The subsequent subsections outline the details of the architectural design.
4.1. Input Data Representation
Continuous time-series vital sign readings, such as heart rate, blood pressure, oxygen saturation, and respiratory rate, comprise the input data. Each patient would have multiple channels representing various physiological data types.
Let be the input time-series readings, where t is the number of time steps in the sequence, and C is the number of features (also called channels) corresponding to the various vital signals such as heart rate, blood pressure, etc. Every input sample is represented as X = [x1, x2, …, xT], where xt is a vector of vital sign readings at time step t.
The dataset used in this study, the MIMIC II dataset, is a widely recognized resource containing time-series physiological data from over 90 ICU patients, including subjects with diverse medical conditions. For this study, two subjects, Subject 330 and Subject 441, were selected to validate the proposed HATCN-AD model. The dataset includes critical vital sign data such as heart rate, blood pressure (both systolic and diastolic), oxygen saturation, temperature, and respiration rate, which are essential for monitoring the health of elderly individuals. However, there are several considerations regarding the alignment of the dataset with the intended target population—elderly people. The MIMIC II dataset primarily contains data from ICU patients, who may not represent the general elderly population who are not hospitalized. Elderly individuals in non-acute settings might have different physiological patterns than those in intensive care, where the conditions are more severe and the medical interventions are more frequent. Consequently, while the dataset is valuable for developing and testing the model, the model’s generalizability to the broader elderly population, especially in non-ICU settings, may be limited.
4.3. Hybrid Attention-Based Temporal Convolutional Network Architecture
The proposed model incorporates attention mechanisms to address important patterns in the data and Temporal Convolutional Networks (TCNs) to handle sequential data.
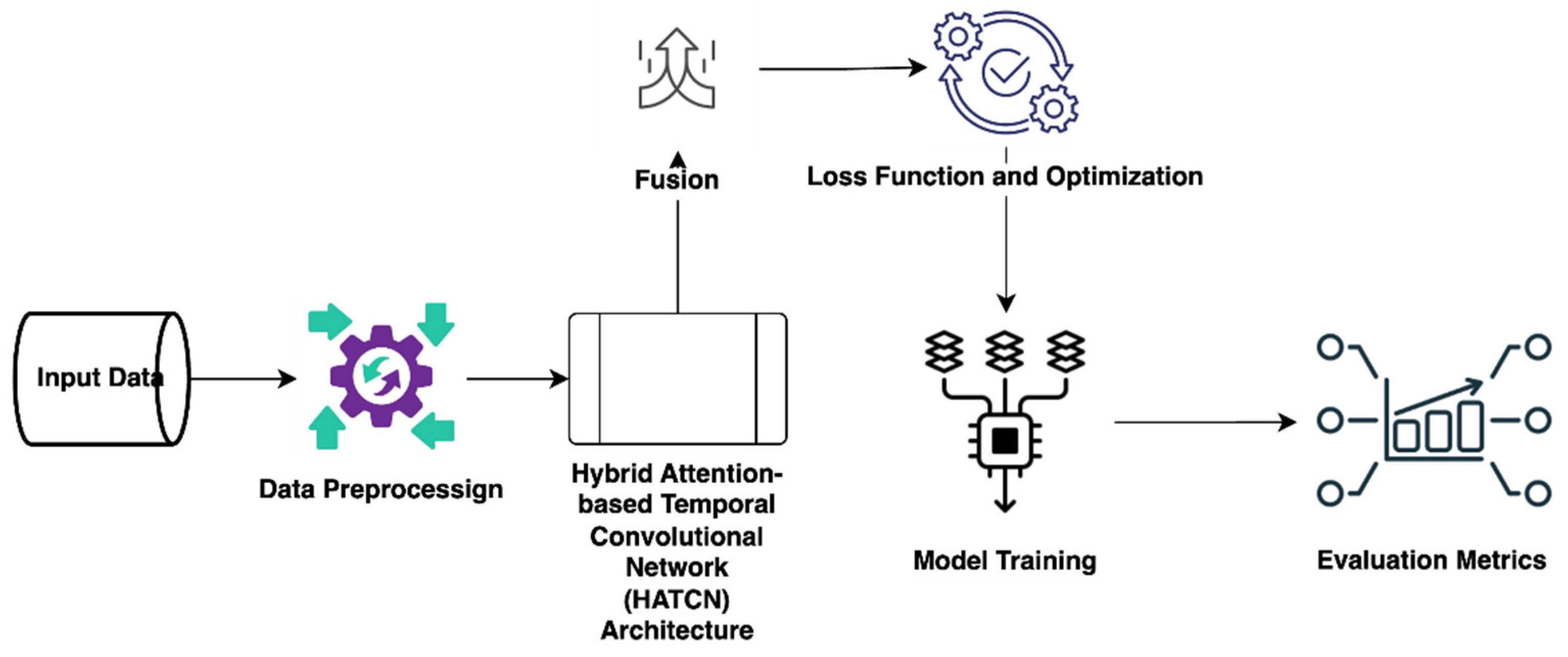
Figure 3 depicts HATCN architecture.
The architecture of the Hierarchical Attention-based Temporal Convolutional Network (HATCN-AD) model, illustrated in
Figure 3, integrates multiple phases designed to process and classify time-series physiological data effectively.
The core elements of this architecture include signal preprocessing, feature extraction using Temporal Convolutional Networks (TCNs), hierarchical attention mechanisms, and a final classification layer. Each phase plays a critical role in extracting meaningful information from the time-series data and ensuring accurate classification of vital signs.
1. Signal preprocessing and spectrogram generation: The initial phase of the architecture emphasizes the preparation of input data, namely time-series vital sign measurements, including heart rate, blood pressure, oxygen saturation, and respiration rate. The continuous physiological signals were extracted from the MIMIC II dataset, comprising data from more than 90 ICU patients. The preprocessing phase includes normalization and handling missing data, ensuring the dataset is in a uniform format appropriate for deep learning models. Upon preprocessing the data, the model produces spectrograms for each input channel (e.g., heart rate, blood pressure). Spectrograms are time-frequency representations enabling the model to examine signals’ temporal and spectral attributes. This method is crucial in time-series data, as it records significant changes over time, facilitating the identification of anomalous patterns and trends in vital signs.
2. Temporal Convolutional Networks (TCNs): Following the generation of the spectrograms, the data are processed by Temporal Convolutional Networks (TCNs). Temporal Convolutional Networks (TCNs) are explicitly engineered to capture temporal dependencies within time-series data. The primary characteristic of TCNs is their utilization of dilated convolutions, enabling the model to expand the receptive field without additional layers. This allows the model to capture long-term temporal dependencies, crucial for monitoring vital signs over long durations. TCNs analyze the spectrograms produced in the prior stage, extracting feature representations that incorporate notable patterns in the time-series data. These feature representations incorporate the temporal properties of physiological signals, which are essential for identifying irregularities in vital signs.
3. Hierarchical attention mechanism: The next phase integrates a hierarchical attention mechanism, enhancing the model’s capacity to focus on relevant details within the data. This technique captures both temporal and channel-specific dependencies, enabling the model to selectively select different components of the time-series data and focus on the most essential information. The attention mechanism is structured in two tiers:
Temporal Attention: This mechanism assigns different weights to the time steps in the sequence, allowing the model to focus on important timestamps and ignore irrelevant ones. By assigning higher attention scores to crucial moments, the model can emphasize significant changes in the vital signs.
Channel Attention: This tier allows the model to focus on the most important vital sign channels (e.g., heart rate, blood pressure) and discard less relevant ones. By assigning different attention weights to each channel, the model can prioritize features more indicative of abnormal health patterns, improving the classification performance. Together, these two attention mechanisms help the model identify both intra- and inter-channel relationships in the physiological data, enabling it to make more informed predictions.
4. Hybrid attention layer: The outputs from the temporal and channel attention mechanisms are integrated into a hybrid attention layer, which combines the information derived from both levels of attention. This hybrid attention layer aggregates the attended temporal and channel aspects, effectively expressing the vital sign data. Integrating these two attention layers guarantees that the model effectively captures significant temporal dynamics and utilizes the most relevant attributes across all channels.
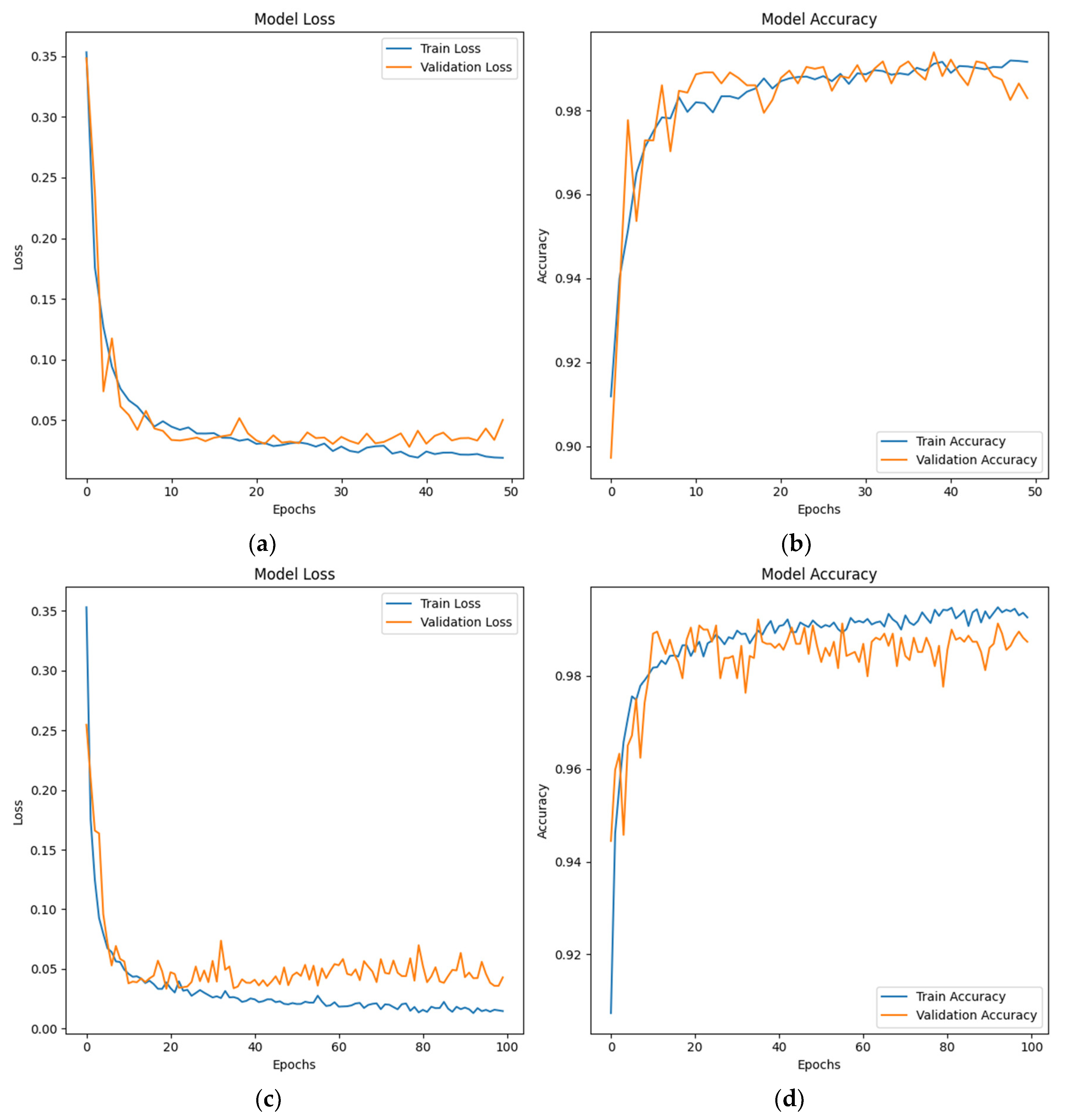
5. Classification: once the hybrid attention layer generates the final feature representation, it is passed through a softmax classification layer for binary classification. The classification task involves determining whether the input signals are normal or abnormal based on the extracted features. The softmax function assigns a probability to each class, and the model classifies the signals as either normal (no anomaly detected) or deviated (anomaly detected) based on the highest probability. This final classification phase enables the model to provide real-time feedback on patient conditions, classifying vital signs and detecting anomalies that may require further medical attention. The following subsections detail the mathematical modeling of the various steps involved in HATCN design.
A. Temporal Convolutional Network (TCN): To capture temporal dependencies, TCN applies dilated convolutions over the time dimension when processing the time series data.
- i.
Dilated Convolutions
The definition of a one-dimensional (1D) dilated convolution at layer
l is represented in Equation (1):
where:
- -
is the output at time step t.
- -
is the index of the kernel, which ranges from 0 to (where is the size of the kernel). Each kernel in the convolution operation is applied to different time steps of the input sequence.
- -
is the convolution filter of size K, which is a kernel size at layer l.
- -
is the dilation factor that grows exponentially with each layer (for example, d = 1, 2, 4, …).
- -
: The dilation factor is multiplied by the kernel index to determine the actual time step shift for each filter weight. This means that for each kernel , the input at time is used in the convolution operation. The higher the dilation factor , the more spread out the kernel is in terms of the time steps it operates over.
- -
is the input from the previous layer at time step t − d.k.
- -
is the bias.
The mission of the dilated convolution is to allow the TCN to have a larger receptive field, which leads to covering more time steps with fewer layers.
- ii.
Residual Connections
Deep network training is stabilized by adding residual connections, which are represented in Equation (2):
where:
- -
is the output following the residual connection at layer l.
- -
is a non-linear activation function, such as ReLU.
B. Attention Mechanism: The attention mechanism enables the model to concentrate on significant portions of the time-series data at the temporal or channel level.
In
temporal attention, the different time stamps in the sequences are assigned different weights. Equation (3) shows how to calculate the attention score for each time step:
where:
- -
is the matrix of learned weights.
- -
is the vector of bias values.
The
softmax function over all time steps is used to compute attention weights, as shown in Equation (4):
where:
- -
represents the weight of attention for each time step t, such that .
The
, which represents the attended temporal context vector, can be calculated as the weighted sum of the time step representations as shown in Equation (5):
The input channels (vital signs) are given varying weights in channel attention. The attention score for each channel is provided, as shown in Equation (6):
where:
- -
are the channels of learned weight matrices.
- -
is the bias term.
The
softmax function is then used to compute the attention weights, as shown in Equation (7):
where:
- -
represents the weight of attention for channel c, such that .
The context vector of the attended channel is calculated by using Equation (8):
C: Hybrid Attention Layer: The outputs of the temporal and channel attention mechanisms are combined in the hybrid attention layer. This is demonstrated in Equation (9):
where:
- -
is the representation of the final attention.
- -
and are the acquired weights used to combine the context vectors for the temporal and channel attention.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}