Abstract
With the exponential growth of cyberbullying cases on social media, there is a growing need to develop effective mechanisms for its detection and prediction, which can create a safer and more comfortable digital environment. One of the areas with such potential is the application of natural language processing (NLP) and artificial intelligence (AI). This study applies a novel hybrid-structure Hybrid Transformer–Enriched Attention with Multi-Domain Dynamic Attention Network (Hyb-KAN), which combines a transformer-based architecture, an attention mechanism, and BiLSTM recurrent neural networks. In this study, a multi-class classification method is used to identify comments containing cyberbullying features. For better verification, we compared the proposed method with baseline methods. The Hyb-KAN model demonstrated high results on the multi-class classification dataset, achieving an accuracy of 95.25%. The synergy of BiLSTM, Transformer, MD-DAN, and KAN components provides flexibility and accuracy of text analysis. The study used explainable visualization techniques, including SHAP and LIME, to analyze the interpretability of the Hyb-KAN model, providing a deeper understanding of the decision-making mechanisms. In the final stage of the study, the results were compared with current research data to confirm their relevance to current trends.
1. Introduction
In recent years, the problems of cyberbullying [1], phone fraud [2], and deepfake detection [3] have become among the significant threats in the digital space. The expansion of social networks, instant messenger, and other online platforms has led to an increase in cyberbullying cases, which contributes to a negative impact on the psychological, emotional, and social well-being of people, primarily children and adolescents. The difficulty of identifying cyberbullying is determined by its various forms, hidden nature, and distribution scale. Traditional methods of monitoring and analysis are often not effective enough to detect incidents of aggressive behavior on the Internet, which in turn necessitates the development of more accurate and automated approaches. Neural network technologies have become widespread in the data economy and are used to ensure cybersecurity [4,5,6,7] and classify objects in industry robotics [8] Additionally, advances in autonomous mobile robot docking automation using bidirectional RRT demonstrate new capabilities for multi-agent robotic systems with transformable structures [9].
The development of machine learning technologies, big data analysis, and natural language processing opens up new opportunities for creating effective tools for identifying cyberbullying. The integration of these technologies allows not only automating the process of analyzing texts, images, and videos but also predicting potential risks to prevent incidents.
KAN methods developed to describe complex nonlinear systems represent a unique approach to analyzing structured and unstructured data. KAN methods allow us to effectively analyze hidden dependencies and complex nonlinear relationships in texts. This feature is fundamental in the tasks of detecting cyberbullying, where aggression can manifest itself through ironic, sarcastic, or indirect statements that traditional text processing algorithms often cannot correctly interpret.
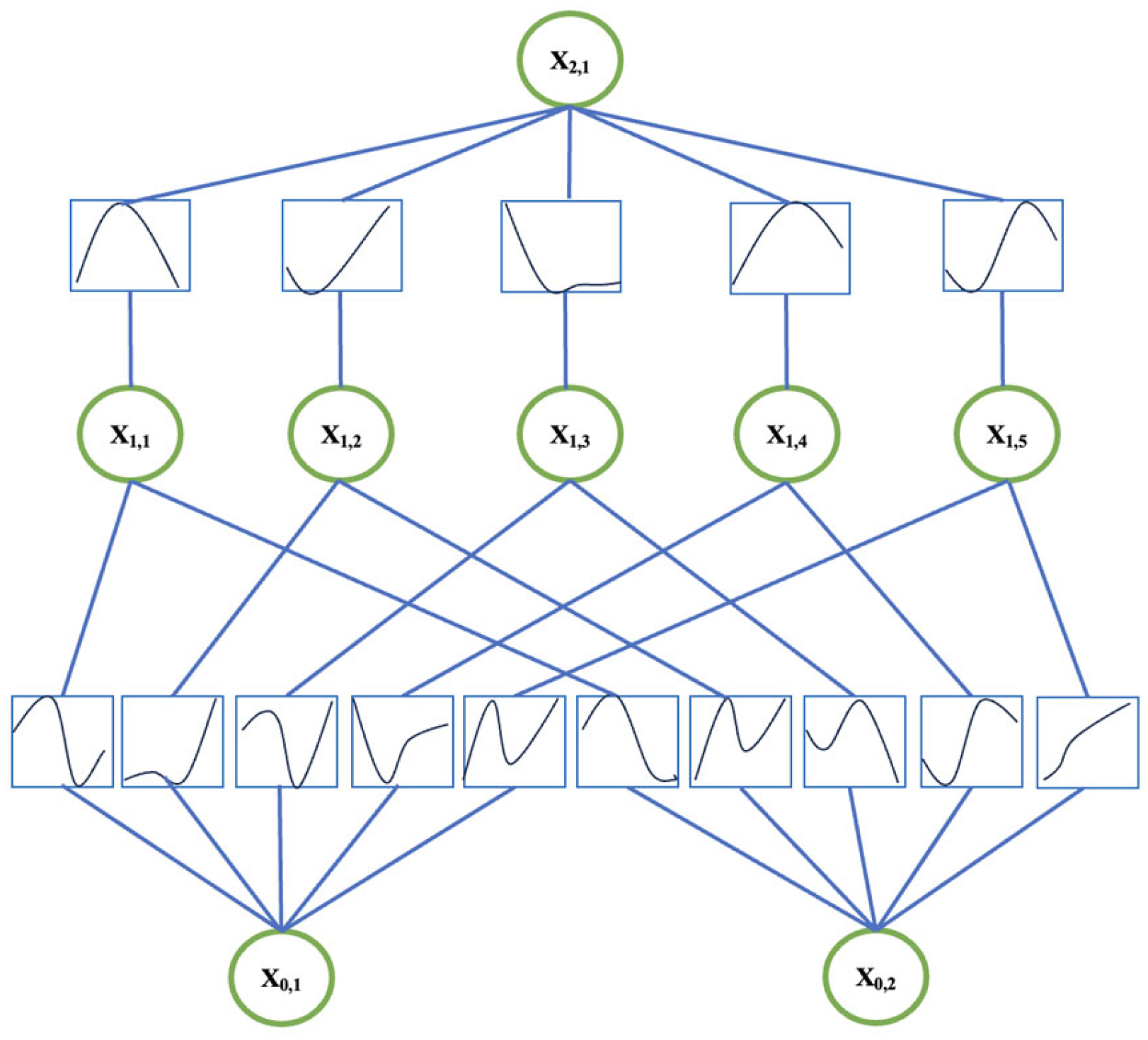
Based on the Kolmogorov–Arnold representation theorem, J. Liu et al. [10] described Kolmogorov–Arnold networks (KANs) as a promising alternative to traditional multilayer perceptrons (MLPs). KANs demonstrate a new approach in the field of neural networks, forming the basis for the further development of modern machine learning (ML). KANs, which are based on the theorem on the representation of arbitrary continuous functions, are represented as combinations of functions of one variable. The key characteristic of these networks is the approximation of complex dependencies while maintaining high interpretability of the models and improving their computational efficiency. KANs serve as a promising replacement for multilayer perceptrons (MLPs). KANs have trainable activation functions on the edges (“weights”). KANs do not have linear weights—each weight parameter is replaced by a one-dimensional function parameterized as a spline [11]. The structure of a KAN network is shown in Figure 1.
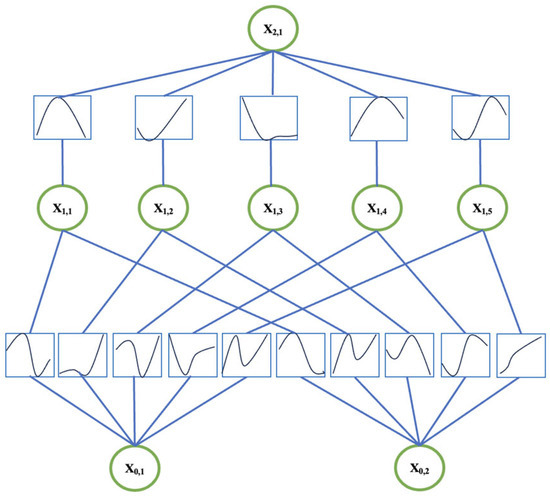
Figure 1.
KAN network structure.
KAN, unlike MLP, can process new input information without catastrophic forgetting; this feature helps to keep the model up to date. The learning dynamics are changed by moving the activation functions to the edges, rather than to the core of the neuron, to implement a nonlinear transformation instead of a combination of weights and activation functions in a multilayer perceptron; this property increases interpretability. Differential processing of features and control over the influence of inputs on outputs occurs due to the use of nonlinearity before summation.
KANs are used in a wide variety of fields of science, technology, and medicine.
KANs are effective in quantum computing. In the study [12], KANs are used to prepare quantum states, demonstrating superiority over traditional approaches based on a multilayer perceptron (MLP). In particular, KANs achieved a success rate 2–5 times higher in noise-free environments and showed greater resistance to noise. In addition, the integration of KANs into QAS algorithms including reinforcement learning has reduced the number of 2-qubit gates and circuit depth in solving quantum chemistry problems, demonstrating the advantages of KANs in improving the efficiency of quantum circuit design. KANs hold promise for their application in quantum simulation and computing.
KANs show high potential in time series processing. Genet et al. [13] propose a new neural network architecture, TKAN, which combines KAN and LSTM, which can perform time series forecasting with increased accuracy and efficiency. The study [14] proposes two variants of KAN for time series forecasting: T-KAN and MT-KAN. T-KAN focuses on identifying concept drift and explaining nonlinear relationships, making it suitable for dynamic environments. MT-KAN effectively exploits complex dependencies between variables in high-dimensional time series, improving accuracy and interpretability. In their study, the authors of [15] showed that KANs provide performance comparable to or better than MLPs on 128 time series datasets due to their efficient structure, regardless of the use of the b-spline function. The low Lipschitz constants characteristic of KANs and the hybrid MLP_KAN structure provide high robustness and resilience to disturbances. In [16], a hybrid GRU-KAN model is proposed that combines the capabilities of GRU for temporal feature extraction with KAN for modeling complex nonlinear relationships. The model uses GRU for temporal feature extraction and KAN to capture complex nonlinear relationships, which enables efficient production forecasting based on oil well data. Test results showed that GRU-KAN achieves high accuracy and computational efficiency compared to other models. In [17], a hybrid power system control method using the MPC-LSTM-KAN structure is presented. KAN helps to model nonlinearities and refine LSTM predictions, which improves system stability and energy efficiency in dynamic conditions.
KANs show significant potential for solving partial differential equations (PDEs). KANs have proven to be an effective alternative to traditional neural networks, especially in problems that require high interpretability and a minimum number of parameters. In the paper [18], the authors presented a physically informed Kolmogorov–Arnold network (PIKAN) based on JAX for solving partial differential equations (PDEs). The implemented adaptive learning and basis function engineering methods provided up to 84-fold acceleration of the training time and a 43.02% reduction in the L2 error. Experiments showed that PIKAN achieves or exceeds the accuracy of more complex models with up to 8.5 times more parameters.
An important aspect of KAN applications is their use in graph analysis problems. Integrating KANs with graph structures allows for improving the interpretability of models. The Qedgix framework proposed in [19] integrates graph neural networks (GNNs) and the QMIX algorithm to optimize the age of information (AoI) in distributed systems. The use of the KAN representation theorem allows for achieving permutation invariance and efficient network training in the context of decentralized, partially observable Markov processes. For example, in the study [20], GraphKAN demonstrated the successful integration of KANs into graph neural networks (GNNs). Improvement in feature extraction was achieved due to more efficient capture of dependencies within graphs. The study [21] confirms that B-spline and radial basis function-based KAN implementations are a competitive alternative to MLPs, improving node classification, graph classification, and regression problems. Kolmogorov–Arnold networks demonstrate high potential in medical diagnostics. A recent study [22] proposed a temporal modification of KAN, TCKAN, which integrates temporal data, continuous features, and ICD codes into a single model. This multimodal strategy enables TCKAN to outperform existing machine learning and deep learning approaches in accuracy, sensitivity, and specificity for identifying patients at high risk of sepsis. Tests on MIMIC-III and MIMIC-IV datasets showed the high performance of TCKAN, achieving an AUC of 87.76% and 88.07%, respectively. Moreover, TCKAN effectively copes with the problem of data imbalance, improving the identification of patients at increased mortality risk and facilitating timely medical intervention. In [23], KAN demonstrated high performance in predicting radiation pneumonitis when integrated with a bimodal combination of features derived from CT images and clinical data. The KAN-based classifier with adaptive feature fusion achieved 74% accuracy, 73% recall, and 86% AUC, outperforming the results of single modalities. The KAN network demonstrated high performance in a study [24] on oncology prediction to build a model for determining drug resistance in ovarian cancer cells. The model with KAN architecture equipped with a flexible activation function provided high accuracy in identifying patient subtypes with different drug responses. Its performance was validated on three independent datasets (GSE17260, GSE26712, GSE51088). In [25], the TCNN-KAN model was proposed, which combines a triple convolutional neural network with a KAN network to improve the accuracy of sEMG (surface electromyography signals)-based gesture recognition. KAN is used to replace fully connected layers by adding learnable activation functions and improving the performance of the model. The authors’ CardiOT model [26], based on the combination of optimal transport (OT), structural remapping (SR), and KAN networks, is developed to predict the cardiotoxicity of compounds. OT optimizes the joint distribution of data, SR takes into account the chemical structure, and KAN improves interpretability. Experiments have confirmed the robustness of CardiOT under uneven distribution and data sparseness. The study [27] presents a comparison of KAN with traditional multilayer perceptrons (MLPs) on the task of detecting the positions of the upper and lower body parts based on data obtained through MediaPipe. The results show that KAN outperforms MLP in accuracy (97.03% for the upper body and 92.11% for the lower body) with significantly fewer parameters. The paper [28] presents the SCKansformer model for bone marrow blood cell classification, which improves the accuracy and efficiency of the analysis. Replacing the MLP layer with a KAN network in the Kansformer Encoder strengthens the nonlinear feature representation and interpretability of the model. In the study [29], KAN was integrated with various prediction models including LSTM, ST-LSTM, A-LSTM, and A-ST-LSTM to analyze the incidence of hepatitis E based on the Baidu index. The results showed that KAN improves the prediction performance by combining exogenous data with existing architectures. In addition, researchers are applying KANs to solve problems in other fields, such as design and engineering. In engineering problems such as electromagnetic device design, KANs are integrated with genetic algorithms to optimize the solenoid structure. The combination shows significant improvements in magnetic field uniformity and coverage efficiency. A study [30] presents an improved single-core tightly wound solenoid structure with an auxiliary coil, whose parameters are optimized using GA-KAN. Experiments show that the new approach increases the effective magnetic field coverage by 2–5 times compared to traditional solenoids at different tolerance levels.
In the field of network security and the Internet of Things (IoT), KANs demonstrate high accuracy in classification and anomaly detection problems. The CKAN model proposed by the authors [31], which combines KAN with convolutional neural network (CNN) architecture, outperforms traditional deep learning (DL) models such as CNN, RNN, and Autoencoder in key metrics such as precision, recall, and F1-score. On the NSL_KDD, CICIoT2023, and TONIoT datasets, the CKAN model achieved up to 99.93% accuracy for binary classification, demonstrating efficiency and compactness compared to MLP. This highlights the promise of KAN in the development of IDS and IoT applications. The approach presented by the authors [32] improves the autonomous vehicle path tracking controller (DD-PTC) by integrating data-driven enhancements. One of the key components is the use of KANs to estimate tire lateral forces and dynamically adjust tire stiffness during cornering, which improves the predictive driving model. In addition, Gaussian process regression (GPR) can take into account the unmodeled vehicle dynamics, creating a more accurate control model. The paper [33] presents the results of the analysis of three MLP models, KAN, and its optimized version. The experiments showed that KAN and its improved version outperform MLP in the accuracy of detecting fraudulent transactions while reducing the number of model parameters. The paper [34] investigates the resilience of various KAN-based architectures, including KAN, KAN-Mixer, KANConv_KAN, and KANConv_MLP, to adversarial attacks, which is an important aspect that has not been sufficiently studied in current research. The experimental results showed that KAN-based models, especially KAN-Mixer, have excellent resilience to adversarial attacks, maintaining high accuracy on clean data and showing significant improvement over MLP under the FGSM attack. KANs demonstrate high efficiency in modeling complex data, which makes them a promising tool for image analysis tasks. In [35], a KAN-based network, AEKAN, is presented for unsupervised change detection in high-resolution satellite images. The model uses a Siamese KAN encoder to extract common features between images and dual KAN decoders to reconstruct data, improving interpretability. A hierarchical loss function optimizes training by minimizing feature divergence. Tests on five datasets confirmed the superiority of AEKAN over state-of-the-art approaches, highlighting the effectiveness of KAN in satellite image processing. In [36], KAN is investigated for pixel-wise classification of hyperspectral images. The authors replaced the standard layers of six state-of-the-art neural networks, including 1D, 2D, and 3D CNNs and SSFTT transformers, with KAN-based counterparts. Experiments on seven datasets showed significant improvement in classification accuracy, especially in transformer models. In [37], a hybrid KAN architecture using 1D, 2D, and 3D versions is presented for hyperspectral image (HSI) classification. The application of KANs provides high accuracy and efficiency in analyzing complex HSI data. The paper [38] presents the KARAN model, which uses KANs to improve medical image analysis. Innovations include KA-MLA, an attention block that integrates KANs and state space model (SSM) into the Transformer architecture for efficient feature extraction. The RanPyramid module uses random convolutions to improve noise robustness and optimize feature integration. Experiments show high segmentation accuracy and lower computational complexity. The paper [39] proposes a novel hybrid HKAN model for tissue defect segmentation based on the fusion of CNNs and Transformers using KANs to enhance feature extraction capabilities. Innovative components are developed in the HKAN framework, including a KANConv block based on KAN convolutions and a lightweight KANTransformer block where MLP is replaced by KAN. These elements are integrated into a hybrid KAN block, which acts as the encoder and bottleneck of the model. Experiments with several tissue datasets demonstrate the superiority of HKAN over existing segmentation models.
Special attention is paid to the application of KANs in the problems of forecasting and diagnostics in engineering systems. For example, the paper [40] presents an MD-HRL approach for task scheduling that combines hierarchical reinforcement learning and the use of a KAN network. KAN integrates the encoding of task and resource information, which simplifies the model and improves the accuracy of subtask priority estimation. Training MD-HRL agents provide optimal resource allocation, minimize execution time and energy consumption, and balance the system load. Predicting the strength of oil well cement based on porosity and pore size distribution is an important task for optimizing cementing quality. Conventional deep learning models and empirical methods often face accuracy limitations. The authors of [41] apply KANs in this area and show excellent results. The study [42] proposed a hybrid approach integrating long short-term memory (LSTM) networks with KANs to predict the deformation of a concrete gravity dam. The model includes a two-stage attention (DA) mechanism, which improves accuracy and interpretability. Comparison analysis with traditional models showed that DA-LSTM-KAN significantly outperforms them. In [43], a novel battery state of health (SOH) estimation method is proposed by integrating KAN and LSTM. KAN improves the interpretability and efficiency of extracting key battery characteristics such as voltage and temperature. The integration with LSTM improves dynamic modeling, achieving high accuracy of SOH estimation based on real operating data. In [44], a new approach is presented for power transformer fault diagnosis using KAN. The developed KAN Diag system effectively solves the diagnostic problem of imbalanced data by using the SyMProD method for balancing. The model achieves the minimum Hamming loss (0.0323), demonstrating high accuracy and robustness. In [45], a cross-state bearing diagnosis method, MCR-KAResNet-TLDAF, is proposed, which uses the Kolmogorov–Arnold representation theorem to improve the residual network. The method processes vibration signals, converts them into images, and uses KAN to detect fault signs. Experiments have shown high diagnostic accuracy of 99.36% and 99.889% on two datasets. In [46], a new generative adversarial network based on the KAN representation, denoted as KGAN, is presented for action recognition (HAR) under semi-supervised domain adaptation. The main focus is on using KGAN to generate synthetic data, which effectively solves the problem of lack of labeled data in target domains and provides improved processing of high-dimensional data due to the approximation of structured functions. In [47], a KAFIN framework based on the KAN representation is presented to improve financial modeling and analytical calculations. The KAFIN architecture demonstrates high accuracy, minimizing residual errors and achieving agreement with analytical solutions. In [48], an improvement of the Bidirectional Long Short-Term Memory (BILSTM) model is proposed by integrating KANs, which can significantly improve the representation ability of the network. Embedding KANs in the model improves its interpretability and reduces the number of parameters, solving the main problems of the traditional Multilayer Perceptron (MLP).
Despite its many advantages, KANs face certain challenges, including training complexity and sensitivity to noise in the data. These issues have been actively studied, and several researchers have proposed various methods to improve the robustness of these networks. In [49], an oversampling method combined with denoising is proposed to mitigate the impact of noise, and diffusion map-based kernel filtering is used to pre-filter noisy data for training the KAN. Chen Zeng et al. [50] investigate the performance of KANs and MLPs on irregular or noisy features. The experiments demonstrate that MLP outperforms or performs comparable to KANs for some types of features. Thus, KANs have demonstrated a wide range of applications in various fields. The use of KANs improves the accuracy, robustness, and efficiency of models in various tasks. One of the key areas of research in recent years has been the use of KANs to process big data, such as text information and social networks. Recent advances in natural language processing (NLP) have improved the quality of classification, but the use of multilayer perceptrons (MLPs) in such tasks often leads to an increase in memory and complexity. To solve this problem, the authors of [51] proposed the use of KANs, which demonstrate high efficiency with a smaller number of parameters. In particular, on the European Patent Office (EPO) dataset, KAN achieved an accuracy of up to 75.12%, which is comparable to or better than MLP and other methods such as Random Forest and XGBoost. These results confirm the potential of KAN as a powerful tool for text classification and open up opportunities for its application in patent analytics and other areas.
The potential of KANs in text processing lies in their ability to improve the interpretability of the model, provide high accuracy, as well as interpret the importance of various features when classifying test information. Kolmogorov’s ideas can be useful for analyzing or designing new architectures that combine aspects of universal approximation and text structuring [52,53]. Even though KANs have demonstrated high results in various areas, their application to text classification in social networks remains underexplored. This motivates our study, which aims to evaluate the effectiveness of KANs compared to traditional MLPs in detecting cyberbullying.
2. Related Works
In the field of scientific research on cyberbullying detection in social networks, various works have been conducted to improve the detection using different approaches. In the study by Aldhyani, T.H.H. et al., a cyberbullying detection system based on deep learning algorithms was proposed. The authors compared the effectiveness of the hybrid architecture CNN-BiLSTM and the BiLSTM model on the tasks of binary and multi-class classification of social media messages. The highest accuracy (up to 94%) was achieved by the CNN-BiLSTM model for multi-class classification [54]. In the study by Raj et al., the authors proposed a cyberbullying detection system based on machine and deep learning methods, which is able to evaluate social media messages in real time and recognize cyberbullying content in English, Hindi, and Hinglish; the achieved accuracy was 95% [55]. In the study [56], the authors evaluated the performance of four different neural network architectures for the task of automatic offensive language detection: convolutional neural network (CNN), bidirectional long short-term memory (Bi-LSTM), Bi-LSTM with attention mechanism, and a combined CNN-LSTM architecture. The CNN-LSTM model showed the best result in terms of recall, with an indicator of 83.46% [56]. In the study by Iwendi et al., a comparative analysis of four deep learning architectures—RNN, LSTM, GRU, and BLSTM—was conducted for the task of detecting cyberbullying on social networks. The BLSTM model showed the best results in terms of accuracy and F1-measure (82.18%) [57].
In a recent paper [58], an incremental iKAN framework for human activity recognition based on wearable sensor data was proposed, based on the use of Kolmogorov–Arnold Networks (KANs). Unlike traditional approaches, iKAN simultaneously solves two key problems—the problem of catastrophic forgetting and working with non-uniform input data—by replacing MLP with a spline-oriented architecture with high local plasticity. The results obtained on six publicly available datasets demonstrated significant superiority in the F1-score metric (up to 84.9%) over existing IL methods, such as Elastic Weight Consolidation and Experience Replay.
Modern research in the field of emotion recognition from speech demonstrates the effectiveness of multimodal approaches that combine audio and text characteristics. Thus, in [59], the TS-MEFM (Text and Speech Multimodal Emotion Fusion Model) model is proposed, combining speech and text features using improved encoders (TMAK and SMTK), the SMAM attention module, and the compact nonlinear SFKAN block. Experiments conducted on the IEMOCAP and MELD datasets showed the superiority of TS-MEFM over existing methods in terms of accuracy and resistance to variations in input data, which is also confirmed by the results of ablation studies. In [60], a modification of KANFeel-Attent is proposed—a multimodal architecture in which the traditional attention mechanism in the transformer is replaced by a Kolmogorov–Arnold Networks (KAN) block, which made it possible to significantly increase the accuracy and F1-measure in emotion recognition on three open datasets compared to current basic and state-of-the-art approaches.
3. Materials and Methods
3.1. Dataset
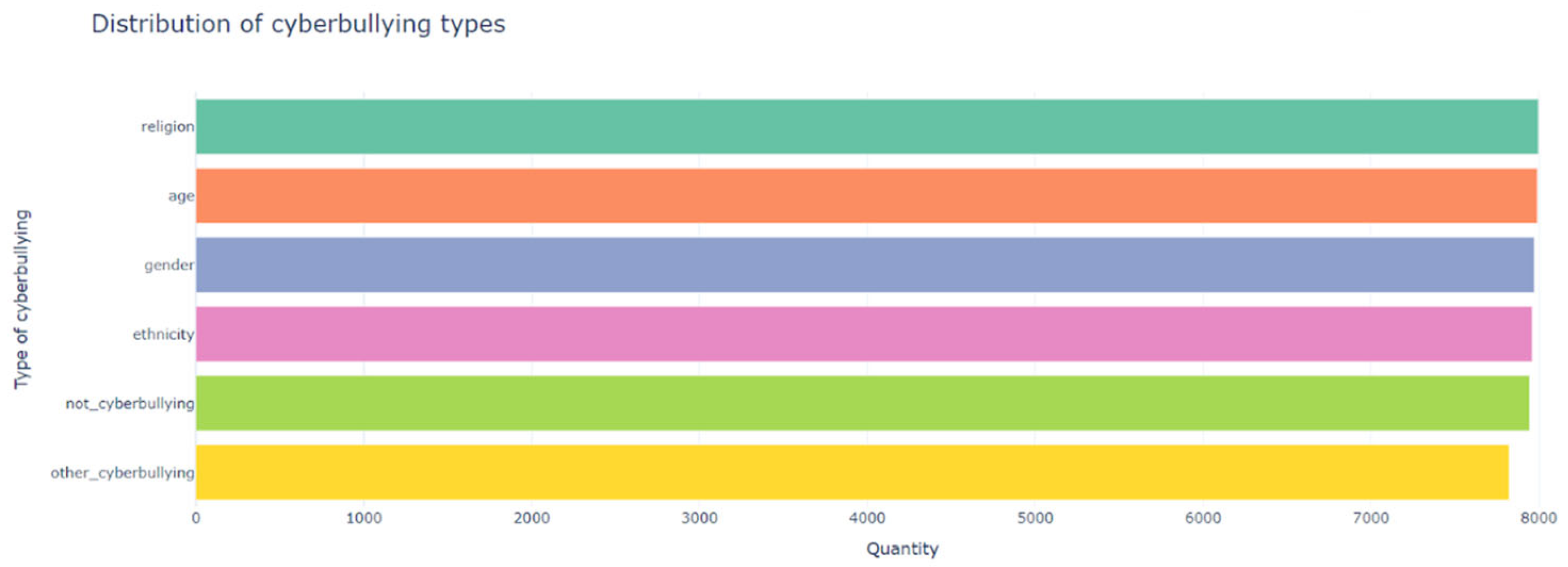
The task of detecting cyberbullying is a complex task due to the diversity of cyberbullying types. The following resources were used to search the dataset: Google Dataset Search, Kaggle, and UCI Machine Learning Repository. The cyberbullying dataset is a collection of tweets based on such actions as racism, discrimination, offensive language, and threats that reflect cyberbullying. A multi-class dataset openly available on Kaggle will be used for the study. This dataset collects tweets from Twitter and Facebook groups. The dataset contains more than 47,000 tweets labeled according to the cyberbullying class: age, ethnicity, gender, religion, other types of cyberbullying, and non-cyberbullying; according to this, the data are divided into six classes (Figure 2). The data are balanced and include 8000 instances for each class. Figure 1 demonstrates the distribution of classes. The dataset contains two columns containing tweets, and labels. Figure 3 shows an example of tweets from each category in the dataset.
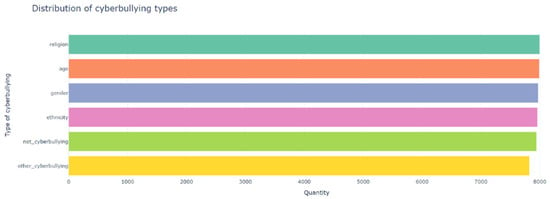
Figure 2.
Types of cyberbullying.

Figure 3.
Example tweets from each category of the dataset.
3.2. Data Preparation and Pre-Processing
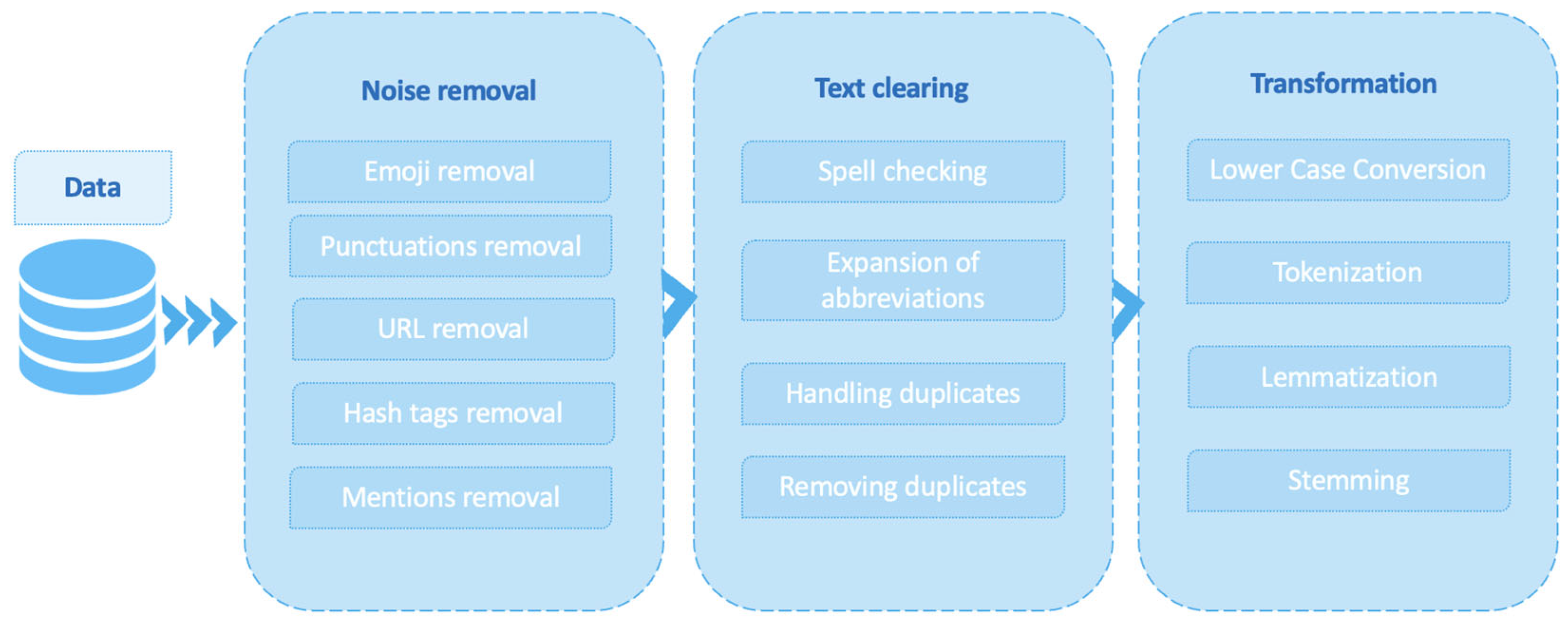
The approach proposed by the authors consists of several stages, including data pre-processing and tokenization. Data pre-processing consists of the following stages: noise removal (special characters, HTML tags, URLs); all words are written in lower case, stop words are removed (“and”, “or”, “in”); repeating characters are removed from words; numbers and punctuation marks are removed; strange characters are removed; abbreviations are expanded; duplicates are handled; missing values are handled; stemming is performed; and text formats are standardized (Figure 4). The tokenized input data are passed through the RoBERTa Transformer. The Transformer extracts the global context for each token. The study applies a RoBERTa-based transformer model for the tokenization and labeling of the text transcript, which allows for accurate and efficient text processing. The advantages of RoBERTa include high performance when applied to natural language analysis tasks.
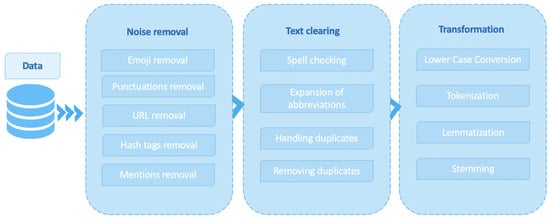
Figure 4.
Data preparation and pre-processing.
3.3. The Proposed Approach
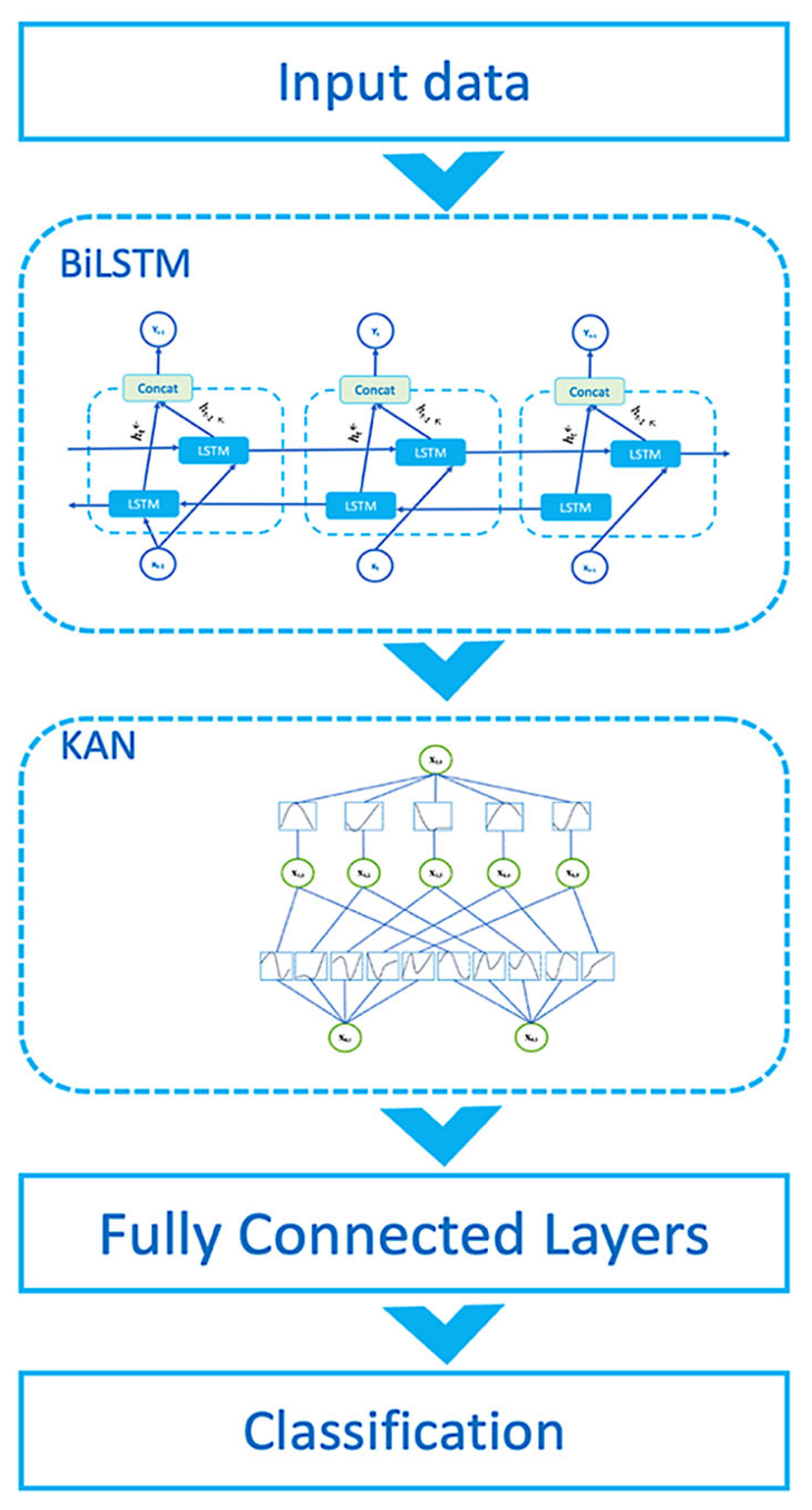
In this study, the authors propose a hybrid structure, a Hybrid KAN-Transformer-Enriched with Multi-Domain Dynamic Attention Network Model for Cybersecurity (Hyb-KAN), which combines the advantages of BiLSTM, Transformer, and the multi-domain dynamic attention network (MD-DAN) and KAN. The proposed structure combines the advantages of BiLSTM in detecting long-term dependencies and the advantages of Transformer in processing contextual information. MD-DAN increases the effectiveness of the model by focusing on the semantics, context, and temporal aspects of the data. KAN can model complex nonlinear dependencies between features extracted by previous modules. The hybrid structure allows complementing the advantages of Transformer and BiLSTM when processing test data, and the integration with KAN improves the model’s ability to take into account complex feature interactions, which are essential for text data processing tasks. The structure consists of several modules, including the BiLSTM module, the Transformer module, the Multi-Domain Dynamic Attention Network (MD-DAN), the feature fusion layer, the KAN network, and the final classifier. The key features of Hyb-KAN include multi-level analysis, in which BiLSTM captures local dependencies; the Transformer processes the global context; MD-DAN provides detailed analysis of semantics, context, and temporal aspects; and KAN allows for additional identification of complex dependencies between features and dynamic fusion of domain features, which improves the overall classification quality. KAN enhances the model’s ability to model complex interactions. The synergy of the BiLSTM, Transformer, MD-DAN, and KAN components provides flexibility and accuracy of text analysis. The model is easily adaptable to different text domains and tasks due to its hybrid structure and the use of KAN to handle nonlinear interactions. The advantages of integrating KANs are to model more complex dependencies between foci of attention and improve the quality of predictions, especially in the presence of hidden nonlinear relationships in the data. The structure of the proposed model is shown in Figure 5.
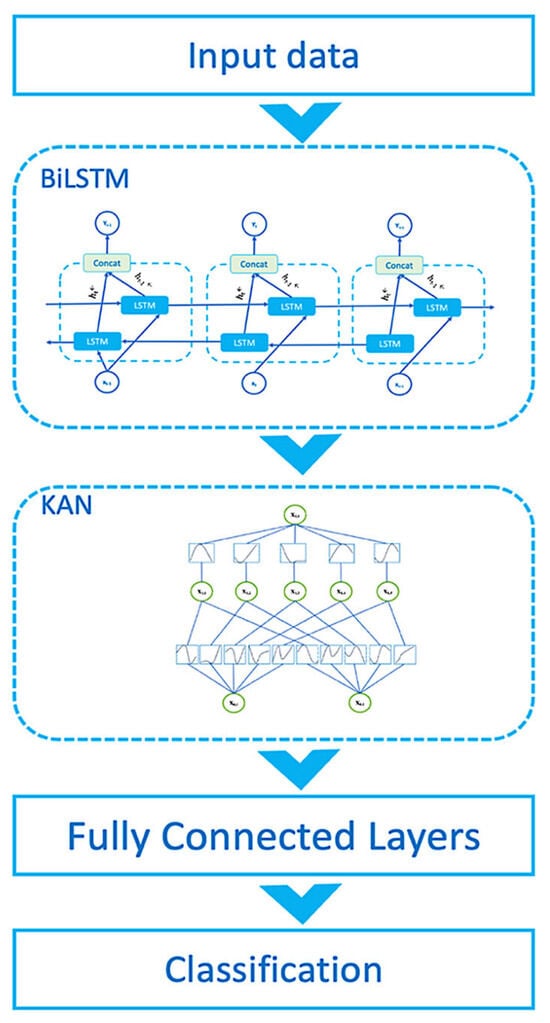
Figure 5.
Generalized structure of the proposed model.
3.3.1. BiLSTM (Bidirectional Long Short-Term Memory)
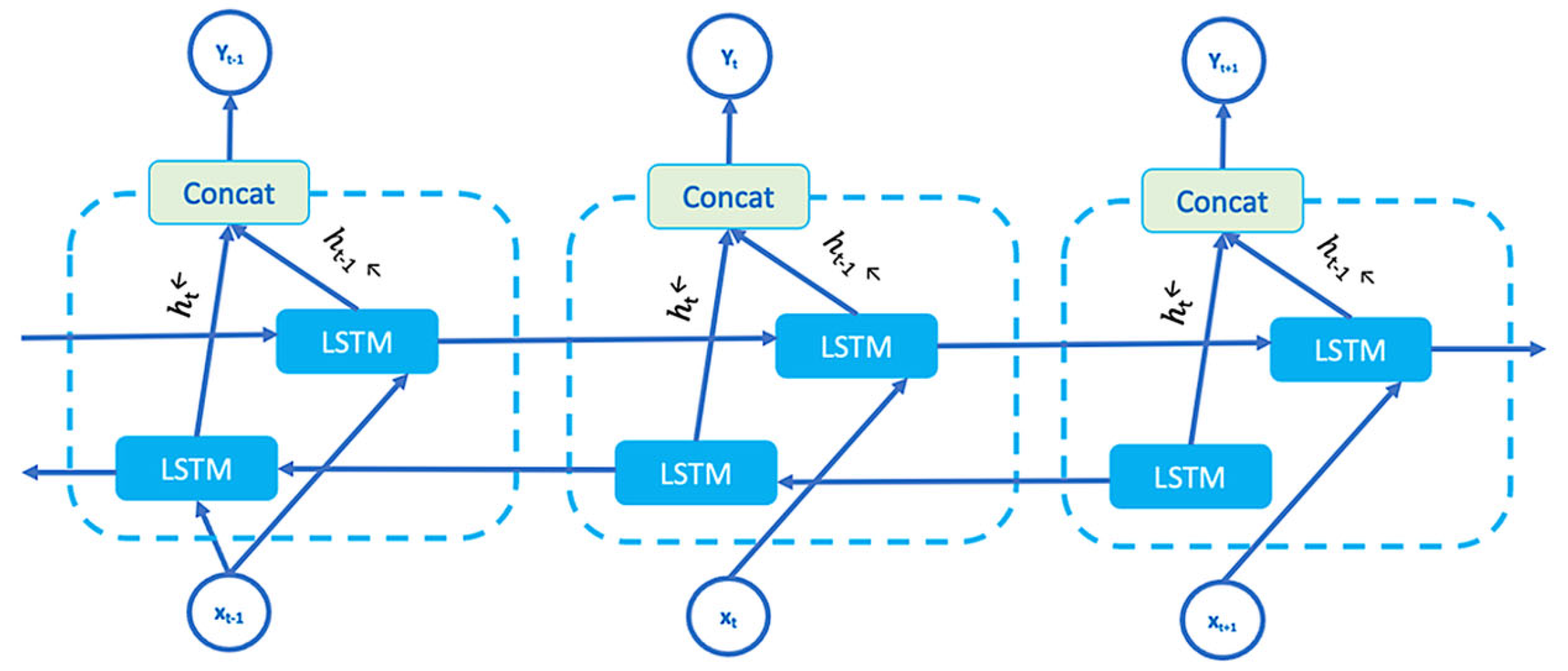
BiLSTM is designed to capture sequential data. In the Hyb-KAN architecture presented by the authors, BiLSTM is designed to extract local temporal dependencies, generating features for each token, which are then passed to the Transformer and MD-DAN for further analysis, including context-sensitive data representation. BiLSTM is of greatest importance in multi-level text analysis, complementing the capabilities of the Transformer module. Unlike standard LSTMs, BiLSTM processes data in both directions, which allows for taking into account both the previous and subsequent context for each token. BiLSTM consists of two directions: the forward direction processes the text sequence from left to right, and the backward direction processes the sequence from right to left (Figure 6). The final representation of each token is the union of the outputs from the forward and backward directions.
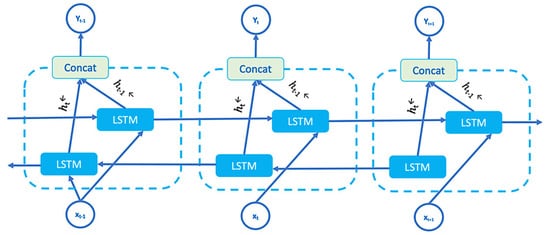
Figure 6.
BiLSTM structure.
The method processes both forward and backward information from trajectory data.
where and are hidden vectors belonging to the forward and backward LSTM layers at time t, respectively. These vectors are independent of each other and interact only within their respective LSTM layers. yt corresponds to the weighted concatenation of hidden layers, and concat is the activation function.
The advantages of BiLSTM include bidirectionality; BiLSTM handles sequential data well, including long dependencies, and can also be used to extract features before feeding them to another MD-DAN module. Based on this, the use of BiLSTM in the structure proposed by the authors allows extracting local dependencies between words; the outputs are integrated with global features from Transformer and multi-domain attention from MD-DAN, which makes it possible to take into account both local context and global text patterns.
3.3.2. RoBERTa
The study uses the RoBERTa model, in the form of a transformer model. RoBERTa is a modified version of BERT, including various optimizations, including modified batch sizes and training speed. It is focused on processing text sequences and extracting global dependencies between tokens. The application is aimed at improving efficiency and productivity. This module is aimed at providing high-quality feature extraction for further analysis.
3.3.3. MD-DAN Layer
The MD-DAN framework is used for dynamic text analysis across multiple domains. Its main function is to adapt data from multiple domains. This mechanism allows the model to highlight key aspects of the text that are most relevant to the classification task. Below, we describe the main stages of implementation and the operation of individual components of MD-DAN.
MD-DAN consists of three main levels of attention. Semantic attention analyzes the meaning of words and phrases. Contextual attention identifies dependencies between words within the text. Temporal attention processes temporal relationships and sequences of events. These levels work independently and are then combined to create a multi-domain representation of the text.
Semantic attention highlights meaningful words and phrases that are important for understanding the overall meaning of the text.
The mechanism consists of the following stages:
Embedding matrix:
Each word is represented by an embedding , where d is the embedding dimension.
Semantic attention vector:
Initialized with a vector of parameters that learn in the process.
Semantic importance of the word:
where S reflects the significance of semantic elements of the text.
Contextual attention is used to take into account the dependence between words in the text.
Sequence processing:
Sequences of tokens are used
A self-attention matrix is used to evaluate the importance of each word relative to others.
Attention matrix:
Calculated by pairs of words:
where Q, K, V are the matrices of queries, keys, and values, respectively.
The resulting attention vectors are summed up and transformed into a contextual representation C, Vector C, which reflects the dependencies of words in the text.
Temporal attention processes evaluate temporal dependencies in the data (if any).
Timestamps: If the data contain temporal characteristics (e.g., the order of events), each timestamp is represented as For each token, the temporal importance is calculated.
where are trainable parameters.
Then the time embeddings are weighted:
The text representation is formed, taking into account the time weights.
Vector T reflects the temporal structure of the text.
Dynamic merging of multi-domain representations:
Merge the outputs of all three layers (S,C,T) into a single multi-domain vector.
where [;] means vector concatenation.
Dynamic weighting:
Introducing learnable parameters ws, wc, wt.
This allows the model to highlight the most significant aspects of classification. The final representation, Final, contains information about the meaning of words (semantics), about the connections between words (context), and about time dependencies (time). This vector is fed to the next level of the architecture (classification layer). The model structure can adapt to different tasks by adjusting the weights.
3.3.4. Feature Fusion Layer
Next, all outputs are combined. The results of BiLSTM, Transformer, and MD-DAN are combined. The combination is performed using concatenation (joining along the axes) and addition methods, taking into account the weights for each source. The resulting representation combines local, global, and multi-domain contexts.
We obtain a combined and consistent representation of the text for further analysis.
3.3.5. KAN Network
The KAN layer plays the main role in the proposed architecture. This layer is designed to reveal hidden correlations between features. The KAN network is integrated to take into account the nonlinear dependence between the features extracted by the MD-DAN attention mechanism. KAN transforms the combined features (semantic, contextual, temporal) into a nonlinear representation, emphasizing complex dependencies. Instead of a simple concatenation or linear combination of features, we apply the KAN network to transform the combined features into a new spatial representation. The architecture of the layer can be described in more detail as follows. The input of the KAN layer is a vector of combined features from the Feature Fusion Layer. This vector includes the outputs of BiLSTM, Transformer, MD-DAN, and other layers. The layer applies several nonlinear functions to the input vector (e.g., hyperbolic tangent, ReLU, or more complex functions such as sine or polynomials). KAN transforms the input data using the formula:
where —trainable weights for the j-th feature in the i-th output,
—offset for the i-th output function,
—nonlinear activation function for the i-th output,
—functions of one variable that depend on certain subspaces of the original features,
—notation for the j-th element of the input vector X.
Next, we will look at the steps in the KAN layer in detail:
- Linear transformation: for each input feature :
- 2.
- Nonlinear transformation: transformation of the resulting value through the activation function:
- 3.
- Combining results: for each output feature:
- 4.
- Resulting vector: output vector:
After processing through KAN, the features will be fed to the input of the classification head for the final prediction. We obtain a nonlinearly transformed representation of the text for better interpretation and classification.
KAN allows taking into account the interaction of features that cannot be captured by traditional methods. In the context of Hyb-KAN, KAN serves as the last nonlinear transformation before the final classification. It combines the advantages of BiLSTM and Transformer, adding a layer of feature processing. The Kolmogorov–Arnold Network (KAN) layer plays the role of a key module in the Hyb-KAN architecture, providing mechanisms for deep feature analysis. Its flexibility, adaptability, and ability to handle nonlinear dependencies make it an important part of the architecture.
3.3.6. Final Classifier
The final classifier is the final module of the Hybrid Transformer-Enriched Attention with Multi-Domain Dynamic Attention Network (Hyb-KAN) architecture. This module accepts integrated and enriched representations of data from the previous layers (BiLSTM, Transformer, MD-DAN, and KAN). The input to the classifier is the integrated representations obtained after processing the data from the following components of the architecture. The outputs of these modules are combined to form the input feature vector for the final classifier. This vector is the result of concatenation, which ensures maximum information preservation.
The final classifier consists of several components:
Fully connected layers:
Fully connected layers perform a linear transformation of features to identify high-level patterns. Formally, the operation in each fully connected layer is represented as:
where h is the input feature vector, W is the learnable weight matrix, and b is the displacement vector.
Activation functions:
Using nonlinear activation functions such as ReLU (Rectified Linear Unit) enables the model to capture complex relationships between features. The ReLU activation formula is:
Dropout:
Dropout regularization is used to reduce the probability of model overfitting. During the training process, some neurons are randomly switched off, which helps to increase the generalization ability of the classifier.
Output layer:
To determine class membership, the SoftMax function is used for multi-class classification. This layer produces the probability of text belonging to a class.
The result of this process is a multi-class classification.
To understand the methodology, the algorithm is described below in pseudocode, Algorithm 1.
| Algorithm 1. Algorithm of the model Hyb-KAN. |
|
4. Results
This section presents the experimental results and comparative analysis of the effectiveness of the method proposed by the authors with the most well-known methods. The performance of the proposed method was evaluated with various deep learning-based models, including CNN, LSTM, BERT, and attention-based models. The following metrics were used for comparative analysis: accuracy, recall, and the F1-coefficient.
4.1. Data Processing Tools
The Python 3.9.13 programming language and the TensorFlow machine learning library were used to develop the algorithm. The experimental platform was equipped with a DEPO Storm 3450T4R server (DATSN.466219.013-03) SMD/2xG6230/1024GBRE16/L9361-8i/2DT480/4T4000G7/2DT960L/2DT960L/8HSDA/DATSN.469535.001/16D/6E/4GLAN/IPMI+/RTX3080/RTX3080/1200W2HS/FP/ONS3S, 2xG6230 processor [20 cores, 40 threads, 2.1 GHz, 27.5 MB cache, 125 W], 1024GB RAM: 8 × 128 GB DDR4 ECC REG.
4.2. Evaluation Metrics
The criteria used to evaluate the performance on the training and test sets were precision, recall, and F1, which were calculated as described in the equations below [52,53]:
where TP (True Positive) indicates the number of correctly detected values; FP (False Positive) indicates the number of falsely detected values; and FN (False Negative) indicates the number of missed values.
5. Experimental Results
5.1. Model Results
This section presents the experimental results achieved using the developed Hyb-KAN model for detecting and classifying cyberbullying-related linguistic expressions into different categories. The proposed model is tested in multi-class classification mode on a real cyberbullying-related dataset.
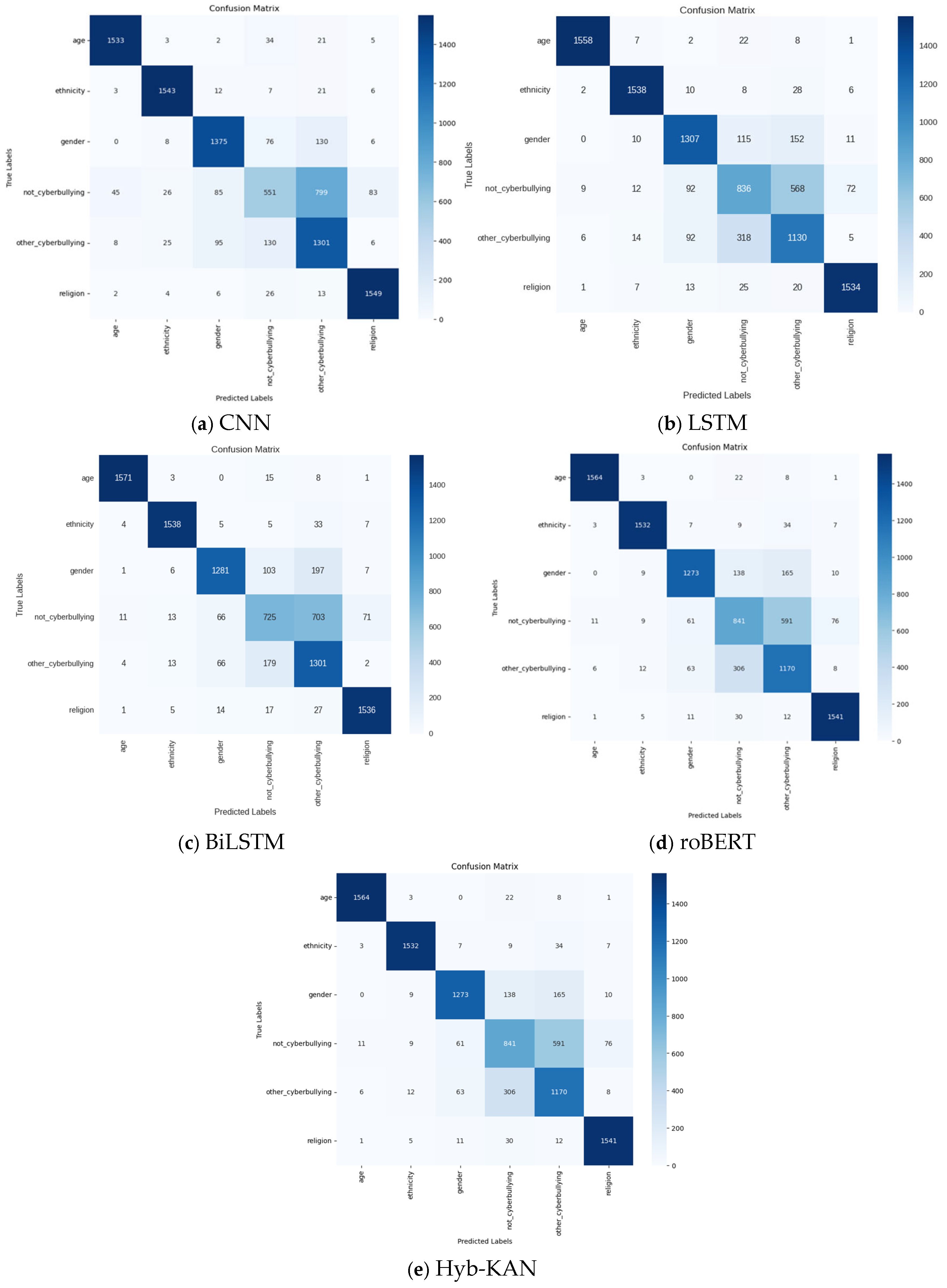
The model is trained using the Adam optimizer, with a given learning rate and a loss function in the form of categorical cross-entropy. The classification accuracy score is chosen as the metric. To improve the efficiency of training, checkpoints, early termination of training, and additional callbacks are used. The early stopping mechanism monitors the dynamics of the loss during the validation stage and automatically saves the optimal parameters of the model, preventing its overfitting. The model is trained on the training data and tested on the validation set. The results of the work are displayed in the confusion matrix (Figure 6).
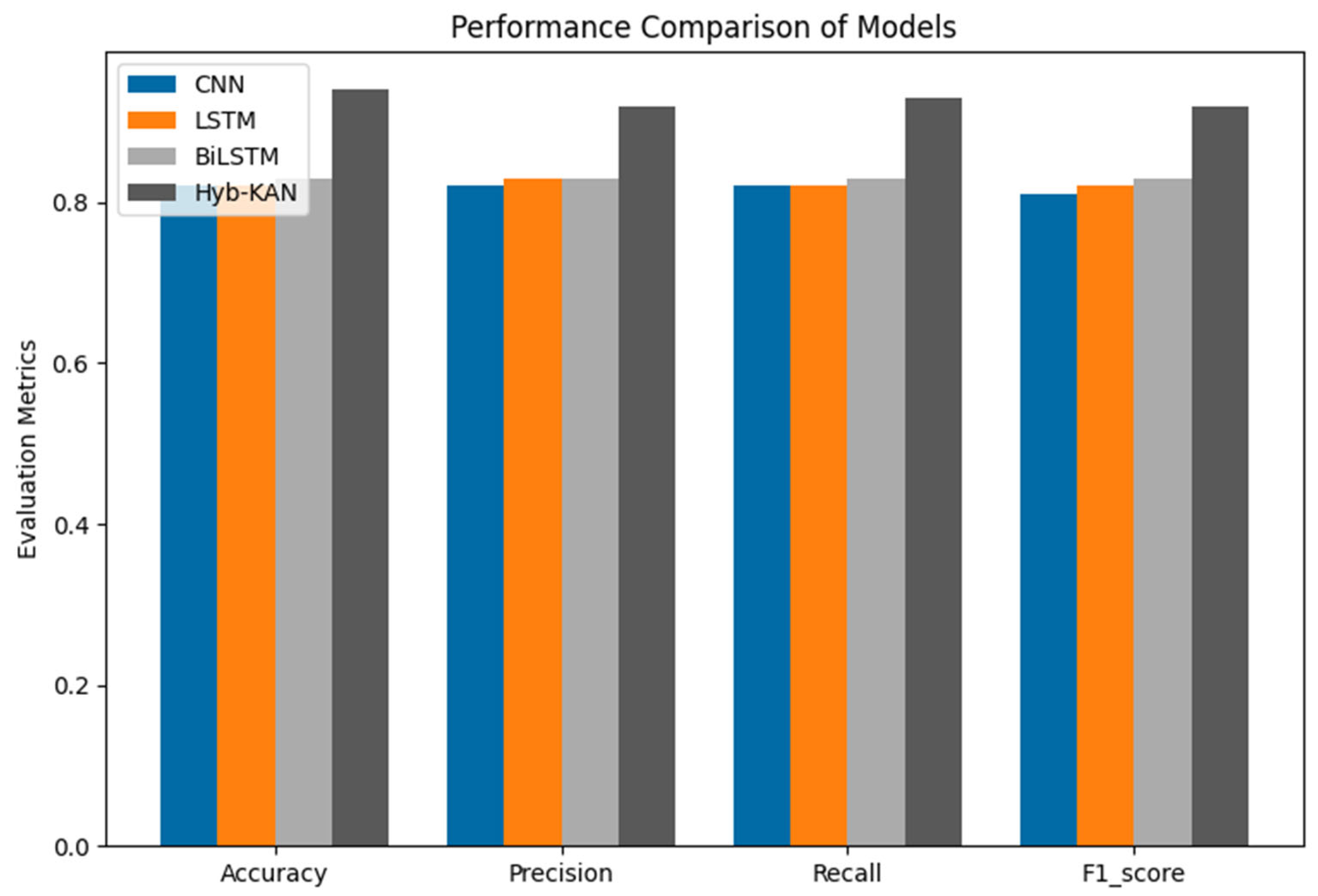
The model proposed by the authors in the study was compared with three baseline classification models: convolutional neural networks (CNNs), long short-term memory (LSTM) networks, biLSTM, and bidirectional encoding representations from transformers (roBERT) (Figure 7). LSTM uses word vectors (GloVe) to represent each word as a fixed-length numeric vector. Next, a matrix is created where each row corresponds to a word vector. If a word is missing from the pre-trained embeddings, its vector is initialized to zeros.
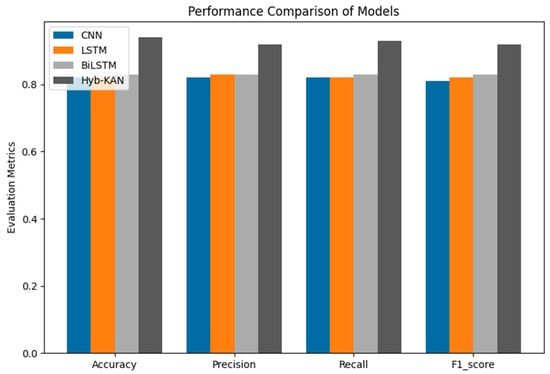
Figure 7.
Performance comparison of models.
When analyzing the accuracy rates for different neural network architectures (CNN, LSTM, BiLSTM, and RoBERTa), it is observed that their classification results were similar (Figure 8). This similarity in performance can be explained by several factors that are important to consider when interpreting data and building models. In all experiments, the same pre-trained embeddings, GloVe, were used to represent text data. Since these embeddings are static and provide the same word representation for all models, they limit the ability of the architectures to exploit contextual information. This may offset the potential benefits of context-aware models (e.g., BiLSTM and RoBERTa) over static models (CNN).
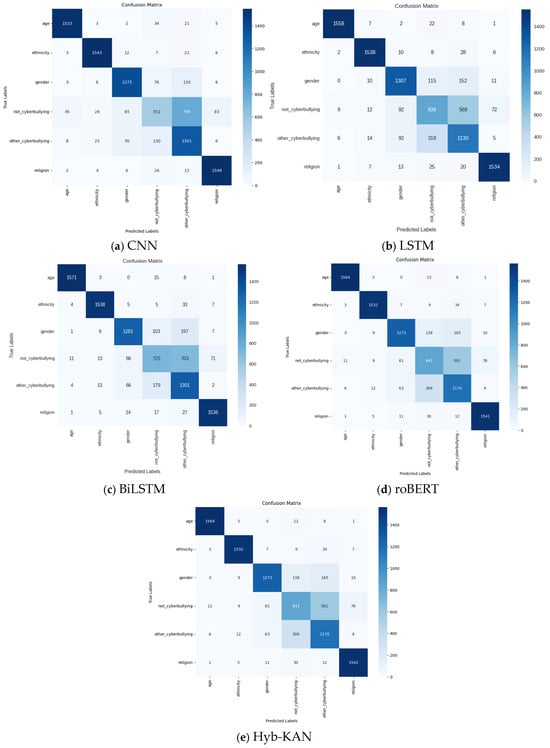
Figure 8.
Confusion matrix.
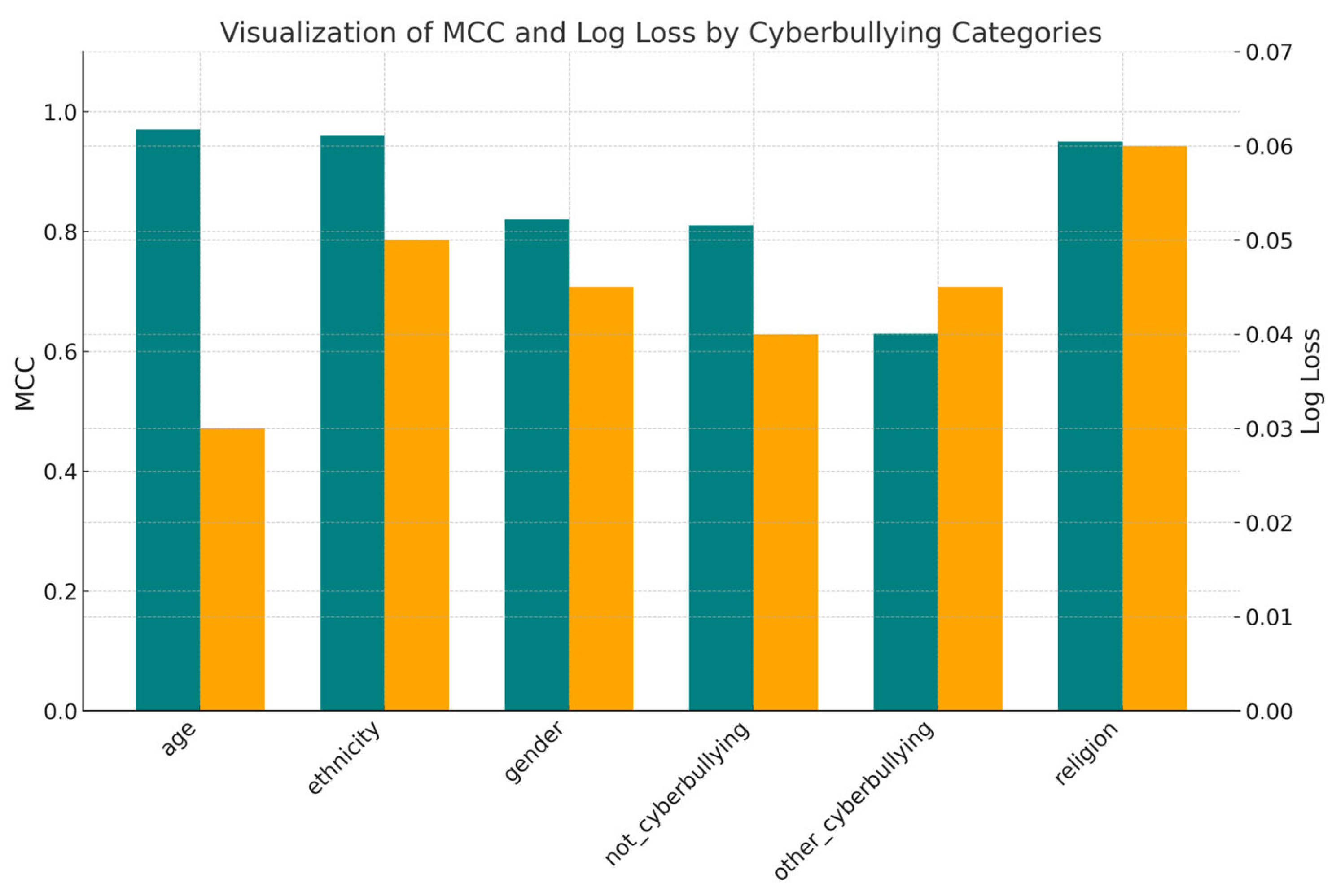
For a comprehensive evaluation of the HybTran-MDA-KAN model performance, additional metrics, the Matthews Correlation Coefficient (MCC) and log loss, were analyzed (Figure 9). The MCC metric is useful in cases of imbalanced classes. This metric provides an objective evaluation by considering true positives, false positives, true negatives, and false negatives simultaneously. The log loss metric measures how well the model approximates class probabilities. A comprehensive evaluation using these metrics helps to accurately characterize the strengths of the model and its applicability to real-world scenarios.
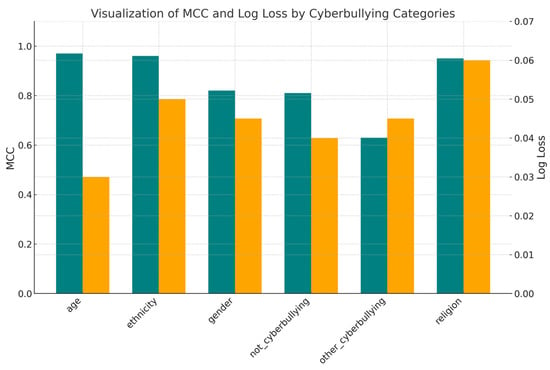
Figure 9.
Matthews Correlation Coefficient (MCC) and log loss.
The age and ethnicity categories demonstrated high values of the Matthews Correlation Coefficient (0.9785 and 0.9656) and the lowest values of the log loss (0.0260 and 0.0462), indicating high accuracy and confidence of the model in classifying data. At the same time, the not_cyberbullying and other_cyberbullying categories demonstrated the lowest values of the MCC (0.8106 and 0.6307) and relatively low values of the log loss (0.0373 and 0.0446). This result may indicate high confidence of the model in forming predictions.
Combining methods can significantly improve classification results. Combining methods allows using the strengths of each architecture to improve the accuracy and robustness of the model. We consider the studies obtained by combining different models, such as LSTM-CNN, ensemble classifiers, CNN, FAST-RNN, CNN-BiLSTM, CNN-LSTM, and BLSTM (Table 1). The data presented in the table demonstrate their effectiveness and the main differences in performance.

Table 1.
Comparison of different models.
The Hyb-KAN model developed by the authors was compared with baseline models on the same dataset to solve the problem of cyberbullying classification. As shown in the table, the Hyb-KAN model demonstrates a high level of accuracy, outperforming most other models. This provides an understanding that the combination of different methods allows using the strengths of each architecture to improve the accuracy and robustness of the model.
5.2. Interpretability Analysis
Let us consider the interpretability analysis of the proposed model using the SHAP and LIME methods to interpret the results [64]. SHAP (SHapley Additive exPlanations) is a framework that allows us to explain and interpret the results of machine learning models. In situations where features are missing, the SHAP value shows how the transition from the base or expected value of the model to its actual prediction is carried out. These values help us understand how the features affect the model output, including the direction of their impact. For example, if a feature’s SHAP value is 1 or −1, then the feature has a significant impact on the prediction for a given data point, either positively or negatively. A feature with a SHAP value close to 0 has a minimal impact on the final prediction.
SHAP values are calculated using the formula:
—SHAP- the value of feature i in the context of a given set of input data,
N—set of all signs,
S—a subset of features that excludes i,
f(S)—prediction of a model using features from a set S,
—prediction of a model with an added feature i.
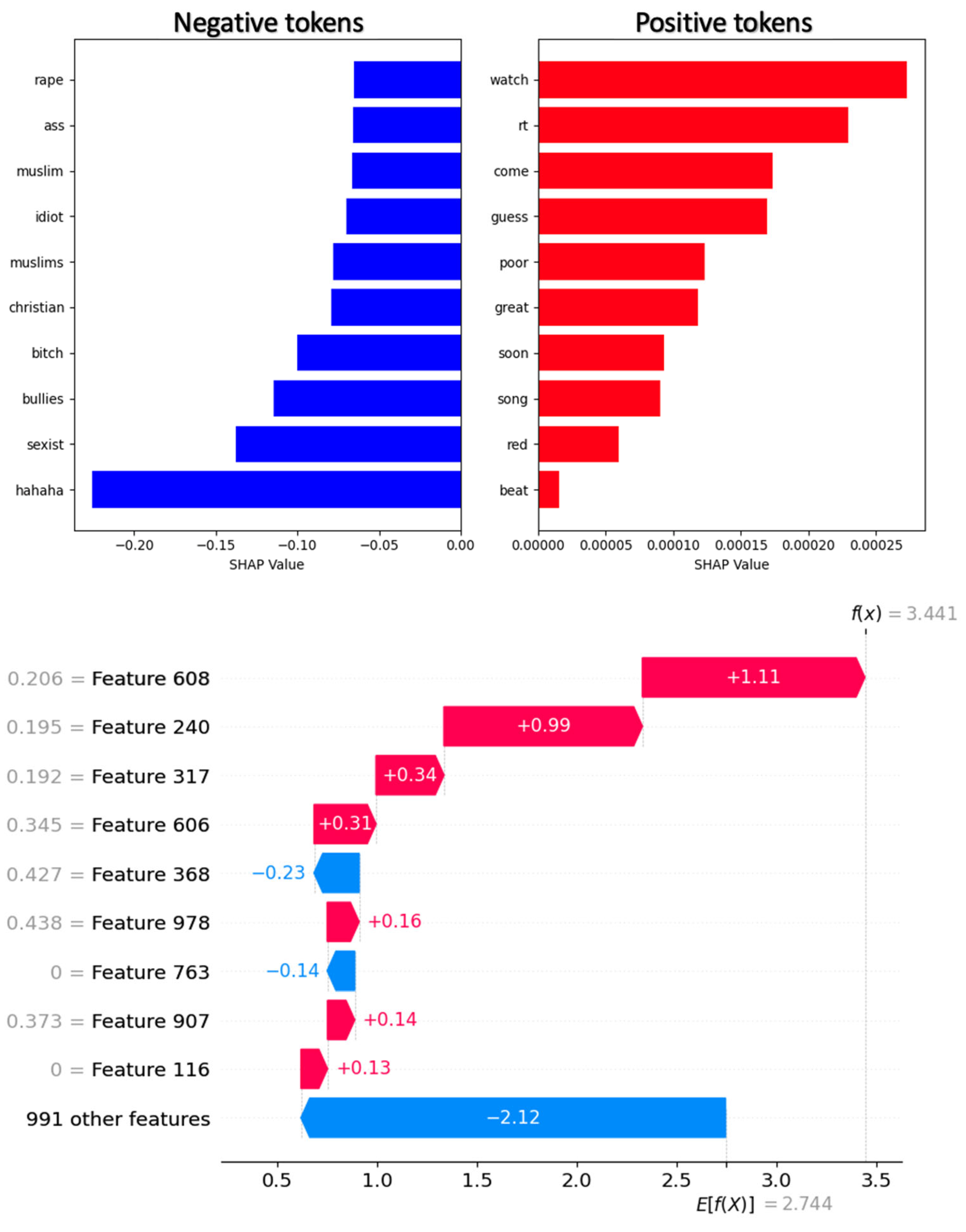
The SHAP framework also offers various visualization tools that help explore the contribution of features, making it easier to interpret models. This makes SHAP useful for understanding and explaining the decisions made by models. Figure 10 shows how individual tokens in a text fragment influence the results of the TRABSA model. Red areas of the text indicate areas that strengthen the model’s prediction, while blue areas weaken it. This visualization superimposes token weights on the original text, allowing us to assess how certain words or phrases shape the overall perception of the text.

Figure 10.
The importance of individual tokens in predicting cyberbullying.
Figure 11 presents global summaries of token influence across a natural language processing dataset. The chart visualizes the degree to which each token influences the model’s predictions at the dataset level. The height of the bars reflects the magnitude of the influence: the higher the bar, the greater the token’s contribution to the predictions.
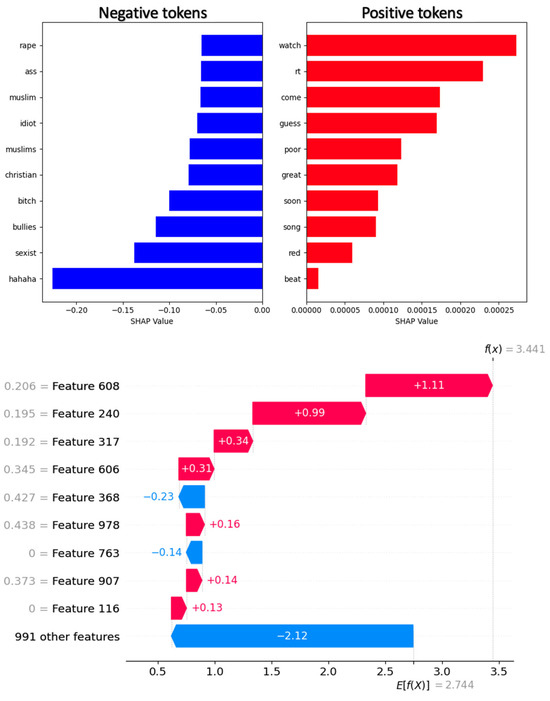
Figure 11.
Global generalizations of the influence of tokens within a set.
LIME Text Explainer provides a visualization tool to show how individual words or tokens in the text influence the model predictions. In Figure 12, tokens are plotted along the horizontal axis, and their influence on the output is displayed along the vertical axis. The graph shows the importance of tokens and their influence on the model prediction. To properly interpret the graph, it is important to evaluate the magnitude and direction of each token’s contribution. The most important tokens are highlighted by a strong positive or negative contribution, while those with a close to zero contribution have little or no effect on the output. Such visualizations also help to identify keywords or expressions that have a significant impact on the model’s decision-making process.

Figure 12.
LIME Text Explainer vertical bar chart in descending order of token contribution, illustrating the influence of each token on the model’s predictions.
6. Discussions
Practical results obtained using Hyb-KAN for cyberbullying classification demonstrate significant improvement over existing approaches in this area. The proposed architecture includes a transformer, bidirectional LSTM (BiLSTM), attention mechanisms, and KAN. The combination proposed by the authors allows for efficient recognition of complex patterns and contextual dependencies in text data. The comparison showed the superiority of Hyb-KAN over state-of-the-art models.
The analysis of the obtained results confirms that the Hyb-KAN model demonstrated the correct relationship between low log loss values and high MCC values for most classes. This indicates not only the accuracy but also the high confidence of the model in the predictions made. It is necessary to note the metrics for the age and ethnicity classes, where the best ratio between accuracy and reliability is observed. Lower MCC values at a moderately low log loss in the not_cyberbullying and other_cyberbullying categories indicate that the model makes confident but not always correct predictions in the conditions of intersection or blurring of classes. This indicates the complexity of interpretation tasks in the field of cyberbullying recognition and the importance of components such as KAN, which are able to highlight latent features. Thus, the Hyb-KAN architecture not only provides effective metrics, but also shows resistance to structural features of the data.
In the approach proposed by the authors, a number of key advantages can be highlighted: ensuring high classification accuracy due to a combination of transformers, BiLSTM and KAN; efficiency in detecting hidden and context-dependent features in text; resistance to noise and ambiguous expressions; generalization ability without significantly increasing the computational load.
The key role of KAN in the model architecture is its ability to highlight the most significant parts of the text, facilitating accurate interpretation and classification of cyberbullying. In this type of task, significant features are hidden in the surrounding noisy data. KAN allows Hyb-KAN to focus on key aspects of the message, such as offensive words, expressions, or context. This increases the potential of the model to process complex and ambiguous texts. The experiments confirmed the robustness and versatility of the model on cyberbullying datasets. Unlike simpler models, the architecture proposed by the authors can provide a balance between accuracy and computational efficiency. With further optimization of the architecture, for example, using more advanced regularization methods or additional training on specific data, the authors predict that high performance can be achieved without significantly increasing computational costs. The architecture proposed by the authors provides ample scope for adaptation and further improvement. One of the main contributions of this paper is the demonstration of a combination of transformers for context processing, BiLSTM for sequence analysis, and KAN for key information extraction. Computational experiments confirm that this combination allows the model to cope with aspects of cyberbullying text.
7. Conclusions
Hyb-KAN is an architecture for cyberbullying classification problems. This architecture combines transformer architectures, bidirectional recurrent networks, BiLSTM, attention mechanism, and KAN. Practical results show improvement in cyberbullying classification. The authors’ proposed model for cyberbullying classification demonstrates 95.25% accuracy. The main advantage is the ability to analyze contextual relationships and highlight significant aspects of texts.
In the course of the study, we use transformers to extract contextual representations, supplemented by BiLSTM to capture temporal dependencies and the KAN mechanism to highlight key elements of the text. This hybrid architecture allows for achieving high accuracy.
In computational experiments, the proposed architecture demonstrated high results in precision, recall, and F1-score metrics on a set of cyberbullying categories. This demonstrates the ability to classify subtle differences between different forms of online aggression, in particular, discrimination by age, gender, religion, or ethnicity. The hybrid structure of the model makes it easily adaptable to new language environments, data formats, and application scenarios.
The practical application of the proposed Hyb-KAN architecture has a wide range of significant practical applications: social networks—automatic detection and filtering of offensive messages; education and corporate culture—detection of cases of cyberbullying among students or employees; government and public organizations—analysis and development of strategies to combat cyberbullying.
The inclusion of the KAN mechanism allows the model to focus on critical aspects of the text, which increases both its accuracy and interpretability. This is especially important for tasks that require the explainability of algorithms, such as content moderation and analysis of social problems.
In the future, it is advisable to focus on the development of improved modifications of KAN aimed at increasing the accuracy of classification and improving the interpretability of the model. Possible directions include the integration of balanced sampling methods to effectively deal with unbalanced data, as well as a detailed analysis of decision-making mechanisms in KANs, which will increase the level of trust in this architecture among users and regulators.
Author Contributions
Conceptualization, S.G.; Methodology, A.C. and E.P.; Software, E.P.; Investigation, A.C.; Data curation, A.C.; Writing—original draft, E.P.; Writing—review & editing, S.G.; Visualization, E.P.; Supervision, S.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
The study did not require ethical approval.
Informed Consent Statement
Not applicable.
Data Availability Statement
The cyberbullying datasets can be downloaded from https://www.kaggle.com/datasets/shauryapanpalia/cyberbullying-classification (accessed on 14 February 2025). The code is available upon request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Pleshakova, E.S.; Gataullin, S.T. KAN-BiLSTM: Hybrid Neural Network Model with Multi-Domain Attention for Threat Analysis in Digital Space; Certificate of State Registration of Computer Program No. 2025619243; EDN ORSBNY; Rospatent Federal Service on Intellectual Property: Moscow, Russia, 2025. (In Russian) [Google Scholar]
- Korchagin, S.A.; Pleshakova, E.S.; Gataullin, S.T.; Osipov, A.V. Software Package for Countering Telephone Fraud; Certificate of State Registration of Computer Program No. 2022667657; EDN GHVLGF; Rospatent Federal Service on Intellectual Property: Moscow, Russia, 2022. (In Russian) [Google Scholar]
- Hu, J.; Liao, X.; Wang, W.; Qin, Z. Detecting Compressed Deepfake Videos in Social Networks Using Frame-Temporality Two-Stream Convolutional Network. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1089–1102. [Google Scholar] [CrossRef]
- Efanov, D.; Aleksandrov, P.; Mironov, I. Comparison of the effectiveness of cepstral coefficients for Russian speech synthesis detection. J. Comput. Virol. Hack. Tech. 2024, 20, 375–382. [Google Scholar] [CrossRef]
- Boltachev, E. Potential cyber threats of adversarial attacks on autonomous driving models. J. Comput. Virol. Hack. Tech. 2024, 20, 363–373. [Google Scholar] [CrossRef]
- Ivanyuk, V. Forecasting of digital financial crimes in Russia based on machine learning methods. J. Comput. Virol. Hack. Tech. 2024, 20, 349–362. [Google Scholar] [CrossRef]
- Pleshakova, E.; Osipov, A.; Gataullin, S.; Gataullin, T.; Vasilakos, A. Next gen cybersecurity paradigm towards artificial general intelligence: Russian market challenges and future global technological trends. J. Comput. Virol. Hack. Tech. 2024, 20, 429–440. [Google Scholar] [CrossRef]
- Andriyanov, N.; Khasanshin, I.; Utkin, D.; Gataullin, T.; Ignar, S.; Shumaev, V.; Soloviev, V. Intelligent System for Estimation of the Spatial Position of Apples Based on YOLOv3 and Real Sense Depth Camera D415. Symmetry 2022, 14, 148. [Google Scholar] [CrossRef]
- Golubov, V.V.; Manko, S.V. Automation of autonomous mobile robot docking based on the counter growth rapidly exploring random tree method. Russ. Technol. J. 2024, 12, 7–14. [Google Scholar] [CrossRef]
- Liu, J. Kolmogorov-Arnold networks for symbolic regression and time series prediction. J. Mach. Learn. Res. 2024, 25, 95–110. [Google Scholar]
- Liu, Z.; Wang, Y.; Vaidya, S.; Ruehle, F.; Halverson, J.; Soljačić, M.; Hou, T.Y.; Tegmark, M. Kan: Kolmogorov-Arnold networks. arXiv 2024, arXiv:2404.19756. [Google Scholar]
- Kundu, A.; Sarkar, A.; Sadhu, A. KANQAS: Kolmogorov-Arnold Network for Quantum Architecture Search. EPJ Quantum Technol. 2024, 11, 76. [Google Scholar] [CrossRef]
- Genet, R.; Inzirillo, H. Tkan: Temporal Kolmogorov-Arnold networks. arXiv 2024, arXiv:2405.07344. [Google Scholar] [CrossRef]
- Xu, K.; Chen, L.; Wang, S. Kolmogorov-Arnold Networks for Time Series: Bridging Predictive Power and Interpretability. arXiv 2024, arXiv:2406.02496. [Google Scholar]
- Dong, C.; Zheng, L.; Chen, W. Kolmogorov-Arnold Networks (KAN) for Time Series Classification and Robust Analysis. In Advanced Data Mining and Applications; Sheng, Q.Z., Dobbie, G., Jiang, J., Eds.; ADMA 2024. Lecture Notes in Computer, Science; Springer: Singapore, 2025; p. 15390. [Google Scholar]
- Qiu, B.; Zhang, J.; Yang, Y.; Qin, G.; Zhou, Z.; Ying, C. Research on Oil Well Production Prediction Based on GRU-KAN Model Optimized by PSO. Energies 2024, 17, 5502. [Google Scholar] [CrossRef]
- Gong, S.; Chen, W.; Jing, X.; Wang, C.; Pan, K.; Cai, H. Optimization of Hybrid Energy Systems Based on MPC-LSTM-KAN: A Case Study of a High-Altitude Wind Energy Work Umbrella Control System. Electronics 2024, 13, 4241. [Google Scholar] [CrossRef]
- Rigas, S.; Papachristou, M.; Papadopoulos, T.; Anagnostopoulos, F.; Alexandridis, G. Adaptive Training of Grid-Dependent Physics-Informed Kolmogorov-Arnold Networks. IEEE Access 2024, 12, 176982–176998. [Google Scholar] [CrossRef]
- Pan, Y.; Wang, X.; Xu, Z.; Cheng, N.; Xu, W.; Zhang, J.-J. GNN-Empowered Effective Partial Observation MARL Method for AoI Management in Multi-UAV Network. IEEE Internet Things J. 2024, 11, 34541–34553. [Google Scholar] [CrossRef]
- Zhang, F.; Zhang, X. GraphKAN: Enhancing Feature Extraction with Graph Kolmogorov Arnold Networks. arXiv 2024, arXiv:2406.13597. [Google Scholar]
- Bresson, R.; Nikolentzos, G.; Panagopoulos, G.; Chatzianastasis, M.; Pang, J.; Vazirgiannis, M. Kagnns: Kolmogorov-Arnold networks meet graph learning. arXiv 2024, arXiv:2406.18380. [Google Scholar]
- Dong, F.; Li, S.; Li, W. TCKAN: A novel integrated network model for predicting mortality risk in sepsis patients. Med. Biol. Eng. Comput. 2024, 63, 1013–1025. [Google Scholar] [CrossRef]
- Tang, J.; Wang, H.; Wu, D.; Kong, Y.; Huang, J.; Han, S. Radiation Pneumonitis Prediction Using Dual-Modal Data Fusion Based on Med3D Transfer Network. J. Digit. Imaging Inform. Med. 2024, 1–17. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, J.; Chen, S.; Sun, L.; Li, K.; Lai, G.; Peng, B.; Zhong, X.; Xie, B. Artificial intelligence in ovarian cancer drug resistance advanced 3PM approach: Subtype classification and prognostic modeling. EPMA J. 2024, 15, 525–544. [Google Scholar] [CrossRef] [PubMed]
- Al-Qaness, M.A.A.; Ni, S. TCNN-KAN: Optimized CNN by Kolmogorov-Arnold Network and Pruning Techniques for sEMG Gesture Recognition. IEEE J. Biomed. Health Inform. 2024, 29, 188–197. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Wang, H.; Du, Z.; Zhuo, L.; Fu, X.; Cao, D.; Xie, B.; Li, K. CardiOT: Towards Interpretable Drug Cardiotoxicity Prediction Using Optimal Transport and Kolmogorov-Arnold Networks. IEEE J. Biomed. Health Inform. 2024, 29, 1759–1770. [Google Scholar] [CrossRef]
- Carneros-Prado, D.; Cabañero-Gómez, L.; Johnson, E.; González, I.; Fontecha, J.; Hervás, R. A Comparison Between Multilayer Perceptrons and Kolmogorov-Arnold Networks for Multi-Task Classification in Sitting Posture Recognition. IEEE Access 2024, 12, 180198–180209. [Google Scholar] [CrossRef]
- Chen, Y.; Zhu, Z.; Zhu, S.; Qiu, L.; Zou, B.; Jia, F.; Zhu, Y.; Zhang, C.; Fang, Z.; Qin, F.; et al. SCKansformer: Fine-Grained Classification of Bone Marrow Cells via Kansformer Backbone and Hierarchical Attention Mechanisms. IEEE J. Biomed. Health Inform. 2024, 29, 558–571. [Google Scholar] [CrossRef]
- Guo, Y.; Zhang, L.; Pang, S.; Cui, X.; Zhao, X.; Feng, Y. Deep learning models for hepatitis E incidence prediction leveraging Baidu index. BMC Public Health 2024, 24, 3014. [Google Scholar] [CrossRef]
- Zhu, X.; Xing, M.; Ye, J.; Liu, X.; Ren, Z. Design and optimization of a novel solenoid with high magnetic uniformity. Sci. Rep. 2024, 14, 24650. [Google Scholar] [CrossRef]
- Elaziz, A.; Fares, I.A.; Aseeri, A.O. CKAN: Convolutional Kolmogorov–Arnold Networks Model for Intrusion Detection in IoT Environment. IEEE Access 2024, 12, 134837–134851. [Google Scholar] [CrossRef]
- Guo, J.; Xie, Z.; Liu, M.; Hu, J.; Dai, Z.; Guo, J. Data-Driven Enhancements for MPC-Based Path Tracking Controller in Autonomous Vehicles. Sensors 2024, 24, 7657. [Google Scholar] [CrossRef]
- Yeonjeong, H.; Kang, H.; Kim, H. Robust Credit Card Fraud Detection Based on Efficient Kolmogorov-Arnold Network Models. IEEE Access 2024, 12, 157006–157020. [Google Scholar]
- Ibrahum, A.D.M.; Shang, Z.; Hong, J.E. How Resilient Are Kolmogorov–Arnold Networks in Classification Tasks? A Robustness Investigation. Appl. Sci. 2024, 14, 10173. [Google Scholar] [CrossRef]
- Liu, T.; Xu, J.; Lei, T.; Wang, Y.; Du, X.; Zhang, W.; Lv, Z.; Gong, M. AEKAN: Exploring Superpixel-Based AutoEncoder Kolmogorov-Arnold Network for Unsupervised Multimodal Change Detection. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5601114. [Google Scholar] [CrossRef]
- Firsov, N.; Myasnikov, E.; Lobanov, V.; Khabibullin, R.; Kazanskiy, N.; Khonina, S.; Butt, M.A.; Nikonorov, A. HyperKAN: Kolmogorov–Arnold Networks Make Hyperspectral Image Classifiers Smarter. Sensors 2024, 24, 7683. [Google Scholar] [CrossRef]
- Jamali, A.; Roy, S.K.; Hong, D.; Lu, B.; Ghamisi, P. How to Learn More? Exploring Kolmogorov–Arnold Networks for Hyperspectral Image Classification. Remote Sens. 2024, 16, 4015. [Google Scholar] [CrossRef]
- Gu, X.; Chen, Y.; Tong, W. KARAN: Mitigating Feature Heterogeneity and Noise for Efficient and Accurate Multimodal Medical Image Segmentation. Electronics 2024, 13, 4594. [Google Scholar] [CrossRef]
- Li, M.; Ye, P.; Cui, S.; Zhu, P.; Liu, J. HKAN: A Hybrid Kolmogorov–Arnold Network for Robust Fabric Defect Segmentation. Sensors 2024, 24, 8181. [Google Scholar] [CrossRef]
- Zhang, Z.; Xu, C.; Liu, K.; Xu, S.; Huang, L. A resource optimization scheduling model and algorithm for heterogeneous computing clusters based on GNN and RL. J. Supercomput. 2024, 80, 24138–24172. [Google Scholar] [CrossRef]
- Wen, Y.; Chen, Z.; He, Y.; Liu, H.; Zhang, Z.; Liu, l.; Meng, R.; Zeng, Y. Predictive methods for the evolution of oil well cement strength based on porosity. Mater. Struct. 2024, 57, 215. [Google Scholar] [CrossRef]
- Xu, R.; Liu, X.; Wei, J.; Ai, X.; Li, Z.; He, H. Predicting the Deformation of a Concrete Dam Using an Integration of Long Short-Term Memory (LSTM) Networks and Kolmogorov–Arnold Networks (KANs) with a Dual-Stage Attention Mechanism. Water 2024, 16, 3043. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, R.; Liu, X.; Zhang, C.; Sun, G.; Zhou, Y.; Yang, Z.; Liu, X.; Chen, S.; Dong, X.; et al. Advanced State-of-Health Estimation for Lithium-Ion Batteries Using Multi-Feature Fusion and KAN-LSTM Hybrid Model. Batteries 2024, 10, 433. [Google Scholar] [CrossRef]
- Cabral, T.W.; Gomes, F.V.; de Lima, E.R.; Filho, J.C.; Meloni, L.G. Kolmogorov–Arnold Network in the Fault Diagnosis of Oil-Immersed Power Transformers. Sensors 2024, 24, 7585. [Google Scholar] [CrossRef] [PubMed]
- Tang, Z.; Hou, X.; Wang, X.; Zou, J. A Cross-Working Condition-Bearing Diagnosis Method Based on Image Fusion and a Residual Network Incorporating the Kolmogorov–Arnold Representation Theorem. Appl. Sci. 2024, 14, 2076–3417. [Google Scholar] [CrossRef]
- Khan, P.; Chaudhuri, S.; Singh, D.S.; Amaan, F. KGAN-Based Semisupervised Domain Adapted Human Activity Recognition. IEEE Sens. Lett. 2024, 8, 7006004. [Google Scholar] [CrossRef]
- Liu, C.Z.; Zhang, Y.; Qin, L.; Liu, Y. Kolmogorov–Arnold Finance-Informed Neural Network in Option Pricing. Appl. Sci. 2024, 14, 11618. [Google Scholar] [CrossRef]
- Hao, Z.; Zhang, D.; Honarvar Shakibaei Asli, B. Motion Prediction and Object Detection for Image-Based Visual Servoing Systems Using Deep Learning. Electronics 2024, 13, 3487. [Google Scholar] [CrossRef]
- Shen, H.; Zeng, C.; Wang, J.; Wang, Q. Reduced effectiveness of Kolmogorov-Arnold networks on functions with noise. arXiv 2024, arXiv:2407.14882. [Google Scholar]
- Zeng, C.; Wang, J.; Shen, H.; Wang, Q. KAN versus MLP on Irregular or Noisy Functions. arXiv 2024, arXiv:2408.07906. [Google Scholar]
- Alam, K.S.; Bhowmik, S.; Prosun, P.R.K. Cyberbullying detection: An ensemble based machine learning approach. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 710–715. [Google Scholar]
- Olson, D. Advanced Data Mining Techniques; Springer: Berlin/Heidelberg, Germany, 2008; Available online: https://ezpro.fa.ru:2696/10.1007/978-3-540-76917-0 (accessed on 22 May 2025).
- Aldhyani, T.H.; Alsubari, S.N.; Alshebami, A.S.; Alkahtani, H.; Ahmed, Z.A. Detecting and analyzing suicidal ideation on social media using deep learning and machine learning models. Int. J. Environ. Res. Public Health 2022, 19, 12635. [Google Scholar] [CrossRef]
- Cheon, M.; Mun, C. Towards efficient patent classification: Kolmogorov Arnold networks as an alternative to MLP. J. Theor. Appl. Inf. Technol. 2024, 102, 7688–7696. [Google Scholar]
- Aryan, N.P.; Trivedi, R.B.; Goyal, S.R. Cyberbullying Detection Using CNN Prediction Model. In Cyber Security and Intelligent Systems; ISDIA 2024. Lecture Notes in Networks and Systems; Bhateja, V., Lin, H., Simic, M., Attique Khan, M., Garg, H., Eds.; Springer: Singapore, 2024; Volume 1056. [Google Scholar]
- Hashmi, E.; Yayilgan, S.Y. Multi-class hate speech detection in the Norwegian language using FAST-RNN and multilingual fine-tuned transformers. Complex Intell. Syst. 2024, 10, 4535–4556. [Google Scholar] [CrossRef]
- Bhowmik, S.; Sultana, S.; Sajid, A.A.; Reno, S.; Manjrekar, A. Robust multi-domain descriptive text classification leveraging conventional and hybrid deep learning models. Int. J. Inf. Tecnol. 2024, 16, 3219–3231. [Google Scholar] [CrossRef]
- Aldhyani, T.H.H.; Al-Adhaileh, M.H.; Alsubari, S.N. Cyberbullying Identification System Based Deep Learning Algorithms. Electronics 2022, 11, 3273. [Google Scholar] [CrossRef]
- Wei, W.; Zhang, B.; Wang, Y. TS-MEFM: A New Multimodal Speech Emotion Recognition Network Based on Speech and Text Fusion. In Proceedings of the International Conference on Multimedia Modeling 2025, Nara, Japan, 8–10 January 2025; pp. 454–467. [Google Scholar]
- Fang, L.; Chai, B.; Xu, Y.; Wang, S.J. KANFeel: A Novel Kolmogorov-Arnold Network-Based Multimodal Emotion Recognition Framework. In Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 26 April–1 May 2025; pp. 1–8. [Google Scholar]
- Raj, M.; Singh, S.; Solanki, K.; Selvanambi, R. An Application to Detect Cyberbullying Using Machine Learning and Deep Learning Techniques. SN Comput. Sci. 2022, 3, 401. [Google Scholar] [CrossRef]
- Mohaouchane, H.; Mourhir, A.; Nikolov, N.S. Detecting offensive language on arabic social media using deep learning. In Proceedings of the 2019 Sixth International Conference on Social Networks Analysis, Management and Security (SNAMS), Granada, Spain, 22–25 October 2019; pp. 466–471. [Google Scholar]
- Iwendi, C.; Srivastava, G.; Khan, S.; Maddikunta, P.K.R. Cyberbullying detection solutions based on deep learning architectures. Multimed. Syst. 2023, 29, 1839–1852. [Google Scholar] [CrossRef]
- Jahin, M.A.; Shovon, M.S.H.; Islam, M.S.; Shin, J.; Mridha, M.F.; Okuyama, Y. QAmplifyNet: Pushing the boundaries of supply chain backorder prediction using interpretable hybrid quantum-classical neural network. Sci. Rep. 2023, 13, 18246. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).