementation costs in
Figure 2. With the least expensive implementation and optimum energy efficiency, LPWAN seems to be the ideal choice. LPWAN typically offers up to forty kilometers of wide coverage in rural areas with strong Line of Sight (LoS) and ten kilometers in urban areas with weak LoS, with a 10-year minimum battery life [
1,
2]. One of the most important criteria for LPWAN systems is the ability to accommodate a large number of devices sending small quantities of traffic across long distances. The increasing densities of linked devices must be supported by these technologies. In our proposal, we will select SigFox, one of the best LPWAN technologies for deployment. In Europe and Asia, SigFox is extensively used [
3]. The main advantage of Sigfox is its resistance to collisions and interferences, which is enabled by the use of a diversity mechanism that takes into account both time and frequency. As a result, each sensor sends a data packet at three randomly selected times via three communication channels. This approach adds redundancy at the communication level, but it has a major disadvantage because it increases channel occupancy and, implicitly, the chance of collisions. [
4]. Reinforcement Learning (RL) offers a promising approach to addressing the scalability challenges of Low-Power Wide-Area Networks (LPWANs), such as SigFox and LoRa. As LPWANs accommodate an increasing number of devices, managing limited resources like bandwidth and communication slots becomes critical. RL enables systems to adapt dynamically by learning optimal strategies for resource allocation and collision avoidance through trial-and-error interactions with the network environment. By leveraging RL, LPWAN systems can efficiently assign communication slots, reduce collisions, and improve metrics like throughput and Packet Delivery Ratio (PDR), even as the number of connected devices scales up. This adaptability ensures network reliability while maintaining energy efficiency, making RL a key tool in enhancing the performance and scalability of LPWANs in IoT ecosystems. Our contribution is to propose a novel Reinforcement Learning (RL) based enhancement of the Slot and Channel Allocation Protocol (SCAP) [
5], called RL-SCAP. By introducing an adaptive slot allocation technique, this protocol addresses issues with interference and resource usage by enabling nodes to dynamically learn the best communication schedules. Particularly:
Improved Slot Allocation: By using RL to enable autonomous slot allocation based on collision input, RL-SCAP dramatically lowers collision rates and boosts network efficiency. Each node independently observes the outcome of its previous transmissions and uses this local feedback to adapt its slot selection policy. The protocol aims to achieve a mutually exclusive slot assignment among nodes, where convergence is reached when no collisions occur. This decentralized learning process is guided by lightweight feedback from the gateway, ensuring informed decision-making without requiring full centralization.
Performance Optimization: Through simulations, we thoroughly assess RL-SCAP, demonstrating how well it improves important metrics, including throughput, collision rate, and packet delivery ratio (PDR) across a variety of network settings. The adaptability of the protocol to dynamic environments ensures consistently better performance compared to static slot allocation.
Scalability and Energy Efficiency: The protocol is appropriate for Internet of Things applications involving battery-constrained devices since it is made to scale effectively in big networks while consuming the least amount of energy through highly reduced collisions and retransmissions. RL-SCAP maintains low complexity and overhead, making it suitable for LPWANs with limited resources.
Hybrid Distributed Architecture: RL-SCAP introduces a lightweight, partially decentralized architecture in which nodes make local decisions based on observations and minimal guidance from the gateway. This hybrid setup allows efficient convergence to collision-free communication while maintaining low complexity and minimal overhead, making it suitable for real-world LPWAN deployments.
These contributions show how RL-SCAP can be used to solve problems with scalability, efficiency, and reliability in dynamic Internet of Things environments.
The rest of this paper is organized as follows:
Section 2 examines Related Work, classifies AI and non-AI solutions, designed to address LPWAN scalability issues.
Section 3 addresses the scalability problems in SCAP and the requirement for improved slot allocation mechanisms.
Section 4 introduces the RL-SCAP protocol and describes its reinforcement learning architecture and slot allocation method.
Section 5 includes the experimental setup, measures, and results. Finally,
Section 6 concludes the paper and highlights future research directions.
3. Problem Statement
LPWAN encompasses a number of technologies, including SigFox, Long Range (LoRa), Narrowband-IoT (NB-IoT), Ingenu RPMA, Long Term Evolution for Machines (LTE-M), DASH7, Telensa and others. The aforementioned technologies have similar operational principles, but they differ in how they are implemented and behave. While unlicensed LPWAN technologies, such as LoRa, Sigfox, and RPMA, perform exceptionally well in terms of battery life, network capacity, and cost, licensed LPWAN technologies, such as NB-IoT, LTE-M, and EC-GSM-IoT, are more effective in terms of service quality (QoS), reliability, latency, and range. Therefore, the requirements of IoT applications must be taken into consideration when choosing the right LPWAN technology. The capacity to support a large number of devices sending small amounts of traffic across long distances is one of the most crucial requirements for LPWAN technology. The increasing densities and quantity of connected devices must be supported by these technologies. However, the LPWAN technologies that have been developed up to this point face difficulties with medium access mode, duty cycle, and the optimal distribution of transmission parameters that severely restrict the scalability of the network. Sigfox, one of the most famous and deployed LPWAN technologies, uses the ALOHA access mode, which is simple since it is a random-access protocol that allows any device to send a packet at any time. Despite its simplicity, when there are several devices, it has been demonstrated that ALOHA raises the collision rate. In addition to the medium access mode, duty cycling is another main scalability constraint of Sigfox technology. Although it helps regulate access to the common channel and reduce energy consumption, duty cycling may prevent the optimal configuration of the network. For instance, in Sigfox, due to the use of the free unlicensed ISM band, the duty cycle will help share the free band among several technologies. However, it will highly constrain downlink communication that may be targeted to optimally configure the network for better performance and better scalability. Indeed, Sigfox provides the possibility to send multiple redundant copies of the same packet over a large number of narrowband channels. The non-optimal configuration of the redundancy factor and the selected channels for transmission may increase the collision rates and the packet error rates, which will end up highly reducing the scalability of Sigfox technology. For instance, the Sigfox gateway can link hundreds of thousands of end devices; however, studies [
6,
7,
8,
11] show that performance declines as the number of devices rises over a few hundred. Therefore, scalability is a critical issue for Sigfox networks.
4. Protocol Description
Sigfox is a well-known Low-Power Wide-Area Network (LPWAN) technology that enables long-range, energy-efficient communication for Internet of Things networks. Sigfox exploits narrowband communication to provide scalability and large coverage while operating in the unlicensed sub-GHz ISM band. In the European band, SigFox uses a sub-GHz band with a width of 192 kHz, which produces 1920 partially overlapping channels with a width of 100 Hz each, of which only 360 are orthogonal. However, issues like channel allocation and collision avoidance, which are essential for guaranteeing dependable network performance, are brought on by the increasing density of connected devices.
The Slot and Channel Allocation Protocol (SCAP) is a protocol designed for wireless communication systems, particularly in Sigfox, to optimize resource utilization in dense IoT networks. SCAP tackles the challenges of limited communication resources by assigning both time slots and communication channels to devices based on their geographical locations, to ensure collision-free communication to the maximum possible extent [
5].
SCAP assumes that the base station is located at the center of a circular network field. The field is partitioned into sectors, each with an angle
, as seen in
Figure 3, where nodes in the same sector are assigned the same channel. In fact,
can be expressed easily as follows if
M channels are to be used:
Note that since the SCAP goal was to use every orthogonal channel, then
M = 360 and, hence,
.
After determining the angle
, the network radius, represented by R, is the maximum distance between the center of the network (gateway or base station) and its furthest node. The following formula can be used to find the area of a sector with an angle
:
In SCAP, the network operates within organized time frames, each subdivided into multiple time slots. These time slots are allocated to devices in the same sector to ensure collision-free communication, as no two devices transmit simultaneously on the same channel. Time slot assignment typically follows a static or predetermined schedule, simplifying network coordination but limiting adaptability to dynamic traffic conditions.
This dual-layered approach of assigning time slots and orthogonal channels prevents collisions and enhances network scalability by efficiently distributing communication resources among devices [
5].
While SCAP effectively reduces collisions and interference, its static time slot allocation mechanism is less suited to dynamic environments where the network conditions frequently change. Moreover, SCAP nodes in the same sector that are within the same distance from the gateway will end up using the same slot, and hence, collisions will be experienced. These limitations are addressed in RL-SCAP by introducing reinforcement learning, enabling dynamic and adaptive slot assignment tailored to real-time network conditions [
5].
In order to overcome the drawbacks of static allocation and improve the network performance of SigFox, particularly in extremely dynamic environments with fluctuating node densities and unpredictable traffic patterns, in this work, we proposed a Reinforcement Learning-Based Slot and Channel Allocation Protocol (RL-SCAP). RL-SCAP is a machine learning extension of the classic Slot and Channel Allocation Protocol (SCAP). SCAP provides a straightforward, deterministic method for channel and time slot allocation, but it is not flexible enough to optimize communication in real-time as network conditions change. By using Reinforcement Learning (RL) to automatically allocate communication time slots based on dynamic observations, RL-SCAP increases network throughput, packet delivery ratio (PDR), and energy efficiency while minimizing interference and collisions. The main advantage of RL-SCAP over SCAP is its ability to learn from experience and adapt to changing network conditions. Every device in the network uses Q-learning to automatically choose the optimal timeslots for its transmissions based on local observations and historical data, continuously enhancing its slot selection method. In addition to allowing for the effective use of available slots, this RL-based method helps the protocol manage the scalability issues that large-scale IoT networks confront, where static allocation would become unfeasible and inefficient. In contrast to SCAP, which uses preset time slot allocation, RL-SCAP dynamically adjusts the slot allocation based on feedback from the environment. Rewards and penalties based on the success or failure of transmission efforts and the present status of the network as a whole drive the decision-making process of each node. Through this adaptive process, RL-SCAP can reduce collisions, increase the network’s overall communication efficiency, and progressively improve its performance.
4.1. Slot Allocation
RL-SCAP assigns time slots to IoT devices in a given sector using a reinforcement learning technique. As an RL agent, every node chooses the best time slot for its communication requirements by continuously learning from previous transmissions. To reduce interference and increase transmission reliability, the protocol makes sure that every slot is exclusively used by one sensor node.
Time is divided into fixed-length frames by RL-SCAP, and each frame has many time slots. In order to minimize the possibility of collisions with other devices in the network, each device independently determines the optimal time slot for data transmission. The selection procedure is based on Q-learning, in which each device modifies its strategy based on input it has observed, reducing the chance of having several transmissions during the same time slot.
4.2. Autonomous Decision-Making Using Reinforcement Learning
Since collisions may happen only among nodes sharing the same channel, our RL-SCAP will be run independently on every sector. Accordingly, each sensor node in a given sector of angle functions as an RL agent that learns to choose the best time slot for its transmissions, according to the reinforcement learning paradigm that underpins the RL-SCAP slot allocation. Every device can observe its surroundings, make decisions depending on its current condition, and receive reward feedback that directs its learning process as described in Algorithm 1. The following are the primary steps in the RL-SCAP slot allocation procedure:
State Observation: Each device monitors its environment to gather information about the network, including the following:
Previous transmission failures or successes (deliveries or collisions). More specifically, each node needs to know which selected slots suffered collisions or hosted successful transmissions and which ones were not selected.
The level of congestion or interference observed in the previous frame. More precisely, each node needs only to know the maximum number of collisions experienced in selected slots that suffered interference. Our solution is designed to be scalable and can support up to 72,000 nodes by dividing the network into 360 sectors, with each sector handling up to 200 nodes. The proposed solution is not fully centralized. In a centralized setup, the gateway or server would run the entire RL algorithm and send the selected slots to the nodes. Instead, our approach is partially decentralized. This design allows the nodes to participate in the decision-making process by observing the network conditions—particularly whether a collision has occurred—and then making informed choices. However, relying solely on a fully distributed solution is not suitable, since nodes only have access to their local views. This limited perspective may lead to incorrect slot selections, preventing the algorithm from converging. In our case, convergence means that every node eventually selects a mutually exclusive slot, with no collisions. To address this, we adopt a hybrid solution where nodes use their local observations to learn and make decisions, while the gateway supports them by sending a small vector containing the number of collisions per slot. This vector is lightweight and can be transmitted easily, without creating communication overhead. The gateway’s guidance ensures that nodes make better-informed decisions, improving convergence and scalability.
Selection of Actions: Every device chooses an action (i.e., a particular time slot) in order to maximize the expected reward based on its current state. Actions are first chosen at random (exploration), but as the device gains experience, it starts to prioritize actions that will result in successful transmissions (exploitation).
Reward Feedback: The device is rewarded based on whether the transmission was successful or unsuccessful after every transmission. The device is penalized if the transmission causes a collision, and rewarded if the transfer is successful. More precisely, if the node transmission on a given slot is successful, a very high reward will be assigned in order to foster the selection of that slot. However, if the node experiences a collision on the selected slot, it has to change its slot. To do so, it will assign a reward to every slot based on the level of congestion on that slot. In particular, the node will assign a negative reward to the previously selected slot that hosts a successful transmission. By doing so, we guarantee that such a slot will not be selected by the node in order not to cause future collision. However, the higher the level of congestion in a given slot, the lower the assigned reward to that slot. Please note that slots that suffered collisions need to have inversely proportional positive reward in order to enable their selection in the upcoming transmissions. Indeed, assigning negative rewards to those slots will totally exclude them from the selection process and thus they will be totally unused. The device receives feedback from the reward, which directs its learning process. The device’s Q-values, which show the anticipated long-term benefits of choosing specific slots, are updated using this feedback.
Q-Value Update: Every device tracks the anticipated rewards for every time slot it has access to in a Q-table. Following feedback, the device uses the following formula to update its Q-values:
The Q-value update rule is given by the following:
where
is the Q-value for the state and action (time slot choice) at time t.
is the reward received after taking action .
is the learning rate (how much the new Q-value affects the old one).
is the discount factor (how much future rewards are valued).
is the maximum Q-value for the next state .
By iteratively updating the Q-values, the device gradually improves its ability to select time slots that minimize collisions and maximize successful data transmissions.
This procedure enables nodes to continuously modify their communication techniques in response to the observed rewards, which eventually results in fewer collisions and more effective resource consumption.
| Algorithm 1: Reinforcement Learning Slot Allocation Protocol (RL-SCAP) |
![Technologies 13 00255 i001]() |
4.3. Collision Detection and Mitigation
The main goal of the RL-SCAP protocol is to reduce collisions and maximize the distribution of mutually exclusive data transmission time slots. An adaptive reward assignment system makes this possible by enabling nodes to modify their transmission in real time in response to the results of prior transmission attempts. The protocol allows each node to gradually improve its behavior by giving feedback in the form of rewards or penalties, which lowers interference and increases network performance. A major objective of RL-SCAP is to reduce node collisions, which happen when two or more devices in the same sector try to send simultaneously on the same time slot. In a given sector, to keep track of each device’s slot assignments and identify collisions, RL-SCAP employs a collision vector at the gateway that describes the level of congestion in every slot. This vector will be used by every node to autonomously assign rewards to every slot.
Reward Assignment: The first step in the reward assignment process is to assess the collision status of the node’s allocated time slot. The node receives a significant positive reward if there are no collisions. This reinforces effective behavior by encouraging the node to keep its selected time slot for subsequent broadcasts. On the other hand, the protocol imposes different penalties or lesser rewards based on the degree of congestion during the time window when a collision occurs.
- –
High congestion, which occurs when several nodes use the same slot for transmission, results in a low positive reward. Indeed, assigning a negative reward to that slot will result in excluding it from the selection process. Consequently, it will end up unused. That being said, assigning that slot a relatively low reward will enable its potential selection while being unfavorable.
- –
Moderate congestion, which occurs when fewer nodes use the same slot for transmission, results in a slight positive reward, indicating that, with prudence, the slot might still be available for future transmissions.
- –
No congestion, which occurs when a single node sends in the slot, results in a severe penalty to prevent the node from selecting that slot. Indeed, if a node transmission experiences a collision, it most probably has to change its slot. However, it does not have to switch to another slot that was previously selected by another node and hosted a successful transmission. By doing so, we prevent future collisions on that slot.
- –
A non-selected slot will be assigned a relatively high reward in order to favor its selection in the subsequent trial.
The following Algorithm 2 shows that how reward is assigned:
| Algorithm 2: Reward Assignment Algorithm |
![Technologies 13 00255 i002]() |
By learning from both successful and unsuccessful transmissions, nodes are able to continuously modify their slot selection technique thanks to this reward system.
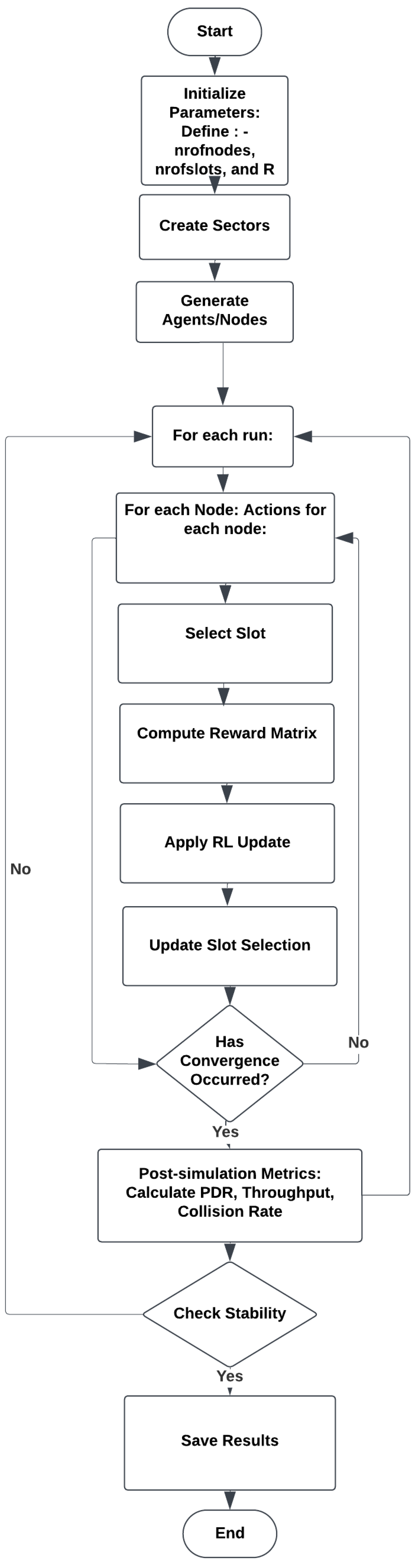
Figure 4 illustrates the workflow of the RL-based slot allocation protocol’s (RL-SCAP) mechanisms for a clearer understanding of how the protocol works. The process starts by initializing important parameters, such as the network radius (R), number of slots (nrofslots), and number of nodes (nrofnodes). The system generates sectors and agents or nodes within them. After that, the process goes into a loop, where the simulation is performed several times. Each node performs actions in each episode of each run by choosing a slot, applying a reinforcement learning update, calculating a reward matrix depending on performance, and modifying its slot selection accordingly. This iterative process continues until convergence is reached. Post-simulation parameters, including collision rate, throughput, and packet delivery ratio (PDR) are computed after convergence. After verifying that the results are stable, the system saves them if the stability requirements are satisfied. The workflow then comes to an end, monitoring stability and important performance parameters while using reinforcement learning to ensure an optimal slot allocation method.
4.4. Description of Algorithm
As shown in Algorithm 1 an organized process is used by the Reinforcement Learning Slot Allocation Protocol (RL-SCAP) to ensure a mutually exclusive slot assignment for Internet of Things devices. The first step is to define the network parameters, such as the number of slots, channels, and Internet of Things devices. Key reinforcement learning parameters are set by each IoT device, which initializes a Q-table to store learned policies. These parameters include the exploration rate (), which balances exploration and exploitation, the discount factor (), which establishes the significance of future rewards, and the learning rate (), which regulates the amount that new information supersedes old values.
In order to stabilize slot allocation, the learning process is iterative and continues until convergence. The network state is monitored at every time step, recording the current slot allocation as well as collision feedback. These assignments are tracked using a frame table (ft). Then, every IoT device determines if the auto-assigned slot has experienced a collision. If there is a collision, the collision_vector(i) is updated appropriately; if not, it is reset to zero.
Each IoT device uses a -greedy policy to choose an action in order to identify the best slot assignment. By randomly choosing a slot with probability , this policy permits exploration; however, exploitation takes place with probability by selecting the most well-known assignment from the Q-table. Each device’s slot_vector(i) is updated by the chosen action. After an action is performed, the result is assessed by a reward function as shown in Algorithm 2. A successful transmission carries a positive reward, whereas a collision carries a penalty or a relatively small reward.
Lastly, the typical Q-learning update rule is applied to update the Q-table is updated using reward Equation (
5). Over time, the system can learn the best slot assignment thanks to this approach.
Table 1 shows symbols and their descriptions used in the RL-SCAP Protocol.
5. Performance Evaluation
In this section, we evaluate the performance of our proposed protocol, RL-SCAP, and we compare it to SCAP SigFox in terms of collisions, the packet delivery ratio, and the network throughput. The MATLAB platform was chosen because of its strong machine learning and reinforcement learning (RL) capabilities. With built-in functions and toolboxes like the Reinforcement Learning Toolbox, which supports a variety of training strategies, policy optimization techniques, and deep learning integrations, MATLAB R2024b offers a complete environment for developing RL algorithms. Additionally, MATLAB is a good option for creating and assessing the RL-SCAP protocol because of its capacity to effectively manage large-scale simulations, depict intricate system dynamics, and interface with other modeling tools. In this study, two different cases were examined to analyze the performance of the RL-SCAP protocol:
Case 1: Fixed Number of Slots, Variable Number of Nodes: In this case, the number of nodes grew while the number of time slots that were accessible remained fixed. This made it possible to test the RL-SCAP protocol in an environment of growing network congestion, where distributing limited resources (slots) among an increasing number of nodes was a challenge. The other reason for implementing such a scenario is that finding the number of needed slots is usually challenging. To deal with this, one of the solutions is to estimate the number of needed slots by estimating the number of nodes as derived in (
3). However, estimating the number of needed slots
m may result in either overestimation or underestimation in a real case scenario. Implementing such a scenario allows us to study both the overestimation case, when the number of nodes is less than the number of slots, and the underestimation case, when the number of nodes is greater than the number of available slots. With increasing network density, system performance was monitored in terms of collision rate, packet delivery ratio (PDR), throughput, and convergence time.
Case 2: Equal Number of Slots and Nodes: In this case, there were exactly the same amount of nodes and slots available. This configuration evaluated the effectiveness of the RL-SCAP protocol in allocating resources when the system’s available slots and nodes are equal. The RL model’s ability to sustain an ideal slot allocation approach in a setting where the number of available slots is equal to the number of nodes was examined.
Table 2 provides a summary of the main simulation parameters that we employed in our assessment.
Our solution is built upon the SCAP protocol, which relies on network partitioning to manage scalability and performance. The number of nodes we considered ranges from 20 to 200 within a single sector of the network. This choice aligns with the SCAP design principle, which divides the entire network into 360 sectors based on the angular division of a circle (each sector spans 1 degree). The selection of 20 to 200 nodes per sector reflects a realistic and scalable scenario. Indeed, since each sector operates independently, the total number of nodes in the entire network can be up to 72,000 (i.e., 200 nodes × 360 sectors). This level of scalability is made possible by Sigfox’s ability to support 360 orthogonal channels, ensuring that nodes in different sectors do not interfere with each other. We emphasize that our reinforcement learning (RL) solution is applied locally within each sector. As such, even with a large number of total nodes, each RL instance only manages a limited, sector-specific subset (up to 200 nodes). This design guarantees numerical stability and computational feasibility, even when the overall network size grows substantially.
5.1. Evaluation of RL-SCAP Q-Learning Algorithm
To evaluate the speed of our Q-Learning algorithm, we examine the reduction in the average number of collisions over episodes as shown in
Figure 5. A bar plot was created with an emphasis on the first 20 episodes. In this instance, we employed a fixed number of slots and nodes equal to 60.
The system’s collision pattern indicates that the highest collision rates occur during the initial episodes, especially the first one. Nonetheless, there is a notable decrease in collisions throughout the first ten episodes. Following episode 30, the decrease becomes more gradual until it reaches minimal levels. After the initial episodes, the system shows quick stabilization in collision reduction with respect to convergence behavior. This pattern is consistent with the reinforcement learning (RL) process, in which the model moves from an exploration phase, which is marked by a high number of collisions, to an exploitation phase, which is when it distributes slots effectively and with few conflicts. Notably, there are 50 fewer collisions than there were in the first episode (about 130) compared with 80 in the second. This notable decrease in early episodes suggests that our RL model learns and optimizes slot allocation rapidly, hence reducing network interference to a large degree.
The initial contention is successfully handled by the RL-based method, indicating the protocol’s flexibility and effective slot allocation as learning advances. This analysis demonstrates the ability of the RL-SCAP protocol to manage congestion and attain convergence, resulting in a notable decrease in collisions as episodes go.
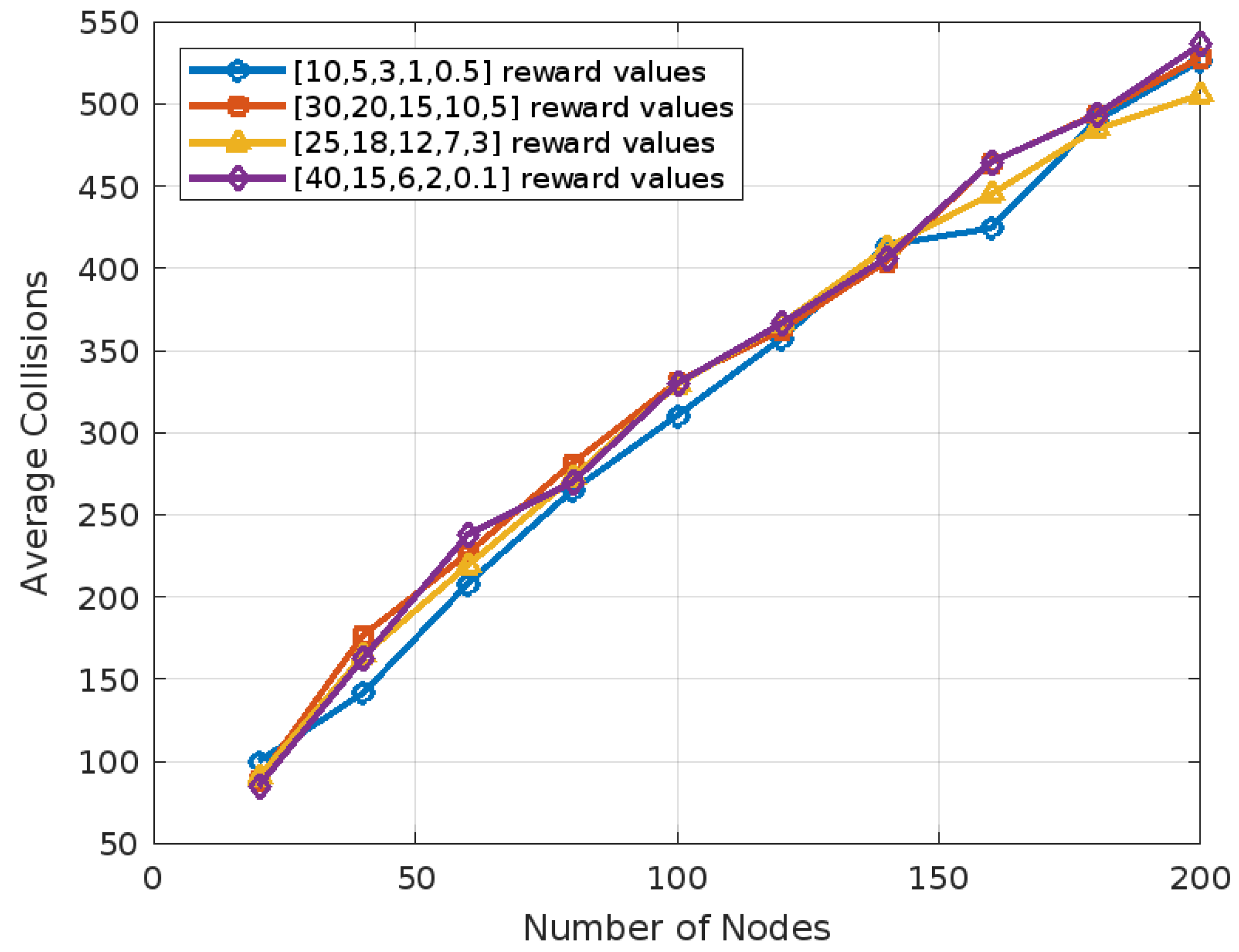
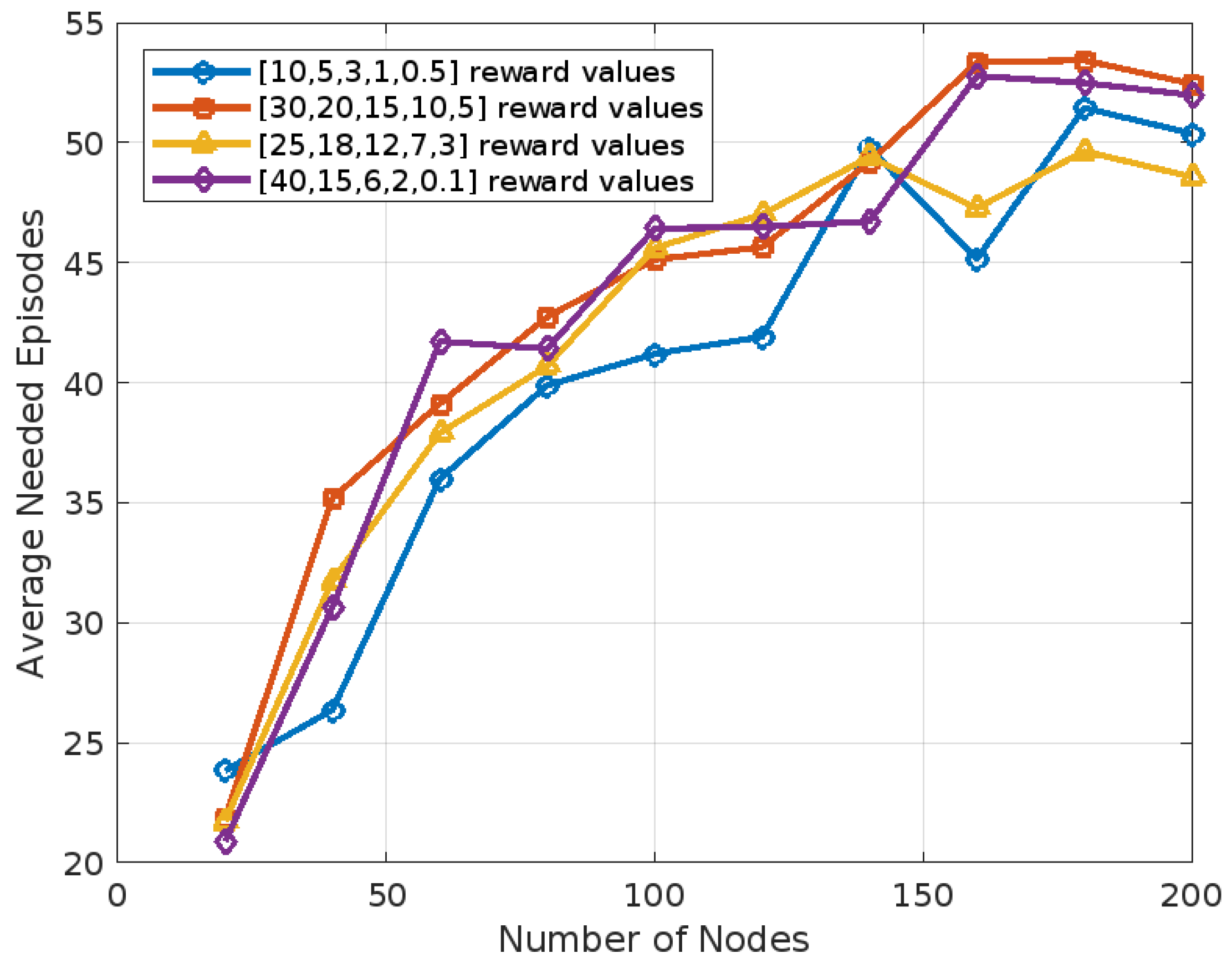
To evaluate the impact of different reward value sets on the performance of our reinforcement learning algorithm, we conducted a sensitivity analysis by testing several decreasing reward configurations. Specifically, we compared the baseline reward set with three alternative sets: [30, 20, 15, 10, 5], [25, 18, 12, 7, 3], and [40, 15, 6, 2, 0.1]. In each case, we examined the number of collisions and the number of episodes required for convergence, as shown in
Figure 6 and
Figure 7, respectively. Our findings show that the Q-learning algorithm is not highly sensitive to the exact values of the rewards, provided that the reward values decrease in magnitude. For instance, as shown in
Figure 6, the percentage difference in the number of collisions compared with the original reward set was 7.22% for [30, 20, 15, 10, 5], 5.28% for [25, 18, 12, 7, 3], and 6.91% for [40, 15, 6, 2, 0.1], yielding an average deviation of 6.47%. A similar trend was observed in the number of episodes required to reach convergence. As shown in
Figure 7, the percentage difference relative to the original set was 10.33% for [30, 20, 15, 10, 5], 7.18% for [25, 18, 12, 7, 3], and 10.01% for [40, 15, 6, 2, 0.1], with an average difference of 9.17%. These results confirm the robustness of our learning framework with respect to reward shaping, as long as the reward structure remains consistently decreasing.
5.2. Evaluation of RL-SCAP
This section evaluates our RL-SCAP protocol in two distinct scenarios to determine its performance:
We used the following performance criteria to assess the performance of RL-SCAP:
Number of Collisions until Convergence: The total number of collisions observed until the learning process stabilizes.
Number of needed episodes until Convergence: The number of episodes needed to achieve convergence in the RL-based slot allocation.
Packet Delivery Ratio (PDR): The ratio of successfully transmitted packets to the total packets sent, indicating communication reliability.
We used the following formula to calculate PDR:
Throughput: A measure of network efficiency that shows the total amount of data delivered successfully over time.
We used the following formula to calculate Throughput:
5.2.1. Scenario 1: Fixed Slots and Varying Number of Nodes
In this case, the number of nodes varies from 20 to 200, while the protocol performance is assessed with a fixed number of slots that equals 80.
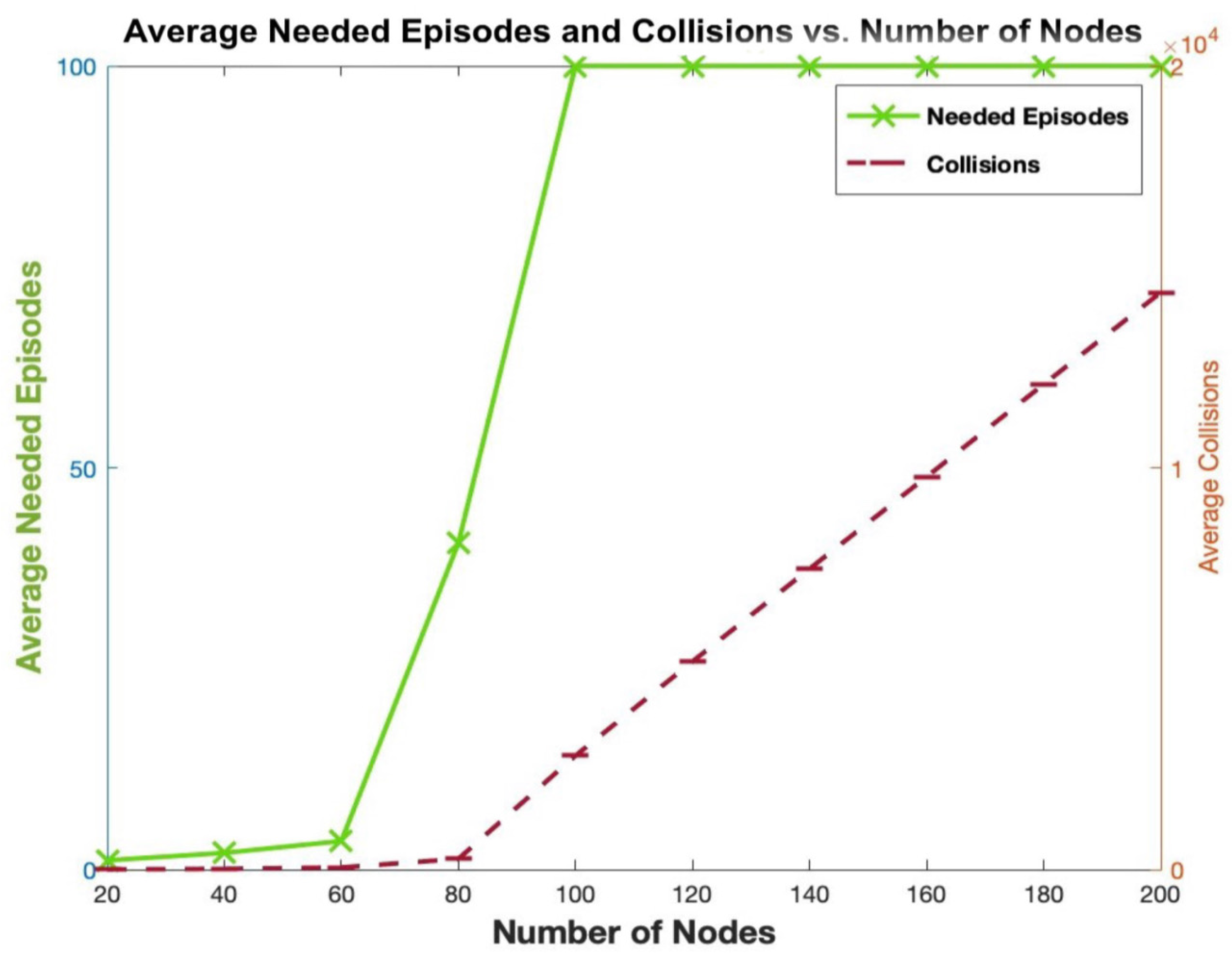
As shown in
Figure 8, two behaviors can be noted. The first one is when the number of nodes is less than or equal to the number of available slots (80), there is a gradual increase in the number of collisions and needed episodes until convergence is observed. The second behavior is experienced when the number of nodes is higher than the number of available slots. In this case, an important increase in the number of collisions is experienced between two consecutive values of the number of nodes, as convergence will never be reached. Indeed, when the number of nodes is higher than the number of available slots, mutually exclusive assignment of slots will never be reached; hence, the number of needed episodes is 100, which is the maximum set value in our simulations.
Regarding the PDR, as shown in
Figure 9, a local minimum is observed at 60 nodes, while a global maximum occurs at 80 nodes. This behavior is driven, first, by the increasing number of collisions as more nodes compete for limited slots, and second, by the simultaneous rise in the number of transmissions, which temporarily enhances packet delivery. The trade-off between these two factors leads to the formation of local and global optima. After 80 nodes, both PDR and Throughput decline. For instance, when the number of nodes reaches 200 (which is 2.5 times the number of available slots), the PDR drops to approximately 0.88–0.89, while the Throughput stabilizes around 4.5 pps. This confirms that beyond 80 nodes, increased contention negatively impacts PDR, but Throughput remains steady, likely due to a balance between successful transmissions and collisions.
5.2.2. Scenario 2: Equal Slots and Nodes
This scenario assesses the performance of our RL-SCAP when the number of slots is set equal to the number of nodes. In this case, convergence is possible as the mutually exclusive slot assignment can be achieved.
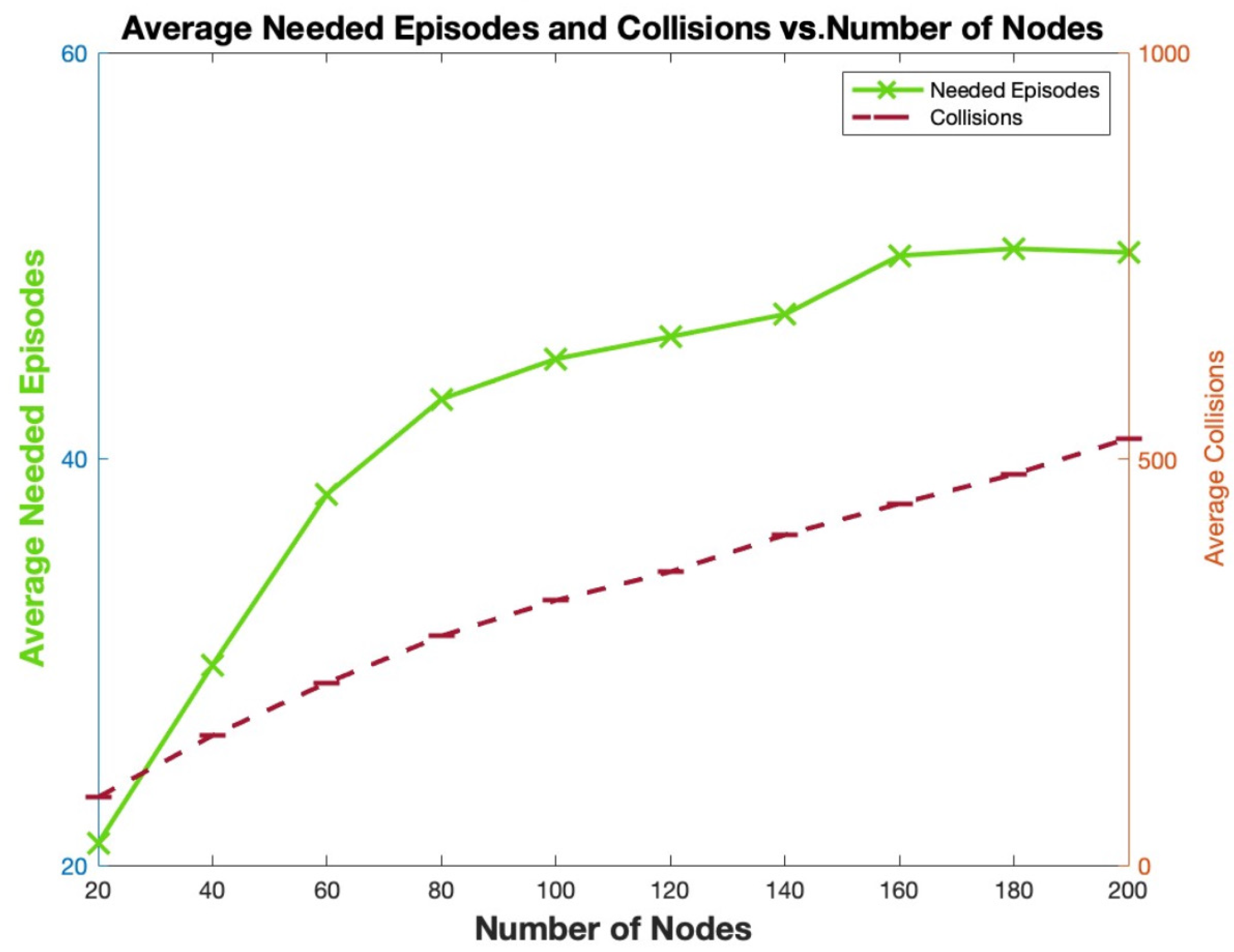
As shown in
Figure 10, when the number of nodes increases, as expected, the number of collisions until convergence increases, as well as the episodes needed to achieve the mutually exclusive slot assignment.
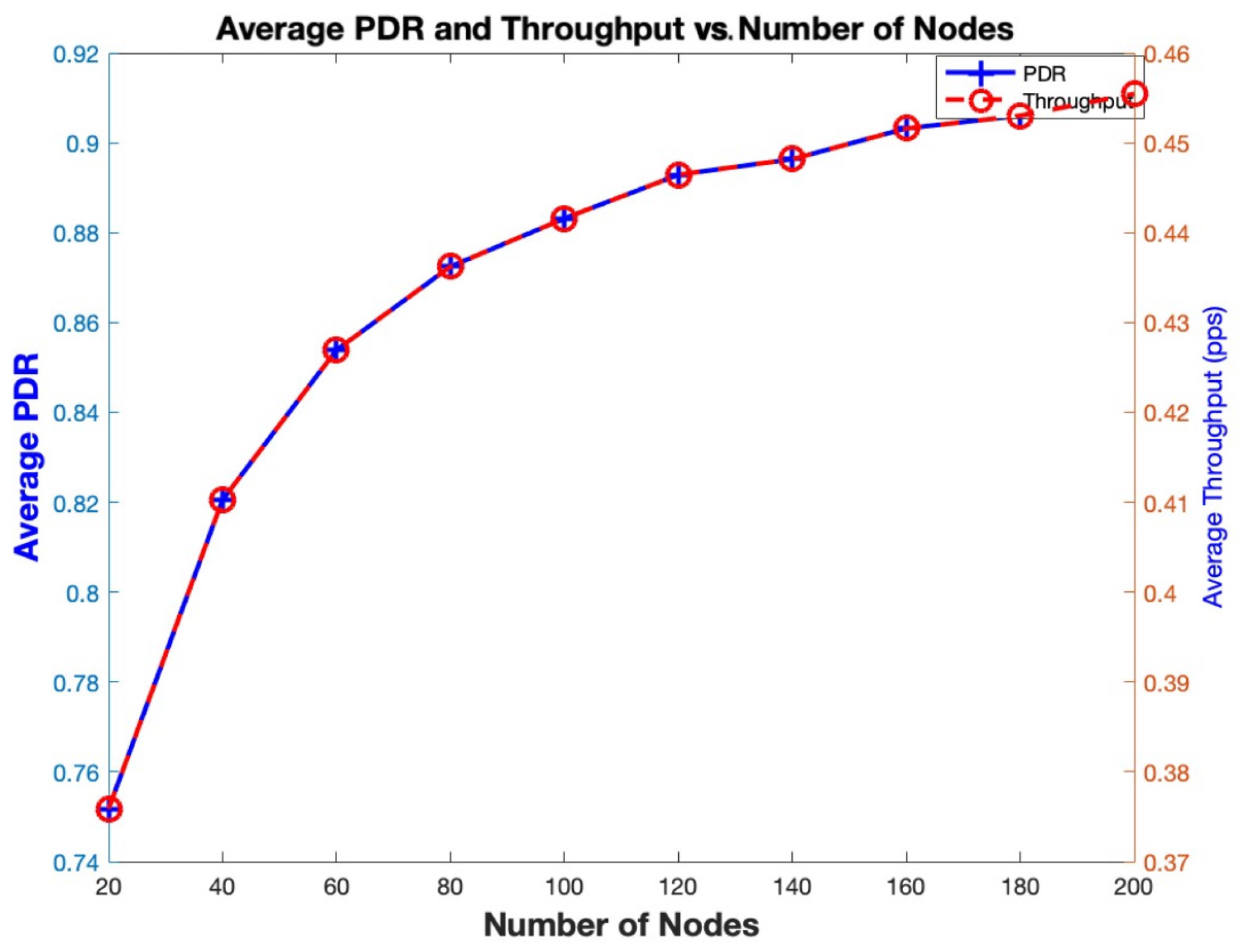
Figure 11 shows an increase in the throughput as well as the packet delivery ratio (PDR) when the number of nodes increases. Indeed, thanks to our adopted Q-learning algorithm, increasing the number of nodes will increase the number of successfully received packets in every episode faster than the increase in the number of collisions which confirms the scalability of our protocol. For instance, at 80 nodes, PDR
, Throughput
pps. At 200 nodes, PDR
and Throughput
pps.
5.3. Comparison of RL-SCAP with SCAP
In this section, we compare the performance of RL-SCAP with SCAP SigFox. Recall that RL-SCAP was built upon SCAP SigFox, which highly outperforms the original SigFox protocol.
5.3.1. Case 1 Scenario
In
Figure 12, as the number of nodes increases, the number of collisions in SCAP and RL-SCAP rises. However, RL-SCAP regularly achieves lower collisions than SCAP, especially when the number of nodes is greater than or equal to 80, which is the number of available slots. Initially, both protocols encounter insignificant collisions when the number of nodes is small (less than 80), as the number of available slots is larger than the number of nodes. Indeed, with increased network density, more nodes tend to be within the same vicinity, which, according to SCAP, will end up selecting the same slot as they are within the same distance from the gateway, whereas RL-SCAP grows more steadily. Although both protocols achieve high collisions as the number of nodes is greater than the number of available slots, in greater node densities (above 100 nodes), the disparity in the number of collisions becomes more noticeable, suggesting that RL-SCAP is more effective in preventing collisions. By using reinforcement learning, RL-SCAP improves slot allocation and decreases node contention, leading to better collision management and increased network efficiency. We can see that RL-SCAP reduces collisions by an average of 37.71%.
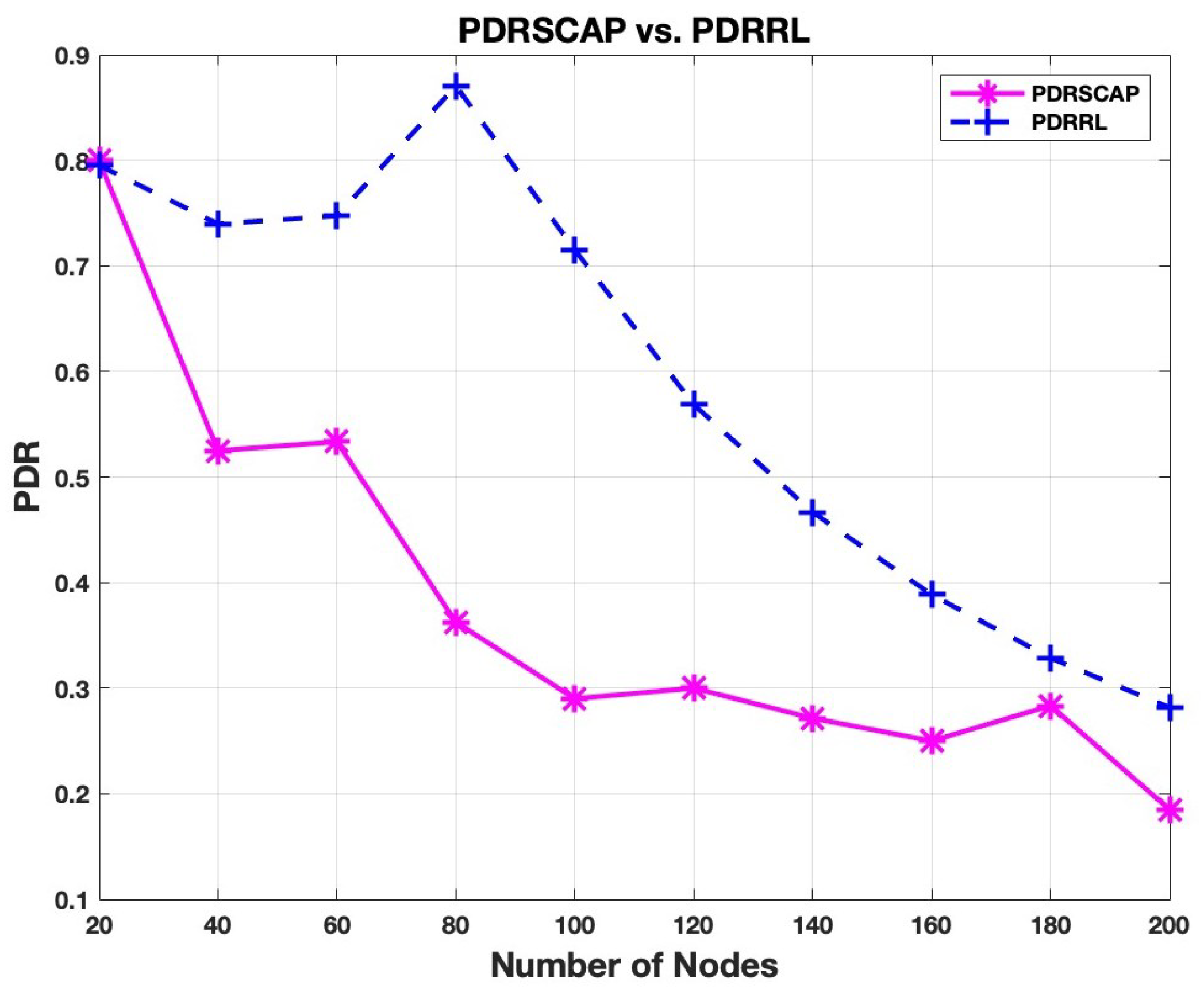
Packet Delivery Ratio (PDR) comparisons between the two protocols are shown in
Figure 13. Although RL-SCAP PDR falls when the number of nodes exceeds the number of available slots, it still achieves higher values than the SCAP one, even when the number of nodes is less than the number of available slots. Indeed, since SCAP uses a distance-based slot assignment, as the number of nodes increases in a given sector of angle
, the number of nodes that are within the same distance from the gateway will increase. Thus, the number of nodes selecting the same slot will increase, which will highly impact the ratio of successfully received packets to the total sent packets, since in SCAP, nodes sharing the same slot will always collide. For instance, when the number of nodes exceeds 40, SCAP’s PDR drops precipitously, falling below 0.5 to reach less than 0.2 when the number of nodes equals 200. However, despite growing network congestion, RL-SCAP maintains a noticeably higher PDR across all node counts. The learning-based slot allocation appears to increase transmission success rates, as indicated by the peak PDR for RL-SCAP (0.85). Our improvement in PDR can reach up to 66.66%.
Better packet delivery performance is shown by RL-SCAP, indicating its capacity to efficiently handle network conflict. An improved PDR denotes greater use of resources, which makes the communication network more dependable.
Similar to the PDR, RL-SCAP achieves higher throughput than the SCAP protocol as shown in
Figure 14. Despite its low achievement, the throughput of SCAP slowly increases until saturation is reached when the number of nodes equals 180, after which it starts decreasing. Indeed, in the first phase, when the number of nodes is less than 180, the SCAP network succeeds in delivering slightly more packets despite the high increase in collisions as the number of transmissions increases with the number of nodes. In fact, as the throughput is a compromise between the number os transmission attempts and the number of collisions, when the number of nodes is less than 180, the total number of transmissions is greater than the number of collisions. However, after saturation, the number of collisions highly dominates the number of transmission attempts, hence the decrease in throughput.
Despite the fact that RL-SCAP performs better by effectively allocating slots to balance transmissions and reduce collisions, SCAP’s growing throughput is caused by the increased total number of transmissions. The dramatic increase in collisions, however, highlights SCAP’s inefficiency and eventually restricts its scalability. This distinction shows why RL-SCAP is a preferable method for dense networks because it generates a more stable and effective throughput curve. On average, RL-SCAP increases throughput by 39.12%.
Overall Findings:
Decreased Collisions: RL-SCAP effectively reduces collisions, improving network stability.
Increased PDR: By guaranteeing that more packets are delivered successfully, the reinforcement learning-based strategy increases communication dependability.
Increased Throughput: In situations involving dense networks, RL-SCAP performs better than SCAP in terms of data transmission efficiency.
5.3.2. Case 2 Scenario
Figure 15 compares the collisions between SCAP and RL-SCAP. As the number of nodes rises, SCAP shows a substantial rise in collisions. When the number of available slots equals the number of nodes, RL-SCAP consistently maintains noticeably lower collision rates. As the number of nodes increases, the difference between SCAP and RL-SCAP becomes wider, suggesting that RL-SCAP scales more effectively. SCAP continues to have significant collision rates despite slots growing proportionally. This implies that the deterministic slot allocation method of SCAP is unable to adjust to the expansion of the network. In contrast, RL-SCAP uses reinforcement learning to allocate slots efficiently, lowering congestion and enhancing network stability. RL-SCAP decreases collisions by an average of 79.37%, with a highest reduction of 80.00%.
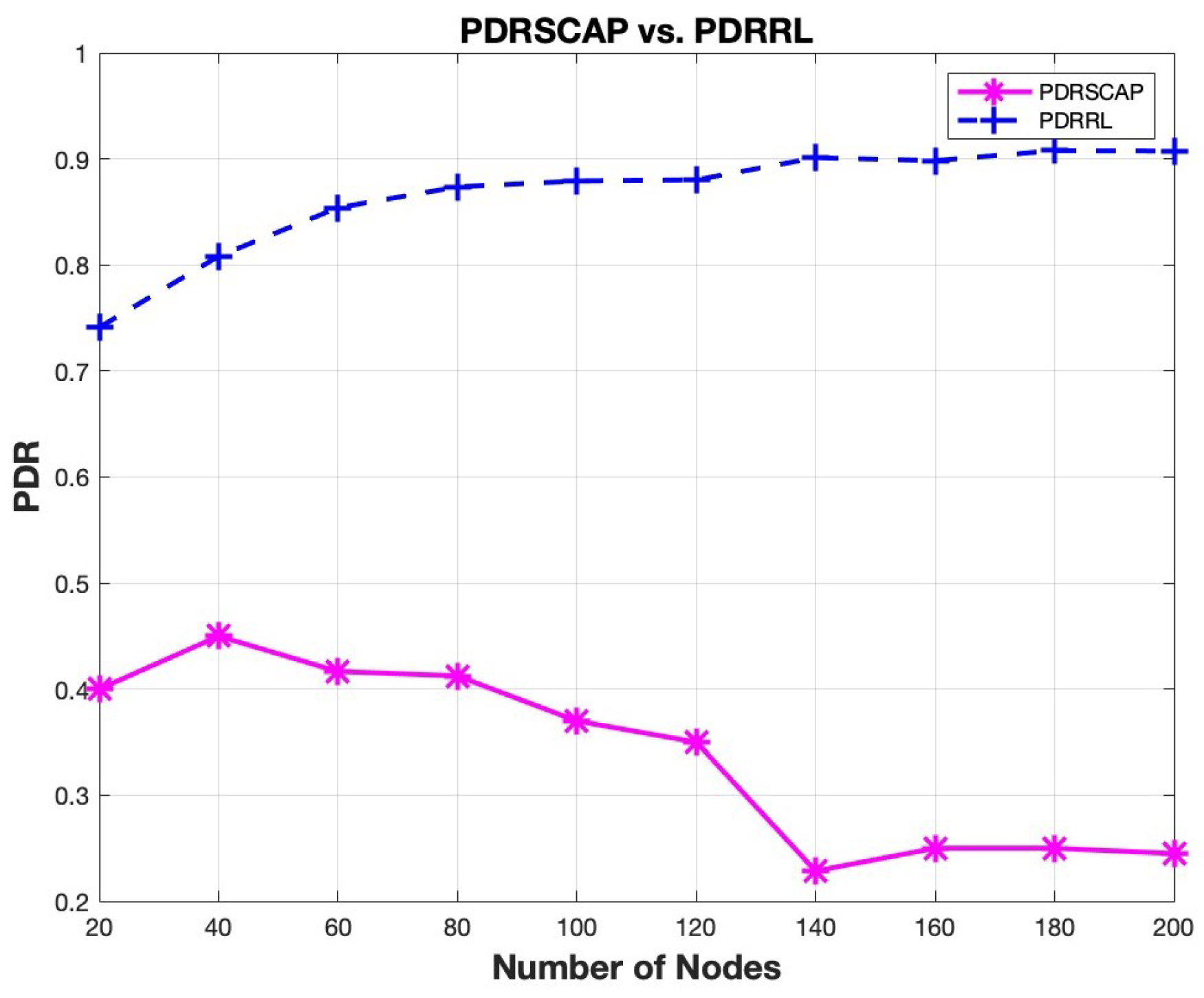
A comparison of the two protocols’ PDR performance is shown in
Figure 16. A consistently high PDR ( 0.75 to 0.95) is attained with RL-SCAP when the number of available slots equals the number of nodes, indicating efficient packet delivery. SCAP, in contrast, has lower PDR values, which range from 0.4 to ultimately falling as the number of nodes rises. RL-SCAP’s PDR exhibits a steady trend as the number of nodes rises. Even as the network grows, packet delivery becomes more dependable thanks to RL-SCAP’s adaptive slot allocation. On the other hand, SCAP’s lower PDR results from ineffective scheduling and frequent collisions, which prevent many packets from successfully reaching the gateway. RL-SCAP boosts PDR by an average of 60.58%, with a maximum improvement of 74.47% when the number of available slots is set equal to the number of nodes.
The throughput of the two protocols when the number of nodes equals the number of available slots is depicted in
Figure 17. As the number of nodes rises, RL-SCAP attains a significantly higher throughput than SCAP, reaching about 0.45 pps. As the number of nodes grows, SCAP’s throughput decreases and stays low. Although the number of available slots equals the number of nodes, the deterministic distance-based slot assignment of SCAP poorly allocates the slots, as nodes within the same distance from the gateway will always share the same slots, leaving a number of available slots unused. Consequently, increasing the number of nodes in the same sector area will increase the number of nodes within the same distance from the gateway that will select the same slot despite the availability of unused slots. Thus, RL-SCAP is taking full advantage of the number of available slots as opposed to SCAP. The learning-based methodology of RL-SCAP dynamically adjusts to network conditions, guaranteeing effective utilization of available slots, whereas SCAP is unable to utilize the full available number of slots effectively. The average throughput improvement with RL-SCAP is 60.90%.
Overall Findings
RL-SCAP Reduces Collisions More Effectively—SCAP still has significant collision rates despite the availability of more slots.
RL-SCAP Preserves a High PDR—SCAP’s performance deteriorates with network growth, whereas the RL-based method guarantees reliable packet delivery.
RL-SCAP Achieves Higher Throughput: By making the most use of the resources at hand, RL-SCAP outperforms SCAP in terms of throughput.
5.4. Summary of SCAP vs. RL-SCAP Performance
In order to demonstrate the performance enhancements that RL-SCAP achieves over SCAP, we present a side-by-side comparison of important performance metrics in both cases. As seen in
Table 3, RL-SCAP performs significantly better than SCAP in terms of collision reduction, throughput, and packet delivery ratio (PDR).
6. Conclusions
In this study, we introduced RL-SCAP, an extension of the SCAP [
5] protocol based on reinforcement learning, which is intended to increase slot allocation for massive IoT networks. In order to achieve effective resource usage and minimize collisions, our protocol dynamically adjusts to network conditions by utilizing reinforcement learning. We showed through an extensive performance test that RL-SCAP outperformed classical SCAP in terms of important metrics, including collision rate, throughput, and packet delivery ratio (PDR). According to our findings, RL-SCAP, on average, lowers collisions by 58.54%. Furthermore, RL-SCAP improves packet delivery performance significantly; the average PDR improvement was 53.82%. Additionally, network performance is increased by RL-SCAP, with an average improvement of 50.01%. These enhancements demonstrated that RL-SCAP could scale and manage high node densities without sacrificing energy efficiency. With this work, we improved network scalability and efficiency while preserving energy efficiency by optimizing slot allocation in low-power IoT networks. Because of these enhancements, RL-SCAP is especially well suited for applications, such as environmental monitoring, smart cities, and industrial IoT.
While RL-SCAP demonstrates promising results in collision reduction and throughput improvement, several limitations remain. First, the current evaluation is based on simulations with static and homogeneous node distributions, which may not fully capture the dynamics of real-world IoT deployments involving node mobility, heterogeneous traffic loads, or varying transmission priorities. Second, the protocol assumes synchronized time slots and accurate sectorization, which may require additional infrastructure in practical deployments. Finally, energy consumption overhead from continuous learning and slot monitoring may impact battery-constrained devices, especially in large-scale deployments. Future work will address these aspects by extending the protocol to handle adaptive reward tuning, real-world deployment constraints, and mobility-aware decision-making. Future research will focus on transitioning RL-SCAP from simulation to real-world deployment and evaluating its effectiveness in practical IoT environments. Please note that the transition from simulation to real deployment is relatively straightforward in our case due to the protocol’s lightweight design and decentralized decision-making. Each node can locally determine its sector assignment based on its known geographic coordinates and those of the gateway, exactly as conducted in SCAP. This spatial sectoring step does not require complex computation or centralized control. Once the sector is identified, the RL-based slot selection operates as described, using local observations (i.e., collision feedback) and lightweight assistance from the gateway. This will help uncover real-world implementation challenges related to energy consumption, deployment scalability, and hardware constraints. Additionally, further research will explore adaptive energy management techniques to extend battery life while maintaining high network efficiency. To further enhance RL-SCAP’s performance in large-scale deployments, future work could focus on refining RL-based decision-making at the gateway, leveraging historical network conditions to optimize slot allocation more effectively.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}