


Transformative Approach for Heart Rate Prediction from Face Videos Using Local and Global Multi-Head Self-Attention





Abstract
:1. Introduction
- Introducing LGTransPPG, an end-to-end transformer-based framework for heart rate prediction from face videos that eliminates the need for extensive pre-processing steps.
- Incorporating local and global aggregation techniques to capture both fine-grained facial details and spatial context, improving the accuracy of heart rate estimation.
- The Frequency-Aware Correlation Loss (FACL) is designed to facilitate accurate heart rate prediction by emphasizing the alignment of frequency components.
- We evaluate our approach on multiple publicly available datasets, showcasing its efficiency and accuracy compared to existing approaches.
2. Related Works
Attention Mechanism and Transformers
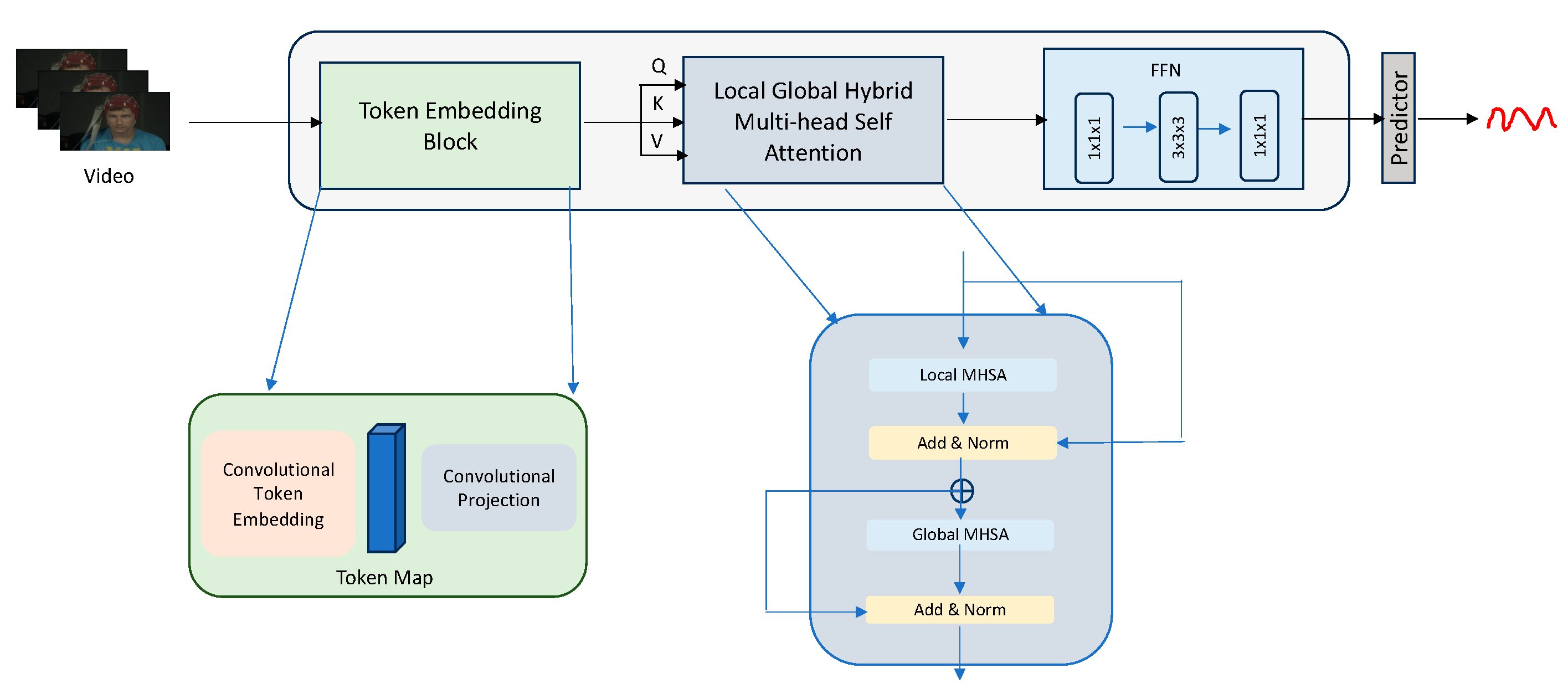
3. Proposed Approach
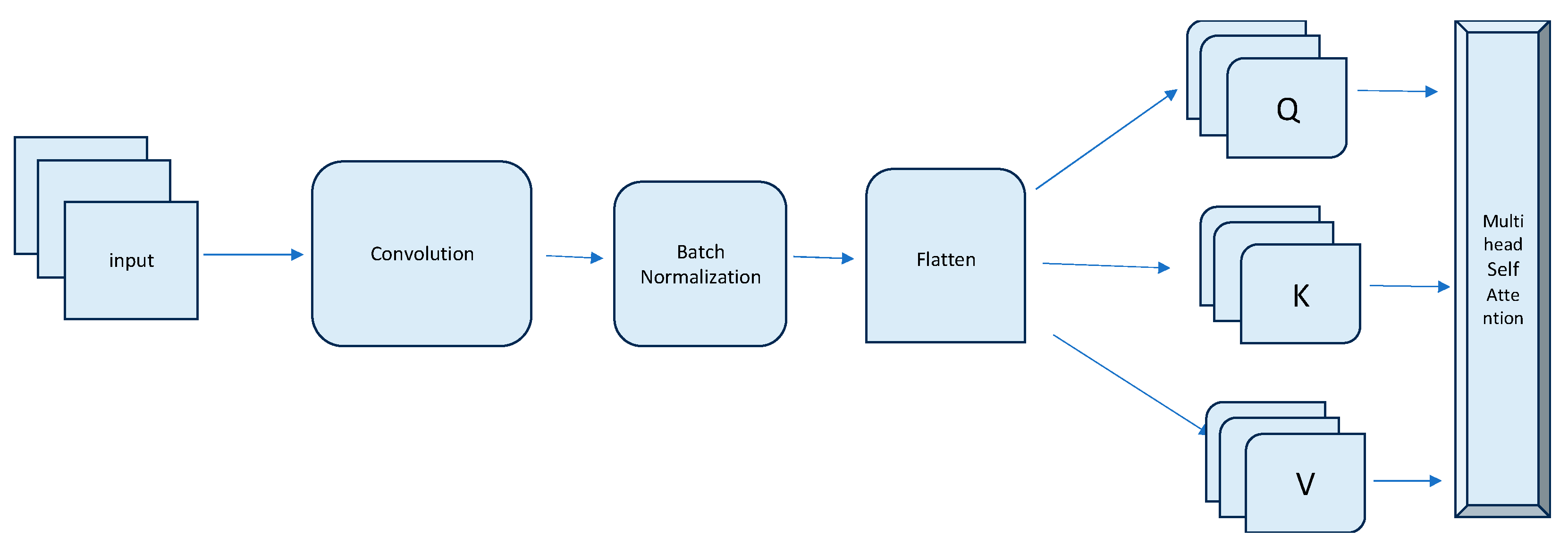
3.1. Token-Embedding Module
3.2. Local–Global Hybrid MHSA Transformer
4. Experiments
Datasets and Evaluation Metrics
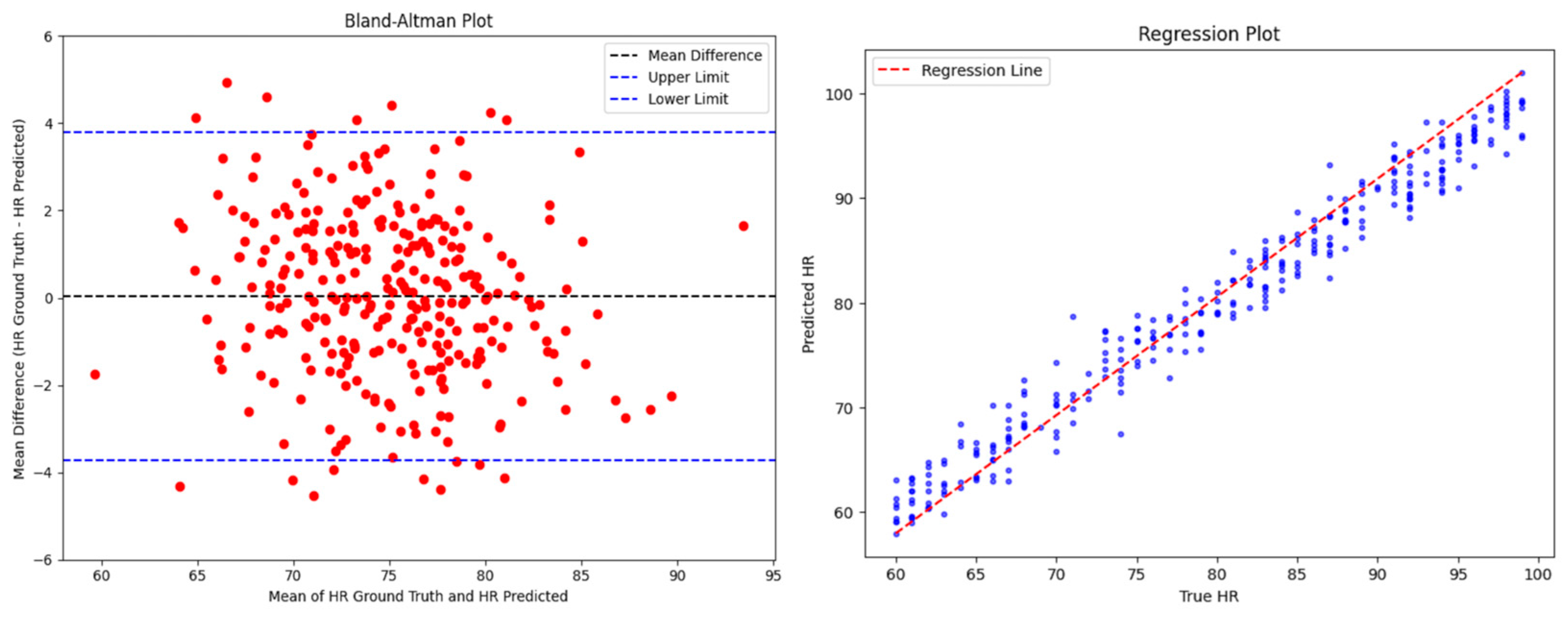
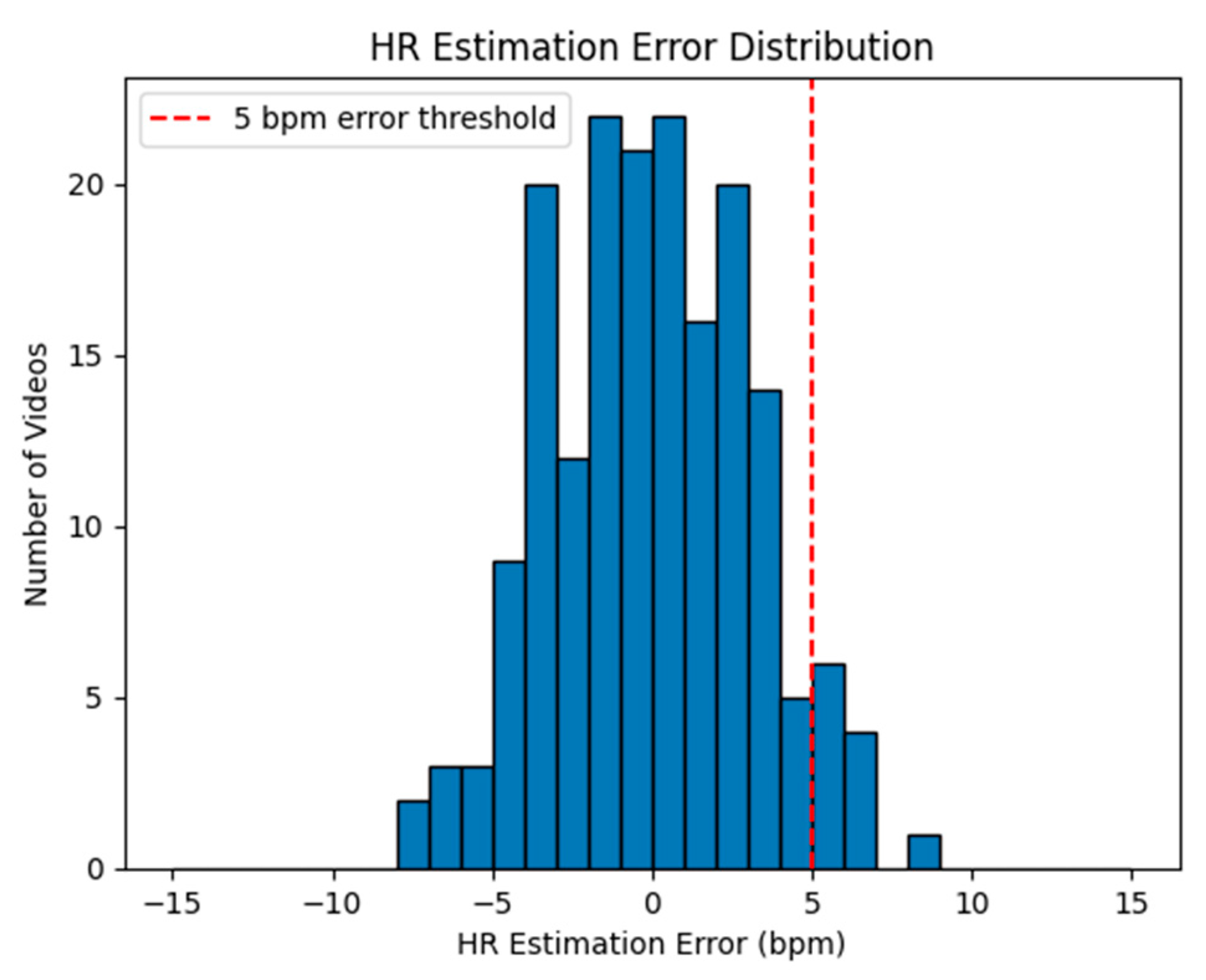
5. Results and Discussion
5.1. Cross Dataset Validation
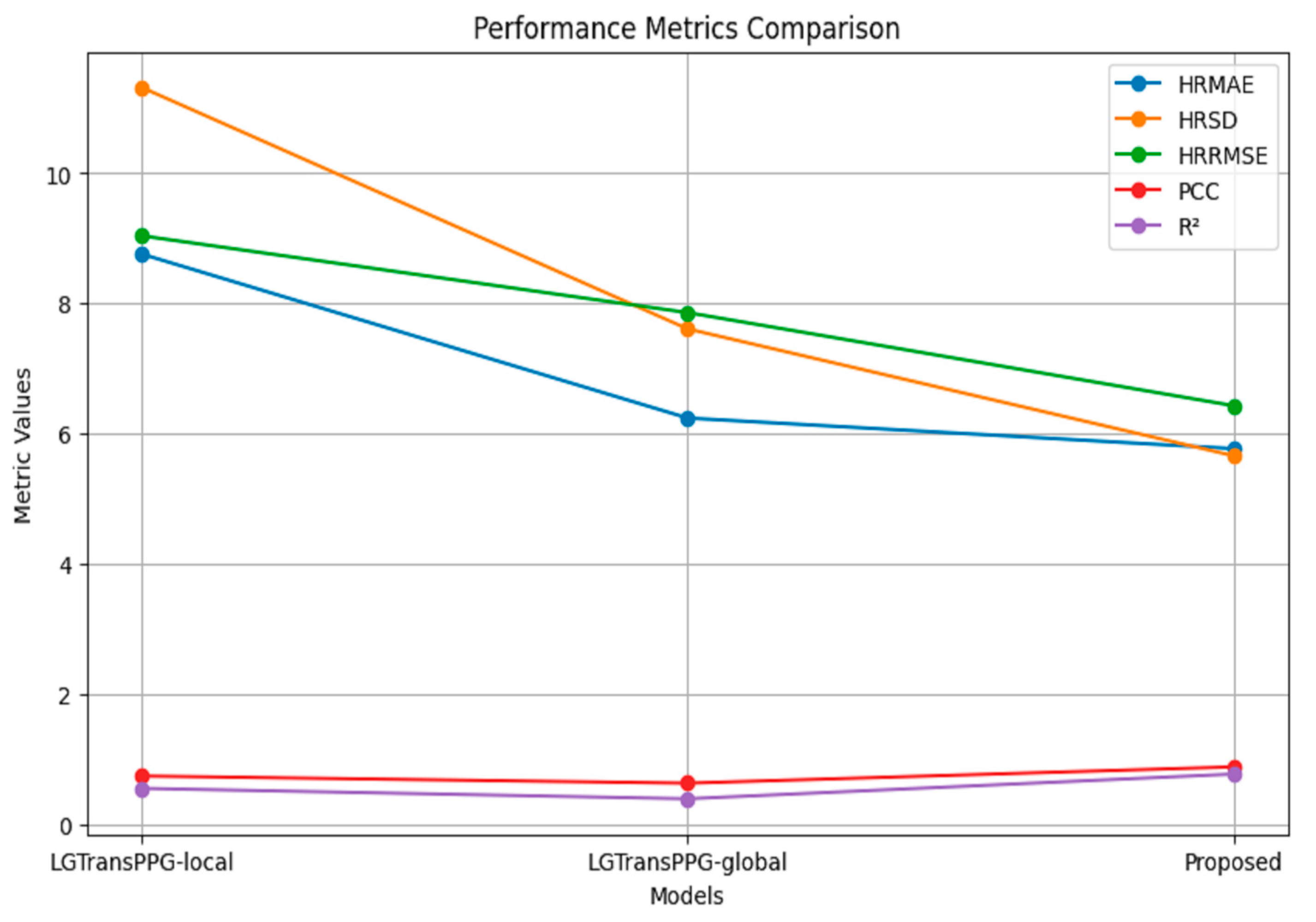
5.2. Ablation Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Poh, M.-Z.; McDuff, D.J.; Picard, R.W. Advancements in Noncontact, Multiparameter Physiological Measurements Using a Webcam. IEEE Trans. Biomed. Eng. 2010, 58, 7–11. [Google Scholar] [CrossRef] [PubMed]
- Yu, X.; Laurentius, T.; Bollheimer, C.; Leonhardt, S.; Antink, C.H. Noncontact Monitoring of Heart Rate and Heart Rate Variability in Geriatric Patients Using Photoplethysmography Imaging. IEEE J. Biomed. Health Inform. 2021, 25, 1781–1792. [Google Scholar] [CrossRef] [PubMed]
- Sasangohar, F.; Davis, E.; Kash, B.A.; Shah, S.R. Remote patient monitoring and telemedicine in neonatal and pediatric settings: Scoping literature review. J. Med. Internet Res. 2018, 20, e295. [Google Scholar] [CrossRef] [PubMed]
- Hebbar, S.; Sato, T. Motion Robust Remote Photoplethysmography via Frequency Domain Motion Artifact Reduction. In Proceedings of the 2021 IEEE Biomedical Circuits and Systems Conference (BioCAS), Berlin, Germany, 7–9 October 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Sinhal, R.; Singh, K.; Raghuwanshi, M.M. An Overview of Remote Photoplethysmography Methods for Vital Sign Monitoring. Adv. Intell. Syst. Comput. 2020, 992, 21–31. [Google Scholar] [CrossRef]
- Chang, M.; Hung, C.-C.; Zhao, C.; Lin, C.-L.; Hsu, B.-Y. Learning based Remote Photoplethysmography for Physiological Signal Feedback Control in Fitness Training. In Proceedings of the 15th IEEE Conference on Industrial Electronics and Applications (ICIEA), Kristiansand, Norway, 9–13 November 2020; pp. 1663–1668. [Google Scholar] [CrossRef]
- Zaunseder, S.; Trumpp, A.; Wedekind, D.; Malberg, H. Cardiovascular assessment by imaging photoplethysmography-a review. Biomed. Tech 2018, 63, 529–535. [Google Scholar] [CrossRef]
- Huang, P.W.; Wu, B.J.; Wu, B.F. A Heart Rate Monitoring Framework for Real-World Drivers Using Remote Photoplethysmography. IEEE J. Biomed. Health Inform. 2021, 25, 1397–1408. [Google Scholar] [CrossRef]
- Wu, B.F.; Chu, Y.W.; Huang, P.W.; Chung, M.L. Neural Network Based Luminance Variation Resistant Remote-Photoplethysmography for Driver’s Heart Rate Monitoring. IEEE Access 2019, 7, 57210–57225. [Google Scholar] [CrossRef]
- Kuncoro, C.B.D.; Luo, W.-J.; Kuan, Y.-D. Wireless Photoplethysmography Sensor for Continuous Blood Pressure Bio signal Shape Acquisition. J. Sens. 2020, 2020, 7192015. [Google Scholar] [CrossRef]
- Hilmisson, H.; Berman, S.; Magnusdottir, S. Sleep apnea diagnosis in children using software-generated apnea-hypopnea index (AHI) derived from data recorded with a single photoplethysmogram sensor (PPG): Results from the Childhood Adenotonsillectomy Study (CHAT) based on cardiopulmonary coupling analysis. Sleep Breath. 2020, 24, 1739–1749. [Google Scholar] [CrossRef]
- Wilson, N.; Guragain, B.; Verma, A.; Archer, L.; Tavakolian, K. Blending Human and Machine: Feasibility of Measuring Fatigue through the Aviation Headset. Hum. Factors 2020, 62, 553–564. [Google Scholar] [CrossRef]
- Verkruysse, W.; Svaasand, L.O.; Nelson, J.S. Remote plethysmographic imaging using ambient light. Opt. Express 2008, 16, 21434–21445. [Google Scholar] [CrossRef] [PubMed]
- McDuff, D. Camera Measurement of Physiological Vital Signs. ACM Comput. Surv. 2023, 55, 176. [Google Scholar] [CrossRef]
- Premkumar, S.; Hemanth, D.J. Intelligent Remote Photoplethysmography-Based Methods for Heart Rate Estimation from Face Videos: A Survey. Informatics 2022, 9, 57. [Google Scholar] [CrossRef]
- Malasinghe, L.; Katsigiannis, S.; Dahal, K.; Ramzan, N. A comparative study of common steps in video-based remote heart rate detection methods. Expert Syst. Appl. 2022, 207, 117867. [Google Scholar] [CrossRef]
- Chen, W.; McDuff, D. DeepPhys: Video-Based Physiological Measurement Using Convolutional Attention Networks. In Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018. Proceedings, Part II. [Google Scholar] [CrossRef]
- Niu, X.; Yu, Z.; Han, H.; Li, X.; Shan, S.; Zhao, G. Video-based remote physiological measurement via cross-verified feature disentangling. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part II 16; Springer International Publishing: Cham, Switzerland, 2020; pp. 295–310. [Google Scholar]
- Lu, H.; Han, H.; Zhou, S.K. Dual-gan: Joint bvp and noise modeling for remote physiological measurement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12404–12413. [Google Scholar]
- Lewandowska, M.; Rumiński, J.; Kocejko, T.; Nowak, J. Measuring pulse rate with a webcam—A non-contact method for evaluating cardiac activity. In Proceedings of the 2011 Federated Conference on Computer Science and Information Systems (FedCSIS), Szczecin, Poland, 18–21 September 2011; pp. 405–410. [Google Scholar]
- Zhang, B.; Li, H.; Xu, L.; Qi, L.; Yao, Y.; Greenwald, S.E. Noncontact heart rate measurement using a webcam, based on joint blind source separation and a skin reflection model: For a wide range of imaging conditions. J. Sens. 2021, 2021, 9995871. [Google Scholar] [CrossRef]
- Poh, M.-Z.; McDuff, D.J.; Picard, R.W. Non-contact, automated cardiac pulse measurements using video imaging and blind source separation. Opt. Express 2010, 18, 10762–10774. [Google Scholar] [CrossRef]
- de Haan, G.; Jeanne, V. Robust Pulse Rate From Chrominance-Based rPPG. IEEE Trans. Biomed. Eng. 2013, 60, 2878–2886. [Google Scholar] [CrossRef]
- Wang, W.; Stuijk, S.; de Haan, G. A novel algorithm for remote photoplethysmography: Spatial subspace rotation. IEEE Trans. Biomed. Eng. 2016, 3, 1974–1984. [Google Scholar] [CrossRef]
- Yu, Z.; Li, X.; Zhao, G. Remote photoplethysmograph signal measurement from facial videos using spatio-temporal networks. arXiv 2019, arXiv:1905.02419. [Google Scholar]
- Liu, X.; Fromm, J.; Patel, S.; McDuff, D. Multi-task temporal shift attention networks for on-device contactless vitals measurement. Adv. Neural Inf. Process. Syst. 2020, 33, 19400–19411. [Google Scholar]
- Niu, X.; Shan, S.; Han, H.; Chen, X. RhythmNet: End-to-End Heart Rate Estimation From Face via Spatial-Temporal Representation. IEEE Trans. Image Process. 2019, 29, 2409–2423. [Google Scholar] [CrossRef] [PubMed]
- Yu, Z.; Peng, W.; Li, X.; Hong, X.; Zhao, G. Remote heart rate measurement from highly compressed facial videos: An end-to-end deep learning solution with video enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 151–160. [Google Scholar]
- Qiu, Y.; Liu, Y.; Arteaga-Falconi, J.; Dong, H.; El Saddik, A. EVM-CNN: Real-time contactless heart rate estimation from facial video. IEEE Trans. Multimed. 2018, 21, 1778–1787. [Google Scholar] [CrossRef]
- Hu, M.; Qian, F.; Guo, D.; Wang, X.; He, L.; Ren, F. ETA-rPPGNet: Effective time-domain attention network for remote heart rate measurement. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar] [CrossRef]
- Niu, X.; Han, H.; Shan, S.; Chen, X. Synrhythm: Learning a deep heart rate estimator from general to specific. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; IEEE: New York, NY, USA; pp. 3580–3585.
- Song, R.; Chen, H.; Cheng, J.; Li, C.; Liu, Y.; Chen, X. PulseGAN: Learning to generate realistic pulse waveforms in remote photoplethysmography. IEEE J. Biomed. Health Inform. 2021, 25, 1373–1384. [Google Scholar] [CrossRef]
- Hsu, G.S.; Ambikapathi, A.; Chen, M.S. Deep learning with time-frequency representation for pulse estimation from facial videos. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017; IEEE: New York, NY, USA; pp. 383–389.
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Minissi, M.E.; Chicchi Giglioli, I.A.; Mantovani, F.; Alcaniz Raya, M. Assessment of the autism spectrum disorder based on machine learning and social visual attention: A systematic review. J. Autism Dev. Disord. 2022, 52, 2187–2202. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, L.; Hamilton, W.; Long, G.; Jiang, J.; Larochelle, H. A universal representation transformer layer for few-shot image classification. arXiv 2020, arXiv:2006.11702. [Google Scholar]
- Wang, Y.; Xu, Z.; Wang, X.; Shen, C.; Cheng, B.; Shen, H.; Xia, H. End-to-end video instance segmentation with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 8741–8750. [Google Scholar]
- Gao, H.; Wu, X.; Shi, C.; Gao, Q.; Geng, J. A LSTM-based realtime signal quality assessment for photoplethysmogram and remote photoplethysmogram. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3831–3840. [Google Scholar]
- Lee, E.; Chen, E.; Lee, C.Y. Meta-rppg: Remote heart rate estimation using a transductive meta-learner. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Part XXVII 16; Springer International Publishing: Cham, Switzerland, 2020; pp. 392–409. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3202–3211. [Google Scholar]
- Shi, C.; Zhao, S.; Zhang, K.; Wang, Y.; Liang, L. Face-based age estimation using improved Swin Transformer with attention-based convolution. Front. Neurosci. 2023, 17, 1136934. [Google Scholar] [CrossRef]
- Li, L.; Lu, Z.; Watzel, T.; Kürzinger, L.; Rigoll, G. Light-weight self-attention augmented generative adversarial networks for speech enhancement. Electronics 2021, 10, 1586. [Google Scholar] [CrossRef]
- McDuff, D.J.; Wander, M.; Liu, X.; Hill, B.L.; Hernández, J.; Lester, J.; Baltrušaitis, T. SCAMPS: Synthetics for Camera Measurement of Physiological Signals. arXiv 2022, arXiv:2206.04197. [Google Scholar]
- Selva, J.; Johansen, A.S.; Escalera, S.; Nasrollahi, K.; Moeslund, T.B.; Clap’es, A. Video Transformers: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12922–12943. [Google Scholar] [CrossRef] [PubMed]
- Hassanin, M.; Anwar, S.; Radwan, I.; Khan, F.S.; Mian, A.S. Visual Attention Methods in Deep Learning: An In-Depth Survey. arXiv 2022, arXiv:2204.07756. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.C.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. CvT: Introducing Convolutions to Vision Transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 22–31. [Google Scholar]
- Liang, Y.; Zhou, P.; Zimmermann, R.; Yan, S. DualFormer: Local-Global Stratified Transformer for Efficient Video Recognition. arXiv 2021, arXiv:2112.04674. [Google Scholar]
- Ma, F.; Sun, B.; Li, S. Logo-Former: Local-Global Spatio-Temporal Transformer for Dynamic Facial Expression Recognition. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Ming, Z.; Yu, Z.; Al-Ghadi, M.; Visani, M.; Luqman, M.M.; Burie, J.-C. Vitranspad: Video Transformer Using Convolution and Self-Attention for Face Presentation Attack Detection. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 4248–4252. [Google Scholar] [CrossRef]
- Aksan, E.; Kaufmann, M.; Cao, P.; Hilliges, O. A spatio-temporal transformer for 3d human motion prediction. In Proceedings of the 2021 International Conference on 3D Vision (3DV), London, UK, 1–3 December 2021; IEEE: New York, NY, USA; pp. 565–574.
- Yu, Z.; Shen, Y.; Shi, J.; Zhao, H.; Torr, P.; Zhao, G. PhysFormer: Facial Video-based Physiological Measurement with Temporal Difference Transformer. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; pp. 4176–4186. [Google Scholar] [CrossRef]
- Yu, Z.; Shen, Y.; Shi, J.; Zhao, H.; Cui, Y.; Zhang, J.; Torr, P.; Zhao, G. PhysFormer++: Facial Video-Based Physiological Measurement with SlowFast Temporal Difference Transformer. Int. J. Comput. Vis. 2023, 131, 1307–1330. [Google Scholar] [CrossRef]
- Zhang, X.; Yang, C.; Yin, R.; Meng, L. An End-to-End Heart Rate Estimation Scheme Using Divided Space-Time Attention. Neural Process. Lett. 2022, 55, 2661–2685. [Google Scholar] [CrossRef]
- Heusch, G.; Anjos, A.; Marcel, S. A reproducible study on remote heart rate measurement. arXiv 2017, arXiv:1709.00962. [Google Scholar]
- Revanur, A.; Dasari, A.; Tucker, C.S.; Jeni, L.A. Instantaneous physiological estimation using video transformers. In Multimodal AI in Healthcare: A Paradigm Shift in Health Intelligence; Springer International Publishing: Cham, Switzerland, 2022; pp. 307–319. [Google Scholar]
- Soleymani, M.; Lichtenauer, J.; Pun, T.; Pantic, M. A Multimodal Database for Affect Recognition and Implicit Tagging. IEEE Trans. Affect. Comput. 2012, 3, 42–55. [Google Scholar] [CrossRef]
- Wang, Z.; Ba, Y.; Chari, P.; Bozkurt, O.D.; Brown, G.; Patwa, P.; Vaddi, N.; Jalilian, L.; Kadambi, A. Synthetic generation of face videos with plethysmograph physiology. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20587–20596. [Google Scholar]
- Zheng, K.; Ci, K.; Li, H.; Shao, L.; Sun, G.; Liu, J.; Cui, J. Heart rate prediction from facial video with masks using eye location and corrected by convolutional neural networks. Biomed. Signal Process. Control. 2022, 75, 103609. [Google Scholar] [CrossRef]
- Wang, W.; Den Brinker, A.C.; Stuijk, S.; De Haan, G. Algorithmic principles of remote PPG. IEEE Trans. Biomed. Eng. 2016, 64, 1479–1491. [Google Scholar] [CrossRef]
- Wang, Z.-K.; Kao, Y.; Hsu, C.-T. Vision-Based Heart Rate Estimation via a Two-Stream CNN. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3327–3331. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | MAHNOB | COHFACE | UCLA-rPPG | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Signal Processing methods | SNR (dB) | MAE | RMSE | ρ | SNR (dB) | MAE | RMSE | ρ | SNR (dB) | MAE | RMSE | ρ | |
| ICA [13] | 2.47 | 5.14 | 7.84 | 0.15 | 1.23 | 18.99 | 14.67 | 0.21 | 13.54 | 24.68 | 0.43 | ||
| CHROM [23] | 1.74 | 4.32 | 9.64 | 0.23 | 16.05 | 23.54 | 0.17 | 1.25 | 19.44 | 11.23 | 0.22 | ||
| POS [61] | 3.43 | 8.33 | 10.24 | 0.45 | 0.76 | 17.67 | 18.76 | 0.13 | 0.61 | 15.78 | 13.33 | 0.11 | |
| Learning Based methods | TS-CAN [26] | 3.22 | 1.06 | 4.55 | 0.76 | 2.32 | 8.32 | 9.74 | 0.54 | 1.98 | 8.04 | 12.48 | 0.43 |
| HR-CNN [62] | 2.91 | 2.42 | 6.26 | 0.44 | 10.04 | 19.38 | 0.37 | 5.51 | 9.81 | 14.98 | 0.58 | ||
| PhysNet [25] | 8.67 | 1.43 | 2.45 | 0.67 | 5.01 | 2.46 | 9.61 | 0.87 | 3.79 | 10.27 | 2.45 | 0.43 | |
| DeepPhys [17] | 9.54 | 0.87 | 1.67 | 0.89 | 4.03 | 1.96 | 6.43 | 0.94 | 6.38 | 1.96 | 1.98 | 0.97 | |
| Ours | 10.01 | 0.94 | 1.36 | 0.94 | 4.16 | 1.33 | 4.43 | 0.97 | 6.22 | 1.36 | 1.97 | 0.97 | |
| Method | (a) | (b) | |||||
|---|---|---|---|---|---|---|---|
| MAHNOB | UCLA rPPG | ||||||
| MAE | RMSE | ρ | MAE | RMSE | ρ | ||
| ICA [13] | 7.92 | 5.98 | 0.72 | 8.28 | 9.28 | 0.55 | |
| POS [61] | 3.42 | 6.72 | 0.85 | 5.43 | 3.4 | 0.75 | |
| CHROM [23] | 5.54 | 6.01 | 0.87 | 3.69 | 5.41 | 0.77 | |
| DeepPhys [17] | 3.82 | 2.78 | 0.98 | 1.42 | 1.8 | 0.84 | |
| Ours | 2.98 | 3.12 | 0.99 | 0.94 | 1.76 | 0.87 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Premkumar, S.; Anitha, J.; Danciulescu, D.; Hemanth, D.J. Transformative Approach for Heart Rate Prediction from Face Videos Using Local and Global Multi-Head Self-Attention. Technologies 2024, 12, 2. https://doi.org/10.3390/technologies12010002
Premkumar S, Anitha J, Danciulescu D, Hemanth DJ. Transformative Approach for Heart Rate Prediction from Face Videos Using Local and Global Multi-Head Self-Attention. Technologies. 2024; 12(1):2. https://doi.org/10.3390/technologies12010002
Chicago/Turabian StylePremkumar, Smera, J. Anitha, Daniela Danciulescu, and D. Jude Hemanth. 2024. "Transformative Approach for Heart Rate Prediction from Face Videos Using Local and Global Multi-Head Self-Attention" Technologies 12, no. 1: 2. https://doi.org/10.3390/technologies12010002
APA StylePremkumar, S., Anitha, J., Danciulescu, D., & Hemanth, D. J. (2024). Transformative Approach for Heart Rate Prediction from Face Videos Using Local and Global Multi-Head Self-Attention. Technologies, 12(1), 2. https://doi.org/10.3390/technologies12010002