
An Efficient Hybrid CNN Classification Model for Tomato Crop Disease




Abstract
1. Introduction
- A hybrid-enhanced CNN model is proposed for tomato disease identification. An inception block was added to the VGG16 model in order to take use of the capabilities of simultaneous multiscale feature extraction. The hybrid CNN model has powerful feature extraction qualities and uses these capabilities.
- The effectiveness of the proposed hybrid CNN model was analyzed through rigorous high-level simulations. The results obtained from the developed hybrid CNN model were compared against the most recent and state-of-the-art models.
2. Related Work
3. Proposed System
3.1. Dataset Description
3.2. Data Augmentation
3.3. Split Dataset
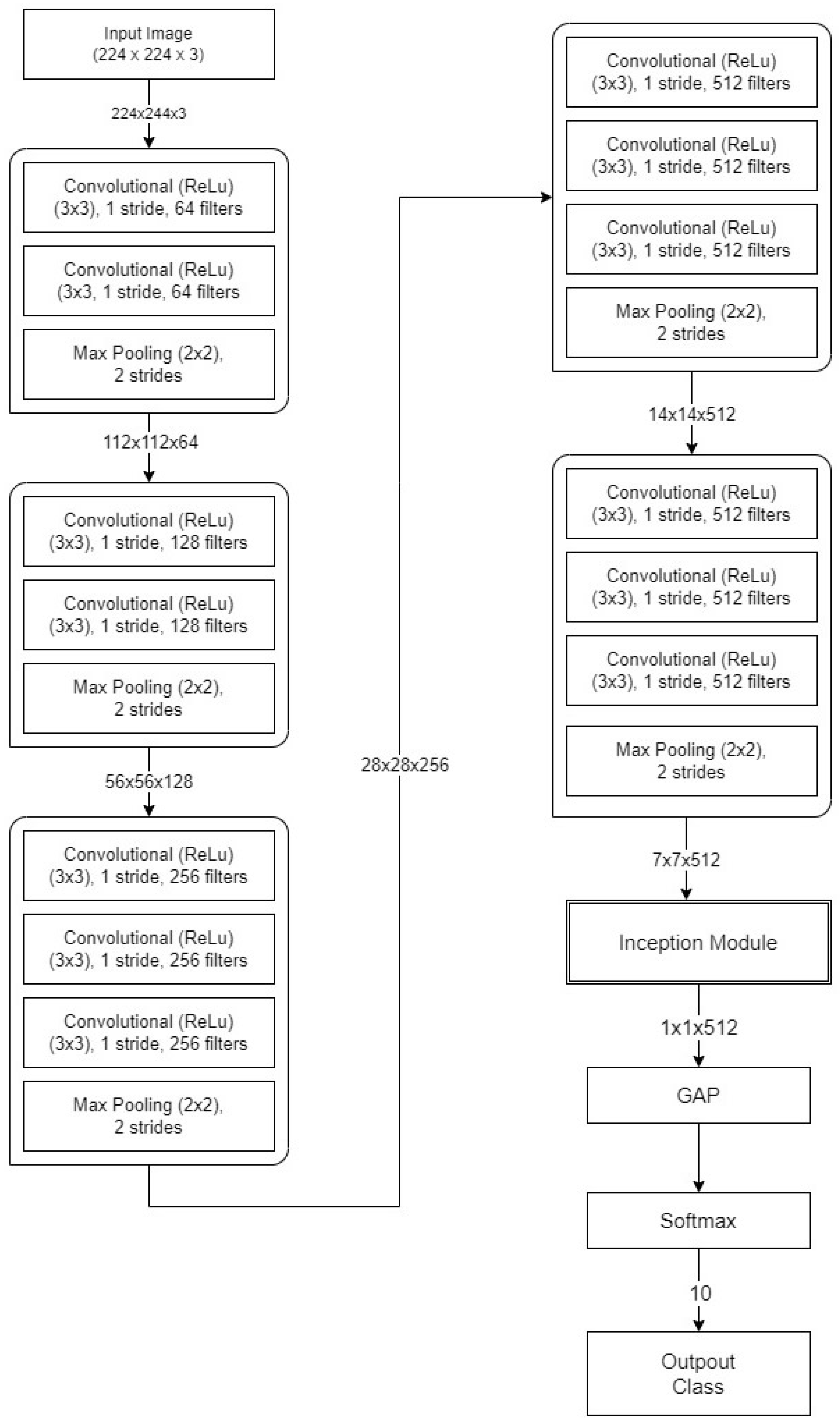
3.4. Hybrid CNN Model for Tomato Crop Disease
3.5. Implementation Specification
3.6. Performance Metrics
4. Results
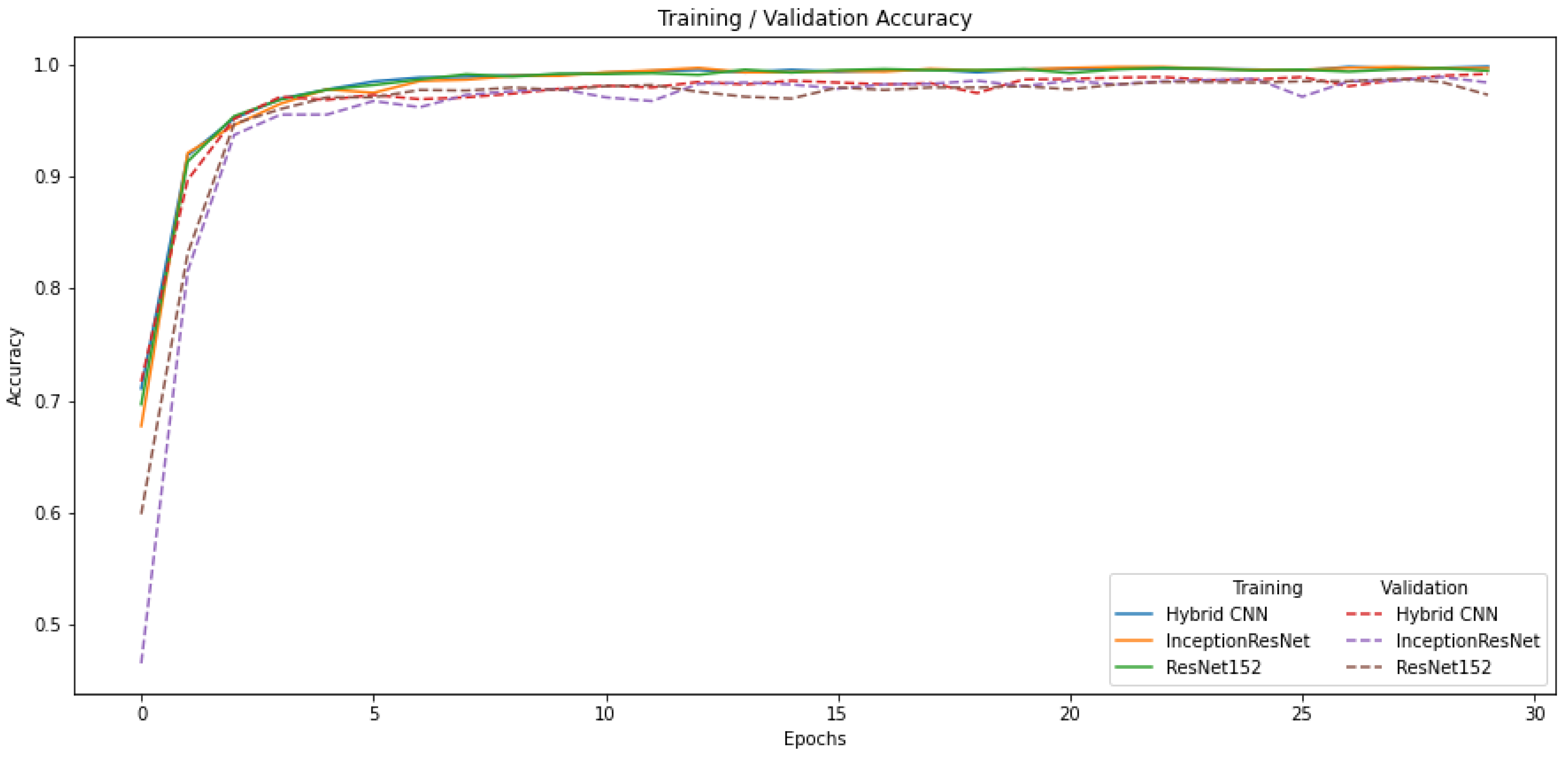
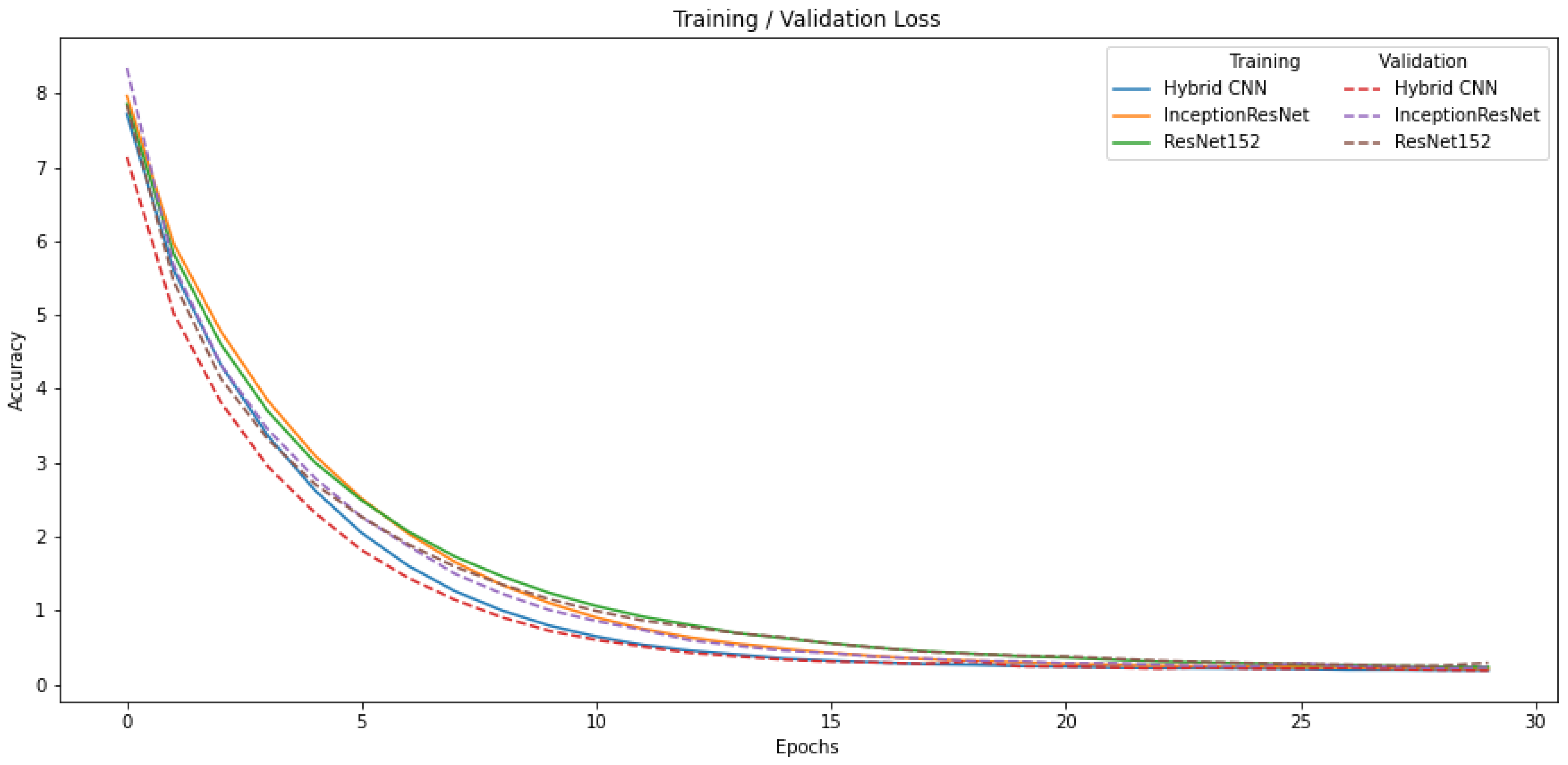
4.1. Training Loss and Accuracy
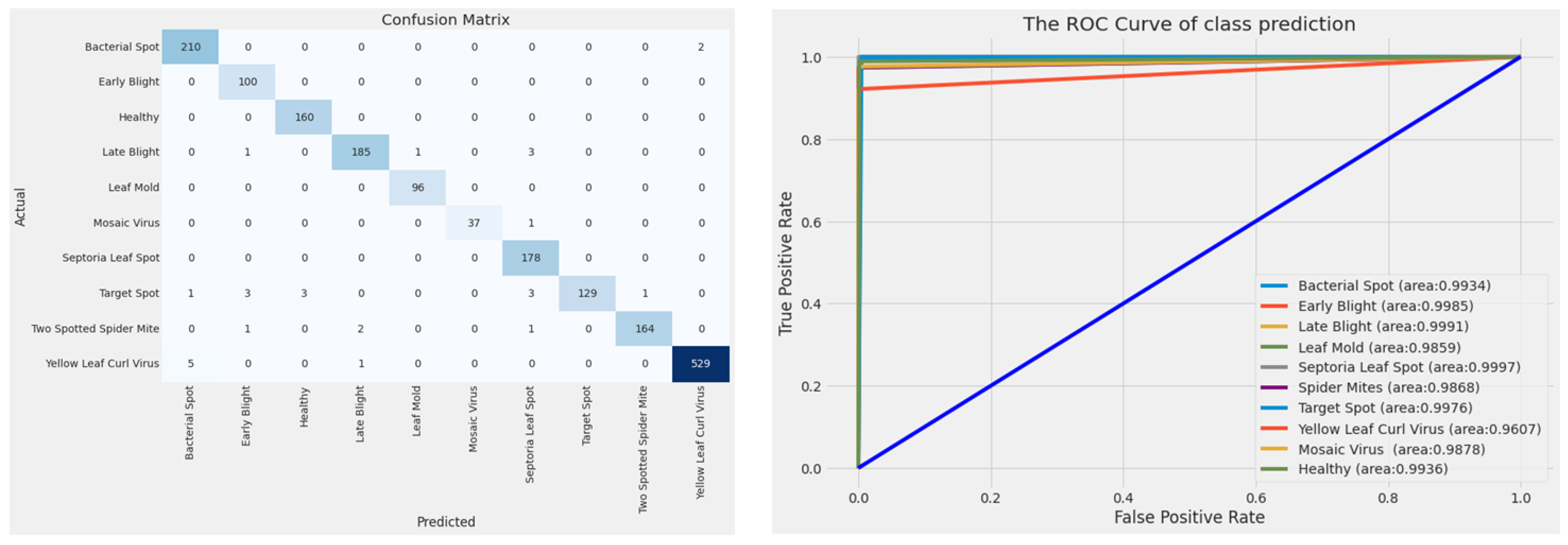
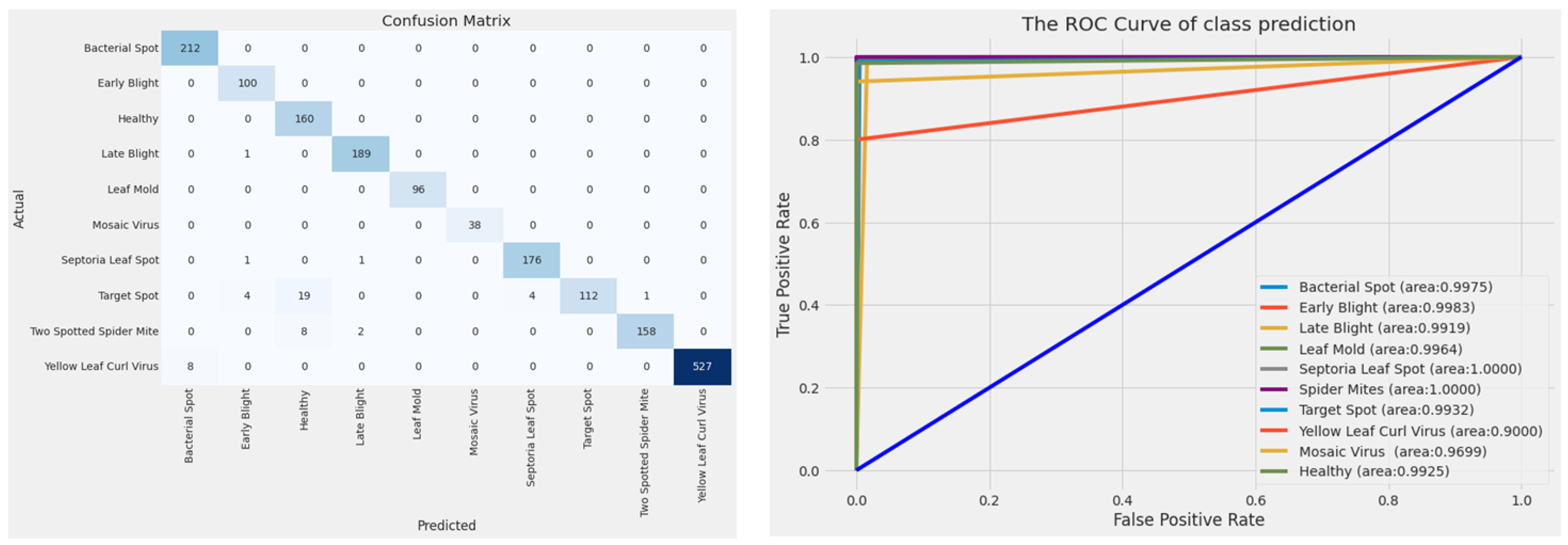
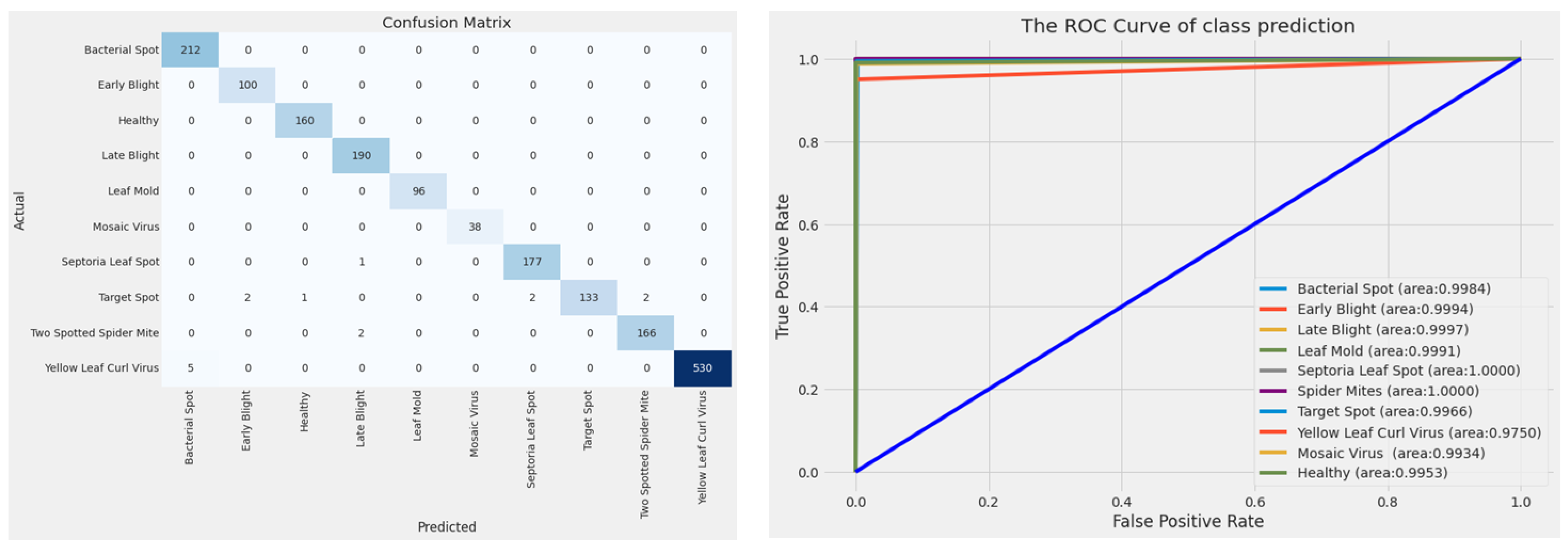
4.2. Evaluation of Models on the Test Dataset
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AUC | Area Under the Curve |
| CBAM | Convolutional Attention Module |
| CNN | Convolutional Neural Network |
| DL | Deep learning |
| FAO | Food and Agriculture Organization of the United Nations |
| MDPI | Multidisciplinary Digital Publishing Institute |
| ROC | Receiver Operating Characteristic Curve |
| SVM | Support Vector Machine |
| VGG | Visual Geometry Group |
References
- Salehi, B.; Sharifi-Rad, R.; Sharopov, F.; Namiesnik, J.; Roointan, A.; Kamle, M.; Kumar, P.; Martins, N.; Sharifi-Rad, J. Beneficial effects and potential risks of tomato consumption for human health: An overview. Nutrition 2019, 62, 201–208. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Chen, H.; Chen, W.; Zhong, Q.; Zhang, G.; Chen, W. Beneficial effects of tomato juice fermented by Lactobacillus plantarum and Lactobacillus casei: Antioxidation, antimicrobial effect, and volatile profiles. Molecules 2018, 23, 2366. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Wang, X. Tomato diseases and pests detection based on improved Yolo V3 convolutional neural network. Front. Plant Sci. 2020, 11, 898. [Google Scholar] [CrossRef] [PubMed]
- Gould, W.A. Tomato Production, Processing and Technology; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Barbedo, J.G. Factors influencing the use of deep learning for plant disease recognition. Biosyst. Eng. 2018, 172, 84–91. [Google Scholar] [CrossRef]
- Tatas, K.; Al-Zoubi, A.; Christofides, N.; Zannettis, C.; Chrysostomou, M.; Panteli, S.; Antoniou, A. Reliable IoT-Based Monitoring and Control of Hydroponic Systems. Technologies 2022, 10, 26. [Google Scholar] [CrossRef]
- Sujatha, R.; Chatterjee, J.M.; Jhanjhi, N.; Brohi, S.N. Performance of deep learning vs. machine learning in plant leaf disease detection. Microprocess. Microsyst. 2021, 80, 103615. [Google Scholar] [CrossRef]
- Aboneh, T.; Rorissa, A.; Srinivasagan, R.; Gemechu, A. Computer Vision Framework for Wheat Disease Identification and Classification Using Jetson GPU Infrastructure. Technologies 2021, 9, 47. [Google Scholar] [CrossRef]
- Waldamichael, F.G.; Debelee, T.G.; Schwenker, F.; Ayano, Y.M.; Kebede, S.R. Machine Learning in Cereal Crops Disease Detection: A Review. Algorithms 2022, 15, 75. [Google Scholar] [CrossRef]
- Benos, L.; Tagarakis, A.C.; Dolias, G.; Berruto, R.; Kateris, D.; Bochtis, D. Machine learning in agriculture: A comprehensive updated review. Sensors 2021, 21, 3758. [Google Scholar] [CrossRef]
- Ojo, M.O.; Zahid, A. Deep Learning in Controlled Environment Agriculture: A Review of Recent Advancements, Challenges and Prospects. Sensors 2022, 22, 7965. [Google Scholar] [CrossRef]
- Dhaka, V.S.; Meena, S.V.; Rani, G.; Sinwar, D.; Ijaz, M.F.; Woźniak, M. A survey of deep convolutional neural networks applied for prediction of plant leaf diseases. Sensors 2021, 21, 4749. [Google Scholar] [CrossRef] [PubMed]
- Sanida, T.; Sideris, A.; Tsiktsiris, D.; Dasygenis, M. Lightweight neural network for COVID-19 detection from chest X-ray images implemented on an embedded system. Technologies 2022, 10, 37. [Google Scholar] [CrossRef]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Hasan, M.; Van Essen, B.C.; Awwal, A.A.; Asari, V.K. A state-of-the-art survey on deep learning theory and architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef]
- Sanida, T.; Sideris, A.; Chatzisavvas, A.; Dossis, M.; Dasygenis, M. Radiography Images with Transfer Learning on Embedded System. In Proceedings of the 2022 7th South-East Europe Design Automation, Computer Engineering, Computer Networks and Social Media Conference (SEEDA-CECNSM), Ioannina, Greece, 23–25 September 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Rangarajan, A.K.; Purushothaman, R.; Ramesh, A. Tomato crop disease classification using pre-trained deep learning algorithm. Procedia Comput. Sci. 2018, 133, 1040–1047. [Google Scholar] [CrossRef]
- Agarwal, M.; Gupta, S.K.; Biswas, K. Development of Efficient CNN model for Tomato crop disease identification. Sustain. Comput. Inform. Syst. 2020, 28, 100407. [Google Scholar] [CrossRef]
- Agarwal, M.; Singh, A.; Arjaria, S.; Sinha, A.; Gupta, S. ToLeD: Tomato leaf disease detection using convolution neural network. Procedia Comput. Sci. 2020, 167, 293–301. [Google Scholar] [CrossRef]
- Altalak, M.; Uddin, M.A.; Alajmi, A.; Rizg, A. A Hybrid Approach for the Detection and Classification of Tomato Leaf Diseases. Appl. Sci. 2022, 12, 8182. [Google Scholar] [CrossRef]
- Mim, T.T.; Sheikh, M.H.; Shampa, R.A.; Reza, M.S.; Islam, M.S. Leaves diseases detection of tomato using image processing. In Proceedings of the 2019 8th International Conference System Modeling and Advancement in Research Trends (SMART), Moradabad, India, 22–23 November 2019; pp. 244–249. [Google Scholar] [CrossRef]
- Zhou, C.; Zhou, S.; Xing, J.; Song, J. Tomato leaf disease identification by restructured deep residual dense network. IEEE Access 2021, 9, 28822–28831. [Google Scholar] [CrossRef]
- Ouhami, M.; Es-Saady, Y.; Hajji, M.E.; Hafiane, A.; Canals, R.; Yassa, M.E. Deep transfer learning models for tomato disease detection. In Proceedings of the International Conference on Image and Signal Processing, Marrakesh, Morocco, 4–6 June 2020; pp. 65–73. [Google Scholar] [CrossRef]
- Trivedi, N.K.; Gautam, V.; Anand, A.; Aljahdali, H.M.; Villar, S.G.; Anand, D.; Goyal, N.; Kadry, S. Early detection and classification of tomato leaf disease using high-performance deep neural network. Sensors 2021, 21, 7987. [Google Scholar] [CrossRef]
- Brahimi, M.; Boukhalfa, K.; Moussaoui, A. Deep learning for tomato diseases: Classification and symptoms visualization. Appl. Artif. Intell. 2017, 31, 299–315. [Google Scholar] [CrossRef]
- Kumar, A.; Vani, M. Image based tomato leaf disease detection. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Gonzalez-Huitron, V.; León-Borges, J.A.; Rodriguez-Mata, A.; Amabilis-Sosa, L.E.; Ramírez-Pereda, B.; Rodriguez, H. Disease detection in tomato leaves via CNN with lightweight architectures implemented in Raspberry Pi 4. Comput. Electron. Agric. 2021, 181, 105951. [Google Scholar] [CrossRef]
- Maeda-Gutiérrez, V.; Galvan-Tejada, C.E.; Zanella-Calzada, L.A.; Celaya-Padilla, J.M.; Galván-Tejada, J.I.; Gamboa-Rosales, H.; Luna-Garcia, H.; Magallanes-Quintanar, R.; Guerrero Mendez, C.A.; Olvera-Olvera, C.A. Comparison of convolutional neural network architectures for classification of tomato plant diseases. Appl. Sci. 2020, 10, 1245. [Google Scholar] [CrossRef]
- Hughes, D.; Salathé, M. An open access repository of images on plant health to enable the development of mobile disease diagnostics. arXiv 2015, arXiv:1511.08060. [Google Scholar] [CrossRef]
- Khalifa, N.E.; Loey, M.; Mirjalili, S. A comprehensive survey of recent trends in deep learning for digital images augmentation. Artif. Intell. Rev. 2021, 55, 2351–2377. [Google Scholar] [CrossRef] [PubMed]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using deep learning for image-based plant disease detection. Front. Plant Sci. 2016, 7, 1419. [Google Scholar] [CrossRef]
- Sanida, T.; Tsiktsiris, D.; Sideris, A.; Dasygenis, M. A heterogeneous implementation for plant disease identification using deep learning. Multimed. Tools Appl. 2022, 81, 15041–15059. [Google Scholar] [CrossRef]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2020, 17, 168–192. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Algorithm | Accuracy (%) |
|---|---|---|
| [18] | VGG16 AlexNet | 97.29 97.49 |
| [19] | Modified VGG16 | 98.40 |
| [20] | CNN model | 91.20 |
| [21] | CNN-SVM-CBAM | 97.20 |
| [22] | CNN model | 96.55 |
| [23] | Restructured residual dense network | 95.00 |
| [24] | DensNet161 DensNet121 VGG16 | 95.65 94.93 90.58 |
| [25] | CNN model | 98.49 |
| [26] | GoogleNet AlexNet | 99.18 98.66 |
| [27] | VGGNet LeNet ResNet50 Xception | 99.25 96.27 98.65 98.13 |
| [28] | Xception NasNetMobile MobileNetV2 MobileNetV3 | 100.00 084.00 075.00 098.00 |
| [29] | InceptionV3 GoogleNet AlexNet ResNet50 ResNet18 | 98.65 99.39 98.93 99.15 99.06 |
| Parameter | Value |
|---|---|
| Random rotation | [+12, −12] |
| Width shift | [0.6, 1.1] |
| Zoom | [0.5, 0.9] |
| Fill mode | Nearest |
| Horizontal flip | True |
| Height shift | 0.15 |
| Shearing transformation | 0.25 |
| Vertical flip | True |
| Categories | Number of Original Images | Training Images | Training Images after Augmentation | Validation Images | Test Images |
|---|---|---|---|---|---|
| Early Blight | 1000 | 810 | 4050 | 90 | 100 |
| Target Spot | 1404 | 1138 | 5688 | 126 | 140 |
| Mosaic Virus | 373 | 302 | 1508 | 34 | 38 |
| Septoria Leaf Spot | 1771 | 1434 | 7169 | 159 | 178 |
| Late Blight | 1909 | 1547 | 7736 | 172 | 190 |
| Healthy | 1591 | 1288 | 6440 | 143 | 160 |
| Spider Mites | 1676 | 1357 | 6786 | 151 | 168 |
| Bacterial Spot | 2127 | 1724 | 8618 | 192 | 212 |
| Leaf Mold | 952 | 770 | 3852 | 86 | 96 |
| Yellow Leaf Curl Virus | 5357 | 4340 | 21,699 | 482 | 535 |
| Total Images | 18,160 | 14,709 | 73,544 | 1634 | 1817 |
| Parameter | Value |
|---|---|
| Optimizer | Adam |
| Batch size | 16 |
| Loss function | Cross-entropy |
| Epochs | 30 |
| Learning rate | 0.0001 |
| Performance Metrics (%) | InceptionResNet | ResNet152 | Hybrid CNN |
|---|---|---|---|
| Training accuracy | 99.69 | 99.45 | 99.83 |
| Testing accuracy | 98.40 | 97.30 | 99.17 |
| Precision | 98.27 | 97.19 | 99.13 |
| Recall | 98.24 | 97.09 | 99.23 |
| F1-score | 98.23 | 96.95 | 99.17 |
| AUC | 99.03 | 98.39 | 99.56 |
| Model | Categories | Precision | Recall | F1-Score |
|---|---|---|---|---|
| InceptionResNet | Bacterial Spot | 0.9722 | 0.9906 | 0.9813 |
| Healthy | 0.9816 | 1.0000 | 0.9907 | |
| Mosaic Virus | 1.0000 | 0.9737 | 0.9867 | |
| Two Spotted Spider Mites | 0.9939 | 0.9762 | 0.9850 | |
| Late Blight | 0.9840 | 0.9737 | 0.9788 | |
| Early Blight | 0.9524 | 1.0000 | 0.9756 | |
| Septoria Leaf Spot | 0.9570 | 1.0000 | 0.9780 | |
| Leaf Mold | 0.9897 | 1.0000 | 0.9948 | |
| Yellow Leaf Curl Virus | 0.9962 | 0.9888 | 0.9925 | |
| Target Spot | 1.0000 | 0.9214 | 0.9591 | |
| ResNet152 | Bacterial Spot | 0.9636 | 1.0000 | 0.9815 |
| Healthy | 0.8556 | 1.0000 | 0.9222 | |
| Mosaic Virus | 1.0000 | 1.0000 | 1.0000 | |
| Two Spotted Spider Mites | 0.9937 | 0.9405 | 0.9664 | |
| Late Blight | 0.9844 | 0.9947 | 0.9895 | |
| Early Blight | 0.9434 | 1.0000 | 0.9709 | |
| Septoria Leaf Spot | 0.9778 | 0.9888 | 0.9832 | |
| Leaf Mold | 1.0000 | 1.0000 | 1.0000 | |
| Yellow Leaf Curl Virus | 1.0000 | 0.9850 | 0.9925 | |
| Target Spot | 1.0000 | 0.8000 | 0.8889 | |
| Hybrid CNN | Bacterial Spot | 0.9770 | 1.0000 | 0.9883 |
| Healthy | 0.9938 | 1.0000 | 0.9969 | |
| Mosaic Virus | 1.0000 | 1.0000 | 1.0000 | |
| Two Spotted Spider Mites | 0.9881 | 0.9881 | 0.9881 | |
| Late Blight | 0.9845 | 1.0000 | 0.9922 | |
| Early Blight | 0.9804 | 1.0000 | 0.9901 | |
| Septoria Leaf Spot | 0.9888 | 0.9944 | 0.9916 | |
| Leaf Mold | 1.0000 | 1.0000 | 1.0000 | |
| Yellow Leaf Curl Virus | 1.0000 | 0.9907 | 0.9953 | |
| Target Spot | 1.0000 | 0.9500 | 0.9744 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sanida, M.V.; Sanida, T.; Sideris, A.; Dasygenis, M. An Efficient Hybrid CNN Classification Model for Tomato Crop Disease. Technologies 2023, 11, 10. https://doi.org/10.3390/technologies11010010
Sanida MV, Sanida T, Sideris A, Dasygenis M. An Efficient Hybrid CNN Classification Model for Tomato Crop Disease. Technologies. 2023; 11(1):10. https://doi.org/10.3390/technologies11010010
Chicago/Turabian StyleSanida, Maria Vasiliki, Theodora Sanida, Argyrios Sideris, and Minas Dasygenis. 2023. "An Efficient Hybrid CNN Classification Model for Tomato Crop Disease" Technologies 11, no. 1: 10. https://doi.org/10.3390/technologies11010010
APA StyleSanida, M. V., Sanida, T., Sideris, A., & Dasygenis, M. (2023). An Efficient Hybrid CNN Classification Model for Tomato Crop Disease. Technologies, 11(1), 10. https://doi.org/10.3390/technologies11010010