
Preprocessing Selection for Deep Learning Classification of Arrhythmia Using ECG Time-Frequency Representations



Abstract
1. Introduction
2. Materials and Methods
2.1. Database
2.2. Preprocessing
- Beat segmentation;
- Beat labeling;
- Denoising (depending on the experimental setup);
- 2D feature extraction
2.2.1. Beat Segmentation
2.2.2. Beat Labeling
2.2.3. Denoising
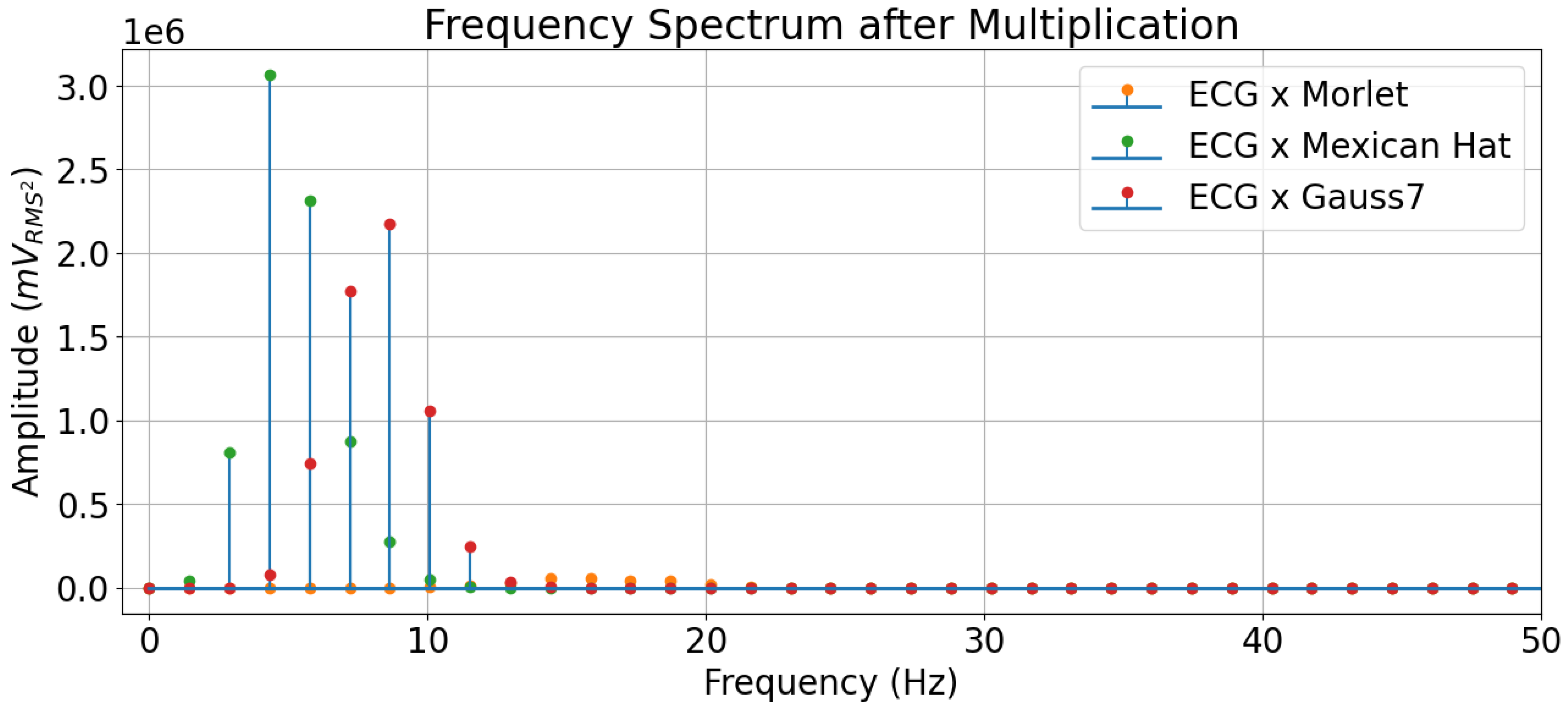
2.2.4. Two-Dimensional Feature Extraction
2.3. Model

2.4. Experimental Setup
2.4.1. Feature Representations
- No filter;
- BW filter;
- PLI filter;
- BW + PLI filter
2.4.2. Dataset Configurations
2.4.3. Model Configurations
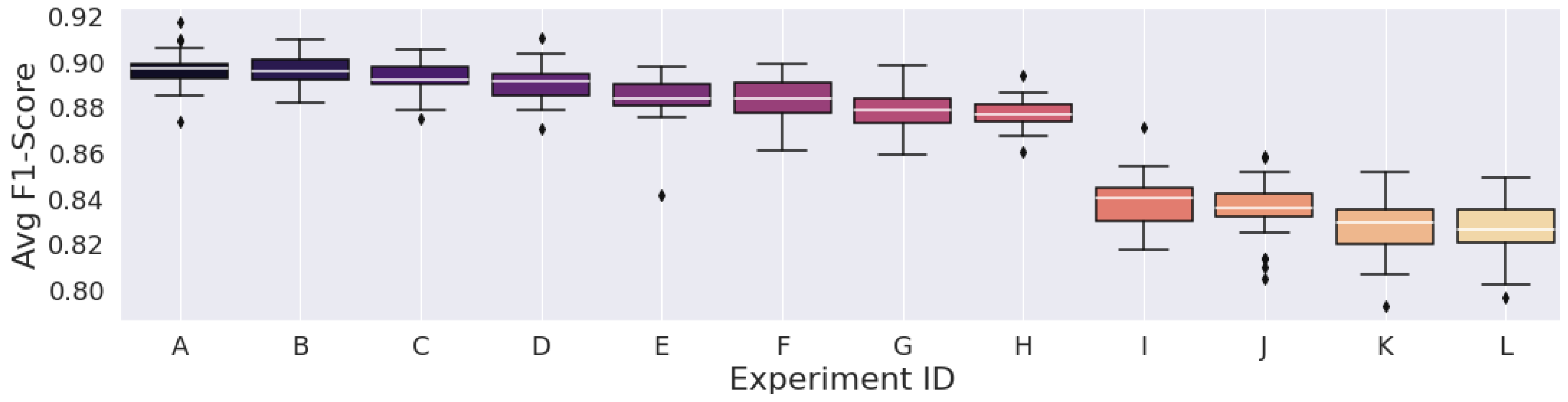
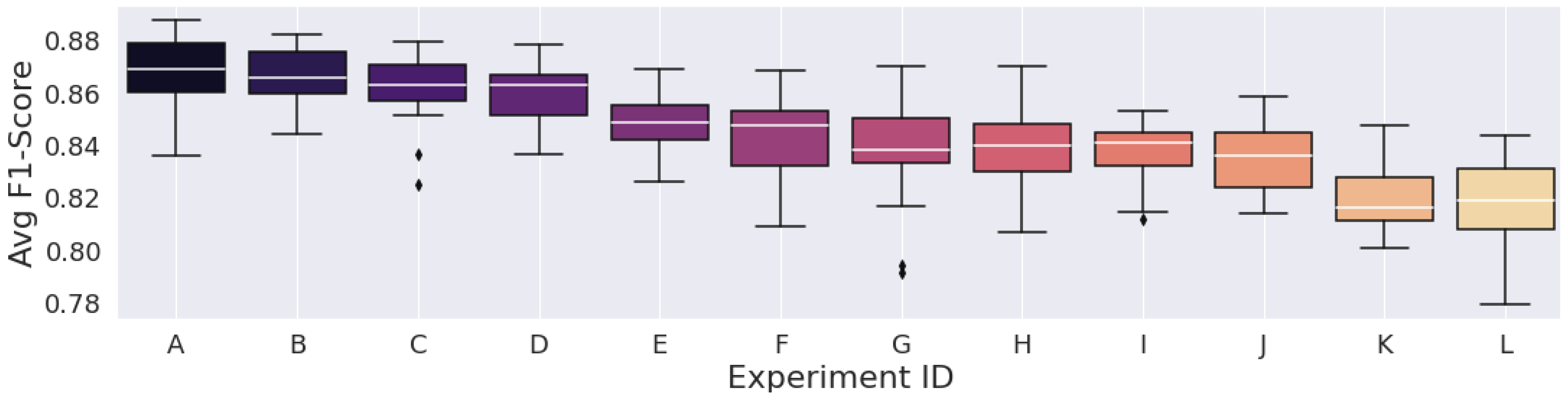
3. Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment ID | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | E | F | G | H | I | J | K | L | |
| Scales | 64 | 32 | 64 | 32 | 16 | 32 | 32 | 64 | 64 | 16 | 16 | 16 |
| BW Filter | Yes | Yes | Yes | No | Yes | Yes | No | No | No | No | Yes | No |
| PLI Filter | No | Yes | Yes | Yes | Yes | No | No | Yes | No | Yes | No | No |
| Avg. F1-Score (%) | 90.1076 | 89.9660 | 89.9559 | 89.7400 | 89.7398 | 89.6619 | 89.6226 | 89.5942 | 89.5159 | 89.4974 | 89.4843 | 89.4533 |

| Experiment ID | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | E | F | G | H | I | J | K | L | |
| Scales | 64 | 64 | 64 | 64 | 32 | 32 | 32 | 32 | 16 | 16 | 16 | 16 |
| BW Filter | Yes | Yes | No | No | Yes | Yes | No | No | Yes | Yes | No | No |
| PLI Filter | No | Yes | No | Yes | No | Yes | Yes | No | No | Yes | No | Yes |
| Avg. F1-Score (%) | 89.6635 | 89.6296 | 89.2273 | 89.0742 | 88.3949 | 88.3348 | 87.8553 | 87.6770 | 83.8375 | 83.5241 | 82.8184 | 82.6222 |

| Experiment ID | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | E | F | G | H | I | J | K | L | |
| Scales | 64 | 64 | 64 | 64 | 32 | 32 | 32 | 32 | 16 | 16 | 16 | 16 |
| BW Filter | Yes | Yes | No | No | Yes | Yes | No | No | Yes | Yes | No | No |
| PLI Filter | No | Yes | No | Yes | No | Yes | Yes | No | No | Yes | No | Yes |
| Avg. F1-Score (%) | 88.9853 | 88.8406 | 88.0451 | 87.9009 | 85.5765 | 85.2684 | 84.0790 | 83.9770 | 79.5599 | 79.3363 | 77.8124 | 77.2947 |

| Experiment ID | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | E | F | G | H | I | J | K | L | |
| FFT/ Window Size | 64 | 64 | 32 | 32 | 128 | 64 | 128 | 64 | 32 | 32 | 128 | 128 |
| BW Filter | Yes | Yes | Yes | Yes | Yes | No | Yes | No | No | No | No | No |
| PLI Filter | No | Yes | No | Yes | No | No | Yes | Yes | No | Yes | Yes | No |
| Avg. F1-Score (%) | 86.7556 | 86.6069 | 86.2168 | 86.0142 | 84.7389 | 84.3025 | 83.8166 | 83.8125 | 83.7484 | 83.4633 | 81.9681 | 81.7185 |

| Experiment ID | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | E | F | G | H | I | J | K | L | |
| FFT/ Window Size | 64 | 64 | 128 | 32 | 32 | 128 | 64 | 64 | 128 | 128 | 32 | 32 |
| BW Filter | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No |
| PLI Filter | No | Yes | No | Yes | No | Yes | No | Yes | No | Yes | No | Yes |
| Avg. F1-Score (%) | 87.1210 | 86.9639 | 86.4369 | 86.1286 | 86.0712 | 85.9963 | 84.8144 | 84.7086 | 84.1529 | 84.1522 | 84.0212 | 83.9235 |

| Experiment ID | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | E | F | G | H | I | J | K | L | |
| FFT/ Window Size | 64 | 64 | 32 | 128 | 32 | 128 | 64 | 128 | 128 | 64 | 32 | 32 |
| BW Filter | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No |
| PLI Filter | Yes | No | No | No | Yes | Yes | Yes | Yes | No | No | No | Yes |
| Avg. F1-Score (%) | 86.6833 | 86.6600 | 86.4335 | 86.3896 | 86.1367 | 86.0198 | 84.8327 | 84.7946 | 84.7190 | 84.5660 | 84.1327 | 84.0701 |

4. Discussion
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- WHO Expert Committee on Problems Related to Alcohol Consumption: Second Report; Number 944; World Health Organization: Geneva, Switzerland, 2007.
- Shi, A.; Tao, Z.; Wei, P.; Zhao, J. Epidemiological aspects of heart diseases. Exp. Ther. Med. 2016, 12, 1645–1650. [Google Scholar] [CrossRef] [PubMed]
- Podrid, P.J.; Kowey, P.R. Cardiac Arrhythmia: Mechanisms, Diagnosis, and Management; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2001. [Google Scholar]
- Antzelevitch, C.; Burashnikov, A. Overview of basic mechanisms of cardiac arrhythmia. Card. Electrophysiol. Clin. 2011, 3, 23–45. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Li, J.; Wei, S.; Zhou, F.; Li, D. Heartbeats Classification Using Hybrid Time-Frequency Analysis and Transfer Learning Based on ResNet. IEEE J. Biomed. Health Informatics 2021, 25, 4175–4184. [Google Scholar] [CrossRef] [PubMed]
- Lei, Y. 2—Signal processing and feature extraction. In Intelligent Fault Diagnosis and Remaining Useful Life Prediction of Rotating Machinery; Lei, Y., Ed.; Butterworth-Heinemann: Oxford, UK, 2017; pp. 17–66. [Google Scholar] [CrossRef]
- Zhang, Z.; Moore, J.C. Chapter 2—Time-Frequency Analysis. In Mathematical and Physical Fundamentals of Climate Change; Zhang, Z., Moore, J.C., Eds.; Elsevier: Boston, MA, USA, 2015; pp. 49–78. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Guo, L.; Sim, G.; Matuszewski, B. Inter-patient ECG classification with convolutional and recurrent neural networks. Biocybern. Biomed. Eng. 2019, 39, 868–879. [Google Scholar] [CrossRef]
- He, R.; Wang, K.; Zhao, N.; Liu, Y.; Yuan, Y.; Li, Q.; Zhang, H. Automatic detection of atrial fibrillation based on continuous wavelet transform and 2D convolutional neural networks. Front. Physiol. 2018, 9, 1206. [Google Scholar] [CrossRef] [PubMed]
- Sultan Qurraie, S.; Ghorbani Afkhami, R. ECG arrhythmia classification using time frequency distribution techniques. Biomed. Eng. Lett. 2017, 7, 325–332. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Lan, T.; Yang, C.; Nie, Z. A novel method to detect multiple arrhythmias based on time-frequency analysis and convolutional neural networks. IEEE Access 2019, 7, 170820–170830. [Google Scholar] [CrossRef]
- Moody, G.B.; Mark, R.G. The impact of the MIT-BIH arrhythmia database. IEEE Eng. Med. Biol. Mag. 2001, 20, 45–50. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Lin, Z.; An, Z.; Zuo, S.; Zhu, W.; Zhang, Z.; Mu, Y.; Cao, L.; García, J.D.P. Automatic electrocardiogram detection and classification using bidirectional long short-term memory network improved by Bayesian optimization. Biomed. Signal Process. Control 2022, 73, 103424. [Google Scholar] [CrossRef]
- Mondéjar-Guerra, V.; Novo, J.; Rouco, J.; Penedo, M.G.; Ortega, M. Heartbeat classification fusing temporal and morphological information of ECGs via ensemble of classifiers. Biomed. Signal Process. Control 2019, 47, 41–48. [Google Scholar] [CrossRef]
- Sörnmo, L.; Laguna, P. The electrocardiogram—A brief background. In Bioelectrical Signal Processing in Cardiac and Neurological Applications; Academic Press: Cambridge, MA, USA, 2005; pp. 411–452. [Google Scholar]
- Sabut, S.; Pandey, O.; Mishra, B.; Mohanty, M. Detection of ventricular arrhythmia using hybrid time–frequency-based features and deep neural network. Phys. Eng. Sci. Med. 2021, 44, 135–145. [Google Scholar] [CrossRef]
- Bracewell, R.N.; Bracewell, R.N. The Fourier Transform and Its Applications; McGraw-Hill: New York, MY, USA, 1986; Volume 31999. [Google Scholar]
- Owens, F.; Murphy, M. A short-time Fourier transform. Signal Process. 1988, 14, 3–10. [Google Scholar] [CrossRef]
- Yamada, M. Wavelets: Applications. In Encyclopedia of Mathematical Physics; Françoise, J.P., Naber, G.L., Tsun, T.S., Eds.; Academic Press: Oxford, UK, 2006; pp. 420–426. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Abhang, P.A.; Gawali, B.W.; Mehrotra, S.C. Chapter 4 - Time and Frequency Analysis. In Introduction to EEG- and Speech-Based Emotion Recognition; Abhang, P.A., Gawali, B.W., Mehrotra, S.C., Eds.; Academic Press: Cambridge, MA, USA, 2016; pp. 81–96. [Google Scholar] [CrossRef]
- Al Abdi, R.M.; Jarrah, M. Cardiac disease classification using total variation denoising and morlet continuous wavelet transformation of ECG signals. In Proceedings of the 2018 IEEE 14th International Colloquium on Signal Processing & Its Applications (CSPA), Penang, Malaysia, 9–10 March 2018; pp. 57–60. [Google Scholar] [CrossRef]
- Burke, M.; Nasor, M. Wavelet based analysis and characterization of the ECG signal. J. Med. Eng. Technol. 2004, 28, 47–55. [Google Scholar] [CrossRef] [PubMed]
- Zeng, C.; Lin, H.; Jiang, Q.; Xu, M. QRS Complex Detection Using Combination of Mexican-hat Wavelet and Complex Morlet Wavelet. J. Comput. 2013, 8, 2951–2958. [Google Scholar] [CrossRef]
- Morlet, D.; Couderc, J.; Touboul, P.; Rubel, P. Wavelet analysis of high-resolution ECGs in post-infarction patients: Role of the basic wavelet and of the analyzed lead. Int. J. Bio-Med Comput. 1995, 39, 311–325. [Google Scholar] [CrossRef] [PubMed]
- 3 - Wavelet Transforms and Time-Frequency Analysis. In An Introduction to Wavelets; Wavelet Analysis and Its Applications; Chui, C.K., Ed.; Academic Press: Cambridge, MA, USA, 1992; Volume 1, pp. 49–80. [Google Scholar] [CrossRef]
- Akansu, A.N.; Haddad, R.A. Chapter 6—Wavelet Transform. In Multiresolution Signal Decomposition, 2nd ed.; Akansu, A.N., Haddad, R.A., Eds.; Academic Press: San Diego, CA, USA, 2001; pp. 391–442. [Google Scholar] [CrossRef]
- Bai, Y.W.; Chu, W.Y.; Chen, C.Y.; Lee, Y.T.; Tsai, Y.C.; Tsai, C.H. Adjustable 60Hz noise reduction by a notch filter for ECG signals. In Proceedings of the 21st IEEE Instrumentation and Measurement Technology Conference (IEEE Cat. No. 04CH37510), Como, Italy, 18–20 May 2004; Volume 3, pp. 1706–1711. [Google Scholar]
- Jagtap, S.K.; Uplane, M. The impact of digital filtering to ECG analysis: Butterworth filter application. In Proceedings of the 2012 International Conference on Communication, Information & Computing Technology (ICCICT), Mumbai, India, 19–20 October 2012; pp. 1–6. [Google Scholar]
- Van Erven, T.; Harremos, P. Rényi divergence and Kullback-Leibler divergence. IEEE Trans. Inf. Theory 2014, 60, 3797–3820. [Google Scholar] [CrossRef]




| MIT-BIH Heartbeat Class | AAMI Heartbeat Class |
|---|---|
| Normal (N) Left Bundle Branch Block (L) Right Bundle Branch Block (R) | Normal Beat (N) |
| Atrial premature beat (A) Aberrated atrial premature beat (a) Nodal (junctional) Premature (J) Supraventricular Premature (S) Atrial Escape (e) Nodal Escape (j) | Supraventricular Ectopic Beat (SVEB) |
| Premature Ventricular Contraction (V) Ventricular Escape (E) | Ventricular Ectopic Beat (VEB) |
| Fusion of Ventricular and Normal (F) | Fusion Beat (F) |
| Paced (/) Fusion of Paced and Normal (f) Unclassified (Q) | Unknown Beat (Q) |
| Layer | Kernel Dimension | No. of Filters | Output Shape | No. of Parameters |
|---|---|---|---|---|
| Input | - | - | 1 × 64 × 64 | 0 |
| Conv2D | 3 × 3 | 16 | 16 × 64 × 64 | 160 |
| ReLU | - | - | 16 × 64 × 64 | 0 |
| MaxPool2D | 2 × 2 | - | 16 × 32 × 32 | 0 |
| Conv2D | 3 × 3 | 32 | 32 × 32 × 32 | 4640 |
| ReLU | - | - | 32 × 32 × 32 | 0 |
| MaxPool2D | 2 × 2 | - | 32 × 16 × 16 | 0 |
| Conv2D | 3 × 3 | 64 | 64 × 16 × 16 | 18,496 |
| ReLU | - | - | 64 × 16 × 16 | 0 |
| MaxPool2D | 2 × 2 | - | 64 × 8 × 8 | 0 |
| Dropout | - | - | 64 × 8 × 8 | 0 |
| Dense | - | - | 16 | 65,552 |
| Dense | - | - | 4 | 68 |
| Total = 88,916 |
| S = 1 | S = 16 | S = 32 | S = 64 | |
|---|---|---|---|---|
| Morlet | 292.5 Hz | 18.281 Hz | 9.141 Hz | 4.570 Hz |
| Mexican Hat | 90.0 Hz | 5.625 Hz | 2.812 Hz | 1.406 Hz |
| Gauss7 | 216.0 Hz | 13.5 Hz | 6.750 Hz | 3.375 Hz |
| N | VEB | SVEB | F | |
|---|---|---|---|---|
| Train | 60,946 | 4423 | 1847 | 531 |
| Validation | 5224 | 379 | 159 | 45 |
| Test | 20,897 | 1516 | 633 | 182 |
| Total | 87,067 | 6318 | 2639 | 758 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Holanda, R.; Monteiro, R.; Bastos-Filho, C. Preprocessing Selection for Deep Learning Classification of Arrhythmia Using ECG Time-Frequency Representations. Technologies 2023, 11, 68. https://doi.org/10.3390/technologies11030068
Holanda R, Monteiro R, Bastos-Filho C. Preprocessing Selection for Deep Learning Classification of Arrhythmia Using ECG Time-Frequency Representations. Technologies. 2023; 11(3):68. https://doi.org/10.3390/technologies11030068
Chicago/Turabian StyleHolanda, Rafael, Rodrigo Monteiro, and Carmelo Bastos-Filho. 2023. "Preprocessing Selection for Deep Learning Classification of Arrhythmia Using ECG Time-Frequency Representations" Technologies 11, no. 3: 68. https://doi.org/10.3390/technologies11030068
APA StyleHolanda, R., Monteiro, R., & Bastos-Filho, C. (2023). Preprocessing Selection for Deep Learning Classification of Arrhythmia Using ECG Time-Frequency Representations. Technologies, 11(3), 68. https://doi.org/10.3390/technologies11030068