

A Novel Dataset for Early Cardiovascular Risk Detection in School Children Using Machine Learning

 , and
, and 
Abstract
1. Introduction
- The introduction of a new dataset focused on pediatric populations, incorporating novel markers, which distinguishes it from other datasets related to cardiovascular risk.
- A comprehensive benchmark study evaluating different ML techniques applied to the PROCDEC dataset, aimed at identifying the best-performing algorithms in terms of cardiovascular risk classification and execution time.
- A thorough study of the most relevant indicators for risk classification through the application of different feature selection methods.
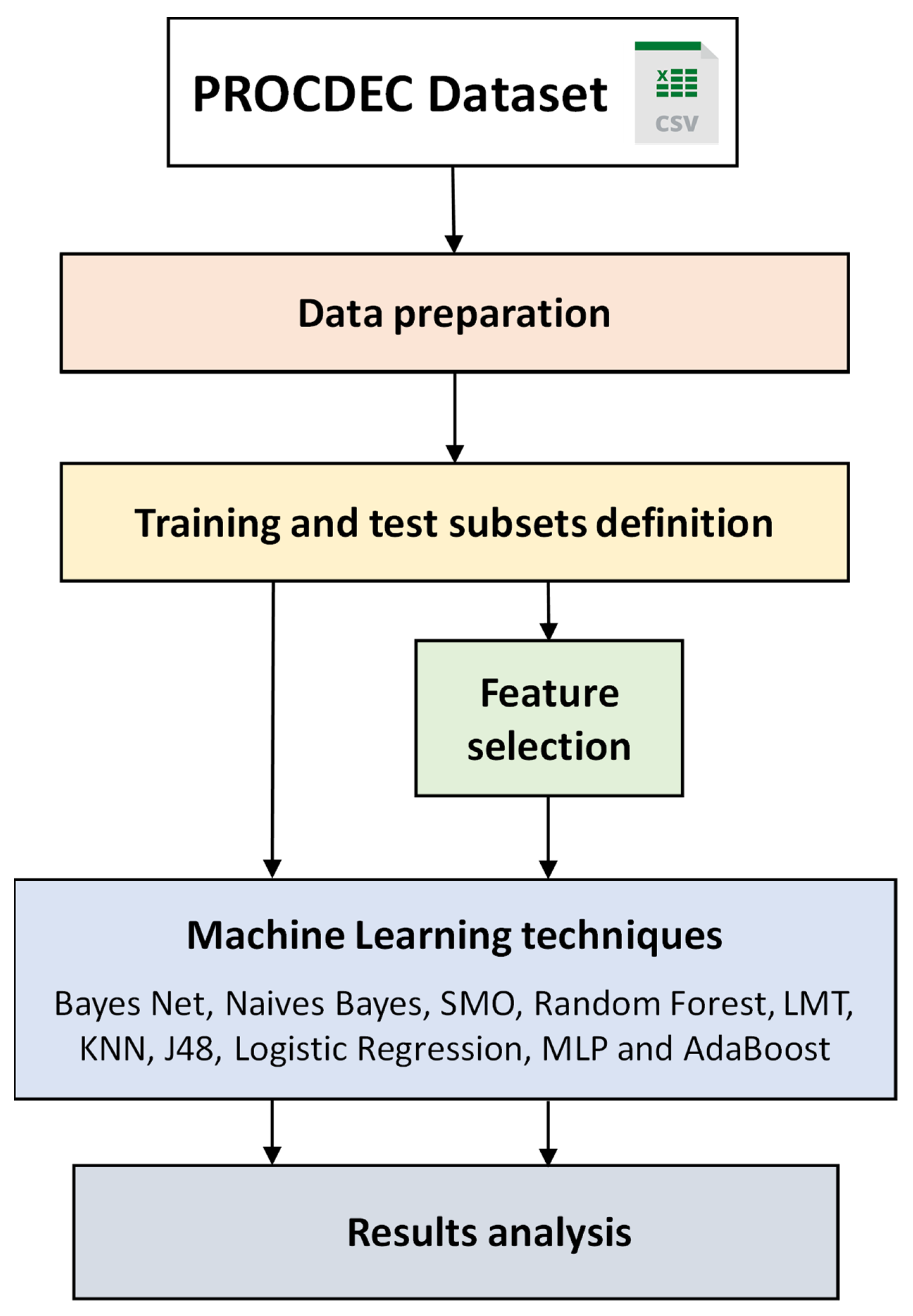
2. Materials and Methods
2.1. Description of the PROCDEC Dataset and Exploratory Data Analysis
2.2. Machine Learning Techniques for Classification
- Bayes Net
- Naive Bayes
- Sequential Minimal Optimization (SMO)
- Random Forest (RF)
- Logistic Model Tree (LMT)
- K-Nearest Neighbors (KNN)
- J48
- Logistic Regression
- Multilayer Perceptron (MLP)
- AdaBoost (AB)
2.3. Performance Indicators
- Accuracy: Defined as the ratio of correctly classified instances to the total number of instances. Its complement, 1-Accuracy, represents the error rate. Accuracy is commonly used to evaluate the effectiveness of classification algorithms and is also referred to as the classification rate (CR). However, in highly imbalanced domains, accuracy may be misleading. In such cases, it is necessary to rely on alternative metrics, such as recall and precision, to provide a more accurate assessment of the model’s performance.
- Recall or True Positive Rate (TPR): Represents the probability that an “at risk” instance is correctly identified by the classifier. It is also referred to as the detection rate (DR) or sensitivity.
- Precision: Represents the ratio of “at risk” instances to all instances classified as “at risk”. It is a measure of the estimated probability of a correct positive prediction and is also known as the Positive Predictive Value (PPV). While precision measures the frequency of true positives (“at risk”) among all instances classified as positive by the classifier, recall measures the frequency of true positives (“at risk”) among all actual positive instances in the dataset.
- Negative Predictive Value (NPV): Represents the ratio of “no risk” instances to all instances classified as “no risk”. This metric was selected with the aim of minimizing the number of false negatives. False negatives could lead to situations where individuals do not receive necessary treatment because their true condition is overlooked in the classification process. This, in turn, poses a risk to those incorrectly classified as “no risk”. The reasoning above suggests that a high NPV value serves as a strong indicator of confidence in cardiovascular risk prediction.
- F-Measure or F1-Score: Combines precision and recall in a single weighted indicator. When equal weight is assigned to both precision and recall, the F-measure is referred to as the F1-score. This metric reflects the reliability of the algorithm for each classification model. It is essential for the algorithm to accurately identify individuals at risk to achieve the highest possible F1-score.
3. Methodology for Cardiovascular Risk Classification
3.1. Data Preparation
3.2. Training and Test Subsets Definition
3.3. Feature Selection
- Attribute evaluator: CfsSubsetEval (locally-Predictive = True; missing-Separate = False; precompute Correlation-Matrix = False)
- Search method: best first (lookupCach-eSize = 1; direction = Forward; search-Termination = 5).
3.4. ML Techniques
- Naive Bayes: Num-Decimal-Places = 2; use-Kernel-Estimator = False.
- Bayes Net: Estimator = Simple-Estimator-A 0.5; Num-Decimal-Places = 2; search-algorithm = K2-P1-SBAYES.
- Logistic: num-Decimal-Places = 4; ridge = 1.0 × 10−8; do-Not-Standardize-Attributes = False.
- Multilayer Perceptron: hidden-Layers = 1; learning-Rate = 0.3; validation-Threshold = 20; training-Time = 300 epochs.
- SMO: complexity-parameter-C = 1.0; Kernel = Poly-Kernel; calibrator = Logistic.
- Ibk: Num-Decimal-Places = 2; KNN = 1; nearest-Neighbour-Search-Algorithm = LinearNNSearch.
- AB: classifier = Decision-Stump; num-Iterations = 10; weight-Threshold = 100.
- J48: confidence-Factor = 0.25; num-Folds = 3; min-Num-Obj = 2; use-MDL-correction = True.
- LMT: Fast-Regression = True; min-Num-Instances= 15; Num-Decimal-Places = 2; num-Boosting-Iterations = −1; split-On-Residuals = False.
- Random Forest: num-Iterations = 100; max-Depth = un-limited; bag-Size-Percent = 100; num-Features = int(log_2(#predictors) + 1).
4. Results and Discussion
4.1. Classification Results Using All the Attributes
4.2. Analysis of Attribute Relevance
5. Strengths and Limitations of the Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AB | AdaBoost |
| BMI | Body mass index |
| CFS | Correlation-Based Feature Subset Selection |
| F1 | F1-score |
| FN | False negatives |
| FP | False positives |
| FPH | Family Pathological History |
| FS | Feature selection |
| FFR | Filter Feature Ranking |
| FSS | Filter-Feature Subset Selection |
| KNN | K-Nearest Neighbors |
| HTA | Hypertension |
| LMT | Logistic Model Tree |
| ML | Machine learning |
| MLP | Multilayer Perceptron |
| NPV | Negative Predictive Value |
| PPV | Positive Predictive Value |
| RF | Random Forest |
| SMO | Sequential Minimal Optimization |
| SWT | Sustained Weight Test |
| TN | True negatives |
| TP | True positives |
| TPR | True Positive Rate |
| WEKA | Waikato Environment for Knowledge Analysis |
| WFS | Wrapper-Based Feature Selection |
References
- Naser, M.A.; Majeed, A.A.; Alsabah, M.; Al-Shaikhli, T.R.; Kaky, K.M. A Review of Machine Learning’s Role in Cardiovascular Disease Prediction: Recent Advances and Future Challenges. Algorithms 2024, 17, 78. [Google Scholar] [CrossRef]
- Singh, S.; Tiwari, S.; Singh, P. Machine learning algorithms in cardiovascular disease prediction: A systematic literature review. Pharma Innov. 2019, 8, 05–08. [Google Scholar] [CrossRef]
- Castel-Feced, S.; Malo, S.; Aguilar-Palacio, I.; Feja-Solana, C.; Casasnovas, J.A.; Maldonado, L.; Rabanaque-Hernández, M.J. Influence of cardiovascular risk factors and treatment exposure on cardiovascular event incidence: Assessment using machine learning algorithms. PLoS ONE 2023, 18, e0293759. [Google Scholar] [CrossRef]
- Chang, V.; Bhavani, V.R.; Xu, A.Q.; Hossain, M. An artificial intelligence model for heart disease detection using machine learning algorithms. Health Anal. 2022, 2, 100016. [Google Scholar] [CrossRef]
- Pal, M.; Parija, S.; Panda, G.; Dhama, K.; Mohapatra, R.K. Risk prediction of cardiovascular disease using machine learning classifiers. Open Med. 2022, 17, 1100–1113. [Google Scholar] [CrossRef]
- Biswas, N.; Uddin, K.M.M.; Rikta, S.T.; Dey, S.K. A comparative analysis of machine learning classifiers for stroke prediction: A predictive analytics approach. Health Anal. 2022, 2, 100116. [Google Scholar] [CrossRef]
- Dalal, S.; Goel, P.; Onyema, E.M.; Alharbi, A.; Mahmoud, A.; Algarni, M.A.; Awal, H. Application of Machine Learning for Cardiovascular Disease Risk Prediction. Comput. Intell. Neurosci. 2023, 2023, 9418666. [Google Scholar] [CrossRef]
- Shahid, S.; Khurram, H.; Billah, B.; Akbar, A.; Shehzad, M.A.; Shabbir, M.F. Machine learning methods for predicting major types of rheumatic heart diseases in children of Southern Punjab, Pakistan. Front. Cardiovasc. Med. 2022, 9, 996225. [Google Scholar] [CrossRef]
- Besharati, R.; Tahmasbi, H. Hypertension Prediction in Primary School Students Using an Ensemble Machine Learning Method. J. Health Biomed. Inform. 2022, 9, 148–157. [Google Scholar] [CrossRef]
- Wu, X.; Yuan, X.; Wang, W.; Liu, K.; Qin, Y.; Sun, X.; Ma, W.; Zou, Y.; Zhang, H.; Zhou, X.; et al. Value of a Machine Learning Approach for Predicting Clinical Outcomes in Young Patients With Hypertension. Hypertension 2020, 75, 1271–1278. [Google Scholar] [CrossRef] [PubMed]
- Cardiovascular Disease Dataset. Available online: https://www.kaggle.com/datasets/sulianova/cardiovascular-disease-dataset (accessed on 6 February 2025).
- Halder, R.K.H. Cardiovascular Disease Dataset. IEEE, 10 November 2020. Available online: https://ieee-dataport.org/documents/cardiovascular-disease-dataset (accessed on 6 February 2025).
- Janosi, W.S.A. Heart Disease; UCI Machine Learning Repository: Oakland, CA, USA, 1989. [Google Scholar] [CrossRef]
- Uddin, K.M.M.; Ripa, R.; Yeasmin, N.; Biswas, N.; Dey, S.K. Machine learning-based approach to the diagnosis of cardiovascular vascular disease using a combined dataset. Intell. Med. 2023, 7, 100100. [Google Scholar] [CrossRef]
- Hammer, L.D.; Kraemer, H.C.; Wilson, D.M.; Ritter, P.L.; Dornbusch, S.M. Standardized Percentile Curves of Body-Mass Index for Children and Adolescents. Arch. Pediatr. Adolesc. Med. 1991, 145, 259–263. [Google Scholar] [CrossRef] [PubMed]
- Xi, B.; Zong, X.; Kelishadi, R.; Litwin, M.; Hong, Y.M.; Poh, B.K.; Steffen, L.M.; Galcheva, S.V.; Herter-Aeberli, I.; Nawarycz, T.; et al. International Waist Circumference Percentile Cutoffs for Central Obesity in Children and Adolescents Aged 6 to 18 Years. J. Clin. Endocrinol. Metab. 2020, 105, e1569–e1583. [Google Scholar] [CrossRef] [PubMed]
- Riordan, A.O.; Howard, S.; Gallagher, S. Blunted cardiovascular reactivity to psychological stress and prospective health: A systematic review. Health Psychol. Rev. 2022, 17, 121–147. [Google Scholar] [CrossRef]
- Lovallo, W.R. Cardiovascular reactivity: Mechanisms and pathways to cardiovascular disease. Int. J. Psychophysiol. 2005, 58, 119–132. [Google Scholar] [CrossRef]
- Whittaker, A.C.; Ginty, A.; Hughes, B.M.; Steptoe, A.; Lovallo, W.R. Cardiovascular stress reactivity and health: Recent questions and future directions. Psychosom. Med. 2021, 83, 756–766. [Google Scholar] [CrossRef]
- Mitchell, T.M. Machine Learning; McGraw-Hill: New York, NY, USA, 1997; ISBN 9780070428072. [Google Scholar]
- Kubat, M. An Introduction to Machine Learning; Springer International Publishing: Cham, Switzerland, 2021. [Google Scholar] [CrossRef]
- Heckerman, D. A Tutorial on Learning with Bayesian Networks, en Learning in Graphical Models. Jordan, M.I., Ed.; Springer Netherlands: Dordrecht, The Netherlands, 1998; pp. 301–354. [Google Scholar] [CrossRef]
- John, G.H.; Langley, P. Estimating continuous distributions in Bayesian classifiers. In Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence, Montreal, QU, Canada, 18–20 August 1995; pp. 18–20. [Google Scholar]
- Platt, J.C. Fast training of support vector machines using sequential minimal optimization. Adv. Kernel Methods 1998, 185–208. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Landwehr, N.; Hall, M.; Frank, E. Logistic Model Trees. Mach. Learn. 2005, 59, 161–205. [Google Scholar] [CrossRef]
- Aha, D.W.; Kibler, D.; Albert, M.K. Instance-based learning algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4. 5: Programs for Machine Learning; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Le Cessie, S.; Van Houwelingen, J.C. Ridge estimators in logistic regression. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1992, 41, 191. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks and Learning Machines, 3/E; Pearson Education India: Noida, India, 2009. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a New Boosting Algorithm, en icml, Citeseer. 1996, pp. 148–156. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=d186abec952c4348870a73640bf849af9727f5a4 (accessed on 23 December 2024).
- Frank, E.; Hall, M.A.; Witten, I.H. The WEKA Workbench. Online Appendix for “Data Mining: Practical Machine Learning Tools and Techniques”. 2016. Available online: https://researchcommons.waikato.ac.nz/entities/publication/d1c32263-dd7f-48fc-899d-2893b45205c7 (accessed on 29 July 2018).
- Foulds, J.; Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; Elsevier: Amsterdam, The Netherlands, 2025. [Google Scholar]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the 2014 Science and Information Conference, London, UK, 27–29 August 2014; pp. 372–378. [Google Scholar]
- Guyon, I.; Gunn, S.; Nikravesh, M.; Zadeh, L.A. Feature Extraction: Foundations and Applications; Springer: Berlin/Heidelberg, Germany, 2008; Volume 207. [Google Scholar]
- Wah, Y.B.; Ibrahim, N.; Hamid, H.A.; Abdul-Rahman, S.; Fong, S. Feature selection methods: Case of filter and wrapper approaches for maximising classification accuracy. Pertanika J. Sci. Technol. 2018, 26, 329–340. [Google Scholar]
- Hall, M.A. Correlation-Based Feature Selection for Machine Learning. Ph.D. Thesis, The University of Waikato, Hamilton, New Zealand, 1999. Available online: https://researchcommons.waikato.ac.nz/handle/10289/15043 (accessed on 23 December 2024).
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef]
- Balogun, A.O.; Basri, S.; Mahamad, S.; Abdulkadir, S.J.; Almomani, M.A.; Adeyemo, V.E.; Al-Tashi, Q.; Mojeed, H.A.; Imam, A.A.; Bajeh, A.O. Impact of Feature Selection Methods on the Predictive Performance of Software Defect Prediction Models: An Extensive Empirical Study. Symmetry 2020, 12, 1147. [Google Scholar] [CrossRef]

{kind=link}
| N | Attribute |
|---|---|
| 1 | Age |
| 2 | Sex |
| 3 | Real BMI |
| 4 | Hyperreactivity |
| 5 | Glycemia |
| 6 | Uric Acid |
| 7 | Cholesterol |
| 8 | Triglycerides |
| 9 | Physical Activity |
| 10 | Hypertension (Individual) |
| 11 | Hypertension (Father) |
| 12 | Hypertension (Mother) |
| 13 | Hypertension (Sibling) |
| 14 | Hypertension (Maternal Grandparent) |
| 15 | Hypertension (Paternal Grandparent) |
| 16 | Obesity (Father) |
| 17 | Obesity (Mother) |
| 18 | Obesity (Sibling) |
| 19 | Obesity (Maternal Grandparent) |
| 20 | Obesity (Paternal Grandparent) |
| 21 | Diabetes (Father) |
| 22 | Diabetes (Mother) |
| 23 | Diabetes (Sibling) |
| 24 | Diabetes (Maternal Grandparent) |
| 25 | Diabetes (Paternal Grandparent) |
| 26 | Dyslipidemia (Father) |
| 27 | Dyslipidemia (Mother) |
| 28 | Dyslipidemia (Sibling) |
| 29 | Dyslipidemia (Maternal Grandparent) |
| 30 | Dyslipidemia (Paternal Grandparent) |
| Attributes | Father Yes/No (Missing) | Mother Yes/No (Missing) | Siblings Yes/No (Missing) | Paternal Grandparents Yes/No (Missing) | Maternal Grandparents Yes/No (Missing) |
|---|---|---|---|---|---|
| Hypertension | 210/816 (114) | 139/889 (112) | 28/1000 (112) | 401/626 (113) | 517/510 (113) |
| Obesity | 105/922 (113) | 111/917 (112) | 16/1012 (112) | 115/913 (112) | 161/867 (112) |
| Diabetes | 29/997 (114) | 19/1009 (112) | 5/1023 (112) | 208/820 (112) | 232/796 (112) |
| Dyslipidemia | 52/976 (112) | 27/1001 (112) | 4/1023 (113) | 156/872 (112) | 110/918 (112) |
| Bayes Net | Naive Bayes | Logistic | MLP | SMO | KNN | J48 | LMT | RF | Ada Boost | |
|---|---|---|---|---|---|---|---|---|---|---|
| Precision | 0.875 | 0847 | 0.853 | 0.839 | 0.868 | 0.859 | 0.842 | 0.875 | 0.934 | 0.914 |
| Recall | 0.787 | 0.754 | 0.822 | 0.861 | 0.814 | 0.772 | 0.834 | 0.808 | 0.666 | 0.719 |
| Accuracy | 0.903 | 0886 | 0.905 | 0.910 | 0.908 | 0.896 | 0.904 | 0.908 | 0.887 | 0.896 |
| NPV | 0.913 | 0.901 | 0.926 | 0.940 | 0.923 | 0.907 | 0.930 | 0.921 | 0.872 | 0.891 |
| F1-score | 0.829 | 0.798 | 0.837 | 0.850 | 0.840 | 0.813 | 0.838 | 0.840 | 0.777 | 0.805 |
| Bayes Net | Naive Bayes | Logistic | MLP | SMO | KNN | J48 | LMT | RF | Ada Boost | |
|---|---|---|---|---|---|---|---|---|---|---|
| Model building | 0.88 | 0.15 | 1.84 | 7.43 | 1.99 | 1758.43 | 0.69 | 16.18 | 3.93 | 1.33 |
| Class\Prediction | At Risk | No Risk |
|---|---|---|
| At risk | 282 | 56 |
| No risk | 53 | 749 |
| Class\Prediction | At Risk | No Risk |
|---|---|---|
| At risk | 225 | 113 |
| No risk | 16 | 789 |
| Relevance | Gain Ratio | Attribute |
|---|---|---|
| 1 | 0.1985117 | HTA (individual) |
| 2 | 0.1271846 | Hyperreactivity |
| 3 | 0.0901285 | Real BMI |
| 4 | 0.0499216 | Dyslipidemia (sibling) |
| 5 | 0.0404037 | Cholesterol |
| 6 | 0.0403338 | Obesity (mother) |
| 7 | 0.0320212 | Obesity (father) |
| 8 | 0.0301546 | Triglycerides |
| 9 | 0.0266643 | Age |
| 10 | 0.0242773 | Glucose |
| 11 | 0.0213532 | Obesity (sibling) |
| 12 | 0.0194491 | HTA (sibling) |
| 13 | 0.0169969 | Uric Acid |
| 14 | 0.0168717 | HTA (mother) |
| 15 | 0.0124389 | Obesity (paternal aunt/uncle) |
| 16 | 0.0113923 | Obesity (maternal aunt/uncle) |
| 17 | 0.0104232 | Dyslipidemia (father) |
| 18 | 0.0093344 | Diabetes (mother) |
| 19 | 0.0087188 | HTA (father) |
| 20 | 0.0068116 | Dyslipidemia (mother) |
| 21 | 0.0048233 | HTA (paternal aunt/uncle) |
| 22 | 0.0044644 | Diabetes (sibling) |
| 23 | 0.0026934 | HTA (maternal aunt/uncle) |
| 24 | 0.0017668 | Diabetes (father) |
| 25 | 0.0006764 | Diabetes (maternal aunt/uncle) |
| 26 | 0.0004441 | Diabetes (paternal aunt/uncle) |
| 27 | 0.0002678 | Dyslipidemia (maternal aunt/uncle) |
| 28 | 0.0001317 | Sex |
| 29 | 0.0000999 | Dyslipidemia (paternal aunt/uncle) |
| 30 | 0.0000600 | Physical Activity |
| Relevance | Info Gain | Attribute |
|---|---|---|
| 1 | 0.2415 | HTA (individual) |
| 2 | 0.1657 | Hyperreactivity |
| 3 | 0.1544 | Real BMI |
| 4 | 0.0555 | Cholesterol |
| 5 | 0.0525 | Triglycerides |
| 6 | 0.0234 | Age |
| 7 | 0.0216 | Glucose |
| 8 | 0.0199 | Obesity (mother) |
| 9 | 0.0152 | Obesity (father) |
| 10 | 0.0133 | Uric Acid |
| Bayes Net | Naive Bayes | Logistic | MLP | SMO | KNN | J48 | LMT | RF | Ada Boost | |
|---|---|---|---|---|---|---|---|---|---|---|
| Precision | 0.870 | 0.884 | 0.860 | 0.852 | 0.864 | 0.813 | 0.816 | 0.846 | 0.854 | 0.849 |
| Recall | 0.790 | 0.763 | 0.817 | 0.852 | 0.787 | 0.799 | 0.840 | 0.828 | 0.793 | 0.796 |
| Accuracy | 0.902 | 0.900 | 0.906 | 0.912 | 0.900 | 0.885 | 0.896 | 0.904 | 0.898 | 0.897 |
| NPV | 0.914 | 0.905 | 0.924 | 0.937 | 0.913 | 0.915 | 0.931 | 0.928 | 0.915 | 0.916 |
| F1-score | 0.828 | 0.819 | 0.838 | 0.852 | 0.824 | 0.806 | 0.828 | 0.837 | 0.822 | 0.821 |
| Bayes Net | Naive Bayes | Logistic | MLP | SMO | KNN | J48 | LMT | RF | Ada Boost | |
|---|---|---|---|---|---|---|---|---|---|---|
| Model building | 0.01 | 0.01 | 0.04 | 0.24 | 0.07 | 530.34 | 0.02 | 0.62 | 0.18 | 0.03 |
| Logistic | MLP | LMT | |
|---|---|---|---|
| Precision | 0.862 | 0.852 | 0.852 |
| Recall | 0.814 | 0.852 | 0.820 |
| Accuracy | 0.906 | 0.912 | 0.904 |
| NPV | 0.923 | 0.937 | 0.925 |
| F1-score | 0.837 | 0.852 | 0.836 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Olivera Solís, R.A.; González Rodríguez, E.F.; Castañeda Sheissa, R.; Lorenzo-Ginori, J.V.; García, J. A Novel Dataset for Early Cardiovascular Risk Detection in School Children Using Machine Learning. Technologies 2025, 13, 222. https://doi.org/10.3390/technologies13060222
Olivera Solís RA, González Rodríguez EF, Castañeda Sheissa R, Lorenzo-Ginori JV, García J. A Novel Dataset for Early Cardiovascular Risk Detection in School Children Using Machine Learning. Technologies. 2025; 13(6):222. https://doi.org/10.3390/technologies13060222
Chicago/Turabian StyleOlivera Solís, Rafael Alejandro, Emilio Francisco González Rodríguez, Roberto Castañeda Sheissa, Juan Valentín Lorenzo-Ginori, and José García. 2025. "A Novel Dataset for Early Cardiovascular Risk Detection in School Children Using Machine Learning" Technologies 13, no. 6: 222. https://doi.org/10.3390/technologies13060222
APA StyleOlivera Solís, R. A., González Rodríguez, E. F., Castañeda Sheissa, R., Lorenzo-Ginori, J. V., & García, J. (2025). A Novel Dataset for Early Cardiovascular Risk Detection in School Children Using Machine Learning. Technologies, 13(6), 222. https://doi.org/10.3390/technologies13060222