
Implementation of Machine Vision Methods for Cattle Detection and Activity Monitoring

 , ,
, ,  , , ,
, , ,  ,
, 
Abstract
1. Introduction
2. Materials and Methods
2.1. Experimental Environment and Data Collection
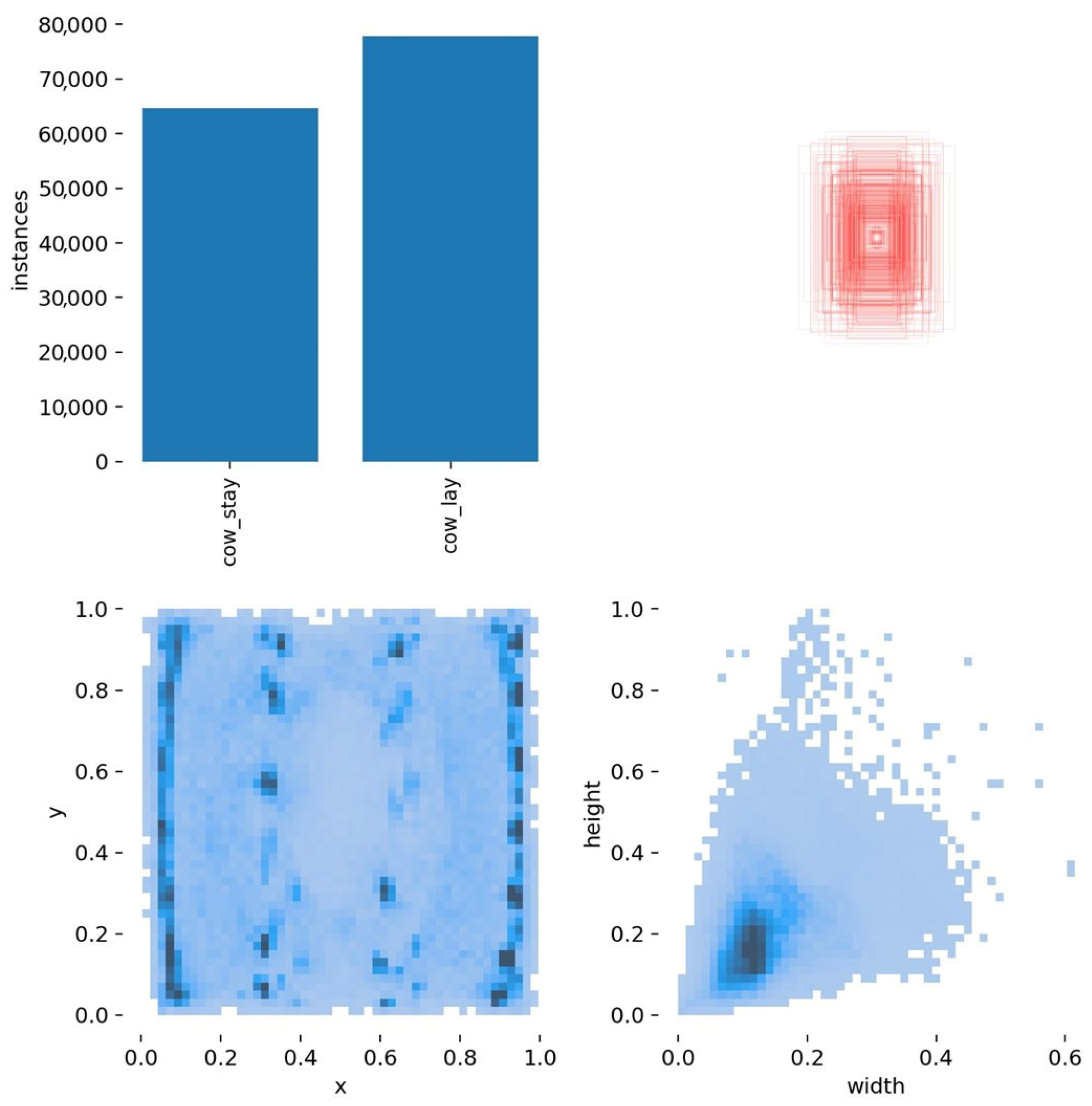
2.2. Dataset Creation
2.3. Model Selection
2.4. Examined Hyperparameters
2.4.1. Learning Rate (LR)
2.4.2. Batch Size (BS)
2.4.3. Optimizer
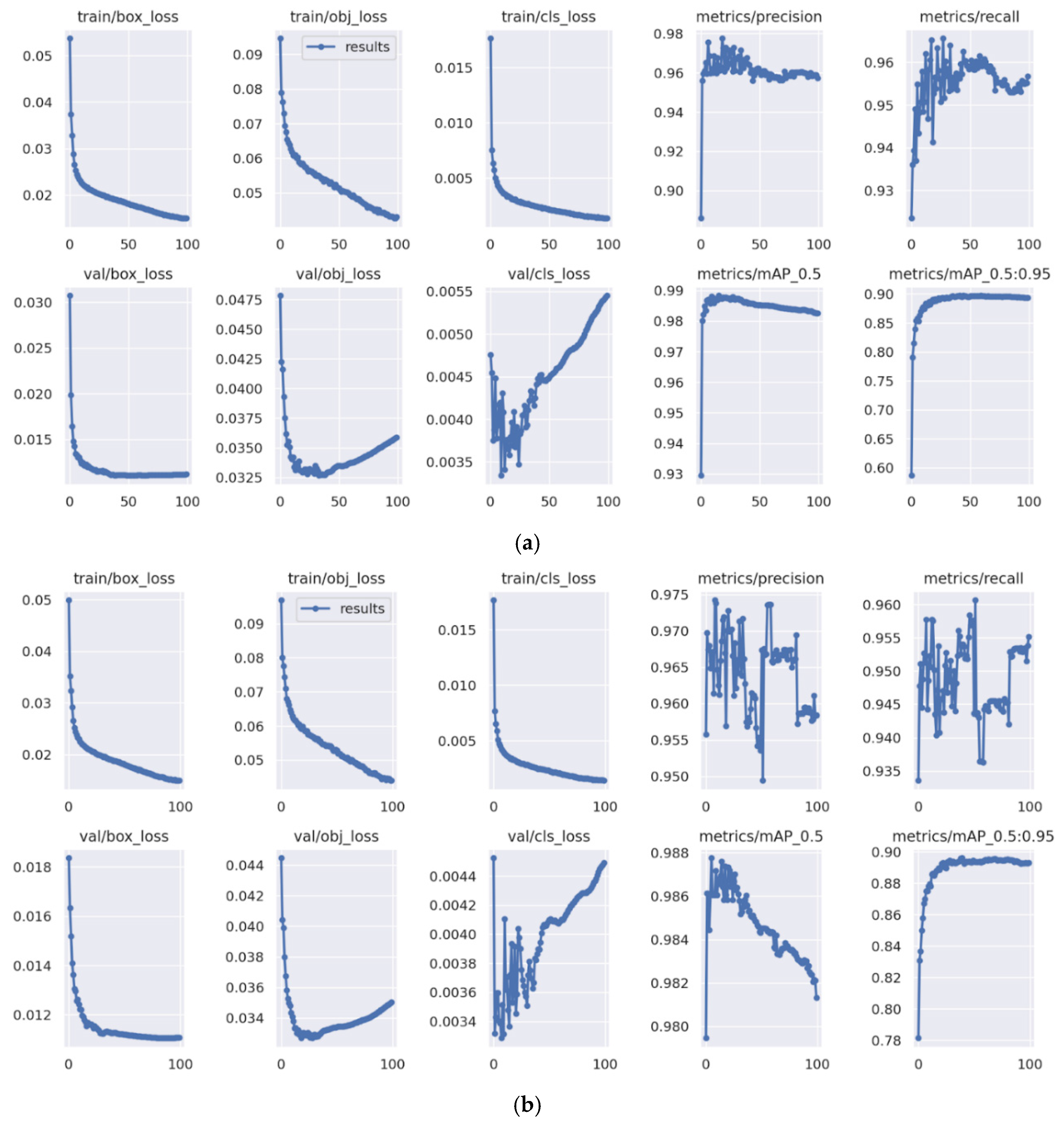
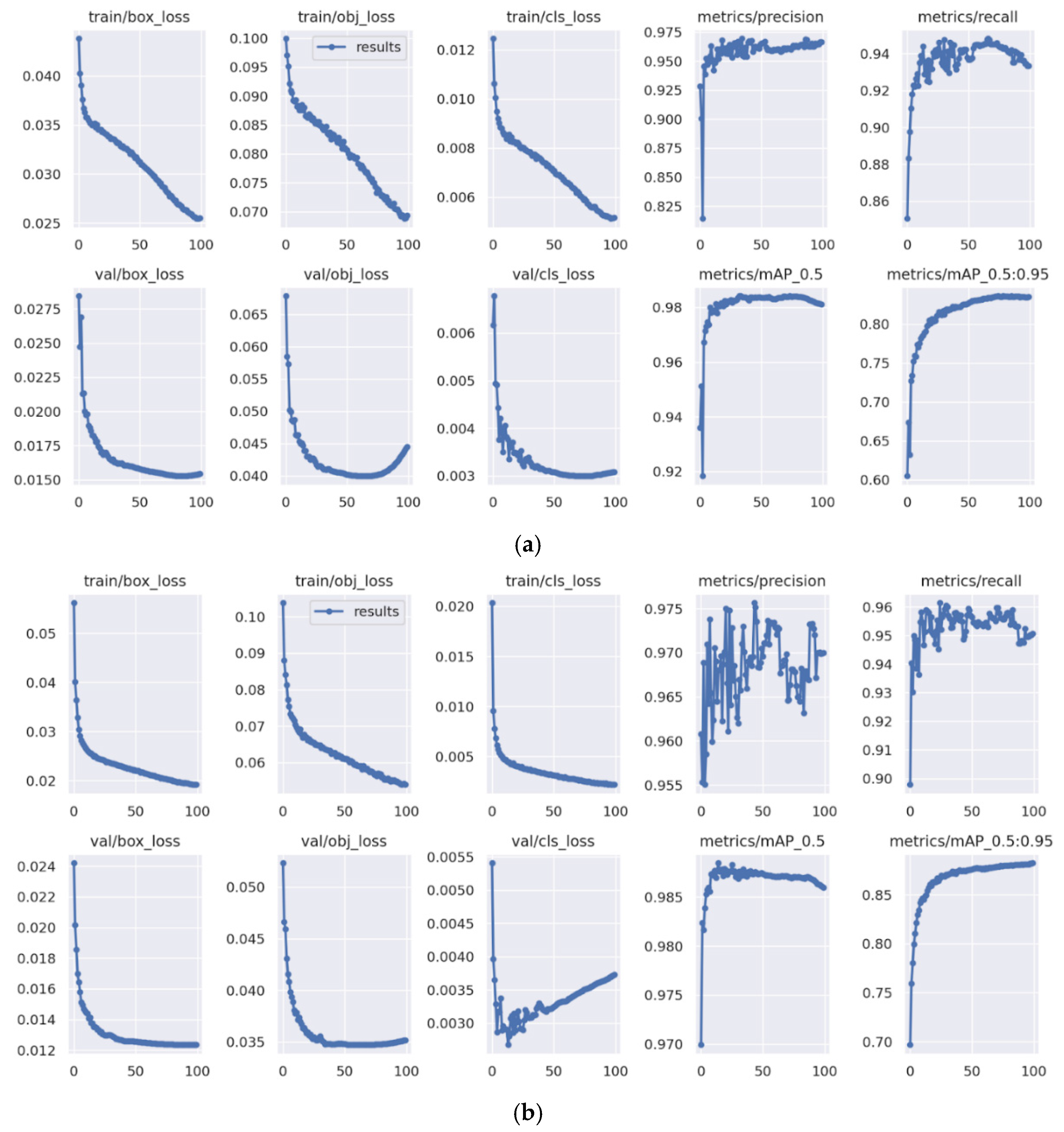
2.5. The Training Process and Model Evaluation
3. Results and Discussion
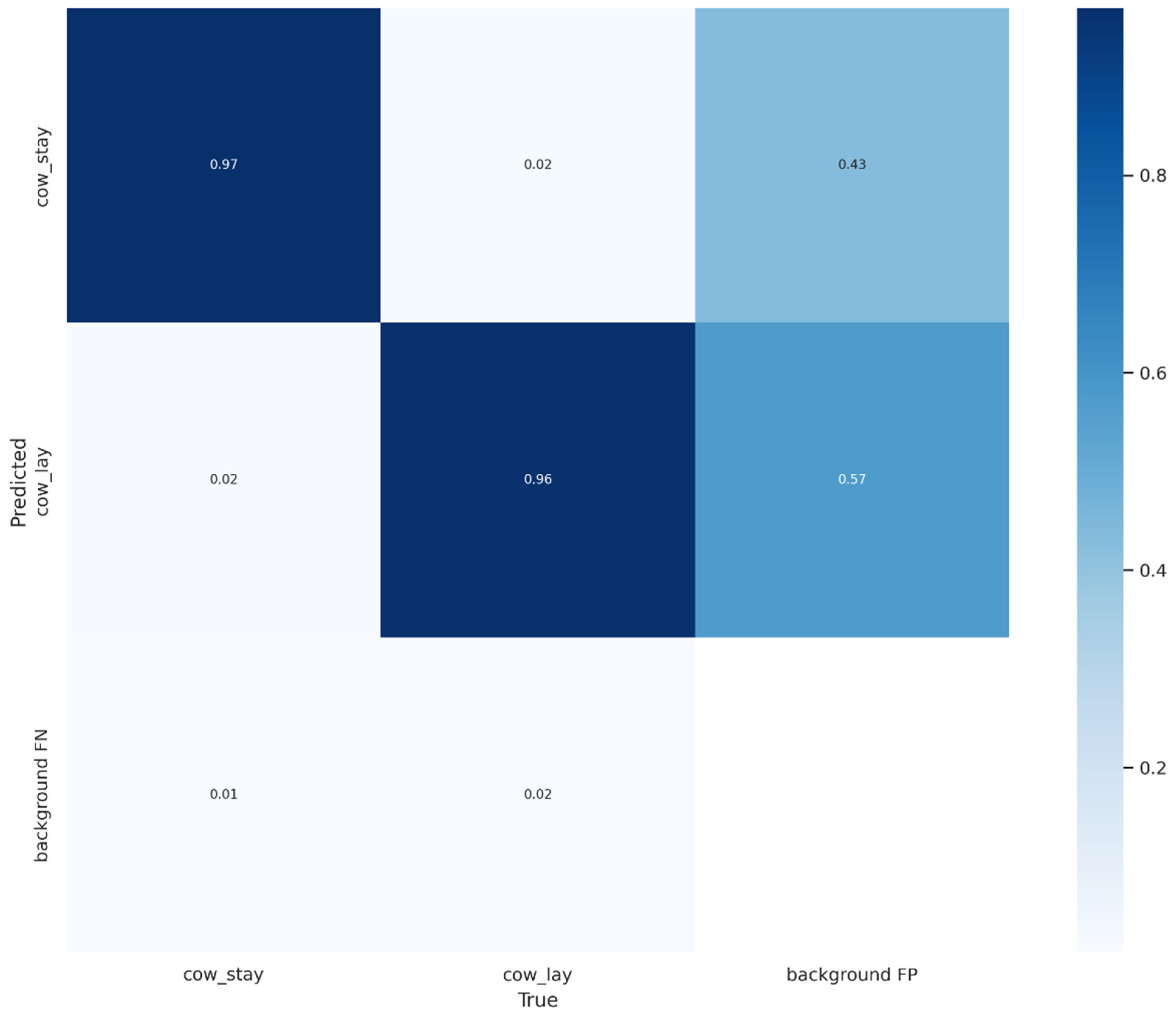
3.1. Error Analysis and Model Limitations
3.2. Comparison of YOLOv5 Network Types
3.3. The Impact of Learning Rate
3.4. The Impact of Batch Size
3.5. Comparison of Optimizers
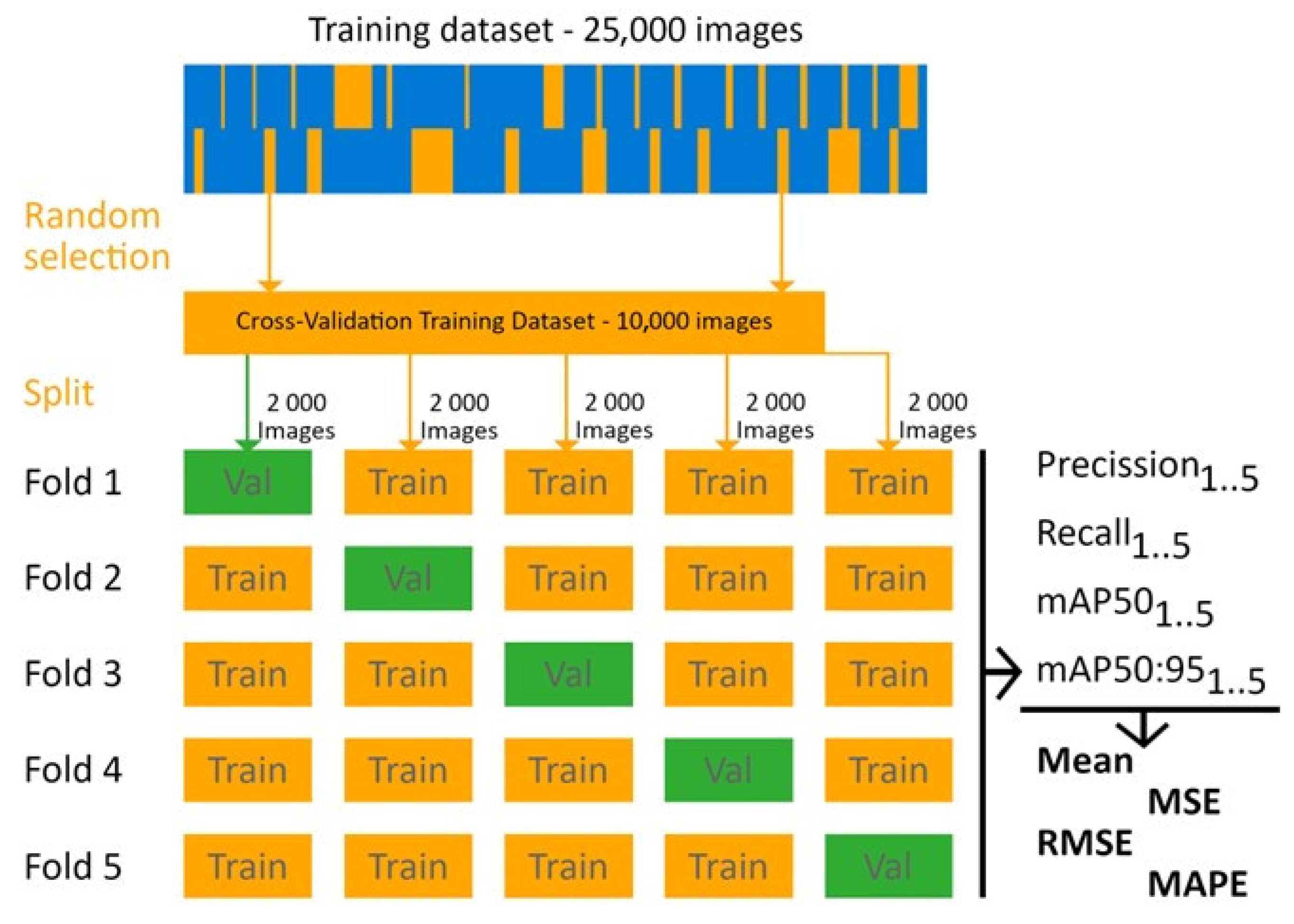
3.6. Evaluation of Model Generalization Using 5-Fold Cross-Validation
4. Comparison with Other Studies
5. Limitations and Future Directions
5.1. Dataset Limitations and Generalization Challenges
5.2. Occlusions and Crowding Effects
5.3. Scalability and Computational Constraints
5.4. Extension to a Broader Range of Behaviors
5.5. Validation Through Cross-Validation and Independent Testing
5.6. Advancements in YOLO Architectures
5.7. Deployment Feasibility and Cost Considerations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wanapat, M.; Suriyapha, C.; Dagaew, G.; Matra, M.; Phupaboon, S.; Sommai, S.; Pongsub, S.; Muslykhah, U. Sustainable Livestock Production Systems Are Key to Ensuring Food Security Resilience in Response to Climate Change. Agric. Nat. Resources 2024, 58, 537–546. [Google Scholar] [CrossRef]
- Zheng, Z.; Qin, L. PrunedYOLO-Tracker: An Efficient Multi-Cows Basic Behavior Recognition and Tracking Technique. Comput. Electron. Agric. 2023, 213, 108172. [Google Scholar] [CrossRef]
- Linstädt, J.; Thöne-Reineke, C.; Merle, R. Animal-Based Welfare Indicators for Dairy Cows and Their Validity and Practicality: A Systematic Review of the Existing Literature. Front. Vet. Sci. 2024, 11, 1429097. [Google Scholar] [CrossRef] [PubMed]
- Wu, D.; Han, M.; Song, H.; Song, L.; Duan, Y. Monitoring the Respiratory Behavior of Multiple Cows Based on Computer Vision and Deep Learning. J. Dairy. Sci. 2023, 106, 2963–2979. [Google Scholar] [CrossRef]
- Shu, H.; Bindelle, J.; Guo, L.; Gu, X. Determining the Onset of Heat Stress in a Dairy Herd Based on Automated Behaviour Recognition. Biosyst. Eng. 2023, 226, 238–251. [Google Scholar] [CrossRef]
- Arablouei, R.; Currie, L.; Kusy, B.; Ingham, A.; Greenwood, P.L.; Bishop-Hurley, G. In-Situ Classification of Cattle Behavior Using Accelerometry Data. Comput. Electron. Agric. 2021, 183, 106045. [Google Scholar] [CrossRef]
- Rohan, A.; Rafaq, M.S.; Md Hasan, J.; Asghar, F.; Bashir, A.K.; Dottorini, T. Application of Deep Learning for Livestock Behaviour Recognition: A Systematic Literature Review. Comput. Electron. Agric. 2024, 224, 109115. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, W.; Norton, T. Behaviour Recognition of Pigs and Cattle: Journey from Computer Vision to Deep Learning. Comput. Electron. Agric. 2021, 187, 106255. [Google Scholar] [CrossRef]
- Kříž, P.; Horčičková, M.; Bumbálek, R.; Bartoš, P.; Smutný, L.; Stehlík, R.; Zoubek, T.; Černý, P.; Vochozka, V.; Kuneš, R. Application of the Machine Vision Technology and Infrared Thermography to the Detection of Hoof Diseases in Dairy Cows: A Review. Appl. Sci. 2021, 11, 11045. [Google Scholar] [CrossRef]
- Ufitikirezi, M.J.D.; Bumbalek, R.; Zoubek, T.; Bartos, P.; Havelka, Z.; Kresan, J.; Stehlik, R.; Kunes, R.; Olsan, P.; Strob, M.; et al. Enhancing Cattle Production and Management through Convolutional Neural Networks. A Review. Czech J. Anim. Sci. 2024, 69, 75–88. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, S.; Yan, Y.; Tang, S.; Zhao, S. Identification and Analysis of Emergency Behavior of Cage-Reared Laying Ducks Based on YoloV5. Agriculture 2022, 12, 485. [Google Scholar] [CrossRef]
- Cheng, M.; Yuan, H.; Wang, Q.; Cai, Z.; Liu, Y.; Zhang, Y. Application of Deep Learning in Sheep Behaviors Recognition and Influence Analysis of Training Data Characteristics on the Recognition Effect. Comput. Electron. Agric. 2022, 198, 107010. [Google Scholar] [CrossRef]
- Jiang, M.; Rao, Y.; Zhang, J.; Shen, Y. Automatic Behavior Recognition of Group-Housed Goats Using Deep Learning. Comput. Electron. Agric. 2020, 177, 105706. [Google Scholar] [CrossRef]
- Yin, X.; Wu, D.; Shang, Y.; Jiang, B.; Song, H. Using an EfficientNet-LSTM for the Recognition of Single Cow’s Motion Behaviours in a Complicated Environment. Comput. Electron. Agric. 2020, 177, 105707. [Google Scholar] [CrossRef]
- Wang, Y.; Li, R.; Wang, Z.; Hua, Z.; Jiao, Y.; Duan, Y.; Song, H. E3D: An Efficient 3D CNN for the Recognition of Dairy Cow’s Basic Motion Behavior. Comput. Electron. Agric. 2023, 205, 107607. [Google Scholar] [CrossRef]
- Wu, D.; Wang, Y.; Han, M.; Song, L.; Shang, Y.; Zhang, X.; Song, H. Using a CNN-LSTM for Basic Behaviors Detection of a Single Dairy Cow in a Complex Environment. Comput. Electron. Agric. 2021, 182, 106016. [Google Scholar] [CrossRef]
- Shang, C.; Wu, F.; Wang, M.; Gao, Q. Cattle Behavior Recognition Based on Feature Fusion under a Dual Attention Mechanism. J. Vis. Commun. Image Represent. 2022, 85, 103524. [Google Scholar] [CrossRef]
- Fuentes, A.; Yoon, S.; Park, J.; Park, D.S. Deep Learning-Based Hierarchical Cattle Behavior Recognition with Spatio-Temporal Information. Comput. Electron. Agric. 2020, 177, 105627. [Google Scholar] [CrossRef]
- Zong, Z.; Ban, Z.; Wang, C.; Wang, S.; Yuan, W.; Zhang, C.; Su, L.; Yuan, Z. A Study on Multi-Scale Behavior Recognition of Dairy Cows in Complex Background Based on Improved YOLOv5. Agriculture 2025, 15, 213. [Google Scholar] [CrossRef]
- Wang, R.; Gao, R.; Li, Q.; Zhao, C.; Ma, W.; Yu, L.; Ding, L. A Lightweight Cow Mounting Behavior Recognition System Based on Improved YOLOv5s. Sci. Rep. 2023, 13, 17418. [Google Scholar] [CrossRef]
- Yu, R.; Wei, X.; Liu, Y.; Yang, F.; Shen, W.; Gu, Z. Research on Automatic Recognition of Dairy Cow Daily Behaviors Based on Deep Learning. Animals 2024, 14, 458. [Google Scholar] [CrossRef] [PubMed]
- Tong, L.; Fang, J.; Wang, X.; Zhao, Y. Research on Cattle Behavior Recognition and Multi-Object Tracking Algorithm Based on YOLO-BoT. Animals 2024, 14, 2993. [Google Scholar] [CrossRef] [PubMed]
- Jia, Q.; Yang, J.; Han, S.; Du, Z.; Liu, J. CAMLLA-YOLOv8n: Cow Behavior Recognition Based on Improved YOLOv8n. Animals 2024, 14, 3033. [Google Scholar] [CrossRef]
- Tian, X.; Li, B.; Cheng, X.; Shi, X. Target Detection and Cow Standing Behavior Recognition Based on YOLOv5 Algorithm. In Proceedings of the 2022 3rd International Conference on Information Science, Parallel and Distributed Systems (ISPDS), Guangzhou, China, 22–24 July 2022; pp. 206–210. [Google Scholar]
- Li, D.; Wang, J.; Zhang, Z.; Dai, B.; Zhao, K.; Shen, W.; Yin, Y.; Li, Y. Cow-YOLO: Automatic Cow Mounting Detection Based on Non-Local CSPDarknet53 and Multiscale Neck. Int. J. Agric. Biol. Eng. 2024, 17, 193–202. [Google Scholar] [CrossRef]
- Mu, Y.; Hu, J.; Wang, H.; Li, S.; Zhu, H.; Luo, L.; Wei, J.; Ni, L.; Chao, H.; Hu, T.; et al. Research on the Behavior Recognition of Beef Cattle Based on the Improved Lightweight CBR-YOLO Model Based on YOLOv8 in Multi-Scene Weather. Animals 2024, 14, 2800. [Google Scholar] [CrossRef]
- Jocher, G.; Stoken, A.; Borovec, J.; NanoCode012; Stan, C.; Changyu, L.; Laughing; Tkianai; Nong, Y.X.; Hogan, A.; et al. Ul-tralytics/Yolov5: V4.0—Nn.SiLU() Activations, Weights & Biases Logging, PyTorch Hub Integration; Zenodo: Geneva, Switzerland, 2021. [Google Scholar]
- Hammel, B. What Learning Rate Should I Use. Bdhammel. com, 23 March. 2019. Available online: http://www.bdhammel.com/learning-rates/ (accessed on 1 January 2025).
- Luo, L.; Xiong, Y.; Liu, Y.; Sun, X. Adaptive Gradient Methods with Dynamic Bound of Learning Rate. arXiv 2019, arXiv:1902.09843. [Google Scholar]
- Ruder, S. An Overview of Gradient Descent Optimization Algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Padilla, R.; Netto, S.L.; Da Silva, E.A. A Survey on Performance Metrics for Object-Detection Algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niterói, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar]
- Henderson, P.; Ferrari, V. End-to-End Training of Object Class Detectors for Mean Average Precision. In Proceedings of the Computer Vision–ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Revised Selected Papers, Part V. Lai, S.-H., Lepetit, V., Nishino, K., Sato, Y., Eds.; Springer International Publishing: Cham, Switherland, 2017; pp. 198–213. [Google Scholar]
- Sim, H.; Kim, T.; Lee, C.; Choi, C.; Kim, J.S.; Cho, H. Optimizing Cattle Behavior Analysis in Precision Livestock Farming: Integrating YOLOv7-E6E with AutoAugment and GridMask to Enhance Detection Accuracy. Appl. Sci. 2024, 14, 3667. [Google Scholar] [CrossRef]
- Ahmad, M.; Zhang, W.; Smith, M.; Brilot, B.; Bell, M. IYOLO-FAM: Improved YOLOv8 with Feature Attention Mechanism for Cow Behaviour Detection. In Proceedings of the 2024 IEEE 15th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 17–19 October 2024; pp. 0210–0219. [Google Scholar]
- Guarnido-Lopez, P.; Ramirez-Agudelo, J.-F.; Denimal, E.; Benaouda, M. Programming and Setting Up the Object Detection Algorithm YOLO to Determine Feeding Activities of Beef Cattle: A Comparison between YOLOv8m and YOLOv10m. Animals 2024, 14, 2821. [Google Scholar] [CrossRef]
- Li, G.; Sun, J.; Guan, M.; Sun, S.; Shi, G.; Zhu, C. A New Method for Non-Destructive Identification and Tracking of Multi-Object Behaviors in Beef Cattle Based on Deep Learning. Animals 2024, 14, 2464. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 17–18 April 2024; pp. 1–6. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step | Adjustment | Description |
| 01 | Creation of cut-outs | Based on the random position, 3 cuts of pre-selected size of 720 × 720 pixels are created from the original image. |
| 02 | Resizing | The original image is resized to match the size of the cut-outs (720 × 720 pixels). At the same time, the coordinates of the individual points of the polygonal masks are changed according to the corresponding image operation. |
| 03 | Image rotation | The images are rotated by a random angle from three pre-selected intervals. |
| 04 | image flipping | The images are flipped according to the vertical and horizontal axis. |
| 05 | Change of perspective | The perspective of the image is adjusted three times. The coordinates of the corner points are randomly selected. The coordinates of the left corner are from the intervals , the coordinates of the right-hand corner are from the intervals , the coordinates of the bottom left corner are from the intervals , and the coordinates of the bottom right corner are from the intervals , where w is the width and h is the height. |
| 06 | Image blurring | The image is blurred using the Gaussian Blur type where the blur radius is 7. |
| 07 | Histogram equalization | Functions from the openCV library are used, which allow us to select standard equalization or the CLAHE method. First, the color image is converted to HSV color space and then the Value channel is equalized. |
| 08 | Contrast change | The value of 128 is subtracted from all pixel values of the images, the result is multiplied by a selected coefficient from the range of 0.5 to 1.5 and then the value of 128 is added again. The contrast is reduced if the coefficient is less than 1 and increased if the coefficient is greater than 1. |
| 09 | Brightness change | The product of 255 and a constant from the interval 〈−0.5; 0.5〉 was added to the value of all pixels. After performing this summation, a new value is assigned to each pixel. If the value is greater than 255, it is automatically set to 255, and similarly, if the value obtained is less than 0. the value is set to 0. |
| 10 | Noise addition | Changing randomly selected RGB channel pixels, where the original pixel value is rapidly increased. |
| 11 | Color scale shift | After converting the image to HSV, a randomly selected value from the interval −20 to 20 is added to the H-channel values resulting in a color shift. |
| Class | Precision | Recall | mAP_0.5 | mAP_0.5:0.95 |
|---|---|---|---|---|
| cow_stay | 0.954 | 0.958 | 0.981 | 0.883 |
| cow_lay | 0.967 | 0.949 | 0.989 | 0.910 |
| Model Type—Number of Parameters | mAP 0.5 | mAP 0.5:0.95 | Training Time | |
|---|---|---|---|---|
| A30_v5x_e100_b8_lr01_SGD | v5x—86.7 mil. | 0.9880 | 0.9070 | 16:53:27 |
| A30_v5l_e100_b8_lr01_SGD | v5l—46.5 mil. | 0.9885 | 0.9060 | 11:07:17 |
| A30_v5m_e100_b8_lr01_SGD | v5m—21.2 mil. | 0.9887 | 0.8969 | 7:48:19 |
| A30_v5s_e100_b8_lr01_SGD | v5s—7.2 mil. | 0.9885 | 0.8824 | 5:31:42 |
| A30_v5n_e100_b8_lr01_SGD | v5n—1.9 mil. | 0.9877 | 0.8536 | 5:29:17 |
| Learning Rate | mAP 0.5 | mAP 0.5:0.95 | Time | |
|---|---|---|---|---|
| A30_v5m_e100_b8_lr1_SGD | 0.1 | 0.9884 | 0.8897 | 7:47:17 |
| A30_v5m_e100_b8_lr01_SGD | 0.01 | 0.9887 | 0.8969 | 7:48:19 |
| A30_v5m_e100_b8_lr001_SGD | 0.001 | 0.9887 | 0.9028 | 7:47:43 |
| Batch Size | mAP 0.5 | mAP 0.5:0.95 | Time | |
|---|---|---|---|---|
| A30_v5m_e100_b4_lr01_SGD | 4 | 0.9878 | 0.8961 | 12:50:48 |
| A30_v5m_e100_b8_lr01_SGD | 8 | 0.9887 | 0.8969 | 7:48:19 |
| A30_v5m_e100_b16_lr01_SGD | 16 | 0.9882 | 0.8985 | 6:36:25 |
| A30_v5m_e100_b32_lr01_SGD | 32 | 0.9884 | 0.8973 | 6:07:13 |
| Optimizer | mAP 0.5 | mAP 0.5:0.95 | Time | |
|---|---|---|---|---|
| A30_v5m_e100_b8_lr01_SGD | SGD | 0.9887 | 0.8969 | 7:48:19 |
| A30_v5m_e100_b8_lr01_Adam | Adam | 0.9842 | 0.8361 | 7:48:05 |
| Model | Metric | Precision | Recall | mAP_0.5 | mAP_0.5:0.95 |
|---|---|---|---|---|---|
| YOLOv5x | Mean | 0.9879 | 0.9846 | 0.9934 | 0.9611 |
| MSE | 3.82 × 10−7 | 7.28 × 10−7 | 1.78 × 10−8 | 5.48 × 10−7 | |
| RMSE | 0.0006 | 0.0009 | 0.0001 | 0.0007 | |
| MAPE | 0.0578% | 0.0777% | 0.0097% | 0.0669% | |
| YOLOv5l | Mean | 0.9873 | 0.9841 | 0.9933 | 0.9585 |
| MSE | 2.05 × 10−7 | 9.57 × 10−7 | 4.89 × 10−8 | 1.45× 10−7 | |
| RMSE | 0.0005 | 0.0010 | 0.0002 | 0.0004 | |
| MAPE | 0.0378% | 0.0876% | 0.0168% | 0.0370% | |
| YOLOv5m | Mean | 0.9855 | 0.9811 | 0.9930 | 0.9469 |
| MSE | 2.34 × 10−6 | 6.15 × 10−7 | 6.05 × 10−8 | 3.07 × 10−7 | |
| RMSE | 0.0015 | 0.0008 | 0.0002 | 0.0006 | |
| MAPE | 0.1276% | 0.0736% | 0.0184% | 0.0541% | |
| YOLOv5s | Mean | 0.9832 | 0.9778 | 0.9925 | 0.9339 |
| MSE | 1.84 × 10−6 | 2.11 × 10−6 | 2.27 × 10−8 | 2.70 × 10−7 | |
| RMSE | 0.0014 | 0.0015 | 0.0002 | 0.0005 | |
| MAPE | 0.1042% | 0.1141% | 0.0140% | 0.0466% | |
| YOLOv5n | Mean | 0.9764 | 0.9678 | 0.9906 | 0.8957 |
| MSE | 9.50 × 10−6 | 9.92 × 10−7 | 1.88 × 10−7 | 3.03 × 10−7 | |
| RMSE | 0.0031 | 0.0010 | 0.0004 | 0.0006 | |
| MAPE | 0.2979% | 0.0813% | 0.0380% | 0.0469% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bumbálek, R.; Zoubek, T.; Ufitikirezi, J.d.D.M.; Umurungi, S.N.; Stehlík, R.; Havelka, Z.; Kuneš, R.; Bartoš, P. Implementation of Machine Vision Methods for Cattle Detection and Activity Monitoring. Technologies 2025, 13, 116. https://doi.org/10.3390/technologies13030116
Bumbálek R, Zoubek T, Ufitikirezi JdDM, Umurungi SN, Stehlík R, Havelka Z, Kuneš R, Bartoš P. Implementation of Machine Vision Methods for Cattle Detection and Activity Monitoring. Technologies. 2025; 13(3):116. https://doi.org/10.3390/technologies13030116
Chicago/Turabian StyleBumbálek, Roman, Tomáš Zoubek, Jean de Dieu Marcel Ufitikirezi, Sandra Nicole Umurungi, Radim Stehlík, Zbyněk Havelka, Radim Kuneš, and Petr Bartoš. 2025. "Implementation of Machine Vision Methods for Cattle Detection and Activity Monitoring" Technologies 13, no. 3: 116. https://doi.org/10.3390/technologies13030116
APA StyleBumbálek, R., Zoubek, T., Ufitikirezi, J. d. D. M., Umurungi, S. N., Stehlík, R., Havelka, Z., Kuneš, R., & Bartoš, P. (2025). Implementation of Machine Vision Methods for Cattle Detection and Activity Monitoring. Technologies, 13(3), 116. https://doi.org/10.3390/technologies13030116