
Resource Sizing for Virtual Environments of Networked Interconnected System Services



Abstract
1. Introduction
- (1)
- For services of a networked interconnected system that process and transmit data to each other after processing, the problem of minimizing free resources under conditions of unknown ratios of the use of distributed resources between services is formalized.
- (2)
- An experimental approach is proposed for determining the regression dependencies of the consumed resources of each interconnected service on the number of requests. The approach allows for identifying bottlenecks in the system and relationships between the resource usage of other services on the resource usage of the service with the bottleneck, which consumes all the resources allocated to it.
- (3)
- A procedure is proposed that allows for the efficient redistribution of resources in interconnected systems in such a way that all available resources are used to the maximum extent. This is achieved by allocating the maximum possible volume of resources to the bottleneck service, while ensuring that the other services do not become such a bottleneck and have sufficient resources to process a proportional amount of data.
2. Related Works
3. Materials and Methods
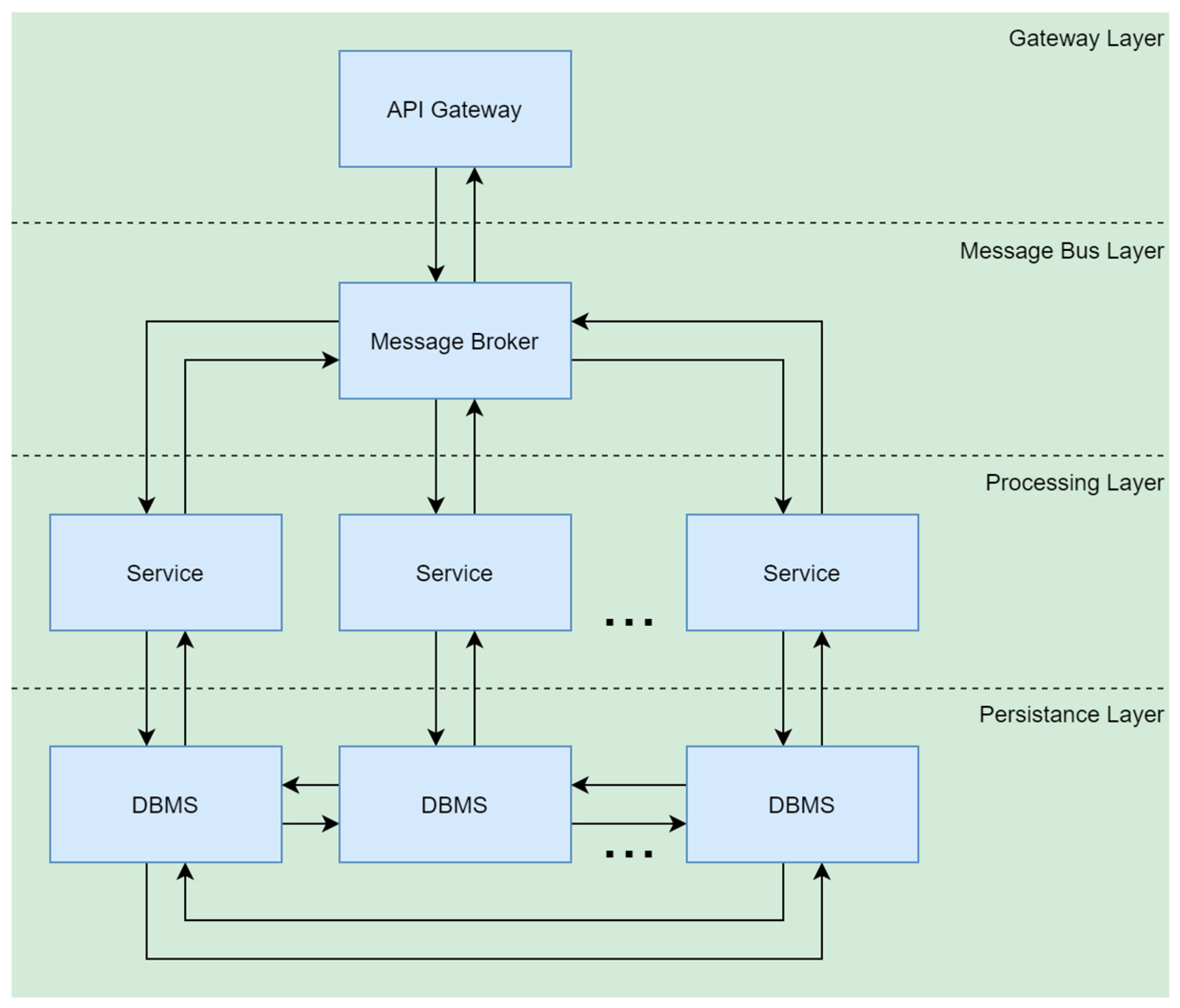
3.1. Networked Interconnected System Model
- CPU: AMD Ryzen 7 3700X 3.6 GHz;
- RAM: 32 GB;
- Disk: Samsung SSD QVO 2TB.
- Host OS: Windows 10 Pro;
- Hypervisor: VirtualBox 6.1.30;
- Guest OS: Ubuntu 20.04.6 LTS.
- DBMS: Apache Cassandra v4.1.3;
- Message Broker: RabbitMQ v3.8.2;
- Processing Service and REST API: Node.js v18.17.1;
- REST API framework: Express.js v4.18.2.
3.2. Resource Allocation Model and Procedure
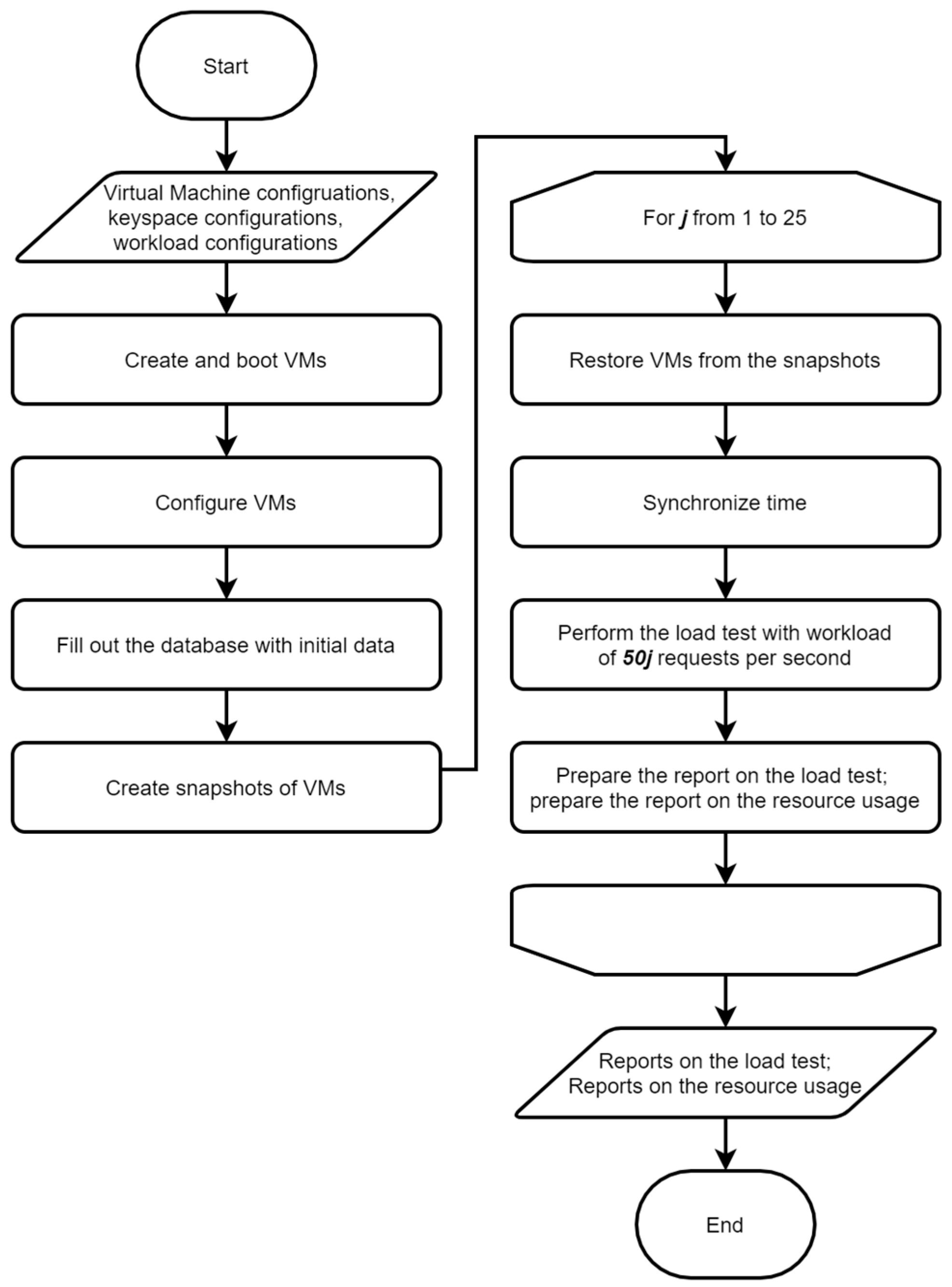
- Implementation of the experimental setup. The setup represents the target networked interconnected system and its components’ virtual environments given the total volume of CPU resources is .
- Preparation of the experimental study algorithm. The algorithm defines the load testing process and target workload corresponding to real requests to the networked interconnected system.
- Performing a series of load tests. These tests imply increasing workload up to the throughput limit under conditions of partitioning into
- Processing of experimental data. Data obtained from the load tests undergo preprocessing and then used for identification of models (1).
- Search for an efficient solution to problem (1)–(3). The search is performed under the conditions of the found dependencies .
- Experimental verification of the theoretical solution. A series of load tests are carried out with the obtained resource partitioning, and the experimental value of the objective function (3) is calculated.
4. Experiment and Results
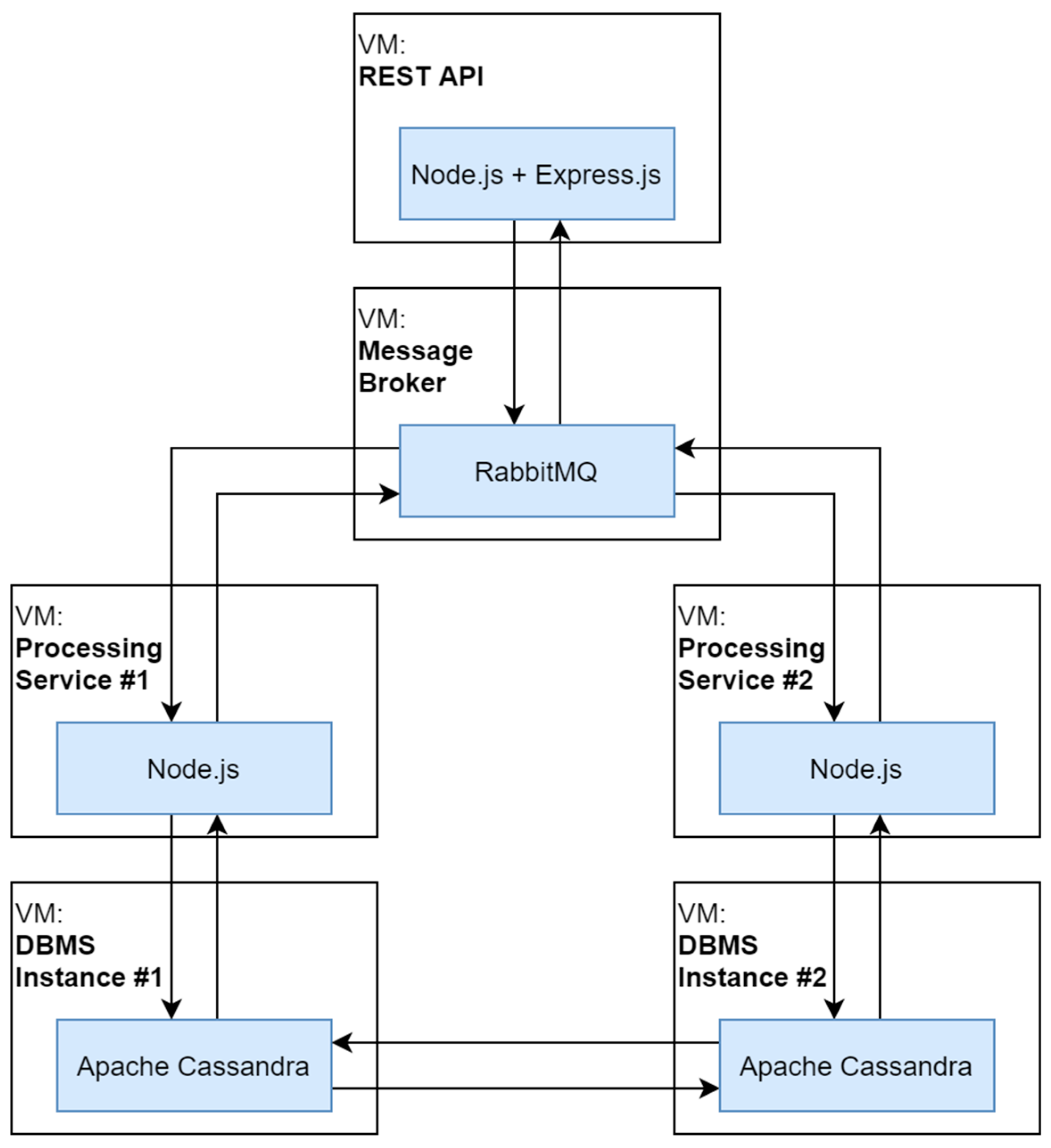
4.1. Implementation of the Experimental Setup
4.2. Preparation of the Experimental Study Algorithm
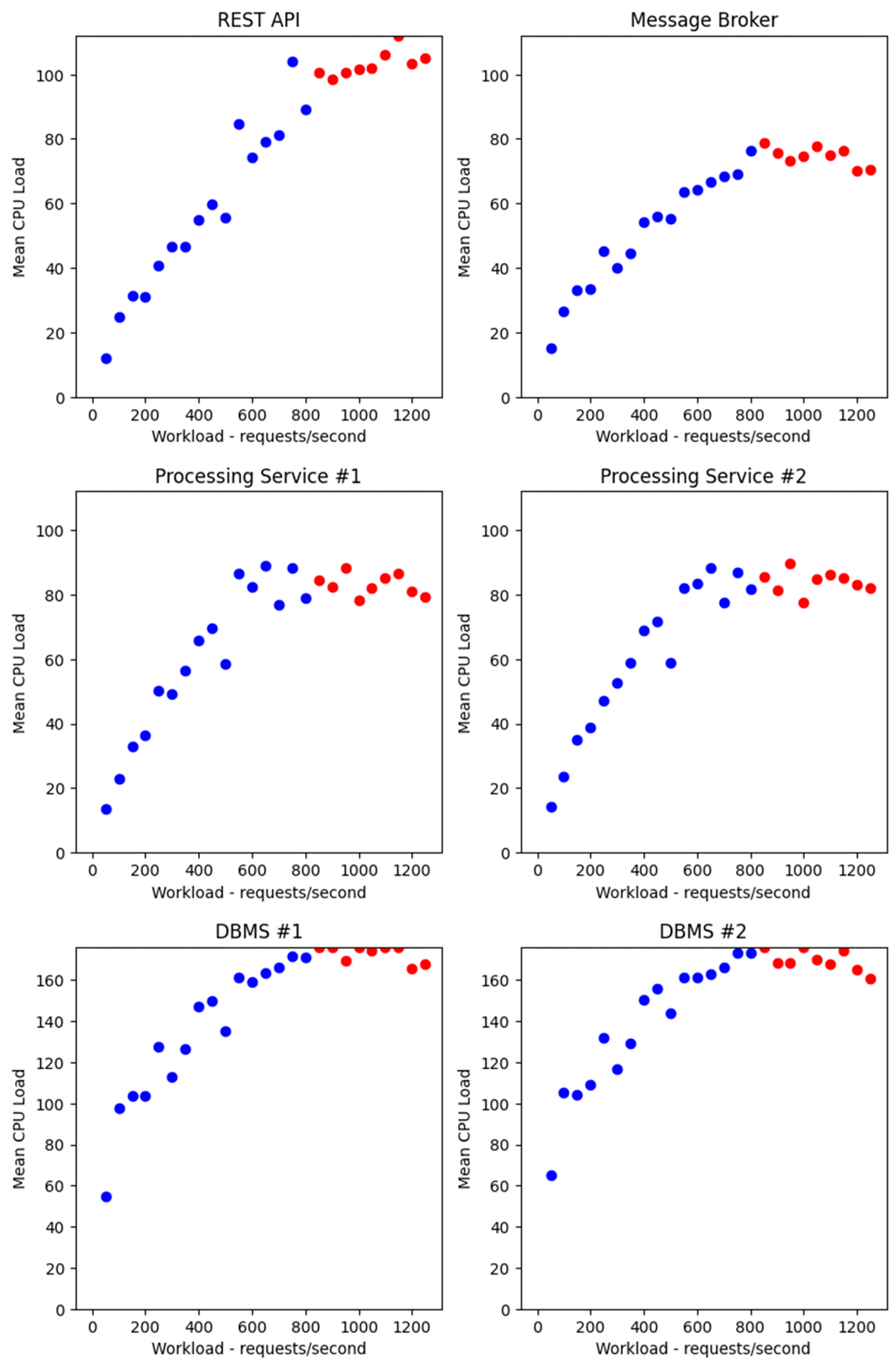
4.3. Performing a Series of Load Tests
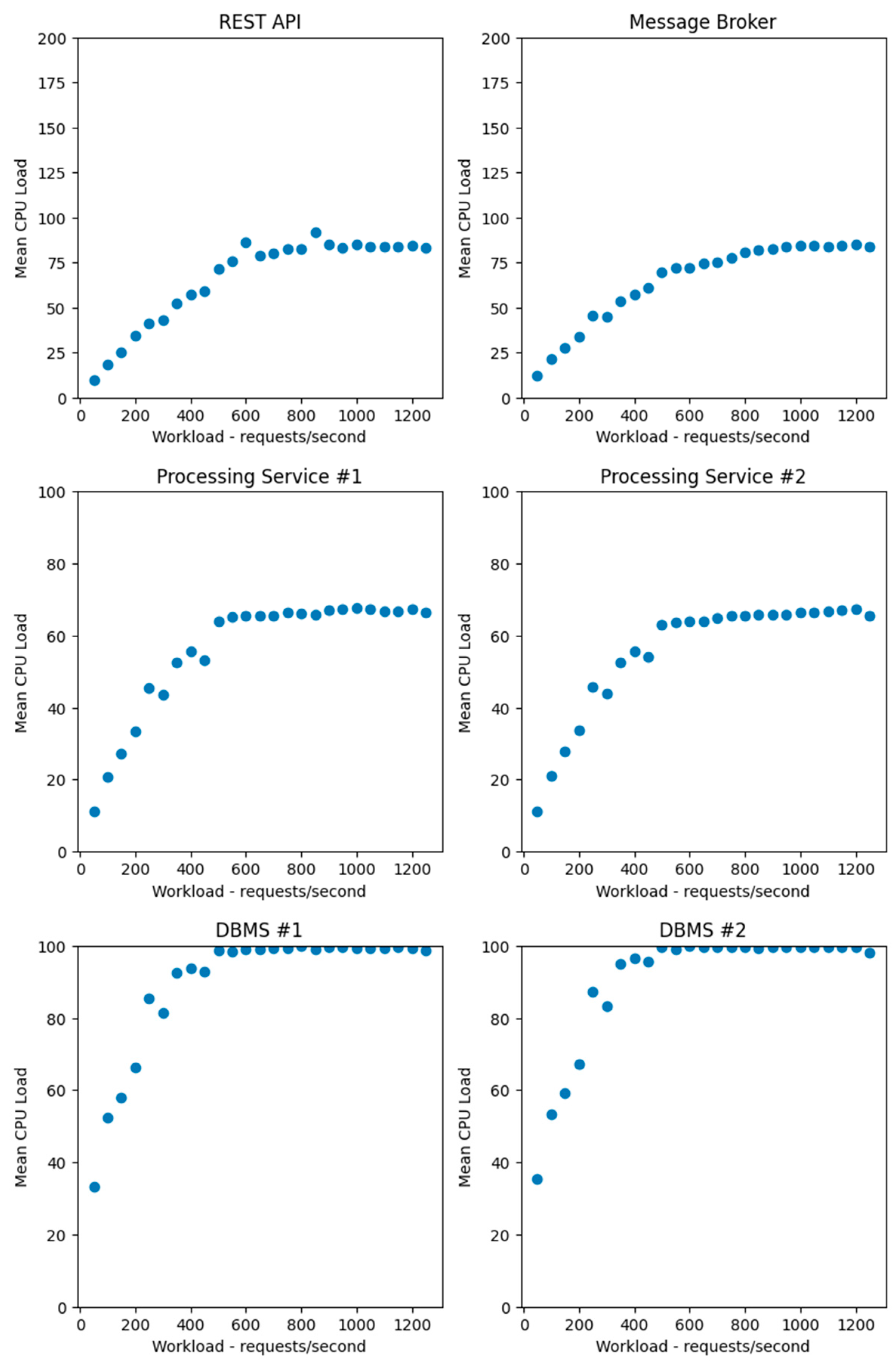
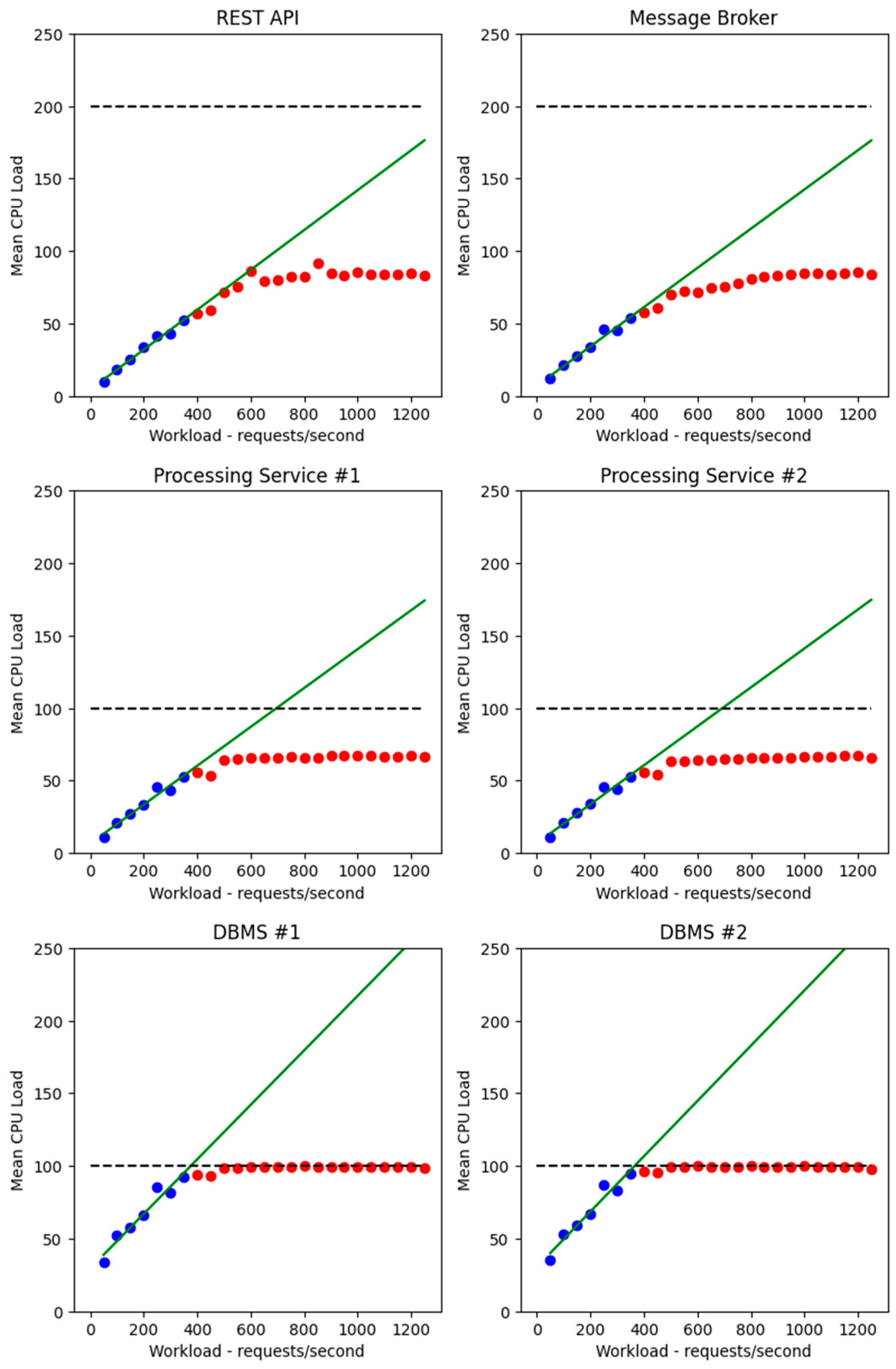
4.4. Processing of Experimental Data
- The missing values were replaced with the values for the previous second.
- A 600 s time frame was detected during which the load was applied, and the remaining measurements were discarded.
- Outliers (negative values and values exceeding the allocated CPU time multiplied by the number of cores) were replaced with values corresponding to the boundaries.
- The mean value was calculated for the CPU usage data.
4.5. Search for an Efficient Solution
4.6. Experimental Verification of the Theoretical Solution
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ullah, A.; Nawi, N.M.; Ouhame, S. Recent advancement in VM task allocation system for cloud computing: Review from 2015 to 2021. Artif. Intell. Rev. 2022, 55, 2529–2573. [Google Scholar] [CrossRef] [PubMed]
- Rawat, P.S.; Dimri, P.; Saroha, G.P. Virtual machine allocation to the task using an optimization method in cloud computing environment. Int. J. Inf. Technol. 2020, 12, 485–493. [Google Scholar] [CrossRef]
- Talebian, H.; Gani, A.; Sookhak, M.; Abdelatif, A.A.; Yousafzai, A.; Vasilakos, A.V.; Yu, F.R. Optimizing virtual machine placement in IaaS data centers: Taxonomy, review and open issues. Clust. Comput. 2020, 23, 837–878. [Google Scholar] [CrossRef]
- Baarzi, A.F.; Kesidis, G. Showar: Right-sizing and efficient scheduling of microservices. In Proceedings of the ACM Symposium on Cloud Computing, Seattle, WA, USA, 1–4 November 2021; pp. 427–441. [Google Scholar]
- Agarwal, P.; Lakshmi, J. Cost aware resource sizing and scaling of microservices. In Proceedings of the 2019 4th International Conference on Cloud Computing and Internet of Things, Changchun, China, 6–7 December 2019. [Google Scholar]
- Rattihalli, G. Exploring potential for resource request right-sizing via estimation and container migration in Apache Mesos. In Proceedings of the 2018 IEEE/ACM International Conference on Utility and Cloud Computing Companion (UCC Companion), Zurich, Switzerland, 17–20 December 2018; pp. 59–64. [Google Scholar]
- Sinha, P.; Kaffes, K.; Yadwadkar, N.J. Online Learning for Right-Sizing Serverless Function Invocations. In Architecture and System Support for Transformer Models (ASSYST @ISCA). 2023. Available online: https://openreview.net/forum?id=4zdPNY3SDQk (accessed on 9 October 2024).
- Eismann, S.; Bui, L.; Grohmann, J.; Abad, C.L.; Herbst, N.R.; Kounev, S. Sizeless: Predicting the optimal size of serverless functions. In Proceedings of the 22nd International Middleware Conference, Québec City, QC, Canada, 6–10 December 2021; pp. 248–259. [Google Scholar]
- Schuler, L.; Jamil, S.; Kühl, N. AI-based resource allocation: Reinforcement learning for adaptive auto-scaling in serverless environments. In Proceedings of the 2021 IEEE/ACM 21st International Symposium on Cluster, Cloud and Internet Computing (CCGrid), Melbourne, Australia, 10–13 May 2021; pp. 804–811. [Google Scholar]
- Gusev, A.; Ilin, D.; Kolyasnikov, P.; Nikulchev, E. Effective selection of software components based on experimental evaluations of quality of operation. Eng. Lett. 2020, 28, 420–427. [Google Scholar]
- Nikulchev, E.; Ilin, D.; Gusev, A. Technology stack selection model for software design of digital platforms. Mathematics 2021, 9, 308. [Google Scholar] [CrossRef]
- Abbasi, A.A.; Abbasi, A.; Shamshirband, S.; Chronopoulos, A.T.; Persico, V.; Pescapè, A. Software-defined cloud computing: A systematic review on latest trends and developments. IEEE Access 2019, 7, 93294–93314. [Google Scholar] [CrossRef]
- Chauhan, S.S.; Pilli, E.S.; Joshi, R.C.; Singh, G.; Govil, M.C. Brokering in interconnected cloud computing environments: A survey. J. Parallel Distrib. Comput. 2019, 133, 193–209. [Google Scholar] [CrossRef]
- Abraham, G.; Aasheesh, K.; Samira, K.; Sihang, L.; Vidushi, D.; Sagar, K.; Jichuan, C.; Krste, A.; Parthasarathy, R. Profiling hyperscale big data processing. In Proceedings of the 50th Annual International Symposium on Computer Architecture, Orlando, FL, USA, 17–21 June 2023; pp. 1–16. [Google Scholar]
- Nguyen, C.N.; Lee, J.; Hwang, S.; Kim, J.S. On the role of message broker middleware for many-task computing on a big-data platform. Clust. Comput. 2019, 22, 2527–2540. [Google Scholar] [CrossRef]
- Blinowski, G.; Ojdowska, A.; Przybyłek, A. Monolithic vs. microservice architecture: A performance and scalability evaluation. IEEE Access 2022, 10, 20357–20374. [Google Scholar] [CrossRef]
- Erdei, R.; Toka, L. Minimizing resource allocation for cloud-native microservices. J. Netw. Syst. Manag. 2023, 31, 35. [Google Scholar] [CrossRef]
- Al-Dhuraibi, Y.; Paraiso, F.; Djarallah, N.; Merle, P. Elasticity in cloud computing: State of the art and research challenges. IEEE Trans. Serv. Comput. 2017, 11, 430–447. [Google Scholar] [CrossRef]
- Kenga, D.M.; Omwenga, V.O.; Ogao, P.J. Autonomous virtual machine sizing and resource usage prediction for efficient resource utilization in multi-tenant public cloud. Int. J. Inf. Technol. Comput. Sci. 2019, 5, 11–22. [Google Scholar] [CrossRef]
- Berg, B.; Harchol-Balter, M.; Moseley, B.; Wang, W.; Whitehouse, J. Optimal resource allocation for elastic and inelastic jobs. In Proceedings of the 32nd ACM Symposium on Parallelism in Algorithms and Architectures, Virtual Event, 15–17 July 2020; pp. 75–87. [Google Scholar]
- Hadary, O.; Marshall, L.; Menache, I.; Pan, A.; Greeff, E.E.; Dion, D.; Dorminey, S.; Joshi, S.; Chen, Y.; Russinovich, M.; et al. Protean: VM allocation service at scale. In Proceedings of the 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), Virtual Event, 4–6 November 2020; pp. 845–861. [Google Scholar]
- Jeong, B.; Jeon, J.; Jeong, Y. Proactive resource autoscaling scheme based on SCINet for high-performance cloud computing. IEEE Trans. Cloud Comput. 2023, 11, 3497–3509. [Google Scholar] [CrossRef]
- Fawwaz, D.Z.; Chung, S.H.; Ahn, C.W.; Kim, W.S. Optimal distributed MQTT broker and services placement for SDN-edge based smart city architecture. Sensors 2022, 22, 3431. [Google Scholar] [CrossRef]
- Chin, K.; Zhao, J.; Shan, E.; Zong, Z. Using virtual machine size recommendation algorithms to reduce cloud cost. J. Stud. Res. 2022, 11, 1–10. [Google Scholar] [CrossRef]
- Delul, P.Y.; Griffith, R.; Holler, A.M.; Shankari, K.; Zhu, X.; Soundararajan, R.; Jagadeeshwaran, A.; Padala, P. Crowdsourced resource-sizing of virtual appliances. In Proceedings of the 2014 IEEE 7th International Conference on Cloud Computing, Anchorage, AK, USA, 27 June–2 July 2014; pp. 801–809. [Google Scholar]
- Osypanka, P.; Nawrocki, P. QoS-aware cloud resource prediction for computing services. IEEE Trans. Serv. Comput. 2023, 16, 1346–1357. [Google Scholar] [CrossRef]
- Rampérez, V.; Soriano, J.; Lizcano, D.; Lara, J.A. FLAS: A combination of proactive and reactive auto-scaling architecture for distributed services. Future Gener. Comput. Syst. 2021, 118, 56–72. [Google Scholar] [CrossRef]
- Fard, M.V.; Sahafi, A.; Rahmani, A.M.; Mashhadi, P.S. Resource allocation mechanisms in cloud computing: A systematic literature review. IET Softw. 2020, 14, 638–653. [Google Scholar] [CrossRef]
- Li, X.; Fan, Z.; Wang, S.; Qiu, A.; Mao, J. A Distributed fault diagnosis and cooperative fault-tolerant control design framework for distributed interconnected systems. Sensors 2022, 22, 2480. [Google Scholar] [CrossRef]
- Abhishek, M.K. Dynamic Allocation of high performance computing resources. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 3538–3543. [Google Scholar] [CrossRef]
- Karabutov, N.N. On identification of interconnected systems. Russ. Technol. J. 2024, 12, 63–76. [Google Scholar] [CrossRef]
- Yang, G.; Lee, K.; Lee, K.; Yoo, Y.; Lee, H.; Yoo, C. Resource analysis of blockchain consensus algorithms in Hyperledger Fabric. IEEE Access 2022, 10, 74902–74920. [Google Scholar] [CrossRef]
- Albychev, A.S.; Kudzh, S.A. Development of a research environment for the operational and computational architecture of central bank digital currency software. Russ. Technol. J. 2023, 11, 7–16. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Virtual Machine | CPU, Cores | CPU Time per Core, Clock Ticks | RAM, GB |
|---|---|---|---|
| Load Generator | 4 | 100 | 2 |
| REST API | 2 | 100 | 1 |
| Message Broker | 2 | 100 | 1 |
| Processing Service #1 | 1 | 100 | 1 |
| Processing Service #2 | 1 | 100 | 1 |
| DBMS #1 | 1 | 100 | 2 |
| DBMS #2 | 1 | 100 | 2 |
| Workload, Requests/Second | Actual Throughput, Requests/Second | Mean Response Time, Milliseconds | Free CPU Resources, Clock Ticks |
|---|---|---|---|
| 50 | 48.9051 | 42.6043 | 686.4758 |
| 100 | 98.8906 | 39.9333 | 612.7913 |
| 150 | 148.1972 | 59.1269 | 575.4825 |
| 200 | 198.2722 | 72.2949 | 531.6661 |
| 250 | 247.9629 | 58.7410 | 449.0985 |
| 300 | 296.8385 | 92.6427 | 460.0634 |
| 350 | 347.3128 | 97.2142 | 401.4007 |
| 400 | 395.1900 | 122.1140 | 383.8948 |
| 450 | 446.3347 | 131.2374 | 383.9199 |
| 500 | 495.5722 | 187.7537 | 333.1636 |
| 550 | 538.6977 | 245.3518 | 325.2988 |
| 600 | 584.8866 | 293.5404 | 313.1035 |
| 650 | 618.4665 | 341.9627 | 318.1386 |
| 700 | 650.8521 | 375.7756 | 314.9316 |
| 750 | 686.7718 | 391.2822 | 308.6244 |
| 800 | 702.3511 | 426.1200 | 305.4608 |
| 850 | 725.1637 | 443.6361 | 296.0067 |
| 900 | 748.6596 | 460.2285 | 299.8197 |
| 950 | 741.6275 | 497.8828 | 300.5392 |
| 1000 | 772.2201 | 504.2026 | 296.8865 |
| 1050 | 757.0539 | 544.1691 | 298.8247 |
| 1100 | 767.0819 | 564.1533 | 299.7629 |
| 1150 | 743.3609 | 610.2197 | 298.7930 |
| 1200 | 781.5163 | 605.7285 | 296.4407 |
| 1250 | 778.3480 | 634.0605 | 304.0968 |
| Virtual Machine | CPU, Cores | CPU Time per Core, Clock Ticks | RAM, GB |
|---|---|---|---|
| Load Generator | 4 | 100 | 2 |
| REST API | 2 | 56 | 1 |
| Message Broker | 2 | 56 | 1 |
| Processing Service #1 | 2 | 56 | 1 |
| Processing Service #2 | 2 | 56 | 1 |
| DBMS #1 | 2 | 88 | 2 |
| DBMS #2 | 2 | 88 | 2 |
| Workload, Requests/Second | Actual Throughput, Requests/Second | Mean Response Time, Milliseconds | Free CPU Resources, Clock Ticks |
|---|---|---|---|
| 50 | 44.5947 | 80.3336 | 625.3823 |
| 100 | 95.8191 | 55.7040 | 498.8047 |
| 150 | 142.6736 | 66.7153 | 459.1553 |
| 200 | 180.5712 | 104.2168 | 447.6678 |
| 250 | 230.4296 | 100.8436 | 357.0985 |
| 300 | 282.3206 | 116.5228 | 382.0050 |
| 350 | 330.2252 | 127.4006 | 337.4591 |
| 400 | 377.1159 | 128.9022 | 258.7780 |
| 450 | 421.4804 | 146.0458 | 236.8214 |
| 500 | 403.5352 | 228.8908 | 292.7713 |
| 550 | 519.8181 | 177.2931 | 160.4925 |
| 600 | 561.9751 | 187.0312 | 175.2788 |
| 650 | 608.3979 | 205.0485 | 150.8915 |
| 700 | 636.0103 | 233.9468 | 163.4007 |
| 750 | 697.7407 | 260.1756 | 106.6694 |
| 800 | 724.9086 | 287.0579 | 129.5342 |
| 850 | 820.8133 | 282.3659 | 78.2204 |
| 900 | 824.8766 | 304.6717 | 111.2504 |
| 950 | 859.3860 | 334.1597 | 110.3372 |
| 1000 | 870.2509 | 365.6972 | 114.9599 |
| 1050 | 900.5932 | 385.3228 | 108.6795 |
| 1100 | 936.5267 | 409.8609 | 102.7496 |
| 1150 | 954.2838 | 422.1929 | 84.8564 |
| 1200 | 938.4528 | 474.1304 | 131.6711 |
| 1250 | 939.8610 | 500.5904 | 135.0634 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Albychev, A.; Ilin, D.; Nikulchev, E. Resource Sizing for Virtual Environments of Networked Interconnected System Services. Technologies 2024, 12, 245. https://doi.org/10.3390/technologies12120245
Albychev A, Ilin D, Nikulchev E. Resource Sizing for Virtual Environments of Networked Interconnected System Services. Technologies. 2024; 12(12):245. https://doi.org/10.3390/technologies12120245
Chicago/Turabian StyleAlbychev, Alexandr, Dmitry Ilin, and Evgeny Nikulchev. 2024. "Resource Sizing for Virtual Environments of Networked Interconnected System Services" Technologies 12, no. 12: 245. https://doi.org/10.3390/technologies12120245
APA StyleAlbychev, A., Ilin, D., & Nikulchev, E. (2024). Resource Sizing for Virtual Environments of Networked Interconnected System Services. Technologies, 12(12), 245. https://doi.org/10.3390/technologies12120245