
Analysis, Evaluation, and Future Directions on Multimodal Deception Detection





Abstract
1. Introduction
- To gather and systematically organize the scientific literature on automated multimodal deception detection from videos;
- To provide evidence on important research questions related to (i) features extracted from different modalities, (ii) methods for the fusion of multimodal features, (iii) methods for the classification of fake and true results, and (iv) used datasets;
- To discuss the metrics mainly used for the evaluation of multimodal deception detection;
- To provide a vision of future research directions of multimodal deception detection.
2. Multimodal Deception Detection from Videos
3. Materials and Methods
- RQ1: What are the multimodal features extracted for automated deception detection?
- RQ2: Which methodologies are used for the fusion of multimodal features?
- RQ3: What are the classification algorithms used for multimodal deception detection?
- RQ4: Which datasets are used for the analysis of multimodal deception detection?
- RQ5: Which metrics for the evaluation of multimodal deception detection are used?Which are the best-performing multimodal deception detection methods?
- RQ6: What are the future directions on multimodal deception detection?
- Multimodal features (e.g., visual, audio, textual, temporal, EEG);
- Multimodal fusion techniques;
- Deception detection classification approaches;
- Evaluation datasets, metrics, and scores;
- Future works.
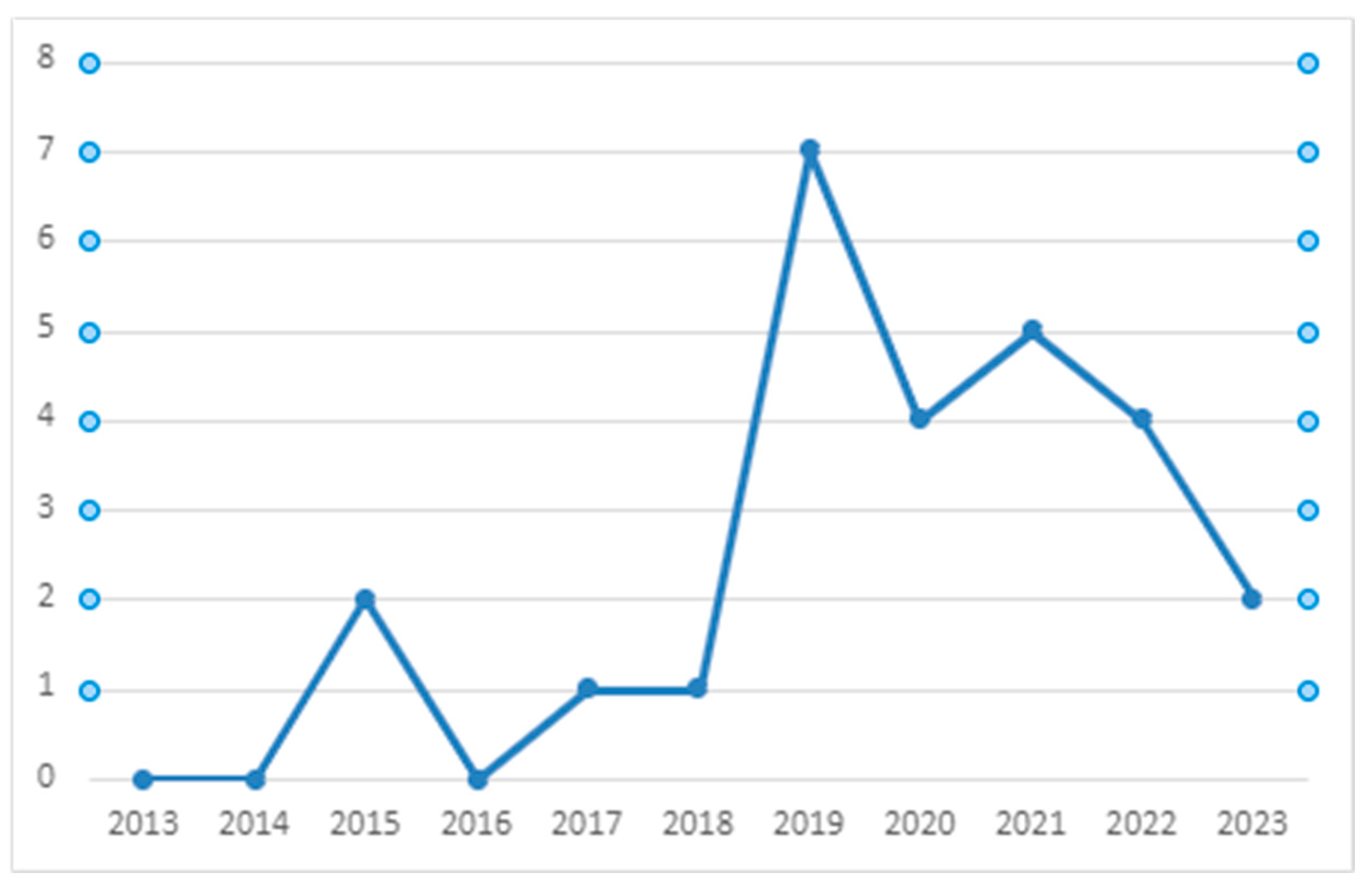
4. Results of the Application of the SLR Methodology
5. Discussion
5.1. Multimodal Features Extracted for Automated Deception Detection
5.2. Methodologies Used for the Fusion of Multimodal Features
5.3. Classification Algorithms for Multimodal Deception Detection
5.4. Datasets for the Analysis of the Multimodal Deception Detection
6. Metrics for the Evaluation of the Multimodal Deception Detection
7. Future Directions on Multimodal Deception Detection
8. Conclusions
- -
- Overcoming the lack of a complete multimodal dataset for use in multimodal deception detection;
- -
- Developing more efficient fusion techniques to produce richer representations of the information;
- -
- Developing explainable frameworks to help better understand and interpret predictions made by multimodal sensing models;
- -
- Developing general and transferable multimodal deception detection models.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- D’Ulizia, A.; D’Andrea, A.; Grifoni, P.; Ferri, F. Detecting Deceptive Behaviours through Facial Cues from Videos: A Systematic Review. Appl. Sci. 2023, 13, 9188. [Google Scholar] [CrossRef]
- Ding, M.; Zhao, A.; Lu, Z.; Xiang, T.; Wen, J.R. Face-focused cross-stream network for deception detection in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7802–7811. [Google Scholar]
- Abouelenien, M.; Perez-Rosas, V.; Mihalcea, R.; Burzo, M. Detecting deceptive behavior via integration of discriminative features from multiple modalities. IEEE Trans. Inf. Forensics Secur. 2016, 12, 1042–1055. [Google Scholar] [CrossRef]
- Wu, Z.; Singh, B.; Davis, L.S.; Subrahmanian, V.S. Deception detection in videos. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- D’Andrea, A.; D’Ulizia, A.; Ferri, F.; Grifoni, P. EMAG: An extended multimodal attribute grammar for behavioural features. Digit. Sch. Humanit. 2015, 32, fqv064. [Google Scholar] [CrossRef]
- D’Andrea, A.; Caschera, M.C.; Ferri, F.; Grifoni, P. MuBeFE: Multimodal Behavioural Features Extraction Method. JUCS J. Univers. Comput. Sci. 2021, 27, 254–284. [Google Scholar] [CrossRef]
- Yang, F.; Ning, B.; Li, H. An Overview of Multimodal Fusion Learning. In Mobile Multimedia Communications. MobiMedia 2022; Chenggang, Y., Honggang, W., Yun, L., Eds.; Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Springer: Cham, Switzerland, 2022; Volume 451. [Google Scholar] [CrossRef]
- D’Ulizia, A. Exploring multimodal input fusion strategies. In Multimodal Human Computer Interaction and Pervasive Services; IGI Global: Hershey, PA, USA, 2009; pp. 34–57. [Google Scholar]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. Int. J. Surg. 2021, 88, 105906. [Google Scholar] [CrossRef] [PubMed]
- Pranckutė, R. Web of Science (WoS) and Scopus: The Titans of Bibliographic Information in Today’s Academic World. Publications 2021, 9, 12. [Google Scholar] [CrossRef]
- Paez, A. Grey literature: An important resource in systematic reviews. J. Evid. Based Med. 2017, 10, 233–240. [Google Scholar] [CrossRef] [PubMed]
- Krishnamurthy, G.; Majumder, N.; Poria, S.; Cambria, E. A deep learning approach for multimodal deception detection. In Proceedings of the International Conference on Computational Linguistics and Intelligent Text Processing, Hanoi, Vietnam, 18–24 March 2018; Springer Nature: Cham, Switzerland, 2018; pp. 87–96. [Google Scholar]
- Mathur, L.; Matarić, M.J. Affect-aware deep belief network representations for multimodal unsupervised deception detection. In Proceedings of the 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), Jodhpur, India, 15–18 December 2021; IEEE: New York, NY, USA, 2021; pp. 1–8. [Google Scholar]
- Chebbi, S.; Jebara, S.B. An Audio-Visual based Feature Level Fusion Approach Applied to Deception Detection. In Proceedings of the 15th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP) 2020, Valletta, Malta, 27–29 February 2020; pp. 197–205. [Google Scholar]
- Bai, C.; Bolonkin, M.; Burgoon, J.; Chen, C.; Dunbar, N.; Singh, B.; Subrahmanian, V.S.; Wu, Z. automatic long-term deception detection in group interaction videos. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; IEEE: New York, NY, USA, 2019; pp. 1600–1605. [Google Scholar]
- Gupta, V.; Agarwal, M.; Arora, M.; Chakraborty, T.; Singh, R.; Vatsa, M. Bag-of-lies: A multimodal dataset for deception detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Sehrawat, P.K.; Kumar, R.; Kumar, N.; Vishwakarma, D.K. Deception Detection using a Multimodal Stacked Bi-LSTM Model. In Proceedings of the International Conference on Innovative Data Communication Technologies and Application (ICIDCA), Dehradun, India, 14–15 March 2023; IEEE: New York, NY, USA, 2023; pp. 318–326. [Google Scholar]
- Chebbi, S.; Jebara, S.B. Deception detection using multimodal fusion approaches. Multimed. Tools Appl. 2021, 82, 13073–13102. [Google Scholar] [CrossRef]
- Pérez-Rosas, V.; Abouelenien, M.; Mihalcea, R.; Burzo, M. Deception detection using real-life trial data. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Motif Hotel, Seattle, WA, USA, 9–13 November 2015; pp. 59–66. [Google Scholar]
- Kopev, D.; Ali, A.; Koychev, I.; Nakov, P. detecting deception in political debates using acoustic and textual features. In Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; IEEE: New York, NY, USA, 2019; pp. 652–659. [Google Scholar] [CrossRef]
- Javaid, H.; Dilawari, A.; Khan, U.G.; Wajid, B. EEG Guided Multimodal Lie Detection with Audio-Visual Cues. In Proceedings of the 2nd International Conference on Artificial Intelligence (ICAI), Islamabad, Pakistan, 30–31 March 2022; IEEE: New York, NY, USA, 2022; pp. 71–78. [Google Scholar]
- Rill-García, R.; Jair Escalante, H.; Villasenor-Pineda, L.; Reyes-Meza, V. High-level features for multimodal deception detection in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Karimi, H. Interpretable multimodal deception detection in videos. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; pp. 511–515. [Google Scholar]
- Mathur, L.; Matarić, M.J. Introducing representations of facial affect in automated multimodal deception detection. In Proceedings of the 2020 International Conference on Multimodal Interaction, New York, NY, USA, 25–29 October 2020; pp. 305–314. [Google Scholar]
- Karnati, M.; Seal, A.; Yazidi, A.; Krejcar, O. LieNet: A deep convolution neural network framework for detecting deception. IEEE Trans. Cogn. Dev. Syst. 2022, 14, 971–984. [Google Scholar] [CrossRef]
- Raj, C.; Meel, P. Microblogs Deception Detection using BERT and Multiscale CNNs. In Proceedings of the 2nd Global Conference for Advancement in Technology (GCAT), Bangalore, India, 1–3 October 2021; IEEE: New York, NY, USA, 2021; pp. 1–6. [Google Scholar]
- Zhang, J.; Levitan, S.I.; Hirschberg, J. Multimodal Deception Detection Using Automatically Extracted Acoustic, Visual, and Lexical Features. In Proceedings of the INterspeech, Shanghai, China, 25–29 October 2020; pp. 359–363. [Google Scholar] [CrossRef]
- Sen, M.U.; Perez-Rosas, V.; Yanikoglu, B.; Abouelenien, M.; Burzo, M.; Mihalcea, R. Multimodal deception detection using real-life trial data. IEEE Trans. Affect. Comput. 2021, 13, 306–319. [Google Scholar] [CrossRef]
- Belavadi, V.; Zhou, Y.; Bakdash, J.Z.; Kantarcioglu, M.; Krawczyk, D.C.; Nguyen, L.; Rakic, J.; Thuriasingham, B. MultiModal deception detection: Accuracy, applicability and generalizability. In Proceedings of the Second IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), Atlanta, GA, USA, 28–31 October 2020; IEEE: New York, NY, USA, 2020; pp. 99–106. [Google Scholar]
- Kamboj, M.; Hessler, C.; Asnani, P.; Riani, K.; Abouelenien, M. Multimodal political deception detection. IEEE Multimed. 2020, 28, 94–102. [Google Scholar] [CrossRef]
- Bai, C.; Bolonkin, M.; Regunath, V.; Subrahmanian, V. POLLY: A multimodal cross-cultural context-sensitive framework to predict political lying from videos. In Proceedings of the 2022 International Conference on Multimodal Interaction, Bengaluru India, 7–11 November 2022; pp. 520–530. [Google Scholar]
- Venkatesh, S.; Ramachandra, R.; Bours, P. Robust algorithm for multimodal deception detection. In Proceedings of the IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019; IEEE: New York, NY, USA, 2019; pp. 534–537. [Google Scholar]
- Mathur, L.; Mataric, M.J. Unsupervised audio-visual subspace alignment for high-stakes deception detection. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: New York, NY, USA, 2021; pp. 2255–2259. [Google Scholar]
- Pérez-Rosas, V.; Abouelenien, M.; Mihalcea, R.; Xiao, Y.; Linton, C.J.; Burzo, M. Verbal and nonverbal clues for real-life deception detection. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2336–2346. [Google Scholar]
- Venkatesh, S.; Ramachandra, R.; Bours, P. Video based deception detection using deep recurrent convolutional neural network. In Proceedings of the Computer Vision and Image Processing: 4th International Conference, CVIP 2019, Jaipur, India, 27–29 September 2019; Revised Selected Papers, Part II. Springer: Singapore, 2020; Volume 4, pp. 163–169. [Google Scholar]
- Karpova, V.; Popenova, P.; Glebko, N.; Lyashenko, V.; Perepelkina, O. “Was It You Who Stole 500 Rubles?”-The Multimodal Deception Detection. In Proceedings of the Companion Publication of the 2020 International Conference on Multimodal Interaction, Virtual, 25–29 October 2020; pp. 112–119. [Google Scholar]
- D’Ulizia, A.; Caschera, M.C.; Ferri, F.; Grifoni, P. Fake news detection: A survey of evaluation datasets. PeerJ Comput. Sci. 2021, 7, e518. [Google Scholar] [CrossRef] [PubMed]
- Lloyd, E.P.; Deska, J.C.; Hugenberg, K.; McConnell, A.R.; Humphrey, B.T.; Kunstman, J.W. Miami University deception detection database. Behav. Res. Methods 2018, 51, 429–439. [Google Scholar] [CrossRef] [PubMed]
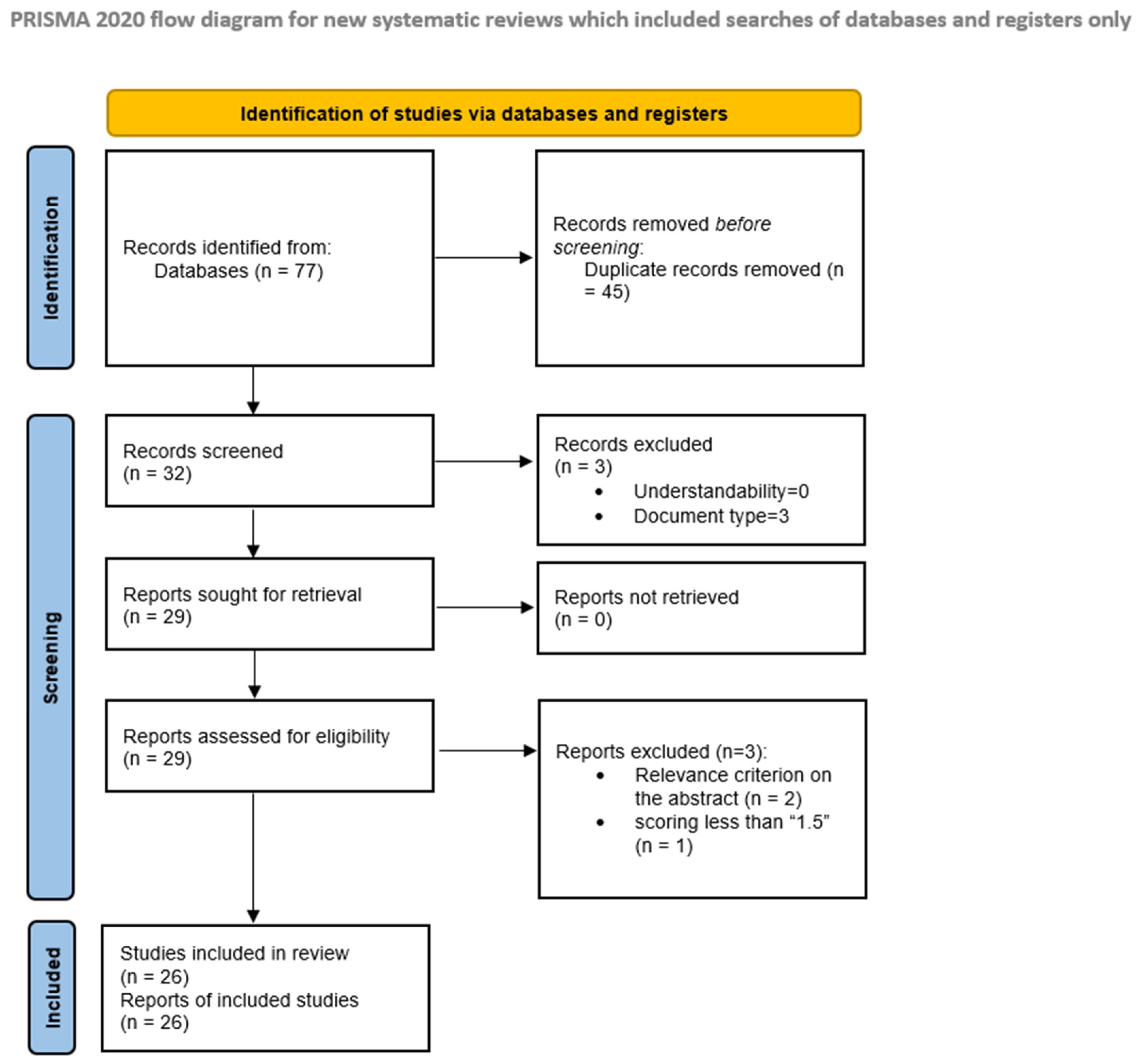

{kind=link}
{kind=link}
| Screening Phase | Eligibility Phase |
|---|---|
| Exclusion Criteria | |
e1. Understandability criterion:
| e3. Availability criterion:
|
| Inclusion criteria | |
i1. Temporal criterion:
| i2. Document type criterion:
|
| Questions of the Quality Evaluation Checklist | Scores |
|---|---|
| Does the article describe the multimodal extracted features? | 1—yes, the extracted multimodal features are fully described. 0.5—partially, the extracted multimodal features are just summarized without further descriptions. 0—no, the extracted multimodal features are not described. |
| Does the article describe the fusion methods? | 1—yes, the fusion methods are fully described. 0.5—partially, the fusion methods are just summarized without further descriptions. 0—no, the fusion methods are not described. |
| Does the article describe the classification algorithm? | 1—yes, the classification algorithm is fully described. 0.5—partially, the classification algorithm is just summarized without further descriptions. 0—no, the classification algorithm is not described. |
| Does the article describe the dataset(s) and metrics for evaluating the method? | 1—yes, both datasets and metrics are described. 0.5—partially, only the dataset(s) or the metrics are described. 0—no, datasets and metrics are not described. |
| Does the article describe the future works? | 1—yes, future works are described. 0—no, future works are not described. |
| Ref. | Short Description | Source Title | Publication Type |
|---|---|---|---|
| [12] | This study proposes a multimodal neural model based on a deep learning approach for multimodal deception detection. | At the 2018 International Conference on Computational Linguistics and Intelligent Text Processing | Conference paper |
| [13] | This study proposes an unsupervised multimodal approach for affect-aware Deep Belief Networks (DBN) to learn discriminative representations of deceptive and truthful behaviors. | From the 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition | Conference paper |
| [14] | This study develops a feature-level fusion approach, combining audio and video modalities to build an automated system that can help in the decision making of honesty or a lie. | 15th International Conference on Computer Vision Theory and Applications 2019 | Conference paper |
| [15] | This study proposes an ensemble-based automated deception detection framework called LiarOrNot for deception detection in group interaction videos. | From the 2019 IEEE International Conference on Multimedia and Expo | Conference paper |
| [16] | This study presents a benchmark multimodal dataset named Bag-of-Lies for deception detection. | From the Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops | Conference paper |
| [17] | This study designed a deception detection system based on a multimodal stacked Bi-LSTM model that discriminates between deceptive and truthful behaviors using text, audio, and video modalities. | From the 2023 International Conference on Innovative Data Communication Technologies and Application | Conference paper |
| [18] | This study investigates several multimodal fusion approaches for automatically distinguishing between deceit and truth based on audio, video, and text modalities. | Multimedia Tools and Applications | Article |
| [19] | This study explores the use of verbal and non-verbal modalities to build a multimodal deception detection system that aims to discriminate between truthful and deceptive statements. | From the Proceedings of the 2015 ACM on international conference on multimodal interaction | Conference paper |
| [20] | This study develops a multimodal deep-learning architecture for detecting deception in political debates, which combines textual and acoustic information. | From the 2019 IEEE Automatic Speech Recognition and Understanding Workshop | Conference paper |
| [21] | This study investigates the importance of visual, acoustic and EEG information on a human subject for a deception detection task. | From the 2022 2nd International Conference on Artificial Intelligence (ICAI) | Conference paper |
| [2] | This study proposes a face-focused cross-stream network (FFCSN) that induces meta learning and adversarial learning into the training process for deception detection in videos. | From the Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition | Conference Paper |
| [22] | This study aims to explore high-level features, extracted from different modalities, which can be interpreted by humans while being useful for the automatic detection of deception in videos. | From the Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops | Conference Paper |
| [23] | This study proposes an end-to-end framework named DEV to detect DEceptive Videos automatically. | From the Proceedings of the 20th ACM international conference on multimodal interaction 2018 | Conference Paper |
| [24] | This study presents a novel analysis of the discriminative power of the facial act for automated deception detection, along with interpretable features from visual, vocal, and verbal modalities. | From the Proceedings of the 2020 International Conference on Multimodal Interaction | Conference paper |
| [25] | This study presents a multimodal deception detection framework named LieNet based on a deep convolution neural network for differentiating between falsehoods and truth. | IEEE Transactions on Cognitive and Developmental Systems | Article |
| [26] | This study proposes a novel framework using BERT and Multiscale CNNs to perform multimodal fake news classifications. | From the 2021 2nd Global Conference for Advancement in Technology | Conference paper |
| [27] | This study tests the use of fully automatically extracted multimodal features for truly automated deception detection. | INTERSPEECH 2020 | Conference paper |
| [28] | This study presents a multimodal system that detects deception in real-life trial data using verbal, acoustic, and visual modalities. | IEEE Transactions on Affective Computing | Article |
| [29] | This study explores the feasibility of applying AI/ML techniques to detect lies in videos using multiple datasets. | From the 2020 Second IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications | Conference paper |
| [30] | This study introduces a novel multimodal dataset for political deception detection. | IEEE MultiMedia | Article |
| [31] | This study proposes an automated multimodal system named POLLY to predict whether a politician is lying in a video using visual, audio and textual features. | From the Proceedings of the 2022 International Conference on Multimodal Interaction | Conference paper |
| [32] | This study proposes a framework for automatic deception detection based on micro expressions, audio, and text data captured from videos. | From the 2019 IEEE Conference on Multimedia Information Processing and Retrieval | Conference paper |
| [33] | This study proposes a multimodal unsupervised transfer learning approach that detects real-world, high-stakes deception in videos without using high-stakes labels. | From the ICASSP 2021 IEEE International Conference on Acoustics, Speech and Signal Processing | Conference paper |
| [34] | This study explores the use of multimodal real-life data for the task of deception detection. | From the Proceedings of the 2015 conference on empirical methods in natural language processing | Conference paper |
| [35] | This study presents a novel technique for video-based deception detection using the deep recurrent convolutional neural network. | From the 2020 Computer Vision and Image Processing: 4th International Conference | Conference paper |
| [36] | This study develops a multimodal neural network for lie detection by videos. | From the Companion Publication of the 2020 International Conference on Multimodal Interaction | Conference paper |
| Ref. | Multimodal Features | ||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Visual (Not Specified) | Visual Features | Audio (Not Specified) | Audio Features | Textual (Not Specified) | Textual Features | Temporal Representation | EEG | ||||||||||||||||||||||||||||||||
| Facial Features | Body Features | ||||||||||||||||||||||||||||||||||||||
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | AA | AB | AC | AD | AE | AF | AG | AH | ||||||
| [12] | X | X | X | ||||||||||||||||||||||||||||||||||||
| [13] | X | X | X | X | X | X | X | X | X | X | |||||||||||||||||||||||||||||
| [14] | X | X | X | X | X | X | X | X | X | X | |||||||||||||||||||||||||||||
| [15] | X | X | X | X | X | X | X | ||||||||||||||||||||||||||||||||
| [16] | X | X | X | X | X | X | X | X | X | ||||||||||||||||||||||||||||||
| [17] | X | X | X | ||||||||||||||||||||||||||||||||||||
| [18] | X | X | X | X | X | X | X | X | X | X | X | ||||||||||||||||||||||||||||
| [19] | X | X | X | X | X | X | X | X | X | X | X | ||||||||||||||||||||||||||||
| [20] | X | X | X | X | |||||||||||||||||||||||||||||||||||
| [21] | X | X | X | X | X | ||||||||||||||||||||||||||||||||||
| [2] | X | X | X | ||||||||||||||||||||||||||||||||||||
| [22] | X | X | X | X | X | X | X | X | |||||||||||||||||||||||||||||||
| [23] | X | X | X | ||||||||||||||||||||||||||||||||||||
| [24] | X | X | X | X | X | X | X | X | X | ||||||||||||||||||||||||||||||
| [25] | X | X | X | X | |||||||||||||||||||||||||||||||||||
| [26] | X | X | |||||||||||||||||||||||||||||||||||||
| [27] | X | X | X | X | X | X | X | X | X | X | |||||||||||||||||||||||||||||
| [28] | X | X | X | X | X | X | X | ||||||||||||||||||||||||||||||||
| [29] | X | X | X | X | X | X | X | X | X | X | X | X | |||||||||||||||||||||||||||
| [30] | X | X | X | X | X | X | X | X | X | X | X | X | X | ||||||||||||||||||||||||||
| [31] | X | X | X | X | X | ||||||||||||||||||||||||||||||||||
| [32] | X | X | X | X | X | X | X | X | X | ||||||||||||||||||||||||||||||
| [33] | X | X | X | ||||||||||||||||||||||||||||||||||||
| [34] | X | X | X | X | |||||||||||||||||||||||||||||||||||
| [35] | X | X | X | X | X | ||||||||||||||||||||||||||||||||||
| [36] | X | X | X | X | |||||||||||||||||||||||||||||||||||
| Combination of Modalities | Ref. |
|---|---|
| Visual—audio—textual (11) (42%) | [12,17,22,23,24,27,28,29,31,32,35] |
| Visual—audio—temporal (1) (4%) | [13] |
| Visual—audio—EEG (3) (12%) | [16,21,25] |
| Visual—audio (5) (19%) | [14,15,18,33,36] |
| Visual—textual (4) (15%) | [19,26,30,35] |
| Visual—temporal (1) (4%) | [2] |
| Audio—textual (1) (4%) | [20] |
| Ref. | What Kind of Multimodal Fusion? | Which Fusion Method? | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model-Independent Fusion | Model-Dependent Fusion | Belief Theory | Deep Belief Networks (DBNs) | Concatenation | Hadamard + Concatenation | Score Level | Probability Avg | Ensemble | Deep Correlation Analysis | Temporally “Informed” | Majority Voting | |||||
| Early Fusion | Intermediate Fusion | Late Fusion | Hybrid Fusion | LSTM Model with Attention | Deep Belief Networks (DBNs) | |||||||||||
| [12] | X | X | X | |||||||||||||
| [13] | X | X | ||||||||||||||
| [14] | X | |||||||||||||||
| [15] | X | |||||||||||||||
| [16] | X | X | ||||||||||||||
| [18] | X | X | X | |||||||||||||
| [20] | X | X | X | X | ||||||||||||
| [21] | X | X | ||||||||||||||
| [2] | X | X | ||||||||||||||
| [22] | X | X | X | X | X | |||||||||||
| [23] | X | |||||||||||||||
| [24] | X | X | X | X | ||||||||||||
| [25] | X | X | ||||||||||||||
| [26] | X | X | X | |||||||||||||
| [28] | X | X | X | |||||||||||||
| [30] | X | |||||||||||||||
| [31] | X | X | ||||||||||||||
| [32] | X | X | ||||||||||||||
| [33] | X | X | X | X | ||||||||||||
| [35] | X | X | X | X | X | |||||||||||
| [36] | X | |||||||||||||||
| Ref. | S vs. U | Neural Networks | K-Nearest Neighborhood | Support Vector Machine | Logistic Regression | SRKDA | Random Forest | Boosting Algorithm | Decision Tree | Gaussian Naive Bayes | ExtraTrees | LightGBM | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MLP NN | Feed-Forward NN | CNN | R-CNN | Multiscale CNN | Long Short-Term Memory | Deep Belief Networks | ||||||||||||
| [12] | S | X | ||||||||||||||||
| [13] | U | X | ||||||||||||||||
| [14] | S | X | ||||||||||||||||
| [15] | S | X | X | X | X | X | ||||||||||||
| [16] | S | X | X | |||||||||||||||
| [17] | S | X | X | |||||||||||||||
| [18] | S | X | ||||||||||||||||
| [19] | S | X | X | |||||||||||||||
| [20] | S | X | X | |||||||||||||||
| [21] | S | X | ||||||||||||||||
| [2] | S | X | ||||||||||||||||
| [22] | S | X | ||||||||||||||||
| [24] | S | X | ||||||||||||||||
| [25] | S | X | ||||||||||||||||
| [26] | S | X | ||||||||||||||||
| [27] | S | X | ||||||||||||||||
| [28] | S | X | X | X | ||||||||||||||
| [29] | S | X | ||||||||||||||||
| [30] | S | X | ||||||||||||||||
| [31] | S | X | X | X | ||||||||||||||
| [32] | S | X | X | X | X | X | ||||||||||||
| [33] | U | X | ||||||||||||||||
| [34] | S | X | X | X | ||||||||||||||
| [35] | S | X | X | |||||||||||||||
| [36] | S | X | X | X | X | X | X | |||||||||||
| Ref. | Dataset | Availability | Size | Source |
|---|---|---|---|---|
| [12] | Real-life trial | Available upon request | 121 videos (61 D/60 T) | “The Innocence Project” website |
| [13] | Real-life trial | Available upon request | 121 videos (61 D/60 T) | “The Innocence Project” website |
| [14] | Real-life trial | Available upon request | 121 videos (61 D/60 T) | “The Innocence Project” website |
| [15] | Resistance dataset | Not available | 185 videos (113 D/172 T) | 5 sites of social games |
| [16] | Bag-of-Lies dataset | Publicly available | 325 recordings (162 D/163 T) | Spontaneous environment |
| [17] | Real-life trial | Available upon request | 121 videos (61 D/60 T) | “The Innocence Project” website |
| Bag-of-Lies dataset | Publicly available | 325 recordings (162 D/163 T) | Spontaneous environment | |
| Miami University Deception Detection Database | Available upon request | 320 videos (160 D/160 T) | Storytelling about social relationships | |
| [18] | Real-life trial | Available upon request | 121 videos (61 D/60 T) | “The Innocence Project” website |
| [19] | Real-life trial | Available upon request | 121 videos (61 D/60 T) | “The Innocence Project” website |
| [20] | CT-FCC-18 corpus | Publicly available | 286 recordings (130 D/93 T/63 HT) | Political debates from Youtube |
| [21] | Bag-of-Lies dataset | Publicly available | 325 recordings (162 D/163 T) | Spontaneous environment |
| [2] | Real-life trial | Available upon request | 121 videos (61 D/60 T) | “The Innocence Project” website |
| [22] | Real-life trial | Available upon request | 121 videos (61 D/60 T) | “The Innocence Project” website |
| Novel Spanish Abortion/Best Friend Database | Not available | 42 videos (21 D/21 T) | Storytelling about social relationships | |
| [23] | Real-life trial | Available upon request | 121 videos (61 D/60 T) | “The Innocence Project” website |
| [24] | Real-life trial | Available upon request | 121 videos (61 D/60 T) | “The Innocence Project” website |
| [25] | Real-life trial | Available upon request | 121 videos (61 D/60 T) | “The Innocence Project” website |
| Bag-of-Lies dataset | Publicly available | 325 recordings (162 D/163 T) | Spontaneous environment | |
| Miami University Deception Detection Database | Available upon request | 320 videos (160 D/160 T) | Storytelling about social relationships | |
| [26] | Twitter dataset | Publicly available | Not available | Tweets from Twitter |
| Sina Weibo dataset | Publicly available | Not available | Microblogs from the authoritative news agency of China, Xinhua News Agency, and Weibo | |
| [27] | Box of Lies corpus | Publicly available | 25 videos | TV shows on Youtube |
| [28] | Real-life trial | Available upon request | 121 videos (61 D/60 T) | “The Innocence Project” website |
| [29] | Real-Life Trial | Available upon request | 121 videos (61 D/60 T) | “The Innocence Project” website |
| Opinion dataset | Not available | Not available | Storytelling of movies | |
| Crime dataset | Not available | Not available | Interviewees under a controlled environment | |
| [30] | Kamboj et al.’s dataset | Not available | 180 videos | Political debates |
| [31] | POLLY dataset | Publicly available | 146 videos (73 D/73 T) | Political speeches |
| [32] | Real-Life Trial | Available upon request | 121 videos (61 D/60 T) | “The Innocence Project” website |
| [33] | Real-life trial | Available upon request | 121 videos (61 D/60 T) | “The Innocence Project” website |
| UR Lying Dataset | Publicly available | 107 videos (63 D/44 T) | controlled game scenarios | |
| [34] | Perez-Rosas et al.’s dataset | Publicly available | 118 video clips | TV shows |
| [35] | Real-Life Trial | Available upon request | 121 videos (61 D/60 T) | “The Innocence Project” website |
| [36] | TRuLie dataset | Available upon request | 10.000 annotated videos | Controlled—mock crime interrogations |
| Ref. | Evaluation Metrics | Obtained Values | Best Performing Method |
|---|---|---|---|
| [12] | ACC | 96.14% | Multilayer perceptron neural network |
| ROC-AUC | 0.9799 | ||
| [13] | AUC | 80% | Deep Belief Networks |
| ACC | 70% | ||
| Precision | 88% | ||
| [14] | ACC | 97% | K-Nearest Neighborhood |
| Precision | 97% | ||
| Recall | 100% | ||
| F1 Score | 94% | ||
| TPR | 94% | ||
| TNR | 100% | ||
| [15] | AUC | 0.705 | Logistic Regression + random forest+ linear SVM + Gaussian Naive Bayes |
| F1 | 0.466 | ||
| FNR | 0.621 | ||
| FPR | 0.142 | ||
| Precision | 0.666 | ||
| Recall | 0.379 | ||
| [16] | ACC | 66.17% | Not available |
| [17] | ACC | 98.1% | CNN + LSTM |
| [18] | ACC | 94% | K-Nearest Neighborhood |
| Precision | 88% | ||
| Recall | 100% | ||
| F1 Score | 94% | ||
| TPR | 100% | ||
| TNR | 87% | ||
| [19] | ACC | 75.2% | Decision trees |
| [20] | Mean Absolute Error (MAE) | 0.67 | Feed-forward neural network |
| Macro-average Mean Absolute Error (MMAE) | 0.69 | ||
| ACC | 51.04 | ||
| Macro-average F1 | 45.07 | ||
| Macro-average Recall (MAR) | 47.25 | ||
| [21] | ACC | 83.5% | CNN |
| Precision | 0.86 | ||
| Recall | 0.82 | ||
| F1-score | 0.83 | ||
| [2] | ACC | 97% | R-CNN |
| AUC | 99.78% | ||
| [22] | AUC ROC | 0.671 | Support vector machine |
| [23] | ACC | 84.16% | N/A |
| [24] | AUC | 0.91 | Support vector machine |
| ACC | 0.84 | ||
| F1-score | 0.84 | ||
| [25] | ACC | 95 | CNN |
| Precision | 96 | ||
| Recall | 94 | ||
| F1 Score | 95 | ||
| [26] | ACC | 73% | Multiscale CNN |
| Precision | 0.870 | ||
| Recall | 0.891 | ||
| F1 Score | 0.878 | ||
| [27] | ACC | 73% | Random forest |
| AUC | 0.77 | ||
| Precision | 0.75 | ||
| Recall | 0.77 | ||
| F1 Score | 0.74 | ||
| [28] | ACC | 83.62% | Feed-forward neural network |
| [29] | ACC | 53% | Random forest |
| AUC | 0.68 | ||
| [30] | ACC | 69% | Decision tree |
| Recall | 75% | ||
| [31] | ACC | 0.628 | Not available |
| AUC | 0.714 | ||
| F1-score | 0.636 | ||
| [32] | ACC | 97% | Linear SVM, SRKDA, LSTM, random forest. |
| [33] | AUC | 0.64 | K-Nearest Neighborhood |
| ACC | 0.60 | ||
| F1-score | 0.69 | ||
| [34] | ACC | 82.14% | SVM |
| [35] | ACC | 100% | R-CNN + LSTM |
| [36] | ACC | 0.675 | LightGBM |
| Balanced accuracy | 0.638 | ||
| Precision | 0.778 | ||
| Recall | 0.739 | ||
| F1 Score | 0.757 |
| Ref. | Future Research Directions |
|---|---|
| [12] |
|
| [13] |
|
| [14] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [30] |
|
| [31] |
|
| [34] |
|
| [36] |
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
D’Ulizia, A.; D’Andrea, A.; Grifoni, P.; Ferri, F. Analysis, Evaluation, and Future Directions on Multimodal Deception Detection. Technologies 2024, 12, 71. https://doi.org/10.3390/technologies12050071
D’Ulizia A, D’Andrea A, Grifoni P, Ferri F. Analysis, Evaluation, and Future Directions on Multimodal Deception Detection. Technologies. 2024; 12(5):71. https://doi.org/10.3390/technologies12050071
Chicago/Turabian StyleD’Ulizia, Arianna, Alessia D’Andrea, Patrizia Grifoni, and Fernando Ferri. 2024. "Analysis, Evaluation, and Future Directions on Multimodal Deception Detection" Technologies 12, no. 5: 71. https://doi.org/10.3390/technologies12050071
APA StyleD’Ulizia, A., D’Andrea, A., Grifoni, P., & Ferri, F. (2024). Analysis, Evaluation, and Future Directions on Multimodal Deception Detection. Technologies, 12(5), 71. https://doi.org/10.3390/technologies12050071