1. Introduction
The deep learning (DL) approach is one of the most successful machine learning (ML) paradigms, producing outstanding results on several complex cognitive tasks [
1,
2]. Training a deep learning model, however, usually requires an enormous amount of data. Even when the dataset is large enough to allow for effective training, such data will be finite and noisy, inevitably leading to issues such as overfitting. However, when addressing the dynamics of a physical system, there is often prior knowledge about its behavior and the laws that shape it, usually in the form of a system of integro-differential equations.
Physics-informed neural networks [
3] are a promising tool to discover and address the parametrization of a system governed by partial differential equations (PDEs) or integro-differential equations [
4]. This rather new family of models has already shown success in a plethora of different fields [
5,
6], thanks to their ability to learn the implicit solution of a PDE even when given little to no data [
7]. It allows to build models able to more efficiently simulate those systems and even to discover new physics [
8]. Furthermore, integrating the physical knowledge of the system in the training process allows to prevent overfitting. They have been widely applied in fluid dynamics [
8,
9,
10], where, among many other things, they have been used in predictive large-eddy-simulation wall modeling, to obtain a model with improved extrapolation capabilities to flow conditions that are not within the training data. Unknown physics has been discovered by improving on empirical models for viscosity in non-Newtonian fluids. There, the PINN model removes an unphysical singularity present in the empirical one. In astrophysics [
11], they have been used to compute the first quasinormal modes of the Kerr geometry via the Teukolsky equation. The resulting model allows to compute the oscillation frequencies and the damping times for arbitrary black hole spins and masses. They have also been employed in scattering in composite optical materials [
12], reconstruction of top quark kinematic properties [
13], and to compute the electronic density in complex molecular systems [
14]. However, in all the aforementioned cases, the physics has just been used as a way to augment experimental data. The approach explained in this paper is rather different. Here, the aim is to solve Schrödinger’s equation for a system given its governing potential, in an unsupervised way.
Previously, some of us have developed both supervised [
15,
16,
17] and unsupervised [
18] machine learning methods, including supervised quantum machine learning to address ground state classification [
19,
20,
21] of a physical system. The quantum anharmonic oscillator, typically used to describe the quantum dynamics of the Josephson junctions in superconducting qubits, has been addressed despite being non-integrable [
7]. Following this latter approach, we aim to formalize the unsupervised solution of Schrödinger’s equation [
22] and explore the potential of physics-informed neural networks (PINNs) for solving partial differential equations (PDEs) as a paramount representative application to nontrivial physical phenomena.
This tutorial explains how to apply unsupervised PINNs to Schrödinger’s equation of a quantum mechanical system in a self-consistent way, in order to find both the ground state and the excited states of it. As an illustrative embodiment of this method, the infinite potential well and the particle in a ring are solved [
23]. This tutorial is structured as follows: In
Section 2, we explain how to build the PINN and, in particular, its loss function. Then, in
Section 3, we show how to evaluate the training of the model to tune its hyperparameters in a more informed way. Lastly, in
Section 4, we solve the two systems that exemplify the method.
2. Materials and Methods
In this section, we explain how to build a PINN and how to design the loss function and to apply heuristics to optimize the network’s hyperparameters. First,
Section 2.1 contains in a concise form the required background information on artificial neural networks and deep learning. Then, in
Section 2.3, we give a detailed explanation of what a PINN is and how to build it, and the auxiliary output method used to calculate the normalization is explained. Afterwards, in
Section 2.4, we explain how to analyze the problem to understand the best possible way to encode the physics in the loss function of the PINN. After that, in
Section 2.5, we show how to enforce the physical constraints of the system, such as the normalization and boundary conditions. After those sections, the reader should have gained a picture of the main losses needed to find an eigenstate for the given potential. More work is, however, required to find the corresponding eigenvalue. In
Section 2.6, we show how to find the energy by solving the equation in a self-consistent way. Next, the problem of inducing the PINN to converge to a specific eigenstate is addressed. In particular,
Section 2.7 demonstrates how to build a series of PINNs where the first predicts the ground state of the system while each subsequent network predicts the next state, in order of increasing energy. At this point, the problem has been set up. The next sections show how to build the best possible computational framework to solve it: In
Section 2.8, it is explained how to set the best weights, which are given special attention since those are the main hyperparameters to tune for the PINN. Then, in
Section 2.9, we introduce a method to choose the best set of training points, and in
Section 2.10, how to choose the computational domain. Lastly,
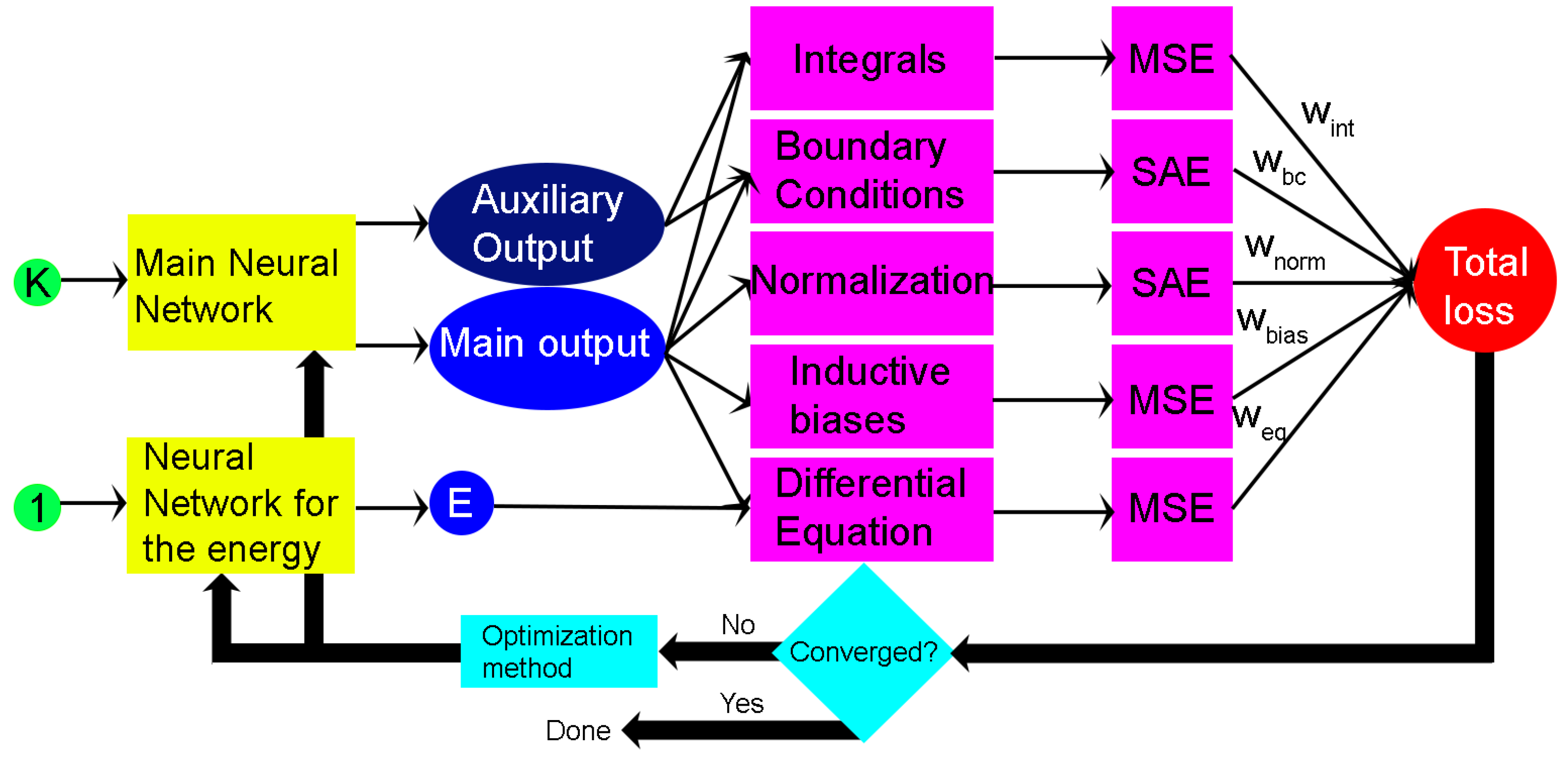
Section 2.11 gives some pointers on how to best build the actual network, with the number of neurons, hidden layers, activation function, and loss metrics. This pipeline is summarized in
Figure 1.
2.1. Neural Networks and Deep Learning
This section gives a broad qualitative overview of the basic tools needed for this tutorial, namely, deep neural networks. The information here has been largely taken from Refs. [
24,
25]. Artificial neural networks are information processing systems whose structure and operation principles are inspired by the nervous system and the brain of animals and humans. They consist of a large number of fairly simple units, the so-called neurons, which are working in parallel. These neurons communicate by sending information in the form of activation signals, along directed connections, to each other. Deep learning algorithms face a series of challenges to train them effectively. For instance, one of the most common issues is the problem of overfitting. With a larger number of hidden neurons, a neural network may adapt not only to the regular dependence between outputs and inputs we try to capture, but also to the accidental specifics (and thus also the errors and deviations) of the training dataset. This is usually called overfitting. Overfitting will usually lead to the effect that the error a neural network with many hidden neurons yields on the validation data (a second dataset whose labels are known that is not employed in training but only to obtain a more accurate estimate of the error of the network) will be greater than the error on the training data. This is due to the fact that the validation dataset is likely distorted in a different fashion, since the errors and deviations are random. Furthermore, while DL methods are known to be extremely effective when immense amounts of data are available, this availability is not a given in all circumstances. For instance, the data might be costly to obtain. Or they might be tied to the observation of some phenomenon that cannot be replicated at will and is not common enough to allow the training of a DL model that relies on big data. PINNs aim to address both the problem of data availability and to mitigate overfitting by making use of the underlying physics of the system.
Mathematically, an artificial neural network is a (directed) graph
whose vertices
are called neurons or units and whose edges
are called connections. The set
U of vertices is divided into the set
of input neurons, the set
of output neurons, and the set
of hidden neurons. These sets must fulfill the following conditions:
Each connection
carries a weight
and to each neuron
three real-valued quantities are assigned: the network input
, the activation
, and the output
. In addition, each input neuron
has a fourth quantity, the external input
. Each neuron
also possesses three functions:
with which the network input
, the activation
, and the output
of the neuron u are computed.
and
depend on the type and the number of arguments of the functions. The neurons are divided into input, output, and hidden neurons in order to specify which neurons receive input from the environment (input neurons) and which emit output to the environment (output neurons). The remaining neurons have no contact with the environment (but only with other neurons) and thus are “hidden”. To operate, for each neuron of the neural network, the network input function
computes the network input
from the inputs
, … ,
(which correspond to the outputs
, … ,
of the predecessors of the neuron
u) and the connection weights
, … ,
. This computation may be influenced by additional parameters. The activation function
computes the new activation
of the neuron
u. Finally, the output of the neuron
u is computed by the output function
from its activation. Note that the choice of the activation function, in particular, can greatly influence the convergence of the network. The network’s parameters can be determined by training it utilizing gradient descent and back-propagation. The idea is that we aim to train the network’s parameters so that they minimize a function, the loss function, that quantifies the distance from the network’s output and the desired output. By choosing a sufficiently smooth activation function (i.e., the logistic function or
), it is possible to compute the gradient of the loss with respect to the parameters. Then, by changing the parameters in the inverse direction to this gradient, we can minimize the loss function. This also means that we need a differentiable function that has a non-vanishing derivative in at least a sufficiently large region, where it provides direction information. However, computing this gradient for a deep neural network is not trivial. It requires a method to compute the derivatives of the outputs (and, therefore, of the loss) with respect to the weights of both the output layers and the hidden layers. This method is called error back-propagation. It exploits the chain rule to obtain a layer-wise recursion formula for computing the derivatives of the neurons of the hidden layers. Note that this method can easily be extended to compute the derivative of the outputs with respect to the inputs, which is crucial for training PINNs.
2.2. Materials
Due to the pedagogical nature of this article, we decided to not use examples that require expensive computational resources. Therefore, all the results in the paper are reproducible using a laptop with an NVIDIA GeForce RTX 3060 Laptop GPU.
2.3. Physics-Informed Neural Networks
In this section, we revise the ideas behind a generic physics-informed neural network. The particular kind of PINN used here is then detailed for solving Schrödinger’s equation, the A-PINN [
4] (physics-informed neural network with auxiliary output). Physics-informed neural networks [
3], or PINNs, are a category of neural networks that aim to solve partial differential equations by encoding prior knowledge about the physical system, most importantly the differential equation itself, in their loss function. This loss can be written as:
is the standard loss for a neural network: take a set of
N training points
with
and the corresponding labels
, where
is the value that the objective function assumes in
. Given the network outputs
for the inputs
,
will be:
where Err represents a chosen metric. We will now list the relevant ones for this tutorial:
Note that in our case, this
will not be present since we are working in an unsupervised setting. Those metrics are still used to compute the unsupervised losses.
corresponds to the losses given by the physical constraints of the system, like the boundary conditions and the initial conditions. Lastly,
is the error for the differential equation. For instance, given a PDE with an implicit solution
that depends on
and its derivative
with respect to the independent variable
t, the differential equation can be written as:
where
N is a nonlinear operator and
is some set of parameters. Given this, we can write
(using MSE as metric) for a network designed to solve this equation as:
where
is the set of
n points, called collocation points, where the PDE will be evaluated. This makes it possible to train neural networks even in the presence of noisy or very little data, and even in a fully unsupervised setting, such as in this paper.
However, when working with quantum mechanical systems, we are usually not just dealing with partial differential equations, but often with integro-differential Equations. At the very least, there is always the need to compute an integral to enforce the wave function’s normalization. Normally, to compute an integral, numerically finite difference methods are employed. Those methods utilize a mesh, a set of finite elements used to represent the function, to compute the integral. However, being mesh-free is one of the advantages of utilizing a neural method. This advantage can be retained if we are able to employ a mesh-free way to compute the required integrals. To this end, we employ so-called auxiliary outputs; beyond the wave function, we add an additional output to the network for each integral we need to compute. For instance, an integral is needed for the normalization in a domain
. It can be represented by the auxiliary output
, defined as:
and the normalization will be fulfilled if
;
. Note that there is a trade-off here. On the one hand, the discretization error can be potentially removed using an auxiliary output. On the other hand, using it makes the network harder to train due to the additional outputs and losses. Therefore, the choice to utilize an auxiliary output or a finite difference method has to be made on a case-by-case basis.
2.4. Potential Analysis
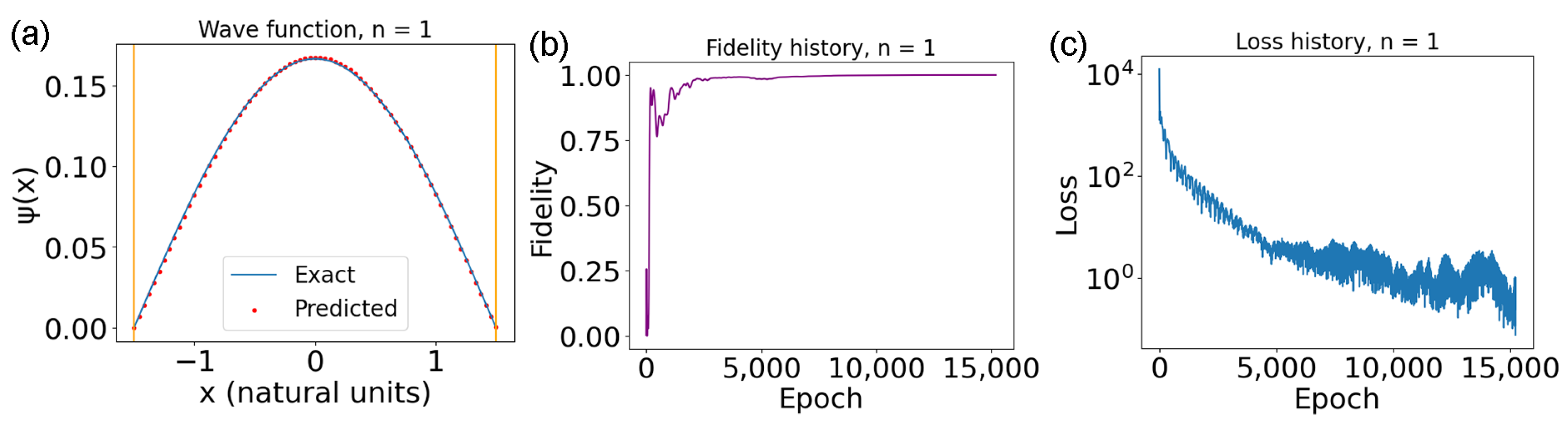
This section enters into the specifics of how to build a PINN to solve Schrödinger’s equation. Here, we focus, in particular, on the analysis of the potential to find the optimal representation of the problem. The potential is then used to define the associated Schrödinger equation. Beyond that, it is also important to identify the independent variables that will make up the input of the neural network. Likewise, we must identify any integrals that will make up the auxiliary output. For instance, for an infinite potential well, the representation of the Schrödinger equation will just contain the kinetic part, and the potential
can be represented by having
be the computational domain and the imposing Dirichlet boundary conditions:
The position
x will be the input. The outputs will be the main one,
, and an auxiliary one,
, as defined in (
8).
2.5. Physical Constraints and Inductive Biases
After defining the main differential equation loss in the previous section, here, we explain the other losses used to build a neural network capable of solving the equation. In particular, here are defined the losses linked to the physical constraints of the system. We also add a kind of loss not essential to solving the equation but which greatly improves convergence, namely, the inductive biases.
To define these losses, one needs to understand which are the physical constraints of the system and if any symmetries can be exploited to obtain an inductive bias. By inductive bias, we mean a set of conditions that leads the network to prioritize a set of solutions over another, for instance, prioritizing solutions that follow a given symmetry. Biases can be invaluable because they limit the search space, and thus reduce the number of epochs needed to obtain a solution.
A condition that is always needed is the normalization:
where
is the domain of the wave function, chosen depending on the dimensionality and nature of the system. For instance, for a one-dimensional infinite potential well in
,
can be restricted to
. It is important to note that imposing the condition defined in (
11) is the only thing that forces the wave function to be nonzero. Otherwise,
for all
x would exactly satisfy all losses. This integral can be solved by utilizing an auxiliary output
with form (
8) and by imposing
;
. However, we must first train the network so that
has the desired form (
8). Once again, this can be achieved by exploiting automatic differentiation to compute
and thus use the following as a loss:
obtaining the integral loss. We typically need to set some boundary conditions. In general, one can either use hard or soft boundary conditions. The former choice forces the network output to fulfill the boundary conditions exactly. This can be performed by employing a change of variable or modifying the output in some way, such as by multiplying it by another function. The latter choice makes the network learn the BCs via an additional loss, the boundary condition loss. This loss is 0 when the BCs are fulfilled. For instance, in the infinite potential well to impose soft Dirichlet boundary conditions (
10), we can add to the network’s loss
. In this tutorial, we always use soft boundary conditions.
Further constraints can be required on a case-by-case basis, but normalization and boundary conditions are always essential. Moreover, we can also employ an additional kind of loss—the inductive biases. These are losses that are not required to obtain a solution, but can instead be added to allow the network to converge much faster. They are usually based on the symmetries of the potential; for instance, the infinite well is symmetric with respect to 0. This symmetry makes its eigenfunctions alternatively even and odd with respect to 0. A condition that can be enforced in the PINN by the symmetry loss:
where
s is 1 for symmetric states and
for anti-symmetric ones (the value of
s is switched each time a network is trained, starting from
s = 1). In general, we can utilize as inductive biases any kind of additional constraint that we know the wave function must follow. The implementation depends on the inductive bias we want to add, but in general, it can be added as an additional loss. Like all neural network losses, it must always be nonnegative, and must reach 0 when the bias is satisfied. It is usually effective to give such additional losses a higher weight compared to the other losses in order to let the inductive bias better fulfill its role as a condition that limits the space of the solution. For instance, in the example in Equation (
13), the total loss will greatly increase for each pair of points that does not follow the symmetry constraint. This leads the neural network to only explore the space of symmetric or anti-symmetric solutions (depending on the value of
s).
2.6. Self-Consistent Computation of the Eigenenergy
In this section, we explain how to find the eigenvalue to pair with the eigenfunction obtained thanks to the techniques described in the previous sections.
Currently, the network can only find the eigenfunction of the potential when the energy is known. However, in general, when solving the Schrödinger equation, that will not be the case. Therefore, a way to find it in parallel with the eigenfunction is needed. There are two ways to do this: the first is to set the energy E itself as a trainable parameter, but this seems to result in fairly slow training. The second is to build a second neural network to train in parallel with the one that predicts the wave function. It will take as input a constant stream of “1”s of the same length as the input vector, and output a guess for the energy E. Since the output is constant, this second network will have no hidden layers and there will be no nonlinear activation function. The network will just perform a linear transformation from 1 to the value of the energy, based on a trainable parameter.
2.7. Finding the Desired State
A crucial step is to build the losses that allow the network to distinguish the desired eigenstate from the infinite spectrum of the Hamiltonian. This is explained in this section. By training the PINN with the current losses, it will solve the Schrödinger equation for a random state anywhere in the spectrum. Usually, however, we are looking for some amount of eigenstate starting from the ground state and going in order of increasing energy. In particular, it is especially important to build a network that finds the ground state first. This can be achieved by introducing an energy minimization condition in the loss:
where
is the predicted energy,
a is a hyperparameter. and
is either another hyperparameter when training the network to predict the ground state, or the energy of the previous state, for the excited states. The choice to increase
as the quantum number increases was made to avoid the loss exploding for higher energy states due to its exponential increase. Otherwise, the network might fail to converge at all. We also have to take into account that this energy minimization loss keeps pushing the network to lower energies even when the correct solution is reached. This moves the global minima of the loss from the eigenstate to a lower energy state, causing the loss to converge to an incorrect state. To avoid such a situation, the weight of the loss is gradually decreased as the training continues. This reduction should be such that the loss becomes approximately 0 towards the end of the training. Thanks to this, in the earlier epochs, this loss will steer the network towards the desired lower energy state. On the other hand, in the latter epochs, the energy minimization loss will become negligible and allow the network to settle to the correct solution. The resulting neural network can now find the ground state of the wave function. We now want to obtain the excited states. To do so, a sequence of networks is built, each of which predicts one of the Hamiltonian’s eigenstates and the corresponding eigenvalue, in order of increasing energy. To do so, an additional loss is employed—the orthogonality loss. This loss forces each network’s output to be orthogonal to all the ones before it:
where
are the known eigenfunctions. This loss will, of course, always be 0 when training the first network. But each time a network converges, it will be saved and utilized to obtain the
needed to compute this loss for the networks following it in the sequence.
2.8. Weights
In the previous sections, the losses to minimize were defined. In the following section, it is explained how to build the actual computational framework that ensures the network is able to minimize those losses. In this section, in particular, some pointers are given on how to tune one of the most important sets of hyperparameters—the weights. Usually, when training PINNs, it is better to set weights that ensure all the losses have the same scale. That is not the case for this problem; it is very easy for a network that has to predict eigenfunctions to get stuck in local minima, such as or an already discovered eigenvector. This means that it is actually better to set the weights in such a way that the network first enforces the physical constraints of the system, such as normalization and orthogonality. Only once these are fulfilled should the network be trained to actually solve the equation. This means setting the losses for those physical constraints higher than those of the differential equations.
In general, this means that the integral loss should have the highest weight, then the normalization, needed to avoid the constant solution, and the orthogonality, needed to avoid repeating solutions. At this point, the network should minimize the boundary conditions loss. The last loss to minimize is the differential equation loss. However, since solving the differential equation is the main objective of the network, it is often beneficial to gradually increase its loss weight. This allows the network to learn how to enforce the physical conditions in the first epochs but makes it focus more on the differential equation in the latter epochs. It is important to stress that weights are probably the most impactful hyperparameters to tune; a correct choice of weights will be the difference between quick convergence and a network getting stuck on a suboptimal solution.
2.9. Choice of Training Points
In order to train the PINN, the losses must be evaluated on a set of points, known as collocation points. These can be taken anywhere in the domain, and this section contains the optimal way to choose them. When training a PINN such as this, each batch of training points should span the whole domain. Furthermore, since no dataset is being used, the choice of points is not constrained in any way—they can be taken anywhere in the domain. This can be exploited to basically work with an infinitely large dataset. To fully take advantage of this, first a batch size N is decided. Then, a mesh of N points that spans the whole domain is built. Each of these points will be the center of a normal distribution from which one of the points in the given batch will be sampled. This results in batches that are always slightly different but always span the whole domain, thus ensuring the maximum exploration and fastest possible convergence.
2.10. Domain Definition
This computational framework inevitably requires the collocation points to be chosen within a certain domain. In this section, the best way to identify this domain is explained. The choice of the computational domain is crucial for an effective convergence of the network. First of all, this method only makes sense if almost all of the nonzero part of the desired wave function exists within the chosen domain. This means that outside it, the wave function must be either exactly 0 or vanishingly small and thus negligible. On the other hand, if the computational domain is too wide, then the network will be trained on a vast area of just
that will provide no information to it, resulting in greatly slowed down training. This means that more points in each batch would be needed to properly sample the “interesting” part of the domain. In the case of the well, the choice of the optimal domain is an immediate consequence of the structure of the system; as mentioned in
Section 2.4, just using
is ideal since the wave function will be nonzero only inside the well. For more complex potentials, the choice of the domain must be made based on an analysis of the potential under study. One needs to find out at which distance from the origin the wave function becomes negligible. Doing this will probably require some trial and error.
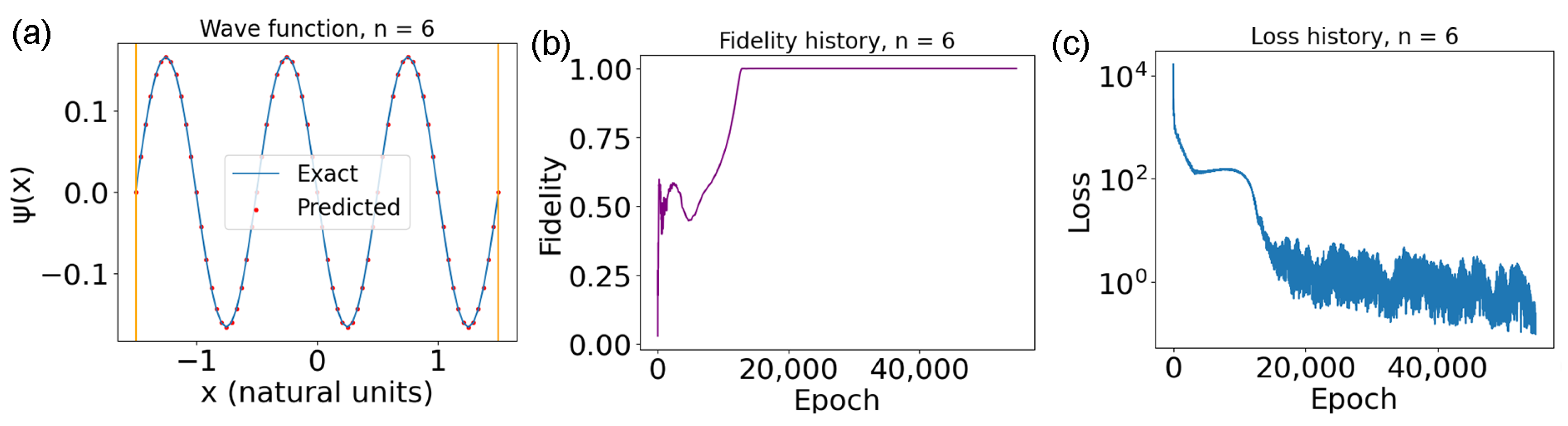
2.11. Network Architecture
In this section, we give some suggestions and tricks on how to better build a feed-forward neural network to solve the Schrödinger equation in a physics-informed way. We focus on which metrics to use for the loss and which activation function should be employed in the network. PINNs tend to work better as relatively shallow but wide networks. For instance, in [
7], the main network was made up of 7 hidden layers of 256 neurons each. In general, the physics-informed approach can can be applied to any kind of neural network, since its implementation is based on modifying just the loss function, independently of the network’s architecture. Here, we choose to focus on feed-forward PINNs due to their being the simplest architecture, which makes them ideal for a tutorial. The number of hidden layers, of course, depends on the problem we need the PINN to address. For the examples given in this tutorial, we employed a PINN with 6 hidden layers to solve the infinite potential well and one with 10 hidden layers to find the spectrum of the particle in a ring. As for the activation function, an infinitely differentiable one, such as
, is needed, otherwise, the network would be unable to compute higher-order derivatives via automatic differentiation. Choosing an activation function of this type, instead of something like
, might, however, cause vanishing gradient problems. If this happens, it might be beneficial to look into adaptive activation functions [
26] as a solution. For this tutorial, we always employ
as the activation function. The output of each layer was not normalized, since empirically it was found that output normalization does not improve convergence. Lastly, it is not necessary to compute all the partial losses using the same metric. It usually makes more sense to utilize something like the sum of absolute errors for the losses enforcing the physical conditions of the system, such as the boundary conditions loss or the normalization loss. This is because the rest of the training makes sense only if those losses are approximately 0 in all points. And this is enforced more strictly with SAE rather than something like MSE. On the other hand, the mean squared error is usually the best choice for the integral and differential equation losses. Utilizing the sum of squared error to compute these losses is also worth considering. This is especially true when the wave function is expected to have a complex behavior in a small section of the domain and a relatively simple one in the rest. This choice of metric will avoid underestimating the loss due to the averaging of the error for the points in the large “simple” area and the small “complex” area. As for the optimizer, Adam [
27] is usually rather effective.
3. How to Evaluate Training
In this section, some ways to evaluate the PINNs training to optimize their architecture and hyperparameters are shown. The focus will be on some typical pathological behaviors and some ways to understand what causes them and how to fix them. The behavior of the loss actually tends to be a quite reliable metric when training PINNs in an unsupervised way, and is actually more reliable than for standard neural networks. This is because a PINN follows a given physical law, and the loss quantifies how well its output follows the given law. It does not have a set of training points it might memorize instead of learning the underlying law.
As such, overfitting on some training sets is not a risk and it does not make sense to build the training, the validation, and the test sets from a dataset. In spite of this, due to the complexity of the loss function, just looking at the full loss does not tell the whole story of what is happening during training. In the following subsections, some ways to interpret the behavior of the network during training more deeply will be detailed. This should allow one to make more informed decisions when tuning hyperparameters.
3.1. Partial Losses
The first thing to look at when the PINN does not converge is to try to understand which loss (or losses) is failing to converge. At this point, the first thing one can do to try and improve the training can be to try to either increase the weight for the losses that are struggling to converge or reduce the weights for other, competing losses. One very common problem is the orthogonality loss failing to converge while other losses get very close 0. This means that the network is predicting an already discovered eigenfunction (in low dimensions, this can also be seen by looking at partial plots). For this, increasing the weight of the orthogonality loss is usually a quite safe solution.
Another common occurrence is the normalization loss staying high while all other losses become 0. This usually means that the network has converged to the local minimum
. While it could be fixed by increasing the normalization loss’ weight (this usually means also increasing the normalization integral’s weight, since the normalization loss does not have any meaning if the normalization integral is incorrect), it can also be useful to change the initialization of the network, for instance, going from Xavier uniform [
28] to Kaiming normal [
29], in order to start the network further from this local minimum. This could also be a sign of the energy minimization loss having excessive weight or growing too quickly. A way to decide this in low dimensions is to display the plot of the best wave function (i.e., the one with the lowest loss) every number of epochs, and look for any pathological behavior in its evolution. Another example is the case in which the boundary condition loss seems to fail to converge; in this case, if the plotted wave function resembles what we expect for the given potential but does not vanish at the border of the domain, it might mean that a larger domain is needed. It is important to note that a plateauing loss is not always a sign of a failed convergence. While training, it might happen that the PINN’s loss remains stuck around a certain value for thousands of epochs but will start decreasing again after some time. On the other hand, wild oscillations of the loss might be a sign of an excessively high learning rate. Note that these are only some empirical heuristics and might not apply in all cases. It is important to look at the loss’ behavior on a case-by-case basis and adjust the weights depending on what is best in the current circumstances.
3.2. Evaluation Metrics
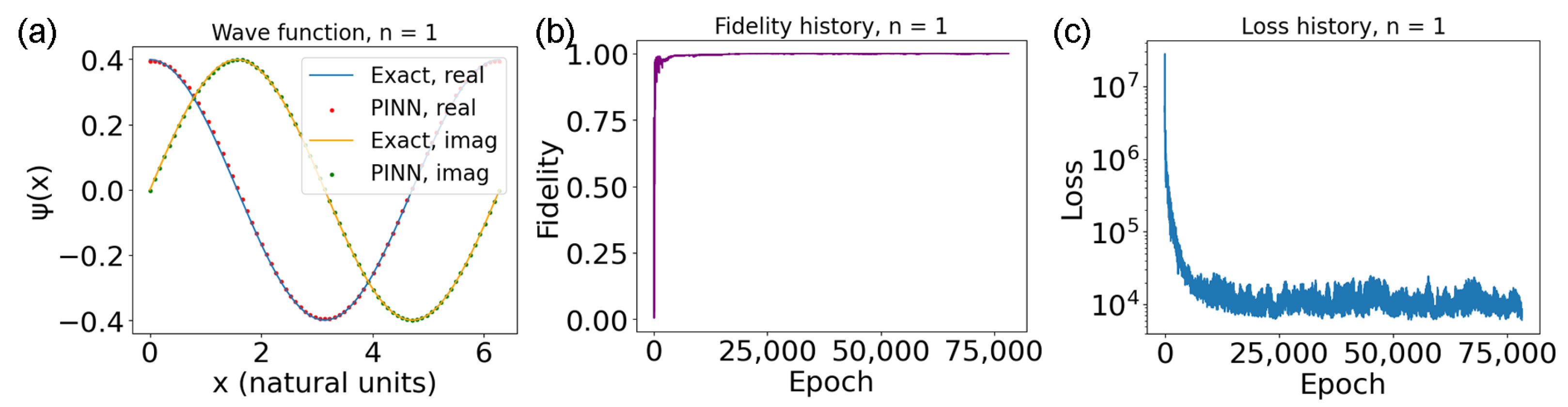
In the previous section, only the losses have been utilized to understand how successful the training has been. However, depending on the problem, other, more informative, metrics might be available. In this section, two metrics that allow to gauge the goodness of the PINN’s solution for the Schrödinger equation are detailed. When a solution is already known due to different numerical methods or because the potential has an analytic solution, the correctness of the PINN’s output can be easily evaluated by utilizing fidelity [
30,
31,
32] and relative error on the energy. To gauge the eigenvalue’s correctness, the relative error for the energy is used:
where
is the analytic value of the energy, while
is the one predicted by the network. On the other hand, to evaluate the eigenvector, the fidelity between the predicted wave function and the exact one is employed:
numerically evaluated as:
where the
are a set of points spanning the whole domain, and
and
are the values of the wave function at the point
x, as given by the analytic expression and by the network, respectively. Both of the vectors will be normalized before calculating the similarity, to avoid obtaining incorrect results due to inaccurate scaling. This should equal one when the two wave functions are the same (or if their difference is just a nonphysical phase).
5. Challenges, Limitations, and Potential of PINNs
PINNs have the potential to be able to scale rather well with the complexity of the system. This is thanks to the extreme expressive power of deep neural networks, which are known to be able to successfully approximate any continuous function [
33,
34,
35,
36], given a sufficient amount of parameters. However, PINNs do have limitations and disadvantages compared to other computational methods. First of all, the multiple losses create an extremely complex loss landscape, which can be very frustrated [
37]. This makes training the PINN rather difficult, and makes it very likely for it to get stuck in a local minimum if the hyperparameters have not been set correctly or if the initialization was especially unlucky. Overcoming this challenge is essential to make the method feasible for more complex systems. A way to do that would be to optimize the way weights are set, going beyond heuristics and trial-and-error [
38,
39,
40]. Furthermore, for potentials with degenerate states, the PINN has no way to prefer any particular set of states, and is equally likely to output any linear combination of the degenerate states. This is generally not an issue if we are just looking for solutions of Schrödinger’s equation for the given potential, since the PINNs will output valid solutions. However, if a particular set of eigenfunctions is preferred, we need to add further physical constraints to the network to ensure the correct output. It is also important to note that for these simple systems, the PINN’s performances are inferior to those of numerical solvers, both from the point of view of accuracy and speed, if we take into account the training time. For instance, numerical inversion of the Hamiltonian for the particle in a ring leads to errors for the eigenvalues of the order of
and can be performed in a few seconds. However, while there are still many challenges with PINNs, especially related to their training, this tool is potentially able to represent any quantum mechanical system given either the governing potential or a sufficient amount of data, possibly even going beyond what current numerical solvers are able to do. Furthermore, a PINN trained on a more complex system could be utilized to quickly output the wave function
at any point
, possibly faster then classical solvers.




{kind=link}
{kind=link}
{kind=link}
{kind=link}