
MIRA: Multi-Joint Imitation with Recurrent Adaptation for Robot-Assisted Rehabilitation


Abstract
1. Introduction
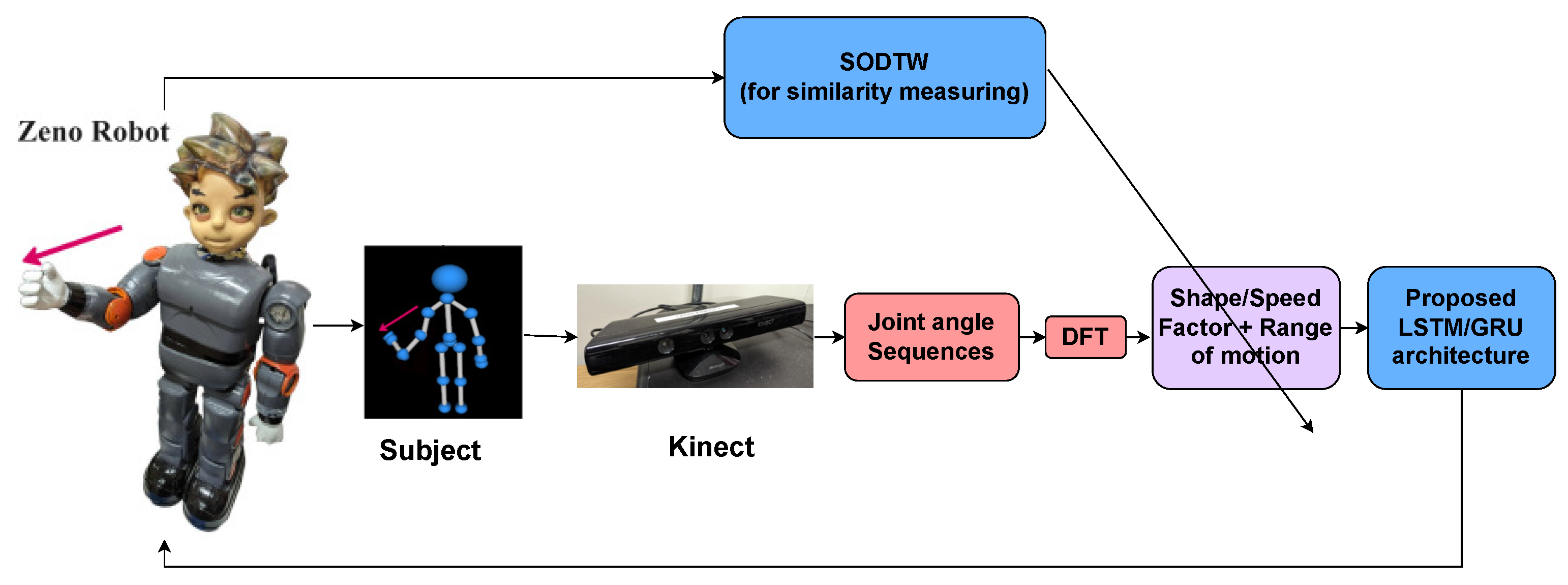
2. Proposed MIRA Framework
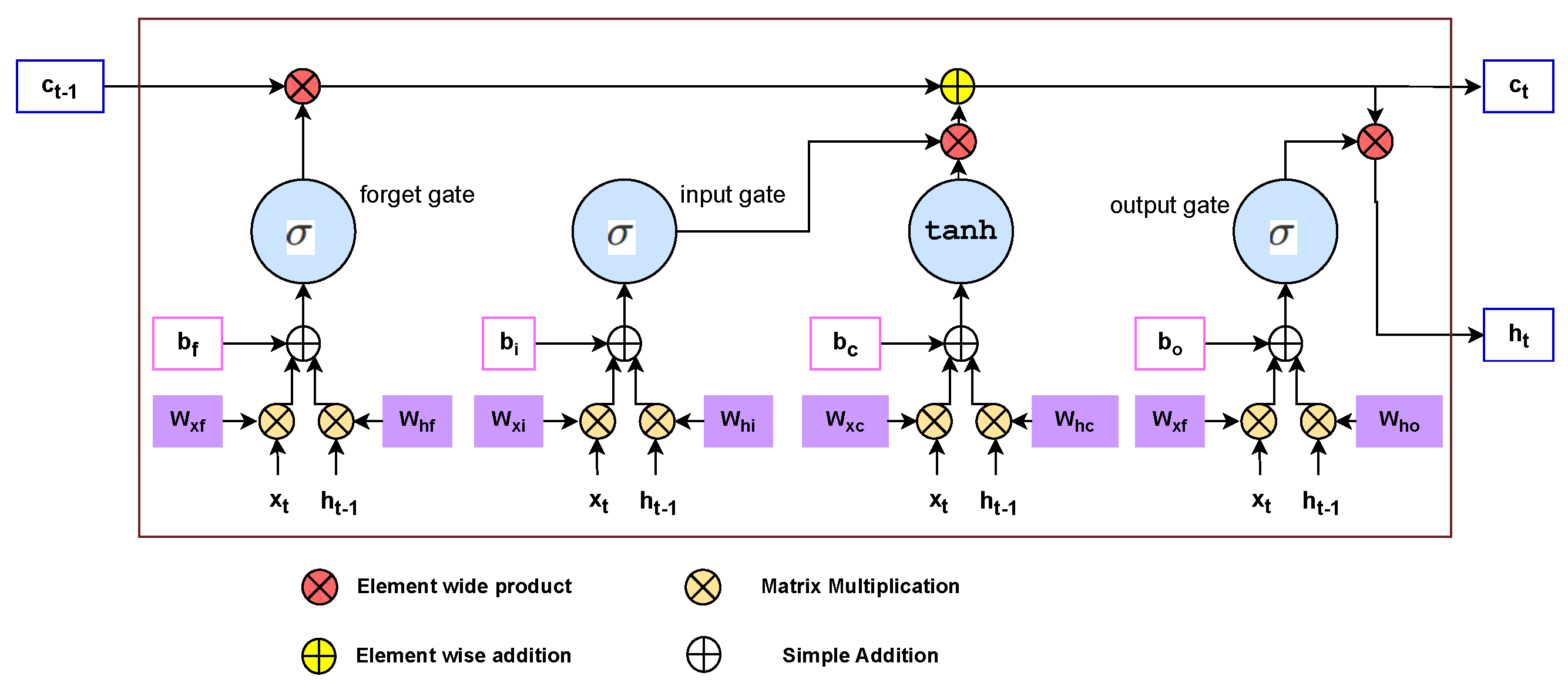
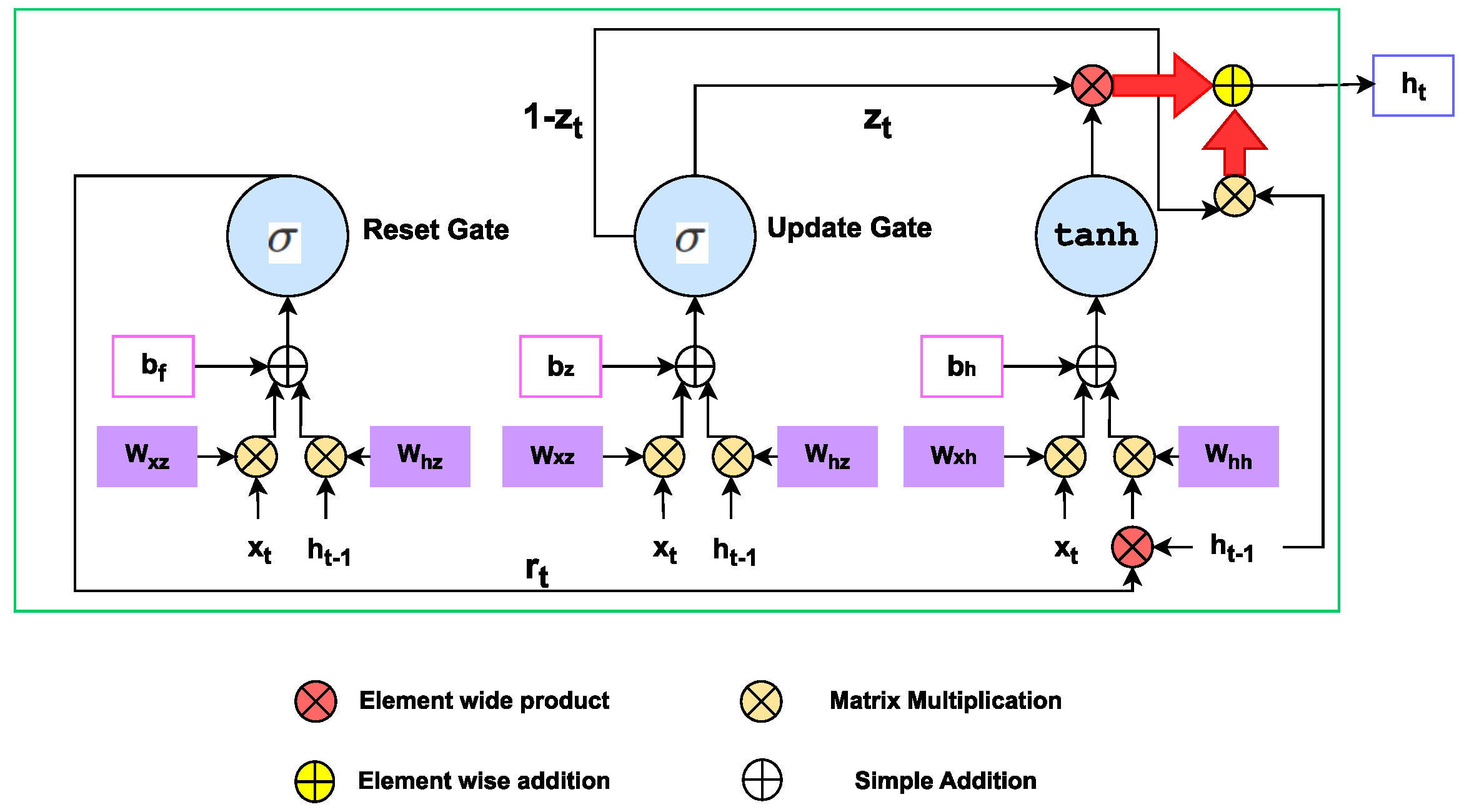
3. Recurrent Neural Network (RNN) Architectures for Reference Generation
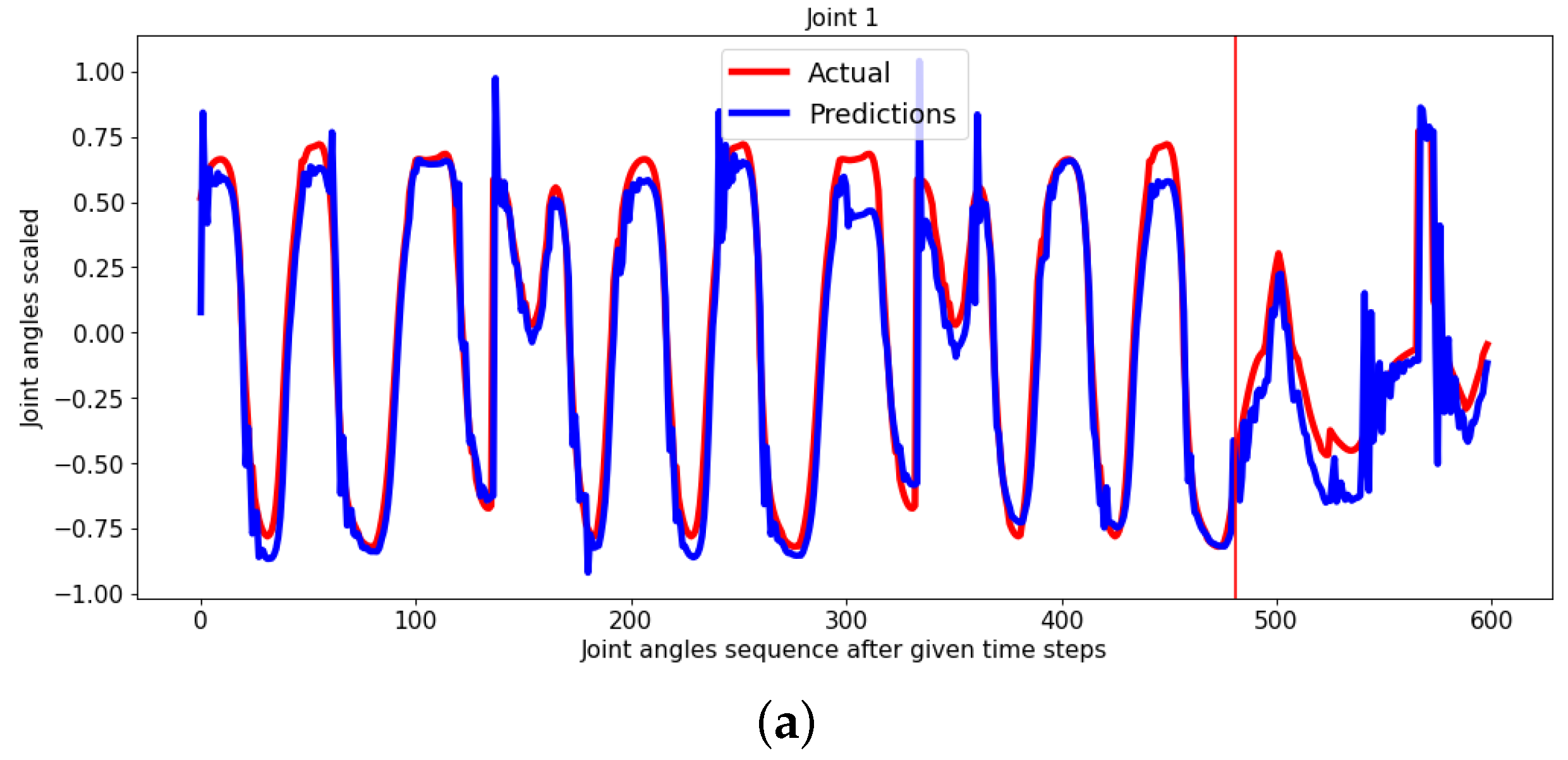
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Andrade, R.M.; Ulhoa, P.H.F.; Vimieiro, C.B.S. Designing a Highly Backdrivable and Kinematic Compatible Magneto-Rheological Knee Exoskeleton. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 5724–5730. [Google Scholar] [CrossRef]
- Nazzi, E.; Canzi, E.; Piga, G.; Galassi, A.; Lippi, G.; Benassi, G. Segment Online DTW for Smart Rehabilitation of ASD Children: A Preliminary Study. In Proceedings of the 4th EAI International Conference on Smart Objects and Technologies for Social Good (GOODTECHS), Rome, Italy, 26 October 2015; pp. 122–126. [Google Scholar]
- Frolov, A.; Kozlovskaya, I.; Biryukova, E.; Bobrov, P. Use of robotic devices in post-stroke rehabilitation. Neurosci. Behav. Physiol. 2018, 48, 1053–1066. [Google Scholar] [CrossRef]
- Goyal, T.; Hussain, S.; Martinez-Marroquin, E.; Brown, N.A.T.; Jamwal, P.K. Stiffness-Observer-Based Adaptive Control of an Intrinsically Compliant Parallel Wrist Rehabilitation Robot. IEEE Trans. Hum.-Mach. Syst. 2023, 53, 65–74. [Google Scholar] [CrossRef]
- Kirtay, M.; Chevalère, J.; Lazarides, R.; Hafner, V.V. Learning in Social Interaction: Perspectives from Psychology and Robotics. In Proceedings of the 2021 IEEE International Conference on Development and Learning (ICDL), Beijing, China, 23–26 August 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Wijayasinghe, I.B.; Ranatunga, I.; Balakrishnan, N.; Bugnariu, N.; Popa, D.O. Human–Robot Gesture Analysis for Objective Assessment of Autism Spectrum Disorder. Int. J. Soc. Robot. 2016, 8, 695–707. [Google Scholar] [CrossRef]
- Mahdi, H.; Akgun, S.A.; Saleh, S.; Dautenhahn, K. A survey on the design and evolution of social robots—Past, present and future. Robot. Auton. Syst. 2022, 156, 104193. [Google Scholar] [CrossRef]
- Abbeel, P.; Ng, A.Y. Apprenticeship Learning via Inverse Reinforcement Learning. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; pp. 1–8. [Google Scholar]
- Argall, B.D.; Chernova, S.; Veloso, M.; Browning, B. A Survey of Robot Learning from Demonstration. Robot. Auton. Syst. 2009, 57, 469–483. [Google Scholar] [CrossRef]
- Ashary, A.; Rayguru, M.M.; Dowdy, J.; Taghavi, N.; Popa, D.O. Adaptive Motion Imitation for Robot Assisted Physiotherapy Using Dynamic Time Warping and Recurrent Neural Network. In Proceedings of the 17th International Conference on PErvasive Technologies Related to Assistive Environme, Crete Greece, 26–28 June 2024; Association for Computing Machinery: New York, NY, USA, 2024. [Google Scholar] [CrossRef]
- Ashary, A.; Rayguru, M.M.; SharafianArdakani, P.; Kondaurova, I.; Popa, D.O. Multi-Joint Adaptive Motion Imitation in Robot-Assisted Physiotherapy with Dynamic Time Warping and Recurrent Neural Networks. In Proceedings of the SoutheastCon 2024, Atlanta, GA, USA, 15–24 March 2024; pp. 1388–1394. [Google Scholar] [CrossRef]
- Hussein, A.; Gaber, M.M.; Elyan, E. Imitation Learning: A Survey of Learning Methods. Artif. Intell. Rev. 2017, 48, 31–60. [Google Scholar] [CrossRef]
- Zheng, Z.; Young, E.M.; Swanson, A.R.; Weitlauf, A.S.; Warren, Z.E.; Sarkar, N. Robot-Mediated Imitation Skill Training for Children With Autism. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 24, 682–691. [Google Scholar] [CrossRef]
- Liu, W.; Peng, L.; Cao, J.; Fu, X.; Liu, Y.; Pan, Z.; Yang, J. Ensemble Bootstrapped Deep Deterministic Policy Gradient for Vision-Based Robotic Grasping. IEEE Access 2021, 9, 19916–19925. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1856–1865. [Google Scholar]
- Park, S.; Park, J.H.; Lee, S. Direct Demonstration-Based Imitation Learning and Control for Writing Task of Robot Manipulator. In Proceedings of the 2023 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 6–8 January 2023; pp. 1–3. [Google Scholar] [CrossRef]
- Xu, W.; Huang, J.; Wang, Y.; Tao, C.; Cheng, L. Reinforcement learning based shared control for walking aid robot and its experimental verification. Adv. Robot. 2015, 29, 1463–1481. [Google Scholar] [CrossRef]
- Xu, J.; Xu, L.; Li, Y.; Cheng, G.; Shi, J.; Liu, J.; Chen, S. A multi-channel reinforcement learning framework for robotic mirror therapy. IEEE Robot. Autom. Lett. 2020, 5, 5385–5392. [Google Scholar] [CrossRef]
- Bishe, S.S.P.A.; Nguyen, T.; Fang, Y.; Lerner, Z.F. Adaptive ankle exoskeleton control: Validation across diverse walking conditions. IEEE Trans. Med Robot. Bionics 2021, 3, 801–812. [Google Scholar] [CrossRef]
- Taghavi, N.; Alqatamin, M.H.A.; Popa, D.O. AMI: Adaptive Motion Imitation Algorithm Based on Deep Reinforcement Learning. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 798–804. [Google Scholar] [CrossRef]
- Zhao, Z.; Wang, J.; Tao, Q.; Li, A.; Chen, Y. An unknown wafer surface defect detection approach based on Incremental Learning for reliability analysis. Reliab. Eng. Syst. Saf. 2024, 244, 109966. [Google Scholar] [CrossRef]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A Critical Review of Recurrent Neural Networks for Sequence Learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Yang, S.; Zhang, W.; Song, R.; Cheng, J.; Wang, H.; Li, Y. Watch and Act: Learning Robotic Manipulation From Visual Demonstration. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 4404–4416. [Google Scholar] [CrossRef]
- Doering, M.; Glas, D.F.; Ishiguro, H. Modeling interaction structure for robot imitation learning of human social behavior. IEEE Trans. Hum.-Mach. Syst. 2019, 49, 219–231. [Google Scholar] [CrossRef]
- Kim, H.; Ohmura, Y.; Nagakubo, A.; Kuniyoshi, Y. Training robots without robots: Deep imitation learning for master-to-robot policy transfer. IEEE Robot. Autom. Lett. 2023, 8, 2906–2913. [Google Scholar] [CrossRef]
- Yang, S.; Zhang, W.; Song, R.; Lu, W.; Wang, H.; Li, Y. Explicit-to-Implicit Robot Imitation Learning by Exploring Visual Content Change. IEEE/ASME Trans. Mechatronics 2022, 27, 4920–4931. [Google Scholar] [CrossRef]
- Du, X.; Vasudevan, R.; Johnson-Roberson, M. Bio-LSTM: A biomechanically inspired recurrent neural network for 3-d pedestrian pose and gait prediction IEEE Robot. Autom. Lett 2019, 4, 1501. [Google Scholar] [CrossRef]
- Kawaharazuka, K.; Kawamura, Y.; Okada, K.; Inaba, M. Imitation learning with additional constraints on motion style using parametric bias. IEEE Robot. Autom. Lett. 2021, 6, 5897–5904. [Google Scholar] [CrossRef]
- Torres, N.A.; Clark, N.; Ranatunga, I.; Popa, D. Implementation of interactive arm playback behaviors of social robot Zeno for autism spectrum disorder therapy. In Proceedings of the 5th International Conference on PErvasive Technologies Related to Assistive Environments, Crete, Greece, 6–8 June 2012; pp. 1–7. [Google Scholar]
- Taghavi, N.; Berdichevsky, J.; Balakrishnan, N.; Welch, K.C.; Das, S.K.; Popa, D.O. Online Dynamic Time Warping Algorithm for Human-Robot Imitation. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 3843–3849. [Google Scholar]
- Balakrishnan, N. Motion Learning and Control For Social Robots In Human-Robot Interaction. Master’s Thesis, The University of Texas at Arlington, Arlington, TX, USA, 2015. [Google Scholar]
- Medsker, L.R.; Jain, L. Recurrent Neural Networks: Design and Applications; CRC Press: Boca Raton, FL, USA, 2001; Volume 5, p. 2. [Google Scholar]
- Sutskever, I.; Martens, J.; Hinton, G.E. Generating text with recurrent neural networks. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 1017–1024. [Google Scholar]
- Balluff, S.; Bendfeld, J.; Krauter, S. Meteorological data forecast using RNN. Int. J. Grid High Perform. Comput. 2017, 9, 61–74. [Google Scholar] [CrossRef]
- Hewamalage, H.; Bergmeir, C.; Bandara, K. Recurrent neural networks for time series forecasting: Current status and future directions. Int. J. Forecast. 2021, 37, 388–427. [Google Scholar] [CrossRef]
- Mishra, R.; Welch, K.C. Towards Forecasting Engagement in Children with Autism Spectrum Disorder using Social Robots and Deep Learning. In Proceedings of the SoutheastCon, Orlando, FL, USA, 1–16 April 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 838–843. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Tsantekidis, A.; Passalis, N.; Tefas, A. Chapter 5—Recurrent neural networks. In Deep Learning for Robot Perception and Cognition; Iosifidis, A., Tefas, A., Eds.; Academic Press: Cambridge, MA, USA, 2022; pp. 101–115. [Google Scholar] [CrossRef]



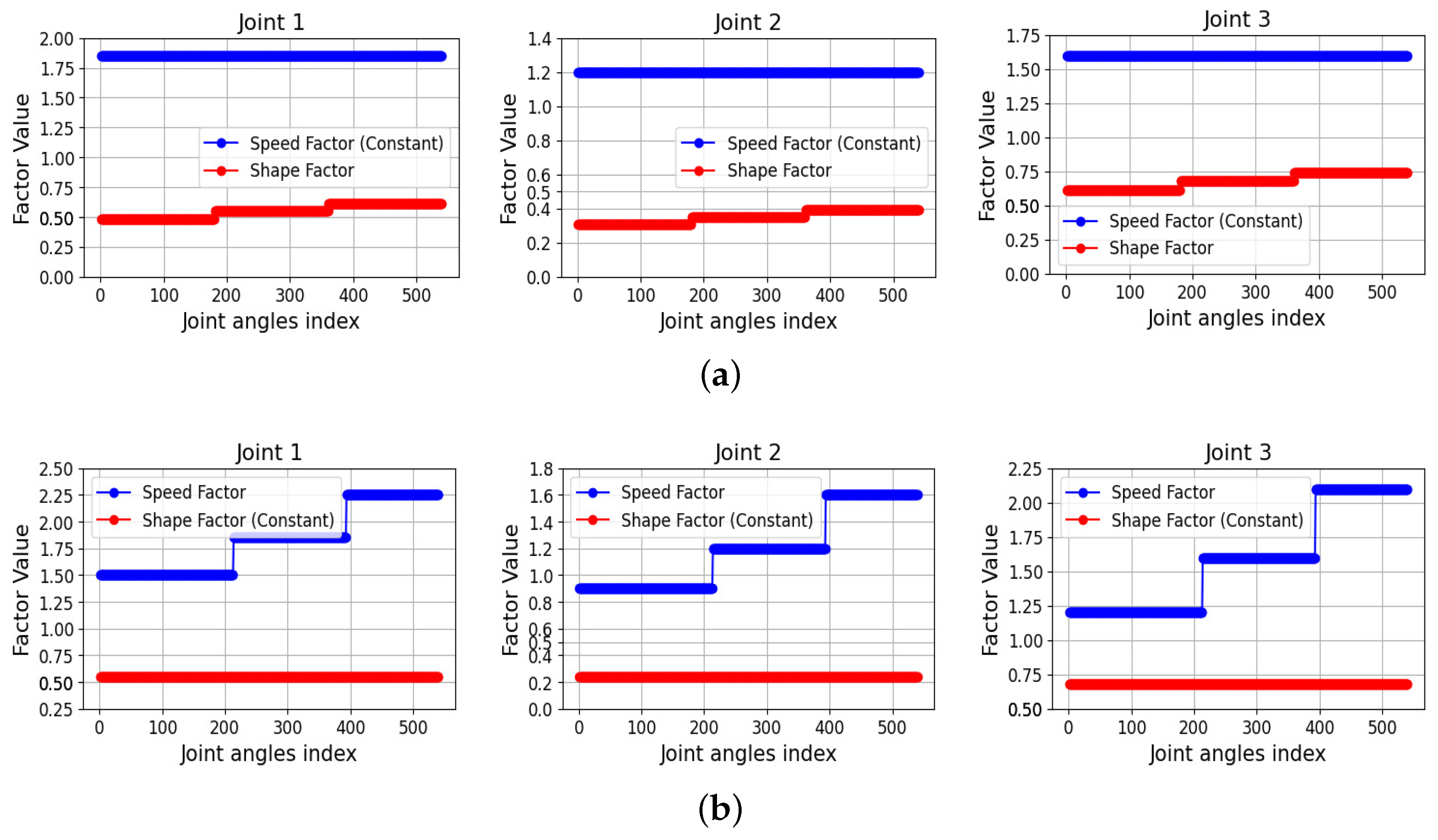


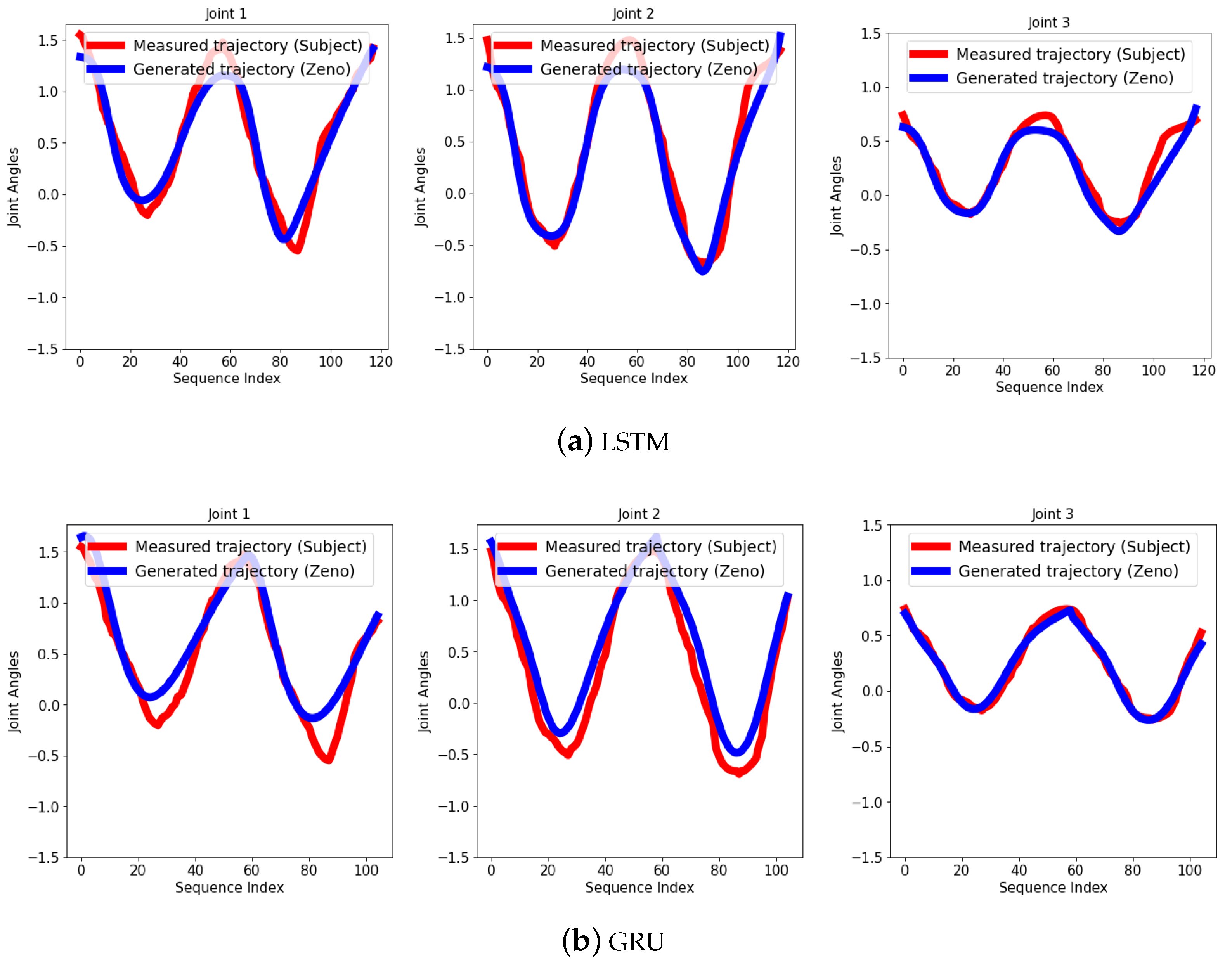


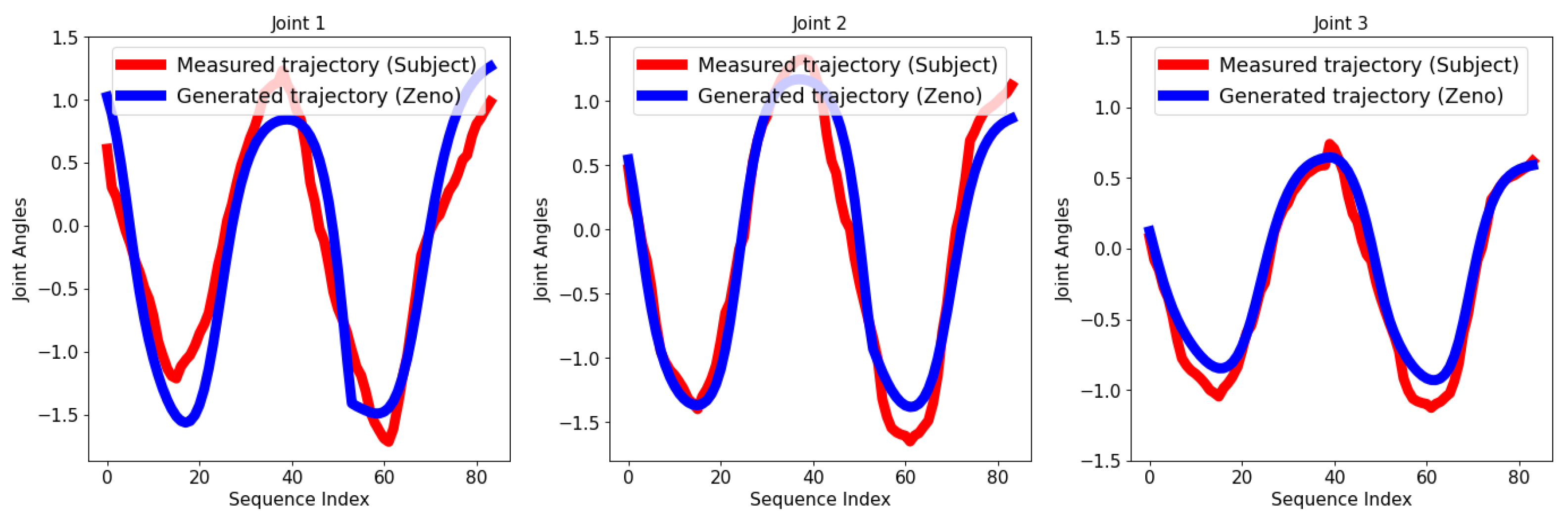

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Joint Angle | Right-Hand Hammer Motion |
|---|---|
| 0.685548411 | |
| 0.592682412 | |
| 0.042457816 | |
| 0.741227326 |
| Task Variation | LSTM | GRU |
|---|---|---|
| Slower speed | 0.060 | 0.076 |
| Faster speed | 0.050 | 0.055 |
| Lower range | 0.043 | 0.046 |
| Higher range | 0.033 | 0.033 |
| Combination (higher range and faster speed) | 0.052 | — |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ashary, A.; Mishra, R.; Rayguru, M.M.; Popa, D.O. MIRA: Multi-Joint Imitation with Recurrent Adaptation for Robot-Assisted Rehabilitation. Technologies 2024, 12, 135. https://doi.org/10.3390/technologies12080135
Ashary A, Mishra R, Rayguru MM, Popa DO. MIRA: Multi-Joint Imitation with Recurrent Adaptation for Robot-Assisted Rehabilitation. Technologies. 2024; 12(8):135. https://doi.org/10.3390/technologies12080135
Chicago/Turabian StyleAshary, Ali, Ruchik Mishra, Madan M. Rayguru, and Dan O. Popa. 2024. "MIRA: Multi-Joint Imitation with Recurrent Adaptation for Robot-Assisted Rehabilitation" Technologies 12, no. 8: 135. https://doi.org/10.3390/technologies12080135
APA StyleAshary, A., Mishra, R., Rayguru, M. M., & Popa, D. O. (2024). MIRA: Multi-Joint Imitation with Recurrent Adaptation for Robot-Assisted Rehabilitation. Technologies, 12(8), 135. https://doi.org/10.3390/technologies12080135