Abstract
Human gesture image recognition is the process of identifying, deciphering, and classifying human gestures in images or video frames using computer vision algorithms. These gestures can vary from the simplest hand motions, body positions, and facial emotions to complicated gestures. Two significant problems affecting the performance of human gesture picture recognition methods are ambiguity and invariance. Ambiguity occurs when gestures have the same shape but different orientations, while invariance guarantees that gestures are correctly classified even when scale, lighting, or orientation varies. To overcome this issue, hand-crafted features can be combined with deep learning to greatly improve the performance of hand gesture image recognition models. This combination improves the model’s overall accuracy and dependability in identifying a variety of hand movements by enhancing its capacity to record both shape and texture properties. Thus, in this study, we propose a hand gesture recognition method that combines Reset50 model feature extraction with the Tamura texture descriptor and uses the adaptability of GAM to represent intricate interactions between the features. Experiments were carried out on publicly available datasets containing images of American Sign Language (ASL) gestures. As Tamura-ResNet50-OptimizedGAM achieved the highest accuracy rate in the ASL datasets, it is believed to be the best option for human gesture image recognition. According to the experimental results, the accuracy rate was 96%, which is higher than the total accuracy of the state-of-the-art techniques currently in use.
1. Introduction
Technological advancements in computers and hardware components have increased our daily exposure to human–computer interactions (HCIs). Individuals are interested in HCIs incorporating hand gestures because they are a pleasant way to interact with the computer [1]. Since gestures are the building blocks of language and can transmit a wide range of information, they are crucial to interactions between people. Actions and statements without gestures are inadequate; they are devoid of true feelings and thoughts. There are four types of hand gestures: informal, manipulative, controlling, and communicative [2,3,4].
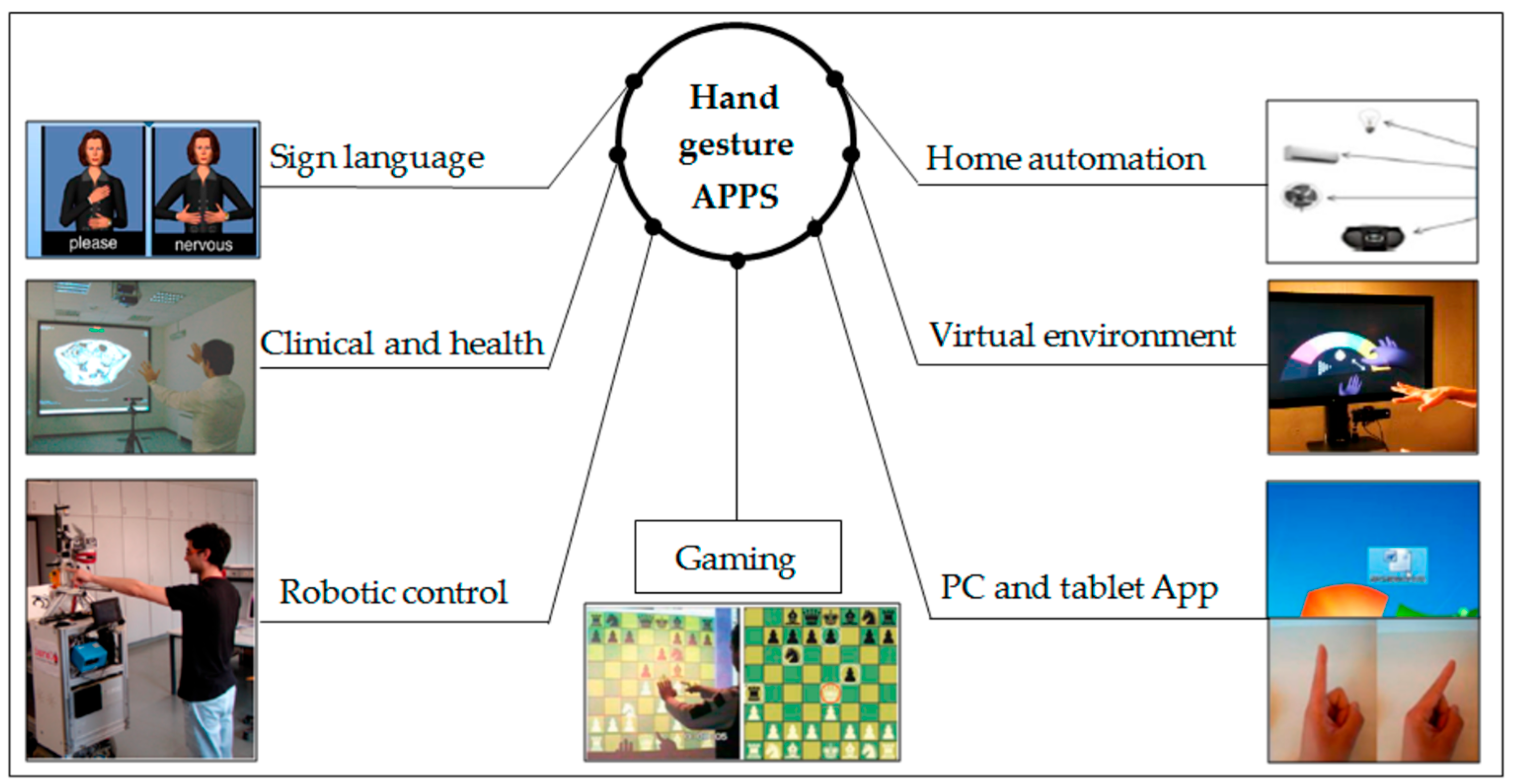
Hand gesture recognition is an essential part of HCIs and is an important topic in computer science. The main aim of hand gesture recognition is to interpret the meaning conveyed by the hand’s location and posture [5]. Hand gesture recognition has applications in many different fields and is used in gaming, IoT devices, virtual reality (VR), augmented reality (AR), robotics, sign language interpretation, assistive technologies, sports activity assistance, underwater rescue, firefighting assistance, etc., as shown in Figure 1 [6,7,8,9].
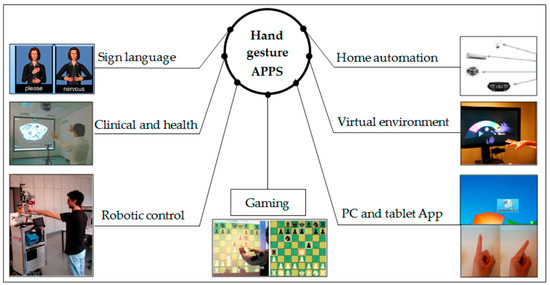
Figure 1.
Most common applications of hand gesture recognition systems [10].
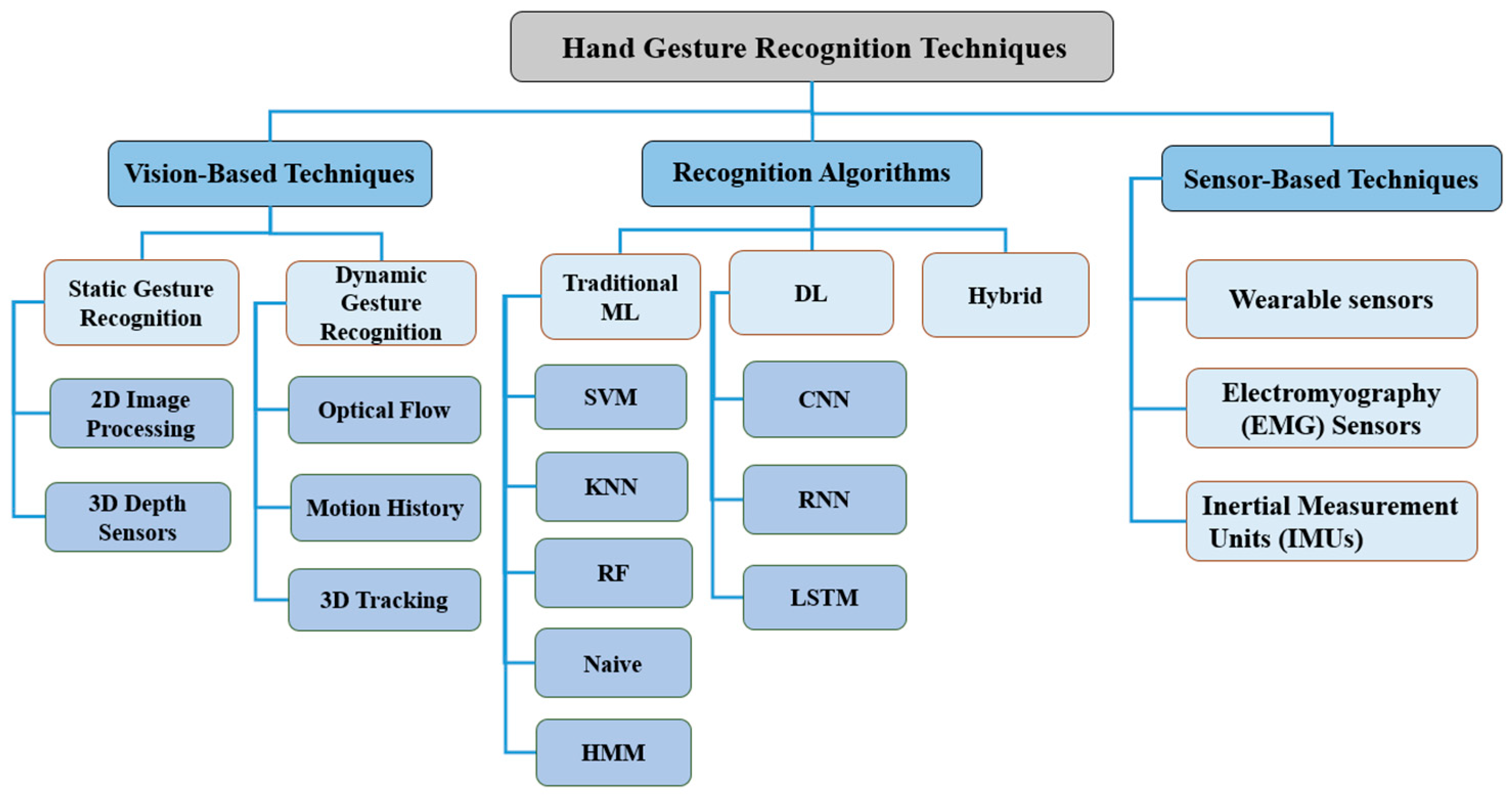
Static hand gestures are defined by a single, fixed hand form or position; dynamic gestures, on the other hand, incorporate movement across time, as shown in Figure 2. Our research focuses on static hand gesture detection, which is crucial in domains such as computer vision, human–computer interaction, and sign language interpretation. Methods of identifying these gestures frequently entail analyzing hand locations and shapes using image processing, machine learning, and deep learning.
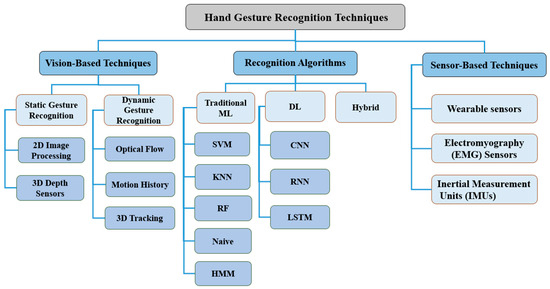
Figure 2.
Categorization of hand gesture recognition techniques.
In static hand gesture recognition, shape and orientation are two essential characteristics that enable systems to differentiate between hand gestures. When combined, they offer the information required to distinguish the shape of the gesture and the location of the hand and fingers in space.
Nonetheless, there are two issues with static hand gesture recognition that must be addressed: (i) ambiguity, which occurs when gestures present identical shapes but distinct orientations—or vice versa—and both features are not taken into account, and (ii) invariance, which requires recognition algorithms to guarantee that gestures can be accurately categorized regardless of alterations in orientation, lighting, or scale. Therefore, the creation of a reliable system for hand gesture recognition is urgently required.
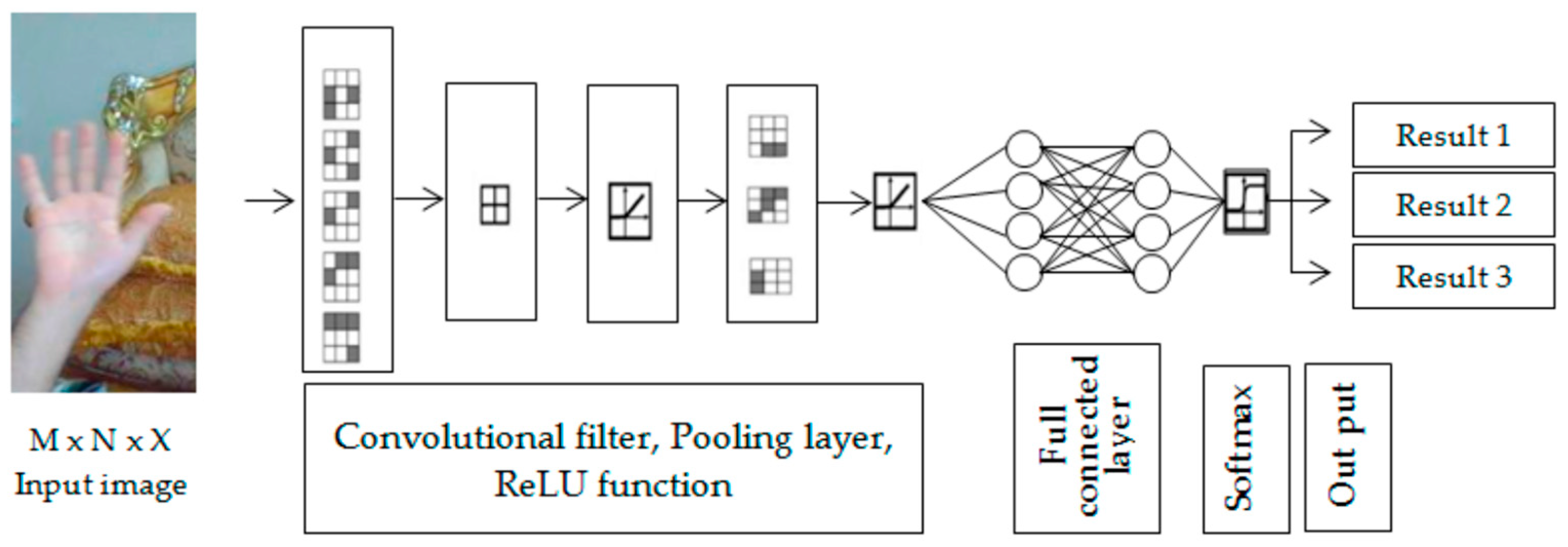
Convolutional neural networks (CNNs) are strong deep learning tools that can be used to extract and make use of shape features in images. Furthermore, deep learning models are capable of immediately acquiring strong orientation features and are less affected by changes in lighting, scale, and noise. Therefore, a CNN is able to resolve the two important issues mentioned above: ambiguity and invariance. Figure 3 shows an example of a deep learning convolutional neural network. Pre-trained CNN models are quite successful at visual recognition tasks because they are very good at extracting complicated, hierarchical information from images. A lot of data and processing power would be needed to train a CNN from scratch on a hand motion dataset; however, the use of a pre-trained CNN model can save considerable time and resources [11].
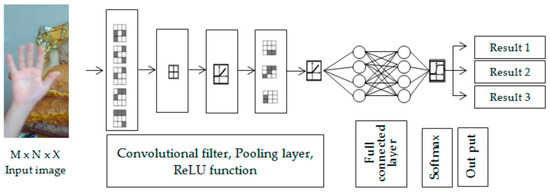
Figure 3.
Architecture of a basic DL CNN.
In order to extract more complete gesture data, we incorporate shape features with other kinds of features, such as texture and orientation. CNNs are frequently employed when shape and orientation features are involved.
When choosing the best texture descriptor method, it is important to take into account characteristics including resilience to changes in rotation, lighting, and scale and the capacity to depict the delicate texture patterns of the hand. Thus, Tamura is one of the most effective texture descriptor methods used in hand gesture recognition. Therefore, our proposed hand gesture recognition method combines the generalized feature extraction of a pre-trained CNN with the discriminative texture analysis of Tamura descriptors. This method achieves a balanced and robust approach to hand gesture recognition.
The contributions of the proposed method are as follows:
- It presents an effective technique for hand gesture recognition that combines the reliable ResNet50 model for feature extraction with Tamura features, which record global texture characteristics, to improve the recognition of gestures with the same shapes but different textures.
- The combination can improve recognition resilience and accuracy, especially in situations with varying gesture texture, image quality, or lighting.
- By enabling the model to distinguish motions based on both shape and small textural changes, the proposed method reduces misclassification errors, particularly when gestures have the same shapes but variable surface textures.
- A median filter is applied to the images to perform low-pass filtering, smoothing the images and reducing noise, thereby enhancing the reliability of the analysis.
- The Tamura–ResNet50–Optimized GAM framework improves overall accuracy and resilience in recognizing a variety of hand motions while reducing the time required for processing.
2. Related Works
Feature extraction has become increasingly important to achieving accurate classification, particularly when dealing with noisy or complicated backgrounds. Researchers have used feature extraction techniques, machine learning, and deep learning models in a variety of fields, including hand gesture recognition and numerous other sign language identification applications. Prior to the widespread adoption of deep learning technology, the hand-crafted method was the preferred method for image recognition, especially vision-based recognition.
Gupta et al. (2016) [12] presented a hand gesture recognition method based on a combination of the Histogram of Oriented Gradients (HOG) algorithm and the scale-invariant feature transform (SIFT) algorithm. Gestures are categorized using the standard k-nearest neighbor (KNN) classification technique. When massive datasets are involved, the KNN technique may not be the most appropriate choice due to its high computational and storage requirements. Sadeddine et al. (2018) [13] presented a hand posture recognition method based on a number of descriptors, including Hu’s Moment Descriptor (Hu’s MD), the Zernike Moments Descriptor (ZMD), the Generic Fourier Descriptor (GFD), and the Local Binary Pattern Descriptor (LBPD). The proposed method was tested on three separate databases: the NUS Hand Posture, Arabic Sign Language (ArSL), and American Sign Language (ASL) datasets. Gestures are categorized using a probabilistic neural network (PNN) classification technique. Zhang et al. (2018) [14] presented a hand gesture recognition method based on the Histogram of Oriented Gradients (HOG) and LBP. The proposed method was tested on the NUS dataset. Gestures were categorized using SVM with the radial basis function (RBF) classification technique. Sahoo et al. (2018) [15] presented a hand gesture recognition method based on a discrete wavelet transform (DWT) and Fisher’s ratio (F-ratio). The proposed method was tested on the American Sign Language (ASL) hand alphabet. A linear support vector machine (SVM) was used for classification. Geometric data present in an image, such as lines, curves, and contours, cannot be clearly extracted via conventional transformations like wavelet and Gabor transforms [16]. Gajalakshmi and Sharmila (2019) [17] presented a hand gesture recognition method based on chain code histogram (CCH) feature extraction. The region of interest was divided using Ridler and Calvard thresholding (RCT). An SVM was used for classification. The proposed method was tested on the NUS dataset. Li et al. (2022) [18] presented a hand gesture recognition method based on efficient feature extraction for a multi-scale and multi-angle algorithm. The Gaussian model and K-means method were used to obtain features from a complicated backdrop, which were further subjected to HOG and 9ULBP. A linear support vector machine (SVM) was used for classification, and the method was tested on the NUS and MU Hand Images ASL datasets. Sayed et al. (2024) [19] presented a hand gesture recognition method based on a Histogram of Gradients feature extraction method. Multiple classification algorithms were used, including SVM, KNN, and decision tree algorithms. The method was tested on the American MNIST sign language dataset.
Deep learning-based hand gesture recognition has attracted considerable interest because of its efficiency and prospective uses in a number of domains, including robotics, sign language interpretation, and human–computer interaction. The following studies serve as noteworthy examples of development in this field: Nyirarugira et al. (2013) [20] presented a hand gesture recognition method based on a CNN, which was tested on the CoST dataset. Multiple classification algorithms were used, including random forest (RF), boosting algorithms, and decision trees. Aurangzeb et al. (2024) [21] presented a hand gesture recognition method based on the CNN architecture of the VGG16 model. An optimized CNN was used for classification. The method was suitable for real-time application and tested on the Massey University Dataset (MUD) and the American Sign Language (ASL) Alphabet Dataset (ASLAD).
All things considered, pre-trained deep learning models are an effective tool for developing hand gesture detection technology because of their shorter training time, enhanced feature learning, and versatility. Owing to these significant benefits, multiple studies have been conducted on hand gesture recognition.
Ozcan and Basturk (2019) [22] presented a hand gesture recognition method combining a transfer learning-based CNN structure, such as the AlexNet pre-trained CNN model, with heuristic optimization. The proposed method was tested on the ASL Digits dataset and the ASL dataset. Sahoo et al. (2022) [23] presented a hand gesture recognition method in which the classifier was based on a combined architecture integrating the AlexNet and VGG16 models. In tests on the Massey University (MU) and HUST American Sign Language (HUST-ASL) datasets, the accuracy of the proposed model was found to be 90.26% and 56.18%, respectively. Mujahid et al. (2021) [24] presented a hand gesture recognition method based on the YOLO (You Only Look Once) v3 and DarkNet-53 convolutional neural networks. The proposed model was evaluated on a labeled dataset of hand gestures in both Pascal VOC and YOLO format. The classifier used for hand gesture recognition was based on the YOLO (You Only Look Once) v3 architecture, specifically utilizing the DarkNet-53 backbone.
Deep learning models are being combined with machine learning models to further improve image classification methods. Edmond et al. (2020) [25] presented a hand gesture recognition method based on Lightweight VGG16 combined with an Ensemble classification approach. The proposed method was tested on the American Sign Language (ASL), ASL Digits, and NUS Hand Posture datasets. A CNN was used as the classifier. Their experimental findings show that the proposed approach, which combines random forest with lighter VGG16, performs better than alternative approaches. Wang et al. (2021) [26] presented a hand gesture recognition method based on a MobileNet model. The framework of the suggested model combined machine learning for classification with a CNN for feature extraction. The classifier used for hand gesture recognition was based on random forest.
In hand gesture recognition, combining hand-crafted features with deep learning models has emerged as a promising strategy since it combines the advantages of both techniques for more reliable and accurate detection. Kika et al. (2018) [27] presented a hand gesture recognition method based on a convolutional neural network and Histogram of Oriented Gradients features. An SVM was used for classification. The proposed method was tested on the American Sign Language (ASL) hand alphabet. Rastgoo et al., 2018, [28] presented a hand gesture recognition method based on Gabor filters and Haar-like features. The method was tested on the ASL, Massey, NYU, and ASL image databases. A Boltzmann machine was used for classification. Damaneh et al. (2022) [29] presented a hand gesture recognition method based on a convolutional neural network with feature extraction using an ORB descriptor and a Gabor filter. The proposed method was tested on three separate databases: Massey, ASL Alphabet, and American Sign Language (ASL). A CNN was used for classification. A collection of research publications based on deep learning, hand-crafted, and combination feature extraction techniques is shown in Table 1.

Table 1.
Summary of various research publications.
The majority of researchers want to develop a strong hand gesture recognition system that can overcome the most common issues with a precise and dependable output and fewer limitations. As previously mentioned, these limitations include sensitivity to background noise and occlusions; sensitivity to variations in lighting; and sensitivity to extreme variations in scale, orientation, and partial occlusions. A poor recognition rate for differentiating similar gestures, a huge feature vector dimension, and declining performance in practical applications are further limitations. Our proposed method addresses and overcomes the majority of these issues by implementing a lightweight DL model and texture features that can be used to recognize and classify hand gestures accurately.
3. Proposed Method
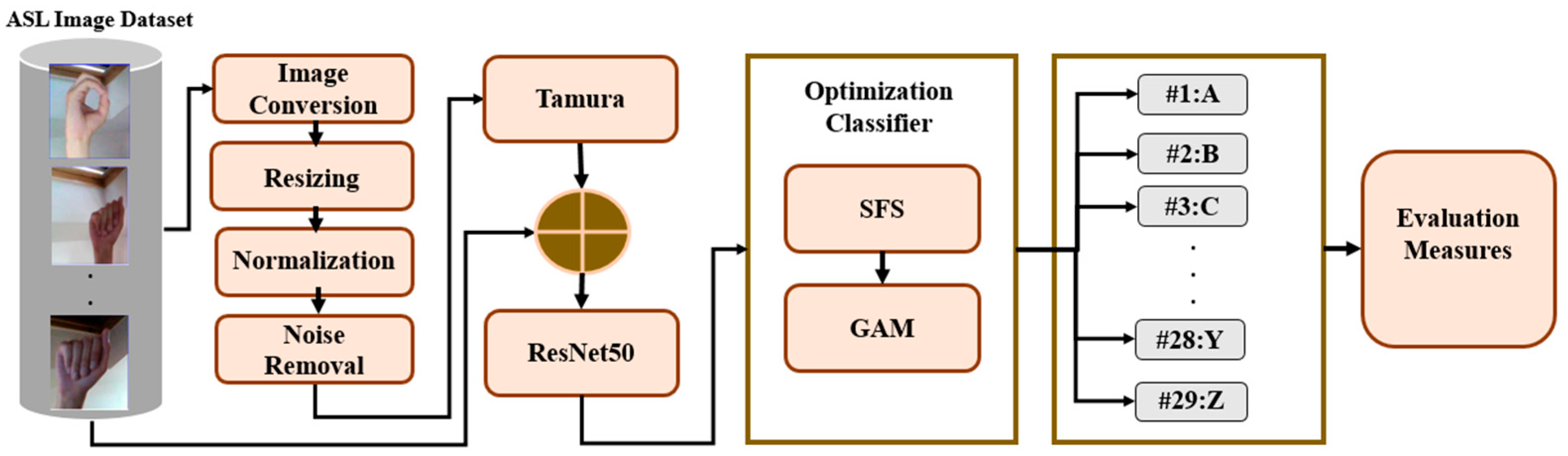
This section offers a concise, well-structured summary of our proposed hand gesture recognition method. It explains every technical element, assisting readers in comprehending the specific process and justifying each design decision. Image preparation and preprocessing, feature extraction, and optimizing classification using feature selection are the three primary stages of the proposed method. An illustration of the proposed method for hand gesture recognition is shown in Figure 4. The complete details of each stage are provided in the subsections that follow.
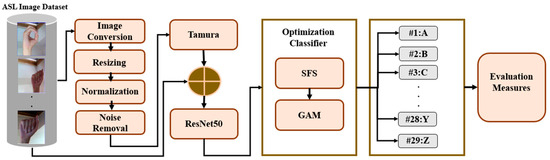
Figure 4.
Flowchart of proposed method.
3.1. Image Preparation and Preprocessing
Image preprocessing is a critical phase in preparing the model. Important steps included in this phase are image conversion, resizing and normalization, noise removal, and image smoothing. The purpose of image preprocessing is to increase computer recognition accuracy and identification time. Algorithm 1 for image preparation and preprocessing is shown below, followed by a discussion of the various preprocessing steps.
| Algorithm 1: Image preparation and preprocessing for hand gesture recognition. |
| Input: Unprocessed hand gesture images. |
| Output: Preprocessed images that are prepared for feature extraction and classification stage. |
| Begin |
| For |
| 1. Import every image through the dataset in RGB or greyscale format. |
| 2. Transform the Unprocessed images to grayscale for simplified processing and concentrate on important details. |
| 3. Resize all images to a consistent dimension (for example, 224 × 224 pixels) to make sure that every image is compatible for the ResNet50 model. |
| 4. Normalize pixel values to an interval (usually [0, 1] or [−1, 1]) to enhance training convergence. |
| 5. Gaussian or median filters can be used to eliminate noise in images, removing unnecessary noise while maintaining important information. |
| 6. Store the preprocessed images that they can be used later for the feature extraction and classification stage. |
| End for |
| End |
3.1.1. Image Conversion
RGB images must be converted to greyscale format. In situations in which color is not essential to the work at hand, transforming RGB images into greyscale images provides a more effective and simple representation, simplifying and speeding up several forms of image processing while decreasing complexity, storage requirements, and computational costs [30]. This is particularly helpful in specialized domains where structural information is more crucial than color, such as medical imaging, real-time systems, and machine learning. The process of converting an RGB image to greyscale is shown in Figure 5. The receptivity of human vision to various colors is reflected by the weights 0.2989, 0.5870, and 0.1140.

Figure 5.
Conversion process diagram.
3.1.2. Resizing and Normalization
Resizing and normalization must occur before images are fed into a machine learning model, especially for deep learning models like convolutional neural networks (CNNs), which guarantee a consistent input. The images in an ASL dataset may have different dimensions; therefore, resizing will guarantee that all images have the same size (e.g., 128 × 128 or 224 × 224 pixels). Normalization involves dividing by 255 to scale the resized image’s pixel values to the interval [0, 1]. This helps the model converge more quickly throughout training and prevents problems with very large or small numbers that could impair the model’s performance. As a result, the CNN operates more quickly in the 0–1 range than in other ranges. The process of converting an RGB image to greyscale is shown in Figure 6.

Figure 6.
Resizing and normalization: (a) original image; (b) resized image; (c) normalized image.
3.1.3. Noise Removal and Image Smoothing
To smooth the images and decrease noise, we used the median filter, which serves as a kind of low-pass filter. The median filter effectively eliminates noise while preserving the image’s borders and properties. Since greyscale images require only one channel, noise reduction may be a simpler procedure. The process of applying the median filter to an image is shown in Figure 7.

Figure 7.
Noise removal and image smoothing: (a) noisy image; (b) enhanced image.
3.2. Feature Extraction
The level of feature extraction has a major impact on how well gesture recognition techniques work. The goal of feature extraction is to collect important information regarding gestures, such as their posture, direction, position, and temporal development. To accomplish this, automated techniques are frequently created to recognize and encode particular aspects of images, such as color, texture, and shape. Efficient feature extraction is necessary for gesture recognition systems to comprehend and classify complex gestures.
As previously mentioned, both shape and orientation offer useful information for hand gesture detection, including the directionality and alignment of hand motions. Nevertheless, they have drawbacks that affect how well a gesture recognition method works. By integrating shape and orientation features with other types of features, including texture, these limitations can be reduced, and hand gesture recognition algorithms can achieve better performance. Texture features describe the surface characteristics and patterns found in specific areas of an image; they record details about how pixel intensities are arranged spatially.
Generalized feature extraction of a pre-trained CNN is frequently employed for shape and orientation features. Among pre-trained models, ResNet50 is the best option for reducing feature dimension. It is particularly effective for distinguishing subtle differences in hand postures, shapes, and orientations. Tamura is the best texture descriptor because it can capture the subtle texture patterns of the hand and is resilient to variations in rotation, lighting, and scale. Tamura is the best option for our needs since it is resilient and requires less computing power than other approaches. The feature extraction process is demonstrated in Algorithm 2. Each step of the algorithm is covered in detail in the subsequent sections.
| Algorithm 2: Feature extraction for hand gesture recognition. |
| Input: Preprocessed grayscale image I of size M × N. |
| Output: 1 × 1 × 2048 Feature vector dimension |
| Begin |
| For |
| 1. Apply Tamura texture descriptor: |
| 1.1 For every Preprocessed grayscale image, Calculate the Tamura features (coarseness, contrast, and directionality). |
| 1.2 Store the generated Tamura feature vector with 1 × 3 dimension. |
| 2: Combine Tamura Features with Image Data using the following: |
| 2.1 Create a 1D vector by flattening the Tamura features. |
| 2.2 To create a more comprehensive feature collection, immediately combine the Tamura features with the image data that has been flattened. |
| 2.3 Save the combined texture-based and pixel-based data that has been generated. |
| 3. Apply ResNet50 as a Feature Extractor: |
| 3.1 Load the pre-trained ResNet50 model |
| 3.1.1 Import the pre-trained ResNet50 model from a library. |
| 3.1.2 To concentrate on feature extraction, remove the last classification layer. |
| 3.2 Freeze the first several layers of ResNet50 to maintain the pre-trained features. |
| 3.3 Preprocessed the combined data by resizing it to 224 × 224 pixels and normalizing it (typically within 0 and 1). |
| 3.4 Feed the preprocessed data over the ResNet50 model to extract deep features. |
| 3.5 The feature can be extracted from the final pooling layer (average pooling 5). |
| 3.6 The features map is flattened to an array of one dimensions. |
| 4. Store the extracted feature vector in 1 × 1 × 2048 dimensions. |
| End for |
| End |
3.2.1. Tamura Feature Extraction
Examining the texture in different kinds of photographs provides significant benefits and demonstrates sound analysis. A multitude of details regarding the composition and surface properties of items in an image can be gathered from their texture. Regularity, scale, coarseness, contrast, and orientation are some texture characteristics that collectively determine how the surface of an object or scene appears [31]. In order to recognize items, evaluate their surface characteristics, and differentiate between various materials or settings, the human visual system (HVS) depends mostly on texture.
Tamura is one of the most widely used texture descriptors intended to replicate how textures are perceived visually by humans [32]. The following advantages make it appropriate for hand gesture recognition: Tamura can assist in differentiating gestures according to their shape, orientation, and other distinctive features and identifying minute particles in patterns on hands (such as skin texture or creases). It offers a thorough texture analysis that is useful for distinguishing between gestures that have similar shapes but different textures or contrasts. Additionally, incorporating Tamura provides resilience against changes in background, lighting, and hand placement.
Roughness, line-likeness, regularity, directionality, and coarseness are among the six different texture features listed by Tamura. The initial three, which include directionality, contrast, and coarseness, produce outstanding outcomes. Therefore, each Tamura descriptor (coarseness, contrast, and directionality) should be determined for every image. Performing this at different scales enables the capture of both local and global textural information. Readers are encouraged to review [32] for additional information about each Tamura texture feature.
3.2.2. Combine Tamura Features with Image Data
By including hand-crafted features in the input, a deep learning model that has been pre-trained on an enormous collection of data can be further trained on sign language gestures. This method incorporates domain-specific, handmade features for enhanced performance while employing the pre-trained model’s capability to learn a wide variety of features. Therefore, the objective of this step is to efficiently integrate Tamura features with a dataset and feed them through a pre-trained ResNet50 model for the recognition of hand gesture images. The early fusion approach is used to combine the hand-crafted Tamura features with actual image data. The combined data are then sent to the input layer of the ResNet50 model. It is evident that employing an early fusion technique might increase hand gesture recognition accuracy.
3.2.3. ResNet50 Model as a Feature Extractor
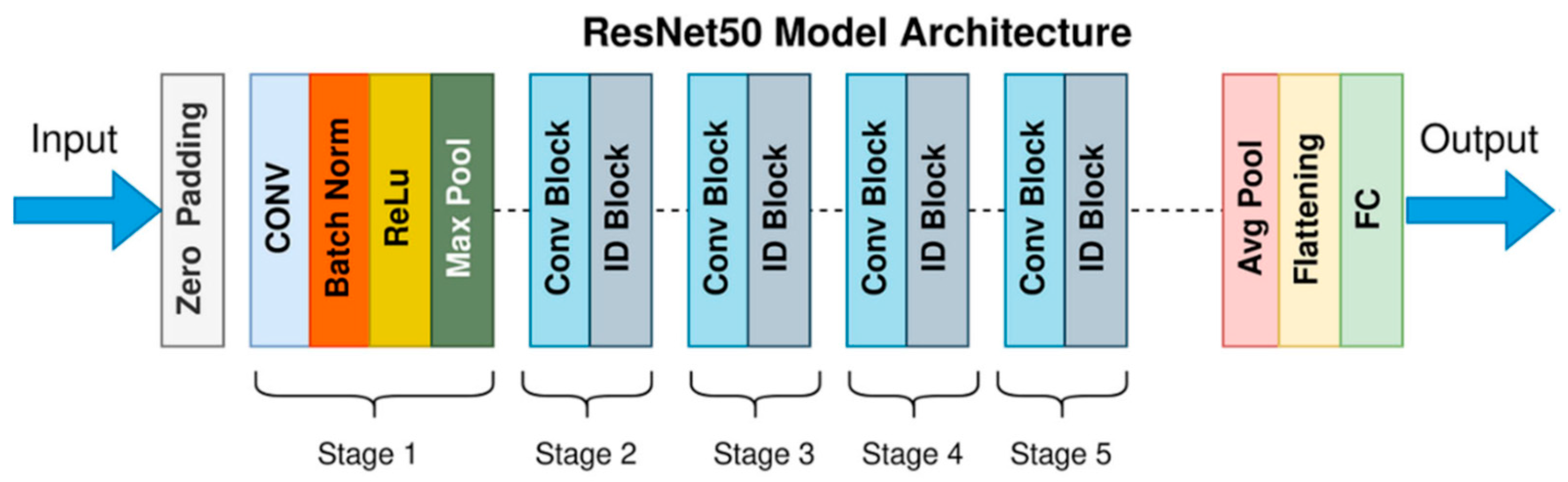
The ResNet50 model has 50 layers and is a member of the ResNet (Residual Network) family [33]. It is renowned for its creative application of residual connections, which aid in resolving the “vanishing gradient” issue that deep neural networks frequently face [34]. The ResNet50 model is easy to employ for transfer learning or fine-tuning in specific applications because it can be used in a variety of deep learning systems. Because it achieves an acceptable balance between computing efficiency and depth, it is one of the most frequently used models in deep learning for image recognition tasks. Figure 8 shows the design of the ResNet50 model.
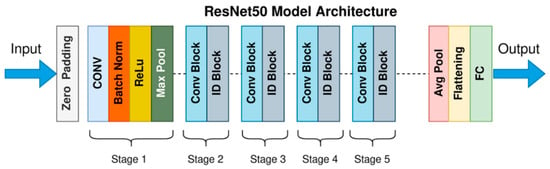
Figure 8.
The fundamental design of ResNet50.
ResNet50 has become a preferred option in hand gesture recognition due to its strong feature extraction skills and ability to handle complicated patterns and changes in gesture images. This makes it especially useful for identifying small variations in hand orientations, shapes, and postures.
Since the ResNet50 is used as a feature extractor, the classification layer is discarded, and the features are extracted from the final pooling layer (average pooling 5). Consequently, the average pooling layer’s output has a 1 × 1 × 2048 dimension. The optimizing classification using feature selection stage uses the 1 × 1 × 2048-dimensional feature vector as input.
The primary elements of the ResNet50 model tailored for feature extraction tasks are shown below and described in Table 2.
Table 2.
A brief description of the properties of the ResNet50 model as a feature extractor.
3.3. Optimizing Classification Using Feature Selection
By finding the most appropriate features and decreasing the total dimension of the collection of features, feature selection can optimize classification, enhancing a classifier’s performance. In addition to increasing the model’s efficiency, this procedure decreases overfitting, increases interpretability, and expedites calculations.
The Generalized Additive Model (GAM) is a powerful model that can be used to solve problems such as gesture recognition since it can detect nonlinear correlations between features and target categories. Each feature may have a different smooth function assigned by the GAM. Consequently, the aggregate of these smooth functions is the last component of the model. To ensure that the model operates effectively with unknown data, a Generalized Additive Model (GAM) classifier must be optimized through a number of steps, such as feature selection and cross-validation.
Iteratively adding or removing features while assessing performance at each stage is the main strategy of Sequential Feature Selection (SFS). Finding the most appropriate features that can be used for classification is the main focus of this approach. Because of its adaptable function, this sequential approach can be employed with a variety of classifiers, making it an effective tool for feature selection in a range of situations.
Cross-validation is a reliable method of choosing the most suitable model parameters, including the ideal number of features for a classifier, while decreasing the possibility of overfitting. To guarantee that the model works effectively with unknown inputs, the data should be split into multiple folds and trained and tested on various data subsets several times. Therefore, we used Sequential Feature Selection (SFS) to optimize the Generalized Additive Model (GAM) classifier in our study. GAM optimization based on Sequential Feature Selection (SFS) is demonstrated in Algorithm 3. Each step in the algorithm intends to optimize the GAM classifier using Sequential Feature Selection (SFS).
| Algorithm 3: GAM optimization based on Sequential Feature Selection (SFS). |
| Input: 1 × 1 × 2048 Feature vector dimension |
| Output: Selected feature subset (Fselected) and Performance measurements. |
| Begin |
| For |
| 1. Load the ResNet50 extracted 2048-dimensional features vector F = {f1, f2, …, f2048}. |
| 2. For all feature vectors, Apply Sequential Feature Selection (SFS) method. |
| 2.1 Begin with an empty set of features Fselected = ∅. |
| 2.2 Implement feature selection iteratively: |
| 2.2.1 Add or remove features from Fselected. |
| 2.2.2 Use cross-validation accuracy as a measure to assess performance. |
| 2.3 Repeat rounds until performance is improved by no more feature additions or deletions. |
| 2.4 Save the final selected features vector (Fselected). |
| 3. Train a Generalized Additive Model (GAM) classifier |
| 3.1 Train a Generalized Additive Model (GAM) classifier on the Fselected. |
| 3.2 Record the nonlinear connections between specific features and the classes of hand gestures that correspond to them. |
| 4. Evaluate the GAM Model |
| 4.1 Use the test dataset to test the trained GAM classifier. |
| 4.2 Calculate the F1-score, recall, accuracy, and precision as indicators of performance. |
| End for |
| End |
4. Results and Discussion
We evaluated the proposed approaches based on multiple indicators, and a discussion of the results is presented below. This section is divided into four subsections: descriptions of the datasets, performance evaluation metrics, assessment results, and a comparison with other methods. The following hardware and software were employed in this study’s experiments:
- HP laptop;
- Intel(R) Core(TM) i7-6500U CPU @ 2.50 GHz 2.60 GHz;
- 8 GB Memory;
- 2 GB GPU Memory;
- MATLAB version R2020a;
- Windows 10 Pro 64Bit Edition;
- Intel® HD Graphics 520 (NVIDIA GTX 950M).
4.1. Dataset Description
American Sign Language (ASL) datasets are collections of images of the American Sign Language alphabet that include twenty-six letters (a–z), 29 classes, and three additional gesture signals (Space, Delete, and Nothing) [35]. A dataset summary is provided in Table 3. There are 87,000 images in all ASL datasets, and 3000 uniformly distributed images with various lighting, backdrop, and hand shape conditions were taken for each class. Figure 9 displays the sample distribution across the various gesture classes included in the datasets. We were able to successfully categorize the ASL hand motion images in our experiment, specifically for the proposed static hand gesture recognition. Figure 10 shows the different images in the ASL datasets.
Table 3.
A brief description of the ASL datasets.

Figure 9.
The distribution of ASL dataset samples among different classes.

Figure 10.
Various samples collected from the ASL datasets [36].
4.2. Performance Evaluation Metric
Performance evaluation measures are crucial for determining the accuracy and resilience of static hand gesture detection systems. The performance evaluation metrics used in this study are described below.
Accuracy reflects the proportion of gestures that were accurately predicted for all gestures. The following formula was applied to determine the accuracy [37]:
According to Equation (2), error is the proportion of images among all images that are classified incorrectly.
According to Equation (3), precision shows the proportion of predicted gestures that are accurately classified.
According to Equation (4), the number of real gestures in a class that are accurately recognized is measured by recall (sensitivity).
A commonly used metric that takes precision and recall into consideration is the F1-score, as shown in Equation (5).
For every class, the confusion matrix provides a thorough analysis of the differences between the predicted and true labels [38]. A detailed evaluation of this method’s classification performance is provided in Figure 11, which highlights the True Positives, False Positives, False Negatives, and True Negatives. Motions that are accurately recognized as being a member of their real class are known as True Positives (TPs). Gestures that are accurately classified as not being a part of a specific class are known as True Negatives (TNs). False Positives (FPs) are gestures that are incorrectly categorized as being in a particular class when they are not. False Negatives (FNs) are gestures that are incorrectly categorized as not belonging to a particular class when, in fact, they do.

Figure 11.
A visual representation of the confusion matrix.
4.3. Evaluation Results
This study used k-fold cross-validation (k-fold CV) [39]. When k = 10, the dataset could be divided into ten parts. The model was trained and tested ten times, with the remaining nine folds serving as the training set and a different fold serving as the test set every single time. The process was repeated until every fold had been used as a test set exactly once. A final assessment score was calculated by averaging the performance parameters (such as recall, F1-score, accuracy, and precision) from each of the ten repetitions. The main advantages of using k-fold cross-validation are consistent assessment, reduced overfitting, and minimized bias.
4.4. Multi-Class Hand Gesture Classification Results
The evaluation findings of the proposed Tamura–ResNet50-OptimizedGAM method for the multi-class hand gesture classification of 29 gestures from the ASL dataset are shown in Table 4. The overall averages for each evaluation measure are also reported in the table. The results offer a number of significant findings.
Table 4.
Evaluation results of proposed method across ASL dataset.
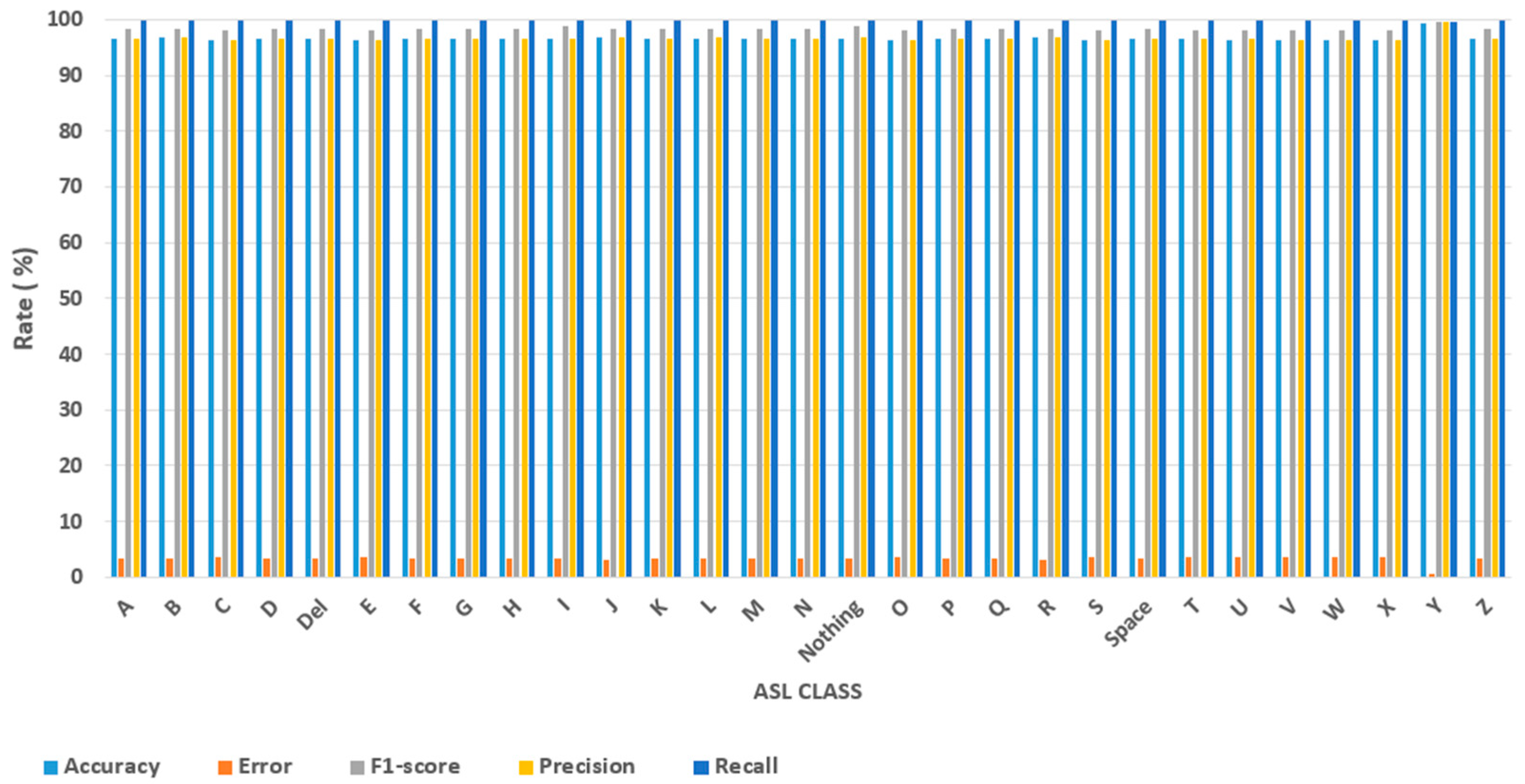
The model’s excellent overall performance is demonstrated by its average metrics for all gestures. The average values of accuracy, F1-score, precision, and recall are 96.69%, 98.35%, more than 96%, and 99.98%, respectively. The durability of the proposed method in managing the complexity and variability of an ASL dataset is demonstrated by its elevated averages over all measures, as illustrated in Figure 12. For real-world applications, such as interpreting sign language systems, the model’s ability to maintain near-perfect recall demonstrates its dependability in gesture recognition tasks. All classes have a continuously low average error rate of 3.31%, with no exceptions indicating noticeably poor results. This shows that there are no notable biases in the model’s generalization across the dataset. Each gesture has a low error rate, often between three and four percent. The approach achieves balance in reducing False Positives and False Negatives, as evidenced by the average precision (96.71%) and recall (99.98%) values. Nonetheless, slightly reduced accuracy and slightly increased incidence of error for some gestures (such as “O” and “L”) indicate some difficulties in differentiating these motions in specific cases. A balanced F1-score metric was obtained, with rates exceeding 98% across every motion. Moreover, the method was equally effective in every class. The effective reduction in False Positives and False Negatives is demonstrated by balanced performance across all measures.
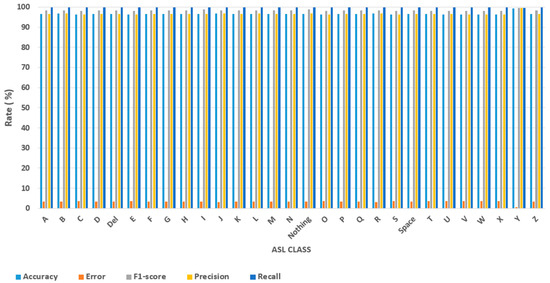
Figure 12.
Overall evaluation metric results across ASL dataset.
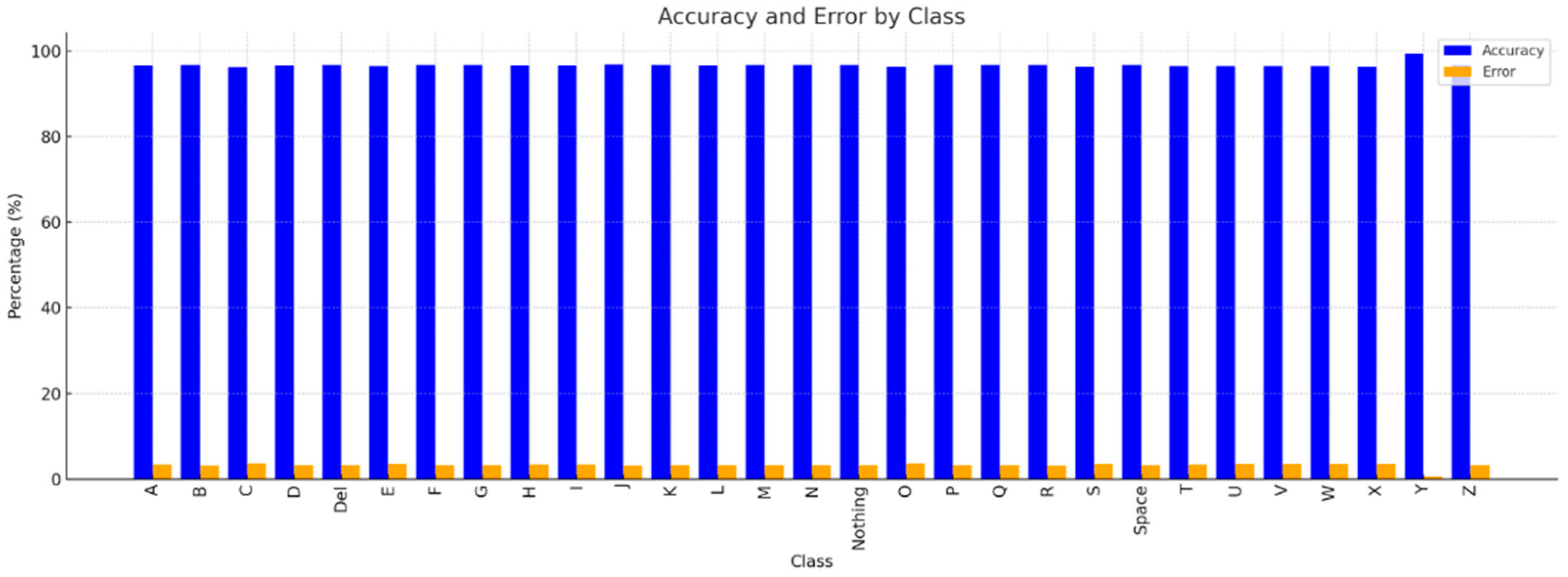
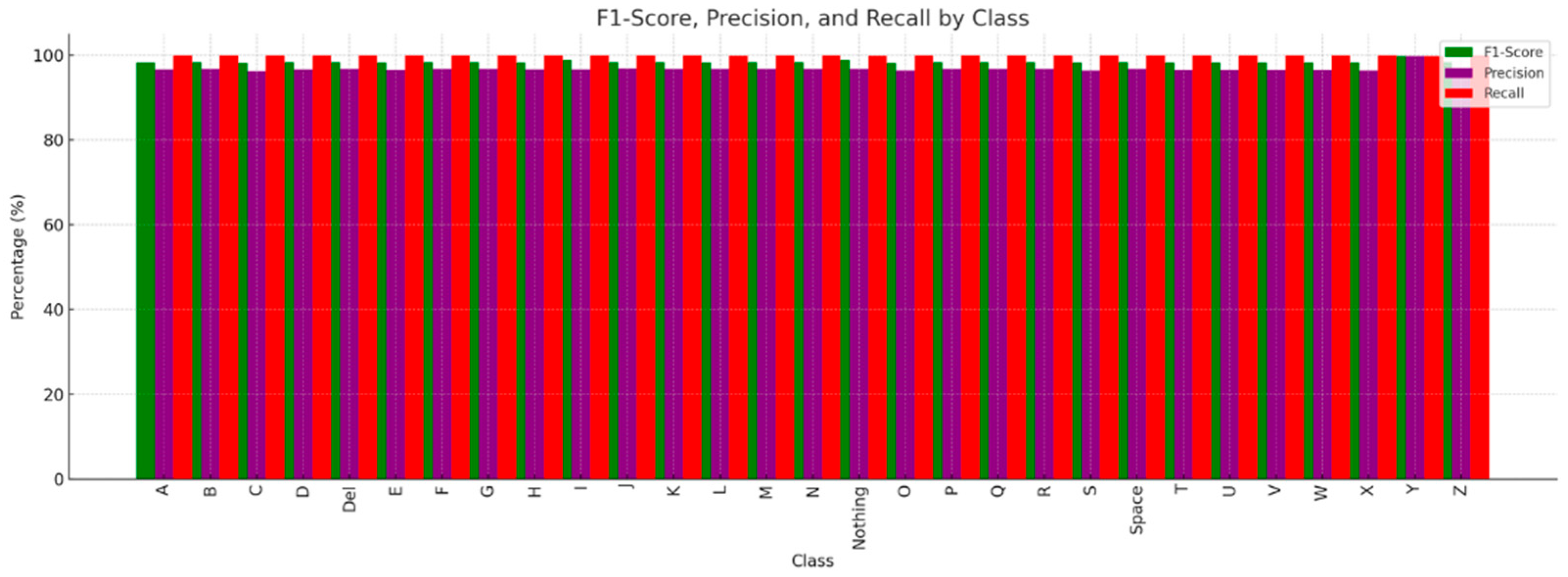
In terms of class-specific observations, Class “Y” performed the best, with an accuracy of 99.40%, precision of 99.70%, recall of 99.68%, and an F1-score of 99.69%, as illustrated in Figure 12. This shows that the model maintained a low number of False Positives (high precision) and accurately detected nearly all cases of gesture “Y” (high recall). The capacity of the model to achieve an excellent equilibrium between precision and recall is demonstrated by the highest F1-score in the dataset, 99.69%, for gesture “Y”. Additionally, gesture “Y” has the lowest error rate—just 0.6%—indicating that the model is quite dependable at identifying this gesture. This means that the best performance was achieved for the motion “Y”, showing that the model has mastered recognizing the gesture. A few potential explanations for this include improved feature descriptions for this gesture and distinctive visual qualities in the dataset that the model can readily distinguish from others. Additionally, the accuracy of some classes, including “X” and “S,” is comparatively lower (96.40% and 96.41%, respectively), as shown in Figure 13. This could indicate that some properties overlap with those of other motions, which would result in somewhat greater error rates. Although the majority of classes display recall values of 100%, categories like “L” and “Nothing” deviate marginally from this tendency, with recall ratings of 99.86% and 99.90%, respectively, as shown in Figure 14. This could occasionally result in misclassification because of the similarity in hand shape or orientation.
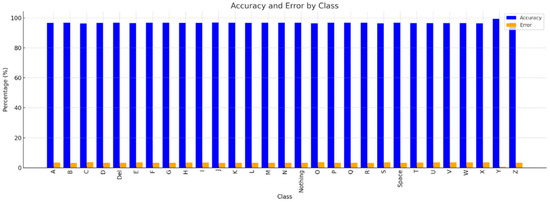
Figure 13.
Accuracy and error metric results across ASL dataset.
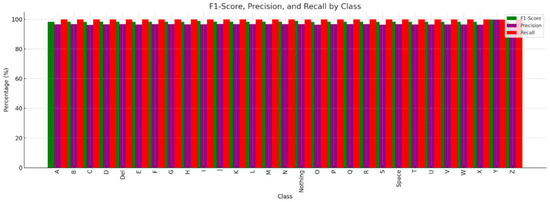
Figure 14.
F1-score, precision, and recall metric results across ASL dataset.
The proposed method shows promise for efficient hand gesture recognition by achieving exceptional outcomes on the ASL dataset. Although further optimization for particular classes should produce better results, excellent accuracy; balance between precision, recall, and F1-score measures; and stability across classes highlight its applicability for multi-class hand gesture classification tasks.
4.5. Results of Comparing Existing Methods
The proposed method was compared with several different cutting-edge hand gesture recognition methods in order to evaluate its effectiveness, as indicated in Table 5. A number of factors, including the types of data analysis, feature extraction techniques, classifier, and datasets utilized and accuracy attained, form the basis of the comparison. The methods in [13,17,40,41,42] rely on hand-crafted features such as HOG, LBP, GLCM, and various other moment descriptors like Hu’s Moment and Zernike moments, while the methods in [22,24,43,44] rely on deep learning models like CNNs, AlexNet, and YOLOv3.
Table 5.
Performance comparison between other models and the proposed method.
The accuracy of [41]’s technique is 86%, which is moderate. Accuracy may be reduced due to changes in lighting or the presence of a cluttered background. Although the approach of [43] achieves outstanding accuracy, the model remains susceptible to variations in lighting and background. Changes in these variables may result in less accurate recognition in practical applications. The accuracy of the model may be impacted by changes in hand shape due to hand sizes, orientations, and even disabilities. Although CNNs are good at generalizing, they may still struggle with some minute nuances in hand shape.
Although the method proposed in [42], which is based on CNNs and hybrid feature extraction (e.g., HOG + PCA), achieves excellent accuracy, it might need more processing resources than conventional methods, including SVM or ELM, requiring a trade-off between system resource requirements and performance. Additionally, the model may still be susceptible to variations in illumination and background noise. The method proposed in [22] achieves an accuracy of 85% on the ASL dataset. However, the most successful results may not always come from this AlexNet-powered effort. Due to its lack of representation in the training dataset, the model may struggle to recognize extremely complicated motions. Different environmental circumstances may decrease the system’s performance. The maximum accuracy of 97% was attained by the approach proposed in [24], which is based on the DarkNet-53 model and YOLOv3. Techniques like YOLOv3 with DarkNet-53 possess more intricate architectures, necessitate deeper models, could be more computationally costly, and are tailored for real-time detection tasks. The YOLOv3 model might not perform well against backgrounds that are extremely complicated or cluttered. On the other hand, the proposed method is an attractive possibility for applications in which computational effectiveness is crucial because it provides high accuracy with potentially lower complexity and resource requirements. The methods described in [13,44] have provided successful outcomes (93%). However, they have drawbacks, such as noise sensitivity and possible difficulties managing different lighting situations. The models’ capacity to generalize well in settings with a lack of labeled data may be constrained by their reliance on sizable training datasets.
With an outstanding accuracy of 96.68%, the proposed Tamura-ResNet50-GAM method ranks as one of the best options in this comparison. The capacity of ResNet50 to learn deep hierarchical features and Tamura features to capture texture-based information, as well as GAM’s assistance in capturing complicated relationships among features, are advantages of this approach. Its excellent accuracy indicates that this combination strikes a balance between the flexibility of the deep learning model and the resilience of handmade features. It offers a comparable alternative with potentially reduced processing requirements, although its accuracy is not higher than that of the YOLOv3–DarkNet-53 combination. It provides an optimal trade-off, especially for high-performance systems in gesture recognition applications.
5. Conclusions
The proposed method integrates ResNet50 model feature extraction with Tamura descriptor features and uses the adaptability of GAM to represent intricate interactions between the features. Hence, the proposed Tamura-ResNet50-OptimizedGAM method exhibits remarkable promise for hand gesture recognition, producing reliable and equitable outcomes for every class in the ASL dataset. With an accuracy rate of 96%, the proposed method outperformed the state-of-the-art techniques already in use. The remarkable accuracy demonstrates the balance established between the strength of handmade features and the flexibility of the deep learning model. Although it is not as accurate as the YOLOv3–DarkNet-53 combination, it is still a good substitute that might require less processing power. This approach offers an optimal trade-off, making the method well suited for high-performance systems in gesture recognition applications. The proposed method did not undergo explicit real-time performance testing, representing an avenue for future research. It could be advantageous to conduct additional testing and refinement for real-time recognition. The suggested approach performed exceptionally well on the ASL dataset; however, it is unknown if this will generalize to other datasets, such as HUST-ASL or LIBRAS. Testing on a wider range of datasets may help confirm the model’s robustness.
Author Contributions
Conceptualization, I.T.A., B.T.H., and E.A.; writing—original draft preparation, I.T.A. and B.T.H.; review and editing, W.H.G. and E.A; validation, B.T.H.; software, I.T.A.; validation, W.H.G.; funding acquisition, E.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original data presented in the study are openly available in [37].
Acknowledgments
The authors are grateful to the Researchers Supporting Project (ANUI/2025/ENG05), Alnoor University, Mosul, Iraq.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wu, C.-H.; Chen, W.-L.; Lin, C.H. Depth-based hand gesture recognition. Multimed. Tools Appl. 2016, 75, 7065–7086. [Google Scholar] [CrossRef]
- Zhang, T.; Ding, Y.; Hu, C.; Zhang, M.; Zhu, W.; Bowen, C.R.; Han, Y.; Yang, Y. Self-Powered Stretchable Sensor Arrays Exhibiting Magnetoelasticity for Real-Time Human–Machine Interaction. Adv. Mater. 2023, 35, 2203786. [Google Scholar] [CrossRef]
- Al Farid, F.; Hashim, N.; Abdullah, J.; Bhuiyan, M.R.; Shahida Mohd Isa, W.N.; Uddin, J.; Haque, M.A.; Husen, M.N. A structured and methodological review on vision-based hand gesture recognition system. J. Imaging 2022, 8, 153. [Google Scholar] [CrossRef]
- Adeyanju, I.A.; Bello, O.O.; Adegboye, M.A. Machine learning methods for sign language recognition: A critical review and analysis. Intell. Syst. Appl. 2021, 12, 200056. [Google Scholar] [CrossRef]
- Qi, J.; Xu, K.; Ding, X. Approach to hand posture recognition based on hand shape features for human–robot interaction. Complex Intell. Syst. 2022, 8, 2825–2842. [Google Scholar] [CrossRef]
- Chakraborty, B.K.; Sarma, D.; Bhuyan, M.K.; MacDorman, K.F. Review of constraints on vision-based gesture recognition for human–computer interaction. IET Comput. Vis. 2018, 12, 3–15. [Google Scholar] [CrossRef]
- Guo, L.; Lu, Z.; Yao, L. Human-machine interaction sensing technology based on hand gesture recognition: A review. IEEE Trans. Hum.-Mach. Syst. 2021, 51, 300–309. [Google Scholar] [CrossRef]
- Hammad, B.T.; Jamil, N.; Rusli, M.E.; Z’Aba, M.R.; Ahmed, I.T. Implementation of Lightweight Cryptographic Primitives. J. Theor. Appl. Inf. Technol. 2017, 95, 5571–5586. [Google Scholar]
- Zahra, R.; Shehzadi, A.; Sharif, M.I.; Karim, A.; Azam, S.; De Boer, F.; Jonkman, M.; Mehmood, M. Camera-based interactive wall display using hand gesture recognition. Intell. Syst. Appl. 2023, 19, 200262. [Google Scholar] [CrossRef]
- Oudah, M.; Al-Naji, A.; Chahl, J. Hand gesture recognition based on computer vision: A review of techniques. J. Imaging 2020, 6, 73. [Google Scholar] [CrossRef]
- López, L.I.B.; Ferri, F.M.; Zea, J.; Caraguay, Á.L.V.; Benalcázar, M.E. CNN-LSTM and post-processing for EMG-based hand gesture recognition. Intell. Syst. Appl. 2024, 22, 200352. [Google Scholar]
- Gupta, B.; Shukla, P.; Mittal, A. K-nearest correlated neighbor classification for Indian sign language gesture recognition using feature fusion. In Proceedings of the 2016 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 7–9 January 2016; pp. 1–5. [Google Scholar]
- Sadeddine, K.; Djeradi, R.; Chelali, F.Z.; Djeradi, A. Recognition of static hand gesture. In Proceedings of the 2018 6th International Conference on Multimedia Computing and Systems (ICMCS), Rabat, Morocco, 10–12 May 2018; pp. 1–6. [Google Scholar]
- Zhang, F.; Liu, Y.; Zou, C.; Wang, Y. Hand gesture recognition based on HOG-LBP feature. In Proceedings of the 2018 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Houston, TX, USA, 14–17 May 2018; pp. 1–6. [Google Scholar]
- Sahoo, J.P.; Ari, S.; Ghosh, D.K. Hand gesture recognition using DWT and F-ratio based feature descriptor. IET Image Process. 2018, 12, 1780–1787. [Google Scholar] [CrossRef]
- Ahmed, I.T.; Der, C.S.; Hammad, B.T. Recent Approaches on No-Reference Image Quality Assessment for Contrast Distortion Images with Multiscale Geometric Analysis Transforms: A Survey. J. Theor. Appl. Inf. Technol. 2017, 95, 561–569. [Google Scholar]
- Gajalakshmi, P.; Sharmila, T.S. Hand gesture recognition by histogram based kernel using density measure. In Proceedings of the 2019 2nd International Conference on Power and Embedded Drive Control (ICPEDC), Chennai, India, 21–23 August 2019; pp. 294–298. [Google Scholar]
- Li, J.; Li, C.; Han, J.; Shi, Y.; Bian, G.; Zhou, S. Robust hand gesture recognition using HOG-9ULBP features and SVM model. Electronics 2022, 11, 988. [Google Scholar] [CrossRef]
- Sayed, U.; Bakheet, S.; Mofaddel, M.A.; El-Zohry, Z. Robust Hand Gesture Recognition Using HOG Features and machine learning. Sohag J. Sci. 2024, 9, 226–233. [Google Scholar] [CrossRef]
- Nyirarugira, C.; Choi, H.-R.; Kim, J.; Hayes, M.; Kim, T. Modified levenshtein distance for real-time gesture recognition. In Proceedings of the 2013 6th International Congress on Image and Signal Processing (CISP), Hangzhou, China, 16–18 December 2013; Volume 2, pp. 974–979. [Google Scholar]
- Aurangzeb, K.; Javeed, K.; Alhussein, M.; Rida, I.; Haider, S.I.; Parashar, A. Deep Learning Approach for Hand Gesture Recognition: Applications in Deaf Communication and Healthcare. Comput. Mater. Contin. 2024, 78, 127. [Google Scholar] [CrossRef]
- Ozcan, T.; Basturk, A. Transfer learning-based convolutional neural networks with heuristic optimization for hand gesture recognition. Neural Comput. Appl. 2019, 31, 8955–8970. [Google Scholar] [CrossRef]
- Sahoo, J.P.; Prakash, A.J.; Pławiak, P.; Samantray, S. Real-time hand gesture recognition using fine-tuned convolutional neural network. Sensors 2022, 22, 706. [Google Scholar] [CrossRef]
- Mujahid, A.; Awan, M.J.; Yasin, A.; Mohammed, M.A.; Damaševičius, R.; Maskeliūnas, R.; Abdulkareem, K.H. Real-time hand gesture recognition based on deep learning YOLOv3 model. Appl. Sci. 2021, 11, 4164. [Google Scholar] [CrossRef]
- Ewe, E.L.R.; Lee, C.P.; Kwek, L.C.; Lim, K.M. Hand gesture recognition via lightweight VGG16 and ensemble classifier. Appl. Sci. 2022, 12, 7643. [Google Scholar] [CrossRef]
- Wang, F.; Hu, R.; Jin, Y. Research on gesture image recognition method based on transfer learning. Procedia Comput. Sci. 2021, 187, 140–145. [Google Scholar] [CrossRef]
- Kika, A.; Koni, A. Hand Gesture Recognition Using Convolutional Neural Network and Histogram of Oriented Gradients Features. In Proceedings of the 3rd International Conference on Recent Trends and Applications in Computer Science and Information Technology (RTA-CSIT 2018), Tirana, Albania, 23–24 November 2018; pp. 75–79. [Google Scholar]
- Rastgoo, R.; Kiani, K.; Escalera, S. Multi-modal deep hand sign language recognition in still images using restricted Boltzmann machine. Entropy 2018, 20, 809. [Google Scholar] [CrossRef]
- Damaneh, M.M.; Mohanna, F.; Jafari, P. Static hand gesture recognition in sign language based on convolutional neural network with feature extraction method using ORB descriptor and Gabor filter. Expert Syst. Appl. 2023, 211, 118559. [Google Scholar] [CrossRef]
- Ahmed, I.T.; Der, C.S.; Hammad, B.T.; Jamil, N. Contrast-distorted image quality assessment based on curvelet domain features. Int. J. Electr. Comput. Eng. 2021, 11, 2595. [Google Scholar] [CrossRef]
- El-Shafai, W.; Almomani, I.; AlKhayer, A. Visualized malware multi-classification framework using fine-tuned CNN-based transfer learning models. Appl. Sci. 2021, 11, 6446. [Google Scholar] [CrossRef]
- Tamura, H.; Mori, S.; Yamawaki, T. Textural features corresponding to visual perception. IEEE Trans. Syst. Man. Cybern. 1978, 8, 460–473. [Google Scholar] [CrossRef]
- Theckedath, D.; Sedamkar, R.R. Detecting affect states using VGG16, ResNet50 and SE-ResNet50 networks. SN Comput. Sci. 2020, 1, 79. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Davis, J.; Shah, M. Recognizing hand gestures. In Proceedings of the Computer Vision—ECCV’94: Third European Conference on Computer Vision, Stockholm, Sweden, 2–6 May 1994; Springer: Berlin/Heidelberg, Germany, 1994; Volume I 3, pp. 331–340. [Google Scholar]
- Fregoso, J.; Gonzalez, C.I.; Martinez, G.E. Optimization of convolutional neural networks architectures using PSO for sign language recognition. Axioms 2021, 10, 139. [Google Scholar] [CrossRef]
- Hammad, B.T.; Ahmed, I.T.; Jamil, N. An secure and effective copy move detection based on pretrained model. In Proceedings of the 2022 IEEE 13th Control and System Graduate Research Colloquium (ICSGRC), Shah Alam, Malaysia, 23 July 2022; pp. 66–70. [Google Scholar]
- Ahmed, I.T.; Jamil, N.; Din, M.M.; Hammad, B.T. Binary and Multi-Class Malware Threads Classification. Appl. Sci. 2022, 12, 12528. [Google Scholar] [CrossRef]
- Ahmed, I.T.; Der, C.S.; Jamil, N.; Hammad, B.T. Analysis of Probability Density Functions in Existing No-Reference Image Quality Assessment Algorithm for Contrast-Distorted Images. In Proceedings of the 2019 IEEE 10th Control and System Graduate Research Colloquium (ICSGRC), Shah Alam, Malaysia, 2–3 August 2019; pp. 133–137. [Google Scholar]
- Neiva, D.H.; Zanchettin, C. A dynamic gesture recognition system to translate between sign languages in complex backgrounds. In Proceedings of the 2016 5th Brazilian Conference on Intelligent Systems (BRACIS), Recife, Brazil, 9–12 October 2016; pp. 421–426. [Google Scholar]
- Srinath, S.; Sharma, G.K. Classification approach for sign language recognition. In Proceedings of the International Conference on Signal, Image Processing, Communication & Automation, Bengaluru, India, 6–7 July 2017; pp. 141–148. [Google Scholar]
- Sharma, A.; Mittal, A.; Singh, S.; Awatramani, V. Hand gesture recognition using image processing and feature extraction techniques. Procedia Comput. Sci. 2020, 173, 181–190. [Google Scholar] [CrossRef]
- Das, A.; Gawde, S.; Suratwala, K.; Kalbande, D. Sign language recognition using deep learning on custom processed static gesture images. In Proceedings of the 2018 International Conference on Smart City and Emerging Technology (ICSCET), Mumbai, India, 5 January 2018; pp. 1–6. [Google Scholar]
- Gao, Q.; Liu, J.; Ju, Z.; Li, Y.; Zhang, T.; Zhang, L. Static hand gesture recognition with parallel CNNs for space human-robot interaction. In Proceedings of the Intelligent Robotics and Applications: 10th International Conference, ICIRA 2017, Wuhan, China, 16–18 August 2017; Part I 10. pp. 462–473. [Google Scholar]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).